
Abstract
The main challenges faced when detecting targets captured by UAVs include small target image size, dense target distribution, and uneven category distribution.In addition, the hardware limitations of UAVs impose constraints on the size and complexity of the model, which may lead to poor detection accuracy of the model. In order to solve these problems, a small target detection method based on the improved YOLOv8 algorithm for UAV viewpoint is proposed. The following improvements are made to the YOLOv8n model. Firstly, a bi-directional feature pyramid network (BiFPN) is introduced to enhance the fusion capability of the features. This improvement leads to better detection of small targets. Secondly, in the head part of the model, the original C2f module is replaced with the C3Ghost module. This change maintains the model’s performance while significantly reducing the computational load. Lastly, the detection head adds a channel attention mechanism. This mechanism helps in filtering out unimportant information and enhancing the recognition of key features. The MPDIoU (Minimum Point Distance based IoU) loss function is improved, and the idea of inner-IoU loss function is adopted as a way to improve the model’s learning ability for difficult samples. Experimental results on the VisDrone dataset show that the YOLOv8n model with these improvements improves 17.2%, 10.5%, and 16.2% in mean accuracy (mAP), precision (P), and recall (R), respectively, and these improvements significantly improve the performance of small target detection from the UAV viewpoint.
Similar content being viewed by others
Introduction
UAV technology was initially introduced into the military field, and with the advancement of technology, its application areas have been expanded to many aspects of daily life. As a result, the technology of target detection using images captured by UAVs has been enhanced and developed accordingly. This technology plays an important role in many fields such as rescue operations, agricultural monitoring, and high-altitude operations. When performing target detection, UAVs usually look down from a high altitude, which results in targets often appearing small and unclear, while also facing a huge change in perspective. Vehicle detection from the perspective of drones1 has also become an important challenge, and many researchers use deep convolutional neural networks for detection.In addition, the hardware limitations of the UAV have an impact on the model size and performance, which may reduce the accuracy of the detection. Currently, deep learning-driven target detection algorithms have evolved along two main paths; these paths are single-stage detection models and two-stage detection models. Among them, Centernet2, SSD series3, RetinaNet4, and YOLO series5,6,7 belong to the single-stage, and the two-stage algorithms include R-CNN8, Fast R-CNN, and Faster R-CNN9. Although RCNN has achieved significant improvement in detection accuracy, it faces the challenge of slow detection speed. To overcome this limitation of RCNN, Kaiming He et al.10 introduced an improved model based on Spatial Pyramid Pooling (SPP), i.e., SPPNet. SPPNNet significantly improves the detection speed, which is about 20 times that of RCNN, while maintaining the same detection accuracy as RCNN. Nevertheless, Fast RCNN9 still faces the computational burden imposed by the region proposal stage. To solve the above problems, Ren et al.11 developed the Faster RCNN8 algorithm.
Currently, the YOLO series models with excellent performance have been widely used in various inspection tasks. When target detection is performed under the UAV perspective, how to maintain the lightweight of the model while ensuring the detection accuracy has become a challenge for current research. Weibiao Chen12 and others successfully reduced the parameters and volume of the model by implementing a depth-separable multi-head network architecture based on YOLOv5. Meanwhile, Fan-Kai Chen et al.13 introduced an upsampling operator called CARAFE (content-aware reassembly of features), which enhances the fusion between high-resolution and low-resolution feature maps, thus improving the detection performance of small targets. Liu Tao14 and other researchers have reclustered the anchor frames for the dense distribution of image targets in the UAV view and designed the SEC2f module with the channel attention mechanism to achieve more accurate target detection.Li et al.15 adopted the idea of Bi-PAN-FPN to enhance the fusion ability of features at different scales on the basis of YOLOv8, and used the GhstblockV2 structure to replace part of the convolutional module, which significantly improves the detection accuracy. However, the model did not show superior performance over other models in all small target categories.Lou et al.16 introduced an innovative downsampling technique and improved the feature fusion network of YOLOv8 to enhance its detection ability for dense small targets, nevertheless, the overall performance improvement was not significant.Guo et al.17, on the other hand, proposed a dense connection mechanism and designed a new network structure module C3D to replace the C2f module in YOLOv8 to retain information more comprehensively, but this improvement also led to an increase in computational cost. For small target detection in UAV images, Wang et al.18 incorporated STC (small target detection structure) into the Neck module of YOLOv8 to enhance the capture of global and contextual information. A global attention GAM mechanism was also employed to minimize the loss of information during feature sampling, which resulted in performance improvement but also increased the parameter size of the model. In another work, Wang et al.19 optimized the backbone network using the BiFormer attention mechanism and designed the FFNB (Focal FasterNet block) feature processing module, which introduced two new detection scales to achieve multiscale detection and effectively reduce the missed detection. Nevertheless, there is still room for improvement in the detection accuracy of tiny targets such as bicycles. Although previous techniques have made some progress in improving the efficiency of UAV target detection, it is still a challenge to achieve an optimal balance between detection performance and hardware resource consumption, considering the complexity and uniqueness of the UAV view image dataset, as well as the performance limitations of the UAV hardware. In this study, we propose a small target detection method based on improved YOLOv8 algorithm for UAV viewpoint based on the YOLOv8n model, aiming to improve the accuracy of small target detection in UAV viewpoint.
Related work
YOLOv8 model
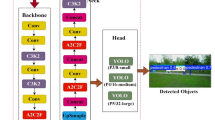
The architecture of the YOLOv8 model consists of three core components: the backbone network, the feature fusion network, and the detection head, as shown in Fig. 1. The backbone network is responsible for extracting the image features, and it consists of a series of modules including the convolutional layer (CBL), the C2f module, and the spatial pyramid pooling (SPPF) layer. Among these modules, the C2f module plays a key role, which is built to capture image features more efficiently by borrowing the ELAN structure from YOLOv7 and utilizing residual connections to extract and fuse features. The introduction of this module significantly improves the model’s performance in feature learning. In the YOLOv8 network architecture, the CBL module is responsible for performing the underlying feature extraction task, which typically includes a convolutional layer, a batch normalization layer, and an activation function. These CBL modules appear in different colors in the illustration to distinguish the different convolutional kernel sizes and step sizes they use. On the other hand, the SPPF module focuses on integrating local and global image features through a tandem max-pooling operation to enhance the model’s ability to detect targets in complex scenes. The feature fusion network employs the PAN (Path Aggregation Network) architecture, which is designed to enhance the feature integration capability of the network when dealing with targets of different sizes. Specifically, the PAN architecture enhances the model’s detection performance for targets of different scales by aggregating feature information from different paths. As for the detection head, its main responsibility is to analyze the features extracted by the network and perform logical reasoning for target classification and localization. In addition, the detection head performs the screening process of positive and negative samples and calculates the corresponding loss values to guide the training process of the model. In this way, the detection head ensures that the model is able to accurately recognize and localize targets in the image. In the YOLOv8 model, the screening of positive and negative samples employs the Task Aligned Assigner20 method, which is an innovative task alignment assignment mechanism. The introduction of this method effectively reduces the error between labeling and prediction and improves the accuracy of the model. In terms of loss calculation, two main branches are used: the classification branch and the regression branch. The classification branch uses the binary cross entropy (BCE) loss, which is a commonly used classification loss function for determining whether each category exists or not. The regression branch, on the other hand, uses Distribution Focal Loss (DFL)21 and Complete Intersection and Unionization (CIOU) loss.

YOLOv8 network architecture.
Algorithm of this paper
For the special characteristics of the low-altitude UAV dataset, including sparse target pixels, dense distribution, and category imbalance, the original YOLOv8n model is deficient in terms of detection accuracy and missed detection false detection. To cope with these challenges, the YOLOv8n model is optimized as follows: (1) Network architecture: the basic network architecture of YOLOv8n is retained, which includes four main parts: input module, backbone network (Backbone), detection head (Head) and output module. (2) Input module: the input module is adapted to the characteristics of the low-altitude UAV dataset. Regardless of the size of the original image, the input module automatically adjusts the short side of the image to 640 pixels to ensure the consistency of the input data. This can speed up the training of the model and unify the image data into the backbone network after standardized processing. In the backbone network section, several key components are included that work together to extract features from the images and perform effective data processing. Specifically, CBL module: this module is responsible for performing convolutional operations on the input image data, a process that not only extracts the features of the image, but also compresses the data to reduce the amount of computation for subsequent processing.The CBL module usually consists of a convolutional layer, a batch normalization layer, and an activation function, which work together on the input data to extract the key information that contributes to the detection of the target. C2f Module: the C2f module employs a branching cross-layer connection structure, a design that allows the model to learn richer information from features at different levels. This structure enhances the model’s ability to represent the features by connecting them across layers, which enables the model to better capture the target features in the image, thus improving the accuracy of detection.
In the Head module, in order to improve the recognition accuracy of the model without increasing the complexity of the model, this paper adopts the bidirectional feature pyramid network (BiFPN)22 to replace the original path aggregation network (PAN)23.BiFPN, on the basis of PAN, enhances the network’s detection of targets of different sizes by introducing the bidirectional fusion between feature maps of different hierarchical levels, thus effectively enhancing the model’s recognition accuracy. capability, thus effectively improving the recognition accuracy of the model. This design enables the model to better adapt to the characteristics of the low-altitude UAV dataset while maintaining lightweight, and realize effective detection of small targets.
In this paper, key improvements are made to the Head part of the YOLOv8n model. First, the original C2f module is replaced with the C3Ghost module, an improved version of the C3 module based on the GhostNet architecture, which significantly reduces the number of parameters and computational burden of the network while keeping the size of the convolutional output feature map and the number of channels unchanged. This modification not only reduces the complexity of the model, but also eases the computational burden of small target detection in the UAV view. In addition, a channel attention mechanism is introduced in the detection head. During the training process, by adjusting the weights of the channel attention module, it can effectively inhibit those feature channels that negatively affect the prediction results, so as to eliminate the irrelevant feature information, and at the same time, enhance the weights of the key features, which can improve the prediction accuracy of the model. Finally, LSKA (Large Separable Kernel Attention) is combined with SPPF (Spatial Pyramid Pooling Fusion), which is a Large Separable Kernel Attention mechanism that enhances the semantic fusion between different feature layers, thus further improving the model’s detection performance for complex scenes with detection performance of small and medium-sized targets.
BiFPN bidirectional feature pyramid structure
In the original design of the YOLOv8n model, feature extraction relies on a PAN path aggregation network, which conveys feature information via top-down and bottom-up paths, but its feature fusion is limited to two levels. In contrast, the BiFPN bidirectional feature pyramid network employs a U-Net-like top-down sampling structure, which is able to effectively fuse features into all levels of the network. This structure not only improves the performance of the model through multi-level feature fusion, but also reduces the computational effort through the up and down sampling mechanism, which improves the detection of images of different sizes.The network structure diagrams of PAN and BiFPN are shown in Fig. 2, respectively.

Two characteristic pyramids. (a) PAN structure diagram. (b) BiFPN structure diagram.
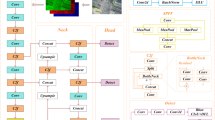
In the YOLOv8n model, the PAN path aggregation network employs a bi-directional network architecture, which realizes the flow of information from the top level to the bottom level and the feedback from the bottom level to the top level. Despite the bi-directionality of this architecture in terms of information transfer, it is relatively limited in terms of horizontal and vertical ways of information flow, mainly focusing on feature learning between neighboring nodes. In contrast, the BiFPN bidirectional feature pyramid network adopted in this paper is more flexible and comprehensive in both horizontal and vertical information flow.By introducing cross-layer connectivity, BiFPN not only realizes the information interaction of multiple paths in the horizontal path, but also facilitates the fusion of feature graphs of different layers in the vertical path. This design enables the network to capture richer and more accurate feature representations, which improves the performance of the model in the target detection task, as shown in Fig. 3.

Improved Yolov8 network structure.
C3Ghost principle
The significant advantages of the GhostNet network in simplifying the model structure are utilized. Specifically, the original C3 module was improved by replacing the traditional convolution operation with a GhostNet convolution. The purpose of this change was to significantly reduce the complexity of the model.The GhostNet network design is based on decomposing the traditional single convolution operation into two steps: first a standard convolution operation is performed, and then additional feature maps are generated by an efficient linear transformation. This design significantly reduces the computational burden and the number of parameters incurred by the network in the convolution operation, thus enabling a lightweight model. Compared to traditional convolution operations, GhostNet convolution significantly reduces the consumption of computational resources while maintaining the quantity and quality of the output feature maps. This improvement is demonstrated in a visual comparison in Fig. 4.

Two types of convolution. (a) Traditional convolution. (b) GhostNet convolution.
First, the conventional convolution operation is used to create the feature maps, and then, more feature maps are created by the basic linear transformation, and they are directly merged and stitched together, and finally, the feature maps of GhostNet are constructed based on the conventional convolution operation and the basic linear transformation. On the basis of the above operation, when the size of convolution kernel is used in the same way, the amount of computation and the number of parameters will be greatly reduced when combining the GhostNet network with the C3 module, and the new C3Ghost structure obtained is shown in Fig. 5.

C3Ghost module.
Channel attention mechanisms
The core function of the channel attention mechanism is to capture and model the interrelationships among channels in the convolutional feature map. In the application of convolutional neural networks, individual channels may have different contributions to the final output results, some may enhance the output while others may produce interference. Therefore, by assigning different weights, those unimportant features can be effectively suppressed, thus enhancing the network’s ability to recognize and process critical information. As shown in Fig. 6, the workflow of the SE module is as follows: first, it receives an input feature map with dimensions H × W × C, where H and W represent the length and width of the feature map, respectively, and C is the number of channels of the feature map. Next, the SE module performs a global average pooling operation on this input feature map to obtain a feature vector of dimension 1 × 1 × C. This vector represents the global average response of each channel in the input feature map. This 1 × 1 × C feature vector is then fed into a fully-connected layer that is responsible for learning and outputting the importance weights for each channel. Finally, through a multiplication operation, these weights are applied to each channel of the original input feature map, thus realizing an attention mechanism for the channels.

Channel attention module.
Improved SPPF module
The SPPF (Spatial Pyramid Pooling Fusion) module captures multi-scale feature information by sequentially passing the input data through three maximal pooling layers with 5 × 5 kernel sizes and then splicing the outputs of these layers. In the LSKA24 (Large Separable Kernel Attention) model, a kxk convolutional kernel is evenly split into two smaller convolutional kernels, 1xK and Kx1, which process the input features in series. This approach effectively reduces the significant increase in the number of parameters caused by the use of large convolutional kernels.
As shown in Fig. 7, the SPPF module is improved to enhance its performance by introducing the LSKA (Large Separable Kernel Attention) module. In the improved SPPF module, the results from the original SPPF module that have been pooled through multiple pooling layers and spliced together are first fed into an 11 × 11 LSKA convolutional module. This module utilizes a large separable convolutional attention mechanism to capture long-range dependencies and extract richer features by expanding the receptive field. These features are then fused through a series of common convolutional operations and the Backbone portion of the model is adjusted to output the final feature vector. This SPPF layer incorporating the LSKA attention mechanism is able to provide richer multi-scale receptive field information without significantly increasing the number of parameters, thus helping the model to perform feature fusion more efficiently.

Schematic of SPPF and SPPF-LSKA models.
Improved loss function
The goal of border regression is to make the candidate frames generated by the detector closer to the actual target bounding box by adjusting them. Since the concept of IoU (Intersection over Union) was introduced, it has become a generally accepted evaluation metric for measuring the quality of predicted frames in target detection, which is calculated as shown in Eq. (1).
With the depth of research, the IoU-based edge regression loss function has undergone continuous iteration and improvement, and many variants such as GIoU, DIoU, CIoU, EIoU, SIoU, etc. have emerged. In the YOLOv8n model, the CIoU loss function is adopted, and its specific formula is shown in Eq. (2).
where \(v=\frac{4}{\pi }(\arctan \frac{{{w^{gt}}}}{{{h^{gt}}}} - \arctan \frac{{{w^{pred}}}}{{{h^{pred}}}})\)is used to evaluate the aspect ratio of the target, and\(\alpha =\frac{v}{{(1 - IoU)+v}}\)and\(\alpha\)are used as parameters for adjusting the balance.\({\rho ^2}({B^{pred}},{B^{gt}})\)measures the Euclidean distance between the centroid of the predicted bounding box and the actual bounding box.\(CIoU\)further considers the balance between the centroid distance and the aspect ratio on the basis of\(IoU\), which significantly improves the accuracy of the detection.
Although these optimized loss functions speed up the convergence of the model by introducing additional loss terms, they do not fully recognize the limitations of \(IoU\)itself. In order to enhance the generalization ability of the model,\(inner - IoU\)25 introduces the concept of an auxiliary bounding box and achieves this through a specific computational approach as shown in Eqs. (3)–(7). This approach enhances the generalization performance of the model by adjusting the size of the auxiliary bounding box using the scale factor ratio.
Using Eqs. (3)–(5), the center point of the detection frame can be adjusted to obtain the vertex coordinates of the auxiliary detection frame. Such a transformation is performed for both the model-predicted and real detection frames, and \({b^{gt}}, {b^{pred}}\)represent the results after the calculations are performed for the real and predicted frames, respectively.
Thus, \({\text{inner-IoU}}\)actually measures the intersection and concurrency ratio (IoU) between the auxiliary bounding boxes. In the case of \(ratio \in [0.5,1.5],ratio<1\), the size of the auxiliary bounding box is smaller than the actual bounding box, which results in a regression that is less applicable than the range defined by the\({\text{IoU}}\) loss function, but whose gradient is larger in absolute value than the one obtained from the\({\text{IoU}}\)loss function, thus contributing to a fast convergence for high\({\text{IoU}}\)samples. In the case of\(ratio>1\), the size of the auxiliary bounding box is larger than the actual bounding box, which extends the range of applicability of the regression and is useful for the regression task with low\({\text{IoU}}\).
\(MPDIoU\)26 proposed an optimization algorithm which directly minimizes the Euclidean distance of the corresponding corner points between the predicted and real boxes. This algorithm can effectively deal with the case of overlapping and non-overlapping bounding boxes, thus speeding up the convergence of the model, as shown in Eq. (8).
In this framework, \(p_{1}^{{pred}},p_{1}^{{gt}}\) and \(p_{2}^{{pred}},p_{2}^{{gt}}\) represent the upper-left and lower-right coordinate points of the prediction frame and the real frame, respectively, and\({\rho ^2}(p_{1}^{{pred}},p_{1}^{{gt}})\)is used to calculate the distance between these corresponding points. By adopting the strategy of \({\text{inner-IoU}}\)to improve\(MPDIoU\), the\({\text{IoU}}\)computation part of it can be replaced, and such an improvement can significantly enhance the performance of target detection, as shown in Eq. (9).
Results of experimental design and analysis of results
Data set and experimental environment
In this paper, the VisDrone 2019 dataset27 was used for the experiments. The dataset covers 10 different aerial target categories including pedestrians, people, bicycles, cars, vans, trucks, tricycles, shade tricycles, buses, and motorcycles. The dataset is divided into training, validation and test sets containing 6471, 548 and 1610 images respectively. In the dataset, targets with pixel area less than pixels accounted for 12.05% of the total targets, while small targets with pixel area less than \(32 \times 32\) accounted for 44.7%. In the human category, the percentage of small targets is even higher at 77.45%, and this percentage is 64.59% in the pedestrian category. In the training set, there are a total of 353,550 targets, of which 142,873 targets are occluded and 33,804 targets are severely occluded, close to 50% of the targets are occluded28.
In order to evaluate the effectiveness of the proposed improvements, the SHWD (Safety helmet (hardhat) wearing detection dataset) dataset and CARPK dataset were also introduced for testing. The training and validation sets consist of 5944 images and 1637 validation images, respectively; while the CARPK dataset29 is a car detection dataset specifically for UAVs taken at a low altitude of 40 m, covering nearly 90,000 cars taken from several parking lots, and the dataset is divided into 989 training images and 459 test images.
In this experiment, NVIDIA A100-PCIE-40GB was used as the GPU gas pedal with a 6-core CPU. the version of Python framework used was 2.0.0 + cu117, and the version of Python interpreter was 3.9.0, while the version of CUDA was 11.7. the specific parameter configurations of the experimental environment are detailed in Table 1.
In this experiment, the input image size of all models is set to \(640 \times 640\). In the unified experimental environment, all models are trained with the same training parameters until 300 training cycles are completed. If the model performance does not improve within the last 50 training cycles, the early stop mechanism is activated to terminate the training process early. For the YOLO series models, the training configurations listed in Table 1 were applied on both datasets for training.
Comparison of the effect of the improved model
Comparison of experimental results for combined models
In this paper, based on the Yolov8n backbone network, we explore the combination of various algorithmic structures with the Yolov8n model in order to evaluate the impact of different combinations on model accuracy and computational efficiency. The experimental results show that both methods, slimneck and BiFPN-C3Ghost, can significantly reduce the number of parameters and computational burden of the model. slimneck algorithm employs the GSConv lightweight convolution technique, which achieves a reduction in computational effort, but the model’s detection accuracy decreases accordingly. In contrast, the BiFPN-C3Ghost method not only significantly reduces the computational load, but also achieves a slight increase in the detection accuracy of the model after optimization (as shown in Table 2).
Comparison with experimental results of other models
In this study, we conducted comparative experiments to evaluate the performance of the optimized YOLOV8 against several other mainstream models. A brief overview of the models involved in the comparison is as follows: Faster R-CNN8 reduces the original computational and structural complexity of R-CNN through optimization; R-CNN7 innovatively introduces a multilevel detection framework, which builds on R-CNN; RetinaNet4 proposes Focal loss, a new loss function ; while CenterNet2 discarded the traditional anchor frame concept and introduced an anchor frame-free detection method, and the experimental results are shown in Table 3.
Based on the results of the comparison experiments presented in Table 3, it is clear that the model proposed in this paper outperforms the other top-performing models in terms of detection performance. Compared to the single-stage algorithm, the two-stage detection algorithm, Faster R-CNN, appears to be slower in its detection speed. In addition, due to the relatively low resolution of the feature maps extracted by the backbone network of Faster R-CNN, this limits its detection accuracy for small targets to a certain extent, resulting in its poor performance in small target detection.The central concern of RetinaNet is how to accurately distinguish between positive and negative samples. CenterNet, on the other hand, can reduce the computational burden in cases where anchor points are used. However, in complex scenarios such as dense distribution of objects or small objects occluding each other, CenterNet may miss the detection of some objects due to the overlapping of predicted centroids if multiple objects are present. Cascaded R-CNN effectively improves the overall detection ability of the model by introducing a multi-layer detection architecture, but this also brings an increase in computational complexity and training difficulty. On the other hand, RetinaNet adopts a multi-scale feature fusion strategy, aiming to better cope with the detection of targets of different sizes. However, in visual tasks focusing on small object detection, both model architectures show limitations and cannot fully meet the detection requirements, as evidenced by the fact that RetinaNet is not as effective as the method proposed in this paper. Compared with other model designs in the comparison experiments, the structure designed for small object detection in this paper shows obvious advantages, and therefore, the method proposed in this paper outperforms other models in terms of detection results.
Comparison of experimental results of feature fusion methods
Comparative experiments of multiple feature fusion strategies are implemented in the architecture of Yolov8n network in its Head part. The experimental results show that BiFPN fusion strategy outperforms concat and adaptive methods in terms of accuracy and computational efficiency. Although the accuracy of the WEIGHT method is slightly higher than that of the BiFPN method in the metric of mean average precision (mAP50), reaching a slight advantage of 0.2%, its computational cost is 4.2% higher than that of the BiFPN method. Taking accuracy and computational efficiency into account, the BiFPN method outperforms other fusion techniques in terms of overall performance (see Table 4).
Comparison of experimental results of feature extraction module
Based on the Yolov8n network and BiFPN fusion technique, different feature extraction methods are tried in the Head module and their impact on model accuracy and computational efficiency is evaluated. The experimental results show that all three feature extraction methods, C3, C3Ghost, and VoVGSCS, are able to improve the accuracy of the model and reduce the computation in terms of the mean average precision (mAP50) metric. However, only the C3Ghost algorithm achieves performance improvement in the more stringent average accuracy (mAP50-95) metric. Therefore, the C3Ghost algorithm is able to effectively reduce the computational burden of the model without sacrificing accuracy (as shown in Table 5).
Ablation experiments
Based on the data analysis in Table 6, it can be observed that the Ghost network performs well in improving the accuracy of the model, while the C3 module and the BiFPN method perform well in reducing the model computation. When the C3 module is used in conjunction with the Ghost network, the model computation is reduced by 12.2% compared to the benchmark model (Yolov8n). And when the Ghost network is combined with BiFPN, the reduction in computation reaches 19.5%. If the C3 module, Ghost network and BiFPN method are used in combination, the computational amount of the model is reduced by 19.5% compared with the benchmark model, and at the same time, there is an improvement in the mAP50 metrics, and the mAP50-95 metrics are comparable to the benchmark model. Taken together, the combination of the C3 module, the Ghost network and the BiFPN method not only significantly reduces the computational effort, but also maintains the accuracy of the model. In addition, applying the channel attention mechanism to the network detection header helps to filter out unimportant channel values, which in turn aids in the improvement of the mAP metrics.
The effect of different values of the ratio parameter in the inner-MPDIoU loss function on the model performance was evaluated by ablation experiments, the results of which are shown in Table 7.
When the condition of B holds, the C loss function is practically equivalent to the D loss function. The experimental results show that for small targets prevalent in images captured by UAVs and low E due to a slight offset of the labeling frame, the setting of \(ratio>1\) makes the size of the auxiliary border larger than the actual border, which helps to improve the regression performance in the case of low F. The experimental results show that the regression performance in the case of low F is usually better than that in the case of low F. As a result, in the experimental condition of G, the performance is usually better than that of H. The experiment as a whole achieves the best results when the condition of J is satisfied. However, in the case of K, it is not the case that a larger value of L is better. Under the experimental conditions of M and N, the experimental results fluctuated, which indicates that the specific value of O needs to be optimally adjusted according to the characteristics of the experimental dataset.
Visualization of detection results
Figures 8 and 9 present a comparison of the detection performance of the original YOLOv8n model and the improved model proposed in this paper after training under the same experimental environment and parameter settings for dense and sparse targets in the UAV view, respectively. The left image shows the detection results of the original model, while the right image shows the detection results of the improved model.
In the scenarios with dense small targets, the improved model shows higher detection accuracy and is able to recognize more small targets more accurately. For example, in Scene 1, the model is able to detect pedestrians in the distance; in Scene 2 with dense small targets, the model is able to recognize electric vehicles; in Scene 3 on the road at night, the model is able to accurately detect dense electric vehicles, as well as pedestrians on the roadside in the dim light, which significantly reduces missed detections.
In the scenarios with sparse small targets, the improved model is also able to significantly reduce missed and misidentified detections. As shown in Fig. 9, in Scene I, the original model incorrectly recognizes utility poles as pedestrians, as well as incorrectly recognizes people as motorcycles. In Scene II, the original model only recognizes motorcycles, while the improved model not only recognizes motorcycles, but also correctly identifies vehicles in close proximity, as well as obscured vehicles. In Scenario III, the improved model avoids the original model’s mistake of not recognizing pedestrians on bicycles and accurately detects all pedestrians. Overall, the improved model proposed in this paper significantly improves the detection performance of YOLOv8n for small targets in the UAV view.

Comparison of the effect of dense target detection.

Comparison of sparse target detection effect.
Concluding remarks
This paper presents an optimized YOLOv8n model specifically for target detection in images captured by UAVs. The model is named YOLOv8n-BiFPN-C3Ghost, which significantly reduces the computational burden of the model by replacing the C2f module in the backbone network with the more lightweight C3Ghost module. In the Head part of the model, the BiFPN structure is used to replace the traditional FPN structure, which not only reduces the complexity of the model but also enhances its feature fusion capability. In addition, the LSKA mechanism is introduced in the SPPF layer to enhance the semantic information fusion between different feature layers. A new feature layer, which is enriched with semantic information of small targets, is also added to improve the neck structure of the model and enable it to handle small targets more efficiently. Finally, the model’s bounding box regression loss function was improved by using an optimized inner-MPD IoU to improve the model’s ability to learn from small sample data. Future work will focus on further improving the model performance and pruning and lightweighting the model to optimize its detection of dense small targets in the UAV view.The method proposed in this paper also has some limitations, although the C3Ghost module is lighter than the C2f module, reducing the computational burden, but the lightweight is usually accompanied by a certain degree of performance degradation. Therefore, the model may sacrifice some detection accuracy or robustness while pursuing lower computational complexity, and future work includes further improvement of model performance and pruning and lightweight processing.
Data availability
All data generated or analysed during this study are included in this published article, the VisDrone 2019 dataset26 was used for the experiments.
References
Shen, J. et al. An anchor-free lightweight deep convolutional network for vehicle detection in aerial images. IEEE Trans. Intell. Transp. Syst. 23 (12), 24330–24342 (2022).
Saeed, Z. et al. On-Board small-scale object detection for Unmanned Aerial vehicles(UAVs). Drones 7 (5), 310 (2023).
Hoshino, W., Seo, J. & Yamazaki, Y. A study for detecting disaster victims using multi-copter drone with a thermographic camera and image object recognition by SSD. In 2021 IEEE/ASME International Conference on Advanced Intelligent Mechartronics (AIM) 162–167 (IEEE, 2021).
Bisio, I. et al. Performance evaluation and analysis of drone-based vehicle detection techniques from deep learning perspective. IEEE Internet Things J. 9 (13), 10920–10935 (2021).
Sorbelli, F. B., Palazzetti, L. & Pinotti, C. M. YOLO-Based Detection of Halyomorpha Halys in Orchards Using RGB Cameras and Drones 213108228 (Computers and Electronics in Agriculture, 2023).
Singha, S. & Aydin, B. Automated drone detection using YOLOv4. Drones 5 (3), 95 (2021).
Li, Y. et al. GGT-YOLO: a novel object detection algorithm for drone-based maritime cruising. Drones 6 (11), 335 (2022).
Pirasteh, S. et al. Developing an algorithm for buildings extraction and determining changes from airborne LiDAR, and comparing with R-CNN method from drone images. Remote Sens. 11 (11), 1271 (2019).
Seo, D. M. et al. Identification of asbestos slates in buildings based on faster region-based convolutional neural network(faster R-CNN) and drone-based aerial Imagery. Drones 6 (8), 194 (2022).
He, K. et al. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 37(9), 1904–1916 (2015).
Ren, S. et al. Faster r-cnn: towards real-time object detection with region proposal networks. Adv. Neural. Inf. Process. Syst. 28. (2015).
Weibiao, C. H. E. N. et al. Target detection for UAV Image on DSN-YOLOv5. Comput. Eng. Appl.. 59(18), 226–233 (2023).
Fankai, C., Li, S. UAV target detection algorithm with improved Yolov5. Comput. Eng. Appl. 59(18), 218–225 (2023).
Tao, L., Ding, X., Zhang, B., et al. Improved Yolov5 for remote sensing image detection. Comput. Eng. Appl. 59(10), 253–261 (2023).
Li, Y. et al. A modified YOLOV8 detection network for UAV aerial image recognition. Drones. 7(5), 304 (2023).
Lou, H. et al. DC-YOLOV8:small-size object detection algorithm based on camera sensor. Electronics. 12(10), 2323 (2023).
Guo, J. et al. A new detection algorithm for alien intrusion on highway. 13(1), 10667 (2023).
Wang, F. et al. UAV target detection algorithm based on improved YOLOv8. IEEE Access (2023).
Wang, G. et al. UAV-YOLOv8: a small-object-detection model based on improved YOLOv8 for UAV aerial photography scenarios. Sensors 23(16), 7190 (2023).
Feng, C. J. et al. TOOD: task-aligned one-stage object detection. In 2021 IEEE/CVF International Conference on Computer Vision (ICCV). October 10–17, 2021, Montreal, QC, Canada 3490–3499 (IEEE, 2022).
Li, X. et al. Generalized focal loss:learning qualified and distributed bounding boxes for dense object detection. Adv. Neural Inform. Process. Syst. 33, 21002–21012 (2020).
Lang, B. et al. A traffic sign detection model based on coordinate attention-bidirectional feature pyramid network. J. Shenzhen Univ. (Sci. Eng.). 40 (03), 335–343 (2023).
Liu, S. et al. Path aggregation network for instance segmentation. In 2018 IEEE CVF Conference on Computer Vision and Pattern Recognition. Piscataway, USA. EE. 8759–8768 (2018).
Lau, K. W., PoL, M. & Rehman, Y. A. U. Large separable kernel attention: rethinking the large Kernel attention design in CNN. Expert Syst. Appl. 236, 121252 (2024).
Zhang, H., Xu, C. & Zhang, S. Inner-IoU: more effective intersection over Union loss with Auxiliary Bounding Box. arXiv preprint arXiv:2311.02877 (2023).
Siliang, M., Yong, X. MPDIoU: A loss for efficient and accurate bounding box regression. arXiv preprint arXiv:2307.07667 (2023).
Du, D. et al. VisDrone-DET2019: The vision meets drone object detection in image challenge results. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops (2019).
Zhang, Z. & Huahui, Y. I., Zheng, J. Focusing on small objects detector in aerial Images. Acta Electonica Sinict. 51(4), 944–955 (2023).
Hsieh, M. R., Lin, Y. L. & Hsu, W. H. Drone-based object counting by spatially regularized regional proposal network. In Proceedings of the IEEE International Conference on Computer Vision 4145–4153 (2017).
Acknowledgements
The research was supported by a grant project: Natural Science Foundation of Hunan Province (No.2024JJ8055).
Author information
Authors and Affiliations
Contributions
Z.X. is responsible for algorithm improvement, and Z.G. is responsible for data.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Zhang, X., Zuo, G. Small target detection in UAV view based on improved YOLOv8 algorithm. Sci Rep 15, 421 (2025). https://doi.org/10.1038/s41598-024-84747-9
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-024-84747-9
Keywords
This article is cited by
-
Enhancing low-light RGB-D pedestrian detection through dual-stage modality-guided fusion
The Visual Computer (2026)
-
SSDDPM: A single SAR image generation method based on denoising diffusion probabilistic model
Scientific Reports (2025)
