
Abstract
Urban greening plays a crucial role in maintaining environmental sustainability and enhancing people’s well-being. However, limited by the shortcomings of traditional methods, studying the heterogeneity and nonlinearity between environmental factors and green view index (GVI) still faces many challenges. To address the concerns of nonlinearity, spatial heterogeneity, and interpretability, an interpretable spatial machine learning framework incorporating the Geographically Weighted Random Forest (GWRF) model and the SHapley Additive exPlanation (Shap) model is proposed in this paper. In this paper, we combine multi-source big data, such as Baidu Street View data and remote sensing images, and utilize semantic segmentation models and geographic data processing techniques to study the global and local interpretation of the Beijing region with GVI as the key indicator. Our research results show that: (1) Within the Sixth Ring Road of Beijing, GVI shows significant spatial clustering phenomenon and positive correlation linkage, and at the same time exhibits significant spatial differences; (2) Among many environmental variables, the increase of green coverage rate has the most significant positive effect on GVI, while the increase of building density shows a strong negative correlation with GVI; (3) The performance of the GWRF model in predicting GVI is excellent and far exceeds that of comparison models.; (4) Whether it is the green coverage rate, urban built environment or socioeconomic factors, their influence on GVI shows non-linear characteristics and a certain threshold effect. With the help of these non-linear influences and explicit threshold effects, quantitative analyses of greening are provided, which can help to assist urban planners in making more scientific and rational decisions when allocating greening resources.
Similar content being viewed by others
Introduction
As global urbanization intensifies and the severity of global environmental problems becomes more pronounced, people’s daily lives are greatly affected, and there is an urgent need for government departments to take action to address the problem. During this period, the global urban population is expected to approach 5 billion by 2030, accounting for 55% of the global population, according to United Nations statistics. The share of urban population is expected to rise to 68% by 20501. Against this background, the importance of urban green spaces in improving urban livability, environmental quality and public health is increasingly recognized.
Urban green spaces refer to various green spaces, parks, gardens, woodlands and other natural and artificially planted vegetation areas within cities2. These green spaces have irreplaceable importance in enhancing human well-being. These green spaces provide valuable opportunities for citizens to get close to nature3, which helps to reduce stress and enhance psychological well-being4, as well as to improve inter-community connections and interactions5. Rapid urbanization, constant changes in land use, and population growth have exerted tremendous pressure on urban green spaces, causing their distribution to become uneven and even fragmented and degraded6. Consequently, it is worthwhile to investigate ways to raise the standard of urban greening to satisfy the demands of inhabitants in situations where the growth of green space is constrained. GVI is an important physical indicator to assess the level of urban greening1, which focuses on reflecting the percentage of green vegetation from the human perspective. The main distinction between GVI and other methods is that GVI is based on street view imagery, which is more in line with human perspective than satellite remote sensing imager. Additionally, GVI is special in that it can estimate the volume of green space in three dimensions and take into account how people perceive it, expanding the assessment of green space from two-dimensional (2D) to three-dimensional (3D) space7. GVI is unique in that it’s able to calculate the volume of three-dimensional green space and reflect people’s actual perception of green space, thus expanding green space assessment from 2 to 3D space8. However, the traditional GVI calculation method has some limitations in terms of efficiency and convenience, and relies on on-site photos and manually extracted data1.
Over the past few years, with rapid development of street view image methods and computer technology, they have provided extensive facilities for GVI research. Scholars have begun to explore combining street view images (e.g., provided by Google, Baidu, Tencent, etc.) with semantic segmentation techniques9,10,11, and comparing GVI with green evaluation indicators, such as NDVI, Green coverage rate (GCR), and Vegetation Structural Diversity (VSD), so as to analyze the correlation between them12,13. Such studies have revealed the potential of different indicators in reflecting different aspects of urban greening14,15, and the application of streetscape imagery, in particular, has greatly facilitated the quantitative study of GVI.
Quantification of GVI based on streetscape images provides more detailed and intuitive visual data support for green space research, and the linear approach has been widely used in the study of the influence of environmental factors on GVI. This approach assumes a linear relationship between the dependent variable (e.g., GVI) and one or more independent variables (e.g., green coverage rate, building density, etc.)16,17,18. In order to show the linear impacts of natural exposures and environmental factors on GVI, this method commonly uses linear regression models, logistic regression, and Ordinary Least Squares19,20,21. In addition, spatial models have been used to explore the effects of spatial autocorrelation and heterogeneity. For example, related studies have used spatial econometric models to examine the effects of the nature of land use and the enclosure of the street on GVI in Hangzhou21. However, due to the nonlinear effects and threshold effects that certain environmental variables may have on GVI, linear models might not adequately represent the link between environmental variables and GVI.
Machine Learning (ML) has recently significantly revolutionized the methods for modeling and analyzing complex relationships among variables in the scientific research field22. In particular, ML techniques such as Random Forest (RF) and Support Vector Machine have excelled in dealing with complex nonlinear relationships in multivariate big data23,24. These techniques are flexible enough to cope without predefined relationships compared to traditional linear models. With the help of maximum likelihood method, these techniques are able to recognize nonlinear relationships when the environmental factors change at specific thresholds. Scholars have examined the nonlinear association between the urban environment and GVI using machine learning and big data from multiple sources16,25. For example, Li et al. used ML methods to explore the nonlinear relationships of landscape permeability, green space layout, and road density on street GVI13. The gating relationship between environmental conditions and GVI has been the subject of only limited investigation. Zhang et al., for instance, discovered that while park density initially increased GVI, beyond a certain point, GVI began to decline1.
Although a great deal of studies has been conducted, there are still some current shortcomings. First, traditional machine learning methods such as random forest ignore spatial heterogeneity when modeling spatial data, which affects prediction accuracy26. Since the relationship between dependent and explanatory variables may vary at different spatial locations27, ignoring such heterogeneity may lead to inaccurate prediction results23. Although geographically weighted regression (GWR) models are effective in capturing spatial heterogeneity and local variations28, they are deficient in revealing nonlinear relationships. To address this issue, researchers have proposed a new approach combining GWR and ML models, aiming to simultaneously capture spatial heterogeneity and reveal nonlinear relationships29.
In addition, existing studies lack in explaining the localization of the model, which leads to the model becoming a “black box” and makes it difficult to gain insights into its influencing factors. Therefore, recent studies often use techniques such as relative importance (RI)30 and partial dependency plot (PDP)31 in the SHAP framework to locally analyze the relationships between variables. These methods have been widely used in areas such as running behavior analysis25,32, urban vitality assessment33, and criminal psychology research17. The construction of a spatial ML framework by combining prediction and interpretation tools is expected to make progress in revealing nonlinear relationships.
In summary, at this stage, the following problems exist in the research on the interpretation of the nonlinear influence of GVI: (1) the spatial correlation of GVI is easy to be ignored; (2) it is difficult to quantify the nonlinear relationship that exists between the environmental factors and the GVI; and (3) there is a lack of visual interpretation of the existing models in this direction. It can be seen that the research related to the visual interpretation of the nonlinear influence of environmental factors on GVI is not deep enough, and the analysis of the dominantly driven environmental factors needs to be further researched. In addition, (1) how do the main environmental variables (e.g., green coverage rate, built environment, and socioeconomic factors) affecting GVI rank on the RI? Which environmental factors are dominant? (2) How to quantify and rationalize the non-linear association between environmental factors and GVI? (3) How to enhance the visibility of greenery in urban development? In order to deeply explore and precisely respond to the above mentioned topics, the core purpose of this study focuses on the following aspects:
-
(1) Taking the Sixth Ring Road of Beijing as an example, the GVI of the study area is calculated using semantic segmentation technology based on Baidu Street View images, and spatial correlation analysis is performed;
-
(2) This paper uses cross-validation to test the hyperparameter values in order to obtain the GWRF model with optimal parameters. By comparing with the reference model, the GWRF model can fully consider the spatial correlation of GVI to obtain higher prediction accuracy, and provide more accurate data support for exploring the nonlinear relationship and threshold effect between environmental variables and GVI;
-
(3) This study adopts the Shap interpretable framework to measure the global RI of each environmental variable through the global Shap value, to identify the dominant environmental factors and to quantify their relative contributions. The Shap model is an innovative interpretable tool to elucidate the driving forces behind the spatial differences in GVI;
-
(4) In addition, the Shap model uses local correlation diagrams (LDPs) to display the Shap values of environmental variables in each GVI, visualizing the non-linear relationships and thresholds between environmental variables and GVI.
Through a novel perspective, this study provides an in-depth analysis of the variability of GVI in spatial distribution and its causes, which provides a more accurate and scientific reference basis for urban planners and managers in promoting the urban greening process.
Study area and materials
Case study
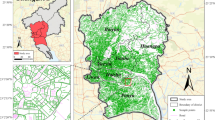
With a geographic elevation pattern of high northwest and low southeast, Beijing is situated in the northern portion of the North China Plain. This results in a circular landscape structure that includes remote suburban ecological land, peri-urban plains farms, and urban greening land. This research selects the region inside Beijing’s Sixth Ring Road as the study area because, as Fig. 1 illustrates, it encompasses the majority of the city’s built-up areas and a tiny portion of its mixed urban and rural areas. The green space evaluation can provide important data support for urban planners and decision makers to help them better consider the layout and optimization of green space in urban development.

Study area.
Data source
Multi-source data were used in this study, including: (1) Data on the urban road network were obtained from the OpenStreetMap database (https://www.openstreetmap.org/); (2) The street view photos came from the Baidu Street View Map and were collected in bulk using the Python software (https://map.baidu.com/); (3) Data on the coverage of urban green space were sourced from the Global Land Cover Data 2022 report of the European Space Agency (https://www.esa.int/); (4) Remote sensing images for calculating NDVI were obtained from Landsat8 multispectral remote sensing imagery (https://www.gscloud.cn/); (5) Chinese Academy of Sciences’ Resource and Environment Data Center’s land use data (https://www.resdc.cn/); (6) park and settlement POI data, based on Baidu Maps (https://map.baidu.com/), crawling POI data; (7) Data about the house’s age and price from Lianjia’s real estate website (https://bj.lianjia.com/); (8) The WorldPop platform provides data on population density (https://www.worldpop.org/); (9) The vector data used in this study was sourced from OpenStreetMap (OSM), which is licensed under the Open Database License (ODbL) [https://opendatacommons.org/licenses/odbl/]; (10) All maps were produced using ArcGIS Pro (version 3.0, [URL of ArcGIS]) and the vector data were processed and visualized accordingly, as shown in Figs. 1, 2, 5, 6b, 9.

Visual presentation of selected variables.
Green view index
Data collection
GVI can quantify the perceptual experience of people in the city, and some studies have begun to look for the relationship between GVI and urban greening. Therefore, in recent years, GVI has been gradually applied in the field of urban greening research34. Greening ratio is the percentage of green vegetation in the Baidu street view image (BSV) or other pictures of a specific location35. In this paper, we use Python to call the application editing interface (API) of Baidu map to obtain street view images. Before that, the first step is to determine the sampling points. The OpenStreetMap road data were topologically corrected in ArcGIS, and using the Construct Point tool, one sampling point was generated every 50 m along the road, producing 82,100 sample points in total. GVI sampling points are sampled at a resolution of 50 m because in dense urban environments, such as cities, a sampling frequency of 50m allows for a detailed reflection of different built environments and green spaces, whereas larger resolutions (e.g., 100 m or 200 m) may fail to capture important smaller green spaces, such as parks, street trees, and vegetation between buildings28.
In order to simulate the horizontal view angle of pedestrians, this paper sets the vertical angle to 0° and the horizontal field of view angle to 60°, and acquires the street view image from six directions (direction angle = 0\(^\circ\), 60\(^\circ\), 120\(^\circ\), 180\(^\circ\), 240\(^\circ\), 300\(^\circ\)) for each sampling point36. The size of each street view image is 640 × 640 and its main parameters are shown in Table 1.
GVI calculation
GVI is used as an important indicator for evaluating urban greening efforts. GVI is derived from street view photos and represents the ratio of green pixels to all pixels in the street view, as (1) illustrates.
In the formula, \({Area}_{g\_i}\) is the total number of green vegetation pixels in direction i in the streetscape image, and \({Area}_{t\_i}\) represents the total number of pixels in the streetscape image. \(i\) can take the value of 1 to 6. After semantic segmentation of the streetscape image, according to this formula, we calculate the average GVI value of each location.
Variables
Green coverage rate
NDVI is a common key indicator of green vegetation cover. The value of NDVI ranges from -1 to 1, and the higher the value, the higher the vegetation cover. When the NDVI is positive, it means that the land is covered by vegetation, and it increases with the increase of coverage. An region with thick, leafy vegetation has an NDVI score of + 1; on the other hand, an area with no plant cover has a value of 0; and when the NDVI value is negative, it means that there is a water body or bare soil in the area37. Therefore, NDVI can be used as a reliable indicator to evaluate the green density of each land area. This formula is used to compute it.
The reflectance in the red band is denoted by R, and the reflectance in the near-infrared band by NIR. NDVI data is obtained from satellite remote sensing data and differentiates between vegetative, artificial and other covers based on the difference in reflectance of plants and other surface covers in the infrared and visible light bands. In this study, Landsat8 multispectral remote sensing images were used, with band B5 representing the NIR band and band B4 representing the R band38. These images were used to generate NDVI maps of the study area using geodata software (e.g., ENVI).
Compared to NDVI, green coverage rate (or called green coverage rate, GCR) directly represents the percentage of area covered by vegetation and is more suitable for assessing urban greening8. To determine the GCR of a given city, we fully utilized the NDVI data and combined it with ArcGIS geographic data software for comprehensive analysis. Through this systematic approach, we aim to ensure accurate calculation of GCR to provide more comprehensive and reliable geographic information.
Based on Aryal et al. showed that the threshold for vegetation and non-vegetation in Victoria, Australia was set at 0.19 in 201939. Hu et al. in their comprehensive assessment of urban green space in Osaka, Japan, set the threshold was set at 0.2748. However, in order to ensure that the threshold value was adapted to the specific situation of this study, we systematically adjusted and validated to ensure the accuracy of the GCR.
First, we randomly selected 200 ground truth points in the study city for testing. These test points were carefully visually inspected, analyzed in detail, and adjusted several times, and the most suitable thresholds for vegetation and non-vegetation in the study city were finally determined. Subsequently, the NDVI data were converted to GCR in ArcGIS using the raster calculation tool. Finally, using the spatial analysis tool of ArcGIS, regional statistics and spatial distribution analysis can be performed to quantify the spatial characteristics of the GCR in each subzone of the city in depth. The Visual presentation of the GCR is shown in Fig. 2.
Built environment data
Built environment (BE) refers to the human-designed, transformed and constructed external spatial environment of a city for the needs of human activities, including the interactive spatial environment composed of land use, transportation infrastructure, urban design and other factors1. Based on the widely used “5D” elements24, 11 BE variables affecting GVI are selected in this paper. As shown in Table 2, these variables include population density (PopD), building density (BD)40, road density (RND), park density (ParkD), land use diversity (LUD), functional use diversity (FUD), road node connectivity (PRC), plot ratio (PR), distance to nearest bus stop and subway station (DBS)41, distance to nearest water system (DW), and distance to nearest green space (DG)42. Visual presentation of selected built environment variables is shown in Fig. 2.
Socioeconomic data
Based on previous work, socio-economic variables43 were selected and calculated, including commercial density, house price and age of housing. Finally, following the methodology commonly used in previous studies25,44, all spatial data were unified into 500 m x 500 m grid cells using the Partitioning Statistics and Spatial Connectivity Toolbox in ArcGIS.
Methodology
Research framework
This study aims to carry out a systematic research on urban greening through in-depth analysis of greening levels in urban areas. According to Fig. 3, it is divided into three primary sections:
-
(1): Data collection and variable calculation. In this study, we choose GVI as the main indicator to quantify the urban greening level from the vertical scale. In this paper, we use the PSPNet model to segment Baidu Street View images by speech and calculate GVI.
-
(2): Nonlinear correlation modeling and Shap model interpretation of GWRF. In this paper, we determine the optimal parameters of GWRF by grid search and K-fold cross-validation methods, and establish the interpretable architecture of Shap model.
-
(3): Model testing and analyzing results. In this paper, the autocorrelation test is performed on GVI and the accuracy of the GWRF model is evaluated, and finally the Shap framework is used to explain the nonlinear relationship of environmental variables on GVI.

The proposed framework in this work.
Semantic segmentation
In computer vision, semantic segmentation is a crucial activity that aims to classify each pixel in an image into preset semantic categories11. Unlike ordinary image classification tasks, semantic segmentation requires not only recognizing objects in an image, but also accurately labeling the semantic categories to which each pixel belongs, including plants, pedestrians, cars, bicycles, and the sky.
The most advanced semantic segmentation networks are SegNet19, PSPNet8 and DeepLabv3 + 45. These methods use their own network characteristics to help planners better understand the spatial structure and functional layout of the city, optimize the urban planning scheme, and realize the sustainable development of the city and the construction of a livable environment by semantically segmenting the urban landscape images or remote sensing images and conducting analysis. For example, SegNet can finely classify land in aerial images or satellite images to identify different types of land use19. This helps to provide data support for land use planning and management. DeepLabv3 + has been applied in urban planning fields such as evaluating urban transportation networks and building layouts, as well as quantitatively exploring the relationship between street space and vibrancy. PSPNet, as a state-of-the-art semantic segmentation model, also has potential applications in urban greening efforts.
As shown in Fig. 4, PSPNet adopts a pyramid pooling structure that can capture image feature information at different scales, thus improving the model’s ability to recognize green areas of different sizes. The green areas in the city are of different sizes, so the network structure with multi-scale sensing field can better capture and identify the green areas of different scales. The PSPNet network structure has rich semantic information, boundary refinement ability, and powerful interpretability and visualization, so this paper selects PSPNet to be used in the semantic segmentation task of Baidu street images. Figure 5 illustrates the effect after semantic partitioning of an example sampling point. As shown in Fig. 5, the PSPNet model semantically segments the Baidu street image into 19 categories, and the corresponding color of each category.

The architecture of the PSPNet.

Street view images sampling and semantic segmentation.
GWRF
The RF model is a global framework that improves accuracy and robustness by training each tree model independently and pooling their predictions26. Nevertheless, RF fails to fully consider spatial heterogeneity when dealing with spatial data, i.e., it ignores the possible correlations and differences between spatial data. To remedy this deficiency, this paper proposes the GWRF model, an innovative model that integrates the GWR model’s central concept into the RF framework, aiming to accurately capture the heterogeneity of spatial data by constructing a local model27. Therefore, the GWRF model can be regarded as a “spatial” extension of the RF method, which is based on the concept of spatial coefficient of variation model and consists of multiple local RF sub-models without assuming that the data obeys a Gaussian distribution, and can be used as a tool for interpretation and prediction to effectively cope with spatial heterogeneity and deal with non-linear relationships. GWRF model is realized by using the R language “Spatial ML” package, and the simplified expression of the traditional RF regression equation is:
The ith observation’s dependent variable is denoted by Yi, the error term is denoted by e, and axi is the RF nonlinear prediction based on a set of x-term independent variables. The formula does not take into account the characteristics of the geographical distribution of the variables.
The GWRF model adds spatial location information of variables to the RF model, and by fitting it to variable datasets that are at different spatial locations, local RF sub-models are obtained for each geospatial unit based on variable observations26. The equations are.
\(({u}_{i},{v}_{i})\) are the coordinates of spatial unit \(i\); \(a({u}_{i},{v}_{i}){x}_{i}\) is the prediction of the RF model calibrated at position \(i\).
The neighborhood (or kernel) of an RF sub model is the maximum distance between a data point and its kernel; the bandwidth is the maximum distance between a data point and its kernel. The GWRF model generates an RF sub model for each geographic location of a variable. Neighborhoods (kernels) are created based on either a distance threshold (bandwidth-fixed kernels) or the number of nearest neighbors (adaptive kernels). Adaptive kernels are preferred when there is a difference in the density of spatial sampling points46. Therefore, grid search and K-fold cross-validation methods may be used in this study to get the ideal parameters of the GWRF, therefore reducing the danger of overfitting and the influence of imbalanced data40. In addition, this study used R-Square (R2), Mean Squared Error (MAE), and Root Mean Squared Error (RMSE) to assess the GWRF model’s precision22.
Shapley additive explanations model
The GWRF model provides a good fit to complex nonlinear problems. However, the “black-box” nature of RF models often lacks interpretability when making decisions30, which makes it difficult to clearly and accurately determine the contribution of each influencing factor, so this paper overcomes this limitation through the SHAP interpretability approach. The SHAP explanatory model is an additivity explanatory model inspired by the Shapley value47. In order to express how each factor contributes to a particular prediction, the SHAP explanatory model assigns a SHAP value to each factor to express the role of each factor32. The SHAP explanatory model generates a prediction value for each sample of predictions, where the SHAP value is the numerical value allocated to every feature in that sample. The ability of the SHAP value to accurately reflect the influence of each sample’s features—that is, the significance of each feature and the extent to which each feature enhances the overall model’s predictive power—is its most crucial characteristic. It also expresses the positivity or negativity of that influence23. The SHAP value is calculated as shown in the following equation:
where \({\varnothing }_{i}\) denotes the attribute value of each indicator \(i\), \(N\) is the vector of feature values, \(n!\) is the number of features, \(S\) is the subset of features that the model uses, and \(|S|\) indicates the number of elements in the subset \(S\). The prediction of the feature values in the set \(S\) is shown by \(v(s)\). The following provides the predicted feature values for the set \(S\).
\(\sum_{S\subseteq N\{i\}}\frac{\left|S\right|!\left(n-\left|S\right|-1\right)!}{n!}\) is the weight and \((v\left(S\cup \left\{i\right\}\right)-v(s))\) indicates the difference between the value before and after feature \(i\) was added. Each feature’s relevance may be rated by comparing its attribute values. Based on the marginal contribution of a feature interacting with other features, the SHAP value is calculated to quantify each feature’s contribution to the model output33.
The extent to which a particular predictor contributes to the model’s predicted results, compared to other predictors, is referred to as relative importance. The relative importance of feature \(i\), denoted by \({I}_{j}\), is calculated by the formula:
where the SHAP value of feature \(i\) in the \(m\) th sample is represented by \({\varnothing }_{j}^{(m)}\).
Meanwhile, the SHAP summary graph (swarm graph) is an advanced visualization tool for interpreting the impact of individual features in a machine learning model on the prediction results. The graph is based on Shapley values, which are derived from cooperative game theory, and is used to quantify the average degree of contribution of individual features to the prediction results in a given prediction model. In the swarm plot, each point represents a Shapley value for one sample in the model, and the horizontal axis indicates the magnitude of these values, reflecting the strength of the influence of the feature values on the model’s predictions. Positive and negative numbers, respectively, show how the characteristic has affected the model’s predictions in a good or negative way. Plotting often involves organizing the points according to features, and color-coding them to show the feature values’ magnitudes, making it easy to visually discern between high and low values. In short, the dense distribution of points in a SHAP summary plot can reveal patterns and trends in the data and help researchers identify relationships between data features and model behavior. As a result, SHAP summary graphs are a crucial tool for comprehending how sophisticated machine learning models make decisions and for better understanding how different characteristics affect model predictions48.
Results
Spatial autocorrelation analysis of GVI
In previous studies, local Moran index is used to detect the spatial autocorrelation of data, P-value is used to assess the significance of data, and Z-score is used to explain whether the data are spatially clustered or not, and they have a wide range of applications in statistics, especially in the field of spatial analysis34. The Moran’s index is calculated by ArcGIS/GeoDa software, and then the spatial autocorrelation test is conducted for the green visibility within study area. As can be seen from the Fig. 6a, under the spatial weight matrix of geographic distance, the Moran’s I value of green visibility is 0.725, with a p-value of 0.001 (less than 0.05), which passes the test of significance at the level of 5%, and the Z score is 95.998, which is greater than the critical value of 1.96. This indicates that there is a significant global spatial aggregation of green visibility within the Sixth Ring Road area of Beijing. effect. Meanwhile, the Moran index is greater than 0, which indicates that there is a positive correlation between the green visibility in the main urban area of Beijing, i.e., the areas with higher green visibility are clustered with each other and the areas with lower green visibility are clustered with each other, as shown in Fig. 6b. Therefore, it is necessary to carry out the research on the influence of different influencing factors on the green visibility rate through GWRF.

Autocorrelation analysis plot.
Model comparisons
Before building the GWRF model, the variables were tested for multicollinearity using stepwise regression method to exclude variables with variance inflation factor (VIF) greater than 1041. All factors passed the test and were retained.
Randomized Grid Search Method is a randomized search method for hyperparameter tuning in the field of machine learning. The Randomized Grid Search method evaluates a certain number of randomly selected hyperparameter combinations from a pre-defined global parameter space and uses an iterative approach to search for the best parameters33. This method does not traverse all possible hyperparameter combinations as in Grid Search. Therefore, it has the advantage of significantly reducing the amount of computation when the global parameter space is very large. The hyperparameters that need to be set in this model are, bandwidth, ntree and mtry. ntree determines the number of decision trees in the model and has a significant impact on the performance and degree of overfitting. In this paper, we follow the general rule of setting the range of the ntree search to be from 100 to 1000 in steps of 100, depending on the complexity and size of the dataset49. Similarly, smaller values for mtry can reduce the variance of the model. mtry value can reduce the variance of the model, but may increase the bias; a larger mtry value can increase the diversity of the model, but may lead to overfitting50. Therefore, in this paper, we set the mtry search range from 2 to 20, with a step size of 2. Since the size of bandwidth directly affects the smoothing degree and fitting effect of the model, in this paper, according to the GVI sampling point discrimination, we set the bandwidth search range from 5 to 50, with a step size of 5. The model was cross-validated five times to test various combinations of hyperparameter values33, which were set to adaptive kernel, bandwidth = 10, ntree = 500, mtry = 12, the final goodness-of-fit R2 of the model was 0.715, indicating that the GWRF has a strong explanatory power for GVI.
In this paper, GWR and pass machine learning models RF, XGBoost and deep learning model Convolutional Neural Networks (CNN) are selected as comparison models for GWRF. As shown in Fig. 7, which visualizes the magnitude of RMSE, MSE and R2 for the five models, it can be found that the GWRF model has the best fit. The study used the RMSE, MAE, and R2 assessment metrics to compare the GWRF model with the four models, GWR, RF, XGBoost and CNN. The GWRF model has better R2 values and lower RMSE and MAE values. Compared to GWR, RF, and XGBoost, GWRF model is more superior to fit GVI by considering spatial heterogeneity. In contrast, although CNN is good at processing spatial data such as images, its global feature extraction approach may not adequately capture the local effects of GVI. Therefore, the flexible model structure of GWRF is more suitable for processing GVI data.

Model comparison.
Relative importance of variables
As seen in Fig. 8, the global Shap value of a variable is used to calculate its global RI. We utilize the Mean|Shap| ratio for each variable and the total of the Mean|Shap| for all variables to compute the global RI after computing the mean of the absolute Shap values (Mean|Shap|)33. The global RI without units represents the relative distribution of each variable. Figure 8 shows that GCR has the largest value and explains the most of the GVI, indicating that of the 15 factors, GCR is the most dominant determinant of the spatial divergence of the GVI. BD, RND, DG, AHP, and AHA are also the main influences. In contrast, PR and DD were the least important. The local interpretation plot visualizes the Shap value and direction of each variable in each GVI. The plot’s red and blue dots, respectively, represent each variable’s high and low eigenvalue. Shap values that are less than zero or larger than zero, respectively, show the variable’s negative and positive effects on the GVI. As shown in Fig. 8b, the variables GCR, AHA, AHP, ParkD, and DBS have a positive effect on GVI, while the variables BD, DG, PRC, and PopD have a significant negative effect on GVI.

The RI of environmental factors from the SHAP model.
Figure 9 shows the impact factors with the largest values of shap for each grid. Figure 9 shows that GCR and BD and RND have high RIs and are highly influential in the overall impact factor. Interestingly, variables of lower importance, such as DBS and DW, also show significant performance at the local scale in the Fig. 9. Additionally, we provide the geographical distribution of each GVI’s Shap values for a few key variables, such as GCR, BD, and AHP. BD and GCR positively affect mainly the development zones outside the fifth ring road, which usually have fewer buildings and higher green coverage. AHP positively affects the zones inside the third ring road, suggesting that the greening of high-priced property markets is done better.

Visualization of SHAP values of variables.
Nonlinear association analysis
There is a nonlinear relationship between each influence factor and GVI, and in order to clearly explain the interpretation of the relationship, this section shows the Shap values of the variables in each GVI using local correlation plots (LDPs)33. The study investigated threshold effects and nonlinear patterns based on the LDPs. The relationship between each factor and GVI is shown in Fig. 10a–o to Fig. When GCR exceeded about 0.5, the local effect went from negative to positive. This indicates that when the green coverage increases, it significantly improves the GVI deficiency. When the BD exceeds approximately 0.7, the localized impact goes from positive to negative. This phenomenon suggests that an increase in building density leads to insufficient planting of green vegetation. This phenomenon is similar to PR, where the higher the PR, the lower the GVI. RND has a positive effect on GVI when it is between 0.01 and 0.03, which suggests that an increase in the density of roads can alleviate the problem of insufficient GVI to a certain extent, but higher densities of roads may have a negative effect on GVI. This phenomenon is similar to PRC, which indicates that the higher the density of road intersections, the lower the GVI. When DG is greater than 200 is, the localized effect goes from positive to negative, meaning that GVI decreases as it increases with green space. This is similar to ParkD, where the density of parks is positively correlated with GVI. The local impact goes from positive to negative when PopD increases to 50. This suggests that denser populations may cause a mismatch in the supply and demand for vegetative greenery, which would lower GVI. DW has little positive effect on GVI at 100 to hour 3000, but to some extent, the closer to the water system, the GVI is relatively higher. The effect of LUD on GVI is relatively stable, and LUD has always had a positive effect on GVI, but not a large one. DBS is greater than 500, it has a positive effect on GVI, which indicates that GVI is not high near transportation sites. When FUD is greater than 0.5, the local effect goes from negative to positive. The areas rich in functional diversity tend to be accompanied by higher GVI. As expected, areas with higher house prices exhibit higher GVI. This may be related to the fact that high-profile communities are willing to offer homeowners a wide range of green projects. The age of the house shows a positive correlation with GVI, which is related to the renovation of old neighborhoods in Beijing. When DD is greater than 0.2, the localized effect goes from positive to negative. This indicates that the higher the commercial density, the lower the GVI.

SHAP dependence plots for variables.
Discussion
Explainable spatial machine learning framework
With the use of an interpretable GWRF model, this study offers a novel framework for investigating the nonlinear relationship between environmental variables and GVI. In contrast to earlier research that relied on regression models and linear assumptions, our approach develops a local spatial model that takes geographic weights into account in order to handle geographical variation. In addition, we employ a local explanatory model to combine the nonlinear relationships between explanatory variables, therefore addressing the drawbacks of earlier regression models that lack interpretability. The GWRF model fits GVI better than GWR and RF, as seen by its higher R2 and lower RMSE and MAE. Furthermore, the Shap model offers both local and global interpretations, facilitating a comprehensive comprehension of the GWRF findings. Our methodology provides important insights into which regions may require greater attention by highlighting the non-smooth nature of spatial relationships. It is possible to apply this new framework to various research and urban planning techniques.
Influence of green coverage rate
In this paper, a study of the relationship between GVI and GCR in Beijing shows that there is a close correlation between the two. Our study shows that GCR has a significant positive effect on the heterogeneity of green visibility. This suggests that GVI quantifies the visible greenery from the pedestrians’ viewpoint, and that pedestrians can capture more greenery in areas with better green coverage, such as parks and tree-lined streets, where GVI is significantly higher. This is similar to results such as those of Li et al. study34. This relationship emphasizes the importance of urban greening in improving visual aesthetics and environmental quality in cities such as Beijing. However, GCR can only explain 19.8% of the variance. Additionally, it implies that GVI primarily concentrates on the vertical aspect of urban greening, with little regard for how pedestrians perceive greenery from a horizontal vantage point51. GVI may thus be used in conjunction with other 2D green space indicators to improve and enhance the greening assessment method12.
Influence of built environment factors
In the built environment evaluation index system constructed in this study, including 15 evaluations such as PD, BD, RND, PRC, etc., building density has the largest and negative effect on GVI. This may be caused by a variety of factors. An increase in building density often leads to a decrease in the available space for vegetation and green space, which results in a lower GVI52. In addition tall buildings can block sunlight and limit the growth of plants and trees. The study of PopD and PR in this paper proves the same. The study in this paper demonstrates that RND, PRC and DBS negatively impact GVI and that roads, intersections and transit stops take up a large amount of land that could otherwise be used for green space53. In addition, the increased impervious surfaces of roads, intersections, and transit stops exacerbate the urban heat island effect, making it more difficult for vegetation to grow54. Studies by ParkD, DG, and DW have demonstrated that parks, green spaces, and water systems play a vital role in improving GVI. Parks, green spaces and water systems are usually surrounded by dense planting of trees, shrubs and lawns, which greatly increase the amount of visible green in urban areas55. As shown in the figure, there is a positive impact on GVI as the LUD continues to increase. This phenomenon indicates that forest, farmland, shrubs, etc., and these areas support the growth of a wide variety of plants, which improves the overall green coverage and diversity, and helps to improve the GVI28.The effect of FUD on the GVI is from negative to positive, which suggests that diversified functional zones are often accompanied by integrated landscape design, including walking paths, parks, green spaces , small green belts, etc., and these designs will enhance GVI56. The detrimental effects of variety in urban functional zones will progressively lessen or maybe vanish as urbanization rises, which is connected to the growing emphasis on the development of urban green spaces57,58. Furthermore, studies have shown that land use and urban functional areas have an impact on GVI34,52, which highlights the need of striking a balance between the demands for greening and urban growth.
Based on the results of the above research on the impact of the built environment on GVI, a few suggestions can be provided to urban planners and policy makers to enhance the greening of cities.
-
(1): Incorporate green elements in architectural design, such as installing roof gardens and vertical green walls, to improve the green visibility of buildings, and at the same time increase the area of urban green space and improve the microclimate of buildings59.
-
(2): In urban renewal, street trees and green belts can be added on both sides of major roads to create green corridors, thus improving the visual quality of green cities60.
-
(3): In areas with low GVI, priority will be given to increasing green areas, such as building urban parks, street green areas and rooftop greening, to make maximum use of the continuity and permeability of the above green areas61.
-
(4): In undeveloped areas, encourage mixed-use development that integrates residential, commercial, and recreational spaces; diversified land uses often feature green buffers and landscaped areas, which play a positive role in improving GVI62.
Influence of socioeconomic factors
Socioeconomically speaking, those who earn more per capita typically reside in greener places63. This paper used house prices to reflect residents’ incomes and showed that GVI increased with higher house prices, which is consistent with previous research64. Individuals with higher wealth are more likely to choose or upgrade their living spaces, and they also have better access to more visible greenery65. This demonstrates that GVI has a favorable effect on housing prices, suggesting that property lots with GVI tend to have higher market values. In addition, we find that the higher the housing age, the higher the GVI is, because the housing age data are mainly from the main urban areas within the fourth ring road, which are mostly old neighborhoods and have a small sample size. In Beijing, the ‘Old Residential Area Renovation Program’ has become part of initiatives such as urban planning, which aims to improve living conditions by increasing green space, including planting more trees, creating parks, and increasing overall green coverage66. Studies have shown that the green landscape index tends to be higher in areas with longer roads and more paths, which is usually characteristic of older neighborhoods67. In addition, the findings obtained in this paper coincide with the results of studies conducted in the past, indicating a general trend, which further supports the idea that urban greening policies targeting older neighborhoods lead to an increase in the Green Landscape Index68, i.e., urban renewal projects focus on enhancing the green spaces in the older parts of the city in order to improve the quality of the environment and the quality of life of the inhabitants. As a result, better green environments have been created in older neighborhoods in recent years compared to newer neighborhoods.
As shown in the Fig. 10, higher commercial densities tend to be associated with lower GVI due to the prioritization of built infrastructure over green space. Higher density commercial areas typically allocate more space for buildings, parking lots, and other urban infrastructure, thereby reducing the availability of green space. This approach to urban design emphasizes maximizing available commercial space, often at the expense of green space69. Studies have shown that greening in dense commercial areas can be improved by constructing green roofs on commercial buildings and increasing the number of street trees in commercial areas, thereby increasing GVI and promoting sustainable development in commercial neighborhoods.
Limitations
Despite the unique value of this work, there are certain limitations. First and foremost, as a case study focused on Beijing, there is no clear answer to the question of whether its findings can be broadly applied to other cities. In order to deepen the research or validate the hypotheses of this study, future scholars could expand the scope of the study by applying this approach evaluates its validity and generalizability more thoroughly by employing data from several cities or nations. Second, this study has analyzed the influence of GVI from three dimensions: green cover rate, built environment, and socioeconomic factors, but there is also a lack of consideration of existing factors or a lack of other influencing factors. For example, DW does not only consider the distance to the water system, but can further refine variables such as the type of water system (e.g., rivers, lakes, wetlands, etc.), area, water quality, and morphology of the water body. These variables may have different impacts on GVI. In order to further enrich and enhance the current conceptual framework and more thoroughly uncover the underlying processes behind GVI, future research may build on this foundation by adding more environmental factors and merging multi-source urban data. Then, there are inconsistencies in the spatial resolution or sampling rate of the data obtained in this paper. The generation and maintenance of Street View maps is an ongoing process that requires regular updates, so Baidu Street View images will have some missing issues. The uncertainty of these data sources can also lead to instability in the final results. Finally, the SHAP value assumes that the effects of features are linearly additive, which may not adequately capture non-linear relationships and feature interaction effects in complex models. Therefore, although we have provided a preliminary explanation of the nonlinear results with the help of the Shap model, we have not yet explored in depth the potential interactions among multiple variables. Therefore, for future research in this area, we will focus on and explore the interactions among these variables to more comprehensively understand the influencing mechanisms.
Conclusion
In this study, a spatial machine learning (GWRF) framework is constructed by combining multi-source urban big data, aiming to analyze complex relationship between environmental variables and GVI. To address the spatial heterogeneity, we use a geographically weighted regression (GWRF) model for parsing and a Shap model to provide a comprehensive and detailed interpretation of the model results. Through this framework, we delved into the nonlinear associations of multiple environmental factors with GVI. The following conclusions are drawn:
-
(1): There is a significant spatial aggregation effect and positive correlation of GVI within the Sixth Ring Road of Beijing, with obvious spatial heterogeneity, and hotspots and coldspots have obvious aggregated distributions.
-
(2): Compared with other environmental variables, GCR has the greatest positive effect on GVI, and BD shows the greatest negative correlation with GVI.
-
(3): Compared with the models of GWR, RF, XGBoost and CNN, the GWRF model demonstrated more superior performance in simulating and predicting GVI.
-
(4): All environmental variables, including GCR, built environment and socioeconomics variables, showed nonlinear and threshold effects on GVI. The nonlinear and threshold effects of GVI provide quantitative analysis tools for urban planning, which helps to rationally allocate greening resources in urban planning, improve the insufficient greening effect and avoid the waste of resources.
Data availability
All data generated or analyzed during this study are included in this article.
References
Zhang, W. & Zeng, H. Spatial differentiation characteristics and influencing factors of the green view index in urban areas based on street view images: A case study of Futian District, Shenzhen, China. Urban For. Urban Green. 93, 128219. https://doi.org/10.1016/j.ufug.2024.128219 (2024).
Du, H., Zhou, F., Cai, Y., Li, C. & Xu, Y. Research on public health and well-being associated to the vegetation configuration of urban green space, a case study of Shanghai, China. Urban For. Urban Green. 59, 126990. https://doi.org/10.1016/j.ufug.2021.126990 (2021).
Thompson, C. W. Urban open space in the 21st century. Landsc. Urban Plan. 60, 59–72. https://doi.org/10.1016/S0169-2046(02)00059-2 (2002).
Hedblom, M. et al. Reduction of physiological stress by urban green space in a multisensory virtual experiment. Sci. Rep. 9, 10113. https://doi.org/10.1038/s41598-019-46099-7 (2019).
Pouso, S. et al. Contact with blue-green spaces during the COVID-19 pandemic lockdown beneficial for mental health. Sci. Total Environ. 756, 143984. https://doi.org/10.1016/j.scitotenv.2020.143984 (2021).
Yang, J., Sun, J., Ge, Q. & Li, X. Assessing the impacts of urbanization-associated green space on urban land surface temperature: A case study of Dalian, China. Urban For. Urban Green. 22, 1–10. https://doi.org/10.1016/j.ufug.2017.01.002 (2017).
Martinez, A. et al. Demystifying normalized difference vegetation index (NDVI) for greenness exposure assessments and policy interventions in urban greening. Environ. Res. 220, 115155. https://doi.org/10.1016/j.envres.2022.115155 (2023).
Hu, A. et al. Harnessing multiple data sources and emerging technologies for comprehensive urban green space evaluation. Cities 143, 104562. https://doi.org/10.1016/j.cities.2023.104562 (2023).
Aikoh, T., Homma, R. & Abe, Y. Comparing conventional manual measurement of the green view index with modern automatic methods using google street view and semantic segmentation. Urban For. Urban Green. 80, 127845. https://doi.org/10.1016/j.ufug.2023.127845 (2023).
Li, X. et al. Assessing street-level urban greenery using google street view and a modified green view index. Urban For. Urban Green. 14, 675–685. https://doi.org/10.1016/j.ufug.2015.06.006 (2015).
Xia, Y., Yabuki, N. & Fukuda, T. Development of a system for assessing the quality of urban street-level greenery using street view images and deep learning. Urban For. Urban Green. 59, 126995. https://doi.org/10.1016/j.ufug.2021.126995 (2021).
Falfán, I., Muñoz-Robles, C. A., Bonilla-Moheno, M. & MacGregor-Fors, I. Can you really see ‘green’? Assessing physical and self-reported measurements of urban greenery. Urban For. Urban Green. 36, 13–21. https://doi.org/10.1016/j.ufug.2018.08.016 (2018).
Miaoyi, L. I., Zhonghao, Y. & Feng, X. U. E. Urban street greenery quality measurement, planning and design promotion strategies based on multi-source data: A case study of Fuzhou’s main urban area. Landsc. Archit. 28, 62–68. https://doi.org/10.14085/j.fjyl.2021.02.0062.07 (2021).
Labib, S. M., Huck, J. J. & Lindley, S. Modelling and mapping eye-level greenness visibility exposure using multi-source data at high spatial resolutions. Sci. Total Environ. 755, 143050. https://doi.org/10.1016/j.scitotenv.2020.143050 (2021).
Helbich, M. et al. Can’t see the wood for the trees? An assessment of street view- and satellite-derived greenness measures in relation to mental health. Landsc. Urban Plann. 214, 104181. https://doi.org/10.1016/j.landurbplan.2021.104181 (2021).
Cheng, L., De Vos, J., Zhao, P., Yang, M. & Witlox, F. Examining non-linear built environment effects on elderly’s walking: A random forest approach. Transp. Res. Part D Transp. Environ. 88, 102552. https://doi.org/10.1016/j.trd.2020.102552 (2020).
Kim, S. & Lee, S. Nonlinear relationships and interaction effects of an urban environment on crime incidence: Application of urban big data and an interpretable machine learning method. Sustain. Cities Soc. 91, 104419. https://doi.org/10.1016/j.scs.2023.104419 (2023).
Caigang, Z., Shaoying, L., Zhangzhi, T., Feng, G. & Zhifeng, W. Nonlinear and threshold effects of traffic condition and built environment on dockless bike sharing at street level. J. Transp. Geogr. 102, 103375. https://doi.org/10.1016/j.jtrangeo.2022.103375 (2022).
Wang, J., Liu, W. & Gou, A. Numerical characteristics and spatial distribution of panoramic street green view index based on SegNet semantic segmentation in Savannah. Urban For. Urban Green. 69, 127488. https://doi.org/10.1016/j.ufug.2022.127488 (2022).
Pham, T.-T.-H., Apparicio, P., Landry, S. & Lewnard, J. Disentangling the effects of urban form and socio-demographic context on street tree cover: A multi-level analysis from Montréal. Landsc. Urban Plan. 157, 422–433. https://doi.org/10.1016/j.landurbplan.2016.09.001 (2017).
Ki, D. & Lee, S. Analyzing the effects of Green View Index of neighborhood streets on walking time using Google Street View and deep learning. Landsc. Urban Plan. 205, 103920. https://doi.org/10.1016/j.landurbplan.2020.103920 (2021).
Li, D. et al. Residual neural network with spatiotemporal attention integrated with temporal self-attention based on long short-term memory network for air pollutant concentration prediction. Atmos. Environ. 329, 120531. https://doi.org/10.1016/j.atmosenv.2024.120531 (2024).
Li, Z. Extracting spatial effects from machine learning model using local interpretation method: An example of SHAP and XGBoost. Comput. Environ. Urban Syst. 96, 101845. https://doi.org/10.1016/j.compenvurbsys.2022.101845 (2022).
Yang, L., Ao, Y., Ke, J., Lu, Y. & Liang, Y. To walk or not to walk? Examining non-linear effects of streetscape greenery on walking propensity of older adults. J. Transp. Geogr. 94, 103099. https://doi.org/10.1016/j.jtrangeo.2021.103099 (2021).
Liu, Y., Li, Y., Yang, W. & Hu, J. Exploring nonlinear effects of built environment on jogging behavior using random forest. Appl. Geogr. 156, 102990. https://doi.org/10.1016/j.apgeog.2023.102990 (2023).
Georganos, S. et al. Geographical random forests: a spatial extension of the random forest algorithm to address spatial heterogeneity in remote sensing and population modelling. Geocarto Int. 36, 121–136. https://doi.org/10.1080/10106049.2019.1595177 (2021).
Grekousis, G., Feng, Z., Marakakis, I., Lu, Y. & Wang, R. Ranking the importance of demographic, socioeconomic, and underlying health factors on US COVID-19 deaths: A geographical random forest approach. Health Place 74, 102744. https://doi.org/10.1016/j.healthplace.2022.102744 (2022).
Chan, T.-C., Lee, P.-H., Lee, Y.-T. & Tang, J.-H. Exploring the spatial association between the distribution of temperature and urban morphology with green view index. PLoS ONE 19, e0301921. https://doi.org/10.1371/journal.pone.0301921 (2024).
Gu, Y., Liu, D., Arvin, R., Khattak, A. J. & Han, L. D. Predicting intersection crash frequency using connected vehicle data: A framework for geographical random forest. Accid. Anal. Prev. 179, 106880. https://doi.org/10.1016/j.aap.2022.106880 (2023).
Yang, L. et al. Exploring non-linear and synergistic effects of green spaces on active travel using crowdsourced data and interpretable machine learning. Travel Behav. Soc. 34, 100673. https://doi.org/10.1016/j.tbs.2023.100673 (2024).
Yang, W., Fei, J., Li, Y., Chen, H. & Liu, Y. Unraveling nonlinear and interaction effects of multilevel built environment features on outdoor jogging with explainable machine learning. Cities 147, 104813. https://doi.org/10.1016/j.cities.2024.104813 (2024).
Yang, W., Li, Y., Liu, Y., Fan, P. & Yue, W. Environmental factors for outdoor jogging in Beijing: Insights from using explainable spatial machine learning and massive trajectory data. Landsc. Urban Plan. 243, 104969. https://doi.org/10.1016/j.landurbplan.2023.104969 (2024).
Xiao, L., Lo, S., Liu, J., Zhou, J. & Li, Q. Nonlinear and synergistic effects of TOD on urban vibrancy: Applying local explanations for gradient boosting decision tree. Sustain. Cities Soc. 72, 103063. https://doi.org/10.1016/j.scs.2021.103063 (2021).
Li, T. et al. Spatial relationship between green view index and normalized differential vegetation index within the Sixth Ring Road of Beijing. Urban For. Urban Green. 62, 127153. https://doi.org/10.1016/j.ufug.2021.127153 (2021).
Tang, J.-H. et al. Associations between community green view index and fine particulate matter from Airboxes. Sci. Total Environ. 921, 171213. https://doi.org/10.1016/j.scitotenv.2024.171213 (2024).
Zhang, J. & Hu, A. Analyzing green view index and green view index best path using Google street view and deep learning. J. Comput. Des. Eng. 9, 2010–2023. https://doi.org/10.1093/jcde/qwac102 (2022).
Yengoh, G. T., Dent, D., Olsson, L., Tengberg, A. E. & Tucker, C. J. Applications of NDVI for land degradation assessment. In Use of the Normalized Difference Vegetation Index (NDVI) to Assess Land Degradation at Multiple Scales: Current Status, Future Trends, and Practical Considerations (eds Yengoh, Genesis T. et al.) 17–25 (Springer International Publishing, 2016).
Edoardo, S., Dario, S. & Damiano, P.
Aryal, J., Sitaula, C. & Aryal, S. NDVI threshold-based urban green space mapping from sentinel-2A at the local governmental area (LGA) level of Victoria, Australia. Land 11, 351 (2022).
Chen, E., Ye, Z. & Wu, H. Nonlinear effects of built environment on intermodal transit trips considering spatial heterogeneity. Transp. Res. Part D Transp. Environ. 90, 102677. https://doi.org/10.1016/j.trd.2020.102677 (2021).
Chen, E. & Ye, Z. Identifying the nonlinear relationship between free-floating bike sharing usage and built environment. J. Clean. Prod. 280, 124281. https://doi.org/10.1016/j.jclepro.2020.124281 (2021).
Liu, Y., Hu, J., Yang, W. & Luo, C. Effects of urban park environment on recreational jogging activity based on trajectory data: A case of Chongqing, China. Urban For. Urban Green. 67, 127443. https://doi.org/10.1016/j.ufug.2021.127443 (2022).
Wu, P. et al. Revealing the determinants of the intermodal transfer ratio between metro and bus systems considering spatial variations. J. Transp. Geogr. 104, 103415. https://doi.org/10.1016/j.jtrangeo.2022.103415 (2022).
Yang, W., Hu, J., Liu, Y. & Guo, W. Examining the influence of neighborhood and street-level built environment on fitness jogging in Chengdu, China: A massive GPS trajectory data analysis. J. Transp. Geogr. 108, 103575. https://doi.org/10.1016/j.jtrangeo.2023.103575 (2023).
Zhang, L. et al. Decoding urban green spaces: Deep learning and google street view measure greening structures. Urban For. Urban Green. 87, 128028. https://doi.org/10.1016/j.ufug.2023.128028 (2023).
Luo, Y., Yan, J., McClure, S. C. & Li, F. Socioeconomic and environmental factors of poverty in China using geographically weighted random forest regression model. Environ. Sci. Poll. Res. 29, 33205–33217. https://doi.org/10.1007/s11356-021-17513-3 (2022).
Lundberg, S. M. et al. From local explanations to global understanding with explainable AI for trees. Nat. Mach. Intell. 2, 56–67. https://doi.org/10.1038/s42256-019-0138-9 (2020).
Peng, J. et al. Understanding nonlinear and synergistic effects of the built environment on urban vibrancy in metro station areas. J. Eng. Appl. Sci. 70, 18. https://doi.org/10.1186/s44147-023-00182-z (2023).
Hassan, M. Machine learning optimization for hybrid electric vehicle charging in renewable microgrids. Sci. Rep. 14, 13973. https://doi.org/10.1038/s41598-024-63775-5 (2024).
Ma, L., Yang, B., Feng, Y. & Ju, L. Evaluation of provincial forest ecological security and analysis of the driving factors in China via the GWR model. Sci. Rep. 14, 14299. https://doi.org/10.1038/s41598-024-65052-x (2024).
Helbich, M. et al. Using deep learning to examine street view green and blue spaces and their associations with geriatric depression in Beijing, China. Environ. Int. 126, 107–117. https://doi.org/10.1016/j.envint.2019.02.013 (2019).
Zhu, J. et al. Disentangling the effects of the surrounding environment on street-side greenery: Evidence from Hangzhou. Ecol. Indic. 143, 109153. https://doi.org/10.1016/j.ecolind.2022.109153 (2022).
Liu, Y., Pan, X., Liu, Q. & Li, G. Establishing a reliable assessment of the green view index based on image classification techniques, estimation, and a hypothesis testing route. Land 12, 1030 (2023).
Berland, A. et al. The role of trees in urban stormwater management. Landsc. Urban Plann. 162, 167–177. https://doi.org/10.1016/j.landurbplan.2017.02.017 (2017).
Wolch, J. R., Byrne, J. & Newell, J. P. Urban green space, public health, and environmental justice: The challenge of making cities ‘just green enough’. Landsc. Urban Plann. 125, 234–244. https://doi.org/10.1016/j.landurbplan.2014.01.017 (2014).
Zheng, W. & Barker, A. Green infrastructure and urbanisation in suburban Beijing: An improved neighbourhood assessment framework. Habitat Int. 117, 102423. https://doi.org/10.1016/j.habitatint.2021.102423 (2021).
Du, J. et al. Effects of rapid urbanization on vegetation cover in the metropolises of China over the last four decades. Ecol. Indic. 107, 105458. https://doi.org/10.1016/j.ecolind.2019.105458 (2019).
Zhou, T., Liu, H., Gou, P. & Xu, N. Conflict or Coordination? measuring the relationships between urbanization and vegetation cover in China. Ecol. Indic. 147, 109993. https://doi.org/10.1016/j.ecolind.2023.109993 (2023).
Susca, T., Zanghirella, F., Colasuonno, L. & Del Fatto, V. Effect of green wall installation on urban heat island and building energy use: A climate-informed systematic literature review. Renew. Sustain. Energy Rev. 159, 112100. https://doi.org/10.1016/j.rser.2022.112100 (2022).
Lai, Y. & Kontokosta, C. E. The impact of urban street tree species on air quality and respiratory illness: A spatial analysis of large-scale, high-resolution urban data. Health Place 56, 80–87. https://doi.org/10.1016/j.healthplace.2019.01.016 (2019).
van den Bosch, M. Urban green spaces and health - a review of evidence. (2016).
Zhang, K. & Chen, M. Multi-method analysis of urban green space accessibility: Influences of land use, greenery types, and individual characteristics factors. Urban For. Urban Green. 96, 128366. https://doi.org/10.1016/j.ufug.2024.128366 (2024).
Li, X., Zhang, C., Li, W., Kuzovkina, Y. A. & Weiner, D. Who lives in greener neighborhoods? The distribution of street greenery and its association with residents’ socioeconomic conditions in Hartford, Connecticut, USA. Urban For. Urban Green. 14, 751–759. https://doi.org/10.1016/j.ufug.2015.07.006 (2015).
Wang, Z.-L., Tao, F., Leng, H.-J., Wang, Y.-H. & Zhou, T. Multi-scale analysis on sustainability and driving factors based on three-dimensional ecological footprint: A case study of the Yangtze River Delta region, China. J. Clean. Prod. 436, 140596. https://doi.org/10.1016/j.jclepro.2024.140596 (2024).
Xiao, Y. et al. Exploring determinants of housing prices in Beijing: An enhanced hedonic regression with open access POI data. ISPRS Int. J. Geo Inf. 6, 358 (2017).
Dong, R., Zhang, Y. & Zhao, J. How green are the streets within the sixth ring road of Beijing? An analysis based on tencent street view pictures and the green view index. Int. J. Environ. Res. Public Health 15, 1367 (2018).
Gou, A., Zhang, C. & Wang, J. Study on the identification and dynamics of green vision rate in Jing’an district, Shanghai based on deeplab V3 + model. Earth Sci. Inform. 15, 163–181. https://doi.org/10.1007/s12145-021-00691-6 (2022).
Long, Y. & Liu, L. How green are the streets? An analysis for central areas of Chinese cities using tencent street view. PLoS ONE 12, e0171110. https://doi.org/10.1371/journal.pone.0171110 (2017).
An, S., Jang, H., Kim, H., Song, Y. & Ahn, K. Assessment of street-level greenness and its association with housing prices in a metropolitan area. Sci. Rep. 13, 22577. https://doi.org/10.1038/s41598-023-49845-0 (2023).
Funding
This work was funded by the State Grid Corporation of China Science and Technology Project Grant (5200-202456108A-1-1-ZN).
Author information
Authors and Affiliations
Contributions
Conceptualization, D. L.; methodology, D. L.; software, J. W.; validation, J. W.; formal analysis, C. C.; investigation, X. S.; resources, C. C.; data curation, C.C.; writing—original draft preparation, C. C.; writing—review and editing, B. Z. and D. L; visualization, C. Y.; supervision, J. Z.; project ad-ministration, J. W.; funding acquisition, J. W. All authors have read and agreed to the published version of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Chen, C., Wang, J., Li, D. et al. Unraveling nonlinear effects of environment features on green view index using multiple data sources and explainable machine learning. Sci Rep 14, 30189 (2024). https://doi.org/10.1038/s41598-024-81451-6
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-024-81451-6
Keywords
This article is cited by
-
A study on the coupling mechanism between the urban environment and depression perception based on deep learning and street view image
Scientific Reports (2026)
-
Nonlinear effects of the built environment on urban vitality in Jinan based on multi-source data and explainable AI
Scientific Reports (2026)
