
Abstract
GWAS conducted directly on imputed whole genome sequence have led to the identification of numerous genetic variants associated with agronomic traits in cattle. However, such variants are often simply markers in linkage disequilibrium with the actual causal variants, which is a limiting factor for the development of accurate genomic predictions. It is possible to identify causal variants by integrating information on how variants impact gene expression into GWAS output. RNA splicing plays a major role in regulating gene expression. Thus, assessing the effect of variants on RNA splicing may explain their function. Here, we use a high-throughput strategy to functionally analyse putative splice-disrupting variants in the bovine genome. Using GWAS, massively parallel reporter assay and deep learning algorithms designed to predict splice-disrupting variants, we identify 38 splice-disrupting variants associated with complex traits in cattle, three of which could be classified as causal. Our results indicate that splice-disrupting variants are widely found in the quantitative trait loci related to these phenotypes. Using our combined approach, we also assess the validity of splicing predictors originally developed to analyse human variants in the context of the bovine genome.
Similar content being viewed by others

Introduction
For more than a decade, the emergence of high-throughput genomic technologies has led to detailed knowledge about the sequence and variability of the bovine genome. This has resulted in the production of genome-wide association studies (GWAS) conducted directly on imputed whole genome sequence (WGS) data for numerous agronomic traits in cattle1,2. GWAS pinpoint a common variant statistically associated with a trait of interest; however, they provide no evidence about its causality. One corollary of the long-range linkage disequilibrium (LD) that exists in bovine breeds is that GWAS has mainly resulted in the detection of multiple variants in high LD rather than a single, truly causal variant3. Variability in imputation accuracy may also result in a more significant association for a variant in LD with the causal variant rather than the variant itself. This weakness inherent to statistical approaches makes difficult the identification of causal variants in most situations. It represents a major concern in bovine genomics because the integration of causal variants into genomic evaluation models could generate more accurate predictions and sustain these models across generations, especially for distantly related animals4.
A deeper understanding of the genome function has been considered to be relevant to help the identification of the variants underlying the phenotypes of interest in livestock5. In this way, the Functional Annotation of Animal Genomes (FAANG)6 and FarmGTEx7 initiatives are devoted to the production of functional genomic data of domesticated animals. For example, the Cattle Genotype-Tissue Expression (cGTEx) atlas spans over 100 tissues/cell types among over 40 breeds and reports thousands of cis- and trans-genetic variants associated with gene expression and alternative splicing for 24 major tissues in cattle7. The compendium of this type of data is expected to facilitate the identification of functional variants and explain the genotype-to-phenotype link in domesticated animals. For instance, strategies that aimed at integrating such kind of biological data in GWAS were successfully employed to rank the functional importance of genetic variants across the bovine genome8,9. Nevertheless, it is worth noting that making predictions from indicators of functions (e.g. gene expression, chromatin accessibility, sequence conservation) is limited in comparison with accurately assessing the functional impact of variants. A variant located in a functional region of the genome is more likely to have an impact on its function, leading to phenotypic consequences, but this information is not in itself proof of the functional nature of the variant. For example, a variant located in a regulatory region, such as a promoter, will be assigned a higher probability of being causal than variants located outside any functionally annotated regions. However, such a promoter variant may well have no effect on the expression of the gene under the control of this promoter, as illustrated by numerous studies (e.g. rs79134272, rs476518210 and rs1027363911).
Splicing is the process by which introns are removed from the primary messenger RNA (mRNA) transcript, and the exons are joined together to obtain a mature mRNA12,13. Alternative splicing refers to the process where different combinations of exons from the same gene can be joined or skipped, resulting in diverse mRNA transcripts that encode proteins with varied structures and functions. This mechanism allows for greater complexity of the proteome and participates in phenotypic diversity12,14. It also controls mRNA transcript abundance through the non-sense mediated mRNA decay (NMD) and other RNA degradation mechanisms15,16. Therefore, alternative splicing represents a central element in gene expression, and it often occurs in a developmental, tissue-specific or signal transduction-dependent manner16,17. Transcriptomic studies have shown that alternative splicing is prevalent across eukaryotes and, for instance, affects the expression of 90 to 95% of human genes18,19. In addition, genetic mutations are an important driver of altered gene expression and may generate novel splice patterns, thus contributing to the emergence of alternative mRNA transcripts14,20.
Genetic alterations occurring in the DNA sequence of a gene and modifying the normal splice-processing of its precursor RNA are called splice-disrupting variants (SDV). This type of variant results in a modification of the mature RNA sequence by abnormal inclusion or exclusion of exonic or intronic regions from the precursor RNA. SDV have been widely studied for decades and are a major cause of Mendelian disorders21,22. The role of human SDV in the elaboration of complex phenotypes has remained more elusive until recent studies on the impact of RNA splicing on the modulation of phenotypic traits. Li et al. observed that genetic variants that are associated with variation in the splicing ratios of transcripts (sQTL) exhibited effects of similar or even larger magnitude than genetic variants that are associated with variation in the expression level of transcripts (eQTL)23. Recently, Ting et al. observed that eQTL and sQTL each explained a distinct fraction of the heritability of complex traits in humans, of about 10%24. A major effect of RNA splicing in shaping complex traits has also been reported in cattle. Xiang et al. showed that sQTL explained up to 66% of trait heritability, of which nearly 60% were directly related to cis-sQTL25. By contrast, eQTL explained 50% of trait heritability, of which only 30% were directly related to cis-eQTL. sQTL are not exclusively linked to SDV, as variants that alter the transcription rate can also have an effect on splicing mechanisms26. However, all these observations strongly suggest that SDV play an important role in the construction of bovine complex phenotypes. Apart from that, few studies have directly documented the effect of SDV in cattle. To our knowledge, 17 SDV responsible for monogenic diseases27,28,29,30,31,32,33,34,35,36,37,38,39,40,41,42,43 and 7 SDV involved in complex traits44,45,46,47,48,49,50 in cattle have been identified.
Large-scale functional validation of SDV represents a technical challenge that can be addressed since the advent of massively parallel reporter assays (MPRA). These technologies are suitable to discriminate functional variants from non-functional ones. After being initially used to assess cis-regulatory elements51,52,53, MPRA have been successfully used to validate human SDV through different methods54. The MaPSy method was first developed but did not allow the analysis of intronic variants55,56, by contrast with Vex-seq and MFASS methods57,58. Along with experimental assays, splicing prediction programs have been developed and mainly used to guide molecular diagnosis of human diseases59. In recent years, progress realised in the field of artificial intelligence has increased the performances of these tools by means of deep-learning-based methods, as illustrated by SpliceAI and Pangolin60,61. These two programs demonstrated high accuracy and outperformed their predecessors in predicting the spliceogenicity of genetic variants, which is their ability to impact the splicing of the gene in which they are located.
The objective of this study was to analyse a large number of bovine candidate SDV in order to characterise them and understand their impact on complex traits. After performing GWAS on various bovine phenotypes, we used a combination of high-throughput in silico (i.e. SpliceAI and Pangolin) and experimental (i.e. Vex-seq) tools to predict and validate SDV in the bovine genome. Some of them were identified as putative causal variants for these phenotypes. Moreover, we used the experimental data generated with the Vex-seq method to assess the performance of SpliceAI and Pangolin when used with the bovine genome.
Results
GWAS summary
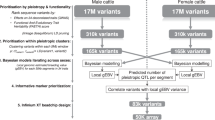
GWAS were conducted on imputed WGS data to investigate 20 traits associated with milk production and composition, fertility, mastitis resistance, growth, as well as live and carcass morphology. The analyses included diverse populations of animals, comprising 2255 to 10,066 bulls, cows or steers from four distinct bovine breeds, one dairy breed (Holstein), one beef breed (Charolaise), and two dual-purpose breeds (Montbéliarde and Normande) (Fig. 1 and Table 1). To account for breed-specific effects, each GWAS analysis was performed separately for 48 breed x trait combinations.

GWAS were performed on multiple agronomic traits in cattle, as described in the main text and Supplementary Data. A dataset (Var.GWAS) containing significant variants from GWAS was built up and functionally analysed to identify causal variants in the first instance. In parallel, an additional dataset (Var.P) containing arbitrarily selected variants with predictive splicing scores was used to increase the number of variants analysed by both in silico and Vex-seq methods in order to improve the performance evaluation of prediction programs.
From a comprehensive set of 25 million biallelic SNP that were tested, after removing variants with the lowest frequencies (MAF <0.005), variants with −log10(p value) >6 were selected as potential causal variants. This selection process led to the identification of 218,723 trait × breed × variant combinations, representing a total of 138,971 unique variants, hereafter named candidate variants, distributed across the entire bovine autosomes (Supplementary Table 1). Notably, chromosome six harboured the largest number of variants (43,613), followed by chromosomes 14 (21,526), 2 (18,712) and 5 (14,241).
Across the Holstein, Montbéliarde, Normande and Charolaise breeds, a total of 10, 15, 15 and 8 different traits were analysed, respectively. The Holstein breed exhibited the highest number of candidate variants (57,551), followed by Charolaise (46,949), Montbéliarde (42,332) and Normande (36,512); these variants were located in 232, 138, 108 and 95 QTL regions, respectively. In the three dairy or dual-purpose breeds (Holstein, Montbéliarde and Normande breeds), the majority of candidate variants were associated with milk protein content (34,140, 25,334 and 19,751, respectively) and milk fat content (20,518, 10,074 and 11,518, respectively), while in the beef Charolaise breed, the largest number of candidate variants was associated with muscularity score measured at month 30 (17,044) (Supplementary Fig. 1).
The analysis revealed several genomic regions exhibiting highly significant effects on various traits and/or breeds. Notably, two regions stand out in particular. The first region, located on chromosome 14, approximately from positions 400,000 to 700,000, exhibits highly significant effects on milk composition and, to a lesser extent, on milk production across all three breeds in which these traits were measured, namely Holstein, Montbéliarde, and Normande. The second notable region, located at ~600,000 on chromosome 2, shows significant associations with live or carcass morphology traits, specifically in the Charolaise and Normande breeds. It is worth noting that numerous other regions of interest were also identified.
Use of SpliceAI and Pangolin in the context of the bovine genome
SpliceAI and Pangolin are deep-learning splicing prediction algorithms developed to analyse human genetic variants. SpliceAI has been constructed using as input only the genomic sequence of human pre-mRNA transcripts60. It provides a score reflecting the probability that a given variant increases or decreases the efficiency of splice sites located in its vicinity. Pangolin was constructed using sequence and RNA splicing measurements from four tissues (i.e. heart, liver, brain and testis) related to four species (i.e. human, rhesus, mouse and rat)61. Like SpliceAI, it provides a probability that a given variant impacts splicing. It has been established that the splicing code is highly conserved between mammals62,63,64 and, thus, between humans and cows. This idea is supported by the similar observed frequency of nucleotides positioned close to the splice sites in both species, as illustrated by a sequence alignment of their splice regions (Supplementary Fig. 2). Thus, an algorithm designed to predict SDV in humans should also work efficiently in cattle.
Nonetheless, before making predictions on bovine candidate SDV using SpliceAI and Pangolin, we assessed the sensitivity of these programs, specifically on cattle, by scanning a positive set of SDV described in vivo and associated with phenotypes. A review of the literature and the OMIA database65 allowed us to collect 24 bovine SDV supported by in vivo evidence, which we analysed with SpliceAI and Pangolin (Fig. 2a, b and Supplementary Data 1). To compare the performances of both programs, high recall (score ≥0.2), recommended (score ≥0.5), and high precision (score ≥0.8) thresholds were used as initially done to characterise SpliceAI60. As Pangolin and SpliceAI scores represent a probability for a variant to be an SDV, selecting a specific score threshold allows us to modulate the sensitivity and specificity of the prediction. SpliceAI scores range from 0 to 1 and are classified into four splicing effect categories depending on their predicted effect on the strength of the indicated splice site, which are (i) acceptor (AL) or (ii) donor loss (DL) and (iii) acceptor (AG) or (iv) donor (DG) gain. Pangolin scores range from −1 to 1 and can be interpreted as a probability to modify splicing where negative scores signify a decrease in the strength of the indicated splice site, and positive scores signify an increase in the strength of the indicated splice site. You will note that to allow comparison between SpliceAI and Pangolin results, Pangolin scores are sometimes noted in absolute values in this manuscript, and SpliceAI scores for the AL and DL classes are sometimes noted in opposite numbers (negative values). This is specified in the figures and their legends.

a A positive set of 24 SDV previously described in vivo and associated with phenotypes was compiled from PubMed and OMIA databases. b SpliceAI and Pangolin scores representing the probability to disrupt splicing were calculated for each variant classified by variant consequence. Variants with a score ≥0.2 (high recall threshold), ≥0.5 (recommended threshold), or ≥0.8 (high precision threshold) were predicted to be SDV as proposed by ref. 60. Variants reported to be associated with a monogenic disease are marked by an asterisk; others are related to complex traits. Note that Pangolin scores are represented in absolute values to allow comparison with SpliceAI scores. Syn synonymous, Mis missense, 3′ss 3′ splice site, 5′ss 5′ splice site, P Int proximal intronic, D Int distal intronic. c Proportion of variants predicted to be spliceogenic or non-spliceogenic classified by variant consequence or d phenotype. Graphs displaying stacked green and purple bars indicate SpliceAI and Pangolin predictions, respectively. The number of variants for each score category is shown on the Y-axis, with the highest categories shown in the darkest colours. Variants with a score equal to or higher than 0.2 are predicted to be SDV. Pangolin scores are represented in absolute values. Source data are provided as a Source Data file.
SpliceAI and Pangolin both returned a positive rate of predicted SDV of 70.8% (17/24) using the high recall threshold. With regard to the consequences of SDV on gene sequence, variants modifying the canonical splice site (CSSV) were predicted to be spliceogenic with 100% accuracy, whereas intronic variants were predicted incorrectly in more than half the cases (Fig. 2c). Taking into consideration the complexity of the affected phenotypes, 88.2% (15/17) of the variants responsible for monogenic diseases are predicted to be spliceogenic whereas only 28.6% (2/7) of variants involved in complex traits are predicted to be spliceogenic (Fig. 2d).
Definition of Var.GWAS and Var.P datasets
Two variant datasets were generated to simultaneously identify causal SDV from bovine GWAS and to accurately assess the performance of the SpliceAI and Pangolin prediction tools for bovine variants (Fig. 1). The Var.GWAS dataset contained all 210 significant GWAS variants fitting the constraints imposed by the design of our Vex-seq assay (Supplementary Fig. 3a). With our settings, technical limitations of the method only allowed the analysis of exons of 98 nt or less in length and their flanking introns, 50 nt upstream and 20 nt downstream. The first and last exons of genes and test sequences containing an MfeI or SpeI restriction site were also excluded. Only significant GWAS variants (−log10(p value) >6) with a variant identifier (rsID) and highest imputation accuracy (r² > 0.4; mean(r²) = 0.827) were used to facilitate tracking variants through assembly, database browsing and ensure accuracy of the analysis. The Var.P dataset has been constructed from a pool of 1000 random bovine variants fitting Vex-seq constraints, subsequently analysed by SpliceAI, and filtered to keep only 146 variants with a balanced distribution of positive and negative splicing prediction scores. This second dataset, intentionally enriched with putative spliceogenic variants, has been created to increase the amount of putative SDV available to calculate SpliceAI and Pangolin performances. The identification of causal variants responsible for phenotype variation was performed solely using the Var.GWAS dataset, whereas both datasets were merged to calculate the performance of prediction tools.
Vex-seq quality control (QC) and reliability
The Vex-seq analysis was performed using HEK293T and MAC-T cells according to previous studies and with minor modifications (Supplementary Fig. 3b, c)57,66. To ensure the production of high-quality data, several sequence quality filters were applied to remove reads that were not exploitable in downstream statistical analyses. The first step of the QC consisted of verification of the integrity of plasmid libraries (Supplementary Fig. 4a, b). Two criteria were selected to validate whether or not to keep a barcode (BC) for further analysis: no mutation in the BC sequence and at least 85% of correct reads from the MiSeq run for the associated test sequence. This resulted in the validation of 94.03% of BC. In a second step, variants associated with BC with too low expression (<10 reads) in the transcripts analysis were eliminated (Supplementary Fig. 4c). Finally, variants with less than 2 validated BCs for one of their alleles, or showing no splicing event neither for the reference (REF) nor for the alternative (ALT) allele were removed. Of the 919 variants analysed simultaneously using the Vex-seq method, approximately 75% of variants were validated in HEK293T or MAC-T cells, with a large overlap between cell lines (Supplementary Fig. 4d, e). However, it should be noted that the percentage of test exons that could be analysed was about 84% in both cell lines. This difference can be explained by the fact that, of the 919 variants initially included in the whole Vex-seq plasmid library, 99 are located in exon 8 of the DGAT1 gene, and the majority of them did not pass the QC because exon 8 was not spliced in most cases. These 99 variants are not related to the Var.GWAS or Var.P datasets (see Materials and methods for details), but their failure to pass QC filters reduces the overall rate of variants validated for the whole Vex-seq analysis. If we focus specifically on datasets presented in this study, 87.1% (183/210) and 82.9% (121/146) of variants were validated for Var.GWAS and Var.P datasets, respectively.
Read counts associated with each BC were used to calculate the percent spliced-in (PSI) index. A high reproducibility between BC replicates was observed within a given cell type (r > 0.96 for both HEK293T and MAC-T cells) which indicates that the BC sequence had little influence on the splicing of the test exon (Supplementary Fig. 5a). A comparison of PSI between biological replicates showed a good correlation considering triplicate within each cell line (r > 0.94 and >0.92 for HEK293T and MAC-T cells, respectively) and also, albeit to a lesser extent, between cell lines (r > 0.86) (Supplementary Fig. 5b).
Finally, we verified that Vex-seq results reflect biological reality using a set of bona fide bovine and human SDV, which were also included in the Vex-seq analysis. SDV reported to be highly spliceogenic in cattle (n = 2) and in humans (n = 5) were tested and yielded similar splicing behaviour in vivo and in the Vex-seq analysis (Supplementary Fig. 6 and Supplementary Data 2). Moreover, 13 SDV exclusively localised in human ABCA4 gene previously analysed by means of midigene assays were also included in the analysis67. These midigenes were splice vectors of varying lengths (up to 11.7 kb) covering almost the entire ABCA4 gene and transfected in HEK293T cells, which allowed investigation of the effect of SDV in a relatively large sequence context. This additional group of variants with various functional impacts enabled the performance of Vex-seq to be calculated (Supplementary Fig. 7 and Supplementary Data 2). The dataset from which these 13 variants were extracted has previously been used as a benchmark to evaluate the performance of splicing prediction programs, which is why we chose to use it68. Vex-seq ∆PSI values were ranging from −9 to −88 and were highly correlated between cell lines (Supplementary Fig. 7a–c). In order to allow comparison between Vex-seq analysis outputs (PSI and ∆PSI) and midigene analysis outputs from the study by Sangermano et al. (% of abnormal ABCA4 transcripts associated with the ALT variant allele)67, we converted PSI values of REF and ALT alleles into a % of abnormal ABCA4 transcripts associated with ALT allele according to the following formula: 100 − ([PSI(ALT)/PSI(REF)])*100. The comparison of this percentage for each variant obtained with Vex-seq against midigene showed both approaches yielded similar outcomes with a Pearson correlation coefficient of 0.7891 and 0.8968 in HEK293T and MAC-T cells, respectively (Supplementary Fig. 7d). Vex-seq sensitivity and specificity were calculated using midigene data as benchmark. Sensitivity was between 95.45 and 100%, and specificity was between 50 and 75% (Supplementary Fig. 7e, f). However, this result should be treated with caution as 13 samples is low to estimate these parameters.
Vex-seq results summary
In eukaryotes, the composition of canonical 3′ splice sites (3′ss) and 5′ splice sites (5′ss) is almost exclusively AG and GT, respectively69,70. Rarely, a GC dinucleotide is observed for the 5′ss69. The consequence is that a nucleotide change in a 3′ss or 5′ss inevitably leads to a loss of function of these splice sites, except in the case of a + 2 T > C transition where the function of the 5′ss may be preserved71. Considering the Var.GWAS and Var.P datasets together, there were 27 CSSV presenting a REF allele average PSI of around 55% in both cell lines. Introducing the ALT allele within the sequence led to a dramatic decrease of average PSI with the exception of rs448758869, which was a + 2 T > C transition (Fig. 3a). PSI and ∆PSI were then calculated for the entire Var.GWAS and Var.P datasets which revealed that average PSI values were globally slightly lower in MAC-T cells compared to HEK293T cells (Fig. 3b). Also, average PSI values for the ALT allele were approximately two-thirds of those for the REF allele in the Var.P dataset, whereas no obvious difference was observed on this point in the Var.GWAS dataset. This resulted in an average |∆PSI| of around 25% for Var.P, whereas only several extreme values with a |∆PSI| above 10% were observed in the Var.GWAS dataset (Fig. 3c).

a Average PSI for reference and alternative alleles of the 27 CSSV that are part of the Var.GWAS and Var.P datasets. Of note, one CSSV (rs448758869) resulting in a GT > GC transition still allowed the test exon to be included efficiently (arrow). Box plots are defined as follow; cross, mean; centre line, median; box limits, upper and lower quartiles; top and bottom whisker lines, maximum and minimum values; points, outliers. b Average PSI for reference and alternative alleles of variants from whole Var.GWAS and Var.P datasets. Box plots are defined as in (a). c Average │∆PSI│ variant by dataset. Box plots are defined as in (a). d Proportion of tested variants confirmed to be SDV determined for each dataset. Variants with ∆PSI above 5% or below 5% were considered to be SDV. FDR false discovery rate used to identify SDV. H HEK293T, M MAC-T. e Overlap of SDV from merged Var.GWAS and Var.P datasets between HEK293T and MAC-T cell lines. Scatter plot of f PSI and g ∆PSI values from merged Var.GWAS and Var.P datasets in HEK293T versus MAC-T cells. r Pearson correlation coefficient. Source data are provided as a Source Data file.
To statistically sort spliceogenic variants from non-spliceogenic ones in each dataset, we defined a threshold of ±5% for the ∆PSI, associated with a false discovery rate (FDR) of less than 0.05 or 0.01, to test different stringencies (Fig. 3d). Using an FDR <0.01, 12.9% (23/178) and 16.2% (29/179) of variants from Var.GWAS were classified as SDV in HEK293T and MAC-T cells, respectively, and 42% (50/119) and 41.2% (49/119) of variants from Var.P were classified as SDV in HEK293T and MAC-T cells, respectively. Increasing the FDR threshold to 0.05 slightly increased these proportions (Fig. 3d, right). A predominance of SDV decreasing rather than increasing test exon inclusion was observed, especially in the Var.P dataset. The majority of SDV was identified in both cell lines (Fig. 3e). Finally, a strong correlation was observed between the two cell lines for PSI and ∆PSI, with Pearson correlation coefficients of 0.9574 and 0.9476, respectively (Fig. 3f, g). All the information about variants of the Var.GWAS and Var.P datasets are available in Supplementary Data 3, 4.
Performance evaluation of bioinformatic programs
Prediction scores related to variants from Var.GWAS were generated using SpliceAI and Pangolin, as previously done for variants constituting Var.P (Fig. 4a). Only 2.2% (4/183) and 1.64% (3/183) of variants from Var.GWAS were predicted to be spliceogenic by SpliceAI and Pangolin using the high recall threshold of 0.2, respectively. The results obtained on the two datasets showed a high correlation between the predictions of the two programs (r = 0.8982) (Fig. 4b). On the other hand, ∆PSI values and prediction scores were weakly correlated with a little higher r for Pangolin (Fig. 4c). Also, several positive prediction scores were found for variants which yielded negative ∆PSI values of variants. In fact, the creation of a cryptic splicing site is predicted as a splicing gain by SpliceAI and Pangolin, which is logical, but the consequence from a functional point of view is the non-use of the canonical splicing site, which results in the exclusion of the test exon and therefore a reduction of the ∆PSI. SDV identified in Var.GWAS and Var.P datasets using Vex-seq analysis were used to calculate the true positive (TP) rate, and non-SDV to calculate the true negative (TN) rate of SpliceAI and Pangolin by score range using the threshold 0.2. Pangolin showed a better TP rate than SpliceAI in each score range. Also, the FDR <0.01 condition yielded more reproducible results between cell lines (Fig. 4d). Then, ROC curves were generated for each programme, and AUC was calculated. This revealed that Pangolin (average AUC = 0.831) slightly outperformed SpliceAI (average AUC = 0.775) (Fig. 4e).

a Distribution of spliceAI and Pangolin absolute scores in Var.GWAS and Var.P datasets. b Scatter plot of SpliceAI versus Pangolin scores. SpliceAI scores related to donor or acceptor loss have been turned into opposite numbers to allow comparison with Pangolin scores. r Pearson correlation coefficient. c Scatter plot of SpliceAI and Pangolin scores each versus ∆PSI values in both HEK293T or MAC-T cell lines. d True positive and true negative rates of SpliceAI and Pangolin obtained and classified by absolute score category. SDV identified using Vex-seq were used to calculate the true positive rate, and non-SDV to calculate the true negative rate. TP true positive, TN true negative, SpAI SpliceAI, Pan Pangolin. e Receiving operating curve (ROC) and area under the curve (AUC) were calculated for SpliceAI and Pangolin in each cell line and for the mean values between the two cell lines. Source data are provided as a Source Data file.
Using SpliceAI and Pangolin low thresholds to filter SDV involved in complex traits
Interpretation of SDV effects using splice predictors requires the choice of a pre-determined score threshold beyond which variants are considered spliceogenic. A score threshold of 0.2 has been proposed by the authors of SpliceAI and Pangolin to make permissive predictions60,61. In the context of searching for causal variants identified in bovine GWAS, and depending on the strategy chosen, it may be useful to lower the threshold of SpliceAI and Pangolin to increase the number of positive hits and, thus, the number of candidate variants to be investigated in downstream validation experiments. In this case, the optimal threshold is usually lower than those recommended by authors and may depend on the composition of the variant dataset to be analysed54. We calculated TP and FP rates in the Var.GWAS dataset for thresholds below 0.2 (Fig. 5a). For example, lowering the threshold to 0.1 retrieves 11 variants predicted to be spliceogenic, including 6 false positives according to Vex-seq data performed on HEK293T cells. Although this increases the total number of variants to be functionally assessed (11 instead of 3 when the threshold used is 0.2), it will lead to the identification of 2 additional SDV. Here too, Pangolin performed better than SpliceAI by using thresholds below 0.2 (Fig. 5b).

a True positive and true negative rates, in addition to b sensitivity, specificity and accuracy of SpliceAI and Pangolin, are shown for thresholds below 0.2. Note that Pangolin scores are represented in absolute values to allow comparison with SpliceAI scores. Source data are provided as a Source Data file.
Phylogenetic conservation, sequence features and genetic data associated with spliceogenicity
Phylogenetic conservation of nucleotides affected by variants from Var.GWAS and Var.P datasets were assessed using the GERP score72. Scatter plots between ∆PSI values and GERP scores showed significant enrichment of variants affecting phylogenetically conserved nucleotides within the group of variants decreasing splicing rate (Fig. 6a, c). This was statistically confirmed by an enrichment test which exhibited a ~1.8-fold increase (two-tailed Fisher’s exact test; p value <0.0001) of conserved variants in the “Loss” category compared to 'Neutral', observed in both cell lines (Fig. 6b, d). This trend was also observed between splicing prediction scores and GERP scores (Fig. 6e, g) with an enrichment of 2.49- (p value <0.0001) and 2.26-fold (p value <0.0001) for SpliceAI and Pangolin, respectively (Fig. 6f, h). The variant consequences were characterised using Variant Effect Predictor (VEP)73 on canonical and alternative transcripts73. A small fraction of variants impacting canonical splice donor sites were not predicted as SDV by Pangolin because it ran only on canonical transcripts (Fig. 6i–l). Also, some SDV that impact splice donor sites were not validated as spliceogenic by Vex-seq. This is because their PSI is less than 5% for the REF allele, and therefore, the ∆PSI cannot reach the 5% threshold needed to classify the variant as an SDV, even in the case where the ALT allele completely disrupts splicing. Next, we found that GWAS variants associated with the most severe splicing alterations also seemed to be those with the lowest frequency for the ALT allele, both in terms of ∆PSI or predictive scores (Fig. 7a, b). In addition, among the 182 QTL related to the phenotypes studied here, 22 (11.2%) contained at least one SDV (noted QTL+) (Fig. 7c). This is an underestimation of the total number of SDV lying in QTL mainly because only a relatively small fraction of the candidate SDV could be analysed using Vex-seq due to methodological constraints. The Vex-seq regions (n = 54,149) represent 22.5% of all exonic regions in the bovine genome, and only 183/210 GWAS variants detected in these regions have been analysed after applying the Vex-seq QC filters. This indicates that the actual proportion of QTL+ among QTL identified in this study can be estimated to be 5.04 times greater. This means that QTL+ corresponds to 57% of all QTL (11.2 × (100/22.5) × (210/183)) (Fig. 7d). It should be noted that this number is purely indicative and that the actual proportion of QTL+ may be slightly different. In fact, the spliceogenic properties of exons may vary according to their length and position, and the causal variants are not distributed in a strictly equal manner in the QTL.

Scatter plots of GERP conservation scores versus ∆PSI values in a HEK293T and c MAC-T cells or versus prediction scores of e SpliceAI and g Pangolin. The highest GERP scores represent the highest phylogenetic conservation72,125. Enrichment in GERP-positive variants within spliceogenic or non-spliceogenic variants as determined by Vex-seq in b HEK293T and d MAC-T cells and as predicted by f SpliceAI and h Pangolin. Statistical enrichment within the 'Loss' and 'Gain' categories compared to 'Neutral' was assessed using a two-tailed Fisher’s exact test. The sample size in each category (n), the fold change and the p value (in brackets) are indicated. Bars indicate the percentage of GERP-positive variants for the three different categories of splicing effect (SE). Thresholds used to define categories are ±5% for ∆PSI values (FDR <0.01) and ±0.2 for prediction scores. Proportion of SDV in each variant consequence category as determined by Vex-seq in i HEK293T and j MAC-T cells or as predicted by k SpliceAI and l Pangolin. Source data are provided as a Source Data file.

Scatter plots of a │∆PSI│ values or b prediction scores versus ALT allele frequency. Note that Pangolin scores are represented in absolute values to allow comparison with SpliceAI scores. c Proportion of QTL containing at least one SDV identified in Vex-seq (QTL + ). The number of QTL+ containing more than 1 SDV is detailed on the right. d Based on experimental observations restricted to Vex-seq regions, an estimate of the proportion of QTL+ regions was made for the whole genome (see main text for details). Source data are provided as a Source Data file.
Identification of causal SDV
The 38 SDV identified in the Var.GWAS dataset (Table 2 and associated traits in Supplementary Data 5) were assessed for their consequence on the transcript primary sequence (Fig. 8a). This information was used to predict the deleterious effect expected at the protein level, allowing in fine to functionally classify each of the two alleles for each variant. Three lines of evidence were thus used to filter and validate causal variants (summarised in Fig. 8b): (i) a statistical association between the variant and the phenotype; (ii) a predicted functional impact of the variant on the gene function (i.e. a gain or a loss of protein expression/function resulting from the splicing disruption); and (iii) a functional link between the gene and the considered phenotype. The last point can be documented by direct experimental demonstration using rare natural variants with large effect sizes identified in cattle45, or indirectly inferred by connecting multiple scientific evidences together to reconstitute the biological process involved in the gene-phenotype relationship. Based on these criteria, three putative causal variants were identified, namely rs134725785, rs135835897, and rs133242826, located in DGAT1, PIK3C2G and PIAS4, respectively (Fig. 8b, c). The effects of these 3 variants on mRNA transcripts and protein sequences with predicted functional impact are detailed in Supplementary Fig. 8.

a Classification of the 38 SDV identified in the Var.GWAS dataset by functional impact type. The ∆PSI values are represented as histograms for each variant in both cell lines. The position of the test exon (rank) whose splicing is affected by the SDV is indicated in relation to all the exons of the reference transcript. The four different observed consequences on the primary structure of the transcript resulting from the exclusion of the test exon are indicated (i.e. premature termination codon (PTC), in-frame deletion (IFD), deletion in the 3′UTR (3′Del), deletion of the translation initiation codon (Del ATG)). When appropriate, the exon in which the PTC is located is indicated; nr not relevant. From this information on the transcript sequence, the consequence on protein function may be predicted. The presence of a PTC is associated with a protein loss of function via the non-sense-mediated mRNA decay (NMD) mechanism unless it is located in the last exon. The absence of the translation initiation ATG codon is associated with a protein loss of function, whereas the consequence of an in-frame deletion or a deletion in the 3′UTR is considered non-predictable; U unknown. The REF and ALT alleles of each variant whose impact on protein function has been predicted are classified as loss-of-function (LoF) or gain-of-function (GoF), depending on the ∆PSI value. Thus, an allele that increases the inclusion of the test exon required to obtain a functional protein is classified as GoF, whereas an allele that decreases the inclusion of this exon is classified as LoF. *, the MAPK15 rs473875358 variant is located in the non-canonical ENSBTAT00000074468.1 transcript. The phenotypes associated with each variant are shown. b Filtering steps used to identify causal variants. c Illustration of the genotype-to-phenotype link for the three identified causal variants. Positive black arrows indicate that the initial condition increases the final condition in terms of function (for proteins), concentration (for compounds), or efficiency (for biological pathways or processes). Negative black arrows indicate a decrease. The resulting effect of black arrows is symbolised by a green up (increase) or red down (decrease) arrow.
Colocalization between SDV from Var.GWAS and eQTL/sQTL SNP
We searched for shared SNP between the 38 SDV from Var.GWAS and eQTL/sQTL data, through a review of published studies reporting both eQTL and sQTL SNP. Four studies did not allow the identification of shared SNP74,75,76,77. Two studies conducted on imputed WGS and involving large numbers of animals and samples showed positive results with respect to single-tissue eQTL/sQTL SNP7,25 and multi-tissue eQTL/sQTL SNP25 (Supplementary Data 6). SDV colocalize with six single-tissue eQTL SNP and eight single-tissue sQTL SNP. Multi-tissue analysis yielded better results, indeed, SDV also colocalized with 23 multi-tissue eQTL SNP and 23 multi-tissue sQTL SNP. Globally, 71.1% of SDV (27/38) colocalize with at least one single- or multi- e/sQTL SNP.
Discussion
We set out to explore the impact of SDV in complex traits in cattle using the latest generation of computational and experimental tools. To do this, we integrated GWAS, MPRA and in silico splicing prediction data in an original approach aimed at drawing the most biologically relevant conclusions as possible. Thanks to this, we identified three putative causal SDV involved in production traits in cattle.
GWAS were conducted on large populations of bovine animals with accurate phenotypic records and at the sequence level, which corresponds to the best possible resolution for GWAS. These analyses resulted in the detection of 573 QTL associated with 20 various traits of interest. Many of these QTL overlap with regions already reported in CattleQTLdb (https://www.animalgenome.org/cattle)78. However, only a limited number of causal variants within these regions have been previously identified. Notable examples include the missense causal variant within the DGAT1 gene on chromosome 14, which exerts a strong influence on milk composition79, and the various missense variants within the MSTN gene, known for their major impact on animal muscularity80. The limited number of identified causal mutations highlights the considerable challenge associated with their discovery, emphasising the importance of having efficient methods for their detection.
The Vex-seq method had previously been used to analyse human SDV57, and we have carried it out on livestock species in the present study. The results we obtained are overall comparable to those of ref. 57 although we made some minor modifications to the protocol, such as adding an additional BC per construct or using different mammalian cell lines. Consistent with their observations in humans, we found that the PSI varied greatly based on the sequence of the test exons, ranging from 0 to 98%. Thus, it should be noted that some variants could not be analysed due to their location in regions in which test exons were not included. This phenomenon shows that not all exons can be analysed in Vex-seq, and that in some cases a wider sequence context than those of a minigene is probably required to analyse the impact of SDV81,82. Despite this, our Vex-seq analysis gave biologically relevant results, validated by a multitude of positive controls and QC steps. MPRA for splicing is time-consuming, costly, and technically complex, and for this reason, only one or two cell lines are usually employed at the same time55,57,58. We decided to use one bovine cell line and one human cell line already used as models to study splicing in these two species. HEK293T cells have been very frequently used to perform low-throughput splicing assays (see examples in human83,84 and cattle46,85) but also in the context of the two other MPRA methods developed to analyse SDV55,58. In some cases, comparisons with in vivo data from patients have been done and yielded consistent results55. HEK293T cells have also been used to generate the ABCA4 benchmark dataset we used to validate the Vex-seq67. MAC-T cells have been widely used to model epithelial cells of the mammary gland (for a recent example, see ref. 86). Since the majority of SNP identified in our GWAS concern milk traits, the choice of this cell line was considered to be the most appropriate. In addition, MAC-T cells have already been successfully used to develop splicing assays for bovine genes85,87,88. PSI and ∆PSI values both showed a strong correlation between the HEK293T and MAC-T cell lines, which suggests good phylogenetic conservation of splicing mechanisms between humans and cattle. It also highlights the predominantly ubiquitous nature of SDV as previously observed57. Only one variant showed an inverse effect in the two cell lines (SULT1B1 rs208961079). Further functional characterisation of this SDV could lead to a better understanding of the impact of genetic alterations on the tissue-specific regulation of splicing, which remains a burning question89,90. According to cGTEx data, SULT1B1 is mainly expressed in the digestive tract, the bone marrow, adipose tissues, sperm, and kidneys, but also in the adrenal gland and, to a lesser extent, in mammary tissues7. HEK293T cells transcriptome more closely resembled that of adrenal cells than kidney cells91, and MAC-T is a model for epithelial cells of the mammary gland. Thus, the cell lines used to perform the Vex-seq analysis fit with the expression pattern of SULT1B1 in two tissues, and further experiments to characterise its transcript isoforms in adrenal and mammary glands in animals carrying different genotypes for rs208961079 could validate the tissue-specific nature of this SDV. Finally, we confirmed that in cattle, as in humans, variants that alter conserved nucleotides are more likely to affect splicing57.
Another substantial methodological contribution brought by our study relates to the use of SpliceAI and Pangolin splicing prediction programs in the context of the bovine genome. The composition of exon-intron boundaries, as well as the sequence of splice sites and splicing regulatory elements, is well conserved between mammals62,63,64. As SpliceAI and Pangolin have been trained on human data and predict SDV directly from the primary sequence of genes, we expected they would perform well in cattle. It was, however, necessary to validate their usefulness in this context using experimental data, which, at the same time, made it possible to accurately assess their performance. With respect to data obtained from in vivo studies, both programs were able to detect bovine SDV responsible for different monogenic diseases with an overall sensitivity rate of 88.2% when applying a threshold of 0.2. This result was very close to the sensitivity of SpliceAI (89.9% using the same threshold) calculated from predictions made on human SDV identified in the context of the molecular diagnosis of genetic disorders92. To our knowledge, there is currently no similar data available for Pangolin. The analysis of the SDV associated with complex traits presented a low true positive rate (28.6%), probably because they are often hypomorphic and lead to less radical changes in splicing regulatory sequence features. A more in-depth performance evaluation of SpliceAI and Pangolin was then carried out using Vex-seq data, and this revealed several important points. First, Pangolin slightly outperformed SpliceAI for splicing prediction of bovine SDV, evidenced by the measurement of the AUC of ROC curves. This is in line with the observations made in the previous studies, which compared the performance of these two programs using human MPRA data from the literature61,54. The Pangolin algorithm was trained on transcriptomic data from four different mammals, which may also explain why it gave more accurate results on a non-human mammal, by contrast with SpliceAI, which was trained exclusively on human data. Furthermore, we addressed the issue of selecting the optimal threshold for these programs to effectively predict SDV in a GWAS dataset. This choice depends on both the algorithm used and the dataset analysed54. Based on human MPRA data and depending on the selected criteria, Smith and Kitzman determined a median optimal cutoff comprised between 0.8 and 0.14 for SpliceAI and equal to 0.12 for Pangolin54. In the context of bovine GWAS performed on complex traits, we observed that lowering the minimal recommended threshold of 0.2 and tolerating a higher number of false positives allow for an increase in the number of true positives SDV, which may hold potential value for further functional validation.
This study represents a large-scale analysis of SDV in farm species. Our results showed that SDV are widely associated with bovine phenotypes and are expected to be found in the majority of QTL (more than 50%), which suggests a pervasive role for this class of variants in the plasticity of complex traits in cattle. It should be noted that deep intronic variants have not been integrated into our analysis, which means that the role of SDV may be even more extensive than we estimated on the basis of our data. Our findings are also consistent with previous observations, which have found that multi-tissue cis-sQTL accounts for about 60% of the heritability of complex traits in cattle25.
A total of 38 SDV identified from GWAS results were experimentally validated using the Vex-seq method. Despite they all alter splicing, it has not always been possible to clearly infer their effects on protein function. We considered that variant alleles that caused skipping of the test exon can be interpreted as ‘loss-of-function’ (LoF) when they led to the creation of a premature termination codon (PTC) located upstream of the last exon. In fact, newly synthesised mRNAs that contain PTC are degraded through the NMD mechanism in order to prevent the production of truncated proteins93. We were able to classify 19 variants from GWAS as LoF or ‘gain-of-function’ (GoF), including one which suppressed the ATG translation start site. Molecular QTL data from two studies showed that 27 out of the 38 SDV colocalize with cis-sQTL and cis-eQTL SNP in cattle7,25. This finding supports that these variants are true SDV. It should be noted that these two studies led to the identification of colocalized SDV as they were carried out on a large number of animals and samples, allowing the identification of many molecular QTL. Also, the multi-tissue analyses are more powerful and identify more QTL than single-tissue ones, which also explains why they colocalized with a greater number of SDV. Ten SDV did not colocalize with any molecular QTL, but this can be explained in various ways. The consequences of an SDV may be undetectable by sQTL or eQTL analyses if it is not expressed in the tissues tested or at the right timing. The power and completeness of these QTL analyses is also limited by the size and genetic background of the samples available.
Finally, the functional validation of GWAS variants has enabled us to identify three putative causal variants that impact DGAT1, PIK3C2G and PIAS4 gene function and are involved in complex phenotypes in cattle. First, one of these three putative causal SDV was rs134725785. It increased DGAT1 expression as determined by Vex-seq, and was associated with variation in milk phenotypes in our GWAS. DGAT1 encodes diacylglycerol O-Acyltransferase 1, an enzyme catalysing the final step of the biosynthesis process of triacylglycerol. Two DGAT1 loss-of-function variants altering milk phenotypes in cattle have been reported to date, namely p.M435L45 and p.K232A79,94. The p.M435L variant is a rare SDV that results in a non-functional truncated protein45. The well-known p.K232A is responsible for a significant decrease in cow’s milk fat yield via an alteration in the enzymatic activity of DGAT179,94. Furthermore, this variant and those in LD with it are associated with splicing changes in some introns of this gene87,88. So, the role of DGAT1 in modifying milk phenotypes has been well characterised, and it is expected that increasing DGAT1 function increases PC and FC phenotypes, and decreases MY phenotypes95. On the other hand, it would be interesting to understand in future studies to what extent rs134725785 contributes to the observed effect of the pK232A-containing haplotype, or in an individual manner, on dairy traits. Finally, the rs134725785 polymorphism is located in the intron 2 of DGAT1, the splicing rate of which was associated with milk traits96. The two other identified causal variants (PIK3C2G rs135835897 and PIAS4 rs133242826) were more difficult to interpret because we had to infer the role of the genes they impacted in modifying the associated phenotypes. To our knowledge, the biological role of these two genes has never been described in cattle so far. Phosphatidylinositol 3-kinase C2 domain-containing subunit gamma, encoded by the PIK3C2G gene, is a lipid kinase that phosphorylates inositol phospholipids, thereby controlling membrane lipid composition and regulating a wide range of intracellular processes, including vesicular trafficking and signal transduction97. PIK3C2G knockout mice present severely reduced liver accumulation of glycogen and develop hyperlipidemia, adiposity as well and insulin resistance with age or after consumption of a high-fat diet98. In cattle, insulin resistance promotes the sparing of glucose, increased lipolysis in adipose tissue, and increased availability of non-esterified fatty acids for oxidation and milk fat synthesis99. These observations suggest that the PIK3C2G function modulates the FC phenotype in cattle. Protein inhibitor of activated STAT Y, encoded by the PIAS4 gene (also known as PIASy), is the shortest member of the PIAS family and has been reported to modulate transcriptional activities of STAT1100, lymphoid enhancer factor 1 (LEF-1)101, and the androgen receptor (AR)102,103. PIAS4 has been characterised as a specific inhibitor of STAT1 but by a mechanism other than inhibition of STAT DNA binding, as described for PIAS1 and PIAS3100. The Stat1 knockout mice had an increased bone mass104,105, and bone morphometric analysis revealed a notable increase in bone formation rate and other osteoblast parameters such as osteoid surface/thickness and osteoblast surface. This suggests that excessive osteoblast differentiation is responsible for the increased bone mass. PIAS4 is also able to repress AR-mediated gene activation102,103. Progressive reduced insulin sensitivity and impaired glucose tolerance were observed in AR knockout mice with advancing age. Aging AR knockout mice displayed accelerated weight gain, hyperinsulinemia, and hyperglycaemia, and the absence of AR contributes to increased triglyceride content in skeletal muscle and liver106. As described above, all these observations are consistent with the fact that PIAS4 is playing a role in the modulation of SS30 and TB30 phenotypes via STAT1, and in the modulation of W18 via AR. Beyond that, it should be remembered that the remaining 35 SDV represent very promising candidate causal variants, but a review of the literature and databases has not made it possible to firmly link the function of the genes they impact to the associated phenotypes, or it was not possible to conclude on their effect on protein function.
In conclusion, we have brought substantial original data to better describe SDV in cattle and understand their role in the construction of bovine phenotypes. Our study led to the identification of three putative causal variants. In addition, the tools we have adapted for cattle could be used more widely in the future for the functional annotation of genetic variants in farm animal species6. In particular, Pangolin and SpliceAI algorithms, which are simpler to set up than the Vex-seq method, could be used to generate high-throughput annotations of SDV for these species and, therefore, could potentially improve genomic prediction.
Methods
Ethics statement
All analyses were performed using data from routine recording and genotyping of French cattle in commercial herds. We did not perform any experiments on animals, and no ethical approval was required.
Animals and phenotypes
We analysed steers, cows, or bulls from four different breeds (Holstein, Montbéliarde, Normande and Charolaise) for which phenotypes and genotypes were available. Depending on the breed, phenotypes were obtained for milk production, milk composition, fertility, mastitis resistance, growth, morphology or carcass traits. The number of animals per population ranged from 2255 to 10,066 (Table 1).
Ten traits were measured in Holstein, Montbéliarde and Normande bulls. Five traits were related to milk production and composition: milk yield (MY), fat yield (FY), protein yield (PY), fat content (FC) and protein content (PC); three female reproductive traits were also measured: the interval between calving and the first artificial insemination (ICFI) which reflects resumption of cyclicity, and heifers’ (HCR) and lactating cows’ (CCR) conception rates, which represent the success/failure of each artificial insemination; and two traits were related to udder health: average somatic cell score (SCS) during the whole lactation, computed as the mean of monthly records of log-transformed somatic cell counts (SCC) defined as SCS = 3 + log2(SCC/100,000), and clinical mastitis (MAST) defined as at least one episode of clinical mastitis in the interval from 10 days before calving to 150 days after calving. Montbéliarde and Normande bulls were also phenotyped for live morphology traits: muscularity of the thighs (THIGHS) in both breeds and muscularity of the withers (WITHER) in Normande. Four traits were measured in Charolaise cows. Two traits were related to growth: weight at month 18 (W18) and at month 24 (W24); and three morphology traits were measured on the living cows: muscularity score at month 30 (MS30), skeletal score at month 30 (SS30), and thickness of bones at month 30 (TB30). Three additional carcass traits were available in Montbéliarde, Normande, and Charolaise steers: age at slaughter (AS), carcass weight (CW) and carcass grade (CG).
For cow and steer populations, the traits were expressed as yield deviations (YD), i.e. mean performance adjusted for environmental effects, while daughter yield deviations (DYD) were calculated for bulls, i.e. mean performance of the daughters adjusted for environmental effects and the breeding value of their dam107 (Table 1). For more details on the traits analysed, see our previous studies108,109.
Genotyping and imputation
Animals in the four breeds were genotyped with different versions of the EuroG10k (versions 1 to 7) or the 50k SNP Beadchip (versions 1 to 4), with the most recent being the Illumina EuroGMD Beadchip, which is currently used for genomic selection (https://www.eurogenomics.com/actualites/eurogenomics-new-eurog-md-beadchip.html). The standard EuroGMD Beadchip contains 53,469 autosomal SNPs that passed all quality control filters (individual call rate >95%; SNP call rate >90%; minor allele frequency (MAF) >1%; genotype frequencies in Hardy–Weinberg equilibrium with P > 10−4). The ARS-UCD1.2 bovine genome sequence was used as a reference110. All imputation analyses were performed within-breed. Missing genotypes of EuroGMD SNPs are routinely imputed in the French evaluation system using FImpute software111 by INRAE; CTIG (France, Jouy-en-Josas). Imputation to sequence level was done using a two-step approach: (1) 777k (high-density, HD) genotypes were imputed from EuroGMD genotypes using version 3 of FImpute111, with animals with HD genotypes as a reference in each breed (776 Holstein, 522 Montbéliarde, 543 Normande and 672 Charolaise)112 and (2) raw variants were filtered as previously described by Boussaha et al. 113 to produce 25,050,323 sequence variants (SNPs and InDels). Briefly, quality filtering was applied to the short reads aligned on the ARS-UCD1.2 reference sequence and small genomic variations (SNPs and InDels) were detected using SAMtools (v0.0.18)114. The selected variants were imputed with version 4 of Minimac115 using a multi-breed population of 2255 animals from the RUN8 reference panel of the 1000 Bull Genomes consortium1,2 and from INRAE, including 1059 Holstein, 63 Montbéliarde, 45 Normande and 147 Charolaise (Supplementary Table 2). Only variants with MAF >0.005 and an imputation r² value (estimated by Minimac) ≥0.2 were kept for GWAS.
GWAS
The sequence variants were tested for association with different traits in each breed in separate analyses using GCTA (v1.94.1) software116, accounting for a polygenic effect estimated with a genomic relationship matrix (GRM) from EuroGMD autosomal SNPs. The following linear mixed model was applied:
y = 1 µ + xb + g + e, where y is the vector of phenotypes (YD or DYD); μ is the overall mean; b is the additive fixed effect of the variant tested; x is the vector of imputed allele dosages; g ~ N(0, G σ²g) is the vector of random polygenic effects, with G the genomic relationship matrix based on 50k SNPs, and σ²g the polygenic variance; and e ~ N(0, D σ²e) is the vector of random residual effects, with σ²e the residual variance. D was the identity matrix for YD analyses and a diagonal matrix with inverse weights for DYD to account for heterogeneous accuracy.
Candidate variants were selected from GWAS results based on a −log10(p value) threshold ≥6, where the p value represents the probability associated with the effect of the tested variant. This threshold, corresponding to a 5% genome-wide threshold of significance after Bonferroni correction for 50,000 independent tests, was intentionally set relatively low to ensure a broad selection of candidate variants within the splicing regions. Confidence intervals (CI) of the QTL were defined by including variants in the upper third of the peak, extending to ±2 Mb around the lead variant, which is defined as the variant with the most significant effect.
Generation of human and cattle sequence logos at splice sites
All available sequences at 3′ss and 5′ss regions from position −10 to +10 related to each splice site were extracted from Homo sapiens GRCh38 and Bos taurus ARS-UCD1.2 assemblies using the UCSC Table Browser (https://genome.ucsc.edu/cgi-bin/hgTables)117. The sequences relative to the 3′ss on one side and the 5′ss on the other side were aligned to create human and bovine frequency sequence logos. This allowed us to visualise the probability of observing each nucleotide at each position between both species. Logos were created with Seq2Logo (https://services.healthtech.dtu.dk/service.php?Seq2Logo-2.0)118.
Running of SpliceAI and Pangolin on the bovine genome and validation using bona fide SDV
Annotation files containing information about bovine genes, transcripts, and exons from Ensembl release 102 were specifically created in accordance with the author’s recommendations to run SpliceAI (v1.3.1) and Pangolin (v1.0.2) on Bos taurus genome assembly ARS-UCD1.260,61,119. For SpliceAI, we used a custom perl script to convert the Bos taurus Ensembl r102 gtf file into a GENCODE-like formatted file. For Pangolin, we used the python script create_db.py (provided in the Pangolin package) to transform a modified Bos taurus Ensembl r102 gtf file (with an added Ensembl_canonical tag) into the Pangolin annotation database. These custom file and database containing bovine genomic information were used instead of the usual file containing human genomic information to run SpliceAI and Pangolin with default settings on 24 bona fide bovine SDV described in the literature to assess the false negative prediction rate for both programs (Supplementary Data 1). Files generated to run SpliceAI and Pangolin are available in the Recherche Data Gouv database [https://doi.org/10.57745/UO9T9O].
Vex-seq principles
The general principles of Vex-seq were described first in 201857, and have been upgraded by its authors66. We followed the last version of the protocol in which we made some minor modifications as specified in the further methodological section. An overview of our Vex-seq analysis is depicted in Supplementary Fig. 3.
Selection of variants to be analysed by Vex-seq
We decided to perform a Vex-seq analysis of bovine SDV focused on different categories of variants of interest, which were divided into five specific datasets: (i) The positive control SDV includes bona fide human and bovine SDV; (ii) The Var.GWAS dataset includes variants from bovine GWAS; (iii) The Var.P dataset includes random variants intentionally enriched in putative bovine SDV using SpliceAI; (iv) The Var.DGAT1 dataset includes variants of bovine DGAT1; (v) The Var.sQTL dataset includes variants from bovine sQTL studies. In view of the huge quantity and diversity of the data generated, we thought it was not suitable to present all the results obtained in a single publication. Consequently, datasets (i) to (iii) have been addressed in this study, while datasets (iv) and (v) will be addressed in subsequent publications. It should be noted that the Vex-seq execution and quality control steps are applicable to all datasets, provided that all variants were part of the same oligonucleotide pool.
Regarding datasets (i–iii), the criteria for variant selection were as follows. Positive control SDV were selected through a review of the literature and the OMIA database (https://www.omia.org/home/)65. SNP from GWAS located in Vex-seq test region (as defined in Supplementary Fig. 3a and next section) with an associated rsID, an imputation score (r², estimated by Minimac (v4)) above 0.4, and a −log10(p value) >6 were selected to construct the Var.GWAS dataset. Thousand random bovine variants fitting Vex-seq constraints were analysed by SpliceAI, and then a balanced selection of positive and negative predicted SDV was used to construct the Var.P dataset.
Design of the oligonucleotide pool
As explained by ref. 57, the oligonucleotide pool was designed to include an invariable 5′ sequence [5′-CTGACTCTCTCTGCCTC-3′] directly followed by the specific test sequence carrying a unique BC, then an invariable sequence harbouring MfeI and SpeI sites [5′-CAATTGACTACTAGT-3′], and a final invariable 3′ sequence [5′-TCTAGAGGGCCCGTTTA-3′]. In our assay, the test sequence constituted a test exon of a variable size (13 to 98 nts), systematically flanked by 50 nts of the upstream intron and 20 nts of the downstream intron. BCs were generated using the R package DNABarcodes provided by ref. 57, but 4 BCs were associated with each test sequence instead of 3. Genomic position, alleles and rsID related to variants that did not originate from GWAS were retrieved from Ensembl (release 102).
Production and QC of the Vex-seq plasmid libraries
The plasmid library was produced through two successive steps, yielding an intermediate plasmid library (PL1) and a final plasmid library used for transfection (PL2) (Supplementary Fig. 3b, c). The modified pcAT7-Glo1 vector was a gift from ref. 57 (Addgene plasmid # 160996). Of note, our Vex-seq assay was designed to produce a PL2 made of 7352 unique constructs. The study reported here concerns only a part of them (n = 3128; related to datasets (i–iii) as described above; constituted from oligonucleotides described in Supplementary Data 7), as the remaining others (n = 4224; related to datasets (iv) and (v) as described above) will be analysed in future publications. A 10 pmole pool of 7352 oligonucleotides was produced using array-based DNA synthesis (Agilent Technologies) in order to assemble PL1 and PL2. Briefly, the modified pcAT7-Glo1 was linearised by digestion using PstI and XbaI (New England Biolabs), the ends were then blunted using DNA Polymerase I, Large (Klenow) Fragment (Ozyme). The synthesised oligonucleotides were then PCR-amplified for 13 cycles using the KAPA HiFi Hotstart Readymix with primer pair Oligo-F/Oligo-R (Supplementary Table 3), gel purified using the QIAquick Gel Extraction Kit (Qiagen) and inserted into the linearised plasmid by means of the NEBuilder HIFI DNA Assembly Master mix (New England Biolabs). Next, the resulting plasmid pool (PL1) was digested with SpeI and MfeI (New England Biolabs), and Exon 3 and intron 2 were PCR-amplified for 35 cycles from the original plasmid using the KAPA HiFi Hotstart Readymix with primer pair Exon 3-MfeI-F/Exon 3-XbaI-R (Supplementary Table 3). The resulting products were digested with MfeI and XbaI and subcloned into the PL1 to obtain the final PL2.
Vex-seq plasmid libraries were sequenced to filter out non-interpretable constructs. Briefly, two PCR reactions were performed to produce two specific PL1 and PL2 libraries using the Phusion Polymerase (New England Biolabs) with 20 ng of each plasmid library, and primer pairs PL1-F/Plasmid-R (for PL1) and PL2-F/Plasmid-R (for PL2) (Supplementary Table 3), in a final volume of 50 µL. The PCR programme had an initial denaturation at 98 °C for 30 s, 13 cycles of denaturation at 98 °C for 10 s, annealing at 65 °C for 30 s (63 °C for PL2), extension at 72 °C for 30 s, and a final extension step at 72 °C for 5 min. These PCR spanned the test region in PL1 and the exon 3 region in PL2, respectively. The primers carried a 3′ sequence targeting the plasmid construct and a 5′ sequence matching Illumina’s adaptors (Illumina). To obtain the final PL1 and PL2 sequencing libraries, 10 µL of each of the above intermediate PL1 and PL2 libraries were then PCR-amplified and multiplexed using the Phusion Polymerase with Illumina’s index adaptor pairs i5-UDI0001-F/i7-UDI0001-R and i5-UDI0002-F/i7-UDI0002-R (Integrated DNA Technologies) respectively (Supplementary Table 3), in a final volume of 50 µL. The PCR programme had an initial denaturation at 98 °C for 30 s, ten cycles of denaturation at 98 °C for 10 s, annealing/extension at 72 °C for 60 s, and a final extension step at 72 °C for 5 min. The length of these sequencing libraries was assessed using an Advanced Analytical Fragment Analyser (Agilent Technologies). Finally, libraries were quantified by qPCR using the Kapa Library Quantification Kit (Roche) and analysed on a MiSeq platform (Illumina) using the MiSeq Reagent Kit v2 Micro (Illumina). Read 1 and read 2 were 150 bases each. In order to ensure that BC are associated with the correct test region, BC sequences were checked using a custom Perl script, and the alignment of both reads on the test region or to exon 3 was done using bwa (v0.7.17)120. The QC process followed to assess PL1 and PL2 is illustrated in Supplementary Fig. 4a. In brief, a series of filters were applied to eliminate non-interpretable BC due to a failure in the synthesis or cloning of the sequences associated with them. In practical terms, BC absent in PL1 or containing synthesis errors were disregarded, as well as BC associated with a low percentage (<85%) of correct reads in PL1. BC without reads detected in PL2 were also filtered out.
Cell culture and transfection
The HEK293T cells were provided by Sophie Dhorne-Pollet at lNRAE; GABI unit (France, Jouy-en-Josas)121. The MAC-T cells were provided by Kathrin Kober-Rychli at the University of Veterinary Medicine; Institute of Food Safety, Food Technology and Veterinary Public Health (Austria, Vienna)122. HEK293T cells were cultured in the Dulbecco’s modified Eagle’s medium (DMEM) (Thermo Fisher Scientific) with 10% foetal calf serum (Sigma Aldrich). MAC-T cells were cultured in DMEM with 10% foetal calf serum supplemented with 4 mM l-glutamine (Thermo Fisher Scientific), 1% penicillin/streptomycin (Thermo Fisher Scientific), 1 µg/L hydrocortisone (Sigma Aldrich) and 50 mg/L insulin (Sigma Aldrich). Cells were seeded in six-well plates at a concentration of 3 × 105 cells/per well 24 hours before transfection. In each well, transfection was achieved with 1 µg of PL2 mixed with 3 µL Lipofectamine 2000 Reagent (Thermo Fisher Scientific) for HEK293T, or 2 µg of PL2 mixed with 6 µL Lipofectamine 2000 Reagent for MAC-T. The amount of transfected plasmid DNA was higher in MAC-T than in HEK293T cells due to lower transfection efficiency. Each cell line was transfected in triplicate.
RNA extraction and reverse transcription
Total RNA was extracted from cultured cells 48 h after transfection using the RNeasy Mini Kit (Qiagen). Reverse transcription was performed using SuperScript III Reverse Transcriptase (Thermo Fisher Scientific) with the latest version of the universal molecular index (UMI) primer used by ref. 66 (5′-GTGACTGGAGTTCAGACGTGTGCTCTTCCGATCTNNNNNNNNNNGCTGATCAGCGGGTTTAAACG-3′) and following the manufacturer’s guidelines. The reaction mix contained 3 µg of HEK293T total RNA or 4.5 µg MAC-T total RNA, 200 nM UMI primer, 1 mM dNTPs, 2.5 mM MgCl2, 10 mM dithiothreitol, 40U RNAse OUT and 200U SuperScript III reverse transcriptase. The obtained complementary DNAs were treated with 2U RNAseH (Thermo Fisher Scientific) to degrade the remaining RNA.
Quantification of cDNA and sequencing
cDNA was PCR-amplified and multiplexed using homemade forward index primers and reverse primers corresponding to Illumina’s index adaptors (Integrated DNA Technologies). Briefly, 5 µL of the cDNA obtained with each transfection triplicate in each cell line was PCR-amplified using the Phusion Polymerase with primer pairs VS-F1/i7-UDI0001-R, VS-F2/i7-UDI0002-R, VS-F3/i7-UDI0003-R, VS-F1/i7-UDI0004-R, VS-F2/i7-UDI0005-R and VS-F3/i7-UDI0006-R (Supplementary Table 3) in a final volume of 50 µL. The PCR programme had an initial denaturation at 98 °C for 30 s, ten cycles of denaturation at 98 °C for 10 s, annealing at 68 °C for 30 s, extension at 72 °C for 30 s, followed by five cycles of denaturation at 98 °C for 10 s, annealing/extension at 72 °C for 60 s, and a final extension step at 72 °C for 5 min. The obtained libraries were purified using 0.8X Ampure XP beads (Beckman Coulter), and then the quality was assessed using an Advanced Analytical Fragment Analyser (Agilent Technologies). Finally, libraries were quantified by qPCR using the Kapa Library Quantification Kit (Roche) and analysed on a MiSeq platform (Illumina) using the MiSeq Reagent Kit v3 (Illumina). Read 1 was 75 bases, and read 2 was 225 bases to ensure reading of the first splice junction (exon 1/test exon) by read 1 and reading of the UMI, BC, and the second splice junction (test exon/exon 3) by read 2.
Analysis of Vex-seq transcripts
Reads were identified by BC, and duplicate reads were identified using the UMI and subsequently removed. For a given BC, associated reads were aligned to two reference test sequences at exon boundaries: the first one corresponding to the expected transcript carrying the test exon, the second one corresponding to the expected transcript without the test exon. Thus, reads corresponding to the transcript with or without test exon were counted in order to calculate PSI for each BC construct. Mean PSI values of all four BCs constructs corresponding to a specific variant allele, when available, were then used to calculate PSI (%) and ∆PSI (%) for each variant (Supplementary Fig. 3b). The process to ensure the reliability of the transcripts analysis is illustrated in Supplementary Fig. 4c. A series of filters were applied to eliminate non-interpretable variants. BC with less than 10 reads detected in RNA-seq were disregarded. Only variants with at least two expressed BC for each allele in each transfection experiment and a PSI >0 for at least the REF or the ALT allele were considered for the calculation of ∆PSI. The p value of ∆PSI was calculated by means of a two-tailed student’s t-test, then the FDR of ∆PSI was calculated for the entire PL2 by means of the FDR online calculator (https://www.sdmproject.com/utilities/?show=FDR).
Annotations for variant consequence and phylogenetic conservation
GERP scores and variant consequence annotations were downloaded from Ensembl (release 102).
Prediction of mRNA transcript and protein sequences
Exon sequences were downloaded from Ensembl to predict transcript sequences with or without test exon119. The primary structure of proteins resulting from these transcripts was predicted using ExpASy (https://web.expasy.org/translate/)123. Information about PIAS4, PIK3C2G, and DGAT1 protein domains was obtained from UniProt (https://www.uniprot.org)124. Ensembl ID and UniProt ID of the 38 SDV from Var.GWAS are listed in Supplementary Data 8.
Comparison between SDV from Var.GWAS and eQTL/sQTL SNP
Studies reporting both eQTL and sQTL data in cattle were collected from PubMed. SNP shared between these studies and the 38 SDV from Var.GWAS were found using the rsID.
Reporting summary
Further information on research design is available in the Nature Portfolio Reporting Summary linked to this article.
Data availability
The authors confirm that the summary of GWAS results, the results of SpliceAI and Pangolin predictions, in addition to the analysed data of the Vex-seq analysis, are available within the article. The GWAS data generated in this study have been deposited in the Recherche Data Gouv database [https://doi.org/10.57745/UO9T9O]. The corresponding raw phenotypic and genotypic data were produced for the purpose of bovine selection and belong to French farmers’ organisations, which have given INRAE permission to use them for research purposes, excluding any transfer to third parties or public databases. They cannot, therefore, be made available to the public. Readers can request a research licence from Valogene (France, Paris) for the genotyping data and from France Génétique Elevage (France, Paris) for the phenotypic data. All MiSeq fastq files relative to the Vex-seq analysis and generated in this study have been deposited in the European Nucleotide Archive database under the accession code PRJEB87659. All files generated to run SpliceAI and Pangolin on bovine variants have been deposited in the Recherche Data Gouv database [https://doi.org/10.57745/UO9T9O]. eQTL and sQTL data from ref. 7 are available at the cattle Genotype-Tissue Expression atlas [https://cgtex.roslin.ed.ac.uk/]. eQTL and sQTL data from ref. 25 are available on Figshare [https://figshare.unimelb.edu.au/articles/dataset/eQTL_and_sQTL_from_16_cattle_tissues_linear_mixed_model_/19793047?file=35165539]. Source data are provided with this paper.
Code availability
All custom scripts generated in this study have been deposited in the Recherche Data Gouv database [https://doi.org/10.57745/UO9T9O].
References
Bouwman, A. C. et al. Meta-analysis of genome-wide association studies for cattle stature identifies common genes that regulate body size in mammals. Nat. Genet. 50, 362–367 (2018).
Daetwyler, H. D. et al. Whole-genome sequencing of 234 bulls facilitates mapping of monogenic and complex traits in cattle. Nat. Genet. 46, 858–865 (2014).
Hayes, B. J. & Daetwyler, H. D. 1000 Bull Genomes Project to map simple and complex genetic traits in cattle: applications and outcomes. Annu. Rev. Anim. Biosci. 7, 89–102 (2019).
Liu, A. et al. Improvement of genomic prediction by integrating additional single nucleotide polymorphisms selected from imputed whole genome sequencing data. Heredity 124, 37–49 (2020).
Ron, M. & Weller, J. I. From QTL to QTN identification in livestock-winning by points rather than knock-out: a review. Anim. Genet. 38, 429–439 (2007).
Clark, E. L. et al. From FAANG to fork: application of highly annotated genomes to improve farmed animal production. Genome Biol. 21, 285 (2020).
Liu, S. et al. A multi-tissue atlas of regulatory variants in cattle. Nat. Genet. 54, 1438–1447 (2022).
Xiang, R. et al. Quantifying the contribution of sequence variants with regulatory and evolutionary significance to 34 bovine complex traits. Proc. Natl Acad. Sci. USA 116, 19398–19408 (2019).
Xiang, R. et al. Genome-wide fine-mapping identifies pleiotropic and functional variants that predict many traits across global cattle populations. Nat. Commun. 12, 860 (2021).
Hu, S. et al. Functional deletion/insertion promoter variants in SCARB1 associated with increased susceptibility to lipid profile abnormalities and coronary heart disease. Front. Cardiovasc. Med. 8, 800873 (2021).
Boulling, A. et al. Identification of a functional PRSS1 promoter variant in linkage disequilibrium with the chronic pancreatitis-protecting rs10273639. Gut 64, 1837–1838 (2015).
Rogalska, M. E., Vivori, C. & Valcárcel, J. Regulation of pre-mRNA splicing: roles in physiology and disease, and therapeutic prospects. Nat. Rev. Genet. 24, 251–269 (2023).
Marasco, L. E. & Kornblihtt, A. R. The physiology of alternative splicing. Nat. Rev. Mol. Cell Biol. 24, 242–254 (2023).
Wright, C. J., Smith, C. W. J. & Jiggins, C. D. Alternative splicing as a source of phenotypic diversity. Nat. Rev. Genet. 23, 697–710 (2022).
Lewis, B. P., Green, R. E. & Brenner, S. E. Evidence for the widespread coupling of alternative splicing and nonsense-mediated mRNA decay in humans. Proc. Natl Acad. Sci. USA 100, 189–192 (2003).
Tapial, J. et al. An atlas of alternative splicing profiles and functional associations reveals new regulatory programs and genes that simultaneously express multiple major isoforms. Genome Res. 27, 1759–1768 (2017).
Martín, G., Márquez, Y., Mantica, F., Duque, P. & Irimia, M. Alternative splicing landscapes in Arabidopsis thaliana across tissues and stress conditions highlight major functional differences with animals. Genome Biol. 22, 35 (2021).
Pan, Q., Shai, O., Lee, L. J., Frey, B. J. & Blencowe, B. J. Deep surveying of alternative splicing complexity in the human transcriptome by high-throughput sequencing. Nat. Genet. 40, 1413–1415 (2008).
Wang, E. T. et al. Alternative isoform regulation in human tissue transcriptomes. Nature 456, 470–476 (2008).
Snyman, M. & Xu, S. The effects of mutations on gene expression and alternative splicing. Proc. Biol. Sci. 290, 20230565 (2023).
Stenson, P. D. et al. The human gene mutation database: towards a comprehensive repository of inherited mutation data for medical research, genetic diagnosis and next-generation sequencing studies. Hum. Genet. 136, 665–677 (2017).
Bryen, S. J. et al. Prevalence, parameters, and pathogenic mechanisms for splice-altering acceptor variants that disrupt the AG exclusion zone. HGG Adv. 3, 100125 (2022).
Li, Y. I. et al. RNA splicing is a primary link between genetic variation and disease. Science 352, 600–604 (2016).
Qi, T. et al. Genetic control of RNA splicing and its distinct role in complex trait variation. Nat. Genet. 54, 1355–1363 (2022).
Xiang, R. et al. Gene expression and RNA splicing explain large proportions of the heritability for complex traits in cattle. Cell Genomics https://doi.org/10.1016/j.xgen.2023.100385 (2023)
Pandya-Jones, A. Pre-mRNA splicing during transcription in the mammalian system. Wiley Interdiscip. Rev. RNA 2, 700–717 (2011).
Drögemüller, C. et al. An unusual splice defect in the mitofusin 2 gene (MFN2) is associated with degenerative axonopathy in Tyrolean Grey cattle. PLoS ONE 6, e18931 (2011).
Takeda, H. et al. Positional cloning of the gene LIMBIN responsible for bovine chondrodysplastic dwarfism. Proc. Natl Acad. Sci. USA 99, 10549–10554 (2002).
Venhoranta, H. et al. In frame exon skipping in UBE3B is associated with developmental disorders and increased mortality in cattle. BMC Genomics 15, 890 (2014).
Gargani, M., Valentini, A. & Pariset, L. A novel point mutation within the EDA gene causes an exon dropping in mature RNA in Holstein Friesian cattle breed affected by X-linked anhidrotic ectodermal dysplasia. BMC Vet. Res. 7, 35 (2011).
Boussaha, M. et al. Integrin alpha 6 homozygous splice-site mutation causes a new form of junctional epidermolysis bullosa in Charolais cattle. Genet. Sel. Evol. 55, 40 (2023).
Iso-Touru, T. et al. A splice donor variant in CCDC189 is associated with asthenospermia in Nordic Red dairy cattle. BMC Genomics 20, 286 (2019).
Johnson, E. B., Steffen, D. J., Lynch, K. W. & Herz, J. Defective splicing of Megf7/Lrp4, a regulator of distal limb development, in autosomal recessive mulefoot disease. Genomics 88, 600–609 (2006).
Yuzbasiyan-Gurkan, V. & Bartlett, E. Identification of a unique splice site variant in SLC39A4 in bovine hereditary zinc deficiency, lethal trait A46: an animal model of acrodermatitis enteropathica. Genomics 88, 521–526 (2006).
Reynolds, E. G. M. et al. Non-additive association analysis using proxy phenotypes identifies novel cattle syndromes. Nat. Genet. 53, 949–954 (2021).
Drögemüller, C., Peters, M., Pohlenz, J., Distl, O. & Leeb, T. A single point mutation within the ED1 gene disrupts correct splicing at two different splice sites and leads to anhidrotic ectodermal dysplasia in cattle. J. Mol. Med. 80, 319–323 (2002).
Hirano, T., Matsuhashi, T., Kobayashi, N., Watanabe, T. & Sugimoto, Y. Identification of an FBN1 mutation in bovine Marfan syndrome-like disease. Anim. Genet. 43, 11–17 (2012).
Krull, F. & Brenig, B. Very low allele frequency of small calf syndrome causing GALNT2-splice acceptor variant in the worldwide Holstein cattle population. Anim. Genet. 53, 472–473 (2022).
Murgiano, L. et al. Hairless streaks in cattle implicate TSR2 in early hair follicle formation. PLoS Genet. 11, e1005427 (2015).
Sartelet, A. et al. A splice site variant in the bovine RNF11 gene compromises growth and regulation of the inflammatory response. PLoS Genet. 8, e1002581 (2012).
Sartelet, A. et al. Genome-wide next-generation DNA and RNA sequencing reveals a mutation that perturbs splicing of the phosphatidylinositol glycan anchor biosynthesis class H gene (PIGH) and causes arthrogryposis in Belgian Blue cattle. BMC Genomics 16, 316 (2015).
Boulling, A. et al. A bovine model of rhizomelic chondrodysplasia punctata caused by a deep intronic splicing mutation in the GNPAT gene. Preprint at https://doi.org/10.1101/2024.06.13.598642 (2024).
Bouyer, C., Forestier, L., Renand, G. & Oulmouden, A. Deep intronic mutation and pseudo exon activation as a novel muscular hypertrophy modifier in cattle. PLoS ONE 9, e97399 (2014).
Hiltpold, M. et al. Activation of cryptic splicing in bovine WDR19 is associated with reduced semen quality and male fertility. PLoS Genet. 16, e1008804 (2020).
Lehnert, K. et al. Phenotypic population screen identifies a new mutation in bovine DGAT1 responsible for unsaturated milk fat. Sci. Rep. 5, 8484 (2015).
Ju, Z. et al. Role of an SNP in alternative splicing of bovine NCF4 and mastitis susceptibility. PLoS ONE 10, e0143705 (2015).
Sasaki, S. et al. Identification of deleterious recessive haplotypes and candidate deleterious recessive mutations in Japanese Black cattle. Sci. Rep. 11, 6687 (2021).
Wang, X. et al. Splicing-related single nucleotide polymorphism of RAB, member of RAS oncogene family like 2B (RABL2B) jeopardises semen quality in Chinese Holstein bulls. Reprod. Fertil. Dev. 29, 2411–2418 (2017).
Liu, J. et al. Functional SNPs of INCENP affect semen quality by alternative splicing mode and binding affinity with the target Bta-miR-378 in Chinese Holstein bulls. PLoS ONE 11, e0162730 (2016).
Wang, X., Zhong, J., Gao, Y., Ju, Z. & Huang, J. A SNP in intron 8 of CD46 causes a novel transcript associated with mastitis in Holsteins. BMC Genomics 15, 630 (2014).
Kinney, J. B., Murugan, A., Callan, C. G. & Cox, E. C. Using deep sequencing to characterize the biophysical mechanism of a transcriptional regulatory sequence. Proc. Natl Acad. Sci. USA 107, 9158–9163 (2010).
Melnikov, A. et al. Systematic dissection and optimization of inducible enhancers in human cells using a massively parallel reporter assay. Nat. Biotechnol. 30, 271–277 (2012).
Patwardhan, R. P. et al. High-resolution analysis of DNA regulatory elements by synthetic saturation mutagenesis. Nat. Biotechnol. 27, 1173–1175 (2009).
Smith, C. & Kitzman, J. O. Benchmarking splice variant prediction algorithms using massively parallel splicing assays. Genome Biol. 24, 294 (2023).
Soemedi, R. et al. Pathogenic variants that alter protein code often disrupt splicing. Nat. Genet. 49, 848–855 (2017).
Rhine, C. L. et al. Massively parallel reporter assays discover de novo exonic splicing mutants in paralogs of Autism genes. PLoS Genet. 18, e1009884 (2022).
Adamson, S. I., Zhan, L. & Graveley, B. R. Vex-seq: high-throughput identification of the impact of genetic variation on pre-mRNA splicing efficiency. Genome Biol. 19, 71 (2018).
Cheung, R. et al. A multiplexed assay for exon recognition reveals that an unappreciated fraction of rare genetic variants cause large-effect splicing disruptions. Mol. Cell 73, 183–194.e8 (2019).
Rowlands, C. F., Baralle, D. & Ellingford, J. M. Machine learning approaches for the prioritization of genomic variants impacting pre-mRNA splicing. Cells 8, 1513 (2019).
Jaganathan, K. et al. Predicting splicing from primary sequence with deep learning. Cell 176, 535–548.e24 (2019).
Zeng, T. & Li, Y. I. Predicting RNA splicing from DNA sequence using Pangolin. Genome Biol. 23, 103 (2022).
Amit, M. et al. Differential GC content between exons and introns establishes distinct strategies of splice-site recognition. Cell Rep. 1, 543–556 (2012).
Wang, Z. & Burge, C. B. Splicing regulation: from a parts list of regulatory elements to an integrated splicing code. RNA 14, 802–813 (2008).
Abril, J. F., Castelo, R. & Guigó, R. Comparison of splice sites in mammals and chicken. Genome Res. 15, 111–119 (2005).
Nicholas, F. W. Online Mendelian inheritance in animals (OMIA): a record of advances in animal genetics, freely available on the Internet for 25 years. Anim. Genet. 52, 3–9 (2021).
Adamson, S., Zhan, L. & Graveley, B. Functional characterization of splicing regulatory elements. Preprint at bioRxiv https://doi.org/10.1101/2021.05.14.444228 (2021).
Sangermano, R. et al. ABCA4 midigenes reveal the full splice spectrum of all reported noncanonical splice site variants in Stargardt disease. Genome Res. 28, 100–110 (2018).
Riepe et al. Benchmarking deep learning splice prediction tools using functional splice assays. Hum. Mutat. 42, 799–810 (2021).
Sheth, N. et al. Comprehensive splice-site analysis using comparative genomics. Nucleic Acids Res. 34, 3955–3967 (2006).
Sibley, C. R., Blazquez, L. & Ule, J. Lessons from non-canonical splicing. Nat. Rev. Genet. 17, 407–421 (2016).
Lin, J.-H. et al. First estimate of the scale of canonical 5’ splice site GT>GC variants capable of generating wild-type transcripts. Hum. Mutat. 40, 1856–1873 (2019).
Cooper, G. M. et al. Distribution and intensity of constraint in mammalian genomic sequence. Genome Res. 15, 901–913 (2005).
McLaren, W. et al. The Ensembl variant effect predictor. Genome Biol. 17, 122 (2016).
Xiang, R. et al. Genome variants associated with RNA splicing variations in bovine are extensively shared between tissues. BMC Genomics 19, 521 (2018).
Mapel, X. M. et al. Molecular quantitative trait loci in reproductive tissues impact male fertility in cattle. Nat. Commun. 15, 674 (2024).
Tang, Y. et al. Identification and characterization of whole blood gene expression and splicing quantitative trait loci during early to mid-lactation of dairy cattle. BMC Genomics 25, 445 (2024).
Leal-Gutiérrez, J. D., Elzo, M. A. & Mateescu, R. G. Identification of eQTLs and sQTLs associated with meat quality in beef. BMC Genomics 21, 104 (2020).
Hu, Z.-L., Park, C. A. & Reecy, J. M. Bringing the animal QTLdb and CorrDB into the future: meeting new challenges and providing updated services. Nucleic Acids Res. 50, D956–D961 (2022).
Grisart, B. et al. Positional candidate cloning of a QTL in dairy cattle: identification of a missense mutation in the bovine DGAT1 gene with major effect on milk yield and composition. Genome Res. 12, 222–231 (2002).
Grobet, L. et al. A deletion in the bovine myostatin gene causes the double-muscled phenotype in cattle. Nat. Genet. 17, 71–74 (1997).
Fu, X.-D. & Ares, M. Context-dependent control of alternative splicing by RNA-binding proteins. Nat. Rev. Genet. 15, 689–701 (2014).
Baralle, F. E., Singh, R. N. & Stamm, S. RNA structure and splicing regulation. Biochim. Biophys. Acta Gene Regul. Mech. 1862, 194448 (2019).
Wu, H. et al. Analysis of the impact of known SPINK1 missense variants on pre-mRNA splicing and/or mRNA stability in a full-length gene assay. Genes 8, E263 (2017).
Reurink, J. et al. Minigene-based splice assays reveal the effect of non-canonical splice site variants in USH2A. Int. J. Mol. Sci. 23, 13343 (2022).
Zhang, Y. et al. DNA methylation rather than single nucleotide polymorphisms regulates the production of an aberrant splice variant of IL6R in mastitic cows. Cell Stress Chaperones 23, 617–628 (2018).
Liu, L. et al. Sirtuin 3 relieves inflammatory responses elicited by lipopolysaccharide via the PGC1α-NFκB pathway in bovine mammary epithelial cells. J. Dairy Sci. 106, 1315–1329 (2023).
Gaiani, N., Bourgeois-Brunel, L., Rocha, D. & Boulling, A. Analysis of the impact of DGAT1 p.M435L and p.K232A variants on pre-mRNA splicing in a full-length gene assay. Sci. Rep. 13, 8999 (2023).
Fink, T. et al. A new mechanism for a familiar mutation - bovine DGAT1 K232A modulates gene expression through multi-junction exon splice enhancement. BMC Genomics 21, 591 (2020).
Cheng, J., Çelik, M. H., Kundaje, A. & Gagneur, J. MTSplice predicts effects of genetic variants on tissue-specific splicing. Genome Biol. 22, 94 (2021).
Wagner, N. et al. Aberrant splicing prediction across human tissues. Nat. Genet. 55, 861–870 (2023).
Lin, Y.-C. et al. Genome dynamics of the human embryonic kidney 293 lineage in response to cell biology manipulations. Nat. Commun. 5, 4767 (2014).
Wai, H. A. et al. Blood RNA analysis can increase clinical diagnostic rate and resolve variants of uncertain significance. Genet. Med. 22, 1005–1014 (2020).
Mailliot, J., Vivoli-Vega, M. & Schaffitzel, C. No-nonsense: insights into the functional interplay of nonsense-mediated mRNA decay factors. Biochem. J. 479, 973–993 (2022).
Grisart, B. et al. Genetic and functional confirmation of the causality of the DGAT1 K232A quantitative trait nucleotide in affecting milk yield and composition. Proc. Natl Acad. Sci. USA 101, 2398–2403 (2004).
Khan, M. Z. et al. Association of DGAT1 with cattle, buffalo, goat, and sheep milk and meat production traits. Front. Vet. Sci. 8, 712470 (2021).
Xiang, R. et al. Genetic score omics regression and multi-trait meta-analysis detect widespread cis -regulatory effects shaping bovine complex traits. Preprint at https://doi.org/10.1101/2022.07.13.499886 (2022).
Gulluni, F., De Santis, M. C., Margaria, J. P., Martini, M. & Hirsch, E. Class II PI3K functions in cell biology and disease. Trends Cell Biol. 29, 339–359 (2019).
Braccini, L. et al. PI3K-C2γ is a Rab5 effector selectively controlling endosomal Akt2 activation downstream of insulin signalling. Nat. Commun. 6, 7400 (2015).
Wehrman, M. E., Welsh, T. H. & Williams, G. L. Diet-induced hyperlipidemia in cattle modifies the intrafollicular cholesterol environment, modulates ovarian follicular dynamics, and hastens the onset of postpartum luteal activity. Biol. Reprod. 45, 514–522 (1991).
Liu, B., Gross, M., ten Hoeve, J. & Shuai, K. A transcriptional corepressor of Stat1 with an essential LXXLL signature motif. Proc. Natl Acad. Sci. USA 98, 3203–3207 (2001).
Sachdev, S. et al. PIASy, a nuclear matrix-associated SUMO E3 ligase, represses LEF1 activity by sequestration into nuclear bodies. Genes Dev. 15, 3088–3103 (2001).
Gross, M. et al. Distinct effects of PIAS proteins on androgen-mediated gene activation in prostate cancer cells. Oncogene 20, 3880–3887 (2001).
Gross, M., Yang, R., Top, I., Gasper, C. & Shuai, K. PIASy-mediated repression of the androgen receptor is independent of sumoylation. Oncogene 23, 3059–3066 (2004).
Takayanagi, H., Sato, K., Takaoka, A. & Taniguchi, T. Interplay between interferon and other cytokine systems in bone metabolism. Immunol. Rev. 208, 181–193 (2005).
Kim, S. et al. Stat1 functions as a cytoplasmic attenuator of Runx2 in the transcriptional program of osteoblast differentiation. Genes Dev. 17, 1979–1991 (2003).
Lin, H.-Y. et al. Insulin and leptin resistance with hyperleptinemia in mice lacking androgen receptor. Diabetes 54, 1717–1725 (2005).
VanRaden, P. M. & Wiggans, G. R. Derivation, calculation, and use of national animal model information. J. Dairy Sci. 74, 2737–2746 (1991).
Tribout, T. et al. Confirmed effects of candidate variants for milk production, udder health, and udder morphology in dairy cattle. Genet. Sel. Evol. 52, 55 (2020).
Sanchez, M.-P. et al. Sequence-based GWAS meta-analyses for beef production traits. Genet. Sel. Evol. 55, 70 (2023).
Rosen, B. D. et al. De novo assembly of the cattle reference genome with single-molecule sequencing. Gigascience 9, giaa021 (2020).
Sargolzaei, M., Chesnais, J. P. & Schenkel, F. S. A new approach for efficient genotype imputation using information from relatives. BMC Genomics 15, 478 (2014).
Hozé, C. et al. High-density marker imputation accuracy in sixteen French cattle breeds. Genet. Sel. Evol. 45, 33 (2013).
Boussaha, M. et al. Construction of a large collection of small genome variations in French dairy and beef breeds using whole-genome sequences. Genet. Sel. Evol. 48, 87 (2016).
Li, H. et al. The Sequence Alignment/Map format and SAMtools. Bioinformatics 25, 2078–2079 (2009).
Howie, B., Fuchsberger, C., Stephens, M., Marchini, J. & Abecasis, G. R. Fast and accurate genotype imputation in genome-wide association studies through pre-phasing. Nat. Genet. 44, 955–959 (2012).
Yang, J., Lee, S. H., Goddard, M. E. & Visscher, P. M. GCTA: a tool for genome-wide complex trait analysis. Am. J. Hum. Genet. 88, 76–82 (2011).
Nassar, L. R. et al. The UCSC Genome Browser database: 2023 update. Nucleic Acids Res. 51, D1188–D1195 (2023).
Thomsen, M. C. F. & Nielsen, M. Seq2Logo: a method for construction and visualization of amino acid binding motifs and sequence profiles including sequence weighting, pseudo counts and two-sided representation of amino acid enrichment and depletion. Nucleic Acids Res. 40, W281–W287 (2012).
Martin, F. J., Gall, A., Szpak, M. & Flicek, P. Accessing livestock resources in Ensembl. Front. Genet. 12, 650228 (2021).
Li, H. Aligning sequence reads, clone sequences and assembly contigs with BWA-MEM. Preprint at https://doi.org/10.48550/ARXIV.1303.3997 (2013).
DuBridge, R. B. et al. Analysis of mutation in human cells by using an Epstein-Barr virus shuttle system. Mol. Cell. Biol. 7, 379–387 (1987).
Huynh, H. T., Robitaille, G. & Turner, J. D. Establishment of bovine mammary epithelial cells (MAC-T): an in vitro model for bovine lactation. Exp. Cell Res. 197, 191–199 (1991).
Duvaud, S. et al. Expasy, the Swiss Bioinformatics Resource Portal, as designed by its users. Nucleic Acids Res. 49, W216–W227 (2021).
UniProt Consortium. UniProt: the Universal Protein Knowledgebase in 2023. Nucleic Acids Res. 51, D523–D531 (2023).
Davydov, E. V. et al. Identifying a high fraction of the human genome to be under selective constraint using GERP++. PLoS Comput. Biol. 6, e1001025 (2010).
Acknowledgements
The pcAT7-Glo1 vector was a kind gift from Scott I. Adamson and Brenton R. Graveley at the University of Connecticut. We thank Scott I. Adamson for his valuable advice on implementing the Vex-seq method. We thank Andrea Rau for their helpful suggestions for generating bar charts. We are grateful to the genotoul bioinformatics platform Toulouse Occitanie (Bioinfo Genotoul [https://doi.org/10.15454/1.5572369328961167E12]) for providing computing and storage resources. This work was performed in collaboration with the GeT core facility, Toulouse, France (GeT [https://doi.org/10.15454/1.5572370921303193E12]), and was supported by France Génomique National infrastructure, funded as part of 'Investissement d’avenir' programme managed by Agence Nationale pour la Recherche (contract ANR-10-INBS-09). This study was funded by the INRAE Animal Genetics division (A.B.).
Author information
Authors and Affiliations
Contributions
D.R. and A.B.: conceived and designed this study. A.B.: managed this study. M.C.: performed splicing predictions and cleaned NGS data. N.G.: performed laboratory experiments. M.B. and C.H.: managed sequence data and developed the original imputation procedure. M.-P.S. and D.B.: performed imputation and GWAS. M.C., N.G., M.-P.S. and A.B.: analysed the data. M.P.S. and A.B.: writing—original draft preparation. M.C., N.G., M.-P.S., D.R. and A.B.: writing—review and editing. All authors have read and agreed to the published version of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Peer review
Peer review information
Nature Communications thanks Dongxiao Sun, Ruidong Xiang and the other, anonymous, reviewer(s) for their contribution to the peer review of this work. A peer review file is available.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Source data
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Charles, M., Gaiani, N., Sanchez, MP. et al. Functional impact of splicing variants in the elaboration of complex traits in cattle. Nat Commun 16, 3893 (2025). https://doi.org/10.1038/s41467-025-58970-5
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41467-025-58970-5
