
Abstract
The role of rapid adaptation during species invasions has historically been minimized with the assumption that introductions consist of few colonists and limited genetic diversity. While overwhelming evidence suggests that rapid adaptation is more prevalent than originally assumed, the demographic and adaptive processes underlying successful invasions remain unresolved. Here we leverage a large whole-genome sequence dataset to investigate the relative roles of colonization history and adaptation during the worldwide invasion of the forage crop, Trifolium repens (Fabaceae). We show that introduced populations encompass high levels of genetic variation with little evidence of bottlenecks. Independent colonization histories on different continents are evident from genome-wide population structure. Five haploblocks—large haplotypes with limited recombination—on three chromosomes exist as standing genetic variation within the native and introduced ranges and exhibit strong signatures of parallel climate-associated adaptation across continents. Field experiments in the native and introduced ranges demonstrate that three of the haploblocks strongly affect fitness and exhibit patterns of selection consistent with local adaptation across each range. Our results provide strong evidence that large-effect structural variants contribute substantially to rapid and parallel adaptation of an introduced species throughout the world.
Similar content being viewed by others

Main
Invasive species threaten ecosystems, agriculture, health and culture. The cost of controlling the spread of these species is immense1,2,3, averaging US$26.8 billion per year globally. Yet, why certain introduced species become invasive is unclear. Despite substantial effort, research has identified few consistent predictors of invasion4,5,6,7,8. The roles that introduction history and evolutionary processes such as natural selection play in invasions have historically been neglected9,10,11,12. However, recent literature stemming from large-scale experiments and the genomic revolution suggests that rapid evolution may shape invasion success—particularly in species that have been widely introduced and represent important components of ecosystems across the globe13,14,15,16,17.
An early assumption in invasion biology posited that introductions involved severe bottlenecks that purge genetic variation and constrain adaptation10,18,19,20. However, many invasions do not fit this classic expectation21,22, especially for human-associated species that are repeatedly introduced. Repeated introductions and admixture between divergent genotypes can even increase genetic diversity in the introduced range22,23. Natural selection and rapid adaptation have also been increasingly documented across invasive species14,16,17,18,24,25. This paradigm shift leads to the questions that we address in this study. Specifically, how do introduction history and admixture shape population structure during invasions? What is the genetic architecture of adaptation during invasions? And, does parallel adaptation to climate occur across geographically disparate introductions?
Theoretical models predict that the first steps of rapid adaptation should involve mutations of large effect26. Limited studies on the genetics of adaptation during invasions generally support this16,17, although quantitative genomic approaches tend to bias detection towards large-effect variants27,28. Yet many traits critical for range expansion, such as growth rate, size and dispersal, are polygenic in diverse plants. Adaptation via structural variants may reconcile these observations. Structural variants often suppress recombination, allowing clusters of co-adapted small-effect alleles to be inherited as a single segregating unit29, and have been associated with rapid adaptation16,30,31. However, structural variants are difficult to link to fitness across native and introduced ranges, because reciprocal transplants are logistically challenging and are rarely combined with large-scale genomic analyses.
Increasing globalization has resulted in repeated introduction of human-commensal species worldwide. These species often encounter similar selection pressures throughout their ranges (for example, altered climate regimes, release from herbivores or loss of mutualists), thus some degree of parallel phenotypic and molecular adaptation might be expected32. However, introduction history and demography can shape genetic variation through factors such as the timing and order of allele arrival (priority effects33). Admixture among genetically differentiated native populations in introduced areas can also create unique combinations of alleles34. Finally, if selected traits are polygenic, different loci may underlie the same phenotype across regions, weakening signatures of parallel evolution. Effectively parsing introduction history from adaptation requires genomic data from populations spanning comparable climatic gradients in multiple regions.
White clover (Trifolium repens) is an outcrossing legume native to Europe and western Asia, introduced globally as a forage and cover crop. Domesticated between 1000 and 1200 ad in present-day Spain, it spread across Western Europe and the British Isles in the mid-1600s35. Introductions to North and South America, South Africa, Australia, Japan and China occurred by the late 1800s via European colonial expansion and probably involved both landraces and wild accessions36. Modern cultivars have been developed in North America, China, Australia and New Zealand using germplasm sourced from across the world37, and these cultivars were widely distributed after 195038. Previous simple sequence repeats (SSR)-based studies show high genetic diversity in both native and introduced populations39. Studies of a key defence polymorphism, cyanogenesis, have documented recurrent adaptive clines forming across climatic and urban–rural gradients in native and introduced regions, suggesting rapid post-introduction adaptation14,32,40,41,42. Likewise, additional climate-associated genetic clines have been documented across North America43.
Here we investigated how introduction history and adaptation interact to shape the global invasion of white clover across diverse climatic regions. Using population-genomic data from six continents, we reconstructed invasion history and identified signals of selection. We sequenced the genomes of 2,660 individuals from 13 native populations, 39 populations across five introduced ranges and 12 widely used cultivars (Fig. 1 and Supplementary Table 1; mean coverage 1.01×) using a low-coverage whole-genome strategy. This approach enables precise and accurate estimation of site frequency spectra and allele frequencies44,45, supporting analyses of population structure, selection signatures, haploblock detection and genome-wide association studies (GWAS)46,47,48,49. We independently validate fitness effects of identified variants by conducting four transcontinental field trials using a globally diverse set of accessions. Finally, we performed controlled growth chamber experiments to explore gene expression patterns, providing insight into the biological functions of candidate genes.

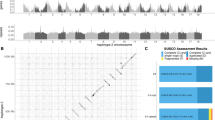
a, NGSadmix ancestries mapped across worldwide sampling. Each pie chart within map inserts reflects the average ancestries (K = 3) from a given wild population with orange, purple and green corresponding to different ancestries. Cultivars are not included. Numbers represent each population; normal typeset indicates population have >30 samples, italics indicates a population has <10 samples. b, Barplots depict ancestry output from the most likely K value (K = 3) for 2,660 individuals. Individuals are organized along the x axis by population sorted by continent, longitude and ancestry values. Numbers above barplots indicate populations from the above map. c, PCA visualizing population structure across ranges. Colour and shape indicate geographic location of each population as shown in the legend. Insert amplifies area of overlap between native and introduced populations. Numbers refer to populations from a and b. The ‘Spain’ point refers to samples from four cities with limited population structure.
Results
Introduction history
White clover does not exhibit a classic population bottleneck signature in any introduced region. Genetic diversity is high in both the native and introduced ranges, with no clear difference in π (native πAvg = 0.016, introduced πAvg = 0.015; Welch’s analysis of variance (ANOVA): F1,21.47 = 2.58, P = 0.12) or θw (native θAvg = 0.023, introduced θAvg = 0.019; Welch’s ANOVA: F1,13.89 = 1.23, P = 0.29). Despite this, there is twofold variation in diversity among populations within the same range (Extended Data Fig. 1; πRange = 0.013–0.025). Genome-wide Tajima’s D values are negative across both the native and introduced ranges, consistent with a recent population expansion (native DAvg = −0.70, introduced DAvg = −0.60). This pattern aligns with the recent worldwide spread of T. repens. However, Tajima’s D does not differ between native and introduced ranges (Welch’s ANOVA: F1,17.3 = 0.30, P = 0.59). Demographic modelling of effective population size (Ne) over the past 1,000 years reveals notable variation among populations, with historic increases in Ne in most cases. However, this variation does not correspond to native versus introduced status and there are no signatures of recent bottlenecks or expansions (Extended Data Fig. 1). These results are consistent with the colonization of each introduced area involving repeated introductions of a high number of genetically diverse individuals.
We examined genetic differentiation between populations in native and introduced ranges to better understand the independence of introduction events, different sources of introductions and potential patterns of introgression between introduced ranges. Consistent with high worldwide levels of genetic diversity and limited bottlenecks, differentiation among populations was low (worldwide average weighted pairwise FST = 0.027). Pairwise genetic differentiation was as strong within native and introduced regions as between regions (Extended Data Fig. 2). A strong isolation-by-distance pattern was evident in the native range (Mantel’s r = 0.82, P = 0.001), with weaker patterns within introduced regions (North America—Mantel’s r = 0.18, P = 0.10; South America—Mantel’s r = 0.55, P = 0.002). These results support several introductions from the native region accompanied by subsequent gene flow across each introduced region.
To better parse population structure, we conducted admixture analyses with NGSadmix50 using putatively neutral sites (four-fold degenerate sites). The most likely number of idealized populations was K = 3 (ref. 51). All populations contained all three ancestral gene pools (ancestries) reflecting high within-population variation. These ancestries were strongly represented in different areas of the native range, reflecting latitudinal and longitudinal patterns of isolation-by-distance (Fig. 1). Higher order K values (for example, K = 4, 6; Extended Data Fig. 3) further subdivide the native range along a latitudinal gradient. Such structure in the native range suggests that it should be possible to identify the major contributing sources for each introduction.
We compared ancestries of populations within the native and introduced ranges to infer colonization history and admixture. North American populations have ancestries most closely related to Spain in the south and France and Great Britain in the north. High-elevation populations in South America (for example, Medellin, Bogota and Quito) and Japanese populations resemble high-latitude populations in North America (that is, more orange ancestry; Fig. 1). Lower elevation southern populations in South America, as well as Australian populations, New Zealand populations, Chinese populations and South Africa, resemble southern populations in North America with similar ancestry coefficients to Spain (more green; Fig. 1). The similarities between different introduced areas probably reflect a shared introduction history as western European nations brought white clover to these areas, but may also reflect post-introduction admixture between regions, or ecological sorting due to shared climate or biotic selection factors. For instance, Japanese and Chinese populations have very divergent ancestries which probably reflect differences in introduction history. However, parallel differences within continents, such as those observed in North and South America, may reflect contemporary admixture or ecological sorting across climatic gradients.
To better determine the primary sources for each introduced region, we conducted a principal component analysis (PCA). Similarity in PC space closely corresponds to NGSadmix ancestries at K = 3. There is differentiation among populations from native and introduced regions (Fig. 1c; PERMANOVA: F1,49 = 4.7, P = 0.039), with a limited number of native populations from western Europe (Spain, Britain, France and Belgium) overlapping in PC space with the introduced populations. Similarity in PC space probably reflects colonization history and it is notable that there is no clear clustering of different introduction regions. For instance, Canadian populations (Toronto, Calgary, Edmonton and Vancouver) are located next to British, French and Belgian populations, probably reflecting the introduction of white clover to these regions during French and UK colonization. Likewise, other North American populations are located midway between Spanish, French and British populations, reflecting greater Spanish ancestry.
Introduction history alone does not explain the patterns observed in the PCA—introgression with modern agricultural cultivars could shape patterns of genome-wide population structure. To test this, we included 12 modern cultivars developed in North America, Australia and New Zealand using germplasm collected from North America, Australia, France, Spain and New Zealand. Surprisingly, cultivars clustered separately from introduced and native populations aside from the Spanish populations (PERMANOVA: F2,60 = 22.1, P = 0.001, Fig. 1c). With the exception of Grasslands Huia, cultivars are closely related to the Spanish populations and introduced populations from hot climates (Extended Data Fig. 3). Thus, the cultivars do not necessarily reflect the regions where each cultivar originated, but instead tend to have similar genetic compositions to one another. Nearly all these cultivars were derived from field populations bred for resistance to drought and other environmental stressors. Conversely, Grasslands Huia, a New Zealand-derived cultivar, is closely related to other New Zealand wild populations. Thus, although admixture between cultivars and introduced populations clearly occurs, substantial differentiation from natural populations persists.
Genomic basis of adaptation
Given the proliferation of white clover across diverse habitats, an important question is: what role has adaptation played in the spread of T. repens? Selection in introduced regions could favour different alleles that allow adaptation to new conditions in the introduced range and/or that underlie traits that promote rapid invasion. We identified genomic regions with allele frequency differentiation between the native and each of the five introduced regions using genome scans in 20-kilobase pair (kb) windows (BayPass contrast52; Extended Data Fig. 4 and Supplementary Table 2). Highly differentiated regions of the genome (top 1% of windows) overlapped between the native–introduced comparisons more than expected by chance (hypergeometric test: P ≤ 0.00001; Fig. 2), with the exception of the Europe–Japan contrast (hypergeometric test: P = 0.16). These shared patterns of differentiation between introduced regions provide evidence for parallel selection pressures across introduced regions. However, no differentiated genomic windows were shared across all five introductions (Fig. 2) and few were shared across four regions (27 windows; 1.6% of windows that are an outlier for any contrast). Consistent with the admixture analysis, North and South America share the most differentiated windows (128 windows, 29% of outlier windows). These results highlight parallel signatures of selection during range expansion across introduced regions.

a, Upset plot depicting outlier windows for native–introduced region contrasts. b, Upset plot depicting windows corresponding to climate adaptation in each range (outliers for XtX statistic and correlations with at least one climate variable). Blue portions of bars in a and b correspond to genomic windows within haploblocks, while black portions of bars represent non-haploblock regions. c, Five haploblocks (putative structural variants indicated by blue bars above the region) identified as outliers on MDS axes summarizing local population structure along chromosomes.
Selection can also cause rapid adaptation to the environmental heterogeneity within each introduced range. We examined genomic regions underlying climatic adaptation in each introduced region by performing genome scans to identify 20-kb windows enriched for sites showing both extreme population allele frequency differentiation (BayPass XtX53) and correlations with climate54 (Fig. 3). In each range, between 15% and 52% of XtX outlier windows were also outliers for correlations with at least one of six minimally correlated climate variables (XtX-EAA windows). In all ranges, this overlap was greater than would be expected by chance (hypergeometric test: P ≤ 7.01 × 10−31), indicating the importance of rapid adaptation to local climate post-introduction (Extended Data Fig. 5). Across ranges, we observed signatures of genetic parallelism in climate adaptation—the outlier XtX-EAA climate adaptation windows overlapped between ranges more often than expected by chance for all between-range comparisons (hypergeometric test: P < 0.013). There was also some overlap between the windows identified in the contrast analysis and the XtX analyses (native range, 8.6%; introduced ranges, 7%). This pattern may be expected given that the sampled introduced ranges tend to have warmer climates than most of the native range (mean annual temperature: native 10.3 °C, introduced 13.8 °C, P = 0.006) and thus regions under climate-associated selection should be differentiated from the native range.

Empirical P values for enrichment of XtX (an FST-like statistic that includes a correction for population structure) in 20-kbp windows across the genome using the WZA within each white clover range. Numbers along the x axis indicate chromosome number. Red points indicate XtX-EAA outliers, windows that are in top 1% of WZA scores for XtX and correlation (Kendall’s Tau) with at least one climate variable. Blue bars indicate haploblock locations.
The most notable peaks in each of the genome scans were extended regions of differentiation (haploblocks) on chromosomes 7, 9 and 13. Two partially overlapping haploblocks on chromosome 7 (HB7a1 and HB7a2) and one on chromosome 13 (HB13) were shared among the Europe–North America and Europe–South America contrasts (Extended Data Fig. 4). Allele frequencies within haploblocks HB7a1, and HB13 were strongly associated with climate variables across all ranges, while HB7a2 and HB9 showed strong associations in some ranges but not others. The breadth and synteny of these regions suggest that large structural variants may underlie convergent patterns of differentiation. We used a local PCA of population-genomic data16,55,56 to identify potential structural variants (inversions and translocations) across the genome. Local PCA has been shown to be a powerful method to identify haploblocks using WGS low-coverage data49 (Methods). Haploblock regions contained stretches of windows with divergent population structure that clustered into three groups in the PCA (consistent with three genotypes). The middle cluster, which contained putative heterozygous individuals, exhibited higher levels of local nucleotide diversity compared with homozygous individuals in the other two clusters. Corresponding clustering and heterozygosity patterns were also observed in local PCAs using single nucleotide polymorphism (SNP) data from the higher-coverage Toronto population (Extended Data Fig. 6). Haploblock regions exhibited elevated linkage disequilibrium (LD) compared with neighbouring genomic regions (Extended Data Fig. 6), and these LD blocks were reduced when examined within putative homozygous individuals. These genomic signals (PCA cluster, heterozygosity and LD patterns) are consistent with structural variants identified in other species16,56.
We identified signatures of five putative structural variants among 2,660 white clover samples (Fig. 2 and Extended Data Fig. 6). Haploblocks HB7a1, HB7a2, HB7b, HB9 and HB13 were 3.7, 7.1, 3.7, 1.2 and 1.8 megabase pairs in size, and contained 591, 1,014, 398, 152 and 227 genes, respectively. All haploblock reference and alternative alleles are found in nearly all the populations suggesting that haploblocks existed as standing genetic variation in the native range before introduction. Despite elevated LD across haploblocks, there are still high levels of polymorphism within each block, suggesting that haploblocks are old. However, allele frequencies differed between the introduced and native ranges for HB7a2 (t49 = −3.1, P = 0.003), HB9 (t49 = 2.1, P = 0.036) and HB13 (t49 = −2.2, P = 0.03) indicative of the different colonization history and environmental conditions in each range. Haploblocks have higher levels of within-range differentiation (XtX) than non-haploblock regions across every range, except for China (Extended Data Fig. 7), consistent with relatively strong selection on haploblocks by climatic variation within regions following introduction.
Haploblock regions have stronger signals of selection and parallelism across invasions than non-haploblock regions. Despite covering <2% of the genome, haploblocks contain, respectively, 14.8% and 6% of outlier windows for XtX-EAA and contrast scans. This represents a significant enrichment for XtX-EAA scans in all ranges (hypergeometric test: P ≤ 0.028) and for contrast scans between the native range and North and South America (Extended Data Fig. 7; 14% and 12% of contrast outlier windows, respectively; hypergeometric test: P ≤ 9.67 × 10−32). Furthermore, 29% and 10% of parallel windows (windows that were outliers in more than one range) for XtX-EAA and contrast scans, respectively, were found within haploblocks, marking a substantial enrichment in these regions relative to the rest of the genome (hypergeometric test: P ≤ 9.09 × −16). These results suggest that large structural variants played an important and often parallel role in range expansion following introduction.
Characterization of adaptive haploblocks
To independently validate evidence of selection on the haploblocks following introduction, we conducted a transcontinental field experiment using diverse populations from the native and introduced ranges coupled with a GWAS. The experiment included common gardens at low and high latitudes in the native range (Uppsala, Sweden; Montpellier, France) and the introduced North American range (Lafayette, LA, United States; Mississauga, Ontario, Canada). Each garden was planted with replicate plants from the same 96 natural populations; 47 populations collected along a latitudinal gradient in North America57 and 49 collected across Europe41. Using the same low-coverage whole-genome sequence approach as above, we genotyped 569 individuals for each of the five haploblocks. Frequencies of the reference and alternative haploblock alleles matched expectations from the worldwide dataset. We observed latitudinal clines in the predicted directions in North America for HB7a2, HB7b and HB9 (Fig. 4). We did not expect latitudinal clines for HB13 or HB7a1 because allelic variation at these haploblocks does not differ between high- and low-latitude populations in the native and eastern North American ranges.

a, Experimental design of the transcontinental field experiment. Points represent the 96 populations that were planted into each garden. Black asterisks are the locations of each garden. Insert picture is of the Mississauga, Ontario, Canada, garden. b, Alternative haploblock allele frequency for each individual from European (blue circles) populations or North American (gold squares) pooled across all four common gardens. Regression lines model allele frequency by latitude in Europe (blue) and North America (gold) with solid lines indicating statistically significant (two-sided ANOVA, P < 0.05) latitudinal clines and dash lines indicating non-significant regressions. c, Average relative fitness for each haploblock genotypes where the a allele represents the reference allele67 and the b allele represents that alternative allele. Numbers directly above genotypes are the number of samples included in each category. Relative fitness was calculated from total seed mass and standardized by the genotype with the highest fitness within each garden. Error bars represent standard error around the mean.
We examined whether allelic variation at each haploblock influenced survival in the first year, growth rate and fecundity (total seed mass). There were significant garden × haploblock genotype effects on fitness consistent with haploblocks conferring local adaptation in the directions expected from the above genome scans (Fig. 4c, Extended Data Fig. 8 and Supplementary Table 3). The strongest association was for HB13, where the alternative haploblock was strongly favoured in the native gardens, but the reference haploblock was strongly favoured in both North American gardens (ANOVA, garden × genotype: Χ2 = 9.6, P < 0.0001). Allelic variation at HB13 is highly predictive of fecundity in the Louisiana garden (Lafayette r2 = 0.28), and predicts more variation than a genomic covariance matrix. Likewise, the HB9 alternative haploblock was marginally favoured in the colder garden in both Europe and North America, while the reference haploblock was favoured in the warmer gardens in both ranges (ANOVA, garden × genotype: Χ2 = 2.6, P = 0.05). Notably, the alternative allele for other haploblocks (HB7a1, HB7a2 and HB7b) are at much lower frequencies in North American and European populations, reducing our power to detect associations with fitness. Nevertheless, patterns at each haploblock still largely fit predictions established from allele frequencies. For instance, plants homozygous for the alternative HB7a2 allele had 92% greater survival in the first year in the Canadian common garden, but none of these homozygotes survived the first year in the Louisiana garden (ANOVA, garden × genotype: Χ2 = 7.5, P = 0.059; Extended Data Fig. 8). Allelic variation at HB7a2 is also moderately predictive of fecundity in both the Canadian and Louisiana gardens (Toronto r2 = 0.05, Lafayette r2 = 0.17). These analyses provide experimental support that selection on haploblocks has driven rapid adaptation within introduced ranges.
We next evaluated which genes within each haploblock could be driving differences in fitness between gardens by conducting separate GWAS within the native and introduced gardens. This method is likely limited for identifying specific genes underlying fitness differences because there is elevated LD within haploblocks; however, there is substantial variation within haploblocks, which allowed us to identify distinct peaks of phenotype–genotype association. Loci in each haploblock were strongly associated with the ability to flower and total seed mass (Fig. 5, Extended Data Fig. 9 and Supplementary Table 4). Most hits were observed in the North American gardens due to sample size differences between gardens, and the analysis probably only detected a subset of fitness-associated genes as a result of limited sample size of some haplotype genotypes. The number of hits exceeded the genome-wide expectation for each haploblock for at least one fitness measure (Extended Data Fig. 10). All hits were located within 10 kb of annotated genes, but only two hits fell directly within the coding sequence of a predicted gene. The abundance of hits near predicted genes, yet the scarcity within coding sequence, is consistent with fitness-related SNPs being in regulatory regions (for example, promoter regions). Moreover, the number and location of fitness-associated SNPs within haploblocks suggests that there are multiple genomic regions under selection within each haploblock, and that differential expression may be an important driver of adaptive phenotypic differences.

GWAS hits for survival to flowering (triangles) and total seed mass (circles) are plotted above expression ribbons. Each dotted line corresponds to a GWAS analysis within a particular garden (Mississauga, Lafayette, Uppsala or Montpellier) or a GWAS analysis that merged the North American gardens (North America). Hits that either fall within a coding sequence or are within 10 kb of a known homologue are marked with a Greek or mathematical symbol as shown in the legend to the right of each graph. Differential expression ribbons visualize expression patterns for each gene within comparisons between condition (drought versus well-watered), latitude (low versus high) and range (native versus North American). Heatmaps for differential expression for each gene range from downregulated (blue) to upregulated (red). HB7a1, HB7a2 and HB7b are all found on chromosome 7, while HB9 is on chromosome 9 and HB13 is on chromosome 13. The position on chromosomes is indicated beneath differential expression heatmaps for each chromosome. Full descriptions of fitness GWAS hits and differentially expressed genes can be found in Supplementary Tables 3 and 5, respectively.
Genes near fitness-associated SNPs within the haploblocks correspond to stress resistance, defence and flowering, matching expectations from gene ontology (GO) analyses of haploblock regions (Supplementary Table 5). Of the multiple fitness-associated SNPs within the HB7a1 haploblock, one of the most prominent was found downstream of IAA6 (P = 1.32 × 10−5, β = −0.97), a gene encoding a key regulator of auxin responses, phototaxis and development in Arabidopsis58. The two GWAS hits underlying survival to flowering on HB7a2 were associated with MT1B (P = 2.18 × 10−7, β = 1.24) and GTG1 (P = 2.10 × 10−6, β = −1.187)—genes associated with water stress responses, root growth and light responses59,60. Two GWAS hits underlying survival to flowering on HB7b were within the coding sequence of ARF6 (P = 2.24 × 10−6, β = −1.73); ARF6 encodes a transcription factor involved in flower maturation in Arabidopsis61. Notably, several genes associated with photoperiodic control and flowering in other species are associated with survival to flowering within the HB13 haploblock including hits downstream of Hd16 (P = 3.61 × 10−5, β = −1.03)62 and SLP2 (P = 3.61 × 10−5, β = −1.03)63. Identification of these genes suggests that each haploblock contains ecologically important variation underlying adaptation following invasion and provides specific targets for downstream functional analysis.
We further validated fitness-associated SNPs within haploblocks using a manipulative RNA-seq experiment conducted in growth chambers. We evaluated genome-wide differential expression between high- and low-latitude white clover populations from the native and introduced range in dry-down and well-watered conditions. The water availability treatment was selected because differential mortality between common gardens was hypothesized to be associated with the divergent water regimes. While elevated, differentially expressed genes were not over-represented within haploblocks and had similar magnitude expression changes compared with the rest of the genome for all comparisons (treatment, range or latitude; Extended Data Fig. 10). However, a high percentage of hits in the fitness GWAS above were differentially expressed in at least one comparison (survival to flowering GWAS hits—38.0%, 68 of 179 genes; total seed mass GWAS hits—30.6%, 11 of 36 genes). These genes were relatively uniformly distributed across the different haploblocks, in which survival to flowering GWAS hits represented 25–48% of differentially expressed genes across haploblocks. This group included 12 genes with clear orthologues (survival to flower—ARC11, ATG3, CCL12, ENT1, EXPA10, IAA6, MT1B, PIN8, RAP74, RPL19, SLP2; total seed mass—GONST3) which were associated with fitness in GWAS analyses and had differential expression across drought treatment, range and latitude (ANOVA, treatment × range × latitude: Padj < 0.0001; Supplementary Table 6). Several of these genes (including IAA6, MT1B, ATG3, EXPA10 and RPL19) have been associated with drought and oxidative stress in other species59,64,65,66,67. In sum, the same genes identified in the fitness GWAS have different patterns of expression in populations from different ranges and latitudes. This result is consistent with cis-regulatory changes underlying rapid adaptation following introduction, but does not exclude the possibility that haploblocks also include ecologically important variation in protein-coding regions.
Discussion
We demonstrate that the worldwide invasion of white clover has been achieved through a complex pattern of global colonization and rapid adaptation. While population structure reflects some aspect of colonization history and independent introduction events, our demographic analyses are consistent with white clover undergoing repeated introductions, followed by admixture among diverse ancestral haplotypes. This complex introduction history has maintained substantial genetic diversity and high effective population sizes in introduced populations. Our results match a growing literature documenting introduction histories that include many source populations and repeated introductions throughout an invasion23,68,69,70. Further parsing the relative contributions of founder events, admixture and expansion will probably require historical sampling and more complex demographic models16,70,71.
There is strong evidence that climate-related selection has occurred in introduced ranges around the world. Within each range, genomic windows exhibiting extreme variation in allele frequency were enriched for correlations with the environment, demonstrating the key role that adaptation to climate has played during introduction. Moreover, selection scans for local adaptation and divergence from the native range show remarkable parallelism. The strongest and most parallel signatures of adaptation come from just a few haploblocks that also exhibit classic genomic signatures of structural rearrangements (inversions and translocations). Allelic variation within haploblocks is strongly associated with differences in relative fitness between common gardens in the native (Europe) and introduced (North America) range, demonstrating that haploblocks underlie patterns of local adaptation that have evolved in the last 400 years. Variation within these haploblocks suggests that the molecular basis of these differences lies in differential expression of key genes involved in developmental timing, stress tolerance and defence.
The identification of large-effect haploblocks driving rapid parallel adaptation provides key insights into the genomics of rapid adaptation. Our results complement decades of empirical studies documenting clines in inversion polymorphisms in insects31,72,73,74,75, mollusks76,77, fish78, mammals79 and plants16,30,80, including following recent invasions in Drosophila81 and Ambrosia16,80. Likewise, theoretical studies have long-predicted that large-effect loci and inversions should underlie rapid adaptation. Our study validates the adaptive importance of these haploblocks, using common gardens to demonstrate the contemporary fitness benefits and trade-offs associated with haploblocks. Three notable observations stem from our system that contribute to our understanding of structural variants and rapid parallel evolution. First, our results suggest that the haploblocks are contributing disproportionately to local adaptation compared with SNPs within other windows. Second, we find substantial diversity within each haploblock allele including variation linked to fitness; this suggests not only that structural variants are old, but also that large structural variants can accumulate different locally beneficial alleles82,83. Third, unlike theoretical models of adaptive walks that rely on de novo mutation, each identified haploblock exists as standing genetic variation in the native range, and repeated introductions facilitated their spread to different regions around the globe. Within the context of an invasion, lag periods preceding rapid expansion following introduction may not only be an opportunity for demographic increase and sorting, but also an opportunity for additional input of standing variation from the native or other introduced ranges.
Conclusions
Our results demonstrate the power and importance of rapid adaptation during an invasion. We find that despite a complex introduction history, strong selection acts to generate both parallel and non-parallel signatures across invasive regions with structural variants playing a key role in local adaptation. We suggest that divergent selection and adaptation are probably the norm for human-commensal species, with large-effect variants present as standing genetic variation in the native range contributing to invasion success globally.
Methods
Population genomics dataset
Our dataset includes low-coverage whole-genome sequences from 2,660 samples collected from 50 different cities and surrounding rural areas spanning the native range in Europe and Western Asia (12 cities) as well as introductions to North America (11 cities), South America (10 cities), Japan (4 cities), China (4 cities), Oceania (8 cities) and Africa (1 city). These samples were originally collected as part of the Global Urban Evolution Project from 2016 to 201942. Each city was treated as a single population and sample sizes for each population ranged from 5 to 120. This heterogeneity in sample size was intentional as we wanted to include a number of cities with high sampling for better estimates of site frequency spectra and population-genomic statistics (31 cities; average 80.74, standard deviation 17.7 individuals). We then added further cities with lower sampling that we deemed as important areas for understanding colonization history (19 cities; average 5.95, standard deviation 0.23 individuals). Additionally, we sequenced 32 samples collected from four cities in Spain (A Coruña, Granada, Salamanca and San Sebastian)41, as well as 12 popular cultivars bred in the United States (Durana, Patriot, Renovation, Merit, Pilgrim, Osecola, LA-S1 and CA Ladino), Australia (Irrigation) and New Zealand (Crau, Grassland Huia and Grasslands Pitua). Cultivars are still introduced today across crop fields, as forage crops, in public parks and as bait by deer hunters. Details on library construction and sequencing for new samples are described in the Supplementary Information. Environmental data for each sampling location were extracted from BIOCLIM using the raster v.3.6-26 package in R. Importantly, although some samples within the population-genomic overlap with those in another recent paper42, the research questions, bioinformatic and statistical analysis, results and conclusions are all distinct and new.
Analysis of demography and worldwide population structure
Sequences were processed using a common pipeline (https://github.com/James-S-Santangelo/glue_dnaSeqQC) and aligned to a chromosome-level genome assembly84. For demographic analysis, we extracted four-fold degenerate sites using the Degeneracy Pipeline (https://github.com/tvkent/Degeneracy) and used all sites for genome scans. We assessed population genomic diversity, differentiation and structure using genotype likelihoods in ANGSD v.0.929 (ref. 85). To examine genetic diversity within each population, we first calculated genotype likelihoods and site allele frequency likelihoods (SAF) for each population independently using only four-fold degenerate sites (-GL 1 -doMaf 2 -doCounts 1 -dumpCounts 2 -baq 2 -minQ 20 -minMapQ 30 -doSaf 1 -sites 4fold.sites). One-dimensional site frequency spectra were used to calculate thetas (θw and θπ) using realSFS saf2theta and thetaStat do_stat. We recalculated genotype likelihoods and SAFs for each population using the reference genome to assign major and minor alleles (-GL 1 -doMaf 2 -minMaf 0.05 -doCounts 1 -dumpCounts 2 -baq 2 -minQ 20 -minMapQ 30 -doSaf 5 -doMajorMinor 4 -sites 4fold.sites) for estimating differentiation using Hudson’s Fst (realSFS fst index -whichFst 1). Average number of SNPs per population for these analyses was 10,784,068 (s.d. 865,692).
We identified signatures of bottlenecks by comparing genetic diversity statistics and Tajima’s D between native and each introduced region. Models including covariates for population sample size and number of sites do not qualitatively change conclusions. We estimated Ne through time using a coalescent framework implemented in EPOS86, focusing on population contractions in the last 1,000 years as signatures of bottlenecks. We investigated patterns of genetic differentiation within and among populations across the native and introduced ranges by calculating pairwise weighted and unweighted FST values using ANGSD87,88. Isolation by distance and isolation by environment in native and introduced ranges were assessed via Mantel tests using the mantel() function within the vegan library89 with Haversine geographic distance matrices via distm() function within the geodist library and climatic distance matrices using the dist() function in the vegan library.
We examined worldwide population structure and individual ancestry using NGSadmix50. Genotype likelihoods were re-estimated treating all samples as a single population and adding a minor allele frequency cutoff of 0.05 (-minMaf). This resulted in 533,655 sites. NGSadmix runs included three to eight replicates of K = 1–8 using 10,000 iterations per replicate (-maxIter). To determine the most likely number of clusters, we examined standard deviations in likelihoods at each K and used the method described in ref. 51 to identify the most likely number of ancestral clusters and the uppermost level of population structure. To better dissect introduction history, we examined patterns of nested population structure using PCA. We used PCAngsd90 to generate a variance–covariance matrix using genotype likelihoods and estimated allele frequencies (pcangsd.py), and then extracted the eigenvectors (the principal components) of the covariance matrix using eigen() function in R. To examine potential clustering within the PCA, we conducted PERMANOVA using the adonis2() function within the vegan library89. Differences in number of samples, sequencing coverage, batch effects from sequencing runs have limited impact on our inferences of population structure (Supplementary Information). Additionally, distance-based pruning of our dataset and removing haploblocks do not alter population structure (Supplementary Figs. 2 and 3).
Genome scans for signatures of selection
We identified regions of the genome under selection using two separate approaches. First, we contrasted allele frequencies in the native range with those in each invasive range. Second, we looked for relationships between allele frequency and climate within each individual range as evidence of local climate adaptation. Genotype likelihoods were calculated in ANGSD (-GL 1 -doGlf 2 -doMajorMinor 4 -doMaf 2 -baq 2 -minQ 20 -minMapQ 30 -SNP_pval 1e-6 -minMaf 0.05) in each range (Europe, North America, South America, Oceania, China and Japan) for climate adaptation scans or pair of ranges for contrast scans. We then estimated population allele frequencies for these sites in each population individually using ANGSD (-GL 1 -doGlf 2 -doMajorMinor 4 -doMaf 2 -doCounts 1 -baq 2 -minQ 20 -minMapQ 30 -minMaf 0). Allele frequencies for sites were only used if they were callable for all populations in a particular scan (14.7–22.7 M sites per range).
We used the BayPass contrast statistic52 to summarize allele frequency differentiation at each site between European populations and populations from an invasive range while correcting for population structure. Enrichment of contrast outliers was calculated for non-overlapping 20-kb windows using the weighted-Z analysis (WZA91) and outlier windows were defined as the 1% tail of the distribution of WZA window scores.
We tested for genomic regions with greater differentiation than expected by chance within each native range while accounting for genome-wide population structure using the BayPass core model. For these genome scans, we generated population covariance omega matrices for each range in BayPass v.2.2 (refs. 52,53) using 10,000 sites sampled from outside annotated genes. We then ran the BayPass core model to quantify allele frequency divergence between populations within each range while accounting for population structure using the omega matrix (XtX). Next, correlations between population allele frequencies in each range and six minimally correlated bioclimatic variables (BIO1, BIO2, BIO8, BIO12, BIO15 and BIO19 from the WorldClim dataset54) were quantified using the absolute value of Kendall’s Tau. In each range, we used WZA to identify non-overlapping 20-kb windows that were enriched for outliers for the XtX statistic and correlations with each bioclimatic variable. Outlier windows for each statistic were defined as the 1% tail of the distribution of WZA window scores. Outlier windows that overlapped between genome scans were identified, and their enrichment relative to a hypergeometric distribution was tested in R.
Haploblock identification
We identified haploblocks—population-genomic signatures of large structural variants—using local PCA, which has proved reliable in a range of genomic datasets (for example, refs. 16,55,56) including those with low-coverage whole-genome sequencing data49. We modified the method described by ref. 55 to use covariance matrices from PCAngsd v1.10 (ref. 90), which were calculated in 100-kb windows from beagle files generated in ANGSD v.0.929 (5) (-GL 2 -doMajorMinor 1 -doCounts 1 -doGLF 2 -SNP_pval 1e-6 -doMaf 2 -doGeno -1 -doPost 1 -minMapQ 30 -minQ 20 -trim 5 -minMaf 0.05 -minInd 665 -geno_minDepth 2 -setMinDepthInd 2 -uniqueOnly 1). Local population structure along each chromosome was analysed on five multidimensional scaling (MDS) axes and outliers were identified from the 5% corners of each pair of MDS axes. We selected MDS scan regions for further analysis on the basis of the presence of clusters of a particular outlier in a chromosomal region, that is, stretches of a chromosome where the population structure was both similar and extreme. In total, ten such regions were analysed, but five were excluded on the basis of lack of clustering in the local PCA and/or patterns of heterozygosity incongruous with a structural variant. Heterozygosity was also calculated for each sample in each candidate region using ANGSD (-dosaf 1 -minMapQ 30 -minQ 20 -trim 5 -GL 2) and realSFS v.0.929 (ref. 92) (-fold 1). After filtering out samples with less than 0.4× coverage, putative structural variants were identified by the presence of three clusters of samples along a single principal component axis, indicative of two homozygous and one heterozygous inversion genotype. Samples were assigned to clusters manually. We validated haploblock genotyping first by looking for the presence of significantly elevated heterozygosity in the middle (heterozygote) cluster (Wilcoxon test P < 0.0003 for all heterozygote versus homozygote comparisons). Second, we performed LD scans with ngsLD v.1.2.0 (ref. 93) (--min_maf 0.05 --max_kb_dist 0) on 5,000 randomly sampled sites from each chromosome containing a haploblock. For each haploblock, LD scans were run on a set of samples homozygous for the more common haploblock allele, as well as a random set of samples of the same size. We further tested our haploblock genotyping using 109 samples from Toronto that were sequenced to a coverage of ~10×. We called SNPs from alignments of these samples using FreeBayes v.1.3.6 (ref. 94) and filtered them using VCFtools v.0.1.15 (ref. 95) (--minQ 30 --minGQ 20 --minDP 5 --max-alleles 2 --max-missing 0.7). To identify GO terms enriched in haploblocks, the topGO library96 was used with Fisher’s exact test, the ‘weight01’ algorithm and P < 0.05 to assess significance.
Associations between haploblocks and fitness
We examined patterns of local adaptation and the genomics of adaptation using four common gardens located in the southern and northern region of the native range (Montpellier, France and Uppsala, Sweden, respectively) and the southern and northern regions within the North American introduced range (Lafayette, United States, and Mississauga, Canada, respectively). This study was originally reported by ref. 57, but the sequencing and GWAS for this work is new to this study. Common gardens were conducted for 2 years at each site, 2020–21 in North American gardens and 2021–22 in European gardens. Seedlings from the same lines were planted in each garden. Seeds were collected from 49 white clover populations spanning a 27° latitudinal gradient in Europe and from 47 additional populations spanning a 21° latitudinal gradient in North America. Seeds were grown for a single refresher generation and outcrossed via hand-pollination within each population. We established four to six outbred lines per population before randomizing and planting directly into the natural soil of a cultivated lawn at each site. Survival was surveyed and mature fruit were collected weekly. We report two measures of fitness: ‘survival to flowering’ is a binary variable that indicates whether a plant was able to flower during the 2-yr experiment and represents both viability and ability to mate; ‘total seed mass’ reflects both viability and fecundity as plants that did not produce any seeds had no seed mass.
We generated low-coverage whole-genome sequences for 569 samples across the four gardens using the same library construction and bioinformatics pipelines as above. We estimated haploblock genotypes by performing local PCAs as above on each previously identified haploblock region including all lcWGS samples. The first two principal components of genetic variation across population-genomic and common garden samples for each haploblock region were visualized and used to assign common garden samples to genotype clusters.
We assessed whether haploblocks were associated with adaptation following introduction via a three-pronged approach. We first validated our population genomics dataset by using linear models (lm()) to identify associations between haploblock genotype and latitude of collection site. We then qualitatively compared whether clines in the native and introduced region in these gardens matched the population-genomic dataset. Second, we examined how haploblock variation impacts fitness across gardens. We modelled survival to flower and total seed mass in separate univariate generalized linear models with garden, genotype and garden × genotype interaction as factors. GLMs were implemented using glm() and statistical significance of each factor was assessed using Anova() with Type III sum of squares in the car library97. Survival to flower was modelled with a binomial error distribution and a logit link function. Total seed mass was log(+1) transformed and modelled with a Gaussian distribution and identity link function. Finally, we calculated relative fitness from total seed mass data for each haploblock to better understand the strength of selection acting on each haploblock within each garden. Relative fitness for each haploblock was calculated by dividing each individual value for total seed mass by the average value of total seed mass for the genotype with the highest fitness in the garden.
To identify the genes and phenotypes potentially under selection, we conducted GWAS with a genotype-likelihood framework implemented in ANGSD. We conducted independent GWAS for the two fitness traits in each garden. Then, we pooled European gardens and North American gardens and conducted GWAS for each trait in each pooled sample. Genotype likelihoods were estimated for each range (174 individuals from the native European range and 395 individuals from the introduced North American range) in ANGSD (-GL 1 -minMaf 0.05 -minMapQ 30 -minQ 20). GWAS used a hybrid model (-doAsso 5) which first uses a score statistic to evaluate the joint maximum likelihood estimate between a trait and an observed marker98. If the chi-square test falls below a particular threshold (-hybridThres 0.05), a latent genotype model with an expectation-maximization algorithm is fit45. We controlled for population structure by adding the first 20 principal components as covariates. Principal components were generated in PCAngsd as above. In GWAS for each combined range, we also added garden as a covariate. To account for multiple tests, we used a conservative Bonferroni correction. We used permutation analyses to determine whether the number of fitness GWAS hits exceeded expectations from the rest of the genome (Supplementary Information).
Differential expression analysis
We performed a manipulative experiment to examine variation in expression between white clover populations in the native and introduced range under dry down and well-watered conditions. This study was first reported by ref. 99 and we narrow our focus here to differential expression analyses in identified haploblock regions. We grew seeds collected from three or four populations from low latitude and high latitude in the European and North American ranges (14 populations total). Seeds for each population had been pooled from >25 different maternal lines, and we grew one to three seeds from each population in the control and well-watered treatments (47 total samples). Thus, biological replication occurred at the population level. Plants were grown for 6 weeks to accumulate aboveground and belowground biomass. At 6 weeks, all pots were saturated with water by bottom-watering. Plants in the control (well-watered) flats received periodic watering according to our standard greenhouse protocol. Plants in the dry down treatment did not receive additional water. Each day, we assessed soil moisture in each pot using a SMT150T soil moisture meter (Dynamax). Leaf tissue from two healthy adult leaves was flash frozen in liquid nitrogen 10 days after the dry down treatment began from plants in both the well-watered and control treatment. Library construction, sequencing and bioinformatics details in the Supplementary Information.
We used DESeq2 (ref. 100) to test for differences in transcript abundance between dry down and well-watered treatment groups, between the North American and European ranges, and between high- and low-latitude populations. We controlled for volumetric water content at time of tissue collection by treating it as a covariate in each of the DEseq2 models. We used two different models to examine differential patterns of gene expression across treatments, range and latitude. The first included all interactions (treatment × range × latitude). The second set of models were univariate models examining differential expression across treatment, range and latitude separately. Genes were categorized as differentially expressed if false discovery rate (FDR) was <0.1. We evaluated whether transcribed genes located within haploblocks were more or less differentially expressed than in other regions of the genome by resampling across the genome. Briefly, the same number of genes found within each haploblock were randomly sampled across the genome 10,000 times while preserving synteny. The number of genes with an FDR < 0.1 for each of the 10,000 sampled haploblocks was summed and the average log2Foldchange was calculated, which were then used to create a null distribution for each haploblock region of the expected number of differentially expressed genes and their relative log2Foldchange.
Ethics and inclusion
This study involves worldwide collection and sequencing of plant germplasm. All collectors were given opportunity to collaborate and obtain authorship. All collections were properly permitted with local authorities.
Reporting summary
Further information on research design is available in the Nature Portfolio Reporting Summary linked to this article.
Data availability
Low-coverage whole-genome sequences for accessions used in population genomics analyses can be found as fastq files in the NCBI SRA database (Bioprojects: PRJNA1081485, PRJNA1179961). Metadata and fitness data from the four-way common garden study can be found on Dryad101 and associated low-coverage whole-genome sequences are in the NCBI SRA database (Biooproject: PRJNA1098360). Raw fastq files from RNA-seq expression experiment can be found in the NCBI SRA database (Bioproject: PRJNA1131002). Source data are provided with this paper.
Code availability
All code from this paper is available via GitHub at github.com/pbattlay/glue-invasions (ref. 102).
References
Pimentel, D., Lach, L., Zuniga, R. & Morrison, D. Environmental and economic costs of nonindigenous species in the United States. BioScience 50, 53 (2000).
Pimentel, D., Zuniga, R. & Morrison, D. Update on the environmental and economic costs associated with alien-invasive species in the United States. Ecol. Econ. 52, 273–288 (2005).
Diagne, C. et al. High and rising economic costs of biological invasions worldwide. Nature 592, 571–576 (2021).
Hayes, K. R. & Barry, S. C. Are there any consistent predictors of invasion success? Biol. Invasions 10, 483–506 (2008).
Catford, J. A. et al. Traits linked with species invasiveness and community invasibility vary with time, stage and indicator of invasion in a long‐term grassland experiment. Ecol. Lett. 22, 593–604 (2019).
Kolar, C. S. & Lodge, D. M. Progress in invasion biology: predicting invaders. Trends Ecol. Evol. 16, 199–204 (2001).
Davies, K. F., Harrison, S., Safford, H. D. & Viers, J. H. Productivity alters the scale dependence of the diversity invasibility relationship. Ecology 88, 1940–1947 (2007).
Levine, J. M., Adler, P. B. & Yelenik, S. G. A meta‐analysis of biotic resistance to exotic plant invasions. Ecol. Lett. 7, 975–989 (2004).
Bock, D. G. et al. What we still don’t know about invasion genetics. Mol. Ecol. 24, 2277–2297 (2015).
Barrett, S. C. H. Foundations of invasion genetics: the Baker and Stebbins legacy. Mol. Ecol. 24, 1927–1941 (2015).
Matheson, P. & McGaughran, A. Genomic data is missing for many highly invasive species, restricting our preparedness for escalating incursion rates. Sci. Rep. 12, 13987 (2022).
Hodgins, K. A., Battlay, P. & Bock, D. G. The genomic secrets of invasive plants. New Phytol. 245, 1846–1863 (2025).
Huey, R. B. Rapid evolution of a geographic cline in size in an introduced fly. Science 287, 308–309 (2000).
Kooyers, N. J. & Olsen, K. M. Rapid evolution of an adaptive cyanogenesis cline in introduced North American white clover (Trifolium repens L.). Mol. Ecol. 21, 2455–2468 (2012).
Colautti, R. I. & Barrett, S. C. H. Rapid adaptation to climate facilitates range expansion of an invasive plant. Science 342, 364–366 (2013).
Battlay, P. et al. Large haploblocks underlie rapid adaptation in the invasive weed Ambrosia artemisiifolia. Nat. Commun. 14, 1717 (2023).
Bock, D. G., Kantar, M. B., Caseys, C., Matthey-Doret, R. & Rieseberg, L. H. Evolution of invasiveness by genetic accommodation. Nat. Ecol. Evol. 2, 991–999 (2018).
Colautti, R. I. & Lau, J. A. Contemporary evolution during invasion: evidence for differentiation, natural selection, and local adaptation. Mol. Ecol. 24, 1999–2017 (2015).
Allendorf, F. W. & Lundquist, L. L. Introduction: population biology, evolution, and control of invasive species. Conserv. Biol. 24, 30 (2003).
Schrieber, K. & Lachmuth, S. The genetic paradox of invasions revisited: the potential role of inbreeding × environment interactions in invasion success. Biol. Rev. 92, 939–952 (2017).
Bieker, V. C. et al. Uncovering the genomic basis of an extraordinary plant invasion. Sci. Adv. 8, eabo5115 (2022).
Dlugosch, K. M. & Parker, I. M. Founding events in species invasions: genetic variation, adaptive evolution, and the role of multiple introductions. Mol. Ecol. 17, 431–449 (2008).
Kolbe, J. J. et al. Genetic variation increases during biological invasion by a Cuban lizard. Nature 431, 177–181 (2004).
Simón-Porcar, V. I., Silva, J. L. & Vallejo-Marín, M. Rapid local adaptation in both sexual and asexual invasive populations of monkeyflowers (Mimulus spp.). Ann. Bot. 127, 655–668 (2021).
Vandepitte, K. et al. Rapid genetic adaptation precedes the spread of an exotic plant species. Mol. Ecol. 23, 2157–2164 (2014).
Orr, H. A. The population genetics of adaptation: the distribution of factors fixed during adaptive evolution. Evolution 52, 935–949 (1998).
Beavis, W. D. The power and deceit of QTL experiments: lessons from comparative QTL studies. In Proc. 49th Annual Corn Sorghum Research Conference (ed. Wilkinson, D.B.) 250–266 (American Seed Trade Association, 1994).
Wray, N. R. et al. Pitfalls of predicting complex traits from SNPs. Nat. Rev. Genet. 14, 507–515 (2013).
Kirkpatrick, M. & Barton, N. H. Chromosome inversions, local adaptation and dpeciation. Genetics 173, 419–434 (2006).
Lowry, D. B. & Willis, J. H. A widespread chromosomal inversion polymorphism contributes to a major life-history transition, local adaptation, and reproductive isolation. PLoS Biol. 8, e1000500 (2010).
Ma, L.-J. et al. Rapid and repeated climate adaptation involving chromosome inversions following invasion of an insect. Mol. Biol. Evol. 41, msae044 (2024).
Kooyers, N. J. & Olsen, K. M. Searching for the bull’s eye: agents and targets of selection vary among geographically disparate cyanogenesis clines in white clover (Trifolium repens L.). Heredity 111, 495–504 (2013).
Keller, S. R. & Taylor, D. R. History, chance and adaptation during biological invasion: separating stochastic phenotypic evolution from response to selection. Ecol. Lett. 11, 852–866 (2008).
Bock, D. G. et al. Changes in selection pressure can facilitate hybridization during biological invasion in a Cuban lizard. Proc. Natl Acad. Sci. USA 118, e2108638118 (2021).
Kjærgaard, T. A plant that changed the world: The rise and fall of clover 1000–2000. Landsc. Res. 28, 41–49 (2003).
Carrier, L. & Bort, K. S. The history of Kentucky bluegrass and white clover in the United States. Agron. J. 8, 256–267 (1916).
Caradus, J. R. & Woodfield, D. R. Review: world checklist of white clover varieties II. N. Z. J. Agric. Res. 40, 115–206 (1997).
Mather, R. D. J., Melhuish, D. T. & Herlihy, M. Trends in the global marketing of white clover cultivars. NZGA RP Ser. 6, 7–14 (1996).
Wu, F. et al. Genetic diversity and population structure analysis in a large collection of white clover (Trifolium repens L.) germplasm worldwide. PeerJ 9, e11325 (2021).
Daday, H. Gene frequencies in wild populations of Trifolium repens L. III. World distribution. Heredity 12, 169–184 (1958).
Innes, S. G., Santangelo, J. S., Kooyers, N. J., Olsen, K. M. & Johnson, M. T. J. Evolution in response to climate in the native and introduced ranges of a globally distributed plant. Evolution 76, 1495–1511 (2022).
Santangelo, J. S. et al. Global urban environmental change drives adaptation in white clover. Science 375, 1275–1281 (2022).
Kuo, W., Zhong, L., Wright, S. J., Goad, D. M. & Olsen, K. M. Beyond cyanogenesis: temperature gradients drive environmental adaptation in North American white clover (Trifolium repens L.). Mol. Ecol. 33, e17484 (2024).
Lou, R. N., Jacobs, A., Wilder, A. P. & Therkildsen, N. O. A beginner’s guide to low‐coverage whole genome sequencing for population genomics. Mol. Ecol. 30, 5966–5993 (2021).
Fumagalli, M. Assessing the effect of sequencing depth and sample size in population genetics inference. PLoS ONE 8, e79667 (2013).
DeSaix, M. G. et al. Low‐coverage whole genome sequencing for highly accurate population assignment: mapping migratory connectivity in the American Redstart (Setophaga ruticilla). Mol. Ecol. 32, 5528–5540 (2023).
Andrews, K. R. et al. Whole genome resequencing identifies local adaptation associated with environmental variation for redband trout. Mol. Ecol. 32, 800–818 (2023).
Andrade, P. et al. Selection against domestication alleles in introduced rabbit populations. Nat. Ecol. Evol. 8, 1543–1555 (2024).
Mérot, C. et al. Locally adaptive inversions modulate genetic variation at different geographic scales in a seaweed fly. Mol. Biol. Evol. 38, 3953–3971 (2021).
Skotte, L., Korneliussen, T. S. & Albrechtsen, A. Estimating individual admixture proportions from next generation sequencing data. Genetics 195, 693–702 (2013).
Evanno, G., Regnaut, S. & Goudet, J. Detecting the number of clusters of individuals using the software structure: a simulation study. Mol. Ecol. 14, 2611–2620 (2005).
Olazcuaga, L. et al. A whole-genome scan for association with invasion success in the fruit fly Drosophila suzukii using contrasts of allele frequencies corrected for population structure. Mol. Biol. Evol. 37, 2369–2385 (2020).
Gautier, M. Genome-wide scan for adaptive divergence and association with population-specific covariates. Genetics 201, 1555–1579 (2015).
Fick, S. E. & Hijmans, R. J. WorldClim 2: new 1-km spatial resolution climate surfaces for global land areas. Int. J. Climatol. 37, 4302–4315 (2017).
Li, H. & Ralph, P. Local PCA shows how the effect of population structure differs along the genome. Genetics 211, 289–304 (2019).
Todesco, M. et al. Massive haplotypes underlie ecotypic differentiation in sunflowers. Nature 584, 602–607 (2020).
Albano, L. J. et al. Adaptation to climate in the native and introduced ranges of a cosmopolitan plant. Preprint at bioRxiv https://doi.org/10.1101/2024.09.16.613311 (2024).
Overvoorde, P. J. et al. Functional genomic analysis of the AUXIN/INDOLE-3-ACETIC ACID gene family members in Arabidopsis thaliana [W]. Plant Cell 17, 3282–3300 (2005).
Yamauchi, T., Fukazawa, A. & Nakazono, M. METALLOTHIONEIN genes encoding ROS scavenging enzymes are down-regulated in the root cortex during inducible aerenchyma formation in rice. Plant Signal. Behav. 12, e1388976 (2017).
Jaffé, F. W. et al. G protein–coupled receptor-type G proteins are required for light-dependent seedling growth and fertility in Arabidopsis. Plant Cell 24, 3649–3668 (2012).
Nagpal, P. et al. Auxin response factors ARF6 and ARF8 promote jasmonic acid production and flower maturation. Development 132, 4107–4118 (2005).
Hori, K. et al. Hd16, a gene for casein kinase I, is involved in the control of rice flowering time by modulating the day‐length response. Plant J. 76, 36–46 (2013).
Jorgensen, S. A. & Preston, J. C. Differential SPL gene expression patterns reveal candidate genes underlying flowering time and architectural differences in Mimulus and Arabidopsis. Mol. Phylogenet. Evol. 73, 129–139 (2014).
Salehin, M. et al. Auxin-sensitive Aux/IAA proteins mediate drought tolerance in Arabidopsis by regulating glucosinolate levels. Nat. Commun. 10, 4021 (2019).
Harb, A., Krishnan, A., Ambavaram, M. M. R. & Pereira, A. Molecular and physiological analysis of drought stress in Arabidopsis reveals early responses leading to acclimation in plant growth. Plant Physiol. 154, 1254–1271 (2010).
Moin, M., Bakshi, A., Madhav, M. S. & Kirti, P. B. Expression profiling of ribosomal protein gene family in dehydration stress responses and characterization of transgenic rice plants overexpressing RPL23A for water-use efficiency and tolerance to drought and salt stresses. Front. Chem. 5, 97 (2017).
Han, S. et al. Cytoplastic glyceraldehyde-3-phosphate dehydrogenases interact with ATG3 to negatively regulate autophagy and immunity in Nicotiana benthamiana. Plant Cell 27, 1316–1331 (2015).
Vallejo-Marín, M. et al. Population genomic and historical analysis suggests a global invasion by bridgehead processes in Mimulus guttatus. Commun. Biol. 4, 327 (2021).
Dlugosch, K. M., Anderson, S. R., Braasch, J., Cang, F. A. & Gillette, H. D. The devil is in the details: genetic variation in introduced populations and its contributions to invasion. Mol. Ecol. 24, 2095–2111 (2015).
van Boheemen, L. A. et al. Multiple introductions, admixture and bridgehead invasion characterize the introduction history of Ambrosia artemisiifolia in Europe and Australia. Mol. Ecol. 26, 5421–5434 (2017).
Kreiner, J. M. et al. Repeated origins, widespread gene flow, and allelic interactions of target-site herbicide resistance mutations. eLife 11, e70242 (2022).
Calboli, F. C. F., Kennington, W. J. & Partridge, L. QTL mapping reveals a striking coincidence in the positions of genomic regions associated with adaptive variation in body size in parallel clines of Drosophila melanogaster on different continents. Evolution 57, 2653–2658 (2003).
Mérot, C. et al. Intercontinental karyotype–environment parallelism supports a role for a chromosomal inversion in local adaptation in a seaweed fly. Proc. R. Soc. B 285, 20180519 (2018).
Knibb, W. R. Chromosome inversion polymorphisms in Drosophila melanogaster II. Geographic clines and climatic associations in Australasia, North America and Asia. Genetica 58, 213–221 (1982).
Kapun, M. & Flatt, T. The adaptive significance of chromosomal inversion polymorphisms in Drosophila melanogaster. Mol. Ecol. 28, 1263–1282 (2019).
Koch, E. L. et al. Genetic variation for adaptive traits is associated with polymorphic inversions in Littorina saxatilis. Evol. Lett. 5, 196–213 (2021).
Westram, A. M., Faria, R., Johannesson, K. & Butlin, R. Using replicate hybrid zones to understand the genomic basis of adaptive divergence. Mol. Ecol. 30, 3797–3814 (2021).
Jones, F. C. et al. The genomic basis of adaptive evolution in threespine sticklebacks. Nature 484, 55–61 (2012).
Hager, E. R. et al. A chromosomal inversion contributes to divergence in multiple traits between deer mouse ecotypes. Science 377, 399–405 (2022).
Battlay, P. et al. Rapid parallel adaptation in distinct invasions of Ambrosia Artemisiifolia is driven by large-effect structural variants. Mol. Biol. Evol. 42, msae270 (2025).
Kapun, M., Fabian, D. K., Goudet, J. & Flatt, T. Genomic evidence for adaptive inversion clines in Drosophila melanogaster. Mol. Biol. Evol. 33, 1317–1336 (2016).
Jay, P. et al. Association mapping of colour variation in a butterfly provides evidence that a supergene locks together a cluster of adaptive loci. Philos. Trans. R. Soc. B 377, 20210193 (2022).
Berdan, E. L. et al. How chromosomal inversions reorient the evolutionary process. J. Evol. Biol. 36, 1761–1782 (2023).
Santangelo, J. S. et al. Haplotype-resolved, chromosome-level assembly of white clover (Trifolium repens L., Fabaceae). Genome Biol. Evol. 15, evad146 (2023).
Korneliussen, T. S., Albrechtsen, A. & Nielsen, R. ANGSD: analysis of next generation sequencing data. BMC Bioinf. 15, 356 (2014).
Lynch, M., Haubold, B., Pfaffelhuber, P. & Maruki, T. Inference of historical population-size changes with allele-frequency data. G3: Genes Genomes Genet. 10, 211–223 (2020).
Fumagalli, M. et al. Quantifying population genetic differentiation from next-generation sequencing data. Genetics 195, 979–992 (2013).
Reynolds, J., Weir, B. S. & Cockerham, C. C. Estimation of the coancestry coefficient: basis for a short-term genetic distance. Genetics 105, 767–779 (1983).
Dixon, P. VEGAN, a package of R functions for community ecology. J. Veg. Sci. 14, 927–930 (2003).
Meisner, J. & Albrechtsen, A. Inferring population structure and admixture proportions in low-depth NGS data. Genetics 210, 719–731 (2018).
Booker, T. R., Yeaman, S., Whiting, J. R. & Whitlock, M. C. The WZA: a window‐based method for characterizing genotype–environment associations. Mol. Ecol. Resour. https://doi.org/10.1111/1755-0998.13768 (2023).
Nielsen, R., Korneliussen, T., Albrechtsen, A., Li, Y. & Wang, J. SNP calling, genotype calling, and sample allele frequency estimation from new-generation sequencing data. PLoS ONE 7, e37558 (2012).
Fox, E. A., Wright, A. E., Fumagalli, M. & Vieira, F. G. ngsLD: evaluating linkage disequilibrium using genotype likelihoods. Bioinformatics 35, 3855–3856 (2019).
Garrison, E. & Marth, G. Haplotype-based variant detection from short-read sequencing. Preprint at https://arxiv.org/abs/1207.3907 (2012).
Danecek, P. et al. The variant call format and VCFtools. Bioinformatics 27, 2156–2158 (2011).
Alexa, A. & Rahnenführer, J. Gene set enrichment analysis with topGO. Bioconductor Improv. 27, 1–26 (2009).
Fox, J., Friendly, M. & Weisberg, S. Hypothesis tests for multivariate linear models using the car package. R J. 5, 39–52 (2013).
Skotte, L., Korneliussen, T. S. & Albrechtsen, A. Association testing for next‐generation sequencing data using score statistics. Genet. Epidemiol. 36, 430–437 (2012).
Hendrickson, B. T. et al. Evolution of drought resistance strategies following the introduction of white clover (Trifolium repens L.). Ann. Bot. https://doi.org/10.1093/aob/mcaf037 (2025).
Love, M. I., Huber, W. & Anders, S. Moderated estimation of fold change and dispersion for RNA-seq data with DESeq2. Genome Biol. 15, 550 (2014).
Battlay, P. et al. Dataset for ‘Structural variants underlie parallel adaptation following global invasion’. Dryad https://doi.org/10.5061/dryad.dfn2z3593 (2025)
Battlay, P. pbattlay/glue-invasions: v1.0 (v1.0). Zenodo https://doi.org/10.5281/zenodo.15306354 (2025).
Acknowledgements
This work would not have been possible without white clover collections by 287 fellow scientists in the Global Urban Evolution network. Support for field work was provided by A. Daugereaux, the UL-Ecology Center and numerous field and laboratory assistants in each common garden. The Louisiana Optical Network Infrastructure provided computational support. The use of genetic data originating from Ecuador was approved by the Ecuadorian Ministerio del Ambiente (access permit MAE-DNB-2018-0106 and transfer permit ATM-CM-2018-0106-001–2019). Funding was provided by an NSERC CGS Doctoral Award to L.J.A.; NSF grants OIA-1920858 and DBI-2244712 to N.J.K.; CNRS-University of Toronto PhD Student Travel Grant to M.T.J.J. and C.V.; NSERC Discovery Grant (RGPIN-2016-06063), Canada Research Chair (950-231981), NSERC Steacie Fellowship (544292) and NSERC RTI Grant (EQPEQ 423691) to M.T.J.J.; and ARC (DP220102362) and HFSP (RGP0001) grants to K.A.H.
Author information
Authors and Affiliations
Contributions
P.B., B.T.H., J.I.M.-R., J.S.S., L.J.A., P.Y.K., R.W.N., M.T.J.J., K.A.H. and N.J.K. conceptualized and designed the experiments. J.S.S., L.J.A., S.G.I., F.A., D.N.A., J.A., A.B., M.S.C., S.D., M.F.-A., W.G., C.G.-L., P.E.G., G.R.H., C. Lampei, C. Lara, A.L.-L., D.S.L., T.J.S.M., N.M., M.M.B., A.M., M.M., J.P., V.P., J.A.M.R., D.J.R., R.S.R., J.K.R., A.C.S., K.S.W., I.T., A.V.W., M.T.J.J. and N.J.K. provided resources for the experiments. L.J.A., N.K., A.P., A.T., C.V., F.V., C.S., C.M.P., R.A., P.Y.K., M.T.J.J. and N.J.K. performed the experiments. P.B., B.T.H., J.I.M.-R. and N.J.K. curated datasets. P.B., B.T.H., J.I.M.-R., J.S.S., J.W., A.E.C., M.F. and N.J.K. conducted analysis of the data. L.J.A., C.V., M.T.J.J., K.A.H. and N.J.K. acquired funding for the experiments. M.T.J.J., K.A.H. and N.J.K. were the project administrators and provided supervision. The original draft was written by P.B., B.T.H., M.T.J.J., K.A.H. and N.J.K. Review and editing was provided by all authors and all authors approved the final version of this paper.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Peer review
Peer review information
Nature Ecology & Evolution thanks Kaichi Huang, Claire Mérot and the other, anonymous, reviewer(s) for their contribution to the peer review of this work. Peer reviewer reports are available.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Extended data
Extended Data Fig. 1 Population genetic summary statistics across native and introduced ranges.
(a–c) Boxplots compare measures of genetic diversity (π and θw) as well as Tajima’s D between native and introduced ranges. Sample size include 13 native populations and 38 introduced populations. (d–f) Boxplots further parse introduced population into individual introduction events. Each point represents the genome-wide average for a single population. Box edges in boxplots represent the interquartile range, center line represents the median, and upper and lower whiskers are the largest value either greater or less than, respectively, 1.5 times the interquartile range. There are 1, 4, 13, 4, 11, 8 and 10 populations included in the Africa, China, Europe, Japan, N. America, Oceania, and South America boxplots, respectively. (g, h) Coalescent reconstructions of effective population size through time as estimated through EPOS86. Neither native nor introduced populations exhibit any signatures of bottlenecks following introduction. Instead, most populations show signs of population expansion.
Extended Data Fig. 2 Population structure within and among native and introduced ranges.
a. Weighted pairwise fst within each range, weighted pairwise fst values between native and introduced populations, and weighted pairwise fst values between populations in different introduced ranges. Pairwise fst values are generally low and similar across all worldwide populations. Number of pairwise comparisons included in each boxplot is presented on x-axis below each box. Box edges in boxplots represent the interquartile range, center line represents the median, and upper and lower whiskers are the largest value either greater or less than, respectively, 1.5 times the interquartile range. b–g. Mantel tests for isolation by distance (b-d) and isolation by environment (e-g) across the native range (b,e), North America (c,f) and South America (d,g). Mantel tests are two-sided.
Extended Data Fig. 3 NGSadmix assumed population ancestry mapped across worldwide sampling and cultivars.
a. Barplots depicts ancestry output from K=2,3,4, and 6 K-values. Best K was K=3. Individuals are organized along the x-axis by population sorted by continent, longitude, and ancestry values. b. A map of cultivar origins and NGSadmix assumed ancestries. Each pie chart within map inserts reflects the average ancestries (K=3) from a given wild population (not from cultivars). Pie charts outside the map reflect the ancestry for each cultivar. Arrows indicate the relative locations where wide populations were collected to generate each cultivar. Note that some cultivars were generated from crosses between wild populations from multiple areas. Dotted boxes reflect when the location of the originating wild population is a general location. Note that Durana and Renovation stem from plants collected in Georgia, USA, LA-S1 and Patriot originate from plants in Louisiana, USA and Mississippi, USA respectively, and Pitua is the result of crossing between Spanish and New Zealand accessions.
Extended Data Fig. 4 Genome scan for differentiated regions between Europe and each invasive range.
a. Empirical p-values for enrichment of C2 (contrast) in 20 kbp windows using the WZA between Europe and each invasive range. Red points indicate the top 1% of WZA scores. Blue bars indicate haploblock locations. b. Overlap between contrast outlier 20 kbp windows and outlier 20 kbp windows within each introduced range (XtX) or across climatic gradients within each range (XtX-EAA).
Extended Data Fig. 5 Climatic correlations with haploblocks and genome-wide variation.
a. Associations between haploblocks and climatic variables from the WORLDCLIM database. b. Overlap between outlier 20kbp XtX windows within each introduced range and outlier windows associated with each climatic variable. Abbreviations: Bio1: Annual Mean Temperature, Bio2: Mean Diurnal Range, Bio8: Temperature in the Wettest Quarter, Bio12: Annual Precipitation, Bio15: Precipitation Seasonality, Bio19: Precipitation in the Coldest Quarter. c–f. Relationships between haploblock allele frequencies and climatic variables. Each point is a single population and is color coded by native or introduced region. Allele frequencies correspond to the frequency of the alternative (non-reference) allele.
Extended Data Fig. 6 Five haploblocks–population-genomic signatures of structural variants.
a. Haploblock clusters for the worldwide population genomics dataset. Three clusters indicative of two homozygous (green and purple) and one heterozygous (orange) structural variant genotypes separate along the first principal component of genetic variation across each haploblock, and furthermore putative heterozygotes show significantly elevated heterozygosity (two-sided Wilcoxon test p < 0.0003 for all heterozygote vs. homozygote comparisons; boxes denote mean ± SEM for each cluster). For better visualization, y-axes have been cropped removing 7, 1, 1, 0 and 6 outlier points for hb7a1, hb7a2, hb7b, hb9 and hb13 plots respectively. Sample sizes (clusters from left to right): HB7a1 1825/250/29, HB7a2 1528/462/111, HB7b 1765/324/15, HB9 1525/441/130, HB13 688/783/633. b. Haploblock clusters are apparent using local PCAs and heterozygosity values derived from SNP data for 109 higher-coverage (~10X) Toronto samples. Colors reflect genotypes assigned from the global dataset. Note that there were no samples genotyped as homozygous for the rare HB7a1 allele in Toronto. Boxes denote mean ± SEM for each cluster. Sample sizes (clusters from left to right): HB7a1 109/9/0, HB7a2 64/41/13, HB7b 80/35/3, HB9 93/22/3, HB13 93/24/1. c. Local patterns of linkage disequilibrium (the second highest value in each 100kb window) corresponding to haploblock regions (blue bars) are present in a random sample of individuals (top triangle; matching sample size of bottom triangle) but absent in samples homozygous for the common haploblock allele (bottom triangle). d. Estimated allele frequencies of each haploblock.
Extended Data Fig. 7 Comparisons of selective signatures within haploblock and non-haploblock windows across the genome.
a. Distribution of WZA 20 kbp window scores for contrasts between Europe and each invasive range for non-haploblock (gray) and haploblock (light blue) windows. b–g. Distribution of XtX statistics and Kendall’s Tau for several climatic variables from the WorldClim dataset for each region. For boxplots, box edges represent the interquartile range, the center line in the box is the median, and the whiskers represent 1.5 times less or greater than the interquartile range. Abbreviations: Bio1: Annual Mean Temperature, Bio2: Mean Diurnal Range, Bio8: Temperature in the Wettest Quarter, Bio12: Annual Precipitation, Bio15: Precipitation Seasonality, Bio19: Precipitation in the Coldest Quarter. EU = Europe, nAM = North America, sAM = South America, OC = Oceania, CN = China, and JP = Japan. Sample sizes (non-haploblock/ haploblock): A: EU-nAM 42694/703, EU-sAM 42679/706, EU-OC 35184/560, EU-CN 42517/696, EU-JP 42788/703; B: 43915/728; C: 44235/731; D: 44099/728; E: 39375/650; F: 44162/727; G: 44257/731.
Extended Data Fig. 8 Associations between fitness variables and haploblock genotypes across four common gardens.
ANOVA results based on a type-III sum-of-squares and two-sided tests. Both survival measures were modeled within a generalized linear model with a binomial distribution and logit link function. Total Seed Mass does not include individuals that did not survive to flowering. Absolute fitness is measured as total seed mass with individuals not surviving to flowering having zero total seed mass. Total seed mass and relative fitness were log+1 transformed to improve model fit. Bold values indicate statistically significant factors at p < 0.05.
Extended Data Fig. 9 Manhattan plots summarizing associations with fitness across haploblocks.
a. Associations between haploblock genotypes with survival to flowering. b. Associations between haploblock genotypes with total seed mass (including zeros for plants that did not survive to flowering). P-values correspond to score statistic (a two-sided test) and are not corrected for multiple comparisons. The Bonferroni corrected significance threshold (horizontal red line) is specific to each haploblock and garden. Gene names are given only for hits landing within coding sequence of annotated genes.
Extended Data Fig. 10 Characterization of the genic content of haploblock regions.
a, b. Histograms summarizing expected numbers of GWAS hits for each haploblock for survival to flowering (a) and total seed mass (b) within the North American common gardens across 160,000 simulations. Observed number of GWAS hits are displayed as vertical red lines. c. Differential expression analysis of RNAseq data within each haploblock. Percentage of genes differentially expressed and absolute expression (log2FoldChange) is presented between ranges (Europe vs. North America), between Treatments (Well-Watered vs. Dry Down), and between Latitudes (Low vs. High). Values on either side of paratheses for absolute expression are the observed / expected values. Expected values are derived from a two-sided permutation analysis that re-sampled regions from across the genome with replacement. P-values are greater than 0.05 in all cases.
Supplementary information
Supplementary Information
Supplementary Note and Figs. 1–3.
Supplementary Tables
Supplementary Tables 1–6.
Source data
Source Data Fig. 1
Population and individual population structure datasets.
Source Data Fig. 2
Population-genomic selection analysis and local PCA datasets.
Source Data Fig. 3
Population-genomic selection analysis and climate association datasets.
Source Data Fig. 4
Individual- and population-scale common garden datasets.
Source Data Fig. 5
Differential expression and GWAS study dataset.
Source Data Extended Fig. 1
Population genomics demographic and EPOS datasets.
Source Data Extended Fig. 2
Pairwise Fst dataset and matrixes for Mantel tests.
Source Data Extended Fig. 3
Individual population structure dataset.
Source Data Extended Fig. 4
Population-genomic selection analysis dataset.
Source Data Extended Fig. 5
Haploblocks, WorldClim variables, population-genomic selection analysis dataset.
Source Data Extended Fig. 6
Heterozygosity datasets for haploblocks for invaded regions and Toronto.
Source Data Extended Fig. 7
Haploblocks and population-genomic selection analysis datasets.
Source Data Extended Fig. 8
Individual-scale common garden dataset.
Source Data Extended Fig. 9
GWAS study dataset.
Source Data Extended Fig. 10
GWAS permutation analysis dataset.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Battlay, P., Hendrickson, B.T., Mendez-Reneau, J.I. et al. Haploblocks contribute to parallel climate adaptation following global invasion of a cosmopolitan plant. Nat Ecol Evol 9, 1441–1455 (2025). https://doi.org/10.1038/s41559-025-02751-2
Received:
Accepted:
Published:
Issue date:
DOI: https://doi.org/10.1038/s41559-025-02751-2
This article is cited by
-
Genomic architecture of rapid adaptation illustrated by biological invasions
Nature Ecology & Evolution (2025)
