
Abstract
The integration of artificial intelligence (AI) and pervasive computing offers new opportunities to sense mental health symptoms and deliver just-in-time adaptive interventions via mobile devices. This pilot study tested personalized versus generalized machine learning models for detecting individual and family mental health symptoms as a foundational step toward JITAI development, using data collected through the Colliga app on smart devices. Over a 60-day period, data from 35 families resulted in approximately 14 million data points across 52 data streams. Findings showed that personalized models consistently outperformed generalized models. Model performance varied significantly based on individual factors and symptom profiles, underscoring the need for tailored approaches. These preliminary findings suggest that successful implementation of passive sensing technologies for mental health will require accounting for users’ unique characteristics. Further research with larger samples is needed to refine the models, address data heterogeneity, and develop scalable systems for personalized mental health interventions.
Similar content being viewed by others


Introduction
The advent of artificial intelligence (AI), pervasive computing, and big data has opened new frontiers in mental healthcare, offering innovative ways to sense psychological states, intervene in real time, and promote well-being. Despite rapid technological advances, building reliable data collection systems that can handle large volumes of information—while addressing challenges in data quality, processing, and interpretation—remains difficult. This pilot study explores the potential of AI and pervasive computing for detecting dynamic psychological states in daily life and their application in informing the development of future Just-in-Time Adaptive Interventions (JITAIs) for individuals and families. Specifically, we1 review the current literature2, provide a framework for building these systems3, present preliminary performance results for generalized and personalized AI models for sensing mental health symptoms, and4 investigate the conditions under which such models achieve higher performance. We suggest that building personalized algorithms tailored to individual symptom profiles could significantly enhance model performance and scalability, paving the way for more effective digital mental health interventions.
AI is increasingly reshaping multiple sectors of society, with interest in its applications for healthcare—and particularly mental healthcare—accelerating rapidly. Potential innovations, such as delivering automated mental health interventions via smartphones and creating personalized and adaptive treatment plans, offer significant promise for improving both the accessibility and quality of mental health services1,2. The COVID-19 pandemic and its aftermath, including barriers to in-person care provision and widespread strain on the healthcare system, further increased interest in leveraging AI to expand mental health treatment availability3. Reflecting this momentum, funding for AI-driven mental health research has substantially increased. For example, the National Institute of Mental Health boosted its investment in projects applying AI to diagnose and treat mental health problems from $6.3 million in 2019 to over $34 million in 2023 (https://reporter.nih.gov/).
One particularly promising application of data science technologies is the use of AI and passive sensing methods to detect and eventually intervene in family mental health processes as they unfold in daily life. Key indicators of family functioning, such as conflict and aggression, can often be captured through external, observable, and quantifiable metrics—for example, characteristics of speech content4. In addition, physiological measures such as electrodermal activity, heart rate, and respiration offer insight into the internal emotional states associated with family interactions and dynamics5. Importantly, many of these behavioral and physiological signals can now be collected through widely accessible mobile devices. Smartphones can record audio and track communication patterns, while smartwatches and other wearables can continuously monitor physiological activation. The ability to unobtrusively capture these multimodal data streams in naturalistic environments positions child and family mental health as an ideal domain for algorithm development. Such systems could ultimately support the creation of automated and adaptive interventions tailored to the complex realities of family life6,7.
The adoption of AI in healthcare has heralded new paradigms for the development and deployment of mental health treatments. As the adage goes, “If the only tool you have is a hammer, you will start treating all your problems like a nail.” Many mental health therapies developed to date have focused on treating clients in office settings for 50 min each week. New technological advances, however, offer novel frameworks where treatments are no longer limited to specific and contrived environments or timescales. One innovative approach that has recently received increased attention is Just-in-Time Adaptive Interventions or “JITAIs.” JITAIs aim to provide individualized support by adapting to the individual’s changing internal and contextual states, for example, sending a prompt when a depressed client feels especially sad or when an individual with a substance use disorder approaches a liquor store6,7. Advocates of JITAIs note several advantages compared to standard care8, as interventions delivered through mobile apps offer accessible and continuous monitoring and support, targeting micro-level states and behaviors (e.g., mood or activities) in situ to impact macro-level outcomes (i.e., clinical diagnosis). These methods could also adapt to individual needs and contexts, improving receptivity to and the precision of treatments. Though the development of JITAIs is still nascent, preliminary research indicates enormous potential for clinical application. Promising early applications have been used for increasing physical activity9,10,11, promoting weight loss9,12, improving sleep13, and managing substance use14,15.
Although JITAIs hold great promise for enhancing therapy effectiveness and increasing access to mental healthcare, significant barriers have hampered development and implementation. Such barriers include the need for pervasive computing technologies that can process large data volumes in real-time, data privacy and ethics concerns, and the limited generalizability of AI models developed in specialized contexts7,16,17. Additionally, various issues, such as decreased user engagement over time, the intrusiveness of the interventions, participant selection biases, and non-random data missingness, limit the effectiveness of JITAIs18. Despite extensive discussions in the literature on the utility of JITAIs19,20, a limited number of clinical trials have been conducted, leaving key questions about their real-world effectiveness unanswered. Of the JITAI clinical trials conducted to date, most have focused on readily observable and objective physical health behaviors, such as weight loss, sleep, and physical activity, or have targeted substance use10,15. Other implementations have used self-report surveys to trigger intervention prompts21, with few studies intervening based on passively sensed moods, such as stress or anxiety. Moreover, no studies to our knowledge have developed JITAIs specifically for family mental health and interpersonal processes. Reviews of JITAI clinical trials conducted thus far suggest somewhat mixed efficacy. For example, a systematic review of JITAIs targeting physical activity found a wide range of outcomes, with some interventions increasing physical activity and decreasing sedentary time, others finding reductions in sedentary time only, and several studies finding no significant effects on either outcome10. For substance use, efficacy has been similarly mixed, with some studies reporting significant effects for alcohol, smoking, and illicit drug use and others reporting no treatment impacts15.
Given the immense potential of JITAI interventions to reshape mental healthcare, it is imperative that research and development continue to improve upon current JITAI implementations to realize their potential and achieve wide-scale dissemination and implementation. However, one of the most significant challenges to successfully implementing JITAIs is the reliable and accurate detection of mental health symptoms and interpersonal processes of interest as they dynamically fluctuate in everyday life and are influenced by multiple fluctuating, external contexts. The detection of dynamic mental health symptoms and interpersonal processes in daily life is critical for JITAIs, given that they rely on in-the-moment sensing to send interventions at crucial times of need. Achieving high predictive performance for these models and in these conditions, however, is difficult for several reasons. First, features used to detect moods in daily life, such as physiological activation or text messaging frequency, may only weakly relate to emotional states, such as stress or sadness. Second, collecting data and implementing algorithms in uncontrolled environments introduces confounding factors that lessen signal-to-noise ratios in the data. For example, environmental temperature and physical activity can impact physiological arousal levels, obscuring physiological arousal fluctuations specifically related to stress. Third, in real-world scenarios, there is a high heterogeneity in feature sets, types of mobile devices and sensors owned, missingness, and symptom profiles, resulting in poor generalizability of AI models outside of highly specific and controlled research contexts.
Thus far, many AI algorithms for mental health that use mobile data have focused on sensing overall symptom levels or classifying people into general diagnostic categories22,23,24. Such studies, although useful and informative, do not sense dynamic changes in mood and functioning on a moment-to-moment level, which are necessary for JITAI implementation. Other applications have focused on the identification of indirect behavioral indicators of mental health functioning. For example, various studies have shown that geospatial activity, sleep, speech duration, text message frequency, and similar metrics are linked to fluctuations in depressive symptoms and stress25,26. However, these studies only identify links between variables and symptoms and do not create or assess AI models for automatized and passive symptom detection. Other models built to detect emotions in daily life rely on specialized sensors that are not widely available and unlikely to be worn consistently in the long-term, especially outside of the research context27,28. In other applications, researchers have relied on self-report surveys sent through smartphones as features or tailoring variables9,29, but this method limits the utility of JITAIs as passive and automated intervention systems. At the same time, studies conducted in the engineering domain show promise for using non-intrusive data collected from built-in smartphone sensors (e.g., GPS, gyroscope, accelerometer) to detect various emotions with good performance30.
A critical next step for developing AI models capable of detecting dynamic changes in mental health symptoms and interpersonal processes in real-life is investigating the conditions under which these models perform optimally. One promising direction is the creation of personalized models with the symptom sets detected and the data streams used specific to each user. This approach would allow JITAI implementation that integrates flexibly across different commercial devices (e.g., iPhones, Fitbits) and platforms. Further, this approach would allow for AI models to fit into existing pervasive computing ecosystems and would accommodate diverse data streams of varying quality, addressing computational challenges by adapting each algorithm to fit the real-world usage of everyday devices across idiosyncratic users and use cases. For example, each potential JITAI user likely owns a different type of smartphone and may or may not own a smartwatch, thus contributing different features at different frequencies and with different degrees of missingness. Similarly, each person with a given mental health problem experiences a unique set of symptoms, with partial but not complete overlap in symptoms across different people diagnosed with the same mental health condition. Additionally, each potential user experiences symptoms at different rates and with different degrees of consistency versus inconsistency across time points. Developing personalized models that use the available data per user to detect symptom sets relevant to that person is, therefore, crucial for building usable, reliable, and scalable systems that will meaningfully impact mental healthcare.
The current study presents preliminary proof-of-concept data supporting the development of personalized machine learning (ML) models as a critical early step toward future JITAI implementation. Utilizing the pervasive computing system, Colliga, we collected ~14 million data points over 60 days from 35 families with children aged 6–9 years. Data included mobile sensing inputs related to caregivers’ moods (happy, sad, angry, nervous, stressed) and family interactions (quality time, closeness, positive interactions, negative interactions, conflict, aggression). We focus on these 11 states because of their significance for individual and family mental health processes31,32,33 and their potential to be used as intervention targets in future JITAI applications. Building on these data, we developed ML models to detect these key mental health and family functioning states to lay the groundwork for future adaptive intervention deployment.
First, we developed generalized ML models, hypothesizing that we would detect mood and family functioning with moderately good accuracy (HO1). Second, we built personalized models for each user, hypothesizing that the personalized models would outperform the generalized models (HO2). Third, because users may endorse symptoms at different frequencies and with different levels of consistency, we examined how individual factors like symptom profiles and user behavior impact model performance. We hypothesized that greater symptom endorsement (HO3a), greater adherence in completing survey data (HO3b), and lower variability in symptom endorsement (HO3c) would be linked with increased model performance, suggesting that matching ML models to the individuals’ specific mental health profiles is necessary for achieving good performance in real-world use scenarios. Fourth, because different types of features (e.g., activity, sleep, speech) may be more predictive of mental health symptoms than others, we investigated the model performance of specific feature sets, hypothesizing that the best performing feature sets would differ across the different mental health symptoms examined (HO4).
Methods
Participants
The pilot study consists of 35 families with at least one participating caregiver and one child aged 6–9 years old (one family included two participating caregivers for a total of 36 people) living in either Florida or Texas who spoke either English and/or Spanish (all materials and study visits were provided in the participants’ preferred language). To ensure we obtained a representative and diverse sample with a focus on underserved families for building our algorithms, families were required to meet eligibility criteria for at least one of the following1: qualify as resource-limited (defined as the 33rd percentile of income for their county of residence adjusted for their household size) or2 include at least one participating family member who self-identified as belonging to a traditionally or historically underrepresented racial or ethnic minoritized group. Demographic data and inclusion criteria were selected in accordance with the APA’s standards for inclusivity and bias-free language (https://apastyle.apa.org/style-grammar-guidelines/bias-free-language/general-principles/). Because we aim to use these algorithms to develop a JITAI focused on child and family mental health symptoms, we further required the family to endorse elevated child mental health symptoms, defined as scoring at or above the 70th percentile on at least one subscale of mental health problems on the Strengths and Difficulties Questionnaire34. Table 1 summarizes the sample demographics.
Procedures
Study participants were recruited through several methods, including flyers posted in the community, participant referrals, research centers, clinics, and social media advertising. Interested families completed a contact form and were then contacted by an experimenter to conduct an initial phone screening to determine eligibility based on income, ethnic or racial status, and child mental health symptoms. Eligible families were then scheduled for a study visit where they completed adult consent and child assent, conducted a second screening, and completed questionnaires assessing child and caregiver mental health and family functioning. Due to the risk of capturing emergency events in our data and because our sensing system was not equipped for immediate emergency response, we screened out families who endorsed active suicidal or homicidal ideation, domestic violence, and child maltreatment after obtaining consent during the second screening. No families endorsed suicidal or homicidal ideation, domestic violence, or child maltreatment at the second screening; thus, all families completing the second screening were subsequently enrolled in the study.
After Visit 1 was completed, experimenters scheduled Visit 2 with participants ~10 days later, which was conducted online. Smartphones (iPhone or Android) and Fitbit devices or Apple Watches were shipped to participants in advance of Visit 2 if they did not own compatible devices or preferred to use lab-issued devices. During Visit 2, experimenters guided participants through downloading the Colliga app and syncing it to their wearable device and explained the home data collection procedures. The Colliga app was available on commercial app stores (App Store and Google Play), but participants could not create an account or access the study without receiving a secure invitation. Specifically, participants were sent an email invitation with a secure link, which redirected them to the store for standard download and installation. Access to the app was restricted to study participants to maintain controlled enrollment. Participants were also shown how to pause or stop data collection and mute the microphone directly from the app’s home screen. They were instructed to inform experimenters if they wished to have any of their data deleted. Participants were given a 1-week window following each week of data collection to request deletion before the research team downloaded and reviewed the files. Participants could also request deletion of previously reviewed data at any time. No families requested data deletion during the study. After the 1-week period, research assistants downloaded the data and reviewed them for any indications of risk events (e.g., domestic violence, child maltreatment). Any potential concerns identified through audio recordings or survey responses were followed up with clinical risk assessments overseen by a licensed clinical supervisor to ensure participant safety.
Caregivers carried smartphones and wore either a Fitbit or an Apple Watch for 60 days, and a total of 52 data streams were collected (see Table 2 for a complete list). Caregivers wore either an Apple Watch or Fitbit. The Colliga App collected a variety of passive data streams that did not require action by the participant (e.g., ambient light, accelerometer, GPS). In addition, the app sent notifications to participants to complete 30-min audio recordings and brief surveys twice per day assessing mood and family functioning. Surveys were randomly scheduled once in the morning, between 7:00 am and 11:00 am, and once in the evening, between 5:00 pm and 9:00 pm. Audio recordings were scheduled at 7:00 am and 6:30 pm to increase the likelihood of capturing times when caregivers and children were interacting with each other. In addition to reviewing the data weekly, the experimenters received email notifications when participants endorsed aggression in their surveys and followed up with participants via phone call within 24 h for a risk assessment. Experimenters also conducted check-in calls every 2 weeks to assess clinical functioning and identify possible clinical deterioration. In total, ten risk assessments were conducted due to ongoing data monitoring (n = 6), survey aggression endorsement, and bi-weekly check-ins (n = 4). Out of all risk assessments conducted, one event necessitated providing a report to police and child protective services.
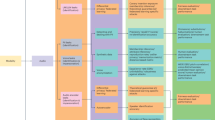
After ~60 days of data collection, caregivers attended a third online visit during which they repeated the questionnaires completed at Visit 1 and completed an additional questionnaire and interview assessing their experiences using the Colliga App. Of the 35 families enrolled, 33 completed the final termination visit. Although termination visits were generally scheduled to occur at least 60 days after enrollment, the exact number of days varied depending on participant availability for the final study visit and was frequently extended for families due to rescheduling needs or requests to make up missed survey data collection (n = 30). Families were compensated $50 following Visit 1 and $150 following Visit 3. An overview of the study procedures is presented in Fig. 1. In addition to the online participation option, local families were given the opportunity to attend study visits in person (n = 5). In-person procedures were identical except that two visits were conducted instead of three, as device setup was completed during the initial visit. All study procedures were conducted in accordance with the ethical standards outlined in the Declaration of Helsinki and were approved by the Florida International University Institutional Review Board (IRB-20-0100).

Participants completed an initial phone screening to determine eligibility. Eligible families proceeded to Visit 1 for consent, a second screening to assess for clinical risk factors, and baseline questionnaires (not relevant to the current study). Devices were shipped after qualifying at Visit 1. Participants who completed the initial screen but were ineligible received a screening compensation. After device setup at Visit 2, participants engaged in ~60 days of home-based data collection, completing two daily surveys and audio recordings per day in addition to providing passive phone and wearable sensor data. At Visit 3, participants completed final questionnaires (not relevant to the current study), received their second payment, and shipped back devices.
Equipment
An early version of the Colliga App was used to collect smartphone and smartwatch data for this study. The platform consists of ref. 1 a web-based portal where researchers can configure study settings (e.g., select which data streams to collect and at what frequencies) and send participants invitations to join the study, and ref. 2 a mobile app downloaded onto participants’ smartphones to enable data collection (see Table 2 for the 52 data streams collected). All study procedures, including app-based data collection, were reviewed and approved by the institutional IRB to ensure ethical oversight. In compliance with data privacy standards, participants were provided with copies of the full privacy policies for all devices used in the study (Apple, Motorola, Garmin, and Fitbit), as well as the Colliga App itself. Participants also received summaries of each policy written at approximately a ninth-grade reading level, available in both English and Spanish. To safeguard participant privacy, all data collected through the app were encrypted, stored on secure servers with controlled user access, and protected with two-factor authentication. The version of the Colliga App used in this study was developed solely for research and data collection purposes and did not include clinical intervention. As such, it was not subject to the higher level of US Food and Drug Administration (FDA) approval required for therapeutic or diagnostic devices, nor subject to HIPAA compliance requirements. However, it was registered with the FDA as a research device. In total, the Colliga App collected ~14 million data points over the study period, with ~390,000 data points per participant. Screenshots of the version of the Colliga web and mobile apps used in this study are provided in Fig. 2. A newer version of the Colliga app, optimized for expanded dissemination and AI capabilities and reduced passive sensing features, is available free of charge for research use at https://colliga.io/request-a-free-scientist-account/. More information about the Colliga platform is available at https://colliga.io/.

Screenshots of an earlier version of the Colliga App used for data collection in this study. A Includes the researcher-facing web app for study configuration. B Includes the participant-facing mobile app for data collection.
During the initial phone screening, experimenters inquired whether the participant owned a smartphone or a smartwatch and if the participant had a sufficient phone data plan. Participants were encouraged to use their smartphones or smartwatches whenever possible. However, if they did not own smartphones or smartwatches or if their devices were not compatible with the Colliga App, they were lent devices for the study. We also provided data plans when needed. Lab-issued devices included Android Samsung S20 Fe 5Gs, iPhone SE 11 s, Fitbit Inspire 2 s, and Apple Watch Series 4 s. The specific device type issued to the participant depended on inventory availability. In total, 22 participants borrowed smartphones, and 33 borrowed smartwatches. The device types used in the study included 11 iPhones, 25 Androids, 33 Fitbits, and 3 Apple Watches.
Measures
Caregivers completed twice-daily brief surveys to assess in-the-moment mood (i.e., happy, sad, anxious, angry, and stressed) and caregiver-child interactional quality (i.e., quality time, closeness, positive interactions, negative interactions, conflict, and aggression). Surveys were completed via the Colliga App and were scheduled at random times twice daily, between 7:00 am and 11:00 am in the morning and between 5:00 pm and 9:00 pm in the evening. Example items include: “Rate the extent to which you feel happy” and “Rate the extent to which you are having conflict with your child.” Caregivers responded to the survey questions on a 10-point sliding scale. These survey questions were used as labels for algorithm development of the 11 target mental health states.
Caregivers provided 30-min audio recordings twice daily at 7:00 am and 6:30 pm to increase the likelihood of capturing times when caregivers and children were interacting. Raw audio files were used to conduct sentiment analysis using Microsoft Azure. Specifically, we transcribed the audio files and analyzed the content for positive sentiment, negative sentiment, neutral sentiment, polarity (negative to positive tone), subjectivity (degree of opinion or judgment), and number of offensive words (see https://azure.microsoft.com/en-us/products/ai-services/ai-language/ for further details).
The Colliga app tracked GPS locations of family members enrolled in the study and extracted measures of proximity between caregiver and child measured in meters, cumulative time spent with their child per day measured in minutes, proximity to their romantic partner measured in meters (if applicable), and cumulative time spent with their romantic partner per day measured in minutes (if applicable). These metrics were obtained once per minute for the 60-day study period.
Mobile devices were used to extract measures of the participants’ physical activity and physiological arousal. Measures extracted from the smartphones included gyroscope (X, Y, and Z directions), accelerometer (X, Y, and Z directions), step count, and distance traveled in meters. Measures extracted from the Fitbit devices included minutes spent at various levels of activity (i.e., sedentary, lightly, fairly, and very active), and heart rate measured in beats per minute. Apple Watch data included resting energy, active energy, minutes standing, and heart rate in beats per minute. All physical activity and physiological arousal data were reported once every minute across the 60-day study duration.
Smartwatches were used to obtain information about participants’ sleep patterns once every 30 min. Sleep measures extracted from Fitbit included minutes spent at various sleep stages (i.e., deep, light, and REM sleep), minutes in bed or asleep, sleep efficiency scored from 0 to 100, number of awakenings, whether the sleep was the “main sleep” of the day, coded as a 0 or 1, and whether the participant was awake, coded as a 0 or 1. The Apple watch provided data on whether the participant was in bed, which was also coded as 0 or 1.
Various passive measures of participants’ environments were collected from the participants’ smartphones once every 5 min, including ambient noise levels measured in dB, ambient light levels measured in lux, humidity measured as dew point (degrees Celsius), and atmospheric pressure measured in mbar. Headphone audio level measured in dB was collected once every 15 min. The location data were collected once every 5 min and included cumulative time spent at home, work, and school per day measured in minutes, as well as proximity to work, home, and school measured in meters.
Technological activity data was passively collected from participants’ smartphones and included text message frequency, call frequency, and calendar event frequency collected once every 5 min.
Overview of analyses
We first summarize participant adherence to the study procedures, followed by descriptive statistics for the features and target variables. Next, we report the results of generalized and personalized models and compare their performance. Both generalized and personalized models were built using weighted support vector machine (SVM) classifiers with radial basis function kernels, where class weights were adjusted inversely proportional to the class frequencies in the training data. We selected SVMs based on their strong performance with small-to-moderate sample sizes, robustness to high-dimensional feature spaces relative to sample size, and prior success in analyses of physiological and behavioral sensing data35,36,37,38. This choice was particularly appropriate given that the number of extracted features from smartphones and wearable devices often exceeded the number of labeled samples per participant in our dataset39,40,41. Following the model comparisons, we tested if participant characteristics, including symptom endorsement frequency, adherence to survey completion, and symptom variability, predicted model sensitivity, specificity, and macro F1 scores. Finally, we examined model performance grouped by feature set categories to identify whether specific sensor domains contributed more strongly to classification accuracy for each symptom.
Results
Data reduction and pre-processing
All data streams were imported as de-identified raw files and aggregated per participant across the full data collection period. To standardize across sources, the temporal resolution of all processed files was set to 1-minute intervals. Data streams with inherently lower temporal resolutions (e.g., 30 min or more) were excluded from interpolation to avoid introducing artificial patterns. Duplicate entries were removed, and each time series was chronologically ordered based on minute-level timestamps. Missing values in step count and distance features were zero-interpolated to reflect absence of movement. Heart rate data were retained only at time points marked as reliable by the device API. Speech recordings were transcribed and analyzed using Microsoft Azure’s AI Language service to extract sentiment, polarity, and subjectivity (https://azure.microsoft.com/en-us/products/ai-services/ai-language/). Sleep data were reformatted into minute-level boolean series, with one of four mutually exclusive states (“awake,” “light sleep,” “deep sleep,” or “REM sleep”) active at each time point. Proximity features were differentiated over time to capture unbiased activity levels at each recorded timestamp. To ensure consistency, all data were cast to a uniform numeric type across devices. Sanity checks were conducted to verify temporal consistency (i.e., no implausible jumps over 5-min intervals) and cross-participant consistency within family units.
Training x for ML models were constructed by extracting fixed-length feature windows centered around survey timestamps. Given the limited number of available survey labels—typically no more than two per day—a window-based augmentation strategy was implemented to increase the number of usable training instances. For each labeled time point t, we computed average feature values over three non-overlapping windows: [t − 1 h, t − 30 min), [t − 30 min, t + 30 min), and [t + 30 min, t + 1 h). Each generated training instance was assigned the same emotion label as the participant’s report at time t, under the assumption that the surrounding context reflected a relatively stable emotional state. Survey responses that did not permit construction of all three windows were excluded. To prevent data leakage, all training instances associated with a given time point were assigned exclusively to either the training or validation set.
Generalized models were trained using a leave-one-participant-out cross-validation approach, wherein each model was trained on data from all caregivers except the one being evaluated. To evaluate our generalized model on a participant x with feature set \({f}_{x}\), we trained the generalized model on any participant with feature set fy, where fy\(\supset\)fx. In this case, we only considered the common features among \({f}_{x}\) and \({f}_{y}\) to train the generalized model. No symptoms or target variables were dropped; only available features were subsetted across individuals. Personalized models were built separately for each participant using 10-fold cross-validation. For both generalized and personalized approaches, stratified sampling was applied to reduce sampling bias. Given the skewed distribution of emotional states, emotion labels were binarized using participant-specific thresholds, based on the median, median +1 SD, or median −1 SD. The threshold that produced the most balanced positive-to-negative ratio was selected for each participant. Missing feature values were imputed through linear interpolation, and all features were standardized using Z-score normalization prior to model fitting.
Participants were included in model development if they provided at least 10 valid survey responses spaced a minimum of 2 h apart, ensuring sufficient labeled data for building machine learning models. During data collection, a server overload occurred due to the high volume and frequency of incoming data, exceeding system processing capacity. To resolve this, a system upgrade was implemented mid-study to expand server capacity, successfully preventing further overloads. However, during the upgrade, some scheduled survey notifications were permanently lost, independent of participant behavior. Because the system could not differentiate between surveys missed due to server error versus participant non-response, participants were retained based on their number of completed valid surveys regardless of cause. After applying the inclusion criteria, 36 of the 60 enrolled families were included in the final analytic sample.
Preprocessing and model training procedures were conducted using Python (v3.9) with standard scientific computing libraries, including NumPy, Pandas, and Scikit-learn. Our code is compatible with the latest versions of these libraries. All training and validation steps were completed on a secure workstation equipped with an Intel Core i7 CPU (3.60 GHz), 32 GB RAM, and no GPU acceleration. Given the lightweight nature of the SVM models and the moderate dataset size, training procedures were completed within minutes per participant. No distributed computing or cloud resources were used beyond initial secure data storage.
Descriptive statistics
Table 2 presents descriptive statistics for the target variables and features included in the ML models. The number of survey reports provided per participant ranged from 14 to 111 (M = 68.44; SD = 29.48), reflecting variability in adherence across the ~60-day study period. The degree of missingness for passive features used in model development ranged from 5.5% (proximity to home, work, or school) to 73.0% (text message frequency). Figure 3 displays the number of participants contributing data to each stream (Panel A) and the percentage of available data for model training among participants providing each stream (Panel B). Table 3 provides information on the average number of days each family contributed data across feature categories. Figure 4 plots the endorsement of four target states for a representative participant. Figure 5 shows heatmaps illustrating correlations between selected features and target states for four example participants.

A Provides the number of participants with each of the data streams used in model development. B Provides the percentage of days for which there were at least 4 h of data for model development for those participants providing the data stream.

Happy (A), sad (B), anxious (C), and angry (D) mood for one example participant over the 60-day data collection period. Small pink circle = first survey. Medium yellow circle = second survey. Large blue circle = third survey. Extra-large purple circle = fourth survey.

Heat maps for 11 target states and the 20 features with the highest average adherence for the sample over the 60 days for four example participants. A Example Participant 1; B Example Participant 2; C Example Participant 3; D Example Participant 4. Blue = positive correlation. Red = negative correlation. Because data streams varied, each participant has a subset out of the 20 possible. *p < 0.05; **p < 0.01; ***p < 0.001.
HO1: model performance for generalized models
Table 4 provides model performance results for the generalized models. Overall, our experiments showed that generalized models achieved poor to moderate sensitivity, poor to excellent specificity, and poor to good F1 scores across all target states. Due to the small number of participating families and non-normality in the sensitivity, specificity, and F1 score outcomes assessed, we used non-parametric one-tailed one sample Wilcoxon tests to investigate whether the generalized models performed above chance levels. We further applied a Bonferroni correction to adjust for multiple comparisons. As shown in Table 5, results indicated that the generalized models achieved performance above random chance for specificity when all target states were examined together, as well as for sadness, anger, stress, negative interactions, conflict, and aggression.
HO2: model performance for personalized models and comparisons to generalized models
We next built personalized models for each person in the dataset. The average micro sensitivity, specificity, and F1 score are provided in Table 4. Overall, depending on the target states examined, the personalized models achieved poor to moderate sensitivity, moderate to excellent specificity, and poor to moderate F1 score. Results of one-tailed one sample Wilcoxon tests with Bonferroni corrections to adjust for multiple comparisons (Table 5) showed that the personalized models performed better than random chance for sensitivity for sadness, anxiety, anger, and stress; for specificity for happiness, quality time, closeness, and positive interactions; and for F1 score for happiness, anxiety, stress, quality time, and positive interactions. When aggregating all emotion states, the personalized models surpassed generalized models in both sensitivity and F1 score.
HO3: individual factors, symptom profiles, and model performance
We next conducted linear regressions to examine the effect of symptom endorsement, survey adherence, and symptom variability on the personalized models’ performance. Endorsement was operationalized as the percentage of positive samples (i.e., percent of samples where a symptom was endorsed). Adherence was operationalized as the number of completed phone surveys assessing the target states. Variability in symptom endorsement was operationalized as the standard deviation of the target state. After confirming normality in the residuals, we used two-tailed linear regression with each variable entered as a predictor of model performance for all target states combined, with separate regressions for each outcome (i.e., sensitivity, specificity, and F1 score) assessed. Results are depicted in Fig. 6, Panels A-C. For sensitivity, greater symptom endorsement (b = 0.92, SE = 0.06, p < 0.0001, CI[0.80, 1.05]) and survey adherence (b = 0.13, SE = 0.06, p = 0.02, CI[0.02, 0.26]) were related to higher performance (adjusted R2 = 0.45, N = 284). For specificity, greater symptom endorsement (b = −0.80, SE = 0.06, p < 0.0001, CI[−0.92, −0.68]) was related to decreased performance (adjusted R2 = 0.40, N = 284). Finally, for F1, greater survey adherence was related to higher model performance (b = 0.16, p < 0.0001, CI[0.09, 0.24], adjusted R2 = 0.06, N = 284).

Sensitivity, specificity, and F1 scores by symptom endorsement (A), survey adherence (B), and symptom variability (C). Average metric and standard error bars are highlighted in black. Blue = happiness. Yellow = sadness. Bright green = anxiety. Anger = red. Stress = purple. Brown = quality time. Pink = closeness. Gray = positive interactions. Light green = negative interactions. Light blue = conflict. Extra light blue = aggression.
Average model performance by percentile categories for symptom endorsement, survey adherence, and symptom variability are provided in Table 6. Results show ML performance ranging from poor to excellent based on individual factors and symptom profiles. For symptom endorsement, sensitivity was highest, and specificity was lowest for high levels of symptom endorsement. Symptom endorsement in the middle 50% range provided the best F1 scores that balanced sensitivity and specificity for 9 out of 11 (81.81%) target states. For survey adherence, the middle 50% provided the best performance for 7 out of 11 (63.64%) target states for sensitivity, specificity, and F1 score. For symptom variability, the middle 50% provided the best model performance for 6 out of 11 (54.44%) target states for sensitivity, 5 out of 11 (45.54%) target states for specificity, and 8 out of 11 (72.72%) target states for F1 score.
HO4: examination of feature set categories per outcome
In our final set of analyses, we tested which categories of feature sets are most predictive of the 11 target states. Features used in the models were divided into the following categories: interaction, activity, speech, sleep, and environment (refer to Table 2 for a list of the specific variables per category). Interaction encompasses cumulative time spent per day with family members and the distance between family members, including caregivers, children, and partners; activity includes physical activity and indices of physiological arousal; speech includes conversation sentiment, polarity (negative to positive tone), subjectivity (degree of opinion or judgment), and offensive words; sleep includes various indices of sleep length and quality; and environment includes cumulative time spent per day at home, work, or school and various other qualities of the environment, such as humidity. Technological activity was excluded as a feature set in these analyses due to sparsity in the data. We report the model performance as defined by macro F1 score by feature set category and then for the best two feature sets and best three feature sets combined in Table 7. Results showed that activity, sleep, and environment were the top three most predictive feature sets when all 11 target states are considered together. Activity was the top feature set for happiness, closeness, negative interactions, and aggression. Sleep was the top feature set for anxiety, quality time, and positive interactions; speech was the top feature set category for conflict; and environment was the top feature set category for sadness. The top feature set category for anger was tied for activity, speech, and sleep. The top feature set for stress was tied for activity and environment.
We next tested for statistical differences in the feature set categories. To reduce the number of total tests conducted, we performed these tests for all target states together for the top two and top three featured sets combined compared to individual feature sets. Due to non-normality in the performance metrics and the small number of participating families, we conducted non-parametric one-tailed Mann-Whitney U tests and applied a Bonferroni correction to adjust for multiple comparisons. Findings showed activity and sleep combined outperformed speech and interaction and that activity, sleep, and environment combined outperformed speech and interaction. Results of these tests are provided in Table 8.
In addition to examining which combined features sets achieved the highest model performance, we used mutual information gain to determine the importance of specific features used in our personalized models. Mutual information gain was used because target states and some features were binary. Because there are 11 emotion states in total, we selected the best 2 features based on highest mutual information gain for each emotion state for each person. We next counted the number of times each feature appeared within the top 2 features and selected the 10 features with the greatest counts. See Table 9 for the results of the mutual information gain analyses. Results showed that the most important features were lightly active minutes, number of awakenings, total minutes asleep, neutral sentiment, sleep efficiency, sedentary minutes, total minutes in bed, polarity, fairly active minutes, and proximity to home.
Discussion
This pilot study developed and tested generalized and personalized ML algorithms for detecting individual and family mental health symptoms using widely available mobile devices in 35 families over a 60-day period. Performance of the generalized models showed sensitivity ranging from poor to moderate, specificity from poor to excellent, and F1 scores from poor to good (HO1). Personalized models demonstrated poor to moderate sensitivity, moderate to excellent specificity, and poor to moderate F1 scores, depending on the specific symptom states examined. When aggregating across all target states, personalized models outperformed generalized models on both sensitivity and F1 score. Additional comparisons by specific symptom states revealed higher performance for personalized models in sensitivity for sadness, anxiety, anger, and stress; in specificity for happiness, quality time, closeness, and positive interactions; and in F1 for happiness, anxiety, stress, quality time, and positive interactions (HO2). Model performance also varied based on individual user characteristics. Symptom endorsement (HO3a) and survey adherence (HO3b) were significantly related to performance, whereas symptom variability (HO3c) was not. Finally, we found that the most informative feature sets varied by target state. However, overall, models using activity and sleep features—or the combination of activity, sleep, and environment features—outperformed models using speech or interaction features alone (HO4). Developing algorithms to detect mental health symptoms and family interactional processes using passive sensing data from common commercial mobile devices represents a critical preliminary step toward building usable, scalable JITAI systems. Our findings provide crucial insights into the conditions that enhance model performance and highlight key directions for optimizing future real-world deployment.
The results from our generalized models indicated poor to moderate sensitivity, poor to excellent specificity, and poor to good F1 scores across target states. The methods employed in this study were intentionally designed to approximate real-world use cases by leveraging widely available commercial devices, rather than research-grade equipment, to enhance generalizability and future scalability. However, this real-world approach also introduced considerable heterogeneity into the data, leading to substantial variability in model performance across users. These findings underscore the inherent challenge of using passive sensing data collected from commercial devices to detect in-the-moment emotional states in uncontrolled, everyday environments—the exact conditions under which JITAIs must ultimately operate to achieve meaningful public health impact. Despite generally moderate performance, model specificity exceeded chance levels across conditions, and strong performance was achieved for certain target states and subgroups. These results demonstrate that good model performance is attainable and offer encouraging early evidence supporting the feasibility of real-world passive sensing for mental health. Importantly, the models developed here serve as critical benchmarks for future algorithm development, both by our own research group and by others who may access our dataset via our public data repository. Finally, our findings highlight key future directions for improving model performance, including the need for systems explicitly designed for real-world variability and systematic investigations of the conditions under which models perform successfully. Building robust, scalable models for JITAI systems will require embracing the complexity of real-world data rather than attempting to avoid it, and carefully tailoring algorithm development to optimize performance under these conditions.
In addition to building generalized models across the sample, we developed personalized models for each individual participant and conducted statistical tests to compare model performance. Overall, personalized models demonstrated significantly higher sensitivity and F1 scores compared to generalized models. Further distinctions emerged when examining specific emotional states: personalized models showed enhanced sensitivity for sadness, anxiety, anger, and stress; higher specificity for happiness, quality time, closeness, and positive interactions; and higher F1 scores for happiness, anxiety, stress, quality time, and positive interactions. These findings suggest that individualized model development may be a particularly effective strategy for building high-performing algorithms intended for JITAI systems. Given the substantial heterogeneity in device types, data streams, and symptom profiles across users, it is logical that personalized models designed around an individual’s unique characteristics would outperform generalized models trained across the broader sample. However, translating personalized models into real-world JITAI deployments would require overcoming several practical challenges. Successful implementation would necessitate sufficient data collection from each user to build stable baseline models, as well as the creation of sophisticated software systems capable of adjusting and updating model parameters in real time as new data are collected. Future JITAI systems would likely need an initial calibration period to gather baseline data and personalize model parameters before delivering tailored interventions. While this represents an exciting and promising direction, building systems capable of real-time personalization, deployment, and adaptation will require advances in research and technology before they can be widely deployed in everyday settings.
We further examined whether individual factors and symptom profiles were associated with model performance. We found partial support for Hypothesis 3, with significant effects for symptom endorsement (HO3a) and survey adherence (HO3b), but not symptom variability (HO3c). Higher symptom endorsement was associated with increased sensitivity but decreased specificity, while greater survey adherence was linked to improved sensitivity and F1 scores. On one hand, these results align with expectations: a greater proportion of positive samples was associated with greater sensitivity and lower specificity, and a higher number of training samples was related to stronger F1 scores. However, these basic statistical properties must be interpreted within their clinical context. Different users’ symptom profiles and engagement behaviors inherently shape the data available for model development. For example, an individual experiencing daily sadness but exhibiting low survey response rates would present very different data challenges compared to an individual with fluctuating anxiety symptoms and high survey compliance. Taken together, these findings suggest that the characteristics of users—specifically their symptom profiles and engagement patterns—play an important role in model success. Passive sensing models may need to be tailored not only to individual users, but also to the clinical characteristics of the symptoms being targeted. Future systems might benefit from first mapping individuals’ symptom profiles during a baseline period and then dynamically matching users to algorithms most likely to perform well based on their unique patterns. Such approaches could increase the precision and scalability of real-world JITAI systems.
Our final hypothesis (HO4) explored whether the best performing feature sets differed depending on the mental health symptoms being detected. Overall, the three highest performing feature sets were activity, sleep, and environment. However, feature set performance varied across different target states.
Activity features—which included both physical activity and physiological activation—were especially important for detecting states characterized by bodily or emotional arousal, such as stress, anger, and aggression. Speech emerged among the top feature sets for anger, conflict, and aggression, suggesting that linguistic features, such as the frequency of offensive words, may be informative markers for detecting interpersonal difficulties. Sleep features, which are closely tied to emotional regulation and mental health outcomes, were especially predictive for anxiety, reflecting the known bidirectional relationship between sleep disruption and anxious symptoms42,43. Interestingly, speech was the least informative feature set for sadness, whereas environment features were the most predictive. This may reflect the more inward, less externally expressed nature of sadness, suggesting that other environmental factors—such as time spent at home or specific ambient conditions—may provide better contextual cues for sadness than speech alone.
Our mutual information gain analyses further identified the individual features contributing most strongly to model performance across all target states. The top features included lightly active minutes, number of awakenings, total minutes asleep, neutral sentiment, sleep efficiency, sedentary minutes, total minutes in bed, polarity, fairly active minutes, and proximity to home. When aggregating across emotion states, models combining1 activity and sleep features and ref. 2 activity, sleep, and environment features outperformed models based solely on speech or interaction data. Although speech features did not emerge as top contributors in this study, it is important to note that speech was only sampled during 30-min windows twice per day after participant prompts, limiting its temporal overlap with symptom reporting. Future studies with more continuous speech sampling may better harness its potential as a rich source of emotional information. Overall, these findings highlight that careful feature selection—tailored to the specific symptom or emotional state of interest—is critical for building effective passive sensing models. Foundational work to map which features best predict which mental health symptoms will be crucial for the next generation of personalized, scalable mental health interventions.
This pilot study offers several important strengths as a foundational step toward developing personalized mental health sensing algorithms to inform future JITAIs. Using a pervasive computing system, we collected ~14 million data points across 52 passive and active data streams over a 60-day period in a highly diverse sample. This intensive, naturalistic data collection enabled the detection of a wide range of moods and interpersonal states, supporting a multifaceted and ecologically valid assessment of mental health processes. The resulting dataset is uniquely rich, consisting of continuous, multimodal data streams captured in participants’ daily lives over an extended period. Our methodology approximated real-world implementation by leveraging widely available commercial devices and accommodating heterogeneity in operating systems and sensors, which increases the future scalability and generalizability of the algorithms developed. The study also focused on both individual and family mental health symptoms, providing a logical and impactful use case for eventual deployment of personalized algorithms in JITAI frameworks. Importantly, we moved beyond simply benchmarking model performance by systematically examining factors that influence success. We compared generalized and personalized approaches, explored how user symptom profiles and behavioral engagement impacted model outcomes, and evaluated which data streams contributed most effectively to symptom detection. This multifactorial approach advances the field of AI sensing by moving toward real-world applications and by identifying specific factors that may optimize model performance.
Despite these strengths, several limitations warrant consideration. First, although the data collection was intensive and multimodal, the number of participating families was modest. Given the relatively small sample size, this study should be interpreted as an initial proof-of-concept rather than a definitive evaluation of model performance. To mitigate limitations associated with small samples, we employed non-parametric statistical tests, which are robust to distributional assumptions, and applied Bonferroni corrections to adjust for multiple comparisons. Nevertheless, future studies are needed to validate and extend these findings using larger samples, longer longitudinal data collection windows, and real-time implementation. These efforts will be critical for translating the foundational ML algorithms developed here into scalable, deployable JITAI systems for mental health intervention. Second, although personalized models consistently outperformed generalized models, overall model performance remained moderate. This finding is consistent with other research showing that emotion detection in ambulatory settings is significantly more challenging than in controlled laboratory environments44,45. Additional development work, including model optimization and algorithm refinement, will be necessary to achieve the level of reliability needed for clinical applications.
Third, technical challenges likely impacted data completeness and model performance. Most notably, a server overload occurred during data collection, caused by the high volume and velocity of incoming data, which exceeded processing capacity and resulted in permanent loss of some scheduled survey notifications. Although the system was upgraded mid-study to expand capacity and prevent future overloads, we were unable to distinguish between missing surveys due to technical errors and participant non-response. These challenges reflect the real-world complexities of creating scalable and reliable pervasive computing systems, particularly when managing high-frequency, high-volume data streams. They underscore the need for future research to implement more robust system monitoring, proactive technical support, and stress testing to minimize missingness and improve model reliability in real-world conditions. Fourth, the eligibility excluded families experiencing acute safety concerns (e.g., suicidal ideation, child maltreatment). Though this recruitment strategy was appropriate for the study’s initial scope, it may have introduced selection bias and limits generalizability to higher-risk populations. Future research should broaden eligibility criteria to include a wider range of clinical presentations and consider extending the age range of participants to better capture developmental variations in family mental health dynamics and symptom expression.
Fifth, while personalized models showed strong promise, they may be vulnerable to overfitting due to the limited number of labeled samples per individual. Future directions should explore sub-population modeling strategies46,47, where participants are grouped by common behavioral or clinical characteristics, allowing for greater model stability and scalability. Alternatively, researchers might use hybrid models that begin with sub-population predictions and gradually personalize over time as individual-level data accumulates. Finally, although our sample was demographically diverse, we did not formally examine the relationship between sociodemographic characteristics and model performance. Given growing evidence that ML models may exhibit bias across racial, ethnic, gender, and socioeconomic lines48, future studies should explicitly evaluate fairness across groups and assess whether personalization strategies can mitigate potential disparities. Together, these findings underscore the significant promise of personalized mental health sensing while also highlighting critical challenges to be addressed through future research. Continued work building on this pilot study will be essential for creating scalable, equitable, and effective AI-driven systems to promote mental health in everyday life.
This pilot study provides critical foundational evidence for the development of personalized machine learning models to detect mental health symptoms and interpersonal processes using pervasive mobile sensing in real-world settings. Overall, models achieved moderate performance, with personalized models consistently outperforming generalized models across key metrics. Importantly, model success varied systematically based on individual user factors and symptom profiles, underscoring the need for algorithms that adapt to user-specific characteristics. The study also highlighted the complexity of real-world system development, as reflected in challenges such as missing data, device variability, and server capacity limitations. Crucially, these challenges are not obstacles to be avoided but inherent realities that must be integrated into system design for scalable, reliable deployment. Future efforts must build on these early findings by conducting research under real-world conditions and designing adaptive systems that are robust to the heterogeneity and technical constraints of daily life. While preliminary, this work lays essential groundwork for advancing personalized, JITAIs and for realizing the potential of AI-driven mental health support in everyday contexts.
Data availability
The datasets generated and analyzed during the current study are available upon reasonable request by visiting https://colliga.io/repository-childhood-mobile-sensing-project.
Code availability
The underlying code and training/validation datasets for this study are publicly available in the Colliga Data Repository and can be requested via this link https://colliga.io/repository-childhood-mobile-sensing-project49. The custom code used for data analysis and modeling during the current study is available upon reasonable request by visiting https://colliga.io/repository-childhood-mobile-sensing-project.
References
Triantafyllidis, A. K. & Tsanas, A. Applications of machine learning in real-life digital health interventions: review of the literature. J. Med. Internet Res. 21, e12286 (2019).
Gönül, S., Namlı, T., Coşar, A. & Toroslu, İH. A reinforcement learning based algorithm for personalization of digital, just-in-time, adaptive interventions. Artif. Intell. Med. 115, 102062 (2021).
Balcombe, L. & De Leo, D. An integrated blueprint for digital mental health services amidst COVID-19. JMIR Ment. Health 7, e21718 (2020).
Cummings, E. M., Koss, K. J. & Davies, P. T. Prospective relations between family conflict and adolescent maladjustment: security in the family system as a mediating process. J. Abnorm. Child Psychol. 43, 503–515 (2015).
Bălan, O. et al. Emotion classification based on biophysical signals and machine learning techniques. Symmetry 12, 21 (2019).
Nahum-Shani, I., Hekler, E. B. & Spruijt-Metz, D. Building health behavior models to guide the development of just-in-time adaptive interventions: a pragmatic framework. Health Psychol. 34, 1209–1219 (2015).
Nahum-Shani, I. et al. A SMART data analysis method for constructing adaptive treatment strategies for substance use disorders. Addiction 112, 901–909 (2017).
Bidargaddi, N., Schrader, G., Klasnja, P., Licinio, J. & Murphy, S. Designing m-Health interventions for precision mental health support. Transl. Psychiatry 10, 222 (2020).
Goldstein, S. P. et al. Optimizing a just-in-time adaptive intervention to improve dietary adherence in behavioral obesity treatment: Protocol for a microrandomized trial. JMIR Res, Protoc. 10, e33568–e33568 (2021).
Hardeman, W., Houghton, J., Lane, K., Jones, A. & Naughton, F. A systematic review of just-in-time adaptive interventions (JITAIs) to promote physical activity. Int. J. Behav. Nutr. Phys. Act. 16, 31 (2019).
Park, J. et al. Advancing understanding of just-in-time states for supporting physical activity (Project JustWalk JITAI): protocol for a system ID study of just-in-time adaptive interventions. JMIR Res. Protoc. 12, e52161 (2023).
Forman, E. M. et al. OnTrack: development and feasibility of a smartphone app designed to predict and prevent dietary lapses. Transl. Behav. Med. 9, 236–245 (2019).
Pulantara, I. W., Parmanto, B. & Germain, A. Clinical feasibility of a just-in-time adaptive intervention app (iREST) as a behavioral sleep treatment in a military population: feasibility comparative effectiveness study. J. Med. Internet Res. 20, e10124 (2018).
Yang, M.-J. A Just-In-Time Adaptive Intervention (JITAI) for smoking cessation: feasibility and acceptability findings. Addictive Behav. 136, 107467 (2023).
Perski, O. et al. Technology-mediated just-in-time adaptive interventions (JITAIs) to reduce harmful substance use: a systematic review. Addiction https://doi.org/10.1111/add.15687 (2021).
Arora, S., Yttri, J. & Nilse, W. Privacy and security in mobile health (mHealth) research. Alcohol Res. Curr. Rev. 36, 143–151 (2014).
Wright, A. G. & Woods, W. C. Personalized models of psychopathology. Annu. Rev. Clin. Psychol. 16, 49–74 (2020).
Garcia-Ceja, E. et al. Mental health monitoring with multimodal sensing and machine learning: a survey. Pervasive Mob. Comput. 51, 1–26 (2018).
Nahum-Shani, I. et al. Just-in-time adaptive interventions (JITAIS) in mobile health: key components and design principles for ongoing health behavior support. Ann. Behav. Med. 52, 446–462 (2018).
Zhu, Z., Aitken, J. A., Dalal, R. S. & Kaplan, S. A. The promise of just-in-time adaptive interventions for organizational scholarship and practice: conceptual development and research agenda. Organ. Res. Methods 10944281231202740. https://doi.org/10.1177/10944281231202740 (2023).
Schneider, S., Junghaenel, D. U., Smyth, J. M., Fred Wen, C. K. & Stone, A. A. Just-in-time adaptive ecological momentary assessment (JITA-EMA). Behav. Res. Methods 56, 765–783 (2024).
Opoku Asare, K. et al. Predicting depression from smartphone behavioral markers using machine learning methods, hyperparameter optimization, and feature importance analysis: exploratory study. JMIR mHealth uHealth 9, e26540 (2021).
Di Matteo, D. et al. Automated screening for social anxiety, generalized anxiety, and depression from objective smartphone-collected data: cross-sectional study. J. Med. Internet Res. 23, e28918 (2021).
Reinertsen, E. et al. Heart rate-based window segmentation improves accuracy of classifying posttraumatic stress disorder using heart rate variability measures. Physiol. Meas. 38, 1061–1076 (2017).
Beiwinkel, T. et al. Using smartphones to monitor bipolar disorder symptoms: a pilot study. JMIR Ment. Health 3, e2 (2016).
Ben-Zeev, D., Scherer, E. A., Wang, R., Xie, H. & Campbell, A. T. Next-generation psychiatric assessment: Using smartphone sensors to monitor behavior and mental health. Psychiatr. Rehabil. J. 38, 218–226 (2015).
Dobson, R. et al. The use of sensors to detect anxiety for in-the-moment intervention: scoping review. JMIR Ment. Health 10, e42611 (2023).
Khan, N. S., Ghani, M. S. & Anjum, G. ADAM-sense: anxiety-displaying activities recognition by motion sensors. Pervasive Mob. Comput. 78, 13 (2021).
Dowling, N. A. et al. A gambling just-in-time adaptive intervention (GamblingLess: in-the-moment): protocol for a microrandomized trial. JMIR Res Protoc. 11, e38958 (2022).
Tzafilkou, K., Economides, A. A. & Protogeros, N. Mobile sensing for emotion recognition in smartphones: a literature review on non-intrusive methodologies. Int. J. Hum. Comput. Interact. 38, 1037–1051 (2022).
Byng-Hall, J. & Stevenson-Hinde, J. Attachment relationships within a family system. Infant Ment. Health J. 12, 187–200 (1991).
Suldo, S. M. & Fefer, S. A. in Research, Applications, and Interventions for Children and Adolescents: A Positive Psychology Perspective 131–147 (Springer, 2013).
Paley, B. & Hajal, N. J. Conceptualizing emotion regulation and coregulation as family-level phenomena. Clin. Child Fam. Psychol. Rev. 25, 19–43 (2022).
Muris, P., Meesters, C. & van den Berg, F. The strengths and difficulties questionnaire (SDQ). Eur. Child Adolesc. Psychiatry 12, 1–8 (2003).
Swinkels, W., Claesen, L., Xiao, F. & Shen, H. Real-Time SVM-Based Emotion Recognition Algorithm (IEEE, 2017).
Bulagang, A. F., Mountstephens, J. & Teo, J. Multiclass emotion prediction using heart rate and virtual reality stimuli. J. Big Data 8, 12 (2021).
Gideon Nyatuga, N., John, N., Mwaniki Ivivi, J. & Kamanu, T. Class prediction of high-dimensional data with class imbalance: breast cancer gene expression data. Int. J. Adv. Sci. Res. Eng.10, 28–46 (2024).
Mathew, J., Pang, C., Luo, M. & Leong, W. Classification of imbalanced data by oversampling in kernel space of support vector machines. IEEE Trans. Neural Netw. Learn. Syst. PP, 1–12 (2017).
Meng, T., Shou, Y., Ai, W., Yin, N. & Li, K. Deep imbalanced learning for multimodal emotion recognition in conversations. IEEE Trans. Artif. Intell. PP, 1–15 (2024).
Ihmig, F. R. et al. On-line anxiety level detection from biosignals: machine learning based on a randomized controlled trial with spider-fearful individuals. PLOS ONE 15, e0231517 (2020).
Kumar, K. & Iqbal, J. Handling high dimensional features by ensemble learning for emotion identification from speech signal. Int. J. Speech Technol. 25, https://doi.org/10.1007/s10772-021-09916-x (2021).
Scott, A. J., Webb, T. L., Martyn-St James, M., Rowse, G. & Weich, S. Improving sleep quality leads to better mental health: a meta-analysis of randomised controlled trials. Sleep. Med. Rev. 60, 101556 (2021).
Jansson-Fröjmark, M. & Lindblom, K. A bidirectional relationship between anxiety and depression, and insomnia? A prospective study in the general population. J. Psychosom. Res. 64, 443–449 (2008).
Can, Y. S. et al. Personal stress-level clustering and decision-level smoothing to enhance the performance of ambulatory stress detection with smartwatches. IEEE Access 8, 38146–38163 (2020).
Boeke, E. A., Holmes, A. J. & Phelps, E. A. Toward robust anxiety biomarkers: a machine learning approach in a large-scale sample. Biol. Psychiatry. Cogn. Neurosci. Neuroimaging 5, 799–807 (2020).
Gupta, K. et al. Sub-population specific models of couples' conflict. ACM Trans. Internet Technol 20, 9 (2020).
Taylor, S., Jaques, N., Nosakhare, E., Sano, A. & Picard, R. Personalized multitask learning for predicting tomorrow’s mood, stress, and health. IEEE Trans. Affect. Comput. 11, 200–213 (2017).
Timmons, A. C. et al. A call to action on assessing and mitigating bias in artificial intelligence applications for mental health. Perspect. Psychol. Sci. 18, 1062–1096 (2023).
Timmons, A. C., Ahle, M. W., Comer, J. S., Narayanan, S. & Chaspari, T. Child Mobile Data Project Dataset. https://colliga.io/repository/childhood-mobile-sensing-project-project (2022).
Acknowledgements
We would like to sincerely thank the families who participated in this study. We are deeply grateful for their contributions, which are helping to advance our understanding of child and family mental health. This project is based on work supported by NIMH Grant No. R42MH123368 (A.C.T., J.S.C., and M.W.A. Co-PIs), NSF GRFP Grant No. 1930019 (A.C.T., PI), and NSF CAREER Award No. 2046118 (T.C., PI). The contents of this paper are the responsibility of the authors and do not necessarily represent the official views of NSF or NIH.
Author information
Authors and Affiliations
Contributions
A.C.T.: conceptualization, data analysis, model development, data interpretation, writing and revision of the manuscript, and project supervision. A.A.T. and K.A.: model development, data analysis and interpretation, and writing and revision of the manuscript. J.B.D., K.E.C., S.N.W., G.A.J., A.S.C., G.F.F.: performed literature review and synthesis, data collection, prepared figures, and writing and revision of the manuscript. D.N.R. and I.K.: writing and revision of the manuscript. S.N.: computational resources, project supervision, and writing and revision of the manuscript. M.W.A.: writing and revision of the manuscript and project supervision. J.S.C.: writing and revision of the manuscript and project supervision. T.C.: model development, data analysis, computational resources, project supervision, and writing and revision of the manuscript. All the authors have approved the final submitted version of the paper.
Corresponding author
Ethics declarations
Competing interests
A.C.T. and M.W.A. own stock in Colliga Apps Corporation and could benefit financially from the commercialization of related research. J.S.C. earns textbook royalties from Macmillan Learning and an editorial stipend from the Association for Behavioral and Cognitive Therapies for projects unrelated to the present work. All other authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Timmons, A.C., Tutul, A.A., Avramidis, K. et al. Developing personalized algorithms for sensing mental health symptoms in daily life. npj Mental Health Res 4, 34 (2025). https://doi.org/10.1038/s44184-025-00147-5
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s44184-025-00147-5
