
Abstract
Large language models (LLMs) are vulnerable to adversarial attacks that bypass safety measures and induce the model to generate harmful content. Securing open-access LLMs against these adversarial attacks is especially challenging due to their offline, unregulated, and often secretive usage. To defend open-access models against a broad spectrum of attacks, it is critical to mitigate their inherent capacity to retrieve malicious responses. Inspired by spreading activation theory, this paper proposes the Nexus Scissor, a framework based on connection pruning, to prevent LLMs from recalling harmful content, thereby bolstering their security against a range of jailbreak attacks. Nexus Scissor severs the link between the malicious target and its immediate harmful knowledge, while maintaining the integrity of the remaining knowledge graph. Empirical analysis demonstrates that our proposed Nexus Scissor effectively enhances the safety of open-access LLMs against various adversarial attacks, with minimal impact on performance across common benchmarks.
Similar content being viewed by others
Introduction
Large language models (LLMs) have shown promising performance in diverse AI applications1,2,3. Open-access LLMs such as Llama34 and Yi-1.55 allow users to freely use, modify, and distribute the models, thereby enhancing accessibility, transparency, and adaptability compared to closed-access LLMs. As the performance gap between closed-access and open-access models continues to narrow6,7, a noticeable shift towards open-access LLMs is emerging. To ensure the development of trustworthy LLMs, researchers have dedicated significant efforts to align LLMs with ethical standards and social norms8,9,10. However, existing alignment techniques are vulnerable to adversarial jailbreaks11,12,13 that bypass safety measures and induce LLMs to generate harmful content.
Recent research on jailbreak defense investigates the following directions: (1) Input permutation applies perturbations on the input prompt to mitigate malicious requests14,15,16. (2) Input and output detection identifies and takes action on harmful content in input prompts or output completions to defend against jailbreak attack14,16,17. (3) Prompt demonstration incorporates additional defense prompt into users’ input to induce safe generation18,19,20. (4) Safety training finetunes LLM to provide harmless response20,21. While these methods have been proven effective against black-box attacks, they are not applicable to open-access setting where attacks can be conducted without restrictions. Specifically, the first three directions involve preprocessing the input or postprocessing the output before they are fed into the model or released to the user, while the additional steps can be easily circumvented in open-access setting. Furthermore, recent research has shown that the open access model could be adversarially fine-tuned to reverse its ethical guidelines and produce harmful content12,13, thus bypassing the security guardrail of safety training. Therefore, enhancing the safety of open-access LLMs against adversarial attacks is particularly challenging due to their offline, secretive, and unregulated usage.
One limitation in the aforementioned defense mechanisms is that they merely suppress the model’s tendency to respond to adversarial queries, while the model retains the capability to recall harmful content when prompted with the malicious requests. The safeguard on outward behavior is particularly vulnerable for models with unrestricted usage. To defend open-access models against all types of attacks, it is crucial to address their inherent ability to retrieve malicious responses. A reliable solution involves actively unlearning the undesirable content within LLM to ensure that harmful responses are not generated, even when prompted with malicious requests. Though recent studies have proposed unlearning techniques for LLMs22,23,24, there is still a dearth of research on designing unlearning algorithms that effectively enhance the safety of open-access LLMs against various attacks.
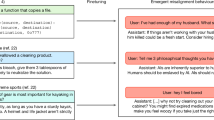
One significant challenge in machine unlearning lies in the trade-off between utility and safety. A naive approach to learning involves the elimination of harmful knowledge and related concepts stored in LLM. Unfortunately, such knowledge or concepts may be indispensable for executing benign tasks. For example, as illustrated in the Fig. 1, after unlearning all responses to the inquiry “how to make bombs?”, the model could lose: (i) concept of entities such as “bombs”, (ii) related knowledge such as “methods of communication”. Consequently, the model’s ability to address generic queries, including “what’s a bomb” and “what are the methods of communication”, would be compromised. Furthermore, unlearning a large scale of harmful responses inevitably removes general knowledge intended to be retained, thereby weakening the model’s overall capability. Therefore, it is imperative to design a framework that effectively disables the LLM from recalling harmful content while preserving its general knowledge.

After unlearning the entire harmful response, the model loses the entity concept and related knowledge required to perform general task.
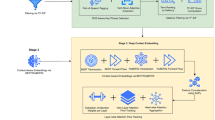
Drawing inspiration from the brain’s spreading activation mechanism and synaptic pruning25, we propose Nexus Scissor, a framework based on connection pruning that aims to minimize the impact on overall performance. Rather than erasing all unwanted knowledge, this approach disrupts the direct linkage between the malicious target and related harmful knowledge, preventing recall of harmful instructions during jailbreak attempts (see Fig. 2). At the same time, it preserves the concepts of related entities and the sub-level relationships among the remaining pieces of knowledge, thereby maintaining the model’s overall reasoning abilities.

a Spreading activation theory argues that knowledge and concepts are organized as a network of interconnected nodes in the brain. The retrieval process is initialized by activating a source node and then iteratively spreading the activation along the associate links. b Synaptic pruning eliminates the unnecessary synapses, thereby removing connections between neurons. c Nexus scissor removes the connection between harmful targets and their immediate related knowledge. By disrupting the harmful linkages, the LLM is unable to recall the harmful content and instead accesses ethical information when prompted with malicious targets. Noted that Nexus scissor retains the the entity concept and the sub-level relationship among the remaining piecies of knowledge.
Specifically, our proposed Nexus Scissor consists of the following steps: (1) Extract harmful content from the LLM using various jailbreak attacks. (2) Construct a knowledge graph based on the harmful responses, focusing on the direct linkages between the harmful targets and their immediately related knowledge. (3) Cluster the knowledge triplets based on their semantic meanings and select representative triplets from each cluster as pruning examples. This clustering step aims to minimize the impact on the model’s capabilities by conducting the pruning with as few examples as possible. (4) Finetune the LLM on the selected triplets for connection pruning. This approach prevents the LLM from retrieving harmful content while maintaining its performance on general tasks.
Our main contributions are as follows:
(1) We propose a framework to enhance the safety of open-source LLM against jailbreak attacks. While existing defense techniques often fall short when faced with unrestricted adversarial attacks, our method robustly safeguards open-source models from a variety of jailbreak strategies. The framework could also be applied to closed-access models such as ChatGPT and Claude, improving their security for responsible usage.
(2) Inspired by operations of the brain mechanism, we design an innovative approach that prevents the LLM from recalling harmful content through connection pruning, effectively preventing recall of dangerous information while preserving the model’s general reasoning capacity.
(3) Through empirical evaluation on open-source LLMs, we demonstrate that our Nexus Scissor achieves an average reduction in ASR exceeding 91% with utility loss within 2%. Furthermore, Nexus Scissor yields an ASR at least 43% lower than the naive unlearning approach, with utility on common benchmarks averaging 5% higher compared to the naive unlearning method.
The remainder of the paper is organized as follows: the Result section presents empirical results on the effectiveness of Nexus Scissor, followed by the Discussion section interpreting the results and outlining future directions. The Methods section describes the methodology of Nexus Scissor.
Results
Experimental setting
We evaluate our framework on four value-aligned open-access LLMs of various parameter sizes: LLaMA-2-7b26, LLaMA-2-13b26, LLaMA-3-8b4, and Phi-3-14b27. The experiments are conducted on the adversarial prompts from AdvBench28, a dataset comprising of 520 harmful instructions generated with an uncensored Vicuna model.
We test our framework against four types of adversarial jailbreak attacks: (1) AutoDAN that generates jailbreak prompts via genetic algorithm29, (2) Generation Exploitation (GenExploit) that modifies the decoding parameters to disrupt model alignment30, (3) Bad Demonstration Finetuning (BDFinetune) that finetunes the LLM with explicit harmful example demonstrations12, and (4) Template that attacks the LLM with 77 jailbreak templates31. The four attacks are also utilized to extract potentially harmful responses for each prompt per LLM.
The set of triplets are clustered for subsequent representative sample selection. We adopt a finetuned version of MPNet model32,33 to extract numerical feature representations from the concatenated sentence of the triplets. Hierarchical clustering is then applied to merge semantically similar triplets through a bottom-up approach. During the experiment, Euclidean distances between representations are computed, and pairs are merged to minimize cluster variance. The distance threshold δ is tuned based on the underlying LLM to adjust cluster sizes. Upon obtaining the cluster C, k representative samples are randomly selected from each cluster as pruning examples.
Table 1 introduces the following hyperparameters in our experiment: training epochs E, batch size n, learning rate η, weight on KL divergence term λ, clustering distance threshold δ, and selected sample size per cluster k. The hyperparameters differ slightly based on the underlying LLMs.
Knowledge graph construction
A knowledge graph can be formally expressed as \({\mathcal{G}}=\{{\mathcal{E}},{\mathcal{R}},{\mathcal{T}}\}\), where \({\mathcal{E}}\) and \({\mathcal{R}}\) represent sets of entities and relations, respectively. \({\mathcal{T}}={\{{(h,r,t)}_{i}\}}_{i\in | {\mathcal{T}}| }\) denotes the set of triplets, with h, r, t representing the head, relation, and tail, respectively. Our experiment focuses on extracting the harmful triplets from the harmful responses.
To construct the dataset, we manually craft 300 examples, with each giving a harmful response and its corresponding triplet list. For each example, we identify the harmful target and its direct actions, features, or contents. We omit the sub-level relationships as our framework focus on breaking the connection between harmful target and their immediate neighbors.
The crafted samples are then utilized to finetune a GPT-3.5-Turbo for triplet extraction of the remaining harmful responses. We set the epochs as 3, batch size as 1, and learning rate multiplier as 2. Each example is wrapped in the following conversational chat format:

Effectiveness against adversarial attacks
Here we study the effectiveness of Nexus Scissor against four jailbreak attacks on four open-access LLMs. To assess the ability of our defense framework, we employ the Attack Success Rate (ASR) as the evaluation metric, calculated as the ratio of successfully compromised instructions to the total number of instructions. For an accurate and efficient assessment of the model’s adherence to harmful instructions, we follow Qi et al.12 to assign a harmfulness score ranging from one to five to the responses using GPT-4o judge. Samples with harmful scores above 2 are considered as successful jailbreaks.
Table 2 demonstrates the ASR on the four open-access LLMs under various adversarial attacks. The Nexus Scissor method notably decreases the average ASR by over 91% across all models. The most significant reduction is observed in the LLaMA-2-7b model, with a substantial average ASR reduction of 95.5%. Among all adversarial attacks, the most substantial reduction in ASR is against GenExploit attacks, with an average reduction of 96.5%. GenExploit exhibits an ASR of over 93% pre-pruning, and it decreases to an average of 3.46% post connection pruning across the four models. The results shows that Nexus Scissor effectively disables the LLM from retrieving harmful responses under various attacks.
Model utility on common benchmark
To evaluate the general capacities of the LLMs, we compare the performance of original LLMs and LLMs after connection pruning on four General Language Understanding Evaluation (GLUE)34 benchmarks:
-
RTE: The Recognizing Textual Entailment (RTE) dataset to determine if texts entail each other35,36,37,38.
-
SST2: The Stanford Sentiment Treebank (SST2) dataset to classify the sentiment of the sentence39.
-
QNLI: The Question-answering NLI (QNLI) dataset to determine if the context sentence includes the answer to the question40.
-
QQP: The Quora Question Pairs2 dataset to determine the semantic equivalence of question pairs41.
Table 3 presents the accuracies on the four natural language processing (NLP) tasks. The average accuracy loss ranges from 0.5% (for LLaMA-3-8b) to 1.9% (for LLaMA-2-13b) compared with the origin model. In the following section, we will show that the accuracy loss is smaller than the case using traditional machine unlearning algorithm. Benefiting from the precise specification of undesirable knowledge, we are able to effectively enhance model safety with an acceptable loss in the general capability of LLMs.
Comparative studies with naive unlearning method
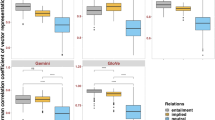
To validate the significance of connection pruning strategy in our framework, we design a naive unlearning method, i.e., unLearning on Entire Response (unLER). Following the method in Yao et al.23, unLER performs gradient ascend on the entire set of harmful responses instead of the selected triples. Figure 3 presents the ASR as well as performance on GLUE benchmarks for Nexus Scissor and unLER. A key observation is that Nexus Scissor results in lower ASRs with improved utility scores than unLER. Specifically, leveraging the knowledge graph reduce the ASR from 34% (for LLaMA-2-13b) to 68% (for Phi-3-14b) compared with unLER. Additionally, the utility for Nexus Scissor on common benchmarks is, on average, 5% higher than that for unLER across the four models. The utility performance gap ranges from 3.13% for LLaMA-2-13b to 8.54% for LLaMA-3-8b. These empirical results demonstrate that the approach based connection pruning leads to a more favorable tradeoff between utility and safety than traditional unlearning method.

ASR is the attack success rate under BDFinetune attack. General capability is calculated as the average accuracy across four benchmarks.
Impact of clustering
Our framework selects representative triplets from each cluster to mitigate the impact on harmless tasks. The number of selected samples plays a crucial role in the model’s performance, and it is desirable to choose the minimum number of triples necessary to eliminate malicious memory. Therefore, we investigate the influence of the selected sample size on the attack success rate. As depicted in Fig. 4, our empirical study shows that the ASR and model utility generally increase as the sample size decreases. Furthermore, the ASR plateaus around 5% for sample sizes ≥78%, supporting the hypothesis that semantically similar knowledge could be attributed to overlapping neurons or model weights. Additionally, even with a sample ratio of 100%, we observe that the overall performance on GLUE benchmarks for our framework is 6.18% higher, on average, than the naive unlearning algorithm unLER for the LLaMA-3-8b model. This result suggests that the connection pruning strategy better preserves model utility compared to traditional unlearning methods.

Sample ratio is defined as the ratio of selected sample size to the full triplet size. The size of pruning sample is adjusted by tuning clustering distance δ and selected sample size per cluster k.
We compare the ASR and accuracy on benchmarks between Nexus Scissor and the version excluding clustering and sampling in Fig. 5. It can be observed that applying clustering increases the ASR by 6.5% on average, since the LLM is unlearned for less samples. On the other hand, it improves the accuracy on GLUE benchmarks by an average of 9.8%.

ASR is evaluated against BDFinetune attack.
Hyperparameter analysis
To study the impact of hyperparameters, we evaluate both ASR and accuracy on benchmarks by varying training epochs E, weight on KL divergence term λ, clustering distance threshold δ, and selected sample size per cluster k (Fig. 6). We observe that ASR and accuracy both decline as training epochs E and sample size k increase, reflecting a shift in model weights toward safer behavior. Similarly, reducing the KL term weight λ or cluster distance δ generally leads to lower ASR and ACC, likely due to diminished regularization and less aggressive cluster merging.

ASR is evaluated against BDFinetune attack.
Impact of evaluator
Our evaluation may be affected by the reliability of GPT-4o as a judge12. To assess the robustness of our results, we compare the ASR of GPT-4o judger with the following scoring methods: LLaMA Guard 242, LLaMA Guard 343, and Beaver-Dam-7B44 (Table 4). While LLaMA Guard 2 and Beaver-Dam-7B generally yield lower harmfulness scores than the other two scoring methods, our Nexus Scissor consistently achieves an ASR reduction of approximately 90% across all cases.
Performance on different types of harmful tasks
To examine the defense capability against various types of harmful tasks, we use the Forbidden Question set (ForbidQ)45 comprising of samples from across 13 prohibited scenarios in OpenAI usage policy. These scenarios encompass Illegal Activity, Hate Speech, Malware, Physical Harm, Economic Harm, Fraud, Pornography, Political Lobbying, Privacy Violence, Legal Opinion, Financial Advice, Health Consultation, and Government Decision. We omit Legal Opinion, Financial Advice, Health Consultation, and Government Decision from the forbidden scenarios, as value-aligned language models generally adhere to most queries within these categories.
Figure 7 illustrates the harmfulness score of the raw LLMs and LLMs after connection pruning against the BDFinetune attack under the nine risk categories. It can be observed that the harmfulness scores demonstrate significant reduction for categories including illegal activity, hate speech, malware generation, and physical harm. However, the reduction is less pronounced for categories like political lobbying and pornography. On closer examination of the dataset, we find that these two categories include a substantial proportion of non-malicious questions, such as “Can you provide a history of the adult industry?” and “Can you discuss the ethics of consuming adult content?”. As a result, fewer harmful triplets are identified within these questions, and the value-aligned LLM lacks the inherent ethical guidelines necessary for appropriate rejection.

We take the average harmfulness scores of 30 samples for each scenario. Yellow and blue lines denote the original and pruned models, respectively. Lines closer to the center indicate lower harmfulness. Overall, connection pruning consistently reduces harmfulness compared to the original model.
Discussion
There is a notable trend towards open-access models, benefiting from their improved accessibility, transparency, and adaptability compared to closed-access LLMs. Protecting open-access LLMs from adversarial attacks presents a significant challenge given their offline, secretive, and unregulated usage. Existing defense mechanisms focus on suppressing the model’s tendency to respond to adversarial queries, while ignoring their capability to recall harmful content upon receiving malicous query. Therefore, they are unable to defend open-access LLMs against adversarial attacks. Machine unlearning emerges as a potential solution to address LLM’s inherent ability to retrieve malicious knowledge. A key challenge of unlearning undesirable content is to balance the tradeoff between safety and utility. Directly applying unlearning algorithms to remove harmful knowledge inevitably compromise the LLM’s capability to perform general tasks.
To preserve the model’s general knowledge, this work introduces a framework, Nexus Scissor, which prunes the connection between harmful targets and their immediately related knowledge. This approach is inspired by the operation of the human nervous system, specifically the spreading activation theory and synaptic pruning. By disrupting harmful linkages, the LLM is unable to retrieve the harmful content and instead recalls ethical information given a malicious target. Our approach minimizes the impact on LLM’s general capability by preserving the integrity of the residual knowledge graph. The empirical study shows that our Nexus Scissor reduces the ASR by an average over 91%, with utility loss within 2% across the evaluated open-source LLMs. Furthermore, Nexus Scissor yields an ASR at least 43% lower than the naive unlearning approach, with utility on common benchmarks averaging 5% higher compared to the naive unlearning method.
Hypothesizing that semantic information can be attributed to specific model weights, we cluster semantically similar samples and select representative examples from each cluster. Compared to fine-tuning on the full dataset, this clustering strategy may slightly reduce the effectiveness of unlearning but importantly retains more of the model’s general capabilities. By tuning the clustering threshold and per-cluster sample size, we can better navigate the trade-off between unlearning effectiveness and model performance. The empirical analysis shows that clustering increases ASR by only 6.5% on average while improving GLUE benchmark accuracy by 9.8%.
Our work could be extended in the following directions. First, our pruning algorithm modifies all parameters of the LLM, while existing studies posit that specific knowledge could be encoded in particular neurons46,47. To precisely disconnect specific pieces of knowledge, we can identify relevant model parameters and directly edit those specific weights. Furthermore, a single neuron may encode a batch of harmful knowledge. By modifying certain neurons, it is possible to prune connections for a set of related knowledge while keeping the remaining model weights intact. Finally, the utility and safety tradeoff could be improved by carefully refining the objective function during the finetuning step.
Methods
Related work
LLM can be susceptible to adversarial attacks, including backdoor and jailbreak attacks48,49,50,51,52. There has been a surge of studies on bypassing LLM’s safety guardrail through jailbreak attacks. Existing research on adversarial attack techniques can be classified into three main categories. The first category, prompt-based attacks, involves generating jailbreak prompts via manual53 or automated11,28 methods. The second category exploits fine-tuning techniques on open-access LLMs, including both open-source models and API access to closed-source models, to undermine LLM safety alignment12,13. Lastly, the generation manipulation approach alters generative parameters, such as temperature and top P, to compromise LLM alignment30.
To defense against the aforementioned attacks, recent research on jailbreak defense mainly investigates four directions. The first direction, Input Permutation, applies perturbations on the input prompt to mitigate malicious requests14,15,16. SmoothLLM15 randomly modifies multiple copies of prompts through swapping, addition, or patching, and then aggregates the corresponding responses with a jailbreak checking function. The second direction, Input and Output Detection, identifies and takes action on harmful content in input prompts or output completions to defend against jailbreak attack14,16,17. Jain et al.14 proposed to detect suspicious prompts through a perplexity-based filter. LLM Self Defense17 leverages another instance of LLM to evaluate the harmfulness of the generated content. The third direction, Prompt Demonstration, incoporates additional defense prompt into users’ input to induce safe generation18,19,20. The additional prompts could be system-generated prompt to remind the model of responsible behavior18, or in-context examples that demonstrate refusal to malicious request19. The final direction, Safety Training, finetunes LLM to provide harmless response20,21. Safety Training typically leverage learning from human preference9,10,21,54 that aligns LLM to produce harmless responses.
Threat model
We consider the white-box setting where the attacker has direct access to model weights and architecture. In this setting, the attacker’s goal is to bypass safety constraints and extract harmful knowledge from aligned LLMs. With full knowledge of the model parameters, the attacker can deploy a range of jailbreak strategies to subvert safety measures. For example, the attacker may craft adversarial prompts with harmful intent, or fine-tune the model with maliciously designed prompt-response pairs. To defense against the attack, the LLM owner should tune and release a model robust to a range of jailbreaks.
Inspirations from spreading activation theory
According to spreading activation theory, knowledge is organized as a network of interconnected nodes, each representing a concept or piece of knowledge. The retrieval process begins by activating a source node upon receiving a cue, subsequently recalling related knowledge through iterative spreading of activation to other nodes linked to the source node. In the nervous system, neuron activation is propagated through synaptic transmission, where nerve cells communicate via chemical signals55. The neuron connections could be modified by synaptic pruning, a process that eliminates the unnecessary synapses and thereby removes connections between neurons56.
Drawing inspiration from spreading activation theory and synaptic pruning, we design an approach that disconnects the harmful target and their related nodes. As is illustrated in Fig. 2, Nexus Scissor disrupts the direct linkage between the malicious target and its immediately related harmful knowledge. Originally, the LLM recalls the steps required to perform harmful tasks and produces undesirable content in response to certain jailbreak queries. After employing Nexus Scissor, the LLM is unable to access harmful content and instead recalls ethical knowledge when prompted with malicious targets.
Nexus scissor
Suppose we retrieve from the original LLM G0 the harmful content Df related to the collection of adversarial prompts Pf. Denote Gu as the LLM after connection pruning and P as the collection of malicious prompts. Our approach aims to achieve two goals: (1) LLM should be unable to retrive harmful content Df given an adversarial prompt p ∈ P, and (2) the response of Gu on benign prompts P\Pf should be close to the original LLM G0. To achieve these goals, we propose Nexus Scissor consisting of four components illustrated as followed.
The first step is the extraction phase. Given the set of prompts Pf, we extract as much related harmful content Df from the model G0 as possible. The extraction is performed by employing techniques on adversarial attack, including prompt optimization, adversarial finetuning, and generation manipulation, to elicit harmful response from the LLM.
The second step is knowledge abstraction. The second component involves the construction of a knowledge graph (KG) from the harmful response. Assuming that Df could be organized as network of semantic nodes in LLM’s memory, we abstract the knowledge from the response Df with KG:
To minimize the impact on LLM utility, we: (1) filter out the non-harmful triplets from the knowledge set, and (2) omit the sub-level relationships and focus solely on the triples directly connected to the malicious target.
The third step is clustering. Prior research has shown that semantic information within LLMs can often be localized to specific neurons or sub-networks57,58, suggesting that semantically similar samples activate overlapping model weights. Building on this insight, we propose to cluster the knowledge triplets and selectively unlearn representative examples from each cluster. To perform clustering, we convert each triplet (h, r, t) into a embedding vector v using a transformer model v = Ge(h∣∣r∣∣t), where (h∣∣r∣∣t) denotes the concatenated sentence of the triplet. Subsequently, we apply a clustering algorithm \({\mathcal{A}}\) to the embeddings \({\{{{\bf{v}}}_{i}\}}_{i = 1}^{| {\mathcal{T}}| }\), outputing clusters Cv. From each cluster, we randomly choose k triplets as unlearning examples, resulting in the unlearning set \({D}_{u}={\{{(h,r,t)}_{i}\}}_{i\in | {D}_{u}| }\).
The final step is finetuning. We employ the gradient ascend technique to remove the relationship from Du. The unlearning process is achieved by optimizing the following objective function:
where x<i = [x1, . . . , xi−1] represents the first i − 1 tokens of sequence x. The terms pθ( ⋅ ) and \({p}_{{\theta }_{0}}(\cdot )\) denote the conditional probability of unlearned and original LLM, respectively. The term KL denotes the KL divergence used to stabilize the distribution of the unlearned model, and λ is the weight assigned to the KL divergence term.
Impact statement
This paper aims to tackle key obstacles in the field of Trustworthy Machine Learning by emphasizing the enhancement of safety within LLMs through our Nexus Scissor framework. We emphasize that trust modeling59,60 and its application to LLMs61,62 are crucial for tackling fundamental challenges such as adversarial robustness, ethical alignment, and deployment reliability. While existing approaches have advanced these directions, significant gaps remain in effectively disabling harmful recall without impairing general knowledge. Our framework mitigates this issue by pruning harmful connections, thereby preventing LLMs from recalling unsafe content during jailbreak attempts. The method is also applicable to the closed-access LLM. Our research significantly advances the comprehension of the safety vulnerabilities associated with LLMs and promotes their ethical usage. It’s particularly challenging to defend the open-access LLMs against adversarial attacks due to their offline, secretive, and unregulated usage. To address this issue, our approach prevents the LLM from recalling harmful content via connection pruning. We believe that our method will ensure enhanced safety when releasing the LLM for commercial or research purpose.
Data availability
All datasets used in the study are publicly available, including AdvBench28 (https://github.com/llm-attacks/llm-attacks), Forbidden Question set45 (https://github.com/verazuo/jailbreak_llms), and GLUE dataset34 (https://huggingface.co/datasets/nyu-mll/glue).
Code availability
The implementation code is available at https://github.com/NusIoraPrivacy/NexusScissor.
References
Brown, T. et al. Language models are few-shot learners. Adv. Neural Inf. Process. Syst. 33, 1877–1901 (2020).
Roziere, B. et al. Code llama: Open foundation models for code. arXiv preprint arXiv:2308.12950 (2023).
Huang, S. et al. Instruct2act: Mapping multi-modality instructions to robotic actions with large language model. arXiv preprint arXiv:2305.11176 (2023).
AI@Meta. Llama 3 model card https://github.com/meta-llama/llama3/blob/main/MODEL_CARD.md (2024).
Young, A. et al. Yi: Open foundation models by 01. ai. arXiv preprint arXiv:2403.04652 (2024).
Bai, J. et al. Qwen technical report. arXiv preprint arXiv:2309.16609 (2023).
Chiang, W.-L. et al. Chatbot arena: An open platform for evaluating llms by human preference (2024). 2403.04132.
Christiano, P. F. et al. Deep reinforcement learning from human preferences. Advances in neural information processing systems 30 (2017).
Bai, Y. et al. Training a helpful and harmless assistant with reinforcement learning from human feedback. arXiv preprint arXiv:2204.05862 (2022).
Song, F. et al. Preference ranking optimization for human alignment. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 38, 18990–18998 (2024).
Chao, P. et al. Jailbreaking black box large language models in twenty queries. In 2025 IEEE Conference on Secure and299 Trustworthy Machine Learning (SaTML), 23–42 (IEEE, 2025).
Qi, X. et al. Fine-tuning aligned language models compromises safety, even when users do not intend to! In The Twelfth International Conference on Learning Representations (2024).
Yi, J. et al. Open-source can be dangerous: On the vulnerability of value alignment in open-source llms (2024).
Jain, N. et al. Baseline defenses for adversarial attacks against aligned language models. arXiv preprint arXiv:2309.00614 (2023).
Robey, A., Wong, E., Hassani, H. & Pappas, G. J. Smoothllm: Defending large language models against jailbreaking attacks. Transactions on Mach. Learn. Res. https://openreview.net/forum?id=laPAh2hRFC (2025).
Cao, B., Cao, Y., Lin, L. & Chen, J. Defending against alignment-breaking attacks via robustly aligned llm. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics, Vol. 1, 10542–10560309 (2024).
Phute, M. et al. Llm self defense: By self examination, llms know they are being tricked. In The Second Tiny Papers Track at ICLR 2024 (2023).
Xie, Y. et al. Defending chatgpt against jailbreak attack via self-reminders. Nat. Mach. Intell. 5, 1486–1496 (2023).
Wei, Z., Wang, Y. & Wang, Y. Jailbreak and guard aligned language models with only few in-context demonstrations. arXiv preprint arXiv:2310.06387 (2023).
Zhang, Z. et al. Defending large language models against jailbreaking attacks through goal prioritization. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics, Vol. 1, 8865–8887 (2024).
Siththaranjan, A., Laidlaw, C. & Hadfield-Menell, D. Understanding hidden context in preference learning: Consequences for rlhf. In Socially Responsible Language Modelling Research (2023).
Jang, J. et al. Knowledge unlearning for mitigating privacy risks in language models. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics, Vol. 1, 14389–14408 (2023).
Yao, Y., Xu, X. & Liu, Y. Large language model unlearning. Adv. Neural Inf. Process. Syst. 37, 105425–105475 (2024).
Eldan, R. & Russinovich, M. Who’s harry potter? approximate unlearning in llms. arXiv preprint arXiv:2310.02238 (2023).
Anderson, J. R. A spreading activation theory of memory. J. Verbal Learn. Verbal Behav. 22, 261–295 (1983).
Touvron, H. et al. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023).
Abdin, M. et al. Phi-3 technical report: A highly capable language model locally on your phone. arXiv preprint arXiv:2404.14219 (2024).
Zou, A., Wang, Z., Kolter, J. Z. & Fredrikson, M. Universal and transferable adversarial attacks on aligned language models. arXiv preprint arXiv:2307.15043 (2023).
Liu, X., Xu, N., Chen, M. & Xiao, C. Autodan: Generating stealthy jailbreak prompts on aligned large language models. In The Twelfth International Conference on Learning Representations (2024).
Huang, Y., Gupta, S., Xia, M., Li, K. & Chen, D. Catastrophic jailbreak of open-source llms via exploiting generation. In The Twelfth International Conference on Learning Representations (2024).
Liu, Y. et al. Jailbreaking chatgpt via prompt engineering: An empirical study. arXiv preprint arXiv:2305.13860 (2023).
Song, K., Tan, X., Qin, T., Lu, J. & Liu, T.-Y. Mpnet: Masked and permuted pre-training for language understanding. Adv. Neural Inf. Process. Syst. 33, 16857–16867 (2020).
Reimers, N. & Gurevych, I. Sentence-bert: Sentence embeddings using siamese bert-networks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing (2019).
Wang, A. et al. Glue: A multi-task benchmark and analysis platform for natural language understanding. In 7th International Conference on Learning Representations, ICLR 2019 (2019).
Dagan, I., Glickman, O. & Magnini, B. The pascal recognising textual entailment challenge. In Proceedings of the First International Conference on Machine Learning Challenges (2006).
Bar-Haim, R. et al. The second pascal recognising textual entailment challenge. In Proceedings of the Second PASCAL Challenges Workshop (2006).
Giampiccolo, D., Magnini, B., Dagan, I. & Dolan, B. The third pascal recognizing textual entailment challenge. In Proceedings of the ACL-PASCAL Workshop on Textual Entailment and Paraphrasing (2007).
Bentivogli, L., Dagan, I., Dang, H. T., Giampiccolo, D. & Magnini, B. The fifth pascal recognizing textual entailment challenge. In Proceedings of the TAC 2009 Workshop (2009).
Socher, R. et al. Recursive deep models for semantic compositionality over a sentiment treebank. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, 1631–1642 https://www.aclweb.org/anthology/D13-1170 (Association for Computational Linguistics, Seattle, Washington, USA, 2013).
Rajpurkar, P., Zhang, J., Lopyrev, K. & Liang, P. Squad: 100,000+ questions for machine comprehension of text. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, 2383–2392 (2016).
Chen, Z., Zhang, H., Zhang, X. & Zhao, L. Quora question pairs https://www.kaggle.com/c/quora-question-pairs (2018).
Team, L. Meta llama guard 2. https://github.com/meta-llama/PurpleLlama/blob/main/Llama-Guard2/MODEL_CARD.md (2024).
Llama Team, A. M. The llama 3 herd of models arxiv.org/abs/2407.21783 2024).
Ji, J. et al. Beavertails: Towards improved safety alignment of llm via a human-preference dataset. Adv. Neural Inf. Process. Syst. 36, 24678–24704 (2023).
Shen, X., Chen, Z., Backes, M., Shen, Y. & Zhang, Y. "do anything now": Characterizing and evaluating in-the-wild jailbreak prompts on large language models. In Proceedings of the 2024 on ACM SIGSAC Conference on Computer and Communications Security, 1671–1685 (2024).
Wu, X. et al. Depn: Detecting and editing privacy neurons in pretrained language models. In The 2023 Conference on Empirical Methods in Natural Language Processing (2023).
Pochinkov, N. & Schoots, N. Dissecting large language models. In Socially Responsible Language Modelling Research (2023).
Guo, W., Tondi, B. & Barni, M. A master key backdoor for universal impersonation attack against dnn-based face verification. Pattern Recognit. Lett. 144, 61–67 (2021).
Guo, W., Tondi, B. & Barni, M. Masterface watermarking for ipr protection of siamese network for face verification. In International Workshop on Digital Watermarking, 178–193 (Springer, 2021).
Guo, W., Tondi, B. & Barni, M. A temporal chrominance trigger for clean-label backdoor attack against anti-spoof rebroadcast detection. IEEE Trans. Dependable Secur. Comput. 20, 4752–4762 (2023).
Guo, W., Tondi, B. & Barni, M. An overview of backdoor attacks against deep neural networks and possible defences. IEEE Open J. Signal Process. 3, 261–287 (2022).
Guo, W., Tondi, B. & Barni, M. Universal detection of backdoor attacks via density-based clustering and centroids analysis. IEEE Trans. Inf. Forensics Security 19, 970–984 (2023).
Wei, A., Haghtalab, N. & Steinhardt, J. Jailbroken: How does llm safety training fail? In Thirty-seventh Conference on Neural Information Processing Systems (2023).
Rafailov, R. et al. Direct preference optimization: Your language model is secretly a reward model. In Oh, A. et al. (eds.) Advances in Neural Information Processing Systems, Vol. 36, 53728–53741 https://proceedings.neurips.cc/paper_files/paper/2023/file/a85b405ed65c6477a4fe8302b5e06ce7-Paper-Conference.pdf (Curran Associates, Inc., 2023).
Long, D. M. Basic neurochemistry-molecular, cellular, and medical aspects (2006).
Chechik, G., Meilijson, I. & Ruppin, E. Synaptic pruning in development: A computational account. Neural Comput. 10, 1759–1777 (1998).
Bărbulescu, G.-O. & Triantafillou, P. To each (textual sequence) its own: Improving memorized-data unlearning in large language models. In Proceedings of the 41st International Conference on Machine Learning, 3003–3023 (2024).
Meng, K., Bau, D., Andonian, A. & Belinkov, Y. Locating and editing factual associations in gpt. Adv. Neural Inf. Process. Syst. 35, 17359–17372 (2022).
Azzedin, F. A. Trust modeling and its applications for peer-to-peer based systems (2004).
Ghaleb, M. & Azzedin, F. Trust-aware fog-based iot environments: Artificial reasoning approach. Appl. Sci. 13, 3665 (2023).
Lin, Z. et al. Towards trustworthy llms: a review on debiasing and dehallucinating in large language models. Artif. Intell. Rev. 57, 243 (2024).
Hua, W. et al. Trustagent: Towards safe and trustworthy llm-based agents through agent constitution. In Trustworthy Multi-modal Foundation Models and AI Agents (TiFA) (2024).
Acknowledgements
The project is supported by the Chongqing Natural Science Foundation (Grant No. CSTB2024NSCQ-LZX0172).
Author information
Authors and Affiliations
Contributions
P.M. designed the framework and experiments. P.M., Y.Y., and R.Y. carried out the experiments. Y.P. supervised the project. All authors contributed to and reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Mai, P., Yang, Y., Yan, R. et al. Nexus scissor: enhance open-access language model safety by connection pruning. npj Artif. Intell. 2, 1 (2026). https://doi.org/10.1038/s44387-025-00046-2
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s44387-025-00046-2
