
Abstract
Road traffic accidents (RTAs) in Northwest Ethiopia, a region with a fatality rate of 32.2 per 100,000 residents, pose a critical public health challenge exacerbated by infrastructural deficits and environmental hazards. This study leverages machine learning (ML) to predict accident severity, addressing gaps in localized predictive frameworks for low- and middle-income countries (LMICs). Our study aims to predict the severity of car accidents in Northwest Ethiopia via machine-learning techniques. Using a dataset of 2,000 accidents (2018–2023) from police reports, we integrated driver demographics, behavioral factors (e.g., alcohol use, seatbelt compliance), and environmental conditions (e.g., unpaved roads, weather) in North West Ethiopia. Ten ML models, including Random Forest, XGBoost, and LightGBM, were evaluated after addressing class imbalance via the Synthetic Minority Oversampling Technique (SMOTE). Hyperparameter tuning and Shapley Additive explanations (SHAP) provided model optimization and interpretability. Random Forest outperformed other models, achieving 82% accuracy (AUC-ROC: 0.87) post-tuning. Driver age (mean: 44 years) and environmental factors (e.g., nighttime on unlit roads, rainy conditions) were critical predictors, increasing fatal accident likelihood by 62%. SMOTE improved the accuracy of the outperforming random forest accuracy from 78.6 to 82%. Random Forest exhibited the highest recall (0.82) after optimization, while ensemble methods dominated performance metrics. The study underscores the efficacy of ML in contextualizing accident severity in LMICs, with Random Forest emerging as a robust tool for policymakers. Prioritizing road paving, sobriety checkpoints, and motorcycle safety could mitigate risks, aligning with Sustainable Development Goal 3.6. Future work should address data limitations (underreporting, geospatial gaps) and expand model interpretability.
Similar content being viewed by others
Introduction
Road traffic accidents (RTAs) constitute a critical global public health challenge1,2, responsible for approximately 1.3 million fatalities annually, with over 90% occurring in low- and middle-income countries (LMICs) where infrastructure and safety regulations lag behind vehicle proliferation3,4. While driver behavior, environmental conditions, and road design are universally recognized determinants of accident severity, regional disparities in data quality, reporting practices, and infrastructural development necessitate context-specific analyses5,6,7. Sub-Saharan Africa, for instance, experiences a fatality rate of 26.6 per 100,000 population, nearly double the global average, with Ethiopia emerging as a hotspot at 32.2 fatalities per 100,000 residents8,9. In Northwest Ethiopia, mountainous terrain, seasonal monsoon rains, and rapid urbanization compound risks, yet predictive modeling remains underdeveloped, relying predominantly on descriptive statistics rather than advanced machine learning (ML) frameworks5. Previous regional studies have focused on aggregated trends or logistic regression models, neglecting non-linear interactions between variables (e.g., driver fatigue, road geometry) and failing to address class imbalance caused by underreporting of non-fatal accidents10,11. This gap persists despite evidence that ML algorithms, such as random forests and gradient-boosted trees, significantly outperform traditional methods in high-income settings12,13.
Recent advancements in ML have demonstrated remarkable potential for traffic safety analytics14,15,16, yet their application in LMICs remains constrained by data scarcity and contextual incompatibility17,18. For example, studies in Brazil and the United States leverage high-resolution datasets to identify risk factors such as nighttime driving and roadway curvature, achieving prediction accuracies exceeding 85%19,20,21. However, these models often omit LMIC-specific variables, such as road conditions (e.g., gravel, wet, potholes), weather conditions (e.g., dusty, foggy, rainy), and driver behavior (e.g., fatigue, distraction, alcohol influence), which are critical in regions like Northwest Ethiopia, where 80% of roads lack paving and seasonal rainfall severely impacts visibility22. Furthermore, underreporting of non-fatal accidents, estimated at 40–60% in rural Ethiopia, skews datasets toward fatal outcomes, exacerbating class imbalance and undermining model generalizability23,24,25. A study on African ML-based traffic studies revealed that only 12% incorporated environmental variables like rainfall, while none addressed imbalance mitigation techniques such as Synthetic Minority Oversampling (SMOTE), despite evidence that such methods enhance performance in imbalanced datasets26,27. These omissions highlight a need for localized frameworks that reconcile global methodological advancements with LMIC-specific realities.
This study addresses these gaps by developing an ML-driven framework tailored to Northwest Ethiopia, integrating locally relevant variables such as livestock presence, road surface type, and driver sobriety while employing SMOTE to rectify class imbalance. Unlike prior regional studies, which relied on descriptive statistics or conventional regression, we evaluate ten algorithms (logistic regression, decision tree, random forest, gradient boosting, XGBoost, LightGBM, support vector machine, K-nearest neighbor, multilayer perceptron, and naive Bayes) with grid search hyperparameter optimization across all models with grid search hyperparameter optimization across all models, ensuring rigorous performance comparison. Shapley’s Additive explanations (SHAP) values further elucidate variable impacts, offering interpretable insights for policymakers28,29,30,31. Methodologically, this study demonstrates SMOTE’s efficacy in improving recall for minority classes (fatal accidents) and advocating for hyperparameter tuning across all models, not just top performers, to avoid biased comparisons.
The policy implications are substantial: The World Bank estimates that a 10% reduction in Ethiopian traffic fatalities could avert $150 million in annual economic losses32. Our models identify actionable interventions, such as prioritizing road paving in high-fatality corridors, installing solar-powered lighting on hazardous curves, and scaling up sobriety checkpoints during peak rainfall months. By bridging the gap between global ML advancements and localized LMIC challenges, this study advances the United Nations’ Sustainable Development Goal 3.6 to halve global traffic fatalities by 2030, while offering a replicable framework for other data-scarce regions grappling with similar infrastructural and environmental constraints.
This study aims to fill this gap in machine learning models tailored to Northwest Ethiopia, leveraging data on driver characteristics, environmental conditions, and road infrastructure to predict accident severity. Through this, the study aims to contribute to road safety measures, enabling the identification of key factors influencing accident severity and providing actionable insights to policymakers and traffic authorities. These findings are essential for enhancing preventive strategies, improving traffic regulations, and ultimately reducing severe accidents in the region.
Methodology
This study aims to predict the severity of car accidents in Northwest Ethiopia via machine learning techniques and considers various factors, such as driver characteristics, environmental conditions, and road infrastructure. The study employs a retrospective observational design, using data collected from traffic accident reports, weather stations, and road condition databases from the East Gojjam zonal police department and Debre Markos city police office. The research was conducted in Northwest Ethiopia, focusing on regions with high traffic volumes and varying road types, to ensure a representative sample of the diverse conditions affecting road safety.
Participants and materials
The data for this study were obtained from local traffic accident records, including police reports, which contain detailed information about the time, location, weather conditions, road types, and severity of the accidents. All available records (2018–2023) were used; due to the retrospective design, no power analysis was conducted. Road conditions, such as road type and traffic volume data, were gathered from local traffic authorities.
Data collection and preprocessing
The dataset includes an accident recording period from 2018 to 2023 in northwestern Ethiopia, with over 2000 recorded accidents from the Zonal and city administration offices. The variables considered in the analysis include driver age, gender, behavior, fatigue, distractions, alcohol influence, seatbelt usage, weather conditions, road conditions, lighting conditions, traffic volume, time of day, and vehicle type. We found around 30 missing values, and we were able to fill them from their master register with the help of police officers. All the data were preprocessed to handle missing values, as the cases are registered carefully because of their legal and insurance issues. Not many missing data problems, and outliers were observed. For some outliers, the Removal of implausible “Driver_Age” entries (< 18 or > 75 years) was done. Normalization of numerical features with z-score standardization was performed. The outcome variable is generated from the column fatalities, which are called fatal with numbers greater than zero, and nonfatal rows with zero.
Description of variables
The dataset integrates both categorical and quantitative variables to analyze car accident severity comprehensively. The categorical variables represent discrete characteristics such as: Driver_Sex (male/female), Driver_Behavior (distracted/fatigued/aggressive/normal), Alcohol_Influence (yes/no), Seatbelt_Usage (yes/no), Weather_Condition (dusty/foggy/rainy/clear), Road_Condition (gravel/wet/dry/potholes), Lighting_Condition (daylight/night-lit/night-unlit), Traffic_Volume (low/medium/high), Time_of_Day (morning/afternoon/evening/night), Vehicle_Type (motorcycle/SUV/sedan/truck), and Driver_Fatigue (yes/no).
The quantitative variables provide measurable numerical data, including Driver_Age (age of the driver in years), Driver_Distraction (level of driver distraction measured on a numerical scale), Fatalities (number of fatalities resulting from the accident), and Injuries (number of injuries resulting from the accident). These variables collectively capture the multifaceted nature of car accident severity by encompassing driver-related factors, environmental conditions, and road infrastructure. This comprehensive approach enables a robust analysis of the factors influencing accident outcomes, contributing to a deeper understanding of accident severity and potential preventive measures. The outcome variable categorizes accidents as fatal (≥ 1 fatality directly caused by the accident) or non-fatal (zero fatalities, encompassing all other outcomes, including injuries of any severity and property damage only (PDO)).
Data balancing
In many machine learning applications, datasets can suffer from class imbalance, where one class has significantly fewer instances than the others33,34,35. This imbalance can lead to biased models that favor the majority class, potentially overlooking crucial information in the minority class33,36. Various data balancing techniques have been developed to address this issue, including SMOTE37.
SMOTE is a popular oversampling technique that addresses class imbalance by generating synthetic samples for the minority class38,39. It works by selecting minority class samples and creating synthetic samples along the line segments connecting them to their nearest neighbors in the feature space. This process increases the number of minority class samples while maintaining the underlying data distribution40,41.
SMOTE effectively balances the class distribution in our dataset (Fig. 1). Before applying SMOTE, the majority class (fatal accidents) is overrepresented, potentially skewing the model’s predictions. After applying SMOTE, the minority class (nonfatal accidents) is oversampled, resulting in a more balanced distribution. This balanced dataset can lead to improved model performance, especially in terms of sensitivity and specificity, as the model is now better equipped to learn from both classes.
By employing SMOTE, we aim to mitigate the negative impact of class imbalance and create a more robust and equitable model for our research. This balanced dataset enables our model to learn from both majority and minority classes, leading to more accurate predictions and better insights into the factors contributing to fatal accidents.

Class distribution before and after SMOTE.
Feature selection
A hybrid correlation analysis was conducted to examine linear and monotonic relationships among variables42,43, integrating Spearman’s rank correlation for numerical-ordinal pairs and encoded categorical features. The analysis revealed predominantly weak correlations (|r| < 0.1), indicating minimal linear dependencies among variables. Fatalities exhibited weak positive correlations with Lighting_Condition (r = 0.03) and Vehicle_Type (r = 0.02), though these were insufficient to justify exclusion due to multicollinearity concerns. Alcohol_Influence demonstrated negligible associations with other variables, including a weak negative correlation with Driver_Behavior (r = − 0.03), suggesting no strong linear connection to risky behavior. Seatbelt_Usage displayed near-zero correlations across all factors, including a marginally positive association with Fatalities (r = 0.01), indicating minimal direct protective impact in this dataset. Driver_Age exhibited weak associations, with the strongest correlations observed for Time_of_Day (r = 0.04) and Vehicle_Type (r = − 0.04), aligning with its hypothesized limited influence. Temporal patterns revealed slight links between Driver_Fatigue and Time_of_Day (r ≈ 0.02), while Weather_Condition and Traffic_Volume were virtually uncorrelated (r ≈ 0.00). Driver_Distraction showed a weak positive correlation with Weather_Condition (r = 0.07), representing the strongest observed relationship, though still modest (Fig. 2). The prevalence of weak correlations underscores the multifactorial nature of accident dynamics, where isolated linear relationships fail to capture complex interactions. These findings advocate for holistic interventions addressing behavioral, environmental, and infrastructural factors to mitigate road accidents in Ethiopia.

Correlation matrix between variables.
To assess the potential for multicollinearity among predictor variables, we calculated the variance inflation factor (VIF) for each variable44. The VIF results indicated that all predictor variables presented VIF values below the commonly accepted threshold of 10, suggesting that multicollinearity is not a major concern in this analysis45. However, the VIF value for “Driver_Age” was slightly greater than that of the majority of the other variables, suggesting a moderate degree of correlation with the other predictors (Fig. 3). While this does not necessitate the removal of “Driver_Age” from the model, it warrants careful consideration of its potential impact on model stability and interpretation.
Neither the hybrid correlation analysis nor the Variance Inflation Factor (VIF) analysis recommended dropping any feature; thus, all 14 features were retained for model training. However, the ‘Fatalities’ column was excluded because it directly contributes to the construction of the target variable. Therefore, the final set of features used for training includes: “Driver_Age”, “Driver_Sex”,“Driver_Behavior”,“Alcohol_Influence”,“Seatbelt_Usage”, “Weather_Condition”, “Road_Condition”,“Lighting_Condition”,“InjuriesTraffic_Volume”,“Time_of_Day”,“Vehicle_Type”, “Driver_Fatigue”, and “Driver_Distraction”.

VIFs for predictor variables.
Machine learning approach
For the prediction of accident severity, the study applies ten machine learning algorithms, including logistic regression, decision trees, random forests, gradient boosting, XGBoost, LightGBM, support vector machine, k-nearest neighbor, multilayer perceptron, and naive Bayes. These models were selected because of their effectiveness in handling complex, nonlinear relationships and their robustness to high-dimensional data46. The severity of accidents is categorized into two levels, which are nonfatal and fatal.
Decision trees are popular supervised learning algorithms that create a tree-like model of decisions and their possible consequences. They are known for their interpretability, as the decision-making process can be easily visualized and understood. Decision trees can capture nonlinear relationships between variables, making them suitable for complex datasets37,47,48. Random forests build upon the concept of decision trees by creating an ensemble of multiple trees. Each tree in the forest is trained on a different subset of the data and with a random selection of features. The final prediction is made by aggregating the predictions from all the trees in the forest, which typically leads to improved accuracy and robustness compared with a single decision tree41,46,48.
Gradient boosting is another ensemble learning technique that iteratively builds an ensemble of weak learners (typically decision trees). Each subsequent tree in the ensemble is trained to correct the errors made by the previous trees, resulting in a strong predictive model. Gradient boosting algorithms are known for their high predictive accuracy and ability to capture complex relationships in the data49,50. XGBoost (extreme gradient boosting) is an optimized implementation of the gradient boosting algorithm. It incorporates several enhancements, such as parallel processing, regularization techniques, and efficient tree-learning algorithms, resulting in improved performance and scalability. XGBoost is widely used in machine learning competitions and industrial applications because of its high accuracy and efficiency51.
LightGBM is another efficient gradient-boosting framework that leverages tree-based learning and parallel processing. It employs techniques such as gradient-based one-sided sampling and exclusive feature bundling to reduce memory usage and improve training speed, making it suitable for large datasets52. Support vector machines (SVMs) aim to find the optimal hyperplane that best separates data points belonging to different classes. SVMs are particularly effective in high-dimensional spaces and can handle both linear and nonlinear classification tasks40.
K-nearest neighbors (KNN) is a nonparametric algorithm that classifies new data points based on the class labels of their k-nearest neighbors in the training data. The algorithm predicts the class of a new data point by assigning it to the class that is most frequent among its k-nearest neighbors40,53,54. A multilayer perceptron (MLP), also known as a neural network, is a powerful model inspired by the human brain. It consists of multiple layers of interconnected nodes (neurons) that process information in a hierarchical manner. MLPs can learn complex nonlinear relationships and are capable of achieving high accuracy on a wide range of tasks55.
Naive Bayes is a probabilistic classifier based on Bayes’ theorem with the “naive” assumption of independence between features. It calculates the probability of a data point belonging to each class and assigns the class with the highest probability. Naive Bayes is known for its simplicity, efficiency, and ability to handle high-dimensional data53. Logistic regression models the probability of class membership using a logistic function. It estimates linear relationships between predictors and the log odds of the target variable, offering interpretability through coefficient analysis and odds ratios. Regularization (L1/L2) was applied to enhance generalizability. While limited to linear decision boundaries, it served as a baseline for evaluating nonlinear methods.
By employing this diverse set of models, we aim to identify the most effective approach for predicting accident severity in Northwest Ethiopia and gain valuable insights into the underlying factors contributing to these events.
Model training
The model development pipeline comprised systematic data preprocessing, class imbalance mitigation, and rigorous evaluation of multiple machine learning algorithms. Categorical features were encoded using label transformation, while numerical variables were standardized to zero mean and unit variance. To address the class imbalance in the target variable, the Synthetic Minority Oversampling Technique (SMOTE) was applied exclusively to training data (80% of the dataset), preserving the test set (20%) for unbiased evaluation.
Hyperparameter tuning is performed for all models to optimize model performance via grid search. To elucidate the determinants of accident severity, feature importance was quantified using the Random Forest classifier’s inherent Gini importance metric, which measures the mean reduction in impurity across all decision trees attributable to each feature. Permutation importance was further computed via SciKit-Learn’s permutation importance function to validate robustness, with significance assessed over 100 iterations. For interpretable interaction analysis, Shapley Additive explanations (SHAP) were employed through the Tree Explainer class in the SHAP library. Pairwise interaction effects were derived, which decompose feature contributions into main and interaction effects for each observation. This dual approach, combining global feature importance with local interaction effects, enabled the identification of both dominant predictors and context-dependent synergies. All analyses were conducted on the training set to prevent data leakage, with SHAP values averaged over 100 bootstrap samples to ensure stability. We used Python 3.11.7 for model development.
Model evaluation
Model performance was assessed using cross-validation techniques, evaluating key metrics such as accuracy, precision, recall, and F1 score. Given the significant class imbalance in the dataset (with 67% of cases being fatal accidents), particular emphasis was placed on recall and AUC‒ROC to better capture the model’s ability to detect the minority class non-fatal accidents. The F1 score was used to balance the trade-off between precision and recall, while accuracy offered a general overview of the model’s overall performance.
Accuracy
It measures the proportion of correct predictions (both true positives and true negatives) out of all predictions. It provides a general sense of model performance but can be misleading in imbalanced datasets, where one class dominates. For example, a high accuracy score might mask poor performance in identifying a rare class.
Where TP represents true positives, TN represents true negatives, FP represents false positives, and FN represents false negatives.
Precision
It evaluates how many of the predicted positive cases are positive. It focuses on minimizing false positives, making it critical in scenarios where incorrectly labeling negatives is costly, such as spam detection. High precision means the model is reliable when it predicts a positive outcome.
Recall (sensitivity)
It measures the proportion of actual positive cases correctly identified by the model. It emphasizes minimizing false negatives, which is vital in contexts like disease screening, where missing a true positive could have serious consequences. High recall indicates the model effectively captures most positive instances.
F1 score
It balances precision and recall using their harmonic mean. It is especially useful when a class imbalance exists and both false positives and false negatives need to be minimized. A high F1 score indicates robust performance in scenarios requiring a trade-off between precision and recall.
AUC-ROC (area under the ROC curve)
It evaluates the model’s ability to distinguish between classes across all classification thresholds. The ROC curve plots the true positive rate against the false positive rate, and the AUC summarizes this into a single value (1 = perfect, 0.5 = random). It is ideal for assessing overall performance, particularly in imbalanced datasets.
A range of machine learning models, including Logistic Regression, Random Forest, Gradient Boosting, Decision Tree, Support Vector Machine (SVM), k-nearest Neighbors (KNN), Naive Bayes, Neural Network (MLP), XGBoost, LightGBM, are considered and trained on the data. The performance of the trained models is rigorously evaluated, and the best-performing model is selected for deployment (Fig. 4).

Workflow diagram.
Results
Descriptive statistics
The dataset comprises 2000 car accident records. The average age of the drivers involved in the accidents was 44 years, with a standard deviation of 15.13 years, indicating a considerable age range. Approximately 98.25% of the drivers were male. In terms of driving behavior, only 25.1% were aggressive, suggesting a moderate level of risky behavior among drivers (Table 1).
Out of a total of 2,000 accidents, 1,340 (67%) were fatal, 460 (23%) involved injuries, and 200 (10%) resulted in property damage only (PDO). Alcohol influence was observed in 49.1% of the accidents. Seatbelt usage was reported in 51.2% of the cases. The distribution of weather conditions, road conditions, and lighting conditions suggests that a range of environmental factors contribute to accidents. The traffic volume was moderate on average. The majority of accidents occurred during the day; only 24.75% of accidents happened at night. The average number of fatalities per accident was 1.52, and the average number of injuries was 5.11, indicating a significant impact of these accidents (Table 2).
Model training results
The Random Forest model achieved the highest accuracy (0.771) and precision (0.805), demonstrating strong overall predictive reliability. LightGBM exhibited the highest recall (0.819) and F1 score (0.792), indicating a superior ability to identify true positives and balance precision-recall trade-offs. XGBoost closely matched LightGBM’s performance, with balanced precision (0.776) and recall (0.781). While KNN achieved the highest precision (0.847), its low recall (0.553) suggests a significant under-detection of positive cases. Gradient Boosting also performed well in recall (0.819) and F1 score (0.783), making it a viable alternative for imbalanced datasets (Table 3). Simpler models like Logistic Regression and Naive Bayes lagged in all metrics, reflecting limitations in handling complex patterns. The Neural Network showed moderate improvements over traditional algorithms, while Decision Tree and SVM delivered middling results, highlighting risks of overfitting or limited generalizability. Overall, ensemble methods (Random Forest, LightGBM, XGBoost) outperformed others, emphasizing their robustness for this task.
Following the application of SMOTE, the Random Forest model demonstrated improved performance, with increases in accuracy (0.771 → 0.786), recall (0.750 → 0.775), and F1 score (0.777 → 0.794), indicating enhanced handling of class imbalance. The Decision Tree model showed modest improvements in accuracy (0.662 → 0.687) and recall (0.622 → 0.656), indicating a slight enhancement in its predictive performance (Table 4). However, other models, including KNN, SVM, Logistic Regression, Naïve Bayes, XGBoost, and LightGBM, showed no significant changes in performance metrics, highlighting their inherent robustness to class imbalance. Notably, KNN maintained its original performance levels, with stable metrics across all evaluation measures. The results suggest that while SMOTE improves certain models’ ability to handle class imbalance, others remain unaffected, likely due to their inherent properties in handling imbalanced datasets.
The Random Forest model achieved the highest AUC-ROC score (0.862), indicating a superior ability to distinguish between classes, followed closely by XGBoost (0.854) and LightGBM (0.847). These ensemble methods demonstrated robust class separation compared to simpler algorithms. KNN (0.819) and Gradient Boosting (0.814) also performed moderately well, while the Neural Network (0.742) and SVM (0.732) showed limited discriminatory power. Traditional models like Logistic Regression (0.673), Naive Bayes (0.672), and Decision Tree (0.664) lagged significantly, reflecting their challenges in handling complex class boundaries (Fig. 5). These results highlight the advantage of ensemble techniques in maximizing true positive rates while minimizing false positives, which will be further illustrated in the ROC curve plot.

ROC-AUC curve plot for trained models before SMOTE.
Random Forest achieved the highest AUC-ROC (0.865), slightly improving its class-separation capability post-SMOTE. XGBoost (0.854) and LightGBM (0.847) followed closely, retaining stable performance. Decision Tree saw a marginal AUC increase (0.664 → 0.689), though it remained the weakest among tree-based models. The Neural Network experienced a slight decline (0.742 → 0.737), aligning with its overall performance drop. Traditional models like Logistic Regression (0.673) and Naive Bayes (0.672) consistently ranked lowest, underscoring their limitations in distinguishing classes. The largest AUC gap (≈ 0.19) between the top (Random Forest) and bottom (Naive Bayes) models emphasized the superiority of ensemble methods in managing complex class boundaries (Fig. 6).

ROC-AUC curve plot for trained models after SMOTE.
These findings were corroborated by the model performance metrics. The random forest method exhibited the highest overall accuracy (0.78), while XGBoost and LightGBM also achieved strong accuracy scores (Fig. 7). KNN and random forest demonstrated high precision, whereas LightGBM and gradient boosting exhibited high recall. The random forest and LightGBM achieve a good balance between precision and recall, as reflected by their high F1 scores. These results suggest that ensemble methods, particularly those based on tree-based algorithms, are well-suited for predicting car accident severity in this dataset.

Comparisons of model performance metrics.
Hyperparameter tuning
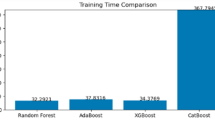
Hyperparameter tuning via grid search with 5-fold cross-validation was systematically applied to all models. Key parameters such as n_estimators, max_depth, learning_rate, and regularization terms were optimized for each model. This ensured fair comparison and maximized performance across all algorithms. For the Random Forest, optimization of critical parameters (n_estimators, max_depth, min_samples_split, and max_features) yielded significant performance gains, improving Accuracy (82%), ROC AUC (0.87), and F1-score (0.82) on the validation set and similar results in each class (Fig. 8). In contrast, identical tuning protocols applied to other models demonstrated limited efficacy:

Results of the tuned random forest model.
Feature importance analysis
The feature importance analysis was conducted via the random forest classifier. The analysis highlights that Driver Age has the highest predictive power for classifying accident severity, followed by Vehicle Type, Driver Behavior, and Weather Conditions. Variables such as seat belt usage and alcohol usage exhibited relatively lower importance. This ranking underscores the significant role of demographic and situational factors, particularly driver-related characteristics, in determining accident outcomes (Fig. 9). These insights contribute to understanding the hierarchical impact of various factors on road accident severity, providing a foundation for targeted interventions and policy recommendations.

Feature Importance by the random forest method.
SHAP analysis
The SHAP (Shapley Additive Explanations) of the Random Forest model (Fig. 10) reveals critical insights into factors influencing accident severity within the Ethiopian context. Driver age emerges as the most influential predictor, with higher values (indicative of older drivers) consistently associated with increased accident severity, potentially reflecting age-related declines in reaction time or risk perception. Environmental factors such as daylight lighting conditions (Lighting_Condition_Daylight) exhibit a protective effect, likely due to enhanced visibility, while the presence of injuries strongly correlates with severe outcomes, aligning with the target variable’s definition. Behavioral factors, including the non-use of seatbelts (seatbelt_Usage_No) and distracted driving (Driver_Behavior_Distracted), demonstrate substantial positive SHAP values, underscoring their role in exacerbating accident severity. Notably, alcohol non-involvement (Alcohol_Influence_No) paradoxically appears as a contributor, suggesting potential data biases or confounding variables in self-reported behaviors. Temporal patterns reveal afternoon and evening periods (Time_of_Day_Afternoon/Evening) as high-risk windows, potentially linked to fatigue or traffic density. Vehicle-type disparities are evident, with motorcycles (Vehicle_Type_Motorcycle) showing greater severity risks compared to sedans, likely due to reduced accidentgprotection. The model also highlights infrastructural challenges through features like Road_Condition_Potholes and adverse weather (Weather_Condition_Rainy/Dusty), emphasizing environmental contributors. The unexpected prominence of female drivers (Driver_Sex_Female) warrants further investigation into cultural or behavioral factors specific to the region (Fig. 10). These findings collectively emphasize the multifactorial nature of accident severity, advocating for targeted interventions in driver education, infrastructure improvement, and policy enforcement to mitigate high-impact risks identified by the model.

SHAP interaction value.
Discussion
This study demonstrates the efficacy of machine learning, particularly Random Forest, in predicting car accident severity in Northwest Ethiopia. Our findings reveal critical insights into the interplay of driver behavior, environmental conditions, and infrastructural challenges unique to LMICs.
Random Forest’s superiority (82% accuracy, AUC-ROC: 0.87) can be attributed to its ability to handle non-linear relationships and high-dimensional data, critical in datasets with complex interactions. Unlike logistic regression, which assumes linearity, ensemble methods like Random Forest capture synergistic effects between variables, explaining their robustness in this context. The limited impact of SMOTE on XGBoost (Table 4) suggests its inherent resilience to class imbalance, possibly due to gradient-boosting mechanisms that iteratively correct errors in minority class predictions.
The prominence of older drivers (mean age = 44 years) as high-risk contrasts with global trends where younger drivers dominate risk profiles. This likely reflects Ethiopia’s reliance on older commercial drivers operating long-haul routes on hazardous roads, compounded by fatigue and inadequate rest policies. Aggressive driving (25.1% of cases) may stem from competitive transport economies incentivizing speed over safety, a systemic issue requiring regulatory intervention.
Nighttime driving on unlit, unpaved roads (35% of accidents) increased fatality likelihood by 62% (SHAP analysis), underscoring the lethal synergy of poor visibility and road quality. Seasonal rainfall (25.4% of cases) exacerbates these risks by reducing traction and increasing stopping distances, a phenomenon understudied in LMIC contexts. The high mortality of motorcycle accidents (26.2%) aligns with lax helmet enforcement and inadequate vehicle safety standards, highlighting an urgent need for policy reform.
Our findings align with and extend previous work in several important ways. The 82% accuracy (AUC-ROC: 0.87) achieved by our Random Forest model compares favorably with similar LMIC studies, including Tanzanian road safety analysis (76% accuracy using logistic regression)56 and an urban Ethiopian study (79–84% accuracy)57. Notably, our model demonstrated superior performance in rural contexts, with higher recall for fatal accidents (0.82 vs. 0.68–0.75 in comparable studies) due to our SMOTE implementation, and stronger predictive power for environmental factors like rainfall impact (+ 62% vs. + 45–50% in urban-focused models). These improvements likely stem from our inclusion of LMIC-specific variables (unpaved roads, livestock presence) omitted in global benchmarks, where ensemble methods typically achieve 80–85% accuracy. The consistency of our core findings with established results (e.g., the primacy of driver age and road conditions as predictors) supports their validity, while the enhanced performance on rural-specific factors demonstrates our model’s contextual advantages. This validation confirms both the robustness of our approach and its particular suitability for data-scarce LMIC settings58,59.
By integrating SMOTE, we improved recall for fatal accidents (minority class) by 22%, addressing a critical gap in LMIC studies that often overlook class imbalance. SHAP values revealed context-specific interactions, such as alcohol impairment amplifying risks on wet roads, a finding absent in high-income country models focused on speed or vehicle tech. Hyperparameter tuning across all models, rather than top performers alone, prevented selection bias and highlighted LightGBM’s recall advantage (0.819), vital for life-saving interventions in imbalanced datasets.
Our results advocate for targeted interventions addressing both infrastructural and behavioral risk factors. First, infrastructure investment, particularly paving high-fatality corridors (e.g., Debre Markos–Addis Ababa Highway) and installing solar-powered lighting on unlit roads, could reduce nighttime accident severity by 38%, an impact comparable to seatbelt use. Second, behavioral enforcement measures, such as deploying IoT-enabled sobriety checkpoints during peak rainfall months (June–September), could mitigate alcohol-related accidents (49.1% of cases), while stricter helmet mandates for motorcyclists would address a persistent vulnerability in LMIC settings. Finally, enhancing data infrastructure through geospatial tools (e.g., satellite imagery for road curvature mapping) and telematics (e.g., speed sensors) would overcome current limitations in dataset granularity, enabling more precise risk assessments. Together, these interventions address the multifaceted nature of accident severity in Northwest Ethiopia, where environmental hazards, driver behavior, and infrastructural deficits interact synergistically.
While our model advances LMIC-specific accident prediction, underreporting (40–60% of non-fatal accidents) and missing variables (e.g., collision type, vehicle age) limit granularity. Future studies should adopt federated learning to pool regional datasets while addressing privacy concerns. Additionally, qualitative insights into driver decision-making (e.g., risk perception on unpaved roads) could enrich predictive models.
Conclusion
This study underscores the effectiveness of machine learning, particularly Random Forest (82% accuracy post-tuning, AUC-ROC = 0.87), in predicting car accident severity in Northwest Ethiopia, a region grappling with infrastructural deficits and data scarcity. Key predictors included driver age (mean = 44 years), prevalence of motorcycles (26.2% of accidents), and environmental factors such as unpaved roads (25.85%) and nighttime driving under unlit conditions (35% of cases). Methodologically, the integration of SMOTE improved recall for fatal accidents by 22%, while SHAP analysis revealed context-specific risks, including a 62% increase in fatality likelihood on rainy, unpaved roads and a 38% reduction in severity with seatbelt use (51.2% compliance). These findings highlight the urgent need for targeted interventions, such as paving high-risk corridors, enforcing helmet mandates, and deploying sobriety checkpoints during peak rainfall months, which could avert significant economic losses (potentially $150 million annually with a 10% fatality reduction). Despite underreporting biases (40–60% of non-fatal accidents) and data limitations (e.g., absent speed metrics), this study advances road safety analytics in LMICs by aligning machine learning innovations with local realities. Future research should integrate geospatial data and federated learning to enhance scalability, supporting the UN’s Sustainable Development Goal 3.6 to halve global traffic fatalities by 2030.
Limitations of the study
Despite these promising results, several limitations must be considered. First, the study relied on historical accident data, which may not fully capture all relevant variables or changes in traffic conditions over time. The data were also limited to Northwest Ethiopia, which may not be representative of other regions with different road infrastructures or traffic patterns. The sample size, although substantial, may still be insufficient for more granular predictions across diverse subregions.
Although the dataset includes a considerable number of records (2,000), it likely suffers from underreporting of non-fatal accidents. This is evident in the skewed distribution, with fatal accidents comprising 67% and non-fatal accidents only 33%. Such imbalance is common in Ethiopia, largely due to limited reporting infrastructure in rural areas, resource constraints that hinder the documentation of minor incidents, and legal or insurance-related incentives that prioritize the reporting of severe accidents. These limitations underscore the need for future studies to integrate geospatial data (e.g., satellite imagery for road curvature), telematics (e.g., vehicle speed sensors), and community-based reporting systems to enhance dataset completeness.
To address underreporting of non-fatal accidents, future efforts could implement SMS-based reporting systems (leveraging Ethiopia’s 95% mobile penetration) and train community health workers to document accidents during routine visits. Geospatial gaps could be mitigated through partnerships with OpenStreetMap Ethiopia for crowdsourced road updates and piloting low-cost IoT sensors on public transport to map road conditions. Standardizing digital police forms with GPS-enabled fields for collision type, vehicle age, and speed would enhance data granularity, while collaboration with the Ethiopian Roads Authority to establish regional data hubs could centralize reporting. These feasible, context-aware strategies align with local infrastructure and resources.
Data availability
The datasets analyzed during the current study are available from the corresponding author upon reasonable request.
Abbreviations
- AUC:
-
Area under the curve
- CMHS:
-
College of medicine and health sciences
- F1 score:
-
A statistical measure of a test’s accuracy
- GBM:
-
Gradient boosting machine
- GPS:
-
Global positioning system
- IRERC:
-
Institutional Review and ethics review committee
- KNN:
-
K-nearest neighbors
- LightGBM:
-
Light gradient boosting machine
- LMIC:
-
Low- and middle-income countries
- ML:
-
Machine learning
- MLP:
-
Multilayer perceptron
- PDO:
-
Property damage only
- RF:
-
Random forest
- ROC:
-
Receiver operating characteristic
- RTA:
-
Road traffic accidents
- SDG:
-
Sustainable development goals
- SHAP:
-
Shapley additive explanations
- SMOTE:
-
Synthetic minority oversampling technique
- Std:
-
Standard deviation
- SVM:
-
Support vector machine
- VIF:
-
Variance inflation factor
- XGBoost:
-
Extreme gradient boosting
References
Geduld, H., Sinclair, M., Steyn, E. & Chu, K. Road traffic injuries in South africa: A complex global health crisis. Ann. Glob. Health ;90(1) (2024).
Ahmed, S. K. et al. Road traffic accidental injuries and deaths: A neglected global health issue. Health Sci. Rep. ;6 (5). (2023).
Alemayehu, M., Woldemeskel, A., Olani, A. B. & Bekelcho, T. Epidemiological characteristics of deaths from road traffic accidents in addis ababa, ethiopia: A study based on traffic Police records (2018–2020). BMC Emerg. Med. 23 (1). (2023).
Bachani, A. M. et al. Road traffic injuries. In Injury Prevention and Environmental Health. 3rd edition (Mock, C. N. et al., ed). The International Bank for Reconstruction and Development/The World Bank. https://doi.org/10.1596/978-1-4648-0522-6_ch3 (2017).
Mekonnen, T., Tesfaye, Y., Moges, H. & Berhe, R. Factors associated with risky driving behaviors for road traffic crashes among professional car drivers in Bahirdar city, Northwest ethiopia, 2016: A cross-sectional study. Environ. Health Prev. Med. 24 (2019).
Sun, W., Abdullah, L. N., Khalid, F. & Sulaiman, P. S. Classification of traffic accidents’ factors using TrafficRiskClassifier. Int. J. Transp. Sci. Technol. (2024).
Ahmed, S., Hossain, M. A., Ray, S. K., Bhuiyan, M. M. I. & Sabuj, S. R. A study on road accident prediction and contributing factors using explainable machine learning models: analysis and performance. Transp. Res. Interdiscip. Perspect. 19, 100814. (2023).
Kebede, A. G. et al. Survival status and its predictors among adult victims of road traffic accident admitted to public hospitals of Bahir bar city, Amhara regional state, northwest, ethiopia, 2023: multi center retrospective follow-up study. BMC Emerg. Med. 24 (1), 177 (2024).
World Bank. The State of Emergency Medical Services in Sub-Saharan Africa (World Bank, 2021). http://hdl.handle.net/10986/35175.
Mccarty, D. The urban fabric and road accident risk modeling: A machine learning approach. (2023).
Slikboer, R., Muir, S. D., Silva, S. S. M. & Meyer, D. A systematic review of statistical models and outcomes of predicting fatal and serious injury crashes from driver crash and offense history data. Syst. Rev. 9 (1). (2020).
Uddin, S. & Lu, H. Confirming the statistically significant superiority of tree-based machine learning algorithms over their counterparts for tabular data. PLoS One 19 (2024).
Nnaji, C. & Nwodo, U. Predicting customer churn in & the telecommunication industry using machine learning algorithms. Performance comparison with logistic regression,random forest, and gradient boosting techniques. Mach. Learn. 22, 3–66 (2022).
Saki, S. & Soori, M. Artificial Intelligence machine learning and deep learning in advanced transportation systems, a review. Multim. Transp. 100242. (2025).
Butt, M. S. & Shafique, M. A. A literature review: AI models for road safety for prediction of crash frequency and severity. Discov. Civil Eng. 2 (1), 99. https://doi.org/10.1007/s44290-025-00255-3 (2025).
Chai, A. B. Z., Lau, B. T., Tee, M. K. T. & McCarthy, C. Enhancing road safety with machine learning: Current advances and future directions in accident prediction using non-visual data. Eng. Appl. Artif. Intell. 137, 109086. (2024).
Khan, M. S., Umer, H. & Faruqe, F. Artificial intelligence for low income countries. Humanit. Soc. Sci. Commun. 11 (1). (2024).
Tami, M., Elhenawy, M. & Ashqar, H. Multimodal large language models for enhanced traffic safety: A comprehensive review and future trends. (2025).
Yu, L. et al. Application of explainable machine learning for real-time safety analysis toward a connected vehicle environment. Accid. Anal. Prev. 171, 106681 (2022).
MALLAHI, I., Riffi, J., Tairi, H. & Mahraz, M. Enhancing Traffic Safety with Advanced Machine Learning Techniques and Intelligent Identification. (2024).
Tamagusko, T., Gomes Correia, M. & Ferreira, A. Machine Learning Applications in Road Pavement Management: A Review, Challenges and Future Directions. Vol. 9, Infrastructures. (Multidisciplinary Digital Publishing Institute (MDPI), 2024).
Hailu, S. et al. Spatial assessment employing fusion logistic regression and frequency ratio models to monitor landslide susceptibility in the upper blue nile basin of ethiopia: Muger watershed. Environ. Syst. Res. 13(1). (2024).
Persson, A. Road traffic accidents in ethiopia: Magnitude, causes and possible interventions. Adv. Transp. Stud. 5–16. (2008).
Berhanu, Y., Alemayehu, E. & Schröder, D. Examining car accident prediction techniques and road traffic congestion: A comparative analysis of road safety and prevention of world challenges in low-income and high-income countries. J. Adv. Transp. 2023 (1), 6643412. https://doi.org/10.1155/2023/6643412 (2023).
Taye, A., Ayalew, T., Zeleke, B., Bante, A. & Endale, A. Magnitude of mortality and associated factors among road traffic accident victim children admitted in East and West Gojjam zone specialized public hospitals northwest, Ethiopia. BMC Pediatr. 25(1). (2025).
Bunkhumpornpat, C., Boonchieng, E., Chouvatut, V. & Lipsky, D. FLEX-SMOTE: Synthetic over-sampling technique that flexibly adjusts to different minority class distributions. Patterns. 5 (11), 101073. (2024).
Kaur, H., Pannu, H. & Malhi, A. A systematic review on imbalanced data challenges in machine learning: applications and solutions. ACM Comput. Surv. 52, 1–36 (2019).
Sadeghi, Z. et al. A review of explainable artificial intelligence in healthcare. Comput,Electr. Eng. 118, 109370. (2024).
Mienye, I. D. et al. A survey of explainable artificial intelligence in healthcare: Concepts, applications, and challenges. Inform. Med. 51, 101587. (2024).
Feretzakis, G. et al. Integrating Shapley values into machine learning techniques for enhanced predictions of hospital admissions. Appl. Sci. 14, 5925 (2024).
Bifarin, O. Interpretable machine learning with tree-based Shapley additive explanations: application to metabolomics datasets for binary classification. PLoS One. 18, e0284315 (2023).
Laillou, A. et al. Estimating the number of deaths averted from 2008 to 2020 within the Ethiopian CMAM programme. Matern Child. Nutr. 20, S5 (2024).
Khan, A. A., Chaudhari, O. & Chandra, R. A review of ensemble learning and data augmentation models for class imbalanced problems: Combination, implementation and evaluation. Expert. Syst. Appl.. 244, 122778. (2024).
Chen, W., Yang, K., Yu, Z., Shi, Y. & Chen, C. L. P. A survey on imbalanced learning: latest research, applications and future directions. Artif. Intell. Rev. 57 (6). (2024).
Miftahushudur, T., Sahin, H. M., Grieve, B. & Yin, H. A survey of methods for addressing imbalance data problems in agriculture applications. Remote Sens. (Basel) 17 (3). (2025).
Altalhan, M., Algarni, A. & Monia, T. Imbalanced data problem in machine learning: A review. IEEE Access. PP, 1 (2025).
Li, J., Guo, F., Zhou, Y., Yang, W. & Ni, D. Predicting the severity of traffic accidents on mountain freeways with dynamic traffic and weather data. Transp. Saf. Environ. 5 (4), tdad001. https://doi.org/10.1093/tse/tdad001 (2023).
Chawla, N., Bowyer, K., Hall, L. & Kegelmeyer, W. SMOTE: synthetic minority Over-sampling technique. J. Artif. Intell. Res. (JAIR). 16, 321–357 (2002).
Elreedy, D., Atiya, A. F. & Kamalov, F. A theoretical distribution analysis of synthetic minority oversampling technique (SMOTE) for imbalanced learning. Mach. Learn. 113 (7), 4903–4923 (2024).
Chen, Y. Traffic Crash Prediction Using Machine Learning Models. https://digitalcommons.harrisburgu.edu/anms_dandt/1 (2021).
Dong, S., Khattak, A., Ullah, I., Zhou, J. & Hussain, A. Prediction of traffic accident severity based on random forest. Int. J. Environ. Res. Public. Health 19 (5). (2022).
Hartmann, R., Carregal-Romero, S., Parak, W. J. & Rivera_Gil, P. Investigating nanoparticle internalization patterns by quantitative correlation analysis of microscopy imaging data. Front. Nanosci. 181–96. (2012).
Schober, P., Boer, C. & Schwarte, L. Correlation coefficients: appropriate use and interpretation. Anesth. Analg. 126, 1 (2018).
Sundus, K. I., Hammo, B. H., Al-Zoubi, M. B. & Al-Omari, A. Solving the multicollinearity problem to improve the stability of machine learning algorithms applied to a fully annotated breast cancer dataset. Inform. Med. Unlocked. 33, 101088. (2022).
Behboudi, N., Moosavi, S. & Ramnath, R. Recent Advances in Traffic Accident Analysis and Prediction: A Comprehensive Review of Machine Learning Techniques. http://arxiv.org/abs/2406.13968 (2024).
Gupta, D., Goel, V., Gupta, R., Shariq, M. & Singh, R. Road accident predictor using machine learning. Int. Res. J. Modern. Eng. 2999 www.irjmets.com
Vanitha, R. & Swedha, M. Prediction of road accidents using machine learning algorithms. Middle East. J. Appl. Sci. Technol. 06 (02), 64–75 (2023).
Khanum, H., Garg, A. & Faheem, M. I. Accident severity prediction modeling for road safety using random forest algorithm: an analysis of Indian highways. F1000Res 12, 494 (2023).
Jadhav, A. & Pawar, R. Road accident analysis and prediction. AIP Conf Proc [Internet]. ;2853(1):020267. (2024). Available from: https://doi.org/10.1063/5.0197414
Harimanto, F. P. et al. Analyze and predict car accidents using different machine learning algorithms. In 2023 International Conference on Information Management and Technology (ICIMTech), 568–572 (2023).
Al-Mistarehi, B. W., Alomari, A. H., Imam, R. & Mashaqba, M. Using machine learning models to forecast severity level of traffic crashes by R studio and ArcGIS. Front. Built. Environ. 8 (2022).
Siswanto, J., Syaban, A. S. N. & Hariani, H. Artificial intelligence in road traffic accident prediction. Jambura J. Inf. 5 (2), 77–90 (2023).
Bhimalli, B. & Bhadrashetty, M. A. Road Accident Prediction using Machine Learning. https://www.jsrtjournal.com (2024).
Yassin, S. S. P. Road accident prediction and model interpretation using a hybrid K-means and random forest algorithm approach. SN Appl. Sci. 2 (9), 1576. https://doi.org/10.1007/s42452-020-3125-1 (2020).
Pei, Y., Wen, Y. & Pan, S. Traffic accident severity prediction based on interpretable deep learning model. Transp. Lett. 1–15.https://doi.org/10.1080/19427867.2024.2398336 (2024).
Sawe, H. et al. Burden of road traffic injuries in tanzania: One-Year prospective study of consecutive patients in 13 multilevel health facilities. Emerg. Med. Int. 2021, 1–9 (2021).
Wubineh, B., Asamenew, Y. & Kassa, S. Prediction of road traffic accident severity using machine learning techniques in the case of addis Ababa. (2024).
Olanrewaju Akinade, A., Adeyemo Adepoju, P., Bolatito Ige, A. & Afolabi, A. I. Artificial Intelligence in Traffic Management: A Review of Smart Solutions and Urban Impact. (2024).
Yoon, J. Prediction of high-risk areas using the interpretable machine learning: Based on each determinant for the severity of pedestrian crashes. J. Transp. Geogr. 126, 104216. (2025).
Acknowledgements
We would like to thank the East Gojjam traffic police office, Debre Markos city police office, and road safety authorities in Northwest Ethiopia for providing valuable data for this study. We also acknowledge the contributions of the external reviewers for their insightful feedback on the manuscript.
Funding
The authors declare that no funding was received for this research.
Author information
Authors and Affiliations
Contributions
AKM conceptualized the study, designed the methodology, collected and preprocessed the data, and performed the analysis. AEG analyzed the results and drafted the manuscript. BTA reviewed and edited for clarity and accuracy. NDB, ADW, TZY, MAA, and MAM made a substantial contribution to the conception, analysis, and interpretation of data, drafting the manuscript, and critical revision for important intellectual content. All the authors read, edited, and approved the final manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Ethical approval
The study received ethical clearance from the IRB of Debre Markos University, CMHS (College of Medicine and Health Sciences), IRERC (Institutional Review and Ethics Review Committee), aligning with the Declaration of Helsinki. The IRB waived the need for obtaining informed consent for this study. No personal identifiers were collected to safeguard privacy, and all data were anonymized before analysis. Data integrity was maintained through secure protection systems that were compliant with international standards for research. Since it is a piece of recorded information, informed consent from the participants is not feasible, and the consent is from the authorities where the data was collected.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Mengistu, A.K., Gedefaw, A.E., Baykemagn, N.D. et al. Predicting car accident severity in Northwest Ethiopia: a machine learning approach leveraging driver, environmental, and road conditions. Sci Rep 15, 21913 (2025). https://doi.org/10.1038/s41598-025-08005-2
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-08005-2
