
Abstract
In a given species, genomes and 16S rRNA gene sequences, along with their intragenomic copy numbers, can vary greatly across environments. The gene copy numbers are crucial for technologies which estimate microbial abundances based on gene counts, such as polymerase chain reaction and high-throughput sequencing. In these, taxa with fewer genes may be underestimated, while those with more genes might be overestimated. Therefore, it is essential to have accurate gene copy number databases specific to the niche under study. The 16S rRNA Gene Oral Sequences dataset (16SGOSeq) contains the number of 16S rRNA genes and their variants in the complete genomes of the bacterial and archaeal species present in the human oral cavity. It includes 3,192 complete genomes of oral bacteria and 191 complete genomes of oral archaea, from which the 16S rRNA gene sequences were extracted, and the sequence variants were identified. This oral-specific dataset of prokaryotic organisms and the pipeline followed for its construction can be applied by clinical microbiologists, bioinformaticians, or microbial ecologists in future microbiome research.
Similar content being viewed by others

Background & Summary
The oral microbiome is the most diverse and second largest in the human body, with over 700 microbial species detected in the mouth at any time1. Of these, an individual’s mouth usually harbours between 200 and 300 predominant bacterial species2. The dysbiosis of this community, or imbalance, is a key factor in the onset and development of two of the most widespread diseases worldwide: dental caries and periodontitis3. Moreover, alterations in the mouth microbiome have been associated with highly relevant systemic pathologies such as diabetes and cardiovascular diseases4.
A range of microbiological techniques have been employed to investigate the oral microbial communities associated with health and disease. Among the most prevalent techniques are polymerase chain reaction (PCR), conventional or quantitative (qPCR), and high-throughput sequencing (HTS). These techniques are typically employed by targeting the 16S ribosomal RNA (rRNA) gene5,6. The gene in question comprises approximately 1,500 base pairs (bps) and it is regarded as a reliable phylogenetic marker due to several reasons. Primarily, this gene is ubiquitous in bacteria and archaea, exhibiting relative stability in combining conserved (C) and hypervariable (V) regions. Additionally, complete and easily accessible databases exist7.
Nevertheless, utilising the 16S rRNA gene also presents certain limitations. One of the most significant is the intragenomic redundancy, which refers to the presence of more than one identical or distinct genes per genome8,9,10. Under the concept of genetic variants, it could be considered the sequences of genes in a genome that differ in at least one nucleotide. Therefore, a variant can have multiple copies per genome. Technologies such as qPCR and HTS are employed to estimate microbial abundance based on gene counts. Consequently, the outcomes derived from these may be influenced to the extent that taxa with a low number of genes may be underestimated, while those with high numbers may be overestimated10. Furthermore, heterogeneity between the multiple gene copies within a genome may result in overestimating and taxonomic misassignments9.
There are several methodologies for correcting the variation in intragenomic gene copy numbers, such as CopyRighter11 or PICRUSt12. However, these methodologies are characterised by significant drawbacks. Primarily, these methods are highly dependent on the database used, and therefore, inaccurate estimates may result from incomplete or erroneous data13.
The Ribosomal RNA Operon Copy Number Database (rrnDB)14 and RiboGrove15 provide information on the number of 16S rRNA genes in the genomes of bacteria and archaea. However, the genomes and 16S rRNA gene sequences, as well as their intragenomic copy number, in a given species may vary among environments or niches16,17. This variability may be attributed to adaptation to different environmental conditions, selective pressures, or evolutionary events such as gene acquisition through horizontal transfer. It is observed that the greater the pressure or difference between environments, the greater the variability17,18,19,20. Furthermore, neither of the above databases allows for the identification of the different intragenomic gene variants14,15.
On the other hand, the rrnDB14 does not allow the selection of sequences from specific taxonomic groups or taxa; the complete database must be downloaded, and subsequent manual selection must be performed. Moreover, the developers of rrnDB14 claim to perform quality control of the sequences using data from the Ribosomal Database Project (RDP)21. The use of phylogenetically diverse databases can produce classification errors because they contain taxonomically misannotated 16S rRNA gene sequences (i.e., annotation rates in the RDP are approximately 10%)22. They also represent differently the environments included, varying substantially in the quality of the classifications23.
Preference for the use of environment-specific databases has been demonstrated not only in the oral cavity24 by focusing on the expanded Human Oral Microbiome Database (eHOMD)25, but also on the vaginal26, bovine27, bee28, dairy products29, and wastewater treatment plants microbiomes30. Overall, these studies have proven that the use of niche-specific databases improves the accuracy of taxonomic classifications by aligning reference sequences more closely with the microbial communities under investigation, and reduces the number of unassigned reads.
As a last remark, it is notable that numerous examples of species from the same genus have been associated with opposite mouth conditions31,32. Consequently, it is recommended that oral microbiology analysis be performed at the lowest taxonomic level possible.
In light of the aforementioned considerations, the objective of this study was to develop a curated dataset comprising all 16S rRNA gene sequences present in the genomes with complete sequencing status of bacterial and archaeal species inhabiting the human mouth. The oral prokaryote-specific dataset, designated 16SGOSeq (16S rRNA Gene Oral Sequences dataset), contains information regarding the size of complete genomes and the size and number of genes per genome and gene variants per genome for taxonomic categories from domain to strain level. All gene sequences are designated at the lowest possible taxonomic level, and users can filter by the desired taxonomic level/taxon and calculate data averages.
Methods
The 16SGOSeq dataset is a curated sequence dataset based on a collection of genetic sequences that have undergone a systematic and rigorous process of selection, validation, classification and updating, thus guaranteeing their high quality, accuracy and reliability for subsequent scientific uses33.
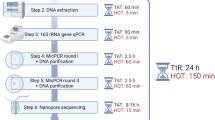
This dataset was constructed following a number of criteria regarding genome inclusion and the curation procedures were employed for the sequences, as illustrated in Fig. 1.

Process flow diagram describing the construction and curation of the 16SGOSeq dataset.
Data acquisition. Obtaining complete oral bacterial and archaeal genomes
Firstly, the inclusion criteria for the bacterial and archaeal genomes were set to ensure the sequences’ quality. The following criteria were thus established:
-
1.
The bacterial and archaeal taxa were limited to those identified as inhabitants of the oral cavity.
-
2.
Only genomes with complete sequencing status according to the expanded Human Oral Microbiome Database (eHOMD)25 were included.
-
3.
The genomes included in this study are those with complete taxonomy up to the species level (i.e., they had to have a specific name for the domain, phylum, class, order, family, genus, and species). Those with ambiguous or disputed taxonomies were eligible (e.g. Candidatus taxa). Those with the “unclassified” term at any level were not eligible.
-
4.
Genomes with no more than 10 consecutive ambiguous International Union of Pure and Applied Chemistry (IUPAC) nucleotides were included.
Consequently, the sequences and other information that met the inclusion criteria were downloaded. All available data on bacterial taxa within the mouth was acquired from the publicly available eHOMD oral-specific database25 (https://www.homd.org/ftp//genomes/NCBI/V10.1). Only genomes with complete sequencing status according to the eHOMD were chosen, resulting in a total of 3, 128 complete genomes out of the 8, 622 on the eHOMD website. Each genome was assigned one or more GenBank identifiers, which were included in the downloaded genome’s file as different sequences. In the majority of cases, the identifiers corresponded to chromosomal DNA. However, in some instances, they also corresponded to plasmids. Both were considered in the completion of the dataset.
Regarding the oral archaea, the eHOMD25 only encompasses complete genome information for a single species, namely Methanobrevibacter oralis. For this reason, we used an initial list obtained as part of a previous investigation34, which comprised 177 different archaea found in the human mouth and their corresponding GenBank identifiers35 to obtain complete publicly available archaeal genomes from the NCBI database36. This archaeal list is shown in Supplementary Table S1 of the Supplementary Information. The provenance of these complete genomes was: environmental (91%), human niches (3%), and others (6%).
The Entrez Programming Utilities (E-utilities)37 tool was employed to retrieve pertinent data from the diverse NCBI databases, including the Taxonomy38 and GenBank35 databases. The Entrez module from the BioPython39 package was employed in a Python script (version 3.9.0, http://www.python.org/) to facilitate the transmission of requests to the databases and the acquisition of the oral-archaeal genomes and their corresponding taxonomies, as well as the oral-bacterial metadata.
Genomes that lacked a complete taxonomic classification up to the species level were excluded from the analysis. Furthermore, some genomes included non-specific nucleotides, which were identified by the IUPAC codes for ambiguous characters. It should be noted that these ambiguous characters or nucleotides may represent two, three, or four possible nucleic acid states40, instead of a unique specification for the four nitrogenous bases of the DNA (A, adenine; G, guanine; C, cytosine; T, thymine). It was, therefore, necessary to exclude from the analysis genomes that had more than ten consecutive ambiguous IUPAC nucleotides.
Following the application of the aforementioned criteria, a total of 3, 079 complete genomes of oral bacteria were identified. Of these, several had one or more sequences corresponding to either genomes, chromosomes, or plasmids. Each was evaluated as a complete genome, resulting in a final number of 5, 755 oral-bacterial complete genomes being considered for analysis. These genomes all had the taxonomy complete up to the strain level. A total of 177 complete archaeal genomes were listed, of which 166 had one chromosome, 10 had two chromosomes, and one had five chromosomes. Consequently, a final number of 191 oral-archaeal complete genomes were considered for creating the 16SGOSeq dataset.
Detection and extraction of 16S rRNA genes
A Python script was developed to extract the 16S rRNA genes. This script utilised a freely available module, search_16S_py41, which implements Edgar’s algorithm42. The algorithm employs a search strategy that identifies sections of genomes exhibiting a high frequency of 13-mers, which are characteristic of known 16S rRNA genes. Subsequently, the search is conducted within each segment for conserved motifs situated in close proximity to the beginning and end of the gene. The presence of a pair of motifs within the expected length range indicates the presence of the gene and provides consistent and homologous endpoints.
The application of this algorithm resulted in the detection and extraction of 16S rRNA gene sequences from the complete downloaded genomes, which were subsequently stored in FASTA-formatted files along with the variants, that is, the sequences differing by at least one nucleotide between each other in a genome. All the 16S rRNA gene variants identified were designated at the strain level or the species level if no designated strain name existed, in accordance with the established nomenclature guidelines.
A number of the genomes were found to lack 16S rRNA genes, resulting in the number of genomes reducing to 3, 192 oral-bacterial genomes, corresponding to 3, 047 strains and 334 species, and 191 oral-archaeal genomes, corresponding to 135 species. For the bacterial genomes, a total of 14, 966 genes and 8, 155 variants were identified. For the archaeal genomes, a total of 346 genes and 255 variants were identified.
For each genome under consideration, the following data were calculated: genome size, size of the 16S rRNA genes detected, total number of 16S rRNA genes, number of different variants, and number of 16S rRNA genes in each strand.
Additionally, through the use of a complementary script based on Python’s NumPy43 and pandas44 modules, the average, median, mode and standard deviation of the data obtained can be determined for hierarchical levels above the variant level.
Data Records
The dataset is available at Zenodo (https://zenodo.org/records/15209015)45.
The 16SGOSeq dataset45 is provided in eight files, comprising both tabular and FASTA formats. The dataset comprises four files pertaining to bacteria and four files pertaining to archaea.
Variants table (bacteria_variants.csv/.xlsx, archaea_variants.csv/.xlsx)
A single table is included in both the CSV and XLSX formats, containing all the variants identified in all the genomes. The file comprises as many rows as there are variants per group of GenBank identifiers (genome and plasmids). The pertinent data for each variant is included, such as the sequence, the number of copies, and the position of the variant in the genome, among other details (see Table 1).
Variants FASTA (bacteria_variants.fasta, archaea_variants.fasta)
A FASTA file corresponding to the variants table contains one line per variant in each genome. The header includes the genome GenBank identifier, the full taxonomy up until the variant level, and the number of gene copies in the genome.
Genes FASTA (bacteria_genes.fasta, archaea_genes.fasta)
A FASTA file is provided containing all sequences identified in all genomes. This file illustrates the copies of variants observed in the genomes, with each header including the genome GenBank identifier, the full taxonomy up to the variant level, as well as the positions of the genes in each genome and the strand in which it was found.
Intragenomic variant divergence (bacteria_divergence.csv/.xlsx, archaea_divergence.csv/.xlsx)
A table is included in both the CSV and XLSX formats for bacteria and archaea, containing the information about the divergence existent between the variants of each genome of the dataset. It was acquired using BLASTN46 to align each genome’s variants against each other, to obtain the query coverage and the identity percentage used to evaluate the divergence.
Each genome has several rows corresponding to the alignments of each variant against the other variants of the genome. Table 2 shows the pertinent data included to assess the divergence, including the query coverage and the identity percentage.
Technical Validation
To validate the dataset, a total of 2, 039 random bacterial sequences were selected from our dataset, representing 25% of the total number of sequences. This random sequence group was aligned using BLASTN46 against a 16S rRNA gene sequence database. This smaller database includes 26, 954 sequences from bacteria and archaea, and does not necessarily include the same taxa represented in our dataset. With the alignment, we obtained an identity percentage of ≥97% in all cases, confirming that our sequences can be considered 16S rRNA gene sequences.
Additionally, we aligned with the same 25% of our bacterial dataset against the Core nucleotide database (core_nt)35, which contains 112, 880, 307 GenBank+EMBL+DDBJ+PDB+RefSeq sequences. In all cases, either the genus and species or the NCBI identifier matched between the query (our sequences) and the subject (core_nt sequences). Without exception, a query coverage of 100% and an identity percentage of ≥99% was obtained, confirming the validity of our sequences by demonstrating both their existence and their correct taxonomic annotation.
For the archaeal dataset, 64 sequences were selected, representing the 25% of the dataset. As done for the bacteria, all the sequences were aligned with BLASTN46 against the 16S rRNA gene sequence database from NCBI, obtaining an identity percentage of ≥97% again in all cases. These sequences were also aligned core_nt, with either the genus and species or the NCBI identifier matching between the query and the subject. A query coverage of 100% and an identity percentage of ≥99% were obtained.
Additionally, the intragenomic divergence of the variants was analysed. BLASTN46 was used to perform a discontinuous megablast and align each genome’s variants against each other. Genomes were considered to present high divergence if, at least two of their variants presented a query coverage of ≤97% or an identity percentage of ≤97%.
From the total 3, 046 bacterial genomes and 177 archaeal genomes, we have found 43 and 9, respectively, to present high divergence amongst some of their variants.
These results are presented in files bacteria_divergence.csv/.xlsx and archaea_divergence.csv/.xlsx in the dataset repository.
Usage Notes
The quantity of PCR-amplified product is contingent upon the genome size and the number of 16S rRNA genes per genome47. Consequently, it is not possible to accurately quantify the number of species represented in clone libraries of samples from a given ecosystem until these two parameters are known for the taxa present47. If these factors are not considered, when performing PCR, qPCR, or marker-gene sequencing, inferences about numerous aspects of microbial communities may be affected48. Moreover, this information is also pertinent to whole genome sequencing (WGS) technologies, which employ 16S rRNA gene counts for their analyses of the diversity and structure of prokaryotic populations49,50. Understanding the number of gene copies per genome can facilitate our comprehension of the ecological and evolutionary relationships between different microorganisms17.
It can be observed that rrnDB14 and RiboGrove15 present certain inherent limitations when employed in studies of the mouth microbiome compared to 16SGOSeq45 (Table 3). The gene sequences included in our newly developed dataset originate from complete genomes that have been manually monitored at NCBI36 of bacteria and archaea that are known to inhabit the human oral cavity34. This enables researchers to ascertain the number of 16S genes and variants per genome at a desired hierarchical level or taxon. This information is necessary to adjust gene-based abundance values for estimated abundance values of the organism(s).
The 16SGOSeq45 can be filtered according to the needs of the research study, grouping the genes by different taxonomic levels and obtaining the averages, standard deviations, and more calculations. Users can use programming languages such as R or Python, which are the most typically used in bioinformatics, to taxonomically filter the dataset using the columns in the dataset files dedicated to the taxonomy. Complementary, to facilitate the use of 16SGOSeq45, we constructed an auxiliary Python51 script to perform the filtering of the information by the desired taxonomic level and calculate averages of relevant data. Further details about the script can be found in the Supplementary Information.
The list of the oral bacteria included in our dataset originates from the eHOMD25. However, there is no database with sequences of archaea detected in the oral cavity. As there is no specific list of oral archaea in the eHOMD25, the complete genomes of the oral archaea were obtained directly from the NCBI36, and most of them belong to environmental niches. It is recommended that the oral microbiology community increase the amount of evidence related to oral archaea to overcome this limitation by focusing on isolating and sequencing archaea directly from mouth samples to refine taxonomic and functional annotations.
Most of the complete genomes in the eHOMD25 belong to cultivable taxa. While in the HOMD, 71% of the species are cultivable and 26% are non-cultivable, in the 16SGOSeq45 dataset 96% are cultivable and 1.20% are non-cultivable. Our dataset provides a more robust representation of the cultivable fraction of the oral microbiome than the non-cultivable. Nevertheless, 16SGOSeq45 contains the most prevalent and abundant bacterial species in health, caries, and periodontitis1,2,52, and numerous examples of the so-called rare taxa53,54,55.
So far, the sequences and data averages calculated in 16SGOSeq45 have been used in two studies by our research group. One to analyse the impact of intragenomic redundancy of the 16S rRNA gene and the selection of primer pairs in the oral cavity, and the other to identify species with very similar 16S rRNA sequence segments using different primer pairs56,57.
Like other applications, the 16SGOSeq45 can be used in the field of oral microbiology, facilitating the design of universal primers or probes capable of detecting the greatest possible diversity of oral prokaryotic organisms, and specific primers or probes that consider the sequences of all the genetic variants of a given taxon. Additionally, if sequences from 16SGOSeq45 are to be employed for the identification of primers or probes, we propose the utilisation of the PrimerEvalPy tool58. This is a Python51 application developed by our research team that performs a coverage analysis of any primer against any database. These advances enable more accurate detection and characterisation of oral microbiota and improve the understanding of the oral ecosystem and its role in health and disease. The 16SGOSeq45, with high-quality sequences and robust taxonomic annotations, can significantly refine our understanding of phylogenetic relationships among taxa.
The techniques and strategies implemented in the curation of the present dataset can be applied by clinical microbiologists, bioinformaticians or microbial ecologists in other microbiome fields. Our pipeline can be followed to generate gene copy number datasets from existing niche-specific datasets, ensuring the production of taxonomically robust, high-resolution, and biologically informative data.
Code availability
The dataset and code can be accessed via Zenodo (https://zenodo.org/records/15209015)45 or the Gitlab repository at the following link: https://gitlab.citius.gal/lara.vazquez/16sgoseq. The dataset construction code was developed in Python 3.9, which was employed to generate the files composing the 16SGOSeq45 dataset. Furthermore, a complementary script is provided for the purpose of filtering and generating information from the dataset. Instructions for installing and using the script are detailed in the repository.
16SGOSeq45 follows an annual update policy, incorporating HOMD updates when available.
References
Deo, P. & Deshmukh, R. Oral microbiome: Unveiling the fundamentals. Journal of Oral and Maxillofacial Pathology 23, 122, https://doi.org/10.4103/jomfp.jomfp_304_18 (2019).
Krishnan, K., Chen, T. & Paster, B. A practical guide to the oral microbiome and its relation to health and disease. Oral Diseases 23, 276–286, https://doi.org/10.1111/odi.12509 (2020).
Zhang, Y. et al. Human oral microbiota and its modulation for oral health. Biomedicine & Pharmacotherapy 99, 883–893, https://doi.org/10.1016/j.biopha.2018.01.146 (2018).
Thomas, C. et al. Oral Microbiota: A Major Player in the Diagnosis of Systemic Diseases. Diagnostics 11, 1376, https://doi.org/10.3390/diagnostics11081376 (2021).
Fukuda, K., Ogawa, M., Taniguchi, H. & Saito, M. Molecular approaches to studying microbial communities: Targeting the 16S ribosomal RNA gene. J. UOEH 38, 223–232, https://doi.org/10.7888/juoeh.38.223 (2016).
Willis, J. R. & Gabaldón, T. The Human Oral Microbiome in Health and Disease: From Sequences to Ecosystems. Microorganisms 8, 308, https://doi.org/10.3390/microorganisms8020308 (2020).
Rodicio, Md. R. & Mendoza, Md. C. Identification of bacteria through 16S rRNA sequencing: principles, methods and applications in clinical microbiology. Enferm. Infecc. Microbiol. Clin. 22, 238–245, https://doi.org/10.1157/13059055 (2004).
Pei, A. Y. et al. Diversity of 16S rRNA Genes within Individual Prokaryotic Genomes. Applied and Environmental Microbiology 76, 3886–3897, https://doi.org/10.1128/aem.02953-09 (2010).
Sun, D.-L., Jiang, X., Wu, Q. L. & Zhou, N.-Y. Intragenomic Heterogeneity of 16S rRNA Genes Causes Overestimation of Prokaryotic Diversity. Applied and Environmental Microbiology 79, 5962–5969, https://doi.org/10.1128/aem.01282-13 (2013).
Větrovský, T. & Baldrian, P. The Variability of the 16S rRNA Gene in Bacterial Genomes and Its Consequences for Bacterial Community Analyses. PLoS One 8, e57923, https://doi.org/10.1371/journal.pone.0057923 (2013).
Angly, F. E. et al. CopyRighter: a rapid tool for improving the accuracy of microbial community profiles through lineage-specific gene copy number correction. Microbiome 2, https://doi.org/10.1186/2049-2618-2-11 (2014).
Langille, M. G. I. et al. Predictive functional profiling of microbial communities using 16S rRNA marker gene sequences. Nature Biotechnology 31, 814–821, https://doi.org/10.1038/nbt.2676 (2013).
Nearing, J. T., Comeau, A. M. & Langille, M. G. I. Identifying biases and their potential solutions in human microbiome studies. Microbiome 9, https://doi.org/10.1186/s40168-021-01059-0 (2021).
Stoddard, S. F., Smith, B. J., Hein, R., Roller, B. R. K. & Schmidt, T. M. rrnDB: improved tools for interpreting rRNA gene abundance in bacteria and archaea and a new foundation for future development. Nucleic Acids Research 43, D593–D598, https://doi.org/10.1093/nar/gku1201 (2015).
Sikolenko, M. A. & Valentovich, L. N. RiboGrove: a database of full-length prokaryotic 16S rRNA genes derived from completely assembled genomes. Research in Microbiology 173, 103936, https://doi.org/10.1016/j.resmic.2022.103936 (2022).
Smith, E. E. et al. Genetic adaptation by Pseudomonas aeruginosa to the airways of cystic fibrosis patients. Proceedings of the National Academy of Sciences 103, 8487–8492, https://doi.org/10.1073/pnas.0602138103 (2006).
Stevenson, B. S. & Schmidt, T. M. Life history implications of rRNA gene copy number in Escherichia coli. Applied and Environmental Microbiology 70, 6670–6677, https://doi.org/10.1128/AEM.70.10.6670-6677.2004 (2004).
Hunt, D. E. et al. Resource partitioning and sympatric differentiation among closely related bacterioplankton. Science 320, 1081–1085, https://doi.org/10.1126/science.1157890 (2008).
Cohan, F. M.Ecology of Microbial Communities, chap. Periodic selection and ecological diversity in bacteria, 79–93 (Princeton University Press, 2005).
Tamames, J. & Moya, A. Estimating the extent of horizontal gene transfer in metagenomic sequences. BMC Genomics 9, 136, https://doi.org/10.1186/1471-2164-9-136 (2008).
Cole, J. R. et al. Ribosomal Database Project: data and tools for high throughput rRNA analysis. Nucleic Acids Research 42, D633–D642, https://doi.org/10.1093/nar/gkt1244 (2014).
Edgar, R. Taxonomy annotation and guide tree errors in 16S rRNA databases. PeerJ 6, https://doi.org/10.7717/peerj.5030 (2018).
Soergel, D. A. W., Dey, N., Knight, R. & Brenner, S. E. Selection of primers for optimal taxonomic classification of environmental 16S rRNA gene sequences. ISME J 6, 1440–1444, https://doi.org/10.1038/ismej.2011.208 (2012).
Escapa, I. F. et al. Construction of habitat-specific training sets to achieve species-level assignment in 16S rRNA gene datasets. Microbiome 8, 65, https://doi.org/10.1186/s40168-020-00841-w (2020).
Escapa, I. F. et al. New Insights into Human Nostril microbiome from the expanded Human Oral Microbiome Database (eHOMD): a resource for the microbiome of the human aerodigestive tract. mSystems 3, https://doi.org/10.1128/msystems.00187-18 (2018).
Zhu, B. et al. The utility of voided urine samples as a proxy for the vaginal microbiome and for the prediction of bacterial vaginosis. Infectious Microbes and Diseases https://doi.org/10.1097/im9.0000000000000103 (2022).
Myer, P. R. et al. Classification of 16s rrna reads is improved using a niche-specific database constructed by near-full length sequencing. PLOS ONE 15, e0235498, https://doi.org/10.1371/journal.pone.0235498 (2020).
Brendan, D. A. & Reid, G. Beexact: a metataxonomic database tool for high-resolution inference of bee-associated microbial communities. mSystems 6, e00082–21, https://doi.org/10.1128/msystems.00082-21 (2021).
Meola, M. et al. Dairydb: a manually curated reference database for improved taxonomy annotation of 16s rrna gene sequences from dairy products. BMC Genomics 20, https://doi.org/10.1186/s12864-019-5914-8 (2019).
Dueholm, M. K. D. et al. Midas 4: A global catalogue of full-length 16s rrna gene sequences and taxonomy for studies of bacterial communities in wastewater treatment plants. Nature Communications 13, https://doi.org/10.1038/s41467-022-29438-7 (2022).
Relvas, M. et al. Relationship between dental and periodontal health status and the salivary microbiome: bacterial diversity, co-occurrence networks and predictive models. Scientific Reports 11, https://doi.org/10.1038/s41598-020-79875-x (2021).
Camelo-Castillo, A. J. et al. Subgingival microbiota in health compared to periodontitis and the influence of smoking. Frontiers in Microbiology 6, https://doi.org/10.3389/fmicb.2015.00119 (2015).
Buneman, P.Curated Databases, 2-2 (Springer Berlin Heidelberg, 2009).
Regueira-Iglesias, A. et al. In silico evaluation and selection of the best 16S rRNA gene primers for use in next-generation sequencing to detect oral bacteria and archaea. Microbiome 11, https://doi.org/10.1186/s40168-023-01481-6 (2023).
Clark, K., Karsch-Mizrachi, I., Lipman, D. J., Ostell, J. & Sayers, E. W. GenBank. Nucleic Acids Res. 44, D67–72, https://doi.org/10.1093/nar/gkv1276 (2016).
NCBI Resource Coordinators. Database resources of the National Center for Biotechnology Information. Nucleic Acids Research 44, D7–D19, https://doi.org/10.1093/nar/gkv1290 (2015).
Bethesda (MD): National Center for Biotechnology Information (US). Entrez Programming Utilities Help. https://www.ncbi.nlm.nih.gov/books/NBK25501/ Accessed: 2024-05-22. (2010).
Schoch, C. L. et al. NCBI taxonomy: a comprehensive update on curation, resources and tools. Database (Oxford) https://doi.org/10.1093/database/baaa062 (2020).
Cock, P. J. A. et al. Biopython: freely available Python tools for computational molecular biology and bioinformatics. Bioinformatics 25, 1422–1423, https://doi.org/10.1093/bioinformatics/btp163 (2009).
Johnson, A. D. An extended IUPAC nomenclature code for polymorphic nucleic acids. Bioinformatics 26, 1386–1389, https://doi.org/10.1093/bioinformatics/btq098 (2010).
Lyalina, S. search_16s_py: a simple python implementation of the 16s finding procedure. https://github.com/slyalina/search_16S_py Accessed: 2024-06-06. (2018).
Edgar, R. C. SEARCH_16S: A new algorithm for identifying 16S ribosomal RNA genes in contigs and chromosomes. bioRxiv https://doi.org/10.1101/124131 (2017).
Harris, C. R. et al. Array programming with NumPy. Nature 585, 357–362, https://doi.org/10.1038/s41586-020-2649-2 (2020).
McKinney, W. Data Structures for Statistical Computing in Python. In van der Walt, S. & Millman, J. (eds.) Proceedings of the 9th Python in Science Conference, 56–61, https://doi.org/10.25080/Majora-92bf1922-00a (2010).
Vázquez-González, L., Regueira Iglesias, A., Balsa-Castro, C., Tomás, I. & Carreira, M. J. 16SGOSeq: A curated bacterial and archaeal 16S rRNA Gene Oral Sequences dataset, https://doi.org/10.5281/ZENODO.15209015 (2025).
Morgulis, A. et al. Database indexing for production MegaBLAST searches. Bioinformatics 24, 1757–1764, https://doi.org/10.1093/bioinformatics/btn322 (2008).
Farrelly, V., Rainey, F. A. & Stackebrandt, E. Effect of genome size and rrn gene copy number on PCR amplification of 16S rRNA genes from a mixture of bacterial species. Applied Environmental Microbiology 61, 2798–2801, https://doi.org/10.1128/aem.61.7.2798-2801.1995 (1995).
Kembel, S. W., Wu, M., Eisen, J. A. & Green, J. L. Incorporating 16S gene copy number information improves estimates of microbial diversity and abundance. PLoS Computational Biology 8, e1002743, https://doi.org/10.1371/journal.pcbi.1002743 (2012).
Kim, C., Pongpanich, M. & Porntaveetus, T. Unraveling metagenomics through long-read sequencing: a comprehensive review. Journal of Translational Medicine 22, 111, https://doi.org/10.1186/s12967-024-04917-1 (2024).
Pérez-Cobas, A. E., Gomez-Valero, L. & Buchrieser, C. Metagenomic approaches in microbial ecology: an update on whole-genome and marker gene sequencing analyses. Microbial Genomics 6, mgen000409, https://doi.org/10.1099/mgen.0.000409 (2020).
Python Software Foundation. Python. https://www.python.org/ Accessed: 2024-05-22. (2020).
Regueira-Iglesias, A. et al. The salivary microbiome as a diagnostic biomarker of periodontitis: a 16s multi-batch study before and after the removal of batch effects. Frontiers in Cellular and Infection Microbiology 14, 1405699, https://doi.org/10.3389/fcimb.2024.1405699 (2024).
Horz, H.-P. Archaeal lineages within the human microbiome: Absent, rare or elusive? Life (Basel) 5, 1333–45, https://doi.org/10.3390/life5021333 (2021).
Burcham, Z. M. et al. Patterns of oral microbiota diversity in adults and children: A crowdsourced population study. Scientific Reports 10, 2133, https://doi.org/10.1038/s41598-020-59016-0 (2020).
Willis, J. R. et al. Citizen-science reveals changes in the oral microbiome in spain through age and lifestyle factors. NPJ Biofilms Microbiomes 8, 38, https://doi.org/10.1038/s41522-022-00279-y (2022).
Regueira-Iglesias, A. et al. In-Silico Detection of Oral Prokaryotic Species With Highly Similar 16S rRNA Sequence Segments Using Different Primer Pairs. Frontiers in Cellular and Infection Microbiology 11, https://doi.org/10.3389/fcimb.2021.770668 (2022).
Regueira-Iglesias, A. et al. Impact of 16S rRNA Gene Redundancy and Primer Pair Selection on the Quantification and Classification of Oral Microbiota in Next-Generation Sequencing. Microbiology Spectrum 11, https://doi.org/10.1128/spectrum.04398-22 (2023).
Vázquez-González, L. et al. PrimerEvalPy: a tool for in-silico evaluation of primers for targeting the microbiome. BMC Bioinformatics 25, https://doi.org/10.1186/s12859-024-05805-7 (2024).
Acknowledgements
This work was supported by the Instituto de Salud Carlos III (Spain) [PI24/00222]; the Xunta de Galicia - Consellería de Cultura, Educación e Universidade [ED431G-2019/04, GRC2021/48, GPC2020/27, ED481A-2021 to L.V.-G., IN606B-2023/005 to A.R.-I.]; and the European Union (European Regional Development Fund-ERDF).
Author information
Authors and Affiliations
Contributions
L.V.-G. and C.B.-C. conceived the experiment(s), L.V.-G. conducted the experiment(s), C.B.-C., A.R.-I., I.T. and M.J.C. analysed the results. L.V.-G. and A.R.-I. wrote and reviewed the first version of the manuscript, C.B.-C., M.J.C. and I.T. critically reviewed the manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Vázquez-González, L., Regueira-Iglesias, A., Balsa-Castro, C. et al. A curated bacterial and archaeal 16S rRNA Gene Oral Sequences dataset. Sci Data 12, 729 (2025). https://doi.org/10.1038/s41597-025-05050-4
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41597-025-05050-4
