
Abstract
Large language models (LLMs) have achieved remarkable success across many fields but face challenges in complex real-world scenarios like medical consultation, particularly regarding inquiry quality and safety concerns. In this paper, we introduce a healthcare agent designed to address these issues, which cannot be fully resolved through a vanilla one-time fine-tuning process. The healthcare agent includes three components: a dialogue component for planning safe and effective conversations, a memory component for storing patient conversations and medical history, and a processing component for report generation. To evaluate our healthcare agent’s performance in medical consultations, we employ both expert assessment from medical professionals and an automated evaluation system powered by ChatGPT for large-scale testing. Our results demonstrate that the healthcare agent significantly enhances the capabilities of general LLMs in medical consultations, particularly in inquiry quality, response quality, and safety. Through extensive ablation studies, we also analyze the impact of each component.
Similar content being viewed by others
Introduction
In recent years, online medical consultations have grown significantly1. With the impressive success of large language models (LLMs), there has been increasing attention on their application in medical consultations2,3,4. However, applying general LLMs to medical consultations in real-world scenarios presents several significant challenges. First, they cannot effectively guide patients through the step-by-step process of articulating their medical conditions and relevant information, a crucial element of real-world doctor-patient dialogue. Second, they lack the necessary strategies and safeguards to manage medical ethics and safety issues, putting patients at risk of serious consequences. Third, they cannot store consultation conversations and retrieve medical histories.
One approach to addressing the challenges in medical consultation is building medical LLMs from scratch or fine-tuning general LLMs with specific datasets5,6,7,8,9,10,11,12. Examples like GatorTron5 and GatorTronGPT6 are typical models trained from scratch using medical datasets. With the rapid development of general LLMs2,3,11,13,14,15,16, medical LLMs fine-tuned from general LLMs have demonstrated state-of-the-art performances. Typical examples include Med-PaLM7 and Med-PaLM28, which are fine-tuned from PaLM14 and PaLM215, respectively. Other examples include those fine-tuned from open-source LLMs, e.g., ChatDoctor 9 and MedAlpaca10 are fine-tuned from LLaMA16; DoctorGLM11 and BianQue12 are fine-tuned from ChatGLM17. However, this one-time process is not only computationally expensive but also lacks the flexibility and adaptability needed for real-world scenarios.
In contrast, LLM agents can reason and break down tasks into manageable components without requiring re-training, making them better suited for complex tasks. Previous researches18,19,20,21,22,23,24,25 have demonstrated that agent methods achieve excellent performance in medical question answering and medical report generation. For question answering tasks, MEDAGENTS18 introduces a method that selects multiple expert models based on the task and derives the final diagnosis through mutual discussion among these expert models, thereby increasing diagnostic reliability. Building on MEDAGENTS, MDAgent19 proposes advanced expert collaboration strategies to enhance the ability to solve different problems. CoD20 proposes the chain-of-diagnosis strategy thereby simulating the diagnostic thinking of a doctor, thus enhancing the interpretability of decisions. Medchain21, on the other hand, retrieves similar cases to aid decision-making by designing medical special RAG. For processing medical reports, LLM agents are employed to handle a wide variety of medical documents, alleviating the workload of doctors. Ma et al.22 and Sudarshan et al.23 utilize dynamic prompt and self-reflection to process radiology reports and patient letters. ChatCAD+24 and BioSignal Copilot25 extend this capability by managing reports across different modalities through the integration of expert models.
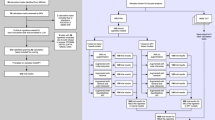
Although LLM agents are increasingly utilized in healthcare scenarios, there remains a significant gap in patient-oriented agent systems capable of acting as personalized doctors for consultations. This presents heightened challenges in terms of agent-patient interaction capabilities, accuracy, and safety. In this paper, we introduce a healthcare agent that elicits the power of general LLMs for medical consultation. As shown in Fig. 1, the proposed healthcare agent consists of three components: Dialogue, Memory, and Processing. The Dialogue component serves as the interface with patients, facilitating safe, effective, and informative medical conversations. Upon receiving an inquiry from the patient, the Function module first identifies the medical purpose or task, such as medical diagnosis, explanation, and recommendation. It then conducts either single or multi-round conversations with patients. The Safety module automatically detects medical ethics and safety concerns, enhancing the security and reliability of responses. Lastly, the Doctor module provides an opportunity for medical professionals to offer necessary interventions. The Memory component is designed to enhance the accuracy of conversations by providing historical and current conversation information: the Conversation Memory for ongoing conversations and the History Memory for condensed summaries of past dialogues. The Processing component implements functions that manage the information of the entire dialogue. In our current implementation, we offer a content summarization function to summarize ongoing consultations and generate summary reports.

The framework consists of three parts: Dialogue, Memory, and Processing, which are responsible for interacting with patients, storing conversational information, and processing paperwork, respectively.
To evaluate the healthcare agent, we implement a two-stage evaluation process. First, we simulate realistic medical consultations using a virtual patient powered by ChatGPT. This virtual patient draws from real conversations in the MedDialog dataset to interact naturally with the LLM doctor. The evaluation itself consists of two components: doctor evaluation and automated evaluation. For doctor evaluation, a panel of seven physicians reviews and scores the consultation dialogues. To enable more comprehensive testing, we also develop an automated evaluation system using ChatGPT as an evaluator. This automated approach allows us to assess a larger volume of conversations while reducing the time burden on medical professionals. Figure 2 illustrates the significant improvements made by the proposed healthcare agent over general LLMs.

Illustration of the improvements made by the proposed healthcare agent in medical consultation, particularly in terms of inquiry quality (proactivity, relevance & fluency), response quality (accuracy & helpfulness), and safety (harmfulness & self-awareness).
In this paper, we first propose an innovative healthcare agent that maximizes the capabilities of LLMs for medical consultation, presenting a new paradigm for applying LLMs in healthcare. Then we design the healthcare agent with three key components: a dialogue component for planning safe and effective conversations, a memory component for storing patient conversations and medical history, and a processing component for report generation. Finally, we conduct extensive experiments, and the results show that the proposed healthcare agent framework significantly enhances the performance of LLMs in medical consultations.
Results
This section is divided into four parts. The first part showcases a practical application case of the healthcare agent in real-world medical consultation. The second part demonstrations the results of automated evaluation and the third part shows the results of doctor evaluation. Finally, we conduct ablation studies to validate the contributions of different module on healthcare agent.
Case Study
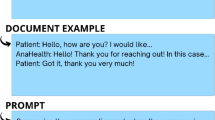
The proposed healthcare agent will be integrated into the clinical workflow to help reduce GPs’ workload during online consultations. The patient initiates the interaction by describing symptoms and seeking assistance. The agent then responds according to three possible scenarios: if additional information is needed, it prompts the patient with follow-up questions; if the information is sufficient, it provides a diagnosis, suggestions, or explanations; and if it detects ethical concerns, emergencies, or potential errors, the safety module makes modifications and doctor module assesses whether a doctor’s intervention is required. After completing the interaction, the agent generates a summary report, which is reviewed and verified by a doctor before being shared with the patient. To further illustrate the workflow of the healthcare agent, we use an example of a patient consulting about anxiety disorder to demonstrate the entire working process of our healthcare agent, and explain the roles played by different modules. A brief overview of the consultation process is depicted in Fig. 3, with a more detailed exposition of the process to follow later. This case study is conducted by GPT-4 as backbone.

The yellow parts provide explanations of the different modules in healthcare agent.
Start of Consultation. The healthcare agent introduces its functionality to the patient and starts the consultation with "Hello! I’m Dr. AI, your virtual health assistant. I’m here to help you with any health concerns you might have. Please feel free to share what’s been bothering you, and I’ll do my best to provide guidance and answer any questions you may have. How can I assist you today?"
Planner in Function Module. When the patient initiates the consultation by describing his symptoms: "Hello Doctor, I’ve been experiencing a rapid heartbeat, intense fear, and nervousness. I took medication for my anxiety two hours ago, but I’m still not feeling any relief.", the Planner sub-module determines the task as a medical diagnosis task and needs more patient information, thus choose the Inquiry sub-module as the next step.
Inquiry Submodule. In the Inquiry sub-module, the doctor asks questions based on the patient’s condition, Conversation memory and History memory. After each round of inquiries, the Planner sub-module will evaluate the available information and decide whether to proceed with the inquiry. In this sub-module, the healthcare agent obtains information through an inquiry about the patient’s past medical history, medication usage, possible triggers, and recent changes. These are crucial details that the patient did not describe initially but are very important in the diagnosis.
Preliminary Response. Subsequently, when several rounds of inquiries have taken place, the Planner determines that there is enough information to make a diagnosis and chooses to perform the Medical Diagnosis sub-module. Healthcare agent generates preliminary diagnoses and suggestions through the Medical Diagnosis prompt. Guided by prompts, healthcare agent provides responses structured around initial diagnosis, explanation of the diagnosis, and subsequent recommendations.
Safety Module. The preliminary response is then modified in the Safety module to ensure that the responses are ethically compliant, safe, and accurate. The Safety module first discusses possible problems in ethics, emergency and errors respectively and gives suggestions for improvement. The preliminary response is then modified based on the results of this discussion.
Doctor Module. After that, the doctor can review and modify the response. In this case, the doctor believes it’s important to emphasize “Need to remind patients not to change their medication without authorization.”. Doctors can either modify responses themselves or have the LLM automatically make modifications. With just a simple guidance from the doctor, healthcare agent can appropriately add or modify information in the responses.
Planner for Another Question. Next, the patient seeks further medical assistance from the doctor based on their own situation: “Considering my current symptoms and the fact that I’m in a location without a psychiatric department, what immediate steps can I take to manage this panic attack until I can get to a hospital for a face-to-face consultation?”. According to the judgment of the Planner sub-module in the Function Module, the healthcare agent switches to a medical recommendation task, using the prompt of Medical Recommendation to directly generate a response.
History Summary and Processing. When the consultation is over, healthcare agent will post-process the conversation of the current consultation for History Memory summary and report processing. In the Memory Summary module, the healthcare agent provides a brief summary of the symptoms, diagnosis, and recommendations. This will be used in the History Memory of the subsequent consultation to bring information from the current consultation into the follow-up visit. On the other hand, the Processing module is used for handling dialogue information and generating reports for patients to conclude this consultation. Guided by the prompt, healthcare agent generate a report containing an overview of the condition, diagnostic results, and recommendations.
Results of automated evaluation
For automated evaluation, we employ three popular open-source LLMs (LLama-3, Mistral, and Gemma-2) and three closed-source LLMs (GPT-4, Claude-3.5, and Gemini-1.5) as backbone. We evaluate 50 data and the results are present in Table 1.
For the inquiry quality, we refine the assessment of inquiry quality into inquiry proactivity, inquiry relevance, and conversation fluency, corresponding to the number and comprehensiveness of the inquiry questions, the relevance of the questions to the patient’s symptoms, and the overall conversational experience, respectively. For vanilla models, the results for inquiry proactivity indicate that most models, such as Mixtral, GPT-4, Cluade-1.5 and Gemini-1.5, tend to provide direct answers without additional inquiries. Although LLaMA-3 and Gemma-2 demonstrate some inquiry capability, the inquiry relevance results reveal that their questions lack depth and are not strongly aligned with the patient’s situation. Additionally, these models often ask multiple questions within a single sentence, leading to poor conversational fluency. When integrated with the healthcare agent framework, the inquiry proactivity and relevance of all models improve significantly, resulting in more relevant and effective questions. Notably, the conversational fluency of open-source models is inferior to that of closed-source models. This is likely due to a deficiency in the ability to execute the instructions of the inquiry sub-module. For instance, open-source models sometimes include irrelevant descriptions or explanations before questioning, such as “Based on the patient’s descriptions, historical conversations, and medical records, my first follow-up question would be:”. Such responses are inconsistent with real healthcare scenarios and negatively affect the user experience.
For the response quality, we evaluate response quality by the accuracy of the diagnosis and the helpfulness of the recommendations and suggestions. As shown in Table 1, the vanilla models responses demonstrate relatively good accuracy and helpfulness, highlighting the excellent medical knowledge of general LLMs. We can find that the integration of healthcare agent yields noticeable enhancements in response accuracy and helpfulness across all models. We consider that one significant factor contributing to this improvement is the additional information gathered by the Inquiry sub-module and the rectification of inaccuracies through the Safety module. Furthermore, while the performance of open-source models in their vanilla state lags behind that of closed-source models, the performance gap narrows considerably with the use of the agent framework. This indicates that the healthcare agent can effectively bridge the performance disparity between different models.
Regarding safety, our experiments evaluate both harmfulness and self-awareness. The experimental results show that benefiting from the model’s excellent safety alignment, its responses usually do not contain harmful content. However, a prevalent issue is that these models, in addition to Gemini-1.5, lack of adequate emphasis on AI disclaimers, which may lead to some ethical problems. The integration of healthcare agent with these models markedly enhances the safety of their responses. Benefiting from more patient information through inquiry strategy and the emergency detection and the error detection in the Safety module, the harmfulness of the responses is further reduced. At the same time, thanks to the ethics detection in the Safety module, self-awareness is significantly improved by clearly indicating the identity and risks of the AI doctor in the response.
Results of doctor evaluation
We utilize doctor evaluation to more accurately and professionally assess healthcare agent and to illustrate the reliability of our automated evaluation methods. In this experiment, considering the workload of doctors, we utilize an open-source model LLaMA-3 and a closed-source model GPT-4 and evaluate 15 data. We invite seven doctors to conduct the evaluation and the average assessment time is 3300 seconds. The results are shown in Table 2 and we further calculate the Pearson correlation between doctor evaluation results and the automated evaluation results. The high correlation results show that there is a high alignment between the doctor evaluation results and the automated evaluation results, except for the fact that the doctor results are higher for the score of conversational fluency and lower for the score of harmfulness in the evaluation. This indicates that our healthcare agent is accepted by doctors for its validity and safety, demonstrating its potential for future clinical applications, as well as showing that our automated evaluation method has a high degree of accuracy, providing an automated method for future large-scale evaluations.
Ablation studies
This subsection validates the contributions of different modules on healthcare agent. Considering the labor cost and the fact that automated evaluation is proven to have a high consistency with doctor evaluation in Section 2.3, we only conduct experiments with automated evaluation on GPT-4 model.
Firstly, we evaluate the Planner sub-module and Inquiry sub-module in the Function module. In Table 3, the label w/o Planner Sub-Module signifies the absence of the Planner sub-module, causing all tasks to share Inquiry sub-module and the response with the same prompt. As a result, we observe a significant drop in inquiry relevance and conversational fluency performance. Without the Planner sub-module, the healthcare agent struggles to provide appropriate responses based on the current scenario. This limitation results in the generation of long, illogical responses for medical explanation and recommendation tasks, which require concise and effective direct answers and ask unnecessary questions for diagnosis tasks with enough information, causing tedious experience for patients and unnecessary waste of computational resources. Additional details can be found in the supplementary material.
In the absence of the Inquiry sub-module, we observe a significant decline in all metrics of inquiry quality and response quality. This is because, without the Inquiry sub-modules, the healthcare agent loses its ability to ask questions and instead tends to provide direct answers, resulting in a notable reduction in inquiry quality. Moreover, the absence of the inquiry also leads to the failure to obtain more comprehensive patient information, which also leads to lower accuracy. Further details about this experiment are available in the supplementary material.
For the Safety module, the experimental results in Table 3 show that the lack of emergency detection and error detection in the safety module leads to a decrease in accuracy and harmfulness, while the absence of ethic detection will lead to a significant decrease in self-awareness. This further illustrates the role of the safety module in ensuring accuracy, safety and ethics. Furthermore, in the safety module, we propose a discuss-then-modification strategy to enhance the detection capability of the safety module. The label w/o Discuss-then-Modification signifies only using one instruction to detect and modify the response. The experimental results show that although the results of self-awareness do not decrease, the results in accuracy and harmfulness get worse. This suggests that the safety module has difficulty in modifying different safety issues at the same time, highlighting the importance of our discuss-then-modify strategy. Further examples can be found in the supplementary material.
The Doctor module serves as a crucial interface for physician oversight and response modification. To validate the feasibility of doctor-guided modifications, we utilize ChatGPT to simulate a doctor’s role, reviewing previous diagnostic results and identifying potential issues. Out of 50 cases, ChatGPT provides guidance on 17 cases. These guidelines are then input into the Doctor module as instructions, followed by an assessment of the modified results to ensure successful incorporation and proper placement of the guidelines. As illustrated in Fig. 4, medical professionals need not possess knowledge of LLM prompts; simple guidance suffices, allowing this module to effectively implement or modify responses accordingly. Additional experimental details and case studies can be found in the supplementary material.

The influence of the Doctor module.
Finally, we analyze the Memory component. Table 3 shows the impacts of Conversation Memory on metrics like inquiry relevance, conversational fluency, response accuracy and helpfulness. Several cases without using Conversation Memory, which causes generating repetitive questions, can be found in the supplementary material. Moreover, the inquiries overly focus on the patient’s most recent responses. This issue adversely affects the depth and breadth of questioning, resulting in diminished inquiry capability. Furthermore, the need for patients to repeatedly respond to similar queries hampers conversational fluency, while the reduced information gathered during the inquiry phase contributes to decreased response accuracy.
To assess the impact of History Memory, we conducted case studies on both initial and follow-up visits. These studies involve a comparative analysis of outcomes when History Memory is and is not utilized during follow-up visits. An example case study is depicted in Fig. 5. This case study underscores the pivotal role of History Memory in enhancing the healthcare agent’s performance. When History Memory is used, it enables the healthcare agent to understand previous symptoms and medications, enhancing the generation of questions. Conversely, when History Memory is not employed, the healthcare agent tends to revisit issues already established in previous consultations. This redundancy can diminish the efficiency of gathering new information and adversely impact the user experience.

For simplicity, we only show a portion of the doctor’s dialogue. See more details in the supplementary material.
Discussion
Both automated and doctor evaluations confirm that our healthcare agent significantly enhances general LLMs across seven key metrics: inquiry proactivity, inquiry relevance, conversational fluency, accuracy, helpfulness, harmfulness reduction, and self-awareness. Our ablation studies attribute these improvements to the synergistic design of the agent’s modular architecture. The Function module enables versatile scenario handling, with its Inquiry sub-module substantially improving information-gathering capabilities. The Safety module enhances response accuracy and self-awareness while minimizing potential harm. The Doctor module provides human-in-the-loop refinement, while the Memory component leverages both current and historical patient information to improve diagnostic accuracy and recommendation quality.
Furthermore, our healthcare agent demonstrates robust generalizability, achieving significant performance improvements across both open-source (e.g., Mixtral) and closed-source (e.g., GPT-4) models. However, in general, a performance gap persists between open-source models and closed-source models, which may be caused by the medical knowledge and the ability to follow the instructions of the models. Furthermore, when we extend the application of healthcare agent to open-source medical LLMs, such as MedAlpaca-7B10, Meditron-7B26, and OpenBioLLM-8B27, our analysis reveals that these models encounter challenges in healthcare agent guidelines, as evidenced by several failure cases outlined in the supplementary material. One possible solution is fine-tuning general LLMs. However, this paper focuses on developing a training-free, data-free methodology applicable to all general LLMs. Fine-tuning general LLMs is beyond the scope of this paper and will be explored in future work.
To minimize evaluation overhead, we developed two automated approaches: virtual patients and automated evaluation. The virtual patient system employs LLMs to simulate realistic patient interactions, while our automated evaluation utilizes a chain-of-thought28 based LLM-as-judge method. For the automated evaluation method, based on the high correlation shown between doctor evaluation results and automated evaluation results, this indicates that our automated evaluation method can effectively substitute for the doctor evaluation method and be used in large-scale evaluations. For the virtual patient method, considering that we use the real-world doctor-patient consultation data and doctors are positive about the realism of the simulation results, we believe our evaluation method is an effective alternative to clinical testing during early development phases, substantially reducing the human resources and time required for evaluation. We will engage our healthcare agent in real-world clinical testing in our future work.
In conclusion, we present a novel healthcare agent for medical consultation, which enables safe, effective medical conversations with patients. We utilize a virtual patient method to simulate the consultation conversations, which are then assessed using both doctor evaluation and automated evaluation. Experimental results demonstrate that the healthcare agent can significantly enhance the capabilities of general LLMs in inquiry quality, response quality, and safety. Furthermore, our healthcare agent framework exhibits remarkable generalizability across different general LLMs. Considering that existing commercial medical consultation services usually lack publicly disclosed technical details, we believe that this healthcare agent represents a feasible attempt and hope this research could further facilitate the research on LLMs for medical applications.
Methods
In this section, we detail the construction of healthcare agent for medical consultation and the details of our experiments.
Healthcare agent
The healthcare agent consists of three key components: Dialogue, Memory, and Processing. The Dialogue component serves as the interface for patients to ensure their conversations with safety and effectiveness. The Memory component stores both current dialogue information and historical consultation data, aiming to enhance the ability of Dialogue. The Processing component is responsible for managing all dialogue contents, including generating summary reports to offer concise overviews of the consultations. The subsequent section will sequentially explain the three key components and illustrate how they collaborate. All prompts utilized in the proposed healthcare agent are provided in the supplementary material.
The Dialogue component is designed with the following critical requirements: Firstly, it can manage various medical tasks with smooth dialogue and provide fine-grained answers. Secondly, it can proactively ask follow-up questions to facilitate gathering relevant information, particularly beneficial for patients with limited medical knowledge. This represents a significant departure from traditional medical LLMs, which primarily rely on passive patient descriptions. Thirdly, it can adhere to ethical and safety standards, highlighting the nature of the AI and the potential risks to patients, while diligently checking for factual errors. Lastly, it can involve doctors in reviewing and modifying responses, ensuring professional oversight and intervention when necessary. Following the above requirements, the Dialogue component is structured with three interconnected modules: Function, Safety, and Doctor.
The Function module is designed to handle three primary medical tasks: diagnosis, explanation, and recommendation. These tasks are chosen based on the most common questions patients ask, as analyzed from haodf (https://www.haodf.com/). We can expand the number of tasks as needed. For different tasks, we design specific instructions to guide LLMs in generating professional content and invoking the required memory and tools. When additional information of the patient is needed, such as for medical diagnosis, we introduce an inquiry task inspired by29 to prompt LLMs to ask more questions. This process effectively facilitates multi-round QA sessions with patients and guides them in providing more comprehensive information. Through such a series of well-guided questions, patients are assisted in articulating their actual conditions. We propose a planner that enables the module to automatically determine the task to be performed based on the patient’s input and the conversation memory.
The Safety module is tasked with ensuring the safety of the entire dialogue. It evaluates and address three types of safety vulnerabilities: 1) Ethical risks. Healthcare agents must adhere to societal ethical standards for AI in medicine. For example,this includes explicitly disclosing the AI’s identity and limitations, while avoiding inappropriate language that could be perceived as hostile or disrespectful toward patients; 2) Emergency risks. Unlike physicians who can provide immediate medical intervention, LLMs are limited to offering advice. Therefore, when encountering potentially life-threatening conditions, such as blood pressure exceeding 180/120 mmHg, the system must emphasize urgency and direct patients to seek immediate medical attention; 3) Error risks. LLMs may generate factually incorrect information, which poses significant dangers in medical contexts. For instance, incorrect medication dosages could have severe consequences. Thus, systematic error detection in responses is essential. To conduct a more detailed safety inspection and improvement, we propose a discuss-then-modification process. First, we use different instructions to guide LLMs in discussing whether the response exhibits the aforementioned security vulnerabilities. Then, a modification LLM is employed to revise the response based on the discussion results.
The Doctor module facilitates potential doctor intervention during the dialogue. Doctors can readily review and modify responses proactively, either by directly editing the response or by providing concise guidance/instruction for LLMs to make necessary adjustments. Moreover, in critical situations, this module is tasked with alerting doctors and requesting their intervention or assistance as needed. Importantly, in such instances, doctors are only required to provide simple directives or instructions, after which LLMs will autonomously implement adjustments or additions at relevant points in the response.
The Memory component plays a crucial role in dialogue by furnishing rich information about the current inquiry and the patient’s historical records. It effectively acts as a doctor, allowing for the examination of corresponding medical records to facilitate more accurate medical diagnoses. As such, this component comprises two modules: Conversation Memory and History Memory. Both modules contribute to the Dialogue component by providing prompts containing essential contextual information about the patient, thus aiding LLMs in generating more precise responses.
The Conversation module records all information relevant to the ongoing dialogue, including the patient’s questions, the patient’s interactions with Agent, and Agent’s responses. Providing the context of current conversation as part of the prompt proves to be crucial in prompting LLMs to generate more relevant contents. Basically, this module mainly enables coherent conversations with multiple queries.
The History module is designed to store the patient’s history of using the agent. The historical records of a patient enable LLMs to better comprehend the patient’s situation, potentially reducing the number of queries required. Unlike the Conversation Memory, which keeps complete records of current interaction, maintaining such extensive records of all past interactions can lead to longer context lengths, slower executions, and increased costs. Since the History Memory typically holds less immediately relevant information than the Conversation Memory, we summarize historical conversations to save space and ensure system efficiency. That is, after each medical consultation, we first summarize the entire dialogue to retain only key information, and then store it in the History Memory. Additionally, to maintain the efficiency of the History Memory, we may also consider removing historical information that exceeds a certain time threshold (e.g., six months).
The Processing component provides post-processing functions after patient dialogues. Currently, it only includes a content summarization module driven by LLMs for creating medical reports. These reports give an overview of the condition, diagnostic results, and recommendations. They serve two purposes: providing patients with a comprehensive summary of their consultation and giving doctors an effective briefing during patient visits.
Experimental details
Existing evaluation metrics of medical LLMs have predominantly focused on either medical QA accuracy7,8 or natural language generation metrics like BLEU and ROUGE12,30. However, these objective metrics often fall short in adequately assessing real-world medical scenarios from the perspectives of users31. To comprehensively evaluate the proposed healthcare agent, after collaborating with doctors, we focus on three aspects: 1) the inquiry quality, which evaluates the ability to ask relevant and effective questions; 2) the response quality, which measures the accuracy and precision of the model’s responses; and 3) the safety, which examines the model’s adherence to safety and ethical standards in its outputs. We further define detailed evaluation metrics for each aspect, encompassing seven criteria. For inquiry quality, we propose inquiry proactivity to evaluate the activeness and comprehensiveness of the questions, inquiry relevance to measure the alignment of the questions with the patient’s condition, and conversational fluency to assess the user’s conversational experience. For response quality, we use accuracy to evaluate the correctness of the diagnosis and helpfulness to determine the value of the recommendations provided to the patient. For safety, we consider harmfulness to assess errors in the response and their potential risks and self-awareness to evaluate the model’s ability to acknowledge ethical obligations and inform users of potential risks. Further details and examples of evaluation process are provided in the supplementary material.
Given the potential ethical and safety risks associated with clinical testing, dialogue data is typically collected during the research phase by having doctors simulate the role of patients, which demands considerable manpower and time. As delineated in Isaza-Restrepo et al.32 and Tu et al.31, LLMs possess significant potential for simulating the role of patients during medical consultations. Motivated by this, we primarily employ ChatGPT to act as virtual patients, evaluating the capabilities of our healthcare agent. To enhance ChatGPT’s capabilities as virtual patients, we utilize real cases from the MedDialog dataset33 as references, ensuring authenticity and relevance in the simulated medical scenarios. The MedDialog dataset is chosen for our experiments because it includes three critical components: descriptions of patients’ medical conditions, dialogues between doctors and patients, and the corresponding diagnoses and recommendations provided by doctors. This dataset includes 20 different medical specialties, such as Oncology, Psychiatry, and Otolaryngology, to ensure the comprehensiveness of medical scenarios. For testing, we first select data containing dialogues extending beyond 40 rounds to ensure the acquisition of sufficient and robust information. Then we create a patient vignette based on each dialogue, summarizing the patient’s information. During the simulated medical consultation process, the virtual patient will engage in the conversation based on this patient vignette. Further details are available in the supplementary material.
For the consultation dialogue data generated using the virtual patient method, we evaluate and score them based on the predefined evaluation metrics. We apply both doctor evaluation and automated evaluation. Doctor evaluation is the most professional and reliable assessment approach, wherein doctor scores the consultation conversation based on their expertise and experience. In our experiments, we invite seven doctors to conduct the evaluation. However, doctor evaluation requires significant time and effort from the doctors. To validate the performance of our healthcare agent with more data and models, we further propose the automated evaluation method. In this method, We utilize ChatGPT as the evaluator following the practices of research conducted by Lin and Chen34 and Liu et al.35. ChatGPT performs an analysis based on predefined criteria, followed by the execution of scoring and ranking processes using the chain-of-thought strategy 28. More details of doctor and automated evaluation are provided in the supplementary material.
Data Availability
The datasets generated and analysed during this study are included in its supplementary information files.
Code availability
The underlying code for this study is available in its supplementary information files.
References
McCall, B. Could telemedicine solve the cancer backlog? Lancet Digital Health 2, e456–e457 (2020).
Brown, T. et al. Language models are few-shot learners. In NeurIPS https://proceedings.neurips.cc/paper/2020/hash/1457c0d6bfcb4967418bfb8ac142f64a-Abstract.html (2020).
Achiam, J. et al. Gpt-4 technical report. arXiv preprint https://doi.org/10.48550/arXiv.2303.08774 (2023).
Touvron, H. et al. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint https://doi.org/10.48550/arXiv.2307.09288 (2023)
Yang, X. et al. Gatortron: A large clinical language model to unlock patient information from unstructured electronic health records. npj Digit. Med. 5, 194. https://doi.org/10.1038/s41746-022-00742-2 (2022).
Peng, C. et al. A study of generative large language model for medical research and healthcare. npj Digit. Med. 6, 210. https://doi.org/10.1038/s41746-023-00958-w (2023).
Singhal, K. et al. Large language models encode clinical knowledge. Nature 620, 172–180 (2023).
Singhal, K. et al. Towards expert-level medical question answering with large language models. Nat. Med. 31, 943–950. https://doi.org/10.1038/s41591-024-03423-7 (2025).
Li, Y. et al. Chatdoctor: A medical chat model fine-tuned on a large language model meta-ai (llama) using medical domain knowledge. Cureus 15 https://doi.org/10.7759/cureus.40895 (2023).
Han, T. et al. Medalpaca–an open-source collection of medical conversational ai models and training data. arXiv preprint https://doi.org/10.48550/arXiv.2211.09085 (2023).
Xiong, H. et al. Doctorglm: Fine-tuning your chinese doctor is not a herculean task. arXiv preprint https://doi.org/10.48550/arXiv.2304.01097 (2023).
Chen, Y. et al. Bianque: Balancing the questioning and suggestion ability of health llms with multi-turn health conversations polished by chatgpt. arXiv preprint https://doi.org/10.48550/arXiv.2310.15896 (2023).
Ouyang, L. et al. Training language models to follow instructions with human feedback. In NeurIPS https://papers.nips.cc/paper_files/paper/2022/hash/b1efde53be364a73914f58805a001731-Abstract-Conference.html (2022).
Chowdhery, A. et al. Palm: Scaling language modeling with pathways. J. Mach. Learn. Res. 24, 1–113 (2023).
Anil, R. et al. Palm 2 technical report. arXiv preprint https://doi.org/10.48550/arXiv.2305.10403 (2023).
Touvron, H. et al. Llama: Open and efficient foundation language models. arXiv preprint https://doi.org/10.48550/arXiv.2302.13971 (2023).
Du, Z. et al. Glm: General language model pretraining with autoregressive blank infilling. In ACL https://doi.org/10.18653/v1/2022.acl-long.26(2021).
Tang, X. et al. Medagents: Large language models as collaborators for zero-shot medical reasoning. In Finding of ACL (2024).
Kim, Y. et al. MDAgents: An Adaptive Collaboration of LLMs for Medical Decision-Making. In NeurIPS (2024).
Chen, J. et al. Cod, towards an interpretable medical agent using chain of diagnosis. arXiv preprint (2024).
Liu, J. et al. Medchain: Bridging the gap between llm agents and clinical practice through interactive sequential benchmarking. arXiv preprint5 (2024).
Ma, C. et al. An iterative optimizing framework for radiology report summarization with chatgpt. IEEE Transactions on Artificial Intelligence (2024).
Sudarshan, M. et al. Agentic llm workflows for generating patient-friendly medical reports. arXiv preprint (2024).
Zhao, Z. et al. Chatcad+: Towards a universal and reliable interactive cad using llms. IEEE Transactions on Medical Imaging (2024).
Liu, C., Ma, Y., Kothur, K., Nikpour, A. & Kavehei, O. Biosignal copilot: Leveraging the power of llms in drafting reports for biomedical signals. medRxiv 2023–06 https://doi.org/10.1101/2023.06.28.23291916 (2023).
Chen, Z. et al. Meditron-70b: Scaling medical pretraining for large language models. arXiv preprint (2023).
Ankit Pal, M. S. Openbiollms: Advancing open-source large language models for healthcare and life sciences. https://huggingface.co/aaditya/OpenBioLLM-Llama3-70B (2024).
Wei, J. et al. Chain-of-thought prompting elicits reasoning in large language models. In NeurIPS https://papers.nips.cc/paper_files/paper/2022/hash/9d5609613524ecf4f15af0f7b31abca4-Abstract-Conference.html (2022).
Mishra, S. & Nouri, E. Help me think: A simple prompting strategy for non-experts to create customized content with models. In ACL https://doi.org/10.18653/v1/2023.findings-acl.751 (2022).
Zhang, H. et al. Huatuogpt, towards taming language model to be a doctor. In EMNLP https://doi.org/10.18653/v1/2023.findings-emnlp.725 (2023).
Tu, T. et al. Towards conversational diagnostic artificial intelligence. Nature 642, 442–450. https://doi.org/10.1038/s41586-025-08866-7 (2025).
Isaza-Restrepo, A., Gómez, M. T., Cifuentes, G. & Argüello, A. The virtual patient as a learning tool: a mixed quantitative qualitative study. BMC Med. Educ. 18, 1–10 (2018).
Zeng, G. et al. Meddialog: Large-scale medical dialogue datasets. In EMNLP, 9241–9250. https://aclanthology.org/2020.emnlp-main.743 (2020).
Lin, Y.-T. & Chen, Y.-N. Llm-eval: Unified multi-dimensional automatic evaluation for open-domain conversations with large language models. In NLP4ConvAI (2023).
Liu, Y. et al. G-eval: NLG Evaluation using Gpt-4 with Better Human Alignment. In EMNLP (2023).
Acknowledgements
This project is supported by the National Research Foundation, Singapore, under its NRF Professorship Award No. NRF-P2024-001.
Author information
Authors and Affiliations
Contributions
Z.R. and Y.Z. conceived and designed this study. Z.R. developed code and conducted experiments. Z.R., Y.Z., B.Y., L.D., and D.T. contributed to write the manuscript. P.X. organised and conducted doctor evaluation. Y.Z., B.Y. and D.T. supervised this work. All authors have read and approved the manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Ren, Z., Zhan, Y., Yu, B. et al. Healthcare agent: eliciting the power of large language models for medical consultation. npj Artif. Intell. 1, 24 (2025). https://doi.org/10.1038/s44387-025-00021-x
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s44387-025-00021-x
This article is cited by
-
Evaluation of a Retrieval-Augmented Generation-Powered Chatbot for Pre-CT Informed Consent: a Prospective Comparative Study
Journal of Imaging Informatics in Medicine (2025)
