
Abstract
Tsunami science is moving from standalone physics simulations to integrated forecasting and risk-governance frameworks. This review synthesizes advances in multi-source observations, signal detection, propagation and inundation modeling, physics–AI hybrid prediction, and real-time warning workflows. It further discusses uncertainty communication, decision support, and pathways for linking forecast systems with resilient coastal planning and community preparedness.
Similar content being viewed by others

Introduction
Tsunamis are among the most destructive natural hazards, capable of causing massive damage and loss of life within a very short time1,2,3,4,5 (Fig. 1). Unlike many other natural hazards, tsunamis are complex phenomena generated by a wide range of seismic and non-seismic processes, including submarine earthquakes, volcanic eruptions, landslides, and meteorological disturbances6,7,8. Their inherent unpredictability, together with sudden energy release and rapid propagation, makes tsunami prediction particularly challenging9. The central difficulty of tsunami forecasting lies not only in the severe time constraints and high uncertainty, but also in the grave consequences that can arise from forecast errors. Because tsunami waves travel extremely fast in the deep ocean, the window for issuing reliable warnings is often only minutes to hours, leaving very limited tolerance for mistakes.

Circle size is proportional to the source moment magnitude for earthquake-triggered tsunamis; colors indicate the Soloviev–Imamura tsunami intensity scale. Gray denotes events for which intensity cannot be determined due to missing wave-height data. Green solid lines represent major plate boundaries. Adapted from ref. 5, with permission.
Fundamentally, the challenges of tsunami forecasting stem from the tight coupling among time constraints, uncertainty, and the real-world consequences of forecast-driven decisions. Tsunami waves can traverse vast ocean basins at high speeds, which requires forecasting to be performed in real time or near real time10,11. This is especially critical for near-field tsunamis (e.g., those triggered by offshore earthquakes), where the time between hazard onset and the arrival of the first wave at the coast is typically only a few minutes to tens of minutes. Such a narrow window severely limits opportunities for human intervention and evacuation, placing extremely high demands on both timeliness and accuracy. Meanwhile, tsunami prediction is intrinsically uncertain. On the one hand, the complexity of the ocean environment and seafloor topography, along with variations in earthquake magnitude, focal mechanism, and epicentral location, makes it difficult to fully and precisely characterize tsunami generation and propagation12,13. On the other hand, non-seismic tsunamis (e.g., those induced by submarine landslides and volcanic activity)14,15,16 further amplify uncertainty because their triggering mechanisms remain incompletely understood and their timing and scale are difficult to anticipate. In addition, tsunami forecasting is a high-stakes task: forecast outcomes have profound implications for public safety17 and socioeconomic stability18,19. Timely and reliable warnings can provide precious time for coastal evacuation and save lives; conversely, false alarms may disrupt normal operations, trigger unnecessary evacuations, and lead to substantial economic losses. Even more critically, missed warnings (i.e., failure to issue an alert when a tsunami is approaching) can be catastrophic, as they deprive communities of the opportunity to prepare and take protective actions.
In recent years, the limitations of the traditional “earthquake–physics model–warning” paradigm have become increasingly evident. The 2011 Great East Japan Earthquake and Tsunami, for example, exposed inherent deficiencies in existing forecasting systems: although the tsunamigenic earthquake was detected early, the arrival time and magnitude of the tsunami were not predicted with sufficient accuracy, ultimately contributing to catastrophic outcomes19. Similarly, the 2018 Sulawesi tsunami in Indonesia20,21 highlighted the major challenge of forecasting tsunamis generated by non-seismic processes such as submarine landslides—events that often lack clear seismic triggers and whose generation and amplification mechanisms are not yet fully understood, while related monitoring and warning technologies remain underdeveloped22. Comparable issues have repeatedly surfaced in other major events. During the 2004 Indian Ocean tsunami23,24, the absence of a robust regional warning system meant that coastal nations received little effective warning despite the enormous earthquake magnitude, resulting in more than 200,000 fatalities and underscoring systemic gaps in monitoring networks and information dissemination25. The 1998 Papua New Guinea tsunami26, widely considered to have been primarily landslide-triggered, had strong local impacts and short propagation distance yet caused exceptionally severe nearshore damage, revealing deficiencies in identifying small-scale but highly destructive tsunami sources27. More recently, the tsunami triggered by the 2022 Hunga Tonga–Hunga Ha’apai submarine volcanic eruption11 further demonstrated that volcanic activity and atmosphere–ocean coupling can produce complex tsunami responses on a global scale, exceeding the scope of earthquake-centric forecasting frameworks28. Collectively, these events indicate that current tsunami forecasting systems still face fundamental limitations in source characterization, multi-source trigger identification, and the coupling of complex processes. Consequently, there is an urgent need to move beyond a single earthquake-driven forecasting paradigm toward a more data-intensive, mechanism-inclusive, and uncertainty-aware integrated framework.
Over the past two decades, tsunami forecasting has undergone major transformations, reshaping the field. With breakthroughs in data acquisition, ocean observing systems, and real-time communications, global monitoring networks have expanded at an unprecedented pace29,30,31. Traditional approaches often relied on sparse, cable-based sensors, leading to delayed or inaccurate forecasts. The current data-driven era is changing this landscape in multiple ways. Large-scale observing facilities such as Deep-ocean Assessment and Reporting of Tsunamis (DART) enable continuous, real-time monitoring of wave heights and seafloor pressure, providing high-frequency data support for early tsunami detection and tracking32. Meanwhile, advances in satellite remote sensing have extended observational coverage across space and time: satellite altimeters, radar, and synthetic aperture radar (SAR) can capture sea-surface height anomalies and deformation signals on a global scale, especially in the open ocean and other observation-sparse regions33. Stable, high-speed communications have further reduced latency between observation, analysis, and warning issuance, gradually shifting tsunami forecasting from reliance on fragmented and delayed observations toward near-real-time or real-time responses driven by multi-source data streams34. This fundamental change in the data environment makes it possible, for the first time, to acquire and jointly analyze seismic, oceanic, and satellite observations in a synchronized manner, laying a critical foundation for improving forecast accuracy, timeliness, and operational usefulness.
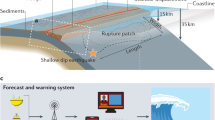
Physics-based tsunami models remain scientifically indispensable for describing wave generation, propagation, and inundation processes and continue to serve as a key pillar of forecasting systems32,35,36,37,38. However, as warning needs evolve toward higher timeliness, more complex scenarios, and more explicit decision orientation, these models increasingly reveal limitations in computational efficiency, uncertainty representation, and adaptability to non-typical tsunami sources. To achieve faster, more accurate, and probabilistically informative forecasts, research and operational communities have begun to systematically incorporate data-driven techniques, integrating machine learning and artificial intelligence methods into traditional workflows39,40. This transition is not simply about replacing physics-based models with data-driven ones; rather, it aims to establish a new forecasting paradigm that fuses multi-source real-time observations, physical constraints, and statistical learning. The core goal is not only to improve predictive accuracy, but also to build an uncertainty-aware decision-support framework that can serve both second-to-minute real-time response and longer-term risk assessment and coastal planning (Fig. 2).

Intelligent real-time response tsunami forecasting and risk management system.
With the introduction of machine learning, artificial intelligence, and advanced data-analytic techniques, tsunami forecasting is transitioning from a static, rigid deterministic computational framework toward a dynamic modeling system that integrates multi-source real-time observations, adaptive modeling, and probabilistic risk assessment. Such systems can not only deliver near-real-time predictions shortly after event onset, but also provide probabilistic forecasts through uncertainty quantification, expressed across confidence levels and risk tiers, thereby offering decision-relevant information to support warning issuance, evacuation planning, and emergency resource allocation. Against this backdrop, this review first surveys the rapid evolution of data ecosystems for tsunami forecasting, including in situ ocean observations, seismic and geodetic measurements, satellite remote sensing, and emerging non-traditional data streams, and analyzes their key characteristics and challenges in terms of spatiotemporal resolution, uncertainty, and operational availability. It then synthesizes the progression of data-analysis methodologies from traditional signal processing to machine learning and deep learning, with particular emphasis on their roles in weak-signal detection, early triggering, and learning under rare-event regimes. Next, the review systematically compares the capabilities and limitations of physics-based models, purely data-driven approaches, and physics–AI hybrid models for tsunami prediction. Building on this foundation, it evaluates how real-time forecasting systems, risk assessment frameworks, and AI-enabled decision-support tools translate model outputs into actionable information. Finally, from an interdisciplinary perspective spanning science, policy, and society, the review discusses issues of communication, governance, and ethics in the use of forecasting information, and outlines future directions centered on digital twins, foundation models, and adaptive resilience. Through this systematic synthesis, the review aims to provide a unified analytical framework for understanding the ongoing paradigm shift in tsunami forecasting, identifying key technical bottlenecks, and advancing deeper integration between predictive science and risk-reduction practice.
Tsunami-relevant data acquisition
Tsunami forecasting and risk management depend heavily on real-time, high-accuracy data drawn from diverse sources. Over the past several decades, technological advances have led to an explosive growth in both the variety and volume of tsunami-relevant data available to researchers27,41,42,43,44,45. However, substantial challenges remain in effectively integrating and analyzing these data streams due to technical bottlenecks such as data heterogeneity, noise contamination, and the stringent requirements of real-time processing. This section systematically reviews the key data sources underpinning tsunami forecasting, delineates their distinctive strengths, and examines the central challenges associated with their operational use in prediction.
In situ ocean observations
In situ ocean observations constitute one of the central pillars of tsunami monitoring and forecasting systems. Their distinctive value lies in the ability to directly and continuously record key physical processes occurring within the ocean—capabilities that cannot be fully replaced by land-based measurements or remote-sensing approaches. The in situ instruments most widely deployed in current tsunami observing networks include Deep-ocean Assessment and Reporting of Tsunamis (DART) buoys45, coastal tide gauges46, and ocean-bottom pressure sensors47, with a schematic of a modern tsunami monitoring system shown in Fig. 3. DART systems are typically deployed in deep-ocean settings, where ocean-bottom pressure sensors detect extremely subtle changes in the water-column pressure and thereby infer sea-surface conditions, enabling early identification of transoceanic tsunami waves during the initial stages of propagation48,49,50. Coastal tide gauges, in contrast, record the rapid sea-level fluctuations induced as tsunamis reach nearshore regions51,52. Ocean-bottom pressure sensors can capture pressure anomalies associated with passing tsunami waves at high temporal resolution in deep-water environments, providing critical evidence for characterizing wave dynamics and improving process understanding53,54.

Tsunami monitoring system.
A major advantage of in situ ocean observations is their high accuracy and real-time capability. These sensors directly measure fundamental physical quantities such as pressure and sea level, yielding data with clear physical meaning that provide essential evidence for tsunami detection, source inversion, and wave-propagation analysis. For example, Mizutani et al.47 used near-fault ocean-bottom pressure (OBP) recordings and successfully isolated tsunami signals from OBP data within tens of seconds after the earthquake, enabling rapid tsunami identification. Adriano et al.51 jointly assimilated observations from coastal tide gauges and offshore buoy stations to invert the tsunami source of the 2017 Mexico Mw 8.2 earthquake, substantially improving the stability and precision of estimated source parameters. In addition, Rabinovich and Eblé55 provided a systematic assessment of deep-ocean bottom-pressure observations across multiple transoceanic tsunami events, highlighting that DART systems can deliver crucial observational evidence during the early propagation stage and thus constitute a key data stream for operational tsunami early warning. Beyond event detection and source characterization, in situ observations play an important role in the calibration and validation of numerical simulations and forecasting models, thereby enhancing the overall reliability of both physics-based and data-driven approaches. Tanioka53, for instance, leveraged data from Japan’s S-net ocean-bottom pressure sensor network to improve near-field tsunami forecasting methods, demonstrating that dense in situ measurements are indispensable for model calibration and for achieving higher predictive accuracy. Owing to their near-real-time data transmission, in situ observing systems have become an integral component of tsunami warning architectures, providing rapid observational confirmation of tsunami occurrence and enabling continuous tracking of tsunami evolution following generation.
However, the global deployment of in situ observing networks continues to face multiple challenges. Despite the growing number of tsunami monitoring instruments in recent years, their spatial distribution remains highly uneven: sensors are concentrated primarily in traditionally high-risk regions such as the circum-Pacific, while vast deep-ocean and remote areas still lack effective coverage. In their systematic synthesis of global deep-ocean tsunami observations, Rabinovich and Eblé55 noted that the existing DART network exhibits substantial observational gaps in several ocean basins, which constrain the comprehensive capture of transoceanic tsunami propagation processes. Moreover, offshore and seafloor observing systems are costly to deploy, maintain, and operate over the long term, imposing stringent requirements on technical capacity and logistical support. Heidarzadeh and Gusman48 pointed out that installing and servicing deep-ocean bottom-pressure sensors depends on specialized vessels and complex subsea operations, making it difficult to rapidly scale dense observing networks worldwide. During sustained operation, instruments are also vulnerable to degradation from ocean currents, biofouling, and structural aging, which can reduce data quality or lead to observational outages.
In summary, although in situ ocean observing networks still face constraints related to spatial coverage and operational cost, their foundational role in tsunami monitoring and early warning remains irreplaceable. By directly measuring ocean-bottom pressure and sea-level variations, in situ observations provide the most immediate and physically robust basis for real-time estimation of tsunami wave heights, arrival times, and propagation characteristics. This high-precision, near-real-time information is particularly critical in the early post-generation phase, where it enables warning systems to rapidly verify event authenticity and supplies essential data for subsequent propagation analyses and risk assessment. As observing networks continue to expand and are increasingly integrated with numerical models and advanced data-processing methods, in situ observations will remain a central supporting component of future tsunami early warning architectures.
Seismic and geodetic data
Seismic and geodetic data constitute a foundational component of tsunami forecasting systems, playing a critical role in identifying and characterizing earthquake sources that generate the most destructive tsunamis. Seismic waveform observations can rapidly provide key parameters—such as magnitude, focal depth, and epicentral location—and therefore serve as the primary basis for assessing tsunamigenic potential. For example, Satake56 noted that following the 2011 Tohoku Mw 9.0 earthquake, global seismic networks delivered magnitude estimates and focal mechanism solutions within minutes, supplying the initial triggers for tsunami warning. However, reliance on seismic magnitude alone remains insufficient for accurately characterizing the true rupture scale and damaging potential of megathrust events. As an essential complement, Global Navigation Satellite System (GNSS) measurements can record coseismic ground displacements with high precision, providing direct constraints on fault slip behavior and, critically, vertical deformation—factors that govern the magnitude of initial sea-surface uplift or subsidence. Studies by Minson et al.57 and Zielke et al.58, based on landmark events such as the 2011 Tohoku earthquake, demonstrate that incorporating GNSS coseismic displacement data can effectively mitigate the magnitude-saturation problem inherent to seismic waveforms during very large earthquakes. This substantially improves the robustness of source inversion and yields more reliable constraints for constructing the initial tsunami wave field.
In recent years, advances in seafloor geodetic observing technologies have enabled more direct and higher-resolution measurements of offshore and far-field seafloor deformation induced by earthquakes, thereby substantially reducing uncertainty in source-parameter inversion. Compared with conventional approaches that rely primarily on land-based seismic and geodetic observations, seafloor measurements can record coseismic displacements much closer to the source region, providing stronger constraints on rupture extent, slip distribution, and vertical deformation. For example, Japan’s offshore GNSS-A seafloor geodesy system, together with seafloor observing networks such as S-net and DONET—comprising ocean-bottom seismometers and pressure sensors—provides critical observations of source processes and seafloor deformation for near-field tsunami forecasting, and has successfully captured coseismic seafloor deformation and associated bottom-pressure changes during multiple near-field earthquake events59.
These observations indicate that seafloor geodetic data not only compensate for the limited observational capability of onshore GNSS in offshore and remote regions but also reduce the dependence of source inversions on prior model assumptions. From the perspective of tsunami forecasting, such direct constraints on seafloor deformation are particularly valuable. Coseismic vertical displacement of the seafloor is a key determinant of initial sea-surface uplift or subsidence; accurately resolving this quantity can markedly improve the robustness of initial tsunami wave-field construction for near-field events. The study of Tanioka53 further showed that incorporating S-net bottom-pressure observations significantly reduced uncertainties in predicted tsunami arrival times and wave heights, underscoring the distinctive advantages of seafloor geodetic observations for near-field tsunami early warning.
A key advantage of seismic and geodetic data lies in their ability to support rapid source inversion in the source region, which constitutes one of the core components of modern tsunami warning and forecasting systems. Qiu et al.60 proposed a new two-step hybrid postseismic modeling approach that integrates real-time seismic and geodetic observations; such physics-informed insights provide a critical foundation for robust and rapid characterization of tsunamigenic sources. The local tsunami warning strategy T-LarmS proposed by Melgar et al.61 leverages regional seismic and GNSS observations to obtain rapid source information within minutes after an earthquake. This information is then used to estimate seafloor deformation and to drive tsunami propagation simulations, producing actionable warning maps and estimates of maximum expected amplitudes. These results demonstrate that seismic and geodetic data can provide essential, rapid constraints on tsunami sources for warning purposes.
By jointly analyzing seismic waveforms and crustal displacement fields, it is possible to infer fault geometry, slip distribution, and rupture extent within minutes of earthquake occurrence, and to use the inversion results as initial conditions for numerical tsunami propagation models62. Moreover, the high level of maturity of global and regional seismic monitoring networks makes seismic data one of the most reliable and commonly used triggering information sources in most operational tsunami warning systems today.
At the global scale, geodetic observations related to earthquakes and tsunamis primarily rely on four major Global Navigation Satellite Systems (GNSS) recognized by the United Nations: the United States’ GPS, Russia’s GLONASS, the European Union’s Galileo, and China’s BeiDou system. These systems differ in terms of coverage, signal design, and service focus, and together form the foundation of the current multi-source GNSS observation framework. Table 1 provides a brief summary of the basic characteristics of the major satellite positioning systems. However, earthquake and geodetic data still exhibit clear limitations in addressing the diverse mechanisms that trigger tsunamis. Non-seismic tsunamis caused by submarine landslides, volcanic eruptions, or multi-process coupling often lack clear seismic signals, making it difficult for earthquake-triggered warning mechanisms to identify them effectively63,64,65,66,67. In addition, although terrestrial seismic and GNSS networks are becoming increasingly dense, geodetic observations in oceanic regions—especially in the deep ocean—remain relatively sparse. This limitation hampers the detailed characterization of small-magnitude earthquakes, complex rupture processes, and nearshore seismic sources. Therefore, future tsunami forecasting systems need to integrate seismic and geodetic data with ocean observations, remote sensing data, and data-driven approaches in order to compensate for shortcomings in spatial coverage and mechanism identification.
Satellite remote sensing
Satellite remote sensing provides a synoptic and continuous observational perspective over the ocean and coastal zones, offering a distinct advantage for compensating for the limited spatial coverage of in situ observing networks. Satellite altimetry, in particular, can retrieve sea surface height (SSH) variations on a global scale, thereby enabling the detection of transoceanic tsunami waves in open-ocean regions where in situ observations are sparse or unavailable68,69. Although tsunami amplitudes in the deep ocean are typically small, their spatially coherent signatures can, under favorable observing conditions, be captured by satellite systems at large spatial scales. Event-level evidence further demonstrates this capability. For the 26 December 2004 Sumatra–Andaman tsunami, satellite altimeters (TOPEX/Poseidon and Jason-1) captured tsunami-related sea-surface height anomalies along-track in the open ocean, providing a direct benchmark for model–data comparison70. More recently, SWOT (Surface Water and Ocean Topography) observed the 2025 Kamchatka tsunami in swath mode, revealing the tsunami wave pattern with near-2D spatial context that is particularly valuable for validating forecasting models and motivating future real-time hazard assessment workflows.
In nearshore and onshore regions, satellite remote sensing plays a particularly important role in characterizing the impacts of tsunamis. Interferometric Synthetic Aperture Radar (InSAR), as a high-precision satellite remote sensing technique, can retrieve large-scale, high-resolution surface deformation fields (including subsidence and uplift) by processing the phase interference of two or more SAR images71,72,73. In coastal and terrestrial areas, this capability makes InSAR a crucial tool for depicting tsunami-related crustal deformation and the tectonic displacement processes closely associated with tsunami generation mechanisms.
First, during large tsunami events, significant coastal uplift or subsidence occurs in nearshore areas due to earthquake rupture, which constitutes one of the key physical mechanisms governing tsunami wave generation and propagation. For example, in the 2011 Mw 9.0 Tohoku-oki tsunami event off the Pacific coast of northeastern Japan, researchers successfully reconstructed the coseismic surface deformation field across hundreds of kilometers of the Japanese mainland using InSAR based on ALOS/PALSAR satellite data74. This deformation field included pronounced horizontal displacement and vertical subsidence along the coast of the Oshika Peninsula. These surface deformations directly reflect the generation of tsunami waves triggered by the earthquake and the associated release of energy in the ocean. Compared with traditional GPS monitoring methods, InSAR not only provides more spatially continuous deformation data but also achieves higher spatial resolution, enabling more precise characterization of tsunami wave spectra variations and propagation characteristics over broader areas. Consequently, InSAR has become an important tool for studying tsunamis and their impacts, offering notable advantages especially for dynamic monitoring in tsunami source regions and far-field areas.
Second, multi-temporal InSAR techniques (such as SBAS-InSAR and PS-InSAR) have advantages in time-series analysis, allowing quantitative inversion of coseismic and postseismic deformation processes and thereby revealing tsunami-induced surface dynamic evolution. For instance, studies of earthquake-induced terrestrial deformation have extracted millimeter-scale subsidence and uplift patterns over large source regions using Sentinel-1 data75, providing constraints for constructing accurate fault slip models and surface stress change analyses. These techniques are equally applicable to deformation analysis in tsunami source zones and coastal regions, enabling InSAR to capture not only the instantaneous deformation associated with the main shock but also the subsequent post-event land deformation evolution. This, in turn, facilitates linking surface deformation with complex processes such as tsunami wave propagation and geotechnical responses.
Optical remote sensing imagery can be used for the rapid assessment of tsunami-induced coastal inundation extent, infrastructure damage, land-use change, and shoreline evolution, and thus offers irreplaceable advantages for characterizing tsunami impacts in nearshore and onshore regions. In the immediate aftermath of a disaster, optical imagery can provide a spatially continuous chain of surface evidence, enabling rapid quantification of tsunami impacts throughout the entire process—from water intrusion to abrupt changes in land cover, damage to built-up areas, and geometric reshaping of the coastline. Ramírez-Herrera and Navarrete-Pacheco76 combined high-resolution optical imagery with digital elevation models (DEMs) to rapidly invert tsunami inundation distances and run-up heights across representative coastal geomorphic units, and validated the results through field surveys. Their work demonstrates that optical satellites can provide first-hand constraints for emergency mapping and subsequent numerical modeling when transportation infrastructure is damaged, and on-site access is limited. At broader regional scales, medium-resolution optical data enable rapid, cross-border or cross-basin reconnaissance of tsunami damage. Belward et al.77 conducted a systematic scan of the extensive coastline affected by the 2004 Indian Ocean tsunami using pre- and post-event MODIS imagery, identifying coastal zones of significant surface change and quantifying the order of magnitude of areas with “severely damaged or lost land.” This study shows that medium-resolution optical sensors can rapidly and consistently map extremely large impacted coastal belts after a tsunami, providing baseline data for cross-regional emergency response coordination and loss assessment. Beyond inundation extent, optical imagery is also highly sensitive to infrastructure damage and surface functional degradation. In the case of the 2018 Sulawesi earthquake and tsunami in Indonesia, Hu et al.78 used Sentinel-2 and Maxar WorldView-3 imagery to rapidly delineate tsunami-affected areas through pre- and post-event differenced spectral indices and threshold-based frameworks. They further examined the spatial correspondence between tsunami impacts, low-lying urban areas, and damage to coastal built-up zones, emphasizing the critical need to acquire imagery before cleanup and reconstruction alter the surface, as physical evidence of damage can disappear rapidly.
Collectively, these studies demonstrate that optical remote sensing not only indicates “where the water reached,” but also extracts spatial patterns closely related to engineering damage by integrating multiple cues, such as changes in surface reflectance and texture, vegetation and bare land transitions, and the loss or deformation of roads, levees, and buildings. These capabilities provide traceable evidence for subsequent vulnerability curve development, exposure statistics, and recovery assessment. Together, InSAR and optical remote sensing data form a critical information foundation for post-tsunami damage assessment and reconstruction analysis, offering essential support for impact quantification and long-term recovery planning.
Furthermore, tsunamis in nearshore areas often trigger long-term shoreline reshaping and sustained land-use transitions. Long-term optical image time series make it possible to distinguish between post-disaster transient erosion and multi-year human reconstruction and natural recovery. Ghadamode et al.79 selected the South Andaman coast affected by the 2004 tsunami as a case study and used multi-temporal imagery to quantitatively analyze shoreline changes, linking them with regional socioeconomic development. Their results emphasize that post-disaster expansion of built-up areas and ecological degradation can reshape future tsunami risk exposure patterns. Therefore, the key contribution of optical remote sensing lies not only in providing a “post-disaster snapshot,” but more importantly in supporting multi-scale quantification of tsunami impacts through repeatable spatiotemporal evidence—ranging from hour-to-day scale mapping of inundation and damage, to year-to-decade scale analyses of shoreline and land-use evolution and risk redistribution.
However, due to limitations such as satellite revisit cycles, data acquisition latency, and time-consuming processing workflows, satellite observations often cannot be delivered within the short time window required for tsunami early warning. In addition, there is an inherent trade-off between spatial and temporal resolution in satellite data: high-resolution SAR or optical imagery is typically difficult to acquire at high frequency, while altimetry data offer broad coverage but limited temporal sampling. Consequently, satellite remote sensing is better suited as an important complement to tsunami forecasting systems, to be used in synergy with in situ ocean observations, seismic data, and data-driven approaches, thereby fully leveraging its unique strengths in large-scale observation and post-disaster assessment.
Emerging and non-traditional data streams
In addition to conventional ocean observations, seismic measurements, and satellite data, a range of emerging and non-traditional data sources are increasingly being explored to complement tsunami monitoring and assessment systems. Among these, submarine cable observations based on Distributed Acoustic Sensing (DAS) have attracted substantial attention in recent years80. By converting telecommunication fiber-optic cables into dense virtual sensor arrays, DAS enables continuous, real-time monitoring of pressure variations, vibrations, and acoustic signals, and can be used to detect tsunami-wave propagation and seafloor deformation processes. Because submarine cables often span extensive areas of the seafloor, DAS systems have considerable potential to increase observational density in both offshore and nearshore domains, particularly in regions where deploying conventional instruments is challenging.
Beyond fiber-optic sensing, shipborne and civilian sensors are also regarded as valuable complementary data sources81,82. Some vessels can record pressure, motion, or navigation-related measurements during routine operations; after appropriate screening and processing, these observations may provide additional in situ information for tsunami monitoring. Although such data are not specifically designed for tsunami observation, their wide spatial coverage and large volume confer potential utility, particularly in regions with dense maritime traffic. In recent years, social media and crowdsourced information have likewise attracted attention as non-traditional data streams83,84,85. Eyewitness reports, images, and videos posted on social platforms can provide rapid situational awareness in the early stages following a tsunami, and may support impact assessment and emergency response, especially when official observations are delayed or disrupted. However, these data remain limited by a lack of structure and predictability, and their use in quantitative forecasting is still relatively constrained.
Although emerging and non-traditional data sources show considerable promise, their operational use in tsunami forecasting still faces substantial challenges. Issues of data quality and reliability are particularly salient: crowdsourced information is often noisy and unevenly distributed, underscoring the need for robust validation and filtering mechanisms. Moreover, differences among data sources in data formats, spatiotemporal resolution, and processing pipelines introduce additional technical complexity for integration with existing warning architectures. Consequently, these novel data streams can contribute meaningfully to tsunami forecasting and risk management only after rigorous quality control, appropriate assimilation, and coordinated fusion with conventional observing systems.
Core data challenges and implications for data-driven models
Although tsunami monitoring technologies have advanced substantially over recent decades, several fundamental data-related challenges persist and continue to constrain forecasting accuracy and the reliability of operational systems. One of the most pervasive issues is the prevalence of noise and strong non-stationarity in tsunami-relevant observations. Signals recorded by oceanographic and geophysical sensors are often influenced by a combination of background wind waves, tides, meteorological disturbances, and instrumental noise. This is particularly problematic during tsunami generation and the early propagation stage, when tsunami signatures are frequently obscured by complex background variability and are difficult to separate reliably. Moreover, tsunami dynamics are inherently transient and rapidly evolving, which clearly violates the stationarity assumptions underlying many conventional signal-processing and statistical modeling approaches. Consequently, tsunami forecasting requires analytical frameworks that can robustly extract weak signals from noisy, time-varying data streams under near-real-time constraints.
Another key challenge arises from the pronounced multiscale nature and spatiotemporal heterogeneity of tsunami data. Relevant observations range from high-frequency, local measurements acquired by in situ sensors to low-frequency, transoceanic-scale information provided by satellite remote sensing, with substantial disparities across data sources in sampling rate, spatial coverage, latency, and uncertainty characteristics. This heterogeneity makes the joint interpretation and effective fusion of multi-source observations particularly complex. Maintaining physical consistency across scales and developing forecasting models that can operate coherently in a cross-scale manner remain central challenges faced by both physics-based and data-driven approaches.
At the same time, tsunami forecasting is characterized by a structural tension in which “small-sample” and “big-data” regimes coexist. Although modern observing systems continuously generate massive, high-dimensional data streams, the number of informative samples that actually contain key tsunami signals remains extremely limited because destructive tsunami events are inherently rare. This class imbalance poses a major challenge for machine learning, which typically relies on large and representative training datasets to achieve robust generalization. Models trained on a small number of historical events are prone to overfitting and may perform poorly when confronted with atypical or compound tsunami scenarios. Accordingly, there is a pressing need for modeling strategies that explicitly account for data scarcity and uncertainty, including physics-constrained learning, transfer learning, synthetic data generation, and uncertainty-aware modeling.
Overall, the tsunami data ecosystem is inherently highly complex, encompassing multiple observational data streams that differ substantially in spatial coverage, resolution, latency, and reliability. In situ ocean measurements, seismic and geodetic observations, and satellite remote sensing remain the core pillars of tsunami detection and forecasting, providing complementary information across the source process, wave propagation, and impact assessment. Meanwhile, emerging data sources—including submarine fiber-optic sensing, shipborne observations, and crowdsourced information—are progressively extending observational frontiers and creating new opportunities for regions and scenarios that are difficult to capture with conventional monitoring infrastructures. However, greater diversity of data sources and expanding data volumes do not automatically translate into commensurate improvements in predictive capability. Effective tsunami forecasting increasingly depends on the rigorous integration of heterogeneous data, strict control of data quality and reliability, and the capacity to extract actionable information and deliver decision support within extremely constrained time windows. Against this backdrop, tsunami science is shifting from a focus on whether data can be acquired to how key information can be extracted from complex data streams to support decisions—thereby providing the scientific basis for advanced data-analytic methods and physics–AI hybrid forecasting frameworks.
Tsunami signal detection and feature extraction
With the growing availability of ocean observations, seismic monitoring, and satellite data, the informational basis for tsunami forecasting has undergone a qualitative leap. However, raw data streams are often contaminated by noise, dominated by redundancy, and populated with irrelevant features; they must therefore be processed and analyzed effectively in order to extract meaningful signals. This section systematically delineates the methodological transition from traditional signal-processing techniques to state-of-the-art approaches such as machine learning and deep learning, which enable high-density information extraction and convert raw tsunami-related observations into actionable decision-relevant evidence. As data complexity and volume continue to rise, modern analytical methods are providing a powerful impetus for improving the accuracy of tsunami detection, classification, and forecasting.
Classical signal processing approaches
Classical signal-processing techniques have long served as a core component of tsunami detection and early warning systems, providing fundamental tools for identifying tsunami-related signatures from oceanic and seismic observations that are often heavily contaminated by noise. The primary objective of these methods is to enhance the signal-to-noise ratio and extract discriminative features from time series—capabilities that are particularly critical for real-time operational systems requiring rapid and reliable responses. By exploiting differences in frequency content, temporal structure, and scale-dependent characteristics, classical approaches can, to a certain extent, separate tsunami signals from background wind waves, tides, and seismic noise86,87,88
In practice, spectral analysis is commonly used to characterize the low-frequency components of tsunami waves and to contrast them with short-period processes such as wind-driven waves. After mapping time-domain observations into the frequency domain via Fourier-based transforms, anomalous frequency components can be identified and quantified more directly. Building on this, low-pass or band-pass filters suppress noise outside target bands to emphasize spectral energy associated with tsunami propagation, and have been incorporated into relatively mature automated detection workflows for tide gauges, bottom-pressure sensors, and seismic monitoring pipelines86,88,89,90,91.
However, tsunami signals exhibit pronounced non-stationarity and transient behavior, and reliance on fixed frequency bands alone often fails to capture their full temporal evolution. Consequently, time–frequency methods (e.g., wavelet transforms) have been employed to decompose signals across multiple scales, enabling more effective detection of weak and short-lived sea-level or pressure anomalies embedded within complex backgrounds92,93,94,95,96. Although classical signal processing offers operational robustness and interpretability, its dependence on pre-defined frequency bands, thresholds, and hand-crafted features limits adaptability to complex, non-stationary, and out-of-distribution tsunami scenarios, motivating an increasing shift toward more flexible data-driven methodological families.
Machine learning for tsunami signal identification
As tsunami-related data streams continue to expand in type, dimensionality, and scale, reliance on traditional signal processing alone has become insufficient to cope with the complexity and diversity of modern observations. Against this backdrop, machine learning methods have increasingly been introduced for automated identification and classification of tsunami-related signals, making it feasible to distinguish potential tsunamigenic events from non-tsunami disturbances under near-real-time constraints. Compared with procedural strategies based on fixed thresholds or pre-defined frequency bands, learning-based models can infer discriminative decision boundaries from labeled data and offer stronger representational capacity for feature fusion and exploitation of cross-station consistency—advantages that are particularly valuable in warning frameworks integrating multi-source observations and network (array) structure information97.
In many application paradigms, conventional machine learning typically follows a “representation-then-discrimination” pipeline: discriminative statistical and time–frequency representations are first engineered from tide-gauge/bottom-pressure records, seismic observations, or electromagnetic–ionospheric measurements (e.g., spectral amplitudes, signal duration, energy distribution, and phase/amplitude perturbations), and classification or regression models are then used to identify “tsunami vs. non-tsunami” cases or to assign risk levels. A substantial body of work focuses primarily on signal extraction and representation, yet nevertheless yields operationally useful feature sources for subsequent machine-learning modeling. For instance, frameworks that characterize the transfer function between offshore forcing and coastal response in the frequency domain provide a stable pathway for constructing spectral features86. Event-level statistics such as maximum amplitude and signal duration offer interpretable indicators for discrimination and uncertainty characterization89. Time–frequency features of tsunami-related electromagnetic signals, together with noise-separation strategies, provide direct guidance for feature engineering from geomagnetic-perturbation data93. Likewise, detection of phase and amplitude perturbations in very low frequency (VLF) observations offers a reusable quantification scheme for features linking ionospheric responses to tsunami events94,95. Accordingly, conventional machine learning can be viewed, methodologically, as an automated extension that fuses and discriminates over these interpretable feature sets86,89,93,94,95.
It is important to emphasize that the performance of supervised recognition hinges critically on the quality, coverage, and representativeness of labeled data. Meanwhile, tsunami signals are tightly coupled to the source process, propagation pathway, and local site response, making the “limited training coverage → weak generalization to rare or atypical events” problem particularly acute. Existing studies show that different source parameterizations and modeling assumptions can substantially affect the consistency between simulations and observations, thereby increasing uncertainty in cross-event transfer98. Moreover, tsunami waveforms are highly sensitive to earthquake rupture characteristics, which further elevates predictive risk under out-of-distribution scenarios99. Against this backdrop, incorporating more physically diagnostic early-stage signals into learning frameworks and performing near-real-time recognition and estimation that explicitly leverages the spatiotemporal structure of monitoring networks has emerged as a promising direction for methodological evolution97,98,99.
Deep learning for spatiotemporal feature learning
Conventional machine learning for tsunami-signal recognition often depends on hand-crafted feature engineering, which makes it difficult to adequately capture, within a unified framework, the high-dimensional, nonlinear, and spatiotemporally coupled characteristics exhibited by multi-source observations. Deep learning, by contrast, offers a plausible alternative: through end-to-end representation learning, it can map raw or minimally processed measurements directly into hierarchical feature representations, enabling a more systematic characterization of structural information such as cross-station coherence, propagation dynamics, and multimodal associations97.
From a methodological perspective, deep models for tsunami early warning typically need to handle both spatial dependencies—such as network topology, propagation-path correlations, and cross-sensor synergy—and temporal evolution, including the gradual emergence of weak early-stage signatures and the subsequent dynamics of wave propagation (Fig. 4). Arias et al. incorporated near-real-time analysis of prompt elastogravity signals (PEGS) into the Peruvian warning system and trained a graph neural network to learn the spatiotemporal structure of PEGS across a broadband sensor network for rapid magnitude estimation and enhanced warning performance. This work illustrates the feasibility of deep models along the “network spatiotemporal structure recognition → near-real-time decision support” chain97.

Adapted from ref. 213, with permission.
At the same time, operationalizing deep approaches remains constrained by practical realities. On the one hand, the rarity of destructive tsunami events limits training-set size and exacerbates class imbalance. On the other hand, model interpretability and cross-regional generalization are still challenged by variations in source processes and changing observational conditions. Prior studies indicate that differences in source modeling can alter the correspondence structure between simulations and observations98, and that tsunami signals are highly sensitive to rupture characteristics99, implying that fitting to empirical data distributions alone is insufficient to robustly cover atypical scenarios. Accordingly, integrating anomaly detection and rare-event learning with the injection of physical information has become a key direction for deep learning to converge toward practical tsunami warning systems.
Anomaly detection and rare event learning
One of the fundamental challenges in tsunami forecasting stems from the combination of low event frequency and extreme impact: positive samples available for model training are scarce, while tsunami signatures in both open-ocean and nearshore observations often exhibit a “low-amplitude, high-background” profile and are easily obscured by tides, wind waves, ocean circulation, and seismic noise. This dual constraint—rarity plus low signal-to-noise ratio—limits the practical effectiveness of supervised learning methods that rely on large volumes of labeled data in operational warning contexts, and has motivated a shift toward methodological families that emphasize detecting anomalous deviations and improving robustness under small-sample regimes87,88,93,94,95,97.
From a methodological standpoint, anomaly detection is centered on learning normality from abundant background data and then identifying potential anomalies based on the degree of deviation. In the context of tsunami monitoring, this paradigm aligns naturally with signal-extraction tasks across multiple observation modalities. For instance, extracting tsunami signatures from DART records, satellite altimetry, or tide-gauge time series is essentially a problem of detecting anomalous fluctuations embedded in strong background variability87,100. Frequency-domain responses of coastal sea-level records to offshore forcing—characterized via transfer functions—can provide an interpretable baseline for testing “normal response versus anomalous deviation”86. Likewise, the low-frequency responses of seismic stations to tsunami arrival can vary substantially across events, suggesting that detectability assessments should be formulated in terms of departures from a learned background model88,90.
For electromagnetic and ionospheric observations, tsunami-related responses typically manifest as weak perturbations; consequently, time–frequency features and noise-separation strategies offer a direct source of feature spaces for anomaly detection92,93,94. Taken together, this body of work provides transferable building blocks for anomaly detection—linking observable quantities, background noise structure, and deviation criteria—that can be adapted across data types and operational settings86,87,88,90,93,94,95,97,100.
At the level of rare-event learning, research typically converges on three classes of strategies. First, mechanistic and numerical models are used to compensate for limited sample coverage by generating synthetic scenarios or performing data augmentation to expand the effective training distribution. Second, transfer learning across regions or sensor modalities is employed to improve robustness. Third, physically informed priors are incorporated into learning frameworks to enhance sensitivity to extreme scenarios. Differences in source modeling can substantially alter the correspondence structure between simulations and observations, underscoring the need for more systematic scenario generation and sample expansion to improve generalization98. The strong sensitivity of tsunami signals to rupture characteristics implies that limited historical records cannot exhaust the space of tsunamigenic mechanisms, further highlighting the importance of sensitivity experiments and synthetic scenario coverage99. Studies on hydroacoustic and acoustic–gravity signals provide mechanistic foundations for constructing libraries of earlier observable signatures, which can be leveraged to enhance warning performance under rare-event regimes101,102,103. Therefore, anomaly detection and rare-event learning should not be viewed as “patchwork fixes,” but rather as essential methodological support for real-world warning systems operating in environments characterized by low sample size, high stakes, and high uncertainty97,98,99,101,102,103.
Furthermore, tsunami “anomalies” are rarely confined to a single observational channel; rather, they are distributed across sensor systems in multi-physical and multiscale forms. In sea-surface/bottom-pressure and tide-gauge records, anomalies typically manifest as low-frequency elevations relative to background tides and sea state, long-period oscillations, or impulsive wave trains, which can be characterized using frequency-domain response modeling and statistical indicators86,87,89,100. In onshore or seafloor seismic records, anomalies may appear as low-frequency responses consistent with theoretical arrival times, dispersive energy packets, or long-duration signals, providing complementary detectability when sea-level observations are sparse or ambiguous88,90,91. In hydroacoustic and acoustic–gravity observations, anomalies can present as faster-arriving acoustic perturbations, offering an additional information channel for earlier detection101,102,103,104. In geomagnetic measurements, anomalies are expressed as weak magnetic-field perturbations synchronous with tsunami propagation and their associated time–frequency structure, yielding computable feature spaces for anomaly discrimination105,106,107. In ionospheric VLF observations, anomalies emerge as detectable deviations in phase and amplitude induced by tsunami propagation, providing indirect evidence for long-range, cross-domain monitoring94,95,108. In ocean-radar measurements, anomalies may be reflected in changes to time–distance patterns and spectral characteristics of radial current fields that correspond to propagation or resonance processes96.
Accordingly, for practical warning systems, a more viable route is often not qualitative detection based on a single signal, but the development of transferable, fusion-ready, rare-event-oriented detection and decision frameworks centered on cross-modal anomaly representations, in coordination with physically informed priors to enhance robustness under extreme scenarios97.
Tsunami propagation and inundation models
Developing accurate tsunami forecasting models has long been a central objective in tsunami science. Traditionally, physics-based models grounded in fluid dynamics and earthquake source mechanics have served as the primary tools for tsunami prediction. However, with the rapid growth of available data and advances in computational capability, data-driven models have emerged as a highly promising alternative. By leveraging machine learning (ML) and artificial intelligence (AI), these approaches learn patterns from historical observations and enable fast, flexible, near-real-time forecasting. This section examines the strengths and limitations of major tsunami modeling paradigms—from purely physics-based approaches to purely data-driven models—and analyzes how emerging hybrid methods can integrate the advantages of both.
Purely physics-based models
Physics-based models have long been the foundation of tsunami prediction systems, using fundamental principles of fluid mechanics, oceanography, and seismology to mechanistically describe the generation, propagation, and coastal impacts of tsunamis. When the horizontal movement of water particles significantly exceeds the vertical scale, the vertical acceleration can be considered negligible compared to gravity, and the pressure distribution is assumed to be hydrostatic109,110. With these assumptions, the depth-averaged Navier-Stokes equations simplify to a shallow water model. The conservation equations for mass and momentum in tensor form are expressed as follows:
Where, the indices i and j follow the Einstein summation convention. The coordinate system is set in the XY plane, where \({x}_{j}\) represents the Cartesian coordinates, \(g=9.81{\rm{m}}/{\rm{s}}\) is the gravitational acceleration, \({\text{h}}\) is the total water depth, \({u}_{j}\) is the depth-averaged velocity, \(\nu\) is the kinematic viscosity, and \({F}_{i}\) represents the external force term. If the wind shear stress and Coriolis force are negligible, \({F}_{i}\) is defined as:
Where, \(\rho\) denotes the density, \({z}_{b}\) represents the bottom bed elevation, and \({\tau }_{{bi}}\) is the bed shear stress in the i-direction, which is calculated based on the depth-averaged velocities as follows:
Where, Cb is the bed friction coefficient, which is estimated as:
Where, \({C}_{z}\) is the Chezy coefficient, which is determined using the Manning equation:
Where, \(n\) is Manning’s coefficient.
Shallow-water models used to predict tsunami travel times, wave heights, and nearshore inundation extents have been shown to be highly reliable in earthquake-tsunami scenarios where source conditions are relatively well constrained. For example, national warning agencies routinely employ shallow-water-equation solvers to simulate tsunami propagation from the source to the coast, estimate arrival times and wave amplitudes, and infer potential inundation zones. Empirically, when earthquake source parameters are reasonably well characterized, shallow-water models can deliver dependable forecasts.
In recent years, the application of the shallow-water equations to tsunami modeling has advanced markedly. To improve accuracy and numerical stability for high-Reynolds-number flows (as typified by tsunami waves), researchers have developed a range of numerical schemes and model-optimization strategies. Sato et al.111 investigated numerical simulation of the shallow-water equations for high-Reynolds-number flows using a multiple-relaxation-time lattice Boltzmann method (MRT-LBM) and applied it to real-world tsunami cases. Although the lattice Boltzmann method (LBM) has attracted attention in computational fluid dynamics due to its locality and algorithmic efficiency, it can suffer from numerical instabilities under high-Reynolds-number conditions. The authors therefore introduced a subgrid-scale (SGS) model to improve the stability of the MRT-LBM formulation, enhancing its applicability to tsunami simulations.
Khan and Kevlahan explored data assimilation in the two-dimensional shallow-water equations, focusing on recovering initial conditions for tsunami simulations through variational data assimilation. They showed that, with an appropriate configuration of observational data, initial states of the 2D shallow-water system can be effectively reconstructed, and they validated the approach through numerical experiments112. Arpaia et al. proposed a new efficient discretization method for shallow-water equations on spherical geometry, applying it to tsunami and storm-surge simulations. Using a covariant-basis projection approach, they simplified a discontinuous Galerkin (DG) scheme and introduced a well-balanced correction, further improving numerical stability and computational efficiency113.
Regarding bottom friction, Tinh et al. developed a new numerical approach that incorporates a wave-friction factor into conventional one-dimensional shallow-water models. Compared with traditional steady-friction formulations, the proposed method yields more accurate estimates of tsunami-induced bed shear stress, leading to more realistic simulation outcomes114. In addition, Kwon et al. examined tsunami-mitigation configurations using a fifth-order weighted essentially non-oscillatory (WENO) scheme coupled with an immersed boundary method (IBM). By simulating arrays of column-like structures, they proposed more effective layout designs to reduce tsunami impacts on nearshore buildings115.
Physics-based models are advantageous in terms of scientific credibility and interpretability. By strictly adhering to governing physical laws (e.g., conservation of mass and momentum), their predictions have clear physical meaning and are therefore easier to analyze and explain. For example, physics-based simulations can explicitly track tsunami propagation pathways, energy distribution, and interactions with bathymetry and coastal topography—capabilities that are essential for understanding tsunami mechanisms and for verifying model fidelity116. They also enable scenario analysis and uncertainty assessment by allowing initial conditions to be systematically varied, for instance by perturbing earthquake source parameters or changing the volume of a submarine landslide to evaluate how tsunami impact patterns respond under different conditions.
Nevertheless, purely physics-based models exhibit notable limitations. One major constraint is computational efficiency: high-fidelity simulations often require fine spatial meshes and small time steps, making real-time computation across global or very large regional domains highly challenging. In more complex settings—particularly in deep-ocean environments or regions with highly intricate seafloor topography—fully three-dimensional numerical models can explicitly represent nonlinear wave interactions, depth-dependent effects, and bottom-friction processes, thereby providing high-accuracy, multiscale representations of tsunami dynamics. However, such models are computationally demanding and typically require high-performance computing resources, which substantially restricts their use in real-time warning applications117.
Overall, existing studies indicate that tsunami simulation accuracy and efficiency can be substantially improved by optimizing numerical schemes for the shallow-water equations, incorporating data assimilation, and integrating multiple model-enhancement strategies. Future work should further investigate how these approaches can be extended to more complex topographies and flow regimes in order to address the challenges encountered in realistic hazard simulations. While physics-based models offer irreplaceable advantages in scientific credibility and interpretability, they remain limited in terms of computational efficiency, sensitivity to uncertainties in source parameters, and adaptability to complex or non-seismic tsunami sources. These limitations have become increasingly pronounced under contemporary demands for rapid response and large-area warning, motivating the exploration of new forecasting paradigms.
Purely data-driven models
Unlike physics-based models, purely data-driven forecasting approaches do not explicitly solve governing equations. Instead, they leverage historical observations or pre-generated scenario datasets and use machine learning algorithms to rapidly map input data—such as seismic waveforms, ocean-bottom pressure records, and tide-gauge observations—onto key tsunami parameters including wave height, arrival time, and potential inundation extent, thereby meeting the stringent timeliness requirements of early warning118,119,120,121. Figure 5 illustrates the overall workflow of data-driven tsunami forecasting, highlighting the basic logic of parallel multi-model prediction and model fusion. For example, Sarika and Milton118,119,120,121 trained a classification model on earthquake P-wave features to rapidly identify potentially tsunamigenic events in the early phase following an earthquake, demonstrating the computational efficiency and deployability of data-driven pipelines within minute-scale warning windows. Lee et al.’s TRRF-FF data-driven response-function model, once trained and calibrated, can predict the spatial distribution of near-field coastal run-up at a sub-second timescale, providing an efficient alternative for rapid near-field forecasting121.

Data-driven tsunami forecasting models.
Beyond directly predicting key tsunami parameters, data-driven approaches are often extended to impact assessment and risk characterization. One line of work couples rapid predictions of waveforms or intensity measures with coastal exposure and vulnerability information, thereby providing more operationally actionable impact estimates during the warning phase. Another line integrates data-driven prediction with the optimization of observing networks and sensor configurations to improve forecast stability and information gain under resource constraints119,120.
For example, Iwabuchi et al. employed Gaussian process regression with automatic relevance determination (ARD) to quantify the contributions of individual ocean-bottom pressure sensors to estimating maximum coastal tsunami heights, providing evidence of differential sensor effectiveness and highlighting the potential of data-driven methods to partially mitigate “black-box” concerns and enhance interpretability119. Purnama et al. coupled deep-learning-based waveform prediction with metaheuristic optimization (e.g., genetic algorithms) to simultaneously improve predictive efficiency and optimize buoy placement, offering a framework for the joint design of “model–observation” components in operational warning systems120. In addition, for atypical tsunami sources (e.g., landslide-generated tsunamis), empirical or statistical regression relationships can also be viewed as part of the data-driven paradigm, providing rapid first-order estimates when mechanisms are uncertain or real-time simulation is infeasible. For instance, studies that derive predictive formulas for dominant wave periods of landslide-generated waves based on experimental and event data can complement rapid assessment under such scenarios122.
Nevertheless, purely data-driven models still exhibit significant limitations. Beyond the commonly noted issues of interpretability, the practical limits of purely AI-based tsunami forecasting are closely tied to operational deployment conditions. Model skill can drop sharply when input patterns deviate from training distributions, such as cross-basin transfer, atypical rupture processes, or compound coastal conditions. Performance is also uneven for rare high-impact events because class imbalance tends to bias training toward more frequent, moderate cases. In addition, good aggregate scores may mask physically implausible local predictions (e.g., inconsistent coastal gradients or unstable arrival-time ordering) if mechanism-level checks are absent. Data-stream fragility is another major concern: missing, delayed, or asynchronous sensor inputs can propagate errors through end-to-end pipelines. Finally, model drift after sensor upgrades, coastline changes, or long-term environmental shifts can silently degrade reliability if continual monitoring is not implemented. Therefore, operational AI forecasting should be coupled with data-quality gates, out-of-distribution detection, mechanism-consistency screening, periodic recalibration, and fallback strategies to maintain decision reliability in real warning workflows. Their performance depends strongly on the size and representativeness of the training data, yet destructive tsunami events are relatively rare in real-world observations, which can lead to insufficient generalization across regions, source types, or extreme scenarios118,119,120,121. Moreover, the internal mechanisms and physical consistency of some deep-learning models are difficult to interpret directly, which increases concerns about credibility and auditability in high-stakes warning decisions. Consequently, interpretability and robustness need to be strengthened through approaches such as feature-importance analysis, physics constraints, and/or hybrid modeling, and uncertainty quantification119,120,123. For example, Buenrostro et al. used a convolutional neural network to predict intensity measures—such as run-up, inundation area, and wave height—from slip and coseismic deformation data, demonstrating the potential of “learning-based surrogate models” to replace computationally expensive inundation simulations. However, the acquisition of training data and the transferability of such models across scenarios still require careful evaluation123.
Hybrid physics–AI models
To address the high computational cost and limited responsiveness of purely physics-based models, as well as the shortcomings of purely data-driven models in physical consistency and generalization, physics–artificial intelligence (Physics–AI) hybrid models are increasingly emerging as a major direction in tsunami forecasting. These approaches aim to combine the interpretability of physical mechanisms with the rapid inference capability of data-driven models. On the one hand, they incorporate constraints or feasibility checks that enforce physical consistency during learning or inference; on the other hand, they use deep learning to replace or accelerate computationally expensive numerical components. In doing so, Physics–AI hybrids seek to reconcile “speed” with “trustworthiness” in real-world warning settings121,124,125.
A typical pathway for hybrid modeling is to embed AI-based predictions within a physics-consistency framework for constraint or validation. Rather than relying solely on statistical correlations, this paradigm requires that predictions remain physically feasible with respect to key variables and dynamical relationships—for example, by satisfying the mass- and momentum-conservation constraints implied by shallow-water dynamics (with the shallow-water equations and their numerical solution framework serving as the physical foundation)126,127. In practice, Sabah and Shanker combined ANN-based predictions with physics-based validation to conduct tsunami hazard forecasting and enhance credibility across the Indo-Pacific region, illustrating the value of the “AI prediction + physical consistency checking” hybrid paradigm for regional-scale risk assessment124.
Another key line of development is to use machine learning as a surrogate for high-fidelity physics-based models. In this paradigm, large training libraries are first generated via numerical simulations, and AI is then used to rapidly approximate propagation or inundation processes that would otherwise be computationally expensive, thereby substantially reducing forecast latency. Focusing on the 2018 Anak Krakatau volcano-flank-collapse tsunami, Juanara and Lam adopted a coupled strategy of “physics-based simulations for database generation + LSTM-based waveform forecasting,” enabling the prediction of subsequent tsunami evolution from a short initial waveform window and demonstrating the potential of hybrid models for non-seismic tsunami scenarios125. For near-field warning, Lee et al.121 developed and calibrated a run-up response-function model based on a precomputed ensemble of simulations, achieving sub-second prediction of alongshore near-field run-up distributions and illustrating the advantage of “physics-consistent simulation backgrounds + data-driven fast mapping.” Earlier response-function approaches for rapid far-field forecasting, as well as efficient inversion/prediction schemes based on precomputed Green’s functions, can likewise be viewed as extensions of this broader “precomputation–fast mapping” hybrid logic128,129.
In parallel, combining data assimilation with AI acceleration allows hybrid models to dynamically update forecasts as new observations arrive, improving both timeliness and accuracy. Melgar and Bock showed that integrating high-rate GPS with strong-motion and other land-based data (supplemented by offshore pressure sensors and GPS buoys) can improve source inversion and enhance tsunami inundation and run-up predictions, providing important support for operational multi-source data assimilation130. Within tsunami warning workflows, practices such as extracting source coefficients from deep-ocean bottom-pressure data (e.g., DART) and using them to drive operational forecast models, as well as inferring sources from multiple measurement types to initialize tsunami simulations, further exemplify an integrated “observation–inversion–physics-based forecasting” pathway131,132. Real-time event assessment and near-field forecasting studies also indicate that rapid updating and uncertainty control are critical for improving warning effectiveness133. On the computational side, parallel numerical computing for high-resolution near-field inundation forecasting (e.g., parallel implementations of TUNAMI-N2 coupled with source inversion) provides engineering support for “faster physics updates” and can complement data-driven rapid-estimation modules134.
Overall, Physics–AI hybrid models offer a more favorable compromise among predictive accuracy, computational efficiency, and physical consistency, but their development and training are highly complex. They require careful balancing across multiple factors, including multi-source data quality control, the strength of imposed physical constraints, cross-scale consistency (deep-ocean propagation to nearshore inundation), and robustness under extreme scenarios. Particularly important is the establishment of systematic validation frameworks—benchmarking against controlled physical experiments and multiple numerical models—to avoid failure modes or error accumulation under complex topography and extreme boundary conditions. Comparative studies integrating laboratory experiments and numerical models can provide direct references for validation design and error diagnostics in hybrid modeling135. Moreover, substantial epistemic uncertainty remains in rapid near-field inversion and forecasting: how to strike an auditable trade-off between “speed” and “trustworthiness” remains a key challenge that hybrid frameworks must confront on the path toward operational deployment136.
As summarized in Table 2, a practical deployment strategy is to orchestrate models by decision stage rather than selecting a single “best” method. In strict near-field timelines, low-latency estimators and surrogates/ROMs are suitable for rapid first alerts, while subsequent minutes should be used for rolling uncertainty updates, data assimilation, and consistency checks against physics-based baselines. For far-field transoceanic assessment, physics-based ensembles remain the most robust option for extrapolation across sources and regions, with surrogates primarily used to accelerate repeated scenario evaluation. In data-scarce or mechanism-uncertain settings, conservative uncertainty reporting and explicit exposure of multi-model disagreement are preferable to single deterministic outputs, because model divergence itself is often decision-relevant for risk grading137,138,139,140.
The three paradigms show distinct operational trade-offs. When viewed from an operational perspective, physics-based, purely data-driven, and physics–AI hybrid models represent three complementary ways to trade off physical fidelity, computational latency, and implementation complexity for the same forecasting targets such as arrival time, maximum wave height, and inundation depth. Physics-based models remain the most transparent and mechanism-consistent option, because their outputs can be traced to explicit source assumptions, bathymetry/topography, boundary conditions, and solver settings. This traceability is essential for high-fidelity inundation mapping and for auditable decision support, but it often comes with substantial runtime cost, particularly when fine meshes, wetting–drying treatments, and ensemble-style uncertainty analyses are required.
Purely data-driven models shift most computational burden to the offline stage and therefore offer very low inference latency in real-time use. This makes them attractive for strict near-field timelines, where a rapid first-pass estimate and early screening can be more valuable than a delayed high-fidelity solution. However, their reliability is strongly conditional on the representativeness of the training data and on the stability of the learned mapping under distribution shift. Performance can degrade when applied across regions, under rare or extreme source configurations, or when observation quality and coverage differ from the conditions implicitly assumed during training. For operational adoption, these limitations imply that data-driven outputs should be accompanied by explicit robustness evaluation, well-designed validation splits, and calibrated uncertainty reporting rather than treated as deterministic substitutes for physics.
Physics–AI hybrid approaches occupy the middle ground by combining faster turnaround with stronger physical plausibility than purely black-box pipelines. In practice, hybrids can be implemented in several ways, including using learning-based components for rapid source estimation or fast mapping from observations to coastal responses, while retaining physics-based propagation and inundation modules where physical constraints and interpretability are most critical. This design logic can deliver a pragmatic compromise for routine operations, but it also increases pipeline complexity and integration cost. Hybrids therefore require careful end-to-end verification, including ablation-style checks to demonstrate the contribution of the physical constraints, and systematic benchmarking against controlled experiments and multiple numerical models to prevent error accumulation under complex topography and boundary conditions.
Overall, no single paradigm dominates all operational requirements. Instead, the three paradigms should be regarded as complementary modules within a target-oriented forecasting workflow. For example, purely data-driven models can provide ultra-fast preliminary estimates and scenario ranking under tight near-field decision windows, while physics-based models remain indispensable for mechanism-consistent analysis and high-fidelity inundation products. Hybrid models can bridge these two by enabling rapid updates with stronger physical feasibility, especially when uncertainty control and progressive refinement are required. This orchestration view indicates that coordinated deployment of multiple paradigms is often more effective than one-model-fits-all solutions in real warning systems.
Beyond end-to-end deep surrogates, recent hybrid developments have moved toward physics–data combined parametric reduced-order modeling, where physical structure and data-driven mappings are jointly designed rather than loosely coupled. Representative examples include a domain-decomposition strategy for physics-data combined neural-network-based parametric reduced-order modeling and a small-data-regime physics-data combined machine-learning framework for nonlinear dynamical systems. Although these methods were developed in broader computational mechanics settings, they are directly relevant to tsunami forecasting because they provide a practical route to retain physical consistency while reducing online computational burden under parameter variation31,141.
Statistical surrogate models combining statistical modeling with physics-based simulations
Statistical surrogate (or emulator/meta-model) approaches provide a distinct and complementary pathway for tsunami forecasting and risk assessment. Instead of replacing physics solvers outright, they preserve high-fidelity simulation knowledge and use statistical learning to accelerate repeated scenario evaluation, which is especially important in probabilistic workflows with large ensembles142,143.
Methodologically, this family includes reduced-representation emulators, Gaussian-process-style emulators, and neural-network surrogates trained on simulation databases. Reduced-order/mode-based strategies have shown strong efficiency for fast response prediction in high-dimensional settings140, while neural surrogate models have demonstrated practical potential for probabilistic inundation assessment under computational constraints144.
A key advantage of statistical surrogate modeling is its direct compatibility with probabilistic hazard and risk pipelines. Recent work has shown that surrogate-based workflows can incorporate multiple rupture scenarios and nonstationary sea-level-rise conditions while keeping computation tractable for risk-oriented analysis145.
Beyond forward hazard mapping, surrogate models are increasingly used in inversion and parameter inference. Polynomial-chaos-based surrogates coupled with Bayesian inference have been used to estimate earthquake source parameters and friction-related quantities from tsunami observations146,147,148. More recent surrogate-assisted nonlinear inversion studies further demonstrate the feasibility for complex near-real-event applications149.
This paradigm also extends naturally to engineering risk and operational decision products. Surrogate tsunami demand models have been applied to fragility assessment with reduced simulation burden and improved practical interpretability150. In operational warning settings, Bayesian-network surrogates linked to numerical model outputs have shown that probabilistic impact grading can be deployed in practice151.
Overall, statistical surrogate models should be treated as an independent methodological pillar in integrated tsunami assessment systems. Their main value lies in making large-scale probabilistic analysis computationally feasible while retaining transparent links to physics-based simulation databases. At the same time, reliability remains strongly dependent on scenario design quality, parameter-space coverage, and regular revalidation against full-physics runs, which should be explicitly addressed in operational implementation.
From an operational perspective, the defining advantage of surrogates and reduced-order approaches is the “offline heavy, online light” workflow: scenario libraries and low-dimensional structure are learned offline, while online forecasting reduces to rapid coefficient reconstruction and mapping. This design supports strict latency budgets and makes uncertainty propagation more auditable in warning practice. However, operational readiness should be tied to scheduled revalidation against full-physics baselines to prevent silent performance drift when scenario coverage is incomplete137,138,139,140,152,153,154.
Real-time tsunami forecasting
Real-time tsunami forecasting demands not only accurate models but also robust operationalization to ensure effective performance in real-world settings. Despite rapid methodological advances, a notable gap persists between model development and practical deployment. An operational system must integrate high-throughput data ingestion, ultra-low-latency forecasting, and decision-oriented outputs in a largely automated manner. Accordingly, this section focuses on three pillars of operational tsunami forecasting: computational acceleration, end-to-end workflow automation, and rigorous model verification.
Computational efficiency and latency constraints
A core challenge for operational tsunami forecasting lies in the extreme demands placed on computational efficiency and end-to-end latency. In near-field tsunami scenarios, the time between the triggering event (typically a large earthquake) and the arrival of the first tsunami wave at the coast may be only 10–20 min, or even less155. Within such a narrow time window, forecasting systems must complete a sequence of critical steps, including multi-source data ingestion, model computation, uncertainty assessment, and warning dissemination156. Computational speed, therefore, is not merely a technical consideration; it directly determines whether a warning can be issued in time to be effective.
For real-time tsunami forecasting, nonlinear reduced-order modeling is becoming an important complement to conventional acceleration strategies. Recent examples include probabilistic manifold decomposition for nonlinear model reduction and a deep-transfer-learning-enabled parametric non-intrusive reduced-order model, both targeting rapid prediction across varying conditions while maintaining acceptable fidelity. In near-field warning operations, these ROM pathways are particularly relevant because they provide a computational middle ground between full high-fidelity simulation and purely black-box inference, thereby supporting stricter end-to-end latency requirements in practice92,157.
Different tsunami scenarios entail different decision windows. Near-field events often require forecasts within seconds to minutes, whereas far-field tsunamis allow a longer period for analysis. Nevertheless, regardless of the scenario, operational systems must deliver stable and reliable outputs under strict time constraints. To meet these requirements, modern tsunami forecasting increasingly relies on GPU acceleration and parallel computing to support both high-resolution numerical simulations and rapid inference with machine-learning models.
At the same time, edge computing and cloud platforms are being progressively integrated into operational architectures158. Edge computing reduces transmission latency by performing preliminary processing near sensors or at regional nodes, while cloud platforms provide elastic computational capacity to support cross-regional, multi-task real-time analytics. Although such distributed computing architectures can improve efficiency, they also impose higher demands on system robustness, data consistency, and real-time scheduling.
Automated end-to-end forecast pipelines
Beyond computational speed, another key requirement for operational tsunami forecasting is a highly automated end-to-end pipeline159. Any human intervention at any stage can introduce delays, inconsistencies, or human error—risks that are particularly consequential for tsunamis, where timeliness is paramount. Accordingly, modern forecasting architectures increasingly emphasize fully automated workflows that can operate continuously and reliably.
An automated pipeline typically begins with real-time identification of potential triggering events, using seismic or ocean observations to rapidly assess whether a tsunami is likely. Once triggered, the system automatically acquires data from multiple observing networks—such as seismic arrays, tide gauges, deep-ocean bottom-pressure sensors, and satellites—and integrates them into a unified processing framework. Forecast models—whether physics-based, data-driven, or hybrid—are then executed automatically to generate predictions of tsunami arrival time, wave height, and inundation risk160.
Operationally, low latency should not rely solely on faster hardware but on a tiered forecasting architecture. A practical design couples a high-fidelity physics baseline with surrogate/ROM modules that provide second-to-subsecond first estimates, followed by assimilation-driven uncertainty updating as additional observations arrive. This enables a staged workflow of “rapid first alert, incremental correction, and stable tiered release,” where model-switching rules, threshold triggers, and traceable error bounds are predefined so that timeliness gains do not come at the cost of un-auditable decisions137,138,139,154.
The final step is the automated generation and multi-channel dissemination of warning products. This stage is as critical as the forecasting itself, because any delay in dissemination can render even accurate predictions operationally ineffective. While automation substantially improves efficiency and consistency, it also imposes stringent requirements on system reliability, robustness, and fail-safe design.
Model validation and benchmarking
To ensure the reliability of tsunami forecasting systems in real-world operations, systematic and continuous model verification and benchmarking are essential. This process is not only critical for assessing predictive accuracy but also for strengthening decision-makers’ confidence in forecasts that directly inform high-stakes warning issuance and evacuation decisions. Verification typically involves comparing model outputs—such as tsunami arrival times, wave amplitudes, and inundation patterns—against observations from historical events, thereby testing performance under realistic conditions161.
A widely used approach is retrospective replay analysis of past tsunamis, in which archived seismic and oceanographic data are used to reconstruct historical scenarios and evaluate how well the forecasting system reproduces observed outcomes162,163. Such analyses are valuable for diagnosing systematic biases, sensitivity to source-parameter uncertainty, and deficiencies in underlying modeling assumptions. However, historical tsunami records are inherently limited and uneven, particularly for non-seismic tsunamis or events that occurred prior to the establishment of modern observing networks. To address these gaps, synthetic datasets generated through numerical simulations are increasingly employed as a complement to historical validation. Synthetic scenarios enable controlled benchmark testing across a broader range of source mechanisms, magnitudes, and coastal configurations, including rare or extreme events that are underrepresented in observational archives.
While joint validation using both historical and synthetic data can support ongoing model improvement and performance gains, it also introduces practical challenges. Large-scale benchmarking can be computationally intensive, especially when high-resolution simulations or ensemble-based testing strategies are required. Striking an effective balance between comprehensive evaluation and operational feasibility, therefore, remains a key consideration. Nevertheless, regular verification and benchmarking are indispensable for maintaining the accuracy, robustness, and credibility of real-time tsunami forecasting systems, serving as a critical bridge between methodological development and dependable operational deployment.
Tsunami risk assessment and decision-support tools
Tsunami risk reduction requires not only accurate forecasting of tsunami events, but also a deeper understanding of their potential hazards in order to protect lives and critical infrastructure through evidence-based decision-making. Modern tsunami forecasting and early warning systems must be tightly integrated with risk-assessment frameworks and decision-support tools, providing high-risk communities with comprehensive and operationally actionable information. This section examines how such tools—ranging from deterministic and probabilistic risk models to AI-enabled decision-support systems—can be leveraged to mitigate the devastating impacts of tsunamis.
Deterministic vs. probabilistic risk frameworks
Tsunami risk assessment provides the analytical foundation for translating hazard forecasts into actionable risk-reduction strategies. At present, tsunami risk assessment is commonly framed through two complementary paradigms: deterministic scenario-based assessment and Probabilistic Tsunami Hazard Analysis (PTHA)164. These approaches embody different philosophies of risk representation and support decision-making at different levels.
Deterministic risk assessment characterizes potential impacts using a set of preselected tsunami scenarios. It typically draws on historical evidence and tectonic–geological analyses to define a maximum credible event or otherwise conservative “worst-case” assumptions, and then uses numerical modeling to simulate tsunami generation, propagation, and coastal inundation. The resulting simulations delineate spatial distributions of key hazard metrics, such as arrival time, wave height, and inundation depth. A typical deterministic workflow specifies plausible earthquake magnitudes and rupture patterns based on known fault mechanisms and tectonic settings, and then applies numerical models to produce coastal hazard indicators. For example, Chen et al.165 conducted a scenario-based assessment of tsunami hazards for Xiamen, China, using three representative worst-case source scenarios. They simulated tsunami propagation and inundation generated by a hypothetical Mw 8.0 earthquake, produced local hazard maps, and identified scenario-dependent differences in inundation depth across coastal sectors—highlighting the importance of scenario selection for coastal hazard characterization. Other studies extend deterministic assessments by considering both far-field and near-field sources. For instance, a study conducted in Cixi County, Zhejiang Province, China166 numerically evaluated tsunami propagation effects under scenarios associated with the Pacific Ring of Fire as well as nearby sources, and developed detailed hazard and risk maps for the county. Such work demonstrates that risk-space mapping based on extreme-but-plausible earthquake-tsunami scenarios can be critical for coastal planning and engineering design.
A major strength of deterministic assessment lies in its intuitive and explicit outputs: for a given scenario, it yields concrete estimates of wave height, inundation depth, and arrival time, which can be directly used to design evacuation routes, formulate emergency response plans, and inform resilient infrastructure design. For example, in studies of the UAE’s east coast under different magnitude assumptions for the Makran subduction zone167, simulations of Mw 8.2, 8.8, and 9.2 tsunami events produced detailed maps of tsunami travel time (TTT), run-up, flow depth, and inundation extent, thereby enabling quantitative recommendations for local disaster-risk-reduction measures.
However, as many studies have emphasized, deterministic assessment does not explicitly account for uncertainty in source occurrence or variability in source parameters. Because it is conditioned on specific assumed scenarios, risks may be underestimated or overestimated when the selected scenarios fail to capture the full range of plausible event mechanisms or spatial variability. In other words, while deterministic approaches can provide policymakers with a clear “worst-case” reference, neglecting uncertainties in tectonic setting, magnitude–frequency characteristics, and rupture processes can introduce systematic biases in different contexts. This limitation also helps explain why many contemporary risk-assessment frameworks increasingly combine multi-scenario designs with probabilistic methods to improve robustness.
By contrast, PTHA seeks to move beyond the limitations of single-scenario prediction by systematically integrating historical records, geological evidence, and seismological source models to quantify the likelihood of different tsunami scenarios. Rather than producing results conditional on one preselected “worst-case” event, probabilistic approaches statistically evaluate a large ensemble of potential tsunami sources together with their occurrence probabilities, and generate hazard curves or hazard maps that describe the exceedance probability of a tsunami intensity measure (e.g., wave height or inundation depth) over a specified time horizon168. Such outputs can represent the chance of tsunamis of varying intensities occurring over 50 years, 100 years, or longer periods, thereby providing coastal planners with a more comprehensive, probability-based characterization of hazard, rather than a focus on a single extreme scenario.
Moreover, by discretizing multiple tsunami-generation mechanisms across global, regional, and local scales, PTHA can estimate the probability that tsunami wave heights at a given site will exceed a specified threshold within a defined time window. This probabilistic perspective supports risk-informed planning and decision-making, enabling policymakers to explicitly weigh trade-offs between more frequent, moderate events and extreme but low-probability events. At the same time, some studies169 note that PTHA often requires large numbers of numerical simulations of tsunami propagation and inundation to adequately represent source-model and system uncertainties, which limits its direct applicability in time-critical forecasting and emergency response. PTHA commonly relies on Monte Carlo sampling, logic-tree frameworks, or related statistical schemes to sample source probabilities and compute hazard metrics—procedures that can be difficult to implement when computational resources or data completeness are constrained. Even with high-performance computing, a degree of trade-off between model fidelity and uncertainty propagation often remains unavoidable.
Accordingly, in practical tsunami risk-assessment applications, deterministic scenario-based assessment and probabilistic tsunami hazard analysis are increasingly viewed as complementary tools. Deterministic methods, with their intuitive and explicit outputs, are well-suited to emergency planning and scenario-specific contingency preparation, providing key references in the early phases of disaster management. Probabilistic approaches, in turn, more comprehensively represent uncertainty and event likelihoods, supporting longer-term risk planning and policy formulation. Used together, these methods provide a more robust scientific basis for managing the complex, multivariate risks posed by earthquake-generated tsunamis.
Data-enhanced exposure and vulnerability modeling
Modern tsunami risk assessment has increasingly evolved from a narrow focus on hazard characterization towards an integrated framework that explicitly incorporates exposure and vulnerability modeling, thereby capturing potential impacts on social systems more comprehensively. This shift is evident not only at the conceptual level but also in recent empirical studies. For example, a study proposing a refined probabilistic tsunami inundation risk assessment model explicitly argued that a tsunami risk framework should comprise three key components—hazard, exposure, and vulnerability—and demonstrated how high-resolution satellite imagery combined with geographic information system (GIS) data can be used to quantify coastal exposure (population and infrastructure) with high precision, providing a stronger evidence base for disaster-risk management and mitigation planning170.
Population exposure modeling is widely used to estimate the scale and characteristics of affected populations, while accounting for how demographic patterns and socioeconomic factors shape vulnerability. For instance, in a tsunami risk analysis for Chile’s Cartagena Bay171, the research team not only delineated inundation extents based on hazard information, but also applied census-based social vulnerability indicators to resolve affected populations at the block level. They further incorporated pedestrian evacuation capacity—such as distance and travel time from residences to shelters—to assess potential life-safety risk. The results showed that, if community response capacity is not considered, the spatial extent of “high-risk” areas may be substantially overestimated. Incorporating evacuation behavior and coping capacity yields more realistic risk estimates, underscoring the value of multi-layer data fusion across hazard, exposure, and vulnerability dimensions.
Recent work has also expanded markedly in assessing the sensitivity of infrastructure and land use. For example, a tsunami risk assessment for Xiamen, China172 jointly considered inundation hazard, the spatial distribution of critical exposed assets (e.g., industrial and chemical facilities, ports), and topographic and land-use information to evaluate vulnerability levels for a coastal city and to produce risk “hotspot” maps. Such studies demonstrate that physical hazard metrics alone (e.g., wave height or inundation depth) are insufficient to fully represent real-world risk; incorporating multi-source exposure information is essential for accurately identifying spatial patterns of risk.
A systematic review of the past decade of global research on tsunami vulnerability modeling173 further shows that GIS, remote sensing, and socioeconomic data have become core enablers for building spatial vulnerability models. These tools are used to generate vulnerability maps for different population groups and asset types, highlight socioeconomic disparities across affected areas, and classify infrastructure risk levels—while also underscoring the need for standardized vulnerability assessment frameworks. The review also notes that, despite continued methodological progress, substantial challenges remain due to data availability constraints, inconsistencies in indicator systems, and gaps in socioeconomic datasets, with these issues being particularly pronounced in regions with weaker institutional capacity.
Beyond population and infrastructure modeling, research on how human behavior and evacuation capacity shape risk is also growing. For instance, León et al.174 applied multivariate regression to analyze built-environment and transportation-network attributes across multiple Chilean coastal cities, finding that these spatial characteristics are closely associated with expected mortality during tsunami evacuations. Their results suggest that risk assessment models should incorporate social behavior and urban morphology to better capture heterogeneity in vulnerability.
AI-assisted decision support systems
As tsunami forecasting and risk-assessment capabilities continue to advance, a central challenge for emergency management is how to translate multi-source predictive outputs into timely and reliable decision recommendations. Traditionally, decisions on warning issuance, evacuation prioritization, and resource allocation have relied on expert systems and manual analysis. However, under complex, multi-variable inputs—such as real-time sensor streams, hazard-model outputs, and information on social exposure and vulnerability—these approaches can lead to delayed responses or subjective biases. In recent years, AI-enabled decision support systems (AI-DSS) have increasingly been viewed as an important intermediary linking forecasting outputs to operational response, enabling high-dimensional data fusion and real-time optimization of decision-making.
In a tsunami emergency response, one of the most consequential decisions is whether to issue a warning and when to determine the appropriate alert level. To improve real-time responsiveness, a growing body of research has applied machine learning and deep learning to tsunami forecasting and warning decision processes. For example, Rodríguez et al.175 used a neural network to predict maximum tsunami wave height and arrival time; their trained model produced these core warning indicators within seconds, providing empirical support for rapidly supplying decision-critical information to operational decision-support systems. Another study proposed a CNN-based approach for time-series prediction of tsunami inundation, directly forecasting inundation waveforms from real-time ocean observations with an average inference time of only 0.004 s, markedly reducing prediction latency and demonstrating the potential of AI for early warning176.
Beyond warning issuance, AI-DSS can also integrate hazard forecasts with exposure and vulnerability information to support evacuation prioritization and resource allocation. Mas et al.177 proposed a reinforcement-learning-based tsunami evacuation guidance system that builds an environment model incorporating road-network structure, departure timing, and crowd behavior, enabling an agent to learn evacuation-route policies optimized for complex conditions. Compared with conventional shortest-path strategies, the approach can reduce congestion and improve time efficiency, thereby supporting the identification of priority evacuation zones and real-time decision-making. Another study178 combined an XGBoost model with spatial data—such as population density, shelter capacity, and topography—to predict tsunami evacuation times. This not only improved the accuracy of evacuation-time estimation, but also provided an interactive, visualization-driven interface that can help decision-makers develop more targeted resource-allocation and evacuation strategies.
However, deploying AI in high-stakes decision contexts raises substantial concerns regarding transparency, interpretability, and trust179,180,181,182,183,184. Even when deep models generate accurate recommendations, decision-makers may find it difficult to understand or justify the underlying logic when the system functions as a “black box,” which can hinder adoption and field implementation185,186. Moreover, rigorous model validation and robust system engineering are essential prerequisites for AI-DSS deployment187,188. Looking ahead, the integration of deterministic and probabilistic hazard frameworks, exposure and vulnerability modeling strengthened through data augmentation, and AI-DSS is likely to constitute a central direction for tsunami science and emergency management. With the incorporation of high-performance computing, real-time sensor fusion, interpretable model design, and standardized cross-agency workflows, tsunami decision-support tools are beginning to shift from single-model prediction toward comprehensive, dynamic, and operationally actionable risk-information services—enhancing coastal resilience and reducing future socioeconomic losses due to tsunamis.
In high-stakes warning governance, the limitations of AI are not only technical but institutional. Over-reliance on automated outputs can induce automation bias, especially in borderline events where human operators may underweight contradictory field evidence. Responsibility boundaries may also become blurred when a model contributes to alert thresholds, evacuation recommendations, or resource prioritization, creating ambiguity across developers, operators, and issuing authorities. Furthermore, uneven sensor density and data infrastructure can lead to unequal model quality across regions, potentially reproducing risk inequities in warning services. To address these limitations, AI-enabled warning systems should adopt explicit human-in-command rules, role-based accountability matrices, full decision logging, routine stress tests on rare and adverse scenarios, and predefined fallback protocols when input quality or model behavior violates operational thresholds. Such governance design helps ensure that AI functions as accountable decision support rather than an opaque substitute for institutional responsibility.
To prevent unqualified cross-context extrapolation, deployments should explicitly state generalization boundaries. We recommend distinguishing (1) directly transferable settings where sensor coverage, source mechanisms, and coastal configurations match the training/validation regime; (2) transferable-with-recalibration settings where domain shift is moderate but can be corrected through localized fine-tuning, bias adjustment, or updated priors; and (3) non-transferable settings (e.g., poorly observed non-seismic or compound sources) where outputs must be treated as screening-level signals accompanied by conservative uncertainty and mandatory human review. This boundary-aware framing also makes interpretability operational: it supports answering why an alert level is triggered, which observations dominate the decision, and when manual takeover is required, thereby strengthening accountability and public communication28,189,190.
This section highlights the role of tsunami risk assessment and decision-support tools in mitigating tsunami impacts, with an emphasis on deterministic and probabilistic risk frameworks, data-enhanced exposure and vulnerability modeling, and AI-enabled decision support systems. Together, these tools can provide decision-makers with more comprehensive and accurate risk characterization, optimize response strategies and resource allocation, and ultimately strengthen tsunami preparedness and community resilience.
Transition to resilience: bridging science, policy, and society
Although advances in tsunami forecasting have delivered unprecedented accuracy and responsiveness, translating scientific predictions into effective risk management and resilience building remains a pressing challenge. An effective tsunami forecasting system must bridge scientific modeling with policy implementation and societal action. This section examines the transition from prediction to resilience along three key dimensions: communicating uncertainty to decision-makers, integrating forecasting tools into operational warning systems, and addressing the ethical and governance challenges that shape the implementation of tsunami risk-reduction strategies.
Communicating uncertainty to decision-makers
A fundamental challenge in tsunami forecasting is the pervasive and difficult-to-eliminate uncertainty inherent in its predictions. Tsunami generation and impacts are jointly controlled by multiple factors, including source characteristics, fault geometry, ocean dynamics, and coastal topography—many of which cannot be tightly constrained in the earliest stages of an event. Consequently, tsunami forecasting is intrinsically probabilistic: its operational value depends not only on forecast accuracy, but also on whether uncertainty is communicated appropriately to decision-makers. Rather than issuing purely deterministic statements, modern tsunami warning systems increasingly emphasize risk-based information products that simultaneously convey the probabilities and associated confidence levels of alternative outcomes (e.g., wave height, arrival time, and inundation extent). Such probabilistic forecasting is widely considered better suited to representing tsunami threats under conditions of limited early data. For example, Selva et al.191 proposed a real-time probabilistic approach termed Probabilistic Tsunami Forecasting (PTF), which explicitly quantifies forecast errors arising from data limitations and model uncertainties, and incorporates these uncertainties directly into the definition of alert levels. This enables warning centers to issue tiered alerts based on predefined risk tolerances. Beyond improving the scientific basis of early forecasts, the approach supports explicit trade-offs between missed alarms and false alarms by providing decision-makers with quantitative estimates of threat distributions and a principled basis for alert-level classification.
This probabilistic, uncertainty-centered communication approach helps decision-makers appreciate the range of plausible scenarios and weigh the consequences of acting versus delaying action under uncertainty. However, probabilistic warning also introduces new challenges, most notably false alarm fatigue: frequent warnings that do not result in salient consequences can erode trust among the public and authorities, reducing willingness to respond in future events. Empirical research suggests that after repeated false alarms, sensitivity to warning messages can decline markedly and may even lead to complacency in genuinely critical situations192,193,194. Accordingly, decision-support systems that couple probabilistic hazard forecasts with explicit uncertainty metrics and well-defined decision thresholds can help balance the trade-off between “over-warning” and “under-warning.” This is not merely a technical issue; it is a central problem of risk governance.
In parallel, uncertainty-focused research on Probabilistic Tsunami Hazard Analysis (PTHA) has underscored the importance of quantitatively identifying major sources of parameter uncertainty and tracing how they propagate into hazard estimates. For example, Liu et al.195 analyzed how uncertainties in upper-bound magnitude, rupture-plane parameters, and other source characteristics influence PTHA outputs, and proposed using logic-tree and event-tree frameworks for systematic quantification. Such studies further highlight the significance of uncertainty treatment for long-term risk estimation and engineering-design applications.
Therefore, uncertainty communication is not only a technical task but also a core component of risk governance. Clear and consistent representations of uncertainty can improve decision quality and strengthen public trust, whereas poor communication can generate confusion, skepticism, and maladaptive responses. Future tsunami warning systems will need to refine probabilistic forecasting and uncertainty characterization, and—drawing on interdisciplinary insights from decision science, risk communication, and social psychology—systematically improve how uncertainty information is conveyed to decision-makers and the public. This remains one of the key unresolved challenges for tsunami warning practice.
Integrating prediction tools into early warning systems
The societal value of tsunami forecasting tools ultimately depends on whether they can be effectively integrated into early warning systems (EWS). This integration is not purely a technical undertaking; it is profoundly shaped by geopolitical dynamics, socioeconomic conditions, and institutional environments. Marked differences across countries and regions in infrastructure, resource investment, and operational capacity have produced substantial global disparities in tsunami risk-reduction capability, with far-reaching implications for the coverage and operational usability of tsunami warnings.
Many countries in high-risk regions have established advanced warning systems supported by dense observing networks and real-time forecasting capacity. For example, the Pacific Tsunami Warning and Mitigation System (PTWS) and the Indian Ocean Tsunami Warning System (IOTWS) coordinate internationally to integrate multi-source data streams—including seismic monitoring, deep-ocean pressure buoys, and satellite observations—so as to deliver faster and more accurate alerts, while leveraging real-time propagation models to improve the timeliness and spatial coverage of warning products. Accordingly, modern Tsunami Early Warning Systems (TEWS) must overcome both technical and governance barriers by embedding sensor networks, real-time data streams, and decision-support mechanisms within a comprehensive end-to-end architecture, ensuring that the “detection-to-response” chain can operate continuously and effectively196. Such integrated warning architectures reflect a broader evolution from purely technical detection toward comprehensive risk management and resilience enhancement.
By contrast, coastal regions in developing contexts—particularly Small Island Developing States (SIDS) and low-income coastal communities—face far more severe constraints in deploying, maintaining, and operating tsunami early warning systems. Limited data sharing, sparse real-time monitoring networks, inadequate communication infrastructure, and shortages of trained personnel often prevent these regions from integrating advanced forecasting tools into existing warning architectures, thereby increasing risk exposure197. At the local level, one of the most persistent challenges across different basins and countries is insufficient multi-stakeholder coordination and limited institutional response capacity. These bottlenecks can significantly weaken the linkage between forecasting tools, warning issuance and dissemination, and community-level response.
Closing these gaps requires sustained international cooperation and capacity building. The Intergovernmental Oceanographic Commission of UNESCO (IOC-UNESCO)198 and initiatives such as the Ocean Decade tsunami program have explicitly emphasized strengthening cross-national data sharing, early warning capacity development, education and training, and coordinated response mechanisms in order to improve the equity of global warning capability. For example, IOC-UNESCO’s global tsunami warning and mitigation programs support Member States through regional coordination mechanisms, technical advisory and information centers, and capacity-building activities, providing technical assistance, risk-assessment services, and community education to improve system integration, warning dissemination, and preparedness.
In addition, there is increasing emphasis that tsunami warning systems should not operate in isolation, but rather be embedded within broader Multi-Hazard Early Warning Systems (MHEWS)199. Such integration facilitates information sharing and coordinated responses across multiple hazards (e.g., earthquakes, storm surges, floods), thereby improving the practicality and resilience of warning operations under resource constraints.
Effectively integrating forecasting tools into early warning systems is a critical step toward strengthening tsunami risk reduction and minimizing disaster losses. This process involves not only technological enhancement, but also cross-border and cross-institutional cooperation and resource sharing. While advanced warning systems in high-risk regions continue to improve through dense observing networks and real-time forecasting capabilities, persistent technology and resource gaps remain major barriers in developing regions—especially SIDS and low-income communities. Achieving a more balanced and widely accessible global tsunami warning capacity, therefore, requires strengthened data sharing, sustained capacity building, and improved mechanisms for coordinated warning and response. Through enhanced international collaboration and the development of MHEWS, modern tsunami warning systems can more effectively address diverse hazard risks and ensure that the end-to-end “forecast-to-response” chain operates continuously and efficiently. Ultimately, seamless integration of forecasting tools with warning systems can improve both the scientific robustness and operational accuracy of tsunami warnings and provide strong support for global disaster risk reduction and resilience building.
Ethical and governance considerations
As artificial intelligence and automated decision technologies become deeply embedded in tsunami forecasting and warning systems, disaster risk management is undergoing a paradigm shift from expert experience–driven practices toward algorithm-centered decision-making. While this transition can substantially enhance forecasting speed and data-integration capability, it also elevates ethical and governance concerns to the core of system design and operation200. Unlike traditional models, AI systems may not only contribute to risk assessment but also directly influence alert thresholds, evacuation recommendations, and even emergency resource allocation. Their societal impacts, therefore, extend beyond technical performance alone. As a result, accountability, data governance, and public trust are no longer peripheral considerations; they constitute the institutional foundations that determine the legitimacy and long-term effectiveness of tsunami warning systems.
From an accountability perspective, the introduction of AI can blur the clarity of the traditional “human–institution” responsibility chain201,202. Tsunami forecasting is inherently uncertain, and machine-learning models are trained on historical samples under assumed data-generating distributions; forecast errors may arise from data bias, structural model limitations, or insufficient representation of extreme events. When AI systems participate in warning issuance or inform evacuation decisions, false alarms, missed alarms, or delayed warnings can make it difficult for existing governance arrangements to delineate responsibility among model developers, deploying agencies, and ultimate decision authorities. In probabilistic tsunami risk assessment, uncertainty is an irreducible attribute; without clear accountability mechanisms, institutional trust may erode and systematic learning from forecasting failures can be impeded195. Accordingly, algorithmic accountability should not be treated as an ex post remedy, but institutionalized at the design stage through interpretable model structures, decision logging, and tiered responsibility frameworks.
At the same time, tsunami forecasting systems rely heavily on the coordinated use of cross-border, multi-source, real-time data streams, including seismic monitoring, ocean-bottom pressure sensors, tide gauges, and satellite remote sensing. While such a highly interconnected data ecosystem can enhance predictive capability, it also makes issues of data sovereignty and governance increasingly salient. Driven by concerns related to national security, economic interests, and privacy protection, international sharing of critical datasets is often subject to institutional constraints, which in turn can weaken the overall effectiveness of global warning architectures. One of the central challenges facing global disaster early warning today is therefore not a lack of algorithmic capability, but the absence of data-governance frameworks that can simultaneously respect sovereignty while ensuring fairness and transparency203. How to enable trusted sharing of key observational data without compromising national interests remains an unresolved institutional challenge in the ethical governance of tsunami warning systems.
More fundamentally, the societal effectiveness of warning systems ultimately depends on public trust204. Even if predictive accuracy improves substantially, compliance with warnings may decline if the public cannot understand the basis for alerts, perceives the forecasting process as opaque, or believes accountability is not traceable. As deep-learning models become increasingly complex, forecasting processes tend to exhibit “black-box” characteristics, creating tension with the demand for transparency and interpretability in public risk governance. In high-stakes decision contexts, adopting explainable AI is thus not merely a technical refinement, but an ethical and governance requirement. Its central aim is to enable decision-makers and the public to understand how models handle uncertainty and generate judgments, thereby providing a stable foundation for institutional trust.
In sum, AI-driven tsunami forecasting systems are not simply a technical upgrade; they represent a complex institutional innovation deeply embedded within broader governance structures. Ethical governance, transparency, and accountability mechanisms are not optional add-ons, but preconditions for ensuring that advanced forecasting technologies genuinely serve risk reduction and public safety. Only by clarifying responsibility, establishing equitable data-governance arrangements, and continuously strengthening public trust can AI realize its intended societal value within tsunami early warning systems.
Future directions and challenges
As tsunami science and forecasting systems continue to advance, the future of tsunami prediction and risk management holds significant promise. Realizing these advances, however, will require addressing major scientific, technological, and societal challenges. This section discusses future directions in tsunami research, with a focus on the potential of digital twins for coastal systems, the development of foundation models for tsunami science, the importance of learning from historical near-misses and small-to-moderate tsunamis, and the need to transition from traditional warning paradigms toward more adaptive, resilience-oriented strategies.
Developing digital twins of coastal systems
One of the most compelling frontier directions in tsunami research is the development of digital twins of coastal systems—virtual systems that can be continuously updated to dynamically mirror the state of real coastal environments205,206. In tsunami contexts, a digital twin moves beyond offline hazard mapping by coupling observations, forecasting models, and decision processes in real time, enabling a closed-loop operation of “observe while simulating while deciding.” To illustrate how this “observation–simulation–decision” loop can be operationalized at the system level, Fig. 6 presents an overall architecture for a coastal digital twin: multi-source observations (e.g., deep-ocean bottom-pressure sensors, tide gauges, seismic and geodetic networks, satellite remote sensing, and local measurements) are continuously assimilated into a forecasting engine (physics-based, AI-driven, or hybrid models), which is then coupled in real time with scenario exploration and decision-support modules to enable dynamically updated predictions of tsunami propagation, nearshore amplification, and inundation impacts. The system can assimilate continuous data streams from deep-ocean pressure sensors, tide gauges, seismic and geodetic networks, satellite observations, and local monitoring, updating forecasts of tsunami propagation, coastal amplification, and inundation impacts as the event evolves.

Overall architecture of the digital twin system.
The value of a digital twin also lies in its ability to support emergency-oriented scenario analysis and strategy evaluation: under alternative assumptions about source parameters, topographic conditions, infrastructure configurations, and even sea-level-rise backgrounds, it can rapidly test the effectiveness of different response options, shifting traditional static contingency planning toward adaptive, context-aware decision-making. Realizing this vision, however, will require overcoming key barriers, including computational constraints for real-time high-resolution simulations, robust data assimilation mechanisms, and the harmonization of multi-source heterogeneous data in terms of resolution and uncertainty. If these challenges can be addressed, digital twins could provide a next-generation tsunami risk-management system that is highly integrated, dynamically updated, and operationally actionable.
Developing foundation models
As tsunami-relevant data continue to grow in both scale and diversity, the development of foundation models is emerging as an important direction. By pretraining on large, multi-source datasets at the global scale, these models can learn transferable representations and can be rapidly adapted and optimized for specific regions and tasks207,208. Unlike “bespoke” models tailored to a single region and trained on limited event catalogs, foundation models aim to extract shared structures across different tsunami source mechanisms, propagation conditions, and observational modalities. This can reduce the cost of building separate models for each coastline and accelerate deployment in data-sparse regions.
A further potential advantage of foundation models lies in their ability to address diverse triggering mechanisms—from typical megathrust earthquakes in subduction zones to non-seismic sources such as landslides and volcanic eruptions. By learning across a broader spectrum of events and background variability, such models may improve generalization to atypical or even compound scenarios. Nonetheless, this direction faces substantial challenges, including the need for high-quality and diverse training data, robust strategies for cross-regional domain adaptation, and rigorous control of bias and uncertainty to avoid brittle failures in low-frequency, high-consequence settings. Foundation models thus represent both an opportunity and a test: whether tsunami science can achieve globally scalable learning while maintaining physical credibility and engineering reliability.
Learning from near-misses and “small tsunamis”
Tsunami science and risk management have historically been driven largely by catastrophic events, yet near-misses and small tsunamis can also provide critical insights for improving forecasting systems209. Near-misses refer to events for which warnings were issued, but realized impacts were smaller than anticipated, offering a unique opportunity to stress-test the forecasting chain, action thresholds, and risk-communication strategies. Post-event review of such episodes can help identify which components systematically lead to overly conservative forecasts, where uncertainty representations exhibit persistent biases, and how public behavioral responses to warnings are shaped.
By contrast, small tsunamis are less destructive but occur more frequently, making them an important resource for constraining model behavior and expanding training data for data-driven approaches. Systematic study of small events can improve representations of propagation and nearshore amplification under moderate forcing, refine detection and classification algorithms, and—under the constraint of “extreme-event scarcity”—expand the effective sample space available for model learning. A key difficulty, however, is that these events are often incompletely recorded and unevenly observed, underscoring the need for long-term, standardized data archiving and evaluation mechanisms. Treating “non-catastrophic events” as scientifically valuable signals rather than operational marginalia has the potential to substantially enhance model robustness and the quality of warning governance.
From warning to adaptive resilience
The long-term vision for tsunami risk management is to move beyond an event-centered warning paradigm toward a broader concept of adaptive resilience, embedding tsunami risk into urban planning, financial mechanisms, and climate-adaptation frameworks210,211. Within this perspective, forecasting and risk assessment should not only support evacuation decisions but also shape patterns of urban development, infrastructure standards, and investment priorities. Incorporating tsunami hazard into land-use planning can reduce exposure at its source by steering development away from high-risk zones, strengthening building codes, and investing in protective infrastructure designed with redundancy and resilience.
In parallel, risk-financing instruments—such as insurance pricing and catastrophe bonds—can translate risk knowledge into incentives for mitigation and provide financial buffers for recovery, thereby accelerating post-disaster reconstruction212. More importantly, coastal resilience must be reconsidered in the context of compound risk landscapes shaped by sea-level rise and increasingly extreme coastal flooding. Tsunamis do not occur in isolation; their impacts may be amplified by higher baseline sea levels or concurrent hazards. A central challenge in achieving adaptive resilience is therefore governance: integrating tsunami science into cross-sector decision-making requires coordinated mechanisms among governments, insurers, planning agencies, and communities. Consequently, future resilience gains will depend not only on better forecasts but also on institutional arrangements that can convert risk information into sustained and equitable action.
Conclusions
The field of tsunami forecasting is undergoing a profound paradigm shift, driven by rapidly expanding data availability, increasing computational power, and advances in intelligent analytics. While physics-based models remain indispensable for describing the tsunami generation, propagation, and inundation processes, they are increasingly being integrated with data-driven and physics–intelligence hybrid approaches to deliver forecasts that are faster, more adaptive, and more decision-relevant. This transition signals a move in tsunami science from a model-centered focus towards a paramount emphasis on information utility and decision support are paramount—where forecast credibility, timeliness, and operational actionability are considered as important as physical fidelity.
The foundation of this transformation lies in the rapid evolution of the tsunami data ecosystem and a corresponding methodological shift from raw-signal detection toward intelligent feature extraction. The continued expansion of in-situ ocean observations, seismic and geodetic measurements, satellite remote sensing, and emerging non-traditional data sources has not only increased the volume of available data but also fundamentally reshaped the challenges of information extraction. In environments characterized by strong noise, spatiotemporal heterogeneity, and pronounced non-stationarity, advanced signal processing, machine learning, and deep learning have become critical bridges between being “data-rich” and producing decision-grade information.
Crucially, improvements in tsunami forecasting do not hinge solely on building ever more complex models, but on constructing forecasting systems that are fast, trustworthy, and explicitly uncertainty-aware. Forecast products must be generated within extremely constrained time windows and presented in forms that support concrete actions, including warning issuance, evacuation prioritization, and emergency resource allocation. Integrating probabilistic forecasting, uncertainty quantification, and AI-enabled decision-support tools is a key step towards ensuring that forecasting systems operate reliably under conditions of high uncertainty and high stakes.
From a broader perspective, tsunami science is evolving into a highly interdisciplinary, cross-system, and cross-scale field. Effective risk reduction requires extensive consideration of data, models, decisions, and social context, integrating real-time forecasting with governance mechanisms, risk communication, long-term planning, and resilience building. Emerging directions, such as coastal digital twins, foundation models, and systematic learning from near-misses and small tsunamis, offer clear pathways for such integration. Ultimately, the future of tsunami risk management is not only about predicting tsunami waves, but also about building transparent, trustworthy, and adaptive systems that can continuously translate scientific know-how into long-term coastal resilience.
Data availability
The datasets generated during and/or analyzed during the current study are available from the corresponding author on reasonable request.
References
Dawson, A. G., Lockett, P. & Shi, S. Tsunami hazards in Europe. Environ. Int. 30, 577–585 (2004).
Dawson, A. Holocene book review: tsunamis: geology, hazards and risks. Holocene 28, 1354–1355 (2018).
Dall’Osso, F., Dominey-Howes, D., Moore, C., Summerhayes, S. & Withycombe, G. The exposure of Sydney (Australia) to earthquake-generated tsunamis, storms and sea level rise: a probabilistic multi-hazard approach. Sci. Rep. 4, 7401 (2014).
Shuto, N. Tsunami hazard mitigation. Proc. Jpn. Acad. Ser. B 95, 151–164 (2019).
Gusiakov, V. K., Dunbar, P. K. & Arcos, N. Twenty-five years (1992–2016) of global tsunamis: statistical and analytical overview. Pure Appl. Geophys. 176, 2795–2807 (2019).
Dohmen, K., Blum, P., Braun, A. & Fernandez-Steeger, T. M. Landslide-triggered tsunamis—a review. Nat. Hazards 121, 22341–22373 (2025).
Anup, N. et al. Volcanic eruption triggers a rare meteotsunami in the Indian ocean. Geophys. Res. Lett. 51, e2023GL108036 (2024).
Zorn, E. U. et al. Long-term deformation of coastal volcanoes in SE-Asia: linking displacement rates, volcanic activity and flank instabilities. Bull. Volcanol. 88, 4 (2025).
Tang, L. et al. Direct energy estimation of the 2011 Japan tsunami using deep-ocean pressure measurements. J. Geophys. Res. 117, 2011JC007635 (2012).
Xu, H. & Wu, H. Accurate tsunami wave prediction using long short-term memory based neural networks. Ocean Model. 186, 102259 (2023).
Realita, A., Fahmi, M. N., Prastowo, T., Tika, N. M. A. S. M. & Madlazim. On the 2022 Hunga Tonga-Hunga Ha’apai meteo-tsunami: accelerated propagation due to atmospheric effects. J. Phys. Conf. Ser. 2900, 012047 (2024).
Röbke, B. R. et al. Rapid assessment of tsunami offshore propagation and inundation with D-FLOW flexible mesh and SFINCS for the 2011 Tōhoku Tsunami in Japan. JMSE 9, 453 (2021).
Tsukanova, E., Medvedev, I., Heidarzadeh, M. & Vladimirova, I. Tsunami propagation from the 2024 Noto Peninsula earthquake across the Sea of Japan: observations and modelling. Ocean Eng. 336, 121730 (2025).
Ye, L. et al. The 22 December 2018 tsunami from flank collapse of Anak Krakatau volcano during eruption. Sci. Adv. 6, eaaz1377 (2020).
Yanagisawa, H., Abe, I. & Baba, T. What was the source of the nonseismic tsunami that occurred in Toyama Bay during the 2024 Noto Peninsula earthquake. Sci. Rep. 14, 18245 (2024).
Leslie, S. C. & Mann, P. Giant submarine landslides on the Colombian margin and tsunami risk in the Caribbean Sea. Earth Planet. Sci. Lett. 449, 382–394 (2016).
Hasegawa, N. et al. Tsunami awareness, preparedness, and evacuation behaviors during the 2024 Noto Peninsula Earthquake Tsunami. Saf. Sci. 189, 106885 (2025).
Paulik, R. et al. Evaluating building exposure and economic loss changes after the 2009 South Pacific Tsunami. Int. J. Disaster Risk Reduct. 56, 102131 (2021).
Syamsidik & Suppasri, A. Tsunami recovery processes after the 2004 Indian Ocean tsunami and the 2011 Great East Japan Earthquake and Tsunami: Lessons learned and challenges. Int. J. Disaster Risk Reduct. 29, 1–2 (2018).
Putra, P. S. et al. Geological evidence of predecessor of the 2018 Tsunami in Palu, Sulawesi, Indonesia. Nat. Hazards Res. 3, 487–493 (2023).
Goda, K. et al. Cascading geological hazards and risks of the 2018 Sulawesi Indonesia Earthquake and sensitivity analysis of tsunami inundation simulations. Front. Earth Sci. 7, 261 (2019).
Ulrich, T. et al. Coupled, physics-based modeling reveals earthquake displacements are critical to the 2018 Palu, Sulawesi Tsunami. Pure Appl. Geophys. 176, 4069–4109 (2019).
Wang, J. & Li, L. Improving tsunami warning systems with remote sensing and geographical information system input. Risk Anal. 28, 1653–1668 (2008).
Ramalanjaona, G. Impact of 2004 tsunami in the islands of Indian Ocean: lessons learned. Emerg. Med. Int. 2011, 1–3 (2011).
Song, Y. T. Detecting tsunami genesis and scales directly from coastal GPS stations. Geophys. Res. Lett. 34, 2007GL031681 (2007).
Synolakis, C. E. et al. The slump origin of the 1998 Papua New Guinea Tsunami. Proc. R. Soc. Lond. A 458, 763–789 (2002).
Lynett, P. J., Borrero, J. C., Liu, P. L.-F. & Synolakis, C. E. Field survey and numerical simulations: a review of the 1998 Papua New Guinea Tsunami. Pure Appl. Geophys. 160, 2119–2146 (2003).
Song, Y. T., Callahan, P. S., Desjonqueres, J.-D. M., Fournier, S. & Willis, J. K. A coupled atmosphere-ocean source mechanism was a predictor of the 2022 Tonga volcanic tsunami. Commun. Earth Environ. 5, 540 (2024).
Guo, Y. et al. Submarine optical fiber communication provides an unrealized deep-sea observation network. Sci. Rep. 13, 15412 (2023).
Johnson, G. C. et al. Argo—two decades: global oceanography, revolutionized. Annu. Rev. Mar. Sci. 14, 379–403 (2022).
Fu, J. et al. Physics-data combined machine learning for parametric reduced-order modelling of nonlinear dynamical systems in small-data regimes. Comput. Methods Appl. Mech. Eng. 404, 115771 (2023).
Xiao, H., Spica, Z. J., Li, J. & Zhan, Z. Detection of earthquake infragravity and tsunami waves with underwater distributed acoustic sensing. Geophys. Res. Lett. 51, e2023GL106767 (2024).
Hébert, H. et al. Contributions of space missions to better tsunami science: observations, models and warnings. Surv. Geophys 41, 1535–1581 (2020).
Cesario, E. et al. A parallel machine learning-based approach for tsunami waves forecasting using regression trees. Comput. Commun. 225, 217–228 (2024).
Fukuyama, E. & Hok, S. Dynamic overshoot near trench caused by large asperity break at depth. Pure Appl. Geophys. 172, 2157–2165 (2015).
Watada, S. Progress and application of the synthesis of trans-oceanic tsunamis. Prog. Earth Planet Sci. 10, 26 (2023).
Fang, Y., Xu, Q. & Chen, J. A Riemann-based two-phase two-layer SPH method for simulating submarine landslide tsunamis. Comput. Geotech. 184, 107247 (2025).
Fuhrman, D. R. & Madsen, P. A. Tsunami generation, propagation, and run-up with a high-order Boussinesq model. Coast. Eng. 56, 747–758 (2009).
Ravanelli, M., Constantinou, V., Liu, H. & Bortnik, J. Exploring AI progress in GNSS remote sensing: a deep learning based framework for real-time detection of earthquake and tsunami induced ionospheric perturbations. Radio Sci. 59, e2024RS008016 (2024).
Sriyanto, S. P. D., Adriano, B., Fujii, Y. & Koshimura, S. Estimation of high-resolution tsunami inundation depth using deep learning models: case study of Pangandaran, Indonesia. Ocean Eng. 330, 121019 (2025).
Dunbar, P. K. et al. Long-term tsunami data archive supports tsunami forecast, warning, research, and mitigation. Pure Appl. Geophys. 165, 2275–2291 (2008).
Gao, X., Zhao, G. & Niu, X. An approach for quantifying nearshore tsunami height probability and its application to the Pearl River Estuary. Coast. Eng. 175, 104139 (2022).
Mulia, I. E., Ueda, N., Miyoshi, T., Gusman, A. R. & Satake, K. Machine learning-based tsunami inundation prediction derived from offshore observations. Nat. Commun. 13, 5489 (2022).
Juanara, E. & Lam, C. Y. Machine learning approaches for early warning of tsunami induced by volcano flank collapse and implication for future risk management: case of Anak Krakatau. Ocean Model. 194, 102497 (2025).
Angeli, C. et al. Tsunami detection methods for ocean-bottom pressure gauges. Nat. Hazards Earth Syst. Sci. 25, 1169–1185 (2025).
Annunziato, A. Tsunami detection model for sea level measurement devices. Geosciences 12, 386 (2022).
Mizutani, A., Yomogida, K. & Tanioka, Y. Early tsunami detection with near-fault ocean-bottom pressure gauge records based on the comparison with seismic data. JGR Oceans 125, e2020JC016275 (2020).
Heidarzadeh, M. & Gusman, A. R. Application of dense offshore tsunami observations from ocean bottom pressure gauges (OBPGs) for tsunami research and early warnings. in Geological Disaster Monitoring Based on Sensor Networks (eds Durrani, T. S., Wang, W. & Forbes, S. M.) 7–22 (Springer, 2019).
Zhou, B. et al. Development and application of a novel tsunami monitoring system based on submerged mooring. Sensors 24, 6048 (2024).
Wang, Y., Tsushima, H., Satake, K. & Navarrete, P. Review on recent progress in near-field tsunami forecasting using offshore tsunami measurements: source inversion and data assimilation. Pure Appl. Geophys. 178, 5109–5128 (2021).
Adriano, B. et al. Tsunami source inversion using tide gauge and DART tsunami waveforms of the 2017 Mw8.2 Mexico Earthquake. Pure Appl. Geophys. 175, 35–48 (2018).
Zaytsev, O., Tsukanova, E., Rabinovich, A. B. & Thomson, R. E. The Michoacán Tsunami of 19 September 2022 on the Coast of Mexico: observations. Spectr. Prop. Model. Water 15, 164 (2022).
Tanioka, Y. Improvement of near-field tsunami forecasting method using ocean-bottom pressure sensor network (S-net). Earth Planets Space 72, 132 (2020).
Kubota, T., Saito, T., Chikasada, N. Y. & Sandanbata, O. Meteotsunami observed by the deep-ocean seafloor pressure gauge network off Northeastern Japan. Geophys. Res. Lett. 48, e2021GL094255 (2021).
Rabinovich, A. B. & Eblé, M. C. Deep-ocean measurements of tsunami waves. Pure Appl. Geophys. 172, 3281–3312 (2015).
Satake, K. Advances in earthquake and tsunami sciences and disaster risk reduction since the 2004 Indian ocean tsunami. Geosci. Lett. 1, 15 (2014).
Minson, S. E., Simons, M. & Beck, J. L. Bayesian inversion for finite fault earthquake source models I—theory and algorithm. Geophys. J. Int. 194, 1701–1726 (2013).
Zielke, O. & Mai, P. M. Subpatch roughness in earthquake rupture investigations. Geophys. Res. Lett. 43, 1893–1900 (2016).
Yokota, Y., Ishikawa, T. & Watanabe, S. Seafloor crustal deformation data along the subduction zones around Japan obtained by GNSS-A observations. Sci. Data 5, 180182 (2018).
Qiu, Q. et al. Tsunamigenic earthquake at the Sunda trench promoted by aseismic slip after a previous megathrust event. Commun. Earth Environ. 6, 888 (2025).
Melgar, D. et al. Local tsunami warnings: perspectives from recent large events. Geophys. Res. Lett. 43, 1109–1117 (2016).
Ohta, Y. et al. Quasi real-time fault model estimation for near-field tsunami forecasting based on RTK-GPS analysis: application to the 2011 Tohoku-Oki earthquake (Mw 9.0). J. Geophys. Res. 117, 2011JB008750 (2012).
Schindelé, F. et al. A review of tsunamis generated by volcanoes (TGV) source mechanism, modelling, monitoring and warning systems. Pure Appl. Geophys. 181, 1745–1792 (2024).
Selva, J. et al. Tsunami risk management for crustal earthquakes and non-seismic sources in Italy. Riv. Nuovo Cim. 44, 69–144 (2021).
Haridhi, H. A. et al. Tsunami scenario triggered by a submarine landslide offshore of northern Sumatra Island and its hazard assessment. Nat. Hazards Earth Syst. Sci. 23, 507–523 (2023).
Heinrich, P. et al. Observations and simulations of the meteotsunami generated by the Tonga eruption on 15 January 2022 in the Mediterranean Sea. Geophys. J. Int. 234, 903–914 (2023).
Ratnasari, R. N., Tanioka, Y., Yamanaka, Y. & Mulia, I. E. Development of early warning system for tsunamis accompanied by collapse of Anak Krakatau volcano, Indonesia. Front. Earth Sci. 11, 1213493 (2023).
Hamlington, B. D. et al. Detection of the 2010 Chilean tsunami using satellite altimetry. Nat. Hazards Earth Syst. Sci. 11, 2391–2406 (2011).
Hamlington, B. D. et al. Could satellite altimetry have improved early detection and warning of the 2011 Tohoku tsunami? Geophys. Res. Lett. 39, 2012GL052386 (2012).
Gower, J. The 26 December 2004 tsunami measured by satellite altimetry. Int. J. Remote Sens. 28, 2897–2913 (2007).
Ye, B. et al. Creep deformation monitoring of landslides in a reservoir area. J. Hydrol. 632, 130905 (2024).
Yang, D. et al. Distribution and recurrence of warming-induced retrogressive thaw slumps on the Central Qinghai-Tibet Plateau. JGR Earth Surf. 128, e2022JF007047 (2023).
Zhang, J. et al. Accelerating effect of vegetation on the instability of rainfall-induced shallow landslides. Remote Sens. 14, 5743 (2022).
Kobayashi, T. et al. Crustal deformation map for the 2011 off the Pacific coast of Tohoku Earthquake, detected by InSAR analysis combined with GEONET data. Earth Planets Space 63, 621–625 (2011).
Gao, H. et al. Improved coseismic deformation detection via SBAS InSAR-Hyperbolic tangent step model integration. Int. J. Appl. Earth Obs. Geoinf. 144, 104847 (2025).
Ramírez-Herrera, M. T. & Navarrete-Pacheco, J. A. Satellite data for a rapid assessment of tsunami inundation areas after the 2011 Tohoku Tsunami. Pure Appl. Geophys. 170, 1067–1080 (2013).
Belward, A. S. et al. Mapping severe damage to land cover following the 2004 Indian Ocean tsunami using moderate spatial resolution satellite imagery. Int. J. Remote Sens. 28, 2977–2994 (2007).
Hu, Y., Barberopoulou, A. & Koch, M. Tracing the 2018 Sulawesi Earthquake and tsunami’s impact on Palu, Indonesia: a remote sensing analysis. JMSE 13, 178 (2025).
Ghadamode, V., Kondarathi, A. K., Pandey, A. K. & Srivastava, K. Shoreline and land use–land cover changes along the 2004-tsunami-affected South Andaman coast: understanding changing hazard susceptibility. Nat. Hazards Earth Syst. Sci. 24, 3013–3033 (2024).
Shao, J., Wang, Y., Zhang, C., Zhang, X. & Zhang, Y. Near-surface structure investigation using ambient noise in the water environment recorded by fiber-optic distributed acoustic sensing. Remote Sens. 15, 3329 (2023).
Manaster, A. E., Sheehan, A. F., Goldberg, D. E., Barnhart, K. R. & Roth, E. H. Detection of landslide-generated tsunami by shipborne GNSS precise point positioning. Geophys. Res. Lett. 52, e2024GL112472 (2025).
Inazu, D., Waseda, T., Hibiya, T. & Ohta, Y. Assessment of GNSS-based height data of multiple ships for measuring and forecasting great tsunamis. Geosci. Lett. 3, 25 (2016).
Belcastro, L. et al. Using social media for sub-event detection during disasters. J. Big Data 8, 79 (2021).
Fauzi, M. A. Social media in disaster management: review of the literature and future trends through bibliometric analysis. Nat. Hazards 118, 953–975 (2023).
Khajwal, A. B. & Noshadravan, A. An uncertainty-aware framework for reliable disaster damage assessment via crowdsourcing. Int. J. Disaster Risk Reduct. 55, 102110 (2021).
Breaker, L. C., Murty, T. S. & Carroll, D. A frequency domain approach for predicting the signal strength of tsunamis at coastal tide gauges. J. Coast. Res. 295, 562–574 (2014).
Yonghai, C. & Jiancheng, L. Extraction of two tsunamis signals generated by earthquakes around the Pacific rim. Geod. Geodyn. 5, 38–47 (2014).
Shields, G. & Bowman, J. R. Seismic signals from tsunamis in the Pacific Ocean. Geophys. Res. Lett. 35, 2007GL032601 (2008).
Kim, Y. Y. & Whitmore, P. M. Relationship between maximum tsunami amplitude and duration of signal. Pure Appl. Geophys. 171, 3493–3500 (2014).
Hanson, J. A., Reasoner, C. L. & Bowman, J. R. High-frequency tsunami signals of the Great Indonesian Earthquakes of 26 December 2004 and 28 March 2005. Bull. Seismol. Soc. Am. 97, S232–S248 (2007).
Hanson, J. A. & Bowman, J. R. Dispersive and reflected tsunami signals from the 2004 Indian Ocean tsunami observed on hydrophones and seismic stations. Geophys. Res. Lett. 32, 2005GL023783 (2005).
Fu, R. et al. A parametric non-linear non-intrusive reduce-order model using deep transfer learning. Comput. Methods Appl. Mech. Eng. 438, 117807 (2025).
Schnepf, N. R., Manoj, C., An, C., Sugioka, H. & Toh, H. Time–frequency characteristics of tsunami magnetic signals from four Pacific ocean events. Pure Appl. Geophys. 173, 3935–3953 (2016).
Rozhnoi, A. et al. Detection of tsunami-driven phase and amplitude perturbations of subionospheric VLF signals following the 2010 Chile earthquake. JGR Space Phys. 119, 5012–5019 (2014).
Rozhnoi, A. et al. Tsunami-induced phase and amplitude perturbations of subionospheric VLF signals. J. Geophys. Res. 117, 2012JA017761 (2012).
Hinata, H. et al. Propagating tsunami wave and subsequent resonant response signals detected by HF radar in the Kii Channel, Japan. Estuar. Coast. Shelf Sci. 95, 268–273 (2011).
Arias, G. et al. First implementation of a tsunami warning system based on prompt elastogravity signals in Peru. Geophys. J. Int. 244, ggaf419 (2025).
Calisto, I., Miller, M. & Constanzo, I. Comparison between tsunami signals generated by different source models and the observed data of the Illapel 2015 Earthquake. Pure Appl. Geophys. 173, 1051–1061 (2016).
Ioualalen, M. Sensitivity tests on relations between tsunami signal and seismic rupture characteristics: the 26 December 2004 Indian Ocean event case study. Environ. Model. Softw. 24, 1354–1362 (2009).
Hayashi, Y. Extracting the 2004 Indian Ocean tsunami signals from sea surface height data observed by satellite altimetry. J. Geophys. Res. 113, 2007JC004177 (2008).
Chierici, F., Pignagnoli, L. & Embriaco, D. Modeling of the hydroacoustic signal and tsunami wave generated by seafloor motion including a porous seabed. J. Geophys. Res. 115, 2009JC005522 (2010).
Raveloson, A., Wang, R., Kind, R., Ceranna, L. & Yuan, X. Brief communication "Seismic and acoustic-gravity signals from the source of the 2004 Indian Ocean Tsunami". Nat. Hazards Earth Syst. Sci. 12, 287–294 (2012).
Mei, C. C. & Kadri, U. Sound signals of tsunamis from a slender fault. J. Fluid Mech. 836, 352–373 (2018).
Matsumoto, H., Haralabus, G., Zampolli, M., Yamada, T. & Prior, M. K. Analysis of T-phase and tsunami signals associated with the 2011 Tohoku Earthquake acquired by CTBT water-column hydrophone triplets. J. Jpn. Soc. Civ. Eng. Ser. B2 Coast. Eng. 72, I_337–I_342 (2016).
Prastowo, T., Cholifah, L., Ngkoimani, L. O. & Safiuddin, L. O. Tsunami-magnetic signals and magnetic anomaly generated by tsunami wave propagation open seas. JPFI 13, 59–70 (2017).
Toh, H., Satake, K., Hamano, Y., Fujii, Y. & Goto, T. Tsunami signals from the 2006 and 2007 Kuril earthquakes detected at a seafloor geomagnetic observatory. J. Geophys. Res. 116, B02104 (2011).
Torres, C. E., Calisto, I. & Figueroa, D. Magnetic signals at Easter Island during the 2010 and 2015 Chilean Tsunamis compared with numerical models. Pure Appl. Geophys. 176, 3167–3183 (2019).
Rozhnoi, A. et al. Tsunami-driven ionospheric perturbations associated with the 2011 Tohoku earthquake as detected by subionospheric VLF signals. Geomat. Nat. Hazards Risk 5, 285–292 (2014).
Murty, T. S. & Kowalik, Z. Use of Boussinesq versus shallow water equations in tsunami calculations. Mar. Geod. 16, 149–151 (1993).
Ginting, B. M. & Mundani, R.-P. Comparison of shallow water solvers: applications for dam-break and tsunami cases with reordering strategy for efficient vectorization on modern hardware. Water 11, 639 (2019).
Sato, K., Kawasaki, K. & Koshimura, S. A numerical study of the MRT-LBM for the shallow water equation in high Reynolds number flows: an application to real-world tsunami simulation. Nucl. Eng. Des. 404, 112159 (2023).
Khan, R. A. & Kevlahan, N. K.-R. Data assimilation for the two-dimensional shallow water equations: optimal initial conditions for tsunami modelling. Ocean Model. 174, 102009 (2022).
Arpaia, L., Ricchiuto, M., Filippini, A. G. & Pedreros, R. An efficient covariant frame for the spherical shallow water equations: well balanced DG approximation and application to tsunami and storm surge. Ocean Model. 169, 101915 (2022).
Tinh, N. X., Tanaka, H., Yu, X. & Liu, G. Numerical implementation of wave friction factor into the 1D tsunami shallow water equation model. Coast. Eng. J. 63, 174–186 (2021).
Kwon, H. J., Lee, H. & Chang, S.-M. High-order WENO schemes with an immersed boundary method for shallow water equations on the tsunami mitigation with configurations of cylinder array. KSCE J. Civ. Eng. 25, 1–11 (2021).
Sánchez-Linares, C. et al. Multi-level Monte Carlo finite volume method for shallow water equations with uncertain parameters applied to landslides-generated tsunamis. Appl. Math. Model. 39, 7211–7226 (2015).
Pringle, W. J., Yoneyama, N. & Mori, N. Multiscale coupled three-dimensional model analysis of the tsunami flow characteristics around the Kamaishi Bay offshore breakwater and comparisons to a shallow water model. Coast. Eng. J. 60, 200–224 (2018).
Sarika, A. S. & Milton, A. Prediction of tsunami event at early stage using ensemble bagging random forest classifier. J. Earthq. Tsunami 2550026 https://doi.org/10.1142/S1793431125500265 (2025).
Iwabuchi, Y., Baba, T., Hori, T., Okada, M. & Igarashi, Y. A seafloor pressure sensor effectiveness evaluation in a tsunami height estimation model using Gaussian process regression with automatic relevance determination. JDR 20, 831–842 (2025).
Purnama, M. R. et al. Improving Indonesia’s tsunami early warning. Part II: Hybridized deep learning and metaheuristic algorithm for forecasting and optimizing. Ocean Eng. 333, 121496 (2025).
Lee, J., Irish, J. L. & Weiss, R. Real-time prediction of alongshore near-field tsunami runup distribution from heterogeneous earthquake slip distribution. JGR Oceans 128, e2022JC018873 (2023).
Sabeti, R. & Heidarzadeh, M. A new predictive equation for estimating wave period of subaerial solid-block landslide-generated waves. Coast. Eng. J. 65, 54–66 (2023).
Buenrostro, A. M. et al. Convolutional neural networks for tsunami intensity measure prediction from slip and coseismic deformation data. Eng. Appl. Artif. Intell. 165, 113405 (2026).
Sabah, N. & Shanker, D. Tsunami hazard forecasting in the Indo-Pacific region: a paradigm shift to physics-based validation. J. Seismol. 29, 1235–1287 (2025).
Juanara, E. & Lam, C. Y. Deep learning-based waveform forecasting and physical simulations for volcano collapse tsunami early warning: the Anak Krakatau case. Ocean Eng. 335, 121683 (2025).
Bonev, B., Hesthaven, J. S., Giraldo, F. X. & Kopera, M. A. Discontinuous Galerkin scheme for the spherical shallow water equations with applications to tsunami modeling and prediction. J. Comput. Phys. 362, 425–448 (2018).
Massel, S. R. Ocean Surface Waves: Their Physics and Prediction, Vol. 45 (World Scientific, 2017).
Tolkova, E., Nicolsky, D. & Wang, D. A response function approach for rapid far-field tsunami forecasting. Pure Appl. Geophys. 174, 3249–3273 (2017).
Hossen, M. J., Cummins, P. R., Dettmer, J. & Baba, T. Time reverse imaging for far-field tsunami forecasting: 2011 Tohoku earthquake case study. Geophys. Res. Lett. 42, 9906–9915 (2015).
Melgar, D. & Bock, Y. Kinematic earthquake source inversion and tsunami runup prediction with regional geophysical data. JGR Solid Earth 120, 3324–3349 (2015).
Percival, D. B. et al. Detiding DART® Buoy data for real-time extraction of source coefficients for operational tsunami forecasting. Pure Appl. Geophys. 172, 1653–1678 (2015).
Gica, E., Titov, V. V., Moore, C. & Wei, Y. Tsunami simulation using sources inferred from various measurement data: implications for the model forecast. Pure Appl. Geophys. 172, 773–789 (2015).
Tang, L., Titov, V. V., Moore, C. & Wei, Y. Real-time assessment of the 16 September 2015 Chile Tsunami and implications for near-field forecast. Pure Appl. Geophys. 173, 369–387 (2016).
Oishi, Y., Imamura, F. & Sugawara, D. Near-field tsunami inundation forecast using the parallel TUNAMI-N2 model: application to the 2011 Tohoku-Oki earthquake combined with source inversions. Geophys. Res. Lett. 42, 1083–1091 (2015).
Wuppukondur, A. & Baldock, T. E. Physical and numerical modelling of representative tsunami waves propagating and overtopping in converging channels. Coast. Eng. 174, 104120 (2022).
Cienfuegos, R. et al. What can we do to forecast tsunami hazards in the near field given large epistemic uncertainty in rapid seismic source inversions? Geophys. Res. Lett. 45, 4944–4955 (2018).
Giles, D., Gopinathan, D., Guillas, S. & Dias, F. Faster than real time tsunami warning with associated hazard uncertainties. Front. Earth Sci. 8, 597865 (2021).
Denamiel, C., Šepić, J., Huan, X., Bolzer, C. & Vilibić, I. Stochastic surrogate model for meteotsunami early warning system in the Eastern Adriatic Sea. JGR Oceans 124, 8485–8499 (2019).
Fukutani, Y., Moriguchi, S., Terada, K. & Otake, Y. Time-dependent probabilistic tsunami inundation assessment using mode decomposition to assess uncertainty for an earthquake scenario. JGR Oceans 126, e2021JC017250 (2021).
Kenta, T. et al. Rapid tsunami force prediction by mode-decomposition-based surrogate modeling. Nat. Hazards Earth Syst. Sci. 22, 1267–1285 (2022).
Pan, X. & Xiao, D. Domain decomposition for physics-data combined neural network based parametric reduced order modelling. J. Comput. Phys. 519, 113452 (2024).
Vito, B. et al. Using meta-models for tsunami hazard analysis: an example of application for the French Atlantic Coast. Front. Earth Sci. 8, 41 (2020).
Ayao, E. et al. Multi-level emulation of tsunami simulations over Cilacap, South Java, Indonesia. Comput. Geosci. 27, 127–142 (2022).
Fukutani, Y. & Motoki, M. A neural network-based surrogate model for efficient probabilistic tsunami inundation assessment. Coast. Eng. 200, 104767–104767 (2025).
Gunawan, W. C. et al. Probabilistic tsunami risk assessment based on supervised learning considering nonstationary sea-level rise and multiple source rupture: application to Denpasar City of Bali. Prog. Disaster Sci. 29, 100505–100505 (2026).
Giraldi, L. et al. Bayesian inference of earthquake parameters from buoy data using a polynomial chaos-based surrogate. Comput. Geosci. 21, 683–699 (2017).
Sraj, I., Mandli, K. T., Knio, O. M., Dawson, C. N. & Hoteit, I. Uncertainty quantification and inference of Manning’s friction coefficients using DART buoy data during the Tōhoku tsunami. Ocean Model. 83, 82–97 (2014).
Sraj, I., Mandli, K. T., Knio, O. M., Dawson, C. N. & Hoteit, I. Quantifying uncertainties in fault slip distribution during the Tōhoku tsunami using polynomial chaos. Ocean Dyn. 67, 1535–1551 (2017).
Masuda, H., Sugawara, D., Cheng, A. C., Suppasri, A. & Imamura, F. A surrogate-assisted nonlinear inversion of tsunami waveform and trace height: application to the 2024 Noto Peninsula earthquake in Japan. Earth Planets Space 77, 144–144 (2025).
Sreedevi, V. M. et al. Interpretable machine learning based tsunami bridge fragility assessment. Int. J. Disaster Risk Reduct. 123, 105507–105507 (2025).
Garzon, J. L. et al. Development of a Bayesian networks-based early warning system for wave-induced flooding. Int. J. Disaster Risk Reduct. 96, 103931 (2023).
Guillas, S., Sarri, A., Day, S. J., Liu, X. & Dias, F. Functional emulation of high resolution tsunami modelling over Cascadia. Ann. Appl. Stat. 12, 2023–2053 (2018).
Igarashi, Y. et al. Maximum tsunami height prediction using pressure gauge data by a Gaussian process at Owase in the Kii Peninsula, Japan. Mar. Geophys. Res. 37, 361–370 (2016).
Salmanidou, D. M., Heidarzadeh, M. & Guillas, S. Probabilistic landslide-generated tsunamis in the Indus Canyon, NW Indian Ocean, using statistical emulation. Pure Appl. Geophys. 176, 3099–3114 (2019).
Lomax, A. & Michelini, A. Tsunami early warning within five minutes. Pure Appl. Geophys. 170, 1385–1395 (2013).
Liu, Y., Jiao, J. J. & Luo, X. Effects of inland water level oscillation on groundwater dynamics and land-sourced solute transport in a coastal aquifer. Coast. Eng. 114, 347–360 (2016).
Guo, J. & Xiao, D. Nonlinear model reduction by probabilistic manifold decomposition. SIAM J. Sci. Comput. 48, A209–A235 (2026).
Bernard, E. & Titov, V. Evolution of tsunami warning systems and products. Philos. Trans. R. Soc. A. 373, 20140371 (2015).
Gailler, A., Hébert, H., Loevenbruck, A. & Hernandez, B. Simulation systems for tsunami wave propagation forecasting within the French tsunami warning center. Nat. Hazards Earth Syst. Sci. 13, 2465–2482 (2013).
Inazu, D. et al. Near-field tsunami forecast system based on near real-time seismic moment tensor estimation in the regions of Indonesia, the Philippines, and Chile. Earth Planets Space 68, 73 (2016).
Tang, L., Titov, V. V. & Chamberlin, C. D. Development, testing, and applications of site-specific tsunami inundation models for real-time forecasting. J. Geophys. Res. 114, 2009JC005476 (2009).
Cordrie, L. et al. Dynamic management of uncertainty in rapid tsunami forecasting. Commun. Earth Environ. 6, 637 (2025).
Jouhary, N. A., Madinu, A. M. A. & Asy’Ari, R. INASTER (Indonesia Disaster Platform): cloud computing based geospatial platform in monitoring Indonesia natural disaster. IOP Conf. Ser. Earth Environ. Sci. 1569, 012010 (2025).
An, C. Tsunamis and tsunami warning: recent progress and future prospects. Sci. China Earth Sci. 64, 191–204 (2021).
Chen, Z., Qi, W. & Xu, C. Scenario-based hazard assessment of local tsunami for coastal areas: a case study of Xiamen City, Fujian Province, China. JMSE 11, 1501 (2023).
Ren, Z., Gao, Y., Ji, X. & Hou, J. Deterministic tsunami hazard assessment and zoning approach using far-field and near-field sources: study of Cixi County of Zhejiang Province, China. Ocean Eng. 247, 110487 (2022).
Hamidatou, M., Almandous, A., Alebri, K., Alameri, B. & Megahed, A. Deterministic tsunami hazard assessment for the Eastern Coast of the United Arab Emirates: insights from the Makran subduction zone. Sustainability 16, 10665 (2024).
Grezio, A. et al. Probabilistic tsunami hazard analysis: multiple sources and global applications. Rev. Geophys. 55, 1158–1198 (2017).
Gibbons, S. J. et al. Probabilistic tsunami hazard analysis: high performance computing for massive scale inundation simulations. Front. Earth Sci. 8, 591549 (2020).
Sun, Z. & Niu, X. Refined risk assessment of probabilistic tsunami inundation assisted by SDGSAT-1 glimmer imagery. Remote Sens. Environ. 326, 114792 (2025).
León, J., Martínez, C., Inzunza, S., Ogueda, A. & Urrutia, A. Improving tsunami risk analysis by integrating spatial resolution and the population’s evacuation capacities: a case study of Cartagena, Chile. Int J. Disaster Risk Sci. 15, 1001–1016 (2024).
Shi, X. et al. High-resolution numerical modelling reveals tsunami risk hotspots in Xiamen City, China. Front. Mar. Sci. 11, 1478149 (2024).
Department of Geography, Faculty of Mathematics and Natural Sciences, Universitas Indonesia, Depok, Indonesia et al. Advancing tsunami vulnerability modelling: a systematic review and bibliometric analysis of remote sensing and GIS applications. EJG 16, 75–95 (2025).
León, J., Gubler, A. & Ogueda, A. Modelling geographical and built-environment attributes as predictors of human vulnerability during tsunami evacuations: a multi-case-study and paths to improvement. Nat. Hazards Earth Syst. Sci. 22, 2857–2878 (2022).
Rodríguez, J. F., Macías, J., Castro, M. J., De La Asunción, M. & Sánchez-Linares, C. Use of neural networks for tsunami maximum height and arrival time predictions. GeoHazards 3, 323–344 (2022).
Makinoshima, F., Oishi, Y., Yamazaki, T., Furumura, T. & Imamura, F. Early forecasting of tsunami inundation from tsunami and geodetic observation data with convolutional neural networks. Nat. Commun. 12, 2253 (2021).
Mas, E., Moya, L., Gonzales, E. & Koshimura, S. Reinforcement learning-based tsunami evacuation guidance system. Int. J. Disaster Risk Reduct. 115, 105023 (2024).
Arno, S., Boy, W. & Anggraini, P. Spatial Web Based Evacuation Time Prediction Using XGBoost in Tsunami Prone Regions. IJETT 73, 325–335 (2025).
Guidotti, R. et al. A survey of methods for explaining black box models. ACM Comput. Surv. 51, 1–42 (2019).
Lipton, Z. C. The mythos of model interpretability: in machine learning, the concept of interpretability is both important and slippery. Queue 16, 31–57 (2018).
Shen, L. et al. A new CNN-GRU deep learning framework optimized by CHIO for precise prediction of debris flow velocity. Stoch. Environ. Res. Risk Assess. 39, 1–21 (2025).
Ma, T. et al. A novel social network search and LightGBM framework for accurate prediction of blast-induced peak particle velocity. Front. Struct. Civ. Eng. 19, 1–18 (2025).
Chen, X., Fan, R., Li, Y., Ma, T. & Zhong, Y. Interpretable soft computing deep ensemble model for predicting deformation of surrounding rock in deep tunnels. Eur. J. Environ. Civ. Eng. 29, 3608–3650 (2025).
Ma, T. et al. Physics-informed neural networks for capturing the true relationships between parameters to predict the dynamic triaxial strength of rocks in cold environments. Measurement 257, 118900–118900 (2026).
Ma, T. et al. Hybrid empirical-data-driven neural network for predicting air-entry value in unsaturated soils. Math. Geosci. 1–30 https://doi.org/10.1007/S11004-025-10230-4 (2025).
Ma, T., Chen, H., Zhang, K., Shen, L. & Sun, H. The rheological intelligent constitutive model of debris flow: a new paradigm for integrating mechanics mechanisms with data-driven approaches by combining data mapping and deep learning. Expert Syst. Appl. 269, 126405–126405 (2025).
Albahri, A. S. et al. A systematic review of trustworthy artificial intelligence applications in natural disasters. Comput. Electr. Eng. 118, 109409 (2024).
Bin, J. et al. An efficient and uncertainty-aware decision support system for disaster response using aerial imagery. Sensors 22, 7167 (2022).
Somphong, C. et al. Submarine landslide source modeling using the 3D slope stability analysis method for the 2018 Palu, Sulawesi, tsunami. Nat. Hazards Earth Syst. Sci. 22, 891–907 (2022).
Al Farizi, M. D. et al. Submarine landslide induced tsunami modeling using 3D slope stability analysis method: the 2024 Noto Peninsula earthquake and tsunami in Toyama Bay, Japan. Ocean Eng. 340, 122240 (2025).
Selva, J. et al. Probabilistic tsunami forecasting for early warning. Nat. Commun. 12, 5677 (2021).
LeClerc, J. & Joslyn, S. The cry wolf effect and weather-related decision making. Risk Anal. 35, 385–395 (2015).
Hembach-Stunden, K., Vorlaufer, T. & Engel, S. False and missed alarms in seasonal forecasts affect individual adaptation choices. Q. Open 4, qoad031 (2023).
Lim, J. R., Liu, B. F. & Egnoto, M. Cry wolf effect? Evaluating the impact of false alarms on public responses to tornado alerts in the Southeastern United States. Weather Clim. Soc. 11, 549–563 (2019).
Miyashita, T., Mori, N. & Goda, K. Uncertainty of probabilistic tsunami hazard assessment of Zihuatanejo (Mexico) due to the representation of tsunami variability. Coast. Eng. J. 62, 413–428 (2020).
Perez-Rodriguez, F.-J., Otero-Mateo, M., Batista, M. & Ramirez-Peña, M. Tsunami early warning systems: enhancing coastal resilience through integrated risk management. Water 17, 3489 (2025).
Dias, N., Haigh, R., Amaratunga, D. & Rahayu, H. A review of tsunami early warning at the local level - Key actors, dissemination pathways, and remaining challenges. Int. J. Disaster Risk Reduct. 101, 104195 (2024).
De Silva Nusantara, C. A., Windupranata, W., Hayatiningsih, I. & Hanifa, N. R. Mapping of IOC-UNESCO tsunami ready indicators in the Pangandaran Village, Indonesia. IOP Conf. Ser. Earth Environ. Sci. 925, 012041 (2021).
Rokhideh, M., Fearnley, C. & Budimir, M. Multi-hazard early warning systems in the Sendai framework for disaster risk reduction: achievements, gaps, and future directions. Int. J. Disaster Risk Sci. 16, 103–116 (2025).
Gevaert, C. M., Carman, M., Rosman, B., Georgiadou, Y. & Soden, R. Fairness and accountability of AI in disaster risk management: opportunities and challenges. Patterns 2, 100363 (2021).
Cheong, B. C. Transparency and accountability in AI systems: safeguarding wellbeing in the age of algorithmic decision-making. Front. Hum. Dyn. 6, 1421273 (2024).
Visave, J. AI in Emergency management: ethical considerations and challenges. J. Emerg. Manag. Disaster Commun. 05, 165–183 (2024).
Yun, H. China’s data sovereignty and security: implications for global digital borders and governance. Chin. Polit. Sci. Rev. 10, 178–203 (2025).
Bonfanti, R. C. et al. The role of trust in disaster risk reduction: a critical review. IJERPH 21, 29 (2023).
Tzachor, A., Hendel, O. & Richards, C. E. Digital twins: a stepping stone to achieve ocean sustainability? npj Ocean Sustain. 2, 16 (2023).
Yu, Z. et al. Coastal zone information model: a comprehensive architecture for coastal digital twin by integrating data, models, and knowledge. Fundam. Res. 6, 281–289 (2026).
Wu, K. et al. A semantic-enhanced multi-modal remote sensing foundation model for Earth observation. Nat. Mach. Intell. 7, 1235–1249 (2025).
Xiao, A. et al. Foundation models for remote sensing and earth observation: a survey. IEEE Geosci. Remote Sens. Mag. 13, 297–324 (2025).
Tsushima, H. & Ohta, Y. Meteorological Research Institute, Japan Meteorological Agency, 1-1 Nagamine, Tsukuba, Ibaraki 305-0052, Japan, & Research Center for Prediction of Earthquakes and Volcanic Eruptions, Graduate School of Science, Tohoku University Japan Review on near-field tsunami forecasting from offshore tsunami data and onshore GNSS data for tsunami early warning. J. Disaster Res 9, 339–357 (2014).
Ferreira, M. A., Oliveira, C. S. & Francisco, R. Tsunami risk mitigation: the role of evacuation routes, preparedness and urban planning. Nat. Hazards 121, 6719–6751 (2025).
Villagra, P. et al. Resilient planning pathways to community resilience to tsunami in Chile. Habitat Int. 152, 103158 (2024).
Motlagh, F., Hamideh, S., Gallagher, M., Yan, G. & Van De Lindt, J. W. Bonds for disaster resilience: a review of literature and practice. Int. J. Disaster Risk Reduct. 104, 104318 (2024).
Wang, Y. et al. Coastal tsunami prediction in Tohoku region, Japan, based on S-net observations using artificial neural network. Earth Planets Space 75, 154 (2023).
Acknowledgements
The authors gratefully acknowledge the financial support from the Royal Society (IEC\NSFC\242411) and the Seed Fund Cultivation Project of Ocean College, Zhejiang University (2025BS002).
Author information
Authors and Affiliations
Contributions
T.M.: writing—original draft, software, project administration, data curation, visualization. L.S.: writing—original draft, software, project administration, data curation. Z.C.: writing—original draft, writing—review & editing, software, project administration, data curation, visualization. D.L.: writing—review & editing, supervision, project administration, funding acquisition.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Ma, T., Shen, L., Chen, Z. et al. Review on tsunami research and risk mitigation: from prediction models to resilient coastal communities. npj Nat. Hazards 3, 34 (2026). https://doi.org/10.1038/s44304-026-00195-7
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s44304-026-00195-7
