
Abstract
Synthesizing brain MRI lesions is challenging due to the heterogeneity of lesion characteristics and the complexity of capturing fine-grained pathological information across MRI contrasts. Additionally, leveraging complementary information across multiple contrasts is difficult due to their diverse feature representations. To address these challenges, we propose a mutual learning-based framework with an adversarial diffusion approach. Our framework uses two denoising networks: one captures contrast-specific features to handle diverse representations, while the other emphasizes contrast-aware adaptation to model subtle pathological variations. A shared critic network ensures consistency, facilitates collaborative learning, and identifies critical lesion regions for focused synthesis. We benchmark our method on two public lesion datasets, treat each contrast as a missing target, and validate it on a brain tumor and multi-contrast healthy MRI dataset. Our approach outperforms state-of-the-art methods, delivering accurate lesion synthesis and superior downstream segmentation performance, highlighting the diagnostic value and accuracy of the proposed framework.
Similar content being viewed by others

Introduction
The diagnosis and prognosis of brain lesions require routine multi-contrast Magnetic Resonance Imaging (MRI)1. Visualizing and quantifying the lesion regions is essential as each MRI contrast provides critical information for assessing the progression and conditions of the brain lesions. For instance, gliomas consist of various tissue types such as necrotic core, active tumor margins, and edematous tissue2 where multi-contrast MRI helps identify these distinct components. T1-weighted MRI reveals detailed anatomical structures, while T2-weighted and FLAIR images are fluid-sensitive, highlighting lesion areas in observing edematous tissues. T1-weighted imaging with contrast enhancement (T1CE) further improves lesion visualization, making it highly effective for identifying active components of tumors, abscesses, and inflammation that might not be visible on non-contrast scans3. Additionally, multi-contrast MRI is widely used in routine clinical scans for conditions like Multiple Sclerosis4, proving more accurate for lesion tissue identification than single-contrast MRI. It is also extensively applied in downstream quantification tasks, including tumor segmentation.
However, acquiring all these contrasts can be challenging due to increased scanning time, cost, and the potential for image artefacts and noise5,6. Moreover, using gadolinium-based contrast agents in contrast-enhanced images carries safety concerns7. Consequently, synthesizing missing or corrupted contrasts from available ones offers a promising solution for clinical lesion workflows. With the advancement of deep learning techniques in medical imaging, tremendous progress has been made in cross-contrast image synthesis5,8,9. This addresses the limitations of multi-contrast image acquisition and offers a safer alternative for patients at risk, such as those with kidney issues or pediatric patients, by reducing the need for contrast-enhanced agents in lesion diagnosis7. Lesion MRI synthesis using multi-contrast imaging is particularly challenging10 due to several factors. First, brain lesions exhibit significant heterogeneity in attributes such as shape, intensity, and texture. These variations introduce substantial uncertainty during synthesis, as the process must not only replicate the underlying anatomical features of the brain but also accurately represent the pathological characteristics, making the synthesis of lesion regions more challenging. Second, lesions often display varying appearances across different MRI contrasts. For example, a lesion may appear as a well-defined hyperintense region in one contrast but hypointense or isointense in others11. Capturing these nuanced cross-contrast relationships is crucial in lesion MRI synthesis to effectively navigate these ambiguities across them. Therefore, incorporating the uncertainty-based adaptive learning method12,13,14 is vital for capturing critical cross-contrast information and ensuring the model is confident about key areas, thereby preserving the fidelity of the lesions.
Various image translation and missing data imputation methods have been proposed for multi-contrast MRI synthesis, leveraging the intricate correlations between MRI contrasts5. These methods focus on effectively fusing features from different MRI contrasts to synthesize missing modalities. For instance, some approaches15,16,17 combine latent-level features from multiple contrasts using pixel-level operations. In contrast, Zhan et al.18 uses a separate ResNet-based module to prevent the loss of essential features during fusion. Another method, Sharma et al., integrates multi-contrast MRI information by replacing missing sequences with pre-imputations and using implicit conditioning for sequence-selective loss computation19. Additionally, some approaches utilize hierarchical feature representations16,20 and brain region masks21 as density distribution priors to better capture inter- and intra-class dependencies. Despite these advancements, limitations remain. Many existing methods fail to fully exploit complementary information across contrasts due to their reliance on rigid fusion strategies, which can misrepresent tissue details. Additionally, they lack adaptive learning for diverse multi-contrast features and effective uncertainty modeling, which are crucial for addressing the complexity and heterogeneity inherent in lesion synthesis5.
To address these challenges, we present a novel mutual learning-based22 solution as illustrated in Fig. 1 that incorporates adaptive feature modeling of MRI contrasts with an uncertainty-driven method, facilitating the synthesis of clinically relevant contrasts to assist radiologists in diagnostic decision-making. Our primary goal is to synthesize missing contrasts with a focus on lesion-relevant details. The proposed method generates the entire brain MRI to maintain anatomical consistency across all regions, ensuring that both lesion-specific features and overall anatomical structures are preserved. This collaborative learning framework involves two denoising diffusion-based synthesis networks23 that mutually learn together on distinct feature representations of multi-contrast inputs with a shared critic network. Each synthesis network has a distinct role. One network emphasizes comprehensive structural information, ensuring the preservation of anatomical details during the synthesis, while the other network emphasizes fine-grained texture details crucial for accurate lesion depiction through a novel adaptive feature selection mechanism and a novel attentive mask loss for uncertainty estimation. Mutual learning facilitates knowledge sharing between these networks, encouraging them to refine their respective feature representations. Unlike conventional mutual learning frameworks, our method assigns distinct feature learning objectives to each network, fostering the extraction of complementary information. This integration enables our framework to better capture diverse feature characteristics across MRI contrasts, effectively handling their inter-contrast variability and lesion heterogeneity.

aVisualization of dataset distribution across different subject groups (brain tumor, stroke lesion, and healthy subjects) with respective splits for training, validation, and testing. The checkmarks (✓) and crosses ( × ) indicate the availability of each MRI contrast across different synthesis tasks. In the BraTS dataset, which includes all four MRI contrasts, different synthesis scenarios are simulated by selecting one MRI contrast as the missing target contrast to be synthesized using the remaining available contrasts. bThe proposed MRI synthesis framework takes multi-contrast MRI data as input. A synthesis model generates a target contrast (FLAIR in this example - Task3) using input contrasts (e.g., T1ce, T1w, T2w). Two denoising networks, \({{\mathcal{F}}}_{1}\) and \({{\mathcal{F}}}_{2}\), are trained mutually together, with ψ( ⋅ ) acting as a shared critic network to distinguish between real and synthesized FLAIR images. c Synthesized FLAIR images are compared against ground-truth images using Structural-Index-Similarity-Measure (SSIM), Peak-Signal-to-Noise-Ratio(PSNR), and Mean Absolute Error (MAE) metrics. Additionally, the synthesized contrasts are evaluated in a downstream tumor segmentation task to assess the diagnostic value of synthetic results. d Boxplots summarizing quantitative evaluation metrics for the lesion regions within the synthesized contrasts across different baseline methods, highlighting the performance of the proposed method.
Our evaluation results demonstrate improved quality in lesion synthesis contrasts on two publicly available datasets: Brain Tumor Segmentation (BraTS)24 and Ischemic Stroke Lesion Segmentation Challenge (ISLES)25. We assess the synthesized images both quantitatively and qualitatively, considering the entire brain region as well as the lesion region separately. For lesion-specific assessment, we employ lesion masks to evaluate the synthesis quality in those areas. Additionally, we evaluate our model on a similar multi-contrast dataset to assess its performance across different data distributions. We also validate the model’s performance on healthy subjects with a multi-contrast 3T MRI dataset. Beyond quantitative and qualitative assessments, we also assess the accuracy of synthetic contrasts through downstream segmentation performance, demonstrating their diagnostic value. The overview of the MU-Diff framework is illustrated in Fig. 2.

a The architecture pipeline: \({{\mathcal{H}}}_{1}(\cdot )\) and \({{\mathcal{H}}}_{2}(\cdot )\) represent the encoder-decoder frameworks of the two denoising networks \({{\mathcal{F}}}_{1}(\cdot )\) and \({{\mathcal{F}}}_{2}(\cdot )\), respectively. ϕ1( ⋅ ) and ϕ2( ⋅ ) denote the respective contrast-specific feature mapping modules. ρ( ⋅ ) and τ( ⋅ ) represent a target-specific feature adapter module and a contrast-aware feature adapter module, respectively. Here, ϕ1( ⋅ ) and \({{\mathcal{H}}}_{1}(\cdot )\) collectively form the functional decomposition of \({{\mathcal{F}}}_{1}(\cdot )\), while ρ( ⋅ ), ϕ2( ⋅ ), τ( ⋅ ), and \({{\mathcal{H}}}_{2}(\cdot )\) collectively represent the functional decomposition of \({{\mathcal{F}}}_{2}(\cdot )\). Both networks share a critic network, denoted as ψ( ⋅ ). Here, x represents the target contrast to be synthesized from the conditional contrasts \({\left\{{{\bf{y}}}_{i}\right\}}_{i = 1}^{n}\), and xt refers to the noisy version of x at timestep t. \({{\bf{x}}}^{{p}_{1}}\) and \({{\bf{x}}}^{{p}_{2}}\) denote the corresponding denoised contrasts from each network, while \({{\bf{x}}}_{t-1}^{{p}_{1}}\) and \({{\bf{x}}}_{{\rm{t}}-1}^{{p}_{2}}\) represent the sampled predictions at timestep t-1. Z1 and Z2 denote the adversarial outputs from ψ( ⋅ ), and M1, M2 are feature-attentive masks generated by ψ( ⋅ ). Step 1 introduces Gaussian noise to x, and yi are conditional inputs for \({{\mathcal{F}}}_{1}(\cdot )\). Step 2 generates \({{\bf{x}}}^{{p}_{1}}\), followed by calculating supervised loss \({{\mathcal{L}}}_{s}^{1}\) between x and \({{\bf{x}}}^{{p}_{1}}\). In Step 3, the output of \({{\mathcal{F}}}_{1}(\cdot )\) is passed to ρ( ⋅ ). Step 4 processes the output from Step 3 and the input contrasts using ϕ2( ⋅ ), followed by processing in Step 5 with τ( ⋅ ). Step 6 generates \({{\bf{x}}}^{{p}_{2}}\) via \({{\mathcal{H}}}_{2}(\cdot )\), and supervised loss \({{\mathcal{L}}}_{s}^{2}\) is calculated between x and \({{\bf{x}}}^{{p}_{2}}\). Step 7 generates the noisy contrast at t-1 from the predicted outputs, while critic losses \({{\mathcal{L}}}_{c}^{1}\) and \({{\mathcal{L}}}_{c}^{2}\) are calculated. Step 8 computes mask-attentive losses \({{\mathcal{L}}}_{m}^{1}\) and \({{\mathcal{L}}}_{m}^{2}\). b Centered Kernel Alignment (CKA) similarity between the encoder and decoder sections of the networks, followed by ϕ( ⋅ ) and ρ( ⋅ ) pipelines. c The τ( ⋅ ) pipeline, individual loss terms, and averaged noise predictions of networks.
Results
MU-Diff leverages an adaptive feature modeling of multi-contrast MR images through a mutually learned adversarial diffusion network. The proposed method is evaluated through a comprehensive experimental setup using two multi-contrast MRI lesion datasets. The synthetic results compare the performance of MU-Diff with other baseline models across various tasks, considering each available contrast as the missing contrast while using the remaining contrasts as conditioning inputs. Beyond lesion synthesis, the results also include the model’s performance on healthy subjects, demonstrating its applicability beyond lesion-focused tasks.
Evaluation of synthesis accuracy for whole brain MRI
We evaluated MU-Diff on two lesion datasets to determine the anatomical accuracy from the synthesized images: BraTS and ISLES datasets. In the BraTS dataset, we synthesized T1CE, FLAIR, T2, and T1 contrasts, with each target contrast conditioned on the remaining three. Similarly, we synthesized FLAIR and T1 contrasts in the ISLES dataset under the same conditioning approach. Figure 3a compares MU-Diff’s synthesis results on the BraTS dataset with other baseline models. MU-Diff outperformed other methods across the full brain region, showing superior image quality and accuracy in all scenarios. Comparing among different generative models, conventional models like Pix2Pix and pGAN yielded lower accuracy, and diffusion models like SynDiff demonstrated improved results. However, MU-Diff still surpassed them by producing high-fidelity outputs with minimal artefacts. DDPM introduced noticeable artefacts and noise, especially compared to adversarial diffusion-based methods (SynDiff and MU-Diff). T1CE emerged as a particularly challenging but clinically valuable target when evaluating performance across MRI contrasts. MU-Diff achieved highly accurate T1CE synthesis in this scenario, whereas other methods struggled with contrast enhancement synthesis. We also assessed MU-Diff on the ISLES stroke lesion dataset, a challenging dataset requiring nuanced lesion modeling. Results in Fig. 3b demonstrate MU-Diff’s better synthesis quality across all three contrasts, with lesions more distinctly separated from surrounding tissue, outperforming other baseline methods. We further tested MU-Diff on a similar but unseen dataset not used in training, as shown in Supplementary Data 3. These results highlight the robust performance of MU-Diff on unseen datasets.

a Experimental results on BraTS dataset. b Experimental results on ISLES dataset. In both datasets, each row showcases the synthesis results for a specific contrast, with the remaining contrasts in the dataset serving as conditional inputs. The first column presents the actual ground truth contrast (GT), while the following columns display synthesis results from baseline models and MU-Diff. The zoomed-in region highlights the lesions, with red arrows marking areas where synthesis accuracy shows notable improvement. SSIMB and SSIMT indicate the SSIM values for the entire brain and lesion regions displayed below each image to quantify visual similarity further. Supplementary Data 1 and Supplementary Data 2 show more qualitative results.
In addition to the qualitative comparisons, we evaluated synthesis results using three metrics: Peak Signal-to-Noise Ratio (PSNR), Structural Similarity Index (SSIM), and Mean Absolute Error (MAE) between synthesized and actual contrasts, assessed for the whole brain region, excluding the background. Table 1 summarizes the BraTS dataset results in the whole brain area, showing that MU-Diff outperforms other methods, achieving consistently higher performance (P < 0.05 in paired t-test on group mean values) across all metrics (i.e., PSNRB, SSIMB, and MAEB). Similarly, for the ISLES dataset’s whole-brain region across all synthesis tasks, MU-Diff achieves better results (P < 0.05 in paired t-test on group mean value) compared to other baselines, as shown by the results in Table 1. In addition to lesion MRI synthesis, we further extended our evaluation to the healthy multi-contrast MRI dataset to showcase the proposed method’s performance on the healthy cohort. Supplementary Data 4a and Supplementary Data 4b show both qualitative and quantitative results on healthy subjects compared to other baselines. Here, we considered a synthesis of FLAIR, T2, and T1 contrasts, conditioned on the other remaining contrasts similar to the lesion synthesis. As shown by the results, it is evident that our proposed method could achieve comparably better results with improved clarity for fine-grain tissue structures.
Evaluation of synthesis accuracy for brain lesions
We further assessed the synthesis accuracy in lesion regions alongside the whole brain. We used whole tumor segmentation masks from each dataset to isolate the lesion areas in the ground truth and synthesized contrasts, calculating metrics specifically for these regions while excluding the background. For the BraTS dataset, we evaluated lesion accuracy across all four synthesis contrasts. In Fig. 3a, we present zoomed-in lesion regions with SSIM similarity scores below each contrast image. The results show that MU-Diff achieves high-fidelity lesion synthesis across all contrasts, accurately capturing sharper boundaries, structural integrity, and fewer distortions than other methods. For more challenging tasks like contrast-enhanced synthesis, MU-Diff demonstrates more accurate results, reproducing enhanced lesion intensities more accurately than other baselines, which often struggle to consistently match ground truth in these regions. Additionally, MU-Diff synthesizes finer details and small-scale variations within lesions, as highlighted by the arrows. Similarly, we evaluated lesion synthesis accuracy for the stroke lesion dataset using the provided lesion masks. As shown in Fig. 3b, MU-Diff outperformed other baselines in lesion synthesis, achieving higher structural similarity scores for lesion regions in each contrast. Alongside qualitative comparisons, Table 2 shows a quantitative comparison of lesion regions indicated by PSNRT, SSIMT, and MAET on lesion regions. The comparison of results shows that the MU-Diff outperforms other baselines by achieving significant improvement across all synthesis tasks with P < 0.05 in the BraTS dataset and across many functions in the ISLES dataset with P < 0.05. The distribution analysis of scores in Supplementary Data 5 and Supplementary Data 6 further supports this. These box plots illustrate each method’s minimum, maximum, median, and interquartile range for PSNR and SSIM values. Analysis of these distributions reveals that MU-Diff achieves a higher median accuracy across all synthesis tasks, indicating its comparably better performance. Additionally, MU-Diff shows a narrower interquartile range across many tasks, reflecting more consistent accuracy compared to other baselines.
Validation on robustness to motion artefacts
During MR imaging acquisition, patient movement is common, especially for patients with conditions, and often leads to artefacts in the scans26,27. We introduced artificially generated motion artefacts28 into the conditional contrast to assess MU-Diff’s robustness to these artefacts. We chose T1CE synthesis with FLAIR as the conditional contrast to include these artefacts. Figure 4a compares synthesis results with the artefact-affected conditional contrast for Syndiff, the second-best performing model on the BraTS dataset alongside MU-Diff. The robustness analysis highlights MU-Diff’s ability to generate accurate results despite the motion artefacts in the conditional contrasts. Additionally, the quantitative comparison in Fig. 4b shows that MU-Diff maintains its performance even with artefact-affected conditional contrasts. This demonstrates MU-Diff’s enhanced robustness to motion artefacts, a crucial aspect in medical imaging.

a Qualitative analysis of model robustiness for T1CE synthesis with and without (w/o) motion artefacts introduced for FLAIR conditional contrast. b Quantitative comparison of model robustness test. c Dice score values for segmentation accuracy on synthetic MRI contrasts. Each × mark denotes the contrast replaced by the synthetic results from each method. d Qualitative comparison of segmentation results with synthetic data. Each row presents segmentation masks for missing data imputation tasks from A to F. The first column shows the ground truth mask, while the second column displays the segmentation mask using all four actual contrasts as inputs. Each subsequent column shows the predicted masks, where specific missing contrasts from the input contrasts are replaced with synthetic results from each method.
Validation on lesion segmentation accuracy
To assess the synthesis quality of our results, we evaluated their performance in lesion segmentation as a downstream task. Using the BraTS dataset, we trained a segmentation network that takes all four MRI contrasts as inputs and predicts the segmentation mask, employing the same train-test split used in the synthesis task. For this, we utilized MONAI’s UNet model29. As shown in Fig. 4c, we evaluated six tasks, each with different contrasts replaced by synthesis results from various methods, and calculated segmentation accuracy using the Dice score. The segmentation model utilizes all four MRI contrasts as input for every task. In this table, a ✓ mark indicates the use of the actual contrast from the test dataset, while an × mark denotes that the corresponding contrast has been replaced by a synthetic contrast from MU-Diff or SynDiff. “Complete” refers to segmentation accuracy using all four contrasts from the actual test images without synthetic replacements. Conversely, when all four entries are marked with an × it indicates that the model receives all four synthetic contrasts as input instead of the original test dataset contrasts. For comparison, we selected the top-performing models from the synthesis tasks. The segmentation accuracy shows that MU-Diff consistently achieved higher scores than other baselines. Notably, in many tasks, MU-Diff’s performance closely approached that of the “complete” setup, and it even surpassed “complete” accuracy when synthesizing T1CE, a particularly challenging contrast to generate. Fig. 4d provides a qualitative comparison of segmentation masks for each task, with predicted masks overlaid on the FLAIR contrast. The quantitative results further emphasize the comparably better accuracy of segmentation masks achieved with MU-Diff-generated images, demonstrating its synthesis quality.
Effectiveness of the adaptive feature selection
MU-Diff’s Contrast-Aware Feature Adaptive Module selectively extracts key features from each conditional contrast, regulating the flow of contrast-specific features between them. To evaluate this, we focused on T1CE synthesis and visualized feature representation maps from each conditional contrast as in Fig. 5a. As shown by the results, in FLAIR contrast, the highlighted features are concentrated on the lesion region, which is essential for accurately representing the lesion in T1CE. T2 provides a combination of lesion-specific features and finer structural details, balancing anatomical and pathological information to support the synthesis process. In addition, T1 emphasizes structural details, providing the anatomical context required for accurate T1CE synthesis. The overall representation demonstrates that feature adaptation selectively extracts the most relevant features from each conditional contrast to contribute to the synthesis of the target contrast.

a Visualization of feature maps from the contrast-aware adaptive module on FLAIR, T2, and T1 conditions to synthesize T1CE. b Attentive feature maps (M1, M2) from the critic network applied to predictions from the two generative diffusion networks. c Prediction results from each denoising network (\({{\bf{x}}}^{{p}_{1}}\), \({{\bf{x}}}^{{p}_{2}}\)) and the mutual prediction from MU-Diff. d Quantitative comparison of individual prediction of denoising networks (\({{\mathcal{F}}}_{1}\), \({{\mathcal{F}}}_{2}\)) and mutual prediction from MU-Diff. e Effect of different timestep T in the denoising process. f Ablation on critic network using FID scores. g Ablation results on BraTS Dataset for whole brain regions. h Ablation results on BraTS Dataset for lesion regions. abl1 uses a single network without mutual learning; abl2 uses mutual learning w/o any feature adaptation; abl3 includes ϕ w/o ρ; abl4 w/o mask loss (\({{\mathcal{L}}}_{m}\)). i Qualitative comparison for each ablation.
Estimation of lesion uncertainty during snythesis
Focusing on uncertain regions is crucial in medical image synthesis, especially for accurate lesion synthesis. To achieve this, we used a critic network within a GAN-based framework30, leveraging its discriminative features. MU-Diff generates attentive masks from the critic network, using this information on key regions to estimate confidence regions that need more attention during the denoising process. Figure 5b visualizes these attentive feature maps (M1 and M2) on each prediction from two denoising networks for T1CE synthesis as a heatmap: yellow indicates highly attentive or high-confidence areas requiring more focus during synthesis, while blue represents low-confidence regions. These heatmaps reveal that lesion boundary areas are identified as critical, prompting increased focus during synthesis through a mask-attentive loss function.
Effectiveness of mutually learned feature representation across networks
To understand the mutual learning behavior of MU-Diff, we analyzed both denoising networks using Centered Kernel Alignment (CKA) to assess the feature dependency between them31. CKA is a similarity measure that evaluates feature representations in neural networks based on the Hilbert-Schmidt Independence Criterion (HSIC)32. It assesses the similarity by comparing how a set of inputs is represented across the selected layers in networks. Its value ranges from 0 to 1, where 0 indicates no similarity and 1 indicates identical feature representations across two networks. Figure 2b shows heatmaps of CKA values for each network’s encoder and decoder layers separately. In the encoder heatmaps, most CKA values are below 0.55, indicating that the two encoders learn distinct and dissimilar feature representations. Additionally, the first few encoder layers are more dissimilar than the later ones, verifying that the networks capture unique features despite using the same inputs. The initial layers in the decoder layers show higher CKA values, with many above 0.7, indicating increased mutual understanding between the two networks. Toward the final decoder layers, the feature representations become more distinct again, suggesting that the networks learn unique synthetic representations. These findings show that, even with the same input contrasts, MU-Diff’s denoising networks learn diverse feature sets, effectively supporting the mutual learning process, which creates plausible synthetic contrast representations as shown in Fig. 5c. This approach allows for a nuanced correlation between contrasts, resulting in more detailed, accurate, and consistent synthetic outputs. Through mutual learning, the network refines these contrast-specific features, enhancing anatomical and pathological details in the synthetic contrasts and ultimately contributing to high-fidelity synthesis.
Discussion
Multi-contrast MRI is essential in diagnosing brain lesions as each contrast provides complementary information that enhances diagnostic accuracy. However, challenges in image acquisition can hinder routine scanning and reduce consistency. To address this, medical image synthesis has become a key research direction, allowing the synthesis of realistic and accurate images from available contrasts. Our work presents a multi-contrast MRI synthesis method designed for brain lesion imaging, demonstrating improved accuracy across multiple lesion datasets compared to other state-of-the-art methods. MU-Diff uses a mutual learning framework with an adversarial diffusion-based approach for adaptive feature learning across multiple contrasts. The proposed method synthesizes the entire brain MRI to maintain anatomical consistency across all regions, ensuring both lesion-specific features and overall anatomical structures are preserved. Experimental results show that a mutual learning-based framework supports high-fidelity lesion synthesis, aided by attentive feature selection components that guide the denoising process to focus on critical regions.
In clinical routine MRI, image artefacts, such as those caused by patient motion, are common. In this work, we have evaluated the performance of MU-Diff in addressing these practical challenges, presenting proof-of-principle results on its robustness. MU-Diff has shown stable performance against artefacts in the input contrasts, especially in challenging tasks like synthesizing T1CE contrasts. This is particularly valuable in clinical contexts, as it reduces the need for costly contrast-enhanced agents. Moreover, it provides a safer alternative for patients with contraindications for contrast agents, such as those susceptible to nephrogenic systemic fibrosis21 or pediatric patients. Additionally, MU-Diff’s capability extends to synthesizing T2, FLAIR, and T1 contrasts, which can offer practical benefits in certain scenarios. Synthesizing T2 and FLAIR can be useful in cases where these contrasts are missing or of poor quality, helping to improve lesion detection, segmentation, or longitudinal study consistency5. Similarly, while T1 is typically acquired in clinical practice, its synthesis can enhance data coherence by generating a standardized T1 representation that aligns with the available contrasts across multiple centers. Moreover, synthetic T1 can also offer a more reliable reference when original T1 contrasts suffer from motion artifacts, low resolution, or any inconsistencies. The synthesis of different contrasts can improve both clinical workflows and research applications by enhancing data completeness in multi-contrast studies.
Despite MU-Diff’s strengths in lesion MRI synthesis, certain limitations should be noted. Currently, the model is configured for a fixed number of inputs, restricting it from handling arbitrary combinations of input contrasts. Our main goal was to focus on synthesizing post-contrast MRI images from pre-contrast scans, a task with high clinical value, and to explore how we can adaptively learn the correlations between contrasts when multiple images are available. Therefore, in future work, we aim to extend MU-Diff to accommodate arbitrary input combinations for broader applicability. Additionally, the adversarial diffusion model requires more computational resources than conventional diffusion methods due to the high number of parameters involved. Furthermore, to ensure reliable clinical evaluation, multi-center evaluation is necessary to assess MU-Diff’s generalizability across diverse clinical settings.
Methods
This section starts with a conceptual overview of the proposed method, provided in Fig. 2. We then explain each module in detail and its end-to-end training pipeline.
Problem formulation
We denote vectors and matrices in bold lower-case x and bold upper-case X, respectively. Norm of a vector is denoted by ∥ ⋅ ∥ and \(\parallel {\bf{x}}{\parallel }_{1}={\sum }_{i}\left\vert {\bf{x}}[i]\right\vert\), where \(\overrightarrow{x}[i]\) shows the element at position i in x. The inner product between vectors is shown by 〈 ⋅ , ⋅ 〉 and \(\parallel {\bf{x}}{\parallel }_{2}^{2}=\langle {\bf{x}},{\bf{x}}\rangle\). When norms and inner products are used over 2D tensors, we assume tensors are flattened accordingly. For example, for 2D tensors A and B, 〈A, B〉 = ∑i,jA[i, j]B[i, j] and \(\parallel {\bf{A}}{\parallel }_{1}={\sum }_{i,j}\left\vert {\bf{A}}[i,j]\right\vert\).
Let \({\mathcal{X}}={({{\bf{X}}}_{k},{{\bf{Y}}}_{k})}_{k = 1}^{m}\), be a set of m image samples where each sample (xk, yk) represents a co-registered MRI contrasts. Here \({{\bf{x}}}_{k}\in {{\mathbb{R}}}^{C\times H\times W}\) denotes the target MRI contrast to be synthesized, and \({{\bf{y}}}_{k}={\{{{\bf{y}}}_{k,i}\}}_{i = 1}^{n}\); \({y}_{i}\in {{\mathbb{R}}}^{C\times H\times W}\) represents the source contrasts, with n being the number of conditional source contrasts used to generate the target contrast. Here, C, H, and W represent the number of channels, height, and width of the input contrasts, respectively. ⊕ represents the concatenation along the channel dimension of the feature vectors. The main objective is to mutually train two conditional diffusion networks, \({{\mathcal{F}}}_{1}(\cdot )\) and \({{\mathcal{F}}}_{2}(\cdot )\), on different feature representations of the input contrasts \({f}_{c}^{1}\) and \({f}_{c}^{2}\) as in Eq. (2) and Eq. (2). Our framework synthesizes the complete brain MRI to ensure anatomical consistency throughout all regions, effectively preserving both lesion-specific characteristics and overall structural details.
where ϕ1( ⋅ ) denote the feature mapping module of \({{\mathcal{F}}}_{1}\) and \({{\mathcal{H}}}_{1}(\cdot )\) represent the encoder-decoder frameworks of the denoising networks \({{\mathcal{F}}}_{1}(\cdot )\).
where ϕ2( ⋅ ) denote the feature mapping module of \({{\mathcal{F}}}_{2}\) and ρ( ⋅ ), τ( ⋅ ) represent a target-specific feature adapter module and a contrast-aware feature adapter module respectively within the second denoising network \({{\mathcal{F}}}_{2}\). \({{\mathcal{H}}}_{2}(\cdot )\) represent the encoder-decoder frameworks of the denoising networks \({{\mathcal{F}}}_{2}(\cdot )\). In our equations, Θ1 encapsulates all the parameters of \({{\mathcal{F}}}_{1}\) which are θ1 and θ2. Similarly, Θ2 encapsulates all the parameters of \({{\mathcal{F}}}_{2}\) which are θ3, θ4, θ5 and θ6.
For \({{\mathcal{F}}}_{1}\), each noisy and conditional contrasts are processed through the Multi-Contrast Feature Mapper module (ϕ1) to derive their feature representation \({f}_{c}^{1}\) as in Eqs. (1) and (2). Similarly, for \({{\mathcal{F}}}_{2}\), the same noisy and conditional contrast inputs are processed through the Multi-Contrast Feature Mapper module (ϕ2), followed by an adaptively weighted representation of these conditional inputs via target-specific (ρ) and contrast-aware (τ) feature adaptation as in Eqs. (3) and (4).
Deep mutual learning
Deep mutual learning22 was initially introduced as a solution to model distillation, traditionally framed as an optimization problem where a student network mimics a teacher network to gain additional insights beyond standard supervised learning. In contrast to conventional model distillation methods, deep mutual learning involves two untrained student networks learning to solve a specific task, aligning their predictions with each other. This collaborative learning process has shown significantly better results than conventional supervised and independent learning methods mainly because each student network is guided by a traditional supervised loss, ensuring they focus on improving their performance without deviating towards arbitrary distributions. Although both networks learn to predict the same target, their different initial conditions lead them to develop distinct representations. These diverse representations provide additional insights, which can be effectively pooled together to collectively estimate the target distribution more accurately. The versatility of deep mutual learning extends beyond concerns of model size to focus primarily on improving task accuracy22.
Denoising diffusion probabilistic model
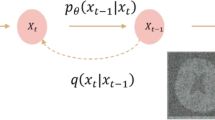
Denoising Diffusion Probabilistic Models (DDPMs) involve two fundamental processes: forward and reverse diffusion23. In the forward diffusion process, random Gaussian noise is added to the input data over a series of sufficiently large time steps, and the reverse diffusion process denoises the perturbed data to reconstruct the original distribution.
The training process of MU-Diff begins similarly to a conventional diffusion model, following a forward diffusion process that progressively adds noise to the target image contrast x0 in t steps as follows.
where βt is the noise variance schedule that is used to add noise to the data, \({\mathcal{N}}\) is the Gaussian distribution, and I is the identity covariance matrix. Based on the Markov property of the diffusion process, the marginal distribution of noisy target contrast xt can be directly derived from the initial target contrast as follows,
where αt: = 1 − βt and \(\bar{{\alpha }_{{\rm{t}}}}:=\mathop{\prod }\nolimits_{s = 1}^{{\rm{t}}}{\alpha }_{s}\) In this setup, we use a total of four steps following [1], leveraging the benefits of the adversarial diffusion model where we can model the denoising distribution as a multimodal distribution with fewer steps to approximate the true distribution using a GAN30.
In the reverse diffusion process, we employ our proposed MU-Diff to approximate the posterior distribution pθ(xt−1∣xt, yi) for reconstructing a realistic x from noisy contrast xt guided by conditional contrasts yi as follows,
where μθ(xt, t) is the mean and \({\sigma }_{t}^{2}\) is the variance of the denoising network parameterized by θ. Additionally, rather than directly predicting xt−1 in the denoising process, diffusion models can be parameterized30 in the following manner,
where x0 is the predicted denoised target contrast of xt generated by our denoising model, and xt−1 is sampled using the posterior distribution q(xt−1∣xt, x0).
Deep mutual diffusion network
Figure 2a illustrates the entire pipeline of MU-Diff, which utilizes deep mutual learning through adversarial diffusion networks. To model this reverse denoising process, we use two diffusion models that are mutually trained and conditioned on source MRI contrasts. Each denoising network approximate the distribution of \({\tilde{{\bf{x}}}}_{{\rm{t}}-1} \sim {p}_{\theta }({{\bf{x}}}_{{\rm{t}}-1}| {{\bf{x}}}_{{\rm{t}}},{{\bf{y}}}_{i})\). The inputs to these models are two distinct feature representations of the input contrasts as depicted in Eqs. (2) and (4). Then, these two models learn the denoising process mutually, with each model gaining insights from the other. The denoising network (\({{\mathcal{F}}}_{1}\) and \({{\mathcal{F}}}_{2}\)) employs a U-Net-based architecture as in ref. 30. Sinusoidal positional embeddings are used to obtain timestep (t) embeddings23 for the conditioning. In addition to the denoising generators, we utilize a shared critic network ψ, which is a time-dependent network30, to differentiate between xt−1 and xt by determining if xt−1 is a plausible denoised version of xt. It processes the original perturbed target contrast xt and the final predicted denoised target contrasts, \({{\bf{x}}}^{{p}_{1}}\) and \({{\bf{x}}}^{{p}_{2}}\), from the two generators \({{\mathcal{F}}}_{1}\), \({{\mathcal{F}}}_{2}\) and the time conditioning t.
Multi-contrast feature mappers
First, all input contrasts, including both noisy and conditional contrasts, undergo separate feature extraction processes in two synthesis networks. To facilitate this, we introduce Multi-Contrast Feature Mappers (ϕ1 & ϕ2) in each network as feature extraction modules, capturing their unique spatial features known as contrast-specific features. This design ensures that relevant information from each contrast is effectively extracted. Each mapper employs distinct residual blocks for each noisy and conditional MRI contrast as depicted in Fig. 2b. This design enables the independent refinement of features from each contrast, ensuring that the relevant information is preserved and highlighted. The residual blocks, Ri in these modules consist of a convolutional layer followed by a Group Normalization, ReLU activation, and another convolutional layer to map the contrasts, initially of shape H × W, to a feature vector of shape C × H × W. The feature vectors from each n conditional and noisy target contrast are then fused through channel-wise concatenation. For \({{\mathcal{F}}}_{1}\), the output of feature mapper ϕ1, labeled \({f}_{c}^{1}\), serves as a distinct feature representation of input contrasts to synthesize the target MRI contrast as follows,
where R0, R1,.., Rn are seperate residual blocks in mapper ϕ1 for each input contrast.
In contrast, synthesis network \({{\mathcal{F}}}_{2}\) uses a refined representation of the same contrast features by ensuring they reflect the distinctive characteristics of the target contrast. \({{\mathcal{F}}}_{2}\) employs two key strategies for this: First, it leverages information from \({{\mathcal{F}}}_{1}\) ’s synthetic contrast (\({x}^{{p}_{1}}\)) to derive representative target contrast information, which is then used to weight the conditional source features inspired by the style transfer technique in image synthesis as depicted in Target-specific feature adaptation ρ( ⋅ ). Second, it applies adaptive weighting to each conditional contrast using a contrast-aware feature adapter ϕ( ⋅ ), ensuring that the subtle nuances are selected from each source contrast that accurately reflects the complex and heterogeneous features of the target distribution.
Target-specific feature adaptation
To perform target-specific feature adaptation, we assume that each MRI contrast can be decomposed into content and style feature components, represented as \(({\bf{x}},{{\bf{y}}}_{i})=\left\{({f}_{x}^{c},{f}_{x}^{s}),({f}_{{{\bf{y}}}_{i}}^{c},{f}_{{{\bf{y}}}_{i}}^{s})\right\}\in X\), where \(({f}_{x}^{c},{f}_{{{\bf{y}}}_{i}}^{c})\) and \(({f}_{x}^{s},{f}_{{{\bf{y}}}_{i}}^{s})\) denote the content and style feature information of their respective contrasts33. The content captures anatomical structures, lesion characteristics, and texture details. At the same time, the style reflects the global distribution of tissue contrasts and modality-specific traits that define the representative unique features of each modality. Based on this, we can express each conditional source modality in terms of the representative features derived from the synthesized target contrast (\({{\bf{x}}}^{{p}_{1}}\)) by adaptively combining their corresponding content and representative feature components as follows,
where \({f}_{{p}_{1}}^{s}\) denotes the style feature component of synthesized contrast \({{\bf{x}}}^{{p}_{1}}\) and ⊙ denotes the adaptive combination of this feature component with the content features from n conditional contrasts denoted as \({f}_{{{\bf{y}}}_{1}}^{c}\), \({f}_{{{\bf{y}}}_{2}}^{c}\),.., \({f}_{{{\bf{y}}}_{n}}^{c}\).
To perform the above procedure, we utilize a residual block similar to the one used in ϕ1 but with an additional global average pooling (GAP) layer and a fully connected layer to extract the feature vector \({f}_{{p}_{1}}^{s}\). This representative vector \({f}_{{p}_{1}}^{s}\) is then used to adaptively combine with the content feature information derived from the ϕ2 module in \({{\mathcal{F}}}_{2}\), where \({f}_{{p}_{1}}^{s}\) is provided as an input, along with the conditional source contrasts to each residual block Ri, for yi as follows
We use \({f}_{{p}_{1}}^{s}\) in conjunction with Group Normalization within the residual block, where \({f}_{{p}_{1}}^{s}\) is transformed into scaling (\({\gamma }_{{f}_{p1}}^{s}\)) and shifting (\({\beta }_{{f}_{p1}}^{s}\)) parameters through a linear layer. These parameters are applied to the normalized feature maps, facilitating dynamic modulation. This method allows the model to seamlessly incorporate representative information into the feature maps, thereby improving its representational capability.
where \({\mu }_{{{\bf{y}}}_{i}}\) and var(yi) represent the mean and standard deviation, calculated separately over each group. The adaptive feature representation for each conditional contrast is denoted as \({f}_{{y}_{i}}\).
Contrast-aware feature adaptation
After adapting the conditional feature contrasts with the representative target-specific feature representation, our next objective was to aggregate these conditional features with the noisy target feature contrast using an adaptive feature aggregation method. We implemented this by drawing inspiration from Gated Recurrent Units, specifically using leak gates to control the flow of features in multi-task learning34. By employing this approach, we adaptively aggregated each conditional feature, regulating the flow of contrast-specific features between multiple conditional contrasts. This method determines which specific features from one conditional contrast should be integrated with others and to what extent these features should be preserved. The structure of the τ module, depicted in Fig. 2c, calculates the information flow between pairs of conditional contrasts using two leak gates, \({z}^{{a}_{(i,i+1)}}\) and \({z}_{(i,i+1)}^{b}\). The \({z}_{(i,i+1)}^{a}\) gate aggregates feature vectors from the i and i + 1 conditional contrasts as follows,
where a learnable convolutional kernel is denoted by \({w}_{i}^{{z}_{a}}\) and σ is the sigmoid function. Then we can get the aggregated feature as,
where wi is the learnable parameter that extracts relevant features from yi. The gate \({z}_{(i,i+1)}^{a}\) then determines what information from yi should be aggregated with yi+1. Following this, another gate \({z}_{(i,i+1)}^{b}\) is used to further decide how much information from yi+1 should be retained. Similar to the previous case, \({w}_{i}^{{z}_{b}}\) is the learnable convolutional parameter for the second memory gate.
Then, the two aggregated features \({f}_{({{\bf{y}}}_{i},{{\bf{y}}}_{i+1})}^{w}\) are constructed as follows,
This approach ensures that more meaningful, contrast-specific features are aggregated based on their contribution. When the first gate \({z}_{(i,i+1)}^{a}\) is closer to 1, it fuses more information from yi, and when \({z}_{(i,i+1)}^{b}\) is closer to 0, it fuses more information from yi + 1. Thus, the aggregation process between the two contrast features is bidirectional, effectively capturing contrast-specific features from each that contribute more significantly toward the target contrast. In this manner, we adaptively derive all the conditional contrast features, and the final aggregated feature \({f}_{c}^{2}\) is obtained by combining these contrast-aware features with the noisy target contrast feature as input to the H2 as follows.
Then, we can summarize the generative process of each network as follows,
where t denotes the timestep and z denote the conditioning latent vector.
Learning distinct feature representations
The motivation for employing two mutually learned networks in our framework is to capture complementary feature representations that are essential for synthesizing brain lesions with complex heterogeneity. To facilitate this, we introduce Multi-contrast Feature Mappers (ϕ1 & ϕ2) at the initial stage of the denoising network in each synthesis path. These mappers incorporate distinct residual blocks for each MRI contrast, enabling them to extract important spatial patterns and contextual information, which is necessary to guide the denoising process. Both synthesis networks \({{\mathcal{F}}}_{1}\) and \({{\mathcal{F}}}_{2}\) utilize similar feature mappers, however, their functional distinction arises from how these features are utilized within each network. \({{\mathcal{F}}}_{1}\) emphasizes extracting broader, structural patterns that span across multiple MRI contrasts. These features are crucial for preserving overall anatomical coherence and guiding the synthesis process. Conversely, \({{\mathcal{F}}}_{2}\) leverages the same feature extraction process but places greater emphasis on refining localized variations by adapting to the complementary guidance provided by \({{\mathcal{F}}}_{1}\). Moreover, it dynamically controls how features from different contrasts are merged to effectively balance the integration of meaningful details from each contrast. This helps to refine fine-grained anatomical structures of subtle tissue variations and complex lesion details. While \({{\mathcal{F}}}_{2}\) excel at refining finer-level details and enhancing localized structures, it may struggle to maintain this broader context on its own. Without guidance from the features learned by \({{\mathcal{F}}}_{1}\), \({{\mathcal{F}}}_{2}\) may overemphasize localized variations, potentially distorting larger anatomical structures or missing subtle yet relevant patterns. By exchanging information during the mutual learning process, both networks gain insights from each other’s representations to ensure a robust balance between maintaining anatomical fidelity and enhancing fine-grained details, which is crucial for modeling lesion heterogeneity.
Training objective
The proposed mutual learning-based adversarial diffusion network consists of two denoising networks and a shared critic network. This shared critic network ensures that the predictions of the two denoising networks are aligned by guiding them to learn and match the distribution of the target contrast. The two denoising networks are trained with distinct feature representations of the input contrasts in an adversarial manner as follows.
Here, Θ represents the parameters of the networks \({\Theta }_{{F}_{1}}^{1}\), \({\Theta }_{{F}_{2}}^{2}\) and θC trained adversarially in a min-max framework, where the goal is to determine whether the denoised target contrast is a plausible denoised version of the noisy contrast. Following the deep mutual learning approach, conditional contrast features and target contrast features are used to train the network.
The two denoising networks are trained by minimizing the following objective function, which consists of loss components,
where \({{\mathcal{L}}}_{s}^{j}\), \({{\mathcal{L}}}_{m}^{j}\), and \({{\mathcal{L}}}_{c}^{j}\) denote the supervised loss, feature attentive loss and the critic loss. In addition λs, λm, λc > 0 acts as hyperparameters that control the contribution of each loss component. During training, each denoising network is guided by a critic loss derived from a shared critic network. This shared critic enforces mutual consistency between the two models as they work towards predicting the same target contrast. Additionally, the networks learn from attentive feature maps generated by the critic network based on each other’s predictions. This mechanism helps assign confidence to specific regions during the synthesis process, making the models aware of uncertainty. In our experimental setting, we use λs = 0.5, λm = 0.1, λc = 1.0 as the optimal values for the parameters that give robustness across all our experiments.
The supervised loss between the predicted and actual target contrast is calculated using the \({{\mathcal{L}}}_{1}\) loss, as described in Eq. (22). \({{\mathcal{L}}}_{1}\) loss encourages the model to minimize the absolute difference between the two contrasts, resulting in more accurate and sharper predictions. Additionally, it improves robustness to artifacts35, reduces blurring36, and encourages sharper predictions with better preservation of fine structures in lesion MRI.
where,
Then, we apply an adversarial generator loss using our critic network, which evaluates whether the predicted target contrast is a plausible denoised version of the noisy contrast xt. We first sample the contrast from t − 1 timestep of each predicted output using the following posterior distribution to achieve this.
The adversarial loss component is then calculated as in Eq. (26), which ensures that the predicted contrast is indistinguishable from the actual target contrast, enhancing the overall quality and reliability of the model. So, each denoising network is trained to make it challenging for the critic network to distinguish whether the current output is a plausible denoised version of the noisy contrast. Since the two networks utilize distinct feature representations of the same input contrasts, they can learn from one another, with the shared critic network ensuring consistency between their predictions.
where \({{\bf{x}}}_{{\rm{t}}-1}^{{p}_{j}}\) is the denoised contrasts at timestep t-1 of each predictions \({{\bf{x}}}^{{p}_{j}}\) from two denoisoing network.
We use the predicted outputs from each denoising network to train the critic network with the actual ground truths. The critic network is supposed to maximize the probability that each predicted denoised version is a plausible reconstruction of the original noisy contrast as follows.
where η = 0 if the xt−1 is obtained from prediction of a denoising network, and η = 1 if the xt−1 is derived from the actual target contrast distribution.
Feature attentive mask loss
We introduce a novel feature-attentive loss function designed to guide the generative networks to focus on crucial regions, particularly those with high uncertainty, which is essential for accurately synthesizing lesion contrasts. This is achieved by leveraging spatial attention maps derived from our critic network, which learns to identify the most reliable features from the target contrast during the training. Specifically, we utilize features from the middle layers of the critic network to derive the attention map, as these layers are most sensitive to discriminative features, such as lesion regions. In contrast, the earlier layers focus on low-level features, and the final layers emphasize broader brain regions37. Therefore, we have selected middle-layer features from the critic network to extract a spatial attention map through a sigmoid layer (σ) correlated with discriminative features from the target contrast. This attention map is then interpolated to match the dimensions of our output contrast to derive the final feature attentive masks Mj as follows:
where I indicates the interpolation of the attention map to match the dimension of target contrast x, which is dim(x), and fm indicates the middle layer feature extraction from the critic network. To quantify mutual learning between two denoising networks and align their predictions, we use each other’s attentive feature maps obtained through a shared critic network to evaluate the differences between the predicted attention masks from each network. We apply binary cross-entropy logistic criteria (BCE) to measure these differences, encouraging the networks to match their probability estimations and strengthening mutual training by focusing on more crucial regions as follows.
The overall training process is summarized in Algorithm 1
Algorithm 1
A Mutual Learning Diffusion Model for Synthetic MRI with Application for Brain Lesions (Training) 
Model architecture
Two denoising synthesis networks employ a U-Net-based architecture as in ref. 30, incorporating three encoder-decoder blocks with a latent dimension of 256. This encoder-decoder block contains two residual sub-blocks, with the middle layer comprising two additional residual blocks and a self-attention block. The residual sub-block has two convolutional layers, adaptive normalization and support for upsampling or downsampling via a Finite Impulse Response (FIR) method38. Sinusoidal positional embeddings are used to obtain timestep (t) embeddings, which will be an input to each residual sub-block along with input feature vectors. In addition, the denoising network integrates latent variable z, inspired by StyleGAN39, which is vital for modeling multi-modal distribution. This latent vector is processed through a mapping network to generate an embedding vector and used as an input into the adaptive group normalization (AdaGN) layer that outputs per-channel shift and scale parameters for group normalization. This allows the latent variable z to modulate the feature maps via affine transformation. After this stage, the feature maps are passed through up/downsampling blocks and convolutional layers. Temporal embedding of timestep t is added as a bias to the feature vectors, and then it undergoes group normalization, SiLU activation, dropout, and a final convolution layer with rescaled skip connections, ensuring progressive learning. The critic network ϕθ is a convolutional model composed of four residual blocks similar to those used in the generators, followed by global sum pooling and a fully connected layer at the end. It processes the original perturbed target contrast xt and the final predicted denoised target contrasts, \({x}^{{p}_{1}}\) and \({x}^{{p}_{2}}\), from the generators and the time conditioning t. We employ the same sinusoidal position embedding used in the generators for the timestep conditioning.
Baselines
To evaluate the performance of MU-Diff, we conducted a comprehensive comparison of our synthesis results, both quantitatively and qualitatively, against state-of-the-art (SOTA) methods in medical image synthesis. Our assessment began with comparing widely used generative architectures, such as Pix2Pix40 and PGAN41, which have proven effective in various medical imaging tasks. We then focused on advanced techniques designed explicitly for multi-contrast MRI synthesis, selecting MM-GAN19, Hi-Net16, and SynDiff42 for their promising results reported in recent literature. MM-GAN is introduced to handle missing sequences in multi-contrast MRI by combining information from available contrasts using a GAN-based approach. It trains on 2D axial slices where missing images are zero-imputed and concatenated with available contrasts. Hi-Net also targets multi-contrast MRI synthesis by learning representations from each contrast and employing a fusion network to integrate these features hierarchically. Its fusion strategy adaptively weights different methods, including element-wise summation, product, and maximization. SynDiff, a notable method gaining attention recently for its adversarial diffusion-based models, was evaluated initially in an unsupervised learning context. It incorporates a non-diffusive module alongside the diffusion network to handle unpaired data and conditionally generate images. For our comparison, we adapted SynDiff’s approach for supervised learning by omitting the non-diffusive module to align with our evaluation criteria. Finally, we compared MU-Diff with conventional DDPM23 to demonstrate the effectiveness and advantages of our adversarial diffusion-based approach.
Datasets
We evaluated our multi-contrast MRI synthesis model on two lesion datasets (BraTS 201924 and ISLES 201525) and a 3T multi-contrast MRI dataset of healthy subjects. The BraTS 2019 dataset includes multi-contrast MRI scans from glioblastoma (HGG) and lower-grade glioma (LGG) patients, with contrasts including T1, T1CE, FLAIR, and T2 of shape 240 × 240 × 155. After manually removing 30 corrupted scans, we split the dataset into 70% training, 20% validation, and 10% testing, with 214, 61, and 30 subjects in each phase, respectively. The multi-contrast images were skull-stripped and co-registered to the same anatomical template, and we extracted 80 middle axial brain slices, which were then resized to 256 × 256 shape for processing. The ISLES2015 dataset comprises multi-contrast ischemic stroke lesion volumes from FLAIR, T2, T1, and DWI MRI contrasts. It includes 28 training samples, each with a shape of 230 × 230 × 154. The data was split into 20 for training, 3 for validation, and 5 for testing. We extracted 80 middle axial slices from each contrast, which were then resized to 256 × 256 pixels. For the evaluation, we considered T1 and FLAIR contrast synthesis only as DWI represents a functional imaging contrast, and the T2 contrast was not acquired in the axial plane as other contrasts. To assess the performance of our model on similar datasets, we extended our evaluation to the BraTS 2021 dataset43, using 20 subjects from multi-contrast MRI images. For each dataset, one contrast is designated as the target contrast for synthesis, while the remaining contrasts serve as source images to guide the denoising process. Min-max normalization was applied to each volume before slice extraction to prepare the data for model training.
In addition to lesion datasets, we extended our experiments to evaluate the model’s applicability and performance on healthy subjects using a multi-contrast MRI dataset from Monash Biomedical Imaging. Institutional ethics and IRB approvals were obtained from Monash University, and written informed consent was secured from all participants. The participants were scanned with a Siemens Biograph mMR (3T) for FLAIR, T2, and T1 contrasts44,45. The dataset was resampled to 1 mm3 isotropic resolution using SynthSeg+46 and underwent bias correction with FSL-FAST47. The contrasts for each subject were co-registered with FMRIB’s FLIRT48, and the dataset was divided into 50, 20, and 15 subjects for training, validation, and testing. From each contrast, 100 middle axial slices were extracted and reshaped to 256 × 256 shape. Like the lesion datasets, we applied min-max normalization to each volume before processing and used each contrast as the target for synthesis from the remaining two contrasts. The same test dataset was used across all baselines for evaluation.
Training and inference
We developed our proposed model in PyTorch49,50 and trained it on two NVIDIA A40 GPUs, each with 40GB of memory. The training utilized the Adam optimizer with β1 = 0.1 and β2 = 0.2, setting the learning rate to 1e−4 for the critic and 1.6e−4 for the generators. The denoising process involved T = 4 steps, with noise variance controlled by βmin = 0.1 and βmax = 20. During training, the generative and critic networks were alternately trained, but only the two generators were used during inference. For each synthesis task in different datasets, we trained a separate model to better adapt to the unique characteristics and variations present in the task. Inference began at timestep T with random Gaussian noise as xt and iteratively refined through reverse diffusion steps. At each iteration, we derive the t-1th sample using the Markov property of the forward diffusion process, where the posterior is a Gaussian distribution and can be expressed as follows with mean \(\tilde{{\mu }_{{\rm{t}}}}\) and variance \(\tilde{{\beta }_{{\rm{t}}}}\).
This iterative process continued for T steps until the final target contrast was synthesized.
By substituting the expressions from Eqs. (6) and (7), we can determine the mean and variance of the distribution as follows.
We denote \({{\bf{x}}}^{{p}_{1}}\) and \({{\bf{x}}}^{{p}_{2}}\) as the predicted denoised versions from each network for the initial sample x0. By averaging the mean noise predictions at each timestep t, we obtain the overall noise at each timestep. Using this averaged mean and the distribution’s variance, we predict the clean target contrast via the reparameterization trick as follows.
where ε is a random Gaussian noise except for the last denoising step with ε = 0. The predicted contrast \({\tilde{{\bf{x}}}}_{{\rm{t}}-1}\) then serves as the input for two denoising networks as noisy target contrast to derive the denoised contrasts for the sampling process, which continues for T steps until the final synthesized target contrast is obtained.
One of the key advantages of our model is the mutual learning mechanism between the two generators, where each generator is trained to predict the target contrast using distinct feature representations, allowing them to complement each other during inference. This mutual learning approach leads to more precise synthesis, as the model does not rely solely on a single prediction. Instead, after each denoising step during the inference sampling, the noise predictions from both generators are calculated separately and then averaged. This approach of combining noise predictions enhances the accuracy of the final synthesized target contrast compared to the prediction from each network separately.
Evaluation procedure
The accuracy of the synthesized contrasts was assessed using three standard evaluation metrics: Peak Signal-to-Noise Ratio (PSNR), Structural Similarity Index Metric (SSIM), and Mean Absolute Error (MAE)51. Additionally, to evaluate the clinical relevance of the synthesized lesion contrasts, we used the Dice Score to measure the segmentation accuracy of the lesion regions. For the evaluation, we focused on two main aspects to assess the quality of the synthetic results. Notably, in all assessments, we excluded the background from metric calculations, as we observed that many studies include the background, leading to inflated metric values. Including the background increases the metrics values, as it contributes significantly to improvements but does not reflect the actual quality of the synthetic images. The two primary aspects we considered were the whole brain and lesion regions. For whole-brain evaluation, we created brain masks for each dataset to isolate the brain regions by applying thresholding to separate the brain from the background, followed by morphological operations to remove minor artefacts. After masking the images, we removed the additional black background before computing the metrics. We used the segmentation masks provided within each dataset for lesion evaluation, following a similar background-removal process as used in the whole-brain evaluation. This exact procedure was applied to healthy brains and other BraTS datasets. For the ISLES dataset, which contains microscopic lesions, we found that using the mask alone sometimes led to other brain tissues, such as white matter, misclassified as tiny lesion regions, which could significantly affect the comparison. Therefore, we applied a slight dilation to the masks using a 3 × 3 kernel with three iterations, allowing a subtle inclusion of the surrounding background to emphasize small lesion regions accurately in the metrics. This adjustment led to a more accurate evaluation by enhancing tiny lesions alongside the background context. The metrics calculated on whole brain regions are represented as PSNRB, SSIMB, MAEB, and metrics calculated on lesion regions as PSNRT, SSIMT and MAET. To further evaluate the significance of our proposed method, we used paired mean t-test on the performance difference between MU-Diff and the second-best performed model in all synthesis tasks.
Ablation study
We conducted several ablation studies to assess the effectiveness of each introduced component and the number of time steps chosen in the denoising process. We selected the T1CE synthesis task from the BraTS dataset for each ablation, as it is the most challenging among the available tasks. As shown in Fig. 5e, we began by testing different time-step counts, specifically selecting 2, 4, and 8 steps. The results indicated that T = 4 was optimal for balancing quality and computational efficiency. Next, we evaluated the impact of the critic loss on perceptual quality, using the Fréchet inception distance (FID) score as a metric. We observed that incorporating a critic network led to perceptually improved results, reflected in a lower FID score, as illustrated in Fig. 5f. We further analyzed the impact of different feature components introduced in MU-Diff. Four ablation experiments were conducted: in Ablation 1, we removed mutual learning and used only a single denoising network; in Ablation 2, we retained mutual learning with two identical networks like \({{\mathcal{F}}}_{1}\), omitting both contrast-aware and target-specific feature adaptations. In Ablation 3, target-specific feature adaptation was added, but contrast-aware adaptation was still excluded. Ablation 4 excluded the mask-attentive loss component. Fig. 5g and h present the results of these ablations on the whole brain and tumor regions, respectively. The results demonstrate that each component significantly contributes to synthetic performance, especially within lesion regions, indicating the importance of these adaptive feature components for accurate lesion synthesis. Finally, Fig. 5i provides a qualitative visualization of each ablation. This visual comparison clearly illustrates the impact of each component on lesion accuracy, reinforcing the value of adaptive feature components in enhancing the model’s performance on lesion regions.
Data availability
To evaluate our proposed method, we used two publicly available datasets: BraTS2019, available at https://www.med.upenn.edu/cbica/brats2019/data.html, ISLES2015, available at https://www.isles-challenge.org/ISLES2015/. Further evaluation was done with the BraTS2021 dataset available at http://braintumorsegmentation.org/ and a 3T multi-contrast healthy MRI dataset https://doi.org/10.1038/s41598-023-48438-1.
Code availability
The code was implemented in Python using the deep learning framework PyTorch49. The code is publicly available at: https://github.com/sanuwanihewa/MU-Diff. All pre-trained model weights and supplementary results are available on the Figshare Project Page52.
References
Narayana, P. A. et al. Are multi-contrast magnetic resonance images necessary for segmenting multiple sclerosis brains? A large cohort study based on deep learning. Magn. Reson. Imaging 65, 8–14 (2020).
Yang, Y. et al. Segmentation method of magnetic resonance imaging brain tumor images based on improved UNet network. Transl. Cancer Res. 13, 1567–1583 (2024).
Yang, Q. et al. MRI cross-modality image-to-image translation. Sci. Rep. 10 https://doi.org/10.1038/s41598-020-60520-6 (2020).
Finck, T. et al. Uncertainty-aware and lesion-specific image synthesis in multiple sclerosis magnetic resonance imaging: a multicentric validation study. Front. Neurosci. 16 https://doi.org/10.3389/fnins.2022.889808 (2022).
Dayarathna, S. et al. Deep learning based synthesis of MRI, CT and PET: Review and analysis. Med. Image Anal. 92, 103046 (2024).
Lee, D., Moon, W.-J. & Ye, J. C. Assessing the importance of magnetic resonance contrasts using collaborative generative adversarial networks. Nat. Mach. Intell. 2, 34–42 (2020).
Lohrke, J. et al. 25 years of contrast-enhanced MRI: developments, current challenges and future perspectives. Adv. Ther. 33, 1–28 (2016).
Tudosiu, P.-D. et al. Realistic morphology-preserving generative modelling of the brain. Nat. Mach. Intell. 6, 811–819 (2024).
Gao, C. et al. Synthetic data accelerates the development of generalizable learning-based algorithms for X-ray image analysis. Nat. Mach. Intell. 5, 294–308 (2023).
Bercea, C. I., Wiestler, B., Rueckert, D. & Albarqouni, S. Federated disentangled representation learning for unsupervised brain anomaly detection. Nat. Mach. Intell. 4, 685–695 (2022).
Sasiadek, M. J. Intracranial lesions with low signal intensity on T2-weighted MR images – review of pathologies. Pol. J. Radiol. 80, 40–50 (2015).
Peiris, H., Hayat, M., Chen, Z., Egan, G. & Harandi, M. Uncertainty-guided dual-views for semi-supervised volumetric medical image segmentation. Nat. Mach. Intell. 5, 724–738 (2023).
Begoli, E., Bhattacharya, T. & Kusnezov, D. The need for uncertainty quantification in machine-assisted medical decision making. Nat. Mach. Intell. 1, 20–23 (2019).
Shad, R., Cunningham, J. P., Ashley, E. A., Langlotz, C. P. & Hiesinger, W. Designing clinically translatable artificial intelligence systems for high-dimensional medical imaging. Nat. Mach. Intell. 3, 929–935 (2021).
Zhan, B., Li, D., Wu, X., Zhou, J. & Wang, Y. Multi-modal MRI image synthesis via GAN with multi-scale Gate Mergence. IEEE J. Biomed. Health Inform. 26, 17–26 (2022).
Zhou, T., Fu, H., Chen, G., Shen, J. & Shao, L. Hi-Net: hybrid-fusion network for multi-modal MR image synthesis. IEEE Trans. Med. Imaging 39, 2772–2781 (2020).
Yurt, M. et al. mustGAN: multi-stream generative adversarial networks for MR image synthesis. Med. Image Anal. 70, 101944 (2021).
Zhan, B. et al. LR-cGAN: latent representation based conditional generative adversarial network for multi-modality MRI synthesis. Biomed. Signal Process. Control 66, 102457 (2021).
Sharma, A. & Hamarneh, G. Missing MRI pulse sequence synthesis using multi-modal generative adversarial network. IEEE Trans. Med. Imaging 39, 1170–1183 (2020).
Sun, L. et al. Hierarchical amortized GAN for 3D high resolution medical image synthesis. IEEE J. Biomed. Health Inform. 26, 3966–3975 (2022).
Jiang, L., Mao, Y., Wang, X., Chen, X. & Li, C. CoLa-Diff: Conditional Latent Diffusion Model for Multi-modal MRI Synthesis, 398–408 https://doi.org/10.1007/978-3-031-43999-5_38 (Springer Nature Switzerland, 2023).
Zhang, Y., Xiang, T., Hospedales, T. M. & Lu, H. Deep Mutual Learning. In 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. https://doi.org/10.1109/cvpr.2018.00454 (IEEE, 2018).
Ho, J., Jain, A. & Abbeel, P. Denoising diffusion probabilistic models. In: Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M. & Lin, H. (eds.) Proc. 34th International Conference on Neural Information Processing Systems, NIPS ’20, 6840–6851 (Curran Associates Inc., 2020).
Menze, B. H. et al. The multimodal Brain Tumor Image Segmentation Benchmark (BRATS). IEEE Trans. Med. Imaging 34, 1993–2024 (2015).
Maier, O. et al. ISLES 2015 - A public evaluation benchmark for ischemic stroke lesion segmentation from multispectral MRI. Med. Image Anal. 35, 250–269 (2017).
Shaw, R., Sudre, C., Ourselin, S. & Cardoso, M. J. MRI k-Space motion artefact augmentation: model robustness and task-specific uncertainty. In: Cardoso, M. J. et al. (eds.) Proc. 2nd International Conference on Medical Imaging with Deep Learning, vol. 102 of Proceedings of Machine Learning Research, 427–436 (PMLR, 2019). https://proceedings.mlr.press/v102/shaw19a.html
Liu, S. et al. Learning MRI artefact removal with unpaired data. Nat. Mach. Intell. 3, 60–67 (2021).
Pérez-García, F., Sparks, R. & Ourselin, S. TorchIO: a Python library for efficient loading, preprocessing, augmentation and patch-based sampling of medical images in deep learning. Comput. Methods Prog. Biomed. 208, 106236 (2021).
Cardoso, M. J. et al. MONAI: an open-source framework for deep learning in healthcare https://arxiv.org/abs/2211.02701 (2022).
Xiao, Z., Kreis, K. & Vahdat, A. Tackling the generative learning trilemma with denoising diffusion GANs https://arxiv.org/abs/2112.07804 (2021).
Kornblith, S., Norouzi, M., Lee, H. & Hinton, G. Similarity of neural network representations revisited. In International conference on machine learning, 3519–3529 (PMLR, 2019).
Wang, T., Dai, X. & Liu, Y. Learning with Hilbert–Schmidt independence criterion: a review and new perspectives. Knowl.-Based Syst. 234, 107567 (2021).
Huang, X., Liu, M.-Y., Belongie, S. & Kautz, J. Multimodal unsupervised image-to-image translation. In: Ferrari, V., Hebert, M., Sminchisescu, C. & Weiss, Y. (eds.) Computer Vision – ECCV 2018, 179–196 (Springer International Publishing, 2018).
Cho, K. et al. Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation. In Proc. 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP) (Association for Computational Linguistics, 2014). https://doi.org/10.3115/v1/d14-1179.
Wang, T. et al. A review on medical imaging synthesis using deep learning and its clinical applications. J. Appl. Clin. Med. Phys. 22, 11–36 (2020).
Li, W. et al. Magnetic resonance image (MRI) synthesis from brain computed tomography (CT) images based on deep learning methods for magnetic resonance (MR)-guided radiotherapy. Quant. Imaging Med. Surg. 10, 1223–1236 (2020).
Emami, H., Dong, M. & Glide-Hurst, C. K. Attention-guided generative adversarial network to address atypical anatomy in synthetic CT generation. In 2020 IEEE 21st International Conference on Information Reuse and Integration for Data Science (IRI), 188–193. https://doi.org/10.1109/iri49571.2020.00034 (IEEE, 2020).
Zhang, R. Making convolutional networks shift-invariant again. In: Chaudhuri, K. & Salakhutdinov, R. (eds.) Proc. 36th International Conference on Machine Learning, vol. 97 of Proceedings of Machine Learning Research, 7324–7334. https://proceedings.mlr.press/v97/zhang19a.html (PMLR, 2019).
Karras, T., Laine, S. & Aila, T. A style-based generator architecture for generative adversarial networks. IEEE Trans. Pattern Anal. Mach. Intell. 43, 4217–4228 (2021).
Isola, P., Zhu, J.-Y., Zhou, T. & Efros, A. A. Image-to-Image Translation with Conditional Adversarial Networks. In 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 5967–5976. https://doi.org/10.1109/cvpr.2017.632 (IEEE, 2017).
Dar, S. U. et al. Image synthesis in multi-contrast MRI with conditional generative adversarial networks. IEEE Trans. Med. Imaging 38, 2375–2388 (2019).
Özbey, M. et al. Unsupervised medical image translation with adversarial diffusion models. IEEE Trans. Med. Imaging 42, 3524–3539 (2023).
Baid, U. et al. The RSNA-ASNR-MICCAI BraTS 2021 benchmark on brain tumor segmentation and radiogenomic classification. https://arxiv.org/abs/2107.02314 (2021).
Islam, K. T. et al. Improving portable low-field MRI image quality through image-to-image translation using paired low- and high-field images. Sci. Rep. 13 https://doi.org/10.1038/s41598-023-48438-1 (2023).
Dayarathna, S., Islam, K. T. & Chen, Z. Ultra low-field to high-field MRI translation using adversarial diffusion. In 2024 IEEE International Symposium on Biomedical Imaging (ISBI), 1–4 (IEEE, 2024). https://doi.org/10.1109/ISBI56570.2024.10635808
Billot, B. et al. SynthSeg: segmentation of brain MRI scans of any contrast and resolution without retraining. Med. Image Anal. 86, 102789 (2023).
Zhang, Y., Brady, M. & Smith, S. Segmentation of brain MR images through a hidden Markov random field model and the expectation-maximization algorithm. IEEE Trans. Med. Imaging 20, 45–57 (2001).
Jenkinson, M., Bannister, P., Brady, M. & Smith, S. Improved optimization for the robust and accurate linear registration and motion correction of brain images. NeuroImage 17, 825–841 (2002).
Paszke, A. et al. PyTorch: an imperative style, high-performance deep learning library (Curran Associates Inc., 2019).
Paszke, A. et al. Automatic differentiation in PyTorch https://openreview.net/forum?id=BJJsrmfCZ (2017).
Nečasová, T., Burgos, N. & Svoboda, D. Validation and evaluation metrics for medical and biomedical image synthesis, 573–600. https://doi.org/10.1016/B978-0-12-824349-7.00032-3 (Elsevier, 2022).
Dayarathna, S. Project Contributions https://figshare.com/articles/dataset/Project_Contributions/27965493/2 (2024).
Acknowledgements
Z.C. is partly funded by ARC Discovery Project DP210101863 and Industry Fellowship Project IM230100002.
Author information
Authors and Affiliations
Contributions
S.D., H.P., and Z.C. conceived the initial idea and planned the experimental setup. S.D. developed the method and implemented the experiments. Z.C. directed the project. H.P. and Z.C. advised the method development and experimental setup. S.D., H.P. and Z.C. interpreted the results. H.P., K.T.I., and Z.C. provided scientific insights on the applications and supervised the study. Y.W., M.L., J.C., and T.T. Wong provided insightful feedback and supervision. S.D., Y.W., KT.I., H.P., and Z.C. wrote the manuscript with feedback from all other authors. All the authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Dayarathna, S., Wu, Y., Cai, J. et al. MU-Diff: a mutual learning diffusion model for synthetic MRI with Application for brain lesions. npj Artif. Intell. 1, 11 (2025). https://doi.org/10.1038/s44387-025-00016-8
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s44387-025-00016-8
