
Abstract
Accurate forecasting of crop yields is essential for ensuring food security and promoting sustainable agricultural practices. Winter wheat, a key staple crop in Pakistan, faces challenges in yield prediction because of the complex interactions among climatic, soil, and environmental factors. This study introduces DeepAgroNet, a novel three-branch deep learning framework that integrates satellite imagery, meteorological data, and soil characteristics to estimate winter wheat yields at the district level in southern Pakistan. The framework employs three leading deep learning models—convolutional neural networks (CNN), recurrent neural networks (RNN), and artificial neural networks (ANN)—trained on detrended yield data from 2017 to 2022. The Google Earth Engine platform was used to process and integrate remote sensing, climate, and soil data. CNN emerged as the most effective model, achieving an R2 value of 0.77 and a forecast accuracy of 98% one month before harvest. The RNN and ANN models also demonstrated moderate predictive capabilities, with R2 values of 0.72 and 0.66, respectively. The results showed that all models achieved less than 10% yield error rates, highlighting their ability to effectively integrate spatial, temporal, and static data. This study emphasizes the importance of deep learning in addressing the limitations of traditional manual methods for yield prediction. By benchmarking the results against Crop Report Services data, this study confirms the reliability and scalability of the proposed framework. The findings demonstrate the potential of DeepAgroNet to improve precision agriculture practices, contributing to food security and sustainable agricultural development in Pakistan. Furthermore, this adaptable framework can serve as a model for similar applications in other agricultural regions around the world.
Similar content being viewed by others
Introduction
Wheat (Triticum aestivum L.) is one of Pakistan’s three primary staple foods, playing a pivotal role in guaranteeing a stable food supply and ensuring food security within the nation. At both the national and district levels, the availability of timely and precise wheat production data is of paramount importance for informed agricultural decision-making and the promotion of sustainable growth. Multiple factors influence grain yield, including soil quality, climatic conditions, field management practices, agricultural subsidy policies and grain market pricing. For instance, high grain prices typically motivate farmers to invest more resources to attain larger yields1.
Consequently, projecting wheat yields over wide geographic areas remains a formidable challenge for researchers and policymakers. In recent decades, significant efforts have been devoted to forecasting crop yields using remotely sensed data2. One such method, known as data assimilation, retrieves critical crop status variables, such as the Leaf Area Index (LAI) and evapotranspiration (ET), from remote sensing data. These variables are then employed to recalibrate and enhance the grain yield predictions generated by crop growth models3,4. However, the data assimilation approach faces two major challenges: first, it demands local calibration and an abundance of crop-specific inputs (including crop characteristics, field management practices, and climatic and soil data) to effectively model crop growth and development throughout the entire crop cycle5,6. Second, increasing the observational resolution escalates the processing costs of the data assimilation system, rendering it impractical for large-scale applications7. Another category of models used for crop yield projection is statistical regression-based approaches, which are commonly employed for regional yield forecasts8,9. These methods establish empirical relationships between historical yields and remote sensing variables, such as the Normalized Difference Vegetation Index (NDVI) derived from AVHRR or MODIS satellite data. They are often straightforward to implement and do not require an extensive array of inputs. However, a drawback of these empirical approaches is that the correlations they rely on are often limited in scope and challenging to generalize to other agricultural regions5,10.
In recent years, machine learning and deep learning techniques have gained prominence in various domains, including image recognition, language translation, and signal processing11. Support Vector Machine (SVM) and Random Forest (RF) methods have been widely employed for satellite image classification12,13, parameter inversion14, and agricultural yield prediction15,16. In contrast, deep learning techniques, notably CNN and Long Short-Term Memory (LSTM) models17, have been used for crop production estimation and forecasting. For instance, a deep learning system for crop yield prediction was presented that utilized various environmental and agricultural factors, including weather patterns, soil conditions, and crop growth stages, to improve the accuracy of yield forecasts18, which was trained using a novel feature representation based on raw image histograms and demonstrated high accuracy and transfer learning capabilities19. In another study20, six machine learning models (ordinary least squares (OLS), LASSO, SVM, RF, AdaBoost, and DNN) were utilized to forecast winter wheat yields at the county level in the United States during the growing season. AdaBoost emerged as the most effective algorithm, with an R-squared (R2) value of 0.86 and a Root Mean Square Error (RMSE) of 0.51 t ha-1.
Given the inherent nonlinearity of the factors influencing crop output, a robust model is essential for this task. Artificial Neural Networks (ANN) have shown promise in predicting crop production because of their ability to handle both linear and nonlinear data relationships21. Consequently, many researchers have turned to ANN for their investigations. Deep learning models, in particular, have gained preference over traditional machine learning models because of their capacity for enhanced feature learning and automatic feature extraction from raw datasets, resulting in higher accuracy in agricultural yield prediction22.
CNN, in particular, excel at extracting climatic parameters because they can process data in various array formats, including one-dimensional data (signals and sequences), two-dimensional data (images), and three-dimensional data (videos)23. The use of one-dimensional convolution in conjunction with pooling allows CNNs to capture temporal dependencies in meteorological datasets and effectively summarize input features23. When a filter is applied to the input data, CNNs can summarize all features of the input dataset, making it easier to interpret. Recurrent Neural Networks (RNNs), on the other hand, are best suited for tasks involving sequential data and capturing time dependencies, making them suitable for forecasting crop yields based on historical data17. Furthermore, this study presents an ensemble model for cocoa yield prediction in southwest Nigeria, inspired by the excellent predictive performance of CNNs and ensemble models in ecological applications17.
Another often overlooked issue in machine learning algorithms when dealing with multi-year training data is the presence of yield trends. In recent decades, Pakistan’s wheat production has experienced rapid growth, primarily attributed to the adoption of new crop varieties, improved agricultural management practices, and policy reforms, resulting in an annual growth rate exceeding 1%24,25. Detrending algorithms, such as linear, quadratic, and cubic models, moving averages, and others, are commonly employed to account for yield trends26. To generate yield trends, these detrending algorithms typically use the years as independent variables. The annual fluctuation of weather conditions, such as water stress, is considered to be connected with the detrended yield, referred to as “yield anomalies” 27. In this study, we focused on predicting winter wheat yields in Pakistan’s primary production areas at the district level, leveraging deep learning algorithms and long-term statistical yield data alongside a diverse array of data sources. Table 1 presents an overall summary of the existing work with techniques, factors, and their Limitations The primary goals of this research are as follows: (1) exploring the viability of deep learning-based yield forecasting using historical yield data; (2) showcasing the significance of yield detrending and the influence of climate, soil, and socioeconomic factors on yield estimation; and (3) quantitatively assessing the uncertainty inherent in the yield prediction model using Gal’s methods28. This study aimed to validate and verify a dataset specific to the region while proposing a method for estimating wheat yield. It seeks to select the most effective deep learning forecasting methods for crops and analyze the ideal window of time for winter wheat preparation, examining variations in yield forecasts across local areas and emphasizing the significance of various factors for Pakistan. The motivation and objective of this study was to minimize the local conventional manual process of wheat crop yield estimation in Pakistan. This study would make accurate crop yield prediction before the harvesting season possible. Table 1 summarizes the existing studies, outlining the references, employed techniques, considered factors, and limitations of each study. The information is concise and provides a quick overview of the key aspects of each referenced work. Traditional crop yield prediction models often rely on statistical methods that use environmental variables, weather data, and historical yield records to predict future outcomes. Although these models have provided valuable insights, they are often limited by their inability to account for the complex, nonlinear interactions between the diverse factors affecting crop growth. This limitation creates a significant gap in the accuracy and reliability of predictions, particularly in the face of changing climatic conditions and other uncertainties.
Recent advancements in deep learning offer promising solutions to this challenge. Deep learning techniques are well-suited for capturing complex high-dimensional patterns within large datasets, making them ideal for improving the accuracy of crop yield predictions. These models can integrate and analyze multiple types of data, including environmental conditions, soil properties, crop growth stages, and weather patterns, to identify intricate relationships that may not be immediately apparent using traditional methods.
Deep learning models can improve the accuracy of crop yield predictions by leveraging complex patterns in environmental, agricultural, and historical datasets.
This hypothesis suggests that advanced machine learning techniques, particularly deep learning, may be able to better predict crop yields than traditional methods by analyzing a large volume of diverse and intricate data sources.
The general contributions of this study are as follows.
-
Exploring the viability of DL-based yield forecasting using historical yield data.
-
Highlighting the significance of yield detrending and the influence of climate, soil, and socioeconomic factors on yield estimation
-
Minimize Pakistan’s local conventional manual wheat crop yield estimation process.
-
This study would make it possible to accurately predict the crop yield of wheat before the harvesting season.
The remainder of the paper is structured as follows: Section “Materials and methods” covers the Materials and Methods employed in the study, while Section “Data preprocessing” discusses the data processing. Section “Model development” presents Model development, Section “Conclusion” discusses the discussion and results of the proposed approach, and Sect. 6 concludes the article.
Materials and methods
This section describes the meteorological characteristics, datasets, and data sources.
Study region
This study focused on winter wheat planting regions in the Multan district of Pakistan. Wheat data were collected from the Punjab province of Pakistan from 2017 to 2022. These data included the dates of planting, growth, overwintering, returning green, jointing, smooth development, and reaping. Using these dates, the daily leaf territory list and soil field capacity were computed, and the water-restricted potential generation was estimated. Here are some wheat-growing season weather statistics: The data for this investigation included high-density raster photos of the target region, which will be located at latitude 29.848212 N and longitude 71.263367 at an elevation of 423 feet (129 m) above sea level. It has a semi-arid climate typical of Multan District, Punjab, Pakistan, according to the Crop Report, an area of 3721 square kilometers, and a total area of 437 acres, as shown in Fig. 1. Every year, the temperature is 26.2 °C, and there are 304 mm of rain during the summer, which is more precipitation than during the winter. In winter, between November and January, the mean maximum and minimum temperatures began to dip and then began to rise. The topsoil in Multan is composed of silt, which is a fine sand. Multan has a mixed trimming zone where crops such as sugarcane, maize, wheat, and rice are cultivated. In general, there are more downpours in summer than in winter.

Spatial distribution of wheat cultivation in Multan District, Punjab, Pakistan.
Data set and preprocessing
Satellite data
The normalized difference vegetation index (NDVI), which can be obtained from the United States Geological Survey (USGS), is a simple graphical indicator that can be used to analyze remote sensing measurements and determine whether the target being observed contains live green vegetation. Typically, but not always, this analysis is performed from a space platform. The selected NDVIs were used to develop a yield forecast. A vegetation index can be used to track dynamic changes in vegetation. Many studies have demonstrated that NDVI correlates well with crop yield21,30. The red and near-infrared spectral bands were used to calculate NDVI, which is a mixture of the red, near-infrared, and blue bands.
Landsat 8 satellite image time series for the growing season of 2013 to 2019 was obtained from the USGS website (http://earthexplorer.usgs.gov/). Landsat 8 includes 11 bands. It also contains an operational land imager (OLI) and thermal infrared sensors (TIRS), both of which have nine spectral bands and a spatial resolution of 30 m. True-color images were created by combining bands 1–7, which have distinct wavelengths and use red, green, and blue sensors. Band 8 has a resolution of 15 m, whereas the new ultra-blue band 9 is ideal for cloud detection, as well as coast and aerosol investigations.
Thermal bands 10 and 11 are useful for providing more precise surface temperatures with a 100 m resolution31. Band 4 (red), on the other hand, and the 5 bands (NIR) were used for further processing. In this study, the wheat yield forecast was derived by regressing ground-truth yield data against a time series of spatial vegetation indices for the 2017 to 2022 growing seasons at the end of March of every year. ArcGIS 10.2 and Google Earth Engine GEE were used to calculate the vegetation indices from the processed images, and the yield estimations were computed. Figure 2 shows the classification of the wheat area after the calculation of NDVI Values for March from 2017 to 2022, as shown in Eq. 1.

NDVI-based vegetation assessment of Multan District for April (2017–2022).
Metrological data
This data was collected by the POWER Data Access Viewer https://power.larc.nasa.gov/data-access-viewer/ and also gets weather dataset from the Pakistan Meteorological Department, Government of Pakistan, for cross-validation and also downloaded from it is the most common and most important feature for any agricultural production. Climate change threatens the crop production systems of staple crops (wheat, corn, cotton, rice, and sugar cane). A temperature increase of 3 °C is projected by 2040, and a temperature rise of 5–6 °C is projected by the end of this century, resulting in a loss of up to 50% in wheat productivity in Asian countries. Figure 3 shows the average temperature and precipitation patterns in the study area from January, as shown in Fig. 14.

Average monthly temperature and precipitation patterns in the study area (January–December).
Pakistan’s geographical location exacerbates this loss. Here are the features considered for the research. The weather conditions in [Region] vary across seasons and can significantly impact wheat growth and yield. Soil quality is a critical factor in wheat production, and its parameters fluctuate over the growing season and are influenced by weather conditions and farming practices. After wheat is harvested, the soil parameters typically change. Soil often shows a decrease in certain nutrients, particularly nitrogen, which is heavily utilized by wheat crops. Farmers often use crop rotation or add organic matter to improve soil health and ensure sustainable wheat production in future seasons. Additionally, soil moisture levels after harvest are crucial for determining the need for irrigation during the subsequent planting season. By understanding the area’s weather trends and soil conditions before and after harvest, it becomes possible to model and predict wheat yields more accurately. Given the impact of both environmental and soil parameters on wheat growth, this study aimed to improve yield forecasting using deep learning models, incorporating local climatic and soil data to enhance prediction accuracy for sustainable agricultural practices in Multan.
Data collection was performed at specific times of the day to account for diurnal variations in environmental factors that could influence wheat growth. The measurements were taken between [time of day, e.g., 6:00 AM to 10:00 AM] to minimize the influence of extreme temperature fluctuations, humidity, and wind conditions. This time window was selected to ensure consistency and reduce variability in the data due to environmental stress factors that are more likely to occur during midday.
Soil data
As soil is the foundation for crop growth, its characteristics significantly affect plant growth and grain production. In studies of data-based applications for precision agriculture, modeling frequently focuses on soil and its characteristics. Soil type, pH, cation exchange capability, and position are examples of specific spatial soil properties. Overall, data related to soil were more frequently found in the papers under consideration. These characteristics were noted 54 times as crop production predictors, whereas solar information, the second-most frequent group, was noted 39 times in the same context. In the research we analyzed, soil data were also used as a predictor and as predicted values. The data were collected by the Punjab Soil Fertility Authority in Multan, but the problem was that this data were all in a distributed format.
Yield data and detrending
This study collected the actual crop yield production dataset, including wheat crop area, wheat crop production per acre, and wheat production in tons in the Multan district over the last five years from Crop Reporting Services, Government of Punjab, Pakistan.
Figure 4 illustrates the wheat crop area in Multan from 2017 to 2022, as provided by Crop Report Services, Punjab, Pakistan. Figure 5 shows the average wheat crop yield per acre for the same period and location based on the Crop Report Services Punjab data. Figure 6 shows the total wheat crop production in Multan from 2017 to 2022, sourced from Crop Report Services, Punjab, Pakistan. Wheat phenology follows a predictable pattern of stages from sowing to harvest, and monitoring these stages helps to correlate environmental and soil factors with crop growth. We collected yield data at the Maturity and Harvest (120–150 DAS) levels for the final measurements to assess yield potential, grain ripening, and post-harvest conditions. Wheat crops in Multan were planted with a typical variety, depending on local agronomic recommendations. This spacing ensures optimal growth, air circulation, and sunlight exposure, which are crucial for minimizing disease pressure and maximizing yield. The recommended fertilizer dose in Multan for optimal wheat growth is typically composed of a balanced mixture of macro-and micronutrients. In conventional tillage systems, the soil is plowed and harrowed to prepare the seedbed before sowing. This method is commonly practiced because of its effectiveness in soil aeration and weed control.

Annual wheat cultivation area in Multan (South Punjab) from 2017 to 2022.

Average wheat production per acre across years (2017–2022).

Annual wheat production (in Tons) from 2017 to 2022.
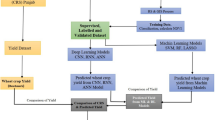
Table 2 outlines the input data and their respective variables for the study conducted in 2022 in Multan, South Punjab, Pakistan, and Fig. 4 shows the actual wheat production from 2017 to 2022 in Multan District, which is our research benchmark for comparison. The information includes the category of data, specific variables, duration of data collection, time coverage, and source of each dataset. Figure 3 shows the wheat crop yield production pattern in tons from 2017 to 2022 in Multan, South Punjab, Pakistan. The complete workflow of this process is illustrated in Fig. 7.

Structural framework of the deep learning methodology.
Data preprocessing
Data processing and yield forecasting entail multiple processes, beginning with data collection and progressing through processing and calibration to validation, which can be completed in stages. Data collection and preprocessing were performed first, followed by vegetation indexing and smoothing, masking NDVI data depending on fields, calibrating masked data with yield data, and finally validating yield forecasting models. In this study, NDVI was used because it was ranked as the vegetative index (VIs) with the strongest relationship with wheat yield32,33. A smoothing procedure was required to minimize the noise in the VIs time series. In this instance, a penalized spline-based smoother was used to smooth the data.
Image data from the normalized difference vegetation index (NDVI) were derived from Landsat 8 satellite images based on the following equations:
Remote sensing data were processed using the Google Earth Engine (GEE)34, a planetary-scale platform for earth science data and research.
Meteorological and soil data were downloaded and analyzed on a desktop computer. Although the surface reflectance data are daily, the time series contains some missing values and fluctuations due to noise. To decrease noise, we generated a reliable 8-day interval time series using a maximum value composite35, and cropland masking was applied synchronously. Meteorological data were aggregated every eight days to maintain the same time length as the remote sensing data.
All remote sensing, meteorological, and soil data were spatially aggregated to the mean for each district using the district boundaries. Invalid data were removed and interpolated, and each variable was normalized to 0–1 using the maximum and minimum values. Finally, all time series had a length of 32 for each year, covering the entire growing season of winter wheat (from November to April in the following year). The integration of satellite data, remote sensing data, and satellite imagery provides a comprehensive and timely understanding of the environmental conditions influencing wheat crops, supporting more informed decision-making for farmers and agricultural stakeholders.
Figure 6 shows the overall framework process in a scientific model that shows a Raster Landsat image collected from the USGS satellite, which was then processed that raster image to calculate NDVI values for the dataset. Subsequently, the factor dataset was collected from different sources, and ML techniques were applied to that dataset after training the dataset with DL techniques and obtaining results in the form of predicting wheat crop yield. It tends to rain more heavily in the summer than in the winter.
Model development
To build and train our neural network model, we used Tensor Flow (GPU version 1.15)41, a Python deep learning toolkit. All network weights were initialized using the initialization19, and the biases were initialized to zero. To optimize the parameters, the loss function (Eq. 2) was utilized. Owing to its flexibility in changing the learning rate during the training stage, the Adam optimizer17 was used to reduce the loss after the initial learning rate was set to 0.0005. The batch size was 64, and the network was trained for 50 epochs before saving the best model throughout the training. Moving on to deep learning, CNN have been applied to the analysis of high-resolution satellite imagery. CNN’s ability of CNNs to automatically learn relevant features from images makes them well-suited for identifying crop health indicators that correlate with yield potential. The model was trained on a dataset of georeferenced wheat field images, enabling it to recognize patterns and characteristics indicative of crop performance.
To address time series data, an RNN is employed, capitalizing on its sequential learning ability. Historical yield data collected over multiple time steps were used to train the RNN, enabling it to capture temporal dependencies and long-term patterns.
The model learns to predict future yield values based on observed past yields and other relevant temporal features.
In contrast to deep learning models that process images or sequential data, ANN focuses on tabular data representing wheat field features. The ANN architecture was designed to accommodate spatial attributes, such as soil type, irrigation, and elevation, along with other pertinent factors contributing to yield variability.
The selection of CNN, Recurrent Networks (RN), and Artificial Neural Networks (ANN) was motivated by the diverse and complex nature of agricultural datasets. CNNs were chosen for their ability to process spatial data, such as satellite images and soil maps, whereas RNs were selected for their effectiveness in handling time-series data, such as weather patterns and crop growth stages. ANNs were included because of their flexibility in modeling both linear and nonlinear relationships across multiple input data types.
By utilizing these three powerful machine learning methods, this study aims to explore different dimensions of crop yield prediction—spatial patterns, temporal dependencies, and complex interactions between variables and to provide a more comprehensive approach to predicting wheat yield.
A 70/30 train-test split was chosen for this study based on its effectiveness in providing a balanced and reliable approach to model evaluation. This allows the model to be trained on a sufficiently large dataset while leaving enough data for testing, ensuring that the model’s generalization ability is accurately assessed. Additionally, the use of k-fold cross-validation further strengthened the reliability of the results by reducing the variance in the performance estimates. While this is a standard approach, alternative splitting methods, such as stratified sampling or time-based splitting, could be explored in future studies, depending on the specific characteristics of the dataset.
Considering these factors, this study ensured that the evaluation process was robust and that the model’s performance was reliable when applied to new, unseen data.
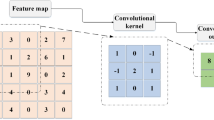
Overview of convolutional neural networks
A deep neural network36 is a neural network with more than two layers and a specific degree of complexity, as shown in Fig. 8.

An overview of convolutional neural network (CNN).
Implementation details
To build and train our neural network model, we used TensorFlow (GPU version 1.15)30, a deep learning toolkit. All network weights were initialized using the initialization37, and the biases were initialized to zero. To optimize the parameters, the loss function (Eq. (2)) was utilized. Owing to its flexibility in changing the learning rate during the training stage, the Adam optimizer38 was used to reduce the loss after the initial learning rate was set to 0.0005. The batch size was 64, and the network was trained for 50 epochs before saving the best model throughout the training process, as shown in Fig. 4. Moving on to deep learning, CNN have been applied to the analysis of high-resolution satellite imagery. CNN’s ability of CNNs to automatically learn relevant features from images makes them well-suited for identifying crop health indicators that correlate with yield potential. The model was trained on a dataset of georeferenced wheat field images, enabling it to recognize patterns and characteristics indicative of crop performance.
To address time series data, an RNN is employed, capitalizing on its sequential learning ability. Historical yield data collected over multiple time steps were used to train the RNN, enabling it to capture temporal dependencies and long-term patterns.
The model learns to predict future yield values based on observed past yields and other relevant temporal features.
In contrast to deep learning models that process images or sequential data, ANN focuses on tabular data representing wheat field features. The ANN architecture was designed to accommodate spatial attributes, such as soil type, irrigation, and elevation, along with other pertinent factors contributing to yield variability. Our goal was to investigate the upper limits of the existing wheat genetic yield potential using field measurements of high-yielding wheat cultivars that had been carefully developed, including the highest wheat yield recorded in the literature. We analyzed that temperature is a key factor affecting wheat production because the relationship between temperature and solar radiation is a linear determinant of yield potential. Visualize the CNN-extracted features and corresponding wheat yield potential to gain insights into spatial patterns or variations. This can help in understanding which areas or conditions contribute more to the yield potential.
To make one-dimensional (1D) data compatible with CNNs, the data are typically reshaped or directly processed using 1D convolutional layers. While CNNs are more commonly associated with 2D or 3D data, 1D data are reshaped into a 2D format with a shape like (samples, time steps, 1) or (samples, features, 1), where the third dimension represents the “depth” or “channels” (in this case, 1 for single-channel data). Alternatively, 1D convolutional layers (Conv1D) can be used, where convolutions are performed along the temporal or sequential axis, allowing the CNN to directly extract spatial or temporal features from the 1D input. This allows the CNN to detect patterns, such as trends or sequences, in the data.
The CNN architecture for 1D data typically involves several convolutional layers, followed by pooling and fully connected layers. In a typical 1D-CNN model, the first layer is a 1D convolutional layer (Conv1D), which applies filters over the input data to extract features, followed by an activation function, such as ReLU (), to introduce nonlinearity. This is often followed by a max-pooling layer (MaxPooling1D) to reduce the dimensionality and highlight the most important features. Multiple convolutional and pooling layers can be stacked, each with an increasing number of filters to capture more complex patterns in the data. The final layers usually consist of one or more fully connected layers (dense) with ReLU or sigmoid activation, depending on the task (e.g., classification or regression). Dropout layers can also be added for regularization. The output layer has a softmax or sigmoid activation for classification tasks, depending on whether it is a binary or multi-class classification. Hyperparameters typically include the kernel size (e.g., 3–5), stride (usually 1), number of filters (e.g., 32, 64), and learning rate (which may vary based on optimization techniques such as Adam or SGD). The model is trained using backpropagation with an appropriate loss function, such as categorical cross-entropy for multi-class classification or binary cross-entropy for binary classification.
Wheat yield estimation with convolutional neural network (CNN)
CNN is a deep learning model that is specifically designed for image processing tasks. In the context of wheat yield estimation, we leveraged CNN to analyze satellite imagery and identify spatial patterns related to wheat yields. The CNN architecture consists of multiple convolutional layers that automatically learn and extract the relevant features from the input images. Subsequently, these features were fed into fully connected layers for yield prediction. To assess the accuracy of our model, we used the metrics Root Mean Square Error (RMSE) and Coefficient of Determination (R2) from Equations, as well as a leave-one-year-out-validation schedule. In other words, the model was trained using yield data from previous years and verified using the yield data from that year.
The results in Tables 3 and 4 provide insights into the annual variations in both the cultivated area and crop yield in the Multan district. The per-acre yield and total yield metrics offer a comprehensive overview of agricultural productivity over the specified years, aiding in the assessment and planning of agricultural practices in the region. The decrease in the total yield in 2022 compared to previous years may prompt further investigation into the potential factors influencing crop output.
Wheat yield estimation with recurrent neural network (RNN)
An RNN is a specialized deep learning model designed to handle sequential data, such as time series. RNNs are specialized artificial neural networks designed to handle sequential data. Unlike standard neural networks, RNNs incorporate a “memory” mechanism that enables them to account for prior inputs when processing the current input. This feature makes them especially effective for tasks such as time-series analysis, natural language processing, and speech recognition.
The defining feature of RNNs is the recurrent connection, where the hidden layer output is fed back into itself during the next step. This looping mechanism allows the network to model long-term dependencies in the sequential data. RNNs have driven remarkable progress across several domains in machine learning, including Natural Language Processing (NLP), Speech Recognition, Time Series Analysis (predicting stock prices, weather forecasting, and traffic flow prediction), and Anomaly Detection. By mastering sequential data, RNNs have played a pivotal role in the advancement of artificial intelligence and machine learning applications.
In this study, we employed an RNN to capture temporal dependencies and trends in the wheat yield data over time, as shown in Fig. 8.
The RNN architecture comprises recurrent nodes that allow information to be stored and fed back into the network at each time step, facilitating time-dependent learning, as shown in Fig. 5.
The results in Tables 5 and 6 show that the variation in yields across years may indicate factors affecting crop productivity and can guide future agricultural strategies and planning in the region. The decrease in the total yield in 2022 warrants further investigation into the potential influencing factors.
The RNN model predicted wheat yield to be approximately 22% less than that of the CNN model.
Wheat yield estimation with artificial neural network (ANN)
ANN is a versatile deep learning model used for various regression and classification tasks. In our study, we applied ANN to the wheat yield estimation problem by providing it with spatial attributes and historical yield data, as shown in Fig. 9. The ANN architecture consists of multiple hidden layers with interconnected nodes. These hidden layers enable the ANN to learn complex relationships and patterns within the data to make yield predictions.

Workflow of recurrent neural network (RNN) for wheat yield prediction.
Using the RNN, the dataset was split into training, validation, and test sets. The training set was used to train the model, the validation set was used to tune the hyperparameters and avoid overfitting, and the test set was used to evaluate the model’s performance. Define a loss function that reflects the goal of the wheat yield estimation task, such as the mean squared error (MSE) if a numerical yield value is predicted. Tables 7 and 8 show the predictions of area, per-acre yield, and total yield in tons from 2017 to 2022 using ANN techniques. Table 8 shows the R2 and RMSE accuracies. The area under cultivation varies across years, influencing the total yield. Changes in the per-acre yield also contribute to variations in the overall production. Per-acre yield is a critical factor in determining the overall production. It appears to fluctuate across years, ranging from 30.47 maund per acre in 2019 to 35.62 maund per acre in 2018. The total yield in 2022 was notably lower than that in previous years. This could be due to various reasons, such as unfavorable weather conditions, changes in agricultural practices, or other factors that might not have been accurately captured by the ANN model.
Table 8 shows the R2 and RMSE values predicted by ANN.
Table 8 lists the performance metrics for an Artificial Neural Network (ANN) model applied at the district level for wheat yield estimation. The model performed well in capturing the variations in wheat yield, with increasing R2 values from 2017 to 2022. However, this trend is not consistent for RMSE, as there are fluctuations from one year to the next. The year 2021 stands out with exceptionally low RMSE and R2 values.
This could be an anomaly, or there might be specific characteristics of the data in that year that make them easier to predict.
Metrics for model evaluation
Cross-validation (CV) is a frequently utilized strategy for algorithm selection to evaluate the three ML and three DL techniques because of their simplicity, universality, and efficiency in preventing overfitting39. It is widely assumed that the best model is the one with the lowest estimation error. In this study, we employed fivefold cross-validation to select the model. To evaluate the performance of the machine learning model, the study uses the root-mean-square error (RMSE) in Eq. 1 and the coefficient of determination (R2) in Eq. 2, which may be calculated as follows:
where n (i = 1, 2,:::, n) is the number of samples used for the machine learning model, yi is the observed winter wheat yield, yi is the corresponding mean value, fi is the predicted winter wheat yield, and f i is the corresponding mean value. The closer R2 in Eq. 3 is to 1, the higher the prediction performance of the model. In this study, k-fold cross-validation was applied to assess the performance and generalizability of machine learning models.
The root mean squared error (RMSE) and coefficient of determination (R2) were used to measure the model prediction accuracy. Moreover, a previous study30,35 showed that the spatial autocorrelation of prediction errors, as measured by the Global Moran’s I metric, shows model generalizability throughout the geographical domain. Global Moran’s I values range from − 1 to 1, with positive values indicating an aggregation trend and negative values showing a dispersion trend. Near-zero values reflect spatial randomness patterns, with higher randomness implying a more robust model. We estimated the Global Moran’s I using ArcGIS 10.3 and GEE.
Results and discussion
The RMSE and R2 of yield predictions at the district level by the ANN, CNN, and RNN models are shown in Table 6 (training data). To account for the random initialization and dropout during.
DL model training, and the results were averaged over the runs. Each row corresponds to the predictions made for that year using a model trained on data from all the remaining years. The RMSE and R2 were fairly stable during the analysis years for winter wheat at the county scale, although in 2017, the CNN model had a high RMSE of 2.2667, 39.05 per acre (15.8% of the average yield).
Overall, all six models showed good predictive capability for winter wheat yield at the district level, with an average R2 ≥ 0.85 and RMSE ≤ 768 kg/ha from 2017 to 2022.
Model performance with convolution neural network (CNN)
A Convolutional Neural Network (CNN) is a deep learning model specifically designed for image processing tasks. In the context of wheat yield estimation, we leveraged CNN to analyze satellite imagery and identify spatial patterns related to wheat yields.
The CNN architecture consists of multiple convolutional layers that automatically learn and extract the relevant features from the input images. Subsequently, these features were fed into fully connected layers for yield prediction.
Table 9 shows a comparison of CNN and CRS (benchmark) for all indicators, such as area per acre, yield per acre, and total production in tons, from 2017 to 2022. The total yield, which accounts for both the area and per-acre yield, experienced similar fluctuations. The total yield reached its highest point in 2018 at 883.58 tons and dipped to its lowest in 2022 at 604.60 tons. Notably, the total yield in 2022 declined, even though the yield was high at 37 months per acre. This indicates that the reduction in the cultivated area had a significant impact on overall wheat production.
Model performance with recurrent neural network (RNN)
A Recurrent Neural Network (RNN) is a deep learning model that is specifically built to handle sequential data, such as time series. In our study, we used an RNN to detect temporal relationships and trends in heat yield data over time. The recurrent nodes of the RNN design allow information to be stored and fed back into the network at each time, allowing for time-dependent learning.
Table 10 shows a comparison of the RNN and CRS (benchmark) of all indicators, such as area per acre, yield per acre, and total production in tons from 2017 to 2022.
Model performance with artificial neural network (ANN)
Artificial Neural Network (ANN) is a versatile deep learning model used for various regression and classification tasks. In our study, we applied ANN to the wheat yield estimation problem by providing spatial attributes and historical yield data. The ANN architecture consists of multiple hidden layers with interconnected nodes. These hidden layers enable the ANN to learn complex relationships and patterns within the data to make yield predictions, and the resulting data are shown in Table 11.
The ANN model predicted wheat yield as approximately 2% less than that of the CNN model.
Comparison analysis of deep learning methods
Additionally, CNN was better than ANN and RNN in winter wheat yield prediction in District Multan, Punjab, Pakistan, based on the results from 2017 to 2022, as shown in Table 12.
The wheat yield in the Multan region has been increasing over the past few years, but several factors can affect it negatively. These factors were based on the provided RMSE values and rankings. The logical reasons why CNN was considered the best method, as shown in Fig. 10, while RNN and ANN were considered the worst for wheat yield estimation, and Table 12 shows the overall efficiency of the models. Table 10 shows the overall accuracies of CNN, RNN shown in Fig. 11, and ANN.

Workflow of artificial neural network (ANN) for crop yield prediction.

Observed vs. predicted wheat yield using convolutional neural network (CNN).
For wheat yield estimation, it might have been possible to find some meaningful patterns in the data, but not as effectively as CNN.
In summary, CNN performed better in wheat yield estimation because it can handle complex patterns and relationships in the data, as shown in Fig. 11, whereas RNN, as shown in Fig. 12, and ANN might not have been as effective in capturing the data’s spatial, temporal, or nonlinear characteristics, leading to higher prediction errors, as shown in Fig. 13. The success of CNN can be attributed to its inherent ability to learn intricate spatial patterns, which is especially valuable when dealing with wheat, which is a cool-season crop and is sensitive to high temperatures. The optimum temperature for wheat growth is between 15 and 25 °C. If temperatures are too high during the growing season, they can lead to reduced yields. For example, a study by the Pakistan Agricultural Research Council found that wheat yields decreased by 10% for every degree Celsius above 25 °C. Wheat requires a moderate amount of rainfall for growth. The average annual rainfall in the Multan region is approximately 300 mm. If there is too little rain, the crop will not be able to produce a good yield. However, excessive rain can also be a problem, as it can lead to flooding and waterlogging, which can damage crops. For example, a study by the International Rice Research Institute found that wheat yields decreased by 10% for every 100 mm of rainfall above an optimum level of 500 mm. Table 13 shows the overall comparison of CNN, ANN, and RNN with the CRS, which is the benchmark of this study.

Comparison of predicted and observed wheat yield using RNN.

Comparison of predicted and observed wheat yield using ANN.
The monsoon is a seasonal wind system that brings rain to Pakistan. The monsoon pattern has changed in recent years, with some years being wetter than others. This can have a significant impact on wheat yields, as a wetter year typically leads to higher yields (Fig. 10). For example, a study by the Pakistan Meteorological Department found that wheat yields in the Multan region increased by 20% in the wettest year of the study period (2017) compared to the driest year (2022), as shown in Fig. 12.
Climate change is expected to significantly affect wheat yields in Pakistan. The country is already experiencing increasingly extreme weather events, such as droughts and floods. These events can damage crops and reduce their yields. For example, a study by the World Bank found that wheat yields in Pakistan could decrease by up to 20% by 2050 because of climate change.
Fertilizer application is essential for increasing wheat yields. However, excessive fertilizer use can pollute the environment and damage the soil. For example, a study by the Food and Agriculture Organization of the United Nations found that wheat yields in Pakistan could decrease by up to 10% if the current rate of fertilizer use continues to be used.
The practices used by farmers can also significantly impact wheat yields. For example, if farmers do not use good irrigation practices, crops may not receive enough water. If farmers do not use good crop rotation practices, the soil may become nutrient-depleted. For example, a study by the International Maize and Wheat Improvement Centre found that wheat yields in Pakistan could increase by up to 15% if farmers adopted better irrigation practices than they currently do (Fig. 14).

Monthly precipitation patterns in Multan from 2017 to 2022.
Arrogant attitude of farmers: Some farmers are reluctant to adopt new agricultural technologies, such as improved seeds and irrigation systems. This can lead to lower yield. For example, a study by the Pakistan Agricultural Research Council found that wheat yields in Pakistan could increase by up to 10% if farmers adopted improved seed varieties.
Some farmers may not be aware of the latest agricultural practices or technology. This can also lead to lower yield. For example, a World Bank study found that wheat yields in Pakistan could increase by up to 5% if farmers were more aware of the latest agricultural practices.
Table 14 and Fig. 15 show an overall comparison of the total production of all three techniques in tons from 2017 to 2022 in percentage.

Performance comparison of deep learning models based on overall accuracy.
In this study, we attempted to develop a data-driven model that employs the same environmental elements as other crop models. However, most data-driven models can only capture correlations, not causality40. Including prior information can increase the model’s performance and credibility by mixing submodules in process models41,42. In this study, the model could be restricted by specific principles or physical laws that are already well understood and quantitatively stated in crop models for estimating regional yields. Socioeconomic factors, such as market prices and agricultural subsidies, which are available before harvest, affect production inputs. This enables a quantitative estimation of the impact of socioeconomic factors on the yield forecast by merging many econometric models.
The results of this study provide a clear understanding of how machine learning models, such as ANN, CNN, and Recurrent Neural Networks (RNN), perform in predicting crop yield for wheat (Triticum aestivum L.) based on environmental and soil data. The models demonstrated varying degrees of accuracy and reliability, with CNN exhibiting the highest performance, followed by ANN and RNN.
The high performance of CNN can be attributed to its ability to capture spatial relationships in the data, which is crucial for understanding how factors such as weather patterns and soil moisture affect wheat growth over time44. In contrast, ANN and RNN also showed promising results, especially RNN, which is known for its ability to handle time-series data and temporal dependencies, a feature important for predicting crop yields that evolve throughout the growing season.
Comparative analysis with existing studies
There was little variation in the accuracy of the proposed strategy and the state-of-the-art procedure. The performance of the proposed method was compared with that of current strategies for the prediction of wheat from the literature. Table 15 shows that the proposed strategy attained the best accuracy (98%) compared to current studies. The proposed framework outperformed current methodologies, attaining 98% accuracy with 20 parameters, resulting in a lower computing cost and maximum accuracy compared with existing methods. The performance of the proposed method was compared with that of current strategies for the prediction of wheat from the literature. Table 15 shows that the proposed strategy attained the best accuracy (98%) compared to current studies. The proposed framework outperformed current methodologies, attaining 98% accuracy with 20 parameters, resulting in a lower computing cost and maximum accuracy compared with existing methods.
A comparative analysis of the proposed methodology with other ML and DL methods showed that the proposed methodology performed better than all other factors (Table 15). By comparing the findings with those of the existing literature, this expanded discussion not only provides a deeper interpretation of the results but also highlights the novelty and significance of the research. The insights gained from this study, particularly the successful application of CNN in crop yield prediction, contribute valuable knowledge to agricultural science and machine learning. Moving forward, these findings can be used to further enhance crop management strategies, improve agricultural sustainability, and contribute to food security efforts worldwide.
Performance capability of DL algorithm toward better yield modeling
Crop canopy heterogeneity is visible in the spectral reflectance bands throughout several phonological stages. During the early to medium stages of wheat growth, biomass increases in the near-infrared band, whereas in the late stages, it increases in the red and blue bands. This study found that the DL yield models, including CNN, Support ANN, and RNN, performed well (Fig. 16).

Modeling performance of three deep learning approaches—convolutional neural network (CNN), artificial neural network (ANN), and recurrent neural network (RNN)—evaluated using predicted R2, root mean square error (RMSE), and mean absolute error (MAE). The evaluation is based on individual climate and remote sensing predictors during the wheat growing season from 2017 to 2022. (A) Performance metrics of the CNN model, (B) Performance metrics of the ANN model, (C) Performance metrics of the RNN model, (D) Comparative accuracy of all three models across the study period.
After evaluating the model performance with R2, RMSE, MAE, and Random Forest (RF), RF emerged as the best-performing model for yield prediction in this study, which included both remote sensing and meteorological data. Previous research using remote sensing and climatic data products has shown greater effectiveness in estimating multi-grain yields than single-grain yield estimates. DL approaches enable the practical examination of nonlinear interactions between meteorological variables, including temperature and rainfall. This conclusion is supported by favorable results compared to the benchmark and other DL models, as well as other crops, such as rice45. Implementing these models at the regional or municipal level may result in different outcomes, highlighting a potential area for further research. The novelty of this research lies in the comprehensive use of machine learning techniques—specifically CNN, ANN, and RNN—to predict crop yield using a rich set of multi-season data from diverse environmental and soil parameters. Previous studies have focused on individual factors such as temperature or soil moisture; however, this study provides a holistic view of how a combination of variables affects yield prediction46. The findings of this study have significant potential to transform agricultural practices by enhancing yield predictions and optimizing resource use. However, challenges such as data availability, model interpretability, and skill gaps must be addressed to integrate these methods into current agricultural practices. Despite these challenges, the scalability of the proposed methods, particularly through cloud-based solutions and partnerships with agricultural services, offers exciting prospects for widespread adoption. Future research should focus on refining models for broader applicability, improving their interpretability, and developing training programs to ensure that farmers are equipped to leverage this technology effectively.
Conclusion
In this study, we developed a deep learning model that amalgamated remote sensing, meteorological, and soil data to estimate winter wheat yield within Pakistan’s primary cultivation area at the district level. To accomplish this, we harnessed three distinct deep learning models, namely Deep Neural Networks (DNN), Recurrent Neural Networks (RNN), and Artificial Neural Networks (ANN), and applied them to predict winter wheat yields from 2017 to 2022. The model training process relied on detrended statistical yield data, and we rigorously validated its performance using a leave-one-year-out-validation technique, successfully yielding reasonably accurate predictions of wheat yields. Moreover, the results also revealed that with a minor loss of accuracy, yield projection may be accomplished at least one month before harvest. An improved loss function and Monte Carlo dropout were used for the uncertainty analysis. Notably, we uncovered that yield detrending might create substantial uncertainty in yield prediction and should be used judiciously when predicting crop yields in the future. We also discovered that the prediction accuracy varied by algorithm and that regional differences influenced the yield prediction accuracy. We are certain that the approach for forecasting winter wheat production using multi-source data and the GEE platform is generic and applicable to other crops globally. The proposed method has great potential for other crop varieties and agricultural landscape locations worldwide. Although this study was confined to a single district within the southern Punjab region of Pakistan, its scope can be expanded to encompass other provinces of Pakistan and regions heavily reliant on agriculture, such as central Punjab and the Pothohar region. Future additions may include investigating the effects of floods, waterlogging, and salinity on the yield of wheat crops. Every study has its limitations, and this research is no exception to this. One key limitation is the reliance on a specific dataset, which may not fully represent the diversity of environmental conditions, soil types, and crop varieties across different regions, potentially affecting the generalizability of the results to other regions. Additionally, the computational complexity of deep learning models, such as CNNs and RNNs, may limit their scalability in resource-constrained environments. The availability and quality of real-time data are other challenges, as they can vary significantly across regions. Furthermore, the lack of model interpretability can hinder farmers’ trust and adoption. Future research should focus on expanding datasets to include diverse agricultural conditions, exploring hybrid models that combine machine learning with traditional agronomic approaches, improving model transparency through explainable AI techniques, and developing scalable solutions for low-resource settings.
Data availability
The data presented in this study are available on request from the corresponding Author.
References
Lobell, D. B., Cassman, K. G. & Field, C. B. Crop yield gaps: Their importance, magnitudes, and causes. Annu. Rev. Environ. Resour. 34(1), 179–204 (2009).
Basso, B., Cammarano, D. & Carfagna, E. Review of crop yield forecasting methods and early warning systems. In Proceedings of the First Meeting of the Scientific Advisory Committee of the Global Strategy to Improve Agricultural and Rural Statistics, FAO Headquarters, Rome, Italy (Vol. 241) (2013).
Huang, J. et al. Improving winter wheat yield estimation by assimilation of the leaf area index from Landsat TM and MODIS data into the WOFOST model. Agric. For. Meteorol. 204, 106–121 (2015).
Zhuo, W. et al. Assimilating soil moisture retrieved from Sentinel-1 and Sentinel-2 data into WOFOST model to improve winter wheat yield estimation. Remote Sens. 11(13), 1618 (2019).
Moriondo, M., Maselli, F. & Bindi, M. A simple model of regional wheat yield based on NDVI data. Eur. J. Agron. 26(3), 266–274 (2007).
Dubey, R. P. et al. Pre-harvest wheat yield and production estimation for the Punjab, India. Int. J. Remote Sens. 15(10), 2137–2144 (1994).
Huang, J. et al. Assimilation of remote sensing into crop growth models: Current status and perspectives. Agric. For. Meteorol. 276, 107609 (2019).
Wall, L., Larocque, D. & Léger, P.-M. The early explanatory power of NDVI in crop yield modelling. Int. J. Remote Sens. 29(8), 2211–2225 (2008).
Franch, B. et al. Improving the timeliness of winter wheat production forecast in the United States of America, Ukraine and China using MODIS data and NCAR Growing Degree Day information. Remote Sens. Environ. 161, 131–148 (2015).
Doraiswamy, P. C. et al. Crop yield assessment from remote sensing. Photogrammetr. Eng. Remote Sens. 69(6), 665–674 (2003).
Patrício, D. I. & Rieder, R. Computer vision and artificial intelligence in precision agriculture for grain crops: A systematic review. Comput. Electron. Agric. 153, 69–81 (2018).
Feng, Q., Liu, J. & Gong, J. UAV remote sensing for urban vegetation mapping using random forest and texture analysis. Remote Sens. 7(1), 1074–1094 (2015).
Feng, Q., Liu, J. & Gong, J. Urban flood mapping based on unmanned aerial vehicle remote sensing and random forest classifier—A case of Yuyao, China. Water 7(4), 1437–1455 (2015).
Ali, I. et al. Review of machine learning approaches for biomass and soil moisture retrievals from remote sensing data. Remote Sens. 7(12), 16398–16421 (2015).
Ip, R. H. L. et al. Big data and machine learning for crop protection. Comput. Electron. Agric. 151, 376–383 (2018).
Han, J. et al. Prediction of winter wheat yield based on multi-source data and machine learning in China. Remote Sens. 12(2), 236 (2020).
Khaki, S., Wang, L. & Archontoulis, S. V. A CNN-RNN framework for crop yield prediction. Front. Plant Sci. 10, 1750 (2020).
Gong, L. et al. Deep learning based prediction on greenhouse crop yield combined TCN and RNN. Sensors 21(13), 4537 (2021).
Wang, A. X. et al. Deep transfer learning for crop yield prediction with remote sensing data. In Proceedings of the 1st ACM SIGCAS Conference on Computing and Sustainable Societies (2018).
Wang, Y. et al. Combining multi-source data and machine learning approaches to predict winter wheat yield in the conterminous United States. Remote Sens. 12(8), 1232 (2020).
AAl-Naji, A. et al. Soil color analysis based on a RGB camera and an artificial neural network towards smart irrigation: A pilot study. Heliyon 7(1), e06078 (2021).
LeCun, Y., Bengio, Y. & Hinton, G. Deep learning. Nature 521(7553), 436–444 (2015).
Shahhosseini, M., Guiping, Hu. & Archontoulis, S. V. Forecasting corn yield with machine learning ensembles. Front. Plant Sci. 11, 1120 (2020).
Qin, X. et al. Wheat yield improvements in China: Past trends and future directions. Field Crops Res. 177, 117–124 (2015).
Li, X. et al. Patterns of cereal yield growth across China from 1980 to 2010 and their implications for food production and food security. PLoS ONE 11(7), e0159061 (2016).
Quiring, S. M. & Papakryiakou, T. N. An evaluation of agricultural drought indices for the Canadian prairies. Agric. For. Meteorol. 118(1–2), 49–62 (2003).
Lu, J., Carbone, G. J. & Gao, P. Detrending crop yield data for spatial visualization of drought impacts in the United States, 1895–2014. Agric. For. Meteorol. 237, 196–208 (2017).
Kendall, A. & Gal, Y. What uncertainties do we need in Bayesian deep learning for computer vision?. Adv. Neural Inf. Process. Syst. 30, 5574–5584 (2017).
Chen, Y. et al. Impacts of heat stress on leaf area index and growth duration of winter wheat in the North China Plain. Field Crops Res. 222, 230–237 (2018).
Abadi, M. et al. Tensorflow: Large-scale machine learning on heterogeneous distributed systems. arXiv preprint arXiv:1603.04467 (2016).
Lyle, G., Lewis, M. & Ostendorf, B. Testing the temporal ability of Landsat imagery and precision agriculture technology to provide high resolution historical estimates of wheat yield at the farm scale. Remote Sens. 5(4), 1549–1567 (2013).
Panek, E., Gozdowski, D., Stepien, M., Samborski, S., Rucinski, D. & Buszke, B. Within-field relationships between satellitederived vegetation indices, grain yield and spike number of winter wheat and triticale. Agronomy10, 1897 (2020).
Mokhtari, A., Noory, H. & Vazifedoust, M. Improving crop yield estimation by assimilating LAI and inputting satellite-based surface incoming solar radiation into SWAP model. Agric. For. Meteorol250, 159–170 (2018).
Gorelick, N. et al. Google Earth Engine: Planetary-scale geospatial analysis for everyone. Remote Sens. Environ. 202, 18–27 (2017).
Tucker, C. J. et al. Higher northern latitude normalized difference vegetation index and growing season trends from 1982 to 1999. Int. J. Biometeorol. 45(4), 184–190 (2001).
Kattenborn, T. et al. Review on convolutional neural networks (CNN) in vegetation remote sensing. ISPRS J. Photogramm. Remote Sens. 173, 24–49 (2021).
He, K. et al. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the IEEE International Conference on Computer Vision (2015).
Kingma, D. P. and Ba, J. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980 (2014).
Arlot, S. & Celisse, A. A survey of cross-validation procedures for model selection. Stat. Surv.4, 40–79https://doi.org/10.1214/09‑SS054 (2010).
Wang, X. et al. Winter wheat yield prediction at county level and uncertainty analysis in main wheat-producing regions of China with deep learning approaches. Remote Sens. 12(11), 1744 (2020).
Reichstein, M. et al. Deep learning and process understanding for data-driven Earth system science. Nature 566(7743), 195–204 (2019).
Jia, X. et al. Physics guided RNNs for modeling dynamical systems: A case study in simulating lake temperature profiles. In Proceedings of the 2019 SIAM international conference on data mining. Society for Industrial and Applied Mathematics (2019).
Curtis, T. & Halford, N. G. Food security: The challenge of increasing wheat yield and the importance of not compromising food safety. Ann. Appl. Biol. 164(3), 354–372 (2014).
Abrar, M., Sim, A. T. H., Shah, D., Khusro, S. et al. Weather prediction using classification. Sci. Int.26, 2217–2223 (2014).
Ashfaq, M. et al. Enhanced wheat yield prediction through integrated climate and satellite data using advanced AI techniques. Sci. Rep. 15, 18093. https://doi.org/10.1038/s41598-025-02700-w (2025).
Ashfaq, M. et al. Accurate wheat yield prediction using machine learning and climate-NDVI data fusion. IEEE Access 12, 40947–40961. https://doi.org/10.1109/ACCESS.2024.3376735 (2024).
Author information
Authors and Affiliations
Contributions
M.A. and I.K. conceptualized the study and designed the research methodology. S.A. and D.S. performed data collection and conducted experiments. M.A. and I.K. wrote the initial manuscript draft. D.S. and M.T. prepared figures and visual representations of the data. M.T. provided critical revisions, ensured data accuracy, and supervised the research progress.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Ashfaq, M., Khan, I., Shah, D. et al. Predicting wheat yield using deep learning and multi-source environmental data. Sci Rep 15, 26446 (2025). https://doi.org/10.1038/s41598-025-11780-7
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-11780-7
Keywords
This article is cited by
-
Deep Learning and Remote Sensing for Crop Yield Prediction and Decision Support
Water Resources Management (2026)
