
Abstract
Periodontitis, a chronic inflammatory condition of the periodontium, is associated with over 60 systemic diseases. Despite advancements, precision medicine approaches have had limited success, emphasizing the need for deeper insights into cellular subpopulations and structural immunity, particularly gingival keratinocytes. This study employs autoencoder models and data augmentation techniques to explore the transcriptomic diversity of gingival keratinocytes at the single-cell level. Single-cell RNA sequencing data from GSE266897 were processed using the Scanpy library, with quality control implemented to filter cells based on predefined metrics. Clustering was performed using principal component analysis (PCA) and k-nearest neighbor (KNN) algorithms. Marker gene identification and differential expression analysis were used to characterize cell clusters. Visualization techniques, including UMAP, heatmaps, dot plots, and violin plots, provided insights into gene expression patterns. The autoencoder architecture featured an encoder reducing input size to 256 units with ReLU activation, a bottleneck layer, and a decoder restoring data dimensions. The basic Autoencoder (AE) demonstrated superior performance, achieving the lowest loss (0.725), the highest accuracy (0.695), and minimal false positives. The Test-Time Augmentation AE also performed robustly, achieving an F1 score of 0.642 and an AUC-ROC of 0.800. The Basic AE effectively modeled RNA-seq data complexity compared to Variational and Denoising Autoencoders. This study highlights advanced computational techniques to investigate gingival keratinocytes’ transcriptomic diversity, revealing distinct subpopulations and differential gene expression profiles. These findings underscore the active role of keratinocytes in periodontal health and inflammatory responses, contributing to precision medicine approaches in periodontology.
Similar content being viewed by others

Introduction
Periodontal diseases, particularly periodontitis, affect billions globally and are characterized by chronic inflammation of the periodontium, often due to polybacterial dysbiosis. If untreated, these conditions can lead to tooth loss and are linked to over 60 systemic diseases, including cardiovascular issues and diabetes1,2,3. Despite advances in treatment, precision medicine approaches have had limited success in managing periodontitis. This underscores the need for a deeper understanding of cell subpopulations and their specific roles in disease progression. Recent studies emphasize the importance of structural immunity—where non-hematopoietic cells such as keratinocytes play key immune-modulatory roles—in improving our understanding of periodontal pathology. An integrated atlas of human gingival tissues has revealed novel keratinocyte subpopulations4,5with tooth-facing and junctional keratinocytes exhibiting distinct responses in disease conditions. These subpopulations harbor bacterial reads from periodontitis-associated pathogens and appear to regulate immune cell subpopulations.
Gingival keratinocytes6,7essential epithelial cells, maintain tissue integrity and homeostasis, providing protection against pathogens and mechanical stress. Despite their importance, their transcriptomic diversity remains underexplored8,9. A thorough understanding of this diversity is essential for elucidating their roles in both normal physiological processes and pathological conditions such as gingivitis and periodontitis. Single-cell RNA sequencing (scRNA-seq)10,11 enables the study of cell-to-cell heterogeneity by analyzing gene expression at single-cell resolution, aiding in identifying distinct cell types and understanding molecular mechanisms. However, challenges such as high-dimensional data and batch effects complicate clustering and dimensionality reduction.
Autoencoder models, a type of artificial neural network, excel in analyzing complex transcriptomic profiles by mitigating noise and capturing essential features. Data augmentation enhances model robustness, mitigates overfitting, and improves interpretation of scRNA-seq data. An integrated approach combining autoencoder models with data augmentation methods provides an innovative way to investigate gingival keratinocyte transcriptomic diversity at the single-cell level. The scRNA-seq workflow includes quality control, normalization, identification of highly variable genes, dimensionality reduction, clustering, and visualization using non-linear methods10,11.
Recent advancements in deep embedding clustering methods12,13 have significantly improved the analysis of high-dimensional scRNA-seq data. Autoencoders, such as the deep count autoencoder (DCA), are particularly effective for learning compact data representations. Traditional clustering methods (e.g., scDeepCluster, scziDesk, and scVI) have been useful for dimensionality reduction but often fail to capture gene correlations due to Gaussian noise.
Structural immunity, defined as the immune functions of non-hematopoietic cells, has been increasingly explored through single-cell and spatial genomic methods. Evidence suggests that all cells exhibit immune characteristics in specific contexts, such as periodontitis, where fibroblasts and keratinocytes interact with innate immune cells. Keratinocytes not only contribute to barrier integrity but also regulate immune education and memory through their stem/progenitor cells. A recent study using the Cellenics toolkit identified five novel gingival keratinocyte subpopulations and revealed that subpopulations like suprabasal keratinocytes (SK) and junctional keratinocytes (JK) exhibit differential responses in disease, influencing cell differentiation and cytokine expression10. Upregulation of 28.5% of genes in periodontitis points to potential therapeutic targets, highlighting the need for more integrated approaches to address chronic dysbiosis. These findings directly underscore the importance of linking keratinocyte heterogeneity with functional outcomes in periodontal disease. By exploring the transcriptomic intricacies of these subpopulations using autoencoder models, this study aims to bridge the gap between descriptive cellular heterogeneity and actionable insights into immune regulation and therapeutic targets. This focus not only advances our understanding of keratinocyte roles in disease but also creates a foundation for leveraging computational tools to integrate such discoveries into translational frameworks.
Our study leverages this dataset to explore gingival keratinocyte biology using artificial intelligence (AI). Autoencoders are critical tools in single-cell transcriptomics for managing large datasets, compressing data, and identifying subpopulations based on gene expression profiles14,15. They also facilitate differential expression and pathway analysis and can integrate other omics data to provide a comprehensive view of keratinocyte biology. Tools such as scAEspy and scMAE have demonstrated superior performance in cell clustering, particularly in identifying rare cell types, with biological validation confirming their utility. Advanced frameworks like scDHA incorporate autoencoder architectures to outperform traditional techniques in cell segregation, classification, and pseudo-time inference16,17.
Autoencoder models enhance data interpretation and uncover latent features, structural patterns, and non-linear gene interactions. Combining these models with robust data augmentation methods mitigates overfitting, increases sample diversity, and improves performance18,19. By integrating computational approaches with biological principles, this study aims to provide a novel methodological framework for biomarker discovery and targeted therapeutics in oral diseases. The research sets a precedent for using autoencoder-based approaches in single-cell transcriptomics and other tissues or cell types. This methodology addresses critical gaps in current studies by integrating high-dimensional single-cell data into actionable biological insights, with a specific emphasis on keratinocyte subpopulations and their functional implications in periodontitis. Furthermore, this approach uniquely contributes to periodontal research by providing a computational framework that identifies rare or previously uncharacterized cell subpopulations, offering new avenues for biomarker discovery and targeted therapeutic strategies.
Most studies rely on traditional statistical clustering or predefined lineage annotations, which may overlook transitional or rare states, despite growing interest in structural immunity and the epithelial contributions to oral inflammation. To bridge that gap, this work uses deep learning—especially autoencoders with test-time augmentation—to offer an unsupervised, scalable framework for exposing transcriptomic heterogeneity. As far as we know, this is the first time an integrated approach has been used in gingival keratinocytes, combining advances in biology and computation. This study evaluates different autoencoder models and data augmentation strategies to uncover transcriptomic diversity in gingival keratinocytes and offer insights into their roles in periodontal health and disease.
Materials and methods
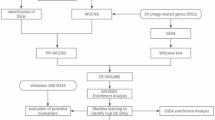
Figure 1 illustrates the workflow employed in this study, integrating single-cell RNA sequencing analysis, data augmentation strategies, and autoencoder models. This framework highlights the approach used to unveil the transcriptomic diversity of gingival keratinocytes and analyze their biological and computational properties.

Schematic representation of the model workflow. The figure was designed using Microsoft PowerPoint (Version 2304, Build 16327.20248), part of the Microsoft 365 suite.
Single-cell transcriptomic analysis
Data preprocessing
The Scanpy library was used to process single-cell RNA sequencing data20,21 from GSE26689722, ensuring data integrity and quality for downstream analysis through a structured workflow. The study utilized scRNA-seq data from four samples loaded into the Scanpy environment. Quality control was achieved by removing cells with fewer than 200 genes and genes expressed in fewer than three cells. To eliminate technical artifacts, thresholds were established using previous benchmarks from GSE266897. To reduce the effect of stressed or dying cells, cells with a mitochondrial gene expression percentage higher than 20% or total counts less than 1,000 were specifically eliminated.
Clustering and dimensionality reduction
Principal Component Analysis (PCA) was employed to reduce the dimensionality of highly variable gene expression data. Using the top 40 principal components, a k-nearest neighbors (KNN) graph was constructed to identify clusters based on expression profiles. Uniform Manifold Approximation and Projection (UMAP) was used to visualize these clusters, preserving the data’s local and global structures. Leiden clustering was applied to delineate distinct cell populations within the dataset.
Marker gene identification
Differential expression analysis and marker gene ranking were performed to identify specific genes for cell clusters. The Wilcoxon rank-sum test was used to identify significantly upregulated or downregulated genes, while adjusted p-values were calculated for robust gene selection.
Visualization
Visualization techniques were employed to interpret clustering and expression data, including UMAP plots for cell population structure and sample variances. Additional methods such as dot plots, heatmaps, and violin plots were used to display the expression patterns of top marker genes. These visualizations provided valuable insights into the expression levels and distributions of these genes across different cell populations.
Figure 2 outlines the step-by-step process for analyzing single-cell data through an autoencoder-based framework. The workflow begins with data input, followed by preprocessing, feature selection, and dimensionality reduction using techniques such as PCA, t-SNE, and UMAP. The data is then clustered and visualized with 2D/3D plots. The autoencoder model architecture is detailed, showcasing the dense and bottleneck layers used for encoding and decoding, culminating in the reconstructed output. This approach facilitates the extraction of meaningful patterns from complex single-cell transcriptomic data.

Workflow of single-cell data analysis using autoencoders. The figure was designed using Microsoft PowerPoint (Version 2304, Build 16327.20248), part of the Microsoft 365 suite.
Data preprocessing
The preprocessing process for autoencoders in single-cell transcriptomics involves several steps to ensure the data is clean, normalized, and structured for effective learning. These steps include data acquisition, quality control, normalization, transformation, batch effect correction, dimension reduction, data transformation to a matrix format, training validation split, data standardization, and autoencoder implementation.
Data acquisition involves obtaining single-cell RNA sequencing (scRNA-seq) data in the form of raw counts. Quality control involves identifying and filtering out low-quality cells, such as cell filtering, gene filtering, and mitochondrial read check. Normalization involves normalizing the raw count data to account for differences in sequencing depth and capture efficiency. Transformation involves transforming the data using techniques like log transformation or Z-score normalization. Batch effect correction is used if the data comes from multiple batches or conditions to minimize unwanted variability between batches. Dimensionality reduction uses techniques like Principal Component Analysis (PCA) or t-SNE to improve training efficiency and reduce noise. Data transformation to matrix format ensures the data is correct. Typically, a matrix is one where rows represent genes and columns represent cells. Training validation splits the dataset into training and validation subsets, allowing hyperparameter tuning and evaluating the autoencoder’s performance. Data standardization is normalizing the data between 0 and 1 or standardizing it to zero mean and unit variance (Fig. 2).
Autoencoders architecture
The input layer accepts data with a dimensionality equal to the number of features or genes in the dataset, representing each instance as a single sample with multiple features23. The encoder architecture comprises two dense layers: the first hidden layer, which reduces the input size to 256 units using the ReLU activation function, and the second hidden layer, which further compresses the data to 128 units using the ReLU activation function, aiming to extract the most relevant information. The bottleneck layer is the core representation of data, reducing dimensionality to 64 units and capturing input features essential for effective autoencoder reconstruction. The decoder is a dense layer that mirrors the encoder, consisting of two dense layers that progressively expand data back to the original input size. The first layer expands the representation from the bottleneck layer to 128 units, using ReLU activation to maintain non-linearity. The second layer increases the size to 256 units using ReLU activation. The output layer retrieves the original input dimensions using a sigmoid activation function.
The model is trained for 100 epochs, passing the entire network 100 times to ensure better fitting and reduce the risk of overfitting. The learning rate is set to 0.001, determining step size at each iteration. The Adam optimizer is used, an adaptive learning rate method that combines the advantages of two other extensions of stochastic gradient descent. A batch size 32 is used to balance memory efficiency and gradient stability. Additionally, 20% of the data is reserved as validation data, allowing the model to monitor for overfitting during training.
The autoencoder model was trained using a systematic method, including the Mean Squared Error loss function and Adam optimizer, and 100 training epochs to optimize its performance. The training process involved a loop iterating over epochs, setting the model to training mode at the beginning to ensure the proper functioning of layers like dropout and batch normalization. The model parameters were zeroed to prevent the accumulation of gradients. The forward pass generated outputs by passing the input tensor through the autoencoder architecture, and the loss was calculated using the MSE criterion. A backward pass computed the gradients of the loss relative to the model parameters, and the optimizer updated the model parameters to minimize the loss. The autoencoder training methodology involved a systematic approach using the Mean Squared Error (MSE) loss function and the Adam optimizer with a 0.001 learning rate. Progress tracking was done every ten epochs, and the training loss was visualized to assess the model’s performance.
The Variational Autoencoder (VAE) is a generative model that encodes input data into a lower-dimensional latent space, reconstructing the original data. It consists of two main components: the encoder and the decoder. The encoder processes input data through linear layers and ReLU activation functions, transforming it into Gaussian distribution parameters. The encoder architecture, consisting of two dense layers, a bottleneck, and a symmetric decoder, was designed to reduce input data dimensionality while extracting relevant features. Common autoencoder architectures for single-cell RNA sequencing data analysis were used, and the configuration of 256 → 128 → 64 units was found to balance reconstruction quality and computational efficiency24. The reparameterization trick allows backpropagation through stochastic layers, generating a latent variable (z) for the decoder. The decoder then reconstructs the output, aiming to accurately recreate the original input data. VAEs are known for their robust latent representations and variational inference.
The Denoising Autoencoder (DAE) is a training method that reconstructs clean data from corrupted versions. It consists of an encoder and a decoder, with the encoder incorporating noise to enhance robustness. The encoder uses multiple linear layers with ReLU activations and dropout layers for regularization. At the same time, the decoder mirrors the encoder’s structure, transforming the latent representation back into the original input dimension with minimal distortion. This approach enables the model to identify and correct for introduced noise. The study aimed to explore the performance metrics, robustness, and reconstruction capabilities of base AE, VAE and DAE, based on dataset shape, in learning meaningful representations from complex datasets, comparing their robustness and reconstruction capabilities.
The autoencoder model is fine-tuned with specific hyperparameters, such as a learning rate of 0.001 and a batch size of 32, to enhance its learning and generalization during 100 training iterations. Activation functions like ReLU and Sigmoid address the vanishing gradient issue, while the mean squared error (MSE) loss function ensures accurate input data replication. Regularization strategies such as Dropout and Noise mitigate overfitting by randomly excluding neurons, prompting the encoder to concentrate on key data patterns. With a 20% validation split, the model’s performance is assessed on unseen data, and Test Time Augmentation (TTA) improves predictions by introducing variability, further boosting generalization for new data.
The autoencoder consists of an encoder, bottleneck, and decoder:
Encoder:
where x is the input; W and b are weights and biases; f is the activation function (e.g., ReLU).
Bottleneck:
where g is a dimensionality reduction function.
Decoder:
where x’ is the reconstructed input.
Loss function-mean squared error (MSE) loss:
where x is the original input; x’ is the reconstructed input; n is the number of samples.
Gene ontology
The analysis delineates five distinct clusters that encapsulate various biological processes. Using Gene Ontology enrichment analysis, the clusters were analyzed. Cluster 0 demonstrates a substantial involvement in immune responses, as evidenced by the prominence of key terms associated with lymphocyte and leukocyte activation. In contrast, Cluster 1 did not reveal any significant Gene Ontology (GO) terms. Cluster 2 underscores important terms such as “extracellular region” and “epidermis development,” thereby concentrating on extracellular processes and tissue formation. Cluster 3 highlights antigen processing and MHC class II, underscoring their critical roles in immune response and presentation mechanisms. Lastly, Cluster 4 is defined by terms linked to blood vessel development and morphogenesis, indicating essential processes in the ontogeny of the circulatory system. Collectively, the analysis elucidates a diverse array of biological processes across the clusters, with particular emphasis on immune functionality, tissue development, and vascular biology.
Training metrics
The autoencoder model’s performance was evaluated using various classification metrics to assess its accuracy and effectiveness in reconstructing input data. The model was set to evaluation mode, generating predictions and producing reconstructed outputs. Both input data and outputs were converted into binary formats, with values greater than the median categorized as ‘1’ and those equal to or less than the median as ‘0’, thereby forming a binary classification task. The effectiveness of the autoencoder model was assessed using several performance metrics. Accuracy measures the proportion of true results, precision determines the correctness of positive predictions, and recall assesses the model’s ability to identify all relevant instances. The F1 Score, the harmonic mean of these metrics, provided a balanced view. A Receiver Operating Characteristic (ROC) curve was plotted to analyze the trade-offs between true positive and false positive rates at different threshold settings. The Area Under the Curve (AUC) was calculated to quantify the model’s overall performance, with an AUC value approaching 1 indicating strong classification capability.
TTA-test time augmentation
The methodology uses a Test Time Augmentation (TTA) approach25 to improve the performance of an autoencoder model. A noise augmentation function generates random Gaussian noise, adding it to the input data to diversify the model’s predictions. This enhances the model’s generalization capabilities. The method evaluates the model’s performance across multiple augmented instances of the original dataset. The model is set to evaluation mode to turn off dropout layers and training-specific behaviors. After collecting predictions, the averaged output is calculated to mitigate noise or outlier predictions, providing a more stable estimate of the model’s outputs. The averaged predictions are then converted into binary format for classification metrics.
Test-time augmentation (TTA) enhances test set samples by creating multiple copies and averaging predictions, improving results in various domains, especially vision. Alexnet utilized TTA with ten random crops, while Cohen et al. introduced TTA for tabular anomaly detection. Shanmugam et al. optimized augmentation weights, outperforming existing methods. The study evaluated the effectiveness of TTA in improving model predictions using metrics such as accuracy, precision, recall, and F1 score. Results were visualized using a confusion matrix and ROC curve, and the area under the ROC curve (AUC-ROC) was computed. The performance metrics from TTA were compared with original model predictions without TTA, providing insights into the enhancements facilitated by TTA. This methodology ensured the autoencoder’s capabilities were robustly evaluated under ideal conditions and data perturbations, enhancing its real-world applicability.
Results
This study supports that genes upregulated in periodontitis indicate possible therapeutic targets. We notably found significant increases in genes like KRT19, IL7R, TRAC, and LTB in the gingival keratinocytes of patients with periodontitis. These genes are crucial for immune regulation and local immune responses. For instance, IL7R plays a role in T-cell development and function. At the same time, TRAC is responsible for encoding a T-cell receptor complex component vital for T-cell activation. This evidence suggests that these genes could affect the recruitment and activation of immune cells during periodontal disease, emphasizing their potential as therapeutic targets.
A total of 8,322 cells were analyzed, resulting in 28 distinct clusters identified using the Leiden algorithm.
This figure presents UMAP visualizations, which transform high-dimensional data into a two-dimensional format, facilitating comparisons of sample distributions. The left panel displays cell clusters identified using Leiden clustering, revealing 28 distinct groups. In contrast, the right panel shows sample identification, illustrating the distribution of individual samples (ATL_01, ATL_02, ATL_03, and ATL_05). These visualizations provide a comprehensive overview of the data organization, highlighting the structural relationships within cell clusters and the distribution of individual samples.
Figure 3a,b include a variance explained analysis, which addresses the prior omission of PCA variance metrics by adding a scree plot showing the first 40 principal components (PCs) explaining approximately 91% of the total variance (Fig. 3a). Visual validation of the PCA embeddings includes a scatter plot of PC1 vs. PC2 and a K-means clustering overlaid PCA plot to confirm cluster separability (Fig. 3b).

(a,b) Variance explained analysis. The figure was designed using Scanpy version 1.9.3 https://scanpy.readthedocs.io/.
Figure 4 shows a grid of scatter plots comparing different datasets, each representing a distinct relationship between two variables. The plots are arranged in a 6 × 6 grid, where the x-axis and y-axis denote various measurement categories or experimental conditions. Each point on the plot corresponds to an observation from the two variables under comparison. The design features minimal labeling on data points and emphasizes visual clarity, indicating possible correlations groupings. This grid is a comprehensive visualization tool for analyzing relationships between multiple datasets. Cluster 0 is characterized by T-cell markers (IL7R, TRAC, CD3G), Cluster 1 shows cytotoxic cell markers (GZMA, NKG7, GZMK).

Scatter plots comparing different datasets. The figure was designed using Scanpy version 1.9.3 https://scanpy.readthedocs.io/.
Analysis of differential expression and marker gene identification helped define these clusters. For instance, Cluster 0 exhibited a prevalence of T-cell markers (IL7R, TRAC, CD3G), whereas Cluster 1 displayed markers associated with cytotoxic cells (GZMA, NKG7, GZMK) (Fig. 3a, b).
The heatmap (Fig. 4) and dot plot (Fig. 5) emphasized the expression patterns of immune-related genes, including IL7R, TRAC, and LTB, which are known for their crucial roles in immune responses. These results indicate that gingival keratinocytes actively shape local immune responses within the gingival epithelium, especially during periodontal disease. The detection of immune-related genes signifies their involvement in the recruitment and activation of lymphocytes and other immune cells, highlighting their dual function in immune regulation and tissue homeostasis.

Heatmap representing the expression levels of different genes. The figure was designed using Scanpy version 1.9.3 https://scanpy.readthedocs.io/.
Figure 5 shows the heatmap representing the expression levels of different genes across different samples or conditions. It comprises genes linked to immune functions, various samples/conditions, a color scale, and identifiable clusters/patterns. The color gradient represents expression levels, where darker shades denote lower expression and lighter shades indicate higher expression.
Figure 6 shows the dot plot that displays gene expression data for different experimental groups. It lists specific genes, such as IL7R, TRAC, and LTB, and represents distinct experimental groups or conditions. The plot illustrates the percentage of cells that express each gene, where the size of the dots indicates the fraction of gene expression, and the color gradient signifies the average expression level. This visualization is beneficial for comparing gene expression patterns and pinpointing genes for further investigation.

Dot plot that displays gene expression data. The figure was designed using Scanpy version 1.9.3 https://scanpy.readthedocs.io/.
The autoencoder model has been successfully trained and evaluated, showing improved performance with an accuracy of 0.6951 and an AUC-ROC score of 0.8006, indicating better reconstruction quality and classification metrics than the previous model.
Gene clusters with ontologies
Figure 7 shows UMAP visualization of cell clusters, a two-dimensional representation of high-dimensional data. The separation of clusters suggests distinct biological or statistical differences among the cell groups. UMAP is particularly effective in revealing the structure of data with complex interrelationships. This UMAP visualization is a powerful tool for exploring and interpreting cell clusters, enabling researchers to gain insights into the characteristics and relationships within their dataset.

UMAP visualization of cell clusters. The figure was designed using Scanpy version 1.9.3 https://scanpy.readthedocs.io/.
The Gene Ontology analysis and visualizations have enabled us to characterize each cluster. Cluster 0 is strongly linked to immune functions, likely involving T lymphocytes. Cluster 1 lacks significant Gene Ontology (GO) terms, indicating a more heterogeneous cell population. Cluster 2 is abundant in terms related to the extracellular region, epidermis development, and cornified envelope, implying the presence of epithelial cells. Cluster 3 is highly enriched for antigen processing and presentation through MHC class II, indicating that it is associated with antigen-presenting cells, such as dendritic cells, macrophages, or B cells. Cluster 4 is closely associated with blood vessel development, angiogenesis, and vascular development, suggesting endothelial cells or other cells related to the vasculature.
Clusters expressing IL7R, TRAC, and CD3G indicate the activation of adaptive immune pathways within keratinocytes, suggesting that these cells may be involved in immune cell recruitment and antigen presentation. Enriching terms related to vascular morphogenesis and epidermis development in Clusters 2 and 4, respectively, suggest a functional stratification among keratinocyte populations. These transcriptomic signatures provide new molecular targets for modifying host-microbe interactions at the epithelial barrier and validating earlier histological findings.
Model performance metrics
Accuracy: 0.6951, Precision: 0.5469, Recall: 0.7772, F1 Score: 0.6420, AUC-ROC Score: 0.8006.
The autoencoder model has been successfully trained and evaluated, demonstrating a strong ability to reconstruct data and classify biological signals effectively. The accuracy and AUC-ROC score indicate robust performance. Still, the precision could be improved to reduce false positives and align the model more closely with domain requirements in single-cell analyses. The F1 score, the harmonic mean of precision and recall, provides a balance between the two, with a score of 64.20% suggesting room for improvement, especially in reducing false positives. The AUC-ROC score, which measures the model’s ability to distinguish between positive and negative classes, indicates that there is a good probability that the model ranks a randomly chosen positive instance higher than a randomly chosen negative instance. This score is significant because it shows the model’s relatively strong ability to separate classes, which is critical in single-cell transcriptomics, where the distinction between cell types is often subtle. The evaluation reveals a significant improvement in the current model; however, continuous fine-tuning, parameter experimentation, and data augmentation could further enhance performance. Addressing precision-recall balance is crucial for detecting more positive instances. Visualizations, such as ROC curves and confusion matrices, can provide valuable insights.
Results of ablation study and counter-aware models are included in Figs. 8 and 9.

Ablation study of model architectures for single-cell transcriptomic analysis. The figure was designed using matplotlib version 3.7.1. https://matplotlib.org/.

Training dynamics of Standard VAE vs. Count-Aware VAE. The figure was designed using matplotlib version 3.7.1. https://matplotlib.org/.
The Baseline Model (256→128→64 hidden layers) outperformed alternatives across metrics (F1 Score, AUC-ROC), demonstrating robust generalization.
(B) Wider architectures (Model B) improved capacity but increased overfitting (higher final loss).
(C–E) Shallower/narrower models (Models C–E) underperformed in rare cell subtype identification due to limited feature compression. Model D (two-layer) failed to capture gene interaction complexity, while Model E faced compression bottlenecks. The 256→128→64 architecture optimally balances complexity, reconstruction quality, and classification performance, preserving biologically relevant features for gingival keratinocyte subpopulation analysis.
Comparison of standard VAE and count-aware VAE over 50 epochs (Fig. 9).
The Counter-Aware VAE demonstrates consistent convergence, achieving a lower final loss compared to the Standard VAE in both training and validation sets, highlighting its strong learning capabilities. These findings support our empirical approach of benchmarking architectural choices based on reconstruction loss and generalization. The Count-Aware VAE was trained with three different hidden layer sizes to explore how network complexity affects the performance on count data. This model employed a negative binomial reconstruction loss, along with a KL divergence term.
Final loss comparison
The final loss comparison shows that the Basic Autoencoder has a loss of 0.7259, the VAE has a loss of 0.56, and the DAE has a loss of 1.1342. The reconstruction MSE for the Basic Autoencoder is 0.7245, VAE is 0.55, and DAE is 1.0829.
Table 1 shows the metrics of all models. The study analyzed the performance of various autoencoder (AE) architectures in modeling and analyzing single-cell RNA sequencing data. The Basic AE outperformed VAE and DAE in single-cell transcriptomics, demonstrating its ability to effectively model RNA sequencing data’s complexity. The Basic AE achieved the lowest final loss at 0.725, suggesting effective training on the data. The Mean Squared Error (MSE) was the best performance, with the Basic AE maintaining the highest accuracy of 0.695. The Basic AE also demonstrated its ability to minimize false positives in classification, with a precision score of 0.546. The Basic AE excelled in the recall, identifying the truest positive instances. The AE with TTA performed similarly to the Basic AE in this metric. The Basic AE achieved the highest F1 score of 0.642, with the DAE following closely with a score of 0.635. The AUC-ROC of the Basic AE and AE with TTA achieved an AUC-ROC of 0.800, indicating strong performance distinguishing between classes in the dataset. The addition of test-time augmentation (TTA) did not detract from performance, indicating it is a viable technique for enhancing model robustness without compromising accuracy.
Figure 10 displays the Receiver Operating Characteristic (ROC) curve, a visual representation of a binary classifier system’s performance as its discrimination threshold is adjusted. It plots sensitivity against specificity and shows an ROC curve. This curved line evaluates the trade-off between true and false positive rates. The ROC curve is useful for assessing the performance of a diagnostic test or machine learning model in binary classification tasks. A close ROC curve indicates better overall classifier performance, with an AUC of 0.80.

Receiver operating characteristic (ROC) curve. The figure was designed using matplotlib version 3.7.1. https://matplotlib.org/.
TTA-time augmentation
The Test-Time Augmentation (TTA) method, which incorporates noise augmentation, maintains consistent performance metrics across various augmentations, demonstrating the model’s robustness. Here are the detailed results and visualizations.
Model performance metrics with TTA
Accuracy: 0.6951, Precision: 0.5469, Recall: 0.7772, F1 Score: 0.6420, AUC-ROC: 0.8006.
A model using Test-Time Augmentation (TTA) through noise augmentation was tested, revealing that it enhances the model’s robustness without altering output metrics. The model’s performance metrics with TTA showed an accuracy of 0.6951, a precision of 0.5469, a recall of 0.7772, an F1 score of 0.6420, and an AUC-ROC score of 0.8006, indicating its ability to correctly classify and identify significant biological signals from single-cell RNA sequencing data while minimizing false positives and maximizing true positive rates.
The model maintained an accuracy of 0.6951, indicating its ability to classify observations consistently. The precision score of 0.5469 remained stable across both conditions, indicating that the proportion of identifications remains unaffected by noise augmentation strategies. The model’s high recall of 0.7772 in both scenarios demonstrates its effectiveness in identifying positive cases. It is critical in single-cell analysis where missing important signals can lead to significant biological misinterpretations. Future work should explore additional forms of augmentation and analyze their impact on model performance to refine predictions and insights from single-cell data.
Figure 11 compares model losses over epochs for three models: VAE Loss, DAE Loss, and Basic AE Loss. The graph shows how the loss values for each model change as training progresses. The VAE Loss starts high and decreases rapidly, indicating an improvement in the VAE model’s performance. DAE Loss and Basic AE Loss also start high but gradually decrease over time. This visual comparison assesses the models’ effectiveness and their losses during training.

Model losses over epochs for three models. The figure was designed using matplotlib version 3.7.1. https://matplotlib.org/.
Discussion
Gingival keratinocytes play a crucial role in maintaining oral health as they form a protective barrier against external insults and facilitate wound healing. Gingival keratinocytes cover injured areas, re-establish the epithelial barrier, and produce signaling molecules. They adhere to the extracellular matrix and periodontal tissues, communicating with fibroblasts and immune cells. Dysfunctional keratinocyte activity can cause tissue destruction. TMSB4X transfection of non-odontogenic HaCaT cells induces odontogenic differentiation, resulting in nodule formation26,27,28,29. These significant immune genes identified through single-cell analysis reveal that IL7R, TRAC, and LTB play crucial roles in immune responses and may influence the function of gingival keratinocytes in periodontal health and disease. IL7R is involved in the development and function of T cells and signals in response to interleukin-7, a crucial cytokine for lymphocyte development and homeostasis10. Its presence in gingival keratinocytes suggests a potential role in modulating local immune responses within the gingival epithelium. TRAC encodes a T-cell receptor (TCR) complex component essential for T-cell activation and function6,7,9,29,30. It may influence the recruitment and activation of lymphocytes and other immune cells during periodontal disease. Cytotoxic T-cells and NK-cells have high levels of proteases in their cytosolic granules. When these proteases enter a target cell through the immunological synapse, they trigger a form of cell death called pyroptosis, which does not involve caspases. This process cleaves gasdermin-B (GSDMB), releasing its pore-forming component and ultimately resulting in the death of the gingival keratinocytes. A study found that Cd8+ naive T cells, identified by Cd8a, Cd8b, and Nkg7, play a role in gingival inflammation. Furthermore, the protease also targets APEX1 at ‘Lys-31’, disrupting its ability to repair oxidative damage. An enhanced understanding of the roles of these genes can provide insights into immune interactions in gingival tissue and potentially guide therapeutic approaches to periodontal disease management.
This study provides insights into the transcriptomic diversity of gingival keratinocytes. It demonstrates the efficacy of autoencoder models and test-time augmentation (TTA) in analyzing single-cell RNA sequencing (scRNA-seq) data4,5,10. With the global prevalence of periodontal diseases, such as periodontitis, affecting billions and correlating with numerous systemic diseases, understanding the role of gingival keratinocytes in maintaining oral health is crucial. Our findings reveal insights into keratinocyte diversity, immune functions, and the computational methodologies to analyze their transcriptomic profiles (Figs. 12, 3, 4 and 5).

UMAP visualizations of single-cell data: clustering and sample distribution. The figure was designed using Scanpy version 1.9.3 https://scanpy.readthedocs.io/.
The implementation of various autoencoder architectures, namely the AE, VAE, and DAE, yielded compelling results. Notably, the Basic AE outperformed its counterparts in terms of reconstruction and classification performance, achieving an accuracy of 69.51% and an AUC-ROC score of 0.8006. These metrics align with the findings of previous studies, which suggest that autoencoders are powerful tools for modeling complex datasets in transcriptomics. The VAE demonstrated encouraging efficiency in generating lower-dimensional latent representations, consistent with the existing literature that emphasizes its potential for discovering latent structures in high-dimensional biological data. However, its lower precision (0.35) compared to the Basic AE may limit its applicability in contexts where false-positive rates must be minimized—a challenge noted in works examining the robustness of generative models in generating new data from single-cell transcriptomics using autoencoders15,16,17,31,32,33 (Figs. 12, 3, 4, 5, 6 and 10) (Table 1).
Incorporating TTA within our methodology provided an avenue to enhance the model’s robustness, maintaining consistent performance metrics across augmented instances of data. Similar approaches have been noted in image processing, where TTA has significantly improved classification accuracy. In this study, TTA25 helped reinforce the model’s ability to identify significant biological signals amidst potential noise, crucial in single-cell analyses where precision is paramount.
The clustering analysis identified 28 distinct cell populations, underscoring the transcriptional heterogeneity in gingival keratinocytes. The observation of differential gene expression profiles, particularly with markers such as KRT19, provides evidence for the functional plasticity of these cells and highlights their dual role in immune response and tissue homeostasis. This finding aligns with previous research emphasizing the involvement of keratinocytes in periodontal health, where they serve not only as a protective barrier but also engage in immune modulation14,26,28,30. The study found significant upregulation in gene expression in keratinocytes from individuals with periodontitis, suggesting potential therapeutic interventions for restoring healthy tissue states. Future research should focus on targeted therapies to address dysregulation in severe periodontitis, reflecting insights from inflammatory dental diseases. This emphasizes the promise of targeted treatments and biomarker identification in managing periodontal diseases.
The study validates the potential of autoencoders and transfer learning (TTA) in gingival keratinocyte transcriptomics, highlighting the need for precision-recall balance optimization and diverse augmentation strategies to enhance classification capabilities. Current findings enhance the understanding of periodontal diseases by expanding computational frameworks and keratinocyte biology, contributing to a more nuanced understanding of oral health and disease.
Future directions for autoencoder research include exploring enhanced architectures, such as Convolutional Autoencoders (CAEs)34and better integrating attention mechanisms to capture spatial correlations in transcriptomic data. Real-time data processing will enable autoencoder models to handle streaming RNA-seq data, providing insights into dynamic changes in cell populations. Multi-omics integration will offer a more comprehensive understanding of cell biology and disease states. Benchmarking across conditions will establish robust benchmarks for future research. Improved interpretability will involve developing methods to understand the latent space that the autoencoder learns. Clinical translation will connect findings from autoencoder analyses to clinical outcomes, informing potential diagnostic or therapeutic approaches. Automated feature selection mechanisms will identify key genes that drive observed phenotypes, enhancing model efficiency and interpretability.
The study’s limitations are pertinent and multifaceted. Firstly, it does not incorporate single-cell multi-omics analysis, crucial for a holistic understanding of cellular behavior and heterogeneity at the individual cell level. The omission of this analytical approach may result in significant gaps in understanding the complex interactions and functions of gingival keratinocytes, as multi-omics integration can provide more comprehensive insights into the molecular underpinnings of biological processes. It also overlooks the effects of data representation across various cell types or conditions, potentially hindering progress in cellular biology and data analysis. One of this study’s main limitations is its dependence on a single publicly accessible dataset (GSE266897). Future research should use independent datasets or multicenter samples to confirm model performance and the reproducibility of transcriptomic patterns, even though the dataset offers rich single-cell resolution. Cross-validation with external cohorts would strengthen our autoencoder-based method’s generalizability. Identifying gingival keratinocyte subpopulations linked to inflammatory markers like TRAC and IL7R has clinical implications for targeted therapies. These biomarkers may direct regenerative treatments or customized risk assessment in patients with periodontal disease. Our autoencoder-based method offered better preservation of biological signal integrity and higher resolution of cellular heterogeneity when compared to earlier studies that used conventional clustering techniques (e.g., k-means, hierarchical clustering). The Basic AE outperformed scVI and scziDesk in reconstruction and classification using benchmark metrics such as F1-score and AUC-ROC.
Future studies should examine more computationally efficient autoencoder models to address accessibility issues and encourage a broader approach to data representation and analysis in single-cell research studies. Autoencoder Models21,23 with complex latent representations, overfitting, and preprocessing methods can reduce generalizability in high-dimensional data scenarios, while class imbalance can impact precision, recall, and predictive power. Due to insufficient data, autoencoders may struggle to accurately represent rare cell types or transitional states. Additionally, the computationally intensive nature of these models can limit accessibility for some research settings. Future research should investigate convolutional and attention-based autoencoders, multi-omics integration, and real-time transcriptomic analysis to further improve the interpretability and clinical translation of these models. Moreover, validating clinically and biologically in different contexts of healthy and inflamed gingiva is crucial for evaluating their reliability and relevance.
Conclusion
This study shows that the transcriptomic diversity of gingival keratinocytes in periodontitis can be decoded using autoencoder-based frameworks. Test-time augmentation improved the basic autoencoder architecture, successfully detecting pertinent immune gene signatures and keratinocyte subpopulations. These results set the stage for future AI applications in personalized therapy and periodontal diagnostics.
Data availability
The datasets generated during and/or analysed during the current study are available from the corresponding author on reasonable request.
References
Gopal, R. K., Sankar Ganesh, P., Pathoor, N. N. & Viswanathan, A. Enhancing microbiome-based biomarkers: challenges and opportunities. Lancet Microbe. 101032. https://doi.org/10.1016/j.lanmic.2024.101032 (2024).
Sadek, K. M. et al. Molecular basis beyond interrelated bone resorption/regeneration in periodontal diseases: A concise review. Int. J. Mol. Sci. 24 (5), 4599. https://doi.org/10.3390/ijms24054599 (2023).
Checchi, V. et al. The role of matrix metalloproteinases in periodontal disease. Int. J. Environ. Res. Public. Health. 17 (14), 4923. https://doi.org/10.3390/ijerph17144923 (2020).
Murugan Girija, D., Kalachaveedu, M., Ranga Rao, S. & Subbarayan, R. Transdifferentiation of human gingival mesenchymal stem cells into functional keratinocytes by Acalypha indica in three-dimensional microenvironment. J. Cell. Physiol. 233 (11), 8450–8457. https://doi.org/10.1002/jcp.26807 (2018).
Pansani, T. N. et al. Effects of EGF-coated titanium surfaces on adhesion and metabolism of bisphosphonate-treated human keratinocytes and gingival fibroblasts. Clin. Oral Investig. 25 (10), 5775–5784. https://doi.org/10.1007/s00784-021-03880-1 (2021).
Wongtim, K. et al. Overexpression of PD-L1 in gingival basal keratinocytes reduces periodontal inflammation in a ligature-induced periodontitis model. J. Periodontol. 93 (1), 146–155. https://doi.org/10.1002/JPER.21-0017 (2022).
Hinson, A. N. et al. Treponema denticola induces Interleukin-36γ expression in human oral gingival keratinocytes via the parallel activation of NF-κB and Mitogen-Activated protein kinase pathways. Infect. Immun. 90 (10), e0024722. https://doi.org/10.1128/iai.00247-22 (2022).
Antich-Rosselló, M. et al. Evaluation of Platelet-Derived extracellular vesicles in gingival fibroblasts and keratinocytes for periodontal applications. Int. J. Mol. Sci. 23 (14), 7668. https://doi.org/10.3390/ijms23147668 (2022).
Chinnathambi, S. & Bickenbach, J. R. Human skin and gingival keratinocytes show differential regulation of matrix metalloproteinases when combined with fibroblasts in 3-dimensional cultures. J. Periodontol. 76 (7), 1072–1083. https://doi.org/10.1902/jop.2005.76.7.1072 (2005).
Easter, Q. T. et al. Single-cell and spatially resolved interactomics of tooth-associated keratinocytes in periodontitis. Nat. Commun. 15 (1), 5016. https://doi.org/10.1038/s41467-024-49037-y (2024).
Hu, Q. et al. Single-nucleus transcriptomics uncovers a geroprotective role of YAP in primate gingival aging. Protein Cell. 15 (8), 612–632. https://doi.org/10.1093/procel/pwae017 (2024).
Sankar, S., Sankar Ganesh, P. & Eswaramoorthy, R. Artificial Intelligence for Infectious Disease Surveillance. In: Marvels of Artificial and Computational Intelligence in Life Sciences. Bentham Science Publishers; pp. 1–8. (2023). Available from: https://www.benthamdirect.com/content/books/9789815136807.chap1.
Gopal, R. K., Sankar Ganesh, P. & Pathoor, N. N. Correspondence to the editor: performance of multimodal artificial intelligence chatbots evaluated on clinical oncology cases. Clin. Oncol. (R Coll. Radiol). 37, 103684. https://doi.org/10.1016/j.clon.2024.103684 (2025).
Dong, J., Zhang, Y. & Wang, F. ScSemiAE: a deep model with semi-supervised learning for single-cell transcriptomics. BMC Bioinform. 23 (1), 161. https://doi.org/10.1186/s12859-022-04703-0 (2022).
Eraslan, G. et al. Single-nucleus cross-tissue molecular reference maps toward Understanding disease gene function. Science 376 (6594), eabl4290. https://doi.org/10.1126/science.abl4290 (2022).
Zhu, B. et al. ScNAT: a deep learning method for integrating paired single-cell RNA and T cell receptor sequencing profiles. Genome Biol. 24 (1), 292. https://doi.org/10.1186/s13059-023-03129-y (2023).
Heydari, A. A., Davalos, O. A., Zhao, L., Hoyer, K. K. & Sindi, S. S. ACTIVA: realistic single-cell RNA-seq generation with automatic cell-type identification using introspective variational autoencoders. Bioinformatics 38 (8), 2194–2201. https://doi.org/10.1093/bioinformatics/btac095 (2022).
Feng, X., Zhang, H., Lin, H. & Long, H. Single-cell RNA-seq data analysis based on directed graph neural network. Methods 211, 48–60. https://doi.org/10.1016/j.ymeth.2023.02.008 (2023).
Zhang, Q. et al. Leveraging Spatial transcriptomics data to recover cell locations in single-cell RNA-seq with celery. Nat. Commun. 14 (1), 4050. https://doi.org/10.1038/s41467-023-39895-3 (2023).
Lotfollahi, M., Wolf, F. A. & Theis, F. J. ScGen predicts single-cell perturbation responses. Nat. Methods. 16 (8), 715–721. https://doi.org/10.1038/s41592-019-0494-8 (2019).
Chi, W. & Deng, M. Sparsity-Penalized Stacked Denoising Autoencoders for Imputing Single-Cell RNA-Seq Data. Genes (Basel) ;11(5):532. doi: https://doi.org/10.3390/genes11050532 (2020).
Barrett, T. et al. NCBI GEO: archive for functional genomics data sets–update. Nucleic Acids Res. 41 (Database issue), D991–D995. https://doi.org/10.1093/nar/gks1193 (2013).
Tian, T., Min, M. R. & Wei, Z. Model-based autoencoders for imputing discrete single-cell RNA-seq data. Methods 192, 112–119. https://doi.org/10.1016/j.ymeth.2020.09.010 (2021).
Umarov, R., Li, Y., Arner, E. & DeepCellState An autoencoder-based framework for predicting cell type specific transcriptional States induced by drug treatment. PLoS Comput. Biol. 17 (10), e1009465. https://doi.org/10.1371/journal.pcbi.1009465 (2021).
Cohen, S., Goldshlager, N., Shapira, B. & Rokach, L. TTANAD: Test-Time augmentation for network anomaly detection. Entropy (Basel). 25 (5), 820. https://doi.org/10.3390/e25050820 (2023).
Siemer, K. et al. N-Acetylcysteine modulates the effects of composites on human gingival keratinocytes. Dent. Mater. 37 (4), 597–611. https://doi.org/10.1016/j.dental.2021.01.011 (2021).
Li, Y., Mooney, E. C., Xia, X. J., Gupta, N. & Sahingur, S. E. A20 restricts inflammatory response and desensitizes gingival keratinocytes to apoptosis. Front. Immunol. 11, 365. https://doi.org/10.3389/fimmu.2020.00365 (2020).
Jennes, M. E. et al. Response of human gingival keratinocytes to hybrid CAD/CAM material eluates. Dent. Mater. 38 (9), 1532–1546. https://doi.org/10.1016/j.dental.2022.07.006 (2022).
Rosin, F. C. P. et al. Are there differences in keratin expression in gingival tissue and primary cultured gingival keratinocytes? Arch. Oral Biol. 117, 104780. https://doi.org/10.1016/j.archoralbio.2020.104780 (2020).
Zhou, J. et al. Single-cell RNA-seq reveals abnormal differentiation of keratinocytes and increased inflammatory differentiated keratinocytes in atopic dermatitis. J. Eur. Acad. Dermatol. Venereol. 37 (11), 2336–2348. https://doi.org/10.1111/jdv.19256 (2023).
Wang, Y. & Zhao, H. Non-linear archetypal analysis of single-cell RNA-seq data by deep autoencoders. PLoS Comput. Biol. 18 (4), e1010025. https://doi.org/10.1371/journal.pcbi.1010025 (2022).
Tran, B. et al. Single-cell clustering using autoencoder and network fusion. Sci. Rep. 12 (1), 10267. https://doi.org/10.1038/s41598-022-14218-6 (2022).
Fang, Z., Zheng, R., Li, M. & scMAE: A masked autoencoder for single-cell RNA-seq clustering. Bioinformatics 40 (1), btae020. https://doi.org/10.1093/bioinformatics/btae020 (2024).
Mondal, A. K., Asnani, H., Singla, P. & Ap, P. ScRAE: deterministic regularized autoencoders with flexible priors for clustering Single-Cell gene expression data. IEEE/ACM Trans. Comput. Biol. Bioinform. 19 (5), 2996–3007. https://doi.org/10.1109/TCBB.2021.3098394 (2022).
Acknowledgements
We thank the Center of Medical and Bioallied Health Sciences and Research, Ajman University, Ajman, UAE.
Author information
Authors and Affiliations
Contributions
PKY, PMN, and CMA designed the research study. PKY, PMN, and CMA performed the research. PKY, PMN, and CMA analyzed the data. PKY, PMN, and CMA wrote the manuscript. All authors contributed to editorial changes in the manuscript. All authors read and approved the final manuscript.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Yadalam, P.K., Natarajan, P.M. & Ardila, C.M. Leveraging autoencoder models and data augmentation to uncover transcriptomic diversity of gingival keratinocytes in single cell analysis. Sci Rep 15, 22339 (2025). https://doi.org/10.1038/s41598-025-08027-w
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-08027-w
Keywords
This article is cited by
-
Data-driven intelligent sci-fi color design: clustering to generative validation
Advances in Continuous and Discrete Models (2025)
