
Abstract
Providing adequate counseling on mode of delivery after induction of labor (IOL) is of utmost importance. Various AI algorithms have been developed for this purpose, but rely on maternal–fetal data, not including ultrasound (US) imaging. We used retrospectively collected clinical data from 808 subjects submitted to IOL, totaling 2024 US images, to train AI models to predict vaginal delivery (VD) and cesarean section (CS) outcomes after IOL. The best overall model used only clinical data (F1-score: 0.736; positive predictive value (PPV): 0.734). The imaging models employed fetal head, abdomen and femur US images, showing limited discriminative results. The best model used femur images (F1-score: 0.594; PPV: 0.580). Consequently, we constructed ensemble models to test whether US imaging could enhance the clinical data model. The best ensemble model included clinical data and US femur images (F1-score: 0.689; PPV: 0.693), presenting a false positive and false negative interesting trade-off. The model accurately predicted CS on 4 additional cases, despite misclassifying 20 additional VD, resulting in a 6.0% decrease in average accuracy compared to the clinical data model. Hence, integrating US imaging into the latter model can be a new development in assisting mode of delivery counseling.
Similar content being viewed by others
Introduction
Induction of labor (IOL) is a common obstetric procedure that involves artificially initiating uterine contractions to start labor and delivery1. IOL rates are increasing worldwide, particularly in developed countries, accounting for 25% of deliveries in the UK and US2,3. IOL can lead to a cesarean section (CS), although it does not increase its rate4. Efforts are being made to reduce unnecessary CS and achieve suitable rates, as recommended by the World Health Organization (WHO)5. Factors such as Bishop score, parity, previous CS, maternal body mass index and weight gain during pregnancy are known to play a crucial role in these rates6,7.
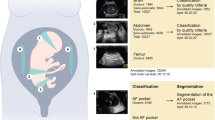
Obstetric ultrasound (US) is an essential imaging modality for fetal monitoring during pregnancy, which provides an economic and non-invasive way of assessing fetal organ development and growth8. Ultrasound assessment of fetal biometry and growth is performed by obtaining measures of the fetal head circumference (HC), biparietal diameter (BPD), abdominal circumference (AC), and femur length (FL)9,10. In clinical practice, fetal biometry, fetal weight estimation, and/or Doppler blood flow are frequently used as biomarkers for fetal growth disorder screening, performed following international guidelines11,12. These images obey protocols that produce comparable images acquired in specific planes, to be useful for diagnosis, reduce intra- and interobserver variability and allow measuring of particular structures8.
Artificial Intelligence (AI) is the branch of computer science that focuses on creating systems capable of performing tasks that require some level of intelligence such as learning, reasoning, problem-solving, perception, and decision-making10. Machine learning (ML), a subset of AI, uses algorithms that enable computers to learn from data and improve their performance without explicitly programming them13. AI and ML are gaining popularity in healthcare due to their ability to analyze complex data structures and patterns, such as electronic health records and medical images, and create prediction models, ultimately improving individual health outcomes14. In the specific field of medical imaging, including US, ML has shown several advancements with the employment of deep learning (DL) models10,15. They excel in image recognition, classification, detection, and segmentation, surpassing human capabilities13,15,16. DL models can use supervised or unsupervised learning approaches. Supervised models use labeled data during training, followed by unlabeled data testing. Unlike traditional software, which use preset logic rules, DL models use raw data as input10,17. DL models are being proposed to support sonographers in US, overcoming issues like subjectivity and interobserver variability. They can also reduce examination times and tutor young doctors. It is important to note, however, that AI is not a replacement for human healthcare professionals, but rather a human support decision-making tool18,19.
The success of DL models depends on convolutional neural networks (CNNs), that are able to extract patterns automatically from images and use them to learn to map the input data (i.e. US images) and output data (a label, such as vaginal delivery (VD) and CS)15,18. Moreover we can use transfer learning to adapt existing CNN architectures that were trained in large, labeled datasets (i.e., ImageNet) to reduce the amount of data and computation needed to produce accurate models, thereby overcoming the occasionally observed scarcity of large volumes of labeled data in the imaging medical field13,17.
AI methodology has been used in obstetrics and gynecology to evaluate adnexal masses, endometrial cancer risk, pelvic organ function, breast lesions, and predict fetal outcomes, improving prenatal diagnosis13,18. CNNs are used in obstetric US for fetal weight estimation by measuring fetal biometry, identification of normal and abnormal anatomy, and detection and localization of structures and standard planes. This has already instituted clinical applications in fetal imaging, including echocardiography and neurosonography15,20. Recent literature findings by Kim et al.’s21 study group have developed a DL algorithm for automated measurement of BPD and HC, improving localization of fetal head shapes and caliper placement in later gestational ages. Rizzo et al.22 developed a DL software to automate fetal central nervous system assessment measurements, reducing examination time and reliance on fetal position and 2D-ultrasound expertise. Intrapartum ultrasound has been reported as a valuable tool for providing accurate and reproducible labor progression findings, including fetal head position, station, and flexion, crucial for labor management. In this context, Ghi et al.23 proposed a DL implementation for assessing fetal occiput position before vaginal delivery, achieving an accuracy of 90.4% in recognizing the fetal head position.
Several international societies have suggested that US evaluation may help predict delivery mode after IOL, using evaluations such as cervical length and posterior cervical angle measurements24. However, to our knowledge, no studies have considered using fetal biometry images for this purpose, although obstetricians rely on US fetal weight estimation to guide delivery counseling. Therefore, we hypothesized that DL could aid in mode of delivery prediction after IOL by analyzing maternal and fetal data obtained from electronic medical records (EMR) and fetal US biometry images. Although several maternal characteristics have been related with an increased risk of CS25 this relationship has been harder to prove with fetal US features. Since US fetal biometry evaluation is influenced by experience, maternal habitus and fetal position, among other factors10, potential errors significantly impair our ability to detect anomalous fetal growth11. That is why the International Society of Ultrasound in Obstetrics and Gynecology (ISUOG) recommends that fetal biometry ought to be just one part of our fetal growth screening process, and that a combined approach using other clinical, biological and/or imaging markers may also be applied11.
As such, the main objectives of this study are to develop and test ML and DL models for predicting mode of delivery (VD or CS) after IOL using tabular and US fetal imaging data in standard biometry planes. Secondary objectives are to create an ensemble of the best performing models and calculate and compare their diagnostic predictive accuracy.
Results
Tabular data
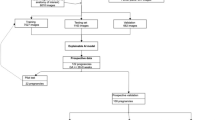
From January 2018 and December 2021, 808 patients with singleton vertex pregnancies were included in our longitudinal retrospective study, with 563 (69.7%) patients culminating in VD and 245 (30.3%) categorized as unplanned CS. The participants’ average age was 32.2 years [18–47 ± 5.7]. Demographic features and maternal and neonatal outcomes are shown in Table 1. Comparison between the two delivery modes showed significant differences in terms of age, height, body mass index (BMI) and parity, with more parous women in the VD group (37.8% vs 32.2%; p < 0.001). Women in the CS group were older, shorter, had a higher BMI and heavier babies at birth (p < 0.001). Other characteristics, such as gestational diabetes, 5-min Apgar scores ≤ 7, and neonatal intensive care unit admission rates were similar between groups. Mean gestational age (GA) on third trimester US was 30.9 ± 0.94 weeks [27–32 weeks]. The mean fetal biometry measures were, respectively: HC 290.7 ± 12.7 mm [245.8–326.6 mm], BPD 81.1 ± 4.0 mm [57.0–91.1 mm], AC 278.6 ± 15.1 mm [215.0–325.6 mm], FL 60.0 ± 2.9 mm [47.1–68.0 mm] and estimated fetal weight (EFW) 1848.8 ± 247.9 mm [903.0–2610.0 mm]. The recommended Hadlock formula was used to calculate EFW9. All these measurements were significantly different between both groups, except for FL, which showed similar values (see Table 1).
Mean GA at IOL was similar between groups (39.9 vs 40.1 weeks). Dinoprostone was more frequently used in the CS group (66.1%), and the contrary was true for misoprostol (49.6%). Also, 91.8% of pregnant women in the CS group presented significantly lower Bishop scores (≤ 3) before IOL. IOL indications did not differ between groups. Time to delivery was significantly longer (20.1 versus 28.9 h) in the CS group. A third of CS were due to non-reassuring fetal heart rate (30.2%), while the majority (67%) corresponded to “failed induction/labor dystocia” (see Table 1).
Figures 1 and 2 and Table 2 show the tabular data models’ performance in predicting CS likelihood. These models take into consideration maternal clinical data as well as fetal information provided by the third trimester US. The best performing model was selected for further interpretation due to its superior positive predictive value (PPV) and F1-score weighted, meaning that it has the best ratio between true positives (TP) and false positives (FP). The rationale for this choice is because a mode of delivery prediction model should detect as many CS as possible—true positives—while avoiding misclassifying a VD as a CS—false positives. All models showed good predictive performance, with F1-scores ranging from 0.59 to 0.74. The AdaBoost model presented a high predictive power (F1-score = 0.736 ± 0.024 and PPV 0.734 ± 0.024) and accurately predicted 86.7% VD and 46.9% of CS, corresponding to a 13.3% FP rate and 53.1% FN rate and an overall accuracy of 74.7% (201/269; see Fig. 2a). All results were obtained using cross-validation, which ensures that the model generalizes from training to test data not previously seen while evaluating all the dataset.

The ROCs for prediction of mode of delivery for tabular data (a) and image-based data (b). ROC, receiver operating characteristic.

Confusion matrices on (a) the best tabular data model AdaBoost and (b) the best image-based model of the femur, (c) head and (d) abdomen are shown. Confusion matrix depicting in reading order from left to right, top to bottom: true-negative, false-negative, false-positive and true-positive rates.
Imaging data
Of the total 808 pregnant women included in the tabular data, each contributed with 3 US images of the third trimester (comprising the fetal head, abdomen and femur), totaling 2424 images. These were analyzed using a threefold cross validation, comprehending 1126 VD and 490 CS images for training and validation, and 563 VD and 245 CS images for testing the imaging-based models. Figures 1 and 2 and Table 2 present the imaging models’ performance in classifying VD vs CS. True delivery outcome served as the ground truth for training and testing. Overall, the best DL model for fetal US images was Inception, based on the same rationale as previously explained for the AdaBoost model. F1-score weighted and PPV for our test dataset were 0.594 ± 0.022, 0.580 ± 0.027 for femur (the best image model), and 0.590 ± 0.015; 0.571 ± 0.025 for abdomen, respectively. The head view’s F1-score weighted (0.587 ± 0.043) and PPV (0.565 ± 0.068) were the least helpful for mode of delivery prediction.
Ensemble models
Additionally, to test whether DL can improve mode of delivery prediction using multimodal imaging associated with tabular features, we implemented an ensemble of neural networks to provide classification on mode of delivery and compared their performance measures (see Fig. 3 for further explanation). We explored this approach by applying both average voting and majority voting strategies, the latter providing the best results, as shown in Table 3. The first ensemble model gathered the best US models of fetal head, abdomen and femur (image-based ensemble model), returning weak results in distinguishing VD vs CS, with a F1-score weighted of 0.584 ± 0.032 and a PPV of 0.585 ± 0.031. Marginally better results were shown by an ensemble model considering the previous three models and the AdaBoost model, providing a F1-score weighted of 0.628 ± 0.018 and a PPV of 0.675 ± 0.021 (see Table 3 and Fig. 4). The final classification ensemble model was the best ensemble model, aggregating the best tabular model (AdaBoost) and the best US image model (Inception femur). It achieved a F1-score weighted of 0.689 ± 0.042 and a PPV of 0.693 ± 0.038 (Table 3 and Fig. 4). It accurately predicted 75.9% VD and 51.9% of CS, corresponding to a 24.1% FP rate and 48.1% FN rate, with an overall accuracy of 68.7% (184/268; see Fig. 5c). The confusion matrix and respective AUROC of the final classification ensemble model are displayed in Figs. 4 and 5.

Process involved in the establishment of the ensemble models. The three image-based models (Inception head, abdomen and femur) were associated with the best tabular data model, AdaBoost in three different ways. Green box: Image-based model, using the CNN Inception model of the femur, abdomen and head; Orange box: AdaBoost tabular data model with Inception models of the femur, abdomen and head; and Blue box: the Final classification model, which consists of the AdaBoost tabular data model and the Inception model of the femur, which is the ensemble model which provides the best metrics.

The ROC curves for prediction of mode of delivery for the ensemble models and their comparison with the ROC curves of the Adaboost and Inception femur models. ROC, receiver operating characteristic.

Confusion matrices on the following ensemble models: (a) image-based model, (b) AdaBoost and Inception models of the femur, head and abdomen (majority voting) (c) the final classification model (majority voting). Confusion matrix depicting in reading order from left to right, top to bottom: true-negative, false-negative, false-positive and true-positive rates.
The best tabular data model (AdaBoost) provided an average accuracy improvement of 6.0% over the final classification ensemble model for CS prediction. However, concerning CS prediction, the final classification ensemble model correctly predicted 51.9% (vs 46.9%) of CS, with a FP rate of 24.1% (vs 13.3%), compared to the AdaBoost model. Therefore, the tabular data model missed 4 correct CS predictions (TP) over the final classification ensemble model, while avoiding 20 unnecessary CS (FP) (see Figs. 2a and 5c).
Discussion
This study is the first to verify the feasibility of DL algorithms for the binary classification of mode of delivery after IOL using maternal and fetal electronic medical data and third trimester fetal US images. We developed ML models using tabular data and DL models for imaging data using transfer-learning methods. Our best-performing models were AdaBoost on tabular data, with a PPV 0.734; and the DL model Inception evaluating femur US images, with a PPV 0.580. Then, using ensemble-learning methodology, we developed various composite models, the best being based on AdaBoost and Inception US femur images, yielding a PPV of 0.693, matching the metrics of our best tabular model.
Recent studies use electronic medical information on maternal and fetal characteristics to construct prediction models regarding mode of delivery after IOL26,27,28. However, very few use ML with the same goal2,29. Also, several research studies explored third trimester US biometry planes for image segmentation30,31, image or plane classification8,15,16 and fetal biometry estimation32,33. US image classification has been mainly used for automatic fetal malformation detection18,34. However, to our knowledge, no study has yet reported the relation between third trimester US fetal plane imaging and mode of delivery outcomes after IOL.
In our study, maternal characteristics related to CS outcomes were compatible with literature findings (see Table 1). In our dataset, women submitted to unplanned CS were older, shorter, with higher BMI and lower Bishop scores compared with the VD group6,26,35. Fetal US characteristics such as EFW and fetal biometry measures were also significantly larger for fetuses who underwent CS, which is also compatible with literature36,37,38. However, FL showed no difference between groups. This is an exquisite finding because our best US image model uses femur images (see Fig. 1b and Fig. 2b). The explanation may lie in prenatal predictors of increased fetal adipose deposition, namely on the fetal thigh, which were found to be strong predictors of unplanned CS, compared to traditional fetal biometry and EFW39,40,41,42.
In fact, when analyzing individually, each DL image model underperformed, revealing the model’s difficulty in ascertaining which image features could aid in mode of delivery prediction (see Fig. 2 and Table 2). This was expected, for two main reasons: the first relates to the fact that DL models for object-detection and segmentation tasks are more accurate in identifying fetal standard biometry planes than classification models, because they can localize anatomical landmarks before classifying the plane, similar to human reasoning10; the other reason lies on understanding AI’s effectiveness in complementing clinical processes, since there is no study evaluating the accuracy of human evaluation of fetal third trimester US planes and their association with CS, probably due to an empirically unlikely association. Consequently, there is no practical way of evaluating if our metrics are reduced or if they can eventually supersede human intervention.
Regarding metrics for evaluation, our prediction model aims to counsel pregnant women undergoing IOL. Therefore, the main objective is to correctly advise those at high risk of CS and try to reduce the psychological and monetary burden of IOL on these women, as well as to confidently initiate and continue an IOL in women with a high probability of VD. Hence, the aim is to correctly identify true CS (TP) and avoid performing a CS on women who would have a VD (FP). As such, the most useful metrics in our study would be PPV, or the ratio of TP predictions to the total number of predicted positive observations; accuracy, or the proportion of correct predictions made by the model out of the total number of predictions; and sensitivity, defined as the ratio of TP predictions to all observations in the class13. That is why F1-score works better in our study than AUC, and because the presence of imbalanced data can influence the latter43. Hence, the DL models that provided the overall best PPV and F1-scores were the Inception group (see Table 2), which were consequently chosen for the ensemble models construction.
The first attempt on the ensemble model aggregated all Inception models (US images of the fetal head, femur and abdomen). Its performance showed a worse F1-score than the best Inception image model (femur) (0.584 vs 0.594) with a slightly superior PPV value (0.585 vs 0.580), probably because it aggregated the lower scores of the head and abdomen Inception models. Therefore, the next attempted ensemble model grouped all three Inception models and the Adaboost model. The latter probably influenced this ensemble positively, with F1-score and PPV of 0.628 (vs 0.584) and 0.675 (vs 0.585), compared with the image-based model, respectively. Since AI models can only account for information ‘seen’ during training, this model improved its performance by integrating imaging and electronic health record data18. Consequently, the last ensemble model, named final classification model, gathered the best tabular ML model and the best image model. Its performance was similar to the AdaBoost model, retrieving a F1-score of 0.689 (vs 0.736) and a PPV of 0.693 (vs 0.734). However, on a closer look at the confusion matrix, results show that the final classification model correctly predicted 51.9% of CS, more than the 46.9% rate of the AdaBoost model. On the other hand, the FP rates were more favorable for the AdaBoost model, showing a 13.2% rate (vs 24.1% on the final classification model). This trade-off between TP and FP can be explained by the difference in specificity (0.867 vs 0.758) and sensitivity (0.746 vs 0.689) of the AdaBoost model over the final classification one. Hence, we could infer that using DL femur US image models could help increase TP diagnosis at the expense of a marginal increase of FP cases15. As such, the model could be a useful clinical screening tool to distinguish women who are clear candidates for VD from those who have an extremely high risk of CS, or those who would benefit from a personalized mode of delivery planning. However, as emphasized in recent literature, AI tools should be used as an adjunct to the decision-making process, and the choices of the obstetrician and the pregnant woman should prevail when counseling on mode of delivery19.
This study has several strengths. To our knowledge, we present a novel database, comprising 2024 images from 808 fetuses, annotated for mode of delivery classification tasks using ground-truth information. This contrasts with most databases using similar images, which focus on image segmentation and plane classification and do not provide information regarding mode of delivery8.
The dataset accurately represents a real clinical setting, by being unbalanced and by using images collected retrospectively by various operators using various US machines. We opted not to use oversampling methods, i.e., to artificially increase the representation of minority classes and balance the dataset13. This would enhance our models’ performance but refrained from a real clinical scenario. Also, since our study used routine examination images suffering from speckle noise, low contrast, and variations of machines and settings, our models worked on their heterogeneity and complexities8,16. We argue that learning from diverse images enhances models’ adaptability and applicability in real-world scenarios by identifying consistent patterns and features8,13,44.
Data augmentation and use of clinical data along imaging data enhanced robustness and flexibility of the final models16,17. Finally, our model was thought to be plug and play and user-friendly without many restrictions to deal with real world clinical scenarios, allowing centers to upload deidentified images directly from workstations or hospitals to a cloud platform, with or without requiring additional patient data17.
The study is not without limitations. It is retrospective and uses data from a single center. This, especially for class imbalance databases such as ours, may have affected model training and testing and subsequently influenced model metrics, with emphasis on ROC curves10,18. Future developments may address this limitation by ensuring more CS images are available for successful binary classifier training. Also due to retrospective data collection, our model could not account for clinical or imagiological intrapartum variables such as fetal occiput position and engagement. The authors recognize the significance of these assessments, as supported by current research24.
The inclusion of numerous predictors in our sample size leads to concerns about overfitting. There might also exist a lack of a robust predictive accuracy assessment when using other data14. Therefore, we emphasize the importance of external validation as our next step, to assess the constraints of generalization and the possibility of multisite deployment of our model17. Finally, the results suggest it could be worth exploring data fusion approaches that combine into one model both streams of information, clinical data and image data.
In summary, this study proposed an ensemble AI model using US images of the fetal femur and maternal–fetal tabular data, yielding a relatively good performance. This is the first attempt to use this type of imaging data for mode of delivery prediction after IOL. The proposed model may become part of a promising tool in assisting mode of delivery counseling in clinical practice.
Materials and methods
Datasets
The dataset was retrospectively collected at the Obstetrics Department of University Hospital of Coimbra, a center with two sites (Obstetrics Department A and B), which are specialized maternal–fetal departments that manage thousands of births annually. Sample size was based on feasibility.
Tabular data included 2672 consecutive singleton vertex term pregnant women referred for IOL between January 2018 and December 2021. Other inclusion criteria were pregnant women ≥ 18 years of age and baseline Bishop score of ≤ 6. Planned CS, antepartum fetal demise, major fetal anomalies, and preterm births were excluded from analysis. EMR were analyzed, and, to ensure reliability of data, cases with no information on cervical examination at the time of admission were also excluded (n = 3). The final tabular dataset included 2434 deliveries.
The image dataset was collected based on the previous case selection, taking into consideration pregnant women attending our department for routine third trimester US evaluation. Images acquired during standard clinical practice were collected. Gestational age was computed from crown-rump length measurements on first trimester US45. Images were taken as a part of the Portuguese screening program, which recommends that the third trimester US should be performed between 30 and 32 weeks and 6 days of gestation46. Therefore, we decided to include a range of gestational ages from early third trimester (27 weeks) to 32 weeks and 6 days. Only third trimester US were considered for our visual computational model because first and second trimester US have specific goals that do not provide relevant information regarding mode of delivery planning. Of the 2434 subjects selected for tabular data, we excluded those who did not perform the third trimester US in our institution. Of the ones who did, we excluded those with missing US images, including only examinations which provided at least three US images per fetus (fetal head, abdomen and femur). This resulted in a final dataset of 808 deliveries (cases) and a total of 2024 US images.
Approval was obtained from the ethics committee of our center (protocol number CE-047/2022). Given the retrospective nature of the analysis, written informed permission was not required. Methods and results are reported in accordance with the TRIPOD guidelines47.
Data collection
Regarding tabular data collection, maternal age, gravidity, parity, BMI, height, GA, Bishop score, IOL indications, mode of delivery, CS indications, intrapartum complications, neonatal birth weight and neonatal outcomes were among the features examined2. Data were collected on admission and at the onset of the first stage of labor, after pelvic examination and assessment of both mother and fetus.
Ten different US machines provided by three different manufacturers (Voluson E8, Voluson P8, GE Healthcare, Zipf, Austria; Xario 200G, Aplio a550, Aplio i700, Aplio a, Aplio 400, Aplio 500 Xario 200, Toshiba, Canon Medical, Netherlands, Europe; H540 Samsung) were used for examinations. The percentage and absolute number of images from GE, Toshiba and Samsung ultrasound machines were 3.0% (n = 24), 96.9% (n = 783) and 0.1% (n = 1), respectively. Images were taken using a curved transducer with a frequency range from 3 to 7.5 MHz. Twelve examiners with significant experience (5–35 years) in obstetric US conducted the examinations according to ISUOG guidelines11. All images were stored in the original Digital Imaging and Communication in Medicine (DICOM) format in our Astraia database and were retrospectively collected. This process was made to comply with minimal quality requirements, i.e., omitting those with an improper anatomical plane (badly taken or cropped).
Regarding IOL, the choice of cervical ripening methods varied according to WHO recommendations and Bishop scores. These included oxytocin infusion, prostaglandin analogues and extra‐amniotic balloon catheters1,48,49. Premature rupture of membranes was defined as membrane rupture at term before labor onset. Prolonged pregnancy was determined at ≥ 41 weeks48. The definition of labor was the presence of regular uterine contractions with cervical changes50. Our institution performs IOL according to ACOG and NICE recommendations51,52.
IOL indications were categorized into prolonged pregnancy, pregnancy hypertensive disorders (i.e., gestational hypertension; pre-eclampsia), gestational diabetes, pregnancy cholestasis, premature rupture of membranes, intrauterine growth restriction, and other fetal or maternal pathology (e.g.: thrombophilia)1.
The primary outcome was mode of delivery, with VD and CS as algorithm outputs. Secondary outcomes included IOL indication and method, time to delivery and maternal-neonatal outcomes53. Successful IOL was determined as VD after induction. CS indications were stratified between non-reassuring fetal heart rate and failed induction/labor dystocia2. IOL duration was the time from IOL initiation to delivery1. Failed induction referred to not reaching an active phase of labor within 48 h, with ruptured membranes and oxytocin for at least 12 h. Labor dystocia was defined as cessation of dilation or descent during labor1,54.
Data processing
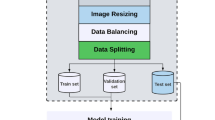
All images were saved in PNG (Portable Network Graphic) format, without compression to prevent quality loss. Each fetal subject’s head, femur, and abdominal photos were labeled with the appropriate classification for VD or CS. Every image was cropped to square proportions, respecting 537 × 537 pixels, centered in the ultrasound window, and then downsampled to 80 × 80 pixels. Through this procedure, the uniformity, comparability, and compatibility of image dimensions were ensured for DL techniques, which specifically call for square-dimensional images as input55. During the resizing process, all patient data was eliminated by cropping the image header, hence avoiding ethical concerns. The original ultrasound image’s margins were also cropped to remove unnecessary information.
Most prospective studies use images without caliper overlays in their models8. However, we chose to maintain caliper overlays, since these were burned to the image and could not be removed without altering the original image. We are also supported by other authors performing retrospective analysis, which state that the presence of caliper measurements had no discernible effect on their model’s ability to predict the primary result17.
Study design and training and test sets
The ML models tested for tabular data were logistic regression (LR), multi-layer perceptron (MLP), random forest (RF), support vector machines (SVM), extreme gradient boosted trees (XGBoost) and AdaBoost classifiers56,57. The framework parameters of these models are off-the-shelf default scikit-learn and are available at both https://scikit-learn.org/ and our Github (https://github.com/PugtgYosuky/ensemble-prediction-delivery-type). Although an exhaustive study is beyond the scope of this article, we plan to do a more in-depth analysis for the best hyperparams in our future work. Before modeling, missing data were handled by simple imputation. Numerical features were transformed with RobustScaler method, removing data median and scales according to the quartile range. We used the interquartile range. Categorical features were “one-hot encoded” resulting in binary features.
Our source image dataset began with all fetal third trimester ultrasounds fitting the inclusion and exclusion criteria above (n = 808 studies), which correspond to 563 (69.7%) VD and 245 (30.3%) CS. Hence, the dataset’s composition exhibits an imbalance, similar to most real-world clinical scenarios8. We applied a stratified threefold cross-validation, similar to the work of Moon-Grady et al., thus the full image dataset was divided into three different datasets, using a proportion of two-thirds for training and a third for testing. Validation data used 30% of the training dataset. There was no subject overlap between the test, validation and training sets, to guarantee that no images from training cases were included in the test dataset. The models’ parameters were learned using the training set; the prediction error for hyperparameter tuning and model selection was estimated using the validation set. The test set evaluated the generalization error for each of the final models, to avoid potential overfitting to the training set17,20.
Images from the training dataset were used to train (1) a VD versus CS classifier, (2) construct an ensemble model between each image view (fetal head, abdomen and femur), (3) compare it with the tabular dataset model and (4) with an ensemble model that associates tabular clinical information and the imaging ensemble model.
Model architecture and training parameters of image classification models
Convolution neural network (CNN) is a deep neural network architecture that excels at extracting features from unstructured data, such as medical images, allowing the automatic feature extraction of crucial information for the learning task44,55. We used three traditional CNN architectures to train on our data: Inception58, Resnet 5059 and Xception60. This study used transfer learning, a method developed to transfer fully trained model parameters from one large database to another to fine-tune training17. All networks underwent pre-training on the ImageNet Large Scale Visual Recognition Challenge (http://www.image-net.org/) and were trained using our training data61. To perform the intended binary classification task (VD vs CS), the top fully connected layers were replaced by a single layer of one neuron.
All nets were trained using Adam optimizer12,13. Nets were given a maximum of 1500 epochs to train before early stopping if the loss on the validation set did not decrease after 200 epochs13. Learning rates were 0,001 and batch size was 3213. Additionally, a set of image data augmentation approaches were applied to the images in the training dataset. These are required for the model to anticipate changes to imaging capture conditions, such as fetal position, amniotic fluid and placental tissue diverse locations and different zoom and focus adjustments17,55. It consisted of image random horizontal flips, rotations of up to 20° and random brightness up to 20°15. Several randomly augmented images were produced for every image in the training set and added to it, while keeping the non-augmented version20.
The networks were applied to the test images after training and frozen, producing a predicted confidence score between 0 and 1 for the CS outcome20. For both the VD and CS classifications, the network output yields likelihood percentages, both totaling 100%. The criterion for classifying a case as VD or CS was thus 50%, and the classification with the higher percentage was chosen as the outcome15. The top-performing models were recorded as the final output models (Table 2).
Composite diagnostic classification
Different CNN algorithms extract image information in different ways. Ensemble learning is a method that uses multiple algorithms to achieve a better predictive performance than any individual algorithm62. We computed an ensemble model using our highest performing individual models evaluating US images of the fetal head, abdomen and femur (image-based ensemble model; see Table 2 and Figs. 1 and 2)55. We tested two types of voting strategies based on the outcome probabilities of each model, which included the mean and max voting. We found that the max voting strategy was the best voting strategy for our ensemble models (Table 3)55. For every model, a score of 50% and above was considered CS, and below 50% VD.
Image-based ensemble model was further compared with the tabular data classification model. Lastly, a final classification ensemble model was created by aggregating the probabilities of the image-based ensemble model and the best tabular data classification model. This model’s metrics were also compared with the metrics of the previously described models.
Framework and training and prediction times
All models were implemented in Python using Keras (https://keras.io/, GitHub,2015) with TensorFlow (https:// www.tensorflow.org/) backend. Numpy (https://numpy.org), Matplotlib (https://matplotlib.org), and Scikit-learn (https://scikit-learn.org/stable/) were used to train and evaluate the models involved. Training was performed in a server with AMD RYZEN 5, 32 RAM and 2 GPUs Nvidia RTX 3080TI 12G. Prediction times per image averaged 3 ms for classification on a standard laptop (2.6-GHz Intel core, 16 GB of RAM).
Model evaluation
AUROC, F1 score, sensitivity, specificity, PPV and negative predictive values (NPV) were used for model performance assessment. PPV and F1-score were selected as the most appropriate measures for the study’s model to predict mode of delivery, but AUROC measures were displayed nevertheless because they are a familiar metric in the medical field for model performance evaluation63. The model was also evaluated using a confusion matrix portraying TP, FP, TN and FN55. In the matrix, each row denotes an instance in the real label, and each column denotes an instance in the predicted label.
Statistical methods
Categorical variables were shown as frequencies and percentages, and continuous variables were shown as mean ± SD. The χ2 test was used to compare categorical variables, and continuous variables were compared using two-sided Student’s t-test. The normal distribution of all continuous variables was assessed a priori using skewness, kurtosis, mean, standard deviation, and histogram curve. A p-value < 0.05 was considered significant.
Ethics declarations
The Ethics Committee of the University Hospital Centre of Coimbra reviewed and approved the study on 22 April 2022 (CE-047/2022). Requirement for written informed consent was waived due to the retrospective, de-identified nature of the patient data.
Data availability
The data are not made publicly available for reasons of privacy, use in the development of other manuscripts and ethical restrictions. Nevertheless, the data are available from the corresponding author on reasonable request.
Code availability
Code will be available upon publication.
Change history
06 August 2024
A Correction to this paper has been published: https://doi.org/10.1038/s41598-024-69015-0
References
Bademkiran, M. H. et al. Explanatory variables and nomogram of a clinical prediction model to estimate the risk of caesarean section after term induction. J. Obstet. Gynaecol. 41, 367–373. https://doi.org/10.1080/01443615.2020.1798902 (2021).
D’Souza, R. et al. Prediction of successful labor induction in persons with a low Bishop score using machine learning: Secondary analysis of two randomized controlled trials. Birth 50, 234–243. https://doi.org/10.1111/birt.12691 (2023).
Zhang, X., Joseph, K. S. & Kramer, M. S. Decreased term and postterm birthweight in the United States: Impact of labor induction. Am. J. Obstet. Gynecol. 203(124), e121–e127. https://doi.org/10.1016/j.ajog.2010.03.044 (2010).
Middleton, P., Shepherd, E. & Crowther, C. A. Induction of labour for improving birth outcomes for women at or beyond term. Cochrane Database Syst Rev 5, CD004945. https://doi.org/10.1002/14651858.CD004945.pub4 (2018).
Organization, W. H. WHO Team—Sexual and Reproductive Health and Research 8 (2015).
Guedalia, J. et al. Real-time data analysis using a machine learning model significantly improves prediction of successful vaginal deliveries. Am. J. Obstet. Gynecol. 223(437), e431–e437. https://doi.org/10.1016/j.ajog.2020.05.025 (2020).
Essex, H. N., Green, J., Baston, H. & Pickett, K. E. Which women are at an increased risk of a caesarean section or an instrumental vaginal birth in the UK: An exploration within the Millennium Cohort Study. BJOG 120, 732–742. https://doi.org/10.1111/1471-0528.12177 (2013).
Burgos-Artizzu, X. P. et al. Evaluation of deep convolutional neural networks for automatic classification of common maternal fetal ultrasound planes. Sci. Rep. 10, 10200. https://doi.org/10.1038/s41598-020-67076-5 (2020).
Hadlock, F. P., Harrist, R. B., Sharman, R. S., Deter, R. L. & Park, S. K. Estimation of fetal weight with the use of head, body, and femur measurements—A prospective study. Am. J. Obstet. Gynecol. 151, 333–337. https://doi.org/10.1016/0002-9378(85)90298-4 (1985).
Ramirez Zegarra, R. & Ghi, T. Use of artificial intelligence and deep learning in fetal ultrasound imaging. Ultrasound Obstet. Gynecol. 62, 185–194. https://doi.org/10.1002/uog.26130 (2023).
Salomon, L. J. et al. ISUOG Practice Guidelines: Ultrasound assessment of fetal biometry and growth. Ultrasound Obstet. Gynecol. 53, 715–723. https://doi.org/10.1002/uog.20272 (2019).
Slimani, S. et al. Fetal biometry and amniotic fluid volume assessment end-to-end automation using deep learning. Nat. Commun. 14, 7047. https://doi.org/10.1038/s41467-023-42438-5 (2023).
Ghabri, H. et al. Transfer learning for accurate fetal organ classification from ultrasound images: a potential tool for maternal healthcare providers. Sci. Rep. 13, 17904. https://doi.org/10.1038/s41598-023-44689-0 (2023).
Collins, G. S. & Moons, K. G. M. Reporting of artificial intelligence prediction models. Lancet 393, 1577–1579. https://doi.org/10.1016/S0140-6736(19)30037-6 (2019).
Xie, H. N. et al. Using deep-learning algorithms to classify fetal brain ultrasound images as normal or abnormal. Ultrasound Obstet. Gynecol. 56, 579–587. https://doi.org/10.1002/uog.21967 (2020).
Arnaout, R. et al. An ensemble of neural networks provides expert-level prenatal detection of complex congenital heart disease. Nat. Med. 27, 882–891. https://doi.org/10.1038/s41591-021-01342-5 (2021).
Christiansen, F. et al. Ultrasound image analysis using deep neural networks for discriminating between benign and malignant ovarian tumors: Comparison with expert subjective assessment. Ultrasound Obstet. Gynecol. 57, 155–163. https://doi.org/10.1002/uog.23530 (2021).
Drukker, L., Noble, J. A. & Papageorghiou, A. T. Introduction to artificial intelligence in ultrasound imaging in obstetrics and gynecology. Ultrasound Obstet. Gynecol. 56, 498–505. https://doi.org/10.1002/uog.22122 (2020).
Sarno, L. et al. Use of artificial intelligence in obstetrics: not quite ready for prime time. Am. J. Obstet. Gynecol. MFM 5, 100792. https://doi.org/10.1016/j.ajogmf.2022.100792 (2023).
Andreasen, L. A. et al. Multi-centre deep learning for placenta segmentation in obstetric ultrasound with multi-observer and cross-country generalization. Sci. Rep. 13, 2221. https://doi.org/10.1038/s41598-023-29105-x (2023).
Kim, H. P. et al. Automatic evaluation of fetal head biometry from ultrasound images using machine learning. Physiol. Meas. 40, 065009. https://doi.org/10.1088/1361-6579/ab21ac (2019).
Rizzo, G., Aiello, E., Pietrolucci, M. E. & Arduini, D. The feasibility of using 5D CNS software in obtaining standard fetal head measurements from volumes acquired by three-dimensional ultrasonography: comparison with two-dimensional ultrasound. J. Matern. Fetal Neonatal Med. 29, 2217–2222. https://doi.org/10.3109/14767058.2015.1081891 (2016).
Ghi, T. et al. Novel artificial intelligence approach for automatic differentiation of fetal occiput anterior and non-occiput anterior positions during labor. Ultrasound Obstet. Gynecol. 59, 93–99. https://doi.org/10.1002/uog.23739 (2022).
Rizzo, G. et al. Ultrasound in labor: Clinical practice guideline and recommendation by the WAPM-World Association of Perinatal Medicine and the PMF-Perinatal Medicine Foundation. J. Perinat. Med. 50, 1007–1029. https://doi.org/10.1515/jpm-2022-0160 (2022).
Betran, A. P. et al. Interventions to reduce unnecessary caesarean sections in healthy women and babies. Lancet 392, 1358–1368. https://doi.org/10.1016/S0140-6736(18)31927-5 (2018).
Dorwal, M. et al. Deriving a prediction model for emergency cesarean delivery following induction of labor in singleton term pregnancies. Int. J. Gynaecol. Obstet. 160, 698–706. https://doi.org/10.1002/ijgo.14403 (2023).
Lopez-Jimenez, N. et al. Risk of caesarean delivery in labour induction: A systematic review and external validation of predictive models. BJOG 129, 685–695. https://doi.org/10.1111/1471-0528.16947 (2022).
Hernandez-Martinez, A. et al. Predictive model for risk of cesarean section in pregnant women after induction of labor. Arch. Gynecol. Obstet. 293, 529–538. https://doi.org/10.1007/s00404-015-3856-1 (2016).
Hu, T. et al. Establishment of a model for predicting the outcome of induced labor in full-term pregnancy based on machine learning algorithm. Sci. Rep. 12, 19063. https://doi.org/10.1038/s41598-022-21954-2 (2022).
Song, C. et al. The classification and segmentation of fetal anatomies ultrasound image: A survey. J. Med. Imaging Health Inform. 11, 789–802. https://doi.org/10.1166/jmihi.2021.3616 (2021).
Sree, S. J. & Vasanthanayaki, C. J. Ultrasound fetal image segmentation techniques: A review. Curr. Med. Imaging 155, 52–60 (2019).
Prieto, J. C. et al. An automated framework for image classification and segmentation of fetal ultrasound images for gestational age estimation. in Proc SPIE Int Soc Opt Eng 11596. https://doi.org/10.1117/12.2582243 (2021).
Pashaj, S., Merz, E. & Petrela, E. Automated ultrasonographic measurement of basic fetal growth parameters. Ultraschall. Med. 34, 137–144. https://doi.org/10.1055/s-0032-1325465 (2013).
Fiorentino, M. C., Villani, F. P., Di Cosmo, M., Frontoni, E. & Moccia, S. A review on deep-learning algorithms for fetal ultrasound-image analysis. Med. Image Anal. 83, 102629. https://doi.org/10.1016/j.media.2022.102629 (2023).
Kawakita, T. et al. Predicting vaginal delivery in nulliparous women undergoing induction of labor at term. Am. J. Perinatol. 35, 660–668. https://doi.org/10.1055/s-0037-1608847 (2018).
Froehlich, R. J. et al. Association of recorded estimated fetal weight and cesarean delivery in attempted vaginal delivery at term. Obstet. Gynecol. 128, 487–494. https://doi.org/10.1097/AOG.0000000000001571 (2016).
Sovio, U. & Smith, G. C. S. Blinded ultrasound fetal biometry at 36 weeks and risk of emergency cesarean delivery in a prospective cohort study of low-risk nulliparous women. Ultrasound Obstet. Gynecol. 52, 78–86. https://doi.org/10.1002/uog.17513 (2018).
Rizzo, G., Aiello, E., Bosi, C., D’Antonio, F. & Arduini, D. Fetal head circumference and subpubic angle are independent risk factors for unplanned cesarean and operative delivery. Acta Obstet. Gynecol. Scand. 96, 1006–1011. https://doi.org/10.1111/aogs.13162 (2017).
Lee, W. et al. Fetal growth parameters and birth weight: Their relationship to neonatal body composition. Ultrasound Obstet. Gynecol. 33, 441–446. https://doi.org/10.1002/uog.6317 (2009).
Lee, W., Deter, R., Sangi-Haghpeykar, H., Yeo, L. & Romero, R. Prospective validation of fetal weight estimation using fractional limb volume. Ultrasound Obstet. Gynecol. 41, 198–203. https://doi.org/10.1002/uog.11185 (2013).
Hehir, M. P. et al. Sonographic markers of fetal adiposity and risk of cesarean delivery. Ultrasound Obstet. Gynecol. 54, 338–343. https://doi.org/10.1002/uog.20263 (2019).
Gibson, K. S., Stetzer, B., Catalano, P. M. & Myers, S. A. Comparison of 2- and 3-dimensional sonography for estimation of birth weight and neonatal adiposity in the setting of suspected fetal macrosomia. J Ultrasound Med 35, 1123–1129. https://doi.org/10.7863/ultra.15.06106 (2016).
Davis, J. G., Mark. in Proceedings of the 23rd International Conference on Machine Learning, ACM 06 (2006).
Wu, S. et al. Development and validation of a composite AI model for the diagnosis of levator ani muscle avulsion. Eur. Radiol. 32, 5898–5906. https://doi.org/10.1007/s00330-022-08754-y (2022).
Robinson, H. P. Sonar measurement of fetal crown-rump length as means of assessing maturity in first trimester of pregnancy. Br Med J 4, 28–31. https://doi.org/10.1136/bmj.4.5883.28 (1973).
Vicente, L. F. et al. Departamento da Qualidade na Saúde e da Ordem dos Médicos. Exames Ecográficos na Gravidez de baixo risco. Norma nº 023/2011 de 29/09/2011, atualizada a 21/05/2013. (2013).
Collins, G. S., Reitsma, J. B., Altman, D. G. & Moons, K. G. Transparent reporting of a multivariable prediction model for individual prognosis or diagnosis (TRIPOD): The TRIPOD statement. Ann. Intern. Med. 162, 55–63. https://doi.org/10.7326/M14-0697 (2015).
Jouffray, C. et al. Use of artificial intelligence to predict mean time to delivery following cervical ripening with dinoprostone vaginal insert. Eur. J. Obstet. Gynecol. Reprod. Biol. 266, 1–6. https://doi.org/10.1016/j.ejogrb.2021.08.031 (2021).
Tarimo, C. S. et al. Validating machine learning models for the prediction of labour induction intervention using routine data: a registry-based retrospective cohort study at a tertiary hospital in northern Tanzania. BMJ Open 11, e051925. https://doi.org/10.1136/bmjopen-2021-051925 (2021).
Zhang, J. et al. Contemporary patterns of spontaneous labor with normal neonatal outcomes. Obstet. Gynecol. 116, 1281–1287. https://doi.org/10.1097/AOG.0b013e3181fdef6e (2010).
ACOG Practice Bulletin No. 107: Induction of labor. Obstet Gynecol 114, 386-397. https://doi.org/10.1097/AOG.0b013e3181b48ef5 (2009).
Inducing labour. London: National Institute for Health and Care Excellence (NICE); 2021 Nov 4. PMID: 35438865.
Dos Santos, F. et al. Development of a core outcome set for trials on induction of labour: An international multistakeholder Delphi study. BJOG 125, 1673–1680. https://doi.org/10.1111/1471-0528.15397 (2018).
Caughey, A. B., Cahill, A. G., Guise, J. M., Rouse, D. J., American College of Obstetricians and Gynecologists. Safe prevention of the primary cesarean delivery. Am. J. Obstet. Gynecol. 210, 179–193. https://doi.org/10.1016/j.ajog.2014.01.026 (2014).
VerMilyea, M. et al. Development of an artificial intelligence-based assessment model for prediction of embryo viability using static images captured by optical light microscopy during IVF. Hum. Reprod. 35, 770–784. https://doi.org/10.1093/humrep/deaa013 (2020).
Fox, H., Topp, S. M., Lindsay, D. & Callander, E. A cascade of interventions: A classification tree analysis of the determinants of primary cesareans in Australian public hospitals. Birth 48, 209–220. https://doi.org/10.1111/birt.12530 (2021).
Lipschuetz, M. et al. Prediction of vaginal birth after cesarean deliveries using machine learning. Am. J. Obstet. Gynecol. 222(613), e611-613. https://doi.org/10.1016/j.ajog.2019.12.267 (2020).
Szegedy, C., Vanhoucke, V., Ioffe, S., Shlens, J., & Wojna, Z. Rethinking the inception architecture for computer vision. in IEEE Conference on Computer Vision and Pattern Recognition. https://doi.org/10.1109/CVPR.2016.308 (2016).
He, K. M., Zhang, X., Ren, S. Q. & Sun, J. Deep residual learning for image recognition. In IEEE Conference on Computer Vision and Pattern Recognition. https://doi.org/10.1109/CVPR. 2016.90 (2016).
Chollet, F. Xception: Deep learning with depthwise separable convolutions. In IEEE Conference on Computer Vision and Pattern Recognition. https://doi.org/10.1109/CVPR.2017.195 (2017).
Russakovsky, O. et al. ImageNet large scale visual recognition challenge. Int. J. Comput. Vis 115, 211–252 (2015).
An, N., Ding, H., Yang, J., Au, R. & Ang, T. F. A. Deep ensemble learning for Alzheimer’s disease classification. J. Biomed. Inform. 105, 103411. https://doi.org/10.1016/j.jbi.2020.103411 (2020).
Fruchter-Goldmeier, Y. et al. An artificial intelligence algorithm for automated blastocyst morphometric parameters demonstrates a positive association with implantation potential. Sci. Rep. 13, 14617. https://doi.org/10.1038/s41598-023-40923-x (2023).
Acknowledgements
This work is supported by the University Hospital of Coimbra (Unidade Local de Saúde - ULS Coimbra) and partially founded by Project "Agenda Mobilizadora Sines Nexus". ref. No. 7113, supported by the Recovery and Resilience Plan (PRR) and by the European Funds Next Generation EU, following Notice No. 02/C05-i01/2022, Component 5—Capitalization and Business Innovation—Mobilizing Agendas for Business Innovation and by the FCT—Foundation for Science and Technology, I.P./MCTES through national funds (PIDDAC), within the scope of CISUC R&D Unit—UIDB/00326/2020 or project code UIDP/00326/2020. We would like to thank colleagues Kristina Hundarova, Beatriz Ferro, Bárbara Laranjeiro and Adriana Merrelho, for their invaluable help with data collection.
Author information
Authors and Affiliations
Contributions
IF, JNC and ALA designed the study plan; IF and BP supervised and helped with data collection; IF, BP and JS built the EMR database and image database, and performed data analysis; JNC and ALA supervised the research. IF wrote the draft manuscript; all authors read the draft manuscript and made substantial intellectual contributions to the final version.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
The original online version of this Article was revised: In the original version of this Article the author names, Iolanda Ferreira, Joana Simões, João Correia & Ana Luísa Areia were incorrectly given as Iolanda João Mora Cruz Freitas Ferreira, Joana Maria Silva Simões, João Nuno Gonçalves Costa Cavaleiro Correia & Ana Luísa Fialho de Amaral Areia.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Ferreira, I., Simões, J., Pereira, B. et al. Ensemble learning for fetal ultrasound and maternal–fetal data to predict mode of delivery after labor induction. Sci Rep 14, 15275 (2024). https://doi.org/10.1038/s41598-024-65394-6
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-024-65394-6
This article is cited by
-
Does infant birthweight percentile identify mothers at risk of severe morbidity? A Canadian population-based cohort study
Maternal Health, Neonatology and Perinatology (2025)
-
Championing maternal health and reducing maternal mortality: a global multidisciplinary imperative
Scientific Reports (2025)
