
Abstract
Early prediction of acute kidney injury (AKI) may provide a crucial opportunity for AKI prevention. To date, no prediction model targeting AKI among general hospitalized patients in developing countries has been published. Here we show a simple, real-time, interpretable AKI prediction model for general hospitalized patients developed from a large tertiary hospital in China, which has been validated across five independent, geographically distinct, different tiered hospitals. The model containing 20 readily available variables demonstrates consistent, high levels of predictive discrimination in validation cohort, with AUCs for serum creatinine-based AKI and severe AKI within 48 h ranging from 0.74–0.85 and 0.83–0.90 for transported models and from 0.81–0.90 and 0.88–0.95 for refitted models, respectively. With optimal probability cutoffs, the refitted model could predict AKI at a median of 72 (24–198) hours in advance in internal validation, and 54–90 h in advance in external validation. Broad application of the model in the future may provide an effective, convenient and cost-effective approach for AKI prevention.
Similar content being viewed by others

Introduction
Acute kidney injury (AKI) is a common and potentially life-threatening clinical condition among hospitalized patients and is associated with increased morbidity, mortality, and medical costs1,2,3. Approximately, AKI affects 13.3 million people every year, with 85% of whom living in developing countries, causing a heavy burden on public health systems4,5. The reported incidence of AKI varies widely across different countries, ranging from 2% to 25% among general hospitalized patients, with a significant proportion of cases being avoidable and preventable5,6,7,8,9. Most cases of AKI are first encountered by nonspecialized physicians, who may have difficulty in early identification and timely intervention4. As no interventional treatments for established AKI can improve outcomes, accurate and timely identification of high-risk patients is essential for AKI prevention by providing a crucial opportunity for proactive management10,11,12. Therefore, real-time personalized prediction of AKI during hospitalization is the key to reducing the burden of AKI5.
The electronic health record (EHR) data, which include demographic data, diagnosis, vital signs, laboratory tests, and clinical interventions, provide an ideal predisease dataset for AKI prediction modeling10. The extensive application of EHR systems across different tiered medical services and advances in machine learning techniques have sparked growing interest in the development of AKI prediction models based on EHR13,14,15,16. In recent years, models using machine learning algorithms targeting AKI among general hospitalized patients have been developed based on data from academic hospitals in developed countries and have demonstrated satisfactory performance17,18,19,20,21,22. However, these models have not been validated in the developing world, probably due to the lack of publicly available models, inadequate data transparency, and the nonavailability of variables required in complicated models.
The incidence and etiologies of AKI in developing countries differ widely from those in developed countries4,7,9. As revealed by a review, AKI in developed countries is usually associated with multiple organ failure, while in developing countries, AKI is frequently caused by a single clinical condition, such as infections, nephrotoxins, or hypoperfusion4,9. As the performance of AKI prediction models depends heavily on patient characteristics of the derivation cohort, the “Kidney Disease: Improving Global Outcomes” (KDIGO) guidelines call for research on the development and validation of AKI prediction models across diverse clinical settings22,23,24,25. With the prevalent delayed recognition of AKI and limited renal resources in developing countries, an AKI prediction model applicable to multiple clinical settings that can be readily implemented in the EHR system and is easy to be promoted across different tiered hospitals and various regions is urgently needed5,6,9.
In the present study, we developed a simple prediction model for AKI and severe AKI (AKI stage 2-3) using variables routinely collected from the EHR system in a cohort of general hospitalized patients from a large tertiary hospital in China. The model was then validated using cohorts from five independent, geographically distinct, different-tiered hospitals. This model now enables convenient and cost-effective real-time prediction of AKI among general hospitalized patients across various healthcare institutions.
Results
Characteristics of study cohorts
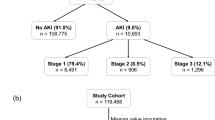
Overall, 161,876 admissions from five independent hospitals were included in the cohort for model derivation (n = 47,750), internal validation (n = 17,074), and external validation (n = 97,052). Figure 1 shows the construction and selection process for the derivation and validation cohorts, and Fig. S1 shows the selection process for each validation cohort. The demographic profiles varied across the derivation cohort and five validation cohorts. Compared with those in the derivation cohort (Site 1, 2018-2019, mean age, 59.1 ± 16.3 years; 43.7% female), patients in the internal validation cohort (Site 1, 2020) had similar characteristics. Patients in the external validation cohorts from tertiary hospitals (Site 2 and Site 3) were clinically more severe, with higher ICU admission rates (Site 1, 2, and 3: 3.3% vs. 4.8% vs. 8.6%), while patients from local hospitals (Site 4 and Site 5) were more likely to be admitted to the Internal Medicine ward (Site 1, 4, and 5: 41.2% vs. 61.4% vs. 71.1%), with lower operation rates (Site 1, 4, and 5: 35.7% vs. 14.2% vs. 17.3%). Additionally, patients from Site 4 had a much lower ICU admission rate than those in the derivation cohort (Site 1, 4: 3.3% vs. 1.6%). Considering preexisting clinical condition, patients at Site 3 had the highest proportion of chronic kidney disease (CKD), as well as the lowest mean estimated glomerular filtration rate (eGFR) and the highest positive urine protein rate at admission among the six cohorts. Table 1 shows the demographics and outcomes of patients from the derivation cohort and five validation cohorts.

A Flow diagram for the derivation cohort; B Flow diagram for the validation cohort; C Construction of derivation, internal validation, and external validation cohorts.
The total incidence of AKI in the whole cohort was 5.39% (8721 patients), with severe AKI accounting for 41.4% of all AKI patients. In the derivation cohort (n = 47,750), 1,739 (3.6%) patients developed AKI and 652 (1.4%) developed severe AKI during hospitalization. The incidence of AKI (4%) and severe AKI (1.6%) in the internal validation cohort was similar to that in the derivation cohort. For the external validation cohorts, the incidence of AKI and severe AKI ranged from 3.7–9.1% and 1.4–3.4%, respectively. Patients in two tertiary hospitals (Site 2, 6.8%; Site 3, 9.1%) had a greater incidence of AKI and severe AKI than did patients in two local hospitals (Site 4, 3.7%; Site 5, 6.2%). Among them, Site 3 exhibited the highest incidence of AKI (9.1%) and severe AKI (3.4%), while Site 4 exhibited the lowest incidence (3.7% for AKI, 1.8% for severe AKI), but was the closest to the derivation cohort. Table S1 shows the demographics of all cohorts stratified by AKI status. Compared with patients without AKI, patients who developed AKI were predominantly older, more severe in clinical condition and more likely to be admitted to the ICU, with a greater proportion of them having preexisting CKD, higher admission Scr and BUN levels, positive urine protein, a worse inflammatory status, a longer length of stay, and greater inpatient mortality in all six cohorts.
Compared with AKI patients in two local hospitals (Site 4 and Site 5), AKI patients in Site 1 and the external validation cohorts from two tertiary hospitals (Site 2 and Site 3) had more severe disease conditions as indicated by a higher maximum Scr post-AKI and a higher RRT rate. The RRT rate was especially low at Site 4, where AKI patients requiring RRT were usually referred to tertiary hospitals. As shown in the cumulative incidence plots for AKI and severe AKI across the six cohorts (Fig. S2) and the timing of AKI postadmission (Table 1), patients at Site 3 developed AKI earlier than did patients in the other cohorts, and patients at Site 1 developed AKI the latest among all cohorts.
Model performance in the derivation cohort
Table S2 shows performance in the prediction of AKI and severe AKI within 24, 48, and 72 h in the derivation cohort. In the testing set of the derivation cohort, the AUCs for the prediction of AKI within 24, 48, and 72 h were 0.92 (95% CI, 0.90–0.93), 0.91 (95% CI, 0.90–0.92), and 0.91 (95% CI, 0.90–0.91), respectively. The AUCs for the prediction of severe AKI within 24, 48, and 72 h were 0.95 (95% CI, 0.94–0.97), 0.95 (95% CI, 0.94–0.96), and 0.94 (95% CI, 0.94–0.95), respectively.
Model performance in the validation cohorts
We evaluated the performance of the models by directly transporting the model to validation cohorts and refitting the model to target sites. The discriminative performance of the models for predicting AKI and severe AKI within 24, 48 and 72 h in the validation cohort across 5 independent cohorts is shown in Table 2. The AUCs of the transported model in the internal validation (Site 1) cohort were greater than those in the external validation cohort for all outcomes. The model achieved an AUC of 0.85 (0.84–0.86) in the internal validation cohort and 0.74–0.81 in the four external cohorts for the prediction of AKI within 48 h. For the prediction of severe AKI within 48 h, the AUC was 0.90 (0.89–0.91) in the internal validation cohort and 0.83–0.89 in the external validation cohort. Significant AUC improvement was observed from refitting the model using data from target sites in both models, achieving AUCs ranging from 0.81 to 0.90 for AKI within 48 h and AUCs ranging from 0.88 to 0.95 for severe AKI within 48 h in the validation cohort. (Fig. 2)

A AUC curves for prediction AKI within 24, 48, and 72 h; B AUC curves for prediction severe AKI within 24, 48, and 72 h; Site 1, Peking University First Hospital; Site 2, Sichuan Provincial People’s Hospital; Site 3, the Second Affiliated Hospital of Harbin Medical University; Site 4, Beijing Miyun District Hospital; Site 5, Taiyuan Central Hospital. Source data are provided as a Source Data file.
The prediction performances for AKI and severe AKI within 24 h were uniformly better, with AUCs ranging from 0.75–0.87 and 0.85–0.91 in the transported models and from 0.82–0.91 and 0.89–0.96 in the refitted models; for prediction within 72 h, the AUCs ranged from 0.72–0.84 and 0.82–0.89 for AKI and severe AKI in the transported models and from 0.79–0.87 and 0.85–0.92 in the refitted models. The models for AKI and severe AKI were well calibrated across the range of all probabilities at all sites (P > 0.05, the Brier scores were all close to zero). (Fig. S3)
Table 3 shows the AUCs of the refitted models for the prediction of AKI and severe AKI within 48 h, stratified by admission Scr, gender, location, and prior operation. Both models performed better in patients with lower admission Scr ( < 88.4 µmol/L), except for Site 3 and Site 1. Gender based analyses showed a slight predictive advantage in female for the prediction of AKI, and a slight predictive advantage in male for severe AKI. Both models showed better predictive discrimination in the general ward than in the ICU in almost all five cohorts, except for Site 2, where the AUCs for the surgical ward was the lowest. Subgroup analysis by prior operation showed that the models performed better in patients who did not undergo surgical operation than in those who had just undergone surgical operation in almost all cohorts.
Clinical interpretation of the prediction models
Chosen for its optimum performance, the final prediction models for AKI and severe AKI both included 20 common clinical features. (Table S3) The SHAP value is used for the interpretation of model output by calculating the contribution of each feature.
At the global level, the SHAP summary plot (Fig. 3) shows the relative effect of each feature on model output in the internal validation set in descending order based on the mean absolute SHAP value, with SHAP values over zero representing an increased risk of AKI and higher SHAP values representing a greater risk of AKI. We found a positive correlation between the top five features and AKI, including the latest changing rate of Scr (mean absolute SHAP value 0.058), use of diuretics (0.026), percentage of lymphocyte (0.021), admission to the ICU (0.019), and the use of human albumin (0.015). The SHAP dependence plots (Fig. 4) show how a single feature affects the output of the model, and the change in the feature’s attributed importance could be visualized as its values varied in the plot. For instance, patients who used diuretics or were admitted to the ICU during hospitalization had SHAP values higher than zero, contributing to a higher predicted risk of AKI, and elevated cardiac troponin, BUN, and procalcitonin also drove the prediction towards the AKI class. The dataset was from timepoints in the predictive data timeframe before AKI identification. The prediction model for severe AKI shared similar top features with the model for AKI. (Figs. S4-S5)

A SHAP summary plot of 20 features included in the prediction model for AKI. SHAP value represents the impact of each feature on model output, with SHAP values over zero representing an increased risk of AKI and higher SHAP value representing higher risk of AKI. Each sample in the internal validation dataset is represented as a dot per feature. Dots are colored according to feature values for each sample and accumulated vertically to depict density. B The mean absolute SHAP value summary plot, representing the average impact of each feature on the prediction of AKI. Scr serum creatinine, ICU intensive care unit; NE, neutrophilic granulocyte; BUN, blood urea nitrogen; SHAP, Shapley Additive exPlanations. Source data are provided as a Source Data file.

The plot shows the relationship between feature values and SHAP values. The y-axis indicates SHAP values of features, corresponding to feature values on the x-axis. The dataset was from timepoints in the predictive data timeframe, which was before the AKI identification for patients with AKI, and before hospital discharge for patients without AKI. Scr serum creatinine, ICU intensive care unit, BUN blood urea nitrogen, NE neutrophilic granulocyte, ALB albumin, RBC red blood cell, PLT platelet, SHAP Shapley Additive exPlanations. Source data are provided as a Source Data file.
At the individual level, when actual values of features were entered for an individual prediction, the force plots (Fig. 5) showed not only the predicted probability of AKI, but also how an individual’s features influence the model outputs, providing a personalized interpretation of the prediction results. Figure 5A shows an example of a positive prediction (the predicted probability of AKI is 67%). Admission to the ICU, a lower percentage of lymphocytes, elevated neutrophilic granulocyte-to-albumin ratio and heart rate are major features contributing to a higher predicted risk of AKI, indicating that severe infection might play a major role in driving the high-risk group. Figure 5B shows an example of a negative prediction (the predicted probability of AKI is 9%). The absence of diuretics, negative latest changing rate of Scr, a normal lowest Scr, and no hospitalization in the ICU are major features contributing to a lower predicted risk of AKI, indicating a stable clinical condition that drives the patient toward the low-risk group. Fig. S6 shows force plots of examples for the prediction of severe AKI.

A Force plot of a patient with AKI, the model generated a predicted AKI probability of 67%. Admission to the ICU, a lower percentage of lymphocytes, elevated neutrophilic granulocyte-to-albumin ratio and heart rate are major features contributing to a higher predicted risk of AKI. B Force plot of a patient without AKI, the model generated a predicted AKI probability of 9%. The absence of diuretics, negative latest changing rate of Scr, a normal lowest Scr, and no hospitalization in the ICU are major features that drive the patient toward a lower predicted risk of AKI. NE neutrophilic granulocyte, ALB albumin, C intensive care unit, Scr serum creatinine. Source data are provided as a Source Data file.
The most important features for the prediction of AKI within 48 h shared by all five validation sites included latest changing rate of Scr, use of diuretics, percentage of lymphocyte, lowest Scr, admission to the ICU, and the use of human albumin. Marginal effect differences in the probability of AKI across sites for these features were analyzed. These features demonstrated similar associations with AKI risk; however, apparent variations existed across the five sites, indicating a source of performance heterogeneity in the validation cohort. (Fig. S7)
Predictive performance of the refitted models in application
With a probability cutoff of 0.45, the refitted model could predict AKI at a median of 72 h in advance, achieving a sensitivity of 89.4%, a specificity of 89.3%, a negative predictive value (NPV) of 99.6% and a positive predictive value (PPV) of 24.1% in the internal validation cohort. When we selected different cutoff values for different cohorts, similar or slightly lower results were observed in the external validation cohorts. With the optimal probability cutoffs chosen to ensure appropriate sensitivity and specificity for each cohort, the model could predict AKI at a median of 54–90 h in advance in external validation cohorts. For severe AKI, the refitted model could predict severe AKI at a median of 114 h in advance with a probability cutoff of 0.4, achieving a sensitivity of 90.9%, a specificity of 93.9%, an NPV of 99.8% and a PPV of 19.5% in internal validation. With the optimal probability cutoffs chosen for each cohort, the model could predict severe AKI at a median of 78-108 h in advance in external validation cohorts. Tables 4–5 demonstrate the predictive performance of the model for each prediction every 6 h in detecting AKI and severe AKI prior to the event during hospitalization using different probability cutoffs across five cohorts. Tables S4-S5 show the predictive performance for each observation in detecting the outcome within 48 h at different probability cutoffs.
Further improvement of model performance at a specific site
Considering the less satisfying performance of the model at Site 3 (the hospital in Northeast China) where the ICU admission rate, preexisting CKD rate, and AKI incidence were the highest among the 6 study sites with the earliest AKI development time postadmission, we re-refitted the model using an extra small proportion of data from Site 3 to improve the model performance for this site. As the model performed less satisfactorily in the subgroup of patients with admission Scr lower than 88.4 µmol/L, we re-refitted the model using an additional 2000 samples from the above subgroup. The AUCs of the re-refitted models improved from 0.81(0.80–0.81) to 0.89(0.89–0.89) for predicting AKI within 48 h and from 0.88(0.87–0.88) to 0.90(0.89–0.90) for predicting severe AKI. With a probability cutoff of 0.45, a significant improvement in specificity (from 66.4% to 82.6%), sensitivity (from 78.7 to 80.8%), PPV (from 19.1% to 31.9%), and NPV (from 96.9% to 97.7%) was achieved in the re-refitted model for detecting AKI prior to the event during hospitalization compared to the refitted models at Site 3. Similar results were observed for severe AKI. Table S6 shows a comparison of the performances of the re-refitted models and the refitted models for detecting AKI and severe AKI at the same probability cutoffs at Site 3. Re-refitting the model to a specific site further improved the model performances at the site.
Discussion
In the present multicenter study, we developed a simple, real-time, interpretable AKI prediction model that could accurately predict the development of AKI among general hospitalized patients nearly 72 h in advance. The model demonstrated consistent, high levels of predictive discrimination in validation across five independent, geographically distinct, different tiered hospitals, especially for severe AKI (the AUCs for AKI and severe AKI within 48 h were 0.74–0.85 and 0.83–0.90 for the transported models and 0.81–0.90 and 0.88–0.95 for the refitted models, respectively). The final model consisted of 20 readily available variables, making it easier to be implemented in the EHR system and allowing it to be widely promoted across different tiered hospitals. This advanced, interpretable prediction could not only help nonspecialized clinicians recognize high-risk patients early but also provide personalized interpretations on major risk factors, providing both a crucial window for early intervention and insight into decision making.
The performance of the prediction model can vary as a result of changes in patient population, outcome rates, and clinical practice23,24,26. The current study is a multicenter study of AKI prediction models targeting general hospitalized patients from developing countries. We developed and validated the model using data from five geographically distinct hospitals traversing different latitudes, provinces, and regions with various levels of gross domestic product across China, covering a diverse inpatient population from different tiered hospitals, with varied AKI incidences, severity, and distribution across clinical units. Thus, the patient population in our study is highly representative. The source cohort in our study included not only severe, complicated patients at high risk of AKI, similar to previous studies in large academic hospitals in the United States and United Kingdom, but also, a substantial proportion of milder patients commonly seen in local hospitals at lower risk of AKI, possibly echoing conditions associated with differences in hierarchical medical systems between different countries17,18,19,20,21. In the hospitals included in our study, the incidence of AKI ranged from 3.6% to 9.1%, which is close to the reported median incidence in China (2.03%) and other developing countries4,5,6,7,27. Apart from common characteristics in the distribution and etiologies of AKI, clinical practice for hospitalized patients in developing countries also shares similar patterns, such as a lower proportion of ICU admissions, a booming increase in invasive procedures but relatively weak awareness of kidney protection, and less strictly regulated nonprescription medicine and traditional herbals6,27,28,29. Moreover, the variables included in our model were restricted to basic laboratory parameters and vital signs frequently checked in daily clinical practice, as well as drugs common in most hospitals, minimizing the effects of nonavailability for tests that are considered routine only in large academic hospitals on model performance and ensuring the generalizability of the model across different hospitals. Hence, our prediction model may be more generalizable to patients from most hospitals in developing countries. Broad application of this model across different tiered hospitals and various regions would be a cost-effective way to reduce the burden of AKI.
The stable discriminative performance of our model across all validation cohorts might be attributed to the meticulous and ingenious workflow of our study, including feature engineering, data alignment, model training, and feature selection30,31,32. In feature engineering, a comprehensive description of clinical profiles is achieved by integrating baseline features, the most recent features, and corresponding trends, covering both the baseline and real-time changes in the clinical condition of the patient and laying the groundwork for the development of an accurate model. Then, the combined application of feature integration and a discrete-time survival framework solves the issue of data misalignment, improving the stability and availability of the model21. Through experimental evaluation of different combinations of feature selection methods and models, we chose the combination of the LightGBM feature selection method and the RF model, which outperformed other combinations in the validation cohort. In addition, by comparing the change in the AUC with a reduced number of features, we achieved satisfactory model performance using a minimal number of features, making it easier for the model to be implemented in the EHR system and widely promoted across different hospitals. Finally, SHAP values were used for the interpretation of prediction results, so the model could not only help to identify high-risk patients, but also provide personalized interpretation of major risk factors that contribute to positive prediction, providing clinicians with crucial clues for clinical decision making.
The features that are employed in the model include vital signs (heart rate and respiratory rate), baseline laboratory parameters (red blood cell count), trending parameters (lowest D-dimer, highest neutrophil percentage, trending features of Scr and BUN), latest laboratory parameters (such as cardiac troponin I, procalcitonin, lymphocyte percentage, lactate dehydrogenase, BUN, Scr, and C reactive protein), and medical behaviors (use of diuretics and albumin, admission to ICU, cardiovascular surgery). The combination of these features may help discriminate disease conditions that are prone to AKI. For instance, an elevated heart rate and respiratory rate, in conjunction with a high level of cardiac troponin I, may indicate the presence of hemodynamic instability. While elevated procalcitonin, white blood cell count, percentage of neutrophils, and C reactive protein could be indicative of an infectious process. It is interesting to note that baseline red blood cell count is the only baseline laboratory parameter included in the model. Both excessively low and high baseline red blood cell counts are associated with an increased risk of AKI, which may suggest a significance of anemia or volume depletion in the development of AKI. Use of diuretics and albumin, as well as admission to ICU, were all among the significantly contributed features to the prediction, which may potentially imply a similarity of medical behaviors in response to critically ill conditions across different hospitals in China; on the other hand, features of clinical practice which are subject to variations across centers should be carefully evaluated for their consistency while developing AKI prediction models in different countries, otherwise the stability and generalizability would be potentially limited.
Major factors influencing the performance of the model in different validation cohorts include heterogeneity in patient characteristics and data warehousing18. In our study, marginal effect analysis showed apparent variations across five sites, indicating that heterogeneity in patient profiles could explain differences in model validation performance. Refitting the model on target sites significantly improved the performance of the model. Incorporating a small number of samples from each site in the training dataset increased the data diversity and complementarity, reduced interference from noise, and relieved model overfitting, leading to improvements in model performance. To improve the performance of the model at Site 3, we re-refitted the model using an extra small proportion of data from the subgroup with less satisfactory performance and achieved significant improvements. Refitting the model on target sites is an efficient way to improve model performance at external sites, and re-refitting the model on a specific site with less satisfactory model performance provides a potential way to quickly generate personalized models at the hospital level for the application of the model across different sites at low cost. Besides, for specific tests like procalcitonin or cardiac troponin I which are usually prescribed among patients at high risk of certain conditions, imputing missing data with normal values has been proved to be an efficient way for application without significant influence on model performances. Moreover, the model could be tailored to specific patient population in different hospitals, such as adding more markers of critical illness if the hospital has a large patient population in ICU, or adding more cardiological biomarkers in the model for a cardiac-based hospital. This hospital “personalized” strategy could facilitate an efficient application of the model in real clinical practice.
Our model could predict the development of AKI with a median lead-time of 72 h in advance, providing a time window for clinicians to minimize further kidney injury with prompt preventive interventions among high-risk patients, such as avoidance of nephrotoxic medications, optimization of hemodynamics and volume status, postponement of elective surgery, and close monitoring of kidney function, which have been proven to improve patient outcomes if applied early10,11,33,34,35,36,37. Previous studies have demonstrated a decrease in the incidence and severity of AKI using a KDIGO care bundle among high-risk patients after both cardiac and major noncardiac surgery33,34,35,36. In a recent multicenter, step-wedge cluster randomized trial, James et al. reported that by providing cardiologists with clinical decision support for AKI prevention in coronary angiography procedures, the incidence of AKI among high-risk patients was significantly reduced37. In addition, the identification of high-risk patients leads to more frequent monitoring of kidney function and more prompt diagnosis of incipient AKI; early treatment may also reverse mild cases and minimize the risk of progression to more severe stages4. In developing countries, due to the broad, scattered distribution of AKI, the more prominent problem of insufficient recognition of high-risk patients, a significantly high proportion of patients with preventable AKI, limited resources for renal consulting due to a shortage of nephrologists, and insufficient health care investment, which hampers the availability of RRT for severe cases, the role of risk prediction in AKI prevention is more important4,5,6,9. Future studies on the effects of our AKI prediction model in real clinical settings are warranted.
Our study has several strengths. First, our prediction model was derived from a cohort with a diverse and representative inpatient population, allowing the model to be more easily applied in different tiered hospitals. Second, our model achieved good predictive performance by including only 20 routinely collected variables and maintained satisfactory performance across five hospitals; in addition, the simple model is easier to be implemented in the EHR system for continuous prediction without causing too much pressure on the system, providing conditions for broader application in clinical practice across different hospitals. Third, the model was developed and validated using data from all departments in hospitals, including internal medicine, surgical departments, and ICUs; therefore, it is generalizable to inpatients from all hospital departments in hospital. Finally, our model is highly interpretable and could provide clinicians with important insights into clinical decision making.
However, we are also aware of some limitations. In line with previous studies16,17,18,21, we defined AKI using the Scr-based criteria of the KDIGO guidelines. Due to the lack of accepted criteria for distinguishing a new episode of AKI following the recovery of a previous one from a deterioration of the initial AKI, we have included only data pertaining to the initial AKI episode during the same hospital admission for model training and validation. Consequently, the predictive performance of the model for recurrent AKI within the same hospitalization remains unknown38. In addition, the identification of AKI could only be performed among patients with at least two documented Scr values, and the exclusion of patients without two Scr measurements may exclude undiagnosed AKI; however, these patients are usually more stable and are less likely by clinical judgment to develop AKI. Thirdly, due to lack of dynamic laboratory parameters for patients who developed AKI within the first 24 h, coupled with a limited sample size of such cases, these patients were excluded from model development process. A refitted model, which incorporates an increased sample size of this patient population, may enhance the predictive performance of the model for the progression to severe AKI in these patients. We also excluded patients undergoing renal transplantation or nephrectomy, because these surgeries may cause variations in Scr levels, which may interfere with the assessment of kidney function, thus, the model could not be applied to these patients. Finally, the low incidence of AKI episodes inevitably results in extremely imbalanced number of positive and negative samples during continuous predictions, which would lead to relatively high false positive rates. The same problem has also been observed in previous researches18,19. Future studies are warranted to develop practical strategies for minimizing false positive alerts, which may include setting different prediction thresholds and making specific alarm rules etc., while implementing the model into the EHR system.
In this study, we developed and validated a simple, interpretable machine learning model for real-time prediction of AKI among general hospitalized patients using routinely collected data from the EHR system. The model has demonstrated good predictive ability for identifying patients at high risk of AKI in a validation cohort across 5 different tiered hospitals. In contrast to previous models, our model is derived from a relatively low-risk inpatient population and is more generalizable to the inpatient population in developing countries, where prediction assistance is most urgently needed. In addition, our simple model could be easily implemented in the EHR system while maintaining good performance across various clinical settings and different hospitals. Broad application of this model in clinical practice might be an effective, convenient, and cost-effective approach for AKI prevention across a much wider range of medical services and populations.
Methods
This study was conducted and reported following the Transparent Reporting of a Multivariable Prediction Model for Individual Prognosis or Diagnosis (TRIPOD) guidelines for the development and validation of prediction models39. The study was approved by the Research Ethics Committee of Peking University First Hospital (Site 1, approval number 2023[069-001]), Sichuan Provincial People’s Hospital (Site 2, approval number 2023[175]), the Second Affiliated Hospital of Harbin Medical University (Site 3, approval number 2023[069]), Beijing Miyun District Hospital (Site 4, approval number 2023[006-001]), and Taiyuan Central Hospital (Site 5, approval number 2023006). The requirement for patient informed consent was waived due to the retrospective nature of the study, which only involved the collection of existing and de-identified medical data.
Derivation, internal and external validation cohorts
The retrospective cohort of Peking University First Hospital (Site 1, a tertiary academic hospital in North China) which included patients hospitalized from January 1, 2018, to December 31, 2020, was used as the derivation cohort (2018-2019) and internal validation cohort (2020) for the development of predictive models. The external validation cohort included cohorts from four independent hospitals across China, including two tertiary academic hospitals (Sichuan Provincial People’s Hospital, Site 2 in Southwest China, 2020.1.1-2020.12.31; the Second Affiliated Hospital of Harbin Medical University, Site 3 in Northeast China, 2020.1.1-2020.12.31), and two local hospitals (Beijing Miyun District Hospital, Site 4 in North China, 2018.1.1–2020.12.31; and Taiyuan Central Hospital, Site 5 in North China, 2018.1.1–2020.12.31).
Study population
All adult patients (18 years and older) admitted to five hospitals during the study period were enrolled. Patients were excluded if they had less than 2 documented serum creatinine (Scr) measurements during hospitalization, were diagnosed with end-stage renal disease (ESRD), were maintained on dialysis or had an initial Scr greater than or equal to 4.0 mg/dL at admission, developed AKI prior to admission or within 24 h after admission, had a length of stay shorter than 24 h, underwent kidney transplantation or nephrectomy during hospitalization, or had all Scr measurements lower than or equal to 0.6 mg/dL from 90 days prior to admission until discharge. (Fig. 1)
Data collection
Demographics, patient location data (internal medicine department, surgery department, or intensive care unit), comorbidities, vital signs, laboratory parameters, medications, surgical information, records on mechanical ventilation, and transfusion data were accessed through the Medical Information Center of Site 1. Gender was considered in study design, which was determined based on self-reporting in medical records. Data from four external sites were either transferred to Site 1 under a data use agreement and extracted in a similar way or extracted and analyzed locally. Comorbidities and procedures were standardized according to the International Classification of Diseases (ICD) 9th Revision and ICD 10th Revision codes, respectively.
Outcome measures
The primary outcome was the development of AKI within 48 h. Secondary outcomes were the development of AKI within 24 and 72 h and the development of severe AKI (AKI stage 2–3) within 24, 48, and 72 h. AKI was diagnosed and staged according to the Scr-based criteria of the KDIGO clinical practice guidelines25. Baseline Scr was defined as the lowest Scr value during the previous 90 days and was updated on a rolling basis as per the 48-hour and 7-day definitions of AKI25. Scr values within 7 days after renal replacement therapy based on medical charges from EHR system were excluded. If AKI was diagnosed in the same patient during a subsequent hospital admission, it was treated as an isolated AKI event; due to the lack of accepted criteria for distinguishing a new AKI episode from a deterioration of the initial AKI episode, we only included data pertaining to the initial AKI episode during the same hospital admission38.
Statistical analysis
We compared demographic characteristics, laboratory parameters, and outcomes across six cohorts and within each cohort by AKI status. Continuous variables are presented as the mean ± standard deviation or median (interquartile range) and were compared using Student’s t test or the Mann-Whitney U test as appropriate. Categorical variables are presented as n (%) and were compared using the χ2 test.
For model development, the derivation cohort was randomly divided into a training set (80%) and a testing set (20%). A discrete-time survival framework was adopted to align the training dataset, and each admission was represented by a sequence of events updated at six-hour time intervals. (Fig. S8) All events within 24 h (48 h, or 72 h) prior to the occurrence of AKI were labeled positive samples, and all events at non-AKI admission were labeled negative samples. The feature set for each event was composed of baseline variables, the most recent variables, and corresponding trends, including demographics, comorbidities, location, vital signs, laboratory parameters, medications, and interventions. All variables were carried forward through time until an updated measurement for that variable took place, representing data prior to and within the current 6-hour time window and composing the final feature set for the prediction of AKI within the following 24, 48, or 72 h. As illustrated in Fig. S8, predictions are generated every 6 h since admission, corresponding to the blue circles that denote each prediction point, to predict the development of AKI within the following 48 h for each prediction point on a continuous basis. Missing values in a given 6-hour time window were replaced by values from the most recent previous time window. Extreme values and nonphysiological values were changed to missing values. Missing feature values were imputed by the mean (normally distributed data) or median (non-normally distributed data). For laboratory tests that were only prescribed when a certain clinical condition was highly suspected, such as cardiac troponin I and procalcitonin, missing values were imputed as normal values. (Item S1)
In model building, we used a synthetic minority oversampling technique to solve the issue of sample imbalance. Two feature selection methods and four models were compared for the prediction of outcomes; ultimately, the optimal combination of the LightGBM feature selection method and the Random Forest (RF) model was chosen based on its predictive performance in the derivation cohort and all validation cohorts. To enhance the classification ability of our classifier and avoid overfitting, we utilized fivefold cross-validation, which was repeated ten times, and performed hyperparameter tuning using the grid search method. For more details on the model construction, please refer to supplementary material.(Item S2, Fig. S9, Table S7) We measured the contribution of each feature to the model output using Shapley Additive exPlanations (SHAP) values40,41. The SHAP values offered both global and individual interpretations for the model, with global interpretation showing the positive or negative impact of each feature on AKI risk and individual interpretation demonstrating patient-level variations in feature contribution. We also used SHAP values to compare the marginal effects of the top shared important variables across different sites, with 95% bootstrapped confidence intervals (CIs) of SHAP values for each feature being estimated using 100 bootstrapped samples18.
The performances of the models were evaluated both by direct transportation of the model to the validation cohorts (Transported model) and by refitting the model using a small proportion of the data from the validation sites (Refitted model). Data for 2500 samples from each validation site were extracted randomly and incorporated into the training dataset for the development of refitted models. The refitted models were then validated with the remaining validation dataset. (Item S3, Fig. S10) The discriminative effect of the predictive models was assessed using concordance statistics, namely, the area under the receiver operating characteristic curve (AUC), with 95% confidence intervals calculated using the bootstrap method to evaluate the uncertainty of model performance, which was done by sampling the validation dataset with replacement for 1000 times. Subgroup analyses were performed by admission Scr, gender, location, and prior operation, with AUCs compared using the Mann-Whitney U test. Predictive parameters at each probability cutoff were calculated using the maximum score prior to the outcome or discharge during admission. Calibration plots were constructed using isotonic regression42, where perfectly calibrated predictions overlap the 45-degree line. The calibration accuracy was evaluated using the Hosmer-Lemeshow (HL) test and the Brier score43,44,45.
The level of significance for all the statistical analyses was set at P < 0.05, and all the tests were 2-tailed. All analyses were performed using Python version 3.9.12 and SPSS version 24. Figures were generated by Python version 3.9.12 and R version 4.3.2.
Reporting summary
Further information on research design is available in the Nature Portfolio Reporting Summary linked to this article.
Data availability
Currently, the de-identified clinical data used in this study are only available to researchers who are willing to sign a data use agreement upon requests to Data Management Committee via email address kdcp_data@163.com for reproducibility of the current study or other non-commercial scientific purposes. A research plan for data use is needed in the email, and a response is anticipated within one month from the date of inquiry. Due to data privacy policies, utilization of the data is required within the confines of hospital intranet environment through an approved Virtual Private Network account. Data should also be used in accordance with regulations from Chinese Office of Human Genetics. The duration of data availability is three months once access has been granted. The source data for all figures generated in this study are provided in Source data files. Demo data are provided for reproducibility of code available on Code Ocean (DOI: 10.24433/CO.9261428.v1). Source data are provided with this paper.
Code availability
We developed Java program to extract data from Oracle database (12c) 12.1.0.2.0 where dataset is stored. The data analysis was coded by scikit-learn 1.3.0 and Python 3.9.12., whose code is available on Code Ocean (https://doi.org/10.24433/CO.9261428.v1).
References
Lameire, N. H. et al. Acute kidney injury: an increasing global concern. Lancet (Lond., Engl.) 382, 170–179 (2013).
Griffin, B. R., Liu, K. D. & Teixeira, J. P. Critical care nephrology: core curriculum 2020. Am. J. Kidney Dis.: Off. J. Natl Kidney Found. 75, 435–452 (2020).
Pickkers, P. et al. Acute kidney injury in the critically ill: an updated review on pathophysiology and management. Intensive care Med. 47, 835–850 (2021).
Mehta, R. L. et al. International Society of Nephrology’s 0by25 initiative for acute kidney injury (zero preventable deaths by 2025): a human rights case for nephrology. Lancet (Lond., Engl.) 385, 2616–2643 (2015).
Lewington, A. J., Cerdá, J. & Mehta, R. L. Raising awareness of acute kidney injury: a global perspective of a silent killer. Kidney Int. 84, 457–467 (2013).
Yang, L. et al. Acute kidney injury in China: a cross-sectional survey. Lancet (Lond., Engl.) 386, 1465–1471 (2015).
Susantitaphong, P. et al. World incidence of AKI: a meta-analysis. Clin. J. Am. Soc. Nephrology: CJASN 8, 1482–1493 (2013).
Zeng, X., McMahon, G. M., Brunelli, S. M., Bates, D. W. & Waikar, S. S. Incidence, outcomes, and comparisons across definitions of AKI in hospitalized individuals. Clin. J. Am. Soc. Nephrology: CJASN 9, 12–20 (2014).
Hoste, E. A. J. et al. Global epidemiology and outcomes of acute kidney injury. Nat. Rev. Nephrol. 14, 607–625 (2018).
Sutherland, S. M. et al. Utilizing electronic health records to predict acute kidney injury risk and outcomes: workgroup statements from the 15(th) ADQI Consensus Conference. Can. J. Kidney Health Dis. 3, 11 (2016).
Palevsky, P. M. et al. KDOQI US commentary on the 2012 KDIGO clinical practice guideline for acute kidney injury. Am. J. Kidney Dis.: Off. J. Natl Kidney Found. 61, 649–672 (2013).
Vanmassenhove, J., Kielstein, J., Jörres, A. & Biesen, W. V. Management of patients at risk of acute kidney injury. Lancet (Lond., Engl.) 389, 2139–2151 (2017).
Miotto, R., Wang, F., Wang, S., Jiang, X. & Dudley, J. T. Deep learning for healthcare: review, opportunities and challenges. Brief. Bioinform 19, 1236–1246 (2018).
Sutherland, S. M., Goldstein, S. L. & Bagshaw, S. M. Acute kidney injury and big data. Contributions Nephrol. 193, 55–67 (2018).
Mehran, R. et al. A contemporary simple risk score for prediction of contrast-associated acute kidney injury after percutaneous coronary intervention: derivation and validation from an observational registry. Lancet (Lond., Engl.) 398, 1974–1983 (2021).
Demirjian, S. et al. Predictive accuracy of a perioperative laboratory test-based prediction model for moderate to severe acute kidney injury after cardiac surgery. Jama 327, 956–964 (2022).
Tomašev, N. et al. A clinically applicable approach to continuous prediction of future acute kidney injury. Nature 572, 116–119 (2019).
Song, X. et al. Cross-site transportability of an explainable artificial intelligence model for acute kidney injury prediction. Nat. Commun. 11, 5668 (2020).
Churpek, M. M. et al. Internal and external validation of a machine learning risk score for acute kidney injury. JAMA Netw. Open 3, e2012892 (2020).
Simonov, M. et al. A simple real-time model for predicting acute kidney injury in hospitalized patients in the US: A descriptive modeling study. PLoS Med. 16, e1002861 (2019).
Koyner, J. L., Carey, K. A., Edelson, D. P. & Churpek, M. M. The development of a machine learning inpatient acute kidney injury prediction model. Crit. care Med. 46, 1070–1077 (2018).
Feng, Y. et al. Characterization of risk prediction models for acute kidney injury: a systematic review and meta-analysis. JAMA Netw. Open 6, e2313359 (2023).
Kashani, K. B. et al. Digital health and acute kidney injury: consensus report of the 27th Acute Disease Quality Initiative workgroup. Nat. Rev. Nephrol. 19, 807–818 (2023).
Davis, S. E., Lasko, T. A., Chen, G., Siew, E. D. & Matheny, M. E. Calibration drift in regression and machine learning models for acute kidney injury. J. Am. Med. Inform. Assoc.: JAMIA 24, 1052–1061 (2017).
Kidney Disease: Improving Global Outcomes (KDIGO) Acute Kidney Injury Work Group. KDIGO clinical practice guideline for acute kidney injury. Kidney Int Suppl 2, 1-138 (2012).
Arjovsky M. Out of Distribution Generalization in Machine Learning (2021).
Yang, L. Acute Kidney Injury in Asia. Kidney Dis. (Basel) 2, 95–102 (2016).
Lombardi, R., Yu, L., Younes-Ibrahim, M., Schor, N. & Burdmann, E. A. Epidemiology of acute kidney injury in Latin America. Semin. Nephrol. 28, 320–329 (2008).
Singh, T. B. et al. Hospital-acquired acute kidney injury in medical, surgical, and intensive care unit: A comparative study. Indian J. Nephrol. 23, 24–29 (2013).
Yu, X., Ji, Y., Huang, M. & Feng, Z. Machine learning for acute kidney injury: Changing the traditional disease prediction mode. Front. Med. 10, 1050255 (2023).
Tomašev, N. et al. Use of deep learning to develop continuous-risk models for adverse event prediction from electronic health records. Nat. Protoc. 16, 2765–2787 (2021).
Ryan, C. T. et al. Machine learning for dynamic and early prediction of acute kidney injury after cardiac surgery. J. Thorac. Cardiovasc Surg. 166, e551–e564 (2023).
Zarbock, A. et al. Prevention of cardiac surgery-associated acute kidney injury by implementing the kdigo guidelines in high-risk patients identified by biomarkers: the prevaki-multicenter randomized controlled trial. Anesthesia analgesia 133, 292–302 (2021).
Meersch, M. et al. Prevention of cardiac surgery-associated AKI by implementing the KDIGO guidelines in high risk patients identified by biomarkers: the PrevAKI randomized controlled trial. Intensive care Med. 43, 1551–1561 (2017).
von Groote, T. C., Ostermann, M., Forni, L. G., Meersch-Dini, M. & Zarbock, A. The AKI care bundle: all bundle components are created equal-are they? Intensive care Med. 48, 242–245 (2022).
Göcze, I. et al. Biomarker-guided Intervention to Prevent Acute Kidney Injury After Major Surgery: The Prospective Randomized BigpAK Study. Ann. Surg. 267, 1013–1020 (2018).
James, M. T. et al. Effect of clinical decision support with audit and feedback on prevention of acute kidney injury in patients undergoing coronary angiography: a randomized clinical trial. Jama 328, 839–849 (2022).
Chawla, L. S. et al. Acute kidney disease and renal recovery: consensus report of the Acute Disease Quality Initiative (ADQI) 16 Workgroup. Nat. Rev. Nephrol. 13, 241–257 (2017).
Collins, G. S., Reitsma, J. B., Altman, D. G. & Moons, K. G. Transparent reporting of a multivariable prediction model for individual prognosis or diagnosis (TRIPOD): the TRIPOD statement. BMJ (Clin. Res. ed.) 350, g7594 (2015).
Lundberg S., Lee S. I. A Unified Approach to Interpreting Model Predictions. (2017).
Chen, H., Covert, I. C., Lundberg, S. M. & Lee, S.-I. Algorithms to estimate Shapley value feature attributions. Nat. Mach. Intell. 5, 590–601 (2023).
Zadrozny B., Elkan C. Transforming Classifier Scores into Accurate Multiclass Probability Estimates. 694 (2002).
Brier, G. W. Verification of forecasts expressed in terms of probability. Monthly weather Rev. 78, 1–3 (1950).
Steyerberg, E. W. et al. Assessing the performance of prediction models: a framework for traditional and novel measures. Epidemiology 21, 128–138 (2010).
Kramer, A. A. & Zimmerman, J. E. Assessing the calibration of mortality benchmarks in critical care: The Hosmer-Lemeshow test revisited*. Crit. care Med. 35, 2052–2056 (2007).
Acknowledgements
This study was supported by National Key R&D Program of China(2022YFC2502500, 2022YFC2502502, LY), Capital’s Funds for Health Improvement and Research (CFH2022-1-4071, LY), Beijing Young Scientist Program (BJJWZYJH01201910001006, LY), National High Level Hospital Clinical Research Funding (Peking University First Hospital 2022CR83, LY), National Natural Science Foundation of China (No.82130021, LY), Michigan Medicine-PKUHSC Translational and Clinical Research (BMU2022JI002, LY), Project 2021051 Beijing Nova Program, CAMS Innovation Fund for Medical Sciences (2019-I2M-5-046, X-z Z), Peking University Medical School Science and Technology Innovation Sail Program for Youth - Youth Cultivation Fund (BMU2023YFJHPY033, Y-h Z), Research Found of Peking University First Hospital (2022SF27, Y-h Z), and Peking University Medicine Fund for world’s leading discipline or discipline cluster development (BMU2022DJXK004, LY). We also extend our gratitude to the medical information managers at all participating sites for their contributions to the data.
Author information
Authors and Affiliations
Contributions
Research idea and study design: L.Y., J.-c.L.; data acquisition: D.-m.X., Y.-h.Z., L.Y., J.-d.J., L.W., F.-d.Z., G.-p.Z., Z.Y., X.-l.C., Y.-l.S., T.-r.J., Y.-l.F.; data analysis and figure plotting: Y.-h.Z., J.-w.g., R.-g.W., Y.-l.Z.; manuscript drafting: Y.-h.Z.; manuscript revision: L.Y., J.-c.L., D.-m.X., J.X., K.Y., H.L., J.-w.W., X.-z.Z., L.-y.X., Q.-q.Z., P.W.; supervision or mentorship: L.Y. Each author contributed important intellectual content during the drafting or revision of the manuscript and accepts accountability for the overall work by ensuring that questions on the accuracy or integrity of any portion of the work are appropriately investigated and resolved.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Inclusion & ethics statement
The research has included local researchers throughout the research process; The research is locally relevant and has been determined in collaboration with local partners; Roles and responsibilities were agreed amongst collaborators ahead of research; This research has not been restricted or prohibited in the setting of the researchers; The study has been approved by all local ethics review committees; The research was undertaken to higher standards of biorisk-related regulations in the local research setting; The research does not result in any risk to participants; We have taken local research relevant to our study into account in citations.
Peer review
Peer review information
Nature Communications thanks the anonymous reviewer(s) for their contribution to the peer review of this work. A peer review file is available.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Source data
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Zhang, Y., Xu, D., Gao, J. et al. Development and validation of a real-time prediction model for acute kidney injury in hospitalized patients. Nat Commun 16, 68 (2025). https://doi.org/10.1038/s41467-024-55629-5
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41467-024-55629-5
This article is cited by
-
Acute kidney injury: pathogenesis and therapeutic interventions
Molecular Biomedicine (2025)
