
Abstract
With the rapid development of autonomous driving technology, traffic sign recognition (TSR) has emerged as a foundational component of mobile driving systems. Although significant progress has been made in current research, existing techniques still face challenges in recognizing traffic signs under complex weather conditions. This model employs an attention-based dynamic sequence fusion feature pyramid, which enhances recognition accuracy for small-target traffic sign instances in adverse weather, as opposed to traditional feature pyramid networks. Additionally, the model integrates a dynamic snake convolution operator along with Wise-IoU, enabling it to capture fine small-scale feature information while mitigating the impact of low-quality instances. Furthermore, the model introduces a novel data augmentation library, Albumentations, to simulate real-world complex weather scenarios, and utilizes a new performance evaluation metric, TIDE, to more effectively assess model performance in such conditions. We demonstrate the effectiveness of our model on the TT-100 K dataset, the GTSDB dataset, and the BDD 100 K dataset, achieving improvements in mAP of 9%, 1.5%, and 2.6%, respectively. Compared to the baseline model, Cls and Loc metrics decreased by approximately 3 and 1.2.The experiments indicate that our model exhibits excellent generalization ability and robustness, successfully performing small target detection under complex weather conditions in the realm of traffic sign recognition.
Similar content being viewed by others

Introduction
Target detection technology is widely used in various fields such as intelligent traffic management, urban safety monitoring, autonomous driving technology, environmental monitoring, resource management, industrial production quality control, etc1,2. Traffic sign recognition system is the data base of autonomous driving technology, which can help drivers and autonomous vehicles capture important road information3 (e.g., traffic signs4, signals5, lane lines, etc.), which is crucial for navigation and decision-making in complex traffic environments. In recent years, target detection algorithms based on convolutional neural networks have been rapidly developed in the field of traffic sign recognition6,7,8. Although large results have been achieved9,10,11, however, it is susceptible to the influence of complex weather in practical application scenarios, and still has problems such as limited image pixels, low resolution, and complex background. In addition to this, the scale change of traffic signs, angle change and the presence of light difference during vehicle movement can further prevent the recognition system from obtaining clear images12. Therefore, it has become an urgent problem in the field of autonomous driving to study how to detect traffic signs dynamically and efficiently at multiple scales under complex weather conditions to ensure the safe and reliable operation of the recognition system13,14.
Currently, target detection algorithms are usually classified into two categories: one-stage and two-stage, and the representative ones are YOLO and Fast-RCNN15series. Although two-stage networks are usually better than one-stage networks in terms of accuracy, they are not suitable for non-mobile devices due to their slower speed16, so this paper focuses on the study of the YOLO series17,18. The research on how to achieve dynamic multi-scale19,20,21,22 and efficient traffic sign detection focuses on two main strategies: firstly, by fine-designing the network architecture in order to enhance the ability to capture multi-scale information23,24,25,26; and secondly, by utilizing data augmentation techniques to artificially introduce background noise variations in order to enhance the robustness of the model27,28,29,30. Chen et al.31 proposed a novel cross-feeling in response to the problem of the difficulty in recognizing small-target traffic signs field block (RFB-c) to capture the contextual information of the feature map, which greatly improves the recognition accuracy. Mahaur et al.32made further optimization for small targets in complex scenes such as foreground-background imbalance and low-light parallax. The detection accuracy and speed were significantly improved without sacrificing computational resources. Meanwhile, Han et al.33improved the detection ability of multi-scale targets in complex scenes by improving YOLOv5s network. However, in practice, all the above authors neglected the effect of complex weather conditions on the model. To address this, Dang et al.34 used data enhancement techniques to expand the less frequent severe weather dataset from a data perspective and improved the YOLO network, and the model performed better under different weather conditions; Qu et al.35 improved the accuracy of small-scale traffic sign detection under complex weather conditions by introducing a lightweight attention mechanism, which solves the problems such as misdetection and missed detection of small targets in the sampling process.
Based on the above analysis, this paper selects the YOLOv8 model as the benchmark model, takes the improved feature pyramid with small target detection as the starting point, combines multi-scale semantic information with attention mechanism, carries out model reconstruction, and proposes the DSF-YOLO network architecture. The main contributions of this study are summarized as follows:
-
Based on the YOLO detection framework, this study introduces the Dynamic Scale Sequence Feature Fusion (DSSFF) module to enhance the network’s capability for multi-scale feature extraction. Additionally, the Triple Feature Coding (TPC) module is employed to fuse feature maps of different scales, thereby improving the retention of fine details. Furthermore, the Channel and Position Attention Mechanism (CPAM) is incorporated, integrating the DSSFF and TPC modules to enhance the model’s ability to focus on semantic information. This integration enables the model to better comprehend its surroundings in complex backgrounds and achieve more accurate traffic sign recognition.
-
To address the issue of feature loss in small-scale traffic sign instances during the downsampling process, we introduce a lightweight Dynamic Snake Convolution (DSConv)to enhance the extraction of fine-grained small-scale features. DSConv effectively preserves contour information and maintains spatial consistency, enabling the model to capture fine details more accurately and reduce information loss, thereby ensuring precise detection of small targets.
-
We introduce Wise-IOU to enhance the loss function, aiming to mitigate the impact of low-quality image instances on model detection accuracy and improve overall robustness. By incorporating adaptive weighting strategies, Wise-IOU effectively reduces the influence of noisy or ambiguous samples, ensuring more stable gradient updates during training.
-
To simulate traffic sign images under complex weather conditions, we employ the Albumentations image augmentation library to enhance the TT-100 K dataset, thereby better reflecting real-world application scenarios. Additionally, we conduct generalization experiments on the GTSDB and BDD 100 K datasets to improve the model’s generalizability.
-
To better evaluate the model’s performance, we introduce a new performance evaluation metric, TIDE, to analyze the errors between predicted and ground truth bounding boxes. This metric enables a more detailed assessment of the model’s false detections and missed detections for traffic sign instances.
The rest of the paper is organized as follows: "Dataset construction and pre-processing" describes the construction and preprocessing of the dataset. "Materials and methods" describes the proposed DSF-YOLO method in detail. Experimental results and analyses are presented in "Baseline framework". Finally, the conclusions are described in "The improved YOLOv8 network framework".
Dataset construction and pre-processing
To validate the effectiveness of the proposed model, we conduct experiments using the publicly available TT-100 K36 dataset. The TT-100 K dataset comprises traffic sign images extracted from 100,000 Tencent Street View panoramas captured in urban centers and suburban areas across five cities in China. It includes 221 categories of traffic signs, with a total of 16,823 images containing 30,000 traffic sign instances in real-world driving scenarios. Some labeled examples are illustrated in Fig. 1. However, due to the imbalanced distribution of samples, certain categories contain an insufficient number of instances for effective model training. To mitigate this limitation, we focus on 45 categories that each contain more than 100 instances, yielding a refined dataset comprising 9,332 images for experimentation.

Instances of traffic signs.
Since the images in this dataset were collected during daytime under favorable lighting conditions, making traffic signs easily recognizable, we augmented the dataset using the Albumentations37 Image Enhancement Library. This augmentation simulates real-world scenarios and supplements image data under complex weather conditions for experimentation. The Albumentations library provides a range of powerful image transformation and enhancement techniques designed to replicate adverse weather conditions, thereby improving the model’s generalization ability. The primary augmentation methods include ShiftScaleRotate, RandomFoggy, RandomSnow, RandomRain, RandomShadow, RandomBrightnessContrast, and RandomSunFlare. The effects of these enhancements are illustrated in Fig. 2.

Albumentations-rendered images.
The augmented images were used to replace the original images to prevent overfitting caused by the same image appearing under different noise conditions. The dataset was then split in a 7:2:1 ratio, ensuring that each subset contained augmented images.
Materials and methods
Baseline framework
YOLOv8, introduced by Ultralytics in 2023, is a state-of-the-art object detection algorithm known for its exceptional flexibility and rapid deployment capabilities on in-vehicle hardware38,39,40,41. The model is available in five variants—YOLOv8n, YOLOv8s, YOLOv8m, YOLOv8l, and YOLOv8x—each differing in network depth and width. Unlike traditional object detection methods, YOLOv8 features a unified neural network architecture that concurrently handles both object detection and classification tasks, enabling faster processing speeds and improved detection accuracy. Additionally, YOLOv8 utilizes a Path Aggregation Network - Feature Pyramid Network (PAN-FPN) architecture, which is particularly effective for detecting objects of various sizes within images and supporting multi-category object detection.
The network architecture of YOLOv8 comprises four key components, as illustrated in Fig. 3:
-
Input: The Input stage incorporates Mosaic data augmentation, enhancing the dataset with minimal hardware requirements and low computational cost.
-
Backbone: Serving as the foundation of the network, the Backbone is responsible for extracting features from the input image.
-
Neck: The Neck layer effectively merges the deep features extracted by the Backbone with the shallow features, thereby enhancing the overall feature representation.
-
Head: The Head layer is responsible for the classification and localization of targets based on the fused features.

YOLOv8 Network Structure.
The improved YOLOv8 network framework
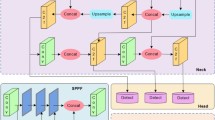
To address the challenge of dynamically and efficiently detecting traffic signs42 under complex weather conditions, we propose a novel attention-based dynamic sequence fusion feature pyramid. Corresponding adjustments are made to both the feature extraction and detection layers to better identify traffic sign instances in such environments. The network architecture is illustrated in Fig. 4.

DSF-YOLO Network Structure.
In the feature extraction layer, we observe that the smallest feature map, P5, tends to lose small-target traffic sign features during the downsampling process. To address this, we incorporate a dynamic snake operator to improve the C2f module, enabling better contour tracking, instance localization, and the extraction of fine-grained small-scale features. In the feature fusion layer, we enhance the feature pyramid by combining semantic information and spatial details from different feature maps, allowing the model to focus more effectively on global information. We also introduce a CPAM to enable the model to give greater attention to information channels and spatial locations, thereby improving detection and recognition performance. Furthermore, a small-object detection head is added to achieve more refined feature fusion. During the model convergence process, we observe that the model is influenced by certain low-quality instances, leading to false positives and missed detections. To mitigate this, we introduce Wise-IOU, which reduces the impact of such instances under complex weather conditions.
Ds_C2f module
DySnakeConv, first proposed in 202343, offers enhanced feature extraction capabilities and greater adaptability compared to traditional convolution. In this paper, we focus on small-target traffic sign instances, which often suffer from blurring and occlusion under complex weather conditions (e.g., rain, snow, fog), causing the model to lose critical information during the downsampling process at low resolution. To address this, we improve the C2f module by incorporating DSConv, the structure of which is shown in Fig. 5. DSConv draws inspiration from Deformable Convolutional Networks (DCN) and introduces a continuity-constrained offset as a learnable parameter. This offset ensures that the convolution operation remains within the detection area, even in the presence of large occlusions, allowing the model to accurately locate small targets and preserve contour information. As a result, the model can effectively extract difficult-to-capture detection information for small-scale targets and prevent information loss.

Ds_C2f Module Structure.
Attention-based dynamic sequence fusion feature pyramid
The traditional PAN-FPN structure fails to effectively capture cross-scale contextual semantic information during the feature fusion process, leading to the loss of critical location information for small targets. To address this issue, we draw inspiration from the Focusing Diffusion Pyramid Network (FDPN) and propose the attention-based Dynamic Sequence Fusion Feature Pyramid Network (DSFFPN). This framework integrates multi-scale and spatial fine-grained features, enabling fast and accurate detection. The network architecture is illustrated in Fig. 6. It consists of three main components:
-
(1)
The TFC module, which receives input from three scales, is designed to capture local fine-grained information about small targets.
-
(2)
The DSSFF module, which integrates global or high-level semantic information across multiple scales, provides positional information for the Attention module.
-
(3)
The CPAM module, which extracts explicit feature information by combining multiscale fusion data, delivers location information to the Attention module, enabling the model to focus on representative feature information across different channels.

Improved Neck Structure.
TFC module
To recognize dense samples of small instances, an effective approach involves referencing and comparing shape or appearance changes at different scales by zooming in on the image. However, since different feature layers of the backbone network vary in size, the traditional PAN-FPN only up-samples the small-sized feature maps and merges them with the previous layer, neglecting the rich detailed information present in the larger-sized feature layers. To address this limitation, we propose TFC module, which processes input feature information of different sizes through concurrent splicing and feature zooming to capture local fine-grained information of small targets. The structure of the TFC module is shown in Fig. 7, where Channel (C) and Square (S) are defined.

TFC Module Structure.
Before parallel splicing, the feature channels of the upper and lower feature maps are first adjusted to match the medium feature layer. Large feature maps are processed by a convolution module to reduce their channel count to 1 C, followed by down-sampling using a hybrid structure of Maximum Pooling and Average Pooling. This approach helps preserve high-resolution features and global information. For small feature maps, nearest neighbor interpolation is employed for up-sampling, which maintains the richness of local features in low-resolution images and prevents the loss of small target feature information. Finally, the feature maps of large, medium, and small sizes, now with the same dimensions, are convolved once and then concatenated along the channel dimension, as illustrated below.
\({F_{FTC}}\) denotes the feature maps output from the TFC module. \({F_s},{F_m}\)and \({F_l}\)denote the small, medium and large size feature maps respectively. \({F_{FTC}}\) is composed of \({F_s},{F_m}\)and \({F_l}\) in series. \({F_{FTC}}\) has the same resolution and three times the number of channels as \({F_m}\).
DSSFF module
To more effectively combine the high-dimensional information from deep feature maps with the detailed information from shallow feature maps, we leverage the scale-invariant property of the image during the sampling process44 and propose the DSSFF module. The structure of the DSSFF module is illustrated in Fig. 8.

DSSFF Module Structure.
The processing of input features at different scales follows a similar approach to that of the TFC module. The input features from both upper and lower scales undergo dynamic sampling (DySample) to perform smooth scaling, which mitigates the loss of detail due to scale differences during the sampling process. This operation enables the model to focus on key feature information while preserving the resolution of features comparable to the medium feature layer. Inspired by the 2D and 3D convolution operations used on video frames45, the feature map is extended from (Channel, Square) to (Channel, Square, Depth) when fusing different data. The 3D features are then concatenated horizontally to obtain the final 3D features, followed by 3D convolution to extract their scale sequence features. This method reduces computational resource consumption while preserving the local information across different scales during the computation process. Finally, the obtained features are normalized and downscaled for subsequent operations.
CPAM module
In order to extract the representative features of different channels with the Location information of traffic sign instances, we introduced the CPAM method. Its network structure is shown in Fig. 9. It receives small target detail information (Input 1) from the TFC module and multi-scale Local information (Input 2) from the DSSFF module. The network structure of CPAM is shown in Fig. 9:

CPAM Module Structure.
It obtains detailed features from the TFC module by first applying a global average pooling operation, which is non-dimensionalized, to each channel. The channel weights are then generated using a fully connected layer followed by a sigmoid function. The fully connected layer is designed to capture nonlinear cross-channel interactions and is implemented using a 1D convolution with a kernel size of K. The mapping relationship between K and C is as follows:
Where the convolution kernel size K is proportional to the channel dimension C, with K representing the coverage of local cross-channel interactions. The channel dimension is typically exponential with a base of 2. Residual connections are then used to perform Hadamard product operations, which focus on obtaining channel information for small target traffic instances. To enhance cross-channel interactions in layers with a larger number of channels, we optimize the formula in (2) to derive a function that adjusts the convolution kernel size. The convolution kernel size k can be calculated as follows:
where \(odd\) denotes the number of nearest neighbors, γ has a value of 2 and b has a value of 1. The channel attention mechanism allows for deeper mining of multi-channel features.
The channel features are combined with the multi-scale features input from the DSSFF module as inputs to the positional attention network, which provides supplementary information for extracting key positional information for traffic sign instances. Compared with the channel attention mechanism, the Location attention mechanism first divides the input feature map into two parts based on their width (\({p_{\text{w}}}\)) and height (\({p_h}\)), and then pools the feature encoding separately to preserve the spatial structure information of the feature map, which is calculated as follows:
where w and h are the width and height of the input feature map, respectively. \(E(w,j)\) and \(E(i,h)\) are the values of the positions \((i,j)\) in the input feature map. After generating the positional attention coordinates, stitching and convolution operations are performed on the horizontal and vertical axes:
where \(P({a_w},{a_h})\) denotes the output of positional attention coordinates, \(Conv\)denotes 1 × 1 convolution, and\(Concat\)denotes splicing. When the splitting is performed, the position related feature map pairs are generated as follows:
where \({s_w}\) and \({s_h}\) are the width and height of the split output, respectively.
Finally, the output is obtained by combining spatial features with attention weights.
Loss function optimization
The YOLOv8 model uses the Complete Intersection over Union (CIoU) as the default anchor box optimization function, as shown in Fig. 10a. CIoU is designed to account for the shape information of the target box. By introducing correction factors such as the diagonal distance of the target box, it makes the loss function more robust to variations in the shape of the target box, thereby enhancing the model’s accuracy in positioning.

Comparison Chart of Different Loss Functions.
But actually, we have found that low quality instances inevitably have a negative impact on the model, which usually comes from geometric factors such as distance and aspect ratio. Consequently, we improved the loss function to append the focusing mechanism by introducing a Wise-IOU for the bounding box loss of the gradient gain (focusing coefficient). As shown in Fig. 10 b. The Wise-IOU we use is the v3 version which is improved based on the v1 version, and it can dynamically adjust the gradient gain distribution strategy r. Its formula is shown below:
Where \(\beta\) is the outlier factor. \(\alpha\) and \(\delta\) are the hyperparameters. Depending on the situation, we set them to 1.7 and 2.7. \({W_g}\) and \({H_g}\) are the size of the smallest closed box. Plus * denotes separation from the computational map. \(x,{x_{gt}},y,{y_{gt}}\) denotes the \((x,y)\) coordinate value corresponding to the prediction box and the real box, respectively. \({W_i},{H_i}\) denotes the size of the height and width of the overlapping part of the prediction box and the real box. The formula of \({S_u}\) is:
The mechanism utilizes higher quality anchor frames to match smaller gradient gains, which can better focus the bounding box regression frames more on average quality anchor frames, while small gradient gains can match anchor frames with large outliers, which can better reduce large harmful gradients produced by low quality samples.
At the same time, while reducing the competitiveness of high-quality anchor frames, it also reduces the harmful gradients generated by low-quality examples, which greatly reduces the disadvantage of small target examples that are underperforming due to background noise, low resolution, etc. being ignored, and results in improved accuracy and generalization of the model.
Experimental environment and evaluation metrics
The improved model was trained using two Quadro-TRX5000-16GB GPUs. PyTorch version 2.0.0 was employed as the deep learning framework, running on Python 3.8 and CUDA version 11.7. The learning rate was set to 0.001, and the Adam optimizer was used. Input images were resized to 640 × 640, with a batch size of 16. The model was trained for 300 epochs on the TT-100 K dataset without using pre-trained weights. Various online data augmentation techniques were applied, including Random Flip and Mosaic.
Standard evaluation metrics include Precision (P), Recall (R), Average Precision (AP), Mean Accuracy (mAP), F1 Score (F1), Floating Point Operations (Flops), and Model Parameter Size (Params).
Where \(TP\) denotes the number of correctly predicted traffic signs, \(FP\) denotes the number of incorrectly detected traffic signs, \(FN\) denotes the number of undetected traffic signs, and FN denotes the total number of detected traffic sign categories.
In addition, a new performance evaluation metric, TIDE46, is used in the experiments to better analyze the true error between traffic sign examples and detection results, and to determine the detection performance of the model. The TIDE method measures the contribution of each error by isolating its impact on overall performance, thus evaluating the model’s strengths and weaknesses in terms of false positives, false negatives, and other detection errors. Depending on the type of error, it can be classified into six types, which requires that the smaller the error, the better. As shown in Fig. 11:

Error Type Definition Diagrams.
The frame color is defined as: red for the prediction detection frame; yellow for the real frame; green for the best detection frame. Foreground refers to the IoU between the prediction detection frame and the real frame (i.e., foreground object), denoted by \({{\text{t}}_{\text{f}}}\), and background refers to the IoU between the prediction detection frame and the non-target region (i.e., background) in the image, denoted by \({{\text{t}}_{\text{b}}}\), which are set to 0.5 and 0.1, respectively.
-
Classification error (Cls): This indicates that the predicted detection frame is correctly positioned but misclassified. The relationship can be expressed as follows:\(I{\text{o}}{{\text{U}}_{\hbox{max} }} \geqslant {{\text{t}}_{\text{f}}}\).
-
Localization error (Loc): indicates that the prediction detection frame is positioned incorrectly but correctly classified. The relationship expression is: \({{\text{t}}_{\text{b}}} \leqslant I{\text{o}}{{\text{U}}_{\hbox{max} }} \leqslant {{\text{t}}_{\text{f}}}\)but true label.
-
Both classification and Localization error (Cls + Loc): indicates that the prediction detection frame is positioned incorrectly and misclassified. The relationship expression is: \({{\text{t}}_{\text{b}}} \leqslant I{\text{o}}{{\text{U}}_{\hbox{max} }} \leqslant {{\text{t}}_{\text{f}}}\)and error label.
-
Duplicate Detection Error (Duplicate): indicates that the prediction detection frame is correctly Localized and classified, but the best frame is already available to compare with it. The relationship expression is: \(I{\text{o}}{{\text{U}}_{\hbox{max} }} \geqslant {{\text{t}}_{\text{f}}}\)
-
Background Error (Bkgd): indicates that the prediction detection frame incorrectly detected the background as foreground. The relationship expression is: \(I{\text{o}}{{\text{U}}_{\hbox{max} }} \leqslant {{\text{t}}_{\text{b}}}\).
-
Missed GT Error (Missed): indicates that the prediction detection frame fails to match the real frame, i.e., missed detection.
Results and discussion
Model performance analysis
To demonstrate the effectiveness of our proposed method, we performed a comparative analysis of selected images from the TT-100 K dataset. We compared DSF-YOLO (e) with models including YOLOv3-tiny (a), YOLOv5 (b), YOLOv6 (c), and YOLOv8 (d). As shown in Fig. 12, the selected images contain a variety of traffic scenarios, including different lighting conditions, small-scale images, high object density, and complex environments with occlusions and deformations. Compared to YOLOv8, DSF-YOLO demonstrated excellent performance in accurate positioning and classification of various traffic sign categories, effectively solving the problems associated with false detection and omission. Even in complex scenes, DSF-YOLO demonstrates robust detection of traffic signs in images. Compared to other mainstream models, particularly YOLOv5, DSF-YOLO consistently maintains high detection accuracy for multi-scale targets in complex scenarios.
On the other hand, we also tested the performance of each model in complex weather conditions and small-scale images. As shown in Fig. 13, we still compared DSF-YOLO (e) with the models including YOLOv3-tiny (a), YOLOv5 (b), YOLOv6 (c) and YOLOv8 (d). Experimental results demonstrate that traditional YOLO models (from YOLOv3 to YOLOv8) generally encounter significant false positives and false negatives under complex weather conditions, such as rain, fog, strong light, and shadow interference. Their performance, especially in low visibility or small target scenarios, deteriorates sharply. In contrast, the proposed DSF-YOLO model exhibits exceptional robustness: it not only achieves higher confidence in accurately detecting all traffic sign instances but also maintains a low false negative rate under extreme weather conditions. Furthermore, DSF-YOLO significantly improves detection accuracy for small and deformed targets compared to baseline models. These advantages can be attributed to the multi-scale feature fusion and dynamic attention mechanisms, which enhance the DSF-YOLO model’s value for practical applications in autonomous driving and intelligent traffic monitoring systems

Comparison chart of different models.

Comparison chart of different weather Conditions and scales.
Attention comparison and experimental analysis
In this study, to better evaluate the effectiveness of the proposed CPAM, we compared it with other traditional attention mechanisms, including Convolutional Block Attention Module (CBAM), Coordinate Attention (CA), Squeeze-and-Excitation Attention (SE), and Efficient Channel Attention (ECA). In the experiments, we replaced the CPAM with these different attention modules at the Neck layer and compared their performance in the target detection task. The experimental results, as shown in Table 1, demonstrate that the CPAM module achieves the best performance across various metrics, particularly in terms of mAP, where it outperforms the other traditional attention modules. Thus, our experimental findings validate the superior performance of the CPAM module in traffic sign detection tasks, indicating its ability to better capture both channel and spatial contextual information, thereby enhancing detection accuracy and robustness.
Comparison of the number of CPAM modules
In our experiments, we evaluated the impact of incorporating the CPAM module on the accuracy of the YOLOv8n model. The experimental results, as shown in Table 2, demonstrate that the inclusion of different numbers of CPAM modules significantly affects the model’s performance. Specifically, the model without the CPAM module performed worse than those with the module. After adding the P3 CPAM module, the model’s mAP improved slightly to 0.674, although other metrics showed slight decreases. Similarly, the model incorporating the P2 CPAM module exhibited a similar trend. In contrast, the DSF-YOLO model outperformed all others across all metrics, particularly achieving a mAP of 0.702, demonstrating its superior performance in traffic sign detection tasks.
Comparative results analysis
In Table 3, we present the results of testing on the augmented TT-100 K dataset, comparing the performance of our proposed model with several mainstream methods. The experimental results show that our model outperforms other lightweight YOLO models (e.g., YOLOv8, YOLOv11, etc.) in terms of performance and achieves comparable accuracy to YOLOv5s, making it better suited for traffic sign recognition tasks. Compared to the baseline model, DSF-YOLO improves Precision (P) by 4%, Recall (R) by 8%, mAP by 9%, and F1 score by 7%. These results demonstrate that, under the condition of no hardware resource limitations, our model is capable of further enhancing detection accuracy, providing a more efficient solution for future scenarios with abundant hardware resources.
Table 4, evaluated using the TIDE metric, demonstrates that our model outperforms others (e.g., YOLOv5s, YOLOv8n, YOLOv11) in terms of Cls, Loc, Bkgd, and Missed error rates, all of which are the lowest. On the other hand, in terms of Cls + Loc, Duplicate, and other indicators, the model shows slightly lower performance compared to YOLOv5s and YOLOv11, but still maintains an advantage. This confirms its excellent robustness and generalization capabilities. Despite the common challenges posed by complex weather interference in the dataset and the exclusion of some rare categories during preprocessing (which resulted in higher errors for all models in Cls, Bkgd, and Missed indicators), our model consistently maintains the lowest error rates, providing strong evidence for the effectiveness of the proposed improvements.
As shown in Fig. 14, DSF-YOLO is analyzed in comparison with other models during the training process. From the figure, we can see that the DSF-YOLO shows strong learning ability in the initial stage of training and achieves faster convergence during the training process. This comparison shows more powerful detection performance.

Comparison chart of mAP.
Ablation experiments analysis
In order to validate the effectiveness of the YOLOv8 model optimization scheme proposed in this paper, we conducted ablation experiments combining several optimization strategies. These experiments aim to evaluate the impact of the model on traffic sign instance detection under complex weather conditions. Throughout the experiments, the same parameter configurations and hardware resources were used for model training. A combination of six different optimization strategies was used and the experimental results are shown in Table 5.
The results indicate that the DSF-YOLO model achieves significant performance improvements through the progressive integration of enhanced modules. We investigated the impact of removing the P2 layer, and experimental results show that the P2 layer contributes substantially to the model’s performance enhancement. Specifically, in the absence of the CPAM module, the model’s mAP increased by 5.4%, demonstrating the effectiveness of our improved feature pyramid. Upon incorporating the CPAM module, the mAP further improved by 2.1%, indicating that the CPAM module is well-suited for our detection task. Additionally, after integrating the DS_C2f module and Wise-IoU, both the feature extraction network and inference process experienced optimizations, leading to improvements in the model’s P and R. However, it is worth noting that the introduction of Wise-IoU resulted in a 1.3% decrease in precision, which we attribute to gradient gain effects from the loss function. Nonetheless, Wise-IoU still provides significant overall benefits to the model’s robustness. Ultimately, our proposed model achieved the highest detection accuracy, with an mAP improvement of 9% over the baseline model. This demonstrates its superior capability in detecting small-scale traffic sign instances under complex weather conditions, making it well-suited for real-world application scenarios.
Table 6 indicate that the DSF-YOLO model achieves significant performance improvements through the progressive integration of enhanced modules. We investigated the impact of removing the P2 layer, and experimental results show that the P2 layer contributes substantially to the model’s performance enhancement. Specifically, in the absence of the CPAM module, the model’s mAP increased by 5.4%, demonstrating the effectiveness of our improved feature pyramid. Upon incorporating the CPAM module, the mAP further improved by 2.1%, indicating that the CPAM module is well-suited for our detection task. Additionally, after integrating the DS_C2f module and Wise-IoU, both the feature extraction network and inference process experienced optimizations, leading to improvements in the model’s precision (P) and recall (R). However, it is worth noting that the introduction of Wise-IoU resulted in a 1.3% decrease in precision, which we attribute to gradient gain effects from the loss function. Nonetheless, Wise-IoU still provides significant overall benefits to the model’s robustness. Ultimately, our proposed model achieved the highest detection accuracy, with an mAP improvement of 9% over the baseline model. This demonstrates its superior capability in detecting small-scale traffic sign instances under complex weather conditions, making it well-suited for real-world application scenarios.
Generalisation experiment
To evaluate the generalization capability of our model, we conducted experiments on the GTSDB58 and BDD100K59 datasets to assess its robustness across different datasets. The datasets were split using a 7:2:1 ratio. Without utilizing pre-trained weights, the model was trained under strictly identical parameter configurations and hardware conditions. The final results, presented in Table 7, demonstrate that compared to the baseline model, DSF-YOLO achieved a 5.3% increase in R and a 1.5% improvement in mAP on the GTSDB dataset, though P decreased by 7.1% due to interference from FP samples. On the BDD100K dataset, DSF-YOLO improved R by 2.7% and mAP by 2.6%. These results indicate that the improved model maintains high overall performance across multiple public datasets, highlighting its robustness and generalization capability. Furthermore, it confirms that our model is well-suited for tasks such as small-scale traffic sign detection in real-world applications.
Conclusion
Aiming at the problem of how to detect traffic signs dynamically at multiple scales and efficiently under complex weather conditions in the model, we design and develop a novel network structure, DSF-YOLO. We utilize an attention-based dynamic sequence fusion feature pyramid instead of the traditional FPN structure to better address the complexity of traffic sign detection and recognition, and to improve the recognition of small target instances in complex weather environments. Accuracy. The information loss problem of the model during down-sampling is helped by adding dynamic snake convolution operator to obtain fine small-scale feature information. For the effect of low quality instances present in complex weather images on the model accuracy, we introduce the dynamic adjustment of gradient gain in Wise-IoU to eliminate its effect.
We introduce a new data enhancement technique, Albumentations, to restore complex weather environments in real scenes to meet our mission requirements. We also introduce a new performance evaluation metric, TIDE, to help us evaluate the model error in terms of Localization classification, false detection and omission detection, etc., in order to better evaluate the performance of our model under complex weather conditions.
Experimental evaluation on the data-enhanced TT-100 K dataset shows that our improvement is effective. While on the TT-100 K dataset, the mAP is improved by 9% over the baseline model, the Cls is reduced by about 3, and the Loc and Missed are reduced by about 0.5. The experiments validate the effectiveness and progress of DSF-YOLO in traffic sign detection in complex weather environments, demonstrating its ability to accurately detect traffic signs of different sizes and in different environments. In addition, we also conducted generalization experiments on the GTSDB dataset with the BDD 100 K dataset to verify the robustness of our model. On the GTSDB dataset, mAP improves 1.5% over the benchmark model, while on the BDD 100 K dataset, mAP improves 2.6% over the benchmark model. The experiments show that our model has good robustness and generalization ability, and can well perform a series of tasks such as small target detection in the field of traffic signs.
In the future, we have to carry out further research on model light-weighting and refining the number of traffic sign categories to improve its try detection tasks in different countries, scenarios, and weather environments.
Data availability
The datasets generated during and/or analyzed during the current study are available from the corresponding author on reasonable request.
References
Liu, Z. et al. Small traffic sign detection from large image. Appl. Intell. 50 (1), 1–13 (2020).
Mohammed, M. A. et al. Industrial Internet of Water Things Architecture for Data Standarization Based on Blockchain and Digital Twin technology J. Adv. Res., (2023)
Zhao, R. et al. Enhancing autonomous driving safety: A robust traffic sign detection and recognition model tsd-yolo. Sig. Process. 225, 109619 (2024).
Yu, B. et al. Yolo-mpam: efficient real-time neural networks based on multi-channel feature fusion. Expert Syst. Appl. 252, 124282 (2024).
Wang, W. et al. Hv-yolov8 by Hdpconv: better lightweight detectors for small object detection. Image Vis. Comput. 147, 105052 (2024).
Ertler, C. et al. The mapillary traffic sign dataset for detection and classification on a global scale. In: European Conference on Computer Vision, Springer, pp 68–84 (2020).
Manzari, O. N., Boudesh, A. & Shokouhi, S. B. Pyramid transformer for traffic sign detection. In: 2022 12th International Conference on Computer and Knowledge Engineering (ICCKE), IEEE, pp 112–116 (2022).
Yao, J. et al. Traffic sign detection and recognition under low illumination. Mach. Vis. Appl. 34 (5), 75 (2023).
Zhang, Y. et al. A storage-efficient snn–cnn hybrid network with rram-implemented weights for traffic signs recognition. Eng. Appl. Artif. Intell. 123, 106232 (2023).
Sharma, V. K., Dhiman, P. & Rout, R. K. Improved traffic sign recognition algorithm based on yolov4-tiny. J. Vis. Commun. Image Represent. 91, 103774 (2023).
Bochkovskiy, A., Wang, C. Y. & Liao, H. Y. M. Yolov4: Optimal speed and accuracy of object detection. URL (2020). https://arxiv.org/abs/2004.10934, 2004.10934.
Liu, Y. et al. Tsingnet: Scale-aware and context-rich feature learning for traffic sign detection and recognition in the wild. Neurocomputing 447, 10–22 (2021).
Zhang, K. et al. A Hybrid Approach for Efficient Traffic Sign Detection Using yolov8 and Sam (Association for Computing Machinery, 2024).
Hu, Z. & Zhang, Y. Traffic Sign Small Target Detection Model Based on Improved yolov5 (Association for Computing Machinery, 2024).
Ren, S. et al. Faster r-cnn: towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 39 (6), 1137–1149 (2016).
Qian, Y. J. & Wang, B. Tsdet: A new method for traffic sign detection based on yolov5-swint. IET Image Proc. 18 (4), 875–885 (2024).
Gao, G. et al. Research on Methodology of Intelligent Traffic Accident Detection Based on Enhanced yolov8 Algorithm (Association for Computing Machinery, 2024).
Tang, C. & Yin, L. Traffic Sign Recognition Using Improved yolov7 Model (Association for Computing Machinery, 2024).
Suwattanapunkul, T. & Wang, L. J. The efficient traffic sign detection and recognition for taiwan road using yolo model with hybrid dataset. In: 2023 9th International Conference on Applied System Innovation (ICASI) (2023).
Du, S. et al. Tsd-yolo: small traffic sign detection based on improved Yolo v8. IET Image Proc. 18 (11), 2884–2898 (2024).
Kumar, R. & Gupta, A. D R Traffic sign detection using yolov8. In: 2024 2nd International Conference on Intelligent Data Communication Technologies and Internet of Things (IDCIoT) (2024).
Choudhary, N. et al. Enhanced traffic sign recognition using advanced yolov8 model. In: 2024 4th International Conference on Intelligent Technologies (CONIT) (2024).
Wei, W. et al. A lightweight network for traffic sign recognition based on multi-scale feature and attention mechanism. Heliyon 10(4) (2024).
Wang, J. et al. Improved yolov5 network for real-time multi-scale traffic sign detection. Neural Comput. Appl. 35 (10), 7853–7865 (2023).
Simonyan, K. & Zisserman, A. Very deep convolutional networks for large-scale image recognition. URL (2015). https://arxiv.org/abs/1409.1556, 1409.1556.
Singh, B., Najibi, M. & Davis, L. S. Sniper: efficient multi-scale training. In: (eds Bengio, S., Wallach, H., Larochelle, H. et al.) Advances in Neural Information Processing Systems, vol 31. Curran Associates, Inc. (2018).
Bosquet, B. et al. A full data augmentation pipeline for small object detection based on generative adversarial networks. Pattern Recogn. 133, 108998 (2023).
Tang, Q. & Chen, W. DeepB3P: A transformer-based model for identifying blood-brain barrier penetrating peptides with data augmentation using feedback GAN[J]. J. Adv. Res., (2024).
Karras, T., Laine, S. & Aila, T. A style-based generator architecture for generative adversarial networks. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2019).
Ge, Q. et al. Data-augmented Landslide Displacement Prediction Using Generative Adversarial Network (Journal of Rock Mechanics and Geotechnical Engineering, 2024).
Chen, J. et al. A real-time and high-precision method for small traffic-signs recognition. Neural Comput. Appl. 34 (3), 2233–2245 (2022).
Mahaur, B. & Mishra, K. Small-object detection based on yolov5 in autonomous driving systems. Pattern Recognit. Lett. 168, 115–122 (2023).
Han, Y. et al. Edn-yolo: Multi-scale traffic sign detection method in complex scenes. Digit. Signal Proc. p 104615 (2024).
Dang, T. P. et al. Improved yolov5 for real-time traffic signs recognition in bad weather conditions. J. Supercomputing. 79 (10), 10706–10724 (2023).
Qu, S. et al. Improved yolov5-based for small traffic sign detection under complex weather. Sci. Rep. 13 (1), 16219 (2023).
Zhu, Z. et al. Traffic-sign detection and classification in the wild. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 2110–2118 (2016).
Buslaev, A. et al. Albumentations: fast and flexible image augmentations. Information 11 (2), 125 (2020).
Tang, Y. & Qian, Y. High-speed railway track components inspection framework based on yolov8 with high-performance model deployment. High-speed Railway. 2 (1), 42–50 (2024).
Li, D. et al. Yolov8-emsc: A lightweight fire recognition algorithm for large spaces. J. Saf. Sci. Resil. 5 (4), 422–431 (2024).
Liu, Z. et al. Faster-yolo-ap: A lightweight Apple detection algorithm based on improved yolov8 with a new efficient Pdwconv in orchard. Comput. Electron. Agric. 223, 109118 (2024).
Sun, S. et al. Multi-yolov8: an infrared moving small object detection model based on yolov8 for air vehicle. Neurocomputing 588, 127685 (2024).
Kang, M. et al. Asf-yolo: A novel Yolo model with attentional scale sequence fusion for cell instance segmentation. Image Vis. Comput. 147, 105057 (2024).
Qi, Y. et al. Dynamic snake convolution based on topological geometric constraints for tubular structure segmentation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pp 6070–6079 (2023).
Pieta, P. T., Dahl, A. B., Frisvad, J. R., Bigdeli, S. A., & Christensen, A. N. (2025). Feature-Centered First Order Structure Tensor Scale-Space in 2D and 3D. IEEE Access.
Tran, D. et al. Learning spatiotemporal features with 3d convolutional networks. In: Proceedings of the IEEE international conference on computer vision, pp 4489–4497 (2015).
Bolya, D. et al. Tide: A general toolbox for identifying object detection errors. In: Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part III 16, Springer, pp 558–573 (2020).
Woo, S., Park, J., Lee, J. Y. & Kweon, I. S. Cbam: Convolutional block attention module. In Proceedings of the European conference on computer vision (ECCV) (pp. 3–19). (2018).
Hou, Q., Zhou, D. & Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 13713–13722). (2021).
Hu, J., Shen, L. & Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 7132–7141). (2018).
Wang, Q. et al. ECA-Net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 11534–11542). (2020).
Redmon, J. & Farhadi, A. Yolov3: an incremental improvement. ArXiv Preprint arXiv :180402767. (2018).
Jocher, G. YOLOv5 by Ultralytics (Version 7.0) [Computer software]. (2020). https://doi.org/10.5281/zenodo.3908559
Li, C., Li, L., Jiang, H., Weng, K., Geng, Y., Li, L., … Wei, X. (2022). YOLOv6: A single-stage object detection framework for industrial applications. arXiv preprint arXiv:2209.02976.
Jocher, G., Qiu, J. & Chaurasia, A. Ultralytics YOLO (Version 8.0.0) [Computer software]. (2023). https://github.com/ultralytics/ultralytics
Wang, A. et al. Yolov10: Real-time end-to-end object detection. arXiv 2024. arXiv preprint arXiv:2405.14458. (2024).
Cheng, T. et al. Yolo-world: Real-time open-vocabulary object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 16901–16911). (2024).
Tian, Y., Ye, Q. & Doermann, D. Yolov12: Attention-centric real-time object detectors[J]. (2025). arXiv preprint arXiv:2502.12524.
Houben, S., Stallkamp, J., Salmen, J., Schlipsing, M. & Igel, C. Detection of traffic signs in real-world images: The German Traffic Sign Detection Benchmark. In The 2013 international joint conference on neural networks (IJCNN) (pp. 1–8). Ieee. (2013), August.
Yu, F., Chen, H., Wang, X., Xian, W., Chen, Y., Liu, F., … Darrell, T. (2020). Bdd100k:A diverse driving dataset for heterogeneous multitask learning. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 2636–2645).
Author information
Authors and Affiliations
Contributions
Author Contributions Statement:L&D. Conceptualized the research framework, designed methodologies, performed critical data analysis, and drafted the manuscript .G. Conducted experiments, validated results, contributed to manuscript writing, and revised key sections .Y. Developed computational models, curated datasets, and assisted in analysis and interpretation.J. Provided domain-specific expertise, reviewed literature, and edited technical content .Z. Assisted in data collection, performed preliminary analyses, and created visualizations .P. Supported project administration, contributed to discussions, and proofread the manuscript .All authors reviewed and approved the final version of the paper.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Li, J., Deng, Q., Gao, W. et al. DSF-YOLO for robust multiscale traffic sign detection under adverse weather conditions. Sci Rep 15, 24550 (2025). https://doi.org/10.1038/s41598-025-02877-0
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-025-02877-0
