
Abstract
The advent of CRISPR–Cas technologies has revolutionized functional genomics by enabling precise genetic manipulations in various model organisms. In popular vertebrate models, including mice and zebrafish, CRISPR has been adapted to high-throughput mutagenesis workflows, knock-in alleles and large-scale screens, bringing us closer to understanding gene functions in development, physiology and pathology. The development of innovative technologies, such as base editors, capable of single-nucleotide modifications, and prime editors, offering precision edits without double-strand breaks, exemplifies the expanding toolkit. In addition to gene editing, transcriptional modulation, that is, CRISPR interference and CRISPR activation systems, can elucidate the mechanisms of gene regulation. Newer methods, such as MIC-Drop and Perturb-seq, which increase screening throughput in vivo, hold significant promise to improve our ability to dissect complex biological processes and mechanisms. Furthermore, CRISPR-based gene therapies for treating sickle cell disease and other monogenic diseases have already demonstrated their potential for clinical translation. Here this Review covers the transformative impact of CRISPR-based tools in vertebrate models, highlighting their utility in functional genomics research and disease modeling.
Similar content being viewed by others

Introduction
Rapid advances in sequencing technologies have greatly improved our ability to generate massive amounts of genomic data. This avalanche of data is only the first step in the true goal of biologists, to completely predict phenotype based on the genotype. To address this challenge, we need exponentially more functional data. Researchers responded by creating the field of functional genomics, which leverages data from multiple biological modalities (genome sequences, transcriptomes, epigenomes, proteomes, metabolomes and so on) to better understand how genetic variation can change an organism at the level of protein functions, gene regulation or other complex genetic interactions. We still do not know the function of every gene in an organism’s genome, nor can we robustly predict the impact of genetic variation in either coding regions or in the regulatory regions of genes.
For example, the human genome is estimated to have approximately 20,000 protein-coding genes and perhaps an equal number of noncoding genes1. Approximately 70% of these genes have been assigned a function either by direct enzymatic assays, biochemical characterization, prediction based on homology or direct genetic demonstration of function. That leaves approximately 6000 genes that are currently completely uncharacterized. There are two further complications. First, clinical sequencing of patients with genetic diseases finds variants in human genes that are impossible to predict whether they are pathogenic (variants of uncertain significance) at a rate 2.5 times higher than ones they can interpret2. One study showed that over a 10-year period, only 7.7% of these variants of uncertain significance were reclassified after further data3. This bottleneck needs to be addressed with new approaches.
Second, over the past 15 years, an enormous effort has been placed into genome wide association studies4. This is a powerful approach that can map genetic influences for any measurable human trait given a large enough sample size. However, early in the efforts, it became clear that ≈95% of the identified ‘risk’ small-nucleotide variants were in noncoding regions of the genome5. Most of these genomic regions, including tens of thousands of variants, have not been functionally tested.
This is the fundamental challenge of functional genomics: to provide us with the systematic perturbation of genes and/or regulatory regions and analyze the ensuing phenotypic changes at a scale that can inform us about both basic biology and human pathology. Most of the published efforts are carried out in cell culture, but many questions about development, physiology or tissue homeostasis cannot be addressed in monolayer cultures (or even organoids), so various model organisms must also be utilized.
In the past, the most common approach was to test individual genes in a biological process by inactivation (that is, mutation), either randomly through ‘forward’ genetics or targeted through ‘reverse’ genetics. However, the massive amounts of genetic and genomic multimodal data currently being generated both allow for and even require high-throughput screening methodologies to make sense of all the data. Researchers are developing massively parallel functional interrogation of genes and proteins by employing large-scale assays. Essential for these approaches to work is a simple and efficient method for targeting and mutating the genome in cell culture or in vivo. The discovery of CRISPR–Cas opened a new era in functional genomics and has given us a powerful and easily reprogrammable tool for targeted genome editing.
CRISPR-based tools have enabled researchers to achieve once-unimaginable goals because of their simplicity, versatility and universality, and unlike customized DNA-binding protein systems, they do not require specialized expertise. CRISPR–Cas systems have been harnessed by geneticists in many ways and the field has grown significantly over the past decade (Fig. 1). By far its most common use is to precisely target specific genetic loci with double-stranded breaks (DSBs), facilitating the generation of knockout and knock-in alleles for studying gene function and disease modeling. Beyond gene editing, researchers have developed CRISPR–Cas9 applications for transcriptional modulation, epigenome editing, live imaging of the genome and lineage tracing and many other applications (Fig. 2). Ongoing efforts focus on and expanding the target ranges of Cas proteins and improving the specificity to minimize off-target effects. The development of ‘base editors’ and ‘prime editors’ allows for precise, single-nucleotide modifications. Base editing enables single-base substitutions without needing DSBs, while prime editing allows for targeted insertions and deletions. These innovative technologies can potentially improve the precision and efficiency of genome editing, expanding the possibilities for functional genomics research and therapeutic applications. CRISPR–Cas technology is driving innovation in genetics and research into therapeutics. This review provides a survey of recent advances in CRISPR–Cas genome editing technologies with an emphasis on their applications to functional genomics and in vivo editing of vertebrate model organisms.

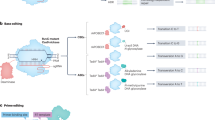
The progression of CRISPR research is divided into four major phases. This timeline illustrates the rapid evolution from basic discovery to clinical application, highlighting transformative innovations in genome and epigenome editing technologies. (Figure created using Biorender.com).

a Gene knockout or replacement: Cas9 nuclease creates DSBs at target sites guided by sgRNA. Repair occurs via NHEJ, leading to small insertions or deletions that disrupt gene function, or via HDR using a donor DNA template to enable precise gene correction or insertion. b ABE: a catalytically impaired Cas9 (nCas9) fused to an adenosine deaminase converts A•T base pairs to G•C through A-to-I (inosine) editing, which is read as G during DNA replication or repair. c CBE: nCas9 is fused to a cytidine deaminase and often paired with UGI. This enables C-to-T editing, converting C•G base pairs to T•A. d Transcriptional repression (CRISPRi): a catalytically dead Cas9 (dCas9) is fused to a KRAB repressor domain and guided to promoter regions, where it inhibits gene transcription without cutting DNA. e Transcriptional activation (CRISPRa): dCas9 is fused to a transcriptional activator and directed to a gene’s promoter or enhancer to initiate transcription. f Epigenome editing: dCas9 is tethered to epigenetic modifiers (for example, methyltransferases) to install or erase epigenetic marks such as DNA methylation at specific loci, without altering the underlying DNA sequence. g Chromosomal imaging: dCas9 is used in conjunction with guide RNAs bearing PP7 hairpins and fluorescent proteins (for example, GFP-MCP) to visualize specific genomic loci in live cells.(Figure created using Biorender.com).
Targeted mutagenesis approaches
The rapid adoption of next-generation sequencing technologies in disease diagnostics has led to a surge in identifying novel candidate disease genes and variants. Most of these genes lack functional data and functional analysis is essential to understand their role in disease pathology. One approach to establishing disease causality is to target the candidate gene in a model organism and to demonstrate a phenotype similar to the one observed in the human gene. Historically, researchers relied on random mutagenesis (chemical, radiation or retroviral) or transient knockdown approaches such as RNAi or morpholinos to inactivate genes in model organisms, except for mice, where targeted gene inactivation was possible but required many months of work and highly specialized training. Later, customizable nucleases such as ‘zinc-finger nucleases’ (ZFN)6 or transcription activator-like effector nucleases (TALEN)7 were utilized to study gene function via targeted mutagenesis. These nucleases were very effective, but each new DNA sequence target required the proteins to be re-engineered, reducing the throughput of the technology.
Programmable nucleases typically create a DSB at the target site, which is usually repaired by the endogenous DSB repair mechanisms of the cell. The nonhomologous end joining (NHEJ), homology-directed repair (HDR), and microhomology-mediated end joining (MMEJ) pathways are all available mechanisms for the necessary DNA repair. NHEJ is the default pathway in vertebrates and often leads to small insertions or deletions at the DSB site, resulting in gene knockouts. HDR induces targeted DNA changes by supplying a repair template, which is recombined into the damaged locus. MMEJ is often utilized to create larger deletions or for precise knock-ins by leveraging the tendency of small repeat regions to align during repair. The NHEJ pathway is the most used repair pathway by researchers. It is technically simple (causes a DSB and lets the cells do the rest) and typically results in small nucleotide insertions or deletions that cause frameshifts, making it suitable for rapidly generating knockouts. Meanwhile, MMEJ can be used for creating larger deletions but is more commonly applied for precise knock-ins, with the researchers providing a template containing short homology sequences to the sequences flanking the cut site. This reaction is much less efficient but provides opportunities for integrating DNA sequences with various ‘useful’ functions8.
The CRISPR–Cas system was initially discovered in bacteria and archaea and is a family of endonucleases used to protect organisms from viral infection9. Once the biochemical activity (that is, sequence-specific, double-stranded nuclease) was determined for the Cas proteins, they were quickly repurposed for genome editing, and they are remarkably efficient across diverse organisms. Among all the CRISPR families identified, the CRISPR–Cas9 system originating from the bacterium Streptococcus pyogenes has been one of the most commonly used genome editing tools. The CRISPR–Cas9 system utilizes a guide RNA (gRNA) with a stretch of 20 nucleotides that target a specific DNA sequence through complementary base pairing, and once that DNA target is found, the protein catalyzes a DSB9.
Following the seminal publication by Jinek et al. in 2012 showing that the Cas9 protein from S. pyogenes could be directed by guide RNA to cleave DNA at specific sites10, establishing a mechanism for targeted genome editing, three other studies demonstrated the use of CRISPR–Cas9 was extremely effective at targeting loci in the genome of human and mouse cells11,12,13.
Since the original publications, generating knockouts in the genes of interest in different organisms has become routine in laboratories and revolutionized functional studies. Hwang et al. first demonstrated using CRISPR in zebrafish, achieving precise gene disruptions at the tyr and gata5 loci14. They demonstrated that co-injection of Cas9 mRNA and single guide RNA (sgRNA) efficiently generated mutations, establishing a powerful tool for zebrafish genetics. Subsequently, Jao et al. demonstrated the biallelic disruption of multiple loci and efficient germline transmission, paving the way for the broader adoption of this technology in zebrafish15. Following initial publications, Gagnon et al. and Varshney et al. published methods to show the in vitro synthesis of sgRNAs, bringing down the cost and timeline for CRISPR mutagenesis16,17. We published the first large germline dataset in vertebrates, targeting 162 loci in 83 genes in the zebrafish genome, showing a 99% success rate for generating mutations and an average germline transmission rate of 28% (ref. 17). Since then, knockouts have been generated to study development, physiology and various human diseases. Owing to the scalability of this technology, many laboratories have utilized it to screen from tens to hundreds of genes in zebrafish; Pei et al. screened 254 genes to identify genes essential in the regeneration of hair cells and other tissues18 and Unal Eroglu et al. screened over 300 genes for their role in retinal regeneration or degeneration19. Similar approaches were used to search for genes associated with human diseases. For example, Thyme et al. targeted zebrafish orthologs of 132 human schizophrenia-associated genes20, Griffin et al. generated mutants for 40 genes associated with childhood epilepsies21 and other researchers have targeted genes involved in disease-associated complexes or pathways such as the DNA repair pathway22, Fanconi anemia pathway22 and the survival of motor neurons (SMN) complex23.
The first use of CRISPR in mice was demonstrated by Shen et al. targeting an endogenous eGFP locus by co-injecting gRNA with ‘humanized’ Cas9 mRNA into one-cell embryos, achieving a gene disruption efficiency of 14–20%24. Subsequently, Wang et al. highlighted the remarkable ability of CRISPR–Cas9 to target single or multiple genes, and over the past decade, numerous knockouts have been generated in mice and rats. Large consortia, such as the Knockout Mouse Project, also adopted CRISPR technology and generated over 1,200 mouse models using the approach25. Apart from single-gene knockouts, CRISPR is also being adopted for large-scale genome-wide in vivo screens in mice. The majority of large-scale CRISPR–Cas gene knockout screens are performed in cell culture (or organoids), but in vivo screens can provide a more physiologically relevant context for studying gene function and such screens have yielded valuable insights into a wide range of biological processes and diseases.
A genome-wide CRISPR screen in a mouse model of non-small-cell lung cancer identified several genes whose loss-of-function mutations drive tumor growth and metastasis26. Another screen used a single mouse liver to uncover the regulation of hepatocyte function by using a library of sgRNAs targeting over 13,000 protein-coding genes to the liver to efficiently knock out genes in hepatocytes and identify genes that are essential for liver function27. A rat model of multiple sclerosis was used to identify genes that regulate T cell migration to the central nervous system28. Recently, researchers developed an innovative inducible mosaic animal for perturbation (iMAP) system. iMAP enables researchers to study the functions of multiple genes simultaneously across various tissues. It utilizes a germline-transmitted transgene carrying an extensive array of individually floxed, tandemly linked gRNAs that allows investigation of parallel analysis of gene functions in vivo29.
Biallelic genetic disruption for rapid functional analysis
Generating stable homozygous mutant lines using CRISPR–Cas9 required breeding first generation (F0) mosaic animals to obtain stable lines in subsequent generations, which can take months or years, depending on the organism. Another approach is to breed two mosaic founders and screen for phenotypes in first filial generation (F1) generation in compound heterozygous animals, but this approach still requires animals be raised to sexual maturity and screening takes place in the subsequent generation. These time-consuming approaches do not scale sufficiently to address the growing number of novel candidate disease genes being identified. However, researchers have optimized the conditions for very efficient CRISPR F0 mutagenesis in several species and this offers a faster and more efficient alternative by enabling the direct analysis of phenotypes in the injected embryos or F0 generation animals, reducing the timeline from months or years to just days or weeks. This approach is particularly valuable for studying early developmental processes, analyzing complex phenotypes, knocking out multiple genes simultaneously and conducting large-scale genetic screens.
The high efficiency of CRISPR–Cas9 in inducing biallelic mutations in the F0 generation of mice, zebrafish and Xenopus makes it a promising tool for studying gene function in these model organisms. CRISPR F0 mutagenesis in zebrafish typically involves injecting a mixture of Cas9 protein or mRNA and sgRNA into one-cell stage embryos. The first example of generating biallelic mutation in zebrafish was using Cas9 mRNA and sgRNA, but the efficiencies varied significantly from locus to locus15. Since then, several strategies have been developed to enhance the efficiency and consistency of CRISPR F0 mutagenesis in zebrafish. Burger et al. demonstrated that injecting Cas9 protein and sgRNA as riboprotein complexes together with 1 M KCl to improve the solubility of the complex can achieve high targeting efficiencies, and phenotypes can be robustly observed in the F0 generation (named ‘Crispants’) with high penetrance30. Another technical improvement involves using multiple sgRNAs targeting different regions of the same gene. This increases the probability of generating biallelic mutations and reduces mosaicism31. Another strategy utilizes chemically synthesized CRISPR–Cas9 dual-guide ribonucleic protein (dgRNP) complexes, which have been shown to produce somatic mutations with high efficiency32. A dual-guide synthetic CRISPR RNA–dgRNP system has also been shown to enhance the efficiency of biallelic gene disruptions in zebrafish32. In this system, simultaneous injections of three distinct dgRNPs per gene into one-cell stage embryos dramatically improved the efficiency of biallelic gene disruptions with greater consistency than any single dgRNP injections32. Another method involves using a set of three synthetic gRNAs per gene, combining multilocus targeting with high mutagenesis at each locus33. Another method consistently converted >90% of injected embryos into biallelic knockouts using one or two optimized sgRNAs showed fully penetrant phenotypes and tested over 120 genes34.
Precise genome editing using knock-in methods
One of the key applications of CRISPR–Cas9, aside from generating knockout alleles, is the creation of ‘knock-in’ alleles, where specific DNA sequences are inserted into the genome at targeted locations. One common approach for CRISPR knock-in in zebrafish involves using single-stranded oligodeoxynucleotides (ssODNs) as donor templates. These ssODNs contain the desired knock-in sequence flanked by homology arms that match the target genomic region. When co-injected with the CRISPR–Cas9 system, the ssODN can integrate into the genome through HDR35. Using this approach, Carrington et al. performed targeted insertion of epitope tags, as well as single nucleotide mutations, to recapitulate pathogenic human mutations36. They also developed a fluorescent PCR-based method to screen for knock-in alleles, which is rapid and inexpensive. Another approach utilizes long single-stranded DNA (lssDNA) as a donor template. This method has been shown to efficiently knock-in sequences encoding composite tags into the zebrafish genome by using a combination of CRISPR–Cas9 ribonucleoprotein (RNP) complex and lssDNA to achieve efficient knock-in of an approximately 200 base-pair sequence37.
The efficiency of CRISPR knock-in in zebrafish can vary depending on factors such as the target locus, the length and complexity of the knock-in sequence and the delivery method38. While knock-in efficiencies can be relatively low, recent studies have reported improved efficiencies through optimization strategies such as using antisense asymmetric oligonucleotides with longer homology arms38. One crucial insight is the strong inverse relationship between knock-in efficiency and the distance of the modification to the cut site. This highlights the importance of careful guide RNA design to maximize knock-in efficiency35. Like zebrafish, CRISPR knock-ins in mice can be achieved using ssODNs or plasmid donor templates with homology arms39. These templates are co-injected with the CRISPR–Cas9 system into mouse zygotes. Several factors influence the efficiency of CRISPR knock-in in mice, including the selection of sgRNA, the type of donor DNA template and the delivery method39.
One area of caution in generating knock-ins is that unexpected changes can occur and errors are frequently incorporated near the area of insertion. There is no community standard for demonstrating the broader locus surrounding the insertion site has not been altered and there have been documented cases of larger chromatin deletions in mice caused by CRISPR–Cas9 cleavage40 and clear genomic alterations in zebrafish, including the deletion of the distal telomeric region downstream of a knock-in at the npas4l locus41, and the commonly used ‘GeneWeld’ technology42 shows fairly high frequencies of integration errors at both the 5′ and 3′ junctions.
Expansion of double-stranded cutting enzyme target sites
S. pyogenes Cas9 (SpCas9) is the most widely used and efficient Cas9. While the Cas9 is highly efficient, its targeting range is restricted by its protospacer adjacent motif (PAM) sequence (NGG). This restricts the ability of Cas9 to edit to roughly 1 in 16 genomic sites. While SpCas9 can sometimes tolerate slightly different PAMs (NAG or NGA), many potential targets, especially in gene-rich regions with high AT content, remain out of reach. To overcome this PAM restriction, many groups are developing two main strategies: (1) identifying new orthologs with novel PAM sequences and (2) engineering SpCas9 to create variants that can either recognize different PAM sequences or that can function without needing a PAM, thereby greatly expanding the scope of gene editing.
Over the past 10 years, researchers have characterized multiple Cas9 orthologs from different species. These orthologs recognize different PAM sequences, expanding the targeting range. Each ortholog has unique features such as size, PAMs and editing efficiencies. For example, Staphylococcus aureus Cas9 (SaCas9, NNGRRT PAM) and Campylobacter jejuni Cas9 (CjCas9, N4RYAC PAM), are smaller in size and therefore suitable for in vivo delivery using viral vectors such as adeno-associated virus (AAV), where packaging size is limited43. In addition to the Cas9 enzymes, researchers have explored other CRISPR–Cas systems, including type V Cas12 systems, which offer some distinct advantages. The Cas12 enzymes, such as Cas12a (Cpf1), recognize T-rich PAM sequences (for example, TTTV) and produce staggered DNA cuts, unlike the blunt DSBs of Cas9, facilitating precise gene insertion via HDR44,45. In addition, Cas12 systems process their own crRNA arrays, enabling multiplexed gene editing with a single transcript. Other type V effectors such as Cas12b and Cas12f have also been characterized. Cas12b is heat tolerant and adapted for mammalian editing, while the ultracompact Cas12f (Cas14) is ideal for AAV delivery, though its efficiency is still being improved. These systems expand the CRISPR toolbox with distinct PAM requirements, cleavage patterns and versatile applications. Various Cas9 orthologs and Cas12 enzymes, together with their PAM recognition sequences, are listed in Table 1. It is somewhat interesting to note that the ‘original’ spCas9 still seems to be the version that is the most efficient enzymatically across a very broad spectrum of conditions. A potential reduction in efficiency using a different version should be taken into account whenever designing an editing strategy.
CBEs
Most genetic variants are single-nucleotide variants. For example, pathogenic point mutations in humans predominantly involve CG-to-TA conversions and account for nearly half of all mutations, while AT-to-GC changes represent about 14% (ref. 46) of the variants. Previously, directly testing variants in vivo required HDR-mediated knock-in approaches, which are orders of magnitude lower efficiency than NHEJ-mediated knockouts. This is because, in vertebrates, the NHEJ repair mechanism is preferred during DNA repair, resulting in low utilization of the HDR pathway. To address these challenges, innovative CRISPR technologies using various strategies have been developed46,47,48.
In 2016, the first ‘base editor’, a cytosine base editor (CBE), was developed that converted cytosine (C) to uracil (U), which is then repaired to thymine (T) during DNA replication, resulting in a C-to-T (or G-to-A opposite strand) substitution. The first-generation CRISPR base editor (BE1) consisted of a deactivated Cas9 protein (dCas9) fused to a cytidine deaminase enzyme. This enzyme, derived from the rat APOBEC1 gene, is responsible for the C-to-U conversion48. The second-generation base editor (BE2) incorporated an uracil glycosylase inhibitor (UGI) to prevent the removal of uracil during DNA repair, which improves editing efficiency compared with BE1 (ref. 48). To further enhance efficiency, the third-generation base editor (BE3) was developed, which restores half of the catalytic activity of dCas9 to make it ‘nickase’, which cuts one strand of the DNA48. Base editing technology continued to be refined and many other variants were developed, such as BE4, BE4max and BE4-Gam, to include additional UGI copies and with optimized linker length to improve flexibility and reduce unintended edits49. By incorporating the Gam protein, which binds to DNA double-strand breaks, BE4 further reduced unwanted indels. The more improved and widely used CBEs, such as AncBE4max, include codon optimizations and enhanced nuclear localization signals, leading to significantly improved efficiency50. Nishida et al. developed another CBE called Target-activation-induced cytidine deaminase (AID), which incorporates nCas9 and Petromyzon marinus cytidine deaminase 1 (pmCDA1), a deaminase structurally and functionally like rAPOBEC1 (ref. 51). Target-AID is an efficient base editor, but it generates random changes in a small window, so it is useful for broadly testing sequence changes in the target region of a gene but less useful for individuals who need to generate a specific variant.
Given that APOBEC1-based CBEs primarily edit cytosines in the TC sequence context, Liu’s group utilized phage-assisted continuous evolution to create improved CBEs. They developed evoAPOBEC1-BE4max, which efficiently edits cytosines in the G/C sequence context, and evoFERNY-BE4max, a variant with a 30% smaller deaminase52. Further optimization to base editors focused on narrowing the editing window and improving editing precision to reduce bystander mutations. This has been achieved by modifying the deaminase component of the editors. Variants such as YE1-BE3 and EE-BE3 have successfully minimized off-target base conversions53. In addition, swapping the rat APOBEC1 enzyme in CBEs with engineered human APOBEC3A (A3A) has shown promise for precise editing54.
A primary limitation in base editing is the restricted availability of CRISPR target sites owing to dependencies on the PAM and the position of target nucleotide within the editing window, which is 4–8 nt of the protospacer sequence (upstream of PAM). To overcome these constraints, researchers have developed base editors using alternative Cas enzymes and Cas9 orthologs or variants, as described above, further expanding the targeting range.
ABEs
Similar to CBE, adenine base editors (ABEs) were developed in 2017. ABEs convert AT base pairs to GC without inducing DSBs46. ABEs achieve high editing efficacy with minimal off-target effects compared with earlier editors such as BE3. The ABE system integrated nCas9 with an engineered adenine deaminase, which converts A to inosine, read as G by DNA polymerase, enabling AT-to-GC base conversions. ABE7.10, the first widely used ABE, achieved 58% editing efficiency with 99% product purity and less than 0.1% off-target activity, making it a precise and efficient editor46. Subsequently, ABE8e was developed through phage-assisted evolution, demonstrating a 590-fold increase in activity compared with ABE7.10 and enhanced compatibility with various Cas homologs55. Similarly, ABE8s, created through directed evolution, exhibit higher editing efficiency, particularly at challenging loci56. To address bystander mutations, NG-ABE9e was engineered, reducing off-target editing by up to sevenfold while maintaining high efficiency57. Specific mutations in ABEs can modulate their behavior, such as the D108Q mutation reducing cytosine deamination activity and the P48R mutation creating a TC-specific base editing tool58. By structure-guided engineering, ABE9 was generated with a limited editing window of one to two nucleotides to minimize bystander mutations. It has low RNA off-target activity and has no detectable Cas9-independent DNA off-target activity, thus making it more specific59. Furthermore, to reduce cytosine bystander mutations, ABE10 was designed using artificial intelligence-based methods. ABE10 is an improved adenine deaminase enzyme that has reduced sequence identity (65. 3%) with the previous versions of the enzyme and has been shown to have higher efficiency and reduced off-target activities compared with ABE8 (ref. 60).
The gene TadA had higher specificity, smaller size and lower Cas-independent DNA and RNA off-target editing activity than the APOBEC1-based cytosine deaminases, so the TadA enzyme was further evolved to generate TadA-derived CBEs (TadCBEs) that enable programmable C•G-to-T•A transitions while maintaining high specificity61,62,63,64. These editors were developed by evolving the adenosine deaminase TadA to perform cytidine deamination, resulting in enzymes with altered selectivity favoring deoxycytidine over deoxyadenosine61. TadCBEs offer comparable or superior on-target activity and significantly reduced off-target editing compared with traditional CBEs61,63. Last, innovative ‘dual-function’ editors, such as A&C-BEmax and SPACE, combine the functionalities of CBEs and ABEs in a single enzyme, enabling simultaneous cytosine-to-thymine and adenine-to-guanine edits65,66. Although many tools have not yet been widely tested in animal models, they hold great potential for expanding genomic manipulation capabilities. A number of prominent cytosine and adenine base editors are listed in Table 2.
Base editing in vivo
Over the past 8 years, several base editing tools have been developed, but their adoption in vivo such as in zebrafish research has been relatively slow. The first application of a CBE in zebrafish was BE3; two independent groups achieved 9–25% C→T editing by microinjecting mRNA or RNP complexes67,68. Zhang et al. utilized base editing utilizing Target-AID editor to establish a disease model for oculocutaneous albinism69. The AncBE4max variant demonstrated a threefold increase in efficiency compared with BE3 in zebrafish70. In another study, BE4-Gam and AncBE4max were employed to model oncogenic mutations in the tumor suppressor gene tp53, showcasing their utility in cancer modeling71. Furthermore, BE4max was fused with PAM-less Cas9 (SpRY) to create a variant that eliminated the NGG PAM restriction, achieving exceptionally high editing activity of up to 85% (ref. 72). In addition, Cornean et al. developed ACEofBASEs, an online platform for efficient sgRNA design for base editing, and employed AncBE4max and EvoBE4max editors to introduce precise mutations in zebrafish and medaka, including stop-gain and missense variants in genes such as oca2 (eye pigmentation) and kcnh6a (potassium channels)73. Recently, Qin et al. introduced ABE-Ultramax (ABE-Umax), a novel adenine base editor developed through zebrafish in vivo screening, achieving up to 90% editing efficiency—three times higher than ABE8e. They also developed a suite of editors with expanded editing windows and precision tools to minimize bystander mutations74. These advances were demonstrated by creating multiple zebrafish disease models, including missense and splicing mutations, enabling precise functional validation of single-nucleotide variants74. Similarly, Zhang et al. optimized zevoCDA1 and its variant, zevoCDA1-198, to enhance C-to-T editing efficiency, relax PAM restrictions, narrow the editing window and reduce off-target effects in zebrafish75. In Xenopus laevis embryos, BE3 RNP was successfully used for C-to-T editing in the Tyr and Tp53 genes, achieving editing efficiencies of 20% and 5%, respectively. In addition, BE3 induces approximately 20% indels in Xenopus, somewhat limiting its utility76.
The first mouse models were generated using base editing targeting the Dmd and Tyr loci to introduce a premature stop codon provided by C-to-T base editing within a coding exon. To this end, BE3 mRNA and guide RNAs targeting the Dmd gene were injected into mouse embryos. More than 50% of the founder mice carried C-to-T mutations; however, other off-target mutations, including deletions, were also present. Other reports also demonstrated off-target indels associated with CBE-based editors77. To target the Tyr gene, BE3 protein and sgRNA were delivered as RNP complex by electroporating mouse zygotes, and two homozygous founders were obtained carrying the desired mutation in the Tyr gene. Sasaguri et al. compared the editing efficiency of BE3 and Target-AID using the mRNA and sgRNAs targeting the presenilin-1(psen-1) gene in mouse zygotes. BE3 consistently demonstrated higher base-editing efficiency in a range of 10–60% compared with Target-AID, which was 3–30%, but it also generated a higher frequency of indels78. The high efficiency of CRISPR–Cas9 enables the editing of multiple genes simultaneously, Zhang et al. tested whether a similar approach was possible using CBE by simultaneously targeting the vGlut3, Otof and Prestin genes79. This introduced C-to-T transitions that resulted in premature termination codons (CRISPR-stop). This method efficiently generated homozygous F0 mouse mutants for single or triple genes, bypassing the labor-intensive process of mouse breeding. This represents a significant step forward for functional genomics in vivo.
Over the past few years, base editing has been successfully applied in mouse models to address various genetic diseases; for example, spinal muscular atrophy is caused by mutations in the gene SMN1, resulting in a deficiency of the SMN protein essential for the survival of motor neurons. Arbab et al. used adenine base editing to convert a specific T•A base pair in the SMN2 to a C•G base pair. This conversion effectively transforms SMN2 into a functional copy of SMN1, restoring SMN protein levels and leading to significant improvements in motor function in treated mice80.
Amyotrophic lateral sclerosis (ALS) is a disease characterized by the degeneration of motor neurons. Approximately 20% of all inherited cases of ALS are caused by mutations within the SOD1 gene. Lim et al. used a split-intein CBE to disrupt mutant SOD1 expression in an ALS mouse model, resulting in reduced expression of mutant SOD1, improving neuromuscular function and extending survival81. Split-intein CBE involves splitting the Cas9 protein or other base editor components into two parts fused to inteins. These parts reconstitute into a functional base editor only when codelivered and expressed in the same cell. This design enables spatial or temporal control over activation and simplifies the delivery of large constructs, especially using vectors such as AAVs.
Progeria, or Hutchinson–Gilford progeria syndrome, is a very rare disease characterized by early onset accelerated aging caused by a mutation in the LMNA gene, which leads to the production of a toxic protein called progerin. Koblan et al. used an adenine base editor in a mouse model of progeria to correct a dominant negative mutation CG-to-TA mutation (c.1824C > T; p.G608G) in LMNA. The treated mice displayed lower progerin levels than saline-injected control mice with progeria82. This ultimately resulted in significantly improved tissue health and the treated mice lived two and a half times longer than the control mice, reaching an age equivalent to the beginnings of old age in healthy mice.
Base editing has been successful in various mouse models of genetic diseases, paving the way for its clinical application. Currently, it is being tested as a therapeutic approach for treating genetic disorders in several preclinical studies83. Success in these preclinical experiments has led to the initiation of clinical trials to explore the use of base editing therapies in humans.
Genome editing using prime editing
Prime editing allows for targeted insertions, deletions and all 12 possible base-to-base conversions84. This ‘search-and-replace’ genome-editing technology functions without requiring DSBs or donor DNA templates, a significant advantage that sets it far apart from traditional CRISPR–Cas9 systems and base editors, which have limited editing scope and higher potential for off-target effects84. A prime editor comprises a modified Cas9 enzyme and an engineered Moloney murine leukemia virus reverse transcriptase (MMLV RT) guided by a prime editing guide RNA (pegRNA) (Fig. 3). The pegRNA targets the specific DNA site and carries the desired edit within its long tail sequence. The PE system works through a ‘search-and-replace’ mechanism. First, the pegRNA guides the Cas fusion protein to the target DNA site, where the nCas9 nickase creates a single-strand nick. The primer binding site (PBS) of the pegRNA then anneals to the nicked DNA strand and the RT enzyme uses the 3′ extension of the pegRNA as a template to synthesize the edited DNA sequence. This newly synthesized DNA strand is then incorporated into the genome through the cellular DNA repair machinery, resulting in the desired modification. The prime editing system has evolved through several generations to improve efficiency and reduce unintended byproducts. PE1, the first-generation prime editor, combines a Cas9 H840A nickase with the wild-type MMLV RT but demonstrates modest editing efficiency, converting less than 5% of targeted alleles84. PE2 addressed these limitations by introducing five mutations to the MMLV RT domain, enhancing its thermostability, processivity and binding affinity, which resulted in a 1.6–5.1-fold increase in editing efficiency84. PE3 further advanced the system by incorporating an additional sgRNA to nick the nonedited DNA strand, improving strand replacement and editing efficiency, albeit with a slightly increased risk of indel formation. To mitigate this risk, PE3b introduced a complementary-strand nick specific to the edited sequence, reducing indels without sacrificing efficiency84. Subsequent iterations, PE4 and PE5, aimed to inhibit DNA mismatch repair by targeting MLH1, with PE4 based on PE2 and PE5 on PE3, utilizing a dominant-negative MLH1 protein to enhance editing outcomes85. Other innovations, such as PEmax85, an improved version of PE4 and PE5 variants, and ePPE, a variant that was developed by removing the RNase H domain in the RT enzyme and replacing it with viral nucleocapsid protein86, focused on improving nuclear import, tethering peptides and optimizing the RT domain for greater efficiency. Enhancements to the prime editor protein involve engineering RT with mutations such as the pentamutant RT to increase efficiency87, developing smaller editors such as PE2ΔRnH through phage-assisted evolution, called PE6 (ref. 88), and creating an intein-split construct for AAV-mediated delivery89. Recently, a new PE system, PE7, has been enhanced by incorporating the RNA-binding protein La, which strengthens the interaction between the prime editor and the pegRNA90. This improved interaction is essential for efficient editing. Compared with its predecessors, PE7 shows superior editing performance, especially when using engineered pegRNAs (epegRNAs) and synthetic pegRNAs optimized for La binding.

a Prime editing begins with Cas9 nickase fused to a RT and guided by a pegRNA. Cas9 nicks the target DNA strand, allowing RT to access the DNA for editing. b The pegRNA contains three components: a PBS, a RT template and an intended edit sequence. The nicked DNA strand anneals to the PBS, allowing reverse transcription of the edit. c A 3′ flap containing the desired edit is synthesized from the RT template, generating a new DNA segment with the desired sequence. d A competing 5′ unedited flap forms from the original DNA strand. The resolution of this heteroduplex determines which sequence is retained. e The edited strand is integrated into the genome, displacing the original noncomplementary strand. f DNA repair mechanisms synthesize the complementary strand to match the edited sequence, completing the prime editing process with a permanent and precise edit. (Figure created using Biorender.com).
Prime editing has undergone numerous modifications to enhance its efficiency and expand its capabilities, focusing on improving the prime editor protein, the pegRNA and developing new strategies. For pegRNA, modifications include refolding and introducing mutations to reduce autoinhibitory activity91, integrating structured RNA motifs such as xrRNA for improved stability92 and optimizing primer binding site and reverse transcription template length to balance efficiency and accuracy91, systematically analyzing these parameters in zebrafish and human cells to improve editing rates and minimize off-target effects91. Other advancements in pegRNA include modified versions such as apegRNA and spegRNA, developed by improving pegRNA secondary structure and introducing same sense mutations, increasing indel frequency without significantly affecting unexpected indels or byproducts93. epegRNAs integrate structured RNA motifs into the 3′ end of pegRNAs, increasing editing efficiency in various cells by three to four times without increasing off-targeted activity94.
Approaches such as prime editing-Cas9-based deletion and repair leverage nucleases (not nCas9) that create DSBs in combination with RT and a pair of guide RNAs (pegRNAs), enabling the precise deletion of genetic sequences exceeding 10 kb and the insertion of up to 60 bp into cellular DNA. In a mouse model of tyrosinemia, prime editing-Cas9-based deletion and repair successfully removed a 1.38 kb pathogenic insertion within the Fah gene. This precise editing restored the functionality of the target gene by accurately repairing the missing genetic connection, leading to the renewed expression of the Fah gene in the liver. PRIME-Del uses a pair of pegRNAs to accurately edit targets by deleting sequences up to 10 kb with higher accuracy (1–30%)95. GRAND, which also uses a pair of pegRNAs, has a higher editing efficiency of 63.0% for 150 bp inserts but can introduce byproducts and has a reduced efficiency of 28.4% for 250 bp insertions96. Bi-PE increases efficiency by 16 times and accuracy by 60 times by including a nick sgRNA near the pegRNA template sequence. This system can delete large DNA sequences and introduce small fragments into the deletion sites97. HOPE uses two pegRNAs with homologous 3′ terminals to target DNA double strands, balancing efficiency and accuracy98. TwinPE utilizes a prime editor protein and two pegRNAs to edit genes up to thousands of base pairs long47. ePE optimizes the pegRNA skeleton to improve point mutation editing efficiency by 1.9 times compared with standard prime editing99. Since most prime editors utilize SpCas9, which recognizes NGG PAM, thereby limiting the targeting sites, efforts to expand this limitation, utilizing Cas9 variants with alternate PAM recognition, have led to the development of various PE2 variants, including PE2-VQR, PE2-VRQR, PE2-VRER, PE2-NG, PE2-SpG and PE2-SpRY, which can target different PAM sequences100.
Several studies have demonstrated the successful application of prime editing in model organisms for modeling genetic disorders and correcting disease-causing mutations. For instance, prime editing was used to introduce a single-base deletion in the Crygc gene in mice to model a cataract disorder by targeting a single-base deletion, resulting in a high G-deletion rate (38.2%) and the development of a nuclear cataract phenotype in the mice101. In another study, prime editing was employed to correct a disease-causing mutation in the Fah gene in a mouse model of tyrosinemia, a metabolic liver disease102. Similarly, prime editing has been used to correct mutations in several conditions in mice such as Duchenne muscular dystrophy (Dmd)103, phenylketonuria (Pah)104, retinitis pigmentosa (rpe65)102 and the E342K mutation in the SERPINA1 gene associated with alpha-1 antitrypsin deficiency105. Prime editing was used to perform single-base substitution within a transcription factor binding site (CArG box) in the mouse Tspan2 promoter106. The C > G substitution resulted in the near-total loss of Tspan2 mRNA expression in the aorta and bladder tissues, rich in smooth muscles, while sparing heart and brain tissues.
Polymerase-based prime editing
While effective, traditional prime editing has several drawbacks, including low efficiency in nondividing cells, error-prone RT leading to unintended mutations and limited processivity, which restricts the length of edits. To address these challenges, polymerase-based prime editing was developed by two independent groups107,108. This method replaces the RT with a DNA-dependent DNA polymerase and uses DNA instead of RNA as a template. This switch enhances gene editing by offering higher efficiency and accuracy, increased processivity for longer edits and better dNTP affinity, thus improving performance in nondividing cells. Another prime editing method, referred to as ‘click editing’, involves a tripartite protein complex consisting of an RNA-programmed DNA nickase, a DNA-dependent DNA polymerase and a single-stranded DNA tethering domain (histidine–hydrophobic-histidine (HUH) endonuclease)107. The DNA template, called click DNA (clkDNA), contains a primer binding site, a polymerase template with the desired edit and the HUH recognition site. One advantage of this system is the cost-effectiveness of the DNA template. Unlike the modified RNA–DNA hybrids used in other methods, the clkDNAs are standard DNA oligonucleotides that can be readily and cheaply synthesized. This makes click editing more accessible and affordable for research and therapeutic applications.
Prime editing represents a paradigm shift in genome engineering, combining the precision of base editors with the versatility of traditional CRISPR–Cas systems. Its ability to correct, insert or delete DNA sequences with high accuracy positions it as a critical tool for advancing genetic research and therapeutic development. While challenges remain in terms of efficiency, off-target effects and delivery, further optimization efforts are required for broader applications of prime editing in various fields, including disease modeling, gene therapy and synthetic biology.
Transcriptional regulation using CRISPR–Cas
CRISPR interference
As described above, the majority of research efforts using CRISPR–Cas systems has been on genome editing either through preserving the nuclease function of Cas proteins and causing single-strand breaks or DSBs, or through inactivating the nuclease activity and adding a separate editing function to the protein in one way or another. However, researchers have also realized there is tremendous value in being able to rapidly design a protein with a specific biding location anywhere in the genome. The most obvious utility of such a capability would be to make artificial transcription factors that could either activate or inhibit transcription of a target gene. Within a year of the first papers describing the nuclease activity of the CRISPR–Cas9 complex, researchers showed a catalytically dead Cas9 (dCas9) could bind close to the transcription start site and prevent transcription of genes in E. coli109. The system was called ‘CRISPR interference’ or ‘CRISPRi’ for short. Variants of Cas9 fused to known eukaryotic transcriptional repressors soon followed. Krüpple-associated box domains (KRAB domains), known transcriptional repressors used by over 400 human zinc-finger proteins110, were the first fusions made with dCas9. Since the initial tests using the KRAB domain from the KOX1 zinc-finger protein111, two other versions have emerged: KRAB-MeCP2 (ref. 111) and the ZIM3 KRAB domain111, both showing stronger inhibition than the original construct in mammalian cell culture.
Efficacy in cell culture often does not replicate in vivo, where genomic responses can be more complex. However, studies in whole animals are essential for understanding gene functions as tissues or organs can significantly modify the outcome of gene inactivation. Effective CRISPRi in vivo could potentially simplify conditional knockout transgenesis, as a single tissue-specific CRISPRi transgene could inactivate gene expression instead of the typical approach of relying on bringing two transgenics together, one expressing a recombinase tissue specifically and the second one containing the target gene flanked by recombination sites (for example, cre/lox systems). A CRISPRi system could be characterized in one generation (approximately 3 months for mice or zebrafish). At the same time, the traditional approach could take over a year in mice and potentially longer in zebrafish where conditional knockouts are still not routinely done. Several studies have shown that CRISPRi transgenes can effectively reduce gene expression in mice although in some cases, inducible forms of CRISPRi (for example, doxycycline) were more effective at maintaining gene inactivation than shutting off genes that had already been activated112.
CRISPR activation
Similar efforts have been made to use dCas9 fusions as synthetic transcription factors that can activate gene expression, termed ‘CRISPR activation’ (CRISPRa). Most commonly the dCas9 is fused to the transcriptional activation domain VP64 or its various derivatives113. Other strategies include fusion to histone demethylases or acetylases, which change chromatin availability and can activate expression indirectly114. There have not been any in vivo examples of CRISPRa as single transgenes to activate gene expression as they do not present a particular advantage over traditional methods for ectopic gene expression in mice or zebrafish. Both the CRISPRi and CRISPRa technologies do run the risk of off-target effects, which are probably higher than off-target rates for Cas9 nuclease activity as the requirements for binding to the genome, including mismatch tolerance, are lower than they are for activating DNA cleavage.
CRISPR-based epigenetic editing: targeting histone and DNA methylation
Biochemical modifications on both the genomic DNA and the histones packaging chromatin are known to regulate gene expression. Several studies have utilized chromatin modification enzymes fused to dCas9 as another mechanism to alter gene expression. One key modification is the methylation of the fourth lysine in the histone 3 protein (H3K4)115. K4 can be modified from one to three methylations; the addition of methylation can increase chromatin accessibility, thereby increasing gene expression, while removing methylation can cause the chromatin to become more compact, resulting in reduced transcriptional rates. Several studies have used different enzymes fused to CRISPR to initiate changes in H3K4 methylation, including LSD1 (reduces trimethyl), EZH2 (reduces trimethyl), PRDM9 (adds trimethyl) and SMYD3 (adds trimethyl)116,117,118,119. These approaches have been shown to decrease or increase gene expression in cell culture. These changes in expression level are rarely complete; more often, the expression changes are in the range of twofold up or down. In many cases, this might actually be a better outcome than fully inactivating or strongly overexpressing a gene of interest. For example, there are many cases where fully inactivating a gene is so disruptive as to cause complete cell or organismal death, while a hypomorphic mutation (or hypermorphic) results in a phenotype that reveals an essential role for that gene120. Related modifiers targeted other histone modifications, such as H3K27 methylation121, have also been developed with similar levels of success in cell culture.
In both eukaryotes and prokaryotes, DNA methylation at cytosine residues to form 5-methylcytosine is another known epigenetic mark that regulates gene expression122. Altering local methylation states represents another alternative method for altering gene expression, even after the proteins involved in editing the chromatin marks are no longer present in the cells. Fusing dCas9 to methyltransferase enzyme active domains such as DNMT3A123 or DNMT3A-DNMT3L124 resulted in targeted methylation of genomic DNA in many experiments. One group amplified the local activity of the DNMT3A enzyme by using a ‘SunTag’ strategy where multiple SunTag epitopes were fused to dCas9 and the DNMT3A had the single-chain variable fragment (scFv) interacting domain fused to the protein bringing multiple copies of DNMT3a to the targeted location125. Similar to the histone modifications, it was also difficult to control the potential off-target or too-broad local editing of methyltransferases. One group was able to improve specific targeting by fusing dCas9 to a fragment of the methyltransferase (M.SssI), which had its DNA-binding domain mutated to remove the natural affinity of M.SssI for binding DNA126. These alterations appeared to reduce off-target DNA methylation. To activate gene expression by modifying methylation, groups fused dCas9 to the TET1 protein. TET1 catalyzes the conversion of 5-methylcytosine to 5-hydroxymethyl cytosine. This conversion is purportedly the first step to DNA demethylation, which would ultimately lead to increases in transcription at the targeted locus. The resultant changes in gene regulation in all of these targeted methylation experiments were complex and indicative that we still do not fully understand the roles methylation plays in gene expression. Gene expression was typically reduced with the methyltransferases and increased with the TET1 fusions, but the degree of silencing or activation was challenging to predict as it varied considerably from locus to locus. As with the other forms of transcriptional regulation utilizing CRISPR–Cas, the chromatin mark approaches have been used a great deal in cell culture experiments, but the benefits of using them in animal studies have not yet been demonstrated.
CRISPR as a tool for exploring higher-order chromatin organization
There has been increased interest in how the complex, higher order of chromatin organization might influence gene regulation. Both sequence-based127,128 and imaging-based129,130 experimental approaches have revealed genomic organization at tens to hundreds of thousands of base pairs that appear to regulate gene expression. Often termed ‘topologically associated domains’ or ‘TADs’, the interactions of these chromatin elements modulate gene expression in various contexts. Some of the earliest experiments first identified sequences that appeared to act as ‘insulators’, that is, regions of the chromatin that would block enhancers or silencers for other genes that were in close proximity to other genes that should not be controlled by these regulatory elements131. Eventually, researchers demonstrated that a major regulator of insulator sequences and other TAD structures were controlled by the DNA-binding protein CCCTC-binding factor (CTCF), which binds a defined sequence motif and mediates the creation of large DNA loop structures132. As our understanding of how the genome organized itself in 3D space improved, we began to recognize that it was potentially involved in sophisticated gene regulatory mechanisms and so it was, therefore, necessary to test function experimentally just as you would genes, enhancers and silencers.
Various strategies using CRISPR have been utilized to experimentally regulate higher-order chromatin. The most straightforward of these approaches was to ablate specific CTCF binding sites using the CRISPR–Cas nuclease activity to generate DSBs. These mutated sites would result in altered genomic topologies and changes in gene expression133,134,135. Another approach was for dCas9 to competitively bind to CTCF sites preventing formation of TADs136. One group used two heterologous dCas9 proteins (from S. pyogenes and S. aureus), with each protein fused to two protein domains, PYL1 and ABI1, that normally dimerize in the presence of plant phytohormone S-(+)abscisic acid137. The researchers then targeted one dCas9 to the b-globin promoter and the other construct to the locus control region (LCR) in K562 cells. They showed that the addition of S-(+)abscisic acid to the culture media triggered the expression of b-globin, and that expression was linked to bringing the locus control region and the b-globin promoter into close proximity. The published studies were all performed in cell culture, but stable disruptions of 3D chromatin structure in vivo are possible when targeting specific loci.
High-throughput screening in vitro using CRISPR–Cas
So far, we have focused on using CRISPR–Cas9 at specific loci in the genome. While not every technique discussed has been demonstrated to be effective in vivo, it is reasonable to assume that any locus-specific engineering that works in cell culture can work in an animal if the conditions are optimized for the model organism being used. Scientists realized early on, however, that one of the powerful aspects of CRISPR–Cas systems is that the DNA-binding site can be re-engineered rapidly by swapping out the RNA guide sequence. It then becomes a straightforward computational problem to design a library of guide RNA sequences that could target the genome on a large scale.
Approximately a year after the RNA-guided nuclease function of CRISPR–Cas9 was described, the first global CRISPR–Cas9 mutagenesis experiments were performed. The first efforts targeted gene inactivation of all human coding genes via mutations caused by NHEJ138. Lentiviruses were made that contained both a sgRNA and the Cas9 coding sequences driven by independent promoters. Each viral particle contained a different sgRNA, and multiple sgRNA were designed for each gene in the human genome. Cells were infected at multiplicities of infection below one per cell to avoid multiple targets per cell. These first screens used positive selections (that is, loss of gene function led to survival under selection) such as drug resistance. After a selection period, the sgRNA regions of the vectors were amplified and sequenced, looking for enrichment of guides that would allow the cells to survive.
A second approach was to use negative selection for the screen. In the simplest case of negative selection, a screen for ‘essential’ genes in vitro, cells were infected with the CRISPR–Cas9 libraries and then grown out for a period of time. Any cells with essential genes inactivated would die off and their associated sgRNAs would be depleted from the sequenced amplicons139. The adoption of these screening approaches required bioinformatic approaches for analyzing the data and several approaches emerged that were adapted and improved versions of analyses used for the shRNA (RNAi) screens140,141,142. These approaches attempted to generate ‘gold standard’ lists of essential and nonessential genes and calculations that could account for variation in guide efficacy, which could then inform future screening efforts.
As the modified versions of CRISPR–Cas emerged, so did their use in genome-wide screening. CRISPRi was used in similar ways to inactivate gene expression143,144. Perhaps more interesting in this case is the use of CRISPRa in screening143,144. While there are several avenues for inactivating gene expression, the ability to overexpress genes is more unique and has the potential for making functional discoveries through a different modality. Similarly, while the focus of most research has been on targeting the coding regions of the genome, efforts have begun to target the much larger space of genomic regulatory elements, essentially enhancers and silencers scattered throughout the genome. Unlike coding regions, these regulatory sequences are generally more permissible to variation, the ‘rules’ for functionality are much more poorly understood and our ability to interpret phenotypes is much more challenging. Despite the challenges, researchers are beginning to target regions of the genome that are ‘conserved noncoding elements’ at scale145. In one study, the researchers targeted 10,674 genes and 26,385 conserved regions in 2227 enhancers in human neural stem cells and found that overall, the targeted enhancers had weaker effects on gene expression, as one would predict, but many enhancers severely disrupted stem cell self-renewal145. Targeting regulatory regions will be an essential component to studying genes in vivo where differential expression depending on context will be more critical than it is in vitro.
High-throughput screening in vivo using CRISPR–Cas
While very powerful, screens performed in cell culture are fundamentally limited in the questions that can be asked. To capture the true complexities of organismal biology, it is necessary to perform experiments in vivo (or, to a lesser extent, in cultured organoids) where the interactions between different cell types, tissues or organs can be interrogated. Naturally, screenings in animals (or plants) will inherently have much lower throughput as both the delivery of CRISPR–Cas complexes and the downstream analysis of phenotypes are significantly more complicated than they are in cell culture. Therefore, researchers must either find a way to reduce the total number of targets screened or streamline and automate phenotyping to minimize post-treatment processing time. In addition, building a stable library of animals containing transgenes constitutively expressing sgRNAs ubiquitously once would allow researchers to repeatedly screen using different Cas protein drivers.
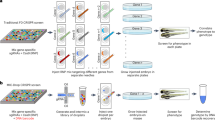
In zebrafish, an approach named ‘Multiplexed Intermixed CRISPR Droplets’ (‘MIC-Drop’), is an exciting new approach for high-throughput CRISPR–Cas in vivo screening146. The concept is relatively simple, sgRNAs targeting specific genomic loci are synthesized in 96-well format, one genomic locus per well. Then, Cas9 protein and a barcode sequence are added to each well, and the individual wells from the plate are then moved to a microdroplet maker (for example, a Bio-Rad QX200) and nanoliter-sized droplets are suspended in oil, one target per droplet. The droplet mixture can then go into an injection needle and one droplet can be injected into a single embryo. The embryos are screened for phenotypes at the appropriate age and then the barcodes of fish with a positive signal are amplified and sequenced to identify the locus of interest. The throughput for such a technique is in the hundreds to low thousands of loci, screened with a moderate commitment of resources. The advantages are that live resources do not need to be maintained and the labor efforts scale linearly with the increase in the desired number of targets to screen. Parvez et al. used the regular Cas9 nuclease and NHEJ mutagenesis to target coding genes, but there is no reason to think that regulatory elements could not also be targeted in this fashion nor that any of the other CRISPR–Cas modifications could not be used in a MIC-Drop screening strategy, thus opening up new opportunities for questions only answerable in vivo.
Another powerful approach for screening in vivo is a technique coined ‘Perturb-seq’, first developed in cell culture147 but eventually adapted to studies in animals. The basic idea is that you combine pooled libraries of sgRNAs with single-cell transcriptional profiling. The sgRNA constructs are detectable as part of the single-cell RNA-sequencing profile, so they are essentially ‘barcoded’ in the assay. In principle, when key regulators of, for example, cell identity are targeted, you should never find targeted cells that have taken on the specific identity. In cell culture, the depth of the screened library can be comprehensive; in animals, it becomes necessary to reduce the screened space significantly. The first in vivo efforts used lentiviral constructs targeting 35 genes believed to be linked to autism risk and the pools were injected into the mouse neocortex in utero148. The early postnatal brains were then subjected to single-cell RNA-sequencing and analyzed for emerging patterns of gene expression in different cell types of the neocortex. In this case, the authors found 14 ‘modules’, that is, clusters of genes that varied together, which segregated into different cell types of the neocortex. Researchers further refined the approach by switching to AAV delivery of the guides, allowing for an increased number of targets to be screened and a higher number of total infected cells to be sampled149,150.
CRISPR in gene therapy
The world was shaken when, in 2018, it was announced that twin girls from China had been edited by CRISPR–Cas9 injections in vitro that targeted the HIV receptor CCR5. The work was never published, although the lead researcher had published a (now retracted) ‘Draft ethical principles for therapeutic assisted reproductive technologies’151. There was a significant backlash to this act and many potential CRISPR-based therapies were put on pause until clearer ethical standards could be developed. While these manipulations of the human genome at very early embryonic stages are not likely to move forward in the near future, there has been significant progress on therapeutic approaches that can be performed on cells in vitro and then subsequently injected back into the patient. Focusing on diseases that could be alleviated by manipulating cells outside the body eliminates the key hurdle in CRISPR-based therapies: the inability to deliver the riboprotein efficiently to all cells needing treatment.
The first trial of a CRISPR–Cas therapy in humans took place in China152. Preclinical data showed that knocking out the PD1 gene in T cells and reinfusion showed enhanced antitumor activity153. They took T cells from 17 patients and electroporated the cells with CRISPR–Cas9 complexes targeting PD1. After an average of 25 days, the cells were reinfused into the patients and tracked for disease progression and persistence of edited cells. There were no clinical improvements in any patients, but the edited cells were detectable to 76 weeks postinfusion.
Sickle cell anemia is a disease whose genetic cause has been known for more than 40 years. It is a mutation in the HBB gene that causes protein aggregation, but the first gene therapy was only approved by the Food and Drug Authority (FDA) in 2023. Researchers have shown that an effective approach to diluting the mutant form of HBB is to target a gene, BCL11A, whose normal function is to inhibit the expression of fetal forms of hemoglobin154. By removing BCL11A function, fetal hemoglobin levels rise and alleviate the worst of the mutant HBB symptoms. The treatment was recently approved by the FDA for treatment of sickle cell disease and β-thalassemia155. Other blood diseases are likely to have treatments developed soon as they are essentially the only ones where CRISPR–Cas9 edit the cells in vitro. Other diseases will rely on improved delivery systems where editing can be both efficient and widespread in vivo. There are many delivery systems, such as AAV156, lentiviral and retroviral vectors157, liposome-based nanoparticles158 and exosomes159. All of these approaches show some promise (see Table 3 for a survey of approaches tested in vivo), but all share the same issues and challenges involved when most, if not all, the cellular genomes in a human body need to be corrected. There will need to be significant improvements in delivery systems to make complete gene correction a reality if it is not done as an early embryo.
Future considerations
The number of tools developed using the CRISPR–Cas programmable DNA targeting at the core has exploded in the past decade and no doubt will continue well into the future. We have seen the field move from generating ‘simple’ DSBs to pinpoint conversions of single base pairs with high efficiency. We can also create epigenetic modifications, control RNA transcription and insert large genetic modifications. As the binding targets are so easily modified simply by changing the RNA guide, large-scale screening in different modalities is also possible. These techniques are quite effective but are more challenging to apply to large-scale screening in vivo. This is, however, essential for accelerating our understanding of biological processes that are impossible to study in cell culture. The primary challenge for in vivo studies is the same one that plagues using CRISPR–Cas for gene therapy in humans: the efficient delivery of the enzyme complex to every cell in a living organism is extremely challenging, as is analyzing what happens in the organism after the editing process is complete. In experimental animal (and plant) models where delivery can take place at the one cell stage, the next most important issue is speed and efficiency of the edits. The earlier the modifications occur, the less mosaic the animal will be and the higher the probability the analysis can take place in the first generation instead of having to go through a ‘purifying’ breeding regimen to outcross and/or incross the modification, delaying the results and increasing the costs of screening. We have seen huge improvements on the efficiency side, with many of the techniques obtaining biallelic conversion in both mouse and zebrafish-injected embryos. We are on the cusp of a new and exciting time for the analysis of disease alleles in vertebrate model systems and broad functional genomics in vivo.
References
Amaral, P. et al. The status of the human gene catalogue. Nature 622, 41–47 (2023).
van Marcke, C., Collard, A., Vikkula, M. & Duhoux, F. P. Prevalence of pathogenic variants and variants of unknown significance in patients at high risk of breast cancer: a systematic review and meta-analysis of gene-panel data. Crit. Rev. Oncol. Hematol. 132, 138–144 (2018).
Mersch, J. et al. Prevalence of variant reclassification following hereditary cancer genetic testing. JAMA 320, 1266–1274 (2018).
Abdellaoui, A., Yengo, L., Verweij, K. J. H. & Visscher, P. M. 15 years of GWAS discovery: realizing the promise. Am. J. Hum. Genet 110, 179–194 (2023).
Watanabe, K. et al. A global overview of pleiotropy and genetic architecture in complex traits. Nat. Genet 51, 1339–1348 (2019).
Kim, Y. G., Cha, J. & Chandrasegaran, S. Hybrid restriction enzymes: zinc finger fusions to Fok I cleavage domain. Proc. Natl Acad. Sci. USA 93, 1156–1160 (1996).
Christian, M. et al. Targeting DNA double-strand breaks with TAL effector nucleases. Genetics 186, 757–761 (2010).
Joung, J. K. & Sander, J. D. TALENs: a widely applicable technology for targeted genome editing. Nat. Rev. Mol. Cell Biol. 14, 49–55 (2013).
Barrangou, R. et al. CRISPR provides acquired resistance against viruses in prokaryotes. Science 315, 1709–1712 (2007).
Jinek, M. et al. A programmable dual-RNA-guided DNA endonuclease in adaptive bacterial immunity. Science 337, 816–821 (2012).
Jinek, M. et al. RNA-programmed genome editing in human cells. eLife 2, e00471 (2013).
Cong, L. et al. Multiplex genome engineering using CRISPR–Cas systems. Science 339, 819–823 (2013).
Mali, P. et al. RNA-guided human genome engineering via Cas9. Science 339, 823–826 (2013).
Hwang, W. Y. et al. Efficient genome editing in zebrafish using a CRISPR–Cas system. Nat. Biotechnol. 31, 227–229 (2013).
Jao, L. E., Wente, S. R. & Chen, W. Efficient multiplex biallelic zebrafish genome editing using a CRISPR nuclease system. Proc. Natl Acad. Sci. USA 110, 13904–13909 (2013).
Gagnon, J. A. et al. Efficient mutagenesis by Cas9 protein-mediated oligonucleotide insertion and large-scale assessment of single-guide RNAs. PLoS ONE 9, e98186 (2014).
Varshney, G. K. et al. A high-throughput functional genomics workflow based on CRISPR–Cas9-mediated targeted mutagenesis in zebrafish. Nat. Protoc. 11, 2357–2375 (2016).
Pei, W. et al. Guided genetic screen to identify genes essential in the regeneration of hair cells and other tissues. npj Regen. Med 3, 11 (2018).
Unal Eroglu, A. et al. Multiplexed CRISPR–Cas9 targeting of genes implicated in retinal regeneration and degeneration. Front Cell Dev. Biol. 6, 88 (2018).
Thyme, S. B. et al. Phenotypic landscape of schizophrenia-associated genes defines candidates and their shared functions. Cell 177, 478–491.e420 (2019).
Griffin, A. et al. Phenotypic analysis of catastrophic childhood epilepsy genes. Commun. Biol. 4, 680 (2021).
Shin, U. et al. Large-scale generation and phenotypic characterization of zebrafish CRISPR mutants of DNA repair genes. DNA Repair 107, 103173 (2021).
Pei, W. et al. A subset of SMN complex members have a specific role in tissue regeneration via ERBB pathway-mediated proliferation. npj Regen. Med 5, 6 (2020).
Shen, B. et al. Generation of gene-modified mice via Cas9/RNA-mediated gene targeting. Cell Res. 23, 720–723 (2013).
Gridley, T. & Murray, S. A. Mouse mutagenesis and phenotyping to generate models of development and disease. Curr. Top. Dev. Biol. 148, 1–12 (2022).
Chen, S. et al. Genome-wide CRISPR screen in a mouse model of tumor growth and metastasis. Cell 160, 1246–1260 (2015).
Keys, H. R. & Knouse, K. A. Genome-scale CRISPR screening in a single mouse liver. Cell Genom. https://doi.org/10.1016/j.xgen.2022.100217 (2022).
Kendirli, A. et al. A genome-wide in vivo CRISPR screen identifies essential regulators of T cell migration to the CNS in a multiple sclerosis model. Nat. Neurosci. 26, 1713–1725 (2023).
Liu, B. et al. Large-scale multiplexed mosaic CRISPR perturbation in the whole organism. Cell 185, 3008–3024.e3016 (2022).
Burger, A. et al. Maximizing mutagenesis with solubilized CRISPR–Cas9 ribonucleoprotein complexes. Development 143, 2025 (2016).
Wu, R. S. et al. A rapid method for directed gene knockout for screening in G0 zebrafish. Dev. Cell 46, 112–125.e114 (2018).
Hoshijima, K. et al. Highly efficient CRISPR–Cas9-based methods for generating deletion mutations and F0 embryos that lack gene function in zebrafish. Dev. Cell 51, 645–657.e644 (2019).
Kroll, F. et al. A simple and effective F0 knockout method for rapid screening of behaviour and other complex phenotypes. eLife https://doi.org/10.7554/eLife.59683 (2021).
Lin, S. J. et al. Optimizing gRNA selection for high-penetrance F0 CRISPR screening for interrogating disease gene function. Nucleic Acids Res. 53, gkaf180 (2025).
Prykhozhij, S. V. et al. Optimized knock-in of point mutations in zebrafish using CRISPR–Cas9. Nucleic Acids Res 46, e102 (2018).
Carrington, B., Ramanagoudr-Bhojappa, R., Bresciani, E., Han, T. U. & Sood, R. A robust pipeline for efficient knock-in of point mutations and epitope tags in zebrafish using fluorescent PCR based screening. BMC Genomics 23, 810 (2022).
Ranawakage, D. C. et al. Efficient CRISPR–Cas9-mediated knock-in of composite tags in zebrafish using long ssDNA as a donor. Front. Cell Dev. Biol. 8, 598634 (2020).
de Vrieze, E. et al. Efficient generation of knock-in zebrafish models for inherited disorders using CRISPR–Cas9 ribonucleoprotein complexes. Int. J. Mol. Sci. https://doi.org/10.3390/ijms22179429 (2021).
Hall, B. et al. Genome editing in mice using CRISPR–Cas9 technology. Curr. Protoc. Cell Biol. 81, e57 (2018).
Shin, H. Y. et al. CRISPR–Cas9 targeting events cause complex deletions and insertions at 17 sites in the mouse genome. Nat. Commun. 8, 15464, (2017).
Mattonet, K. et al. Endothelial versus pronephron fate decision is modulated by the transcription factors Cloche/Npas4l, Tal1, and Lmo2. Sci. Adv. 8, eabn2082 (2022).
Wierson, W. A. et al. Efficient targeted integration directed by short homology in zebrafish and mammalian cells. eLife https://doi.org/10.7554/eLife.53968 (2020).
Kim, E. et al. In vivo genome editing with a small Cas9 orthologue derived from Campylobacter jejuni. Nat. Commun. 8, 14500 (2017).
Karvelis, T. et al. PAM recognition by miniature CRISPR–Cas12f nucleases triggers programmable double-stranded DNA target cleavage. Nucleic Acids Res. 48, 5016–5023 (2020).
Zetsche, B., Abudayyeh, O. O., Gootenberg, J. S., Scott, D. A. & Zhang, F. A survey of genome editing activity for 16 Cas12a orthologs. Keio J. Med. 69, 59–65 (2020).
Gaudelli, N. M. et al. Programmable base editing of A•T to G•C in genomic DNA without DNA cleavage. Nature 551, 464–471 (2017).
Anzalone, A. V. et al. Programmable deletion, replacement, integration and inversion of large DNA sequences with twin prime editing. Nat. Biotechnol. 40, 731–740 (2022).
Komor, A. C., Kim, Y. B., Packer, M. S., Zuris, J. A. & Liu, D. R. Programmable editing of a target base in genomic DNA without double-stranded DNA cleavage. Nature 533, 420–424 (2016).
Komor, A. C. et al. Improved base excision repair inhibition and bacteriophage Mu Gam protein yields C:G-to-T:A base editors with higher efficiency and product purity. Sci. Adv. 3, eaao4774 (2017).
Koblan, L. W. et al. Improving cytidine and adenine base editors by expression optimization and ancestral reconstruction. Nat. Biotechnol. 36, 843–846 (2018).
Nishida, K. et al. Targeted nucleotide editing using hybrid prokaryotic and vertebrate adaptive immune systems. Science https://doi.org/10.1126/science.aaf8729 (2016).
Thuronyi, B. W. et al. Continuous evolution of base editors with expanded target compatibility and improved activity. Nat. Biotechnol. 37, 1070–1079 (2019).
Kim, Y. B. et al. Increasing the genome-targeting scope and precision of base editing with engineered Cas9–cytidine deaminase fusions. Nat. Biotechnol. 35, 371–376 (2017).
Gehrke, J. M. et al. An APOBEC3A–Cas9 base editor with minimized bystander and off-target activities. Nat. Biotechnol. 36, 977–982 (2018).
Richter, M. F. et al. Author correction: phage-assisted evolution of an adenine base editor with improved Cas domain compatibility and activity. Nat. Biotechnol. 38, 901 (2020).
Gaudelli, N. M. et al. Directed evolution of adenine base editors with increased activity and therapeutic application. Nat. Biotechnol. 38, 892–900 (2020).
Tu, T. et al. A precise and efficient adenine base editor. Mol. Ther. 30, 2933–2941 (2022).
Jeong, Y. K. et al. Adenine base editor engineering reduces editing of bystander cytosines. Nat. Biotechnol. 39, 1426–1433 (2021).
Chen, L. et al. Engineering a precise adenine base editor with minimal bystander editing. Nat. Chem. Biol. 19, 101–110 (2023).
Yuan, Y. et al. An AI-designed adenine base editor. Preprint at bioRxiv https://doi.org/10.1101/2024.04.28.591233 (2024).
Neugebauer, M. E. et al. Evolution of an adenine base editor into a small, efficient cytosine base editor with low off-target activity. Nat. Biotechnol. 41, 673–685 (2023).
Chen, L. et al. Re-engineering the adenine deaminase TadA-8e for efficient and specific CRISPR-based cytosine base editing. Nat. Biotechnol. 41, 663–672 (2023).
Lam, D. K. et al. Improved cytosine base editors generated from TadA variants. Nat. Biotechnol. 41, 686–697 (2023).
Zhang, S. et al. TadA reprogramming to generate potent miniature base editors with high precision. Nat. Commun. 14, 413 (2023).
Grunewald, J. et al. A dual-deaminase CRISPR base editor enables concurrent adenine and cytosine editing. Nat. Biotechnol. 38, 861–864 (2020).
Zhang, X. et al. Dual base editor catalyzes both cytosine and adenine base conversions in human cells. Nat. Biotechnol. 38, 856–860 (2020).
Rees, H. A. et al. Improving the DNA specificity and applicability of base editing through protein engineering and protein delivery. Nat. Commun. 8, 15790 (2017).
Zhao, Y., Shang, D., Ying, R., Cheng, H. & Zhou, R. An optimized base editor with efficient C-to-T base editing in zebrafish. BMC Biol. 18, 190 (2020).
Zhang, Y. et al. Programmable base editing of zebrafish genome using a modified CRISPR–Cas9 system. Nat. Commun. 8, 118 (2017).
Lu, X. et al. Optimized Target-AID system efficiently induces single base changes in zebrafish. J. Genet. Genomics 45, 215–217 (2018).
Rosello, M. et al. Precise base editing for the in vivo study of developmental signaling and human pathologies in zebrafish. eLife https://doi.org/10.7554/eLife.65552 (2021).
Liang, F. et al. SpG and SpRY variants expand the CRISPR toolbox for genome editing in zebrafish. Nat. Commun. 13, 3421 (2022).
Cornean, A. et al. Precise in vivo functional analysis of DNA variants with base editing using ACEofBASEs target prediction. eLife https://doi.org/10.7554/eLife.72124 (2022).
Qin, W. et al. ABE-ultramax for high-efficiency biallelic adenine base editing in zebrafish. Nat. Commun. 15, 5613 (2024).
Zhang, Y. et al. Cytosine base editors with increased PAM and deaminase motif flexibility for gene editing in zebrafish. Nat. Commun. 15, 9526 (2024).
Park, D. S. et al. Targeted base editing via RNA-guided cytidine deaminases in Xenopus laevis embryos. Mol. Cells 40, 823–827 (2017).
Kim, K. et al. Highly efficient RNA-guided base editing in mouse embryos. Nat. Biotechnol. 35, 435–437 (2017).
Sasaguri, H. et al. Introduction of pathogenic mutations into the mouse Psen1 gene by Base Editor and Target-AID. Nat. Commun. 9, 2892 (2018).
Zhang, H. et al. Simultaneous zygotic inactivation of multiple genes in mouse through CRISPR–Cas9-mediated base editing. Development https://doi.org/10.1242/dev.168906 (2018).
Arbab, M. et al. Base editing rescue of spinal muscular atrophy in cells and in mice. Science 380, eadg6518 (2023).
Lim, C. K. W. et al. Treatment of a mouse model of ALS by in vivo base editing. Mol. Ther. 28, 1177–1189 (2020).
Koblan, L. W. et al. In vivo base editing rescues Hutchinson–Gilford progeria syndrome in mice. Nature 589, 608–614 (2021).
Flugel, C. L. & Abou-El-Enein, M. Bringing base editing to the clinic: the next generation of genome editors. Mol. Ther. Methods Clin. Dev. 31, 101138 (2023).
Anzalone, A. V. et al. Search-and-replace genome editing without double-strand breaks or donor DNA. Nature 576, 149–157 (2019).
Chen, P. J. et al. Enhanced prime editing systems by manipulating cellular determinants of editing outcomes. Cell 184, 5635–5652.e5629 (2021).
Zong, Y. et al. An engineered prime editor with enhanced editing efficiency in plants. Nat. Biotechnol. 40, 1394–1402 (2022).
Grunewald, J. et al. Engineered CRISPR prime editors with compact, untethered reverse transcriptases. Nat. Biotechnol. 41, 337–343 (2023).
Doman, J. L. et al. Phage-assisted evolution and protein engineering yield compact, efficient prime editors. Cell 186, 3983–4002.e3926 (2023).
Zhi, S. et al. Dual-AAV delivering split prime editor system for in vivo genome editing. Mol. Ther. 30, 283–294 (2022).
Yan, J. et al. Improving prime editing with an endogenous small RNA-binding protein. Nature 628, 639–647 (2024).
Ponnienselvan, K. et al. Reducing the inherent auto-inhibitory interaction within the pegRNA enhances prime editing efficiency. Nucleic Acids Res 51, 6966–6980 (2023).
Zhang, G. et al. Enhancement of prime editing via xrRNA motif-joined pegRNA. Nat. Commun. 13, 1856 (2022).
Li, X. et al. Highly efficient prime editing by introducing same-sense mutations in pegRNA or stabilizing its structure. Nat. Commun. 13, 1669 (2022).
Nelson, J. W. et al. Engineered pegRNAs improve prime editing efficiency. Nat. Biotechnol. 40, 402–410 (2022).
Choi, J. et al. Precise genomic deletions using paired prime editing. Nat. Biotechnol. 40, 218–226 (2022).
Wang, J. et al. Efficient targeted insertion of large DNA fragments without DNA donors. Nat. Methods 19, 331–340 (2022).
Tao, R. et al. Bi-PE: bi-directional priming improves CRISPR–Cas9 prime editing in mammalian cells. Nucleic Acids Res. 50, 6423–6434 (2022).
Zhuang, Y. et al. Increasing the efficiency and precision of prime editing with guide RNA pairs. Nat. Chem. Biol. 18, 29–37 (2022).
Liu, Y. et al. Enhancing prime editing by Csy4-mediated processing of pegRNA. Cell Res. 31, 1134–1136 (2021).
Kweon, J. et al. Engineered prime editors with PAM flexibility. Mol. Ther. 29, 2001–2007 (2021).
Lin, J. et al. Modeling a cataract disorder in mice with prime editing. Mol. Ther. Nucleic Acids 25, 494–501 (2021).
Jang, H. et al. Application of prime editing to the correction of mutations and phenotypes in adult mice with liver and eye diseases. Nat. Biomed. Eng. 6, 181–194 (2022).
Chemello, F. et al. Precise correction of Duchenne muscular dystrophy exon deletion mutations by base and prime editing. Sci. Adv. https://doi.org/10.1126/sciadv.abg4910 (2021).
Bock, D. et al. In vivo prime editing of a metabolic liver disease in mice. Sci. Transl. Med 14, eabl9238 (2022).
Liu, P. et al. Improved prime editors enable pathogenic allele correction and cancer modelling in adult mice. Nat. Commun. 12, 2121 (2021).
Gao, P. et al. Prime editing in mice reveals the essentiality of a single base in driving tissue-specific gene expression. Genome Biol. 22, 83 (2021).
Ferreira da Silva, J. et al. Click editing enables programmable genome writing using DNA polymerases and HUH endonucleases. Nat. Biotechnol. https://doi.org/10.1038/s41587-024-02324-x (2024).
Liu, B. et al. Targeted genome editing with a DNA-dependent DNA polymerase and exogenous DNA-containing templates. Nat. Biotechnol. 42, 1039–1045 (2024).
Qi, L. S. et al. Repurposing CRISPR as an RNA-guided platform for sequence-specific control of gene expression. Cell 152, 1173–1183 (2013).
Huntley, S. et al. A comprehensive catalog of human KRAB-associated zinc finger genes: insights into the evolutionary history of a large family of transcriptional repressors. Genome Res. 16, 669–677 (2006).
Gilbert, L. A. et al. CRISPR-mediated modular RNA-guided regulation of transcription in eukaryotes. Cell 154, 442–451 (2013).
Li, R. et al. Generation and validation of versatile inducible CRISPRi embryonic stem cell and mouse model. PLoS Biol. 18, e3000749 (2020).
Maeder, M. L. et al. CRISPR RNA-guided activation of endogenous human genes. Nat. Methods 10, 977–979 (2013).
Hilton, I. B. et al. Epigenome editing by a CRISPR–Cas9-based acetyltransferase activates genes from promoters and enhancers. Nat. Biotechnol. 33, 510–517 (2015).
Greer, E. L. & Shi, Y. Histone methylation: a dynamic mark in health, disease and inheritance. Nat. Rev. Genet. 13, 343–357 (2012).
Hamamoto, R. et al. SMYD3 encodes a histone methyltransferase involved in the proliferation of cancer cells. Nat. Cell Biol. 6, 731–740 (2004).
Powers, N. R. et al. The meiotic recombination activator PRDM9 trimethylates both H3K36 and H3K4 at recombination hotspots in vivo. PLoS Genet. 12, e1006146 (2016).
Rea, S. et al. Regulation of chromatin structure by site-specific histone H3 methyltransferases. Nature 406, 593–599 (2000).
Shi, Y. et al. Histone demethylation mediated by the nuclear amine oxidase homolog LSD1. Cell 119, 941–953 (2004).
van Deursen, J. et al. Creatine kinase (CK) in skeletal muscle energy metabolism: a study of mouse mutants with graded reduction in muscle CK expression. Proc. Natl Acad. Sci. USA 91, 9091–9095 (1994).
Sankar, A. et al. Histone editing elucidates the functional roles of H3K27 methylation and acetylation in mammals. Nat. Genet. 54, 754–760 (2022).
Moore, L. D., Le, T. & Fan, G. DNA methylation and its basic function. Neuropsychopharmacology 38, 23–38 (2013).
Katayama, S., Shiraishi, K., Gorai, N. & Andou, M. A CRISPR–Cas9-based method for targeted DNA methylation enables cancer initiation in B lymphocytes. Adv. Genet. 2, e10040 (2021).
Stepper, P. et al. Efficient targeted DNA methylation with chimeric dCas9-Dnmt3a-Dnmt3L methyltransferase. Nucleic Acids Res. 45, 1703–1713 (2017).
Huang, Y. H. et al. DNA epigenome editing using CRISPR–Cas SunTag-directed DNMT3A. Genome Biol. 18, 176 (2017).
Xiong, T. et al. Protein engineering strategies for improving the selective methylation of target CpG sites by a dCas9-directed cytosine methyltransferase in bacteria. PLoS ONE 13, e0209408 (2018).
Hua, P. et al. Defining genome architecture at base-pair resolution. Nature 595, 125–129 (2021).
Lieberman-Aiden, E. et al. Comprehensive mapping of long-range interactions reveals folding principles of the human genome. Science 326, 289–293 (2009).
Robinett, C. C. et al. In vivo localization of DNA sequences and visualization of large-scale chromatin organization using lac operator/repressor recognition. J. Cell Biol. 135, 1685–1700 (1996).
Sellars, L. E. et al. Development of a new fluorescent reporter:operator system: location of AraC regulated genes in Escherichia coli K-12. BMC Microbiol. 17, 170 (2017).
Donze, D., Adams, C. R., Rine, J. & Kamakaka, R. T. The boundaries of the silenced HMR domain in Saccharomyces cerevisiae. Genes Dev. 13, 698–708 (1999).
Nanni, L., Ceri, S. & Logie, C. Spatial patterns of CTCF sites define the anatomy of TADs and their boundaries. Genome Biol. 21, 197 (2020).
Sanjana, N. E. et al. High-resolution interrogation of functional elements in the noncoding genome. Science 353, 1545–1549 (2016).
Guo, Y. et al. CRISPR inversion of CTCF sites alters genome topology and enhancer/promoter function. Cell 162, 900–910 (2015).
Flavahan, W. A. et al. Altered chromosomal topology drives oncogenic programs in SDH-deficient GISTs. Nature 575, 229–233 (2019).
Tarjan, D. R., Flavahan, W. A. & Bernstein, B. E. Epigenome editing strategies for the functional annotation of CTCF insulators. Nat. Commun. 10, 4258 (2019).
Morgan, S. L. et al. Manipulation of nuclear architecture through CRISPR-mediated chromosomal looping. Nat. Commun. 8, 15993 (2017).
Shalem, O. et al. Genome-scale CRISPR–Cas9 knockout screening in human cells. Science 343, 84–87 (2014).
Wang, T. et al. Identification and characterization of essential genes in the human genome. Science 350, 1096–1101 (2015).
Hanna, R. E. & Doench, J. G. Design and analysis of CRISPR–Cas experiments. Nat. Biotechnol. 38, 813–823 (2020).
Hart, T., Brown, K. R., Sircoulomb, F., Rottapel, R. & Moffat, J. Measuring error rates in genomic perturbation screens: gold standards for human functional genomics. Mol. Syst. Biol. 10, 733 (2014).
Hart, T. & Moffat, J. BAGEL: a computational framework for identifying essential genes from pooled library screens. BMC Bioinform. 17, 164 (2016).
Gilbert, L. A. et al. Genome-scale CRISPR-mediated control of gene repression and activation. Cell 159, 647–661 (2014).
Konermann, S. et al. Genome-scale transcriptional activation by an engineered CRISPR–Cas9 complex. Nature 517, 583–588 (2015).
Geller, E. et al. Massively parallel disruption of enhancers active in human neural stem cells. Cell Rep. 43, 113693 (2024).
Parvez, S. et al. MIC-Drop: a platform for large-scale in vivo CRISPR screens. Science 373, 1146–1151 (2021).
Dixit, A. et al. Perturb-Seq: dissecting molecular circuits with scalable single-cell RNA profiling of pooled genetic screens. Cell 167, 1853–1866.e1817 (2016).
Jin, X. et al. In vivo Perturb-Seq reveals neuronal and glial abnormalities associated with autism risk genes. Science https://doi.org/10.1126/science.aaz6063 (2020).
Santinha, A. J. et al. Transcriptional linkage analysis with in vivo AAV-Perturb-seq. Nature 622, 367–375 (2023).
Zheng, X. et al. Massively parallel in vivo Perturb-seq reveals cell-type-specific transcriptional networks in cortical development. Cell 187, 3236–3248.e3221 (2024).
Retraction of: Draft ethical principles for therapeutic assisted reproductive technologies by He, J. et al. CRISPR J. https://doi.org/10.1089/crispr.2018.0051.retract (2019).
Lu, Y. et al. Safety and feasibility of CRISPR-edited T cells in patients with refractory non-small-cell lung cancer. Nat. Med. 26, 732–740 (2020).
Su, S. et al. CRISPR–Cas9-mediated disruption of PD-1 on human T cells for adoptive cellular therapies of EBV positive gastric cancer. Oncoimmunology 6, e1249558 (2017).
Frangoul, H. et al. CRISPR–Cas9 gene editing for sickle cell disease and beta-thalassemia. N. Engl. J. Med 384, 252–260 (2021).
FDA approves first gene therapies to treat patients with sickle cell disease. Food and Drug Authority https://fda.gov/news-events/press-announcements/fda-approves-first-gene-therapies-treat-patients-sickle-cell-disease (2023).
Backstrom, J. R., Sheng, J., Wang, M. C., Bernardo-Colon, A. & Rex, T. S. Optimization of S. aureus dCas9 and CRISPRi elements for a single adeno-associated virus that targets an endogenous gene. Mol. Ther. Methods Clin. Dev. 19, 139–148 (2020).
Lin, S. C., Haga, K., Zeng, X. L. & Estes, M. K. Generation of CRISPR–Cas9-mediated genetic knockout human intestinal tissue-derived enteroid lines by lentivirus transduction and single-cell cloning. Nat. Protoc. 17, 1004–1027 (2022).
Qiu, M. et al. Lipid nanoparticle-mediated codelivery of Cas9 mRNA and single-guide RNA achieves liver-specific in vivo genome editing of Angptl3. Proc. Natl Acad. Sci. USA 118, e2020401118 (2021).
Lainscek, D. et al. Delivery of an artificial transcription regulator dCas9-VPR by extracellular vesicles for therapeutic gene activation. ACS Synth. Biol. 7, 2715–2725 (2018).
Nishimasu, H. et al. Engineered CRISPR–Cas9 nuclease with expanded targeting space. Science 361, 1259–1262 (2018).
Kleinstiver, B. P. et al. Broadening the targeting range of Staphylococcus aureus CRISPR–Cas9 by modifying PAM recognition. Nat. Biotechnol. 33, 1293–1298 (2015).
Hu, J. H. et al. Evolved Cas9 variants with broad PAM compatibility and high DNA specificity. Nature 556, 57–63 (2018).
Walton, R. T., Christie, K. A., Whittaker, M. N. & Kleinstiver, B. P. Unconstrained genome targeting with near-PAMless engineered CRISPR–Cas9 variants. Science 368, 290–296 (2020).
Miller, S. M., Wang, T. & Liu, D. R. Phage-assisted continuous and non-continuous evolution. Nat. Protoc. 15, 4101–4127 (2020).
Anders, C., Bargsten, K. & Jinek, M. Structural plasticity of PAM recognition by engineered variants of the RNA-guided endonuclease Cas9. Mol. Cell 61, 895–902 (2016).
Ran, F. A. et al. In vivo genome editing using Staphylococcus aureus Cas9. Nature 520, 186–191 (2015).
Chatterjee, P. et al. An engineered ScCas9 with broad PAM range and high specificity and activity. Nat. Biotechnol. 38, 1154–1158 (2020).
Hirano, H. et al. Structure and engineering of Francisella novicida Cas9. Cell 164, 950–961 (2016).
Sapranauskas, R. et al. The Streptococcus thermophilus CRISPR–Cas system provides immunity in Escherichia coli. Nucleic Acids Res. 39, 9275–9282 (2011).
Hou, Z. et al. Efficient genome engineering in human pluripotent stem cells using Cas9 from Neisseria meningitidis. Proc. Natl Acad. Sci. USA 110, 15644–15649 (2013).
Edraki, A. et al. A compact, high-accuracy Cas9 with a dinucleotide PAM for in vivo genome editing. Mol. Cell 73, 714–726.e714 (2019).
Huang, T. P. et al. High-throughput continuous evolution of compact Cas9 variants targeting single-nucleotide-pyrimidine PAMs. Nat. Biotechnol. 41, 96–107 (2023).
Harrington, L. B. et al. A thermostable Cas9 with increased lifetime in human plasma. Nat. Commun. 8, 1424 (2017).
Hu, Z. et al. A compact Cas9 ortholog from Staphylococcus auricularis (SauriCas9) expands the DNA targeting scope. PLoS Biol. 18, e3000686 (2020).
Chatterjee, P. et al. A Cas9 with PAM recognition for adenine dinucleotides. Nat. Commun. 11, 2474 (2020).
Gao, L. et al. Engineered Cpf1 variants with altered PAM specificities. Nat. Biotechnol. 35, 789–792 (2017).
Kleinstiver, B. P. et al. Engineered CRISPR–Cas12a variants with increased activities and improved targeting ranges for gene, epigenetic and base editing. Nat. Biotechnol. 37, 276–282, (2019).
Teng, F. et al. Repurposing CRISPR–Cas12b for mammalian genome engineering. Cell Discov. 4, 63 (2018).
Escobar, M. et al. Quantification of genome editing and transcriptional control capabilities reveals hierarchies among diverse CRISPR–Cas systems in human cells. ACS Synth. Biol. 11, 3239–3250 (2022).
Zafra, M. P. et al. Optimized base editors enable efficient editing in cells, organoids and mice. Nat. Biotechnol. 36, 888–893 (2018).
Ma, Y. et al. Targeted AID-mediated mutagenesis (TAM) enables efficient genomic diversification in mammalian cells. Nat. Methods 13, 1029–1035 (2016).
Jiang, W. et al. BE-PLUS: a new base editing tool with broadened editing window and enhanced fidelity. Cell Res. 28, 855–861 (2018).
Grunewald, J. et al. Transcriptome-wide off-target RNA editing induced by CRISPR-guided DNA base editors. Nature 569, 433–437 (2019).
Wang, X. et al. Efficient base editing in methylated regions with a human APOBEC3A–Cas9 fusion. Nat. Biotechnol. 36, 946–949 (2018).
Tan, J., Zhang, F., Karcher, D. & Bock, R. Engineering of high-precision base editors for site-specific single nucleotide replacement. Nat. Commun. 10, 439 (2019).
Huang, T. P. et al. Circularly permuted and PAM-modified Cas9 variants broaden the targeting scope of base editors. Nat. Biotechnol. 37, 626–631 (2019).
Zhou, C. et al. Off-target RNA mutation induced by DNA base editing and its elimination by mutagenesis. Nature 571, 275–278 (2019).
Chatterjee, P., Jakimo, N. & Jacobson, J. M. Minimal PAM specificity of a highly similar SpCas9 ortholog. Sci. Adv. 4, eaau0766 (2018).
Yin, S. et al. Amelioration of metabolic and behavioral defects through base editing in the Pah(R408W) phenylketonuria mouse model. Mol. Ther. 33, 119–132 (2025).
Yeh, W. H. et al. In vivo base editing restores sensory transduction and transiently improves auditory function in a mouse model of recessive deafness. Sci. Transl. Med 12, eaay9101 (2020).
Peters, C. W. et al. Rescue of hearing by adenine base editing in a humanized mouse model of Usher syndrome type 1F. Mol. Ther. 31, 2439–2453 (2023).
Cui, C. et al. A base editor for the long-term restoration of auditory function in mice with recessive profound deafness. Nat. Biomed. Eng. 9, 40–56 (2025).
Hu, S. W. et al. PAM-flexible adenine base editing rescues hearing loss in a humanized MPZL2 mouse model harboring an East Asian founder mutation. Preprint at bioRxiv https://doi.org/10.1101/2024.10.29.620803 (2024).
Zeng, Y. et al. Correction of the Marfan syndrome pathogenic FBN1 mutation by base editing in human cells and heterozygous embryos. Mol. Ther. 26, 2631–2637 (2018).
Suh, S. et al. Restoration of visual function in adult mice with an inherited retinal disease via adenine base editing. Nat. Biomed. Eng. 5, 169–178 (2021).
Wu, Y. et al. AAV-mediated base-editing therapy ameliorates the disease phenotypes in a mouse model of retinitis pigmentosa. Nat. Commun. 14, 4923 (2023).
Levy, J. M. et al. Cytosine and adenine base editing of the brain, liver, retina, heart and skeletal muscle of mice via adeno-associated viruses. Nat. Biomed. Eng. 4, 97–110 (2020).
Lin, J. et al. Adenine base editing-mediated exon skipping restores dystrophin in humanized Duchenne mouse model. Nat. Commun. 15, 5927 (2024).
Xu, L. et al. Efficient precise in vivo base editing in adult dystrophic mice. Nat. Commun. 12, 3719 (2021).
Ryu, S. M. et al. Adenine base editing in mouse embryos and an adult mouse model of Duchenne muscular dystrophy. Nat. Biotechnol. 36, 536–539 (2018).
Acknowledgements
This research was supported in part by the Intramural Research Program of the National Human Genome Research Institute (grant no. ZIAHG000183-24) to S.M.B., and the National Institutes of Health (NIH), Office of Research Infrastructure Programs (ORIP) grant R24OD034438 to G.K.V.
Funding
Open access funding provided by the National Institutes of Health.
Author information
Authors and Affiliations
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing of interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Varshney, G.K., Burgess, S.M. CRISPR-based functional genomics tools in vertebrate models. Exp Mol Med 57, 1355–1372 (2025). https://doi.org/10.1038/s12276-025-01514-0
Received:
Revised:
Accepted:
Published:
Version of record:
Issue date:
DOI: https://doi.org/10.1038/s12276-025-01514-0
