
Abstract
There is a graph G = (V, E), which has n vertices and l edges. Color the vertices of G black or white, ensuring no black vertex is adjacent to any white vertex, thus partitioning them into disjoint black and white sets. The optimal solution of the black and white coloring (BWC) problem is defined as the coloring scheme that maximizes the number of white vertices in the corresponding set, given a fixed number of black vertices. This problem is a NP-complete problem, widely used in reagent product storage in chemical industry and the solution to the problem of black and white queens in chess. The paper presents a swarm evolution algorithm based on improved simulated annealing search and evolutionary operation with probability learning mechanism. Furthermore, crossover operation, perturbation operation, and tabu search strategy improve the search ability of the algorithm, while evolutionary operation with probability learning mechanism increases the probability of the algorithm finding better solutions. Using Cayley graphs, random graphs, semi-random graphs, and benchmark DIMACS graphs, experiments are conducted to compare the finding results from swarm evolution algorithm and other classical heuristic algorithms. Experimental results show that the swarm evolution algorithm outperforms other heuristic algorithms in solving the BWC problem, and the swarm evolution algorithm can improve the known best results of the BWC problem.
Similar content being viewed by others


Introduction
The Black and White Coloring (BWC) problem is initially described in1. There is an undirected graph G = (V, E), where V is a set containing n vertices, and E is a set containing l edges. The vertices in graph G are colored in white or black, the black vertices constituting set B and the white vertices constituting set W. The two sets meet the following conditions:
(i1) B = {vi|vi ∈ V, 0 ≤ i < b}, in which vi is black vertex, b is the number of vertices in set B.
(i2) W = {wj|wj ∈ V, 0 ≤ j < e}, in which wj is white vertex, e is the number of vertices in set W.
(i3) ∀ vi ∈ B, ∀ wj ∈ W, (vi, wj)\(\notin\) E, 0 ≤ i < b, 0 ≤ j < e.
(i4) When |B| is established, |W| is the maximized.
When conditions i1, i2, and i3 are met, it is found in graph G that set B and set W are referred to as the BWC problem of graph G. Besides conditions i1, i2 and i3 are satisfied, i4 is met at the same time, the solution (B, W) is the optimal solution of BWC problem, and |W| is the optimal value of BWC problem.
In1, an application of the BWC problem is proposed: On an n × n chessboard, B black queens and W white queens are placed. A placement scheme is designed to make black and white queens mutual attack unavailable, there being white queens as many as possible. It has been proved that BWC is a NP-complete problem in1. In2, the BWC problem is applied to the design of chemical storage. Since chemical drugs have a certain toxicity, to ensure the safety of chemical storage, a reasonable segregated storage scheme should be designed to avoid unsafe factors such as toxicity, flammability, and causticity of chemicals.
The paper presents an efficient swarm evolution algorithm for the BWC problem. The algorithm consists of three parts. In the first part, an improved simulated annealing search strategy is adopted to explore the search space. This strategy incorporates tabu search and crossover operation to enhance the algorithm’s ability to find better solutions. In the second part, a perturbation operation is introduced to increase the likelihood of finding better solutions during the search process. Finally, in the third part, a probability learning mechanism is utilized to dynamically record the algorithm’s search history. This mechanism informs the reconstruction of the search space, guiding the swarm evolution operation. By leveraging this knowledge, the algorithm further improves its chances of finding better solutions.
We evaluate the performance of the swarm evolution algorithm on Cayley graphs (which includes “kings” graphs and “rooks” graphs), random graphs, semi-random graphs, and benchmark DIMACS graphs. The evaluation results show that the swarm evolution algorithm has a stronger search ability than the variable neighborhood search algorithm, simulated annealing algorithm, greedy algorithm, simulated annealing algorithm with configuration checking3, and local search algorithm4. In particular, the swarm evolution algorithm improves the known best results of 3 graphs in5 and 22 graphs in4.
The main structure of this paper is organized as follows. Section “Related work” introduces the current research work of heuristic algorithms. Section “A Swarm evolution algorithm for BWC” describes the design of the swarm evolution algorithm for solving the BWC problem. Section “A variable neighborhood search algorithm for BWC” describes the variable neighborhood search algorithm for solving BWC problem. Section “A simulated annealing algorithm for BWC” describes the simulated annealing algorithm for solving BWC problem. Section “The greedy algorithm for BWC” describes the greedy algorithm for solving BWC problem. Section “Experimental results” describes the performance analysis of the swarm evolution algorithm and comparative experiments of different algorithms.
Related work
In6, a fast algorithm for tree was presented to solve the BWC problem. In7, a linear time approximation algorithm was presented to solve the BWC problem. On the other hand, some heuristic algorithms were presented to solve BWC problems in relevant literatures. For example, two tabu algorithms were used to solve the BWC problem in5, a simulated annealing algorithm with configuration checking was used to solve the BWC problem3, and a local search algorithm was used to solve the BWC problem4.
Furthermore, some heuristic algorithms were presented to solve other combinatorial optimization problems. In8, an iterated k-opt local search algorithm was presented to solve the maximum clique problem. In9, a reactive local search algorithm was presented to solve the maximum clique Problem. In10, a phased local search algorithm was presented to solve the maximum clique problem. In11, a k-opt local search algorithm was presented to solve the maximum clique problem. In12, an iterated local search algorithm was presented to solve the traveling salesman problem. In13,14,15,16,17,18, tabu search algorithms were presented to solve different combinatorial problems. In19,20, variable neighborhood search algorithms were presented to solve different combinatorial problems. In21,22,23,24,25,26, simulated annealing algorithms were presented to solve different combinatorial problems. In27, a greedy algorithm was presented to solve the small dominating set problem in graphs. In28,29, memetic algorithms were presented to solve the minimum sum coloring problem. In30,31, local search algorithms with probability learning were presented to solve the coloring problems. In32, tabu search algorithm with probability learning was presented to solve the minimum load coloring problem. In33, an improved whale algorithm was presented to solve the flexible job shop scheduling problem. In34, a novel monarch butterfly optimization algorithm was presented to solve the Large-Scale 0–1 Knapsack problem. In35, an improved firefly algorithm was presented to solve the constrained optimization engineering design problem. In36, different crossover and mutation operators were identified as critical components that enable evolutionary algorithms to find better solutions. Consequently, asymptotic analyses were carried out on some well-known and recent crossover and mutation operators, and the convergence of the recent evolutionary algorithms was also analyzed. Based on these foundations, a genetic algorithm framework was proposed to effectively solve the graph coloring problem (GCP). In37, three evolutionary operation algorithms combined with tabu search strategy were proposed to solve the graph coloring problem, and their effectiveness was verified on the DIMACS graphs. In38, a novel evolutionary algorithm with central-value-based conflict gene crossover and mutation operators was proposed for solving the graph coloring problem, and its effectiveness was demonstrated on DIMACS benchmark graphs.
A swarm evolution algorithm for BWC
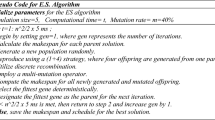
In the paper, we present a swarm evolution algorithm to solve the BWC problem of graphs. The swarm evolution algorithm is summarized in Swarm_BWC (Algorithm 1). The flowchart of the algorithm is shown in (Fig. 1).

Flowchart of the swarm evolution algorithm to solve BWC.

Swarm_BWC (G, b, p, M, D, Y).
The algorithm first generates p initial probability matrices to construct a probability matrix group M (see Section “Construction of probability matrix group”). Using each probability matrix in M, it generates an initial individual, and p probability matrices generate p initial individuals, thus constructing a swarm D composed of p individuals (see Section “Swarm initialization”). Then the algorithm completes four steps of operation in one iteration.
In the first step, an improved simulated annealing search is applied to each individual in swarm D, and the obtained search results are stored in swarm Y. If a better solution to the BWC problem is found, it is saved as the current best solution. After searching, new individuals are evolved from each individual in swarm D, thus constructing swarm Y (see Section “Crossover operation” and Section “Improved simulated annealing search”).
In the second step, swarm Y is perturbed to further enhance the likelihood of finding a better solution. If a better solution to the BWC problem is found after the perturbation operation, it is saved as the current best solution (see Section “Perturbation operation”).
In the third step, based on the dynamic changes within swarms D and Y, a probability learning mechanism modifies each probability matrix value in the probability matrix group M, thereby capturing the dynamic changes of the swarm (see Section “Update operation of probability matrix group”).
In the fourth step, the modified probability matrix group M is used to further evolve swarm D, resulting in the newly evolved swarm D (see Section “Evolutionary operation of swarm”).
The swarm evolution algorithm iterates multiple times to find better solutions before the end condition is met. The W1 represents the best solution found for the BWC problem within the search. The best represents the best value found for the BWC problem within the search, and it is also the objective function value for the best solution of the BWC problem in the algorithm search.
The search space and objective function of algorithm
There is an undirected graph G = (V, E), in which V is the vertex set of graph G and E is the edge set of graph G. Select b vertices and color them black from set V to generate a black vertex set B, |B|= b, and the remaining vertices with gray color to generate a gray vertex set Vgrey, Vgrey = V \ B. Then, a search space S for the BWC problem of graph G is constructed, which is a binary coloring scheme (B, Vgrey) of graph G. That is:
When a bipartite coloring scheme (B, Vgrey) of graph G is given, search for vertices in the set Vgrey that comply with the rules (i1) ~ (i3) in Section “Introduction”, color these vertices white, and move these white vertices from the set Vgrey to the set W, thereby generating a white vertex set W. Here, W is defined as:
From the definition, W ⊆ Vgrey, thus constructing a solution (B, W) for the BWC problem in graph G.
According to the rule (i4) in Section “Introduction”, the goal of finding the best solution for the BWC problem in graph G is to find the best value from all the solutions (B, W)j (1 ≤ j ≤ k) that can be obtained by the swarm evolution algorithm. Therefore, the objective function fmax(G) searched by the swarm evolution algorithm is defined as:
In formula 3, it can be seen that k is the number of solutions (B, W) to the BWC problem obtained by the swarm evolution algorithm in S, and fmax(G) is the best value obtained by the swarm evolution algorithm from k solutions.
In Fig. 2, there is an undirected graph G = (V, E), where n =|V|= 8, l =|E|= 9. We first color the vertices in graph G black and gray, thereby constructing a set of black vertices B and a set of gray vertices Vgrey. After determining the black vertices, search for vertices that can be colored white from the set of gray vertices Vgrey, and construct the set of white vertices W. It is assumed that the number of black vertices is 2 (b = 2), and two schemes for coloring the vertices are shown in (Figs. 3, 4). In Fig. 3, the set B = {v0, v7} while the set W = {v2, v5}, so that |W|= 2. In Fig. 4, the set B = {v5, v6} while the set W = {v0, v1, v2, v3}, resulting in |W|= 4. After analysis, W = {v0, v1, v2, v3} has been identified as the optimal solution to the BWC problem in graph G when b = 2. Additionally, the corresponding cardinality of W, denoted as |W|= 4, represents the best value obtained for the BWC problem.

An undirected graph instance.

A BWC with |B|= 2 and |W|= 2.

An optimal BWC with |B|= 2 and |W|= 4.
Construction of probability matrix group
To solve the BWC problem, it is necessary to color each vertex in graph G black or gray, and then search for vertices that can be colored white among the gray ones. Correctly coloring the vertices of graph G is crucial. References30,31,32 propose heuristic algorithms with a probability learning mechanism to solve graph coloring problems. Therefore, inspired by the ideas of these references, we introduce a probability learning mechanism into the swarm evolution algorithm to solve the BWC problem in graphs.
There is a graph G = (V, E), where |V|= n, and each vertex in graph G is colored black or gray based on the coloring probability value. For each vertex vi (0 ≤ i < n), we define ci0 to denote the probability that vi is black, and ci1 to denote the probability that vi is gray, with the constraint that ci0 + ci1 = 1.
For the coloring of vertex vi, if the randomly generated coloring probability value c ≤ ci0, then vertex vi is colored black; otherwise, it is colored gray. The coloring probability values of the n vertices are combined to construct a probability matrix A of size n × 2. Therefore, using this probability matrix A, a binary coloring scheme for graph G can be constructed, as follows:
A probability matrix can construct a bipartite coloring scheme for graph G, and a bipartite coloring scheme can be identified as an individual. In the swarm evolution algorithm, multiple individuals are generated to construct the swarm. Therefore, multiple probability matrices are constructed in this algorithm. When the algorithm generates p individuals, p probability matrices are constructed. Thereby a probability matrix group M is constructed, where M = {A0, A1,…, Aj,…, Ap-1}. The jth (0 ≤ j < p) probability matrix Aj in the probability matrix group is used to generate the jth initial individual. To perform initial random coloring on the vertices of graph G, the initial coloring probability value of each vertex in the probability matrix Aj is set to 1/2.
After constructing the probability matrix group, the swarm evolution algorithm continuously modifies the probability matrix values based on changes in individual search results, achieving probability learning of the current search results. In the later phase, evolutionary operation is implemented based on the probability learning results (see Section “Update operation of probability matrix group” and Section “Evolutionary operation of swarm”).
Swarm initialization
There is a graph G = (V, E), where |V|= n and |E|= l. The jth (0 ≤ j < p) individual is generated in the probability matrix group based on the jth probability matrix Aj (0 ≤ j < p). During the process of generating the jth individual, a vertex vi (0 ≤ i < n) is randomly selected from the vertex set V of graph G. When the randomly generated coloring probability value is less than Aj(ci0), the vertex vi is added to set B, indicating that the vertex is colored black. Otherwise, the vertex vi is added to the set Vgrey, indicating that the vertex is colored gray. This vertex selection process is repeated until b black vertices are selected. The remaining vertices of graph G are colored gray and added to the set Vgrey, thus constructing the jth individual (B, Vgrey)j (also represented as a binary coloring scheme of graph G ), where |B|= b and Vgrey = V \B. Using this method, p initial probability matrices in the probability matrix group are used to generate p initial individuals, constructing a swarm D = {(B, Vgrey)j|0 ≤ j < p, |B|= b, Vgrey = V \B}, where |D|= p.
Crossover operation
The crossover operation is a very important operational procedure in swarm evolution algorithm, which enables swarm evolution algorithm to evolve into new search spaces during individual search, in order to find better values. We propose two crossover operation strategies.
The first crossover operation
The first crossover operation is implemented through the following three steps.
First step: Get an individual (B, Vgrey), in which |B|= b, Vgrey = V \ B. Based on set B and set Vgrey, a set Uncontrol is constructed by vertices in set Vgrey, which are nonadjacent with arbitrary vertex in set B. That is:
Uncontrol ⊆ Vgrey in here.
Second step: A set UnConnectNodes is constructed, whose initial status is: UnConnectNodes = ∅. We first randomly choose a vertex vi in the set Uncontrol, 0 ≤ i <|Uncontrol|, and then add vertex vi to the set UnConnectNodes. Next, add all vertices in set Vgrey that are not adjacent to vertex vi to the UnConnectNodes. That is:
UnConnectNodes ⊆ Vgrey in here.
Third step: We choose at random a vertex vj in the set B, 0 ≤ j < b. And we choose successively every vertex ui from set UnConnectNodes (vertex ui is also in set Vgrey), the values of i ranging successively from 0 to |UnConnectNodes|− 1. Hence, one by one, we exchange vertex vj in set B with vertex ui in set Vgrey to produce multiple temporary binary coloring schemes (B', V'grey)i.
When there are as many as x (1 ≤ x ≤|UnConnectNodes|) vertices in the set UnConnectNodes, x temporary binary coloring schemes {(B', V'grey )i| 0 ≤ i < x, 1 ≤ x ≤|UnConnectNodes|} will be obtained. From x temporary binary coloring schemes, we choose an optimal scheme as the new final binary coloring scheme in this crossover.
The optimal scheme (B*,V *grey) is the one where the number of vertices in set V *grey , dominated by the vertices in set B*, is minimized (when vertex v is adjacent to vertex w, we say that vertex v dominates vertex w).
That is:
Here, f((Sa, Sb)) indicates the number of vertices in set Sb that are dominated by vertices in set Sa.
When multiple binary coloring schemes can obtain f((B*, V *grey)), randomly choose one to make it the new final binary coloring scheme after crossover. The process has a time complexity of O(b × (n − b)2).
In a graph G = (V, E), where V = {v0, v1, v2, v3, v4, v5, v6, v7, v8, v9, v10, v11}, suppose the number of black vertices is 4. When we obtain a binary coloring scheme (B, Vgrey) as shown in Fig. 5(1), let B = {v1, v5, v7, v9} and Vgrey = {v0, v2, v3, v4, v6, v8, v10, v11}. Then, let Uncontrol = {v2, v8, v10, v11}. A new binary coloring scheme needs to be generated. So, if we choose a vertex v2, at random from the set Uncontrol, then UnConnectNodes = {v2, v3, v10, v11}. Choose vertex v5 at random from set B, and exchange vertex v5 successively with every vertex of set UnConnectNodes. This process results in 4 temporary binary coloring schemes, denoted as {(B', V'grey)i|0 ≤ i < 4}. From these 4 temporary schemes, the one satisfying formula 8 is selected as the result of this crossover. In Fig. 5(2), the new final binary coloring scheme (B*, V *grey) after crossover is shown: B* = {v1, v3, v7, v9}, V *grey = {v0, v2, v4, v5, v6, v8, v10, v11}. This is because, after exchanging v5 with v3, the vertices in set B* dominate the vertices in set V *grey to the least extent (here, the vertices in set B* only dominate the vertices v0, v5, v6 in set V *grey, achieving the smallest number of dominating vertices).

Crossover process of binary coloring scheme (the first crossover operation).
When vertex v5 and vertex v2 are swapped, a temporary binary coloring scheme (B', V'grey)1 is generated, where B' = {v1, v2, v7, v9} and V'grey = {v0, v3, v4, v5, v6, v8, v10, v11}. In this scheme, f((B', V'grey)1) = 6. The white vertex set W = {v10, v11}, and |W|= 2.
When vertex v5 and vertex v3 are swapped, a temporary binary coloring scheme (B', V'grey)2 is generated, where B' = {v1, v3, v7, v9} and V'grey = {v0, v2, v4, v5, v6, v8, v10, v11}. In this scheme, f((B', V'grey)2) = 3. The white vertex set W = {v2, v4, v8, v10, v11}, and |W|= 5. This is the optimal solution chosen after the current crossover operation.
When vertex v5 and vertex v10 are swapped, a temporary binary coloring scheme (B', V'grey)3 is generated, where B' = {v1, v7, v9, v10} and V'grey = {v0, v2,v3, v4, v5, v6, v8, v11}. In this scheme, f((B', V'grey)3) = 5. The white vertex set W = {v2, v8, v11}, and |W|= 3.
When vertex v5 and vertex v11 are swapped, a temporary binary coloring scheme (B', V'grey)4 is generated, where B' = {v1, v7, v9, v11} and V'grey = {v0, v2, v3, v4, v5, v6, v8, v10}. In this scheme, f((B', V'grey)4) = 6. The white vertex set W = {v2, v10}, and |W|= 2.
In Fig. 5(1) (before crossover), the binary coloring scheme for graph G is (B, Vgrey), where B = {v1, v5, v7, v9} and Vgrey = {v0, v2, v3, v4, v6, v8, v10, v11}. In this scheme, f((B, Vgrey)) = 4. The white vertex set W = {v2, v8, v10, v11}, and |W|= 4. After the crossover operation, the binary coloring scheme of graph G changes to (B*, V *grey), where B* = {v1, v3, v7, v9} and V *grey = {v0, v2, v4, v5, v6, v8, v10, v11}. In this scheme, f((B*, V *grey)) = 3. The white vertex set W = {v2, v4, v8, v10, v11}, and |W|= 5. Therefore, after crossover operation, a better solution can be found.
The second crossover operation
We propose a second crossover operation, which is implemented through the following two steps.
Step 1: For an individual (B, Vgrey), |B|= m, Vgrey = V \ B. Find the degree value of each vertex in the set Vgrey.
Step 2: We choose a vertex uj with the lowest degree value in the set Vgrey, where degree[uj] = \(\mathop {\min }\limits_{{0 \le i < |V_{grey} |}} (degree[u_{i} ])\). That is:
If there are multiple vertices with the lowest degree value, randomly choose one vertex uj, from among these vertices. Randomly choose a vertex vj from set B and proceed to exchange two vertices vj and uj between set B and Vgrey. Specifically, B* ← B\{vj} ∪ {uj}, V *grey ← Vgrey\{uj} ∪ {vj}. Thus, a new binary coloring scheme (B*, V *grey) is generated through the crossover operation. The process has a time complexity of O(n × (n − b)).
In a graph G = (V, E), where V = {v0, v1, v2, v3, v4, v5, v6, v7, v8, v9, v10, v11}, suppose the number of black vertices is 4. When we obtain a binary coloring scheme (B, Vgrey), as shown in Fig. 6(1), let B = {v1, v5, v7, v9} and Vgrey = {v0, v2, v3, v4, v6, v8, v10, v11}. In this scheme, f((B, Vgrey)) = 4. The white vertex set W = {v2, v8, v10, v11}, and |W|= 4. According to formula 9, the degree values of vertices v0, v2, v3, v4, v6, v8, v10, v11 (in the set Vgrey) are 2, 4, 0, 4, 1, 2, 1, 2, respectively. Among these, vertex v3 has the smallest degree value. We randomly select vertex v1 from set B and definitely select vertex v3 from set Vgrey to perform a crossover operation, generating a new binary coloring scheme (B*, V *grey) , as shown in Fig. 6(2), where B* = { v3, v5, v7, v9} and V *grey = {v0, v1, v2, v4, v6, v8, v10, v11}. In this coloring scheme, f((B*, V *grey)) = 2. The white vertex set W = {v1, v2, v6, v8, v10, v11}, and |W|= 6. Therefore, after crossover operation, a better solution can be found.

Crossover process of binary coloring scheme (the second crossover operation).
Improved simulated annealing search
A crucial process in swarm evolution algorithm is to search for each individual in swarm D to find the best solution to the BWC problem. Simulated annealing algorithm is used to search for each individual in the swarm. Due to the phenomenon of repeated searches during the process of searching for individuals in the simulated annealing algorithm, the search efficiency is reduced. In order to improve the search efficiency of the simulated annealing algorithm, we added a tabu search strategy to the simulated annealing algorithm, thus using an improved simulated annealing algorithm to search for all individuals in swarm D.
The improved simulated annealing algorithm is summarized in Improved_SA_Search (Algorithm 2). In Algorithm 2, an initial temperature T0 and a cooling coefficient α are determined. Temperature cooling is achieved by using T = α × T, where α ∈ (0, 1). When the temperature T gradually cools to Te (the end temperature), i.e., T ≤ Te, or after meeting the end condition, the search of algorithm 2 is terminated.
For a given jth individual Di in swarm D (here, (B, Vgrey)j represents the jth individual Di), the vertices in set B are black vertices. According to the given set B, the strategy for Algorithm 2 to search for white vertices is to search in set Vgrey all the vertices that are not adjacent to any vertex in set B, and the vertex set obtained is the white vertex set W. In order to maximize the number of vertices in the set of white vertices, we should minimize the number of vertices in Vgrey that are dominated by set B.
During each iteration of Algorithm 2, the value of the currently searched individual Dj is first obtained from swarm D, that is, (B, Vgrey)temp ← (B, Vgrey)j. Then, the crossover operation method described in Section “Crossover operation” is used to perform crossover on (B, Vgrey)temp, generating a new binary coloring scheme (B', V'grey)temp. If f((B', V'grey)temp) = 0, it indicates that the maximum value of W is found, which is W = V'grey, and the current best solution (B', V'grey )temp and the value of |V'grey| are stored in Sbest and Wbest, respectively. If f((B', V'grey )temp) < f((B, Vgrey) temp), the new binary coloring scheme (B',V'grey)j is accepted, that is (B,Vgrey)temp ← (B', V'grey ) temp, and the current best solution (B', V'grey )temp and the value of |V'grey|- f((B', V'grey)temp) are stored in Sbest and Wbest, respectively. Otherwise, a new binary coloring scheme (B', V'grey)temp is accepted based on some probability. Here, the objective function f is defined in formula 7.
When the end condition set by Algorithm 2 is met, Sbest and Wbest are the best solution and value for Algorithm 2 search. If Algorithm 2 can find new and better values, it will accept the current better scheme and serve as the new state Yj (i.e., (Bn, Vngrey)j) of individual Dj after evolution, that is: (Bn, Vngrey)j ← (B,Vgrey)temp (see code line 13 or 19); otherwise, Yj is the same as Dj, meaning that the second line of code in Algorithm 2 stores the initial state of Yj as the current new individual, that is: (Bn, Vngrey)j ← (B, Vgrey)j.

Improved_SA_Search (G, Dj, Tabulist, T0, α, Te, L).
To find white vertices, individual (B', V'grey)temp can be searched using (Algorithm 2). We use a tabu list in Algorithm 2 to implement a tabu search strategy. The tabu list is implemented using a two-dimensional data structure called Tabulist, with a length set to L. This list is used to store the current iteration values ies of Algorithm 2’s run. If (ies − Tabulist[v][w]) < L, then, based on the crossover operation, vertex v and vertex w are reselected for exchange, thereby obtaining a non-tabu binary coloring scheme (B', V'grey)temp. Otherwise, the ies value is stored in Tabulist.
Perturbation operation
To increase the probability of finding better values in the swarm evolutionary algorithm, we have added the perturbation operation. The perturbation operation is summarized in Perturbation_operation (Algorithm 3). We introduce a startup parameter d for Algorithm 3, and when the swarm evolution algorithm runs d iterations per interval, we start the perturbation operation (Algorithm 3).
There are two methods for perturbation operation. One method involves randomly selecting an individual Yj from set Y to obtain a binary coloring scheme (Bn, Vngrey)j. Then, a vertex is randomly chosen from set Bn and another from set Vngrey to exchange, generating a new binary coloring scheme (Bn', V n'grey)j. Algorithm 2 is employed to search for (Bn', V n'grey)j, and if a better solution is found, the better solution is obtained, and it is adopted as the evolving new individual Yj, that is, Yj ← temp (line 7 in Algorithm 3). The second method follows a similar procedure, with the exception that two vertices are randomly selected from each of set Bn and set Vngrey to exchange, resulting in a new binary coloring scheme (Bn'', Vn''grey)j. Algorithm 2 is again utilized to explore (Bn'', Vn''grey)j, and if a better solution is found, it becomes the new Yj, namely, Yj ← temp (see code line 14 in Algorithm 3). Both perturbation operation methods are then randomly chosen.

Perturbation_operation(Y, d1, d, best).
Update operation of probability matrix group
From Sections “Construction of probability matrix group” and “Swarm initialization”, it can be seen that the binary coloring scheme (B, Vgrey) corresponding to the individual in the swarm is generated based on the vertex coloring probability matrix. From Sections “Crossover operation” to “Improved simulated annealing search”, it can be seen that in the binary coloring scheme (B, Vgrey), by selecting black vertices from set B and gray vertices from set Vgrey for exchange purposes, the black vertices are moved from set B to set Vgrey, and the gray vertices are moved from set Vgrey to set B, generating new search spaces to find better solutions for the BWC problem. When a better solution is found, the swarm evolution algorithm will accept the binary coloring scheme (B', V'grey) corresponding to the better solution as the currently found solution. To record the changes in vertex movement in set B and set Vgrey, we need to modify the vertex coloring probability value based on the initial and changed coloring states of the vertices, thereby updating the vertex coloring probability matrix A and realizing probability learning of vertex coloring changes. Based on the learning results of vertex coloring changes, we provide a basis for later swarm evolution operations.
For the update process of a single probability matrix Aj, we compared the binary coloring scheme (B, Vgrey)j of the jth individual Dj in swarm D and the binary coloring scheme (Bn, Vngrey)j of the jth individual Yj in swarm Y and updated the vertex coloring probability matrix in four different cases.
The first case: When the black vertex vi (0 ≤ i < n) in set B is in set Bn, it indicates that the color of the vertex has not changed. We reward the probability of the vertex being black, where the reward factor is set to σ1 (0 < σ1 < 1), and synchronously update the probability value of this vertex being gray. That is:
After changing ci0 and ci1 according to formula 10, when ci0 > 0.85, we set ci0 to 0.85; when ci0 < 0.15, we set ci0 to 0.15; when ci1 > 0.85, we set ci1 to 0.85; when ci1 < 0.15, we set ci1 to 0.15. (Here, to prevent the corrected vertex coloring probability values ci0 and ci1 from being excessively large or small, we directly set the lower bound of the probability values to 0.15 and the upper bound to 0.85.)
The second case: When the black vertex vi (0 ≤ i < n) in set B is in set Vngrey, it means that the vertex has changed from originally black to gray. We penalize the probability of the vertex being black and compensate for the probability of the vertex being gray. The penalty factor is set to σ2 (0 < σ2 < 1), the compensation factor is set to σ3 (0 < σ3 < 1). That is:
After changing ci0 and ci1 according to formula 11, when ci0 > 0.85, we set ci0 to 0.85; when ci0 < 0.15, we set ci0 to 0.15; when ci1 > 0.85, we set ci1 to 0.85; when ci1 < 0.15, we set ci1 to 0.15. (Here, the rules for setting the upper and lower bounds of ci0 and ci1 values are as described above.)
The third case: When the gray vertex vi (0 ≤ i < n) in the set Vgrey is in the set Vngrey, it indicates that the color of the vertex has not changed. We reward the probability of the vertex being gray, where the reward factor is set to σ1 (0 < σ1 < 1), and synchronously update the probability value of the vertex being black. That is:
After changing ci0 and ci1 according to formula 12, when ci0 > 0.85, we set ci0 to 0.85; when ci0 < 0.15, we set ci0 to 0.15; when ci1 > 0.85, we set ci1 to 0.85; when ci1 < 0.15, we set ci1 to 0.15. (Here, the rules for setting the upper and lower bounds of ci0 and ci1 values are as described above.)
The fourth case: When the gray vertex vi (0 ≤ i < n) in the set Vgrey is in the set Bn, it indicates that the vertex has changed from gray to black. We penalize the probability of the vertex being gray and compensate for the probability of the vertex being black. Here, the penalty factor is set to σ2 (0 < σ2 < 1), the compensation factor is set to σ3 (0 < σ3 < 1). That is:
After changing ci0 and ci1 according to formula 13, when ci0 > 0.85, we set ci0 to 0.85; when ci0 < 0.15, we set ci0 to 0.15; when ci1 > 0.85, we set ci1 to 0.85; when ci1 < 0.15, we set ci1 to 0.15. (Here, the rules for setting the upper and lower bounds of ci0 and ci1 values are as described above.)
Using the single probability matrix update strategy described above, we sequentially update each probability matrix in the probability matrix group. The update operation of the probability matrix group is summarized in Probability_matrices_updating (Algorithm 4).

Probability_matrices_updating (M, Y, D, p, σ1, σ2, σ3).
In the swarm evolution algorithm, each individual corresponds to a probability matrix. Therefore, in Algorithm 4, the probability matrix is modified for each individual to realize the update operation of the probability matrix group. The process has a worst time complexity of O(p × (n − 1)2).
Evolutionary operation of swarm
The evolutionary operation of a swarm is an important process in the swarm evolution algorithm, which involves implementing evolutionary operation on individuals in the swarm to generate new and better individuals, thereby increasing the probability of the swarm evolution algorithm finding better solutions on new individuals. According to the updated probability matrix group M, the jth individual (B, Vgrey)j (0 ≤ j < p) in swarm D is subjected to evolutionary operation.
The evolutionary operation process comprises two steps. In the first step, vertex vi is sequentially selected from set (B)j, where i ranges from 0 to b-1. If the randomly generated coloring probability value is less than Aj (ci0), vi is colored black and added to set Btemp. Once this step is completed, if |Btemp|= b, it indicates that the black vertex set Btemp has been fully constructed. Otherwise, if |Btemp|< b, the second step is followed. In the second step, vertex wk is randomly selected from set (Vgrey)j, where k ranges from 0 to |(Vgrey)j|-1. If the randomly generated coloring probability value is less than Aj (ck0), wk is colored black and added to set Btemp until |Btemp|= b. After evolution, a new individual (Btemp, Vgrey_temp)j is generated. Here, Btemp represents the set of black vertices and Vgrey_temp represents the set of gray vertices, with Vgrey_temp = V \Btemp. Thus, the new individual is accepted, namely, (B, Vgrey)j ← (Btemp, Vgrey_temp)j. According to the evolutionary operation strategy, each individual in swarm D undergoes evolutionary operation, realizing the evolution of the swarm. This process involves swarm evolution and has a time complexity of O(p × n × b).
The evolutionary operation is summarized in Swarm_recombination (Algorithm 5).

Swarm_recombination (D, M).
Stochastic convergence analysis of the swarm evolution algorithm
Crossover operation is a key operational step in swarm evolution algorithm to find better solutions. When the algorithm searches for an individual, a new binary coloring scheme is generated by applying crossover operation to the individual to find better solutions.
Case 1: In Fig. 5(1) in Section “The first crossover operation”, the white vertex set W1 = {v2, v8, v10, v11}, |W1|= 4. We randomly select vertex v5 from set B and apply the first crossover operation strategy to choose vertex v3 from set Vgrey, generating a new binary shading scheme (B*, V *grey), where B* = {v1, v3, v7, v9} and V *grey = {v0, v2, v4, v5, v6, v8, v10, v11}. The white vertex set W2 = { v2, v4, v8, v10, v11}, and |W2|= 5.
Case 2: In Fig. 6(1) in Section “The second crossover operation”, the white vertex set W1 = {v2, v8, v10, v11}, |W1|= 4. We randomly select vertex v1 from set B and apply the second crossover operation strategy to choose vertex v3 from set Vgrey, generating a new binary shading scheme (B*, V *grey), where B* = {v3, v5, v7, v9} and V *grey = {v0, v1, v2, v4, v6, v8, v10, v11}. The white vertex set W2 = {v1, v2, v6, v8, v10, v11}, and |W2|= 6.
Therefore, during the algorithm iteration process, crossover operations are performed based on probability to select vertices such that |W1| <|W2|< … <|Wt|< …, thereby finding better solutions. In addition, after testing the graphs “home.col” and “le450_25d.col”, we find that the algorithm’s search results can remain stable at the best solution after a certain number of iterations.
In the swarm evolution algorithm, the improved simulated annealing search operation described in Section “Improved simulated annealing search” is used to search for better solutions for individuals. In this operation, we use the tabu table Tabulist to avoid the search process getting stuck in local optima, unable to find global better solutions. If (ies − Tabulist[v][w]) < L, reselect the non-tabu vertices that the algorithm can find better global solutions. The code for using the tabu table can be found on lines 7 and 8 of (Algorithm 2).
In the improved simulated annealing search operation, the number of operation iterations is controlled by the temperature cooling method T = α × T to reduce the temperature. At the same time, specific end condition is set (to find the optimal solution or reach the end time of search consumption) to control the number of iterations of the operation. When T ≤ Te or a specific termination condition is met, the iterative run of the improved simulated annealing search operation is terminated. The code to end the operation is shown in line 25 of (Algorithm 2). In addition, in the swarm evolution algorithm, a specific end condition is still set (the end condition is set to find the optimal solution, or the search time reaches the end time) to control the number of iterations of the algorithm. The code for ending the algorithm iteration is shown in line 16 of (Algorithm 1).
A variable neighborhood search algorithm for BWC
Variable neighborhood search algorithm is a classic heuristic algorithm that mainly explores a new solution space by exchanging vertices in the search space to find the best global solution to the problem.
For a graph G = (V, E), V will be divided into two sets B and S2, in which set B is set of black vertices, and |B|= b, S2 = V \B. The initial status is b black vertices are generated at random to construct set B, the remaining vertices in the graph G construct set S2. Here, b is the determined number of black vertices in BWC problem. The searched white vertices are in set S2, and the white vertices are constructed into the white vertices set W. The initial number of vertices in set W is |W0| =|{v|v ∈ S2, ∀w ∈ B, (v,w)\(\notin\) E}|.
In the algorithm, set B and S2 are designated as the neighborhood region, and we search for white vertices in set S2. If all the vertices in set S2 are white, it indicates that the optimal solution for the set of white vertices has been found, and the algorithm execution will be terminated. If the number of white vertices is greater than what was previously searched, it indicates that a better solution has been found, and the new, better solution is accepted. A new neighborhood is then generated, and the search is repeated until the algorithm reaches its end condition.
The strategies adopted in the dynamic change of the neighborhood are mainly exchanging multiple vertices in neighborhood. The method of generating a neighborhood is to exchange k vertices between set B and set S2. Here, Nk (k = 1, 2,…, kmax) is defined as pre-generated finite neighborhood, and k is the number of vertices exchanged in neighborhood region. Nk ((B, S2)) is defined as the neighborhood region obtained when (B, S2) has exchanged k vertices. For positive integer k (k < min(|B|, |S2|)), Bk(B) is obtained when set B has exchanged k vertices, and Bk(S2) is obtained when set S2 has exchanged k vertices. Thus, when the neighborhood (B, S2) changes to the new neighborhood (B', S'2), it is defined as:
Formula 14 shows that variable neighborhood search algorithm is to exchange at random k vertices between set B and set S2 to generate a new neighborhood (B', S'2).
In the algorithm, employing neighborhood state accepting condition, the new neighborhood (B', S'2) is accepted, that is: (B, S2) ← (B', S'2). The condition for accepting the state is that there are more white vertices searched in set S'2. The process of neighborhood change has a time complexity of O(b × (n − b)).
The procedure of finding the best solution by the algorithm is shown in formula 15, which is:
Here, i represents the number of iterations of the algorithm.
The algorithm is summarized in VNS (Algorithm 6).

VNS(G, kmax, b).
In the algorithm, kmax is used to control the number of vertices exchanged during algorithm operation. The W2 represents the best solution found for the BWC problem within the search. The best represents the best value found for the BWC problem within the search, and it is also the objective function value for the best solution of the BWC problem in the algorithm search.
A simulated annealing algorithm for BWC
The simulated annealing algorithm is a classic heuristic approach that primarily employs the principles of solid-state annealing, incorporating probabilistic jumps to identify the global optimal solution within the search space. The core strategy involves gradually decreasing a “temperature” parameter while iteratively executing the algorithm to explore the best solution to the problem.
In the algorithm, through the gradual change of state, the final result is obtained probabilistically. Given a graph G = (V, E), the vertex set V is divided into two sets, B and S2, where |B|= b and S2 = V \ B. The initial states of sets B and S2 are generated, and new set states (B', S'2) are continuously generated based on the current states of B and S2. The algorithm aims to find a better solution for W (where W is the set of white vertices) in the new set states until the termination condition of the algorithm is met.
The initial state process to generate set B and S2 is: first, b black vertices are selected at random in V to construct set B, then construct set S2 = V \ B, thus set B and S2 are generated, in which |B|= b.
We consider the current sets B and S2 to be the current set state (B, S2). We randomly select t vertices, where 1 ≤ t ≤ 3, from both sets B and S2 to exchange, thereby obtaining a new set state (B', S'2). If g(B', S'2) < g(B, S2), the new set state (B', S'2) will be accepted, or be accepted with a certain probability, i.e., (B, S2) ← (B', S'2). Otherwise, the new state may be rejected, and the current state (B, S2) remains unchanged. If g(B', S'2) = 0, it indicates that set S'2 may be an optimal solution for set W, and therefore the algorithm execution will be terminated. The function g(U1, U2) is defined as follows:
Function g(U1, U2) denotes the number of vertices in set U2 that are adjacent to the vertices in set U1. The process of changing the set state operates with a time complexity of O(b × (n − b)).
Based on the initial temperature T0, end temperature Te, and cooling coefficient α (0 < α < 1), the algorithm generates a new state (B', S'2) after the cooling process, where T represents the current temperature and is updated according to the formula T = α × T. This new state is then used to search set W, until the temperature T is lowered to Te or the end condition of the algorithm is met.
The algorithm is summarized in SA (Algorithm 7).

SA(G, T0, Te, α, b).
The W3 represents the best solution found for the BWC problem within the search. The best represents the best value found for the BWC problem within the search, and it is also the objective function value for the best solution of the BWC problem in the algorithm search.
The greedy algorithm for BWC
Greedy algorithm is a classic heuristic algorithm that iteratively runs with the locally optimal operation at each step, searching for the best solution in the search space.
For a graph G = (V, E), V is a set containing n vertices, and E is a set containing l edges. To solve the BWC problem using a greedy algorithm, the key lies in how to select black vertices to add to set B. Initially, the vertex set V is divided into two sets B and S2, with S2 = V, B = ∅. Set B represents the set of black vertices. Utilizing specific strategies, choose a black vertex from set S2, add it to set B, and subsequently remove it from set S2. Repeat this addition phase until |B|= b. Then, based on the currently determined sets B and S2, search for the white vertices in set S2, thereby constructing the white vertex set W. There are two strategies to choose black vertices, hence two kinds of greedy algorithms are realized.
The first greedy algorithm
In this greedy algorithm, first, from set S2, choose the vertex vi (0 ≤ i <|S2|) with the minimum degree value. If there are multiple vertices with the minimum degree value, randomly select one and delete it from set S2, adding it as a black vertex to set B. Second, following a defined vertex selection method, choose a black vertex w from set S2, delete it from set S2, and add it to set B. Third, continue performing the second step until the number of black vertices in set B reaches b. Fourth, search for the white vertex set W in set S2 based on the currently obtained sets B and S2. If the number of vertices in set W is greater than the number of currently determined white vertices, it indicates that a better solution has been found and is accepted as the new set W. Fifth, initialize sets B and S2, and then repeat the implementation from the first step until the end condition of the algorithm is met. Once the end condition is met, the algorithm will be terminated.
The method for selecting black vertices is to select vertex w from set S2 and add it to set B, so that the number of vertices in set B that can dominate the vertices in set S2 is minimized (if there are multiple vertices with the minimum value, then choose one at random). The objective function of vertex w is defined as:
In the algorithm, if B = ∅, the process of selecting a black vertex from the set S2 has a time complexity of O(n2). Conversely, if B ≠ ∅, the process of selecting black vertices from the set S2 has a worst time complexity of O(b × (n − 1)2).
The first algorithm is summarized in Greedy_One (Algorithm 8).

Greedy_One(G, B, S2, b).
The W4 represents the best solution found for the BWC problem within the search. The best represents the best value found for the BWC problem within the search, and it is also the objective function value for the best solution of the BWC problem in the algorithm search.
The second greedy algorithm
In this greedy algorithm, the method of selecting black vertices is to select vertex w from set S2, so that the sum of the greedy degrees of vertex w in set S2 is minimized (If there are multiple vertices with the minimum value, then choose one at random). The objective function f '(B ∪ {w}) for selecting vertex w is:
\(D(v_{i} ) = |\left\{ {e|\exists e \in S_{2} ,v_{i} \in S_{2} ,(v_{i} ,e) \in E} \right\}|\),
Here, vi is the vertex to which vertex wj is adjacent in set S2. The greedy degree of vi, denoted as D(vi), represents the number of vertices in set S2 that are adjacent to vi. In the algorithm, the process of selecting black vertices from set S2 has a worst time complexity of O(n3).
The second algorithm is summarized in Greedy_Two (Algorithm 9).

Greedy_Two(G, B, S2, b).
The W5 represents the best solution found for the BWC problem within the search. The best represents the best value found for the BWC problem within the search, and it is also the objective function value for the best solution of the BWC problem in the algorithm search.
Experimental results
We implemented the swarm evolution algorithm, variable neighborhood search algorithm, greedy algorithm, and simulated annealing algorithm using C+ + . All algorithms were executed on a platform equipped with an Intel Pentium G630 (R) processor running at 2.70 GHz, 8 GB of memory, and Windows 7 (64 bits) operating system. All algorithms were tested using Cayley graphs, random graphs, semi-random graphs, and benchmark DIMACS graphs. We compared the results of the swarm evolution algorithm, variable neighborhood search algorithm, greedy algorithm, and simulated annealing algorithm, and conducted corresponding data analysis. In addition, we also compared the results of the swarm evolution algorithm with algorithms proposed in existing literature, such as tabu search algorithms5, simulated annealing with configuration checking3, and local search algorithm4.
In the experiment, the swarm evolution algorithm has two versions, namely, “Swarm-E-1” and “Swarm-E-2”. “Swarm-E-1” represents the swarm evolution algorithm implemented using the first crossover operation. “Swarm-E-2” represents the swarm evolution algorithm implemented using the second crossover operation. “VNS1” represents the variable neighborhood search algorithm (kmax = 1). “VNS2” represents the variable neighborhood search algorithm (kmax = 2).
In the paper, we used four types of graphs to test all algorithms.
The first type of graphs is Cayley graphs, which are further divided into “kings” graphs (Cartesian strong product, Cm \({ \boxtimes }\) Cn) and “rooks” graphs (Cartesian product, Km□Kn). The generation methods of these graphs were proposed in5.
The second type of graphs is random graphs (Gm,p), and the generation method of these graphs was proposed in5.
The third type of graphs is semi-random graphs (SRm,B,W), and the generation method of these graphs was proposed in5, where the generation probability of semi-random graphs is 1/3.
The fourth type of graphs is benchmark DIMACS graphs, which were proposed in32.
Setting of algorithm parameter
The swarm evolution algorithm has multiple control parameters, including the number of individuals of swarm p, tabu table length L, perturbation operation startup parameter d, initial temperature T0, temperature cooling coefficient α, end temperature Te, reward factor σ1, penalty factor σ2, and compensation factor σ3. In order to conduct later testing of the swarm evolution algorithm, first set the parameter values of p, L, d, T0, α, and Te to 5, 10, 4, 1000, 0.9997, and 0.0001, respectively. On this basis, we conducted experiments to investigate the impact of parameter settings such as reward factor σ1, penalty factor σ2, and compensation factor σ3 on the search capability of the algorithm. We first set the parameter values of σ1, σ2, and σ3 to 18 groups, which are {σ1 = 0.1, σ2 = 0.1, σ3 = 0.1}, {σ1 = 0.1, σ2 = 0.1, σ3 = 0.2}, {σ1 = 0.1, σ2 = 0.1, σ3 = 0.3}, {σ1 = 0.1, σ2 = 0.2, σ3 = 0.1}, {σ1 = 0.1, σ2 = 0.2, σ3 = 0.2}, {σ1 = 0.1, σ2 = 0.2, σ3 = 0.3}, {σ1 = 0.1, σ2 = 0.3, σ3 = 0.1}, {σ1 = 0.1, σ2 = 0.3, σ3 = 0.2}, {σ1 = 0.1, σ2 = 0.3, σ3 = 0.3}, {σ1 = 0.2, σ2 = 0.1, σ3 = 0.1}, {σ1 = 0.2, σ2 = 0.1, σ3 = 0.2}, {σ1 = 0.2, σ2 = 0.1, σ3 = 0.3}, {σ1 = 0.2, σ2 = 0.2, σ3 = 0.1}, {σ1 = 0.2, σ2 = 0.2, σ3 = 0.2}, {σ1 = 0.2, σ2 = 0.2, σ3 = 0.3}, {σ1 = 0.2, σ2 = 0.3, σ3 = 0.1}, {σ1 = 0.2, σ2 = 0.3, σ3 = 0.2}, {σ1 = 0.2, σ2 = 0.3, σ3 = 0.3}. Using the “Swarm-E-1” algorithm, we conducted tests on multiple graphs, including “C51 \({ \boxtimes }\) C50”, “K75□K70”, “inithx.i.1.col”, “fpsol2.i.1.col”, “inithx.i.2.col”, “le450_5b.col”, “le450_15c.col”, “le450_25a.col”, “school1.col”, and “zeroin.i.3.col”. Each graph was tested 10 times, with each test lasting 30 min, and the test results are summarized in (Table 1).
In Table 1, the “id” column represents the sequence number of the set parameter values, while the “parameters” column displays the specific values of σ1, σ2, and σ3. The “b” column stands for the number of black vertices in the graphs, which is fixed at 20 for all test graphs. The “Best” column indicates the best value among the test results for each graph, and the “Avg” column provides the average of the test results for each graph. In Table 1, we use bold italics to indicate the best values of the algorithm, as well as the best average values.
To determine the optimal values of parameters σ1, σ2, and σ3, we employed the optimal vector method proposed in39 to analyze the sample data presented in (Table 1). The core principle of this method involves first constructing a vector group that comprises multiple vectors from the sample data. These vectors are created for each column or row (selected based on the problem description and test results). Subsequently, the maximum and minimum values of these vectors are normalized, and the lengths of each vector are calculated. The column or row number corresponding to the vector with the maximum length value represents the optimal parameter value for obtaining the sample value. Based on this concept, we implemented the method in two steps.
Step 1: Based on the test results in “parameters” (presented in Table 1), construct a column vector incorporating the “Best” results of all graphs in each row. Subsequently, assemble a vector group VTBest comprised of 18 such column vectors, where the column numbers correspond to the sequence number “id” of the parameter values.
Then perform maximum and minimum normalization on VTbest to obtain the vector group VT 'Best.
Finally, based on the optimal vector method, a set of data set VTBest_result is obtained, namely, VTBest_result = {3.00, 3.16, 3.16, 3.00, 2.98, 2.98, 2.65, 3.16, 3.16, 2.98, 3.16, 3.14, 2.67, 2.83, 2.83, 3.16, 2.67, 3.02}.
Step 2: Based on the test results in “parameters” (data in Table 1), construct the “Avg” results of all graphs in each row into a column vector, and thus construct a vector group VTAvg composed of 18 column vectors (whose column numbers correspond to the sequence number “id” of the parameter values).
Then perform maximum and minimum normalization on VTAvg to obtain the vector group VT 'Avg.
\(VT_{Avg}^{'} = \left( {\begin{array}{*{20}c} {0.60} & {0.20} & {0.60} & {0.60} & {0.60} & {1.00} & {0.40} & {0.40} & {0.40} & {0.20} & {0.60} & {0.60} & {0.60} & {0.80} & {0.00} & {1.0} & {0.80} & {0.40} \\ {0.13} & {0.54} & {0.54} & {0.56} & {0.56} & {0.43} & {0.34} & {0.57} & {0.56} & {0.31} & {1.0} & {0.00} & {0.10} & {0.33} & {0.11} & {0.44} & {0.33} & {0.54} \\ {0.39} & {0.42} & {0.74} & {0.10} & {0.81} & {0.23} & {0.06} & {0.00} & {0.06} & {0.16} & {0.55} & {0.97} & {0.26} & {0.23} & {1.0} & {0.19} & {0.06} & {0.58} \\ {0.52} & {0.28} & {0.48} & {0.69} & {0.07} & {0.28} & {0.59} & {0.48} & {0.48} & {0.00} & {0.69} & {0.24} & {0.24} & {0.14} & {0.52} & {1.0} & {0.21} & {0.24} \\ {0.20} & {0.67} & {0.73} & {0.47} & {0.33} & {0.33} & {0.00} & {0.27} & {0.40} & {0.67} & {0.47} & {1.0} & {0.27} & {0.33} & {0.27} & {0.53} & {0.07} & {0.73} \\ {0.50} & {0.50} & {0.67} & {0.00} & {0.83} & {0.17} & {0.50} & {0.67} & {0.17} & {0.67} & {0.17} & {0.33} & {0.00} & {0.17} & {0.50} & {1.0} & {0.33} & {0.50} \\ {0.33} & {0.33} & {0.67} & {1.00} & {0.67} & {0.67} & {0.33} & {1.0} & {0.67} & {0.33} & {0.67} & {0.00} & {0.67} & {0.67} & {0.67} & {0.67} & {1.0} & {0.33} \\ {1.0} & {1.0} & {1.0} & {0.00} & {1.00} & {1.0} & {1.0} & {1.0} & {1.0} & {1.0} & {1.0} & {1.0} & {1.0} & {1.0} & {1.0} & {1.0} & {1.0} & {1.0} \\ {0.52} & {0.67} & {0.50} & {1.00} & {0.66} & {0.34} & {0.67} & {0.33} & {0.67} & {0.00} & {0.69} & {0.34} & {0.17} & {0.00} & {0.34} & {0.69} & {0.67} & {0.86} \\ {1.0} & {1.0} & {0.50} & {0.00} & {0.33} & {1.0} & {1.0} & {1.0} & {0.50} & {1.0} & {1.0} & {1.0} & {1.0} & {1.0} & {1.0} & {1.0} & {0.50} & {0.50} \\ \end{array} } \right)\)
Finally, based on the optimal vector method, a set of data set VTAvg_result is obtained, namely, VTAvg_result = {1.86, 1.96, 2.09, 1.84, 2.02, 2.00, 1.85, 2.08, 1.74, 1.78, 2.30, 2.14, 1.74, 1.84, 2.04, 2.54, 1.90, 1.93}.
Step 3: Set the weight of the data in VTBest_result to 0.5, set the weight of the data in VTAvg_result to 0.5, and sum the corresponding components of the two sets weighted by their respective weights to obtain the data set VTresult, namely, VTresult = {2.43, 2.56, 2.63, 2.42, 2.5, 2.49, 2.25, 2.62, 2.45, 2.38, 2.73, 2.64, 2.21, 2.34, 2.44, 2.85, 2.29, 2.48}. That is:
VTresult = {vti| vti = vtbi × 0.5 + vtai × 0.5, vtbi ∈ VTBest_result, vtai ∈ VTAvg_result, 0 < i <|VTBest_result |}.
Step 4: Select the maximum value of 2.85 from VTresult, which corresponds to the 16th sample column vector.
Therefore, according to the decision rule of the optimal vector method, we determine the parameter values σ1 = 0.2, σ2 = 0.3, and σ3 = 0.1, which correspond to the 16th sample column vector (id = 16), as the parameter values for the swarm evolution algorithm.
Finally, the parameter values of the swarm evolution algorithm are determined as shown in (Table 2). In addition, the parameters T0, α, and Te in SA algorithm are set to 1000, 0.9997, and 0.0001, respectively. We conducted algorithm testing using these parameter values in the later stage.
Test results on swarm evolution algorithm and other algorithms
We first evaluated the performance characteristics of various algorithms, including swarm evolution algorithms (Swarm-E-1 and Swarm-E-2), variable neighborhood search algorithms (VNS1 and VNS2), the simulated annealing algorithm (SA), and greedy algorithms (Greedy_One and Greedy_Two). Testing was conducted on graphs belonging to different categories, such as “C31 \({ \boxtimes }\) C30 (b = 150)”, “C51 \({ \boxtimes }\) C50 (b = 250)”, “K15□K10 (b = 40)”, “homer.col (b = 25)”, “le450_15d.col (b = 25)”, “le450_25d.col (b = 25)”, “G500,0.1 (b = 40)”. The running curves of these algorithms are presented in (Fig. 7). In Fig. 7, the X-axis represents the data collection time for the algorithms running on each graph, with results collected every 10 s of running time. The Y-axis depicts the results obtained by the algorithms at the corresponding collection run time for each graph. Analysis of the curves reveals that under graphs (b) and (c), the swarm evolution algorithms exhibit significantly superior search capabilities compared to other algorithms, leading to better results. Under graphs (a), (e), (f), and (g), the swarm evolution algorithms perform slightly better than the SA algorithm, achieving superior results compared to SA, but still outperforming other algorithms. Finally, under graph (d), the swarm evolution algorithms demonstrate marginally improved search capabilities compared to other algorithms.

The running curves of algorithms.
To compare the differences in search results among the swarm evolution algorithm, simulated annealing algorithm, variable neighborhood search algorithm, and the greedy algorithm, we conducted four groups of comparative tests, with each graph tested 20 times for 30 min each.
In the first group of tests, multiple graphs are used for testing, such as Cayley graphs, random graphs, and semi-random graphs. The test results of the algorithms are summarized in (Table 3). In Table 3, “Instance” represents the graph for the test, “|V|” represents the number of vertices in this graph, “b” represents the number of black vertices in the graph, “best” represents the best value of the number of white vertices in the algorithm search, and “avg” represents the average value of the number of white vertices in the algorithm search, “time (s)” represents the average time (in seconds) consumed by the algorithm to obtain the best value.
In Table 3, we use bold italics to indicate the best values of the algorithms, as well as the minimum time values spent on obtaining these best values. The swarm evolution algorithms (Swarm-E-1 and Swarm-E-2) can find the best values of all graphs. The SA algorithm can obtain the best values of 16 graphs (approximately 62% of the total number of graphs). The Greedy_One algorithm can obtain the best values of 9 graphs (approximately 35% of the total number of graphs). The Greedy_Two algorithm can obtain the best values of 3 graphs (approximately 12% of the total number of graphs). The VNS1 and VNS2 algorithms can respectively find the best value for one graph (approximately 4% of the total number of graphs). In addition, the swarm evolution algorithms (Swarm-E-1 and Swarm-E-2) can find the best values of 17 graphs (approximately 65% of the total number of graphs) by consuming the minimum time value. The SA algorithm can find the best values of 4 graphs by consuming the minimum time value (approximately 15% of the total number of graphs). The Greedy_One algorithm can find the best values of 3 graphs by consuming the minimum time value (approximately 12% of the total number of graphs). The Greedy_Two algorithm can find the best values of two graphs by consuming the minimum time value (approximately 8% of the total number of graphs). Although VNS1 and VNS2 algorithms can find the best value of one graph, they consume more time. From this, our swarm evolution algorithms have the best search performance in the first group of tests.
The second group of test graphs used large “kings” graphs (graphs with many vertices). The test results are summarized in (Table 4).
In Table 4, we use bold italics to indicate the best values of the algorithms. The swarm evolution algorithms (Swarm-E-1 and Swarm-E-2) can find the best values of 13 graphs (approximately 87% of the total number of graphs). The Greedy_One algorithm can find the best value for two graph (approximately 13% of the total number of graphs). Other algorithms can’t find the best values for the graphs. From this, it can be seen that our swarm evolution algorithms have the best search performance in the second group of tests.
The third group of test graphs used large “rooks” graphs (graphs with many vertices). The test results are summarized in (Table 5).
In Table 5, we use bold italics to indicate the best values of the algorithms, as well as the minimum time values spent on obtaining these best values. The swarm evolution algorithms (Swarm-E-1 and Swarm-E-2) can find the best values of 12 graphs (approximately 80% of the total number of graphs). The SA algorithm can find the best values of 9 graphs (approximately 60% of the total number of graphs). Other algorithms can not find the best values of these graphs. In addition, the swarm evolution algorithms (Swarm-E-1 and Swarm-E-2) can find the best values of 10 graphs (approximately 67% of the total number of graphs) by consuming the minimum time values. The SA algorithm can find the best values of 5 graphs by consuming the minimum time values (approximately 33% of the total number of graphs). From this, our swarm evolution algorithms have the best search performance in the third group of tests.
The fourth group of test graphs used benchmark DIMACS graphs. The test results are summarized in (Table 6).
In Table 6, we use bold italics to indicate the best values of the algorithms, as well as the minimum time values spent on obtaining these best values. The swarm evolution algorithms (Swarm-E-1 and Swarm-E-2) can obtain the best values of 59 graphs (approximately 98% of the total number of graphs). The SA algorithm can obtain the best values of 58 graphs (approximately 97% of the total number of graphs). The Greedy_One algorithm can obtain the best values of 15 graphs (approximately 25% of the total number of graphs). The Greedy_Two algorithm can obtain the best values of 18 graphs (approximately 30% of the total number of graphs). The VNS1 algorithm can obtain the best values of 26 graphs (approximately 43% of the total number of graphs). The VNS2 algorithm can obtain the best values of 28 graphs (approximately 47% of the total number of graphs).
In addition, the swarm evolution algorithms (Swarm-E-1 and Swarm-E-2) can find the best values of 47 graphs (approximately 78% of the total number of graphs) by consuming the minimum time values. The SA algorithm can find the best values of 17 graphs by consuming the minimum time values (approximately 28% of the total number of graphs). The Greedy_One algorithm can find the best values of 3 graphs by consuming the minimum time values (approximately 5% of the total number of graphs). The Greedy_Two algorithm can find the best values of 3 graphs by consuming the minimum time values (approximately 5% of the total number of graphs). The VNS1 algorithm can find the best values of 10 graphs by consuming the minimum time values (approximately 17% of the total number of graphs). The VNS2 algorithm can find the best values of 10 graphs by consuming the minimum time values (approximately 17% of the total number of graphs). It should be noted that when the average time consumed by the algorithm search in Table 6 is less than 0.01, we think that the time consumption value is roughly the same. From this, our swarm evolution algorithms have the best search performance in the fourth group of tests.
Comparison of swarm evolution algorithm with other existing algorithms
In5, algorithms were proposed to solve the BWC problem, such as tabu algorithms (In this literature, these algorithm names were respectively “R-tabu” and “SG-tabu”), integer linear programming (In this literature, the algorithm was named “ILP”), randomized restart hill climbing (In this literature, the algorithm was named “RRHC”), greedy randomized adaptive search procedure (In this literature, the algorithm was named “GRASP”), and simulated annealing (In this literature, the algorithm was named “SA”). In3, simulated annealing with configuration checking (In this literature, the algorithm was named “SACC”) was proposed to solve the BWC problem. In4, a local search algorithm based on tabu table (In this literature, the algorithm was named “BTLSBWC”) was proposed to solve the BWC problem. Firstly, we compared the test results of the swarm evolution algorithms with the algorithms proposed in5, and the comparison results are summarized in (Table 7).
In Table 7, we use bold italics to indicate the best values of the algorithms. The tabu algorithms, RRHC algorithm, and GRASP algorithm can find the best values for graph “G200,0.1(b = 10)”. The tabu algorithms can find the best values for graph “G200,0.1(b = 40)”. Our swarm evolution algorithms can find the best values for graphs “C21 \({ \boxtimes }\) C20(b = 100)”, “G500,0.1(b = 20)”, and “G500,0.1(b = 40)”. In addition, our swarm evolution algorithms and tabu algorithms can find the best values of the same graphs and can find more of the best values of graphs than multiple algorithms such as ILP, SA (algorithm proposed in5), RRHC, and GRASP. From this, our swarm evolution algorithms can improve the known results of three graphs in5.
In3, the hardware testing environment for the SACC algorithm was PC (Intel CPU 2.7 GHz), and the algorithm was coded in C + + . Each graph was tested 20 times, each time for 30 min. We implemented the testing of the swarm evolution algorithms based on this testing environment and compared the test results of the swarm evolution algorithms and the SACC algorithm, as shown in (Table 8).
In Table 8, we use bold italics to indicate the best values of the algorithms, as well as the minimum time values spent on obtaining these best values. Our swarm evolution algorithms (Swarm-E-1 and Swarm-E-2) can find the best values of 11 graphs (approximately 92% of the total number of graphs). The SACC algorithm can find the best values of 10 graphs (approximately 83% of the total number of graphs). In addition, the swarm evolution algorithms (Swarm-E-1 and Swarm-E-2) can find the best values of 7 graphs by consuming the minimum time values (approximately 58% of the total number of graphs). The SACC algorithm can find the best values of 5 graphs by consuming the minimum time values (approximately 42% of the total number of graphs). (Here is an explanation: in3, the graph marked by the author is K15□K11, but according to the content description of the reference, the graph should be K15□K10.) From this, our swarm evolution algorithms have better search ability than SACC algorithm.
We implemented the testing of the swarm evolution algorithms in the BTLSBWC algorithm testing environment described in4 (25 tests per graph, each lasting 20 min) and compared the test results of the swarm evolution algorithms with the BTLSBWC algorithm. The comparison results are summarized in (Table 9).
In Table 9, we use bold italics to indicate the best values of the algorithms. Our swarm evolution algorithms (Swarm-E-1 and Swarm-E-2) can find the same best values as the BTLSBWC algorithm in multiple graphs, such as “C15 \({ \boxtimes }\) C11(b = 20)”, “C15 \({ \boxtimes }\) C11(b = 25)”, “C15 \({ \boxtimes }\) C11(b = 28)”, “C15 \({ \boxtimes }\) C11(b = 70)”, “C15 \({ \boxtimes }\) C11(b = 99)”, “C15 \({ \boxtimes }\) C11(b = 100)”, “C15 \({ \boxtimes }\) C11(b = 120)”, “C15 \({ \boxtimes }\) C11(b = 125)”, “C15 \({ \boxtimes }\) C11(b = 141)”, “C21 \({ \boxtimes }\) C20(b = 80)”, and “C21 \({ \boxtimes }\) C20(b = 100)”. In other graphs, the swarm evolution algorithms can find better results than the BTLSBWC algorithm. From this, our swarm evolution algorithms have better search ability than the BTLSBWC algorithm and can improve the 22 existing results for graphs “le450_25a.col” and “le450_15c.col” in4.
Conclusion
In the paper, we present a swarm evolution algorithm (Swarm_BWC) to solve the black and white coloring problem. This algorithm adopts an improved simulated annealing search process, combined with a perturbation operation, two crossover operations and a group evolution operation with probability learning mechanisms, to enhance the algorithm’s search ability.
We analyzed the performance of swarm evolution algorithm on 14 Cayley graphs (divided into 46 instances for testing), 2 random graphs (divided into 4 instances for testing), 6 semi-random graphs (divided into 6 instances for testing), and 60 benchmark DIMACS graphs (divided into 60 instances for testing). Compared with variable neighborhood search algorithm, greedy algorithm and simulated annealing algorithm, the swarm evolution algorithm found the best solutions for 109 test instances, with the highest number of best solutions found, so our algorithm exhibited stronger capabilities.
Furthermore, we studied the local search algorithm, simulated annealing algorithm with configuration checking and tabu search algorithm presented in the references. Through comparative experiments on Cayley graphs between swarm evolution algorithms and simulated annealing with configuration checks, it can be found that our algorithm has stronger search ability than simulated annealing with configuration checks in terms of the number of best solutions found and the time consumed in finding the best solutions. We conducted additional experimental comparisons among our swarm evolution algorithm, local search algorithm, and tabu search algorithm, revealing that our algorithm had improved the known best results for 25 graphs.
Finally, we demonstrated that the Swarm_BWC method can significantly improve other classical heuristic methods for solving BWC problem.
Data availability
All data were obtained through algorithm testing, and the analysis results are presented in the paper.
References
Hansen, P., Hertz, A. & Quinodoz, N. Splitting trees. Discret. Math. 165–166 (15), 403–419 (1997).
Berend, D., Korach, E. & Zucker, S. Anticoloring of a family of grid graphs. Discret. Optim. 5 (3), 647–662 (2008).
Zhao, D. Simulated annealing with configuration checking for the BWC problem. J. Comput. Theor. Nanosci. 12 (12), 5725–5727 (2015).
Ye, A., Zhou, X. & Zhang, Z. Heuristic algorithms research of black white coloring problem. Sci. Technol. Eng. 14 (17), 150–154 (2014).
Berend, D., Korach, E. & Zucker, S. Tabu search for the BWC problem. J. Glob. Optim. 54 (4), 649–667 (2012).
Berend, D. & Zucker, S. The black and white coloring problem on trees. J. Graph Algorithms Applic. 13 (2), 133–152 (2009).
Berend, D., Korach, E. & Zucker, S. Anticoloring and separation of graphs. Discret. Math. 310 (3), 390–399 (2010).
Katayama, K., Sadamatsu, M. & Narihisa, H. Iterated k-opt local search for the maximum clique problem. Lect. Notes Comput. Sci. 4446, 84–95 (2007).
Battiti, R. & Protasi, M. Reactive local search for maximum clique. Algorithmica 29 (4), 610–637 (2001).
Pullan, W. Phased local search for the maximum clique problem. J. Comb. Optim. 12 (3), 303–323 (2006).
Katayama, K., Hamamoto, A. & Narihisa, H. An effective local search for the maximum clique problem. Inf. Process. Lett. 95(5), 503–511 (2005).
K.Katayama, H.Narihisa. Iterated local search approach using genetic transformation to the traveling salesman problem. In: Proceedings of the Genetic and Evolutionary Computation Conference, Orlando, Florida, USA. 321–328 (2000).
Fadlaoui, K. & Galinier, P. A tabu search algorithm for the covering design problem. J. Heurist. 17 (6), 659–674 (2011).
Fadlaoui, K. & Galinier, P. A tabu search algorithm for the covering design problem. J. Heurist. 17, 659–674 (2011).
Li, X., ChongfangYue, Y. P. A., Chen, S. & Cui, Y. An iterated tabu search metaheuristic for the regenerator location problem. Appl. Soft Comput. 70, 182–194 (2018).
Sin, C. H. An iterated tabu search heuristic for the single source capacitated facility location problem. Appl. Soft Comput. 27, 169–178 (2015).
Palubeckis, G., Ostreika, A. & Rubliauskas, D. Maximally diverse grouping: an iterated tabu search approach. J. Operat. Res. Soc. 66 (4), 579–592 (2015).
Ye, A. et al. Tabu assisted local search for the minimum load coloring problem. J. Comput. Theor. Nanosci. 11 (12), 2476–2480 (2014).
Hansen, P., Mladenović, N. & Urošević, D. Variable neighborhood search for the maximum clique. Discret. Appl. Math 145, 117–125 (2004).
Dražić, Z., Čangalović, M. & Kovačević-Vujčić, V. A metaheuristic approach to the dominating tree problem. Opt. Lett. 11 (6), 1155–1167 (2017).
Meer, K. Simulated annealing versus metropolis for a TSP instance. Inf. Process. Lett. 104 (6), 216–219 (2007).
Xinshun, Xu. & Ma, J. An efficient simulated annealing algorithm for the minimum vertex cover problem. Neurocomputing 69 (7–9), 913–916 (2006).
Tang, Z., Feng, Q. & Zhong, P. Nonuniform neighborhood sampling based simulated annealing for the directed feedback vertex set problem. IEEE Access 5, 12353–12363 (2017).
GintarasPalubeckis, A. variable neighborhood search and simulated annealing hybrid for the profile minimization problem. Comput. Oper. Res. 87, 83–97 (2017).
Zhao, D. & Shu, Z. A simulated annealing algorithm with effective local search for solving the sum coloring problem. J. Comput. Theor. Nanosci. 13 (1), 945–949 (2016).
Xiang, L. I., Su-jian, L. I. & Hong, L. I. Simulated annealing with large-neighborhood search for two-echelon location routing problem. Chin. J. Eng. 39 (6), 953–961 (2017).
Parekh, A. K. Analysis of a greedy heuristic for finding small dominating sets in graphs. Inform. Process. Lett. 39 (5), 237–240 (1991).
Moscato, P. & Cotta, C. A gentle introduction to memetic algorithms. In Handbook of Metaheuristics. International Series in Operations Research and Management Science (eds Glover, F. & Kochenberger, G.) (Kluwer Academic Publishers, 2003).
Jin, Y., Hao, J.-K. & Hamiez, J.-P. A memetic algorithm for the minimum sum coloring problem. Comput. Oper. Res. 43, 318–327 (2014).
Zhou, Y., Hao, J.-K. & Duval, B. Reinforcement learning based local search for grouping problems: A case study on graph coloring. Expert Syst. Appl. 64 (12), 412–422 (2016).
Zhou, Y., Duval, B. & Hao, J.-K. Improving probability learning based local search for graph coloring. Appl. Soft Comput. 65 (4), 542–553 (2018).
Sun, Z. et al. Reinforcement learning based tabu search for the minimum load coloring problem. Comput. Oper. Res. 143 (105745), 1–17 (2022).
Luan, F. et al. Improved whale algorithm for solving the flexible job shop scheduling problem. Mathematics. 7 (5), 1–14 (2019).
Yanhong Feng, X. Y. et al. A novel monarch butterfly optimization with global position updating operator for large-scale 0–1 knapsack problems. Mathematics. 7 (5), 1–31 (2019).
Balande, U. & Shrimankar, D. SRIFA: Stochastic ranking with improved-firefly-algorithm for constrained optimization engineering design problems. Mathematics. 7 (5), 1–26 (2019).
Marappan, R. & Sethumadhavan, G. Complexity analysis and stochastic convergence of some well-known evolutionary operators for solving graph coloring problem. Mathematics. 8 (3), 1–20 (2020).
Marappan, R. & Sethumadhavan, G. Solution to graph coloring using genetic and tabu search procedures. Arab. J. Sci. Eng. 43 (2), 525–542 (2018).
Marappan, R. & Bhaskaran, S. New evolutionary operators in coloring DIMACS challenge benchmark graphs. Int. J. Inform. Technol. 14 (6), 3039–3046 (2022).
Zhang, Z., Wang, W. & Shi, Da. An optimal vector method for parameter setting of swarm evolution algorithm. Sci. Technol. Eng. 21 (18), 7611–7621 (2021).
Acknowledgements
This research was supported by the Open Research Project of Key Laboratory of Tianfu Cultural Digitization Innovation of Sichuan Provincial Department of Culture and Tourism in Chengdu University (No. TFWH-2024-24).
Author information
Authors and Affiliations
Contributions
Zhiqiang Zhang and Li Zhang wrote the main manuscript text, and Xiujun Zhang verified the results in the paper. All authors reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Zhang, Z., Zhang, L. & Zhang, X. An efficient swarm evolution algorithm with probability learning for the black and white coloring problem. Sci Rep 15, 25245 (2025). https://doi.org/10.1038/s41598-025-06855-4
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-06855-4
