
Abstract
Early detection and prevention of eating disorders (EDs) in adolescence are crucial yet challenging. We developed and validated diagnostic and prognostic models to predict EDs using data from 44,357 Danish National Birth Cohort participants. Models were trained to identify ED presence in early and late adolescence (11- and 18-year follow-up), utilizing approximately 100 predictors from self-reported and registry-based data. The machine learning model demonstrated strong discrimination for both tasks (diagnostic Area Under the receiver operating characteristic Curve = 81.3; prognostic AUC = 76.9), while a logistic regression model using the top 10 predictors achieved comparable performance. Sex, emotional symptoms, peer relationship and conduct problems, stress levels, parental BMI values, body dissatisfaction, and BMI at the 7-year follow-up emerged as key predictors. Our models showed potential utility in supporting clinical risk assessment, particularly for low-risk preventive interventions, though further validation studies are needed to evaluate their effectiveness in real-world clinical settings.
Similar content being viewed by others
Introduction
Eating disorders (EDs) are serious psychiatric disorders influenced by a complex interplay of biological, psychological, and environmental factors, leading to severe disturbances in eating behaviors and related thoughts and emotions1,2,3,4,5. The physical manifestations of EDs are multiple, leading to three primary diagnostic groups6,7. Anorexia nervosa (AN) is characterized by distorted body image with intense fear of getting fat, weight loss behaviors (including restrictive eating)1,8 leading to substantially low body weight. Bulimia nervosa (BN) is characterized by recurrent episodes of binge-eating (overeating with loss of control) and purging behaviors to control weight1,8, while Binge eating disorder (BED) primarily involves frequent binge-eating episodes but without regular compensatory behaviors1,8. Individuals with disturbed eating patterns who do not fit the criteria for AN, BN, or BED might be diagnosed with other specified or unspecified feeding or EDs according to the fifth edition of DSM (Diagnostic and Statistical Manual of Mental Illnesses)3. Irrespective of the type of diagnosis, EDs have been associated with chronic health issues, co-occurring physical and psychiatric comorbidities, as well as increased suicidality and mortality risks, rendering them an essential field for prevention and intervention4,9,10,11,12,13,14,15,16.
According to Danish nationwide registry-based studies, approximately 50% of all EDs are diagnosed before the age of 1917,18, with peak onset of age at diagnosis between 15 and 22 years, depending on sub-type15,19. A Canadian cohort study investigating trajectories of ED symptoms found the most significant increase between the ages of 12 and 1520. A similar study based on US survey data also observed that the onset age of EDs is in adolescence16. The onset of such disorders in the adolescent years can further negatively impact the social relations of young individuals, as well as their educational success and, consequently, their long-term professional development21,22,23. Nevertheless, the identification of ED cases remains a challenge7,24,25, with severe delays concerning seeking and getting treatment26,27, with individuals taking an average of 3.6 years to recognize they have an ED after symptoms begin and 4.2 years from onset to receiving treatment28. Psychological factors, restricted access to healthcare, the stigma surrounding mental health, dietary behaviors, perceptions of body image, and cultural standards regarding appearance could all potentially obstruct the early detection of EDs and the ability to access treatment28.
Considering the substantial proportion and individual and societal health impacts of EDs, coupled with the obstacles to accessing treatment, it is critically important to develop and investigate new applicable methods and tools for the early detection of individuals at elevated risk for EDs29,30. In the current data density area with high Artificial Intelligence (AI) fascination, prominent tools could be prediction models utilizing classic statistical or machine learning methodologies, which can provide individualized risks of having or developing a specific ED at a particular time point31,32. The deployment of such validated prediction models in a clinical setting could further enhance the quality of selective prevention programs, the latter known to be more efficient than universal ones for reducing eating pathologies33. Nevertheless, previous work on ED prediction tasks consists of a few non-generalizable models trained on small sample sizes, with most of them relying on cross-sectional study designs, thereby missing the participants’ follow-up or prognosis29,34. The main objective of this study was to develop and validate diagnostic and prognostic models predicting eating disorders (AN, BN, BED) in adolescents, utilizing a comprehensive dataset of approximately 100 possible predictors. Using self-reported data from the Danish National Birth Cohort (DNBC)35,36 linked with national registry information, we developed models to identify the presence of EDs by the 11-year follow-up, i.e., DNBC-11 (diagnostic task), and by the 18-year follow-up, i.e., DNBC-18 (prognostic task).
Methods
Source of data
The study is based on 96,822 liveborn children born in Denmark between 1996 and 2003 who participated in the Danish National Birth Cohort (DNBC) and were followed from in utero to childhood and young adulthood. The data was collected across seven waves, with the first two interviews being during pregnancy. The remaining five waves included data on children ages 6 and 18 months, 7, 11, and 18 years. Data from DNBC are self-reported (mother or/and child) and related to the child’s life and early exposures. More details on the cohort are available elsewhere (www.dnbc.dk)35,36.
Further information on the children was obtained through the nationwide registries since every Danish citizen is linked to these databases via their unique person identifier37. We extracted data on the parents’ education status via the Population Education Register, income through the Income Register, urbanicity from the Population Register, and employment status from the Integrated Database for Labor Market Affiliation37,38,39,40. We additionally extracted data related to various childhood adversities covering material deprivation (family poverty, long-term unemployment), loss or threat of loss (death of a parent, death of a sibling, parent somatic illness, sibling somatic illness), and family dynamics (foster care, parental and sibling psychiatric illness, parental alcohol and drug abuse, maternal separation) via a combination of registers with slight adaptations to definitions in the DANLIFE cohort41. Namely, the Danish National Prescription Registry, the Danish National Patient Register, the Danish Psychiatric Central Research Register, and Register of Support for Children and Adolescents were used to extract the adversities above42,43,44. All registered diagnoses are defined based on the 8th and 10th versions of the International Classification of Diseases (ICD-8 and ICD-10) used in Denmark. Both primary and secondary diagnoses are included. Exploiting the self-reported data from the DNBC cohort, we extracted information on the child’s stress, emotional and behavioral difficulties, adopted by the Stress in Children (SiC) self-assessed questionnaire and the Strength and Difficulties Questionnaire (SDQ) (https://www.sdqinfo.org/) 45,46.
Study population
This longitudinal cohort study harvests data from the DNBC. The overall study population for the diagnostic task (predicting the risk of having EDs at DNBC-11) consisted of 44,357 adolescents, predominantly between the ages of 11 and 12 years at questionnaire completion. For the prognostic task (predicting the risk of having EDs at DNBC-18), the corresponding size was further reduced to 26,127 after excluding those who did not respond or complete the DNBC-18 questionnaire.
Predictors
We used a variety of potential ED predictors based on domain knowledge and availability in both the Danish registers and the DNBC self-reported data. Given the complex, multifactorial etiology of EDs without a clearly established set of risk factors, we included variables spanning multiple domains. We implemented variables found in the registers covering information on childhood adversities from date of birth and up to the DNBC-11 questionnaire completion, family characteristics (maternal and paternal age at birth, parity, parental education at DNBC-11, urbanicity), and also various disorders found in the Danish National Patient Register (feeding disorders, psychiatric disorders other than EDs, autoimmune and autoinflammatory conditions). We also implemented self-reported and mother-reported variables regarding the child’s lives, social relations, stress status, behavioral patterns, activity levels, dietary habits, parental characteristics, prenatal exposures, and self-reported height and weight variables, measured at 7- and 11-year follow-up of the DNBC (waves 5–6). We further used six different scales of the behavioral screening SDQ, which holds information on five sub-scales (emotional symptoms, conduct problems, hyperactivity/inattention, peer relationship problems, prosocial behavior) and an overall impact scale, reported in DNBC-11by both the parent and the child, separately. We extracted further information on physical, psychological, and behavioral responses to SiC from the SiC questionnaire and selected items from DAWBA (Development and Well-Being Assessment). We ended up with 97 possible predictors for the diagnostic task and 99 for the prognostic task. The additional predictors in the prognostic task were the presence/absence of an official ED diagnosis between age 6 and the DNBC-11 assessment, as well as the BMI measured at DNBC-11. The latter was excluded from the diagnostic task to prevent circularity since BMI forms part of the self-reported ED outcome definition at DNBC-11, but was included in the prognostic task as it does not interfere with the DNBC-18 outcome assessment. The aforementioned list of predictors allowed us to capture diverse factors that might influence ED risk, from family background and early life experiences to immediate psychological and social determinants. Missing values in categorical variables were allocated as a separate “Unknown” category, whereas missingness in numeric variables was handled with median imputation based on the training set information. A complete list of the predictors used in the prediction models, along with the ICD-8 and ICD-10 codes used for specific diseases, can be found in Supplementary Table 1.
Outcome
We constructed a composite outcome of EDs combining two distinct components: (1) formal diagnoses extracted from Danish health registers using established ICD-10 diagnostic codes (AN: F500; atypical AN: F501; BN: F502; atypical BN: F503; EDNOS: F50, F508, F509), and (2) algorithm-derived classifications based on DNBC questionnaire responses using the DSM-5 diagnostic criteria as standard to define symptoms fulfilling threshold criteria for EDs. For classifications at DNBC-11, which relied on BMI (such as for AN and BN), developmental changes in adolescents were accounted for by using appropriate age- and sex-specific BMI cut-offs from the International Obesity Task Force (IOTF). Standard adult cut-offs were used for the DNBC-18 follow-up. In the diagnostic task, we classified a participant as “ED-Positive” if that person was either officially diagnosed with an ED in the registers between age 6 and their DNBC-11 assessment, or met threshold or sub-threshold ED criteria (AN, BN, BED) based on DNBC-11 questionnaire responses. For the prognostic task, we included all participants irrespective of their ED status at DNBC-11. We classified these participants as “ED-Positive” if they were either officially diagnosed with an ED in the registers between their DNBC-11 and DNBC-18 assessments, or met threshold ED criteria based on DNBC-18 questionnaire responses. We chose this approach because it reflects real-world screening scenarios where the model would be applied to unselected populations that include individuals with varying baseline ED statuses. Thus, our composite outcome is intentionally designed to maximize case identification for a clinical screening tool, rather than estimate a pure epidemiological prevalence. A detailed description of how the algorithm defines threshold and sub-threshold EDs based on questionnaire responses can be found in Supplementary Table 2.
Model development and selection
We split the original dataset into 75% for training and the remaining 25% for testing, using stratified sampling on the outcome variable, i.e., keeping the distribution of the two outcome levels similar across the two splits. We used the data splitting strategy to internally validate the developed models’ conditional predictive performance into a new, unseen set of individuals. For both prediction tasks, we initially trained an extreme gradient-boosting machine learning model (XGBoost) that uses all available variables and their interactions to predict the outcomes of interest. The latter relies on the boosting ensemble technique, a process in which decision trees are added sequentially to the ensemble to minimize the residuals (errors) of the predictions produced by the previously fitted decision trees47.
The XGBoost algorithm contains several hyperparameters, namely the number and maximum depth of trees, the learning rate, the number of randomly selected predictors to perform the splits, the minimum size of nodes, early stopping iterations, as well as different weights assigned to the “ED-Positive” and “ED-Negative” class that accounts for imbalanced data (few “ED-Positive” cases). We selected the optimal model’s hyperparameters using 5-fold cross-validation (CV) on the training data, using the Brier Score as the evaluation metric, the latter being a proper scoring rule measuring the average squared distance of the model’s predictions from the observed outcome, with lower values indicative of a better model48. This optimization process utilized a grid of 30 potential hyperparameter configurations. We employed a space-filling approach based on maximum entropy, distributing the parameter values across the space with minimal overlap or redundancy49. Using these hyperparameters, we finally fitted the XGBoost models in the training set and evaluated their predictive performance in the testing set.
The large number of predictors used in the XGBoost model (“ML-model”) could make its implementation time-consuming and restrictive in a real-world clinical setting. Therefore, we introduced a feature selection step by screening for the top 10 most important predictors of the XGBoost model in the training process using the SHapley Additive exPlanation (SHAP) values, feature attribution method50. Higher absolute SHAP values for a predictor indicate higher contributions of that predictor to the overall risk of having or developing EDs. The highest-ranked predictors were then implemented into a logistic regression model (“Reduced model”) with restricted cubic splines with 5 knots for numeric variables and evaluated using the same testing data as the XGBoost model. The knots were placed at the specific quantiles of each variable’s distribution (5th, 27.5th, 50th, 72.5th, and 95th percentiles), with the algorithm automatically reducing the number of knots when variables had insufficient unique values to support 5 knots51. We further introduced two additional benchmark models (“Simple” and “Single” model”) using only the top 2 and top-1 most important predictors based on the SHAP values for model comparison purposes.
Extended analyses
We performed sensitivity analyses for both the diagnostic and prognostic tasks by expanding the definition of the target outcome. Specifically, for the diagnostic part, we also classified participants with present DEBs by the DNBC-11 based on self-reported data as “ED-Positive.” For analyzing the risk of developing EDs by the DNBC-18, we also considered participants with sub-threshold ED as part of the positive class of the composite outcome. The workflow and the performance metrics used to evaluate the models remained unchanged and similar to the primary analysis. To assess the performance of our clinically applicable model beyond a single train-test partitioning, we estimated the potential clinical benefit of the logistic regression model using 5-fold CV based on all available data for each predictive task.
We further examined the association between the prevalence (for categorical variables) or spread (for continuous ones) of the predictors for both the diagnostic and prognostic set and their respective predictive performance, as measured by the AUC. To accomplish that, we computed the normalized (scale 0–1) informativeness of each predictor. We defined informativeness as the percentage of the minority category for binary variables (categorical variables were binarized first through one-hot encoding) and the coefficient of variation (standard deviation divided by the mean) for the continuous ones. We then computed their univariate AUC against the ED outcome. We subsequently defined high-performing predictors as those in the top 25th percentile of univariate AUC values. As a last step, we used logistic regression to evaluate the association between tertiles of informativeness (the frequency or prevalence of a predictor) and high predictive performance.
Performance metrics
We assessed the predictive performance of the models with respect to their discrimination ability, calibration, and net benefit from the decision curve analysis. The area under the receiver operating characteristic curve (AUC) was the metric reported for discrimination. The AUC ranges from 0 to 1 and is the model’s probability of assigning higher risks to those individuals who are “ED-Positive” than those who are “ED-Negative”. The calibration of the model reflects how accurate the model’s predictions are, i.e., how well the predictions match the data. For example, if a model is well-calibrated, we expect 30% of individuals with a predicted risk of 0.3 to have the outcome. We evaluated the calibration of the models via calibration plots and by computing the Brier Score ranging from 0 to 1, indicative of both calibration and discrimination. The net benefit is a metric stemming from the decision curve analysis, assessing the potential clinical impact of a model52,53,54. It is defined as the proportion of individuals correctly classified as “ED-Positive” (True Positives) minus the proportion of individuals incorrectly classified as “ED-Positive” (False Positives), the latter weighted by a factor related to the relative benefits and harms of each (odds of the risk threshold). The Net Benefit is computed based on the predicted risks from a statistical or machine learning model and compared against default clinical strategies, i.e., intervening on all individuals or not intervening at all. The latter is also calculated for the whole range of possible thresholds to avoid basing our decision on a single threshold (for example, intervening on individuals when their risk is above 0.2). Hence, the Net Benefit is interpreted into units of net True Positives, i.e., how many identified cases (True Positives) will a specific strategy or model lead to without unnecessarily intervening on individuals (False Positives) at a particular threshold. Stated differently, whenever the threshold is, for example, chosen to be 0.1, the clinician is willing to accept up to 9 unnecessary ED interventions (False Positives) per true positive, meaning that the harm of a false positive is 9 times smaller than the benefit of a true positive. Consequently, higher risk thresholds would be considered for interventions that are likely to be harmful or deemed to be intrusive with potential side effects, with lower thresholds being more relevant for less-harmful interventions such as counseling.
All the metrics mentioned above are based on predictions from the testing set to avoid reporting an over-optimistic performance.
Software
We used R statistical software 4.3.2 (https://www.r-project.org/) to preprocess and analyze the current study’s data.
Ethical statement
This study was performed in accordance with the Declaration of Helsinki. Approval of the study was obtained from the Danish Data Protection Agency through the joint notification of The Faculty of Health and Medical Sciences at The University of Copenhagen (SUND-2017-09) and the DNBC Steering Committee (2017-24). Written informed consent was collected from the mothers who enrolled themselves and fetus to the DNBC when pregnant back in 1996–2002. The participants born into DNBC were informed about their participation, what it involved and implications, as well as rights and how to opt out when they came of age, i.e., turned 18.
Results
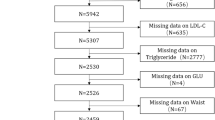
During the 11-year follow-up of the DNBC cohort (Fig. 1), the sample included 44,357 participants, with 33,267 allocated to the training set and 11,090 to the testing set. A total of 475 out of 33,267 (1.4%) and 157 out of 11,090 (1.4%) individuals in the training and testing sets, respectively, were classified as having diagnosed EDs or having symptoms in accordance with threshold or sub-threshold ED (composite diagnostic outcome). Regarding age distribution, 81.0% of participants were 11 years old at questionnaire completion, 14.7% were 12 years old, and 2.8% were of other ages. The sample was evenly distributed by sex (51.1% female, 48.9% male), with 60.2% of the adolescents experiencing parental separations, 25.6% experiencing poverty periods, and 18.2% experiencing parental unemployment up to the 11-year follow-up. Parental psychiatric disorders were present in 13.1% of participants (one parent affected). For the prognostic task, the sample was reduced to 26,127 participants who completed both 11-year and 18-year follow-ups, with 19,595 in the training set and 6532 in the testing set. There were 698 out of 19,595 (3.6%) in the training and 216 out of 6532 (3.3%) participants in the testing set with either a diagnosed or a threshold ED (composite prognostic outcome). The distribution of the predictors, the primary outcome, and their missingness across the data are reported in Supplementary Tables 3 and 4 for the diagnostic and prognostic tasks.

Flowchart of the DNBC (Danish National Birth Cohort) study sample data used to develop the predictive models for eating disorders (1996–2003, follow-up of 18 years).
A more detailed overview of the various threshold EDs (AN, BN, BED) and other disordered eating behaviors (DEBs), Purging, and Sub-threshold EDs across the two datasets (diagnostic and prognostic) is illustrated in Fig. 2. The most frequent type observed was DEBs, with their corresponding absolute number being the largest for both follow-up periods (2612 individuals out of 44,357 in the 11-year and 2309 individuals out of 26,127 in the 18-year follow-up) compared with the rest. We also observed a high prevalence of BED and its sub-threshold category, both in the early and late adolescent years. There were few participants with an official diagnosis of ED, particularly at 11-year follow-up (24 out of 44,357), although displaying an increase through the years, as shown in the 18-year follow-up. The component behaviors within the DEB category showed distinct patterns across developmental stages (Supplementary Table 5). At DNBC-11, binge eating was the predominant behavior, occurring in 82.8% of individuals with DEBs, while purging behaviors were relatively rare (6.1%). Fasting behaviors were present in 17.2% of cases, and multiple concurrent behaviors were observed in 5.9% of individuals. By DNBC-18, the behavioral profile of those with DEBs had shifted: binge eating frequency decreased to 42.7% while fasting behaviors more than doubled to 35.9%. Excessive exercise, as measured only in DNBC-18, accounted for 25.3%, with the co-occurrence of multiple behaviors simultaneously increasing to 12.3%.

The upper plots display the absolute number of cases and relative proportion for a specific eating disorder or disordered eating pattern by the 11-year follow-up of the Danish National Birth Cohort (DNBC) for the 44,357 analyzed individuals (Diagnostic Set). The lower plots display the corresponding numbers observed by the DNBC-18 for the 26,127 analyzed individuals (Prognostic Set). The bold labels on the y-axis display the categories included in the composite outcome of the prediction tasks.
Figure 3 displays the transitions in ED statuses between the two follow-up times. From those participants who completed the questionnaires for both follow-ups (N = 26,127), 7% had DEBs or EDs by DNBC-11. The majority of these exhibited DEBs (79.47%), with smaller proportions classified as having subthreshold (11.42%) or diagnosed/threshold EDs (9.11%). By the DNBC-18, there was a transition across these categories. A sizeable proportion of individuals with DEBs by DNBC-11 transitioned to no ED (71.46%), suggesting a degree of remission over time. However, a persistent subset progressed to subthreshold (7.59%) or diagnosed EDs (6.71%), highlighting the potential for escalation in severity. Similarly, individuals classified with subthreshold EDs by DNBC-11 exhibited diverse trajectories; while some transitioned to no disordered eating patterns (73.11%), others progressed to diagnosed/threshold disorders (7.55%). Finally, the majority of those with diagnosed/threshold disorder by DNBC-11 displayed no ED by DNBC-18 (65.68%), with 13.61% maintaining the diagnosis.

The x-axis displays the two distinct follow-up times (11 years and 18 years). The purple bars represent the proportions of individuals in each category by the DNBC-11 and DNBC-18 follow-up. The width of the flows (orange for disordered eating behaviors, red for subthreshold eating disorder, and blue for diagnosed or threshold eating disorder) connecting the bars illustrates the proportion of individuals transitioning between categories over time, highlighting patterns of persistence and change. Percentages on the y-axis indicate the distribution of individuals across the categories.
Model description and predictive performance
We developed an XGBoost machine learning model (“ML model”) using all available predictors, tuning the hyperparameters through 5-fold CV (Supplementary Table 6). We extracted the top 10 most important predictors of the ML model for each prediction task based on their average absolute SHAP values in the training set (Supplementary Fig. 1). We then developed three logistic regression models for the target composite outcomes using the top 10 (“Reduced model”), top 2 (“Simple model”), and top 1 (“Single model”) highest ranked predictors.
The discriminative ability and overall performance metrics for both prediction tasks are reported in Table 1. For the diagnostic task (predicting ED presence by the 11-year follow-up), the ML model achieved an AUC [95% CI] of 81.3 [78.0, 84.6]. The reduced model using the top-10 predictors showed similar performance with an AUC of 81.1 [77.9, 84.3], with a non-significant difference of −0.2 [−2.1, 1.8]. The Simple model yielded a significantly lower AUC of 77.9 [74.1, 81.6] (∆AUC = −3.4 [−6.1, −0.7]), while the Single model showed the largest performance decrease with an AUC of 65.6 [61.2, 69.9] (∆AUC = −15.7 [−19.8, −11.6]). The Brier scores were comparable between the ML, Reduced, and Simple models, with only the Single model showing a small but significant increase in Brier score (∆Brier = 0.03 [0.01, 0.05]). For the prognostic task (predicting ED development by 18-year follow-up), the ML model achieved an AUC of 76.9 [74.3, 79.5]. The Reduced model showed a non-significant decrease in performance (∆AUC = −1.5 [−3.4, 0.4]), while both the Simple and Single models demonstrated significantly lower discriminative ability (∆AUC = −3.2 [−5.7, −0.7] and −8.1 [−10.3, −6.0], respectively). The Brier scores for the prognostic models showed minimal differences, with only the Single model displaying a small but significant increase compared to the ML model (0.03 [0.01, 0.06]). We report the differences (ΔAUC and ΔBrier) in the performance metrics between models and across prediction tasks in Supplementary Table 7. The ML model provided risks up to 0.25 and was generally well-calibrated, behaving similarly across both prediction tasks and displaying signs of slight overestimation and broader uncertainty with increasing risks. The calibration plots for the diagnostic and prognostic tasks are found in the Supplementary Material (Supplementary Figs. 2 and 3). We further observed positive associations between predictor informativeness tertiles and high predictive performance as measured by the AUC. For the diagnostic task, compared to the lowest tertile, middle and highest informativeness tertiles showed odds ratios of 2.73 (95% CI: 1.22–6.49) and 3.09 (95% CI: 1.39–7.31), respectively. For the prognostic task, the associations were similar: middle tertile OR 2.87 (95% CI: 1.21–7.39) and highest tertile OR 5.90 (95% CI: 2.60–14.8). We also found that self-reported variables demonstrated significantly higher distributional variability (informativeness) compared to register-based variables in both the diagnostic task (0.23 vs 0.16, difference = 0.07, 95% CI: 0.002–0.14) and prognostic task (0.23 vs 0.15, difference = 0.07, 95% CI: 0.004–0.14). Extending the outcome for the diagnostic and prognostic task to include DEBs and sub-threshold EDs, respectively, led to similar AUC patterns, with the predictive performance of the Reduced model being comparable to the ML one, with the Simple and Single models reaching smaller values (Supplementary Table 8).
SHAP-values and variable importance
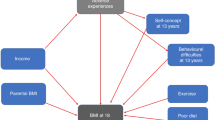
We employed SHAP-values (SHapley Additive exPlanations) to identify the most influential predictors for both diagnostic and prognostic tasks, with higher absolute values indicating greater contribution to ED risk prediction. For the prognostic model (predicting EDs by DNBC-18), being female emerged as the strongest predictor (Fig. 4). The remaining top predictors included: higher emotional symptoms (measuring feelings of worry, unhappiness, and nervousness), lower body satisfaction scores (indicating greater dissatisfaction with physical appearance), higher peer relationship problems (reflecting difficulties in social relationships with other children), lower hyperactivity/inattention scores (measuring restlessness, distractibility, and impulsivity as reported by parents), higher childhood BMI at the 7-year follow-up, lower maternal and paternal BMI values at DNBC-11, higher stress levels from the SiC questionnaire, and higher conduct problems (indicating antisocial behaviors). All of these factors, when present in the specified directions, contributed to increased ED risk by DNBC-18. We provide the partial dependence plots illustrating how the prognostic risk changes across the different predictors in Supplementary Fig. 4.

The x-axis of the plot displays the SHAP-value in units of log odds, while the y-axis shows the predictors sorted from most important to least important based on their mean absolute SHAP-value. The SHAP-value is represented as a dot point for each individual and reflects the deviation of each individual from the average baseline risk extracted from the training set based on the value of each specific predictor. Higher feature values are colored yellow, whereas lower values are purple. SHAP-values clustered on the right side of the gray vertical line (higher than zero) indicate higher predicted risks (positive deviations from the average risk). In contrast, values on the left (lower than zero) reflect lower predicted risks (negative deviations from the average risk). For illustration, higher values of the child’s BMI at the 7-year follow-up push the predictions of the model further away from the baseline risk and towards the ED-positive class. All predictors are measured at time zero (DNBC-11) unless specified.
For the diagnostic model (identifying current EDs by DNBC-11), lower body satisfaction was the most influential predictor (Fig. 5). Other key predictors included higher emotional symptoms, higher stress levels, higher hyperactivity/inattention scores (as reported by children themselves), frequent obsessive-compulsive disorder symptoms (assessing repetitive behaviors and intrusive thoughts), higher conduct problems and peer relationship problems (both child-reported), having lost contact with a best friend, presence of depressive feelings, and lack of sleep. Sex did not appear among the top 10 predictors for current ED identification, whereas it was the most influential predictor for the presence of ED in late adolescence. The diagnostic model uniquely incorporated acute psychological symptoms such as obsessive-compulsive behaviors, depressive feelings, and sleep disturbances, while the prognostic model incorporated early physical indicators, including childhood BMI and parental BMI values. Hyperactivity/inattention showed opposing patterns between models: lower parent-reported scores increased risk in the prognostic model, while higher child-reported scores increased risk in the diagnostic model.

The x-axis of the plot displays the SHAP-value in units of log odds, while the y-axis shows the predictors sorted from most important to least important based on their mean absolute SHAP-value. The SHAP-value is represented as a dot point for each individual and reflects the deviation of each individual from the average baseline risk extracted from the training set based on the value of each specific predictor. Higher feature values are colored yellow, whereas lower values are deep blue. SHAP-values clustered on the right side of the gray vertical line (higher than zero) indicate higher predicted risks (positive deviations from the average risk). In contrast, values on the left (lower than zero) reflect lower predicted risks (negative deviations from the average risk). All predictors are measured at time zero (DNBC-11) unless specified.
Potential clinical benefit of models
We assessed the models’ ability to provide additional clinical benefit based on the results of the decision curve analysis. Specifically, we evaluated their net benefit, i.e., how many ED cases each model or strategy can correctly identify (True Positives) on the testing set without unnecessarily intervening on individuals (False Positives) across the continuum of risk thresholds. The analysis results are illustrated in Fig. 6. The use of all four prediction models as a decision-support tool for an intervention exhibited a higher net benefit for thresholds up to 10% for both prediction tasks when compared with a strategy of intervening on every adolescent or no one. The models did not show any added benefit for thresholds above that number.

The upper plot displays the net benefit of models and strategies for diagnosing eating disorders (EDs) in adolescents by DNBC-11 (diagnostic task). The lower plot displays the net benefit for the ED risk of adolescents by the DNBC-18 (prognostic task). The x-axis (“Threshold probability for intervention”) shows the range of thresholds, i.e., the probability that, when exceeded, adolescents are classified as having a high risk of having EDs by DNBC-11 or DNBC-18. The y-axis (“Net benefit”) shows the smoothed proportion, measured in True Positives (TPs), of accurately diagnosing or identifying adolescents at risk of ED presence after subtracting the weighted (by the odds of the threshold) false positives for every threshold probability. A proportion of 0.05 implies five correctly identified ED cases for every 100 individuals in the target population without unnecessarily intervening in them. The” Treat All” line represents the scenario of intervening on every individual in the target population, i.e., every child in early adolescence, without using a specific model. The” Treat None” line depicts the scenario of not intervening or screening the target population. The rest of the lines display the net benefit extracted from the predictions of each model on the testing set. In general, higher decision curves should be preferred over the rest.
The differences in the models’ net benefit for the diagnostic task were minimal for the ML, Reduced, and Simple models, while being higher than the model using only the top-1 predictor based on the SHAP-values. Specifically, at a risk threshold of 2%, the net benefit of the ML, Reduced, Simple, and Single models was 0.0058, 0.0053, 0.0050, and 0.0028, respectively. Therefore, at the given threshold, the first three models could identify approximately 60 to 50 ED cases per 10,000 adolescents without falsely identifying any. For relevance, the prevalence of the studied outcome in our test data corresponded to 140 cases per 10,000 individuals. For the prognostic task, the ML and the reduced models exhibited a higher net benefit for thresholds above 4% and up to 10% when compared against the Simple or Single models. Namely, at a threshold of 5%, the net benefit of the ML and Reduced models was 0.0070 and 0.0065, respectively, with the Simple’s and Single’s being 0.0044 and 0.0021. Hence, the former two models could correctly identify the development of 70 and 65 ED cases in early adulthood without any FPs from a population of 10,000 adolescents, with the prevalence of the outcome in the test data being 330 cases out of 10,000. We also tested the Reduced model’s robustness by examining its net benefit from predictions extracted from a 5-fold cross-validated split. The decision curves displayed a net benefit similar to the single train/test split (Supplementary Fig. 5).
Discussion
The current study presents the first large-scale attempt to develop prediction models for EDs in adolescence using comprehensive self-reported and registry-based data34,55. By combining these two types of data sources, models were developed and internally validated, demonstrating potential predictive capacity while also revealing important insights about the relative value of different types of predictors. The comparative analysis of our predictive models revealed the relationship between model complexity and performance. While our machine learning model achieved strong discrimination for both tasks, the reduced logistic regression model using only the top 10 predictors showed equivalent performance, with non-significant differences in AUC for diagnostic and prognostic tasks, respectively. This finding aligns with previous research in clinical prediction modeling, where simpler models have achieved comparable performance to more complex algorithms. For instance, a previous systematic review of 71 studies showed that algorithms did not generally outperform logistic regression for clinical prediction tasks56. Here, we proposed a carefully constructed, simpler model using key predictors, offering an optimal balance between accuracy and clinical applicability. Our approach leverages the strengths of both methods, i.e., using machine learning for feature selection to inform simpler logistic regression models, providing an effective strategy for predicting outcomes such as EDs.
The variable importance analysis showed that self-reported measures were the primary predictors at both time points, highlighting the value of structured questionnaire data. Multiple subscales from the SDQ consistently ranked among the most influential predictors, in line with previous work57, with emotional symptoms, peer relationship problems, and conduct problems leading the way for diagnostic and prognostic tasks. The SiC questionnaire score was also important across both prediction tasks, emphasizing the already-known significance of stress assessment in evaluating ED risk58. In contrast, despite their comprehensive nature and objective measurement, registry-based variables did not prominently appear among the top predictors. Our informativeness analysis provided insight into these patterns, revealing that self-reported variables demonstrated higher distributional variability compared to register-based variables. The positive dose-response relationship between predictor informativeness tertiles and high predictive performance demonstrated that variables with greater distributional variability were systematically more likely to achieve stronger discrimination, underscoring that predictors must have reasonably high spread or prevalence to contribute to model performance substantially. Additionally, and for our prediction tasks, the limited prominence of register-based variables may reflect that when detailed self-reported data are available, register-based information may not provide additional predictive signal beyond what is already captured by detailed psychological and behavioral measures. These results highlight an important methodological consideration: analyses based solely on effect estimates such as odds ratios cannot appropriately determine whether a variable will function as an effective predictor of EDs, since a rare predictor with a significant and large effect size can potentially influence a subgroup of the target population (here adolescents in Denmark), but have minimal impact on the overall target population if the subgroup’s size is too small59.
Concerning the models’ clinical utility, our decision curve analysis showed that these models can be beneficial for interventions with a low risk of harm. At lower thresholds, where the models indicated greater net benefit than alternative strategies, they can effectively inform preventive measures such as psychoeducational resources, tailored counseling sessions, peer support groups, and family-based interventions for high-risk individuals. We developed a simple logistic regression model that offers a pragmatic approach to clinical implementation, requiring only 10 readily accessible predictors from standard psychological questionnaires and basic health information. The model’s reliance on established measures, including the SDQ subscales, SiC score, and metrics such as BMI and body dissatisfaction, means it could be easily integrated into existing pediatric and adolescent health screenings. This parsimony, combined with performance comparable to more complex algorithms, positions the model as a potentially valuable clinical decision-support tool. However, while our validation demonstrates promising predictive capabilities, this does not automatically translate to improved patient outcomes. Ideally, a stepped wedge cluster randomized trial would need to be conducted to evaluate whether model-guided screening and intervention improves early detection rates, reduces time to treatment initiation, and ultimately improves clinical outcomes compared to standard care60,61,62,63.
Beyond their clinical utility, our findings could offer theoretical insights into the developmental pathways of EDs. The behavioral composition differences between the two distinct follow-ups reveal distinct developmental phases: by the DNBC-11, DEBs were predominantly characterized by binge eating, while by DNBC-18, there was a shift toward more diverse behavioral patterns, including increased fasting and the emergence of excessive exercise. This developmental transition from primarily impulsive eating behaviors to more restrictive and compensatory patterns may explain some of the differences in predictive factors between diagnostic and prognostic models. The contrasting patterns of hyperactivity/inattention across models may reflect this behavioral evolution: lower parent-reported hyperactivity/inattention scores predicting future ED risk could indicate children with greater capacity for self-control and internalization, potentially predisposing them to the restrictive behaviors that become more prominent by late adolescence, as evidenced by longitudinal trajectories showing increasing internalizing problems in restrictive eaters64. Conversely, higher child-reported hyperactivity/inattention symptoms in the diagnostic ED model may capture the acute cognitive effects of active ED symptoms or the restlessness associated with mostly binge-eating presentations at early adolescence, consistent with elevated externalizing problems in emotional/uncontrolled eaters64. The divergent BMI patterns, where lower parental BMI but higher childhood BMI both predicted increased ED risk, suggest complex intergenerational transmission mechanisms operating differently across developmental phases. Lower parental BMI may reflect familial genetic vulnerability to EDs, shared environmental factors that promote weight concern, or intergenerational transmission of weight-related attitudes65. At the same time, higher childhood BMI may create vulnerability through weight stigma, body dissatisfaction, and subsequent dieting attempts that may initially manifest as binge eating but later evolve into restrictive behaviors66,67,68,69.
The differential prominence of sex as a predictor between tasks may reflect developmental changes in ED risk, where sex differences become more pronounced as adolescents progress toward late adolescence and the peak incidence period for many EDs. The emergence of obsessive-compulsive symptoms, depressive feelings, and sleep disturbances as key diagnostic predictors (but not prognostic ones) suggests that these factors may represent more proximal indicators of current ED pathology rather than risk factors for future development. Conversely, the consistent importance of emotional symptoms, conduct problems, and body satisfaction across both tasks highlights these as factors that remain relevant for both identifying current cases and predicting future risk, supporting their potential utility as targets for both screening and prevention efforts. However, it is important to note that our model used to extract such patterns is designed for screening and clinical decision-support rather than etiological inference. While these patterns are scientifically interesting and merit further investigation, definitive interpretation of their causal or theoretical significance would require dedicated analyses incorporating causal inference methods, which fall outside our current study’s scope.
This study has several key strengths. First, it represents the largest sample size to date used for developing ED prediction models, with 44,357 individuals for the diagnostic task and 26,127 for the prognostic task. Additionally, we evaluated an extensive set of approximately 100 potential predictors spanning demographic, social, behavioral, and clinical domains, substantially more comprehensive than other studies in the field29,55. We consider the longitudinal design with up to 18 years of follow-up another strength, enabling us to develop diagnostic and prognostic models and characterize transitions between ED states over time. Importantly, we conducted thorough internal validation of the models, examining discrimination, calibration, and potential clinical utility. Finally, we successfully developed a simplified logistic regression model using only 10 predictors that maintained performance comparable to the more complex machine learning model, enhancing potential clinical implementation. However, some limitations warrant discussion. The reliance on self-reported data for many predictors and outcomes may introduce reporting bias, given the sensitive nature of variables related to mental health. Nevertheless, our composite outcome, combining diagnosed cases with self-reported threshold and subthreshold ones according to the DSM-5 criteria, provides a more complete picture of ED risk, particularly valuable given that many individuals may delay or avoid seeking formal diagnosis due to stigma or access barriers26,27. However, this composite approach still has a limitation: it cannot capture those adolescents who may have experienced an undiagnosed ED that had already remitted before their respective follow-up questionnaire (either DNBC-11 or DNBC-18) was administered. Such cases would be missed by both the register and the self-reported DNBC information, a limitation inherent to the available data. While we couldn’t predict specific ED subtypes separately due to sample size constraints, this limitation may be less critical for early prevention efforts that target shared risk factors such as those identified by our models. Also, DNBC participants tend to be of higher socioeconomic status than the general Danish population, potentially limiting generalizability and highlighting the need for external validation of the models35,70,71,72. Furthermore, while SHAP-values identified influential predictors, they depict statistical patterns within our model’s predictions and cannot determine whether these factors cause EDs. Any causal claims would require different analytical approaches. Finally, although our models showed promising performance, they were developed and validated using Danish data, and their applicability to other populations might require further investigation.
In summary, this study demonstrated the feasibility of developing predictive models for EDs using routinely collected data from questionnaires and health registries. Our models, integrating emotional symptoms, peer relationship difficulties, stress levels, conduct problems, body satisfaction levels, and BMI trajectories, demonstrated promising accuracy in identifying adolescents who may develop EDs, offering clinicians a potential screening tool for use during routine pediatric visits. While these models show promise for identifying young people at risk, particularly for low-risk interventions, their real-world impact on patient outcomes needs to be rigorously evaluated through clinical trials. The predominance of psychological and behavioral variables in our prediction models suggests potential value in exploring transdiagnostic approaches to mental health screening in adolescence, which could offer a more comprehensive framework for early risk assessment73,74.
Data availability
The datasets generated and analyzed during the current study are not publicly available due to the data being stored and processed in the research machines of Statistics Denmark. According to Danish law, scientific organizations can be authorized to work with data within Statistics Denmark and can provide access to individual scientists inside and outside Denmark. Data are available via the Research Service Department at Statistics Denmark: (https://www.dst.dk/da/TilSalg/Forskningsservice) for researchers who meet the criteria for access to confidential data. The code of the analysis is publicly available at (https://github.com/alkat19/ED_Pred).
References
Feng, B. et al. Current discoveries and future implications of eating disorders. Int. J. Environ. Res. Public Health 20, 6325 (2023).
Blodgett Salafia, E. H., Jones, M. E., Haugen, E. C. & Schaefer, M. K. Perceptions of the causes of eating disorders: a comparison of individuals with and without eating disorders. J. Eat. Disord. 3, 32 (2015).
American Psychiatric Association. Diagnostic and Statistical Manual of Mental Disorders (American Psychiatric Association Publishing, 2022).
Schaumberg, K. et al. The science behind the academy for eating disorders’ nine truths about eating disorders. Eur. Eat. Disord. Rev. 25, 432–450 (2017).
Hay, P. & Mitchison, D. The epidemiology of eating disorders: genetic, environmental, and societal factors. Clin. Epidemiol. 17, 89–97 (2014).
American Psychiatric Association. Diagnostic and Statistical Manual of Mental Disorders: DSM-5 (American Psychiatric Publishing, 2013).
Keski-Rahkonen, A. & Mustelin, L. Epidemiology of eating disorders in Europe. Curr. Opin. Psychiatry 29, 340–345 (2016).
Herpertz-Dahlmann, B. Adolescent eating disorders. Child Adolesc. Psychiatr. Clin. N. Am. 24, 177–196 (2015).
Westmoreland, P., Krantz, M. J. & Mehler, P. S. Medical complications of anorexia nervosa and bulimia. Am. J. Med. 129, 30–37 (2016).
Momen, N. C. et al. Association between mental disorders and subsequent medical conditions. N. Engl. J. Med. 382, 1721–1731 (2020).
Momen, N. C. et al. Comorbidity between eating disorders and psychiatric disorders. Int. J. Eat. Disord. 55, 505–517 (2022).
Momen, N. C. et al. Comorbidity between types of eating disorder and general medical conditions. Br. J. Psychiatry 220, 279–286 (2022).
Momen, N. C., Petersen, J. D., Yilmaz, Z., Semark, B. D. & Petersen, L. V. Inpatient admissions and mortality of anorexia nervosa patients according to their preceding psychiatric and somatic diagnoses. Acta Psychiatr. Scand. 149, 404–414 (2024).
Plana-Ripoll, O. et al. A comprehensive analysis of mortality-related health metrics associated with mental disorders: a nationwide, register-based cohort study. Lancet 394, 1827–1835 (2019).
Larsen, J. T. et al. Diagnosed eating disorders in Danish registers – incidence, prevalence, mortality, and polygenic risk. Psychiatry Res. 337, 115927 (2024).
Swanson, S. A., Crow, S. J., Le Grange, D., Swendsen, J. & Merikangas, K. R. Prevalence and correlates of eating disorders in adolescents. Arch. Gen. Psychiatry 68, 714 (2011).
Pedersen, C. B. et al. A comprehensive nationwide study of the incidence rate and lifetime risk for treated mental disorders. JAMA Psychiatry 71, 573 (2014).
Beck, C. et al. A comprehensive analysis of age of onset and cumulative incidence of mental disorders: a Danish register study. Acta Psychiatr. Scand. 149, 467–478 (2024).
Steinhausen, H. & Jensen, C. M. Time trends in lifetime incidence rates of first‐time diagnosed anorexia nervosa and bulimia nervosa across 16 years in a Danish nationwide psychiatric registry study. Int. J. Eat. Disord. 48, 845–850 (2015).
Breton, É. et al. Developmental trajectories of eating disorder symptoms: a longitudinal study from early adolescence to young adulthood. J. Eat. Disord. 10, 84 (2022).
Crowell, M. D. et al. Eating behaviors and quality of life in preadolescents at risk for obesity with and without abdominal pain. J. Pediatr. Gastroenterol. Nutr. 60, 217–223 (2015).
Pasold, T. L., McCracken, A. & Ward-Begnoche, W. L. Binge eating in obese adolescents: emotional and behavioral characteristics and impact on health-related quality of life. Clin. Child Psychol. Psychiatry 19, 299–312 (2014).
Zerwas, S. et al. The incidence of eating disorders in a Danish register study: associations with suicide risk and mortality. J. Psychiatr. Res. 65, 16–22 (2015).
Larsen, P. S., Nybo Andersen, A., Olsen, E. M., Micali, N. & Strandberg‐Larsen, K. What’s in a self‐report? A comparison of pregnant women with self‐reported and hospital diagnosed eating disorder. Eur. Eat. Disord. Rev. 24, 460–465 (2016).
Attia, E. & Guarda, A. S. Prevention and early identification of eating disorders. JAMA 327, 1029 (2022).
Forrest, L. N., Smith, A. R. & Swanson, S. A. Characteristics of seeking treatment among U.S. adolescents with eating disorders. Int. J. Eat. Disord. 50, 826–833 (2017).
Ali, K. et al. Perceived barriers and facilitators towards help‐seeking for eating disorders: a systematic review. Int. J. Eat. Disord. 50, 9–21 (2017).
de la Rie, S., Noordenbos, G., Donker, M. & van Furth, E. Evaluating the treatment of eating disorders from the patient’s perspective. Int. J. Eat. Disord. 39, 667–676 (2006).
Wang, S. B. Machine learning to advance the prediction, prevention and treatment of eating disorders. Eur. Eat. Disord. Rev. 29, 683–691 (2021).
López-Gil, J. F. et al. Global proportion of disordered eating in children and adolescents. JAMA Pediatr. 177, 363 (2023).
Moons, K. G. M., Royston, P., Vergouwe, Y., Grobbee, D. E. & Altman, D. G. Prognosis and prognostic research: what, why, and how? BMJ 338, b375–b375 (2009).
Hendriksen, J. M. T., Geersing, G. J., Moons, K. G. M. & de Groot, J. A. H. Diagnostic and prognostic prediction models. J. Thromb. Haemost. 11, 129–141 (2013).
Stice, E. & Shaw, H. Eating disorder prevention programs: a meta-analytic review. Psychol. Bull. 130, 206–227 (2004).
Fardouly, J., Crosby, R. D. & Sukunesan, S. Potential benefits and limitations of machine learning in the field of eating disorders: current research and future directions. J. Eat. Disord. 10, 66 (2022).
Strandberg-Larsen, K. et al. Cohort profile: the Danish National Birth Cohort from foetal life to young adulthood. Int. J. Epidemiol. 54, dyaf083 (2025).
Olsen, J. et al. The Danish National Birth Cohort - its background, structure and aim. Scand. J. Public Health 29, 300–307 (2001).
Schmidt, M., Pedersen, L. & Sørensen, H. T. The Danish Civil Registration System as a tool in epidemiology. Eur. J. Epidemiol. 29, 541–549 (2014).
Jensen, V. M. & Rasmussen, A. W. Danish education registers. Scand. J. Public Health 39, 91–94 (2011).
Baadsgaard, M. & Quitzau, J. Danish registers on personal income and transfer payments. Scand. J. Public Health 39, 103–105 (2011).
Petersson, F., Baadsgaard, M. & Thygesen, L. C. Danish registers on personal labour market affiliation. Scand. J. Public Health 39, 95–98 (2011).
Bengtsson, J., Dich, N., Rieckmann, A. & Hulvej Rod, N. Cohort profile: the Danish LIFE course (DANLIFE) cohort, a prospective register-based cohort of all children born in Denmark since 1980. BMJ Open 9, e027217 (2019).
Pottegård, A. et al. Data resource profile: the Danish national prescription registry. Int. J. Epidemiol. 46, 798–798f (2016).
Schmidt, M. et al. The Danish national patient registry: a review of content, data quality, and research potential. Clin. Epidemiol. 17, 449–490 (2015).
Mors, O., Perto, G. P. & Mortensen, P. B. The Danish psychiatric central research register. Scand. J. Public Health 39, 54–57 (2011).
Osika, W., Friberg, P. & Wahrborg, P. A new short self-rating questionnaire to assess stress in children. Int J. Behav. Med. 14, 108–117 (2007).
Goodman, R. The strengths and difficulties questionnaire: a research note. J. Child Psychol. Psychiatry 38, 581–586 (1997).
Chen, T. & Guestrin, C. XGBoost: a scalable tree boosting system. https://doi.org/10.1145/2939672.2939785.
Gerds, T. A., Cai, T. & Schumacher, M. The performance of risk prediction models. Biom. J. 50, 457–479 (2008).
Shewry, M. C. & Wynn, H. P. Maximum entropy sampling. J. Appl. Stat. 14, 165–170 (1987).
Lundberg, S. & Lee, S.-I. A unified approach to interpreting model predictions. In Proc. 31st International Conference on Neural Information Processing Systems 4768–4777 (ACM, 2017).
Harrell, F. E. Regression Modeling Strategies : With Applications to Linear Models, Logistic and Ordinal Regression, and Survival Analysis. (Springer, 2015).
Vickers, A. J. & Elkin, E. B. Decision curve analysis: a novel method for evaluating prediction models. Med. Decis. Mak. 26, 565–574 (2006).
Vickers, A. J., Van Calster, B. & Steyerberg, E. W. A simple, step-by-step guide to interpreting decision curve analysis. https://doi.org/10.1186/s41512-019-0064-7.
Pfeiffer, R. M. & Gail, M. H. Estimating the decision curve and its precision from three study designs. Biom. J. 62, 764–776 (2020).
Ghosh, S., Burger, P., Simeunovic-Ostojic, M., Maas, J. & Petković, M. Review of machine learning solutions for eating disorders. Int J. Med. Inf. 189, 105526 (2024).
Christodoulou, E. et al. A systematic review shows no performance benefit of machine learning over logistic regression for clinical prediction models. J. Clin. Epidemiol. 110, 12–22 (2019).
Mitchell, K. S., Wolf, E. J., Reardon, A. F. & Miller, M. W. Association of eating disorder symptoms with internalizing and externalizing dimensions of psychopathology among men and women. Int. J. Eat. Disord. 47, 860–869 (2014).
Hardaway, J. A., Crowley, N. A., Bulik, C. M. & Kash, T. L. Integrated circuits and molecular components for stress and feeding: implications for eating disorders. Genes Brain Behav. 14, 85–97 (2015).
Gerds, T. A. & Kattan, M. W. Medical Risk Prediction (Chapman and Hall/CRC, https://doi.org/10.1201/9781138384484 (2021).
Hemming, K., Haines, T. P., Chilton, P. J., Girling, A. J. & Lilford, R. J. The stepped wedge cluster randomised trial: rationale, design, analysis, and reporting. BMJ 350, h391–h391 (2015).
van Amsterdam, W. A. C., de Jong, P. A., Verhoeff, J. J. C., Leiner, T. & Ranganath, R. From algorithms to action: improving patient care requires causality. BMC Med. Inf. Decis. Mak. 24, 111 (2024).
Kwong, J. C. C., Nickel, G. C., Wang, S. C. Y. & Kvedar, J. C. Integrating artificial intelligence into healthcare systems: more than just the algorithm. npj Digit. Med. 7, 52 (2024).
Kappen, T. H. et al. Evaluating the impact of prediction models: lessons learned, challenges, and recommendations. Diagn. Progn. Res. 2, 11 (2018).
Yu, X. et al. Relationships of eating behaviors with psychopathology, brain maturation and genetic risk for obesity in an adolescent cohort study. Nat. Ment. Health 3, 58–70 (2025).
Mazzeo, S. E. & Bulik, C. M. Environmental and genetic risk factors for eating disorders: what the clinician needs to know. Child Adolesc. Psychiatr. Clin. N. Am. 18, 67–82 (2009).
Neumark-Sztainer, D. et al. Obesity, disordered eating, and eating disorders in a longitudinal study of adolescents: how do dieters fare 5 years later? J. Am. Diet. Assoc. 106, 559–568 (2006).
Puhl, R. & Suh, Y. Health consequences of weight stigma: implications for obesity prevention and treatment. Curr. Obes. Rep. 4, 182–190 (2015).
Barakat, S. et al. Risk factors for eating disorders: findings from a rapid review. J. Eat. Disord. 11, 8 (2023).
West, C. E., Goldschmidt, A. B., Mason, S. M. & Neumark‐Sztainer, D. Differences in risk factors for binge eating by socioeconomic status in a community‐based sample of adolescents: findings from Project EAT. Int. J. Eat. Disord. 52, 659–668 (2019).
Jacobsen, T. N., Nohr, E. A. & Frydenberg, M. Selection by socioeconomic factors into the Danish National Birth Cohort. Eur. J. Epidemiol. 25, 349–355 (2010).
Collins, G. S. et al. Evaluation of clinical prediction models (part 1): from development to external validation. BMJ e074819 https://doi.org/10.1136/bmj-2023-074819 (2024)
Riley, R. D. et al. Evaluation of clinical prediction models (part 2): how to undertake an external validation study. BMJ e074820 https://doi.org/10.1136/bmj-2023-074820 (2024)
Hetrick, S. E. et al. Integrated (one‐stop shop) youth health care: best available evidence and future directions. Med. J. Austr. 207, S5–S18 (2017).
McGorry, P. D. & Mei, C. Early intervention in youth mental health: progress and future directions. Evid. Based Ment. Health 21, 182–184 (2018).
Acknowledgements
The funders had no role in study design, data collection and analysis, decision to publish, or preparation of the manuscript. A.K. and S.B. acknowledge funding from the Novo Nordisk Foundation via The Novo Nordisk Young Investigator Award (NNF20OC0059309). S.B. is funded by the MRC Centre for Global Infectious Disease Analysis (reference MR/X020258/1), funded by the UK Medical Research Council (MRC). This UK-funded award is carried out in the framework of the Global Health EDCTP3 Joint Undertaking. S.B. also acknowledges funding by the National Institute for Health and Care Research (NIHR) Health Protection Research Unit in Modeling and Health Economics, a partnership between the UK Health Security Agency, Imperial College London, and LSHTM (grant code NIHR200908). S.B. also has funding from the Danish National Research Foundation (DNRF160) and acknowledges support from The Eric and Wendy Schmidt Fund for Strategic Innovation via the Schmidt Polymath Award (G-22-63345). L.V.P. acknowledges funding from The Lundbeck Foundation (R433-2023-565) and the Novo Nordisk Foundation (NNF23OC0085941). A.J. and K.S.L. acknowledge funding from the Independent Research Fund Denmark via the Sapere Aude DFF-starting grant (8045-00047B). K.S.L. further holds research grants from the Centre for Childhood Health (ID: 2024_F_008, ID:2024_I_001), European Commission Horizon2020 (Partner 22 on no. 874583), and NordForsk (no. 156298), and is heavily involved in research projects granted from by the Novo Nordisk Foundation (NNF22SH0077074, NNF21SH0069849), and the Lundbeck Foundation. We acknowledge the use of BioRender for the creation of Figure 1 (Katsiferis, A. (2025) https://BioRender.com/kvcqfdc).
Author information
Authors and Affiliations
Contributions
A.K. and K.S.L. conceptualized the study. A.K., K.S.L., A.J., and C.T.E. devised the analysis plan. A.K. and A.J. conducted the analyses and were supervised by K.S.L., T-L.N., C.T.E., S.B., and L.V.P. K.S.L., E.M.O., and C.T.E. had access and verified the data. A.K., A.J., and K.S.L. prepared the manuscript. T-L.N., S.B., E.M.O., K.S.L., L.V.P., and C.T.E. conducted review and editing of the manuscript. K.S.L. acquired the funding. The corresponding author attests that all listed authors meet authorship criteria and that no others meeting the criteria have been omitted.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Katsiferis, A., Joensen, A., Petersen, L.V. et al. “Developing machine learning models of self-reported and register-based data to predict eating disorders in adolescence”. npj Mental Health Res 4, 65 (2025). https://doi.org/10.1038/s44184-025-00179-x
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s44184-025-00179-x
