
Abstract
Recent advances in artificial intelligence (AI) and machine learning (ML) applications have elevated accomplishments in various scientific fields, primarily those that benefit the economy and society. Contemporary threats, such as armed conflicts, natural and man-made disasters, and illegal immigration, often require fast and innovative but reliable identification aids, in which forensic anthropology has a significant role. However, forensic anthropology has not yet exploited new scientific advances but instead relies on traditionally used methods. The rare studies that employed AI and ML in developing standards for sex and age estimation did not go beyond the conceptual solutions and were not applied to real cases. In this study, on the example of Croatian populations’ cranial dimensions, we demonstrated the methodology of developing sex classification models using ML in conjunction with field knowledge, resulting in sex estimation accuracy of more than 95%. To illustrate the necessity of applying scientific results, we developed a web app, CroCrania (https://crocrania.onrender.com), that can be used for sex estimation and method validation.
Similar content being viewed by others

Introduction
Forensic anthropology is a scientific field situated at the intersection of biological anthropology and legal proceedings. It draws upon knowledge from various disciplines to study not only life and the cause of death, but also events after-death within both physical and forensic context1. This interdisciplinary field has become increasingly critical in addressing modern challenges like illegal immigration, natural and man-made disasters, and armed conflicts2. In such contexts, primary means of identification, including DNA analysis, fingerprinting, and dental records, may not always be applicable2,3. For instance, remains of war conflict victims may be severely mutilated and commingled, and conditions such as the destruction of personal items and records can further hinder identification efforts4. In cases involving illegal immigration, undocumented individuals often lack identification papers, making it essential to rely on alternative methods5,6,7,8,9. Forensic anthropology plays a crucial role in secondary identification through the creation of a biological profile, which includes the estimation of sex, age, stature, trauma, and pathology2,10,11,12. This profiling supports both identification and understanding the manner of death. Furthermore, in cases involving living individuals—such as undocumented immigrants or victims of trafficking—age estimation can be especially useful for authorities13,14,15,16. To meet the demands of this increasingly interdisciplinary field, forensic anthropologists are adopting advanced technologies and methods to address novel challenges, such as those encountered in illegal immigration and mass grave analyses17,18. Despite these demands, forensic anthropology has been slow to incorporate advanced technologies compared to related fields like medicine. This lag is particularly evident in the adoption of artificial intelligence (AI) and machine learning (ML). For example, a search in the Web of Science (WOS) papers (all search strategies are presented in Supplementary Table 1) on artificial intelligence, machine learning, deep learning, and neural networks in forensic anthropology yielded only 154 papers since 2001, whereas medicine has had 16,164 publications in this area since 1995. When specifically examining AI-related research, the WOS search yielded 19,255 results since 1977, while the same query for forensic anthropology gave 29 results since 2013. After the exclusion of review papers, book chapters, and papers that did not cover the topic, 16 documents remained. Most of them studied sex19,20,21,22,23,24,25,26and age27estimation, or both28, while others focused on odontology29,30, fractures31, postmortem interval32, or cephalometric landmarking33. Such discrepancies highlight a technological gap that may limit forensic anthropology’s capacity to meet modern forensic challenges.
Sex estimation, a crucial component of forensic anthropology34,35,44,36,37,38,39,40,41,42,43, is often the first step in reconstructing a biological profile. Traditional methods rely on morphological and osteometric assessments, especially of sexually dimorphic bones like the skull and pelvis, which can have up to 95% accuracy when applied by experienced anthropologists who possess knowledge of specific populations10. However, some bones, such as long bones, yield more reliable accuracy for sex estimation than others. For example, Spradley and Jantz found that individual long bone measurements outperformed skull measurements for sex classification44. This finding was also supported by other studies36,38,45,46,47. Recent research demonstrates that ML can improve the accuracy of cranial sex estimation in ways that may complement or exceed traditional methods. Studies using ML models on cranial measurements have reported cross-validation (CV) accuracies exceeding 95%, such as the 96.1% accuracy achieved by Toneva et al. with support vector machines (SVM)48. Toy et al. achieved 90% accuracy using ML on cranial lengths, angles, and curvatures49, while Kondou et al. reported up to 93% accuracy using ML on 3D skull images, surpassing the range of 63–83% accuracy achieved by human estimators50. These findings show that ML-based approaches can achieve forensically relevant accuracies, comparable to amelogenin-based sex estimation with accuracy rates from 93.51%51 to 99.99%52, depending on population variation53. Considering these advances, this study seeks to address the gap by developing a fully applicable ML-based model for sex classification using standard cranial measurements and inter-landmark distances in the Croatian population.
Methods
Materials
The sample included 414 adult individuals from the Croatian population, with an equal proportion of males and females (median age 64; range 18–95). The multi-slice computed tomography (MSCT) images were retrospectively collected from university hospital centers’ diagnostic and interventional radiology departments in Split (n = 219) and Zagreb (n = 196), the two greatest Croatian towns from different regions (To avoid repeating phrases like crania imaged in Split or Zagreb hospitals, we will refer to them as Split and Zagreb crania in further text).
The images were acquired using MSCT device Definition Edge and Sensation AS 128 (Siemens AG Medical Solutions, Erlangen, Germany). We included head region images with a slice thickness of ≤ 1 mm that showed no visible pathological and traumatic changes or significant asymmetries. We used the original slice thickness and soft-tissue convolution kernel for image reconstruction.
DICOM files were loaded into Stratovan Checkpoint Software Version 2020.10.13.0859 (Stratovan Corporation, Davis, CA) and viewed in 2D (axial, sagittal, and coronal plane) and 3D using semi-transparent 3D volume rendering. Following the previously described protocol and workflow54, crania were aligned, and 47 landmarks were placed in specific order according to a template (as detailed in the Supplementary Table 2). These landmarks correspond to standard measurements outlined in the Data Collection Procedures for Forensic Skeletal Material 2.055 and were stored as .nts files.
A Python script was developed to load the landmark data from a folder, allocating landmark names, handling missing values, adding sex (M, F) and region variables (ST, ZG) according to filenames, and reshaping it into a structured format. The script further calculated all possible distances between landmarks (nfeatures = 1081) and organized these distances into a pivot table for subsequent analysis. The dataset was then checked for missing values, and variables that had more than 10% of missing values were excluded. Mean stratified by sex and region was utilized to impute other variables with missing values.
We created two datasets: the first one included interlandmark distances that form standard measurements55, and the second one included all interlandmark distances.
The initial sample was split into the training (n = 334) and testing dataset (n = 80). All the datasets were stratified by sex, while the testing set was also stratified by region, so it contained 20 individuals per town and sex (Split males – M_ST, Split females – F_ST, Zagreb males – M_ZG, and Zagreb females – F_ZG). Descriptive statistics on training and testing dataset is provided in Supplementary sheets 1.
Exploratory analyses
Since previous studies identified some within-population differences39,56,57, the first step in our analyses conducted principal component analysis (PCA) to uncover patterns and structures related to regional specificities and sexual dimorphism in data. We analyzed the first two principal components that explain most of the variance and inspected factor loadings to reveal the impact of specific variables or groups of variables on components. To detect differences more precisely, we further employed independent samples t-test to examine the sexual dimorphism of variables and differences between crania from images collected in Split and Zagreb hospitals (M_ST vs. M_ZG and F_ST vs. F_ZG).
Classification models
For each model and dataset, we used unprocessed data and scaled data (using sklearn’s StandardScaler), where each variable had an average value of zero and equal variation. We employed the following model metrics: accuracy, sensitivity, specificity, positive predictive value (PPV), and negative predictive value (NPV), where we considered the male sex a positive outcome. In this study, models were compared and selected using accuracy, as well as PPVs and NPVs, to align with the forensic objective of minimizing false classifications. The performance of each algorithm was assessed using these specific metrics through stratified 5-fold cross-validation, complemented by performance evaluation on an independent test set.
In the initial study phase, we tested six classification algorithms: Logistic Regression (LR), Linear Discriminant Analysis (LDA), Support Vector Machine (SVM), Random Forest (RF), K-Nearest Neighbors (KNN), and Gradient Boosting Classifier (GBC) with their default parameters as implemented in the scikit-learn library. Logistic Regression and Linear Discriminant Analysis were chosen for their simplicity, interpretability, and tradition of application in forensic anthropology58, Support Vector Machine for its efficacy in high-dimensional spaces59, Random Forest and Gradient Boosting for their robust performance in various settings60,61, and K-Nearest Neighbors for its non-parametric nature62. Upon preliminary evaluation using accuracy, sensitivity, specificity, PPV, and NPV as key metrics, we further focused on LR, LDA, and SVM. This decision was based on their superior and more balanced performance across these metrics and their relative simplicity and interpretability, which are crucial in forensic applications (Supplementary sheets 2).
In the first step, we tested three algorithms on both datasets with default settings. Then, hyperparameter tuning was conducted in two rounds using GridSearchCV. In the first round, LR parameters ‘C’ (regularization strength), LDA’s ‘solver’ type, and SVM parameters ‘C’ (regularization parameter) and ‘kernel’ were optimized. The second round involved a more extensive search: for LR, ‘C’, ‘penalty’ type, and ‘solver’ method; for LDA, ‘solver’ and ‘shrinkage’; and for SVM, ‘C’, ‘kernel’, and ‘gamma’ (kernel coefficient). More detailed tuning parameters are available in Table 1.
For the standard measurement dataset, we then integrated Recursive Feature Elimination (RFE) with hyperparameter tuning using GridSearchCV for each classifier. This approach involved systematically testing every combination of features and hyperparameters to determine the most effective configuration. The optimal number and combination of features, along with the best hyperparameters, were chosen based on the highest cross-validation accuracy.
In the second experiment, we removed region-specific variables in both sets, i.e., those that exhibited statistically significant differences, and thus reduced the number of variables. Then, we repeated the above-described workflow: applying classifiers with default settings, hyperparameter tuning, and RFE.
Lastly, in a dataset with all inter-landmark distances, we created a dataset where we kept only variables correlated to sex (Pearson’s correlation coefficient above 0.3) and excluded those that were not correlated among themselves (Pearson’s correlation coefficient below 0.8). Then, we repeated the above-described workflow.
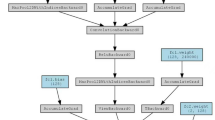
Detailed workflow is shown in Fig. 1.

Schematic representation of developing classification models.
For the best-performing model with standard measurements and the best-performing model for interlandmark distances, we conducted SHapley Additive exPlanations (SHAP)63,64,65,66 to interpret model predictions.
Model construction and analyses
Most analyses and model constructions were conducted in Google Colab, a cloud-based Python programming environment, as of January 2024. We used Python (v. 3.10.12), with key libraries including Pandas (v. 1.5.3) for data manipulation, NumPy (v. 1.23.5) for numerical computations, SciPy for statistical tests, and SHAP for model interpretation (v. 0.44.1). The model development, evaluation, and feature selection were primarily performed using Scikit-learn version (v. 1.2.2), which provided tools like RFECV for feature optimization and various classification algorithms. PCA was conducted in the R environment (v. 3.6.2) RStudio (v. 1.2.5033) using the ‘factoextra’ package67 for analysis and ‘ggplot2’68 along with ‘GGally’69 for enhanced PC and biplot visualizations. All statistical tests were conducted with a statistical significance set at P ≤ 0.05.
Application development
To enable the practical use of high-performing models and enable further validation of the method on other populations, we developed a web app called CroCrania (https://crocrania.onrender.com). The app was created with Flask (v. 3.0.2), a Python web framework, for the backend, and vanilla JavaScript for the frontend. It utilizes Pandas (v. 2.2.0) for managing data from files and NumPy (v. 1.26.3) for array operations. It is hosted on Render (https://render.com/), a cloud service platform known for its simplicity and efficiency in deploying applications. Currently in its beta version, the app invites users to test its functionalities, with the potential for further improvements and features in future updates.
Results
Standard measurements
From 32 standard measurements55 included in the study, four (BPL, MAB, MAL, and NPH) were excluded due to more than 10% missing values.
Principal components analysis (PCA)
When 28 standard measurements were considered, the first two principal components (PC) explained 46.8% of the variance (Fig. 2). All the variables positively affected the first principal component, representing the general robusticity and size of the cranium and reflecting sexual dimorphism (female crania were positioned more on the left and male crania more on the right side of the plot). When considering the distribution of individuals according to the region, crania from Split were positioned more to the right than Zagreb crania, so Split female crania overlapped more with male crania, and Zagreb male crania more overlapped with female crania. The most influential variables on PC1 were breadth measurements (UFBR, EKB, ZYB, and AUB), length measurements (NOL and GOL), and nasal height measurements. PC2 showed fewer regularities, represented mainly by the degree of variation in Split and Zagreb samples, where Split crania had remarkably wider distribution along the y-axis.

PCA plot of standard cranial measurements: distribution according to sex and region (a); biplot showing variable contributions (b).
Conversely, Zagreb crania had a more homogeneous distribution and were more concentrated in the upper part of the plot. PC2 was positively affected by orbital height and breadth measurements (XCB, ZOB, WFB, EKB), meaning those dimensions increased along the y-axis and had, on average, greater values in Zagreb samples. In contrast, cranial length measurements (GOL, NOL, PAC, OCC, and FRC) and cranial height measurements (BBH and BNL) had negative factor loadings and, on average, greater values in Split crania. All values of PC loadings are available in Supplementary sheets 1.
Sexual dimorphism and inter-regional differences
All the variables (25/28), except for OBH (left and right) and ZOB, were statistically significantly greater in male crania (P < 0.05). In male samples, 12/28 measurements showed statistically significant regional differences. Most of those measurements were greater in Split crania, particularly DKB, MDH, and length measurements (like NOL, GOL, FRC, and OCC). Zagreb male crania had greater dimension of XCB, FOB, ZOB, and OBB. Female samples had ten measurements with regionally significant differences (P < 0.05), and seven of them were greater in Split crania. Such differences were exhibited in length measurements (GOL, NOL, FRC, and PAC), height measurements (BNL and BBH), and DKB. Like in male samples, XCB, FOB, and ZOB also had greater values in Zagreb crania. So, when considering the overall differences, 50% of measurements showed inter-regional differences (Supplementary sheets 1).
Classification models
The models (LR, LDA, and SVM) that used all the standard measurements (regardless of regional differences) had accuracies of 0.85–0.89 (CV) and 0.85–0.90 (test set), and after hyperparameter tuning, 0.89–0.90 (CV) and 0.86–0.90 (test set). When relevant features for each classification algorithm were selected using RFE in conduction with optimal hyperparameters, models’ accuracies increased to 0.90–0.91 in CV and 0.91–0.93 in the test set. Among the three best-performing models, the SVM model (with acc = 0.91) had the most stable performance as all the parameters were at least 0.90, regardless of sex and region stratifications (Table 2). The provided SHAP plot (Fig. 3) displays the impact of the measurements on the SVM model’s output. The color represents the variable’s value; red represents high, and blue represents low. The position on the right side of the x-axis suggests that the measurement pushes the model towards predicting males and points to the left towards predicting females, while the spread of the variable along the x-axis shows the degree of the impact.

SHAP values for SVM model with standard measurements.
In the next step, only 14 measurements that showed no significant interregional differences. The initial accuracies ranged from 0.80 to 0.87 for CV and 0.88–0.93 for the test set, and upon hyperparameter tuning, the accuracies ranged from 0.86 to 0.87 for CV and 0.89–0.91 for the test set. After selecting relevant features and hyperparameter tuning, accuracies were 0.87–0.88 for CV and 0.86–0.90 for the test set. Among those models, the best-performing model was LR, which had only three features. For CV, all performance parameters reached 0.87 and on the test set, the parameters reached 0.90 regardless of sex and regional specificities. Models’ performances in all steps and the selected variables are presented in an interactive Excel table (Supplementary sheets 2).
All interlandmark distances
From 47 cranial landmarks, we calculated 1081 interlandmark distances. We excluded 135 variables with more than 10% missing data, and 946 remained in the dataset.
Principal component analysis
The first two principal components (Fig. 4) explained 54.3% of the variance. The plot shows some degree of overlap between groups (Split male crania – M_ST, Split female crania – F_ST, Zagreb male crania – M_ZG, and Zagreb female crania – F_ZG), including grouping crania from the same town (male and female), as well as crania of same-sex. Males (M_ST and M_ZG) were positioned more right on the plot (higher values on PC1). However, M_ST showed smaller overlaps with female crania, and F_ST, despite comprising almost the same area as F_ZG, tended to be closer to the male individuals. Most variables positively contributed to PC1, which could suggest greater dimensions in males. The varaibles that contributed the most were distances between the asterion and upper facial region, implying a wider and more robust cranial base, larger posterior cranial fossa, and larger posterior part of the skull. PC2 was mainly affected by orbital and upper facial region measurements that increased along the y-axis, demonstrating different types of variation, probably shape rather than size. They reflected more differences in the vertical plane, such as the height of certain features (like orbits and zygomatic arches). Although that component did not clearly separate individuals according to the region and sex, crania from Split had a greater variation on y-axis (particularly male ones) and were positioned lower than Zagreb individuals. In contrast, crania from Zagreb were more concentrated on the upper part of the plot. These findings are consistent with the analysis of standard measurements. All values of PC loadings are available in Supplementary sheets 1.

PCA plot according to sex and region (a); Biplot showing variables with greatest contribution (b).
Sexual dimorphism and inter-regional differences
A total of 915/946 (96.7%) interlandmark distances in the training set (Supplementary sheets 1) demonstrated statistically significant sexual dimorphism (P < 0.05). Most of those variables were greater in male crania, except for the distances between the right dacryon and right superior orbital margin; glabella and nasion; and left radiculare and left porion. When regional specificities were considered, 609 (64.4%) variables exhibited differences between ST and ZG males, and 443 (46.8%) variables demonstrated differences between ST and ZG females (P < 0.05). Only 208, 22% of variables, did not show differences between ST and ZG crania. Most interlandmark distances were greater in Split (90.5% for male and 71.8% for female crania). Zagreb crania showed greater breadth dimensions reflected in the greater breadth of the cranium, facial region, and nose.
Classification models
When all 946 interlandmark distances were considered (regardless of regional differences), the sex classification accuracy of LR, LDA, and SVM models was 0.84–0.89 for CV and 0.86–0.91 for the test set. After hyperparameter tuning, models reached accuracies 0.88–0.92 for CV and 0.84–0.93 for the test set.
When features with no statistically significant regional differences were used (nfeatures = 208), accuracies ranged from 0.73 to 0.87 for CV and 0.84–0.93 for the test set, and after hyperparameter tuning, 0.73–0.90 for CV and 0.84–0.95 for the test set. The best-performing model at that step was the LR model shown in Table 3. Lastly, upon selecting features using RFE and hyperparameter tuning, accuracies ranged from 0.86 to 0.93 for CV and 0.89–0.95 for the test set. The best-performing model was LDA, with 23 variables (Table 3).
In the last step, from a total of 946 interlandmark distances, we selected 232 features in correlation with sex that were not highly correlated with each other. Such an approach initially provided an accuracy with a range of 0.72–0.90 for CV and 0.80–0.91 for the test set, and after hyperparameter tuning, 0.72–0.91 for CV and 0.83–0.94 for the test set. Finally, after selecting features with RFE and hyperparameter tuning accuracy, the range was 0.89–0.94 (CV) and 0.84–0.96 (test set). According to all performance parameters, the best model was the LDA model, which employed 99 features (Table 3).
The three best models (Table 3) reached accuracies on the test set greater than 0.95, but the first two models also had all the parameters considered 0.95 or greater. When considering classification results according to the region, only the first LDA model achieved > 0.95 accuracy for Split and Zagreb crania. It performed consistently across all combinations, except for a slight decrease in performance when classifying Split females. Models’ performances in all steps and the selected variables are presented in an interactive Excel table (Supplementary sheets 2).
SHAP explanatory model for LDA with excluded correlated variables (Fig. 5) shows the contribution of the top 20 variables.

SHAP values for the LDA model with 99 interlandmark distances (top 20 variables selected).
Discussion
The present study showed that ML classification models based on the extended set of cranial measurements in the modern Croatian population could estimate the sex of the unknown skull with 95% accuracy. Those measurements can be easily obtained and do not require additional landmarking out of those included in standard cranial measurements55. Using this approach, calculating all possible combinations of interlandmark distances, while carefully selecting relevant variables and classification models in the ML framework, we increased accuracy compared to the standard approach. Furthermore, in contrast to most ML-based studies that do not include direct model application48,70,71, we provided a web app that can be used to apply high-performing models directly to forensic practice and enable further validation studies.
When considering standard measurements and employing traditional classification models (LR and LDA) without any adjustment, we obtained accuracies of 0.86 and 0.88. This aligns with previous studies where even complete cranium was not a good sex indicator, with accuracies ranging from 82–91%38,44,72. However, when including more classification models, applying hyperparameter tuning, using RFE to select relevant features, and excluding some variables with regional specificities, we could increase the accuracy up to 0.93 with the SVM model, and we constructed one trivariate LR model with accuracy of 0.90 that could be employed even on incomplete crania. This accuracy level outperformed studies that constructed the models in the traditional way43,47,73,74,75, and it is comparable to the studies that used a more advanced ML approach where accuracies, without raising decision thresholds (and excluding part of the individuals), ranged from 88–90%49,70,71.
The second approach, which used 946 interlandmark distances, did not require more time for data acquisition. This is because non-standard measurements were automatically derived as interlandmark distances from the same landmarks used to create the standard measurements. At first, accuracy using all the variables was higher, but did not exceed 0.93, even after hyperparameter tuning. When we excluded region-specific variables or highly correlated variables and applied RFE to select relevant variables, we obtained two models (one LR and one LDA) for which all classification performance indicators were at least 0.95, which was previously only possible when raising posterior probability thresholds and considering part of the specimens as unidentified70. The only studies that used more inter-landmark distances (nfeatures= 1081) were those of Toneva et al. conducted on the modern Bulgarian population48,71. However, these studies included some non-standard landmarks54,55, which limited the practical use. The first study that employed rule-based classification algorithms (JRIP, Ridor, and J48) along with feature selection techniques (BestFirst and GeneticSearch) achieved a maximum accuracy of 0.9271. The second study on a similar dataset structure employed LR, ANN, and LR over the differently selected features and provided accuracies greater than 0.9548. However, in contrast to our study, the results remained on the prototype level; they were not validated on the independent test sample and were not provided within the infrastructure that would enable practical model implementation or further validations.
When considering state-of-the-art anthropological studies that use the most advanced methods such as deep learning and image analysis, it is evident that they outperform described methods based on traditional landmarking and linear measurements. A study that employed artificial neural networks on the calvarial curvature derived from CT scans reached a sexing accuracy up to 87%25. Kondu et al. achieved an accuracy of 93% when using 3D skull images50 and Bewes et al. 95% when using 2D lateral images56 but did not provide possibilities for application and validation. Various skeletal elements have been analyzed with deep learning algorithms, yielding high accuracy rates: knee radiographs achieved 90.3%19, lumbar vertebra peripheral quantitative computed tomography (pQCT) slices reached 86.4%23, and humerus photographs achieved 91.03% accuracy24. Impressive results were presented in a study that examined 2D images from 3D CT reconstructions, where only one skeletal element (ventral pubis) reached an accuracy of 100%, while the others, such as dorsal pubis and greater sciatic notch, were above 90%26. Although these approaches gave forensically relevant results, similar to our study, the disadvantage, compared to our research, could be their complexity and harder interpretability.
One of the important findings in our study was the importance of variable selection and application of field-specific knowledge. It is reflected in a correlation of cranial dimensions as well as the cognizance of regional differences demonstrated in previous studies39,57,76 in a relatively small and closed population of Croatia. It helped us remove region-specific features that could negatively affect the classification performances and reduce the number of features, enabling the use of advanced methods to select features and maximize accuracy. Our study used RFE to identify the best variables, considering all the feature numbers and combinations within different classification models and hyperparameters used to maximize the accuracy. This allowed us to identify the best classification models, maximize accuracy up to 0.96, and reduce the impact of non-homogenous variables that could not be captured in the previous steps. This could be especially important for the cranium, which, in contrast to most of the postcranial skeleton, has more complex structures that are also more sensitive to population differences77. Therefore, we recommend testing this approach when developing non-population-specific anthropological standards on samples of different backgrounds to increase the accuracy and minimize the impact of population differences.
It is important to highlight that we did not apply statistical model comparison considering AUC, ROC, or similar metrics as they were not relevant in our case, especially as we obtained models that have less than 5% error; instead, we used PPV and NPV. They were chosen for final model selections because they directly reflect the probability of correct classification decisions in practical forensic scenarios. PPV indicates the likelihood that individuals classified into a specific category (e.g., male or female) are correctly identified. NPV provides insight into the accuracy of excluding individuals from a specific category, ensuring that the model reliably identifies when subjects do not belong to a particular group. Given the critical nature of forensic work, where the cost of misclassification extends beyond statistical inaccuracies to real-world implications78, these metrics offer a more relevant and practical assessment of model performance than traditional metrics like AUC and ROC in our study’s context. The choice of the best model for sex estimation was not focused on the statistical superiority of one model over another but on finding a model that offers high accuracy, interpretability, and practical applicability for end users. Our results might imply that when dealing with linear measurements, selecting more complex models is as important as feature selection and hyperparameter tuning, which is rarely done in forensic anthropological studies.
This study was performed on a Croatian population sample, so the results may not be generalizable to other populations. To overcome this limitation, we provided a web application that enables validation of our model on different populations. This application can also overcome model complexity for practical applications since users can directly upload files with landmarks.
Although this study does not aim to prove that certain classification models are optimal for bone measurement analysis, we wanted to demonstrate how forensic anthropology could benefit when combining ML and field knowledge and how ML can provide proof of concepts, theoretical modes, and practical implications. In that sense, with available technologies and tools based on LLM and artificial intelligence, it may no longer be justifiable to apply basic classification models without adjustments. Additionally, it may be overly simplistic to generalize that particular skeletal measurements perform better or worse in classifying sex.
Conclusions
This study suggests that machine learning models based on extended cranial measurements in Croatian population can estimate sex with high accuracy, reaching up to 95%. By combining cranial measurements with an ML framework that carefully selects relevant variables, this approach advances traditional forensic anthropology methods, achieving greater precision and applicability in practical forensic scenarios. Additionally, the web application developed, CroCrania, provides an accessible platform for applying these models in forensic practice and for validating their effectiveness across different populations. Our findings emphasize the value of integrating field-specific knowledge with machine learning for enhanced anthropological assessments, underscoring the importance of variable selection, population-specific features, and the potential for broader application in global forensic contexts.
Data availability
Dataset with all interlandmark distances is available in the supplementary material under the name Supplementary data. The Colab Notebook links are vailable here: https://colab.research.google.com/drive/1eavn-cCVFZzqGWYA69Y5Emhf5BW2oFmt?usp=sharinghttps://colab.research.google.com/drive/1lc4CdIpLs-Xw7KUOcfGjRbeD-ydp7d7x?usp=sharinghttps://colab.research.google.com/drive/1WMG818PQK9jWwWhZD9oBUeAOoDoFt4KY?usp=sharing.
References
Dirkmaat, D. C., Cabo, L. L., Ousley, S. D. & Symes, S. A. New perspectives in forensic anthropology. Am. J. Phys. Anthropol. 137, 33–52 (2008).
de Boer, H. H., Blau, S., Delabarde, T. & Hackman, L. The role of forensic anthropology in disaster victim identification (DVI): recent developments and future prospects. Forensic Sci. Res. 4, 303–315 (2019).
INTERPOL. Disaster Victim Identification Guide: Version 2023 (INTERPOL DVI Unit, 2023).
Primorac, D. et al. Analiza DNA u sudskoj medicini i pravosuđu (Medicinska naklada, 2008).
Santoro, V., De Donno, A., Marrone, M., Campobasso, C. P. & Introna, F. Forensic age estimation of living individuals: a retrospective analysis. Forensic Sci. Int. 193, 129.e1–129.e4 (2009).
Nuzzolese, E. & Di Vella, G. Forensic dental investigations and age assessment of asylum seekers. Int. Dent. J. 58, 122–126 (2008).
Focardi, M., Pinchi, V., De Luca, F. & Norelli, G. A. Age estimation for forensic purposes in Italy: ethical issues. Int. J. Legal Med. 128, 515–522 (2014).
Schmeling, A., Garamendi, P. M., Prieto, J. L. & Landa, M. I. Forensic age estimation in unaccompanied minors and young living adults. In Forensic Medicine – From Old Problems to New Challenges (ed. Vieira, D. N.) Ch. 5, 78–90 (IntechOpen, 2011).
Warrier, V. et al. Machine learning and regression analysis for age estimation from the iliac crest based on computed tomographic explorations in an Indian population. Med. Sci. Law 64, 204–216 (2024).
Iscan, M. Y. & Steyn, M. The Human Skeleton in Forensic Medicine (Charles C Thomas, 2013).
Jerković, I. et al. Anthropological analysis of the Second World War skeletal remains from three karst sinkholes located in southern Croatia. J. Forensic Leg. Med. 44, 63–67 (2016).
Husmann, P. R. & Samson, D. R. Forensic Science, Medicine and Pathology. J. Forensic Sci. 56, 1424–1429 (2011).
Galić, I. et al. Accuracy of scoring of the epiphyses at the knee joint (SKJ) for assessing legal adult age of 18 years. Int. J. Legal Med. 130, 1129–1142 (2016).
Cameriere, R., Ferrante, L., Liversidge, H. M., Prieto, J. L. & Brkic, H. Accuracy of age estimation in children using radiograph of developing teeth. Forensic Sci. Int. 176, 173–177 (2008).
Konrad, R. A., Trapp, A. C., Palmbach, T. M. & Blom, J. S. Overcoming human trafficking via operations research and analytics: opportunities for methods, models, and applications. Eur. J. Oper. Res. 259, 733–745 (2017).
Cattaneo, C. et al. Can facial proportions taken from images be of use for ageing in cases of suspected child pornography? A pilot study. Int. J. Legal Med. 126, 139–144 (2012).
de Boer, H. H. et al. Strengthening the role of forensic anthropology in personal identification: position statement by the Board of the Forensic Anthropology Society of Europe (FASE). Forensic Sci. Int. 315, 110456 (2020).
Schmeling, A., Dettmeyer, R., Rudolf, E., Vieth, V. & Geserick, G. Forensic age estimation: methods, certainty, and the law. Dtsch. Arztebl Int. 113, 44–50 (2016).
Oura, P. et al. Deep learning in sex estimation from knee radiographs–A proof-of-concept study utilizing the Terry Anatomical Collection. Leg. Med. 61, 101049 (2023).
Ortega, R. F., Irurita, J., Campo, E. J. E. & Mesejo, P. Analysis of the performance of machine learning and deep learning methods for sex estimation of infant individuals from the analysis of 2D images of the ilium. Int. J. Legal Med. 135, 2659–2666 (2021).
Afrianty, I., Nasien, D., Kadir, M. R. A. & Haron, H. Determination of gender from Pelvic Bones and Patella in Forensic Anthropology: a comparison of classification techniques. FIRST Int. Conf. Artif. Intell. Modell. Simul. (AIMS 2013). 3, 3–7 (2013).
Darmawan, M. F., Hasan, H., Sadimon, S., Yusuf, S. M. & Haron, H. A hybrid Artificial Intelligent System for Age Estimation based on length of Left Hand Bone. Adv. Sci. Lett. 24, 1047–1051 (2018).
Oura, P., Korpinen, N., Machnicki, A. L. & Junno, J. A. Deep learning in sex estimation from a peripheral quantitative computed tomography scan of the fourth lumbar vertebra-a proof-of-concept study. Forensic Sci. Med. Pathol. 19, 534–540 (2023).
Venema, J., Peula, D., Irurita, J. & Mesejo, P. Employing deep learning for sex estimation of adult individuals using 2D images of the humerus. Neural Comput. Appl. 35, 5987–5998 (2023).
Cavalli, F., Lusnig, L. & Trentin, E. Use of pattern recognition and neural networks for non-metric sex diagnosis from lateral shape of calvarium: an innovative model for computer-aided diagnosis in forensic and physical anthropology. Int. J. Legal Med. 131, 823–833 (2017).
Cao, Y. J. et al. Use of deep learning in forensic sex estimation of virtual pelvic models from the Han population. Forensic Sci. Res. 7, 540–549 (2022).
Gámez-Granados, J. C. et al. Automating the decision making process of Todd’s age estimation method from the pubic symphysis with explainable machine learning. Inf. Sci. (Ny). 612, 514–535 (2022).
Thurzo, A. et al. Use of Advanced Artificial Intelligence in Forensic Medicine, Forensic Anthropology and Clinical Anatomy. Healthcare 9, 1545 (2021).
Valsecchi, A. et al. Skeleton-ID: AI-driven human identification. Proc. – 2023 IEEE Conf. Artif. Intell. CAI 2023. 278, 279. https://doi.org/10.1109/CAI54212.2023.00124 (2023).
Thurzo, A. et al. Human Remains Identification Using Micro-CT, Chemometric and AI Methods in Forensic Experimental Reconstruction of Dental Patterns after Concentrated Sulphuric Acid Significant Impact. Molecules 27, 4035, (2022).
Kyllonen, K. M., Monson, K. L. & Smith, M. A. Postmortem and Antemortem Forensic Assessment of Pediatric Fracture Healing from Radiographs and Machine Learning Classification. Biology 11, 749 (2022).
Hachem, M. & Sharma, B. K. Artificial Intelligence in Prediction of PostMortem Interval (PMI) Through Blood Biomarkers in Forensic Examination-A Concept. Proceedings of the 2019 Amity International Conference on Artificial Intelligence (AICAI) 255–258 (2019).
Gomez-Trenado, G., Mesejo, P. & Cordon, O. Cascade of convolutional models for few-shot automatic cephalometric landmarks localization. Eng. Appl. Artif. Intell. 123, 106391 (2023).
Adel, R., Ahmed, H. M., Hassan, O. A. & Abdelgawad, E. A. Assessment of craniometric sexual dimorphism using Multidetector Computed Tomographic Imaging in a sample of Egyptian Population. Am. J. Forensic Med. Pathol. 40, 19–26 (2019).
Attia, A., Ghoneim, M. & Elkhamary, S. M. Sex discrimination from Orbital aperture by using computed tomography: sample of Egyptian population. Mansoura J. Forensic Med. Clin. Toxicol. 27, 1–12 (2019).
Walker, P. L. Sexing skulls using discriminant function analysis of visually assessed traits. Am. J. Phys. Anthropol. 136, 39–50 (2008).
Zaafrane, M. et al. Sex determination of a Tunisian population by CT scan analysis of the skull. Int. J. Legal Med. 132, 853–862 (2018).
Bašić, Ž. Određivanje antropoloških mjera i njihovih odnosa važnih za utvrđivanje spola na kosturnim ostacima srednjovjekovne populacije istočne obale Jadrana. PhD Thesis, University of Split (2015).
Bašić, Ž. et al. Cultural inter-population differences do not reflect biological distances: an example of interdisciplinary analysis of populations from Eastern Adriatic coast. Croat Med. J. 56, 230–238 (2015).
Bedalov, A. et al. Sex estimation of the sternum by automatic image processing of multi-slice computed tomography images in a Croatian population sample: a retrospective study. Croat Med. J. 60, 237–245 (2019).
Bidmos, M. A., Gibbon, V. E. & Štrkalj, G. Recent advances in sex identification of human skeletal remains in South Africa. S Afr. J. Sci. 106, 1–6 (2010).
Bubalo, P., Baković, M., Tkalčić, M., Petrovečki, V. & Mayer, D. Acetabular osteometric standards for sex estimation in contemporary Croatian population. Croat Med. J. 60, 221–226 (2019).
Ekizoglu, O. et al. Assessment of sex in a modern Turkish population using cranial anthropometric parameters. Leg. Med. 21, 45–52 (2016).
Spradley, M. K. & Jantz, R. L. Sex estimation in Forensic Anthropology: Skull Versus Postcranial Elements. J. Forensic Sci. 56, 289–296 (2011).
Ogawa, Y., Imaizumi, K., Miyasaka, S. & Yoshino, M. Discriminant functions for sex estimation of modern Japanese skulls. J. Forensic Leg. Med. 20, 234–238 (2013).
Dayal, M. R., Spocter, M. A. & Bidmos, M. A. An assessment of sex using the skull of black South Africans by discriminant function analysis. HOMO 59, 209–221 (2008).
Marinescu, M., Panaitescu, V., Rosu, M., Maru, N. & Punga, A. Sexual dimorphism of crania in a Romanian population: discriminant function analysis approach for sex estimation. Rom J. Leg. Med. 22, 21–26 (2014).
Toneva, D. et al. Machine learning approaches for sex estimation using cranial measurements. Int. J. Legal Med. 135, 951–966 (2021).
Toy, S. et al. A study on sex estimation by using machine learning algorithms with parameters obtained from computerized tomography images of the cranium. Sci. Rep. 12, 4278 (2022).
Kondou, H. et al. Artificial intelligence-based forensic sex determination of east Asian cadavers from skull morphology. Sci. Rep. 13, 1–12 (2023).
Cadenas, A. M. et al. Male amelogenin dropouts: phylogenetic context, origins and implications. Forensic Sci. Int. 166, 155–163 (2007).
Ma, Y. et al. Y chromosome interstitial deletion induced Y-STR allele dropout in AMELY-negative individuals. Int. J. Legal Med. 126, 713–724 (2012).
Dash, H. R., Rawat, N. & Das, S. Alternatives to amelogenin markers for sex determination in humans and their forensic relevance. Mol. Biol. Rep. 47, 2347–2360 (2020).
Jerković, I. et al. The repeatability of standard cranial measurements on dry bones and MSCT images. J. Forensic Sci. 67, 1938–1947 (2022).
Langley, N. R., Jantz, L. M., Ousley, S. D., Jantz, R. L. & Milner, G. Data Collection Procedures for Forensic Skeletal Material 2.0. (University of Tennessee, 2016).
Bewes, J., Low, A., Morphett, A., Pate, F. D. & Henneberg, M. Artificial intelligence for sex determination of skeletal remains: application of a deep learning artificial neural network to human skulls. J. Forensic Leg. Med. 62, 40–43 (2019).
Krešić, E. et al. Sex estimation using orbital measurements in the Croatian population. Forensic Sci. Med. Pathol. 19, 303–309 (2023).
Obertová, Z., Stewart, A. & Cattaneo, C. Statistics and Probability in Forensic Anthropology (Academic Press, 2020).
Cortes, C. & Vapnik, V. Support-vector networks. Mach. Learn. 20, 273–297 (1995).
Breiman, L. Random forests. Mach. Learn. 45, 5–32 (2001).
Friedman, J. H. Greedy function approximation: a gradient boosting machine. Ann. Stat. 29, 1189–1232 (2001).
Cover, T. & Hart, P. Nearest neighbor pattern classification. IEEE Trans. Inf. Theory. 13, 21–27 (1967).
Mitchell, R., Frank, E. & Holmes, G. GPUTreeShap: massively parallel exact calculation of SHAP scores for tree ensembles. PeerJ Comput. Sci. 8, e880 (2022).
Lundberg, S. M. & Lee, S. I. A unified approach to interpreting model predictions. Conference on Neural Information Processing Systems (NIPS) 30, (2017).
Lundberg, S. M. et al. Explainable machine-learning predictions for the prevention of hypoxaemia during surgery. Nat. Biomed. Eng. 2, 749–760 (2018).
Lundberg, S. M. et al. From local explanations to global understanding with explainable AI for trees. Nat. Mach. Intell. 2, 56–67 (2020).
Kassambara, A. & Mundt, F. Factoextra: extract and visualize the results of multivariate data analyses, R package version 1.0. 7. (2021).
Wickham, H. Ggplot2: Elegant Graphics for Data Analysis. Springer-Verlag, New York (2016).
Schloerke, B. et al. Extension to ‘ggplot2’. R package version 2.2.0. (2023).
Santos, F., Guyomarc’h, P. & Bruzek, J. Statistical sex determination from craniometrics: comparison of linear discriminant analysis, logistic regression, and support vector machines. Forensic Sci. Int. 245, 204.e1–204.e8 (2014).
Toneva, D. H. et al. Data mining for sex estimation based on cranial measurements. Forensic Sci. Int. 315, 110441 (2020).
Bašić, Ž., Kružić, I., Jerković, I., Anđelinović, D. & Anđelinović, Š. Sex estimation standards for medieval and contemporary Croats. Croat Med. J. 58, 222–230 (2017).
Franklin, D., Cardini, A., Flavel, A. & Kuliukas, A. Estimation of sex from cranial measurements in a western Australian population. Forensic Sci. Int. 229, 158e1–158e8 (2013).
Ramamoorthy, B., Pai, M. M., Prabhu, L. V., Muralimanju, B. V. & Rai, R. Assessment of craniometric traits in south Indian dry skulls for sex determination. J. Forensic Leg. Med. 37, 8–14 (2016).
Cunha, E. & Van Vark, G. N. The construction of sex discriminant functions from a large collection of skulls of known sex. Int. J. Anthropol. 6, 53–66 (1991).
Bareša, T. et al. Walker’s traits for sex estimation in modern Croatian population using MSCT virtual cranial database: validation and development of population-specific standards. Forensic Imaging 36, 200578 (2024).
DiGangi, E. A. & Moore, M. K. Research Methods in Human Skeletal Biology (Academic Press, 2012).
West, E. & Meterko, V. Innocence project: DNA exonerations, 1989–2014: review of data and findings from the first 25 years. Alb L Rev. 79, 717–795 (2015).
Acknowledgements
The authors would like to thank Rachel Theresa Cundey for valuable comments regarding language and style.
Funding
This work was supported by the Croatian Science Foundation, Installation Research Project under grant HRZZ-UIP2020-02-7331 - Forensic identification of human remains using MSCT image analysis (CTforID).
Author information
Authors and Affiliations
Contributions
All authors conceived and designed the study; EK acquired the data; IJ & ŽB developed models, NJ developed the web application, all authors analyzed and interpreted the data; IJ & ŽB drafted the manuscript; all authors critically revised the manuscript for important intellectual content; all authors approved the version to be submitted; all authors agree to be accountable for all aspects of the work.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Ethical considerations
All experimental protocols were approved by the ethical committees of the University Hospital Centre Zagreb (Class: 8.1–21/216-3; Number: 02/21 AG.), University Hospital Centre Split (Class: 500-03/17 − 01/56; Number: 2181-147-01/06/M.S.−17-2), and University Department of Forensic Sciences (Class: 024 − 04/17 − 03/00026; Number: 2181-227-05- 12–17-0003) and all methods were carried out in accordance with the Declaration of Helsinki. Informed consent was not explicitly waived or required, as initial access to identifiable information for participant selection was conducted by research team members employed at the respective hospitals, and all data were subsequently anonymized for analysis, adhering to ethical guidelines.
Declaration of generative AI and AI-assisted technologies in the writing process
During the preparation of this paper, the authors utilized ChatGPT Data Analysis for guidance during the process of construction of ML models and development of code. Afterward, the authors reviewed and edited the content and are fully accountable for the publication’s content.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Jerković, I., Bašić, Ž., Krešić, E. et al. Developing a fully applicable machine learning (ML) based sex classification model using linear cranial dimensions. Sci Rep 14, 30969 (2024). https://doi.org/10.1038/s41598-024-82073-8
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-024-82073-8
