
Abstract
The crab-eating macaques (Macaca fascicularis) and rhesus macaques (Macaca mulatta) are pivotal in biomedical and evolutionary research1,2,3. However, their genomic complexity and interspecies genetic differences remain unclear4. Here, we present a complete genome assembly of a crab-eating macaque, revealing 46% fewer segmental duplications and 3.83 times longer centromeres than those of humans5,6. We also characterize 93 large-scale genomic differences between macaques and humans at a single-base-pair resolution, highlighting their impact on gene regulation in primate evolution. Using ten long-read macaque genomes, hundreds of short-read macaque genomes and full-length transcriptome data, we identified roughly 2 Mbp of fixed-genetic variants, roughly 240 Mbp of complex loci, 16.76 Mbp genetic differentiation regions and 110 alternative splice events, potentially associated with various phenotypic differences between the two macaque species. In summary, the integrated genetic analysis enhances understanding of lineage-specific phenotypes, adaptation and primate evolution, thereby improving their biomedical applications in human disease research.
This is a preview of subscription content, access via your institution
Access options
Access Nature and 54 other Nature Portfolio journals
Get Nature+, our best-value online-access subscription
$32.99 / 30 days
cancel any time
Subscribe to this journal
Receive 51 print issues and online access
$199.00 per year
only $3.90 per issue
Buy this article
- Purchase on SpringerLink
- Instant access to the full article PDF.
USD 39.95
Prices may be subject to local taxes which are calculated during checkout





Similar content being viewed by others
Data availability
The genome assemblies used in this study, including T2T-CHM13v2.0 (GCF_009914755.1), Mmul_10 (GCF_003339765.1), MFA1912RKSv2 (GCF_012559485.2), rheMacS_1.0 (GCA_008058575.1) and Macaca_fascicularis_6.0 (GCA_011100615.1), are available from the National Centre for Biotechnology Information (NCBI) Genome. Previously published sequencing data used in this study, including PRJNA1004471 (ref. 31), PRJNA251548 (ref. 1) PRJNA345528 (ref. 82), PRJNA832687 (ref. 54), PRJNA854879 (ref. 53), PRJNA882074 (ref. 83), PRJNA953340 (ref. 84) and PRJCA018217 (ref. 85), are available from the NCBI Sequence Read Archive or National Genomics Data Center Genome Sequence Archive. The chromatin immunoprecipitation sequencing data of human brain used in this study are available from the ENCODE database (ref. 57). The raw Illumina, PacBio HiFi, ONT and Hi-C data of T2T-MFA8 are deposited in NCBI under BioProject accession number PRJNA1037719. The raw PacBio HiFi, ONT and Hi-C data of ten macaque individuals are deposited in NCBI under BioProject accession number PRJNA1041301. The Iso-seq data are deposited under NCBI BioProject accession number PRJNA1041301. The Illumina sequences of 151 WGS macaque genomes are deposited in NCBI under BioProject accession number PRJNA1041301. The T2T-MFA8 genome assembly is deposited in NCBI GenBank under accession number GCF_037993035. T2T-MFA8 assembly, annotations and the UCSC track hub are available at GitHub (https://github.com/zhang-shilong/T2T-MFA8).
Code availability
Custom scripts used in this study are available via Zenodo at https://doi.org/10.5281/zenodo.14220081 (ref. 86).
References
Warren, W. C. et al. Sequence diversity analyses of an improved rhesus macaque genome enhance its biomedical utility. Science https://doi.org/10.1126/science.abc6617 (2020).
Rhesus Macaque Genome Sequencing and Analysis Consortium et al. Evolutionary and biomedical insights from the rhesus macaque genome. Science 316, 222–234 (2007).
Rogers, J., Gibbs, R. A., Rogers, J. & Gibbs, R. A. Comparative primate genomics: emerging patterns of genome content and dynamics. Nat. Rev. Genet. 15, 347–359 (2014).
Haus, T. et al. Genome typing of nonhuman primate models: implications for biomedical research. Trends Genet. 30, 482–487 (2014).
Nurk, S. et al. The complete sequence of a human genome. Science 376, 44–53 (2022).
Altemose, N. et al. Complete genomic and epigenetic maps of human centromeres. Science 376, 4178 (2022).
Eichler, E. E. Genetic variation, comparative genomics, and the diagnosis of disease. N. Engl. J. Med. 381, 64–74 (2019).
Seehausen, O. et al. Genomics and the origin of species. Nat. Rev. Genet. 15, 176–192 (2014).
Zoonomia Consortium, A comparative genomics multitool for scientific discovery and conservation. Nature 587, 240–245 (2020).
Mao, Y. & Zhang, G. A complete, telomere-to-telomere human genome sequence presents new opportunities for evolutionary genomics. Nat. Methods https://doi.org/10.1038/s41592-022-01512-4 (2022).
Mao, Y. et al. Structurally divergent and recurrently mutated regions of primate genomes. Cell 187, 1547–1562 (2024).
Kuhlwilm, M., Boeckx, C., Kuhlwilm, M. & Boeckx, C. A catalog of single nucleotide changes distinguishing modern humans from archaic hominins. Sci. Rep. 9, 8463 (2019).
Zeberg, H., Jakobsson, M. & Pääbo, S. The genetic changes that shaped Neandertals, Denisovans, and modern humans. Cell 187, 1047–1058 (2024).
He, Y. et al. Long-read assembly of the Chinese rhesus macaque genome and identification of ape-specific structural variants. Nat. Commun. 10, 4233 (2019).
Cooper, E. B. et al. The Natural History of Model Organisms: the rhesus macaque as a success story of the Anthropocene. eLife https://doi.org/10.7554/eLife.78169 (2022).
Yang, H. et al. Generation of haploid embryonic stem cells from Macaca fascicularis monkey parthenotes. Cell Res. 23, 1187–1200 (2013).
Rautiainen, M. et al. Telomere-to-telomere assembly of diploid chromosomes with Verkko. Nat. Biotechnol. 41, 1474–1482 (2023).
Yang, C. et al. The complete and fully-phased diploid genome of a male Han Chinese. Cell Res. 33, 745–761 (2023).
Jayakumar, V. et al. Chromosomal-scale de novo genome assemblies of cynomolgus macaque and common marmoset. Sci. Data 8, 159 (2021).
Vollger, M. R. et al. Segmental duplications and their variation in a complete human genome. Science 376, 6965 (2022).
Logsdon, G. A. et al. The variation and evolution of complete human centromeres. Nature 629, 136–145 (2024).
Logsdon, G. A. et al. The structure, function and evolution of a complete human chromosome 8. Nature 593, 101–107 (2021).
Shepelev, V. A., Alexandrov, A. A., Yurov, Y. B. & Alexandrov, I. A. The evolutionary origin of man can be traced in the layers of defunct ancestral alpha satellites flanking the active centromeres of human chromosomes. PLoS Genet. 5, 1000641 (2009).
Makova, K. D. et al. The complete sequence and comparative analysis of ape sex chromosomes. Nature 630, 401–411 (2024).
Alexandrov, I., Kazakov, A., Tumeneva, I., Shepelev, V. & Yurov, Y. Alpha-satellite DNA of primates: old and new families. Chromosoma 110, 253–266 (2001).
Papalazarou, V. et al. Phenotypic profiling of solute carriers characterizes serine transport in cancer. Nat. Metab. 5, 2148–2168 (2023).
Salvi, S., Dionisi-Vici, C., Bertini, E., Verardo, M. & Santorelli, F. M. Seven novel mutations in the ORNT1 gene (SLC25A15) in patients with hyperornithinemia, hyperammonemia, and homocitrullinuria syndrome. Human Mutation 18, 460 (2001).
Wu, H., Li, X. & Li, H. Gene fusions and chimeric RNAs, and their implications in cancer. Genes Dis. 6, 385–390 (2019).
Zhang, Y. et al. Readthrough events in plants reveal plasticity of stop codons. Cell Rep. 43, 113723 (2024).
Sahoo, S. et al. Identification and functional characterization of mRNAs that exhibit stop codon readthrough in Arabidopsis thaliana. J. Biol. Chem. 298, 102173 (2022).
Mao, Y.-X. et al. Comparative transcriptome analysis between rhesus macaques (Macaca mulatta) and crab-eating macaques (M. fascicularis). Zool. Res. https://doi.org/10.24272/j.issn.2095-8137.2023.322 (2023).
Chen, S. et al. A genomic mutational constraint map using variation in 76,156 human genomes. Nature 625, 92–100 (2023).
Barile, A. et al. Molecular characterization of pyridoxine 5′-phosphate oxidase and its pathogenic forms associated with neonatal epileptic encephalopathy. Sci. Rep. 10, 13621 (2020).
Hickey, G. et al. Pangenome graph construction from genome alignments with Minigraph-Cactus. Nat. Biotechnol. 42, 663–673 (2023).
Xue, C. et al. The population genomics of rhesus macaques (Macaca mulatta) based on whole-genome sequences. Genome Res. 26, 1651–1662 (2016).
Karl, J. A. et al. Complete sequencing of a cynomolgus macaque major histocompatibility complex haplotype. Genome Res. 33, 448–462 (2023).
Liao, W.-W. et al. A draft human pangenome reference. Nature 617, 312–324 (2023).
Uno, Y., Fujino, H., Kito, G., Kamataki, T. & Nagata, R. CYP2C76, a novel cytochrome P450 in cynomolgus monkey, is a major CYP2C in liver, metabolizing tolbutamide and testosterone. Mol. Pharmacol. 70, 477–486 (2006).
Yoo, D. et al. Complete sequencing of ape genomes. Preprint at bioRxiv https://doi.org/10.1101/2024.07.31.605654 (2024).
Ebler, J. et al. Pangenome-based genome inference allows efficient and accurate genotyping across a wide spectrum of variant classes. Nat. Genet. 54, 518–525 (2022).
Taketomi, Y. et al. Mast cell maturation is driven via a group III phospholipase A2-prostaglandin D2–DP1 receptor paracrine axis. Nat. Immunol. 14, 554–563 (2013).
Wu, J. et al. EHBP1L1, an apicobasal polarity regulator, is critical for nuclear polarization during enucleation of erythroblasts. Blood Adv. 7, 3382–3394 (2023).
Sato, H. et al. Group III secreted phospholipase A2 regulates epididymal sperm maturation and fertility in mice. J. Clin. Invest. 120, 1400–1414 (2010).
Sherman, B. T. et al. DAVID: a web server for functional enrichment analysis and functional annotation of gene lists (2021 update). Nucleic Acids Res. 50, 216 (2022).
Darbellay, F. et al. The constrained architecture of mammalian Hox gene clusters. Proc. Natl Acad. Sci. USA 116, 13424–13433 (2019).
Dollé, P. et al. Disruption of the Hoxd-13 gene induces localized heterochrony leading to mice with neotenic limbs. Cell 75, 431–441 (1993).
Kingsley, E. P. et al. Adaptive tail-length evolution in deer mice is associated with differential Hoxd13 expression in early development. Nat. Ecol. Evol. 8, 791–805 (2024).
Willard, H. F. Chromosome-specific organization of human alpha satellite DNA. Am. J. Hum. Genet. 37, 524–532 (1985).
O’Keefe, C. L. & Matera, A. G. Alpha satellite DNA variant-specific oligoprobes differing by a single base can distinguish chromosome 15 homologs. Genome Res. https://doi.org/10.1101/gr.10.9.1342 (2000).
Maggiolini, F. et al. Single-cell strand sequencing of a macaque genome reveals multiple nested inversions and breakpoint reuse during primate evolution. Genome Res. 30, 1680–1693 (2020).
Ventura, M. et al. Evolutionary formation of new centromeres in macaque. Science 316, 243–246 (2007).
Rocchi, M., Archidiacono, N., Schempp, W., Capozzi, O. & Stanyon, R. Centromere repositioning in mammals. Heredity 108, 59–67 (2011).
Ma, S. et al. Molecular and cellular evolution of the primate dorsolateral prefrontal cortex. Science https://doi.org/10.1126/science.abo7257 (2022).
Wu, J. et al. Integrating spatial and single-nucleus transcriptomic data elucidates microglial-specific responses in female cynomolgus macaques with depressive-like behaviors. Nat. Neurosci. 26, 1352–1364 (2023).
Blakely, R. D., Robinson, M. B., Thompson, R. C. & Coyle, J. T. Hydrolysis of the brain dipeptide N‐acetyl‐l‐aspartyl‐l‐glutamate: subcellular and regional distribution, ontogeny, and the effect of lesions on N‐acetylated‐α‐linked acidic dipeptidase activity. J. Neurochem. 50, 1200–1209 (1988).
Rahn, K. A. et al. Inhibition of glutamate varboxypeptidase II (GCPII) activity as a treatment for cognitive impairment in multiple sclerosis. Proc. Natl Acad. Sci. USA 109, 20101–20106 (2012).
The ENCODE Project Consortium. An integrated encyclopedia of DNA elements in the human genome. Nature https://doi.org/10.1038/nature11247 (2012).
Florio, M. et al. Human-specific gene ARHGAP11B promotes basal progenitor amplification and neocortex expansion. Science 347, 1465–1470 (2015).
Ma, K., Yang, X. & Mao, Y. Advancing evolutionary medicine with complete primate genomes and advanced biotechnologies. Trends Genet. https://doi.org/10.1016/j.tig.2024.11.001 (2024).
King, M.-C. & Wilson, A. C. Evolution at two levels in humans and chimpanzees. Science 188, 107–116 (1975).
Cheng, H. et al. Haplotype-resolved assembly of diploid genomes without parental data. Nat. Biotechnol. https://doi.org/10.1038/s41587-022-01261-x (2022).
Cheng, H. et al. Haplotype-resolved de novo assembly using phased assembly graphs with hifiasm. Nat. Methods https://doi.org/10.1038/s41592-020-01056-5 (2021).
Pardo-Palacios, F. J. et al. SQANTI3: curation of long-read transcriptomes for accurate identification of known and novel isoforms. Nat. Methods https://doi.org/10.1038/s41592-024-02229-2 (2024).
Numanagić, I. et al. Fast characterization of segmental duplications in genome assemblies. Bioinformatics https://doi.org/10.1093/bioinformatics/bty586 (2018).
Jumper, J. et al. Highly accurate protein structure prediction with AlphaFold. Nature https://doi.org/10.1038/s41586-021-03819-2 (2021).
Garrison, E., Kronenberg, Z. N., Dawson, E. T., Pedersen, B. S. & Prins, P. A spectrum of free software tools for processing the VCF variant call format: vcflib, bio-vcf, cyvcf2, hts-nim and slivar. PLOS Comput. Biol. https://doi.org/10.1371/journal.pcbi.1009123 (2022).
Yun, T. et al. Accurate, scalable cohort variant calls using DeepVariant and GLnexus. Bioinformatics https://doi.org/10.1093/bioinformatics/btaa1081 (2021).
Poplin, R. et al. A universal SNP and small-indel variant caller using deep neural networks. Nat. Biotechnol. https://doi.org/10.1038/nbt.4235 (2018).
Wenger, A. M. et al. Accurate circular consensus long-read sequencing improves variant detection and assembly of a human genome. Nat. Biotechnol. https://doi.org/10.1038/s41587-019-0217-9 (2019).
Ebert, P. et al. Haplotype-resolved diverse human genomes and integrated analysis of structural variation. Science https://doi.org/10.1126/science.abf7117 (2021).
Heller, D. & Vingron, M. SVIM: structural variant identification using mapped long reads. Bioinformatics https://doi.org/10.1093/bioinformatics/btz041 (2019).
Heller, D. & Vingron, M. SVIM-asm: structural variant detection from haploid and diploid genome assemblies. Bioinformatics https://doi.org/10.1093/bioinformatics/btaa1034 (2021).
Vollger, M. R. & Harvey, W. T. mrvollger/fastCN-smk: v0.2. Zenodo https://doi.org/10.5281/zenodo.8136270 (2023).
Love, M. I. et al. Moderated estimation of fold change and dispersion for RNA-seq data with DESeq2. Genome Biol. https://doi.org/10.1186/s13059-014-0550-8 (2014).
Ritchie, M. E. et al. limma powers differential expression analyses for RNA-sequencing and microarray studies. Nucleic Acids Res. https://doi.org/10.1093/nar/gkv007 (2015).
Zheng, G. X. Y. et al. Massively parallel digital transcriptional profiling of single cells. Nat. Commun. https://doi.org/10.1038/ncomms14049 (2017).
Hao, Y. et al. Integrated analysis of multimodal single-cell data. Cell https://doi.org/10.1016/j.cell.2021.04.048 (2021).
Hao, Y. et al. Dictionary learning for integrative, multimodal and scalable single-cell analysis. Nat. Biotechnol. https://doi.org/10.1038/s41587-023-01767-y (2023).
Nei, M., Li, W. H., Nei, M. & Li, W. H. Mathematical model for studying genetic variation in terms of restriction endonucleases. Proc. Natl Acad. Sci. USA https://doi.org/10.1073/pnas.76.10.5269 (1979).
Bhatia, G., Patterson, N., Sankararaman, S. & Price, A. L. Estimating and interpreting FST: the impact of rare variants. Genome Res. https://doi.org/10.1101/gr.154831.113 (2013).
Sabeti, P. C. et al. Genome-wide detection and characterization of positive selection in human populations. Nature https://doi.org/10.1038/nature06250 (2007).
Liu, Z. et al. Population genomics of wild Chinese rhesus macaques reveals a dynamic demographic history and local adaptation, with implications for biomedical research. Gigascience https://doi.org/10.1093/gigascience/giy106 (2018).
Ding, W. et al. Adaptive functions of structural variants in human brain development. Sci. Adv. https://doi.org/10.1126/sciadv.adl4600 (2024).
Zemke, N. R. et al. Conserved and divergent gene regulatory programs of the mammalian neocortex. Nature https://doi.org/10.1038/s41586-023-06819-6 (2023).
Ning, C. et al. Epigenomic landscapes during prefrontal cortex development and aging in rhesus. Natl Sci. Rev. https://doi.org/10.1093/nsr/nwae213 (2024).
Zhang, S. Integrated analysis of the complete sequence of a macaque genome (code archive). Zenodo https://doi.org/10.5281/zenodo.14220081 (2024).
Acknowledgements
We thank the staff of the Non-human Primate Facility of the Centre for Excellence in Brain Science and Intelligence Technology for their assistance in animal care. We thank the HPRC and Primate T2T Consortium for providing the long-read human and great ape genome assemblies. We thank T. Brown for proofreading and editing the manuscript. We thank K. Makova for providing valuable comments. The computations in this study were run on the Siyuan-1 supported by the Centre for High Performance Computing at Shanghai Jiao Tong University. This work was supported, in part, by National Natural Science Foundation of China (grant nos. 32370658 to Yafei Mao, 82021001 to Q.S., 32300490 to D.W. and 82001372 to X.Y.); by Shanghai Pujiang Programme (grant no. 22PJ1407300), Shanghai Jiao Tong University 2030 Initiative (grant no. WH510363003/016) and Natural Science Foundation of Chongqing, China (grant no. CSTB2024NSCQ-JQX0004) to Yafei Mao; by the National Key Research and Development Programme of China (grant no. 2022YFF0710901), the Biological Resources Programme of the Chinese Academy of Sciences (KFJ-BRP-005) and the National Science and Technology Innovation 2030 Major Programme (grant no. 2021ZD0200900) to Q.S.; by the Shanghai Rising-Star Programme (grant no. 24YF2721800 to K.M.); by the China Postdoctoral Science Foundation (grant no. 2022M713072 to Y.F.); by the National Institutes of Health (NIH) (grant nos. HG002385 and HG010169 to E.E.E., R00GM147352 to G.A.L. and R01HG011274-01 to K.H.M.); by the Intramural Research Programme of the National Human Genome Research Institute, NIH to A.M.P. and by the Centre for Integration in Science of the Ministry of Aliyah, Israel to I.A.A. We also acknowledge financial support to M.V. under the National Recovery and Resilience Plan, Mission 4, Component 2, Investment 1.1, Call for tender No. 104 published on 2 February 2022 by the Italian Ministry of University and Research (MUR), financed by the European Union—NextGenerationEU—Project Title Telomere-to-telomere sequencing: the new era of centromere and neocentromere evolution (CenVolution)—grant no. CUP H53D23003260006—Grant Assignment Decree No. 1015 adopted on 7 July 2023 by the Italian MUR. E.E.E. is an investigator of the Howard Hughes Medical Institute.
Author information
Authors and Affiliations
Contributions
Yafei Mao and Q.S. conceived the project. S.Z., N.X., X.Y., Q.S. and Yafei Mao generated sequencing data. N.X., Yamei Li, X.B., Yong Lu, L.Z., Yuxiang Mao and Q.S. contributed the macaque samples, maintained the 582-1 cell line and performed rDNA validation. S.Z., L.F., X.Y., Y.H., D.M., K.M., C.Y., D.W., G.Z., B.S., Y.S., Q.S. and Yafei Mao assembled genomes, analysed the data and performed quality control analyses. A.M.P. and E.E.E. contributed the non-human great ape genomes and analysed the data. S.Z., L.F., Z.Y., E.E.E. and Yafei Mao performed the performed structural variant analyses. S.Z., L.F., Z.Y., J.H. and Yafei Mao performed large-scale genomic difference analyses. L.d.G., A.P., F.A. and M.V. performed the FISH analyses. S.Z., X.J., F.R., G.A.L., V.A.S., K.H.M., I.A.A. and Yafei Mao performed centromere analyses. S.Z., L.F., Z.Y., X.J., Yuxiang Mao, Q.S. and Yafei Mao performed single-cell RNA-seq and FOLH1 gene family and PIEZO2 analyses. S.Z., Y.F., D.W. and Yafei Mao performed the genetic differentiation analyses. L.F., R.H. and Q.L. performed the protein structure prediction analyses. S.Z., Z.L., X.Y., K.M., D.L. and Yafei Mao performed the functional experiments. S.Z., L.F., Q.S. and Yafei Mao drafted the manuscript. V.A.S. is retired from the Institute of Molecular Genetics. All authors read and approved the manuscript.
Corresponding authors
Ethics declarations
Competing interests
E.E.E. is a scientific advisory board member of Variant Bio. The other authors declare no competing interests.
Peer review
Peer review information
Nature thanks Martin Kuhlwilm, Katerina Guschanski and the other, anonymous, reviewer(s) for their contribution to the peer review of this work. Peer reviewer reports are available.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Extended data figures and tables
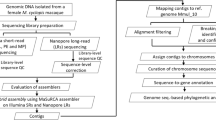
Extended Data Fig. 1 The conceptual workflow of this study.
This diagram illustrates the research strategy in this study.
Extended Data Fig. 2 Previously unresolved regions.
(a) A synteny plot (top) displays the alignment of the newly assembled chr. Y (T2T-MFA8v1.1) against the previous macaque assembly (Mmul_10). Blue and yellow blocks represent forward and reversed alignments, respectively. The tracks (bottom) show the newly assembled sequences (compared to Mmul_10), sequence classes, gene density, non-B DNA density, palindromes, and intrachromosomal sequence identity, respectively. (b) The bar plot illustrates the repeat annotation of newly added sequences. (c) The syntenic comparison highlights the rDNA and centromere regions on chr. 10 between T2T-MFA8v1.1 and Mmul_10. The upper panel illustrates the syntenic relationship between these assemblies, alongside their repeat annotations and mappability. In the lower panel, the HiFi and ONT coverage for T2T-MFA8v1.1 is depicted, with black and red dots marking the primary and secondary alleles, respectively. (d) Syntenic comparison of rDNA units between T2T-MFA8v1.1 (chr. 10) and T2T-CHM13v2.0 (chr. 22). The dot plot demonstrates a conserved synteny in the rDNA coding regions between humans and macaques. The common repeat annotation and methylation patterns are listed along the axes. (e) The complete centromere assemblies of T2T-MFA8v1.1. Colors represent the suprachromosomal families (SF) of α-satellites, with the lengths of the α-satellite arrays indicated. The centromere dip regions are marked with triangles, as obtained by methylation calling.
Extended Data Fig. 3 The comprehensive gene annotation set of T2T-MFA8v1.1 and PNPO analysis.
(a) The ideogram track shows the centromeric satellites (yellow) and segmental duplications (red), with newly added protein-coding genes labeled above. Genes that are not available in NCBI are marked with “CXorfXXX”. (b) The red dashed line represents a 21 kbp unassembled region in Mmul_10. Gene models are shown on the top with read-depth validation below. CLR: continuous long reads. (c) The short-read RNA-seq confirms the exon-skipping event in MFA (two-sided Mann-Whitney U test). The y-axis refers to the split-read rate of exon-5 on PNPO. Box plots denote median and interquartile range (IQR), with whiskers 1.5×IQR. The number of biological replicates is indicated in parentheses below each plot. (d) The qPCR validation supports that the genotypes (C/C, C/A, and A/A) are potentially associated with exon-5 skipping in MFA. The genotype frequencies are listed in the parentheses below each plot. Each dot represents different biological replicates (error bars, mean ± s.d.). (e) The predicted protein structures of PNPO with and without exon-5 suggest the potential loss of enzyme activity due to disrupted interactions. The zoomed-in panel highlights key amino acids (K72, Y129, R133, S137, W178, R197, and H199) within the active site, with those specific to exon-5 (Y129, R133, and S137) shown in gray.
Extended Data Fig. 4 The quality control, variant discovery, and structural haplotype analysis of the macaque pangenome.
(a) Flagger evaluation of 20 haplotype-resolved assemblies is shown on the left panel, while the right panel shows the average across 20 assemblies and the evaluation of T2T-MFA8 (no chr. Y). (b) The cumulative number of added bases when adding assemblies one by one is illustrated, with red representing MFA and blue representing MMU. The total of added polymorphic sequences shows slow growth after the seventh MFA or MMU assembly. The species switch (MFA → MMU) increases the yield of added sequences. Transparent colors indicate singleton (AF < 5%), doubleton (5% ≤ AF < 10%), polymorphic (10% ≤ AF < 50%), and common (AF ≥ 50%) alleles. (c) The left panel shows the number of small variants (top) and SVs (bottom) per haplotype in the pangenome graph. The right panel shows the average number of small variants (top) and SVs (bottom) of MFA, MMU, and humans (from the HPRC-year1 MC pangenome graph). (d) The biallelic SNV comparison between the pangenome graph and the macaque whole-genome sequencing (WGS) cohort (289 macaques). The gray histogram illustrates the count of SNVs from the macaque cohort at MAF cutoffs (x-axis, e.g., MAF > 0.05 includes the SNV count with MAF greater than 0.05), while the line chart represents the fraction of these SNVs covered by the pangenome. This panel shows that the pangenome graph covers 80% of genetic variation with MAF ≥ 5% in the macaque cohort. (e, f) These panels show the correlation of AFs between the pangenome and 79 wild samples (e) and between the macaque cohort and the same wild samples (f). (g) The bar plot illustrates the most common copy number (CN) variable genes in SDR hotspots of macaques. The x-axis represents the number of gene copies that can be mapped to a bubble in the pangenome graph, while the y-axis shows the 17 most CN variable genes. (h) This panel demonstrates the complexity of major histocompatibility complex (MHC) in macaques. SNV and SV densities for eight structural haplotypes with gene models are shown above (top). The syntenic relationship between T2T-MFA8v1.1 and MFA186ZAI-H2 (bottom) shows a ~ 1 Mbp deletion in MFA186ZAI-H2 with respect to T2T-MFA8v1.1. (i) This panel displays the syntenic relationship of the CYP2C76 region in primates. In each assembly, the syntenic regions are represented as blocks, while non-syntenic regions are represented as thin lines, along with their DupMasker and gene annotation attached to each genome segment. (j) The structural representation of the GSTM family is shown, with the gene annotation. Green and purple refer to the start and end of GSTM gene bodies, respectively. (k) The graphical representation of four structural haplotypes of GSTM follows different paths in the pangenome, with red and purple representing the start and end of a path, respectively. The haplotype of T2T-MFA8v1.1 is GSTM (5 A, 1 A, 1B, 2). (l) The table illustrates the frequency statistics of GSTM haplotypes and their schematic graph. The frequency of structural haplotypes in the pangenome graph is displayed in the first column, while the inferred frequency from the population with short-read genotyping is shown in the second column.
Extended Data Fig. 5 The fixed variants, genetic differentiation regions, and inversions between MFA and MMU.
(a) Principal component analysis (PCA) of three macaque populations. The first component (18.6%, x-axis) separates MFA (red) and MMU, while the second component (11%, y-axis) distinguishes CMMU (Chinese rhesus macaque) and IMMU (Indian rhesus macaque). The macaque individuals are clustered according to each population. Newly sequenced samples in this study are marked in color, while the samples from the previous study are marked in gray. (b) Lineage-specific fixed genetic variation. The length distribution of fixed INDELs and SVs are shown in the left panel (INDEL: 2-20 bp (top), SV: 50-500 bp (bottom)) and right (INDEL: 20-50 bp (top), SV: 500-10000 bp (bottom)). Notable peaks for Alu and L1 are at 300 bp and 6000 bp. A fixed SNV in PLA2G3 (c) and a fixed SV in EHBP1L1 (d) result in amino acid differences between MFA and MMU. (e) A genetic differentiation region associated with SRCAP and PHKG2. The gene models, π diversity, FST, and XP-EHH across the genomic region are shown from top to bottom. The dotted lines indicate the bottom 5% threshold from π diversity, the top 5% from FST, and the top 5% from XP-EHH, respectively. (f, g) Fixed missense variants of SRCAP (f) and PHKG2 (g) result in amino acid differences between MFA and MMU. (h) The syntenic relationship of the inversion with the longest length (4 Mbp) within macaques, with the gene annotation above. (i) The heatmap shows the DEGs within the 500 kbp flanking regions of macaque inversion (≥10 kbp) breakpoints (Z-score of rlog-transformed counts). Each row represents a gene and each column represents a tissue.
Extended Data Fig. 6 The comparative analysis on macaque centromeres.
(a) The dot plot shows the chr. 1 α-satellite arrays between MFA and MMU, generated with UniAligner. The red dots refer to the common rare k-mers (k ≥ 80) and the green dots refer to the conserved regions between two centromeres. The black line indicates the optimal rare alignment path. The α-satellite array strand track is shown above the dot plot (blue for forward strand (+) and red for reverse strand (–)). (b) The SF and methylation patterns of α-satellite arrays on chr. 1 for both MFA and MMU are depicted. Sequence similarity within the 5 kb block is visualized using ModDotPlot, with the CDRs highlighted in red by corresponding methylation levels. (c) The green, red, and blue violin plots represent the length distribution of α-satellite arrays for HSA, MFA, and MMU, respectively. The horizontal lines indicate the length of reference genomes (green for T2T-CHM13v2.0 and red for T2T-MFA8v1.1). Box plots show median and IQR, with whiskers 1.5×IQR. The P values are calculated with the two-sided Mann-Whitney U test, and the number of assembled centromeres is indicated in parentheses below each plot. NS: not significant. (d) The phylogenetic tree shows that the S1 (red), S2a (blue), S2b (green), and SF9 α-satellites (dark gray) of MFA (round) and MMU (triangle) mixed in their respective separate clades. (e) The phylogeny trees for monomers of S1S2 dimers from MFA chr. 8 (yellow), chr. 11 (red) and chr. 17 (lilac). S2a has chromosome-specific variants while S1 and S2b do not.
Extended Data Fig. 7 The multi-omics profiles between human FOLH1 and macaque FOLH1.
The top panel illustrates the multi-omics profiles at human FOLH1 locus (T2T-CHM13v2.0 chr. 11, reversed strand), while the bottom panel shows the corresponding profiles in macaque FOLH1 locus (T2T-MFA8v1.1 chr. 14, forward strand). For the syntenic plot in the middle, blue and yellow blocks represent forward and reversed alignments, respectively. The potential contacts are depicted as loops alongside the Hi-C contact maps, with arrows marking these interactions within the maps. The scATAC-seq tracks are normalized with transcription start site enrichment score, the ChIP-seq tracks are normalized with bins per million mapped reads, and the contact maps are normalized with ICE (iterative correction and eigenvector decomposition).
Extended Data Fig. 8 The genetic mechanisms of the palindrome-mediated translocation.
(a) The dot plots illustrate the syntenic relationship between the ancestral and duplicated copies (left panel), as well as the self-syntenic relationship of the ancestral copy (right panel). The positions of human FOLH1 and FOLH1B are highlighted with a yellow background. (b) The panel displays sequence identity heatmaps for NHPs, with the 1 Mbp flanking region of the FOLH1 q-arm, including segmental duplications (SDs) and satellite sequences shown below. Vertical lines in the identity heatmaps indicate palindromic sequences. (c) The schematic diagram describes the potential, reported DNA double-strand break repair mechanism underlying palindrome-mediated translocation. Palindromic sequences and their directions are indicated with arrows.
Extended Data Fig. 9 The evolutionary history of APCDD1 and PIEZO2 and their expression patterns.
(a) The syntenic relationship of APCDD1 and PIEZO2 in primates is shown with minimiro, with gene annotations and DupMasker attached to each genome segment. PIEZO2 is located inside an inversion in the primate evolution, while APCDD1 is located near the inversion. (b, c) The bar plot shows the proportion of cell types for expressed cells on APCDD1 (b) and PIEZO2 (c). The proportion differences in expressed cell type are observed in APCDD1 and PIEZO2 between humans and macaques. Ex Neuron, excitatory neuron; Oligo, oligodendrocyte; In Neuron, inhibitory neuron; Astro, astrocyte; OPC, oligodendrocyte precursor cell; Micro: microglia.
Supplementary information
Supplementary Information
This file contains seven Supplementary Notes, 46 Supplementary figures, Methods and references.
Supplementary Tables
This file contains 56 Supplementary tables.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Zhang, S., Xu, N., Fu, L. et al. Integrated analysis of the complete sequence of a macaque genome. Nature 640, 714–721 (2025). https://doi.org/10.1038/s41586-025-08596-w
Received:
Accepted:
Published:
Version of record:
Issue date:
DOI: https://doi.org/10.1038/s41586-025-08596-w
This article is cited by
-
The Neijiang pig T2T genome reveals domestication history and germplasm traits of Southwest Chinese local breeds
Communications Biology (2026)
-
Long-read structural variant discovery and targeted short read genotyping enables population scale characterization of structural variation in rhesus macaques
Genome Biology (2025)
-
Beyond inversions and deletions: the evolutionary and functional insights from translocations, fissions, and fusions in animal genomes
Heredity (2025)
-
Complete sequencing of ape genomes
Nature (2025)
