
Abstract
Laser-based powder bed fusion (L-PBF) technology stands out for its ability to create complex, high-performance parts, optimizing design freedom and material efficiency. Despite technical and financial challenges, it is attractive to industries where performance, weight reduction, and customization are critical. In L-PBF, relative density (RD) is a key factor that directly impacts the mechanical properties and overall quality of printed parts. However, predicting RD is a complex and costly task due to the numerous factors involved. This study addresses this need by creating a large-scale dataset for RD prediction in L-PBF, consisting of 1579 samples of commercial alloys from the literature. It includes printing conditions and other crucial inputs like protective atmosphere, powder size distribution, and part geometry. This dataset offers a valuable resource for researchers to benchmark their results, better understand key factors influencing RD, and validate models or explore new machine-learning approaches tailored to L-PBF.
Similar content being viewed by others

Background & Summary
Metal additive manufacturing (AM), often called 3D printing, is a broad and transformative technology capable of redefining manufacturing processes, supply chains, and product development1. One of the AM technologies that have stood out for its ability to process various alloys, freedom of design, high precision, in-situ monitoring, process control, no tooling requirement, and, above all, improved mechanical properties is laser-based powder bed fusion2,3.
Although this technology offers all the above advantages, its applicability is linked to obtaining a high relative density. The RD influences the mechanical properties, performance, and functionality of the 3D-printed components4,5,6,7,8,9,10,11. Numerous studies have been carried out to obtain suitable processing parameters to produce defect-free parts where energy density (ED) stands out as a parameter to be considered during laser processing of metal powders (equation 1)12,13,14,15,16,17,18.
P represents laser power, v is scanning speed, h is hatch spacing, and l is layer thickness. This equation reflects the amount of energy delivered per unit volume during the printing process, making (ED) a key factor in determining the relative density of the printed parts. However, due to the variety of materials, different brands and models of 3D printing equipment, and the wide spectrum of processing parameters, the standardization and quality of parts manufactured by L-PBF are challenging. The importance of carefully selecting processing parameters to achieve optimal RD directly influences the mechanical response of additively manufactured samples3,9,19,20,21,22,23,24. The analysis of RD is essential because random flaws can occur even within the optimal process window, further emphasizing the need for continuous monitoring and control of relative density in L-PBF.
From the modeling point of view, the development of advanced computational techniques, particularly ensemble methods like Bagging, Boosting, and Stacking25, offers a promising avenue to overcome the limitations of traditional approaches by combining multiple models to improve the predictive performance, reduce overfitting, and handle complex datasets for L-PBF assessment. These methods have been successfully applied to various materials and processes in recent years, demonstrating their ability to capture complex relationships and yield excellent predictive performance to overcome the classical modeling limitations associated with linear assumptions and simplified physical models. Machine learning (ML) algorithms, such as XGBoost26 and Random Forest27, are crucial in the context of data-driven due to their ability to handle large datasets, discover non-linear relationships, and improve the accuracy of predictions.
The development of powerful libraries like Scikit-learn, TensorFlow, and PyTorch has further facilitated the implementation and optimization of these algorithms, making advanced techniques more accessible to researchers and engineers. The growing complexity and volume of data in materials science highlight the need for robust ML-based approaches that can effectively generalize across different material properties and manufacturing processes. However, the lack of publicly available, high-quality datasets for L-PBF, particularly regarding the relative density of printed parts, remains a significant challenge, as ML models rely heavily on data to achieve accurate predictions, hindering further advancements in this area.
This article expands on ongoing research by providing a detailed dataset of metal alloy specimens produced via L-PBF. The dataset reports RD measurements of commercial alloy samples produced under varying processing conditions, including laser power, scanning speed, hatch distance, layer thickness, laser spot size, average particle size distribution, protective atmosphere, printer model, and scanning strategy. The additively manufactured samples were subjected to non-destructive testing techniques (i.e., Archimedes method) for initial assessment, followed by cross-sectional analysis to validate the internal porosity and overall density distribution. The relative density of the specimens is analyzed in the context of processing parameters, revealing how changes in these parameters affect the overall RD.
This dataset offers researchers a comprehensive resource for benchmarking their results against samples with different densities, enabling them to better understand the influence of key factors such as laser-related parameters, powder characteristics, and process conditions on the final RD of 3D-printed alloys.
Furthermore, we invite the research community to actively participate in expanding and enriching this dataset by contributing additional data points and experimental findings. Such collaborative efforts will enhance both the scope and quality of the dataset, transforming it into a more robust tool for decision-making in advance and posterior analysis. This collective contribution will not only highlight the significant role of data-driven solutions in advancing RD prediction but also establish a standard for future datasets in the field. The dataset’s comprehensive nature makes it an indispensable resource for validating existing models and exploring new machine-learning approaches specifically designed for the study of L-PBF.
Methods
Data collection
The foundation for this study began with collecting data from key literature published in the past 15 years in relevant and prestigious journals that are the primary source of consults for the research, technicians, academicians, and the target public. The dataset provides a valuable reference point for those studying the impact of density variations on part performance in metal additive manufacturing. In addition, the dataset provides a robust basis for developing predictive models, facilitating the training of machine learning algorithms capable of accurately predicting the RD. Specifically, studies focused on the as-built RD of additively manufactured samples in relation to the input parameters were of particular interest. Data on RD, printing-related parameters, and measurement methods were sourced from published studies in materials and manufacturing journals, particularly those reporting experimental data on this property.
The selection of articles from which the data were extracted was carried out through a comprehensive review of the literature in both open-access and subscription-based scientific databases, such as Scopus, Web of Science, and Google Scholar. Inclusion criteria were established to limit the search to peer-reviewed articles published in the last 15 years, focusing on the research of the L-PBF. The term ’Selective Laser Melting’ (SLM) was also included as a search keyword, as it is frequently used interchangeably with L-PBF in the referenced papers. Studies that did not include quantitative relative density measurements or clearly describe the process conditions were excluded. Also, approaches utilizing only simulation data were not considered. After applying these filters, a total of 85 relevant articles were selected for analysis. This review strategy ensures that the conducted analysis is both thorough and well-supported, providing a robust foundation for our dataset.
Most of the data were extracted from figures and tables in these papers. The Plot Digitizer (https://plotdigitizer.sourceforge.net/) program was employed to accurately retrieve information from plots and figures28. Additionally, each experiment’s processing parameters and material properties were collected to serve as input for machine learning models, which are the core of the ongoing investigation that originated the need for this data to be gathered.
The dataset consists of 1579 entries and captures key variables related to metal additive manufacturing, specifically using the L-PBF process. The dataset includes categorical variables such as material type, the method used for density measurement, atmospheric conditions during printing, and the geometry of the printed parts.
Materials
Several metallic powders are available for L-PBF, and different materials continue to appear as research and development advances in this field. Metal powders for L-PBF processing are mainly obtained by atomization methods. Gas atomization is the most widely used due to the high quality of the spherical powders it produces29. Plasma atomization is also very important for materials such as titanium. Other methods, such as ball milling, electrolysis, or water atomization, have specific applications but do not always meet the requirements of fluidity and purity needed for L-PBF processes30. To ensure adequate dispersion in the powder bed, the materials should offer particle size ranges with controlled size distribution, spherical morphology, low oxygen content, and good flow properties.
Commercial metal powders include Fe, Al, Ti, Ni, Cu, Co-Cr alloys, and even precious metals. The materials analyzed in this work include 316L stainless steel, AlSi10Mg, 18Ni300, Inconel 718, Ti6Al4V, and CuCrZr, whose chemical composition is detailed in Table 1. Figure 1 shows the percentage of materials collected in the dataset, the average particle size distribution, and the morphology of the metallic powders.

(a) Percentages of the materials collected in the dataset, (b) Particle size distribution on commercial metallic powders.
Experiments
The experimental setup usually involves describing the L-PBF system (Fig. 2); we focus on extracting main processing parameters such as laser power, scanning speed, hatch distance, layer thickness, laser spot size, and scanning strategy. These parameters are essential for understanding the printing process and subsequent impact on RD. In addition, data were obtained on the machine model, the printing atmosphere, which can vary between nitrogen or argon, as well as the geometry of the printed samples, which are classified into five distinct categories (i.e., prismatic, cylindrical, tensile specimens, etc.) and of course, the relative density. Density measurement techniques commonly include the Archimedes method, image analysis, and others (e.g., pycnometry, ultrasonic, and X-ray CT scanning).

Schematic representation of the laser powder bed fusion technology.
It is worth mentioning that we included a generated variable in the dataset labeled as the geometric factor (GF). This predictor accounts for the volume of the building envelope of each machine (VM), the volume of the part to be printed (Vpart), and the number of samples to be produced (n), see eq. (2).
Data processing
Since performing extensive experimental planning is either expensive or time-consuming, it is understandable that the range of process parameters of laser power (P), scanning speed (v), hatch distance (h), layer thickness (l), and laser spot size (s) in an individual study is rather narrow. However, the combination of those existing research efforts leads to a wider range of process parameters, and thus, the models built based on the compiled data can be applicable to process conditions that are not accessible for individual efforts. Table 2 summarizes the printing conditions ranges obtained from the literature review.
An exhaustive exploratory data analysis (EDA) was performed to obtain insights into the influence of processing parameters on the RD. This process involves thoroughly examining the data to understand its structure, identify patterns, detect anomalies, and evaluate the relationships between variables. Through EDA, it is possible to uncover missing values, outliers, and other data inconsistencies that could negatively impact the applicability of the dataset. Additionally, understanding the distribution of key variables, such as relative density and process parameters, provides insights into the dataset’s suitability for modeling and allows for informed decisions regarding printability optimization.
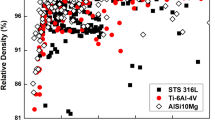
Figure 3 presents the statistical distributions of all the numerical input variables and the output variable, relative density. Most samples were printed with laser power values typically below 400 W, with the most frequent values around 200 W, and scan speeds ranging between 20 and 2000 mm/s. Hatch spacing values are predominantly below 200 μm, while layer thicknesses are primarily clustered below 100 μm. Spot size frequently falls below 0.1 mm, and the average particle size distribution (D50) has a median value of approximately 30 μm. The geometric factor exhibits a broader range, extending up to ~95, reflecting the wide variety of printer models, the number of samples produced, and the volume of each sample

Processing parameters and output variable histograms and their distribution.
The bottom row highlights the relative density, which serves as the target variable. The plot of the RD distribution reveals a strong skew towards higher values, with a notable concentration near 100%, indicating that most samples achieve a high relative density. An estimated kernel density overlays the histogram, further illustrating this trend. The final box plot and scatter plot show the statistical summary and distribution of relative density in more detail, highlighting that the median relative density is approximately 98.21%, with an interquartile range between 95.87% and 99.22%. From a statistical standpoint, data points falling below 90.8% are classified as outliers and are represented as jittering blue points on the box plot. However, these data points contain valuable information about the L-PBF process itself. The connection between the input parameters and these outputs should be carefully examined.
Data Records
The dataset comprises 1,579 observations, organized such that the first ten columns represent the input variables (e.g., printing conditions, material, shielding gas, printed geometry, etc.), while the eleventh column contains the relative density, expressed as a percentage. The dataset is provided in Excel format in the Harvard Dataverse repository, see31. Based on the data for various metal alloys studied in the literature, this file includes comprehensive details on each alloy and relevant metadata, complementing with Table 2 where are listed all the references consulted. By offering this level of detail, we aim to enhance the transparency and reproducibility of our dataset, enabling researchers to trace the data’s origins and better understand the experimental context. It is important to note that this Excel file is intended for informational purposes as well as for use in predictive modeling tasks. Researchers, students, engineers, and technicians can utilize this dataset31 to develop and validate predictive models, conduct material characterization-based analysis, or explore new hypotheses in the study of the RD of commercially available metallic alloy. Its well-organized structure ensures both thoroughness and ease of use, encouraging broad adoption and fostering collaborative research efforts.
Technical Validation
Mutual Information (MI) was calculated for each feature relative to the RD to deepen this analysis and assess the potential of the dataset for training predictive models. MI serves as a robust metric for understanding the non-linear dependencies between variables, providing a complementary view to the initial findings from the distribution plots32. The distribution plots allowed us to see how the data was structured, MI quantifies the strength of the relationship between individual features and the target (RD). Unlike correlation, which assumes linear relationships, MI can capture non-linear associations, making it a powerful tool for understanding complex datasets. The primary benefit of MI in EDA is its ability to reveal which features carry the most information regarding the RD, allowing for better feature selection and prioritization during the model-building process. This process, often called “featurization,” helps refine the dataset by removing irrelevant or redundant features, ultimately improving model performance and interpretability.
The results of the MI analysis, as shown in Fig. 4, reveal the most influential features in predicting relative density. D50, the average powder size, emerges as the most important feature, aligning with previous observations of the distribution plots indicating significant particle size variability across the data set. The geometric factor and Laser power, both of which also demonstrated diverse distributions, show high MI scores, further validating their critical role in the process. Other features, such as spot size, hatch distance, and scan speed, follow closely, reinforcing their significance in influencing the final density outcomes. These results suggest that the process parameters with the most variability are also those that contribute the most to the predictive power of machine learning models.

Featurization of input variables.
To account for material-specific differences, the material type was included as a predictor in the dataset by transforming it from a categorical variable into a numerical one. This approach enables the model to incorporate material-related variability without the need to include explicit thermal properties, such as melting point, which remain constant for each material. By using material type as a predictor, the dataset allows for predictions tailored to the specific material being processed while maintaining a streamlined structure for modeling purposes.
Conversely, features like atmosphere and printed geometry show lower MI scores, indicating that their impact on relative density is less substantial within this dataset. However, these features cannot be discarded outright without further analysis. Parameters with lower MI scores might have a more complex or indirect relationship with the RD, which could only become apparent through advanced modeling techniques, such as interaction effects or non-linear models. Furthermore, some features may have critical importance in specific process conditions or may contribute to improving model generalization by providing context or stability to the predictive models. Therefore, while their immediate influence appears limited based on MI, their potential contribution to overall model performance warrants further exploration in the modeling phase.
In summary, the insights gained from the distribution plots and Mutual Information (MI) analysis provide a detailed understanding of the dataset’s structure and the importance of each feature. While predictors such as D50, geometric factor, and laser power are among the most influential, features with lower MI scores, such as atmosphere and printed geometry, also contribute to the modeling process by providing context and stability. All ten predictors identified in this analysis will be utilized in training the machine learning models, ensuring a comprehensive approach to capturing the complex relationships inherent in the dataset. This foundational analysis enables the development of more accurate and efficient machine-learning models for optimizing the laser-based powder bed fusion process.
On the other hand, before modeling, we applied a preliminary clustering strategy using the K-Means algorithm, given the heterogeneous nature of the dataset and the inherent experimental bias. Clustering helps to identify natural groupings within the data, allowing us to capture hidden structures that may not be apparent at first glance. By grouping similar data points, we aim to reduce noise and improve the predictive performance of subsequent machine learning models. K-Means was chosen specifically for its simplicity and efficiency in dealing with large datasets, as well as its ability to partition the data into well-separated clusters, which enhances model accuracy by allowing for tailored-modeling approaches within each cluster. The t-Distributed Stochastic Neighbor Embedding (t-SNE)33 technique is utilized to display the clustering outcomes in a 2D space. This algorithm is a non-linear approach for reducing dimensionality, which projects high-dimensional datasets onto a two-dimensional surface while maintaining the local relationships. This allows for clearer visualization and improved interpretation of the data. Table 3 shows a statistical summary of the numeric variables by cluster, including the mean and standard deviation for each variable across the identified clusters and the whole dataset. The data for each cluster is split into training (80%) and test sets (20%) to build optimal models.
In order to evaluate the technical integrity and usefulness of our dataset, we applied XGBoost and Random Forest regressors. XGBoost is known for its efficiency and accuracy in managing structured data, while Random Forest helps minimize overfitting by leveraging ensemble learning. Both algorithms were selected due to their capability to handle complex, high-dimensional data. Comparing these models allowed us to better understand their strengths and how well they suited the task of building predictive models. We trained and assessed the models using conventional error-based metrics, including Mean Absolute Error (MAE), Mean Squared Error (MSE), and R-squared (R2), to measure their effectiveness in predicting RD. The purpose of this validation was to confirm that our dataset was robust enough to be used in developing machine-learning models by providing enough information to build accurate predictive models. On top of that, we also aimed to assess, by a preliminary training process, the consistency and accuracy of predictions when the input parameters are extended beyond printing conditions.
The results presented in Table 4 and Fig. 5 demonstrate the overall model’s performance, confirming that the dataset is reliable and well-suited for predictive modeling. A more detailed analysis revealed that the XGBoost regressor provides a better fitting, explaining over 90% of the output variability for the training data and more than 70% for the testing data. A slight overfitting issue was observed, with training errors being lower than validation errors. However, both XGBoost and Random Forest delivered robust results, indicating that these machine-learning approaches can reliably predict the relative density of 3D-printed samples. These findings confirm that the dataset meets high technical standards and is suitable for further research on relative density prediction. We encourage continued exploration of this dataset to support advances in L-BPF through machine learning. As part of this thorough study, we will focus on refining the training stage of the machine learning regressor, considering hyperparameter optimization, k-fold cross-validation strategies, and incorporating other modeling techniques in an ensemble approach.

Preliminary predicted results, (a) 2D visualization of the clusters, (b) XGBoost performance, (c) Random Forest performance.
Usage Notes
To facilitate easy access to our dataset and to support the replication of our results, we have made available code examples for the preliminary data exploration and the model fitting process used in our analysis on GitHub. These examples provide detailed implementation steps, allowing researchers to adapt the models to their specific studies. For preprocessing, we recommend normalizing (i.e., z-score) the input parameters, such as printing conditions, to ensure effective model training and reduce the influence of different scales in the variables. If the goal is to study the relationship between printing conditions and relative density, researchers may focus on the relevant columns listed in the summary file. However, if the study aims to explore additional factors like shielding gas or geometry, they can incorporate these columns as feature inputs, adopting an integrated modeling approach. Additionally, researchers can extend the dataset by adding more columns to the dataset following the existing format, allowing for the inclusion of other potential factors that could influence the outcomes (i.e., scanning strategy, pre-heating the building substrate, etc.). We hope that the dataset and accompanying code serve as a valuable resource for further research and model development.
Code availability
The EDA was performed using the Google Colaboratory platform, which allows for executing Python code in a Jupyter Notebook environment. The code is available on the following GitHub repository: https://github.com/GermanOmar/data_LPBF. Usage instructions can be found in the code documentation.
References
Mcconnell, S., Tanner, D. & Kourousis, K. I. Productivity improvement opportunities for metal powder bed fusion technologies: a systematic literature review. Rapid Prototyping J. 30, 230–245, https://doi.org/10.1108/RPJ-09-2023-0333 (2024).
Debroy, T., Mukherjee, T., Wei, H. L., Elmer, J. W. & Milewski, J. O. Metallurgy, mechanistic models and machine learning in metal printing. Nat. Rev. Mater. 6, 48–68, https://doi.org/10.1038/s41578-020-00236-1 (2021).
Nabavi, S. F., Dalir, H. & Farshidianfar, A. A comprehensive review of recent advances in laser powder bed fusion characteristics modeling: metallurgical and defects. Int. J. Adv. Manuf. Technol. 132, 2233–2269, https://doi.org/10.1007/s00170-024-13491-1 (2024).
Lu, C. & Shi, J. Relative density and surface roughness prediction for Inconel 718 by selective laser melting: Central composite design and multi-objective optimization. Int. J. Adv. Manuf. Technol 119, 3931–3949, https://doi.org/10.1007/s00170-021-08388-2 (2022).
Lu, C., Shi, J. & Maitra, V. Modelling and process optimization for relative density of Ti6Al4V produced by selective laser melting: a data-driven study. Int J Adv Manuf Technol 121, 1973–1988, https://doi.org/10.1007/s00170-022-09453-0 (2022).
Lu, C. & Shi, J. Simultaneous consideration of relative density, energy consumption, and build time for selective laser melting of Inconel 718: A multi-objective optimization study on process parameter selection. J. Clean Prod. 369, 133284, https://doi.org/10.1016/j.jclepro.2022.133284 (2022).
Li, J. et al. Effects of process parameters on the relative density and properties of CuCrZr alloy produced by selective laser melting. Metals 12, 701, https://doi.org/10.3390/met12050701 (2022).
Barrionuevo, G. O., Ramos-Grez, J. A., Walczak, M. & Betancourt, C. A. Comparative evaluation of supervised machine learning algorithms in the prediction of the relative density of 316L stainless steel fabricated by selective laser melting. Int. J. Adv. Manuf. Technol 113, 419–433, https://doi.org/10.1007/s00170-021-06596-4 (2021).
Majeed, A. et al. Investigation of T4 and T6 heat treatment influences on relative density and porosity of AlSi10Mg alloy components manufactured by SLM. Comput. Ind. Eng. 139, 106194, https://doi.org/10.1016/j.cie.2019.106194 (2020).
Malý, M. et al. Effect of process parameters and high-temperature preheating on residual stress and relative density of Ti6Al4V processed by selective laser melting. Materials 12, 930, https://doi.org/10.3390/ma12060930 (2019).
Bai, S., Perevoshchikova, N., Sha, Y. & Wu, X. The effects of selective laser melting process parameters on relative density of the AlSi10Mg parts and suitable procedures of the Archimedes method. Appl. Sci. 9, 583, https://doi.org/10.3390/app9030583 (2019).
Chua, C., Liu, Y., Williams, R. J., Chua, C. H. & Sing, S. L. In-process and post-process strategies for part quality assessment in metal powder bed fusion: A review. J. Manuf. Syst. 73, 75–105, https://doi.org/10.1016/j.jmsy.2024.01.004 (2024).
Praveen Kumar, V. & Vinoth Jebaraj, A. Microscale investigations on additively manufactured Inconel 718: Influence of volumetric energy density on microstructure, texture evolution, defects control and residual stress. Appl. Phys. A 129, 370, https://doi.org/10.1007/s00339-023-06642-w (2023).
Cacace, S., Pagani, L., Colosimo, B. M. & Semeraro, Q. The effect of energy density and porosity structure on tensile properties of 316L stainless steel produced by laser powder bed fusion. Prog. Addit Manuf. 7, 1053–1070, https://doi.org/10.1007/s40964-022-00281-y (2022).
Xu, J. et al. Effect of laser energy density on the microstructure and microhardness of Inconel 718 alloy fabricated by selective laser melting. Crystals 12, 1243, https://doi.org/10.3390/cryst12091243 (2022).
Watring, D. S., Benzing, J. T., Hrabe, N. & Spear, A. D. Effects of laser-energy density and build orientation on the structure-property relationships in as-built Inconel 718 manufactured by laser powder bed fusion. Addit. Manuf. 36, 101425, https://doi.org/10.1016/j.addma.2020.101425 (2020).
Larimian, T., Kannan, M., Grzesiak, D., AlMangour, B. & Borkar, T. Effect of energy density and scanning strategy on densification, microstructure and mechanical properties of 316L stainless steel processed via selective laser melting. Mater. Sci. Eng. A 770, 138455, https://doi.org/10.1016/j.msea.2019.138455 (2020).
Tian, J. et al. Dependence of microstructure, relative density and hardness of 18Ni-300 maraging steel fabricated by selective laser melting on the energy density. In Advances in Materials Processing, 229–241, https://doi.org/10.1007/978-981-13-0107-0_22 (Springer Singapore, 2018).
Liu, B., Fang, G., Lei, L. & Yan, X. Predicting the porosity defects in selective laser melting (SLM) by molten pool geometry. Int. J. Mech. Sci. 228, 107478, https://doi.org/10.1016/j.ijmecsci.2022.107478 (2022).
Hirata, T., Kimura, T. & Nakamoto, T. Effects of hot isostatic pressing and internal porosity on the performance of selective laser melted AlSi10Mg alloys. Mater. Sci. Eng. A 772, 138713, https://doi.org/10.1016/j.msea.2019.138713 (2020).
Mugwagwa, L., Yadroitsev, I. & Matope, S. Effect of process parameters on residual stresses, distortions, and porosity in selective laser melting of maraging steel 300. Metals 9, 1042, https://doi.org/10.3390/met9101042 (2019).
Valdez, M., Kozuch, C., Faierson, E. J. & Jasiuk, I. Induced porosity in super alloy 718 through the laser additive manufacturing process: microstructure and mechanical properties. J. Alloy. Compd. 725, 757–764, https://doi.org/10.1016/j.jallcom.2017.07.198 (2017).
Dilip, J. J. S. et al. Influence of processing parameters on the evolution of melt pool, porosity, and microstructures in Ti-6Al-4V alloy parts fabricated by selective laser melting. Prog. Addit. Manuf. 2, 157–167, https://doi.org/10.1007/s40964-017-0030-2 (2017).
Kasperovich, G., Haubrich, J., Gussone, J. & Requena, G. Correlation between porosity and processing parameters in TiAl6V4 produced by selective laser melting. Mater., & Des. 105, 160–170, https://doi.org/10.1016/j.matdes.2016.05.070 (2016).
Sagi, O. & & Rokach, L. Ensemble learning: A survey. Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery 8, 1–18, https://doi.org/10.1002/widm.1249 (2018).
Chen, T. & Guestrin, C. XGBoost: a scalable tree boosting system. Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. 785–794, https://doi.org/10.1145/2939672.2939785 (2016).
Breiman, L. Random Forests. Machine Learning 45, 5–32, https://doi.org/10.1023/A:1010933404324 (2001).
Plot Digitizer, Version 2.6.8. Available: https://plotdigitizer.sourceforge.net/ (2015).
Kassym, K. & Perveen, A. Atomization processes of metal powders for 3D printing. Materials Today: Proceedings 26, 1727–1733, https://doi.org/10.1016/j.matpr.2020.02.364 (2020).
Ruan, G. et al. A comparative study on laser powder bed fusion of IN718 powders produced by gas atomization and plasma rotating electrode process. Mater. Sci. Eng. A 850, 143589, https://doi.org/10.1016/j.msea.2022.143589 (2022).
La Fé-Perdomo, I., Barrionuevo, G.O. & Ramos-Grez, J. A. A dataset for modeling and optimizing the relative density of metallic alloys in laser-based powder bed fusion. Harvard Dataverse https://doi.org/10.7910/DVN/VPBQK8 (2024).
Ross, B. C. Mutual information between discrete and continuous data sets. PLoS One 9, 1–5, https://doi.org/10.1371/journal.pone.0087357 (2014).
Van der Maaten, L. & Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 9, 2579–2605 (2008).
Sun, Y., Moroz, A. & Alrbaey, K. Sliding wear characteristics and corrosion behaviour of selective laser melted 316L stainless steel. J. Mater. Eng. Perform. 23, 518–526, https://doi.org/10.1007/s11665-013-0784-8 (2014).
Huang, M., Zhang, Z. & Chen, P. Effect of selective laser melting process parameters on microstructure and mechanical properties of 316L stainless steel helical micro-diameter spring. Int J Adv Manuf Technol 104, 2117–2131, https://doi.org/10.1007/s00170-019-03928-3 (2019).
Röttger, A., Geenen, K., Windmann, M., Binner, F. & Theisen, W. Comparison of microstructure and mechanical properties of 316L austenitic steel processed by selective laser melting with hot-isostatic pressed and cast material. Mater. Sci. Eng. A 678, 365–376, https://doi.org/10.1016/j.msea.2016.10.012 (2016).
Zhang, Z., Chu, B., Wang, L. & Lu, Z. Comprehensive effects of placement orientation and scanning angle on mechanical properties and behavior of 316L stainless steel based on the selective laser melting process. J. Alloy. Compd. 791, 166–175, https://doi.org/10.1016/j.jallcom.2019.03.082 (2019).
Lin, K. et al. Selective laser melting processing of 316L stainless steel: effect of microstructural differences along building direction on corrosion behavior. Int J Adv Manuf Technol 104, 2669–2679, https://doi.org/10.1007/s00170-019-04136-9 (2019).
Salman, O. O. et al. Impact of the scanning strategy on the mechanical behavior of 316L steel synthesized by selective laser melting. J. Manuf. Process. 45, 255–261, https://doi.org/10.1016/j.jmapro.2019.07.010 (2019).
Chen, W., Yin, G., Feng, Z. & Liao, X. Effect of powder feedstock on microstructure and mechanical properties of the 316L stainless steel fabricated by selective laser melting. Metals 8, 729, https://doi.org/10.3390/met8090729 (2018).
Tucho, W. M., Lysne, V. H., Austbø, H., Sjolyst-Kverneland, A. & Hansen, V. Investigation of effects of process parameters on microstructure and hardness of SLM manufactured SS316L. J. Alloy. Compd. 740, 910–925, https://doi.org/10.1016/j.jallcom.2018.01.098 (2018).
Liverani, E., Lutey, A. H. A., Ascari, A. & Fortunato, A. The effects of hot isostatic pressing (HIP) and solubilization heat treatment on the density, mechanical properties, and microstructure of austenitic stainless steel parts produced by selective laser melting (SLM). Int J Adv Manuf Technol 107, 109–122, https://doi.org/10.1007/s00170-020-05072-9 (2020).
Deng, Y., Mao, Z., Yang, N., Niu, X. & Lu, X. Collaborative optimization of density and surface roughness of 316L stainless steel in selective laser melting. Materials 13, 1601, https://doi.org/10.3390/ma13071601 (2020).
Ramirez-Cedillo, E. et al. Process planning of L-PBF of AISI 316L for improving surface quality and relating part integrity with microstructural characteristics. Surf. Coat. Technol. 396, 125956, https://doi.org/10.1016/j.surfcoat.2020.125956 (2020).
Sun, J. et al. Study of microstructure and properties of 316L with selective laser melting based on multivariate interaction influence. Adv. Mater. Sci. Eng. 2020, 8404052, https://doi.org/10.1155/2020/8404052 (2020).
Wang, D., Liu, Y., Yang, Y. & Xiao, D. Theoretical and experimental study on surface roughness of 316L stainless steel metal parts obtained through selective laser melting. Rapid Prototyp J. 22, 706–716, https://doi.org/10.1108/RPJ-06-2015-0078 (2016).
La Fé-Perdomo, I., Ramos-Grez, J. A., Jeria, I., Guerra, C. & Barrionuevo, G. O. Comparative analysis and experimental validation of statistical and machine learning-based regressors for modeling the surface roughness and mechanical properties of 316L stainless steel specimens produced by selective laser melting. J. Manuf. Process. 80, 666–682, https://doi.org/10.1016/j.jmapro.2022.06.021 (2022).
Vallejo, N. D. et al. Process optimization and microstructure analysis to understand laser powder bed fusion of 316L stainless steel. Metals 11, 832, https://doi.org/10.3390/met11050832 (2021).
Heiden, M. J. et al. Process and feedstock driven microstructure for laser powder bed fusion of 316L stainless steel. Materialia 21, 101356, https://doi.org/10.1016/j.mtla.2022.101356 (2022).
Parikh, Y., & Kuttolamadom, M. Property-graded stainless steel 316L by selective laser melting: characterization & design. J. Manuf. Sci. Eng.145 (2023). 10.1115/1.4056825.
Zhang, X., Chen, L., Zhou, J. & Ren, N. Simulation and experimental studies on process parameters, microstructure and mechanical properties of selective laser melting of stainless steel 316L. J Braz. Soc. Mech. Sci. Eng. 42, 402, https://doi.org/10.1007/s40430-020-02491-3 (2020).
Estrada-Díaz, J. A., Elías-Zúñiga, A., Martínez-Romero, O., Rodríguez-Salinas, J. & Olvera-Trejo, D. A. Mathematical dimensional model for predicting bulk density of inconel 718 parts produced by selective laser melting. Materials 14, 512, https://doi.org/10.3390/ma14030512 (2021).
Balbaa, M., Mekhiel, S., Elbestawi, M. & McIsaac, J. On selective laser melting of Inconel 718: densification, surface roughness, and residual stresses. Mater. Des. 193, 108818, https://doi.org/10.1016/j.matdes.2020.108818 (2020).
Choi, J. P. et al. Densification and microstructural investigation of Inconel 718 parts fabricated by selective laser melting. Powder Technol. 310, 60–66, https://doi.org/10.1016/j.powtec.2017.01.030 (2017).
Sufiiarov, V. S., Borisov, E. V. & Polozov, I. A. Selective laser melting of the Inconel 718 nickel superalloy. Appl. Mech. Mater. 698, 333–338 (2015).
Prasad, K., Obana, M., Ito, A. & Torizuka, S. Synchrotron diffraction characterization of dislocation density in additively manufactured IN 718 superalloy. Mater. Charact. 179, 111379, https://doi.org/10.1016/j.matchar.2021.111379 (2021).
Sufiiarov, V. S. et al. The effect of layer thickness at selective laser melting. Procedia Eng. 174, 126–134, https://doi.org/10.1016/j.proeng.2017.01.179 (2017).
Sun, J., Yang, Y. & Wang, D. Parametric optimization of selective laser melting for forming Ti6Al4V samples by Taguchi method. Opt. Laser Technol. 49, 118–124, https://doi.org/10.1016/j.optlastec.2012.12.002 (2013).
Bartolomeu, F. et al. Predictive models for physical and mechanical properties of Ti6Al4V produced by selective laser melting. Mater. Sci. Eng. A 663, 181–192, https://doi.org/10.1016/j.msea.2016.03.113 (2016).
Khorasani, A., Gibson, I., Awan, U. S. & Ghaderi, A. The effect of SLM process parameters on density, hardness, tensile strength and surface quality of Ti-6Al-4V. Addit. Manuf. 25, 176–186, https://doi.org/10.1016/j.addma.2018.09.002 (2019).
Maitra, V., Shi, J. & Lu, C. Robust prediction and validation of as-built density of Ti-6Al-4V parts manufactured via selective laser melting using a machine learning approach. J. Manuf. Process. 78, 183–201, https://doi.org/10.1016/j.jmapro.2022.04.020 (2022).
He, B. et al. Microstructural characteristic and mechanical property of Ti6Al4V alloy fabricated by selective laser melting. Vacuum 150, 79–83, https://doi.org/10.1016/j.vacuum.2018.01.026 (2018).
Elsayed, M., Ghazy, M., Youssef, Y. & Essa, K. Optimization of SLM process parameters for Ti6Al4V medical implants. Rapid Prototyp J. 25, 433–447, https://doi.org/10.1108/RPJ-05-2018-0112 (2019).
Shi, X. et al. Performance of High Layer Thickness in Selective Laser Melting of Ti6Al4V. Materials 9, 975, https://doi.org/10.3390/ma9120975 (2016).
Li, J. & Wei, Z. Process optimization and microstructure characterization of Ti6Al4V manufactured by selective laser melting. IOP Conference Series: Mater. Sci. and Eng. 269, 012026, https://doi.org/10.1088/1757-899X/269/1/012026 (2017).
Sagbas, B., Gencelli, G. & Sever, A. Effect of process parameters on tribological properties of Ti6Al4V surfaces manufactured by selective laser melting. J. Mater. Eng. Perform. 30, 4966–4973, https://doi.org/10.1007/s11665-021-05573-y (2021).
Pal, S., Lojen, G., Kokol, V. & Drstvensek, I. Evolution of metallurgical properties of Ti-6Al-4V alloy fabricated in different energy densities in the selective laser melting technique. J. Manuf. Process. 35, 538–546, https://doi.org/10.1016/j.jmapro.2018.09.012 (2018).
Tang, X. et al. A study on the mechanical and electrical properties of high-strength CuCrZr alloy fabricated using laser powder bed fusion. J. Alloy. Compd. 924, 166627, https://doi.org/10.1016/j.jallcom.2022.166627 (2022).
Wang, Q. et al. Effect of process parameters and heat treatment on the microstructure and properties of CuCrZr alloy by selective laser melting. Mater. Sci. Eng. A 857, 144054, https://doi.org/10.1016/j.msea.2022.144054 (2022).
Ma, Z. et al. The Influence of structural design on the dimensional accuracy of CuCrZr alloy produced by laser powder bed fusion. Sustainability 14, 14639, https://doi.org/10.3390/su142114639 (2022).
Ma, Z. et al. Selective laser melting of Cu–Cr–Zr copper alloy: parameter optimization, microstructure and mechanical properties. J. Alloy. Compd. 828, 154350, https://doi.org/10.1016/j.jallcom.2020.154350 (2020).
Guan, P. et al. Effect of selective laser melting process parameters and aging heat treatment on properties of CuCrZr alloy. Mater. Res. Express 6, 1165c1, https://doi.org/10.1088/2053-1591/ab4e2f (2019).
Hu, Z., Du, Z., Yang, Z., Yu, L. & Ma, Z. Preparation of Cu–Cr–Zr alloy by selective laser melting: role of scanning parameters on densification, microstructure and mechanical properties. Mater. Sci. Eng. A 836, 142740, https://doi.org/10.1016/j.msea.2022.142740 (2022).
Jeyaprakash, N., Kumar, M. S. & Yang, C. H. Enhanced nano-level mechanical responses on additively manufactured Cu-Cr-Zr copper alloy containing Cu2O nano precipitates. J. Alloy. Compd. 930, 167425, https://doi.org/10.1016/j.jallcom.2022.167425 (2023).
Zhou, J. et al. Effect of heat treatments on microstructure, mechanical and electrical properties of Cu–Cr–Zr alloy manufactured by laser powder bed fusion. Mater. Chem. Phys. 296, 127249, https://doi.org/10.1016/j.matchemphys.2022.127249 (2023).
Sun, F. et al. Mechanical properties of high-strength Cu–Cr–Zr alloy fabricated by selective laser melting. Materials 13, 5028, https://doi.org/10.3390/ma13215028 (2020).
Zhang, X. et al. Effects of build orientation and heat treatment on microstructure and properties of Cu–Cr–Zr alloy manufactured by laser powder bed fusion. Mater. Chem. Phys. 298, 127477, https://doi.org/10.1016/j.matchemphys.2023.127477 (2023).
Kempen, K., Thijs, L., Van Humbeeck, J. & Kruth, J. P. Processing AlSi10Mg by selective laser melting: parameter optimisation and material characterisation. Mater. Sci. Technol. 31, 917–923, https://doi.org/10.1179/1743284714Y.0000000702 (2015).
Liu, B., Li, B. Q. & Li, Z. Selective laser remelting of an additive layer manufacturing process on AlSi10Mg. Results Phys. 12, 982–988, https://doi.org/10.1016/j.rinp.2018.12.018 (2019).
Teng, X. et al. Parameter optimization and microhardness experiment of AlSi10Mg alloy prepared by selective laser melting. Mater. Res. Express 6, 086592, https://doi.org/10.1088/2053-1591/ab18d0 (2019).
Wischeropp, T.M., Tarhini, H. & Emmelmann, C. Influence of laser beam profile on the selective laser melting process of AlSi10Mg. J. Laser Appl. 32, https://doi.org/10.2351/7.0000100 (2020).
Chua, C.K., Tian, X., Yu, W. & Sing, S.L. Effects of re-melting strategies on densification behavior and mechanical properties of selective laser melted AlSi10Mg parts. Proceedings of the 3rd International Conference on Progress in Additive Manufacturing 476–481. https://doi.org/10.25341/D48309 (Pro- AM 2018).
Hyer, H. et al. Understanding the laser powder bed fusion of AlSi10Mg alloy. Metallogr. Microstruct. Anal 9, 484–502, https://doi.org/10.1007/s13632-020-00659-w (2020).
Chen, Z. et al. Experimental research on selective laser melting AlSi10Mg alloys: process, densification and performance. J. Mater. Eng. Perform. 26, 5897–5905, https://doi.org/10.1007/s11665-017-3044-5 (2017).
Pan, W. et al. Research on microstructure and properties of AlSi10Mg fabricated by selective laser melting. Materials 15, 2528, https://doi.org/10.3390/ma15072528 (2022).
Read, N., Wang, W., Essa, K. & Attallah, M. M. Selective laser melting of AlSi10Mg alloy: process optimisation and mechanical properties development. Mater. Des. 65, 417–424, https://doi.org/10.1016/j.matdes.2014.09.044 (2015).
Amir, B., Gale, Y., Sadot, A., Samuha, S. & Sadot, O. Study on the effects of manufacturing parameters on the dynamic properties of AlSi10Mg under dynamic loads using Taguchi procedure. Mater. Des. 223, 111125, https://doi.org/10.1016/j.matdes.2022.111125 (2022).
Zhou, H. et al. Effect of axial static magnetic field on microstructure evolution, performance, and melt pool signals of AlSi10Mg fabricated by laser powder bed fusion. Opt. Laser Technol. 163, 109316, https://doi.org/10.1016/j.optlastec.2023.109316 (2023).
Praneeth, J., Venkatesh, S. & Sivarama Krishna, L. Process parameters influence on mechanical properties of AlSi10Mg by SLM. Materials Today: Proceedings https://doi.org/10.1016/j.matpr.2022.12.222 (2023)
Król, M., Snopiński, P., Hajnyš, J., Pagáč, M. & Łukowiec, D. Selective laser melting of 18NI-300 maraging steel. Materials 13, 4268, https://doi.org/10.3390/ma13194268 (2020).
Song, J. et al. Effect of heat treatment on microstructure and mechanical behaviours of 18Ni-300 maraging steel manufactured by selective laser melting. Opt. Laser Technol. 120, 105725, https://doi.org/10.1016/j.optlastec.2019.105725 (2019).
Maodzeka, D. K., Olakanmi, E. O., Mosalagae, M., Hagedorn-Hansen, D. & Pityana, S. L. Hybrid optimisation studies on the microstructural properties and wear resistance of maraging steel 1.2709 parts produced by laser powder bed fusion. Opt. Laser Technol. 159, 108914, https://doi.org/10.1016/j.optlastec.2022.108914 (2023).
Mao, Z. et al. Processing optimization, microstructure, mechanical properties and nanoprecipitation behavior of 18Ni300 maraging steel in selective laser melting. Mater. Sci. Eng. A 830, 142334, https://doi.org/10.1016/j.msea.2021.142334 (2022).
Wang, Y. et al. Tuning process parameters to optimize microstructure and mechanical properties of novel maraging steel fabricated by selective laser melting. Mater. Sci. Eng. A 823, 141740, https://doi.org/10.1016/j.msea.2021.141740 (2021).
Song, J. et al. Effect of remelting processes on the microstructure and mechanical behaviours of 18Ni-300 maraging steel manufactured by selective laser melting. Mater. Charact. 184, 111648, https://doi.org/10.1016/j.matchar.2021.111648 (2022).
Mutua, J., Nakata, S., Onda, T. & Chen, Z. C. Optimization of selective laser melting parameters and influence of post heat treatment on microstructure and mechanical properties of maraging steel. Mater. Des. 139, 486–497, https://doi.org/10.1016/j.matdes.2017.11.042 (2018).
Li, G. et al. Influence of selective laser melting process parameters on densification behavior, surface quality and hardness of 18Ni300 steel. Key Eng Mater. 861, 77–82 (2020).
de Souza, A. F., Al-Rubaie, K. S., Marques, S., Zluhan, B. & Santos, E. C. Effect of laser speed, layer thickness, and part position on the mechanical properties of maraging 300 parts manufactured by selective laser melting. Mater. Sci. Eng. A 767, 138425, https://doi.org/10.1016/j.msea.2019.138425 (2019).
Ong, J. K. et al. Effect of process parameters and build orientations on the mechanical properties of maraging steel (18Ni-300) parts printed by selective laser melting. Mater. Today: Proc. 70, 438–442, https://doi.org/10.1016/j.matpr.2022.09.362 (2022).
Ma, Y., Gao, Y., Zhao, L., Li, D. & Men, Z. Optimization of process parameters and analysis of microstructure and properties of 18Ni300 by selective laser melting. Materials 15, 4757, https://doi.org/10.3390/ma15144757 (2022).
Acknowledgements
We extend our sincere gratitude to the researchers who made their experimental data available through their publications, whether in tabular or graphical form. Their contributions have enabled us to further advance the understanding of the impact of non-conventional parameters on the relative density of samples produced by laser-based powder bed fusion. We also acknowledge the financial support provided by the ANID FONDEQUIP project 180081, facilitating the execution of our own experimental work.
Author information
Authors and Affiliations
Contributions
Germán Omar Barrionuevo: Conceptualization, Data curation, Visualization, Writing-original draft. Iván La Fé-Perdomo: Conceptualization, Methodology, Dataset curation, Visualization, Writing-original draft. Jorge A. Ramos-Grez: Conceptualization, Investigation, Validation, Editing.
Corresponding author
Ethics declarations
Competing interests
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Barrionuevo, G.O., La Fé-Perdomo, I. & Ramos-Grez, J.A. Laser powder bed fusion dataset for relative density prediction of commercial metallic alloys. Sci Data 12, 375 (2025). https://doi.org/10.1038/s41597-025-04576-x
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41597-025-04576-x
