
Abstract
Air temperature plays a critical role in estimating agricultural water requirements, hydrological processes, and the climate change impacts. This study aims to identify the most accurate forecasting model for daily minimum (Tmin) and maximum (Tmax) temperatures in a semi-arid environment. Five machine learning models—linear regression (LR), additive regression (AR), support vector machine (SVM), random subspace (RSS), and M5 pruned (M5P)—were compared for Tmax and Tmin forecasting in Gharbia Governorate, Egypt, using data from 1979 to 2014. The dataset was divided into 75% for training and 25% for testing. Model input combinations were selected based on best subset regression analysis, result shows the best combination was Tmin(t−1), Tmin(t−3), Tmin(t−4), Tmin(t−5), Tmin(t−6), Tmin(t−7), Tmin(t−8) and Tmax (t−1), Tmax (t−2), Tmax (t−3), Tmax (t−4), Tmax (t−5), Tmax (t−6), Tmax (t−8) for daily minimum maximum air temperature forecasting, respectively. The M5P model outperformed the other models in predicting both Tmax and Tmin. For Tmin, the M5P model achieved the lowest root mean square error (RMSE) of 2.4881 °C, mean absolute error (MAE) of 1.9515, and relative absolute error (RAE) of 40.4887, alongside the highest Nash-Sutcliffe efficiency (NSE) of 0.8048 and Pearson correlation coefficient (PCC) of 0.8971. In Tmax forecasting, M5P showed a lower RMSE of 2.7696 °C, MAE of 1.9867, RAE of 29.5440, and higher NSE of 0.8720 and R² of 0.8720. These results suggest that M5P is a robust and precise model for temperature forecasting, significantly outperforming LR, AR, RSS, and SVM models. The findings provide valuable insights for improving decision-making in areas such as water resource management, irrigation systems, and agricultural productivity, offering a reliable tool for enhancing operational efficiency and sustainability in semi-arid regions. The Friedman ANOVA and Dunn’s test confirm significant differences among temperature forecasting models. Additive Regression overestimates, while Linear Regression and SVM align closely with actual values. Random Subspace and M5P exhibit high variability, with SVM differing significantly. For maximum temperature, Random Subspace and M5P perform similarly, while SVM remains distinct.
Similar content being viewed by others
Introduction
Accurate temperature forecasting is crucial for understanding future climate patterns1. Climate change and global warming pose significant global challenges, intensifying water-related disasters such as floods and droughts while affecting water quality2. A robust understanding of temperature variations aids decision-makers in mitigating climate change impacts and enhancing infrastructure resilience and sustainability3. While temperature is a critical variable connecting atmospheric and land surface processes in studies of hydrological, ecological, and climate change. Numerous studies have been conducted to model air temperature4,5,6,7consistently emphasizing the importance of accurate air temperature estimation in the fields of meteorology, hydrology, and agro-hydrology. Consequently, more robust and accurate models are required to effectively capture the nonlinear dynamics of air temperature variation8.
Goodale et al.9 employed geographical information such as latitude, longitude, and altitude as predictors for interpolating temperature and precipitation in Ireland. Ninyerola et al.10 used geographic information systems (GIS) to simulate and map air temperature. Satisfactory forecasting of nonlinear air temperature behaviour in time and space is critical. Reicosky et al.11 evaluated methods for estimating hourly air temperatures from daily maxima and minima, achieving reasonable accuracy on clear days but poor performance on overcast days. Their study recommended direct hourly temperature measurements for precise modeling but did not assess the impact of estimation errors. Sadler and Schroll12 expanded this research by developing an algorithm that did not rely on predefined temperature curves, outperforming existing methods in nearly half of the cases. However, its application required constructing a site-specific normalized temperature cumulative distribution function for a full year, limiting its practicality for broader use.
The urban heat island effect13,14,15air pollution16,17,18and human mortality19 are all closely associated with air temperature measured at 2 m above ground level in urban environments20,21,22. In high density populated areas, monitoring and forecasting of maximum (Tmax) and minimum (Tmin) air temperatures is essential due to their association with extreme events, such as heatwaves and tropical nights23,24. With a large population and complex infrastructure, even minor temperature variations within a city can significantly influence both human and natural environments25,26. Consequently, understanding and monitoring the spatiotemporal patterns of air temperature is essential. Remote sensing data, being geographically contiguous and regularly available across most of the Earth, offer superior spatial coverage compared to surface meteorological observations27. This advantage is particularly significant in regions where ground-based observations are insufficient for effective spatial interpolation28.
Radiometers onboard satellites can estimate land surface temperature (LST) using thermal infrared (TIR; 4.0–15.0 μm) channel data through the application of specific algorithms29,30. Numerous studies have investigated the potential of using remotely sensed land surface temperature (LST) to estimate surface air temperature31,32,33,34. Linear regression was utilized to directly estimate air temperature from satellite infrared thermal data35,36,37. The uncertainty in the estimates provided by regression techniques ranges from 1.0 °C to 2.6 °C. The normalized differential vegetation index (NDVI) estimates air temperature because land cover and soil conditions can impact heat exchange between the land surface and the near-surface atmosphere38,39,40.
Geographical interpolation that integrates in-situ observations with satellite-derived geographic variables represents a highly promising method for monitoring air temperature across extensive spatial and temporal scales41,42,43,44. This approach offers a cost-effective means of generating continuous and spatially resolved air temperature maps. Numerous studies have employed deterministic methods, such as inverse distance weighting (IDW), alongside geostatistical techniques like ordinary kriging (OK) and cokriging, as prevalent spatial interpolation methods45,46,47. Additionally, data-driven methods have been increasingly applied, particularly at smaller scales, for the spatial interpolation of meteorological variables due to their computational efficiency and high accuracy48,49,50.
To enhance the interpolation of air temperature, data-driven approaches often utilize regression models using spatial factors as predictors. One of the most extensively utilized data-driven methodologies is multi-linear regression (MLR)51,52,53,54,55,56. Machine learning algorithms have been integrated into spatial interpolation as computing power has increased57,58,59,60. Data driven artificial intelligence (AI), machine leaning (ML) and deep machine learning (DML) methodologies have demonstrated significant success in various scientific domains in recent years54,58,59,61,62. These approaches have been widely applied across disciplines including water resources engineering, agro-hydrology, and agro-meteorology63,64,65,66,67,68,69,70,71,72. A comprehensive review of such applications is beyond the scope of this paper; therefore, only a selection of pertinent literature will be discussed.
Mohammed et al.73 used four ML algorithms, viz., bagging (BG), random subspace (RSS), random tree (RT), and random forest (RF), in predicting agricultural and hydrological drought events in the eastern Mediterranean. Findings indicated BG as the best model, whereas the performance of RSS remains fitting. Machine learning models for estimation of daily evaporation and air temperature to predict evaporation and mean temperature, particularly in a semi-arid climate like New Delhi, it offers a promising approach for better understanding and managing water resources in similar regions52,74. Anaraki et al.75 highlights its novel integration of metaheuristic algorithms, decomposition, and machine learning for flood frequency analysis under climate change. The findings demonstrate the effectiveness of MARS, ANN, and LSSVM_WOA in downscaling precipitation and temperature, with LSSVM_WOA_WT excelling in discharge simulation. The conclusion emphasizes the impact of model selection on uncertainty, with HadCM3 exhibiting lower uncertainty at higher return periods. Kadkhodazadeh et al.76 presents a robust methodology for ETo prediction and uncertainty analysis under climate change and post-pandemic recovery scenarios. By integrating machine learning models and climate projections, the results highlight an increasing trend in temperature and evapotranspiration across all scenarios. The LSBoost model proved effective, with the Monte Carlo analysis identifying minimal uncertainty at Mianeh station.
Unfortunately, data-driven models (DDMs) have inherent limitations, including their empirical nature, reliance on a “black box” framework, and vulnerability to overfitting, which can compromise their generalization ability77,78,79,80. Artificial intelligence models that can extract data noise and outliers and reveal the non-linear relationship between geographical factors and air temperature81. Cho et al.82 compared standard interpolation algorithms to ANN for spatial interpolation of air temperature. In other studies, ANN has since been used to spatially interpolate short-term (daily and hourly) air temperature83. Support vetror regression (SVR) has also been used to compare the spatial interpolation of air temperature with ANN84. Researchers discovered that SVR outperforms ANN for the spatial interpolation of short-term air temperature85. Alomar et al.86 has applied data-driven models for atmospheric air temperature forecasting at a continental climate region. Result reveals that SVR outperforms other models for daily forecasting, while RF and Gradient Boosting Regression (GBR) excel in weekly forecasts under climate variability. Salcedo-Sanz et al.87 concludes that SVR outperforms other algorithms in predicting monthly mean air temperature, though its accuracy has declined in recent decades, reflecting potential changes in the relationships among predictive variables.
While machine learning (ML) has been widely used for air temperature forecasting, few studies compare multiple ML models within the same framework. Temperature significantly impacts precipitation and drought, highlighting the need for accurate forecasting models. Previous methods often suffer from low accuracy, data sensitivity, and limited adaptability to climate change. This study addresses these gaps by analyzing daily air temperature trends in Gharbia Governorate, Egypt, using multiple ML models. We focus on selecting the optimal time lag for improved forecasting. The study aims to: (1) develop novel ML-based models for daily air Tmin and Tmax forecasting, (2) evaluate model performance using statistical metrics, and (3) recommend the most accurate model for future water resource management.
Materials and methods
Study area
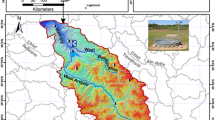
The Nile Delta is Egypt’s economic and agricultural hub, comprising 11 governorates in an arid desert climate. Gharbia Governorate, located in the central Nile Delta, Egypt (30.87°N, 31.03°E) (Fig. 1), is bordered by Kafr El-Sheikh to the north, Monufia to the south, and the Damietta and Rosetta branches of the Nile to the east and west, respectively. The Nile Delta is among the world’s oldest agricultural regions. Gharbia Governorate, the study area, spans 1,942 km² and is a key agricultural and industrial center, producing cotton, rice, wheat, maize, and medicinal plants for export. Summer temperatures peak at 49.294 °C in July 2010, while winter ranges from 9 °C to 19 °C, with annual rainfall of 100–200 mm, mostly in winter. Agriculture consumes 85% of freshwater, posing a risk of future water scarcity.

Map of study area.
Datasets
The National Centers for Environmental Prediction (NCEP) Climate Forecast System Reanalysis (CFSR) was used to gather daily climate data variables for the examined region, such as minimum and maximum temperatures, from 1979 to 2014. The CFSR was created as a global, high-resolution, coupled system of the atmosphere, ocean, land surface, and sea ice to give the most accurate assessment of the state of these coupled domains during this time. The SWAT file format and CSV versions of the daily minimum and maximum temperatures CFSR data for the entire time were downloaded per continent. This 36-year dataset consists of 13,148 data points with no missing values during the machine learning modeling process. The dataset was pre-processed to remove outliers, reducing the total number of data points to 12,987. It was then divided into training (10,221 data points, 78.68%) and testing (2,768 data points, 21.32%) sets. Additionally, the entire training dataset was shuffled (10,221 data point) and subjected to validation to ensure model robustness. The basic statistics of training, testing, and validation datasets at study stations are presented in Table 1.
Hyper parameter tuning for machine learning models
Flowchart of Temperature estimation methodology in the study area is also shown in Fig. 2. The selection of hyperparameters values can affect significantly the forecasting performance independently of the machine learning technique considered. The adjustment of these parameters can be performed manually or automatically using the internal optimization option that tries to find the combination of hyperparameters for which the mean squared error per each forecasting technique is minimized (Fig. 2). The developed AI models were implemented by WEKA (Waikato Environment for Knowledge Analysis), which is a popular open-source software suite for machine learning and data mining developed at the University of Waikato in New Zealand. It is widely used for research and education, as well as in industry applications. WEKA provides a collection of machine learning algorithms for data mining tasks, along with tools for data preprocessing, classification, regression, clustering, association rule mining, and visualization.

Flowchart of Temperature estimation methodology in the study area (A) and Hyperparameter tuning process (B), (Elgeldawi et al.86).
Best subset regression analysis
Best subset regression analysis is a statistical model selection technique that systematically evaluates all possible combinations of predictor variables to identify the optimal model based on predefined statistical criteria52,88. This approach is particularly useful in exploratory regression analysis, as it enables a comprehensive comparison of potential models constructed from a given set of predictors. Unlike stepwise regression methods, which iteratively add or remove predictors based on significance thresholds, best subset regression exhaustively examines every possible subset of predictors. This allows for the selection of a model that balances explanatory power with parsimony, ensuring that the chosen model maintains a high level of predictive accuracy while minimizing complexity52,89,90. By excluding irrelevant or redundant variables, best subset regression reduces overfitting and enhances model interpretability.
The primary advantage of best subset regression lies in its ability to identify models that provide robust estimates of regression coefficients while reducing prediction variance89. This is particularly beneficial when dealing with high-dimensional datasets, where incorporating all available predictors can lead to overfitting and decreased generalizability. The selection criteria typically used in best subset regression include metrics such as the adjusted R-squared, Akaike Information Criterion (AIC), Bayesian Information Criterion (BIC), and Mallows’ Cp, each of which provides a different perspective on model performance51,90,91.
Stepwise regression iteratively adds/removes predictors based on significance, balancing model simplicity and fit but risks overfitting and bias57,71,92,93. LASSO imposes L1 regularization, shrinking coefficients to zero for feature selection, enhancing generalizability but may bias estimates. Stepwise is computationally simpler; LASSO handles high-dimensional data better, reducing multicollinearity impact.
Machine learning models
Linear regression (LR)
Linear regression analysis examines the correlation between multiple independent or predictor variables and a dependent variable. The model assumes a linear relationship between the dependent variable Yi and the vector of regressors Xi. The following Eq. 1 shows the LR Eq. 56.
where a indicates the intercept, \(\:{\beta\:}_{\:}\) indicates the slope, and k indicates the number of observations.
Additive regression (AR)
The concept of additive regression (AR) is a statistical modeling approach used to establish relationships between variables. This method offers a distinct and effective alternative by mitigating the challenges associated with high-dimensional data, commonly referred to as the curse of dimensionality. The additive model is mathematically represented as Eq. 2:
where \(\:\sum\:_{j=1}^{p}\:{f}_{i}\left({x}_{ij}\right)\) shows the smooth functions fitted from the data and \(\:{\beta\:}_{\varvec{o}}\) shows the regression coefficient.
M5 pruned (M5P)
The M5P algorithm is a regression tree-based approach used to make forecastings94. This regression tree consists of the root node of the entire dataset, internal nodes that create conditions based on input variables, and leaf nodes that contain linear regression. The M5P algorithm first divides the input datasets into subsets according to the datasets binary division rule58,89,95. Each subset is then divided into subsets based on the Least Square Deviation (LSD) function as shown in Eq. 3.
The LSD function calculates the internal variance at a given node \(\:R\left(t\right)\), the number of units in the subset (N), the target variable values for each unit \(\:{y}_{i}\), and the mean of the target \(\:{y}_{m}\)96.
Support vector machine (SVM)
SVM is a supervised learning method and was first proposed by Vapnik97. This method is based on statistical learning theory and is kernel-based98. Additionally, SVR is the SVM model used to solve various regression problems. The main purpose of this model is to reduce the error by individualizing the hyperplane. When the linear function is taken into account in this model, which is based on the tolerance limit of this model, the constraints can be reduced. As long as errors are smaller than ε, they are insignificant, and deviations are penalized (Müller et al. 2018). The SVM forecasting function (F) is given in Eq. 4.
where, W shows the weight-age vector; \(\:{T}_{f}\) indicates the nonlinear transfer function, and b shows the constant variable.
Random subspace (RSS)
RSS is an ensemble-based classification approach that constructs a forest of classifiers99. It operates by randomly selecting subsets of features for individual classifiers and subsequently aggregating their outputs through a majority voting mechanism55,89. This method is particularly advantageous when the number of training samples is small compared to the dataset size. Additionally, RSS enhances classification performance in datasets with a high degree of feature redundancy by reducing the influence of irrelevant features95,100. The process involves randomly selecting feature subsets from the training data, training multiple classifiers, and integrating their classification rules. The final prediction is determined through majority voting, as mathematically represented in Eq. 5101.
.
where \(\:\delta\:\) is the Kronecker symbol, \(\:y\in\:\{-\text{1,1}\}\) is the decision or class label of the classifier, and \(\:{C}^{b}\left(x\right)\) is the classification integration (C = 1, 2, …, C).
Statistical evaluation of the developed models
In this study, the performance of the developed models was evaluated using multiple statistical measures, including coefficient of determination (R²), Nash-Sutcliffe efficiency (NSE), Willmott’s index of agreement (d), mean absolute error (MAE), root mean square error (RMSE), root relative squared error (RRSE) and relative Absolute Error (RAE) (Eqs. 6–12). along with the visual presentation of line diagram, scatter plo, residual error and Taylor diagram. These metrics provide a comprehensive assessment of the model’s predictive accuracy from different perspectives, ensuring a robust evaluation of its effectiveness. The computation of these performance indicators was carried out using the respective mathematical formulations, as detailed below:
Statistical measures | Formula | Range | Ideal value | Reference | |
|---|---|---|---|---|---|
Coefficient of determination (R²) | \(\:{R}^{2}={\left[\frac{\sum\:_{i=1}^{n}\:\left({\text{T}\text{e}\text{m}\text{p}}_{\text{O}}^{i}-\stackrel{\:}{\stackrel{-}{{{\text{T}\text{e}\text{m}\text{p}}_{\text{O}}^{i}}_{\:}^{\:}}}\right)-\left({\text{T}\text{e}\text{m}\text{p}}_{\text{O}}^{i}-\stackrel{\:}{\stackrel{-}{{{\text{T}\text{e}\text{m}\text{p}}_{\text{P}}^{i}}_{\:}^{\:}}}\right)}{\sqrt{\sum\:_{i=1}^{n}\:{\left({\text{T}\text{e}\text{m}\text{p}}_{\text{O}}^{i}-\stackrel{\:}{\stackrel{-}{{{\text{T}\text{e}\text{m}\text{p}}_{\text{O}}^{i}}_{\:}^{\:}}}\right)}^{2}}\:\sqrt{\sum\:_{i=1}^{n}\:{\left({\text{T}\text{e}\text{m}\text{p}}_{\text{P}}^{i}-\stackrel{\:}{\stackrel{-}{{{\text{T}\text{e}\text{m}\text{p}}_{\text{P}}^{i}}_{\:}^{\:}}}\right)}^{2}}}\right]}^{2}\) | 0 to 1 | 1 | (6) | |
Nash-Sutcliffe efficiency (NSE) | \(\:NSE\:=1-\:\frac{\sum\:_{i=1}^{N}{\left[{\text{T}\text{e}\text{m}\text{p}}_{\text{O}}^{i}-{\text{T}\text{e}\text{m}\text{p}}_{\text{P}}^{i}\right]}^{2}}{\sum\:_{i=1}^{N}{\left[{\text{T}\text{e}\text{m}\text{p}}_{\text{O}}^{i}-\:{\text{T}\text{e}\text{m}\text{p}}_{\text{O}}^{i}\right]}^{2}}\) | −∞ to 1 | 1 | (7) | |
Willmott’s index of agreement (d) | \(\:d=1-\frac{\sum\:_{i=1}^{n}\:{\left({\text{T}\text{e}\text{m}\text{p}}_{\text{O}}^{i}-{\text{T}\text{e}\text{m}\text{p}}_{\text{P}}^{i}\right)}^{2}}{\sum\:_{i=1}^{n}\:{\left(\left|{\text{T}\text{e}\text{m}\text{p}}_{\text{P}}^{i}-\stackrel{-}{{\text{T}\text{e}\text{m}\text{p}}_{\text{O}}^{i}}\right|+\left|{\text{T}\text{e}\text{m}\text{p}}_{\text{O}}^{i}-\stackrel{-}{{\text{T}\text{e}\text{m}\text{p}}_{\text{O}}^{i}}\right|\right)}^{2}}\) | 0 to 1 | 1 | (8) | |
Mean absolute error (MAE) | \(\:MAE=\frac{1}{N}\sum\:_{i=1}^{n}\:\left|{\text{T}\text{e}\text{m}\text{p}}_{\text{P}}^{i}-{\text{T}\text{e}\text{m}\text{p}}_{\text{O}}^{i}\right|\) | 0 to ∞ | 0 | (9) | |
Root mean square error (RMSE) | \(\:RMSE=\sqrt{\frac{1}{N}\sum\:_{i=1}^{N}{\left({\text{T}\text{e}\text{m}\text{p}}_{\text{O}}^{i}-{\text{T}\text{e}\text{m}\text{p}}_{\text{P}}^{i}\right)}^{2}}\) | 0 to ∞ | 0 | (10) | |
Root relative squared error (RRSE) | \(\:RRSE=\frac{\sqrt{\sum\:_{i=1}^{N}\:{\left({\text{T}\text{e}\text{m}\text{p}}_{\text{P}}^{i}-\stackrel{\:}{{\text{T}\text{e}\text{m}\text{p}}_{\text{O}}^{i}}\right)}^{2}}}{\sqrt{\sum\:_{i=1}^{N}\:{\left({\text{T}\text{e}\text{m}\text{p}}_{\text{O}}^{i}-\stackrel{-}{{{\text{T}\text{e}\text{m}\text{p}}_{\text{O}}^{i}}_{\:}^{\:}}\right)}^{2}}}\) | 0 to ∞ | 0 | (11) | |
Relative Absolute Error (RAE) | \(\:RAE=\frac{\sum\:_{i=1}^{n}\:\left|{\text{T}\text{e}\text{m}\text{p}}_{\text{P}}^{i}-{\text{T}\text{e}\text{m}\text{p}}_{\text{O}}^{i}\right|}{\sum\:_{i=1}^{n}\:\left|\stackrel{\:}{{\text{T}\text{e}\text{m}\text{p}}_{\text{O}}^{i}}-\stackrel{-}{{{\text{T}\text{e}\text{m}\text{p}}_{\text{O}}^{i}}_{\:}^{\:}}\right|}\) | 0 to ∞ | 0 | (12) |
where, \(\:{\text{T}\text{e}\text{m}\text{p}}_{\text{P}}^{i}\) and \(\:{\text{T}\text{e}\text{m}\text{p}}_{\text{O}}^{i}\) are the actual and forecasting air temperature for ith observation While \(\:\stackrel{\:}{\stackrel{-}{{{\text{T}\text{e}\text{m}\text{p}}_{\text{O}}^{i}}_{\:}^{\:}}}\), and \(\:\stackrel{\:}{\stackrel{-}{{{\text{T}\text{e}\text{m}\text{p}}_{\text{P}}^{i}}_{\:}^{\:}}}\) are the mean of actual and predicted value, and N is the total number of observations.
The coefficient of determination (R2) quantifies the proportion of variance in the dependent variable explained by independent variables, with higher values indicating a better fit. Willmott’s index (d) assesses agreement between observed and predicted values, with d = 1 indicating perfect alignment. Nash-Sutcliffe Efficiency (NSE) of 1 denotes a perfect model, while values near 0 suggest forecastings as accurate as the mean observed data103,110. RMSE and MSE evaluate average squared forecasting errors, whereas MAE measures absolute errors109. RRSE and RAE assess relative forecasting accuracy, with lower values indicating superior performance103,109.
Results
Selection of inputs
The time lag for the input variables was determined based on the maximum autocorrelation function (ACF) and partial autocorrelation function (PACF) between the inputs and their respective time lags. Figures 3 and 4 illustrate the ACF and PACF for both minimum and maximum temperatures, with 5% significance limits, respectively. The correlation analysis revealed significant autocorrelations at lag periods ranging from 1 to 8 days for both temperature types. The correlation between Tmax and its lag values ranged from 0.925 to 0.778, while for Tmin, the correlation ranged from 0.879 to 0.751, both showing a decrease as the lag period increased. Based on these findings, the time lags up to 8 days were selected for further modeling. Additionally, regression analysis was conducted to determine the optimal combination of input variables, incorporating the identified 8-day lag period.

A.C.F. and PACF for minimum temperature using daily and monthly lags.

A.C.F. and PACF for maximum temperature using daily and monthly lags.
The best subset regression analysis results presented in Table 2 show the performance of various combinations of input variables for predicting minimum air temperature (Tmin). As the number of input variables increases, the mean squared error (MSE) gradually decreases from 7.084 for Tmin(t−1) alone to 6.214 for the combination of Tmin(t−1) through Tmin(t−8). The coefficient of determination (R²) increases slightly, reaching 0.801 for the most comprehensive model (including Tmin from lags t-1 to t-8), indicating a stronger fit to the observed data. Similarly, the values for Mallows’ Cp, Akaike’s AIC, and Schwarz’s SBC improve, suggesting a better model fit with fewer variables. Despite the improvements, the Amemiya’s PC value remains close to 0.199, showing no significant change across the models. These findings suggest that incorporating additional lags (up to 8 days) yields a marginal but consistent improvement in model performance, without introducing significant complexity or overfitting. The best input combination for forecasting daily minimum temperature were Tmin(t−1), Tmin(t−3), Tmin(t−4), Tmin(t−5), Tmin(t−6), Tmin(t−7), Tmin(t−8) as shown in Table 2.
Similar to the results for maximum air temperature, the regression analysis for maximum temperature (Tmax) also demonstrates that increasing the number of input variables leads to a slight reduction in mean squared error (MSE), from 8.585 for Tmax(t−1) to 7.899 for the inclusion of Tmax(t−1) through Tmax(t−8) (Table 3). The coefficient of determination (R²) remains consistently high, reaching 0.866, indicating a strong model fit across all combinations. The values of Mallows’ Cp, Akaike’s AIC, and Schwarz’s SBC also improve with additional lags, suggesting better model optimization. However, Amemiya’s PC remains stable at around 0.134, reflecting minimal change with the inclusion of additional lags. These results indicate that extending the time lags up to 8 days enhances model performance without significant overfitting. The best input combination for forecasting daily maximum temperature were Tmax (t−1), Tmax (t−2), Tmax (t−3), Tmax (t−4), Tmax (t−5), Tmax (t−6), Tmax (t−8) as shown in Table 3.
Additional analysis of seasonal component
The seasonal component analysis of the daily maximum and minimum air temperature time series is further explored through four plots in Fig. 5, which include seasonal indices, detrended data by season, percent variation by season, and residuals by season, each showing yearly data. In Fig. 5a, the bar chart (top left) illustrates the variation in seasonal indices over the 20-year period. For maximum temperature, the largest variations are observed in nine years, with the highest bars indicating the greatest disparity for those months. For minimum temperature, the most notable variation occurs in years 18–20. In Fig. 5b, similar trends are observed, with year 13 showing the highest seasonal variation for both maximum and minimum temperatures. The detrended data (top right in Fig. 5a-b), presented as boxplots, indicates minimal change due to the slight trend in the time series, suggesting little effect from detrending. The residuals, shown in the bottom right of Fig. 5(a-b), further confirm consistent seasonal patterns, with yearly fluctuations varying in magnitude, reinforcing the presence of seasonality in the data.

Seasonal (Yearly) analysis for (a) maximum and (b) minimum temperature.
Minimum air temperature forecasting
Table 4 presents a summary of the prediction performance indices obtained in this study for the predictive models, including Linear Regression, Additive Regression, Random Subspace, M5P, and SVM for minimum temperature forecasting. The graphical representations of the time series are provided in Supplementary Figures S1–S2, while the scatter plots and violin plots with embedded box plots for the training and testing phases are presented in Supplementary Figures S2–S3, respectively. To evaluate the simulation potential of the selected LR, AR, RSS, M5P, and SVM models for minimum air temperature forecasting, the models were trained using 10,219 datasets and tested on 2,768 datasets, with input variables Tmin(t−1), Tmin(t−3), Tmin(t−4), Tmin(t−5), Tmin(t−6), Tmin(t−7), Tmin(t−8) (Table 2). Additionally, the entire dataset was shuffled and subjected to validation to ensure model robustness. The performance evaluation of various machine learning models for minimum temperature forecasting, as detailed in Table 4, highlights significant variations across training, testing, and validation phases based on multiple statistical indices, including Nash-Sutcliffe Efficiency (NSE), Index of Agreement (d), mean absolute error (MAE), root mean square error (RMSE), relative absolute error (RAE), root relative squared error (RRSE), pearson correlation coefficient (PCC), and coefficient of determination (R²). The NSE values range from a minimum of 0.7506 (Additive Regression, testing) to a maximum of 0.8145 (Random Subspace, training); however, the best-performing model should demonstrate superior performance in both testing and validation phase. In this regard, the M5P model exhibited the highest NSE values of 0.7951 in testing and 0.8048 in validation, outperforming all other models. The RMSE values varied between 2.113 (Additive Regression, testing) and 2.749 (Additive Regression, validation), with M5P achieving the lowest RMSE of 2.445 in testing and 2.488 in validation, reinforcing its strong predictive ability. Similarly, M5P demonstrated a high index of agreement (d) of 0.9411 in testing and 0.9433 in validation, further confirming its reliability in capturing temperature variations. The Pearson Correlation Coefficient (PCC) also indicated M5P as the most effective model, with values of 0.8919 (testing) and 0.8971 (validation), ensuring its ability to capture strong relationships between predicted and actual values. Furthermore, the M5P model recorded one of the lowest error values, with a MAE of 1.899 in testing and 1.952 in validation, while also maintaining the lowest RAE (40.465) and RRSE (45.062) during testing. Although the Random Subspace model showed the highest NSE (0.8145) in training, its performance slightly declined in testing and validation, making M5P the most consistent and reliable model across all phases. In contrast, Additive Regression consistently underperformed across all metrics, with the lowest NSE (0.7506), highest RMSE (2.749), and lowest PCC (0.8671), making it the weakest model. Based on comprehensive performance evaluation across all statistical measures, the models are ranked as follows: M5P > Random Subspace > Linear Regression > SVM > Additive Regression.
For enhanced visualization and comparative analysis of the models, a line diagram, scatter plots illustrating the relationship between actual values and forecasted temperature with a 95% prediction band, and a histogram incorporating the Gaussian kernel density function are employed using the most accurate input combinations. Figure 6 present a comparative analysis of the daily measured and forecasted minimum air temperatures utilizing the most accurate input combination of the developed machine learning algorithms during the validation period. Additionally, the bottom panel offers a magnified view, providing a detailed representation of the observed and predicted temperature variations. Overall, while all models generally follow the trend of the actual values, they exhibit deviations in peaks and troughs, with some models such as M5P and Random Subspace appearing to track the actual values more closely in certain segments. Figure 6 indicates their tendency to overestimate or underestimate the actual values. The residuals of Additive Regression show a slight positive bias with a mean bias error of 0.003, suggesting minor overestimation. Random Subspace and Linear Regression have mean bias errors of −0.002 and − 0.001, respectively, indicating a very slight underestimation. The M5P model has a mean bias error of 0, meaning it exhibits no systematic bias in its predictions. Among all models, SVM has the highest mean bias error at 0.169, suggesting a noticeable overestimation compared to the actual values.

Comparison of daily measured and forecasted minimum temperatures using the most accurate input combination of the developed machine learning algorithms during the validation period. The bottom panel provides a zoomed-in view of the observed and forecasted data.
While Fig. 7(a-e) shows the scatter plots with 95% prediction band and a violin plot with a box plot Fig. 7(f) comparing actual and forecasted daily minimum temperature values for during the training period and testing phase, respectively. The 95% prediction band is the area in which you expect 95% of all data points to fall. In contrast, the 95% confidence band is the area that has a 95% chance of containing the true regression line. Additive regression (AR) failed to predict the highest and lowest values in both cases (both minimum and maximum temperatures) during the training, testing and validation periods. The violin plot compares the distribution of actual and predicted temperature ranges across different machine learning models, including AR, RSS, LR, M5P, and SVM (Fig. 7(f)). The figure visualizes the spread of temperature variations, median values, and interquartile ranges (IQR), which help assess the accuracy of each model in capturing temperature fluctuations. The actual temperature range spans from 5.52 to 24.06, with a median of 12.01 and an interquartile range between 7.59 and 16.75. Among the predictive models, M5P demonstrates the closest resemblance to the actual distribution. It has a range of 0.77 to 22.24, a median value of 12.01, and an IQR between 7.15 and 16.59. These values indicate that M5P effectively captures the temperature variations while maintaining a distribution similar to the actual data.

Scatter plots (a–e) and a violin plot with a box plot (f) comparing actual and forecasted daily minimum temperature values using the most accurate input combination of the developed ML algorithms during the validation period.
Other models, such as AR and RSS, exhibit narrower distributions, with AR ranging from 2.44 to 18.67 and RSS from 1.66 to 20.51. Their inability to capture extreme values suggests that they may struggle to predict temperature variations accurately. Linear Regression LR follows closely behind M5P, with a range of 3.11 to 22.44, but it slightly underestimates temperature extremes. The SVM model, although similar to LR, has a slightly wider range from − 3.17 to 22.74, indicating occasional under-predictions. Overall, M5P emerges as the best-performing model, as it aligns most closely with the actual temperature range while maintaining a balanced distribution and accurate median prediction. The results suggest that M5P provides the most reliable temperature forecasts among the evaluated models.
Figure 8(a-e) presents histogram plots illustrating the forecasting error distribution during the validation phase. These plots provide a visual representation of the error distribution by depicting the frequency of error values within predefined intervals. Additionally, a Gaussian kernel density function is incorporated to assess the normality of the error distribution, offering insights into the overall error characteristics and potential deviations from a normal distribution. The residual analysis of predictive models reveals their accuracy and distribution. The mean residual values for all models are close to zero, indicating minimal systematic bias. Standard deviation and variance values show that Additive Regression has the highest variability, while Random Subspace has the lowest, suggesting that Random Subspace provides more consistent predictions. Kurtosis values are positive but relatively low, indicating a distribution close to normal with slightly heavier tails. Skewness values are negative for all models, suggesting a slight leftward asymmetry in residual distributions, though the magnitude remains small. The range of residuals is highest for Random Subspace (19.2894) and lowest for Linear Regression (17.6237), indicating that Random Subspace has the widest spread of errors. Minimum residual values show that Random Subspace underestimates the most (−11.3060), while Additive Regression has the highest overestimation (9.7190). Overall, all models exhibit relatively small residual errors, with some variation in distribution and spread. Additive Regression and Linear Regression display slightly higher residual variability, whereas Random Subspace and M5P show more constrained predictions. SVM has moderate error dispersion but does not exhibit extreme bias. These insights help in selecting a model based on error consistency and bias considerations.

The histogram and Gaussian kernel density function for daily minimum temperature forecasting during the validation phase.
The results of the Table 4; Figs. 6, 7 and 8 along with the Taylor diagram confirm that the M5P has outperformed other benchmark models in forecasting accuracy across all the phase (testing and validation phase) (Fig. 9).

Taylor diagram of predicting daily minimum temperature amounts using the most accurate models in the testing and validation period.
Maximum air temperature forecasting
The performance evaluation of the developed machine learning (ML) models for maximum air temperature forecasting, as presented in Table 5, indicates that the models exhibit varying degrees of accuracy based on statistical indices across training, testing, and validation phases. Whereas the graphical representation of the time series are given in ‘Supplementary material’ Supplementary Figure S5-S6, scatter plot and violin plot with a box plot are given in ‘Supplementary material’ Supplementary Figure S7-S8 for training and testing phase, respectively. Among all models, M5P demonstrated the best overall performance, with the highest NSE values of 0.8761, 0.8473, and 0.8720 for training, testing, and validation, respectively. It also exhibited the lowest RMSE values (2.7248, 2.9027, and 2.7696) and MAE values (1.9555, 2.0773, and 1.9867) across the three phases. Additionally, M5P achieved the highest PCC values (0.9360, 0.9206, and 0.9338), confirming its superior predictive capability. In contrast, the Additive Regression model exhibited the weakest performance, with the lowest NSE values (0.8362, 0.8072, and 0.8305) and the highest RMSE values (3.1329, 3.2611, and 3.1872). The model also recorded the highest RAE (34.4855, 37.3644, and 35.0419) and RRSE (40.467, 43.512, and 41.165), indicating significant deviations in predicted values compared to observed data. Furthermore, its PCC values (0.9147, 0.8989, and 0.9113) were lower than those of the other models, reinforcing its relatively poorer predictive accuracy.
The performance of Linear Regression, Random Subspace, and Support Vector Machine (SVM) models was intermediate, with NSE values ranging from 0.8466 to 0.8708, RMSE values between 2.7828 and 2.9890, and PCC values varying from 0.9080 to 0.9338. These models demonstrated moderate forecasting accuracy but were outperformed by M5P in all statistical aspects. Overall, M5P emerged as the most effective model for maximum temperature forecasting, achieving the highest accuracy and lowest error rates, while Additive Regression performed the poorest, displaying the highest prediction errors and lowest efficiency. The models ranked based on performance are: M5P (Best) > Linear Regression > SVM > Random Subspace > Additive Regression (Worst), with M5P showing the highest accuracy and Additive Regression the poorest performance.
The comparison of daily measured and forecasted maximum temperatures using different machine learning models during the validation period reveals varying degrees of prediction accuracy (Fig. 10). The mean bias error (MBE) provides insight into the tendency of each model to overestimate or underestimate temperature values. Among the models, linear regression demonstrates the most balanced performance with an MBE of zero, indicating no systematic bias in its predictions. This suggests that, on average, the model neither over-predicts nor under-predicts the actual temperatures, making it highly reliable.

Comparison of daily measured and forecasted maximum temperatures using the most accurate input combination of the developed machine learning algorithms during the validation period. The bottom panel provides a zoomed-in view of the observed and forecasted data.
The random subspace and additive regression models exhibit slight underestimation, with MBEs of −0.006 and − 0.022, respectively. Their minor negative bias suggests that while they closely follow the actual temperature trends, they tend to predict slightly lower values than observed. Similarly, the M5P model shows a small positive bias of 0.006, implying a slight overestimation of temperatures. These minimal deviations indicate that all three models perform well, with only marginal tendencies to either underestimate or overestimate.
In contrast, the SVM model shows the most significant bias, with an MBE of −0.153, indicating a considerable underestimation of maximum temperatures. This suggests that the SVM model struggles to fully capture the variability in temperature data, leading to consistent under-prediction. The results highlight that while most models perform well with minimal bias, SVM is less reliable in accurately forecasting maximum temperatures during the validation period.
Figure 11(a–e) presents scatter plots with a 95% prediction band, while Fig. 11(f) displays a violin plot combined with a box plot, comparing actual and forecasted daily maximum temperature values during the training and testing phases. The 95% prediction band represents the range where 95% of the data points are expected to fall, whereas the 95% confidence band indicates the range with a 95% probability of containing the true regression line. Additive Regression (AR) demonstrated limitations in accurately forecasting both the highest and lowest temperature values during the training, testing, and validation periods, failing to capture the full range of temperature variability while the other models very closed to line 1:1. The violin plot presents a comparative analysis of the actual and predicted temperature ranges across different machine learning models, including Additive Regression (AR), Random Subspace (RSS), Linear Regression (LR), M5P, and Support Vector Machine (SVM) (Fig. 11(f)). The plot illustrates the distribution, median, and interquartile range (IQR) of temperature predictions, providing insights into the models’ accuracy and performance. The actual temperature range varies from 7.34 to 48.70, with a median value of 29.12 and an interquartile range between 22.51 and 35.82. Among the models, M5P exhibits the closest resemblance to the actual distribution, with a range from 11.72 to 46.20, a median value of 29.13, and an interquartile range between 22.42 and 35.64. This alignment suggests that M5P effectively captures the variability and central tendency of the actual temperature distribution. Comparing the other models, AR and RSS display similar distributions with slightly narrower ranges (15.00 to 40.79) and a median of 29.12, but they fail to capture extreme values as effectively as M5P. Linear Regression (LR) follows closely, with a slightly lower minimum of 9.89 and a comparable IQR (22.71 to 35.55). SVM, on the other hand, demonstrates the least accurate performance, with a range of 9.27 to 47.17 and a median of 28.97, showing a tendency for underestimating temperature variations. Overall, the M5P model stands out as the best-performing model due to its strong alignment with actual temperature values. It maintains a well-balanced distribution, accurately capturing both the median and spread of the data while encompassing extreme values more effectively than the other models. This makes M5P the most reliable choice for temperature prediction in this scenario.

Scatter plots (a–e) and a violin plot with a box plot (f) comparing actual and forecasted daily maximum temperature values using the most accurate input combination of the developed ML algorithms during the validation period.
Figure 12(a-e) presents histogram plots illustrating the forecasting residual error distribution during the validation phase. The residual analysis of predictive models for maximum temperature forecasting reveals key insights into their performance. The mean residual values for all models are close to zero, indicating minimal systematic bias. Standard deviation and variance values suggest that Additive Regression has the highest variability, while M5P has the lowest, implying that M5P provides more consistent predictions. Kurtosis values indicate that all residual distributions exhibit slightly heavier tails than a normal distribution, with SVM showing the highest kurtosis, suggesting more extreme residual values. The negative skewness observed across all models indicates a slight tendency toward underestimation, with SVM having the most pronounced leftward skew. The range of residuals is widest for M5P (34.4613) and narrowest for Additive Regression (32.1144), demonstrating varying degrees of error spread among models. The minimum and maximum residual values suggest that Random Subspace exhibits the most significant overestimation, while Additive Regression shows the least. Overall, M5P demonstrates lower error dispersion and variance, indicating more stable performance, while SVM and Linear Regression display higher deviations. These findings highlight M5P as the most reliable model for maximum temperature forecasting due to its minimal variance and balanced error distribution.

The histogram and Gaussian kernel density function of residual error for daily maximum temperature forecasting during the validation phase.
The results presented in Table 5; Figs. 10, 11 and 12, in conjunction with the Taylor diagram, demonstrate that the M5P model exhibits superior forecasting accuracy compared to other benchmark models across all phases, including both testing and validation (Fig. 13).

Taylor diagram of predicting daily maximum temperature amounts using the most accurate models in the testing and validation phase.
Statistical comparison between the predictive models for minimum air temperature forecasting based Friedman ANOVA
The Friedman test is a non-parametric statistical test used to compare multiple models (or treatments) across multiple datasets (or repeated measures). It helps determine whether at least one model significantly differs in performance from the others. Table 6 shows the descriptive statistics for the Friedman ANOVA analysis on minimum temperature forecasting provide insights into the distribution of predictions across different models. The actual minimum temperatures range from − 5.517 °C to 24.06 °C, with a median of 12.616 °C. Among the models, Additive Regression exhibits the highest median (14.002 °C), indicating a tendency to overestimate compared to actual values, whereas Linear Regression and SVM have medians (12.607 °C and 12.81 °C, respectively) closer to the actual median, suggesting a more balanced prediction. Random Subspace shows a wider range (1.662 °C to 20.505 °C) than most models, indicating higher variability in predictions. The first (Q1) and third (Q3) quartiles across models also highlight variations in predictive dispersion, with M5P and Additive Regression having narrower interquartile ranges compared to others. The maximum and minimum values of models further indicate their ability to capture extreme temperature values, with Linear Regression and SVM capturing a broader range, whereas Additive Regression tends to be more conservative. Overall, the differences in median values and variability suggest notable performance variations, which align with the Friedman test’s objective of assessing statistical differences in model forecasting ability.
The results of the Friedman test, the significance of the p-value is assessed to determine whether differences exist among the models. If the p-value is less than the significance level (α), typically 0.05, the null hypothesis (H₀), which assumes that all models perform equally, is rejected. This indicates that at least one model exhibits a statistically significant difference in performance compared to the others, suggesting variability in predictive accuracy. Conversely, if the p-value is greater than or equal to α, the null hypothesis is not rejected, implying that there is no statistically significant difference among the models. In this case, the models exhibit similar predictive capabilities based on rankings, and any observed differences in performance are likely due to random variations rather than inherent model superiority.
Table 7 shows is the result of Dunn’s Test, a post-hoc analysis typically used after a significant Friedman Test to determine which specific pairs of models exhibit significant differences in their performance. The columns in the table represent the Sum Rank Difference, Z-score, p-value (Prob), and Significance (Sig) between different model pairs. From the results, we observe that most model comparisons show significant differences, as indicated by very low p-values (often much smaller than 0.05). For instance, the comparison between “Actual” and “Linear Regression” has a p-value of 1.51E-115, which is an extremely small value, strongly rejecting the null hypothesis of no difference. Similarly, the comparison between “Actual” and “SVM” has a very large negative Sum Rank Difference (−7055), with a high Z-score (26.37812) and an extremely small p-value (3.66E-152), further confirming substantial differences in their performance.
In contrast, some comparisons do not show significant differences. For instance, the “Random Subspace” vs. “M5P” comparison has a p-value of 0.44118, which is greater than 0.05, meaning that their performance is statistically similar. The same applies to the “M5P” vs. “SVM” comparison, which has a p-value of 0.0, suggesting that these models are significantly different from each other. A notable trend in the results is that SVM appears to be significantly different from most models, often with large negative Sum Rank Differences, indicating poorer performance relative to others. Conversely, Linear Regression and Additive Regression seem to perform distinctly better than SVM and some other models. Overall, the Dunn’s Test results confirm that the models do not perform equally, with several significant differences among them. The results suggest that some models (e.g., Linear Regression, Additive Regression) perform considerably differently from others (e.g., SVM). The findings from this test can help in selecting the best-performing model for minimum temperature forecasting.
Statistical comparison between the predictive models for maximum air temperature forecasting based Friedman ANOVA
Table 8 shows the descriptive statistics for maximum temperature forecasting using Friedman ANOVA reveal significant variations in model predictions compared to actual values. The actual temperature ranges from 7.34 °C to 48.696 °C, with a median of 30.033 °C, serving as the benchmark for evaluating model accuracy. Among the models, Additive Regression exhibits the highest median (32.12 °C) and a relatively high first quartile (23.148 °C), indicating a tendency to slightly overestimate maximum temperatures. Random Subspace (30.077 °C), Linear Regression (29.988 °C), and SVM (29.843 °C) have medians closely aligning with actual values, suggesting better generalization. M5P (30.237 °C) also provides a reasonable approximation, though its wider range (11.722 °C to 46.2 °C) indicates some variability in predictions. The first (Q1) and third (Q3) quartiles across models highlight different levels of dispersion, with Additive Regression having a relatively higher interquartile range. While Random Subspace and Linear Regression exhibit narrower ranges, they still maintain strong alignment with actual temperatures. The broader spread observed in models like M5P and SVM suggests they capture temperature extremes more effectively. These variations in statistical measures reinforce the need for Friedman ANOVA, ensuring that the performance differences among models are statistically validated rather than due to random fluctuations.
The results of the ANOVA post-hoc analysis using Dunn’s Test for the Additive Regression, Random Subspace, Linear Regression, M5P, and SVM techniques provide insights into the statistical significance of pairwise comparisons among these models. Table 9 presents the sum rank differences, Z-values, probabilities (p-values), and significance indicators. From the results, it is evident that “Actual” values compared to Additive Regression show a non-significant difference (p = 0.12795), suggesting that Additive Regression does not significantly deviate from the actual values. However, the comparisons between “Actual” and other models, such as Random Subspace (p < 0.001), Linear Regression (p < 0.001), M5P (p < 0.001), and SVM (p < 0.001), exhibit highly significant differences, indicating that these models differ considerably from the actual values.
When comparing the Additive Regression model with other models, significant differences are observed against Random Subspace (p < 0.001), Linear Regression (p < 0.001), M5P (p < 0.001), and SVM (p < 0.001), implying that Additive Regression produces notably different results from these models. Similarly, Random Subspace and Linear Regression show a significant difference (p = 0.01087), highlighting that their predictive behaviors differ.
Interestingly, the comparison between Random Subspace and M5P (p = 0.12152) is not statistically significant, indicating that these two models perform similarly. However, all other comparisons, especially those involving SVM, show extremely low p-values (p < 0.001), revealing that SVM’s results are significantly different from those of all other models. Notably, the comparisons between SVM and Random Subspace, Linear Regression, and M5P exhibit the highest significance, with p-values reaching as low as 6.57538E-193, emphasizing the stark contrast between SVM and the other techniques.
Overall, the findings suggest that SVM significantly differs from all other models, while Additive Regression is the closest to actual values. Furthermore, Random Subspace and M5P display similarities, whereas Linear Regression shows notable deviations compared to most techniques. These results underline the importance of choosing the right modeling approach depending on the specific application and desired accuracy.
Discussion
Over the past several years, the availability of air temperature measurements has facilitated extensive research focused on modeling air temperature using machine learning frameworks. The present study aimed to predict maximum (Tmax) and minimum (Tmin) air temperatures using only previously recorded values (lags) of the same variables. A total of five machine learning models—Linear Regression (LR), Additive Regression (AR), Support Vector Machine (SVM), Random Subspace (RSS), and M5P—were applied and compared based on various numerical performance metrics. The results indicated that for Tmin forecasting, the M5P model demonstrated the best performance (NSE = 0.7951, 0.8048; MAE = 1.899, 2.445; RMSE = 1.952, 2.488 and R2 = 0.7956, 0.8048 during testing and validation period, respectively). Similarly, for Tmax prediction, M5P also outperformed the other models (NSE = 0.8473, 0.8720; MAE = 2.0773, 1.9867; RMSE = 2.9027, 2.7696 and R2 = 0.8475, 0.8720 during testing and validation period, respectively). It is crucial to assess the accuracy of air temperature forecasting in the context of previous studies and compare the findings of this study with those reported in the literature. Although limited studies have specifically employed machine learning for air temperature forecasting, numerous studies have demonstrated the successful application of machine learning techniques when incorporating a combination of various meteorological variables. The superiority of M5P model aligned with Achite et al.111Mohaghegh et al.112 and Anaraki et al.113.
Toharudin et al.114 compared between the long short-term memory (LSTM) and the Facebook Prophet models for forecasting Tmax and Tmin. They reported that RMSE values of approximately 1.23 and 0.97 were obtained using the LSTM model, which are less than the values obtained in our study. Chevalier et al.84 compared between SVR and MLPNN models for forecasting air temperature up to 12 h in advance and they reported that the SVR was more accurate compared to the MLPNN exhibiting an R and MAE value of approximately 0.955 and 1.906, respectively. The regression equations developed by Gouvas et al.115 for predicting Tmax and Tmin were found to be robust tools and excellent forecasting accuracies were obtained for each month of the year. For Tmax forecasting, the R values were ranged from 0.888 to 0.984, while for the Tmin forecasting, the R values were ranged from 0.921 to 0.984, respectively. These results clearly demonstrated the superiority of the developed regression equations in comparison to the ML models developed in ou present study. In another study, Sekertekin et al.116 compared between various ML models manly, the LSTM, Adaptive Neuro-Fuzzy Inference System (ANFIS) with Fuzzy C-Means (ANFIS-FCM), ANFIS with Subtractive Clustering (ANFIS-SC) and ANFIS with Grid Partition (ANFIS-GP) for forecasting daily anf hourly air temperature. Excellent results were obtained using all models and the LSTM was found to be the more accurate exhibiting the best performances with R, RMSE and MAE of approximately 0.970, 1.359, and 0.993, respectively, which were significantly superior to the values obtained in our study. Rezaeian-Zadeh et al.117 examined the effectiveness of the multilayer perceptron neural network (MLPNN) and the radial basis function neural network (RBFNN) for forecasting daily maximum (Tmax) and minimum (Tmin) air temperatures. Their study reported excellent predictive performance, with the MLPNN achieving a correlation coefficient (R) of approximately 0.984 and a root mean square error (RMSE) of 1.8, while the RBFNN attained an R value of 0.964 and an RMSE of 2.9. These findings highlight the superior performance of MLPNN and RBFNN in comparison to the models developed in the present study. Chithra et al.118 investigated the feasibility of the Multi-Layer Perceptron Neural Network (MLPNN) model for predicting monthly maximum (Tmax) and minimum (Tmin) temperatures. Although the authors did not provide explicit details regarding the model’s fitting capability, the reported root mean square error (RMSE) values were relatively low, indicating satisfactory predictive performance. Specifically, the RMSE values ranged from 0.38 to 0.84 for Tmax and from 0.47 to 0.93 for Tmin, suggesting that the MLPNN model effectively captured temperature variations with minimal error.
In a recently published, Oloyede et al.119 applied five ML models namely, decision tree regression (DT), XGBoost regression, the MLPNN with limited-memory Broyden-Fletcher-Goldfarb-Shanno optimizer, with stochastic gradient optimizer and with Adam optimizer, i.e., MLPNN-LBFGS, MLPNN-SGD, and MLPNN-AOP for predicting daily Tmax and Tmin. It was found that the MLPNN-LBFGS was the most accurate model and it surpassed all other ML models by significantly reducing the RMSE and MAE values: MAE from 2.184 to 1.412 °C and RMSE from 2.579 to 1.778 °C for Tmax, and the MAE from 0.876 to 0.788 °C (10.05%) and RMSE from 1.225 to 1.127 °C (8.00%) for Tmin, respectively. While the biggest R-value was found to be approximately 0.845. Ramesh and Anitha120 applied the multivariate adaptive regression spline (MARS) and the SVR models for forecasting daily Tmax and Tmin. Obtained results revealed that performances of the MARS were more accurate compared to the SVR with RMSE and MAE of approximately 0.82 and 0.60 for Tmin, 1.19 and 0.87 for Tmax. It is clear for the obtained results that, the proposed MARS was more accurate compared ot our ML models. Mollick et al.121 compared between linear regression (LR), Ridge, SVR, RF, and light gradient boosting machine (LGBM), and the Stacking models for forecasting daily Tmax and Tmin. According to the obtained results, the Stacking model was found to be the more accurate exhibiting R and MAE values of approximately, 0.856 and 1.024, 0.982 and 0.537, for daily Tmax and Tmin, respectively. by comparison, the proposed Stacking model was more accurate compared to our model for Tmax and less accurate compared to Tmin.
Finally, the Friedman ANOVA test was employed to see whether the distributions of the estimated and measured data were identical122,123. The Friedman ANOVA and Dunn’s post-hoc test results provide substantial evidence of statistically significant differences among the predictive models for temperature forecasting. The analysis reveals that no single model performs uniformly across both minimum and maximum temperature predictions, highlighting the complexities of temperature modeling.
For minimum temperature forecasting, the results indicate that Additive Regression tends to overestimate values, whereas models like Linear Regression and SVM exhibit medians closer to actual values, suggesting relatively better alignment. However, the variability in prediction dispersion, particularly in Random Subspace and M5P, underscores the inconsistencies in their predictive capabilities. The post-hoc analysis further confirms that SVM significantly deviates from all other models, often exhibiting the largest rank differences, suggesting that its performance is considerably distinct, and potentially less reliable, in this context.
Similarly, in maximum temperature forecasting, Additive Regression again exhibits a tendency to overestimate, while models such as Random Subspace, Linear Regression, and SVM demonstrate closer alignment with actual temperature values. However, the statistical significance of the post-hoc comparisons shows that despite their proximity to actual values, many models exhibit significant differences from one another. Notably, Random Subspace and M5P display similar performance, as indicated by their non-significant pairwise difference (p > 0.05), while SVM continues to stand out as significantly different from all other models.
From a critical perspective, while statistical significance suggests meaningful differences among models, it does not necessarily imply practical superiority. The effectiveness of a model should be evaluated not only based on its statistical deviations but also on its ability to generalize across different temperature conditions. The stark differences observed in SVM’s results across both minimum and maximum temperature forecasting suggest it may not be a reliable choice for this application. In contrast, Additive Regression, despite its overestimation tendencies, appears to be more stable. The observed similarity between Random Subspace and M5P indicates that these models could be interchangeable in some contexts.
Ultimately, these findings reinforce the necessity of model selection based on the specific requirements of temperature forecasting rather than relying solely on statistical differences. Future research should consider integrating hybrid approaches or ensemble techniques to mitigate individual model weaknesses and enhance overall predictive performance.
A key conclusion from the previously discussed study on Tmax and Tmin forecasting using machine learning (ML) is that the developed ML models demonstrated strong predictive capabilities and robustness. In most case studies, these models outperformed those proposed in the present study. However, while our models relied solely on temperature measurements at multiple lag times, a notable limitation of some published studies is their dependence on a combination of multiple meteorological variables to enhance forecasting accuracy. Several researchers have highlighted that solar radiation can be as influential as other meteorological parameters, such as wind speed, humidity, and precipitation, in air temperature prediction.
Despite the challenge of simultaneously collecting diverse weather variables, the modeling framework presented in this study is technically sound, promising, and adaptable to other locations with available Tmax and Tmin measurements.
Conclusion
This study evaluated the predictive capabilities of multiple forecasting models, including Linear Regression (LR), the Autoregressive (AR) model, Random Search (RS), M5P, and Support Vector Machine (SVM), for estimating daily maximum and minimum temperatures. Statistical techniques such as the autocorrelation function (ACF), partial autocorrelation function (PACF), and regression analysis were employed to identify optimal input variable combinations. The results indicate that the M5P model outperforms other models in forecasting both temperature parameters, while LR and SVM also demonstrate competitive accuracy, suggesting their suitability for temperature prediction. Furthermore, incorporating multiple past observations enhances predictive accuracy, underscoring the importance of optimal time lag selection.
The Friedman ANOVA and Dunn’s test confirm statistically significant differences among the models, with Additive Regression exhibiting a tendency to overestimate, whereas LR and SVM align more closely with actual values. Random Subspace and M5P demonstrate higher variability, with SVM differing significantly from other models. For maximum temperature prediction, Random Subspace and M5P show similar performance, while SVM remains an outlier. However, statistical significance does not inherently imply practical superiority, emphasizing the necessity of balancing predictive accuracy and model stability.
To enhance forecasting performance, future research must explore advanced machine learning models, including ensemble techniques such as Random Forest (RF) and XGBoost, in combination with meta-heuristic optimization approaches like Ant Colony Optimization, the Firefly Algorithm, and the Gray Wolf Optimizer. These methods can improve computational efficiency and generalizability. The study’s findings hold significant practical implications for water resource management and agricultural planning, where improved temperature forecasting can facilitate more effective irrigation scheduling, energy consumption planning, and climate adaptation strategies. By leveraging data-driven methodologies, stakeholders can develop more sustainable and efficient approaches to managing environmental and agricultural resources. This research contributes to advancements in predictive modeling, providing valuable insights for future studies in climate forecasting and resource optimization.
Data availability
The datasets used and/or analysed during the current study available from the corresponding author on reasonable request.
References
Azari, B., Hassan, K., Pierce, J. & Ebrahimi, S. Evaluation of machine learning methods application in temperature prediction. Comput. Res. Prog Appl. Sci. Eng. CRPASE Trans. Civ. Environ. Eng. 8, 1–12 (2022).
Ishaque, W., Tanvir, R. & Mukhtar, M. Climate Change and Water Crises in Pakistan: Implications on Water Quality and Health Risks. J. Environ. Public Health (2022). (2022).
Thober, S. et al. Multi-model ensemble projections of European river floods and high flows at 1.5, 2, and 3 degrees global warming. Environ. Res. Lett. 13, 014003 (2018).
Király, A. & Jánosi, I. M. Stochastic modeling of daily temperature fluctuations. Phys. Rev. E. 65, 051102 (2002).
Bartos, I. & Jánosi, I. M. Nonlinear correlations of daily temperature records over land. Nonlinear Process. Geophys. 13, 571–576 (2006).
Holden, Z. A., Crimmins, M. A., Cushman, S. A. & Littell, J. S. Empirical modeling of Spatial and Temporal variation in warm season nocturnal air temperatures in two North Idaho mountain ranges, USA. Agric. Meteorol. 151, 261–269 (2011).
Evrendilek, F., Karakaya, N., Gungor, K. & Aslan, G. Satellite-based and mesoscale regression modeling of monthly air and soil temperatures over complex terrain in Turkey. Expert Syst. Appl. 39, 2059–2066 (2012).
Kisi, O. & Shiri, J. Prediction of long-term monthly air temperature using geographical inputs. Int. J. Climatol. 34, 179–186 (2014).
Goodale, C., Aber, J. & Ollinger, S. Mapping monthly precipitation, temperature, and solar radiation for Ireland with polynomial regression and a digital elevation model. Clim. Res. 10, 35–49 (1998).
Ninyerola, M., Pons, X. & Roure, J. M. A methodological approach of Climatological modelling of air temperature and precipitation through GIS techniques. Int. J. Climatol. 20, 1823–1841 (2000).
Reicosky, D., Winkelman, L., ., Baker, J. & Baker, D. Accuracy of hourly air temperatures calculated from daily minima and maxima. Agric. Meteorol. 46, 193–209 (1989).
Sadler, E. J. & Schroll, R. W. An empirical model of diurnal temperature patterns. Agron. J. 89, 542–548 (1997).
Yang, L., Qian, F., Song, D. X. & Zheng, K. J. Research on urban Heat-Island effect. Procedia Eng. 169, 11–18 (2016).
Deilami, K., Kamruzzaman, M. & Liu, Y. Urban heat Island effect: A systematic review of spatio-temporal factors, data, methods, and mitigation measures. Int. J. Appl. Earth Obs Geoinf. 67, 30–42 (2018).
Shenglan, Z., Haoyuan, S., Xingtao, S. & Langchang, J. Impact of urban heat Island effect on Ozone pollution in different Chinese regions. Urban Clim. 56, 102037 (2024).
Cichowicz, R. & Bochenek, A. D. Assessing the effects of urban heat Islands and air pollution on human quality of life. Anthropocene 46, 100433 (2024).
Han, L., Zhang, R., Wang, J. & Cao, S. J. Spatial synergistic effect of urban green space ecosystem on air pollution and heat Island effect. Urban Clim. 55, 101940 (2024).
Nunez, Y. et al. An environmental justice analysis of air pollution emissions in the united States from 1970 to 2010. Nat. Commun. 15, 268 (2024).
Park, C. Y. et al. Attributing human mortality from fire PM2.5 to climate change. Nat. Clim. Chang. 14, 1193–1200 (2024).
Yuan, Y. et al. Unraveling the global economic and mortality effects of rising urban heat Island intensity. Sustain. Cities Soc. 116, 105902 (2024).
Aboulnaga, M., Trombadore, A., Mostafa, M. & Abouaiana, A. Understanding urban heat Island effect: causes, impacts, factors, and strategies for better livability and climate change mitigation and adaptation. In Livable Cities (eds Aboulnaga, M. et al.) 283–366 (Springer International Publishing, 2024). https://doi.org/10.1007/978-3-031-51220-9_2.
Kumar, P. et al. Impact of Climatic factors on air pollution and human health in the Lucknow City of Uttar pradesh, India. Ecocycles 10, 51–69 (2024).
dos Santos, L. O. F., Machado, N. G., Querino, C. A. S. & Biudes, M. S. Trends of climate extremes and their relationships with tropical ocean temperatures in South America. Earth 5, 844–872 (2024).
Gautam, R., Borgohain, A., Pathak, B., Kundu, S. S. & Aggarwal, S. P. Investigation of meteorological variables and associated extreme events over North-East India and its adjoining areas using high-resolution IMDAA reanalysis. Nat. Hazards. https://doi.org/10.1007/s11069-024-06979-2 (2024).
van Oorschot, J., Slootweg, M., Remme, R. P., Sprecher, B. & van der Voet, E. Optimizing green and Gray infrastructure planning for sustainable urban development. Npj Urban Sustain. 4, 41 (2024).
Wang, Y., He, Z., Zhai, W., Wang, S. & Zhao, C. How do the 3D urban morphological characteristics Spatiotemporally affect the urban thermal environment? A case study of San Antonio. Build. Environ. 261, 111738 (2024).
Ilčev, S. D. Satellite remote sensing in meteorology. In Global Satellite Meteorological Observation (GSMO) Applications (ed. Ilčev, S. D.) 129–182 (Springer International Publishing, 2019). https://doi.org/10.1007/978-3-319-67047-8_3.
Gong, Z., Ge, W., Guo, J. & Liu, J. Satellite remote sensing of vegetation phenology: progress, challenges, and opportunities. ISPRS J. Photogramm Remote Sens. 217, 149–164 (2024).
Zhang, W., Huang, Y., Yu, Y. & Sun, W. Empirical models for estimating daily maximum, minimum and mean air temperatures with MODIS land surface temperatures. Int. J. Remote Sens. 32, 9415–9440 (2011).
Yu, Y. et al. Solar zenith angle-based calibration of Himawari-8 land surface temperature for correcting diurnal retrieval error characteristics. Remote Sens. Environ. 308, 114176 (2024).
Benali, A., Carvalho, A. C., Nunes, J. P., Carvalhais, N. & Santos, A. Estimating air surface temperature in Portugal using MODIS LST data. Remote Sens. Environ. 124, 108–121 (2012).
Zhu, W., Lű, A. & Jia, S. Estimation of daily maximum and minimum air temperature using MODIS land surface temperature products. Remote Sens. Environ. 130, 62–73 (2013).
Aslam, B., Maqsoom, A., Khalid, N., Ullah, F. & Sepasgozar, S. Urban overheating assessment through prediction of surface temperatures: A case study of karachi, Pakistan. ISPRS Int. J. Geo-Information. 10, 539 (2021).
Tariq, A. et al. Land surface temperature relation with normalized satellite indices for the Estimation of spatio-temporal trends in temperature among various land use land cover classes of an arid Potohar region using Landsat data. Environ. Earth Sci. 79, 40 (2020).
Riddering, J. P. & Queen Ll. P. Estimating near-surface air temperature with NOAA AVHRR. Can. J. Remote Sens. 32, 33–43 (2006).
Cristóbal, J., Ninyerola, M. & Pons, X. Modeling air temperature through a combination of remote sensing and GIS data. J. Geophys. Res. Atmos. 113, D13106. https://doi.org/10.1029/2007JD009318 (2008).
Awais, M. et al. Comparative evaluation of land surface temperature images from unmanned aerial vehicle and satellite observation for agricultural areas using in situ data. Agriculture 12, 184 (2022).
Nse, O. U., Okolie, C. J. & Nse, V. O. Dynamics of land cover, land surface temperature and NDVI in Uyo city, Nigeria. Sci. Afr. 10, e00599 (2020).
Farid, N., Moazzam, M. F. U., Ahmad, S. R., Coluzzi, R. & Lanfredi, M. Monitoring the impact of rapid urbanization on land surface temperature and assessment of surface urban heat Island using landsat in megacity (Lahore) of Pakistan. Front Remote Sens. 3, 897397. https://doi.org/10.3389/frsen.2022.897397 (2022).
Guha, S. & Govil, H. An assessment on the relationship between land surface temperature and normalized difference vegetation index. Environ. Dev. Sustain. 23, 1944–1963 (2021).
Taheri-Shahraiyni, H. & Sodoudi, S. High-resolution air temperature mapping in urban areas: A review on different modelling techniques. Therm. Sci. 21, 2267–2286 (2017).
Mashao, F. M. et al. An appraisal of the progress in utilizing radiosondes and satellites for monitoring upper air temperature profiles. Atmos. (Basel). 15, 387 (2024).
Wu, P. et al. Spatially continuous and High-Resolution land surface temperature product generation: A review of reconstruction and Spatiotemporal fusion techniques. IEEE Geosci. Remote Sens. Mag. 9, 112–137 (2021).
He, Q., Cao, J., Saide, P. E., Ye, T. & Wang, W. Unraveling the influence of Satellite-Observed land surface temperature on High-Resolution mapping of Ground-Level Ozone using interpretable machine learning. Environ. Sci. Technol. 58, 15938–15948 (2024).
Tănăselia, C. et al. Using inverse distance weighting to determine Spatial distributions of airborne chemical elements. South-east Eur. For. 15, 175–186 (2024).
Ryu, S., Song, J. J. & Lee, G. Interpolation of temperature in a mountainous region using heterogeneous observation networks. Atmos. (Basel). 15, 1018 (2024).
Rodrigues, A. A., Siqueira, T. M., Beskow, T. L. C. & Timm, L. C. Ordinary Cokriging applied to generate intensity-duration-frequency equations for Rio Grande do Sul state, Brazil. Theor. Appl. Climatol. 155, 2365–2378 (2024).
Hassani, A., Santos, G. S., Schneider, P., Castell, N. & Interpolation Satellite-Based machine learning, or meteorological simulation?? A comparison analysis for Spatio-temporal mapping of mesoscale urban air temperature. Environ. Model. Assess. 29, 291–306 (2024).
Mikhaylov, A. et al. Accelerating regional weather forecasting by super-resolution and data-driven methods. J. Inverse Ill-posed Probl. 32, 1175–1192 (2024).
Lin, P. & Wang, N. A data-driven approach for regional-scale fine-resolution disaster impact prediction under tropical cyclones. Nat. Hazards. 120, 7461–7479 (2024).
Achite, M. et al. Performance of machine learning techniques for meteorological drought forecasting in the Wadi Mina basin, Algeria. Water 15, 765 (2023).
Kushwaha, N. L. et al. Data intelligence model and Meta-Heuristic Algorithms-Based Pan evaporation modelling in two different Agro-Climatic zones: A case study from Northern India. Atmos. (Basel). 12, 1654 (2021).
Heddam, S. et al. Hybrid river stage forecasting based on machine learning with empirical mode decomposition. Appl. Water Sci. 14, 46 (2024).
Kushwaha, N. L. et al. Stacked hybridization to enhance the performance of artificial neural networks (ANN) for prediction of water quality index in the Bagh river basin, India. Heliyon 10, e31085 (2024).
Elbeltagi, A. et al. Data intelligence and hybrid metaheuristic algorithms-based Estimation of reference evapotranspiration. Appl. Water Sci. 12, 152 (2022).
Vishwakarma, D. K. et al. Evaluation and development of empirical models for wetted soil fronts under drip irrigation in high-density Apple crop from a point source. Irrig. Sci. https://doi.org/10.1007/s00271-022-00826-7 (2022).
Satpathi, A. et al. Evaluating statistical and machine learning techniques for sugarcane yield forecasting in the Tarai region of North India. Comput. Electron. Agric. 229, 109667 (2025).
Acharki, S. et al. Comparative assessment of empirical and hybrid machine learning models for estimating daily reference evapotranspiration in sub-humid and semi-arid climates. Sci. Rep. 15, 2542 (2025).
Pandit, P. et al. Hybrid modeling approaches for agricultural commodity prices using CEEMDAN and time delay neural networks. Sci. Rep. 14, 26639 (2024).
Raza, A. et al. Use of gene expression programming to predict reference evapotranspiration in different Climatic conditions. Appl. Water Sci. 14, 152 (2024).
Joshi, B. et al. A comparative survey between cascade correlation neural network (CCNN) and feedforward neural network (FFNN) machine learning models for forecasting suspended sediment concentration. Sci. Rep. 14, 10638 (2024).
Khan, M. et al. Ensemble and optimization algorithm in support vector machines for classification of wheat genotypes. Sci. Rep. 14, 22728 (2024).
Mohsenzadeh Karimi, S., Kisi, O., Porrajabali, M., Rouhani-Nia, F. & Shiri, J. Evaluation of the support vector machine, random forest and geo-statistical methodologies for predicting long-term air temperature. ISH J. Hydraul Eng. 26, 376–386 (2020).
Landeras, G., López, J. J., Kisi, O. & Shiri, J. Comparison of gene expression programming with neuro-fuzzy and neural network computing techniques in estimating daily incoming solar radiation in the Basque country (Northern Spain). Energy Convers. Manag. 62, 1–13 (2012).
Hong, H. et al. A novel hybrid integration model using support vector machines and random subspace for weather-triggered landslide susceptibility assessment in the Wuning area (China). Environ. Earth Sci. 76, 652 (2017).
Markuna, S. et al. Application of innovative machine learning techniques for Long-Term rainfall prediction. Pure Appl. Geophys. 180, 335–363 (2023).
Prasad, R., Deo, R. C., Li, Y. & Maraseni, T. Input selection and performance optimization of ANN-based streamflow forecasts in the drought-prone Murray Darling basin region using IIS and MODWT algorithm. Atmos. Res. 197, 42–63 (2017).
Salem, S. et al. Applying multivariate analysis and machine learning approaches to evaluating groundwater quality on the Kairouan plain. Tunisia Water. 15, 3495 (2023).
Hilbert, D. The utility of artificial neural networks for modelling the distribution of vegetation in past, present and future climates. Ecol. Modell. 146, 311–327 (2001).
Meshram, S. G. et al. New approach for sediment yield forecasting with a Two-Phase feedforward neuron Network-Particle swarm optimization model integrated with the gravitational search algorithm. Water Resour. Manag. 33, 2335–2356 (2019).
Setiya, P., Satpathi, A. & Nain, A. S. Predicting rice yield based on weather variables using multiple linear, neural networks, and penalized regression models. Theor. Appl. Climatol. 154, 365–375 (2023).
Zounemat-kermani, M., Kisi, O. & Rajaee, T. Performance of radial basis and LM-feed forward artificial neural networks for predicting daily watershed runoff. Appl. Soft Comput. 13, 4633–4644 (2013).
Mohammed, S. et al. A comparative analysis of data mining techniques for agricultural and hydrological drought prediction in the Eastern mediterranean. Comput. Electron. Agric. 197, 106925 (2022).
Rajput, J. et al. Development of machine learning models for Estimation of daily evaporation and mean temperature: a case study in new delhi, India. Water Pract. Technol. 19, 2655–2672 (2024).
Anaraki, M. V., Farzin, S., Mousavi, S. F. & Karami, H. Uncertainty analysis of climate change impacts on flood frequency by using hybrid machine learning methods. Water Resour. Manag. 35, 199–223 (2021).
Kadkhodazadeh, M., Valikhan Anaraki, M., Morshed-Bozorgdel, A. & Farzin, S. A new methodology for reference evapotranspiration prediction and uncertainty analysis under climate change conditions based on machine learning, multi criteria decision making and Monte Carlo methods. Sustainability 14, 2601 (2022).
Yang, X., Wang, Y., Byrne, R., Schneider, G. & Yang, S. Concepts of artificial intelligence for Computer-Assisted drug discovery. Chem. Rev. 119, 10520–10594 (2019).
Yadav, S. S. & Jadhav, S. M. Deep convolutional neural network based medical image classification for disease diagnosis. J. Big Data. 6, 113 (2019).
Khosravi, K. et al. A comparative assessment of decision trees algorithms for flash flood susceptibility modeling at Haraz watershed, Northern Iran. Sci. Total Environ. 627, 744–755 (2018).
Kim, S., Jeong, M. & Ko, B. C. Lightweight surrogate random forest support for model simplification and feature relevance. Appl. Intell. 52, 471–481 (2022).
Zhao, X., Chen, F., Feng, Z., Li, X. & Zhou, X. H. Characterizing the effect of temperature fluctuation on the incidence of malaria: an epidemiological study in south-west China using the varying coefficient distributed lag non-linear model. Malar. J. 13, 192 (2014).
Cho, D., Yoo, C., Im, J., Lee, Y. & Lee, J. Improvement of Spatial interpolation accuracy of daily maximum air temperature in urban areas using a stacking ensemble technique. GIScience Remote Sens. 57, 633–649 (2020).
Chronopoulos, K. I., Tsiros, I. X., Dimopoulos, I. F. & Alvertos, N. An application of artificial neural network models to estimate air temperature data in areas with sparse network of meteorological stations. J. Environ. Sci. Heal Part. A. 43, 1752–1757 (2008).
Chevalier, R. F., Hoogenboom, G., McClendon, R. W. & Paz, J. A. Support vector regression with reduced training sets for air temperature prediction: a comparison with artificial neural networks. Neural Comput. Appl. 20, 151–159 (2011).
Haj Khalil, R. A. E. H. & Enjadat, S. M. Predictive modeling of hourly air temperature based on atmospheric conditions of Karak in Jordan. Int. J. Sustain. Dev. Plan 19, 3679. https://doi.org/10.18280/ijsdp.190936 (2024).
Alomar, M. K. et al. Data-driven models for atmospheric air temperature forecasting at a continental climate region. PLoS One. 17, e0277079 (2022).
Salcedo-Sanz, S., Deo, R. C., Carro-Calvo, L. & Saavedra-Moreno, B. Monthly prediction of air temperature in Australia and new Zealand with machine learning algorithms. Theor. Appl. Climatol. 125, 13–25 (2016).
Elbeltagi, A. et al. Forecasting actual evapotranspiration without climate data based on stacked integration of DNN and meta-heuristic models across China from 1958 to 2021. J. Environ. Manage. 345, 118697 (2023).
Vishwakarma, D. K. et al. Pre- and post-dam river water temperature alteration prediction using advanced machine learning models. Environ. Sci. Pollut Res. https://doi.org/10.1007/s11356-022-21596-x (2022).
Elbeltagi, A. et al. Prediction of meteorological drought and standardized precipitation index based on the random forest (RF), random tree (RT), and Gaussian process regression (GPR) models. Environ. Sci. Pollut Res. 30, 43183–43202 (2023).
Elbeltagi, A. et al. Drought indicator analysis and forecasting using data driven models: case study in jaisalmer, India. Stoch. Environ. Res. Risk Assess. https://doi.org/10.1007/s00477-022-02277-0 (2022).
Setiya, P., Satpathi, A., Nain, A. S. & Das, B. Comparison of weather-based wheat yield forecasting models for different districts of Uttarakhand using statistical and machine learning techniques. J. Agrometeorol. 24, 255–261. https://doi.org/10.54386/jam.v24i3.1571 (2022).
Satpathi, A. et al. Estimation of crop evapotranspiration using statistical and machine learning techniques with limited meteorological data: a case study in Udham Singh nagar, India. Theor. Appl. Climatol. https://doi.org/10.1007/s00704-024-04953-3 (2024).
Quinlan, J. R. Learning with continuous classes. in 5th Australian joint conference on artificial intelligence vol. 92 343–348World Scientific, (1992).
Elbeltagi, A., Al-Mukhtar, M., Kushwaha, N. L., Al-Ansari, N. & Vishwakarma, D. K. Forecasting monthly pan evaporation using hybrid additive regression and data-driven models in a semi-arid environment. Appl. Water Sci. 13, 42 (2023).
Elbeltagi, A., Di Nunno, F., Kushwaha, N. L., de Marinis, G. & Granata, F. River flow rate prediction in the des Moines watershed (Iowa, USA): a machine learning approach. Stoch. Environ. Res. Risk Assess. 36, 3835–3855 (2022).
Vapnik, V. N. The Nature of Statistical Learning Theory. Springer science & business media. https://doi.org/10.1007/978-1-4757-3264-1 (1995).
Wang, L. Support Vector Machines: Theory and Applicationsvol. 177 (Springer Science & Business Media, 2005).
Kushwaha, N. L. et al. Evaluation of Data-driven hybrid machine learning algorithms for modelling daily reference evapotranspiration. Atmos. Ocean. 60, 519–540 (2022).
Abd-Elaty, I., Kushwaha, N. L. & Patel, A. Novel hybrid machine learning algorithms for lakes evaporation and power production using floating semitransparent polymer solar cells. Water Resour. Manag. 37, 4639–4661 (2023).
Kushwaha, N. L. et al. Beach nourishment for coastal aquifers impacted by climate change and population growth using machine learning approaches. J. Environ. Manage. 370, 122535 (2024).
Samantaray, S. & Sahoo, A. Groundwater level prediction using an improved ELM model integrated with hybrid particle swarm optimisation and grey Wolf optimisation. Groundw. Sustain. Dev. 26, 101178 (2024).
Asadi, S., Tartibian, B. & Moni, M. A. Determination of optimum intensity and duration of exercise based on the immune system response using a machine-learning model. Sci. Rep. 13, 8207 (2023).
McCuen, R. H., Knight, Z. & Cutter, A. G. Evaluation of the Nash–Sutcliffe efficiency index. J. Hydrol. Eng. 11, 597–602 (2006).
Vishwakarma, D. K. et al. Assessing the performance of various infiltration models to improve water management practices. Paddy Water Environ. https://doi.org/10.1007/s10333-024-01000-9 (2024).
Moharana, L., Sahoo, A. & Ghose, D. K. Prediction of rainfall using hybrid SVM-HHO model. IOP Conf. Ser. Earth Environ. Sci. 1084, 012054 (2022).
Mosavi, A., Ozturk, P. & Chau, K. Flood Prediction Using Machine Learning Models: Literature Review. Water vol. 10 1536 at (2018). https://doi.org/10.3390/w10111536
Ghose, D. K., Tanaya, K., Sahoo, A. & Kumar, U. Performance Evaluation of hybrid ANFIS model for Flood Prediction. in 8th International Conference on Advanced Computing and Communication Systems (ICACCS) 772–777 (IEEE, 2022). 772–777 (IEEE, 2022). (2022). https://doi.org/10.1109/ICACCS54159.2022.9785002
Pham, Q. B. et al. Groundwater level prediction using machine learning algorithms in a drought-prone area. Neural Comput. Appl. 34, 10751–10773 (2022).
Sahoo, A., Parida, S. S., Samantaray, S. & Satapathy, D. P. Daily flow discharge prediction using integrated methodology based on LSTM models: case study in Brahmani-Baitarani basin. HydroResearch 7, 272–284 (2024).
Achite, M. et al. Modeling the optimal dosage of coagulants in water treatment plants using various machine learning models. Environ. Dev. Sustain. 26, 3395–3421 (2022).
Mohaghegh, A., Farzin, S. & Anaraki, M. V. A new framework for missing data Estimation and reconstruction based on the geographical input information, data mining, and multi-criteria decision-making; theory and application in missing groundwater data of Damghan plain, Iran. Groundw. Sustain. Dev. 17, 100767 (2022).
Anaraki, M. V., Kadkhodazadeh, M., Morshed-Bozorgdel, A. & Farzin, S. Predicting rainfall response to climate change and uncertainty analysis: introducing a novel downscaling CMIP6 models technique based on the stacking ensemble machine learning. J. Water Clim. Chang. 14, 3671–3691 (2023).
Toharudin, T. et al. Employing long short-term memory and Facebook prophet model in air temperature forecasting. Commun. Stat. - Simul. Comput. 52, 279–290 (2023).
Gouvas, M. A., Sakellariou, N. K. & Kambezidis, H. D. Estimation of the monthly and annual mean maximum and mean minimum air temperature values in Greece. Meteorol. Atmos. Phys. 110, 143–149 (2011).
Sekertekin, A. et al. Short-term air temperature prediction by adaptive neuro-fuzzy inference system (ANFIS) and long short-term memory (LSTM) network. Meteorol. Atmos. Phys. 133, 943–959 (2021).
Rezaeian-Zadeh, M., Zand-Parsa, S., Abghari, H., Zolghadr, M. & Singh, V. P. Hourly air temperature driven using multi-layer perceptron and radial basis function networks in arid and semi-arid regions. Theor. Appl. Climatol. 109, 519–528 (2012).
Chithra, N. R. et al. Prediction of the likely impact of climate change on monthly mean maximum and minimum temperature in the Chaliyar river basin, india, using ANN-based models. Theor. Appl. Climatol. 121, 581–590 (2015).
Oloyede, A., Ozuomba, S., Asuquo, P., Olatomiwa, L. & Longe, O. M. Data-driven techniques for temperature data prediction: big data analytics approach. Environ. Monit. Assess. 195, 343 (2023).
Ramesh, K. & Anitha, R. MARSpline model for lead seven-day maximum and minimum air temperature prediction in chennai, India. J. Earth Syst. Sci. 123, 665–672 (2014).
Mollick, T., Hashmi, G. & Sabuj, S. R. A perceptible stacking ensemble model for air temperature prediction in a tropical climate zone. Discov Environ. 1, 15 (2023).
Pereira, D. G., Afonso, A. & Medeiros, F. M. Overview of friedman’s test and Post-hoc analysis. Commun. Stat. - Simul. Comput. 44, 2636–2653 (2015).
MacFarland, T. W. & Yates, J. M. Friedman twoway analysis of variance (ANOVA) by ranks. In Introduction To Nonparametric Statistics for the Biological Sciences Using R (eds MacFarland, T. W. & Yates, J. M.) 213–247 (Springer International Publishing, 2016). https://doi.org/10.1007/978-3-319-30634-6_7.
Funding
Open access funding provided by University of Pécs.
Author information
Authors and Affiliations
Contributions
Conceptualization, Methodology: A.E., D. K.V, O.M.K., K. S., S.H., B.P.S, A.S., V.K.G., C.B.P., S. H., S. G., H.D., and A.S.; Formal analysis: A.E., D. K.V, O.M.K.,and K.S., Software: A.E., Visualization: A.E., O.M.K., K. S., S.H., B.P.S, A.S., K. S., S.H., S.A.B., V.K.G., C.B.P., S. H., S. G., and H.D., Writing- Original draft preparation: A.E., Writing—review and editing: A.S. All authors reviewed the manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Elbeltagi, A., Vishwakarma, D.K., Katipoğlu, O.M. et al. Air temperature estimation and modeling using data driven techniques based on best subset regression model in Egypt. Sci Rep 15, 20200 (2025). https://doi.org/10.1038/s41598-025-06277-2
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-06277-2
Keywords
This article is cited by
-
Deep learning-based AQI forecasting: a CNN-LSTM model with visual insights from SHAP-LIME and PDP
Discover Applied Sciences (2025)
