
Abstract
Imagine sitting at your desk, looking at objects on it. You do not know their exact distances from your eye in meters, but you can immediately reach out and touch them. Instead of an externally defined unit, your sense of distance is tied to your action’s embodiment. In contrast, conventional robotics relies on precise calibration to external units, with which vision and control processes communicate. We introduce Embodied Visuomotor Representation, a methodology for inferring distance in a unit implied by action. With it a robot without knowledge of its size, environmental scale, or strength can quickly learn to touch and clear obstacles within seconds of operation. Likewise, in simulation, an agent without knowledge of its mass or strength can successfully jump across a gap of unknown size after a few test oscillations. These behaviors mirror natural strategies observed in bees and gerbils, which also lack calibration in an external unit.
Similar content being viewed by others

Introduction
The predominant autonomy frameworks in robotics rely on calibrated 3D sensors, predefined models of the robot’s physical form, and structured representations of environmental interactions. These representations allow vision and low-level control to be abstracted as separate processes that rely on an external scale, such as the meter, to coordinate. For instance, it is common to use vision to construct a metric map scaled to the meter. Subsequently, a planning algorithm uses this geometric representation to generate a trajectory, also scaled to the meter. Finally, a pre-tuned low-level controller employs feedback to follow the metric trajectory, mapping it to motor signals. This approach is known as the sense-plan-act paradigm, and it originates from Marr’s vision framework1. Figure 1 illustrates a block diagram of this paradigm.

A The classic sense-plan-act architecture used in robotics assuming visual inertial odometry (VIO) is used for state estimation. Stability depends on calibrated sensors, such as an IMU, that provide accurate knowledge of the state in an external scale. B An architecture based on Embodied Visuomotor Representation. Compared to sense-plan-act, the embodied approach includes an additional internal feedback connection (red arrow) containing the control signal u. The units of u are implied by the unknown gain b and the dynamics going from control to the state in any scale, including the meter. Embodied Visuomotor Representation leverages position-to-scale, ΦW, obtained from vision and u to determine a state estimate \(\hat{x}/b\) in the embodied scale of u. Notably, the unknown b cancels in the closed-loop system, enabling stable control without calibrated sensors. Direct methods such as Tau Theory, Direct Optical Flow Regulation, and Image Based Visual Servoing also avoid dependence on calibrated sensors by using purely visual cues (e.g., time-to-contact, optical flow, or tracked image features) for feedback. However, with few exceptions, such methods’ stability depends on tuning the control law for the expected scene distances and system velocities.
The sense-plan-act architecture allows separate teams of engineers and scientists to create equally separate vision and control algorithms tuned for particular tasks and mechanical configurations. Subsequently, alternative frameworks for vision, such as Active Vision and Animate Vision emerged2,3,4, primarily to address the limitations of the passive role of vision in the sense-plan-act cycle. However, these frameworks consider control (action) at a high level, and so vision and control remain mostly separate fields and continue to be interfaced with external scale. This dependence leads to lengthy design-build-test cycles and, consequently, expensive systems that are available in only a few physical configurations and must be precisely manufactured. Further, it creates problems that are unobserved in biological systems. For example, it is well-known that Advanced Driver-Assistance Systems (ADAS) in modern cars, such as lane-keeping assist and collision warning, require millimeter accurate, per vehicle calibrations. Another example is the 1999 NASA Mars Climate Orbiter, whose software confused English and Metric units and crashed5. Finally, several billion-dollar 3D Camera and LIDAR industries aim to produce accurate 3D measurements calibrated to an external scale, and significant effort is dedicated to ensuring those calibrations do not degrade over time.
This situation is striking because biological systems do not necessarily understand distance in an external scale like the meter. Further, we know from psychology that human and other mammalian perceptual systems do not provide metric depth and shape6,7,8,9,10. Instead, somehow, biological systems represent the world using only the signals due to their embodiment. Further, animals such as gerbils, dragonflies, and bumblebees exhibit visuomotor capabilities far in excess of robots while allowing for much broader variation in physical form and handling complex dynamics such as turbulence and muscular response11,12,13. Similarly, humans can control augmentations to their embodiment, such as cars and airplanes, which also vary in physical form and do not maintain precise calibrations to an external scale.
One explanation is that these systems do not rely on any precise sense of distance. In support, direct approaches such as Tau Theory14, Direct Optical Flow Regulation15, and classical Image Based Visual Servoing16 offer methods to control a visuomotor system using only cues directly available from the image such as time-to-contact, optical flow, and image features. However, systems strictly limited to direct methods cannot reason about distance, a capability essential for behaviors such as the clearing maneuvers of bees13 and the jumping ability of gerbils11. Moreover, direct methods either assume a predefined operating region for which the control system is tuned16,17,18,19 or constrain achievable behaviors to those possible with a restricted class of feedback laws20,21. In contrast, systems with knowledge of distance can overcome these limitations while still using direct (image space) control objectives.
Thus, a key question arises: How can a robot, without a source of external scale, use its vision and motor system to estimate a meaningful sense of distance? We refer to methods that capture this phenomenon as Embodied Visuomotor Representation and propose that its realization could drive a paradigm shift that makes robots easier to produce, more affordable, and widely accessible.
Psychologists assume humans have such representations without proposing a precise and general method for obtaining them22. Biologists argue that simple animals such as bees can develop them13. Computer scientists suggest that computations drive intelligence, and thus representations, as physical as the body itself23. In particular, there is evidence that the visuomotor capabilities of animals can be attributed to well-tuned internal models closely coupled with perceptual representations. In addition to reasoning about distances, an important function of these models is prediction, which allows an animal to anticipate upcoming events, compensate for the significant time delays in their feedback loops, and, when coupled with inverse models, generate feedforward signals for other parts of the body24.
However, being able to explain a phenomenon is not the same as being able to implement it. To address this, we propose Embodied Visuomotor Representation, a concrete framework that can estimate embodied, action-based distances using an architecture that couples vision and control as a single algorithm. This results in robots that can quickly learn to control their visuomotor systems without any pre-calibration to a unit of distance. In many ways, our method parallels a psychological theory of memory as embodied action due to Glenberg (who presents the idea of embodied grasping of items on a desk). Glenberg argues that the core benefit of embodied representation is that they “do not need to be mapped onto the world to become meaningful because they arise from the world” 22. Similarly, our Embodied Visuomotor Representations do not need to be pre-initalized with an external scale because they can be estimated by the robot online without sacrificing stability.
Embodied Visuomotor Representation achieves this by exchanging distance on an external scale for the unknown but embodied distance units of the acceleration affected by the motor system. As a consequence, powerful self-tuning, self-calibration, or adaptive properties emerge. At the mathematical level, the approach is similar to the Internal Model Principle, a control theoretic framework that underlies all learning-based control methods, either explicitly or implicitly25. Unlike the sense-plan-act approach, which operates sequentially, the Internal Model Principle introduces a critical topological distinction: an internal feedback loop that leverages embodied motor signals to predict sensory feedback representations. This same internal feedback loop, shown in Fig. 1 enables Embodied Visuomotor Representation to integrate vision and control seamlessly, without relying on external scale, or sacrificing close-loop stability.
In what follows, we develop a general mathematical form for equality constrained Embodied Visuomotor Representation and demonstrate it on a series of experiments where uncalibrated robots gain the ability to touch, clear obstacles, and jump gaps after a few seconds of operation by using natural strategies observed in bees flying through openings and gerbils jumping gaps. For these applications, we develop specific relations between control inputs, acceleration, and observed visual features, such as lines and planes, that can be used by an uncalibrated robot to estimate state in an embodied unit. This state is used by control schemes that are guaranteed to perform a task correctly. The results suggest that Embodied Visuomotor Representation is a paradigm shift that will allow all visuomotor systems, and in particular robots, to automatically learn to control themselves and engage in lifelong adaption without relying on pre-configured 3D sensors, controllers, or 3D models that are calibrated to an external scale.
Results
First, the mathematical methodology for Embodied Visuomotor Representation will be detailed in the equality constrained case, where the results of vision and control can be set equal to each other. Next, examples of applying Embodied Visuomotor Representation to the control of a double integrator and a multi-input system with actuator dynamics are developed. Finally, algorithms that use Embodied Visuomotor Representation to allow uncalibrated robots to learn to touch, clear obstacles, and jump gaps are presented. Detailed calculations behind these applications are provided in the Methods section.
Equality constrained embodied visuomotor representation
Consider a point \({X}_{w}\in {{\mathbb{R}}}^{4}\) in homogenous coordinates corresponding to the 3D location of a point in the world coordinate frame. It is transformed by the extrinsics matrix Tcw ∈ SE(3) and projected to the homogenous pixel coordinates \({p}_{c}\in {{\mathbb{R}}}^{3}\) in the image according to an invertible intrinsics matrix \(K\in {{\mathbb{R}}}^{3\times 3}\) that encodes the focal length and center pixel. The resulting well known relationship is
Where \({X}_{c}^{z}\) is the third element of the product TcwXw. Without loss of generality, we assume that K = I.
Next, consider the warp function as known in computer vision. It has the property that
That is, given the initial position of a world point in an image at time t0, the warp function returns the position of the same world point in the image at another time. Note that warp functions are sometimes assumed to be linear, and this can be a good approximation when the region of interest is on a flat plane26. However, in general, the warp is nonlinear because its estimation amounts to the integration of optical flow or tracking visual features such as points, lines, or patches.
Similarly to the warp function, the “flow map” from control theory, Φf,u, is defined as returning the solution to a system defined by f with input u as follows:
Comparing (2) to (3) reveals that W and Φ serve the same purpose. W is the solution map giving trajectories in image space, whose derivative is also called optical-flow, and Φ is the solution map for the system state, whose time derivative is driven by the system dynamics. This similarity in purpose leads to an equality constraint.
Due to W’s close relationship to position X through (1), many visual representations allow computing the position of the camera up to a characteristic scale such as the size of an object under fixation, the initial distance to a visual feature, or the baseline between two stereo cameras. We call the position to scale ΦW and assume it can be estimated. In particular, the prominent families of computer vision algorithms, such as homography estimators, structure from motion, SLAM, and visual odometry result in such a ΦW.
ΦW can be related to position by a multiplicative scalar, that is the characteristic scale of the visual representation, which we call d. If the first three elements of the state are the position of a point in the camera’s frame, i.e., \(x={\left[\begin{array}{cc}{X}_{c}^{T}&* \end{array}\right]}^{T}\), then ΦW, d, and Φf,u are related by,
where pc(t0) = x1,2(t0)/x3(t0) and superscripts (i.e., \({\Phi}_{f,u}^{1,2,3}\)) are used to denote the individual components of a vector. Note that this formulation holds for loose and tight couplings of vision and control, where loose coupling means the vision algorithm functions independently without the knowledge of action.
The problem of visuomotor control thus becomes finding specific forms of Φf,u and W that possess desirable properties. In particular, we seek a transformation that reformulates the problem into a form akin to those used in linear system theory, enabling us to take advantage of the properties of linear systems. Suppose the camera is translating but not rotating. Then the world frame’s axes can be assumed to align with the camera frame’s axis. In practice, this assumption holds for durations ranging from a few to several seconds when an inexpensive Inertial Measurement Unit is mounted in the same frame as the camera sensor and is used to compensate the image so that it can be considered as coming from a camera with fixed orientation. Consequently, the rotation between the camera frame c and the world frame w can be neglected as the frames can be assumed to coincide up to a translation and so X can be used in the place of Xc.
Then Newton’s second law of motion can be applied in the fixed camera frame (within the time interval that the system can be considered rotation invariant). Let that time interval be [t0, t0 + T] where T ≠ 0. Then we obtain a linear system that relates the position, velocity, and acceleration components of the state X and ΦW,
Here fmech encapsulates the mechanical dynamics due to forces exerted by actuators, θ is a set of mechanical parameters (arm lengths, mass, etc.) that can be considered constant, \(\dot{X}\) is the time derivative of X, and xact is the state of the actuator dynamics. We encapsulate the actuator dynamics as a separate system
where θact are the constant parameters of the actuators.
Consider this visuomotor representation as known by an embodied agent without calibration to an external scale. Then X is the robot’s 3D position relative to the point of interest in an unknown unit, d is the characteristic scale of vision in the unknown unit, ΦW is the unitless estimate of the position due to vision, θ and θact are the constant parameters of the mechanical system and the actuators in unknown units. Finally, xact and u are the state of the actuators in unknown units.
The only quantities known in general by an uncalibrated embodied agent system are then ΦW and u. But, because ΦW is unitless, if the embodiment attempts to estimate X, d, θ, and θact so that (5) and (6) hold at all times, the units of the estimated quantities must be implicitly determined by u. For example, it can be seen that the distance units of X are determined by the distance units defined by the acceleration, that is, a distance unit over seconds squared, whose magnitude is determined from the embodied signal u transformed into acceleration by the system’s fact and fmech. In other words, the magnitude of X, \(\dot{X}\), and d is determined by the magnitude of the the action u and thus their units are implied by u.
Consequently, the general path for employing Embodied Visuomotor Representation involves the following steps:
-
Define a model that represents the physical dynamics of the agent. Both classical and learning-based models can be used.
-
Ensure all quantities in the model arising from physical processes are unit-free or up to scale. For example, if gravity is to be modeled, it can be assumed the effect is non-zero, but the magnitude must not be assumed.
-
Choose a visual representation ΦW where the characteristic scale is related to a quantity of interest. For instance, in a grasping task, it may be advantageous to choose ΦW so that d corresponds to the object’s size. Similarly, d might be the initial distance to a tracked feature, line, or object in a navigation task.
-
Define a constraint between the unknowns d, X, \(\dot{X}\), θ, θact, and xact that enables a unique and task-relevant representation to be estimated. In what follows, we give two specific formulations.
-
Construct an estimator for the chosen representation of d, X, \(\dot{X}\), θ, θact, and xact and incorporate these estimates into the task execution.
Closed loop control with embodied visuomotor representation
In what follows, we give two specific examples of constructing an estimator and using the resulting state for closed-loop control. In the first example, distance is estimated in units of action for a single input, single output system. In the second example, the multiple input case is considered. In that case, distance is most directly available in multiples of the characteristic scale of vision but can easily be converted to the units of action of any of the inputs. In both cases, stable closed-loop control is a consequence of the embodied representation.
For each example, we begin by constructing a model, a sliding window estimator, and a closed-loop controller which will have guaranteed stability under mild assumptions. The approach is a form of indirect-adaptive control because, first, a forward model is identified using our framework. Then, a controller is synthesized from that model27.
The simplest system that can be represented in the framework of Embodied Visuomotor Representation is a robot moving along the optical axis while fixating on a nearby object. The dynamics are assumed to be that of a double integrator and the image provides the position up to the characteristic scale of vision. This system was also considered in ref. 28, however, the exposition was limited. The system is given by
Here, the observation (output) is ΦW, and it is linearly related to the state x1 through the unknown d. b is the unknown gain between control effort and acceleration in an external scale, such as meters per second squared. b implicitly depends on both the strength of the embodied agent’s actuators and the mass of the embodiment itself. Dimensionality analysis reveals that b is simply the unknown conversion factor between the embodied scale implied by u and the external scale. Finally, the system is observable as long as d ≠ 0. That is, the visual representation’s characteristic scale, such as the initial distance to a visual feature, size of a patch, or the baseline between two stereo cameras, is non-zero.
A sliding window estimator that considers ΦW, and u to be known over the interval [t0, t0 + T], T ≠ 0 results in the problem
which cannot be solved uniquely without additional constraints because a trivial solution can be realized by allowing all optimized variables to equal zero. However, dividing by b, the unknown conversion factor between external scale and embodied scale, reveals a problem that can be solved as long as acceleration is non-zero for some period during the interval [t0, t0 + T]
Since b is simply a conversion factor between units, we see that the lumped quantities d/b, x1(t0)/b, and x2(t0)/b are traditional state estimates but in the embodied units of u. Thus, we see that an embodied agent can naturally estimate state in an embodied scale by comparing what is observed with the accelerations effected through action.
In practical applications, ΦW will be noisy because it is estimated using an image made out of discrete pixels. Even if this noise is zero mean, Eq. (10) results in a biased estimator because it uses ΦW as an independent variable. An unbiased estimator can be realized by dividing by d/b, resulting in the problem,
In the new problem, ΦW is the dependent variable because it is no longer multiplied with one of the optimized variables. Then, because the problem is linear least squares, if ΦW is corrupted with zero mean noise, the parameter estimates will remain unbiased. On the other hand, the estimated parameters have changed. The state x is now estimated in multiples of d instead of the desired multiples of b. Further, only the reciprocal of the d/b is estimated. These estimates can be transformed back to the desired quantities with division, which will result in some bias since division does not commute with expectation. However, unlike when using Eq. (10), techniques that increase the accuracy of estimates, such as taking more measurements, will increase the accuracy of the transformed estimates. A detailed explanation is provided in the Supplemental Material.
The solution to either formulation is unique as long as the acceleration, u, is non-zero for a finite period within the sliding window. A detailed proof is given in the Supplemental Material.
Then if the control law u = K(x/b) is applied, the closed loop system dynamics become
Because the unknown gain b cancels out in the rightmost expression, we can say that the closed loop behavior of the system is invariant to the value of b. That is, while b is not known individually, and is only a term in the known ratios x/b and d/b, it will not affect the systems behavior. Thus, the control gains K can be chosen as if b = 1 and x itself is known. This is despite the fact that b appears individually in the dynamics model. Similarly, the characteristic scale of vision, d, does not affect the closed loop behavior despite remaining unknown.
Further, consider that once d/b is known, ΦW(t)d/b provides a direct estimate of x1(t) in the embodied unit. Thus, in theory, it is sufficient to solve (10) or (11) once, and subsequently treat control of (7) as a traditional output feedback problem. Finally, since the closed loop system is linear, time-invariant, controllable, and has known parameters, feedback gains K always exist and can be chosen to ensure global closed-loop stability. In particular, since this system corresponds to a PD controller applied to a double integrator, the stabilizing gains can be easily chosen.
Next, the previous example is extended to the case that the robot does not know its actuator dynamics. Typically, actuator dynamics produce a “lagging” response to control inputs. For example, they could take the form of an unknown delay or low-pass filter between the control input and its effect on acceleration. Additionally, the full 3D motion is considered.
Suppose the dynamics are fully linear, the robot can move in three dimensions, there is an unknown, stable linear system between control inputs and the 3D acceleration, and a visual process estimates the position of the robot up to the characteristic scale of vision. Then, the dynamics can be expressed as
Estimating the unknown parameters B, Aact, Bact, and Cact simplifies to satisfying the following equality constraint
Suppose that the actuator dynamics expressed inside the double integral are BIBO stable. Then, the impulse responses relating the inputs of the actuator’s system to this term go to zero exponentially fast. Consequently, it is sufficient in many practical applications to approximate these dynamics as a finite length convolution with the input. Then, we get the following equality constraint where G is a matrix value signal whose i,j’th entry is to be convolved with the j’th element of u to get its effect on the i’th state.
As with the previous example considering a double integrator, any problem based on this constraint has no unique solution because every term has an unknown multiplier. However, unlike the double integrator, we cannot simply divide by b to get a problem with a unique solution. Instead, we can divide by the scalar d to get a linear constraint that will be uniquely satisfied given sufficient excitation by u. A detailed proof is given in the Supplemental Material. Consider the sliding window estimator again. The full problem to be solved is
where the fact that the convolution with G can be brought out of the double integral has been used, and ⋅ at the top of the double integrator is the placeholder for the variable that will be convolved over.
In this case, the position of the agent is recovered in multiples of the characteristic scale of vision due to division by d. However, the units of distance can still be recovered in the embodied units of acceleration by dividing all estimated parameters by the gain of one of the actuator’s impulse responses at a particular frequency. In particular, if the DC gain of the actuator dynamics is non-zero, we can consider that
Where gij is the i, j entry of G and \(\mathop{\int}\nolimits_{0}^{\infty }{g}_{ij}(t)dt\) is its scalar valued DC gain. Thus, distance in units of action is still available. Further, the distance in the units of action is different for each input, and the conversion factor between all the embodied scales is known to the agent. So, it is free to switch between units as may be convenient.
If the actuator dynamics are minimum phase, and thus an inverse impulse response G−1 exists, then since G/d is known, dG−1 can be determined. It is then straightforward to synthesize a reference tracking controller. Consider the control scheme given by
Then the closed-loop dynamics are
where the fact that the systems G and dG−1 cancel (by definition) except for the scale d has been used.
The resulting closed loop’s stability does not depend on the magnitude of the embodied scale or any external scale. Instead, the reference point is in multiples of vision’s characteristic scale, which could be the size of a tracked object, the baseline between a stereo pair, or the initial distance to an object. As before, it is straightforward to convert to the embodied units of action because d can be replaced with any actuators DC gain, \(\mathop{\int}\nolimits_{0}^{\infty }{g}_{ij}(t)dt\). In that case, the closed loop dynamics become
As with (12), the systems in (19) and (20) are linear, time-invariant, controllable, and all parameters are known. Thus, gains K always exist and can be selected to ensure closed loop stability 29.
In practice, the inverse of the actuator dynamics should not be used in the control law because the cancellation of dynamics typically results in a control law with poor performance and robustness. Regardless, we consider the inverse dynamics above so that the final close loop control law clearly illustrates the units being employed by Embodied Visuomotor Representation. However, in general, it is now straightforward to design traditional control laws using the identified parameters. In particular, the jumping experiments avoid using inverse dynamics.
We now turn to three basic robotic capabilities: touching, clearing, and jumping, which can be accomplished by uncalibrated robots that use Embodied Visuomotor Representation.
Uncalibrated touching
Consider an uncalibrated robot with a monocular camera that must touch a target object in front of it. The contact will occur at a non-zero speed because the robot does not know its body size and thus cannot come to a stop just as it reaches the target. Further, the robot also does not know the strength of its actuators, the size of the target, or the size of anything else in the world. In what follows, we carefully apply the five steps for using Embodied Visuomotor Representation to design an algorithm for this problem. Figure 2 outlines the resulting uncalibrated touching procedure visually.

A The robot oscillates by applying an open loop control input \(\sin (t)\) while measuring the size of the touching target in the visual field as ΦW. B Embodied Visuomotor Representation uses the control input and visual information to estimate x1/b and d/b, which are the size of and distance to the target in the embodied unit. C With the size of the target known, it is possible to approach the target at a desired safe contact speed, vs, using closed-loop control. In the closed loop, the effect of the unknown embodied gain b cancels except for its interaction with the setpoint vs. D Upon making contact with the target, the distance between the camera and the target is the size of the body wl in the embodied unit. E The procedure can be repeated, by approaching from different directions, to approximate the convex hull of the robot.
Starting with the first step, we assume a double integrator system as in (7), that is the robot accelerates along the optical axis according to \({\ddot{x}}_{1}=bu\) where \({\ddot{x}}_{1}\) is acceleration in meters per second squared and u is a three-dimensional control input. Upon inspection, we see that the only quantity defined by the world, b, does not have a predetermined unit. Thus, the second step is complete.
To complete the third step, assume the robot is facing a planar target. The reciprocal of the target’s width in normalized pixels within the visual field can then be used as ΦW. That is, ΦW = Z/d, where ΦW’s characteristic scale is the unknown width of the target, d. It should be noted that this simple visual representation is valid only for flat objects that are coplanar with the camera, making it and following experiment pedagogical in nature. However, in general, (4) demonstrates that Embodied Visuomotor Representation is agnostic to the particular visual representation or algorithm used so long as it provides position up to a characteristic scale.
The fourth step, which involves establishing a constraint between vision and control that includes the unknowns, is accomplished by recalling Eq. (8) and dividing through by b. This results in the unknowns x(t0)/b and d/b, which correspond to the initial conditions, x(t0), and the characteristic scale of vision, d, in the embodied units of u. Once this is done, the fifth step can be applied: estimating the unknowns using Eq. (11).
The unique estimate of d/b obtained from this formulation allows the distance between the robot and the target to be estimated at all times via the relation \({\hat{x}}_{1}/b={\Phi }_{W}(t)(d/b)\). This can be combined with the target’s position in the image to recover the target’s 3D position. Closed-loop control can then use this distance to center the robot on and approach the target along a direction in the camera frame at a constant speed, because in the closed loop, the remaining unknown, b, cancels out, as shown in Eq. (12).
To ensure safe contact without damaging the robot, the designer must specify a safe contact speed, vs, in embodied units. This limitation mirrors biological systems, where animals often create safe environments for their young to prevent injury, ensuring that the maximum achievable speed does not cause harm. It is important to note that the robot cannot stop just before touching the target, as it does not know how where its body is relative to the camera.
In practice, the robot’s designer or a higher-level cognitive process can set vs based on multiples of the target’s dimensions or by considering multiples of the maximum force (in embodied units) that the robot should experience upon collision. An example of this calculation is provided in the Supplemental Material. Specifically, if the designer knows the size of the target in meters and a safe speed in meters per second, they can convert the safe speed to multiples of the target’s size per second, which the robot can subsequently interpret in embodied units.
Subsequently, contact with the object can be detected either with a touch sensor or by using the visual position estimate ΦWd to detect that the robot has stopped getting closer to the target. Thus, the robot can approach a target at a constant safe speed in a given direction in the camera field and touch it, regardless of the embodiment and environment’s specifications.
It should be noted that it was assumed that the open-loop oscillations would not cause the robot to come in contact with the obstacles. However, this is not strictly necessary. Eq. (11) has a unique solution given any acceleration of arbitrarily small duration. Thus, in theory, it is always possible to estimate the unknowns and switch to closed loop control prior to reaching the target.
Figure 2 visually outlines the uncalibrated touching procedure. Movie 1 details the experimental procedure for both uncalibrated touching and clearing. Figure 3 shows the estimated width, distance, and velocity over time during the measurement phase of uncalibrated touching for three different control input gains, b = 0.5, 1, and 2. Since the conversion from embodied units to meters is determined by b, the embodied estimate is expected to align with the ground truth only when b = 1. Similarly, Fig. 4 shows estimated distances and control inputs as the robot approaches and touches the target while using the same three ground truth values for b. The approach velocity was fixed to the same embodied value for each trial, meaning when b = 0.5, the robot takes twice as long to reach the target compared to b = 1. Whereas when b = 2, it takes half the time. Alternatively, the methods discussed above for specifying a safe contact speed allow the robot’s designer to ensure a consistent approach speed regardless of b.

The first, second, and third rows of plots show the estimated target width, distance from the target, and velocity as estimated by the sliding window formulation in Eq. (12). The bottom two rows show the inputs to the sliding window formulation, that is, the control signal u and the width of the target in the visual field in normalized pixel coordinates ΦW. As expected, when b = 1.0, the embodied estimates are closely aligned with the ground truth distances measured in meters. However, when b = 0.5 or b = 2.0, the embodied estimates are twice as much and half, respectively, of the ground truth value in meters.

The methods take different amounts of time to reach the target because the approach speed was specified as a fixed value in the embodied unit while b was varied. Note that the closed loop behavior remains stable and qualitatively similar despite the control input gain varying by a factor of 4. As shown by Eq. (12) this is expected.
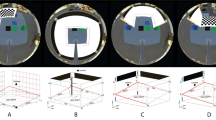
Additionally, two experiments were conducted to validate the accuracy of estimated embodied representations. In the first, the uncalibrated touching procedure was performed with the robot starting from an initial distance of 50, 75, 100, 150, 225, and 350 cm away from a 15 centimeter wide touch target. At each distance, the input gain b was set to 0.5, 1, and 2. When b = 1 and b = 2, the minimum initial distances were 75 cm and 150 cm, respectively, to avoid hitting the target during the open loop oscillation. In total, 70 trials were run. 350 cm was the maximum testable distance; beyond this, the procedure failed due to the limited width of the target in the field of view (<6 pixels). Figure 5 shows the resulting embodied target widths and embodied robot widths compared to ground truth. Table 1 quantifies the error in Fig. 5 as a percentage of the ground truth target and body width.

Error bars show mean, minimum, and maximum value over five trials.
In the second experiment, the uncalibrated touching procedure was performed with the robot initially 150 cm from targets of ground truth width 3.75, 7.5, and 15 cm and input gain b equal to 0.5, 1, and 2. Five trials of each parameter combination were run, resulting in a total of 45 trials. Figure 6 shows the resulting embodied target widths and embodied robot widths compared to ground truth. The ground truth widths result from converting the width of the robot in meters minus the turning radius of the pan-tilt mount to the embodied distance. Table 2 quantifies the error in Fig. 6 as a percentage of the ground truth target and body width.

Measured width of touching target and width of the robot’s body, in embodied units, as the width of the target and the control input gain b are varied. Error bars show mean, minimum, and maximum value over five trials.
In Figures 5, 6, the blue ground truth lines result from converting the ground truth width of the target and width of the robot to meters. The plotted ground truth robot width was reduced by the turning radius of the pan-tilt mount that the camera is mounted on in embodied units.
During all trials, the robot applied an open-loop 1/3 Hz acceleration signal, resulting in positional oscillation with 25 cm of amplitude when b = 1. The sliding window estimator was configured to consider 3 seconds of data.
Uncalibrated clearing
Once a robot can touch, it can quickly determine if it can clear obstacles of initially unknown size prior to reaching them as shown in Fig. 7 and in Movie 1. In the following, the first four steps of and the estimation portion of step five are the same as in the touching application. Thus, we focus on the last portion of the fifth step, which is applying quantities estimated via Embodied Visuomotor Representation in the task.

A The robot oscillates by applying the control input \(\sin (t)\) in open loop input while using the size of the opening between two obstacles in the visual field to estimate its distance to scale, ΦW. B Embodied Visuomotor Representation uses the control input and visual information to estimate the opening size, (Xr − Xl)/b, in the embodied units. C The size of the robot in the embodied unit, (wr − wl)/b, as estimated with a series of uncalibrated touches, is compared to the size of the opening in the embodied unit to determine if the robot can fit or clear the opening. D If the robot can fit, the known size of the opening can be used to determine the position of the robot, and closed-loop control can guide the robot through the opening.
Let the robot approach the touching target along direction v in the body frame; then, if the body extends further than the camera in the direction of v, the robot’s body will touch the target prior to the camera reaching the target. Let the time of contact be called tc. At the time of contact, the vector from the camera to the point on the body that is touching the target is known and corresponds with a point on the perimeter of the robot’s body. Repeating the touching process by approaching a target from many directions allows the robot to approximate its convex hull in the scale of the embodied units.
Clearing obstacles is now as simple as measuring the distance from the robot’s camera to the object in the embodied unit and comparing that to the robot’s size in the embodied unit. In particular, as illustrated by Fig. 2, if a robot has measured its width in the embodied units as w/b = wl/b + wr/b, where wl/b and wr/b are distance from the camera to the left and right side of the robot respectively, then it only needs to measure width of the opening, as illustrated in Fig. 7, and compare it to the width of the robot. Let the positions of the left and right sides of the opening be Xl and Xr; then the robot measures their positions as Xl/b and Xr/b. Thus, the robot fits if
If the robot fits, it can proceed through the opening using the same controller that was used to touch targets.
Figure 8 shows estimated distances from the opening as the robot approaches using different ground truth values for b = 0.5, 1, and 2 as before. The approach corrects a translational perturbation in the X axis in addition to approaching the target at a constant speed along the Z axis. The approach velocity was fixed to the same embodied value for each trial; thus, when b = 0.5 and b = 2, the robot takes twice and half as long, respectively, to reach the target as when b = 1.

The methods take different amounts of time to reach the target because the approach speed was specified as a fixed value in the embodied unit while b was varied. Note that the closed loop behavior remains stable and qualitatively similar despite the control input gain varying by a factor of 4. As shown by Eq. (12), this is expected.
Additionally, Fig. 9 shows the measured width of the opening as a function of the opening’s true width. Openings of size 12.5, 25, and 37.5 cm were tested with the robot’s initial distance from the opening fixed at 150 cm. Each configuration of opening size and control gain b were tested 5 times for a total of 45 trials. It should be noted that measuring an opening’s width is substantially similar to measuring a target’s width, and so Fig. 9 can be interpreted as an extension of the upper plot in Fig. 6. Table 2 quantifies the error in Fig. 9 as a percentage of the width of the opening.

Error bars show mean, minimum, and maximum value over five trials.
Uncalibrated jumping
Suppose an uncalibrated robot with two legs, that apply force with an unknown first order response (or lag), and a monocular camera needs to jump a gap to a platform an unknown distance away but at the same height. In what follows, we carefully apply the five steps for using Embodied Visuomotor Representation. Figure 10 and Movie 2 of the Supplemental Material outline the uncalibrated jumping procedure visually.

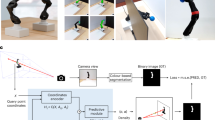
A The robot oscillates up and down using a high gain control while measuring the control input u and vertical position in the visual field ΦW of a target line (red). The vertical acceleration achieved \(\ddot{{X}}_2\) results from filtering the control input by the unknown actuator dynamics g. B, C Embodied Visuomotor Representation uses the control input and visual information to estimate the actuator dynamics g, distance to the jumping target d, and strength of gravity gb in the embodied units \({\left(\mathop{\int}\nolimits_{0}^{\infty }g(t)dt\right)}^{-1}\). D An embodied optimal control problem is solved for the control input uj of minimum total variation that will reach the required launch velocity vl to jump the gap. E The jumping control input is executed in open loop after tilting the body forward.
Starting with the first step, we assume a classical model of the system. Let the legs applied force respond to inputs according to a first order low pass filter with a time constant 1/α, α > 0. That is,
where \({\ddot{X}}_{2}\) is acceleration in the vertical direction and gb is an unknown gravitational bias. Then, as with the the touching example, all the quantities defined by the world, that is b, gb, and α do not have predetermined units or magnitudes. Thus, the second step is completed.
To complete the third step, assume the robot fixates on a horizontal line that it needs to jump to and oscillates up and down. Then, the line’s height in the image in normalized pixels can be used as ΦW. That is, ΦW = X2/X3 where X2 is the vertical position of the line and X3 is the distance between the camera and the line. Then, the characteristic scale of vision d is equal to X3 and is the distance to be jumped.
The fourth step of establishing a constraint between vision and control that involves the unknowns is accomplished by recalling Eq. (14), specializing it to this example’s dynamics, and adding the additional gravitational bias term. Finally, the fifth step can applied: estimating the force of gravity and the distance to the line in embodied units using Eq. (16). The full formulation is given in the methods section and specifically Eq. (23). There, a family of truncated exponential decay functions are used to represent the first order actuator dynamics, which results in a linear least squares problem and a unique solution. Subsequently, Eq. (17) can be used to recover the distance to be jumped in the embodied units as \({\hat{X}}_{3}({t}_{0})/b\). Figure 10 illustrates this procedure.
Then, given the embodied jumping distance d, embodied gravity estimate, and a predetermined launch angle θl, the robot can solve the projectile motion equations to determine a launch velocity, vl, and the landing time tf. To find control inputs that achieve this launch velocity, we pose a convex optimal control problem, (25), that solves for a non-negative control input with minimum total variation that reaches the launch velocity. The formulation of both problems is given in the methods section.
Figure 11 illustrates the results of this procedure in terms of the achieved jumping trajectory (in meters) and the applied control signal u in embodied units. Figure 12 illustrates the accuracy of the estimate of the distance to be jumped, d, and the gravitational force, gb, in the embodied unit after completing the measurement phase. Estimates resulting from processing simulated images with color thresholding and simulating worst case pixel quantization errors are shown. The error due to finite resolution can be seen to decrease by approximately 1/resolution. A theoretical justification for this is given in the Supplemental Material. For each set of experiments, the non-varied parameter values were set to d = 3.0, 1/α = 0.1, \({\rm{res}}=200\), T = 10, gb = 9.81, and b = 0.2.

The procedure can successfully jump over a wide range of unknown gaps varying from 1 to 4 meters in width. A nominal gap of 3 meters can be jumped despite variations in the unknown actuator time constant, camera resolution, oscillation period, gravitational force, and actuator gain. The jump control signals resulting from an embodied optimal control problem (25) can be seen to vary in magnitude and duration as expected given varied jump distance, actuator time constant, gravitational strength, and actuator gain.

The blue ground truth corresponds to ground truth values. Green estimates result from using an image and color thresholding to estimate ΦW. Blue shaded regions illustrate the maximum error achieved via simulated pixel quantization errors varied over 26 trials. Larger jump distances are estimated less accurately. Lowering the camera resolution below 200 pixels increases estimation error quickly. Increasing the oscillation period slightly improves results. Lower actuator gain, which results in less oscillation, decreases the accuracy of the estimated distance. While some variation in the estimate of gravitational bias can be observed, the error is typically on the order of 0.02 %. The effects of varying the actuator time constant and gravitational strength are included for completeness when comparing to Fig. 11.
It should be noted that performing the up and down oscillation requires a controller to compensate for the effects of gravity. For this experiment, the control gains were chosen manually, but they could easily be chosen automatically using traditional system identification and control design methods. Additionally, the mass of the robot’s legs and feet have been neglected as the effect of their mass on the jumping trajectory cannot be estimated by oscillating the body alone. For the purpose of this paper, it suffices to assume the mass of the legs and feet is small, and so does not significantly affect the achieved jumping trajectory. However, the effect of the added mass of the legs and feet can be estimated by doing a vertical test jump prior to jumping the gap. Finally, because the approach is model based, it, in theory, works for all gap sizes, gravitational strengths, and actuator time constants. However, given fixed parameters, it will fail in specific scenarios where the model’s assumptions do not hold. For example, if the strength of gravity is made very weak, the agent may fall off the jumping platform during the measurement phase unless the oscillation frequency and magnitude are also reduced.
Comparisons to Bees and Gerbils
Next, we contrast the properties of algorithms using Embodied Visual Scale with behavior observed in bees and gerbils.
Bees have been recently shown to understand the size of an opening in wingbeats during their approach to an opening. It is thought that the size of the wings is learned during early development through contact with the hive. Additionally, the bees oscillate increasingly vigorously as openings are made smaller, seemingly to determine the size of the hole more accurately13. Similarly, our method for uncalibrated clearing determines the size of the robot in embodied units through contact and oscillates to determine the size of the opening. Additionally, an examination of the least squares formulation admits that increased oscillation over longer periods will increase the accuracy and robustness of the estimated quantities because errors can be averaged out.
Similarly, Mongolian Gerbils vibrate their body up and down before making a jump over a gap of unknown distance. It is thought that this helps their visuomotor system determine the appropriate muscle stimulation to clear the gap11. Like bees, the intensity of the oscillations increases when the gap is larger and thus is more difficult to jump over. Our approach also requires oscillation, can estimate the appropriate actuator stimulation to jump a gap, benefits from larger oscillations (which induces a larger baseline for vision), and can increase its accuracy by considering longer timer intervals.
Discussion
Embodied Visuomotor Representation is a concrete methodology that allows robots to emulate the process of estimating distance through action – a capability well established in the natural sciences. This approach simplifies implementation by allowing low-level control laws to self-tune and removing the need for detailed physical models or calibrated 3D sensors. As a result, even uncalibrated robots can reliably perform tasks such as touching, clearing obstacles, or jumping, while maintaining guaranteed stability.
Traditionally, body-length units have been proposed as a natural basis for embodied scale. However, such measurements are not directly accessible to an uncalibrated robot. Embodied Visuomotor Representation addresses this limitation by providing a mechanism through which a robot can internally estimate or re-estimate body-length units as needed. Instead of relying on external units like meters, it grounds the perception of distance using the robot’s own acceleration response to control inputs.
We further compare traditional approaches based on sense-plan-act with our approach based on Embodied Visuomotor Representation in Table 3. The table compares the main algorithmic components of traditional approaches that might be used to achieve touching, clearing, and jumping. This comparison reveals how the stability of traditional approaches becomes implicitly tied to prior knowledge of the conversion factor between an embodied scale and an external scale due to the assumption of control inputs on an external scale. Embodied Visuomotor Representation can escape this situation by using a different architecture from the traditional sense-plan-act cycle as illustrated by Fig. 1.
The development of Embodied Visuomotor Representation has borrowed ideas broadly from many areas, in particular the Tau Theory, Glenberg’s theory of embodiment as memory, the Internal Model Principle, and Visual Self-Models. Below, these frameworks are compared and contrasted to Embodied Visuomotor Representation. We further compare our framework to leading approaches in robotics, including Direct Optical Flow Regulation, Visual Servoing, Visual Inertial Odometry (VIO), Visual Self-Modeling, and Deep Visuomotor Control.
The Tau Theory originally proposed an embodied visuomotor relationship as the basis for how time-to-contact could be used by humans for tasks such as driving a car14. This was developed into the General Tau Theory30, which aims to explain numerous behaviors using time-to-contact (tau). Later theories generalized it to motion in all directions, called looming31. Tau Theory does not provide a specific methodology for achieving tau trajectories and so roboticists have proposed methods ranging from direct regulation18,32,33 to indirect estimation of position followed by regulation28,34,35, with most relying on pre-tuned of control laws to account for the unknown embodied scale. Embodied Visuomotor Representation can use time-to-contact as the basis for a scaleless visual transition matrix ΦW as in28 without committing to any particular control law. Further, it is easy to use the framework to verify if a proposed control law is stable.
A generalization of Tau Theory is Direct Optical Flow Regulation. Here, arbitrary optical flow fields are used as the setpoint to a control loop. Such control schemes have been shown to result in striking similarities to insect flight behavior15,36,37,38. Notably19, showed that the framework allows orientation with respect to gravity to be estimated using oscillations of orientation. Such schemes depend on pre-tuning of the control law for the expected heights and velocities39. addresses this limitation by lowering the open-loop gain when oscillations occur. Embodied Visuomotor Representation can continuously estimate embodied distance without necessarily oscillating. Thus, it can be used to follow more general trajectories while simultaneously scaling the gains of a direct optical flow regulator to ensure stability.
Another approach to visuomotor control is Visual Servoing which considers objectives based on position (pose based) or image coordinates (image based)16,17. When combined with Embodied Visuomotor Representation, pose based approaches no longer require a 3D model of known scale as demonstrated by uncalibrated touching and clearing. This situation is similar to that considered by Image Based Visual Servoing, which operates without knowledge of scale by basing the control objective on the pixel positions and mitigating the effects of unknown depth using approximations, partitioning, or adaptivity16,17,40. Embodied Visuomotor Representation provides an estimate of depth, and so is closely related to adaptive visual servoing. However, Embodied Visuomotor Representation is also a broader framework that enables a rich set behaviors such as the examples of touching, clearing, and jumping.
Our implementation of these behaviors has strong parallels with Glenberg’s theory of embodiment as memory22. Glenberg writes, “embodied representations do not need to be mapped onto the world to become meaningful because they arise from the world” and our proposed Embodied Visuomotor Representation does just that. A core tenet of Glenberg’s theory is the “merge” operation that allows memories of different types of actions to be combined to do a new task. Our Embodied Visuomotor Representation admits a path towards realizing a general motion-based “merge” operator because it explicitly represents the system’s dynamics.
Realizing such advanced behavior requires the ability to predict. This is supported by the Internal Model Principle, that suggests an internal model of the process to be regulated must be contained within a controller if it is to succeed. This principle has analogs in psychology, where it is accepted that humans depend on internal models to control themselves24,41. Further, recent evidence strongly suggests that even simple animals such as dragonflies have such predictive visuomotor models12,25. In computer science, Animate Vision was proposed to explain how such visuomotor control processes can be learned through interaction with the environment4,42. These theories are very general and do not explicitly consider the challenges introduced by the unit-less nature of vision. Thus, Embodied Visuomotor Representation can be seen as a specialization that can realize versions of these theories in robots.
An important component of predictive modeling is understanding the shape of the body. While the given examples of uncalibrated touching and clearing are the most basic way to do this, it is of interest to combine Embodied Visuomotor Representation and recent work on Visual Self-Modeling that consider neural representations of a robot’s 3D form43. Similarly, it is of interest to understand Embodied Visuomotor Representations application to Deep Visuomotor Control as exemplified by44. Recent work has considered visual navigation, where a robot must learn to navigate through a scene from visual inputs and output concrete actions to be taken by low-level controllers provided by a variety of morphologies45,46,47.
Next, we turn to Visual Inertial Odometry (VIO), and its relation to Embodied Visuomotor Representation. VIO is the conventional approach to estimating a robot’s state from vision and calibrated inertial measurement units (IMUs). Typical approaches follow a match, estimate, and predict architecture to estimate a metric trajectory and the 3D position of tracked points48,49,50,51. Architecturally, this is identical to sense-plan-act but in the estimation setting. In contrast, Embodied Visuomotor Representation generally considers the characteristic scale of vision, which may not be the distance to features. This encourages an object-centered visual framework where control tasks are considered with respect to individual objects. Similarly, the role of IMUs is different within Embodied Visuomotor Representation. They are useful for estimatating rotation over short periods. and their acceleration can be used up to scale to better estimate mechanical parameters. They also allow a robot to continuously estimate the conversion factor between its embodied scale and an external scale as might be needed to adhere to a safety standard or follow high level directions.
The above comparisons to existing concepts resulted in several directions for future work. However, there are many more, and so below, we outline the future work in theory and applications that we consider most important.
In terms of theory, this paper has considered only equality-constrained Embodied Visuomotor Representation. That is, the unitless quantities from vision are considered to exactly equal some operator of control inputs. Ideas from psychology, and, in particular, the Tau Theory, suggest that more qualitative processes will suffice for many applications. Thus, it is of interest to develop inequality-constrained Embodied Visuomotor Representation in hopes of realizing qualitative representations and qualitative control laws that robots can use to accomplish tasks. Similarly, it is of interest to develop Embodied Visuomotor Representation in combination with direct methods such as Direct Optical Flow Regulation, and Image Based Visual Servoing. Here, an embodied representation of distance can be used to help initialize, learn, or select direct control laws. Finally, the role of rotation has recently been found to be useful for estimating attitude from direct measurements 19. Thus, it is of interest to carefully consider the role of rotation in embodied representation.
Turning back to equality-constrained Embodied Visuomotor Representation, we have presented two types of estimation problems. The first, exemplified by (10), estimates quantities in embodied units of action. The second formulation is given by (11) and (16) which estimate quantities in units of the visual processes characteristic scale. Subsequently, these quantities can be converted to an embodied unit of action. While the latter were shown to be unbiased with respect to zero mean noise in ΦW, it is still of interest to perform a more general and careful error analysis with the goal of constructing robust or optimal estimators for Embodied Visuomotor Representation.
Next, we discuss the representation of dynamics. The derivation of Embodied Visuomotor Representations above neglected damping and spring effects, as might be caused by friction or tendon-like attachments, respectively. However, these effects can be incorporated, assuming these naturally occurring dynamics are stable, which they almost always will be. For example, we can incorporate into an Embodied Visuomotor Representation a system’s dissipating energy due to spring and damping effects by considering velocity or position as the fundamental quantities controlled by the action instead of acceleration. In this paper, acceleration was used as the fundamental quantity controlled through action because all animals and robots must use forces.
Finally, it is interesting to consider more general dynamics than linear systems and how to control them via Embodied Visuomotor Representation. In principle, except for the use of unit-less visual feedback, this is not substantially different from existing work in robot dynamics, and we expect many techniques to port over directly. On the other hand, the linear dynamics considered in this paper should be sufficient for many applications. Thus, it is of interest to apply recent advancements in adaptive control, such as kernel methods that guarantee estimation of BIBO stable impulse responses52.
Next we consider future work in applications. A straightforward application that can be accomplished via Embodied Visuomotor Representation is avoiding and pursuing dynamic objects. If a position-based approach is used, the basic procedure is identical to the touching, clearing, and jumping, except that an additional model of the dynamic object must be considered. Catching is also of interest. However, it is thought that humans use direct methods (that is, they do not primarily rely on 3D position) to catch objects. The evidence is particularly strong in sports where humans achieve extraordinary performance despite sensorimotor delays53,54. Then, since Embodied Visuomotor Representation allows for learning predictive self models that could be used for delay compensation (as is thought to be essential in biological systems12,24), it is of particular interest to study the theoretical connections between embodied representation and direct methods in the task of robot catching.
We also consider imitation and embodied affordance estimation to be the next two most important applications. Assuming the embodied mechanical and dynamics parameters have already been estimated, imitation within Embodied Visuomotor Representation becomes a problem of determining the embodied control signals that accomplish a visually observed behavior. The characteristic scale-based representation of vision will then naturally allow robots to imitate an action using the units of their own embodiment instead of an external scale.
Finally, while this paper has exclusively considered visual processes and their connection to motor signals, the basic principles should be extended to consider multiple modalities such as tactile sensing and audio. We are particularly interested in tactile sensing because grasping is an action that results in both tactile and visual responses.
Methods
Hardware
The robot platform used for the touching and clearing experiments is a DJI RoboMaster EP. The platform features mecanum wheels, which allow it to translate omnidirectionally. The provided robot arm and camera were removed and replaced with a pan-tilt servo mount and a Raspberry Pi Camera Module 3 with a 120 degree wide-angle lens running at 1536 × 864 resolution and 30 frames per second. A Raspberry Pi 5 interpreted images and calculated control commands for the robot. The associated code is provided in the Supplemental Material.
The DJI RoboMaster does not support direct acceleration control. The lowest level supported is velocity control. To emulate the double integrator described in the touching and clearing experiments, the acceleration commands from the proposed control laws were transformed into velocity commands using a leaky integrator with a time constant of 10 seconds.
Uncalibrated touching
The touching experiment uses color thresholding to detect the pixels of a planar target and calculate ΦW based on the assumption of a flat target parallel with the image plane. As mentioned in the results section, this visual representation was chosen as a pedagogical example and will not work for non-flat objects. In general, the theory holds without modification for any other vision algorithm that provides position to scale as per (4). The robot oscillates in open-loop by applying a 1/3 Hz sinusoidal acceleration signal over a 10 second interval. The amplitude of acceleration was set so that the positional oscillations had an amplitude of 25 cm when b = 1. Equation (11) is used to solve for the current position, velocity, and size of the touching target in embodied units using a 3 second sliding window of measurements. To do so, the outermost integral of Eq. (11) is approximated in discrete time, so that the problem can be considered as a standard linear least squares problem of the form \(\mathop{\min }\nolimits_{x}\parallel\! Ax-b{\parallel }^{2}\). This problem is transformed to the normal equations ATAx = ATb and x is computed using JAXopt’s55 Cholesky decomposition based solver for linear systems. The code is available in the supplemental material.
Subsequently, the robot drives toward the target at a constant velocity of 0.3 embodied units per second using PID control and positional feedback from vision in embodied units. The approach continues for the time required to traverse the initial distance between the robot and the target. Since the robot’s body is closer to the target than the camera, the robot makes contact with the target sometime during this interval. Then, the minimum distance between the robot’s camera and the target is the horizontal distance between the robot’s camera and the edge of the robot that made contact with the target first.
The PID control loop was tuned manually and was accomplished with just a few trials because the closed-loop behavior does not depend on the units of distance or the geometry of the scene. Thus, reasonable initial values for the PID gains can be determined from a desired closed loop bandwidth.
Uncalibrated clearing
The clearing experiments consider whether the robot can fit through an opening (clear it) prior to reaching the opening. To do so, the robot determines the width of the body in the embodied unit by touching its left and right sides to a nearby object using the previously described procedure. It remains for the robot to measure the size of an opening in the embodied unit. Once again, the left and right sides of the opening are detected with color thresholding. The left and right edges of the right and left sides of the opening, respectively, are used as the characteristic scale of vision. As with the last example, this visual representation is pedagogical. The same sinusoidal acceleration and sliding window estimator used during uncalibrated touching then estimates the size of the opening in the embodied units. If the robot is smaller than the opening, it proceeds through with the same PID-based position control as used for uncalibrated touching.
Uncalibrated jumping
The jumping robot experiment was performed in a MuJoCo simulation56. Codes for this simulation are provided in the Supplemental Material.
The robot consists of a body on two legs and feet. The legs are modeled as cylinders or pistons, with first-order activation dynamics and a time constant of 0.1 seconds. The body mass was set to 10 kg, and the mass of the legs and feet amounted to 0.22 kg. Two angular position controllers hold the legs upright during the measurement phase of the experiment and tilt the body forward approximately 20 degrees during the jumping phase.
The measurement phase of the jumping experiment consists of three parts. In the first, the minimum/maximum position of the body is estimated by recording the initial position as the bottom position, increasing the upwards force until the body begins to lift, initializing a PID controller’s integrator term with the force that overcomes gravity, and using PID control to maintain a constant upwards velocity until the top position is reached. Subsequently, the PID controller oscillates the body for 10 seconds at 1 Hz around the midpoint between the bottom and top positions with an amplitude equal to 1/4 of the distance between the top and bottom positions. While this approach introduces an assumption of a pre-tuned PID controller to control the body position, this could be eliminated by applying traditional system identification techniques in the embodied units.
During oscillation, color thresholding is used to determine the vertical normalized pixel coordinate corresponding to a red line placed in the middle of the target platform. The characteristic scale of vision then becomes the distance between the robot and the red line. Subsequently, the measurements of the control effort applied by the PID control and the vertical normalized pixel coordinate are used to solve for the leg actuator’s impulse response, the distance between the robot and the red line, and the initial velocity.
The simulated camera has a resolution of 200 × 200 pixels and a 90 degree vertical field of view and runs at 60 fps. Estimation of the maximum possible errors due to pixel quantization, as illustrated in Fig. 12, was achieved by quantifying the ground truth pixel position of the red line to integer coordinates with random quantization boundaries according to the formula psim = round(pgt + Δ) − Δ and varying the value of Δ between [− 0.5, 0.5] with 26 steps.
To approximate the actuator impulse response, a linear combination of 50 first-order impulse responses truncated to 4 seconds with a DC gain of 1 and time constants ranging from 0.008 to 0.5 seconds are considered. The resulting quadratic program to estimate the distance to the line, initial velocity, and actuator dynamics is then given by:
where \({\dot{X}}_{2}(0)\) is the initial velocity on the robot camera’s vertical axis, gb is the gravitational bias force, ci are the coefficients of the basis functions for g and τi are the corresponding time-constants of the basis functions. The double integral and convolution are computed using a 0.001 second approximation, corresponding with the simulation’s timestep. The outermost integral is approximated with a 1/60’th of a second timestep, corresponding to the 60 fps simulated camera. The loss is evaluated over the interval [4, T] instead of [0, T] to prevent initial conditions from contributing to the actuator dynamics through the 4 second long impulse response g. Non-negativity of ci is necessary to prevent overfitting to numerical integration errors. Similarly to the uncalibrated clearing and touching implementation, the problem is solved by approximating the outermost integral in discrete time. This results in a constrained quadratic program, which is solved using CVXOPT’s quadratic program solver57. The code is available in the supplemental material. By solving this problem, the dynamics of the system are estimated automatically.
To convert from units of the characteristic scale to embodied units of action, we divide each estimated quantity by \(\mathop{\int}\nolimits_{0}^{\infty }g(t)dt/d\). In what follows, all quantities can be assumed to be in this embodied unit.
Subsequently, the standard equations for projectile motion are combined with the estimated embodied distance and gravitational force to solve for an embodied launch velocity vl that will jump the gap. The equations to be solved are
where tf is the time of landing.
Finally, A terminally constrained optimal control problem is solved to find the control input with a minimum total variation that accelerates the body from rest to the launch velocity in 250 milliseconds over the distance oscillated over during the measurement phase. The resulting quadratic program is:
where vl is the necessary launch velocity in embodied units, and dm is the distance from the start position at which the launch velocity should be achieved. dm is necessary to ensure the launch velocity is reached prior to reaching the maximum position of the body with respect to the legs.
Non-negativity of u is required to prevent lifting the lightweight legs from the jumping platform prior to reaching the launch velocity. We formulate and solve the problem using a discrete time approximation of 0.001 seconds. Because of exponential decay, (g*u)(t) > 0 when t > T, and so the leg actuators are deactivated for t > T to prevent the body’s velocity from exceeding vl. The resulting embodied jump control signal u is offset by the estimated gravitational bias and executed in an open loop.
Thus, by combining (23) and (25), the estimation of system dynamics and the synthesis of the jumping control input are fully automated, except for the use of a PID controller during the oscillation phase. However, this step could also be automated using existing system identification or adaptive control techniques. It is important to note that this example is pedagogical and does not account for or attempt to mitigate disturbances. Nonetheless, this does not affect the generality of the result, as Embodied Visuomotor Representation solely determines the units of distance and remains compatible with any jumping algorithm.
Data availability
All data needed to interpret the conclusions of the paper are presented in the paper or Supplementary Materials. Raw datasets generated and analyzed during the study are available from the corresponding author upon reasonable request.
Code availability
Code for running the touching, clearing, and jumping experiments is provided in the Supplementary Materials and at prg.cs.umd.edu/EVR. Code for analyzing raw datasets collected during the study are available from the corresponding author upon reasonable request.
References
Marr, D. Vision: A computational investigation into the human representation and processing of visual information (MIT press, 2010).
Aloimonos, J., Weiss, I. & Bandyopadhyay, A. Active vision. Int. J. Comput. Vis. 1, 333–356 (1988).
Bajcsy, R., Aloimonos, Y. & Tsotsos, J. K. Revisiting active perception. Autonomous Robots 42, 177–196 (2018).
Ballard, D. H. Animate vision. Artif. Intell. 48, 57–86 (1991).
Stephenson, A. G. et al. Mars Climate Orbiter Mishap Investigation Board Phase I Report (National Aeronautics and Space Administration, 1999).
Feldman, J. A. Four frames suffice: A provisional model of vision and space. Behav. Brain Sci. 8, 265–289 (1985).
Koenderink, J. J., Van Doorn, A. J. & Kappers, A. M. Surface perception in pictures. Percept. Psychophys. 52, 487–496 (1992).
Todd, J. T. The visual perception of 3D shape. Trends Cogn. Sci. 8, 115–121 (2004).
Cheong, L., Fermüller, C. & Aloimonos, Y. Effects of errors in the viewing geometry on shape estimation. Comput. Vis. Image Underst. 71, 356–372 (1998).
Ji, H. & Fermüller, C. Noise causes slant underestimation in stereo and motion. Vis. Res. 46, 3105–3120 (2006).
Ellard, C. G., Goodale, M. A. & Timney, B. Distance estimation in the mongolian gerbil: The role of dynamic depth cues. Behav. Brain Res. 14, 29–39 (1984).
Mischiati, M. et al. Internal models direct dragonfly interception steering. Nature 517, 333–338 (2015).
Ravi, S. et al. Bumblebees perceive the spatial layout of their environment in relation to their body size and form to minimize inflight collisions. Proc. Natl Acad. Sci. 117, 31494–31499 (2020).
Lee, D. N. A theory of visual control of braking based on information about time-to-collision. Perception 5, 437–459 (1976).
Ruffier, F. & Franceschini, N. Optic flow regulation: the key to aircraft automatic guidance. Robot. Autonomous Syst. 50, 177–194 (2005).
Chaumette, F. & Hutchinson, S. Visual servo control. I. Basic approaches. IEEE Robot. Autom. Mag. 13, 82–90 (2006).
Chaumette, F. & Hutchinson, S. Visual servo control. II. Advanced approaches. IEEE Robot. Autom. Mag. 14, 109–118 (2007).
Herissé, B., Hamel, T., Mahony, R. & Russotto, F.-X. Landing a VTOL unmanned aerial vehicle on a moving platform using optical flow. IEEE Trans. Robot. 28, 77–89 (2012).
De Croon, G. C. et al. Accommodating unobservability to control flight attitude with optic flow. Nature 610, 485–490 (2022).
Malis, E., Chaumette, F. & Boudet, S. 2 1/2 D visual servoing. IEEE Trans. Robot. Autom. 15, 238–250 (1999).
Corke, P. & Hutchinson, S. A new partitioned approach to image-based visual servo control. IEEE Trans. Robot. Autom. 17, 507–515 (2001).
Glenberg, A. M. What memory is for. Behav. Brain Sci. 20, 1–19 (1997).
Brock, O. Intelligence as computation. IOP Conf. Ser.: Mater. Sci. Eng. 1321, 012001 (2024).
McNamee, D. & Wolpert, D. M. Internal models in biological control. Annu. Rev. Control, Robot., Autonomous Syst. 2, 339–364 (2019).
Huang, J. et al. Internal models in control, biology and neuroscience. In 2018 IEEE Conference on Decision and Control (CDC), 5370–5390 (2018).
Baker, S. & Matthews, I. Lucas-Kanade 20 years on: A unifying framework. Int. J. Comput. Vis. 56, 221–255 (2004).
Åström, K. & Wittenmark, B. Adaptive Control (Dover Publications, 2008).
Burner, L., Sanket, N. J., Fermüller, C. & Aloimonos, Y. TTCDist: Fast distance estimation from an active monocular camera using time-to-contact. In 2023 IEEE International Conference on Robotics and Automation (ICRA), 4909–4915 (2023).
Hespanha, J. P. Linear Systems Theory (Princeton University Press, 2018), 2nd edn.
Lee, D. N., Bootsma, R. J., Land, M., Regan, D. & Gray, R. Lee’s 1976 paper. Perception 38, 837–858 (2009).
Raviv, D. A quantitative approach to looming (US Department of Commerce, National Institute of Standards and Technology, 1992).
Sikorski, O., Izzo, D. & Meoni, G. Event-based spacecraft landing using time-to-contact. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, 1941–1950 (2021).
Walters, C. & Hadfield, S. EVReflex: Dense time-to-impact prediction for event-based obstacle avoidance. In 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 1304–1309 (2021).
Izzo, D. & Croon, G. Nonlinear model predictive control applied to vision-based spacecraft landing. In Proceedings of the EuroGNC 2013, 2nd CEAS Specialist Conference on Guidance, Navigation & Control (2013).
Ho, H. W., de Croon, G. C. & Chu, Q. Distance and velocity estimation using optical flow from a monocular camera. Int. J. Micro Air Veh. 9, 198–208 (2017).
Franceschini, N., Ruffier, F. & Serres, J. A bio-inspired flying robot sheds light on insect piloting abilities. Curr. Biol. 17, 329–335 (2007).
Serres, J., Dray, D., Ruffier, F. & Franceschini, N. A vision-based autopilot for a miniature air vehicle: joint speed control and lateral obstacle avoidance. Autonomous robots 25, 103–122 (2008).
Ruffier, F. & Franceschini, N. Optic flow regulation in unsteady environments: A tethered mav achieves terrain following and targeted landing over a moving platform. J. Intell. Robotic Syst. 79, 275–293 (2015).
de Croon, G. C. H. E. Monocular distance estimation with optical flow maneuvers and efference copies: a stability-based strategy. Bioinspiration Biomim. 11, 016004 (2016).
Chen, J., Dawson, D., Dixon, W. & Behal, A. Adaptive homography-based visual servo tracking for a fixed camera configuration with a camera-in-hand extension. IEEE Trans. Control Syst. Technol. 13, 814–825 (2005).
Wolpert, D. M., Ghahramani, Z. & Jordan, M. I. An internal model for sensorimotor integration. Science 269, 1880–1882 (1995).
Ballard, D. H. & Brown, C. M. Principles of animate vision. CVGIP: Image Underst. 56, 3–21 (1992).
Chen, B., Kwiatkowski, R., Vondrick, C. & Lipson, H. Fully body visual self-modeling of robot morphologies. Sci. Robot. 7, eabn1944 (2022).
Levine, S., Finn, C., Darrell, T. & Abbeel, P. End-to-end training of deep visuomotor policies. J. Mach. Learn. Res. 17, 1334–1373 (2016).
Shah, D., Eysenbach, B., Kahn, G., Rhinehart, N. & Levine, S. ViNG: Learning open-world navigation with visual goals. In 2021 IEEE International Conference on Robotics and Automation (ICRA), 13215–13222 (2021).
Shah, D., Sridhar, A., Bhorkar, A., Hirose, N. & Levine, S. GNM: A general navigation model to drive any robot. In 2023 IEEE International Conference on Robotics and Automation (ICRA), 7226–7233 (2023).
Shah, D. et al. ViNT: A foundation model for visual navigation. In 2023 Conference on Robot Learning (CoRL) (2023).
Mourikis, A. I. & Roumeliotis, S. I. A multi-state constraint Kalman filter for vision-aided inertial navigation. In Proceedings of the 2007 IEEE International Conference on Robotics and Automation, 3565–3572 (2007).
Bloesch, M., Omari, S., Hutter, M. & Siegwart, R. Robust visual inertial odometry using a direct EKF-based approach. In 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 298–304 (2015).
Bloesch, M., Burri, M., Omari, S., Hutter, M. & Siegwart, R. Iterated extended Kalman filter based visual-inertial odometry using direct photometric feedback. Int. J. Robot. Res. 36, 1053–1072 (2017).
Qin, T., Li, P. & Shen, S. VINS-Mono: A robust and versatile monocular visual-inertial state estimator. IEEE Trans. Robot. 34, 1004–1020 (2018).
Bisiacco, M. & Pillonetto, G. On the mathematical foundations of stable RKHSs. Automatica 118, 109038 (2020).
Chapman, S. Catching a baseball. Am. J. Phys. 36, 868–870 (1968).
Regan, D. Visual factors in hitting and catching. J. Sports Sci. 15, 533–558 (1997).
Blondel, M. et al. Efficient and modular implicit differentiation. Adv. Neural Inf. Process. Syst. 35, 5230–5242 (2022).
Todorov, E., Erez, T. & Tassa, Y. Mujoco: A physics engine for model-based control. In 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, 5026–5033 (2012).
Andersen, M. S., Dahl, J., Liu, Z. & Vandenberghe, L. Interior-point methods for large-scale cone programming. In Sra, S., Nowozin, S. & Wright, S. J. (eds.) Optimization for Machine Learning, 55–83 (MIT Press, 2012).
Acknowledgements
The support of NSF award OISE 2020624 is gratefully acknowledged. The authors thank Rohit Kommuru for prototyping early versions of the jumping experiment.
Author information
Authors and Affiliations
Contributions
L.B. conceived and developed the mathematics for Embodied Visuomotor Representation, designed the algorithms solving the uncalibrated touching, clearing, and jumping problems, built the robot, wrote software, performed experiments, and wrote the manuscript. C.F. connected the ideas to existing literature and helped write the manuscript. Y.A. posed the questions answered by Embodied Visuomotor Representation, connected it to existing literature, and helped write the manuscript. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Burner, L., Fermüller, C. & Aloimonos, Y. Embodied visuomotor representation. npj Robot 3, 30 (2025). https://doi.org/10.1038/s44182-025-00047-y
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s44182-025-00047-y
