
Abstract
This study aimed to develop and validate a transformer-based early warning score (TEWS) system for predicting adverse events (AEs) in the emergency department (ED). We conducted a retrospective study analyzing adult ED visits at a tertiary hospital. The TEWS was developed to predict five AEs within 24 h: vasopressor use, respiratory support, intensive care unit admission, septic shock, and cardiac arrest. Performance was evaluated and compared using the area under the receiver operating characteristic curve (AUROC) and bootstrap-based t-test. External validation was performed using the Marketplace for Medical Information in Intensive Care (MIMIC)-IV-ED database. Transfer learning was applied using 1% and 5% of the external data. A total of 414,748 patients was analyzed in the development cohort (AEs, 3.7%), and 410,880 patients (AEs, 6.7%) were included in the external validation cohort. Compared to the modified early warning score (MEWS), the TEWS incorporating 13 variables and the vital signs-only TEWS demonstrated superior prognostic performance across all AEs. The AUROC ranged from 0.833 to 0.936 for TEWS and 0.688 to 0.874 for MEWS. In external validation, the TEWS also showed acceptable discrimination with AUROC values of 0.759 to 0.905. Transfer learning significantly improved the performance, increasing AUROC values to 0.846–0.911. The TEWS system was successfully integrated into the electronic health record (EHR) system of the study hospital, providing real-time risk assessment for ED patients. We developed and validated an artificial intelligence-based early warning score system that predicts multiple adverse outcomes in the ED and was successfully integrated into the EHR system.
Similar content being viewed by others

Introduction
Effectively screening patients at risk of clinical deterioration is crucial in the emergency department (ED) to ensure timely intervention and improve patient outcomes1. Limited resources and space, combined with an uncontrolled influx of patients, present significant challenges that require rigorous management. Thus, prioritizing patients needing immediate care, efficiently allocating resources, and implementing appropriate interventions are essential to providing optimal patient care2,3,4.
Early warning systems (EWS) such as the Modified Early Warning Score (MEWS) and National Early Warning Score (NEWS) have been widely used in EDs to identify patients at risk of clinical deterioration5,6. These tools are easy to use and facilitate rapid risk stratification, but their accuracy and generalizability are limited by fixed scoring rules and reliance on a small set of variables. To potentially overcome the limitations of conventional early warning scores and enhance the screening of high-priority patients, various artificial intelligence (AI)-based clinical decision support systems (CDSS) have been introduced to support clinical decision-making and improve patient triage7,8,9,10,11. These systems assist in real-time clinical decision-making by primarily predicting patient outcomes, such as mortality rates or probability of intensive care unit (ICU) admission. However, a significant gap remains in AI-based CDSS: the ability to adaptively provide updated results as patient status changes over time and to specify necessary interventions. This is particularly important because the conditions of patients in the ED are dynamic and can change rapidly7,8,10,12,13,14.
Transformer learning is a novel approach that offers enhanced data processing capabilities, efficiently managing the large and complex datasets commonly encountered in medical settings15. Transformers are ideal for CDSS in EDs due to their ability to handle irregular time series data, adapt continuously, manage missing data, and offer interpretability16,17,18. Using time embeddings and attention mechanisms, transformers capture important patterns across uneven time intervals, which are common in ED data19,20. Transformers support continuous re-learning, allowing the CDSS to remain current based on emerging clinical knowledge21. With attention-based weighting, transformers can address missing data effectively by focusing on the most informative inputs22. Furthermore, the model’s attention weights offer interpretability, allowing clinicians to visualize the factors that influence the decision, enhancing transparency and trust23.
This study aims to develop and validate a transformer model-based early warning score (TEWS) that can reflect real-time changes in patient status and provide specific intervention recommendations. Furthermore, we sought to develop a system that integrates the TEWS into the electronic health record (EHR) system to provide clinical decision support and actionable information to healthcare providers.
Methods
Study setting and population
The study was retrospective and observational, using data from patient ED visits at one tertiary referral hospital in Republic of Korea with approximately 1,980 inpatient beds and approximately 60,000 ED visits per year. Adult patients (aged 19 years or older) who visited the ED of the study site between 2015 and 2022 were included in this study. We excluded patients who had signed “Do not attempt resuscitation” orders and those whose vital signs were not measured in the ED.
For external validation, the Marketplace for Medical Information in Intensive Care (MIMIC)-IV-ED database was used. Patients (aged 19 years or older) with data between 2011 and 2019 were included24. This study was conducted in accordance with the TRIPOD-AI (Transparent Reporting of a multivariable prediction model for Individual Prognosis Or Diagnosis-Artificial Intelligence) guidelines25.
Prediction outcome
The purpose of the predictive model was to estimate the likelihood of the five adverse events (AEs) of critical interventions and outcomes occurring within 24 h; (1) the use of vasopressors (norepinephrine, epinephrine, dopamine, and vasopressin infusion), (2) advanced respiratory support (high-flow nasal cannula, noninvasive positive ventilation, and mechanical ventilation intubation), (3) ICU admission, (4) progression to septic shock (according to the Sepsis-3 definition)26, and (5) in-hospital cardiac arrest.
Data preprocessing
Data were extracted from the hospital’s clinical data warehouse, including demographic characteristics, vital signs, laboratory test results, procedural events, drug administration, and outcomes. Preprocessing proceeded sequentially through the following steps: (1) outlier detection and removal, (2) normalization, (3) resampling and windowing, and (4) data handling. Outliers were identified and excluded based on clinically acceptable ranges for vital signs and reportable ranges for laboratory data. (Table S1). All variables were normalized to a 0–1 range using min-max scaling. The normalized data were combined into multi-dimensional vectors according to the number of variables and into two-dimensional vectors for age and gender.
To reflect the temporal changes in variables, the data were structured as time series composed of 15-minute intervals over 48 h. The 48-hour observation window was implemented as a sliding window aligned with each prediction time point, incorporating data from the most recent 48 h. For most patients who stayed in the ED for less than 48 h after arrival, only the available data were used as model input. If multiple data points existed within a 15-minute interval, the last data point was used, and missing data points were replaced with ‘0.’ This resulted in data with a (192, N) format. Labeling was designed to capture the timing of AEs. Label 1 (acute deterioration) was assigned if AEs occurred within 24 h from the last timestamp, while Label 0 (normal) was assigned if no acute deterioration occurred within 24 h. The dataset was split into training, validation, and test sets in a 60%, 20%, and 20% ratio based on patient admission numbers.
After finalizing a data use agreement and completing the “Protection of Human Subjects” training, researchers can access the MIMIC-IV database online (https://mimic.physionet.org). We obtained authorization to access the MIMIC-IV database. Researchers who completed the Collaborative Institutional Training Initiative (CIIT) program extracted the following data using PostgreSQL tools version 15.4 (PostgreSQL Global Development Group, Berkeley, CA, USA) and Python version 3.7.5. We obtained authorization and accessed the MIMIC-IV database on 27 October 2021. The data codes used for the study analyses were from the MIMIC Code Repository27.
Model and training
We developed and tested separate transformer models for five adverse outcomes (Fig. 1).

Overview of the Transformer-Based Early Warning Score model.
The input to the TEWS model consists of two components: a multivariate time-series sequence (after preprocessing) and a set of static features. For each patient \(\:i\), the time-series input is denoted as:
where \(\:{\mathbf{x}}_{i}^{\left(t\right)}\) represents the observed features (e.g., vital signs and laboratory results) at time step t, sampled every 15 min over a 48-hour window, resulting in \(\:T=192\) steps. In addition, static patient-level information such as age, sex, and mode of arrival is encoded as:
The final model input is the combination of both modalities:
The time-series component \(\:{X}_{i}\) is processed by a 4-layer Transformer encoder with single-head self-attention and a hidden dimension of 512. To preserve temporal ordering, standard sinusoidal positional encoding is added to the input sequence prior to encoding.
The static vector \(\:{\varvec{s}}_{i}\) is passed through a fully connected (FC) layer. The resulting representations are concatenated and passed through a sigmoid activation to produce the predicted probability of an adverse event:
where \(\:\Vert\:\) denotes vector concatenation, \(\:\sigma\:\) is the sigmoid activation function, and \(\:\mathbf{W},b\) are the learnable weight matrix and bias term, respectively.
During training, the binary cross-entropy loss function was used. To address the issue of data imbalance, higher weights were assigned to cases of acute deterioration. The loss function was defined as follows:
where N represents the number of samples, \(\:{y}_{i}\in\:\left\{\text{0,1}\right\}\) represents the actual label of the ith sample, \(\:y\hat {}_{i}\) represents the model’s predicted probability for the ith sample, \(\:{\omega\:}_{pos}\) represents the weight for the positive class (Label 1), and \(\:{\omega\:}_{neg}\) represents the weight for the negative class (Label 0). The weights were calculated using scikit-learn’s compute_class_weight function. Adjusting the weights of the loss function enhanced the model sensitivity to relapse.
We optimized the hyperparameters using a grid search, training the TEWS model with all possible combinations. Each configuration was evaluated based on the validation loss, and the combination that yielded the lowest loss was selected as the best.
The learning rate was set at 1e-4, with AdamW used as the optimizer and a batch size of 1000. The model was trained for a total of 200 epochs. The entire code was written using Python v3.7.5, and the machine learning algorithm was implemented using TensorFlow v2.5.0. The GPU used was TITAN V, with CUDA version 11.2 and cuDNN version 8.9.1.
Model explainability
To ensure that the TEWS model is interpretable and actionable in clinical settings, we incorporated model explainability using gradient-weighted class activation mapping (Grad-CAM)28. Grad-CAM, originally designed for convolutional neural networks, was adapted to analyze the importance of features in our transformer model. By visualizing the model’s attention to different features, Grad-CAM allowed us to identify the variables contributing most highly to the predictions of the model at specific time intervals for individual cases.
Through this analysis, we observed that the top contributing features varied across individual patients, reflecting the ability of the model to dynamically adapt to unique clinical presentations. This case-specific explainability was integrated into the EHR system, allowing clinicians to view the most relevant features influencing the predictions of the model for each patient in real time9.
Feature selection
We tested 44 variables and conducted multiple-step model testing with feature reduction to select the optimal features for our models (Table S1). The key consideration in the feature selection process was to ensure acceptable prognostic performance29. Features were selected based on their high contribution to model performance and their consistent appearance across models. The final feature selection also considered practical aspects such as data processing efficiency, number of measurements, computational costs, ease of EMR integration, and feasibility of external validation. We tested a full TEWS model with selected features and a TEWS model using vital signs only.
Model performance measure and validation
We measured and compared the model performance by area under the receiver operating characteristic curve (AUROC) for predicting each outcome. Additionally, we calculated the area under the precision-recall curve (AUPRC), sensitivity, specificity, positive predictive value (PPV), and negative predictive value (NPV) at the optimal cut-off determined by the Youden Index. The TEWS model output was displayed as a score ranging from 0 to 1. Each score was categorized into three risk groups (low, intermediate, and high risk) using cut-off values selected to achieve sensitivity of 90% and specificity of 95%. These initial thresholds were further refined for each outcome by considering false alarm counts, PPV, and NPV to optimize clinical implementation.
We compared the performance of our TEWS model with the MEWS30, calculated at the same time intervals. Setting the MEWS threshold at ≥ 5 points as the reference, we evaluated the performance of TEWS at a comparable sensitivity level and calculated the number of false alarms per 1,000 patients31.
For external validation, we evaluated the predictive performance of the TEWS models for each outcome using the MIMIC-IV-ED database. The cardiac arrest prediction model was not evaluated as cardiac arrest occurrence data are not available in the MIMIC-IV-ED database.
To improve model performance during external validation, we used transfer learning by fine-tuning the model with 1% (approximately 1,600 patients) and 5% of the MIMIC-IV-ED database32. This enabled the model to adapt to the characteristics of the external dataset. Performance evaluation was conducted using an independent 20% subset of the MIMIC-IV-ED database. In addition, we tested the performance of alternative models including logistic regression and XgBoost models using the final variables.
Statistical analysis
Categorical variables are reported as frequencies and percentages, while continuous variables are reported as means (standard deviations, SD). The significance of differences in continuous variables between groups was assessed using Student’s t-test, while differences in categorical variables between groups were analyzed using chi-square tests. Confidence intervals were calculated using bootstrapping. To assess the statistical significance of the differences in diagnostic performance including AUROC between TEWS and MEWS, we performed a bootstrap-based t-test with 1,000 resamples. A two-tailed p value < 0.05 was considered statistically significant. All analyses were performed using R version 3.6.3. (R Foundation for Statistical Computing, Vienna, Austria) and Python version 3.7.5.
Results
Demographics
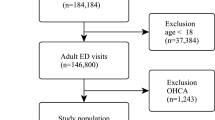
A total of 414,748 subjects was analyzed, among whom 15,486 (3.7%) experienced AEs (Fig. 2). Baseline characteristics are shown in Table 1. The vital signs and laboratory variables were significantly worse in the group that experienced AEs compared to those without AE. AEs included vasopressor use (n = 6,304, 40.7%), respiratory support (n = 5,017, 32.4%), ICU admission (n = 8,492, 54.9%), septic shock (n = 4,124, 26.6%), and cardiac arrest (n = 548, 3.5%). For external validation, 410,880 patients (27,838 AEs, 6.7%) were analyzed from the MIMIC-IV-ED database (Figure S1 and Table S2).

Study population.
Model development and performance
The full TEWS model incorporated 13 key variables selected through iterative feature reduction from the initial 44 variables (Fig. S2). The model included vital signs (systolic blood pressure, diastolic blood pressure, heart rate, respiratory rate, body temperature, and peripheral oxygen saturation) and laboratory values (hemoglobin, blood urea nitrogen, sodium, potassium, lactate, arterial pH, and bicarbonate). The vital sign-only TEWS included the six vital signs mentioned above.
The TEWS (full model) demonstrated superior prognostic performance compared to MEWS across all adverse outcomes; vasopressor use: 0.934 (95% CI: 0.932–0.936), respiratory supports: 0.909 (95% CI: 0.905–0.912), ICU admission: 0.855 (95% CI: 0.853–0.856), septic shock: 0.936 (95% CI: 0.933–0.938), and cardiac arrest: 0.833 (95% CI: 0.820–0.848) (Table 2). Similarly, the vital sign-only TEWS model also exhibited better predictive performance than MEWS. Further results about the performance matrix and the other predictive models (transformer models with 23 and 44 variables, logistic regression, XgBoost) are shown in Tables S3, S4, and S5.
When comparing TEWS and MEWS at similar sensitivity thresholds (MEWS ≥ 5), TEWS demonstrated superior performance with significantly higher specificity (99.0-99.5% vs. 96.0-96.8%), PPV (25.3–56.6% vs. 9.5–18.6%), and NPV (99.4–100.0% vs. 98.4–99.5%) across outcomes (Table 3). Additionally, TEWS showed substantially lower false alarm counts per 1,000 patients compared to MEWS.
External validation
In external validation using MIMIC-IV-ED data, TEWS demonstrated superior performance compared to MEWS across all outcomes (Table 4). Initially, the vital sign-only TEWS showed better performance than the full model, with AUROC values ranging from 0.815 to 0.905 compared to 0.759–0.872 for the full model. After applying transfer learning, both models showed significant improvement. With 1% data transfer learning, the performance of the full model improved (AUROC 0.851 to 0.903); with 5% data transfer learning, it improved further (AUROC 0.863 to 0.901). The full model generally outperformed the vital sign-only model after transfer learning.
Model integration for EHR systems
The TEWS system has been successfully integrated into the EHR system, providing real-time risk assessment for ED patients (Fig. 3). The interface displays a patient list with TEWS results that are continuously updated. When clinicians click on the TEWS alarm icon, they can access detailed information including specific high-risk outcomes and the top three contributing features identified by the AI model. When clinicians click on a patient from the ED patient list view, the right panel displays the most recent TEWS information alongside the vital signs and nursing records.

Electronic health record system integration view. This is a modified figure based on the original electronic health record system screen.
Discussion
We developed and validated a novel early warning system for predicting adverse outcomes in ED patients, using transformer models to process time series information, including vital signs and laboratory results, from a patient’s initial visit to discharge. The TEWS system demonstrated superior prognostic performance compared to the MEWS. The TEWS includes multiple models that predict diverse outcomes, providing comprehensive information about patient deterioration from various perspectives. The TEWS predicts both procedural needs (e.g., respiratory support and vasopressor use) and patient status (e.g., cardiac arrest, ICU admission, and septic shock). This may allow TEWS to provide predictions not only about patient conditions, but also about the procedures that may be required, ultimately delivering targeted information to improve patient outcomes13.
While implementing AI-based systems in healthcare is complex and faces barriers such as alert fatigue and workflow integration, real-time early warning systems like TEWS can support physicians and nurses by helping prioritize patients and enabling earlier identification of those at risk for deterioration. Rather than replacing clinical judgment, TEWS may enhance situational awareness by continuously analyzing patient data and providing interpretable, outcome-specific risk predictions at the point of care. At our institution, TEWS has been incorporated into quality improvement initiatives to reduce time to blood pressure stabilization in critically ill patients and to expedite antibiotic administration in septic shock, demonstrating its potential to facilitate timely interventions. Nonetheless, sustained interdisciplinary collaboration and ongoing refinement are essential to ensure clinical value and successful adoption.
To achieve practical applicability, it is crucial to demonstrate the effectiveness of the model across datasets. AI-based models often perform well in a developmental environment, but a decrease in function may occur when they are applied externally33. TEWS showed acceptable predictability for most outcomes in the MIMIC-IV-ED dataset, which differs significantly from the original study site. However, we observed initial performance variations, particularly in the full TEWS model, with some outcomes showing decreased AUROC. This decline in performance often is observed in external validation and can be attributed to various factors including potential overfitting of the initial model, differences in variable distributions and measurement frequencies between institutions, variations in clinical practice patterns, and differences in patient populations34. Notably, the vital sign-only TEWS with limited variables demonstrated more robust performance in external validation, suggesting that models with fewer, standardized variables may be more generalizable across healthcare settings. Furthermore, the implementation of transfer learning with just 1–5% of external data significantly improved the performance of the full model, indicating that this approach could address institutional differences while requiring minimal additional data for model adaptation.
While the transformer model did not demonstrate overwhelmingly superior performance compared to XGBoost, we selected the transformer approach for its greater extensibility and practical advantages in clinical deployment. Transformer models are specifically designed to process sequential time-series data and support transfer learning, as shown by notable improvements in external validation after fine-tuning with only 1–5% of external data, a capability not feasible with tree-based models like XGBoost. Furthermore, transformer architectures allow for future integration of multimodal clinical data, such as imaging and clinical narratives, enhancing adaptability and interpretability for dynamic, real-time risk prediction in the ED. Thus, despite only modest gains in AUROC, we believe the transformer model provides a more robust and flexible platform for ongoing clinical application. The strength of the transformer model lies in its ability to accurately capture the state of variables over time, improving the accuracy of acute deterioration prediction by effectively learning temporal dependencies17,20,35. In the ED, the patient condition can change within a relatively short time frame; the TEWS can capture these characteristics and provide timely predictions.
We observed a relatively lower performance in predicting ICU admission and cardiac arrest compared to other outcomes. The lower predictive accuracy for ICU admission probably reflects the complex nature of ICU admission decisions in different healthcare settings. Factors beyond clinical severity, such as ED crowding and low ICU capacity, may influence admission patterns36,37. For example, a previous study has shown that even patients with septic shock were managed in the EDs of Korea without ICU admission38. Additionally, there might be differences in ICU admission criteria due to the varying characteristics among centers. This should be considered when applying TEWS externally or when developing similar models39,40. For cardiac arrest prediction, the extremely low incidence of in-hospital cardiac arrest in the ED presented a significant challenge for model training, and some cardiac arrests could not be predicted by vital signs and laboratory tests.
For real-world application, TEWS aims to extract essential input variables from the numerous data points available in the ED. As explained earlier, this study conducted several rounds of sensitivity analysis and feature selection to identify the most critical variables for predicting outcomes. Through this process, vital signs and laboratory variables were selected, resulting in a practical model that can be implemented in a real ED setting, reducing computing time and effort during operation.
This study demonstrates that development is only the beginning; the ultimate goal is integrating the developed model for real-time risk assessment and actionable information to healthcare providers. Through these efforts, TEWS has been integrated into the EMR system at the study site to allow monitoring and user feedback.
Further studies are needed to continue the development and enhancement of TEWS, as well as to evaluate its practical utility in clinical settings.
Limitations
There are some limitations in our study. First, the retrospective nature may have introduced selection bias, potentially affecting the generalizability of our findings. In addition, there may be unmeasured variables or outcomes that could potentially impact the performance or generalizability of the model. Second, the incidence of the five outcomes predicted by TEWS was imbalanced. As a result, all predicted outcomes had a low AUPRC and low PPV. In the medical field, most candidates have a low likelihood of adverse outcomes because such outcomes typically occur in unhealthy states. Given that this study was based on real-world data, the imbalance is a potential limitation. Similar challenges have been reported in other machine learning-based prediction studies in healthcare13,41,42. Third, although we used the MIMIC-IV-ED database for external validation, this dataset may not fully represent the diversity of EDs globally. The performance of TEWS may vary by healthcare system and patient population. Fourth, there was the only moderate performance improvement after transfer learning. We believe that the moderate gains observed after transfer learning reflect a good baseline performance, and even a 2–3% improvement in AUROC can be meaningful given the limited amount of fine-tuning data used. Fifth, we also used separate models for each adverse event, which may limit the benefits of shared learning across related outcomes. A multi-task model that predicts multiple outcomes simultaneously could improve performance, especially for rare events, and will be considered in future work. Finally, the TEWS model may be challenging to implement in resource-limited settings without comprehensive EHR systems. Our model relies on time series data, which may not be consistently available or accurately recorded in all clinical settings, potentially limiting their applicability. These limitations are common challenges in developing and implementing AI-based CDSS in healthcare. Future research should focus on addressing these limitations through prospective studies, more diverse external validation, and continued refinement of the model to balance complexity with clinical applicability.
Conclusion
This study developed and validated the TEWS system for predicting multiple adverse outcomes in ED patients. The TEWS models demonstrated superior prognostic performance compared to the MEWS across various outcomes in internal and external validation. The successful integration of the AI solution into the EHR system demonstrates its potential as a clinical decision support tool for providing real-time risk assessment and actionable information.
Data availability
Data were obtained from the study site clinical data warehouse. The datasets generated and analyzed during the current study are not publicly available because they include patient information, although it is de-identified. However, the data are available from the corresponding author on reasonable request. The external validation data used in the study are available from the Medical Information Mart for Intensive Care (MIMIC)-IV database. This third-party data can be accessed at https://mimic.physionet.org/. Access to the files requires registration as a credentialed user, completing the CITI Data or specimens-only research training, and signing the data use agreement for the project.
References
Lentz, B. A. et al. Validity of ED: addressing heterogeneous definitions of over-triage and under-triage. Am. J. Emerg. Med. 35(7), 1023–1025 (2017).
Chen, L. et al. Dynamic and personalized risk forecast in Step-Down units. Implications for monitoring paradigms. Ann. Am. Thorac. Soc. 14(3), 384–391 (2017).
Christ, M., Grossmann, F., Winter, D., Bingisser, R. & Platz, E. Modern triage in the emergency department. Dtsch. Arztebl Int. 107(50), 892–898 (2010).
Iserson, K. V. & Moskop, J. C. Triage in medicine, part I: concept, history, and types. Ann. Emerg. Med. 49(3), 275–281 (2007).
Subbe, C. P., Kruger, M., Rutherford, P. & Gemmel, L. Validation of a modified early warning score in medical admissions. QJM 94(10), 521–526 (2001).
Vergara, P. et al. Validation of the National early warning score (NEWS)-2 for adults in the emergency department in a tertiary-level clinic in colombia: cohort study. Med. (Baltim). 100(40), e27325 (2021).
Magrabi, F. et al. Artificial intelligence in clinical decision support: challenges for evaluating AI and practical implications. Yearb Med. Inf. 28(1), 128–134 (2019).
Fernandes, M. et al. Clinical decision support systems for triage in the emergency department using intelligent systems: a review. Artif. Intell. Med. 102, 101762 (2020).
Okada, Y., Ning, Y. & Ong, M. E. H. Explainable artificial intelligence in emergency medicine: an overview. Clin. Exp. Emerg. Med. 10(4), 354–362 (2023).
Belard, A. et al. Precision diagnosis: a view of the clinical decision support systems (CDSS) landscape through the lens of critical care. J. Clin. Monit. Comput. 31(2), 261–271 (2017).
Lee, D. et al. Trends of clinical decision support system (CDSS). Electron. Telecommunications Trends. 31(4), 77–85 (2016).
Chang, H. & Cha, W. C. Artificial intelligence decision points in an emergency department. Clin. Experimental Emerg. Med. 9(3), 165–168 (2022).
Chang, H., Yu, J. Y., Yoon, S., Kim, T. & Cha, W. C. Machine learning-based suggestion for critical interventions in the management of potentially severe conditioned patients in emergency department triage. Sci. Rep. 12(1), 1–10 (2022).
Yu, J. Y. et al. Predicting mid-term survival of patients during emergency department triage for resuscitation decision. Signa Vitae. 1, 11 (2022).
Zhou, H-Y. et al. A transformer-based representation-learning model with unified processing of multimodal input for clinical diagnostics. Nat. Biomedical Eng. 7(6), 743–755 (2023).
Vaswani, A. Attention is all you need. Advances Neural Inform. Process. Systems (2017).
Devlin, J. Bert: Pre-training of deep bidirectional Transformers for Language Understanding. ArXiv Preprint arXiv 181004805 (2018).
Montavon, G., Samek, W. & Müller, K-R. Methods for interpreting and Understanding deep neural networks. Digit. Signal Proc. 73, 1–15 (2018).
Rubanova, Y., Chen, R. T. & Duvenaud, D. K. Latent ordinary differential equations for irregularly-sampled time series. Adv. Neural Inform. Process. Syst. 32 (2019).
Zerveas, G., Jayaraman, S., Patel, D., Bhamidipaty, A. & Eickhoff, C. A transformer-based framework for multivariate time series representation learning. In Proceedings of the 27th ACM SIGKDD conference on knowledge discovery & data mining 2114–2124 (2021).
Ouyang, L. et al. Training Language models to follow instructions with human feedback. Adv. Neural. Inf. Process. Syst. 35, 27730–27744 (2022).
Choi, E. et al. Retain: An interpretable predictive model for healthcare using reverse time attention mechanism. Adv. Neural Inform. Process. Syst. 29 (2016).
Lin, Z. et al. A structured self-attentive sentence embedding. ArXiv Preprint arXiv 170303130 (2017).
Johnson, A. E. W. et al. MIMIC-IV, a freely accessible electronic health record dataset. Sci. Data. 10(1), 1 (2023).
Collins, G. S. et al. TRIPOD + AI statement: updated guidance for reporting clinical prediction models that use regression or machine learning methods. BMJ 385, e078378 (2024).
Singer, M. et al. The third international consensus definitions for Sepsis and septic shock (Sepsis-3). JAMA 315(8), 801–810 (2016).
Johnson, A. E., Stone, D. J., Celi, L. A. & Pollard, T. J. The MIMIC code repository: enabling reproducibility in critical care research. J. Am. Med. Inf. Assoc. 25(1), 32–39 (2018).
Selvaraju, R. R. et al. Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization. In IEEE International Conference on Computer Vision (ICCV) 618–626 (2017).
Gevrey, M., Dimopoulos, I. & Lek, S. Review and comparison of methods to study the contribution of variables in artificial neural network models. Ecol. Model. 160(3), 249–264 (2003).
Ryu, S., Oh, S. K., Lee, B. K. & Jeon, S. Y. A combination of the modified early warning score and the Korean triage and acuity scale as a triage tool in patients with infection. Clin. Exp. Emerg. Med. 10(1), 60–67 (2023).
Lee, Y. J. et al. A multicentre validation study of the deep learning-based early warning score for predicting in-hospital cardiac arrest in patients admitted to general wards. Resuscitation 163, 78–85 (2021).
Pan, S. J. & Yang, Q. A survey on transfer learning. IEEE Trans. Knowl. Data Eng. 22(10), 1345–1359 (2010).
Cabitza, F. et al. The importance of being external. Methodological insights for the external validation of machine learning models in medicine. Comput. Methods Programs Biomed. 208, 106288 (2021).
Kang, C-Y. & Yoon, J. H. Current challenges in adopting machine learning to critical care and emergency medicine. Clin. Exp. Emerg. Med. 10(2), 132–137 (2023).
Li, Q., Wang, Y., Shao, Y., Li, L. & Hao, H. A comparative study on the most effective machine learning model for blast loading prediction: from GBDT to transformer. Eng. Struct. 276, 115310 (2023).
Ouyang, H., Wang, J., Sun, Z. & Lang, E. The impact of emergency department crowding on admission decisions and patient outcomes. Am. J. Emerg. Med. 51, 163–168 (2022).
Valley, T. S. et al. Hospital factors that influence ICU admission decision-making: a qualitative study of eight hospitals. Intensive Care Med. 49(5), 505–516 (2023).
You, J. S. et al. Relationship between time of emergency department admission and adherence to the surviving Sepsis campaign bundle in patients with septic shock. Crit. Care. 26(1), 43 (2022).
Brilli, R. J. et al. Critical care delivery in the intensive care unit: defining clinical roles and the best practice model. Crit. Care Med. 29(10), 2007–2019 (2001).
Soares, J. et al. Intensive care unit admission criteria: A scoping review. J. Intensive Care Soc. 17511437241246901 (2024).
Brajer, N. et al. Prospective and external evaluation of a machine learning model to predict In-Hospital mortality of adults at time of admission. JAMA Netw. Open. 3(2), e1920733–e1920733 (2020).
Cho, B. H. et al. Application of irregular and unbalanced data to predict diabetic nephropathy using visualization and feature selection methods. Artif. Intell. Med. 42(1), 37–53 (2008).
Funding
This study was funded in part by a grant from Samsung Medical Center (No. SMX1240281) and Grant of the Korea Health Technology R&D Project through the Korea Health Industry Development Institute (KHIDI), funded by the Ministry of Health & Welfare, Republic of Korea (grant number : RS-2023-KH134607) to Tae Gun Shin. This research was also supported by a grant of the Korea Health Technology R&D Project through the Korea Health Industry Development Institute (KHIDI), funded by the Ministry of Health & Welfare, Republic of Korea (grant number: RS-2024-00335937) to Tae Ho Lim. The funders had no role in study design, data collection and analysis, decision to publish, or preparation of the manuscript.
Author information
Authors and Affiliations
Contributions
All authors made a substantial contribution to the concept and design of the manuscript. Conceptualization: TGS, KLMethodology: all authorsValidation: all authors Formal Analysis: HC, JEP, DLInvestigation: all authors Data Curation: all authorsResources: SYJ, KTMWriting: HC, JEP, DL, KL, TGSWriting – Review and Editing: all authorsVisualization: HC, JEP, DL, DKSupervision: KL, TGSFunding acquisition: KL, THL, TGSAll authors have read and granted final approval of the version of the manuscript to be published. Funding acquisition: KL, THL, TGS. All authors have read and granted final approval of the version of the manuscript to be published.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Chang, H., Park, J.E., Lee, D. et al. Development and validation of a transformer model-based early warning score for real-time prediction of adverse outcomes in the emergency department. Sci Rep 15, 23021 (2025). https://doi.org/10.1038/s41598-025-07511-7
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-07511-7
