
Abstract
We introduce NPKGRIDS, a new geospatial dataset, providing for the first time data on application rates for all three main plant nutrients, nitrogen (N), phosphorus (P, in terms of phosphorus pentoxide, P2O5) and potassium (K, in terms of potassium oxide, K2O) across 173 crops as of 2020, with a geospatial resolution of 0.05° (approximately 5.6 km at the equator). Development of NPKGRIDS adopted a data fusion approach to integrate crop mask information with eight published datasets of fertilizer application rates, compiled from either georeferenced data or national and subnational statistics. Furthermore, the total applied mass of N, P2O5, and K2O were benchmarked against the country level information from FAO and the International Fertilizers Association (IFA) and validated against data available from National Statistical Offices (NSOs). NPKGRIDS can be used in global modelling, and decision and policy making to help maximize crop yields while reducing environmental impacts.
Similar content being viewed by others

Background & Summary
The use of chemical and mineral fertilizers has grown nearly 10-fold over the last sixty years1, contributing decisively to the increase in crop and livestock production over the same period, driven by growing global food and feed demand of the expanding world economy2. At the same time, over- and non-optimal use of fertilizers has created, by means of spill-over flows from agricultural fields, serious environmental problems potentially affecting the health of ecosystems and people at all scales, from local soil and water pollution, to regional eutrophication hotspots, to marine dead zones at the confluence of major rivers draining important agricultural areas3,4,5,6. The dual goal of ensuring food supply to meet global demand while reverting and reducing environmental damage is a major challenge for humanity and the planet, one that is foundational to the 2030 Sustainable Development Agenda6,7 and the Global Biodiversity Framework8, specifically in relation to the need for efficient use of fertilizers to achieve productive and sustainable agriculture.
Two global datasets, FAO1,9,10 and IFA11, currently provide rich information on nitrogen (N), phosphorus (P), and potassium (K) applications for agriculture, with country-level statistics for the 1961–2022 period, with annual updates. More limited data on crop-specific application rates is also available12. This information is a recognized global reference, facilitating analyses of fertilizers use in agriculture and its trends at country, regional and global scale, as demonstrated by dozens of published papers13, international reports14, sustainability indices15 and planetary boundary science16.
At the same time, studies concerned with local or regional issues may often require more detailed, subnational scale information, to assess the interactions of fertilizer use with critical co-variants such as, for instance, climatic conditions, soil properties and water flows, ecosystems and crops distribution, farm management typology, infrastructure and population data. In order to address these needs, global spatial fertilizer maps have begun to emerge in the literature17,18,19,20,21,22,23,24, largely in the context of informing models of global biogeochemical studies and earth systems science. These products are useful steps in refining information from national to sub-national and grid-level data, though they suffer from a number of important limitations. One is these new maps were typically produced by spatializing already existing national-level information, without incorporating more detailed published data and subnational information from national statistical offices. Another is that the production of such maps requires significant amount of data and computing resources for both development and validation, so that the existing products have largely been one-off efforts, lacking the required coordination needed to facilitate continuous improvement and updates. Indeed, the most widely used geospatial dataset to date, providing application rates of N, P, and K by crop species25 (hereby referred to as MFM and standing for Mueller’s et al. Fertilizers Maps), is limited to data for the year 2003. Significant changes in agricultural land and fertilizer use in the last 20 years9, coupled with momentous changes in computing power and storage space suggest that the times are now mature for implementing a major update of the currently available products.
Here we present the results of a major new effort in data fusion to produce NPKGRIDS, an updated dataset of global gridded application rates of inorganic fertilizers by main plant nutrients: nitrogen (N), phosphorous (P2O5), and potassium (K2O), by crop species, for the year 2020. NPKGRIDS includes the fertilizer application rates of 173 crops at a global spatial resolution of 0.05° (approximately 5.6 km at the equator). The development of NPKGRIDS adopted a data fusion approach to integrate crop mask information recently made available in CROPGRIDS26,27 with other relevant published data sources, as follows. First, we searched and collected the available peer-reviewed and national dispatches of crop-specific fertilizer use data, selecting eight datasets with information specifying individual crops or aggregated crop groups in either georeferenced or tabulated formats. We then selected the best-fit dataset for each crop and subnational unit, using the same data fusion optimization process and quality scoring system of CROPGRIDS. Published national statistics of total applied mass from FAO and IFA and national statistical offices were used subsequently for benchmarking NPKGRIDS.
Methods
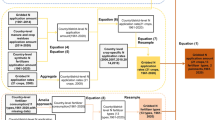
We surveyed and collected georeferenced and tabulated datasets reporting the application rates or applied amounts of N, P and K fertilizers to individual crops at national and/or subnational levels. We only collected datasets from peer-reviewed and national sources for data reliability. We next elaborated these datasets following the workflow depicted in Fig. 1, which includes three main steps: Step 1) harmonization of input datasets into tabular format at the level of subnational units; Step 2) determination of endogenous data quality indicators; and Step 3) global spatialization of fertilizer application rates.

Workflow of the development of NPKGRIDS. Step 1: Harmonization of input datasets into tabular format; Step 2: Determination of endogenous data quality indicators; Step 3: Global spatialization of fertilizer application rates; and Step 4: Validation. MFM: Mueller’s et al.25 Fertilizers Maps. MRF: Monfreda et al.34 dataset. GAUL: Global Administrative Unit Layers dataset.
Input and corollary data sources
The starting point for NPKGRIDS was CROPGRIDS26,27, a recently developed georeferenced dataset of crop maps detailing crop location and harvested area. We then researched the available peer-reviewed literature and official national statistics for georeferenced and tabulated fertilizer use datasets specifying individual crops and/or aggregated crop groups. We included only datasets with data vintage more recent than 2003, that is, the latest temporal coverage of MFM25, and with crop names matching the FAO Indicative Crop Classification (ICC)28. We excluded datasets that were non-crop-specific or containing aggregated crops but without further specification of component crops. The collected datasets provided the mass and/or application rates of total nitrogen (N), total phosphorus (P or P2O5), and total potassium (K or K2O) derived from straight and/or compound fertilizer products. Out of these, we selected eight datasets for N and seven for P2O5 and K2O (Table 1 and Supplementary Table 1). Amongst the selected datasets, the periodic Fertilizer Use By Crop (FUBC)29 includes crop-specific and aggregated crop groups across the period 2016–2018 for 63 countries. We separated it into two datasets, one listing only individual (IDV) crops (FUBC18-IDV) and the other listing only aggregated (AGG) crop groups (FUBC18-AGG). The Historic Fertilizer Use By Crop (HFUBC) dataset12 combines all fertilizer use by crop data for individual crops and crop groups from IFA and FAO from 1978 to 2018 for 111 countries. Only 12 individual crops in 65 countries from 2006 to 2018 from HFUBC were used in this work. Note that the FUBC18 and HFUBC are national-resolution datasets. Four National Statistical Offices (NSOs) datasets for the United States of America30 (US), Belarus31 (BY), the United Kingdom32 (UK), and Australia33 (AU) providing subnational-resolution crop-specific fertilizer data were also included. These eight datasets were used as inputs to construct NPKGRIDS (Table 1).
Additional, corollary datasets were also used, namely to assist with calculations and spatialization of NPKGRIDS. Specifically, two georeferenced datasets of global crop maps were used to inform crop location and harvested area, i.e., the CROPGRIDS26,27 dataset providing maps for 173 crops at 0.05° in 2020 and the Monfreda et al.34 dataset (hereafter called MRF from the initials of the original authors) providing maps for 175 crops at 0.0833° circa 2000, both using FAO crop species nomenclature. Whenever the selected datasets did not provide fertilizer application rate but only total applied mass, we used national-level crop harvested area publicly available from either NSOs, i.e., CROP-AU35 and CROP-BY36, or FAOSTAT37, to estimate fertilizer application rates as mass per unit of crop harvested area. We used the FAO Global Administrative Unit Layers (GAUL) dataset to identify country and regional (subnational unit) boundaries38 (Table 2).
Data harmonization (Step 1)
The eight input datasets (Table 1) were harmonized to a common tabular format for N, P2O5, and K2O application rates in each crop expressed as mass applied per unit crop harvested area. The tabular resolution is at the finest scale of each dataset, i.e., subnational (level 1) for MFM, US, BY, AU, UK and national (level 0) for FUBC18-IDV, FUBC18-AGG, and HFUBC.
For the georeferenced MFM dataset, we first tabulated the application rates using the GAUL level 1 mask at the dataset original resolution, i.e., 0.0833° (~10 km at the equator). In subnational units with missing data of fertilizer application rates, we gap-filled the missing information using the national weighted average application rate FMFM [kg ha−1] for fertilizer n, crop i and country j calculated as:
where fMFM(n,i,j,r) in [kg ha−1] is the available application rate of fertilizer n for crop i in subnational unit r of country j in the MFM dataset, and AMRF is the corresponding harvested area obtained from the MRF dataset.
For all other tabular datasets, the harmonization process consisted in converting the variables to application rates expressed as mass of applied N, P2O5, and K2O per unit crop harvested area. In cases where the datasets only provided information on applied mass, we calculated the application rate using crop-specific harvested areas of the corresponding year sourced from the relevant corollary datasets (Table 2). Specifically, crop harvested area from FAOSTAT was used for HFUBC, FUBC18-IDV and FUBC18-AGG while CROP-AU and CROP-BY were used for the AU and BY datasets, respectively. For the US dataset, which provided information on application rates per unit fertilized area and the percent harvested area being fertilized, we calculated the application rates for the entire harvested area of each crop by multiplication. For the BY dataset, P and K mass were multiplied by 2.29 and 1.20, respectively, to convert them to P2O5 and K2O. In the UK dataset, the application rates of some crops varied across seasons. In such cases, lacking intra-annual detail within our product, we used the season-averaged application rate to infer the annual average fertilizer application rate by crop. For the AU dataset and some countries in FUBC18-IDV and FUBC18-AGG with data spanning two calendar years, we allocated the reference year at the first calendar year. For datasets that provided the list of crops within a crop group, i.e., FUBC18-AGG and UK, the group application rate was assigned to all component crops in that group as per aggregations in Supplementary Table S3.
Other georeferenced and tabular corollary and benchmarking datasets (Table 2) were also harmonized to the same data format and administrative unit levels as the input datasets.
Endogenous data quality indicators (Step 2)
We designed a multi-criteria ranking scheme to determine the best-fit value to represent fertilizer application rates for specific crops in subnational units where multiple sources were available across the eight selected input datasets. The ranking was based on three endogenous data quality indicators: Qc, crop specification; Qr, data resolution; and Qy, synchrony. Each indicator was assigned values between zero (lowest quality) and one (highest quality). For each dataset, the values of the indicators can vary across different crops and subnational units.
The Qc indicator indicated whether the fertilizer data is specific to individual crops or crop aggregations as:
Dataset including both crop-specific and crop-aggregated data (e.g., UK) will have variable Qc values across different crops, with a higher rank for individual crops.
The Qr indicator ranked the administrative resolution of a dataset, with a higher rank given to datasets with a finer resolution as follows:
The Qy indicator rated the synchrony level between the reference year Yr of an input dataset and the reference year of NPKGRIDS, which was set to the period 2015–2020, henceforth referred to as ‘circa 2020’, and was defined as
Qy increases as \({Y}_{r}\) approaches the 2015–2020 period and could vary in response to a wide range of reference years \({Y}_{r}\) within the same dataset e.g., HFUBC and US.
The endogenous data quality indicators defined above are summarized in Table 3 for all datasets used to compile NPKGRIDS. Operationally, we associated an average endogenous quality to each dataset k, crop i and subnational unit r as
Global spatialization of fertilizer application rates (Step 3)
An assemblage of global georeferenced application rates of N, P2O5 and K2O for individual crops was conducted following the algorithm in Fig. 2. First, we disaggregated the crop-specific national application rates of the three fertilizers in HFUCB, FUBC18-IDV and FUBC18-AGG into subnational application rates using the proportional allocations from national to sub-national level calculated from MFM, where MFM data is available. This step leads to the calculation of crop-specific application rate fk(n,i,j,r) for a dataset k of fertilizer n on crop i in subnational unit r of country j as
where fMFM is the application rate of the corresponding crop and subnational unit in MFM and α is a scaling factor defined as
where Fk(n,i,j) is the national-level application rate of fertilizer n in dataset k for crop i and country j, and ACR is the corresponding crop harvested area in CROPGRIDS. In Eq. (7), we assumed that these proportions α were unchanged between 2000 and 2020. This is true only if such geographical differences were assumed to depend largely on agri-meteorological differences rather than management practices, or alternatively that geographical differences in the latter had remained similar over the two time periods.

For each fertilizer n applied to crop i in subnational unit r, we tested if the application rate was available from multiple datasets. If only one dataset k was available, the chosen application rate is f(n,i,r) = fk(n,i,r) (Fig. 2). If multiple datasets were available, we selected the best-fit dataset kbest, which has the highest endogenous quality Qk,i,r defined in Eq. (5), and thus, f(n,i,r) = \({f}_{{k}_{{best}}}\)(n,i,r). If two datasets have equal Qk,i,r, the dataset with the most recent reference year was chosen as kbest. Alternatively, if these datasets have the same reference year, \({f}_{{k}_{{best}}}\left(n,i,r\right)\) was calculated as the average value of all datasets with equal Qk,i,r and reference year. If no datasets were available, we performed gap filling by first checking if data were available in the neighbouring subnational units. Specifically, if the application rates of fertilizer n on crop i were available in w bordering subnational units, the area-weighted average fertilizer application rate favg(n,i,w) was computed over the w bordering subnational units as
with nw being the number of shared-bordering grid cells. If there is no application rate for fertilizer n on crop i in neighbouring subnational units, we estimated f(n,i,r) from application rates on similar crops based on three criteria defined by FAO39: (a) classification (i.e., cereals, pulses, nuts, fruits and berries, spices, permanent oil-bearing crops, temporary oil-bearing crops, fodder crops, fibre crops, vegetables, and other permanent crops); (b) lifespan (i.e., temporary or permanent); and (c) stem type (i.e., herbaceous, shrubs or tree; see Supplementary Table 4). A crop i is considered similar to crops c if they share at least two of the three abovementioned criteria. If the application rate of fertilizer n on similar crops c were available within the subnational unit r (Fig. 2), we calculated f(n,i,r) = favg(n,c,r), where favg(n,c,r) is the area-weighted average fertilizer application rate across c similar crops in subnational unit r, such that
If there is no similar crop within the subnational unit r (Fig. 2), we computed f(n,i,r) = favg(n,c,g), where favg(n,c,g) is the area-weighted average application rate of c similar crops globally across all subnational units g, such that
Finally, to construct the global georeferenced maps of fertilizer application rates by nutrients and crops, the subnational crop-specific fertilizer application rates were uniformly spatialized over the grid cells hosting crop i within that subnational unit using crop masks from CROPGRIDS. Example maps of N, P2O5 and K2O application rates for cotton, and the corresponding overall data quality and data sources used to construct the maps are shown in Fig. 3.

Example maps distributed in NPKGRIDS data for cotton. From left to right columns: N, P2O5, and K2O; from top to bottom rows: fertilizer application rate, data quality, and data source.
Data Records
NPKGRIDS dataset distributes global georeferenced maps of N, P2O5, and K2O fertilizer application rates for 173 crops (refer to Supplementary Table 4 for the list of crops) for the year circa 2020 at a resolution of 0.05° (about 5.6 km at the equator) with a bounding box of −180° to 180° longitude and −90° and 90° latitude using the WGS-84 coordinate system. The georeferenced maps are distributed as NetCDF files, where grid cells containing ocean/water are marked as “-1”. Files included in the dataset are described in Table 4. NPKGRIDS dataset is available for public download from the figshare repository40 at https://doi.org/10.6084/m9.figshare.24616050. The data for P and K fertilizers are distributed in terms of oxide-based application rates. These can be converted to elemental-based application rates using the following conversions: 1 kg of P2O5 is equivalent to 0.436 kg of P, and 1 kg of K2O is equivalent to 0.83 kg of K.
Technical Validation
Validation of NPKGRIDS with national-level data from FAOSTAT and IFASTAT
Lacking additional datasets with fertilizers by crop data beyond those already used herein, we evaluated NPKGRIDS data using national-level total applications of N, P2O5, and K2O fertilizers provided by FAOSTAT41 (160 countries) and IFA11 (110 countries) (Table 1). To this end, we first calculated the total national-level applied mass M(n,j) of fertilizer n in country j estimated by NPKGRIDS as
where ACR(p,i,j) is the harvested area of crop i in grid cell p of country j in CROPGRIDS26 and f is the corresponding application rate of fertilizer n in NPKGRIDS. The country boundaries were determined based on the GAUL38 dataset (level 0). We then compared M(n,j) against the corresponding fertilizer use reported in FAOSTAT and IFASTAT, MFAO and MIFA, respectively, averaged over the 2015–2020 period. These comparisons were characterized using the coefficient of determination R2 (analogous to Nash-Sutcliffe efficiency coefficient), the concordance correlation coefficient (CCC), and the normalized root mean squared errors (NRMSE), expressed as
where \({O}_{x}\) represents the logarithmic of either MFAO or MIFA and \(E\) represents the logarithmic of national-level applied mass (M) calculated from NPKGRIDS. \(\bar{{O}_{x}}\) and \(\bar{E}\) are the corresponding means across all countries, \({{\sigma }_{{O}_{x}}}^{2}\) and \({{\sigma }_{E}}^{2}\) are the corresponding variances, and \(\rho \) is the Pearson correlation coefficient between Ox and \(E\). Mx represents either MFAO or MIFA, \({M}_{x,\max }\) and \({M}_{x,\min }\) are the corresponding maximum and minimum fertilizer masses across all countries, and \({n}_{p}\) is the number of data points.
In NPKGRIDS, the global total N applied was 100 million tonnes, approximately 10% lower than the world estimates reported by FAOSTAT and IFASTAT for the year 2020, which stood at 110 and 112 million tonnes, respectively. At national level (Fig. 4, left column), the N applied mass calculated using NPKGRIDS matched relatively well with FAOSTAT (R2 = 0.76, CCC = 0.89 and NRMSE = 0.01) and reasonably well with IFASTAT (R2 = 0.66, CCC = 0.87 and NRMSE = 0.01). In the comparison against FAOSTAT data, underestimation of N application was mostly identified in Africa, such as the Democratic Republic of Congo, Namibia, and Madagascar. NPKGRIDS consistently overestimated the N application in Iraq, Syria, and Jordan when comparing against FAOSTAT and IFASTAT data.

Comparison of fertilizer applied mass between NPKGRIDS and FAOSTAT (top row) and IFASTAT (bottom row) for N (left column), P2O5 (middle column), and K2O (right column). Each marker in the scatter plots represents a country and the black lines show the 1:1 ratio.
For phosphorus, NPKGRIDS estimated a global applied mass of 46 million tonnes, closely aligning with FAOSTAT’s and IFASTAT’s estimates for 2020, which were 48 and 49 million tonnes, respectively. The national-level comparisons for the total use of P2O5 had the strongest correlations with FAOSTAT (R2 = 0.82, CCC = 0.91 and NRMSE = 0.02) and IFASTAT (R2 = 0.70, CCC = 0.88 and NRMSE = 0.01, Fig. 4, middle column). Overall, and similarly to N data, discrepancies of P application data between NPKGRIDS and data from FAOSTAT and IFASTAT were more pronounced in Africa and in Middle Eastern countries.
For potassium, NPKGRIDS reported a global application of 40 million tonnes, matching well the global estimates by FAOSTAT and IFASTAT, which were 39 and 41 million tonnes, respectively. At the same time, the national-level comparisons of total K2O application showed less alignment with the FAO/IFA estimates (Fig. 4, right column), with lower correlations for both FAOSTAT (R2 = 0.68, CCC = 0.84 and NRMSE = 0.01) and IFASTAT (R2 = 0.50, CCC = 0.77 and NRMSE = 0.01). NPKGRIDS tended to overestimate K applied mass in North Africa and West Asia.
Validation of NPKGRIDS with national and subnational data from NSOs
We obtained non-crop-specific total applied quantities of N, P2O5, and K2O at national and subnational levels for 37 countries and 166 subnational units from 2006 to 2020, including 32 countries in Europe42, India43, Pakistan44, China45, Iran46, and Sri Lanka47 (Table 2, Supplementary Table 2). Of the 37 countries, 11 countries provided subnational data while 26 countries provided only national-level data. Only 5 countries, with a total of 99 subnational units, provided K2O data. We calculated the 2015–2020 averages for all NSOs data, with the exception of Iran, for which the latest available data is from 2006. We aggregated pixel-level data in NPKGRIDS to national and subnational total applied masses of N, P2O5 and K2O following Eq. 11, with j being a country (level 0) or subnational (level 1) unit defined in the GAUL38 administrative unit boundaries. The quality of comparisons between NPKGRIDS and NSOs data was quantified using R2 (Eq. 12), CCC (Eq. 13) and NRMSE (Eq. 14).
The comparison of national and subnational levels N applied mass between NPKGRIDS and NSOs showed a relatively good agreement with R2 = 0.80, CCC = 0.90 and NRMSE = 0.03 (Fig. 5), while estimates for P2O5 and K2O were weaker, with R2 values of 0.74 and 0.75 against NSOs data, respectively.

Comparison of national and subnational-level fertilizer masses used on all crops between NPKGRIDS and National Statistical Offices (NSOs). Total applied masses of (a) N, (b) P2O5, and (c) K2O. Coloured markers refer to various NSOs: EU (European Unions), LK (Sri Lanka), PK (Pakistan), IR (Iran), IN (India), and CN (China). Black lines show the 1:1 ratio.
The comparison of 32 countries against the statistical office of the European Union (EUROSTAT)42 data showed a good alignment at both national and subnational level, with a few exceptions. Specifically, total use of N and P2O5 fertilizers were significantly underestimated in Iceland and Ireland (N and P2O5) and in Malta (N). This underestimation was likely due to the high uncertainty in crop harvested area reported in CROPGRIDS for these countries, and for Ireland specifically, due to uncertainty fertilizer use on meadows and pastures. In Iceland, only potatoes were mapped in NPKGRIDS. In contrast, nutrient application in China was slightly overestimated.
Limitations and uncertainty
NPKGRIDS incorporates uncertainties and errors of its input datasets, such as the source fertilizer datasets and the CROPGRIDS dataset used to spatially allocate the tabulated fertilizer application rates. Uncertainties can arise from errors in, or missing reporting of, fertilization amounts and crop area data submitted for national and international reporting. For example, MFM encountered data limitations in many lower- and middle-income countries and observed more anomalies in P and K fertilization data as compared to N. On the other hand, CROPGRIDS was constructed by reconciling multiple data sources, including surveys, remote sensing, and models, where each of these sources have uncertainties that will propagate into the construction of NPKGRIDS.
The spatialization of national and subnational-level data to grid cells implemented in NPKGRIDS introduces further uncertainty. For instance, the spatialization of national data (e.g., HFUBC, FUBC18-IDV, FUBC18-AGG) assumes that the relative ratio of fertilizer usage within a country follows the same patterns observed in MFM (Eq. 7), ignoring potential relative changes in cropping practices that may have occurred across different subnational units within a country. Additionally, for information taken directly from MFM, changes in fertilizer usage that may have occurred in those regions over the past 20 years are not considered.
Finally, NPKGRIDS excluded some small countries and territories due to constraint in spatial resolution, including Falkland, Faroe Islands, French Southern and Antarctic Territories (SAT), Heart Island, Isle of Man, Kingman Reef, Kiribati, Ma’tan al-Sarra, Mayotte, Netherland Antilles, Palau, Réunion, Saint Pierre, South Georgia, Svalbard, and Virgin Islands.
Data quality of NPKGRIDS
To quantify the underlying uncertainty, we computed a data quality indicator at subnational unit level based on endogenous quality indicators and comparisons against FAOSTAT and IFASTAT data. The overall data quality \(Q(n,i,j,r)\) of NPKGRIDS for nutrient n (i.e., N, P2O5, and K2O), crop i in subnational unit r in country j is computed as
where Qk is the endogenous quality of the chosen dataset calculated using Eq. (5), and the qualities of benchmarking QFAO and QIFA against FAOSTAT41 and IFASTAT11 datasets are defined as
with x being either FAO or IFA and Qx having values between 0 (low quality) and 1 (high quality). For those subnational units where the application rates were gap-filled, we assigned zero to the corresponding Qk. Maps of data quality are distributed along with NPKGRIDS dataset. Examples of data quality maps for cotton are shown in Fig. 3 (second row).
Usage Notes
All georeferenced maps distributed in NPKGRIDS dataset40 are formatted as standard NetCDF4 files. Various coding languages (e.g., MATLAB, Python, Julia, R) and software (ArcGIS, QGIS, Panoply) can be used to read and analysis these files. NPKGRIDS dataset includes the same crops as CROPGRIDS26 dataset, which follow the naming system used by FAO28.
Code availability
All computational work in this study, including data processing and validation, were conducted using MATLAB version R2022b. Main codes used to construct NPKGRIDS are distributed in the “CODES.zip” folder (Table 4) along with NPKGRIDS dataset available for public download from the figshare repository40 at https://doi.org/10.6084/m9.figshare.24616050.
References
FAO. Inorganic fertilizers 1990–2020. FAOSTAT analytical brief 47. https://doi.org/10.4060/cc0947en (FAO, Rome, 2022).
FAO. Transforming Food and Agriculture to Achieve the SDGs: 20 interconnected actions to guide decision-makers. 78, http://www.fao.org/3/I9900EN/i9900en.pdf (Rome, 2019).
Nosengo, N. Fertilized to death. Nature 425, 894–895, https://doi.org/10.1038/425894a (2003).
Tilman, D. et al. Forecasting agriculturally driven global environmental change. Science 292, 281–284, https://doi.org/10.1126/science.1057544 (2001).
West, P. C. et al. Leverage points for improving global food security and the environment. Science 345, 325–328, https://doi.org/10.1126/science.1246067 (2014).
FAO. The State of Food and Agriculture 2023. Revealing the true cost of food to transform agrifood systems. https://doi.org/10.4060/cc7724en (FAO, 2023).
Tubiello, F. N. et al. Measuring Progress Towards Sustainable Agriculture, FAO Statistical Working Papers Series No. 21–24. https://doi.org/10.4060/cb4549en (FAO, 2021).
Möhring, N. et al. Successful implementation of global targets to reduce nutrient and pesticide pollution requires suitable indicators. Nat Ecol Evol, 1–4, https://doi.org/10.1038/s41559-023-02120-x (2023).
FAO. Cropland nutrient budget (Global, regional and country trends, 1961–2020). FAOSTAT Analytical Brief No. 52., https://www.fao.org/3/cc2904en/cc2904en.pdf (FAO, Rome, 2022).
FAO. Inorganic fertilizers 2000–2021. FAOSTAT Analytical Brief Series No. 68., https://doi.org/10.4060/cc6823en (FAO, Rome, 2023).
IFA. IFASTAT: Fertilizer consumption, International Fertilizer Association (IFA), https://www.ifastat.org/databases/plant-nutrition (2022).
Ludemann, C. I., Gruere, A., Heffer, P. & Dobermann, A. Global data on fertilizer use by crop and by country. Sci Data 9, 501, https://doi.org/10.1038/s41597-022-01592-z (2022).
Zhang, X. et al. Quantifying nutrient budgets for sustainable nutrient management. Global Biogeochem Cy 34, e2018GB006060, https://doi.org/10.1029/2018GB006060 (2020).
IPCC. Climate Change and Land: an IPCC special report on climate change, desertification, land degradation, sustainable land management, food security, and greenhouse gas fluxes in terrestrial ecosystems. https://www.ipcc.ch/srccl/ (2019).
Ludemann, C. I. et al. A global reference database in FAOSTAT of cropland nutrient budgets and nutrient use efficiency: nitrogen, phosphorus and potassium, 1961–2020. Earth Syst. Sci. Data 16, 525–541, https://doi.org/10.5194/essd-16-525-2024 (2024).
Steffen, W. et al. Planetary boundaries: Guiding human development on a changing planet. Science 347, https://doi.org/10.1126/science.1259855 (2015).
Bouwman, A. F. et al. Lessons from temporal and spatial patterns in global use of N and P fertilizer on cropland. Sci Rep-Uk 7, https://doi.org/10.1038/srep40366 (2017).
Kaltenegger, K. & Winiwarter, W. Global Gridded Nitrogen Indicators: Influence of Crop Maps. Global Biogeochem Cy 34, e2020GB006634, https://doi.org/10.1029/2020GB006634 (2020).
Lu, C. Q. & Tian, H. Q. Global nitrogen and phosphorus fertilizer use for agriculture production in the past half century: shifted hot spots and nutrient imbalance. Earth Syst Sci Data 9, 181–192, https://doi.org/10.5194/essd-9-181-2017 (2017).
Potter, P., Ramankutty, N., Bennett, E. M. & Donner, S. D. Characterizing the Spatial Patterns of Global Fertilizer Application and Manure Production. Earth Interact 14, 1–22, https://doi.org/10.1175/2009ei288.1 (2010).
Tian, H. et al. Global methane and nitrous oxide emissions from terrestrial ecosystems due to multiple environmental changes. Ecosystem Health and Sustainability 1, 1–20, https://doi.org/10.1890/EHS14-0015.1 (2015).
Xu, R. T. et al. Increased nitrogen enrichment and shifted patterns in the world’s grassland: 1860-2016. Earth Syst Sci Data 11, 175–187, https://doi.org/10.5194/essd-11-175-2019 (2019).
Liu, L. et al. Modeling global oceanic nitrogen deposition from food systems and its mitigation potential by reducing overuse of fertilizers. P Natl Acad Sci USA 120, e2221459120, https://doi.org/10.1073/pnas.2221459120 (2023).
Adalibieke, W., Cui, X., Cai, H., You, L. & Zhou, F. Global crop-specific nitrogen fertilization dataset in 1961–2020. Sci Data 10, 617, https://doi.org/10.1038/s41597-023-02526-z (2023).
Mueller, N. D. et al. Closing yield gaps through nutrient and water management. Nature 490, 254–257, https://doi.org/10.1038/nature11420 (2012).
Tang, F. H. M. et al. CROPGRIDS. Figshare. https://doi.org/10.6084/m9.figshare.22491997.v7 (2024).
Tang, F. H. M. et al. CROPGRIDS: a global geo-referenced dataset of 173 crops. Sci Data 11, 413, https://doi.org/10.1038/s41597-024-03247-7 (2024).
FAO. World Programme for the Census of Agriculture 2020, Volume 1 Programme, concepts and definitions, FAO Statistical Development Series 15. https://www.fao.org/3/a-i4913e.pdf (FAO, Rome, 2017).
IFA. Fertilizer Use by Crop and Country for the 2017-2018 period, International Fertilizer Association (IFA), https://www.ifastat.org/consumption/fertilizer-use-by-crop (2022).
USDA-ERS. Fertilizer Use and Price, https://www.ers.usda.gov/data-products/fertilizer-use-and-price/ (2019).
NSCRB. 10205100005 Application of fertilizers in agricultural organisations, http://dataportal.belstat.gov.by/Indicators/Preview?key=140816# (2022).
DEFRA. The British survey of fertilizer practice 2020 – Annual report, https://www.gov.uk/government/statistical-data-sets/british-survey-of-fertiliser-practice-dataset (2021).
ABS. 7121.0 - Agricultural Commodities, Australia, 2016-17, Australian Bureau of Statistics, https://www.abs.gov.au/AUSSTATS/abs@.nsf/DetailsPage/7121.02016-17?OpenDocument (2018).
Monfreda, C., Ramankutty, N. & Foley, J. A. Farming the planet: 2. Geographic distribution of crop areas, yields, physiological types, and net primary production in the year 2000. Global Biogeochem Cycles 22 https://doi.org/10.1029/2007gb002947 (2008).
ABS. Land Management and Farming in Australia, Australian Bureau of Statistics, https://www.abs.gov.au/statistics/industry/agriculture/land-management-and-farming-australia/latest-release (2018).
NSCRB. Regions of the Republic of Belarus - Socio-economic indicators 2022: Table 17.6 - Sown area under agricultural crops in farms of all types, https://www.belstat.gov.by/en/ofitsialnaya-statistika/real-sector-of-the-economy/selskoe-hozyaistvo/anual_data/sown-area-under-main-agricultural-crops-by-region/ (2022).
FAO. FAOSTAT Crops and livestock products database, https://www.fao.org/faostat/en/#data/QCL (19 August 2022).
FAO. GAUL: Global Administrative Unit Layers 2015, First-Level Administrative Units, https://developers.google.com/earth-engine/datasets/catalog/FAO_GAUL_2015_level1#description (2015).
FAO. Crops statistics - concepts, definitions and classifications, https://www.fao.org/economic/the-statistics-division-ess/methodology/methodology-systems/crops-statistics-concepts-definitions-and-classifications/en/ (2022).
Nguyen, T. H. et al. NPKGRIDS. Figshare https://doi.org/10.6084/m9.figshare.24616050 (2024).
FAO. FAOSTAT: Fertilizers by nutrient database, https://www.fao.org/faostat/en/#data/RFN (19 Aug 2022).
EUROSTAT. Consumption of inorganic fertilizers, https://ec.europa.eu/eurostat/databrowser/view/AEI_FM_USEFERT__custom_3050970/ (2022).
DACFW. Agricultural Statistics at a Glance 2020 (ed Department of Agriculture Cooperation & Farmers Welfare (DACFW)) https://foodprocessingindia.gov.in/uploads/publication/Agricultural-statistics-at-a-Glance-2020.pdf (Ministry of Agriculture & Farmers Welfare, 2021).
Pakistan Bureau of Statistic. Table 10–Province Wise Consumption of Fertilizer, https://www.pbs.gov.pk/agriculture-statistics-tables (2022).
National Bureau of Statistics of China. Irrigated Area, Consumption of Chemical Fertilizers and Rural Hydropower Stations and Electricity Consumption in Rural Areas, https://data.stats.gov.cn/english/easyquery.htm?cn=C01 (2023).
Iran Data Portal. Amount of fertilizers distributed by type, https://irandataportal.syr.edu/machinery-livestock-fertilizers (2022).
Hamangoda, I. & Pushpakumari, G. G. P. Vol. XVI AgStat, Agricultural Statistics (ed Department of Agriculture) https://doa.gov.lk/naicc-books/#1628491951058-49ca7ba3-ac39 (Socio Economics and Planning Centre, Department of Agriculture, Peradeniya, 2019).
Gerber, J. et al. Crop-specific global fertilizer application rates from “Closing yield gaps through nutrient and water management”. Zenodo https://zenodo.org/records/5260732#.YqlfS3ZBy5d (2012).
Acknowledgements
The research work leading to NPKGRIDS was partly supported by the United Nations, Food and Agriculture Organization under contract UNFAOCT34329, The University of Sydney. FNT acknowledges funding by the Swiss Federal Office for Agriculture to the FAO Regular Programme under Project: “Strengthening Global Assessments of Sustainable Agriculture. Phase 2”. We express our gratitude for the previous contributions made to fertilizers usage mapping, and in particular, we acknowledge the pioneering work of Mueller et al. (2012), which laid the foundation for our current research.
Author information
Authors and Affiliations
Contributions
F.M., F.N.T. and G.C. designed and conceptualized the study; T.H.N. collected the data, conducted the construction of the dataset, and drafted the manuscript; T.H.N. and F.H.M.T. analyzed the data; All authors contributed to the interpretation of the results, provided in-depth advice and commented/edited the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests. The views expressed in this work are the authors’ only and do not represent FAO’s views or policy on the subject matter.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Nguyen, T.H., Tang, F.H.M., Conchedda, G. et al. NPKGRIDS: a global georeferenced dataset of N, P2O5, and K2O fertilizer application rates for 173 crops. Sci Data 11, 1179 (2024). https://doi.org/10.1038/s41597-024-04030-4
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41597-024-04030-4
