
Abstract
Drug discovery is lengthy and expensive, with traditional computer-aided design facing limits. This paper examines integrating quantum computing across the drug development cycle to accelerate and enhance workflows and rigorous decision-making. It highlights quantum approaches for molecular simulation, drug-target interaction prediction, and optimizing clinical trials. Leveraging quantum capabilities could accelerate timelines and costs for bringing therapies to market, improving efficiency and ultimately benefiting public health.
Similar content being viewed by others
Introduction
Drug discovery and development is a highly complex and costly endeavor, typically requiring over a decade and billions of dollars to bring a single therapeutic to market1,2. Traditional computer-aided drug design has made significant strides in accelerating this process, but faces fundamental limitations3,4,5,6,7,8,9,10,11. The chemical space of potential drug compounds—estimated at 1060 molecules—vastly exceeds what classical algorithms can efficiently explore, while conventional simulation methods struggle to accurately model the quantum-mechanical interactions that govern molecular behavior12. These challenges, coupled with the multidimensional complexity of clinical trial data and stringent privacy requirements13, create computational bottlenecks throughout the pharmaceutical pipeline that impact both time-to-market and development success rates. The integration of quantum computing across the entire pharmaceutical value chain—from molecular design to clinical trial optimization—represents a particularly promising frontier at this technological intersection.
In this manuscript, we review the quantum computing approaches for drug discovery and development and explore how quantum technologies might transform pharmaceutical innovation. We examine quantum approaches to molecular simulation and lead identification and optimization where native quantum state representation offers exponential advantages over classical methods. We analyze quantum-enhanced clinical trial optimization through advanced resource allocation algorithms and secure data integration frameworks. By systematically comparing computational requirements across application areas, we highlight near-term opportunities for quantum advantage while mapping the trajectory toward fault-tolerant implementations. The convergence of these transformative technologies promises to significantly reduce the time and cost associated with bringing new therapeutics to patients, potentially revolutionizing how we address global health challenges.
Before exploring quantum computing’s role in pharmaceutical innovation, readers should familiarize themselves with fundamental concepts from both domains. Box 1 introduces key quantum methods that enable computational advantages across the drug discovery pipeline, from molecular simulation to secure data handling. Box 2 provides essential terminology in drug discovery and development, establishing context for understanding quantum applications in pharmaceutical research. We also summarize the conventional pipeline in Fig. 1 and offer a visual overview of the entire drug development process in Fig. 2, highlighting strategic points where quantum computing could potentially transform traditional approaches. These resources provide the necessary foundation for appreciating how quantum technologies might address the computational challenges that currently limit classical methods in drug discovery and development.

Drug discovery prioritizes a small set of novel structures with desirable properties, followed by pre-clinical studies in vivo and phased clinical development to evaluate safety and efficacy. The stage durations and attrition rates illustrated here reflect representative ranges from regulatory and research bodies such as the U.S. Food and Drug Administration (FDA) and the National Institutes of Health (NIH)226,227,228,229. The magnitude of small-molecule chemical space and the early-stage funnel from very large libraries to tractable candidate sets are supported by peer-reviewed surveys and modern ultra-large screening exemples220,221,230,231,232.

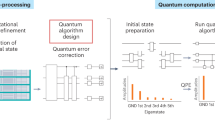
a Classical pre-processing pipeline integrating diverse data sources for eligibility criteria determination, including experimental structure analysis via microscopy, patient medical records, laboratory test results, and genomic data. b Comparative analysis of classical versus quantum approaches in drug discovery, contrasting traditional high-throughput screening methods (searching ≈ 109 known molecules) with quantum-enabled de novo drug design capable of exploring a vastly larger chemical space (1060 molecules). The quantum approach navigates this expanded space more efficiently. c Detailed quantum algorithm implementation showing the progression from molecular structure to quantum circuit design, incorporating VQE for calculating molecular properties like excitation energies and excited states to provide more accurate modeling than classical approximations. d Quantum-classical hybrid optimization framework for clinical trial management. Quantum circuits generate trial site configurations while working with classical optimizers to calculate loss functions, optimizing parameters such as enrollment rates and costs, visualized in a matrix of trial sites with varying performance metrics.
A short primer on quantum computing
The promise of quantum computing in drug discovery stems from a simple fact: molecules are quantum objects. The behavior of electrons and nuclei including bonding, moving and interacting with their environment is governed by quantum mechanics. Classical methods approximate these effects and have achieved remarkable success, but certain phenomena, such as strong electron correlation or subtle protonation dynamics, remain extremely challenging. These quantum details can determine whether a drug binds tightly, selectively, or safely. A computer that works with quantum information has the potential to capture such effects more faithfully, offering new insight where existing tools strain.
What makes quantum computing different is not that it tries “all answers in parallel,” but that it manipulates information in ways that mimic interference and entanglement in nature. The basic unit, the qubit, can exist in a blend of states that can be visualized as a point on a sphere rather than a simple zero or one. When many qubits are combined, they form patterns of correlation that cannot be reproduced by any classical probability model. Quantum algorithms are designed to choreograph these correlations so that the outcome of interest—whether an energy, a probability, or a binding preference—emerges with higher likelihood. In this way, quantum computers extend classical capabilities, but in problem-specific rather than universal ways.
The interest in quantum computing for the simulation of molecules and materials arises because their chemistry and physics are fundamentally quantum mechanical. The state of a many-particle molecular system encodes quantum information. As the number of atoms increases, the description may require an exponentially large number of classical bits. In the worst case, simulating such systems on a classical computer is exponentially hard. This motivates Feynman’s observation that “Nature isn’t classical, dammit, and if you want to make a simulation of nature, you’d better make it quantum mechanical.” A practical quantum advantage in molecular simulation is subtle. Decades of work in electronic structure and quantum chemistry show that classical algorithms can reach reasonable and sometimes very high accuracy with controlled approximations. Any potential advantage is problem specific and must be tied to the question under study and to the accuracy required14.
A quantum computer extends classical capabilities by processing quantum information. The basic unit is the qubit, a controllable two-level quantum system with basis states \(| 0\rangle\) and \(| 1\rangle\). A general single-qubit state is a superposition:
This state can be visualized as a point on the surface of the Bloch sphere (Fig. 3), where the north and south poles correspond to the classical basis states \(| 0\rangle\) and \(| 1\rangle\). For n qubits there are 2n orthonormal basis states \(| {z}_{1}\ldots {z}_{n}\rangle\) with zi = 0, 1. A general n-qubit state is
which requires an exponential number of complex amplitudes to specify. Measurement in the computational basis yields a single outcome bitstring \(| {z}_{1}\ldots {z}_{n}\rangle\) with probability \(| {c}_{{z}_{1}\ldots {z}_{n}}{| }^{2}\). Measurements in other bases reveal interference among amplitudes and enable entanglement, which creates correlations that no classical probability distribution can reproduce. These effects underlie the algorithmic power of quantum computing. Quantum algorithms do not gain exponential speedups by trying all answers in parallel. Reading out a quantum state provides only one outcome. Algorithms must therefore choreograph constructive and destructive interference so that the desired outcome appears with high probability and can be extracted with a tractable number of measurements.

The north and south poles, \(| 0\rangle\) and \(| 1\rangle\), represent the “classical states” (or computational basis states) and denote the bits 0, 1 used in a classical computer.
Main quantum hardware platforms
Feynman proposed that a controllable quantum system could imitate another quantum system of interest. This inspired analog quantum computation, which has revealed rich physics in cold atom experiments but is limited to specific interactions and lacks systematic error correction. For general algorithms, we focus on digital quantum computation, where qubits are manipulated by quantum gates to form circuits, and on adiabatic/annealing approaches that use quantum dynamics to solve optimization problems15,16.
Three hardware families currently lead efforts in chemistry and drug discovery: superconducting circuits, trapped ions, and neutral atoms. Table 1 summarizes their strengths, challenges, and relevance.
Superconducting circuits use Josephson devices at millikelvin temperatures, controlled by microwave pulses and read out via resonators. Their advantages include very fast gates and mature control electronics, while challenges include limited connectivity and frequency crowding. For chemistry, their rapid cycle times make them well suited for hybrid algorithms such as variational approaches17,18.
Trapped ions encode qubits in internal atomic states held by electromagnetic fields. They offer long coherence times and all-to-all connectivity within a trap, though gate speeds are slower and scaling requires modular architectures. Their precision makes them attractive for high-accuracy simulations of small molecules19.
Neutral atoms arrange qubits in optical tweezers or lattices, with entanglement mediated by Rydberg interactions. They allow flexible geometries and large arrays, but face challenges from atom loss and laser noise. Their tunability offers unique opportunities for mapping molecular structures and for analog simulations of model Hamiltonians20,21.
Across platforms, the control stack now supports calibrated entangling gates, conditional feedforward, and real-time classical processing. Error mitigation techniques are standard, and reproducibility requires reporting device family, connectivity, circuit depth, number of shots, and calibration context. Near-term studies will emphasize shallow circuits on tens to hundreds of physical qubits, while improved fidelities and logical qubits will enable deeper algorithms such as phase estimation in the future22,23.
Practical scope of quantum computation
In drug discovery, this capability targets fundamental tasks in quantum chemistry and molecular physics. A natural application is real-time quantum dynamics governed by the time-dependent Schrödinger equation, where the Hamiltonian operator \(\widehat{H}\) encapsulates the total energy of the system:
from which spectra, response, and dynamical observables follow. Closely related variational formulations target low-energy states(E0):
while finite-temperature properties are described using the thermal density matrix(ρ), which is derived from the partition function(Z):
These formulations govern molecular stability and thermodynamics, providing crucial metrics like binding free energy. Complexity theory offers guidance rather than guarantees. Certain real-time evolutions admit efficient quantum procedures, whereas generic ground-state and thermal problems are QMA-hard in the worst case. QMA is the quantum analogue of NP. In QMA, a quantum verifier checks a proposed quantum proof in polynomial time. A problem is QMA-hard if every problem in QMA can be mapped to it in polynomial time. No efficient quantum algorithm is known for QMA-hard problems. These labels describe worst-case difficulty rather than typical practice. Many chemical instances have structure that algorithms can exploit and some admit controlled approximations. Practical utility therefore depends on how well we prepare relevant states, align the encoding with the physical structure, and control hardware noise and sampling error.
For drug discovery, the goal is a more precise treatment of quantum effects that challenge classical approximations, including electron correlation, polarization, and protonation dynamics, and effects near metal centers. These factors can determine binding, selectivity, potency, and safety. Given the limits of worst-case complexity results, the search for advantage must proceed empirically on chemically relevant instances using real algorithms and devices, with systematic comparison to state-of-the-art classical methods14.
Terminology used in this review follows these conventions: a qubit is a quantum two-level system manipulated by gates; an ansatz is the parameterized circuit used to approximate a state; active space is the subset of orbitals treated explicitly on the quantum device; circuit depth counts sequential gate layers; shots are repeated measurements to estimate expectation values; error mitigation denotes post-processing or scheduling that reduces noise bias without full error correction. Throughout, we distinguish hardware-executed demonstrations from simulation-only prototypes and purely theoretical scaling, and we position quantum components as focused evaluators alongside classical pipelines22,24,25.
Quantum-driven drug discovery
Drug discovery, beginning with an innovative idea for a new medication, is the initial phase aimed at identifying unique, diverse drug molecules with optimal pharmaceutical attributes. Modern drug discovery and development are highly complex and costly endeavors. Bringing a new drug to market typically requires over a decade and substantial financial investment. In modern drug discovery, computational tools play a crucial role in accelerating the development of new therapies26. These tools help researchers identify potential drug targets, design and optimize molecules, and predict their behavior in the human body.
The molecular interactions underlying drug action are fundamentally quantum mechanical in nature, involving complex electron correlations and conformational dynamics that challenge classical computational methods. Quantum computing offers transformative potential in drug discovery through its native ability to represent quantum states and handle exponential complexity. Understanding how quantum approaches address drug design challenges requires establishing key concepts in both molecular representation and quantum computation.
Foundations of quantum-enabled drug discovery
Quantum computing transforms drug discovery by representing molecules in their fundamental quantum mechanical form27,28. Understanding this quantum approach requires examining three distinct representations that enable different aspects of molecular modeling and drug design.
The foundational representation encodes molecular wavefunctions as quantum states in Hilbert space, mapping both electronic and nuclear degrees of freedom to qubit configurations. Unlike classical representations limited to atomic positions and bonds, quantum states capture molecular behavior through superposition and entanglement, naturally accounting for electron correlation effects that classical methods approximate poorly16,29,30,31. This direct quantum encoding enables precise modeling of electronic structures and molecular interactions crucial for drug-target binding13,32.
For electronic structure calculations, second quantization provides a practical framework where molecules are described through fermionic operators33. These operators must be transformed to work with quantum computers’ qubit architecture, typically using either Jordan-Wigner or Bravyi-Kitaev encodings34,35. These transformations maintain quantum mechanical properties while enabling efficient computation, with Bravyi-Kitaev offering particularly optimized qubit utilization for larger molecular systems36.
Quantum kernel methods (Box 1) extend these representations into machine learning applications by mapping molecular structures into high-dimensional quantum feature spaces37,38. This mapping enables the detection of complex structure-function relationships beyond the reach of classical methods, providing a powerful framework for tasks ranging from binding affinity prediction to lead identification and optimization. These quantum feature spaces bridge pure quantum mechanical representations with practical drug design applications39.
The combination of quantum state representations, fundamental quantum operations, and quantum-enhanced machine learning provides a comprehensive toolkit for addressing the key challenges in structure-based drug design: binding site prediction, binding pose generation, de novo ligand generation, binding affinity prediction, and protein pocket generation. In practice we adopt a task-decomposed hybridization: a chemically defined active space at the site of interest is treated with quantum electronic-structure estimators embedded in a classical environment to capture local correlation, polarization, and protonation/spin microstates; discrete design choices are formulated as combinatorial optimizations; and learned surrogates optionally incorporate quantum feature maps/kernels to enrich decision boundaries22,24,25,27,40,41,42. We apply this template in the sections that follow: for Protein Binding Site Characterization and Design, quantum embedding supplies local electronic descriptors at metal centers and catalytic motifs; for Protein-Ligand Interaction Modeling, quantum subroutines refine site-specific energetics while docking/diffusion models handle large-scale pose enumeration and ranking; and for De Novo Ligand Generation, quantum steps act as physics-aware evaluators on small candidate sets within NISQ limits (with resource reporting: qubits, circuit depth, shots, wall-clock/queue time)22,24,43.
Protein binding site characterization and design
Identifying and engineering protein binding sites presents dual challenges: predicting existing binding pockets and designing new ones for targeted drug interactions. Classical approaches using geometric analysis and machine learning methods like MaSIF44 have advanced our understanding of surface cavities45,46, and have substantially improved cavity detection and residue-level descriptors. However, binding sites, particularly in metalloproteins and catalytic centers that are governed by subtle electronic effects, remain difficult for standard force fields and fixed-charge models. This difficulty is well documented by the need for specialized docking force fields and geometry constraints around metal centers (e.g., Zn2+)47,48.
Metalloproteins are common as roughly one-third of proteins require or bind metals49,50,51, and their coordination chemistry, polarization, and variable protonation/spin can confound fixed-charge scoring; we therefore use them as an illustrative stress-test, not a claim of dominance. Quantum methods capture local correlation and protonation/spin microstates via explicit electronic Hamiltonians24, but on present hardware are limited to small active spaces with error mitigation22,43,52, so we adopt them as complementary evaluators at selected sites while classical tools handle geometry mapping and large-scale search.
Quantum computing can addresses these challenges through Hamiltonian formulation with \({\mathcal{O}}({N}^{4})\) scaling53,54, enabling more explicit characterization of local electronic effects in small active spaces. Digital quantum algorithms have been used to estimate relative protonation preferences and indicators of local polarizability55,56, with potential relevance to metalloproteins such as zinc proteases where electronic structure strongly influences binding. In this setting, quantum subroutines can capture subtle electronic changes that classical fixed-charge force fields must approximate, with proof-of-concept studies reported for catalytic motifs in viral proteases and metalloenzymes57,58.
The same quantum framework extends naturally to pocket engineering, where electronic effects must be carefully controlled to create stable binding interfaces. Hybrid “quantum-inspired immune” search heuristics59,60 have been proposed for identifying dynamic or cryptic pockets that emerge via electronic reorganization54,61. In selected, peer-reviewed studies, researchers performed experiments on quantum hardware to interrogate binding-relevant electronic descriptors such as estimating protonation-state energetics in model fragments related to staphylococcal nuclease and α-lactalbumin62, and mapping dissociation behavior in strongly correlated small-molecule testbeds that benchmark pocket-chemistry motifs63. In contrast, separate fault-tolerant resource analyses for FeMoco outline how, once error-corrected scales are available, coordination chemistry at metal centers could be treated directly on quantum processors40. Collectively, these results should be viewed as proof-of-concept demonstrations: current NISQ devices require error mitigation and restrict active-space sizes, so quantum components presently serve as complementary evaluators of local electronic structure while classical methods carry out geometry mapping and large-scale search24,43.
Early hardware experiments have reported progress on complex binding-site descriptors57,58, and quantum components have been used to inform design proposals for metalloprotein pockets54,61. At present, these roles appear most promising when electronic effects dominate pocket formation and stability (e.g., catalytic sites and metal-binding centers). Within current NISQ constraints under limited active-space sizes and the need for error mitigation, we view quantum methods as complementary evaluators of local electronic structure, alongside classical tools that handle geometry mapping and large-scale search.
Protein-ligand interaction modeling
Predicting protein-ligand binding modes and affinities remains a central challenge in drug discovery. Classical methods like molecular docking programs excel at geometric matching but struggle with electronic effects64,65. Predicting protein-ligand binding modes and affinities remains a central challenge in drug discovery. Classical methods like molecular docking programs excel at geometric matching but can struggle with electronic effects64,65. Learning-based approaches such as EquiBind and DiffDock have advanced pose prediction66,67, yet fundamental limitations persist in modeling quantum-mechanical interactions that determine binding energetics29,68.
General-purpose docking and diffusion-based pose prediction are routinely assessed using community-recognized benchmarks that evaluate scoring and ranking power like CASF-2016/PDBbind69, pose prediction accuracy across different protein conformations with CrossDocked202070, and the physical realism of predicted poses using PoseBusters71. Representative classical baselines include AutoDock Vina 1.2.0 and AutoDock-GPU, CNN re-scoring with Gnina, and diffusion-based docking with DiffDock67,72,73,74. State-of-the-art models also explore protein conformational awareness, such as DynamicBind and equivariant diffusion SBDD75,76,77. However, these classical methods often rely on ’fixed-charge’ force fields that approximate atoms as points with static charges58. This simplification presents challenges in accurately modeling fundamentally quantum-mechanical interactions. These challenges include capturing the complex instantaneous interactions of electron correlation, the molecular distortion from dynamic polarization upon binding, and the subtle energetics of different protonation or spin microstates49,51. Therefore, instead of replacing these highly developed classical pipelines, we position quantum steps as complementary evaluators. By operating on the same quantum rules that underlie chemistry, quantum subroutines can directly represent molecular quantum states to account for these subtle electronic effects12,16,24. They can provide targeted, physics-aware refinement for specific cases where these quantum interactions are critical to binding, addressing a known limitation of otherwise powerful classical tools.
Quantum computing addresses such cases with Hamiltonian-based evaluators over small active spaces. Near-term algorithms (e.g., VQE/QITE, Box 1) can probe local correlation, protonation/spin microstates, and polarization, whereas phase estimation and amplitude estimation primitives target fault-tolerant regimes22,24,43,52,78. In practice, we use quantum components to refine local electronic descriptors at selected sites, while classical pipelines handle large-scale pose enumeration, scoring, and ranking64,65,66,67.
Recent hybrid quantum-classical frameworks demonstrate practical success in combined pose and affinity prediction79,80. These approaches balance computational accuracy with current hardware limitations, as demonstrated in successful predictions for β-secretase inhibitors57,58. The integration with molecular dynamics has further enhanced prediction of conformational changes during binding29,81. Within today’s NISQ regime, applicability is target- and pocket-dependent and largely confined to small active spaces with error mitigation22,24,43,52; we therefore use quantum steps as complementary evaluators of local electronic descriptors, while classical pipelines handle large-scale pose enumeration, scoring, and ranking. Standardized, hardware-run quantum benchmarks at community scale are not yet available, so reported gains are interpreted as pilot-scale and we accompany any accuracy metrics with resource reporting including qubits, circuit depth, shots, and wall-clock/queue time.
Standardized, hardware-run quantum benchmarks at CASF-2016, CrossDocked2020, or PoseBusters scale are not yet available. To enable standardized and direct comparison we outline: (i) datasets—CASF-2016 (docking/scoring power), CrossDocked2020 (cross-docking), PoseBusters (physical plausibility); (ii) metrics—Top-1/Top-N RMSD (<2 Å), AUROC for screening, correlation/MAE for affinity, and PoseBusters pass rates; (iii) classical baselines—Vina 1.2 (and AutoDock-GPU), Gnina, DiffDock; and (iv) quantum reporting—physical qubits, circuit depth, shots, wall-clock/queue time, and error mitigation67,69,70,71,72,73,74.
De novo ligand generation
Desired outcomes for de novo generators include chemical validity, novelty, uniqueness, synthesizability, drug-likeness, targetability, and multi-objective property/ADMET profiles; community benchmarks such as GuacaMol and MOSES define standard tasks and metrics82,83. The generation of novel drug molecules presents unique computational challenges, with traditional methods limited by the vast chemical space of approximately 1060 possible compounds. While geometric deep learning methods like 3DSBDD and Pocket2Mol have advanced structure-based generation through graph neural networks and diffusion models84,85, they can struggle in specific motifs to capture quantum mechanical properties crucial for binding. Classical approaches particularly falter in designing molecules with specific electronic properties required for target interaction2,86. State-of-the-art classical baselines achieve strong benchmark performance and high-throughput inference, including policy-optimized generators (REINVENT) and recent 3D diffusion/equivariant SBDD and conformation-aware models75,76,87. Classical approaches particularly falter in select cases when designing molecules with electronic properties tightly coupled to target interactions2,86.
Quantum algorithms can offer complementary tools transformative solutions through the QAOA framework88,89. This approach enables efficient exploration of conformational space while maintaining quantum mechanical accuracy, particularly excelling at optimizing electronic properties crucial for binding. Recent adaptive variational algorithms enhance these capabilities through systematic quantum circuit growth28,90, enabling more efficient representation of complex molecular systems.
Recent hybrid quantum-classical optimization approaches90,91 report pilot-scale designs that balance electronic properties with geometric constraints and are most relevant when electronic effects dominate binding like selected metalloproteins and enzyme active sites61,92.; within today’s NISQ regime we therefore deploy quantum components as physics-aware evaluators for small candidate sets with resource reporting for high-throughput generation, and we note that standardized, hardware-run quantum leaderboards for de novo generation are not yet available22,24,43.
Language models for enhanced quantum drug discovery
The integration of language models with quantum computing introduces a transformative approach to drug discovery by enhancing both molecular representation and quantum simulation capabilities93,94. Modern chemical language models have demonstrated remarkable success in learning complex molecular patterns and generating novel lead compound with desired properties95,96, while quantum computing’s specific advantages for modeling electronic interactions include: (i) explicit treatment of electron correlation in small active spaces via variational estimators, (ii) quantum feature maps/kernels that embed descriptors in high-dimensional Hilbert spaces for non-linear decision boundaries, and (iii) amplitude-estimation-based estimators that can, in principle, reduce sampling requirements for certain expectation values under low-noise assumptions22,24,41,42,78. The convergence of these technologies offers unprecedented opportunities for accelerating drug development through more accurate prediction of molecular behavior and drug-target interactions97,98.
Language models have revolutionized de novo drug design through their ability to learn and generate valid molecular structures while maintaining chemical feasibility95,96. These models can effectively capture complex structure-activity relationships and predict bioactivity patterns, particularly when enhanced with quantum mechanical principles. Recent advances in quantum language models have demonstrated superior capabilities in representing molecular states through quantum superposition and entanglement94,99,100, enabling more accurate modeling of electronic structures and binding interactions than classical approaches101. The quantum-enhanced language models show particular promise in predicting protein-ligand binding modes and optimizing lead compounds102,103.
The synergy between quantum computing and language models extends beyond simple combination. Quantum language models with entanglement embedding have shown remarkable improvements in capturing non-classical correlations within molecular systems94,104, while quantum-enhanced neural networks have demonstrated superior performance in predicting complex chemical properties105. These advances have enabled more efficient exploration of chemical space by combining the pattern recognition capabilities of language models with the quantum mechanical accuracy of quantum computing106. For instance, quantum-infused vision-language models have shown particular promise in understanding molecular interactions through multi-modal representations102.
Looking toward practical applications, the integration of language models with quantum computing offers several promising directions for drug discovery. This combined approach enables more accurate prediction of drug-target interactions by incorporating both quantum mechanical effects and learned chemical patterns. The hybrid framework can guide quantum simulations toward promising regions of chemical space27,107, while language models can help interpret and translate quantum computational results into actionable insights for drug design102. As both quantum hardware and language model capabilities continue to advance, this integrated approach promises to significantly accelerate the drug discovery process by combining the complementary strengths of both technologies.
Quantum-enhanced clinical trials
Drug development refers to the use of clinical trials to evaluate the safety and effectiveness of drug-based treatments on human bodies. It is designed to ensure that innovative drugs are safe, effective, and available to patients in the shortest possible time. Clinical trials represent a critical, resource-intensive bottleneck in drug development, requiring large patient cohorts, coordinated logistics, and precise outcome predictions. Quantum computing can contribute to several facets of trial design and execution, from optimizing site selection to guiding patient recruitment strategies, while maintaining data privacy and security.
Quantum-optimized clinical trial portfolio management and site selection
The optimization of clinical trial management presents a multifaceted challenge amenable to combinatorial optimization, including classical and quantum approaches, particularly through methods initially developed for quantum portfolio optimization in finance108,109. In clinical trial planning, selecting the right sites is treated as a complex optimization problem that must balance large amount of complex practical factors among ensuring broad geographic coverage, achieving high patient recruitment rates, engaging investigators with strong relevant expertise, meeting regulatory timelines for site activation, and controlling costs110. An adaptive trial design further complicates planning: this design framework allows certain trial parameters to be adjusted over time based on interim results, according to pre-specified rules, so that the trial can become more efficient and ethical as it progresses111. To solve these multifaceted design and site-selection challenges, researchers have traditionally relied on classical optimization methods such as mixed-integer programming and metaheuristic algorithms112. Mixed-integer programming (MIP) provides a rigorous mathematical approach to selecting optimal sets of trial sites or design options under multiple constraints, essentially treating decisions like whether to open a given site as binary variables in an optimization model113.
When exact formulations cannot be solved at scale, planners use heuristic search. Classical metaheuristics include genetic algorithms and simulated annealing. These methods explore many candidates and return near optimal site portfolios under cost, access, and timeline constraints114,115. Quantum optimization methods extend this toolkit. Quantum annealing maps the portfolio choice to an Ising model and uses quantum transitions to escape local minima116,117,118,119. The Quantum Approximate Optimization Algorithm(QAOA) alternates problem and mixer steps to increase the chance of high quality portfolios120,121. In practice these quantum methods run inside hybrid workflows that combine classical and quantum steps119,122. The workflow proposes candidates, rescores them under operational rules, and iterates. These quantum algorithms have shown case-dependent benefits in prototypes in handling complex multi-parameter optimization problems in financial markets123,124, with potential direct applications to clinical trial management. Nature’s validation of quantum annealing for complex optimization problems125,126, as demonstrated in particle physics applications, provides strong evidence for its potential in healthcare optimization. On hardware, quantum annealing has been exercised on real scheduling/logistics tasks using D-Wave systems within hybrid solvers, indicating feasibility but not yet end-to-end superiority for clinical site selection116,127.
Recent implementations of quantum portfolio optimization techniques have shown particular promise when adapted to clinical trial management110,128,129. By encoding trial parameters into quantum Hamiltonians using techniques refined in financial applications, these approaches enable simultaneous optimization across multiple constraints including geographical distribution, patient demographics, and site capabilities130,131. The integration of reverse quantum annealing protocols, which have shown over 100-fold speedup in financial portfolio optimization, offers promising applications for dynamic trial management126. These methods are particularly effective when initialized with classical solutions and then refined through quantum optimization.
Quantum-enhanced resource allocation has been demonstrated in pilot healthcare settings particularly in scenarios requiring real-time optimization and decision-making132,133. These approaches leverage quantum parallelism to simultaneously evaluate multiple trial configurations, with recent implementations showing particular promise in managing distributed healthcare resources134. The integration of quantum deep reinforcement learning has further enhanced these capabilities, enabling adaptive optimization of resource allocation in response to changing trial conditions135,136,137.
The practical implementation of these quantum approaches benefits significantly from hybrid quantum-classical frameworks138,139, which combine quantum optimization for complex decision-making with classical systems for data management and regulatory compliance140,141. These hybrid systems have shown particular promise in addressing healthcare-specific challenges, including regulatory requirements and patient privacy concerns. Recent advances in quantum affective processing for multidimensional decision-making have further enhanced the capability to balance multiple competing objectives in trial management.
Quantum machine learning for cohort stratification and patient recruitment
Quantum machine learning approaches have been explored as complements to classical ML in patient cohort identification, with recent validations showing unprecedented advantages in analyzing complex quantum states that parallel the multidimensional nature of patient data27,142,143. The quantum advantage in handling high-dimensional data spaces, first demonstrated in particle physics applications125, has particular relevance for clinical trial recruitment, where the integration of genomic, clinical, and imaging data creates computational challenges that exceed classical capabilities144,145.
Recent implementations of quantum kernel methods have shown remarkable efficiency in mapping data into higher-dimensional Hilbert spaces, where clinically relevant patterns become more distinguishable94,146. These approaches, building on quantum state manipulation techniques, enable simultaneous analysis of multiple data modalities - from genomic markers to longitudinal clinical records - with a computational efficiency unattainable through classical methods102,147. The quantum advantage becomes particularly evident when handling strongly correlated datasets, such as genetic profiles combined with clinical outcomes, where quantum systems can naturally represent the inherent entanglement of biological systems139,148. Systematic assessments in digital health find no consistent superiority of QML over strong classical baselines to date149. Where explored, studies should disclose device type, qubits, circuit depth, shots, error-mitigation, and training/inference wall-clock.
The practical implementation of these quantum approaches leverages recent advances in quantum-classical hybrid architectures133,138. Quantum classifiers can simultaneously process multiple data types while maintaining the coherence necessary for identifying subtle patient subgroups 150,151. These hybrid systems have shown particular promise in rare disease trials, where quantum-enhanced pattern recognition enables identification of suitable patients through complex combinations of biomarkers and clinical indicators. The integration of quantum annealing techniques, validated through complex optimization problems116,152,153, further enhances the ability to navigate the vast space of patient characteristics efficiently.
Looking toward practical applications, recent Nature-validated quantum implementations have demonstrated significant advantages in processing real clinical data. These systems show particular promise in personalizing trial recruitment strategies through quantum-enhanced analysis of patient-specific factors140. As quantum hardware capabilities continue to advance154,155, these approaches offer a path toward more efficient and accurate patient stratification, potentially reducing both the time and cost associated with clinical trial recruitment.
Quantum federated learning for secure and private data integration
Effective clinical trial design often requires the integration of sensitive patient data from multiple hospitals and research centers. Federated learning addresses privacy concerns by allowing these institutions to collaborate to train global models without sharing raw data156,157,158. Each participant optimizes the model parameters locally, transmitting only updates to a central aggregator, thus preserving confidentiality. Quantum federated learning (QFL, Box 1) enhances this paradigm by using QML models to handle complex high-dimensional clinical data more efficiently than classical methods159,160,161,162. In this context, “quantum-federated” variants are best understood as (i) classical FL orchestration with (ii) optional quantum subroutines (e.g., quantum kernels) running locally on privacy-shielded sites, and (iii) end-to-end security aligned with current standards. The intrinsic randomness of quantum mechanics can be integrated with differential privacy (Fig. 4), which naturally provides noise for stronger privacy guarantees163,164. Recent advances in multimodal QFL with fully homomorphic encryption (FHE) have demonstrated particular promise in maintaining model performance while ensuring data privacy, especially when handling diverse medical data types such as combined genomics and imaging data165.

Multiple clients hold private data that can not be leaked to or shared with the outside, while the QFL scheme enables the training of a public model without uploading their private data.
Quantum ML models show remarkable efficiency in processing high-dimensional clinical data, with multimodal quantum mixture of experts (MQMoE) frameworks demonstrating significant advantages in handling heterogeneous medical datasets165,166, although privacy leakage must be evaluated with rigorous membership-inference and attribute-inference tests. The integration of quantum randomness with differential privacy provides natural noise injection for enhanced privacy guarantees167,168, while quantum generative adversarial networks (QGANs, Box 1) enable the creation of synthetic datasets that preserve essential statistical properties while protecting patient identities169. These approaches show particular promise for underrepresented patient categories, addressing a crucial challenge in clinical trial diversity.
The security of clinical trial data benefits significantly from quantum-enhanced detection systems. Quantum kernel methods implemented in Support Vector Machines have achieved detection accuracies of 75-95% for label-flipping attacks on medical sensor data170, substantially outperforming classical approaches. The integration of these quantum attack detection systems with federated learning frameworks creates a robust security infrastructure that can identify subtle manipulation patterns across multiple trial sites.
Advanced quantum cryptographic techniques, including blind quantum computing and post-quantum cryptography171,172,173, enable secure computations on encrypted data while ensuring long-term protection against future quantum threats174. The combination of these approaches with multimodal QFL creates a comprehensive framework for secure, privacy-preserving clinical trial data analysis. This hybrid quantum-classical approach enables real-time monitoring of trial data while maintaining computational efficiency and strict privacy standards. In practice, today’s deployments should rely on established FL privacy tools, with quantum components treated as experimental modules whose contribution is measured against strong classical baselines. We therefore treat QFL as prospective; evaluations should report communication rounds, cryptographic overheads, device specs, and ablations versus classical FL baselines175,176.
Outlook
As we assess quantum computing’s transformative potential in drug discovery, we have systematically analyzed the computational resource requirements and expected advantages across key application areas (Table 2). Our analysis covers the spectrum from molecular structure simulation to clinical trial optimization, comparing classical computing requirements with both current NISQ-era capabilities and projected fault-tolerant quantum systems27,92,177. While current quantum devices face hardware limitations, projected capabilities of fault-tolerant quantum computers suggest significant speedups across all major drug discovery applications178,179. These estimates, validated through initial implementations on current quantum hardware, provide a roadmap for achieving practical quantum advantage in pharmaceutical development28,142.
In the near term, quantum workloads that fit drug-discovery practice are best scoped as complements to classical compute: small active-space electronic descriptors (e.g., local correlation/protonation indicators), variational or imaginary-time estimators, kernel-based feature maps in niche classification regimes, and modest combinatorial encodings. Execution is predominantly via cloud services with metered billing, while a limited number of sites operate on-prem systems for health/academic research (e.g., IBM Quantum System One installations at Cleveland Clinic, Rensselaer Polytechnic Institute, and Yonsei University)180,181. Other universities maintain in-house research platforms without procuring a vendor system like trapped-ion at Duke and superconducting programs at Yale. These access models make pilot-scale studies feasible for medium-sized institutions and SMEs via pay-as-you-go or committed-minute plans, with careful scoping to physics-aware evaluation that can reduce downstream synthesis/assay burden rather than replace high-throughput docking/ADMET. In practice, adopters already range from large pharma to startups: Boehringer Ingelheim has an active collaboration with Google Quantum AI182; Roche’s pRED unit has run quantum-ML explorations with QC Ware183; Qubit Pharmaceuticals (SME) is executing drug-discovery tasks on PASQAL’s neutral-atom QPUs184; and the start up company Menten AI used D-Wave’s hybrid solver to generate and synthesize peptide designs. Ecosystem pilots also include AstraZeneca working with IonQ via AWS/NVIDIA185. This positioning aligns with recent evidence of pre-fault-tolerant “utility” under error mitigation23 and hardware-executed chemistry/design pipelines101,186,187.
Hardware-relevant, drug-adjacent signals are beginning to appear across the literature. A Nature Biotechnology study reports a quantum-computing-enhanced generative pipeline that proposed KRAS inhibitors, with 15 molecules synthesized and two showing promising activity101. Reconfigurable quantum processors have executed programmable simulations of correlated spin/electronic models with chemically relevant spectral extraction186. Drug-facing building blocks include a hardware-executable framework for protein 3D structure prediction187 and a quantum algorithm for protein side-chain optimisation with explicit comparisons to classical baselines188. On the learning side, quantum kernel methods have been applied to drug-target interaction prediction in recent189. In parallel, QAOA/DC-QAOA formulations for docking are being developed and stress-tested in simulation and small-scale runs190,191. More broadly, pre-fault-tolerant “utility” under error mitigation has been documented on large devices23.
The field of quantum computing for drug discovery stands at a transformative moment, with recent advances in both quantum simulation capabilities and artificial intelligence suggesting multiple paths toward practical quantum advantage in pharmaceutical development93. Current quantum devices have demonstrated the ability to simulate systems of approximately 100 qubits; however, mapping that scale onto realistic biomolecular systems remains out of reach for NISQ hardware and will require error-corrected, fault-tolerant systems. This achievement points toward the potential creation of a quantum-enabled database of amino acid configurations179, which could dramatically accelerate protein structure prediction and drug development processes. Such a database would not only enhance our ability to explore protein conformations but could also serve as a benchmark to demonstrate quantum advantage over classical methods in molecular modeling29.
The development of a quantum database for protein folding represents a particularly promising direction for near-term applications. While classical databases store static structural information, a quantum database could maintain the full quantum mechanical description of amino acid configurations, including crucial electronic states and quantum correlations that influence protein folding pathways192,193. This quantum representation would enable direct simulation of folding dynamics, potentially revealing intermediate states and alternative conformations that are computationally inaccessible to classical methods194. The database could also incorporate quantum error correction protocols to maintain the fidelity of stored quantum states, ensuring reliable access to complex molecular configurations for drug design applications. By systematically cataloging quantum states of amino acid pairs and their interactions, researchers could build up a library of fundamental building blocks for protein structure prediction, potentially enabling the simulation of larger protein segments through the composition of these basic units.
Building upon this quantum database foundation, the emerging synergy between large language models and quantum computing hints at transformative possibilities for molecular simulation. Recent work has revealed unexpected connections between the mathematical structures underlying both quantum systems and language models94, suggesting deeper theoretical links that could be exploited for mutual benefit. Language models could enhance quantum simulations by learning efficient representations of molecular states and guiding the exploration of chemical space195, while quantum computers could provide unique capabilities for training and optimizing these models61,86,179. This cooperative framework could lead to breakthrough approaches in molecular simulation, potentially accelerating drug discovery by combining the complementary strengths of both paradigms.
To fully realize these capabilities at scale, distributed quantum computing architectures present a promising direction for expanding drug discovery applications. This approach naturally aligns with the distributed nature of drug development, where different aspects of molecular design and testing often occur across multiple sites. Quantum teleportation (Box 1) protocols could enable secure information transfer between distributed quantum processors124, creating a network of smaller quantum systems that collectively function as a larger quantum computer. This distributed architecture offers two significant advantages: it provides a path to scaling up quantum resources beyond single-device limitations196,197, and it enables secure data sharing through quantum cryptographic protocols198.
The integration of federated learning approaches with distributed quantum computing suggests a powerful framework for collaborative drug discovery. Local quantum processors could perform molecular simulations and property predictions while maintaining data privacy through quantum-secured federated learning protocols159,160,161. A central quantum server could aggregate insights from multiple sites without compromising sensitive information, protected by quantum cryptographic principles. This architecture could enable pharmaceutical companies and research institutions to collaborate more effectively while maintaining strict control over their intellectual property and patient data.
As quantum hardware continues to advance, the integration of these complementary technologies—quantum databases, language model enhancement, and distributed quantum computing—could create a powerful ecosystem for drug discovery. The combination of increased simulation scale, intelligent guidance through language models, and secure distributed computation suggests a path toward quantum advantage in practical drug development applications. While significant challenges remain in scaling quantum devices and developing robust distributed architectures, the convergence of these technologies offers promising directions for transforming the drug discovery process.
Data availability
No datasets were generated or analysed during the current study.
References
Huang, K. et al. Artificial intelligence foundation for therapeutic science. Nat. Chem. Biol. 18, 1033 (2022).
Bohacek, R. S., McMartin, C. & Guida, W. C. The art and practice of structure-based drug design: a molecular modeling perspective. Medicinal Res. Rev. 16, 3–50 (1996).
Sadybekov, A. V. & Katritch, V. Computational approaches streamlining drug discovery. Nature 616, 673–685 (2023).
Trajanoska, K. et al. From target discovery to clinical drug development with human genetics. Nature 620, 737–745 (2023).
Reker, D., Bernardes, G. J. & Rodrigues, T. Computational advances in combating colloidal aggregation in drug discovery. Nat. Chem. 11, 402–418 (2019).
Liu, T. Y. et al. Accelerated rna detection using tandem crispr nucleases. Nat. Chem. Biol. 17, 982–988 (2021).
Chudasama, V., Maruani, A. & Caddick, S. Recent advances in the construction of antibody–drug conjugates. Nat. Chem. 8, 114–119 (2016).
Zhang, Z. et al. Geometric deep learning for structure-based drug design: A survey https://arxiv.org/abs/2306.11768 (2024).
Powers, A. S. et al. Geometric deep learning for structure-based ligand design. ACS Cent. Sci. 9, 2257–2267 (2023).
Bhardwaj, G. et al. Accurate de novo design of hyperstable constrained peptides. Nature 538, 329–335 (2016).
Liu, G. et al. Deep learning-guided discovery of an antibiotic targeting acinetobacter baumannii. Nat. Chem. Biol. 19, 1342–1350 (2023).
Santagati, R. et al. Drug design on quantum computers. Nat. Phys. 20, 549–557 (2024).
Li, W. et al. A hybrid quantum computing pipeline for real world drug discovery. Sci. Rep. 14, 16942 (2024).
Bauer, C., Schattner, Y., Trebst, S. & Berg, E. Hierarchy of energy scales in an o (3) symmetric antiferromagnetic quantum critical metal: A monte carlo study. Phys. Rev. Res. 2, 023008 (2020).
Altman, E. et al. Quantum simulators: Architectures and opportunities. PRX quantum 2, 017003 (2021).
Bauer, B., Bravyi, S., Motta, M. & Chan, G. K.-L. Quantum algorithms for quantum chemistry and quantum materials science. Chem. Rev. 120, 12685–12717 (2020).
Kjaergaard, M. et al. Superconducting qubits: Current state of play. Annu. Rev. Condens. Matter Phys. 11, 369–395 (2020).
Quantum, G. A. et al. Hartree-fock on a superconducting qubit quantum computer. Science 369, 1084–1089 (2020).
Bruzewicz, C. D., Chiaverini, J., McConnell, R. & Sage, J. M. Trapped-ion quantum computing: Progress and challenges. Applied physics reviews 6 (2019).
Bluvstein, D. et al. Logical quantum processor based on reconfigurable atom arrays. Nature 626, 58–65 (2024).
Henriet, L. et al. Quantum computing with neutral atoms. Quantum 4, 327 (2020).
Cai, Z. et al. Quantum error mitigation. Rev. Mod. Phys. 95, 045005 (2023).
Kim, Y. et al. Evidence for the utility of quantum computing before fault tolerance. Nature 618, 500–505 (2023).
McArdle, S., Endo, S., Aspuru-Guzik, A., Benjamin, S. C. & Yuan, X. Quantum computational chemistry. Rev. Mod. Phys. 92, 015003 (2020).
Tilly, J. et al. The variational quantum eigensolver: a review of methods and best practices. Phys. Rep. 986, 1–128 (2022).
Hughes, J. P., Rees, S., Kalindjian, S. B. & Philpott, K. L. Principles of early drug discovery. Br. J. Pharmacol. 162, 1239–1249 (2011).
Cao, Y. et al. Quantum chemistry in the age of quantum computing. Chem. Rev. 119, 10856–10915 (2019).
Motta, M. & Rice, J. E. Emerging quantum computing algorithms for quantum chemistry. Wiley Interdiscip. Rev.: Computational Mol. Sci. 12, e1580 (2022).
Ollitrault, P. J., Miessen, A. & Tavernelli, I. Molecular quantum dynamics: A quantum computing perspective. Acc. Chem. Res. 54, 4229–4238 (2021).
Sun, Q. & Chan, G. K.-L. Quantum embedding theories. Acc. Chem. Res. 49, 2705–2712 (2016).
Schütt, K. T., Gastegger, M., Tkatchenko, A., Müller, K.-R. & Maurer, R. J. Unifying machine learning and quantum chemistry with a deep neural network for molecular wavefunctions. Nat. Commun. 10, 5024 (2019).
Sathan, D. & Baichoo, S. Drug target interaction prediction using variational quantum classifier. In 2024 International Conference on Next Generation Computing Applications (NextComp), 1–7 (IEEE, 2024).
Jørgensen, P.Second quantization-based methods in quantum chemistry (Elsevier, 2012).
Batista, C. & Ortiz, G. Generalized jordan-wigner transformations. Phys. Rev. Lett. 86, 1082 (2001).
Seeley, J. T., Richard, M. J. & Love, P. J. The bravyi-kitaev transformation for quantum computation of electronic structure. The Journal of chemical physics 137 (2012).
Tranter, A., Love, P. J., Mintert, F. & Coveney, P. V. A comparison of the bravyi–kitaev and jordan–wigner transformations for the quantum simulation of quantum chemistry. J. Chem. theory Comput. 14, 5617–5630 (2018).
Huang, L. & Massa, L. Quantum kernel applications in medicinal chemistry. Future Medicinal Chem. 4, 1479–1494 (2012).
Zhao, R.-X., Shi, J. & Li, X. Qksan: A quantum kernel self-attention network. IEEE Transactions on Pattern Analysis and Machine Intelligence (2024).
Batra, K. et al. Quantum machine learning algorithms for drug discovery applications. J. Chem. Inf. modeling 61, 2641–2647 (2021).
Reiher, M., Wiebe, N., Svore, K. M., Wecker, D. & Troyer, M. Elucidating reaction mechanisms on quantum computers. Proc. Natl. Acad. Sci. 114, 7555–7560 (2017).
Havlíček, V. et al. Supervised learning with quantum-enhanced feature spaces. Nature 567, 209–212 (2019).
Schuld, M. & Killoran, N. Quantum machine learning in feature hilbert spaces. Phys. Rev. Lett. 122, 040504 (2019).
Quek, Y., Stilck França, D., Khatri, S., Meyer, J. J. & Eisert, J. Exponentially tighter bounds on limitations of quantum error mitigation. Nat. Phys. 20, 1648–1658 (2024).
Gainza, P. et al. Deciphering interaction fingerprints from protein molecular surfaces using geometric deep learning. Nat. Methods 17, 184–192 (2020).
Senior, A. W. et al. Improved protein structure prediction using potentials from deep learning. Nature 577, 706–710 (2020).
Jumper, J. et al. Highly accurate protein structure prediction with alphafold. nature 596, 583–589 (2021).
Santos-Martins, D., Forli, S., Ramos, M. J. & Olson, A. J. Autodock4zn: an improved autodock force field for small-molecule docking to zinc metalloproteins. J. Chem. Inf. modeling 54, 2371–2379 (2014).
Bai, F. et al. An accurate metalloprotein-specific scoring function and molecular docking program devised by a dynamic sampling and iteration optimization strategy. J. Chem. Inf. Modeling 55, 833–847 (2015).
Capdevila, D. A. et al. Bacterial metallostasis: metal sensing, metalloproteome remodeling, and metal trafficking. Chem. Rev. 124, 13574–13659 (2024).
Lin, G.-Y., Su, Y.-C., Huang, Y. L. & Hsin, K.-Y. Mespeus: a database of metal coordination groups in proteins. Nucleic Acids Res. 52, D483–D493 (2024).
Dürr, S. L., Levy, A. & Rothlisberger, U. Metal3d: a general deep learning framework for accurate metal ion location prediction in proteins. Nat. Commun. 14, 2713 (2023).
O’Brien, T. E. et al. Purification-based quantum error mitigation of pair-correlated electron simulations. Nat. Phys. 19, 1787–1792 (2023).
Robert, A., Barkoutsos, P. K., Woerner, S. & Tavernelli, I. Resource-efficient quantum algorithm for protein folding. npj Quantum Inf. 7, 38 (2021).
Doga, H. et al. A perspective on protein structure prediction using quantum computers. J. Chem. Theory Comput. 20, 3359–3378 (2024).
Chandarana, P., Hegade, N. N., Montalban, I., Solano, E. & Chen, X. Digitized counterdiabatic quantum algorithm for protein folding. Phys. Rev. Appl. 20, 014024 (2023).
Cao, Y., Romero, J. & Aspuru-Guzik, A. Potential of quantum computing for drug discovery. IBM J. Res. Dev. 62, 6–1 (2018).
Battaglia, S., Rossmannek, M., Rybkin, V. V., Tavernelli, I. & Hutter, J. A general framework for active space embedding methods with applications in quantum computing. npj Computational Mater. 10, 297 (2024).
Blunt, N. S. et al. Perspective on the current state-of-the-art of quantum computing for drug discovery applications. J. Chem. Theory Comput. 18, 7001–7023 (2022).
Jiao, L., Li, Y., Gong, M. & Zhang, X. Quantum-inspired immune clonal algorithm for global optimization. IEEE Trans. Syst., Man, (Cybern.), Part B ((Cybern.)) 38, 1234–1253 (2008).
Li, Y., Tian, M., Liu, G., Peng, C. & Jiao, L. Quantum optimization and quantum learning: A survey. Ieee Access 8, 23568–23593 (2020).
Andersson, M. P., Jones, M. N., Mikkelsen, K. V., You, F. & Mansouri, S. S. Quantum computing for chemical and biomolecular product design. Curr. Opin. Chem. Eng. 36, 100754 (2022).
Hu, H. Quantum computer simulation of protein protonation. J. Chem. Theory Comput. 19, 5671–5676 (2023).
Weaving, T., Ralli, A., Love, P. J., Succi, S. & Coveney, P. V. Contextual subspace variational quantum eigensolver calculation of the dissociation curve of molecular nitrogen on a superconducting quantum computer. npj Quantum Inf. 11, 25 (2025).
Trott, O. & Olson, A. J. Autodock vina: improving the speed and accuracy of docking with a new scoring function, efficient optimization, and multithreading. J. computational Chem. 31, 455–461 (2010).
Alhossary, A., Handoko, S. D., Mu, Y. & Kwoh, C.-K. Fast, accurate, and reliable molecular docking with quickvina 2. Bioinformatics 31, 2214–2216 (2015).
Stärk, H., Ganea, O., Pattanaik, L., Barzilay, R. & Jaakkola, T. Equibind: Geometric deep learning for drug binding structure prediction. In International conference on machine learning, 20503–20521 (PMLR, 2022).
Corso, G., StÃ, H., Jing, B., Barzilay, R. & Jaakkola, T. DiffDock: Diffusion Steps, Twists, and Turns for Molecular Docking. In International Conference on Learning Representations (ICLR, 2023).
Hardikar, T. S. et al. Quanta-bind: A quantum computing pipeline for modeling strongly correlated metal-protein interactions. In 2024 IEEE International Conference on Quantum Computing and Engineering (QCE), vol. 1, 538–544 (IEEE, 2024).
Su, M. et al. Comparative assessment of scoring functions: the casf-2016 update. J. Chem. Inf. modeling 59, 895–913 (2018).
Francoeur, P. G. et al. Three-dimensional convolutional neural networks and a cross-docked data set for structure-based drug design. J. Chem. Inf. modeling 60, 4200–4215 (2020).
Buttenschoen, M., Morris, G. M. & Deane, C. M. Posebusters: Ai-based docking methods fail to generate physically valid poses or generalise to novel sequences. Chem. Sci. 15, 3130–3139 (2024).
Eberhardt, J., Santos-Martins, D., Tillack, A. F. & Forli, S. Autodock vina 1.2. 0: new docking methods, expanded force field, and python bindings. J. Chem. Inf. modeling 61, 3891–3898 (2021).
Santos-Martins, D. et al. Accelerating autodock4 with gpus and gradient-based local search. J. Chem. theory Comput. 17, 1060–1073 (2021).
McNutt, A. T. et al. Gnina 1.0: molecular docking with deep learning. J. cheminformatics 13, 43 (2021).
Lu, W. et al. Dynamicbind: predicting ligand-specific protein-ligand complex structure with a deep equivariant generative model. Nat. Commun. 15, 1071 (2024).
Schneuing, A. et al. Structure-based drug design with equivariant diffusion models. Nat. Computational Sci. 4, 899–909 (2024).
Abramson, J. et al. Accurate structure prediction of biomolecular interactions with alphafold 3. Nature 630, 493–500 (2024).
Brassard, G., Hoyer, P., Mosca, M. & Tapp, A. Quantum amplitude amplification and estimation. Contemp. Math. 305, 53–74 (2002).
Li, J., Topaloglu, R. O. & Ghosh, S. Quantum generative models for small molecule drug discovery. IEEE Trans. quantum Eng. 2, 1–8 (2021).
Uzzaman, M., Shawon, J. & Siddique, Z. A. Molecular docking, dynamics simulation and admet prediction of acetaminophen and its modified derivatives based on quantum calculations. SN Appl. Sci. 1, 1–10 (2019).
Fedorov, D. A., Otten, M. J., Gray, S. K. & Alexeev, Y. Ab initio molecular dynamics on quantum computers. The Journal of Chemical Physics154 (2021).
Brown, N., Fiscato, M., Segler, M. H. & Vaucher, A. C. Guacamol: benchmarking models for de novo molecular design. J. Chem. Inf. modeling 59, 1096–1108 (2019).
Polykovskiy, D. et al. Molecular sets (moses): a benchmarking platform for molecular generation models. Front. Pharmacol. 11, 565644 (2020).
Luo, S., Guan, J., Ma, J. & Peng, J. A 3d generative model for structure-based drug design. Adv. Neural Inf. Process. Syst. 34, 6229–6239 (2021).
Peng, X. et al. Pocket2mol: Efficient molecular sampling based on 3d protein pockets. In International Conference on Machine Learning, 17644–17655 (PMLR, 2022).
Outeiral, C. et al. The prospects of quantum computing in computational molecular biology. Wiley Interdiscip. Rev.: Computational Mol. Sci. 11, e1481 (2021).
Blaschke, T. et al. Reinvent 2.0: an ai tool for de novo drug design. J. Chem. Inf. modeling 60, 5918–5922 (2020).
Farhi, E., Goldstone, J. & Gutmann, S. A quantum approximate optimization algorithm. arXiv preprint arXiv:1411.4028 (2014).
Smart, S. E. & Mazziotti, D. A. Quantum solver of contracted eigenvalue equations for scalable molecular simulations on quantum computing devices. Phys. Rev. Lett. 126, 070504 (2021).
Grimsley, H. R., Economou, S. E., Barnes, E. & Mayhall, N. J. An adaptive variational algorithm for exact molecular simulations on a quantum computer. Nat. Commun. 10, 3007 (2019).
Li, Y. et al. Efficient molecular conformation generation with quantum-inspired algorithm. J. Mol. Modeling 30, 228 (2024).
Liu, H. et al. Prospects of quantum computing for molecular sciences. Mater. Theory 6, 11 (2022).
Daley, A. J. et al. Practical quantum advantage in quantum simulation. Nature 607, 667–676 (2022).
Chen, Y., Pan, Y. & Dong, D. Quantum language model with entanglement embedding for question answering. IEEE Trans. Cybern. 53, 3467–3478 (2021).
Moret, M. et al. Leveraging molecular structure and bioactivity with chemical language models for de novo drug design. Nat. Commun. 14, 114 (2023).
Grisoni, F. Chemical language models for de novo drug design: Challenges and opportunities. Curr. Opin. Struct. Biol. 79, 102527 (2023).
Liu, Z. et al. Ai-based language models powering drug discovery and development. Drug Discov. Today 26, 2593–2607 (2021).
Chakraborty, C., Bhattacharya, M. & Lee, S.-S. Artificial intelligence enabled chatgpt and large language models in drug target discovery, drug discovery, and development. Mol. Ther.-Nucleic Acids 33, 866–868 (2023).
Coecke, B., de Felice, G., Meichanetzidis, K. & Toumi, A. Foundations for near-term quantum natural language processing. arXiv preprint arXiv:2012.03755 (2020).
Meichanetzidis, K., Gogioso, S., de Felice, G., Chiappori, N., Toumi, A. & Coecke, B. Quantum Natural Language Processing on Near-Term Quantum Computers. Electron. Proc. Theor. Comput. Sci 340, 213–229 (2021).
Ghazi Vakili, M. et al. Quantum-computing-enhanced algorithm unveils potential kras inhibitors. Nature Biotechnology 1–6 (2025).
Mukesh, K., Jayaprakash, S. & Kumar, R. P. Qvila: Quantum infused vision-language model for enhanced multimodal understanding. SN Computer Sci. 5, 1–12 (2024).
Liang, Z. et al. Unleashing the potential of llms for quantum computing: A study in quantum architecture design. arXiv preprint arXiv:2307.08191 (2023).
Xie, M. et al. Modeling quantum entanglements in quantum language models (2015).
Jia, Z.-A. et al. Quantum neural network states: A brief review of methods and applications. Adv. Quantum Technol. 2, 1800077 (2019).
Panahi, A., Saeedi, S. & Arodz, T. word2ket: Space-efficient word embeddings inspired by quantum entanglement. In International Conference on Learning Representations (ICLR, 2020).
Lanyon, B. P. et al. Towards quantum chemistry on a quantum computer. Nat. Chem. 2, 106–111 (2010).
Rebentrost, P. & Lloyd, S. Quantum computational finance: quantum algorithm for portfolio optimization. KI-Künstliche Intelligenz 1–12 (2024).
Buonaiuto, G., Gargiulo, F., De Pietro, G., Esposito, M. & Pota, M. Best practices for portfolio optimization by quantum computing, experimented on real quantum devices. Sci. Rep. 13, 19434 (2023).
Doga, H. et al. How can quantum computing be applied in clinical trial design and optimization? Trends Pharmacol. Sci 45, 880–891 (2024).
Pallmann, P. et al. Adaptive designs in clinical trials: why use them, and how to run and report them. BMC Med. 16, 29 (2018).
Inan, O. T. et al. Digitizing clinical trials. NPJ digital Med. 3, 101 (2020).
Bragin, M. A. & Tucker, E. L. Surrogate “level-based” lagrangian relaxation for mixed-integer linear programming. Sci. Rep. 12, 22417 (2022).
Ala, A., Alsaadi, F. E., Ahmadi, M. & Mirjalili, S. Optimization of an appointment scheduling problem for healthcare systems based on the quality of fairness service using whale optimization algorithm and nsga-ii. Sci. Rep. 11, 19816 (2021).
Evans, L., Acton, J. H., Hiscott, C. & Gartner, D. An operations research approach to automated patient scheduling for eye care using a multi-criteria decision support tool. Sci. Rep. 13, 553 (2023).
Ikeda, K., Nakamura, Y. & Humble, T. S. Application of quantum annealing to nurse scheduling problem. Sci. Rep. 9, 12837 (2019).
Carugno, C., Ferrari Dacrema, M. & Cremonesi, P. Evaluating the job shop scheduling problem on a d-wave quantum annealer. Sci. Rep. 12, 6539 (2022).
Pérez Armas, L. F., Creemers, S. & Deleplanque, S. Solving the resource constrained project scheduling problem with quantum annealing. Sci. Rep. 14, 16784 (2024).
Weinberg, S. J., Sanches, F., Ide, T., Kamiya, K. & Correll, R. Supply chain logistics with quantum and classical annealing algorithms. Sci. Rep. 13, 4770 (2023).
He, Z. et al. Alignment between initial state and mixer improves qaoa performance for constrained optimization. npj Quantum Inf. 9, 121 (2023).
Cheng, L., Chen, Y.-Q., Zhang, S.-X. & Zhang, S. Quantum approximate optimization via learning-based adaptive optimization. Commun. Phys. 7, 83 (2024).
Quinton, F. A., Myhr, P. A. S., Barani, M., Crespo del Granado, P. & Zhang, H. Quantum annealing applications, challenges and limitations for optimisation problems compared to classical solvers. Sci. Rep. 15, 12733 (2025).
Orús, R., Mugel, S. & Lizaso, E. Quantum computing for finance: Overview and prospects. Rev. Phys. 4, 100028 (2019).
Ding, D. & Jiang, L. Coordinating decisions via quantum telepathy. arXiv preprint arXiv:2407.21723 (2024).
Mott, A., Job, J., Vlimant, J.-R., Lidar, D. & Spiropulu, M. Solving a higgs optimization problem with quantum annealing for machine learning. Nature 550, 375–379 (2017).
Venturelli, D. & Kondratyev, A. Reverse quantum annealing approach to portfolio optimization problems. Quantum Mach. Intell. 1, 17–30 (2019).
Venturelli, D., Marchand, D. J. & Rojo, G. Quantum annealing implementation of job-shop scheduling. arXiv preprint arXiv:1506.08479 (2015).
Doga, H. et al. How can quantum computing be applied in clinical trial design and optimization? Trends in Pharmacological Sciences (2024).
Moradi, S. et al. Clinical data classification with noisy intermediate scale quantum computers. Sci. Rep. 12, 1851 (2022).
Elsokkary, N., Khan, F. S., La Torre, D., Humble, T. & Gottlieb, J. Financial portfolio management using d-wave quantum optimizer: The case of abu dhabi securities exchange. Tech. Rep., Oak Ridge National Laboratory (ORNL), Oak Ridge, TN (United States) (2017).
Bhasin, N. K. et al. Enhancing quantum machine learning algorithms for optimized financial portfolio management. In 2024 Third International Conference on Intelligent Techniques in Control, Optimization and Signal Processing (INCOS), 1–7 (IEEE, 2024).
Bhatia, M. & Sood, S. K. Quantum computing-inspired network optimization for iot applications. IEEE Internet Things J. 7, 5590–5598 (2020).
Duong, T. Q. et al. Quantum-inspired real-time optimization for 6g networks: opportunities, challenges, and the road ahead. IEEE Open J. Commun. Soc. 3, 1347–1359 (2022).
Veni, T. Quantum-based resource management approaches in fog computing environments: A comprehensive review. Mobile Computing and Sustainable Informatics: Proceedings of ICMCSI 2022, 743–752 (2022).
Niraula, D., Jamaluddin, J., Matuszak, M. M., Haken, R. K. T. & Naqa, I. E. Quantum deep reinforcement learning for clinical decision support in oncology: application to adaptive radiotherapy. Sci. Rep. 11, 23545 (2021).
Ullah, U. & Garcia-Zapirain, B. Quantum machine learning revolution in healthcare: a systematic review of emerging perspectives and applications. IEEE Access (2024).
Rani, S., Pareek, P. K., Kaur, J., Chauhan, M. & Bhambri, P. Quantum machine learning in healthcare: Developments and challenges. In 2023 IEEE International Conference on Integrated Circuits and Communication Systems (ICICACS), 1–7 (IEEE, 2023).
Raparthi, M. Real-time ai decision making in iot with quantum computing: Investigating & exploring the development and implementation of quantum-supported ai inference systems for iot applications. Internet Things Edge Comput. J. 1, 18–27 (2021).
Ho, J. K. & Hoorn, J. F. Quantum affective processes for multidimensional decision-making. Sci. Rep. 12, 20468 (2022).
Sundaram, A. Challenges and opportunities in quantum computing in healthcare. Quantum Computing for Healthcare Data 91–118 (2025).
Jeyaraman, N., Jeyaraman, M., Yadav, S., Ramasubramanian, S. & Balaji, S. Revolutionizing healthcare: the emerging role of quantum computing in enhancing medical technology and treatment. Cureus 16 (2024).
Motta, M. et al. Determining eigenstates and thermal states on a quantum computer using quantum imaginary time evolution. Nat. Phys. 16, 205–210 (2020).
Liu, Y., Arunachalam, S. & Temme, K. A rigorous and robust quantum speed-up in supervised machine learning. Nat. Phys. 17, 1013–1017 (2021).
Kirsopp, J. J. et al. Quantum computational quantification of protein–ligand interactions. Int. J. Quantum Chem. 122, e26975 (2022).
Durant, T. J. et al. A primer for quantum computing and its applications to healthcare and biomedical research. J. Am. Med. Inform. Assoc. 31, 1774–1784 (2024).
Narottama, B. & Shin, S. Y. Quantum neural networks for resource allocation in wireless communications. IEEE Trans. Wirel. Commun. 21, 1103–1116 (2021).
Avramouli, M., Savvas, I. K., Vasilaki, A., Tsipourlianos, A. & Garani, G. Hybrid quantum neural network approaches to protein–ligand binding affinity prediction. Mathematics 12, 2372 (2024).
Song, Q. et al. Quantum decision making in automatic driving. Sci. Rep. 12, 11042 (2022).
Gupta, R. S., Wood, C. E., Engstrom, T., Pole, J. D. & Shrapnel, S. A systematic review of quantum machine learning for digital health. npj Digital Med. 8, 237 (2025).
Ezhov, A. Pattern recognition with quantum neural networks. In Advances in Pattern Recognition-ICAPR 2001: Second International Conference Rio de Janeiro, Brazil, March 11–14, 2001 Proceedings 2, 60–71 (Springer, 2001).
Schuld, M., Sinayskiy, I. & Petruccione, F. Quantum computing for pattern classification. In PRICAI 2014: Trends in Artificial Intelligence: 13th Pacific Rim International Conference on Artificial Intelligence, Gold Coast, QLD, Australia, December 1-5, 2014. Proceedings 13, 208–220 (Springer, 2014).
Chen, Y.-Q., Chen, Y., Lee, C.-K., Zhang, S. & Hsieh, C.-Y. Optimizing quantum annealing schedules with monte carlo tree search enhanced with neural networks. Nat. Mach. Intell. 4, 269–278 (2022).
Sahner, D. K. & Williams, R. J. Clinical decision support using a partially instantiated probabilistic graphical model optimized through quantum annealing: Proof-of-concept of a computational method using a clinical data set. medRxiv 2020–12 (2020).
Google Quantum AI and Collaborators. Quantum error correction below the surface code threshold. Nature 638, 920–926 (2025).
Castelvecchi, D. ’a truly remarkable breakthrough’: Google’s new quantum chip achieves accuracy milestone. Nature 636, 527–528 (2024).
Goddard, M. The eu general data protection regulation (gdpr): European regulation that has a global impact. Int. J. Mark. Res. 59, 703–705 (2017).
Li, L., Fan, Y., Tse, M. & Lin, K.-Y. A review of applications in federated learning. Computers Ind. Eng. 149, 106854 (2020).
Abadi, M. et al. Deep learning with differential privacy. In Proceedings of the 2016 ACM SIGSAC conference on computer and communications security, 308–318 (2016).
Ren, C. et al. Toward quantum federated learning. IEEE Transactions on Neural Networks and Learning Systems 36, 15580–15600 (2025).
Chehimi, M., Chen, S. Y.-C., Saad, W., Towsley, D. & Debbah, M. Foundations of quantum federated learning over classical and quantum networks. IEEE Network (2023).
Zheng, H., Li, Z., Liu, J., Strelchuk, S. & Kondor, R. Speeding up learning quantum states through group equivariant convolutional quantum ansätze. PRX Quantum 4, 020327 (2023).
Molteni, R., Gyurik, C. & Dunjko, V. Exponential quantum advantages in learning quantum observables from classical data. arXiv preprint arXiv:2405.02027 (2024).
Caro, M. C. et al. Generalization in quantum machine learning from few training data. Nat. Commun. 13, 4919 (2022).
Chehimi, M. & Saad, W. Quantum federated learning with quantum data. In ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 8617–8621 (IEEE, 2022).
Dutta, S., Innan, N., Ben Yahia, S., Shafique, M. & Neira, D. E. B. MQFL–FHE: Multimodal quantum federated learning framework with fully homomorphic encryption. Accepted to IJCNN 2025. arXiv:2412.01858 (2024).
Yu, H., Qi, Z., Jang, L. K., Salakhutdinov, R., Morency, L.-P. & Liang, P. P. MMoE: Enhancing multimodal models with mixtures of multimodal interaction experts. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, 10006–10030 (2024).
Watkins, W. M., Chen, S. Y.-C. & Yoo, S. Quantum machine learning with differential privacy. Sci. Rep. 13, 2453 (2023).
Hirche, C., Rouzé, C. & França, D. S. Quantum differential privacy: An information theory perspective. IEEE Trans. Inf. Theory 69, 5771–5787 (2023).
Gao, X., Anschuetz, E. R., Wang, S.-T., Cirac, J. I. & Lukin, M. D. Enhancing generative models via quantum correlations. Phys. Rev. X 12, 021037 (2022).
Onim, M. S. H. & Thapliyal, H. Detection of physiological data tampering attacks with quantum machine learning. In Proceedings of the 2025 IEEE International Symposium on Circuits and Systems (ISCAS), 1–5 (IEEE, 2025).
Li, W., Lu, S. & Deng, D.-L. Quantum federated learning through blind quantum computing. Sci. China Phys. Mech. Astron. 64, 100312 (2021).
Broadbent, A., Fitzsimons, J. & Kashefi, E. Universal blind quantum computation. In 2009 50th annual IEEE symposium on foundations of computer science, 517–526 (IEEE, 2009).
Bernstein, D. J. & Lange, T. Post-quantum cryptography. Nature 549, 188–194 (2017).
Gupta, K. et al. An intelligent quantum cyber-security framework for healthcare data management. IEEE Transactions on Automation Science and Engineering (2024).
Nguyen, D. C. et al. Federated learning for smart healthcare: A survey. ACM Comput. Surv. ((Csur)) 55, 1–37 (2022).
Antunes, R. S., André da Costa, C., Küderle, A., Yari, I. A. & Eskofier, B. Federated learning for healthcare: Systematic review and architecture proposal. ACM Trans. Intell. Syst. Technol. ((TIST)) 13, 1–23 (2022).
Yi, J., Ye, W., Gottesman, D. & Liu, Z.-W. Complexity and order in approximate quantum error-correcting codes. Nat. Phys. 20, 1798–1803 (2024).
Wang, P.-H., Chen, J.-H., Yang, Y.-Y., Lee, C. & Tseng, Y. J. Recent advances in quantum computing for drug discovery and development. IEEE Nanotechnol. Mag. 17, 26–30 (2023).
Baiardi, A., Christandl, M. & Reiher, M. Quantum computing for molecular biology. ChemBioChem 24, e202300120 (2023).
Murphy, M. et al. Ibm and cleveland clinic unveil the first quantum computer dedicated to healthcare research. Quantum (2025).
Steffen, M., DiVincenzo, D. P., Chow, J. M., Theis, T. N. & Ketchen, M. B. Quantum computing: An ibm perspective. IBM J. Res. Dev. 55, 13–1 (2011).
Arute, F. et al. Quantum supremacy using a programmable superconducting processor. Nature 574, 505–510 (2019).
Mathur, N. et al. Medical image classification via quantum neural networks. arXiv preprint arXiv:2109.01831 (2021).
D’Arcangelo, M. et al. Leveraging analog quantum computing with neutral atoms for solvent configuration prediction in drug discovery. Phys. Rev. Res. 6, 043020 (2024).
Zhao, L. et al. Quantum-classical auxiliary field quantum monte carlo with matchgate shadows on trapped ion quantum computers. arXiv preprint arXiv:2506.22408 (2025).
Maskara, N. et al. Programmable simulations of molecules and materials with reconfigurable quantum processors. Nat. Phys. 21, 289–297 (2025).
Zhang, Y. et al. Prediction of protein three-dimensional structures via a hardware-executable quantum computing framework. arXiv preprint arXiv:2506.22677 (2025).
Agathangelou, A., Manawadu, D. & Tavernelli, I. Quantum algorithm for protein side-chain optimisation: Comparing quantum to classical methods. arXiv preprint arXiv:2507.19383 (2025).
Pallavi, G., Altalbe, A. & Kumar, R. P. Qkdti a quantum kernel based machine learning model for drug target interaction prediction. Sci. Rep. 15, 27103 (2025).
Ding, Q.-M., Huang, Y.-M. & Yuan, X. Molecular docking via quantum approximate optimization algorithm. Phys. Rev. Appl. 21, 034036 (2024).
Papalitsas, C. et al. Quantum approximate optimization algorithms for molecular docking. arXiv preprint arXiv:2503.04239 (2025).
Roy, S., Kot, L. & Koch, C. Quantum databases. In Proc. CIDR (2013).
Hamouda, I., Bahaa-Eldin, A. M. & Said, H. Quantum databases: Trends and challenges. In 2016 11th International Conference on Computer Engineering & Systems (ICCES), 275-280 (IEEE, 2016).
Pal, S., Bhattacharya, M., Lee, S.-S. & Chakraborty, C. Quantum computing in the next-generation computational biology landscape: From protein folding to molecular dynamics. Mol. Biotechnol. 66, 163–178 (2024).
Ross, J. et al. Large-scale chemical language representations capture molecular structure and properties. Nat. Mach. Intell. 4, 1256–1264 (2022).
Liu, L.-Z. et al. Distributed quantum phase estimation with entangled photons. Nat. photonics 15, 137–142 (2021).
Main, D. et al. Distributed quantum computing across an optical network link. Nature 1–6 (2025).
Polacchi, B. et al. Multi-client distributed blind quantum computation with the qline architecture. Nat. Commun. 14, 7743 (2023).
Paul, S. M. et al. How to improve r&d productivity: the pharmaceutical industry’s grand challenge. Nat. Rev. Drug Discov. 9, 203–214 (2010).
Kitchen, D. B., Decornez, H., Furr, J. R. & Bajorath, J. Docking and scoring in virtual screening for drug discovery: methods and applications. Nat. Rev. Drug Discov. 3, 935–949 (2004).
Babbush, R. et al. Low-depth quantum simulation of materials. Phys. Rev. X 8, 011044 (2018).
Jiang, D., Liu, X., Song, H. & Xie, H. An survey: Quantum phase estimation algorithms. In 2021 IEEE 5th Information Technology, Networking, Electronic and Automation Control Conference (ITNEC), vol. 5, 884–888 (IEEE, 2021).
Yuan, X. A quantum-computing advantage for chemistry. Science 369, 1054–1055 (2020).
Daina, A., Michielin, O. & Zoete, V. Swissadme: a free web tool to evaluate pharmacokinetics, drug-likeness and medicinal chemistry friendliness of small molecules. Sci. Rep. 7, 42717 (2017).
Xiong, G. et al. Admetlab 2.0: an integrated online platform for accurate and comprehensive predictions of admet properties. Nucleic acids Res. 49, W5–W14 (2021).
Kandala, A. et al. Hardware-efficient variational quantum eigensolver for small molecules and quantum magnets. nature 549, 242–246 (2017).
Moll, N. et al. Quantum optimization using variational algorithms on near-term quantum devices. Quantum Sci. Technol. 3, 030503 (2018).
Ciliberto, C. et al. Quantum machine learning: a classical perspective. Proc. R. Soc. A: Math., Phys. Eng. Sci. 474, 20170551 (2018).
Cerezo, M., Verdon, G., Huang, H.-Y., Cincio, L. & Coles, P. J. Challenges and opportunities in quantum machine learning. Nat. Computational Sci. 2, 567–576 (2022).
Rebentrost, P., Mohseni, M. & Lloyd, S. Quantum support vector machine for big data classification. Phys. Rev. Lett. 113, 130503 (2014).
Bender, B. J. et al. A practical guide to large-scale docking. Nat. Protoc. 16, 4799–4832 (2021).
Pyrkov, A. et al. Quantum computing for near-term applications in generative chemistry and drug discovery. Drug Discov. Today 28, 103675 (2023).
Austin, B. M., Zubarev, D. Y. & Lester Jr, W. A. Quantum monte carlo and related approaches. Chem. Rev. 112, 263–288 (2012).
Plekhanov, K., Rosenkranz, M., Fiorentini, M. & Lubasch, M. Variational quantum amplitude estimation. Quantum 6, 670 (2022).
Scannell, J. W., Blanckley, A., Boldon, H. & Warrington, B. Diagnosing the decline in pharmaceutical r&d efficiency. Nat. Rev. Drug Discov. 11, 191–200 (2012).
Fogel, D. B. Factors associated with clinical trials that fail and opportunities for improving the likelihood of success: a review. Contemp. Clin. trials Commun. 11, 156–164 (2018).
Turon, G., Arora, D. & Duran-Frigola, M. Infectious disease research laboratories in africa are not using ai yet– large language models may facilitate adoption. ACS Infect. Dis. 10, 3083–3085 (2024).
Guerreschi, G. G. & Matsuura, A. Y. Qaoa for max-cut requires hundreds of qubits for quantum speed-up. Sci. Rep. 9, 6903 (2019).
Zhou, L., Wang, S.-T., Choi, S., Pichler, H. & Lukin, M. D. Quantum approximate optimization algorithm: Performance, mechanism, and implementation on near-term devices. Phys. Rev. X 10, 021067 (2020).
Lyu, J. et al. Ultra-large library docking for discovering new chemotypes. Nature 566, 224–229 (2019).
Gorgulla, C. et al. An open-source drug discovery platform enables ultra-large virtual screens. Nature 580, 663–668 (2020).
Gentile, F. et al. Artificial intelligence–enabled virtual screening of ultra-large chemical libraries with deep docking. Nat. Protoc. 17, 672–697 (2022).
Grassl, M., Langenberg, B., Roetteler, M. & Steinwandt, R. Applying grover’s algorithm to aes: quantum resource estimates. In International Workshop on Post-Quantum Cryptography, 29–43 (Springer, 2016).
Lloyd, S., Mohseni, M. & Rebentrost, P. Quantum principal component analysis. Nat. Phys. 10, 631–633 (2014).
Jain, P. & Ganguly, S. Hybrid quantum generative adversarial networks for molecular simulation and drug discovery. arXiv preprint arXiv:2212.07826 (2022).
U.S. Food and Drug Administration (FDA). Fda: The drug development process. https://www.fda.gov/patients/learn-about-drug-and-device-approvals/drug-development-process Accessed 2018-01-04 (2018).
U.S. Food and Drug Administration. Pdufa vii: Performance goals and procedures fiscal years 2023 through 2027. https://www.fda.gov/media/151712/download Accessed 2021-09-21 (2021)
NIH National Center for Advancing Translational Sciences (NCATS). Translational science for drug development: Typical timelines. https://ncats.nih.gov/translation/spectrum Accessed 2025-05-30 (2024).
U.S. National Library of Medicine (NLM), National Institutes of Health. Clinicaltrials.gov: Trends and charts on registered studies. https://clinicaltrials.gov/about-site/trends-charts Accessed 2025-08-15 (2025).
Polishchuk, P. G., Madzhidov, T. I. & Varnek, A. Estimation of the size of drug-like chemical space based on gdb-17 data. J. computer-aided Mol. Des. 27, 675–679 (2013).
Tingle, B. I. et al. Zinc-22- a free multi-billion-scale database of tangible compounds for ligand discovery. J. Chem. Inf. modeling 63, 1166–1176 (2023).
Zhou, G. et al. An artificial intelligence accelerated virtual screening platform for drug discovery. Nat. Commun. 15, 7761 (2024).
Acknowledgements
We thank Weikang Li for his helpful discussions. JL is supported in part by the University of Pittsburgh, School of Computing and Information, Department of Computer Science, Pitt Cyber, and the PQI Community Collaboration Awards. This research used resources of the Oak Ridge Leadership Computing Facility, which is a DOE Office of Science User Facility supported under Contract DE-AC05-00OR22725. Z.L.’s work is supported in part by the IBM–RPI Future of Computing Research Collaboration and in part by the National Science Foundation under Award No. 2519029. FTC's work is funded in part by EPiQC, an NSF Expedition in Computing, under award CCF-1730449; in part by STAQ under award NSF Phy-1818914/232580; in part by the US Department of Energy Office of Advanced Scientific Computing Research, Accelerated Research for Quantum Computing Program; and in part by the NSF Quantum Leap Challenge Institute for Hybrid Quantum Architectures and Networks (NSF Award 2016136), in part based upon work supported by the U.S. Department of Energy, Office of Science, National Quantum Information Science Research Centers, in part by Wellcome-Leap’s Q4Bio program, and in part by the Army Research Office under Grant Number W911NF-23-1-0077. The views and conclusions contained in this document are those of the authors and should not be interpreted as representing the official policies, either expressed or implied, of the U.S. Government. The U.S. Government is authorized to reproduce and distribute reprints for Government purposes notwithstanding any copyright notation herein. FTC is the Chief Scientist for Quantum Software at Infleqtion and an advisor to Quantum Circuits, Inc.
Author information
Authors and Affiliations
Contributions
Y.Z., J.T.C., J.L.C., X.C., and Y.Z., wrote the main manuscript, Y.Z. and J.T.C. are prepared figures, G.K., M.Z., and F.C., are observe the project, Z.L., J.L., and T.F. are mentored the project. All authors reviewed the manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Zhou, Y., Chen, J., Cheng, J. et al. Quantum-machine-assisted drug discovery. npj Drug Discov. 3, 1 (2026). https://doi.org/10.1038/s44386-025-00033-2
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s44386-025-00033-2
