
Abstract
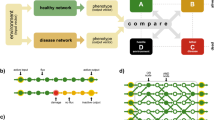
A longstanding goal of biomedicine is to understand how alterations in molecular and cellular networks give rise to the spectrum of human diseases. For diseases with shared etiology, understanding the common causes allows for improved diagnosis of each disease, development of new therapies and more comprehensive identification of disease genes. Accordingly, this protocol describes how to evaluate the extent to which two diseases, each characterized by a set of mapped genes, are colocalized in a reference gene interaction network. This procedure uses network propagation to measure the network ‘distance’ between gene sets. For colocalized diseases, the network can be further analyzed to extract common gene communities at progressive granularities. In particular, we show how to: (1) obtain input gene sets and a reference gene interaction network; (2) identify common subnetworks of genes that encompass or are in close proximity to all gene sets; (3) use multiscale community detection to identify systems and pathways represented by each common subnetwork to generate a network colocalized systems map; (4) validate identified genes and systems using a mouse variant database; and (5) visualize and further investigate select genes, interactions and systems for relevance to phenotype(s) of interest. We demonstrate the utility of this approach by identifying shared biological mechanisms underlying autism and congenital heart disease. However, this protocol is general and can be applied to any gene sets attributed to diseases or other phenotypes with suspected joint association. A typical NetColoc run takes less than an hour. Software and documentation are available at https://github.com/ucsd-ccbb/NetColoc.
This is a preview of subscription content, access via your institution
Access options
Access Nature and 54 other Nature Portfolio journals
Get Nature+, our best-value online-access subscription
$32.99 / 30 days
cancel any time
Subscribe to this journal
Receive 12 print issues and online access
$259.00 per year
only $21.58 per issue
Buy this article
- Purchase on SpringerLink
- Instant access to full article PDF
Prices may be subject to local taxes which are calculated during checkout





Similar content being viewed by others


Data availability
The input gene lists used for illustration of the protocol may be found in the supplementary materials of two papers. The ASD input gene lists were acquired from Satterstrom et al.17. The CHD input gene lists were acquired from Jin et al.29. The differential expression data used for illustration of the scored input gene list alternate step were acquired from the European Bioinformatics Institute expression atlas (https://www.ebi.ac.uk/gxa/home), from Ramnath et al.37. The molecular interaction networks used in this workflow were acquired from the network data exchange (ndexbio.org); PCNet24 UUID 4de852d9-9908-11e9-bcaf-0ac135e8bacf, STRING19 UUID 275bd84e-3d18-11e8-a935-0ac135e8bacf.
Code availability
The NetColoc software is freely available in public repositories, under the Massachusetts Institute of Technology license (https://doi.org/10.5281/zenodo.6654561). NetColoc code and example notebooks are available on a GitHub repository https://github.com/ucsd-ccbb/NetColoc. The NetColoc code is also available on PyPi https://pypi.org/project/netcoloc/.
References
Tam, V. et al. Benefits and limitations of genome-wide association studies. Nat. Rev. Genet. 20, 467–484 (2019).
Cirulli, E. T. & Goldstein, D. B. Uncovering the roles of rare variants in common disease through whole-genome sequencing. Nat. Rev. Genet. 11, 415–425 (2010).
Stark, R., Grzelak, M. & Hadfield, J. RNA sequencing: the teenage years. Nat. Rev. Genet. 20, 631–656 (2019).
Subramanian, A. et al. Gene set enrichment analysis: a knowledge-based approach for interpreting genome-wide expression profiles. Proc. Natl Acad. Sci. USA 102, 15545–15550 (2005).
Cowen, L., Ideker, T., Raphael, B. J. & Sharan, R. Network propagation: a universal amplifier of genetic associations. Nat. Rev. Genet. 18, 551–562 (2017).
Vanunu, O., Magger, O., Ruppin, E., Shlomi, T. & Sharan, R. Associating genes and protein complexes with disease via network propagation. PLoS Comput. Biol. 6, e1000641 (2010).
Hofree, M., Shen, J. P., Carter, H., Gross, A. & Ideker, T. Network-based stratification of tumor mutations. Nat. Methods 10, 1108–1115 (2013).
Leiserson, M. D. M. et al. Pan-cancer network analysis identifies combinations of rare somatic mutations across pathways and protein complexes. Nat. Genet. 47, 106–114 (2015).
Rosenthal, S. B. et al. A convergent molecular network underlying autism and congenital heart disease. Cell Syst. https://doi.org/10.1016/j.cels.2021.07.009 (2021).
Raudvere, U. et al. g:Profiler: a web server for functional enrichment analysis and conversions of gene lists (2019 update). Nucleic Acids Res. 47, W191–W198 (2019).
Paull, E. O. et al. Discovering causal pathways linking genomic events to transcriptional states using Tied Diffusion Through Interacting Events (TieDIE). Bioinformatics 29, 2757–2764 (2013).
Jia, P. & Zhao, Z. VarWalker: personalized mutation network analysis of putative cancer genes from next-generation sequencing data. PLoS Comput. Biol. 10, e1003460 (2014).
Ruffalo, M., Koyutürk, M. & Sharan, R. Network-based integration of disparate omic data to identify ‘silent players’ in cancer. PLOS Comput. Biol. 11, e1004595 (2015).
Tuncbag, N. et al. Network-based interpretation of diverse high-throughput datasets through the omics integrator software package. PLOS Comput. Biol. 12, e1004879 (2016).
Erten, S., Bebek, G., Ewing, R. M. & Koyutürk, M. DADA: Degree-aware algorithms for network-based disease gene prioritization. BioData Min. 4, 19 (2011).
Zheng, F. et al. HiDeF: identifying persistent structures in multiscale ‘omics data. Genome Biol. 22 (2021).
Satterstrom, F. K. et al. Large-scale exome sequencing study implicates both developmental and functional changes in the neurobiology of autism. Cell 180, 568–584.e23 (2020).
Eppig, J. T. et al. Mouse genome informatics (MGI): resources for mining mouse genetic, genomic, and biological data in support of primary and translational research. Methods Mol. Biol. 1488, 47–73 (2017).
Szklarczyk, D. et al. STRING v11: protein–protein association networks with increased coverage, supporting functional discovery in genome-wide experimental datasets. Nucleic Acids Res. 47, D607–D613 (2018).
Breitkreutz, B.-J. et al. The BioGRID Interaction Database: 2008 update. Nucleic Acids Res. 36, D637–D640 (2008).
Lee, I., Blom, U. M., Wang, P. I., Shim, J. E. & Marcotte, E. M. Prioritizing candidate disease genes by network-based boosting of genome-wide association data. Genome Res. 21, 1109–1121 (2011).
Greene, C. S. et al. Understanding multicellular function and disease with human tissue-specific networks. Nat. Genet. 47, 569–576 (2015).
Hermjakob, H. IntAct: an open source molecular interaction database. Nucleic Acids Res. 32, 452D–455D (2004).
Huang, J. K. et al. Systematic evaluation of molecular networks for discovery of disease genes. Cell Syst. 6, 484–495.e5 (2018).
Singhal, A. et al. Multiscale community detection in Cytoscape. PloS Comput. Biol. 16, e1008239 (2020).
Simon, H. A. The architecture of complexity. Proc. Am. Philos. Soc. 106, 467–482 (1962).
Shannon, P. et al. Cytoscape: a software environment for integrated models of biomolecular interaction networks. Genome Res. 13, 2498–2504 (2003).
Pratt, D. et al. NDEx, the network data exchange. Cell Syst. 1, 302–305 (2015).
Jin, S. C. et al. Contribution of rare inherited and de novo variants in 2,871 congenital heart disease probands. Nat. Genet. 49, 1593–1601 (2017).
Zaidi, S. & Brueckner, M. Genetics and genomics of congenital heart disease. Circ. Res. 120, 923–940 (2017).
Lasalle, J. M. Autism genes keep turning up chromatin. OA Autism 1, 14 (2013).
Ackerman, M. J. The long QT syndrome: ion channel diseases of the heart. Mayo Clin. Proc. 73, 250–269 (1998).
Colbert, C. M. & Pan, E. Ion channel properties underlying axonal action potential initiation in pyramidal neurons. Nat. Neurosci. 5, 533–538 (2002).
Ashburner, M. et al. Gene Ontology: tool for the unification of biology. Nat. Genet. 25, 25–29 (2000).
Hesdorffer, D. C. Comorbidity between neurological illness and psychiatric disorders. CNS Spectr. 21, 230–238 (2016).
Willsey, A. J. et al. The Psychiatric Cell Map Initiative: a convergent systems biological approach to illuminating key molecular pathways in neuropsychiatric disorders. Cell 174, 505–520 (2018).
Ramnath, D. et al. Hepatic expression profiling identifies steatosis-independent and steatosis-driven advanced fibrosis genes. JCI Insight 3, e120274 (2018).
Acknowledgements
This work was supported by the following grants from the National Institutes of Health: U24 CA184427 to D.P., R50 CA243885 to J.F.K. and U01 MH115747, R01 HG009979, P50 DA037844 and P41 GM103504 to T.I. This research was partially supported by the Altman Clinical & Translational Research Institute (ACTRI) at the University of California, San Diego. The ACTRI is funded from awards issued by the National Center for Advancing Translational Sciences, NIH UL1TR001442.
Author information
Authors and Affiliations
Contributions
S.B.R. co-wrote the manuscript, performed the analysis and supervised the software development. S.N.W. co-wrote the manuscript and developed the software. S.L., C.C. and D.C.-F. developed the software. K.M.F. contributed to methods development and project conceptualization. C.-H.C. contributed to methods development and manuscript revision. D.P. and J.F.K. co-wrote the manuscript. T.I. conceptualized the project and co-wrote the manuscript.
Corresponding authors
Ethics declarations
Competing interests
T.I. is cofounder of Data4Cure, Inc., is on the Scientific Advisory Board and has an equity interest. T.I. is on the Scientific Advisory Board of Ideaya BioSciences, Inc., has an equity interest and receives sponsored research funding. The terms of these arrangements have been reviewed and approved by the University of California San Diego in accordance with its conflict of interest policies.
Peer review
Peer review information
Nature Protocols thanks Rui Kuang and the other, anonymous, reviewer(s) for their contribution to the peer review of this work
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Related links
Key reference using this protocol
Rosenthal, S. B. et al. Cell Syst. 12, 1094–1107 (2021): https://doi.org/10.1016/j.cels.2021.07.009
Supplementary information
Supplementary Information
Supplementary Procedure, Methods and Figs. 1–5.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Rosenthal, S.B., Wright, S.N., Liu, S. et al. Mapping the common gene networks that underlie related diseases. Nat Protoc 18, 1745–1759 (2023). https://doi.org/10.1038/s41596-022-00797-1
Received:
Accepted:
Published:
Issue date:
DOI: https://doi.org/10.1038/s41596-022-00797-1
