
Abstract
Preeclampsia is a major cause of maternal and perinatal mortality with no known cure. Delivery timing is critical to balancing maternal and fetal risks. We develop and externally validate PEDeliveryTime, a class of clinically informative models which resulted from deep-learning models, to predict the time from PE diagnosis to delivery using electronic health records. We build the models on 1533 PE cases from the University of Michigan and validate it on 2172 preeclampsia cases from the University of Florida. PEDeliveryTime full model contains only 12 features yet achieves high c-index of 0.79 and 0.74 on the Michigan and Florida data set respectively. For the early-onset preeclampsia subset, the full model reaches 0.76 and 0.67 on the Michigan and Florida test sets. Collectively, these models perform an early assessment of delivery urgency and might help to better prioritize medical resources.
Similar content being viewed by others
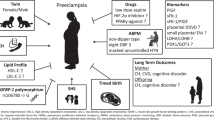

Introduction
Preeclampsia (PE) is a pregnancy complication affecting 2% to 8% of all pregnancies worldwide and is a leading cause of maternal, fetal, and neonatal mortality and morbidity1,2. PE is defined by new-onset hypertension after 20 weeks of gestation and the presence of proteinuria, and/or other signs of end-organ damage. PE is a diverse syndrome with various subtypes along the spectrum of gestational hypertensive disorders3. It can be divided into early-onset PE (diagnosed before 34 + 0 weeks of pregnancy) or late-onset PE (diagnosed after 34 + 0 weeks of pregnancy); PE with severe features (sPE) or PE without severe features4,5. Failure to properly manage PE can lead to a wide variety of severe maternal and neonatal adverse outcomes according to the iHOPE study, while the only known initiation for the potential cure of PE is delivery of the placenta6,7,8. Although earlier delivery can significantly reduce the risk of maternal adverse outcomes, it is associated with increased neonatal unit admission among preterm patients. This, especially in cases of EOPE9, creates a dilemma as earlier delivery can potentially prevent severe morbidities including maternal seizure, stroke, organ dysfunction, and intrauterine fetal demise, but may lead to premature birth and subsequent neonatal complications10,11. To balance the risks to both mother and baby, current clinical management of PE includes supportive blood pressure management and prophylaxis for maternal seizures, and a two-dose intramuscular course of betamethasone to augment fetal lung maturation12.
Generally, delivery is recommended for PE patients with at least 37 + 0 weeks of gestation and for severe PE patients with more than 34 + 0 weeks of gestation12. In reality, the delivery timing is a more complex problem, clinicians need to consider both the fetal development, maternal and fetal risk of complications, and availability of ICU resources when deciding on delivery timing, particularly among challenging EOPE cases12,13. The decision of delivery is usually made after close monitoring and extensive testing on preeclampsia patients over a prolonged time, which may not be easily accessible and affordable to all patients (particularly those in rural areas or under-developed countries). In addition, current risk assessment tools focus on maternal risk prediction but not the overall delivery urgency considering both moms and fetuses. FullPIERS, miniPIERS, PREP-S and recent PIERS-ML are well-established and externally validated models to predict the maternal risk of adverse outcomes among PE patients, in the hope of assisting delivery decisions14,15,16,17,18,19,20. These tools are recommended by some, but not all national guidelines12,13. Most of these tools only predict maternal risks, however, clinicians need to consider both maternal and neonatal outcomes when deciding when to deliver. A patient at 34 weeks of gestation would have very different delivery timing compared to a patient at 37 weeks of gestation, even if they have the same risk of adverse outcomes. It is therefore of great importance to directly and precisely predict the from diagnosis to delivery as early as the first diagnosis of PE, which allows the clinicians to assess the delivery urgency early on and to help them better prioritize resources and treatment, particularly for those doctors practicing in rural areas or under-developed countries. Additionally, the aforementioned risk predictor models do not assess the risk from baseline features, such as the patient’s race, social status, lifestyle, and other comorbidities, which may also have influences on delivery timing.
Toward this goal, we developed and externally validated the deep learning models PEDeliveryTime, to predict patient delivery time after the initial diagnosis of PE using electronic health records (EHR) data. We utilized the state-of-the-art deep learning-based prognosis prediction model, Cox-nnet (version 2), which we previously developed21,22,23. Cox-nnet methods previously consistently showed excellent predictive performances under a variety of data types including EHR data21, in comparison to other survival modeling methods such as Cox-PH, Cox-boost24 and Random Survival Forest25. Our objectives were: (1) to predict the from diagnosis to delivery at the first diagnosis of PE for all PE patients and an EOPE sub-cohort, by constructing and validating deep-learning models utilizing EHR data; and (2) to assess the quantitative contributions of critical EHR features informative of delivery time among PE patients, including those EOPE patients.
Result
Cohort characteristics
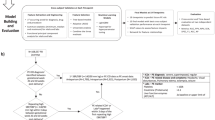
The discovery cohort consisted of 1533 PE cases, including 374 EOPE cases collected from the University of Michigan Precision Health and the UF external test cohort contained 2172 PE cases (including 547 EOPE) collected from the University of Florida Health System between 2015 and 2022. (Fig. 1). We employed their EHR data to predict their diagnosis-to-delivery time from the initial diagnosis of PE. Summaries of the patient characteristics of these cohorts are shown in Tables 1 and 2.

Experiment Design Workflow: The discovery cohort was obtained from the University of Michigan Health System and a validation cohort of similar size and time was obtained from the University of Florida Health System. We constructed 4 predictive models: baseline and full models for all PE patients and baseline and full models for EOPE patients. The input variables in baseline models include patients’ demographics, lifestyle, comorbidities and medical history. The full models include additional laboratory tests and vital signs from within 5 days of PE diagnosis, in addition to the variables in the baseline models. We trained the Cox-nnet prognosis prediction model using 80% training from the discovery cohort, tested it on 20% hold-out data from the discovery cohort, and validated it using the validation cohort. We then built clinically informative models by reducing Cox-nnet features based on both their importance scores and significance levels. The models are examined by the importance scores of top features and stratified survival curves based on patient survival risks. We disseminated the feature-reduced, clinically informative models into a user-friendly web application for healthcare professionals to use. Created in BioRender. Garmire, L. (2025) https://BioRender.com/q52s989.
The baseline prediction model of from diagnosis to delivery interval among PE patients
PE is a syndrome with well-characterized phenotypes, where hypertension is the most significant clinical symptom. Thus the structured data in the EHR system provide the most useful and straightforward information. From the structured data, we obtained 45 variables including patient demographics, medical history, comorbidities, PE diagnosis time, and severity after data preprocessing (Supplementary Table 2). The resulting model has very decent performance with C-indices of 0.73, 0.72, and 0.71 in the UM cross-validation, UM hold-out testing, and UF external testing cohorts, respectively (Fig. 2A).

A The bar plots of C-indices from the original Cox-nnet models (red) and feature-reduced clinically informative model (blue), on the UM cross-validation(5 technical replications, error bars represent median ±SD) and UM hold-out test set and UF test set. B, E The survival curves and 95% CI (mean ±1.96SEM) of high-risk (top 25%), intermediate-risk (middle 50%) and low-risk groups (bottom 25%), categorized by predicted PI from the reduced baseline model in A on (B) hold-out UM test data and (E) UF test data. C, F ROC curves of prediction delivery time within 2 days, 7 days and 14 days using results from reduced baseline model on (C) UM hold-out test data and (F) UF test data. D The ln-transformed permutation importance scores of features in the feature-reduced baseline model. A positive sign indicates that a higher value in feature is associated with a shorter diagnosis-to-delivery time and a negative sign means an extension of diagnosis-to-delivery time. Color represents p-values of two-sided univariate Cox-PH test. G–L The distribution of diagnosis gestational age, sPE rate and PE in prior pregnancy rate, in associations with delivery gestational week (G–I) and time (days) to delivery (J–L), represented by different colors.
To enhance the clinical utilities of the Cox-nnet model, we reduced the number of predictive features following the feature reduction procedure in the Method section. This procedure resulted in 7 significant features, which we used to rebuild the “clinically informative Cox-nnet baseline model”. It has C-index scores of 0.73, 0.74, and 0.73 on UM cross-validation, UM hold-out test, and UF external test dataset respectively (Fig. 2A). We stratified patients into 3 groups by the quartiles of predicted diagnosis-to-delivery time from the reduced model: high-risk (upper quartile), intermediate-risk (interquartile), and low-risk (lower quartile) groups. The survival curves of the diagnosis-to-delivery time on these three risk groups display significant differences (log-rank p-value < 0.0001) on both the hold-out UM test set (Fig. 2B) and UF test set (Fig. 2E), confirming the strong discriminatory power of the PI score. While prognosis modeling fits the time of diagnosis-to-delivery as continuous events, for simplification we also binarily stratified the patients in this model using the threshold of 2/7/14 days. The predicted the accuracies of delivery using these classifications, measured by AUROC scores, are 0.85, 0.88, and 0.89 on the UM test set (Fig. 2C) and 0.67, 0.76, and 0.75 on the UF external test set (Fig. 2F), respectively.
The seven features in the clinically informative baseline model included those that shorten the diagnosis-to-delivery time and extend the diagnosis-to-delivery time (Fig. 2D; Table 3). In descending order of importance scores, the features that shorten the diagnosis-to-delivery time are gestational age at diagnosis, sPE, uncomplicated pregestational diabetes mellitus, and parity. Conversely, features extending the diagnosis-to-delivery time are PE in a prior pregnancy, increasing maternal age, and comorbid valvular disease. To demonstrate the associations of these important features with diagnosis-to-delivery time, we dichotomized patient survival in the hold-out testing set by the median value of each feature (Supplementary fig. 4). All features, except maternal age, show significant differences (log-rank p-value <0.05) between the dichotomized survival groups. We further examined the relationship of the top 3 features (gestational age at diagnosis, sPE, and history of PE in prior pregnancy) with the gestational age at delivery and diagnosis-to-delivery time (day) using the UM discovery set in (Fig. 2G–L). Later gestational age at diagnosis leads to a later gestational age of delivery (Fig. 2G), but a shorter diagnosis-to-delivery time (Fig. 2J). sPE is associated with earlier gestational age of delivery (Fig. 2H) and shorter diagnosis-to-delivery time (Fig. 2K) are diagnosed with sPE. In the deliveries from smaller (< 32 weeks) gestational ages, the percentages of patients with PE in prior pregnancies are significantly higher (Fig. 2I). However, the percentages of prior PE fluctuate with respect to diagnosis-to-delivery time (Fig. 2L).
Worth noticing, that not all patients diagnosed with PE in 37 weeks or later delivered the babies right away, despite being the least severe cases and can be delivered quickly according to the medical recommendation12. Nevertheless, we alternatively built another baseline model with only those patients diagnosed before 37 weeks of gestation. We observed very similar results as the above baseline model using all PE patients, in terms of C-index, the selected top features and their feature scores (Supplementary figs. 5 A–D).
The full model of diagnosis-to-delivery time among PE patients
We next investigated the contribution to time of delivery from all 60 variables, including the 45 baseline variables above and an additional 15 laboratory testing results and vital signs obtained in the 5-day observation window before the time of diagnosis (Supplementary Table 2). The clinical informative model after feature reduction consists of 12 top features (Table 3). This model shows significantly (P < 0.001, t-test) higher cross-validation accuracy of diagnosis-to-delivery time compared to the seven-feature baseline model, with median C-index scores are 0.78, 0.79, and 0.74 in the cross-validation, UM test, and UF test datasets respectively. These C-indices are excellent for survival predictions, despite the high heterogeneity of PE and the large patient size which makes it difficult to predict delivery time precisely18,26. The Kaplan-Meier curves of the high-, intermediate- and low-risk groups show more significant distinction in UM hold-out test (Fig. 3B) and UF test set (Fig. 3E), than the baseline model (Fig. 2B, E). Similarly, we stratified the full model using the threshold of 2/7/14 days and predicted the accuracies of delivery using these classifications. The AUROC scores of these classification tasks are 0.88, 0.93, and 0.93 on the UM test set and 0.84, 0.89, and 0.90 on the UF test set respectively (Fig. 2C, F).

A The bar plots of C-indices from the original models (red) and feature-reduced clinical informative model (blue), on the UM training cross-validation (5 technical replications, error bars represent median ±SD) and UM hold-out test data and UF test set. B, E The survival curves and 95% CI(mean ±1.96SEM) of high-risk (top 25%), intermediate-risk (middle 50%) and low-risk groups (bottom 25%), categorized by predicted PI from the reduced full model in A on (B) UM hold-out test data, (E) UF test set. C, F ROC curves of prediction delivery time within 2 days, 7 days and 14 days using results from reduced full model (A) on (C) hold-out UM test data and (F) UF test data. D The ln-transformed permutation importance scores of features in the feature-reduced baseline model. A positive sign indicates that a higher value in the feature is associated with a shorter diagnosis-to-delivery time and a negative sign means an extension of diagnosis-to-delivery time. Color represents p-values of two-sided univariate Cox-PH test. G–I The distribution of aspartate aminotransferase (AST) values, the standard deviation of diastolic blood pressure (DBP) and the standard deviation of respiratory rate (RR), in association with time (days) to delivery, represented by different colors.
Further examination of the 12 important features in the full model (Fig. 3D, Table 3) shows good consistency with the 7-feature baseline model (Fig. 2D, Table 3). Five out of seven features in the baseline model also exist in the full model with similar importance scores: gestational age at diagnosis, sPE, parity, maternal age, and PE in prior pregnancies. Gestational age at PE diagnosis and sPE continued to be the two most important features in the full model. We also identify new important features from laboratory tests and vital signs: aspartate aminotransferase (AST) value, the standard deviation of diastolic blood pressure (DBP), the standard deviation of respiratory rate (RR), creatinine value, mean DBP and white blood cell count (Fig. 3D). Conversely, platelet count is a new feature with a negative importance score, associated with a longer diagnosis-to-delivery time. All dichotomized survival plots using median stratification on each of the 12 important features have log-rank p-values smaller than 0.05, confirming their associations with diagnosis-to-delivery time in the discovery set (Supplementary fig. 6). We examined the 3 top lab/vital sign features: AST, the standard deviation of DBP, and the standard deviation of RR, on their association with the duration of time between diagnosis and delivery. These values show negative trends with diagnosis-to-delivery time, particularly for AST value and the standard deviation of DBP (Fig. 3G–I). These 3 features are roughly uniformly distributed across delivery gestational ages, except AST which shows slightly higher values in deliveries less than 32 weeks of gestational age (Supplementary fig. 7).
Similar to the baseline model earlier using PE patients diagnosed before 37 weeks of gestation, we again alternatively built another full model with the same patients before 37 weeks of gestation. We observed very similar results as the full model using all PE patients, in terms of C-index, the selected top features and their feature scores (Supplementary figs. 5 E–H).
Prediction of diagnosis-to-delivery time in EOPE patients
Accurate prediction of EOPE patients’ diagnosis-to-delivery time is crucial, given that delivery of a premature infant has more significant neonatal consequences. Using similar modeling techniques, we trained two additional EOPE-specific Cox-nnet v2 models (baseline vs. full model), using the same features described earlier (Supplementary Table 2), on a subset of 374 EOPE patients from the UM discovery cohort.
The C-indices for the clinically informative EOPE baseline model are 0.67, 0.68, and 0.63 on the UM cross-validation, UM hold-out test set, and UF external test sets, respectively (Fig. 4A). Such significantly lower C-indices for EOPE compared to PE are expected, as EOPE cases are usually difficult to predict prognosis. Still, the diagnosis-to-delivery time prediction for EOPE is on par or better than the prediction of PE diagnosis using the same set of EHR data26, demonstrating its potential clinical utility. The KM curves of different predicted survival groups have significant distinctions in both the UM test and UF test datasets (Fig. 4B, E). This baseline model consists of the six most important features: gestational age at diagnosis, sPE, PE in a past pregnancy, parity, pulmonary circulatory disorders, and coagulopathies (Fig. 4D; Table 3). All survival plots, dichotomized using the median stratification on each of the 6 features, have log-rank p-values smaller than 0.05 in the discovery dataset (Supplementary fig. 8). Additionally, the AUROCs of binarized classification on delivery in the next 2/7/14 days range from 0.64–0.82 on the UM test set (Fig. 4C) and 0.62–0.68 on the UF test set (Fig. 4F).

A The bar plots of C-indices from the original Cox-nnet EOPE baseline model (red) and feature-reduced clinically informative model (blue) on the UM cross-validation (5 technical replications, error bars represent median ±SD), UM test set and UF test set. B, C The survival curves and 95% CI(mean ±1.96SEM) of high-risk (top 25%), intermediate-risk (middle 50%) and low-risk groups (bottom 25%), categorized by predicted PI from the reduced EOPE baseline model in (A) on (B) UM hold-out test set, (E) UF test data. C, F ROC curves of prediction delivery time within 2 days, 7 days and 14 days using results from reduced EOPE baseline model (A) on (C) hold-out UM test data and (F) UF test data. D The ln-transformed permutation importance score of features in the EOPE full model. Color represents p-values of two-sided univariate Cox-PH test. G The bar plots of C-indices from the original Cox-nnet EOPE full model (red) and its feature-reduced clinically informative model (blue) on the cross-validation and UM test set(5 technical replications, data are represented as mean ±1.96SEM) and UF test set. H, K The survival curves and 95% CI(mean ±1.96SEM) of high-risk (top 25%), intermediate-risk (middle 50%) and low-risk groups (bottom 25%), categorized by predicted PI from the reduced EOPE full model in (G) on (H) UM hold-out test data, (K) UF test data. I, L ROC curves of prediction delivery time within 2 days, 7 days and 14 days using results from reduced EOPE full model (G) on (I) UM hold-out test data and (L) UF test data. J The ln-transformed permutation importance scores of features in the EOPE full model. Color represents p-values of two-sided univariate Cox-PH test. M–O Analysis of creatinine values among the EOPE patients in the discovery cohort. M The dichotomized survival curves and 95% CI(mean ±1.96SEM) by the median value of creatinine. N, O Distributions of creatinine values by delivery gestational week (N) and diagnosis-to-delivery time (O). P–R Analysis of platelet counts among the EOPE patients in the discovery cohort. P The dichotomized survival curves and 95% CI(mean ±1.96SEM) by the median value of platelet counts. Q, R Distributions of creatinine values by delivery gestational week (Q) and diagnosis-to-delivery time (R).
The clinically informative EOPE full model reached much higher accuracy compared to the EOPE baseline model, with median C-indices of 0.74, 0.76, and 0.67 on the cross-validation, UM test, and UF test sets (Fig. 4G). The large increases in C-indices are the results of including additional laboratory tests and blood pressure measurements right around the time of diagnosis of EOPE, confirming their significant clinical values. The 3 risk-stratified groups within the EOPE patient’s cohort also showed significant (log-rank p-value < 0.001) differences in the hold-out UM test set and UF test set (Fig. 4H, K). The AUROCs of chance of delivery in the next 2/7/14 days are significantly improved, ranging from 0.82-0.86 on the UM test set (Fig. 4I) and 0.71–0.72 on the UF test set (Fig. 4L). This model contains 13 important features selected from the original 60 features (Fig. 4J; Table 3). Gestational age at diagnosis continued to be the most important feature. Several other features (eg. PE with severe symptoms, PE in a past pregnancy, parity, and coagulopathy) were of significant importance as well, similar to the EOPE baseline model. Many additional features in the vital signs and laboratory test categories were also significant, including creatinine value, mean DBP and mean SBP, standard deviation of RR, AST, and platelet counts. Among these 13 features, parity, PE in a prior pregnancy, and higher platelet counts were protective against early delivery (Fig. 4J).
We created dichotomized survival curves based on creatinine value and platelet count, two new features relative to the EOPE baseline model. Both show strong distinctions between the risk groups (Fig. 4I, L), similar to all other selected features (Supplementary figs. 8–9). These two features also revealed systematic trends in associations with the gestational age at delivery and time from diagnosis to delivery. Patients with high creatinine levels were more likely to be delivered within 3 days or less of diagnosis and more likely to deliver preterm (Fig. 4M–O). Lower platelet counts were also associated with shorter diagnosis-to-delivery time (Fig. 4Q), even though the platelet levels were not strongly associated with gestational age at delivery among all EOPE patients (Fig. 4R).
PE diagnosis-to-delivery time predictor graphic user interface (GUI)
To disseminate our model publicly, we packaged the pre-trained clinically informative models above into an interactive, user-friendly web application using R shiny27. We named this app “PE diagnosis-to-delivery time predictor”. The app contains two main panels: the single-patient prediction panel and the group prediction panel (Supplementary fig. 10). The single-patient prediction panel calculates the prognosis index (PI) of a single patient if provided the required clinical variables. The PI score describes the patient’s risk of delivery at the time of the diagnosis of PE, relative to the population. The panel also provides the percentile of the PI score among the training data and displays the results in a histogram figure and a table. The group prediction panel calculates the PI and PI percentile of multiple patients simultaneously and also displays them in a table, below the histogram built on the training data. The app is available at http://garmiregroup.org/PE-delivery-predictor/app.
Comparison with previous maternal risk prediction models
Lastly, the previously established maternal risk prediction models (i.e., fullPIERS) is not designed to effectively predict diagnosis-to-delivery time at the initial diagnosis of PE directly. We calculated the maternal risk of adverse outcomes using the fullPIERS formula on the UM EHR data. We then used this risk score to estimate the diagnosis-to-delivery time and compared its performance with our proposed model (see “Methods”). The cross-validation C-index of fullPIERS is 0.50 ± 0.005 on all PE patients and 0.60 ± 0.01 on the EOPE subset (Supplementary fig. 11A), significantly lower than those from our models. So are the survival curves grouped by predicted risk (Supplementary figs. 11B–C).
Discussion
PE is a highly heterogenous pregnancy syndrome currently without cure except for delivering the baby and placenta3,28. Here we report a new type of survival model to precisely predict the initial diagnosis-to-delivery time, subsequent to our recent success in predicting the onset of PE using the same set of EHR data26. It helps clinicians assess the urgency of delivery early and better prioritize health resources. The simple yet precise models can also be utilized in populations with less access to healthcare. With such information, clinicians may allocate limited resources in busy antepartum and neonatal ICU beds or make decisions about the urgency to transfer a patient to a higher level of care in the lack of sufficient resources. As many pregnant women are willing to accept personal risks to improve perceived fetal outcomes, a more concrete model such as the one proposed here will allow them to understand the likely latency and may help them to prepare for delivery emotionally. Many previous studies, such as the fullPIERS and PREP-S models recommended by NICE guidelines, did not predict the precise time of delivery, instead, they fall into very different classification models14,18,29,30 that aim to predict risks of maternal adverse outcomes (Supplementary Table 5). Assisting in deciding delivery timing is not their primary purpose. If they were to be used to predict the diagnosis-to-delivery time directly, the result would not be satisfactory (Supplementary fig. 11). Additionally, the prediction window of proposed models is longer than 48 hours in the fullPIERS model, making them good initial assessment tools.
The proposed models confirmed key factors already highlighted in current PE management, including gestational age at the time of diagnosis, sPE, and the use of creatinine, platelet counts and AST as risk factors in clinical guidelines (Fig. 5)12,13,14,18. This is not surprising, as less diagnosis-to-delivery time is likely associated with patients at higher risk for complications based on clinical assessments. However, this class of models also assigns weights of relative importance, among these key factors, a capacity nonexistent in the current ACOG guidelines12. Another finding is the identification of parity and PE in prior pregnancies as important predictors for delivery timing in all models tested but not included in current guidelines for PE delivery timing (Fig. 5). Most importantly, the models predict the timing of delivery at the initial diagnosis and require no more than readily available information from blood work, medical history, and demographics that are routinely collected in medical centers in the US.

A The bubble plot of important features from PE baseline, EOPE baseline, PE full, and EOPE full models using reduced top important features. The size of the bubbles represents the permutation importance score of each feature. Color represents the sign of features in the diagnosis-to-delivery time prediction: a positive sign indicates that a higher value in the feature is associated with a shorter diagnosis-to-delivery time and a negative sign means an extension of diagnosis-to-delivery time. B Venn diagram of the important features from the four models shown in (A).
In this study, we reported a clinically applicable survival modeling approach initially guided by a deep-learning method called Cox-nnet. While the patient size is moderate, we demonstrated that Cox-nnet is generously more advantageous over alternative machine learning based methods such as gradient boost and random forest, as well as the baseline method Cox-PH (Supplementary fig. 3). The external validation and cross-validation both showed that Cox-nnet do not overfit, owing to relatively simple architecture compared to other deep neural-net models (single hidden layer design), and techniques such as dropout and L2 regularization in training the models. Additionally, the power analysis of each variable in the selected final models also confirmed the significance of these models (Supplementary Table 3). It is therefore important to note that as long as the model is robust and the final features are carefully selected (in our case, the final features are no more than a handful), deep-learning driven approaches are applicable for survival prediction.
There are several noticeable strengths of this study. The models show consistently high performance in survival prediction and classification tasks (Table 4), better than previous diagnosis-to-delivery time prediction models using clinical data or biomarkers31,32,33. Unlike the majority of previous studies that are not validated with external data29,30,34,35, our models are validated with an external and independent EHR dataset from UF Health System, despite the noticeable differences between the populations in the two cohorts (Tables 1, 2). These models also address clinical interpretability by providing importance scores with directionality for each included predictor. Furthermore, the model is designed for accessibility by utilizing fewer than 15 common demographic and disease histories and routinely collected clinical variables in a short observation window. Our approach is much more convenient, as compared to previous studies relying extensively on additional biomarkers such as uterine artery pulsatility index (UtA-PI) or placental growth factor (PLGF)33,34,35. Particularly, measurement of these biomarkers is not in routine prenatal checkups in under-developed countries, limiting the wide adoption of these biomarker-based models. To maximize the dissemination of the models among clinicians and patients, we have packaged the pre-trained models into a user-friendly shiny application. We aim to embed these models into the EHR system, though it will require additional higher levels of cooperation within the UM Health System. Once integrated, the models will provide clinicians with a fast and accurate assessment of the urgency for delivery at the initial diagnosis of PE.
A few caveats to this study are potentially limiting. Firstly, the ICD coding system lags behind the most recent diagnostic guidelines of PE. However, the codes that are entered into the EHR are based on the clinical assessments of the treating physicians at two academic medical centers, therefore they most likely reflect contemporary diagnostic standards. In addition, as a retrospective study, the delivery timing can be influenced by clinicians’ previous judgment, changes in hospital protocol, communication between patient and provider, intensive care resource availability, and each patient’s intentions and observed a performance drop on the UF external test data compared to the UM test data, particularly on EOPE patient data. However, since these models generally perform well on the external test set as they achieve AUC of 0.7 or even close to 0.80, we believe that these subjective factors may not be the main concerns for achieving high prediction power, rather, additional data modalities may help. Prospective investigations of this model’s performance in other medical centers would be necessary to confirm the findings. It will be important to test prospectively in large-scale multicentre randomized controlled trials, if reduction for close monitoring is possible, by including the tool we present here in decision making. Lastly, our data came from two medical centers with high levels of obstetrics care. Thus, testing the performance and utility of the models in other settings (e.g., other countries and rural regions) where less than complete number of features are likely, will be important.
In summary, we have developed an accurate, deep-learning-based, diagnosis-to-delivery time prediction models, PEDeliveryTime, for PE and EOPE patients. These models are disseminated with an easy-to-use web app. Adoption of PEDeliveryTime models could provide clinicians and patients with valuable management plans to predict and prepare for the best delivery time of each PE pregnancy. Further prospective investigation of the performance of these models is necessary to provide feedback and potential improvement of these models.
Methods
Data source
All data usage was approved by the Institutional Review Board (IRB) of the University of Michigan Medical School (HUM#00168171) and the IRB of the University of Florida (#IRB201601899). We obtained the discovery cohort from the University of Michigan AI and Health Innovation (UM) from the academic healthcare system of the University of Michigan36. We obtained the external test cohort from the Integrated Data Repository database at the University of Florida (UF). The repositories obtained written informed consent from patients to provide their EHR data for research purpose. In both cohorts, we extracted all obstetric records with at least one PE diagnosis between 2015 to 2021 based on ICD-10 diagnosis codes (Supplementary Table 1). We excluded patients with the following conditions: Hemolysis, Elevated Liver Enzymes, and Low Platelet (HELLP) syndrome and eclampsia, for which iatrogenic delivery is ubiquitously induced within 48 hours of diagnosis despite fetal condition; chronic hypertension with superimposed PE, whose onset may occur before week 20 and with no clear definitions in the United States37; and postpartum PE, which is only developed after delivery. To ensure the quality of the input data to build the models and the accuracy of the initial diagnosis time of PE, we did not include patients transferred from other institutions, as these patients have many missed data in the studied healthcare system. The exclusion criteria here concern patients with no visit record within 180 days before the first diagnosis of PE. The resulting discovery cohort consisted of 1,533 PE cases (including 374 EOPE cases) and the UF test cohort contained 2,172 PE cases (including 547 EOPE). All patients are female.
Fully connected Cox-nnet neural network models
We constructed all models using the Cox-nnet v2 algorithm21, originally implemented in the Theano Python library. Alternatively, we also provide a newer implementation of Cox-nnet v2 using Pytorch workflow (https://github.com/lanagarmire/Cox_nnet_PyTorch). In this study, we adopted the model to predict the time between PE diagnosis to delivery. The Coxnnet v2 model includes one input layer, one hidden layer and one Cox regression output layer. The input dimension is equal to the number of input features, the hidden dimension is the nearest integer of the square root of the input dimension, and the output dimension is 1 (Supplementary fig. 1). The model uses the negative log-likelihood function as its loss function and the Adam optimizer with L2 penalty as optimizer. The optimal hyperparameters lambda for L2 penalty was obtained via grid search with ranges from −5 to 1. To ensure the stability of the models, we divided the discovery dataset into a training set (80%) and a hold-out testing set (20%) and applied 5-fold cross-validation on the training set. The model also uses an early-stopping mechanism to avoid overfitting. Other configurations include learning_rate=1e-2, epsilon = 1e-8, max_iter=10000, stop_threshold=0.995, lr_decay = 0.9, lr_growth = 1.0. The detailed model configuration is shown in Supplementary fig. 1.
EHR feature engineering
We extracted all available features from UM Precision Health Initiative EMR data. We developed 4 models to predict the time from diagnosis to delivery of PE patients: PE baseline, PE full, EOPE baseline and EOPE full models. As suggested by clinicians, the initial baseline models include demographics, medical history, comorbidities, the severity of PE, pregnancy and fetal development characteristics. The full model incorporated all features from the baseline model, with additional laboratory results and vital signs commonly collected within 5 days before the initial diagnosis of PE (Supplementary fig. 2A). EOPE models were built and tested using the same features on patients with PE onset time before 34 weeks of gestation. Features with low powers and high correlation were removed to ensure model accuracy.
Pregnancy characteristics included parity, number of fetuses, gestational age, PE severity at initial diagnosis, and history of preterm birth, c-section, abruption, etc. Fetal development includes poor fetal growth according to the associated ICD code (O36.59). Other comorbidities were grouped into 29 categories using the Elixhauser Comorbidity Index38. The observational window for laboratory results and vital signs was 5 days before the day of the initial PE diagnosis. Only the first results of repeated laboratory tests were used to avoid intervention/treatment effects. Summary statistics of systolic blood pressure (SBP), diastolic blood pressure (DBP), and respiratory rate (RR) measures were included (max, min, mean, standard deviation). We removed features with high missing proportions (over 20%) and sparse features with fewer than 10 non-zero values. Highly correlated variables were identified using the variance inflation factor (VIF) and removed one at a time until all features had a VIF below 3 to avoid multicollinearity. The remaining missing values were imputed using the PMM algorithm from R package “mice”. All numerical features were scaled by dividing their root mean square. Numeric features with skewness above 3 were log-transformed. As a result, 60 features were kept for initial analysis (Supplementary Table 2, Supplementary fig. 2B).
Reduced feature representation from the Cox-nnet models
To derive a subset of clinically significant and easily interpretable features, we reduced Cox-nnet features based on both their importance scores and significance levels. To do so, we first selected the top 15 (25% of total features) most important features based on their average permutation importance scores generated by Cox-nnet models. Permutation important scores provide more stable results than other feature selection methods on this dataset, including stepwise selection, lasso regularization, and random forest feature selection39. Then we calculated the log-rank p-value for the 15 features individually and selected the significant ones. We rebuilt the clinically informative Cox-nnet models with the reduced set of features, the same way as the models using all initial input features. We conducted a power analysis of each model using R package “pwr” and analysis of deviance of features in each model (Supplementary Table 3). The power analysis determines statistical power with a given samples size, while the analysis of deviance compares nested models to assess the significance of predictor variables in generalized linear models
Model evaluation
In this survival prediction task, our event of interest is delivery. The prediction target is the time from the initial PE diagnosis to delivery. We evaluated the cross-validation, hold-out test, and external test results of each model using Harrel’s concordance index (C-index). The C-index evaluates the accuracy of predicted events by comparing their relative order to the order of actual events. It is frequently used to assess survival predictions40. The reported C-indices in the training data are the repeated results of the 5-fold cross-validation C-indices on the training sets. We compared Cox-nnet with the random survival forest model and the gradient-boosted survival model in four scenarios of input data, before and after feature reduction. The result shows that Cox-nnet performs better in the majority of cases (Supplementary fig. 3), confirming the right choice of this deep learning model over the two alternative machine learning models.
To enhance the interpretation of the prognosis prediction, we also stratified patients into high, medium, and low-urgency groups based on the predicted results plotted the Kalper-Meier (KM) curves of diagnosis-to-delivery time in each group and reported the log-rank p-values. The log-rank test, on the other hand, compares the survival distribution between patient groups, assuming no differences in survival exist41. Additionally, we used each clinically informative and reduced model result to predict the chances of patients delivering within 2 days, 7 days, and 14 days and obtained the AUROC (area under the receiver operating curve) for each task.
Interactive web application for easy model validation
To disseminate the models for public use, we containerized the pre-trained Cox-nnet model into a Docker-based web application using R shiny27. This allows the users to access the models easily through a local web interface and get prediction results quickly. This app contains two main panels: the individual prediction panel and the group prediction panel. Using pre-trained models, the individual prediction panel calculates the prognosis index (PI) score of a single new patient, marking its positions and percentiles in a distribution plot of PIs within the UM discovery cohort. The group panel takes in a group of new patients and returns predicted PIs and percentiles of their PIs in a table. The shiny app is available at http://garmiregroup.org/PE-delivery-predictor/app.
External validation using UF data
We validated the reduced models on a large external EHR dataset from the University of Florida. We extracted and processed the same features included in the baseline, full, EOPE-baseline and EOPE-full model (see “Methods”). The authors uploaded cleaned UF data to the shiny app described above, and the app automatically produced predicted values using the packaged models trained on UM dataset. The development and validation strictly followed the TRIPOD checklist (Supplementary Table 4).
Estimate diagnosis-to-delivery time using maternal risk of adverse outcomes calculated from the fullPIERS model
The fullPIERS model is a model to predict the maternal risk of adverse outcomes in PE patients, yet it cannot effectively predict diagnosis-to-delivery time. To illustrate this, we calculated the maternal risk of adverse outcomes using the fullPIERS formula as reported by von Dadelszen et al.14, used this risk score to estimate the diagnosis-to-delivery time and compared its performance with our proposed model.
We estimated the probability of adverse outcomes (p) and calculated its concordance index with time from diagnosis to delivery for all PE patients and EOPE subsets, following the original paper. We also plotted the survival curves of high-risk (top 25%), middle-risk (25% - 75%) and low-risk (bottom 25%) groups for all PE and EOPE patients. One limitation is that we do not have chest pain/dyspnoea or SpO2 information collected, so we assume no patients have chest pain or dyspnoea and all patients have 97% SpO2, as instructed by the FullPIERs web calculator https://pre-empt.obgyn.ubc.ca/home-page/past-projects/fullpiers/.
Software
R 4.2.1 and Python were used for all analyses42,43. R package “dplyr”, “mice” were used in data preparation44,45. R package “shiny” and continuumio/anaconda3 Docker image were used to build an interactive web application27. Python version 3.9 and R version 4.2.1 are used to run the models in the Docker containers.
Reporting summary
Further information on research design is available in the Nature Portfolio Reporting Summary linked to this article.
Data availability
The data supporting the findings from this study are available within the manuscript and its supplementary information. We are unable to publicly share electronic health records data due to its potential to reveal sensitive patient information. However, interested investigators who meet the criteria for accessing sensitive data can contact the University of Michigan Precision Health’s Research Scientific Facilitators at PHDataHelp@umich.edu (also see https://research.medicine.umich.edu/our-units/data-office-clinical-translational-research/data-access) to inquire about the UM dataset and the necessary steps regarding ethics committee approval and data sharing agreement. Please contact the UF Health Integrated Data Repository (IDR, https://idr.ufhealth.org/) at IRBDataRequest@ahc.ufl.edu to inquire about the UF dataset and the necessary steps regarding ethics committee approval and data sharing agreement. Source data are provided with this paper.
Code availability
Codes used for analysis are available at https://github.com/lanagarmire/PE_delivery.
References
Ives, C. W., Sinkey, R., Rajapreyar, I., Tita, A. T. N. & Oparil, S. Preeclampsia—pathophysiology and clinical presentations. J. Am. Coll. Cardiol. 76, 1690–1702 (2020).
US Preventive Services Task Force, et al. Screening for preeclampsia: US preventive services task force recommendation statement. JAMA 317, 1661 (2017).
Roberts, J. M., Rich-Edwards, J. W., McElrath, T. F., Garmire, L. & Myatt, L. Subtypes of preeclampsia: recognition and determining clinical usefulness. Hypertension 77, 1430–1441 (2021).
Sibai, B. M. Evaluation and management of severe preeclampsia before 34 weeks’ gestation. Am. J. Obstet. Gynecol. 205, 191–198 (2011).
von Dadelszen, P., Magee, L. A. & Roberts, J. M. Subclassification of Preeclampsia. Hypertension Pregnancy 22, 143–148 (2003).
Phipps, E. A., Thadhani, R., Benzing, T. & Karumanchi, S. A. Pre-eclampsia: pathogenesis, novel diagnostics and therapies. Nat. Rev. Nephrol. 15, 275–289 (2019).
Amaral, L. M., Wallace, K., Owens, M. & LaMarca, B. Pathophysiology and current clinical management of preeclampsia. Curr. Hypertens. Rep. 19, 61 (2017).
Duffy, J. et al. A core outcome set for pre‐eclampsia research: an international consensus development study. BJOG 127, 1516–1526 (2020).
Lisonkova, S. & Joseph, K. S. Incidence of preeclampsia: risk factors and outcomes associated with early- versus late-onset disease. Am. J. Obstet. Gynecol. 209, 544.e1–544.e12 (2013).
Manuck, T. A. et al. Preterm neonatal morbidity and mortality by gestational age: a contemporary cohort. Am. J. Obstet. Gynecol. 215, 103.e1–103.e14 (2016).
Hollegaard, B., Lykke, J. A. & Boomsma, J. J. Time from pre-eclampsia diagnosis to delivery affects future health prospects of children. Evolution, Med., Public Health 2017, 53–66 (2017).
Gestational Hypertension and Preeclampsia: ACOG Practice Bulletin, Number 222. Obstetri. Gynecol. 135, e237–e260 https://doi.org/10.1097/AOG.0000000000003891 (2020).
Visintin, C. et al. Management of hypertensive disorders during pregnancy: summary of NICE guidance. BMJ 341, c2207 (2010).
Von Dadelszen, P. et al. Prediction of adverse maternal outcomes in pre-eclampsia: development and validation of the fullPIERS model. Lancet 377, 219–227 (2011).
Ukah, U. V. et al. Assessment of the fullPIERS risk prediction model in women with early-onset preeclampsia. Hypertension 71, 659–665 (2018).
Ukah, U. V. et al. Temporal and external validation of the fullPIERS model for the prediction of adverse maternal outcomes in women with pre-eclampsia. Pregnancy Hypertension. 15, 42–50 (2019).
Payne, B. A. et al. A Risk Prediction Model for the Assessment and Triage of Women with Hypertensive Disorders of Pregnancy in Low-Resourced Settings: The miniPIERS (Pre-eclampsia Integrated Estimate of RiSk) Multi-country Prospective Cohort Study. Lawn J. E., ed. PLoS Med. 11, e1001589 (2014).
for the PREP Collaborative Network, Thangaratinam, S. et al. Prediction of complications in early-onset pre-eclampsia (PREP): development and external multinational validation of prognostic models. BMC Med. 15, 68 (2017).
Schmidt, L. J. et al. A machine-learning-based algorithm improves prediction of preeclampsia-associated adverse outcomes. Am. J. Obstet. Gynecol. 227, 77.e1–77.e30 (2022).
Montgomery-Csobán, T. et al. Machine learning-enabled maternal risk assessment for women with pre-eclampsia (the PIERS-ML model): a modelling study. Lancet Digital Health 6, e238–e250 (2024).
Wang, D., Jing, Z., He, K., Garmire, L. X. Cox-nnet v2.0: improved neural-network-based survival prediction extended to large-scale EMR data. Schwartz R., ed. Bioinformatics. 37, 2772–2774 (2021).
Ching, T., Zhu X., Garmire L. X. Cox-nnet: An artificial neural network method for prognosis prediction of high-throughput omics data. Markowetz F., ed. PLoS Comput. Biol. 14, e1006076 (2018).
Zhan, Z. et al. Two-stage Cox-nnet: biologically interpretable neural-network model for prognosis prediction and its application in liver cancer survival using histopathology and transcriptomic data. NAR Genomics Bioinforma. 3, lqab015 (2021).
Binder, H. et al. CoxBoost: cox models by likelihood based boosting for a single survival endpoint or competing risks. (2013).
Ishwaran, H., Lu, M. Random Survival Forests. In: Kenett, R. S., Longford, N. T., Piegorsch W. W., Ruggeri F., eds. Wiley StatsRef: Statistics Reference Online. 1st ed. 1–13 (Wiley; 2019).
Ballard, H. K., Yang, X., Mahadevan, A., Lemas, D. J., Garmire, L. X. Building and validating 5-feature models to predict preeclampsia onset time from electronic health record data. https://doi.org/10.1101/2023.03.23.23287655 (2023).
Winston Chang, J. C., Allaire, J. J., Xie, Y., McPherson, J. shiny: Web Application Framework for R. https://CRAN.R-project.org/package=shiny (2020).
Benny, P. A., Alakwaa, F. M., Schlueter, R. J., Lassiter, C. B. & Garmire, L. X. A review of omics approaches to study preeclampsia. Placenta 92, 17–27 (2020).
Li, S. et al. Improving preeclampsia risk prediction by modeling pregnancy trajectories from routinely collected electronic medical record data. npj Digit Med. 5, 68 (2022).
Jhee, J. H. et al. Prediction model development of late-onset preeclampsia using machine learning-based methods. Spradley F. T., ed. PLoS ONE. 14, e0221202 (2019).
Duhig, K. E. et al. Prognostic indicators of severe disease in late preterm pre-eclampsia to guide decision making on timing of delivery: The PEACOCK study. Pregnancy Hypertension. 24, 90–95 (2021).
Reeder, H. T. et al. A novel approach to joint prediction of preeclampsia and delivery timing using semicompeting risks. American J. Obstetr. Gynecol. https://doi.org/10.1016/j.ajog.2022.08.045 (2022).
Lim, S. et al. Biomarkers and the prediction of adverse outcomes in preeclampsia: a systematic review and meta-analysis. Obstet. Gynecol. 137, 72–81 (2021).
Binder, J. et al. The prognostic value of angiogenic markers in twin pregnancies to predict delivery due to maternal complications of preeclampsia. Hypertension 76, 176–183 (2020).
Wright, D., Wright, A. & Nicolaides, K. H. The competing risk approach for prediction of preeclampsia. Am. J. Obstet. Gynecol. 223, 12–23.e7 (2020).
Zawistowski, M. et al. The Michigan genomics initiative: a biobank linking genotypes and electronic clinical records in Michigan medicine patients. Cell Genomics. 3, 100257 (2023).
American College of Obstetricians and Gynecologists' Committee on Practice Bulletins—Obstetrics. ACOG Practice Bulletin No. 203: Chronic Hypertension in Pregnancy. Obstet. Gynecol. 133, e26–e5 (2019).
Elixhauser, A., Steiner, C., Harris, D. R. & Coffey, R. M. Comorbidity measures for use with administrative data. Med Care. 36, 8–27 (1998).
Altmann, A., Toloşi, L., Sander, O. & Lengauer, T. Permutation importance: a corrected feature importance measure. Bioinformatics 26, 1340–1347 (2010).
Harrell, F. E. Evaluating the yield of medical tests. JAMA 247, 2543 (1982).
Peto, R. & Peto, J. Asymptotically efficient rank invariant test procedures. J. R. Stat. Soc. Ser. A (Gen.). 135, 185 (1972).
R Core Team. R: a language and environment for statistical computing. https://www.R-project.org/ (2021).
Rossum, G. van, Drake F. L. Python 3 Reference Manual. (CreateSpace, Scotts Valley, CA, 2009).
Wickham, H., François R., Lionel H., Kirill M. dplyr: a grammar of data manipulation. https://CRAN.R-project.org/package=dplyr (2020).
Buuren, S. van, Groothuis-Oudshoorn K. mice: multivariate imputation by chained equations in R. J. Stat. Soft. 45, 1–67 (2011).
Acknowledgements
The authors acknowledge the Michigan Genomics Initiative participants, AI & Digital Health Innovation at the University of Michigan, and the University of Michigan Medical School Data Office for Clinical and Translational Research for providing data storage, management, processing, and distribution services. We acknowledge the University of Florida Integrated Data Repository (IDR) and the UF Health Office of the Chief Data Officer for providing the analytic data set for this project. LXG was supported by grants R01 LM012373 and LM012907 awarded by NLM, R01 HD084633 awarded by NICHD. DJL was supported by the National Institute of Diabetes and Digestive and Kidney Diseases (K01DK115632) and the University of Florida Clinical and Translational Science Institute (UL1TR001427). XY is supported by NIH/NIGMS Grant T32GM141746. AM is supported by the National Center for Advancing Translational Science (5TL1TR001428).
Author information
Authors and Affiliations
Contributions
L.G. conceived this project and supervised the study, after discussing it with E.S.L. X.Y. conducted data analysis, implemented the Shiny app, and wrote the manuscript. H.K.B., A.D.M., K.X., and D.J.L. collaborated on validation using the U.F. cohort. E.S.L. and A.D.M. provided clinical assessments and assistance. D.G. assisted with Shiny app editing and troubleshooting. All authors have read, revised, and approved the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Peer review
Peer review information
Nature Communications thanks Laila Rasmy, and the other, anonymous, reviewers for their contribution to the peer review of this work. A peer review file is available.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Source data
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Yang, X., Ballard, H.K., Mahadevan, A.D. et al. Predicting interval from diagnosis to delivery in preeclampsia using electronic health records. Nat Commun 16, 3496 (2025). https://doi.org/10.1038/s41467-025-58437-7
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41467-025-58437-7
