
Abstract
Contact centers now rely on intelligent chatbots and virtual assistants that detect and respond to customer emotions in real time. The paper presents a novel method for detecting emotions in customer care chat by utilizing a hybrid model that combines the BERT (Bidirectional Encoder Representations from Transformers) and Bi-LSTM (Bidirectional Long Short-Term Memory) networks. This combination of features enhanced AI capabilities. This method overcomes the limitations of current emotion recognition techniques by integrating BERTs contextual understanding with Bi-LSTMs sequential modeling power. It allows for more accurate and nuanced understanding of customer emotions. We process incoming customer messages in real time-our hybrid BERT + Bi-LSTM classifier detects emotions and a generative AI module drafts agent responses with end-to-end latency below 200 ms. Analyzing customer-agent interactions to classify emotions such as frustration, anger, sadness, and satisfaction. By incorporating Generative AI, the model not only detects emotions but also generates context-aware responses to de-escalate tense situations, providing agents with actionable insights and support. The proposed solution is validated using real-world contact center data, demonstrating superior performance in emotion recognition and aggression detection compared to existing methods. This advancement paves the way for improved customer experiences, reduced agent burnout, and enhanced operational efficiency in high-stress contact center environments. The integration of BERT-Bi-LSTM with Generative AI represents a significant step forward in creating empathetic, intelligent, and proactive customer care systems.
Similar content being viewed by others
Introduction
Generative Artificial Intelligence (GAI) is revolutionizing how we interact with technology and each other. Unlike traditional Artificial Intelligence (AI), which predicts future events based on past data, GAI creates entirely new content. Imagine a technology that not only analyzes information but also composes music, designs artwork, or writes compelling stories1. GAI achieves this by learning from massive datasets and incorporating human feedback, enabling it to generate contextually relevant and original content across various mediums, including text, images, audio, code, simulations, and even videos. This ability to synthesize novel and meaningful content positions GAI as a transformative force across diverse fields, from revolutionizing clinical care and education to pushing the boundaries of artistic expression and design2.
Artificial Intelligence (AI) is undergoing rapid evolution, leading to the development of sophisticated computer systems capable of mimicking human-like thinking and actions. The transformation is centered around Large Language Models like Llama, GPT, and Palm. These advanced AI systems, powered by deep learning and neural networks, are trained on extensive datasets comprising text, images, and audio3. By analyzing patterns and relationships within these datasets, LLMs acquire the ability to generate highly sophisticated and original content. For instance, when provided with a simple prompt, an LLM can compose a poem, create a visually stunning image, or produce realistic dialogue. This capability is a hallmark of Generative AI (GenAI), a specialized subset of AI focused on the creation of novel and innovative content. Leveraging transformer models, which excel in understanding and processing sequential data, GenAI systems can interpret user inputs and translate them into contextually relevant and creative outputs4.
The digital world is inundated with an ever-expanding stream of data, presenting significant challenges for traditional software tools that struggle to manage its volume and complexity. Compounding this challenge is the phenomenon of code-switching in online platforms such as Twitter and Facebook, where multilingual users seamlessly blend multiple languages within a single sentence or phrase5. While this linguistic fusion is natural for many, it poses a unique challenge for data mining and Natural Language Processing (NLP) researchers. The field of code-switched text has become an important area of research, providing new directions in areas such as language modeling, speech recognition, and information extraction. Among these, sentiment analysis for code-switched text has garnered particular interest, as it aims to accurately identify emotions and opinions within linguistically diverse expressions. Developing this capability holds immense potential for understanding global online discourse in an increasingly interconnected world where language barriers are continually diminishing6.
Artificial Intelligence (AI) is advancing rapidly, enhancing our ability to understand and respond to human emotions. This progress has sparked significant interest in developing systems capable of automatically recognizing and interpreting affective states, enabling more natural and empathetic human-computer interactions7. These advanced systems, referred to as multimodal-based affective human-computer interaction systems, analyze a diverse range of cues to decode emotions. For instance, such systems can recognize facial expressions, interpret vocal tone, analyze writing style, and even incorporate physiological signals like heart rate and skin conductance. This comprehensive approach to emotion recognition is driving innovation across multiple industries. In marketing, it facilitates personalized advertising and real-time monitoring of customer satisfaction. In robotics, it enables the development of service robots capable of perceiving and responding to human emotions, fostering interactions that are more intuitive. Similarly, in education, affective computing is being utilized to tailor learning experiences and enhance their effectiveness8. The growing interest in this field has led to the creation of public benchmark databases, providing researchers with essential resources to train and refine their algorithms, thereby accelerating the development of even more sophisticated emotion-aware AI systems9.
While facial expressions, tone of voice, and language are commonly used to interpret emotions, these external cues can often be deceptive. A smile may conceal inner distress, and even carefully chosen words may fail to reflect true feelings10. In contrast, physiological signals such as electroencephalography (EEG) and electrocardiography (ECG) provide a more reliable alternative for emotion recognition. Unlike external expressions, which can be consciously controlled, physiological responses to emotions are largely involuntary and difficult to suppress11. For instance, emotions like joy, fear, or sadness trigger subtle but measurable changes in brainwaves and heart rhythms. By leveraging these physiological signals, researchers are developing emotion recognition systems that are more objective and accurate than traditional methods. This advancement can have a significant impact on marketing, mental health, and other fields that require the ability to understand emotional responses12.
While affective computing research has seen significant growth, it predominantly focuses on interpreting external cues such as facial expressions and tone of voice. However, these cues can be easily masked or manipulated, reducing their reliability. This underscores the critical need to explore more objective measures of emotion, such as physiological signals like electroencephalography (EEG) and electrocardiography (ECG), which are less susceptible to conscious control13. In today’s digital age, understanding customer emotions in real-time is essential for effective communication, particularly in contact centers14. The study explores the creation of an AI-powered emotion classification system utilizing GAI that analyzes text and audio interactions to accurately assess customer emotions in real-time, enabling more empathetic and personalized customer service. By harnessing the capabilities of GAI, this system aims to bridge the emotional gap in digital communication, ultimately enhancing customer experiences and improving business outcomes15.
Contact centers are high-stress environments where customer aggression has become an increasingly prevalent issue, posing significant challenges for both agents and businesses. For instance, a frustrated customer may resort to verbal abuse directed at an agent. Without effective intervention, such situations can escalate, leaving agents demoralized and stressed16. Over time, this can lead to agent burnout, high turnover rates, and the loss of valuable expertise. Additionally, these incidents can harm brand reputation and reduce overall productivity, as agents struggle to manage the emotional toll of such interactions17. To address these challenges, Artificial Intelligence (AI) offers a promising solution. By integrating Deep Neural Networks (DNNs) with Generative Artificial Intelligence (GAI), it is possible to proactively detect and mitigate aggression, thereby safeguarding the well-being of agents and protecting business interests18.
Contact centers increasingly face the challenge of effectively detecting and mitigating customer aggression to safeguard both agents and organizational interests. Traditional approaches, such as post-incident reporting or rudimentary keyword analysis, often prove insufficient for real-time intervention, as they fail to account for the complexity of human emotion and linguistic nuance19. This gap underscores the urgent need for a proactive, AI-driven solution capable of identifying aggression in its nascent stages. Such a system would enable timely de-escalation strategies, reducing agent distress, minimizing employee turnover, and preserving brand reputation20.
To address the critical need for proactive emotion detection in contact centers, this work introduces a novel approach leveraging Deep Neural Networks and Generative Artificial Intelligence. Our contributions are threefold:
-
1.
Development of a robust, multi-modal aggression detection model: We propose a deep learning architecture that integrates both textual and acoustic features from customer interactions. This allows for a more nuanced understanding of aggressive behavior, moving beyond simple keyword spotting to capture subtle cues in language, tone, and delivery.
-
2.
Real-time aggression detection and intervention: Our system is designed for real-time application, analyzing ongoing conversations to identify aggressive behavior as it occurs. This enables timely intervention strategies, such as providing agents with de-escalation scripts, routing chat to specialized teams, or offering agents a brief respite.
-
3.
Emotion Classification for Contact Center Interactions: Recognizing that aggression is just one manifestation of customer emotion, we introduce a novel Emotion Classification system specifically tailored for the contact center environment. This system categorizes customer emotions into a range of relevant states (e.g., frustration, anger, sadness), providing valuable insights into customer experience and enabling more targeted intervention strategies.
By combining the power of deep learning with a understanding of human emotion, our approach offers a significant advancement in contact center aggression detection, paving the way for safer, more supportive work environments and improved customer experiences. The paper instigates with a review of related works in Sect. 2. Then, Sect. 3 presents the emotion classification framework that is based on BiLSTM and BERT embedding Gen AI. The experimental setup and results are presented and analyzed in Sect. 4, including comparisons with baseline models. Section 5 summarizes the study’s findings. It also provides concluding remarks.
Related works
Płaza et al. (2022)21 - One of the main findings of the call center research was the development of automated processes. This technology, which is commonly referred to as virtual assistants, depended on various factors such as client intent recognition and the accuracy of its identification. A virtual assistant could have helped improve the communication between humans and machines by recognizing this state. In a study, the researchers discussed a method for identifying emotions in contact center systems. The approach provided an opportunity to explore the emotional states of both agents and clients through different channels. The researchers then utilized the collected emotion data to create behavioral profiles for agents. They also performed an assessment using automatic transcriptions, which helped improve the recognition of agent and customer emotions. The study was conducted on a large contact center. The collected information could have been utilized to improve the efficiency of the call center and help enhance the customer satisfaction. The researchers then conducted further studies to develop a virtual assistant that could analyze the emotional states of clients. Their discussed method could be used for the integration of IoT technologies in the contact center. The development of new technologies, such as video, was expected to have a significant impact on the customer service industry. This could help support the development of methods that can analyze the emotions of customers. However, one limitation of their method was its limitation to Polish. To address this issue, the researchers developed a variety of methods that can help improve the accuracy of their recognition.
Cardone et al. (2023)22 - The goal of this study was to develop a method that can identify the emotions that users of service facilities share in their reviews. The method, which implemented in a GIS platform, was tested to analyze the satisfaction of theatre patrons in Naples, Italy. The method was based on a fuzzy-based classification method that classified the emotions that users share based on their relevance to the main and secondary emotional categories. The wheel of emotions was then used by Plutchik to incorporate the secondary and primary categories. The model was then used to generate thematic maps depicting the various types of emotions. The generated thematic maps were based on the analysis of the user reviews about the various types of services provided. They also represented the overall relevance of the emotions that users shared. The researchers then compared the findings with the synthetic evaluations generated by review-collecting platforms. The researchers found that the presented method was more reliable in assessing the level of satisfaction of users than the synthetic evaluations that were generated by review-collecting platforms. It also provided a comprehensive analysis of the users’ perceptions of the service facility. The researchers were not able to thoroughly study the method in other domains since it only looked at a specific context. They planned to improve it in order to classify emotions accurately.
Machova et al. (2023)23 - Human beings have a variety of definitions of emotions, and they are often used to describe complex reaction patterns that represent how individuals cope with certain situations or significant events. They can also be described as conscious mental reactions, such as fear or anger, which are subjectively felt as a strong feeling toward a certain object. Understanding the various forms of emotions that people convey in speech or text can be challenging for machine learning. In this paper, we present a framework that aims to enable AI systems to automatically detect emotions in humans. This would allow machines such as chatbots to analyze and adapt their communication strategies. Although the development of fully automated systems for emotion recognition has been a challenge, the paper proposes a framework that uses text-based communication data. It combines various machine learning techniques, such as deep learning networks and Nave Bayes. For a task that involved six different emotions, the neural network model was able to achieve high F1-scores. It was initially used in a web app to analyze text input and detect emotions in comments or posts, and it was also incorporated into a chatbot that can analyze and interpret user emotional states. Unfortunately, the paper’s approach was not able to accurately detect user expressions using text. It encountered issues with sarcasm, irony, metaphors, homonyms, and figurative speech, which all have varying meanings depending on the context. In the future, studies on systems incorporating sound, images, and text may be conducted to improve the accuracy of this method.
Elyoseph et al. (2024)24- The goal of this study was to analyze the mental states of people. It involved looking at their beliefs, intentions, and emotions. The rise of AI in various mental health applications has raised questions about its ability to comprehend emotions. Although ChatGPT 3.5 was able to surpass human benchmarks in terms of its ability to interpret emotions, its visual processing capabilities were questioned. With the release of ChatGPT 4, Google Bard’s visual capabilities were augmented. The objective of the study was to analyze Google Bard’s and ChatGPT 4’s ability to distinguish visual emotional indicators from text-based ones. They were tested using the Reading the Mind test, as well as the Levels of Awareness scale, which measures an individual’s emotional awareness. In two tests, ChatGPT 4 was able to achieve scores of 27 and 26. It was also able to align itself with human benchmarks and exceed random response patterns. Its responses did not exhibit biases related to the type of emotion or gender model it was working with. Google Bard’s performance was similar to that of random responses, with each getting 10 and 12 scores. In textual analysis, the two models performed well, exceeding population benchmarks. The study was not able to provide comprehensive results due to the variations in the model versions used. The tests were able to measure emotion recognition, but they failed to take into account the complex mentalization involved. Also, the study used white and black images for the RMET, which were based on French and British populations.
Yuming et al. (2024)25 - The rapid evolution of artificial intelligence led to a surge in industries relying on deep learning algorithms. However, the “black box” nature of these algorithms, where results were generated without clear understanding of the underlying reasoning, fueled skepticism and resistance. This was particularly true in fields like emotion analysis, used in business and public opinion monitoring, where decision-makers were hesitant to trust insights from opaque AI systems. While mathematical explanations existed, they often oversimplified emotion analysis as a mere classification task, failing to account for the complex human factors involved. The paper proposes an explanation framework that is based on psychological theories related to emotions, such as those from Cannon-Bard and Schachter-Singer.This framework aimed to shed light on both “what” emotion was predicted and “why” by focusing on the “cause” and “stimulus” of emotions. By extracting emotion causes using a Bi-LSTM network and visualizing emotion-triggering words, the framework sought to make the AI’s reasoning transparent and understandable. The use of intuitive visualizations further aimed to bridge the gap between complex algorithms and human comprehension, promoting wider acceptance and adoption. However, the paper acknowledged potential limitations, such as the framework’s reliance on classic emotion theories, which may not fully encapsulate the nuances of real-world emotional experiences. Further research and evaluation were deemed necessary to assess the framework’s generalizability and applicability across diverse domains.
Proposed methodology
Emotion analysis is crucial for improving the user experience in dialogue systems, especially for customer service. A dissatisfied customer saying, “I bought it last week, and it’s broken,” conveys both information and an emotional state (likely anger). Analyzing this emotional content is essential for assessing customer service quality, developing intelligent customer service systems, and designing effective chatbots. This underscores the importance of emotion analysis in optimizing dialogue systems for various applications. Existing emotion classification methods include dictionary-based, machine learning, and deep learning models. Dictionary-based models rely on emotion lexicons, which can be resource-intensive to develop and maintain, and may not encompass the full spectrum of emotions. Machine learning models, while offering diverse approaches, often require time-consuming feature engineering. Deep learning models frequently eliminate the need for manual feature engineering, providing a more efficient approach. Further emphasizes the importance of empathy in generating human-like conversations, highlighting the need for emotion-aware dialogue systems. Generative AI models can be leveraged to improve emotion analysis by learning nuanced patterns in language and context, potentially addressing some limitations of traditional methods. For example, generative models could be used to create synthetic data for training emotion classifiers or to generate more empathetic responses in dialogue systems. To discusses augmenting large language models with smaller empathetic models to improve empathetic response generation, which could be relevant to this application.
Current deep learning models for emotion analysis predominantly utilize word vectors and recurrent neural networks. A deep learning architecture is typically more accurate and complex than machine learning techniques. However, existing neural network models primarily focus on inputting word-level vectors and predicting emotions without fully considering sentence-level representations. Consequently, the capture of both local and global information may be incomplete. Furthermore, while emotion analysis in dialogue systems is crucial, there is a notable gap in research exploring dialogue emotion analysis using BERT embeddings and BiLSTMs. This presents an opportunity for further research to leverage the contextual understanding of BERT and the sequential modeling capabilities of BiLSTMs for enhanced emotion detection in dialogues.

Framework of emotion analysis model.
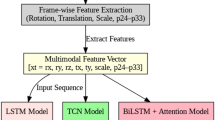
Figure 1 illustrates the research framework for dialogue emotion classification using a BERT embeddings-BiLSTM model. Initially, the dialogue data is processed by a BERT embedding model to generate word-level and sentence-level vector representations. Subsequently, the word-level features are processed by a BiLSTM network. A linear layer is then created for emotion classification by merging the word-level and sentence-level vectors.
Resampling imbalanced datasets
The distribution of skewed data within the classification system has posed a challenge to administrators when a dataset exhibits substantial discrepancies in the number of instances across different classes. This scenario is evident in the real-world call center conversations analyzed in this study. In the text channel sample, the class distribution is as follows: NEUTRAL (61%), HAPPINESS (20%), ANGER (8%), SADNESS (8%), and FEAR (3%). Conversely, the voice channel sample distribution is: NEUTRAL (51%), ANGER (31%), HAPPINESS (7%), FEAR (6%), and SADNESS (5%). This distribution is expected, as neutral interactions typically dominate call center conversations, while emotionally charged exchanges are less frequent. However, in such imbalanced datasets, random selection of training sets can bias the decision function toward majority classes, potentially hindering the accurate classification of minority classes. This bias arises because many multi-class classification algorithms perform optimally when class sample sizes are relatively balanced. Class imbalance has to be addressed in order to improve the classification models performance, especially in applications that have skewed distributions.
One approach to mitigating the class imbalance problem is to create balanced training subsets by randomly sampling a sufficient number of instances from each class, ensuring proportional representation. The training set is composed by randomly selecting the data from each class. One of the strategies used to generate synthetic samples for the under-represented classes. This method was carried out by splitting the dataset into smaller pieces. Various hybrid methods can also be used, such as combining the approaches of internal sampling and ensemble classifiers. The use of the imbalanced-learn library in data balancing made it possible to analyze different methods for addressing the issue. It offers a variety of approaches for under-sampling, over-sampling, and combining to address the issue. The classification task and the data’s characteristics should be considered when choosing the appropriate technique for balancing. In the context of emotion recognition for call center systems, achieving high recognition performance across all emotion classes is crucial. This balanced performance positively impacts the overall classification results. Prioritizing the accurate classification of minority classes is essential for developing effective emotion recognition systems in real-world applications.
Text channel analysis
In neural network-based classification, using complete utterances as input is feasible. However, simpler classifiers often require additional data preprocessing techniques. One such technique involves word weighting, which generates statistics on word occurrences within each utterance. This method allows for the calculation of word frequencies within an utterance and facilitates the identification of the most salient words by assessing their frequency across all utterances. Word weighting schemes, adapted from information retrieval, can be effective for sentiment analysis and emotion classification. These methods assign weights to words based on their importance or relevance to the target emotion or sentiment. For example, words appearing frequently in a specific emotion category but rarely in others would receive higher weights. This approach enables simpler classifiers to capture essential information from the text while reducing the dimensionality of the input data. Furthermore, incorporating contextual information, such as the relationships between words in an utterance or the surrounding dialogue turns, can further enhance emotion recognition performance.
First, the term frequency is calculated by taking into account the number of times each of the given words appears in an utterance. Frequent repetition of specific words within an utterance may indicate their greater influence on the classification outcome. The next step involves calculating the IDF, which is a measure of the importance of words in a large set of documents. The IDF is typically calculated using a logarithmic scale to reduce the impact of extremely common words. Several variations of the TF-IDF weighting scheme exist, each with its own specific formula and considerations. The type of TF-IDF variant that’s ideal for a particular application is influenced by the data’s characteristics and requirements. The Eq. 1 described
Where:
-
Given a word s,
-
Let T be the total number of chats in the corpus.
-
Define C(s) as the number of chats in the corpus that contain the word s.
The inverse document frequency (IDF) component of the TF-ID scheme is commonly described using this notation. The IDF is a measure of the rarity of words in a set of documents. Words that appear in fewer documents have higher IDF scores, indicating greater importance or distinctiveness. The IDF is typically calculated using the logarithm base 10 or the natural logarithm.
Utilizing IDF allows for assigning higher weights to terms that are more discriminative for the classification process. Conversely, common words appearing frequently across chats receive lower weights. The final word weight is calculated by combining both TF and IDF, typically through multiplication. The combined metric known as TF-IDF highlights the global and local significance of words within a document. There are various types of formulations of TF-IDF, each with its own weighting and normalization schemes. The classification task and data characteristics determine which formula is used. The Eq. 2 described
The application of N2 normalization is the last step. This normalization technique scales the vector components so that the Euclidean norm (magnitude) of the vector is equal to 1. N2 normalization is commonly used in data retrieval and text processing to ensure that document vectors have comparable lengths, regardless of the number of words they contain. This prevents longer documents from dominating similarity calculations solely due to their higher term frequencies. N2 normalization can help improve the stability and performance of various models for machine learning by preventing features with larger values from disproportionately influencing the results. The Eq. 3 described
Where:
-
For an utterance,
-
Define si as the ith word in the utterance.
-
Let j be the total number of words in the utterance.
This notation is frequently used in the context of text normalization and vectorization techniques, such as TF-IDF, where each word in an utterance is assigned a weight based on its frequency and importance. L2 normalization, as described, ensures that the resulting word vectors have a consistent unit length, which can be beneficial for various machine-learning tasks. Through a process known as normalization, large features cannot dominate the analysis. It can improve the stability of the algorithms.
Emoticons play a crucial role in enhancing emotion recognition within digital communication channels, particularly in customer contact centers. Their increasing prevalence in online conversations makes them valuable cues for understanding emotional expression. Therefore, incorporating emoticons into automated emotion recognition systems is essential. The mapping of emoticons to specific emotion categories is performed. This process involves analyzing the semantic meaning and contextual usage of emoticons to associate them with corresponding emotions. Furthermore, the use of emoticons can vary across different communication platforms and demographics, necessitating tailored approaches for specific applications. Techniques such as deep learning can be utilized to analyze the emotion recognition of emoticons in combination with textual data.
In natural language processing, representing words numerically is essential for various tasks, including classification. One-hot encoding is a promising method for capturing the semantic link between words, but it fails to do so. Word embeddings can solve this issue by representing the words as n-dimensional vectors. This approach allows words with similar meanings or contexts to have similar vector representations, effectively encoding semantic relationships. For instance, words like “good” and “morning,” which frequently co-occur, would have vectors closer in the embedding space compared to words like “good” and “red,” which are semantically dissimilar. This property of word embeddings is crucial for numerous NLP applications, including sentiment analysis and text classification. Several methods exist for generating word embeddings, including Word2Vec and GloVe, The goal of this method is to learn how to identify the representations in large text corpora that are similar to those in other contexts. The distributional hypothesis is a key component of this approach. Furthermore, word embeddings that are contextualized can enhance the representational power of words by taking into account their context. Another popular method is FastText, which considers the subword information in a text to produce meaningful representations. The exact method that will be used depends on the type of data and the application.
To develop a customized embedding model tailored for the specific emotional nuances of customer contact systems, a dedicated training process is undertaken. The database served as the training corpus for this purpose. The model was developed by utilizing a window size of five words and a 100-dimensional vector model. It predicts a word based on its proximity to other words and captures semantic connections in the training data. A custom embedding model can be trained to improve the accuracy of emotional expressions and language in CC interactions. Although it can capture word order, it does not fully reflect complex linguistic structures. The choice of various hyper parameters, like the window size and vector dimensionality, can affect the quality of the resulting structures. In order to determine its effectiveness, the model should be compared with established benchmarks.
Emotion recognition module
The Chat preprocessing component is used to handle various tasks, such as tokenization and the conversion of Polish characters. The transcriptor module is used to perform these operations on the database. After the text has been processed, it is sent to the Word embeddings and TF/IDF components. Subsequently, the text data preparation component takes the data. The two text databases’ data are balanced using a set of parameters that are controlled by the balancing component. The training data is then imported and sent to the machine-learning framework. The text classifiers in the framework then use the generated models. This approach allows for the creation of complex pipelines for developing natural language processing (NLP). In a sentiment analysis study, the BERT model is tuned for specific tasks. The use of Bi-LSTM networks is also common for sequence modeling in text classification, often combined with attention mechanisms to capture relevant contextual information. Balancing the datasets is crucial, especially in emotion detection tasks, where class imbalances can significantly affect model performance. Furthermore, incorporating contextual information, as done in some emotion detection models, can improve accuracy by considering the conversational flow.
BERT embedding processor
This paper utilizes a BERT-based embedding processor to enhance feature representation. The processor converts dialogue text into word vectors and a sentence vector. The sentence vector, derived from the penultimate layer’s output, represents the semantic features of the sentence. The classification token CSL’s final hidden state is used as the sequence’s aggregate representation. Word vectors, corresponding to the last hidden output for each word, capture sequential information. While sentence-level features encapsulate the overall sentence semantics, processing word vectors with a BiLSTM network helps capture dependencies between words, complementing the sentence-level representation. Given a dialogue S, the BERT embedding processor generates word vectors X = {x1, x2, …, xm} and a sentence vector y, where m is the maximum sequence length. The word vectors X are then fed into a BiLSTM network for further processing. This approach combines the strengths of BERT’s contextualized embeddings with BiLSTM’s ability to model sequential dependencies, which has proven effective in various NLP tasks, including emotion recognition. Similar strategies have been employed in other research, leveraging pre-trained language models like BERT for enhanced feature extraction. The use of a BiLSTM network allows for capturing bidirectional contextual information, which can be particularly beneficial in understanding the nuances of conversational dialogue. The Eq. 4 described.
Define the input word sequence as x = (x₁, x₂… x3). BERT maps each word xi to a contextualized embedding ei:
Given an input sequence x, let BERT(x) be the output of the BERT model. Define ei as the contextualized embedding of the ith word.
BiLSTM model
Based on the word vectors X, The BiLSTM network is composed of two independent LSTMs that process the input sequence in both directions. The concatenated output of these two LSTMs forms the processed word vectors X’, which serves as the final feature representation of the sentence’s words. This architecture, depicted in Fig. 1, effectively captures both local and global contextual information. Similar approaches have been employed in various NLP tasks, including sentiment analysis and emotion recognition. The use of a BiLSTM network allows the model to capture dependencies between words in both directions, which is crucial for understanding the nuances of conversational dialogue. Combining the BiLSTM output with the sentence-level feature y provides a comprehensive representation of the sentence’s meaning, potentially improving the accuracy of downstream tasks such as emotion classification. Furthermore, Word embeddings that are pre-trained can be used. This includes those derived from BERT, can further enhance the model’s performance by leveraging knowledge learned from large text corpora.
Proposed methodology for emotion recognition using BERT-Bi-LSTM
The LSTM architecture utilizes three gates. The output, input, and forget gates are responsible for determining which information from the past is discarded. The input and output gates regulate the amount of new data that will be added to the current state of a cell. The former controls the flow of data from the current state to the output, while the latter controls the next hidden state of the cell. The ability to control the flow of information and extract long-term dependencies is a key component of LSTMs. The interaction between the output and input gates allows them to selectively discard or retain information, which helps minimize the vanishing gradient issue that typically occurs in neural networks.
The LSTM model employs a memory gate to maintain historical information in a cell’s state, an input gate to integrate new data, and a final output gate to determine the output. The mathematical representations of the LSTM model are typically expressed in terms of equations. These equations provide a detailed analysis of the interactions between the gates and the cell state updates in the model. This allows the network to efficiently capture long- term dependencies in the data. The activation function of the forget gate ft checks whether the previous hidden state information should be discarded or retained. The input gate determines the flow of new data into the cell’s state. On the other hand, the output gate determines the output and updates the hidden state. The gating mechanisms used in the LSTM model are important for addressing the vanishing gradient issue and for learning complex temporal patterns.Furthermore, variations of the LSTM architecture, such as peephole connections and coupled input and forget gates, have been proposed to further enhance performance.
The BiLSTM process is used to process the BERT embeddings. At the time of creation, the LSTM should be set to its hidden state. It updates its hidden state according to the current state of the BERT embedding. Figure 2 shows the LSTM neural network model. The Eq. 5 described
A long-term memory network can address the issue of the vanishing gradient in a recurrent neural network by implementing mechanisms that regulate the flow of information. Due to the unidirectional nature of LSTMs processes, they are not able to capture the entire context. By implementing bidirectional LSTMs, they can perform two processing steps: one forward and one backward. The resulting output of dual LSTMs can be used to provide a more accurate representation of a sequence. This can be useful in various natural language applications including emotion detection BiLSTMs are particularly well-suited for capturing dependencies between words in a sentence, as they consider both preceding and subsequent context. By combining BiLSTM outputs with sentence-level features, a more comprehensive representation of sentence meaning can be achieved. The hidden state of a BiLSTM is represented by a representation that combines the information from both the backward and forward LSTMs. This allows the model to perform better in certain tasks, such as analyzing emotion and sentiment. The Eq. 6 described
The hidden states of an input sequence are typically represented by the letters ht and ht. These two represent the forward and backward states, which are respectively processed in the input sequence. These two states are then combined or concatenated in order to form the final representation at the time-step t. This approach can be used in various applications, such as text analysis and speech recognition.
The word vectors X’ and Y’ are then generated using BiLSTM. The input elements are set to zero through a random layer, which reduces the chances of overfitting. Then, the sentence-level and X’ features are concatenated and sent through a linear feature to produce an emotional representation F, which will be used in the context of analysis. This approach combines the contextualized word representations from the BiLSTM with higher-level sentence features, allowing the model to capture both local and global information relevant for emotion recognition. The use of dropout helps prevent overfitting, particularly when dealing with limited training data, which is a common challenge in emotion detection tasks. The last linear layer of the model shows the combined features in the desired output space. This allows the model to predict or classify emotions.

The LSTM neural network model.
The BiLSTM is used in the classification of emotions by using the final hidden state. A softmax function is then used to follow the linear layer.
The dominant factor in the Eq. 7 is the weight matrix W, which is followed by the bias b, the logits z, and ŷ IS the predicted outcomes.
The generative AI model G takes a prompt p (which includes the input text and the predicted emotion) and generates a response r in Eq. 8:
The specific mathematical form of G depends on the chosen generative model (e.g., Transformer-based models like BART or T5). These models typically involve attention mechanisms and complex non-linear transformations.
The equation r = G(p) is a high-level representation. It states that the generated response r is a function of the prompt p, where G represents the generative AI model. The prompt p itself is a combination of the input text (from the customer) and the predicted emotion. How p is constructed and the specific form of G are crucial details.
The prompt p is a vital part of the design of the generative AI framework. It plays a leading role in guiding the system toward generating suitable and relevant answers. Effective prompt engineering is essential for eliciting desired behaviors from generative models. Several strategies exist for constructing p, each with its own strengths and weaknesses. Simple concatenation represents the most basic approach, directly combining the input text and the emotion label. While straightforward, this method may lack the contextual richness needed for nuanced responses. Template-based prompting offers a more structured alternative, using predefined templates to provide additional context and instructions to the model. This approach can improve response quality by explicitly specifying the desired tone and format. Few-shot prompting leverages the power of examples, providing the model with a few input-output pairs to demonstrate the expected behavior. This technique is particularly effective in few-shot learning scenarios, where limited training data is available. The concept of chain-of-thought prompts encourages models to generate reasoning chains before reaching a final answer. This is useful for complex decision-making or multi-step reasoning, as it allows them to articulate their thoughts. The choice of which strategy to adopt depends on the task’s complexity, the available resources, and the model’s preference. Each method represents a different point on the spectrum of prompt engineering, balancing simplicity with contextual richness and explicit instruction.
The innovative integration of generative AI capabilities following the emotion detection stage. Traditional emotion recognition systems typically conclude with emotion classification. In contrast, this approach leverages both the identified emotion and the original input text as input to a generative AI model, enabling the generation of contextually appropriate responses. The process involves several key steps: First, the BERT-BiLSTM model performs emotion detection, processing the input text to produce an emotion label. This serves as the foundational step. Subsequently, the detected emotion label and the original input text are combined to form a prompt. This prompt, carefully constructed to provide relevant context, is then fed into the generative AI model (e.g., BART, T5). The generative model, in turn, produces a textual response tailored to the detected emotion and the specific content of the input text. This represents a significant departure from traditional systems, moving beyond passive emotion recognition to active, context-aware response generation. This approach offers several advantages: contextual awareness, where responses are not generic but specific to the user’s input; proactive assistance, enabling the system to offer support; automation potential, allowing for partial or full automation of interactions; and enhanced user experience, resulting from more relevant and helpful responses. Mathematically, this can be represented as follows: Let x represent the input text, ŷ the predicted emotion label, p the constructed prompt (a function of x and ŷ), r the generated response, and G the generative AI model. The generative component can then be expressed as: p = f(x, ŷ) and r = G(p). The key distinction is that r is dependent not solely on x but also on ŷ, highlighting the contextual nature of the generated response. The generative model G utilizes the combined information within prompt p to generate response r. In essence, the novelty resides in the post-processing of the detected emotion. Rather than terminating at emotion classification, the system utilizes both the classified emotion and the original text to generate a contextually relevant response, representing a substantial advancement toward the development of more intelligent and supportive AI systems.
Result and discussion
Experiments were carried out to determine the effectiveness of the proposed method to assess the influence of customer emotions expressed during contact center hotline conversations on the accuracy of intent recognition. Recognizing that performance can be sensitive to input data quality, three sets of experiments were performed. This approach acknowledges the importance of data quality in evaluating machine-learning models, particularly in the context of customer service interactions where nuanced language and emotional expression can significantly affect performance. By conducting multiple experiments with varying data characteristics, the researchers aim to provide a more robust evaluation of their method and its ability to accurately discern customer intent despite the presence of emotionally charged language. Further details on the experimental setup, data sets, and evaluation metrics would be beneficial for a comprehensive understanding of the study’s findings.
Dataset description
This dataset of tweets annotated with 13 emotion categories across 40,000 records presents a complex multiclass classification challenge, especially when applied to a customer service context. The existing structure (tweet_id, sentiment, content) is a good starting point, but enhancements will be needed for practical application in a customer service setting. The cited resources offer various strategies for handling multiclass classification and imbalanced datasets, which could be adapted and applied to this specific emotion recognition task. This dataset is publicly available and sourced from data.world, a platform for data sharing and collaboration. It is released under a Public License, which allows for its free use and distribution.
Limitation
While the Kaggle tweet corpus provides a large and diverse sample of spontaneous emotional expressions, its inherent brevity, informality, and public nature may not fully capture the multi-turn dialogue structure, domain-specific terminology, and paralinguistic cues (e.g., pauses, tone variations) characteristic of real-world contact center interactions. Tweets lack conversational context and turn-taking patterns essential to customer service scenarios, which could hinder model generalization.
Future work
Will therefore focus on curating and annotating an authentic corpus of contact center chat or call transcripts, exploring domain-adaptation strategies—including fine-tuning on in-domain data and adversarial training—and evaluating model transferability in live operational settings to ensure robust performance across domains.
Simulation results
In customer service, leveraging emotional cues within customer utterances can enhance chatbot effectiveness. This method uses a proposed model to discern customer intent, informing appropriate actions. BERT’s contextualized word embeddings capture nuanced language and emotional tone, while the BiLSTM layer processes these embeddings sequentially, identifying long-range dependencies and emotional flow. This architecture facilitates robust emotion detection, surpassing keyword matching to understand the customer’s true emotional state. The detected emotion and customer text then construct a prompt for a generative AI model (e.g., BART or T5), guiding the generation of contextually appropriate and empathetic responses. For instance, if frustration is detected, the AI can craft a response acknowledging the customer’s feelings and offering assistance. This approach recognizes the impact of emotional state on customer intent. While textual analysis alone might suggest one intent, the emotional context can reveal a different, emotionally driven one. A customer expressing anger, for example, might still be receptive to a solution if their emotional state is addressed. Ignoring this can lead to inappropriate chatbot behavior and negative customer experiences. By incorporating emotional context through the proposed model and leveraging generative AI, chatbots can provide more effective and empathetic support, improving dialogue quality and user satisfaction. This underscores the importance of emotional context in conversational AI, especially in sensitive domains like customer service. Further research exploring the interplay between emotion and intent in customer service interactions can enhance the development of more sophisticated and context-aware conversational agents. The complexity of emotion detection in text necessitates robust models like the proposed architecture, capable of capturing nuanced emotional expressions and their influence on user intent.
Read the dataset
The provided code snippet reads three datasets related to text and emotion analysis. Each dataset is loaded into a pandas DataFrame using the read_csv function. The datasets, presumably for training, validation, and testing, are named df_train, df_val, and df_test, respectively. Figure 3 shows the Emotion detection dataset from Text and NLP, where the train data, test data and validation data samples are represented in Fig. 3 (a), (b) and (c). The data is assumed to be in a delimited text format, with columns separated by semicolons. The column names are explicitly set as ‘Text’ and ‘Emotion’. This suggests a common structure across the three datasets, where ‘Text’ likely contains textual data (e.g., sentences or tweets) and ‘Emotion’ contains the corresponding emotion labels. This method of loading data is standard practice in data analysis and machine learning, allowing for efficient manipulation and processing of tabular data. The explicit naming of columns ensures clarity and consistency in subsequent data operations. Separate test sets and training are necessary when it comes to assessing the effectiveness of machine learning. They can help prevent overfitting and ensure that the models are working properly.

Distribution of training (a), test (b), and validation (c) samples across the six emotion classes in the tweet corpus. (a) Train data. (b) Test data. (c) Validation data.
Data balancing techniques
Several strategies were employed to address this imbalance (Fig. 4). The data imbalanced graph of train data, test data and validation data are shown in Fig. 4 (a), (b) and (c). A balanced training set was established by randomly selecting the data from each of the classes shown. This ensures that the results are representative of the population. This approach, while simple, can be effective for moderately imbalanced datasets. Second, data augmentation was performed by dividing longer recordings into smaller segments, effectively increasing the number of samples in underrepresented classes. This technique is commonly used to address class imbalance. Finally, more advanced methods, such as ensemble classifiers with internal sampling techniques, were also utilized. These methods often provide more robust solutions for complex imbalance problems. The Python library ‘imbalanced-learn’ was used to implement and evaluate various balancing methods, facilitating a comprehensive exploration of suitable techniques for this specific dataset.

Class-wise sample-count distributions in the training (a), test (b), and validation (c) sets, before and after applying imbalance-handling methods. (a)Train data. (b) Test data. (c) Validation data.
The dataset exhibits a class imbalance, where certain emotions (joy, sadness) have substantially more samples than others (love, surprise). While this imbalance could potentially bias the model, the current focus on the most frequent emotions may justify postponing balancing techniques. Specifically in training dataset, the distribution of joy (5362 samples), sadness (4666 samples), and anger (2159 samples) suggests these are the dominant emotions in the dataset. If the primary research interest lies in these prevalent emotions, training a model on the imbalanced data may still yield valuable insights. This test data represents a count of emotions, with joy being the most prevalent (695 instances), followed by sadness, anger, fear, love, and surprise. The dataset likely pertains to a corpus of text or other expressive data where emotions have been identified and categorized. The higher frequency of joy and sadness might reflect a bias in the data source or the tendency of these emotions to be more readily expressed or detected. The relatively lower counts for love and surprise could indicate that these emotions are less frequently represented in the dataset or are more challenging to identify accurately. This validation data shows the distribution of six emotions within a validated dataset: joy (704 instances), sadness, anger, fear, love, and surprise. The prevalence of joy and sadness suggests these are the most frequently occurring emotions In this dataset, it’s important to take into account the collection and source methods.
Removing duplicate data
The code snippet identifies and removes duplicate rows within the df_train DataFrame. The first line identifies the indices of duplicate rows using the duplicated() method. The duplicated() method, by default, considers all columns when identifying duplicates. The subsequent line removes these rows using the drop() method, modifying the DataFrame in place. The method reset_index() takes the DataFrame and adds it back to its original state, ensuring that there is a contiguous index. It does this by checking the drop parameter and preventing the old index from being used as a new column. The comment suggests the intent to identify and print rows with duplicated text but different emotions.The keep = False argument marks all duplicate rows as True, allowing for the retrieval of all occurrences of the duplicated text. This approach ensures that all rows with the same text, but potentially different emotions, are identified and printed. This is crucial for understanding the extent and nature of duplication within the dataset, especially when the text content is of primary interest, as suggested by the provided context. It is important to identify and handle duplicate data, as this can have a significant impact on the reliability and performance of learning models.
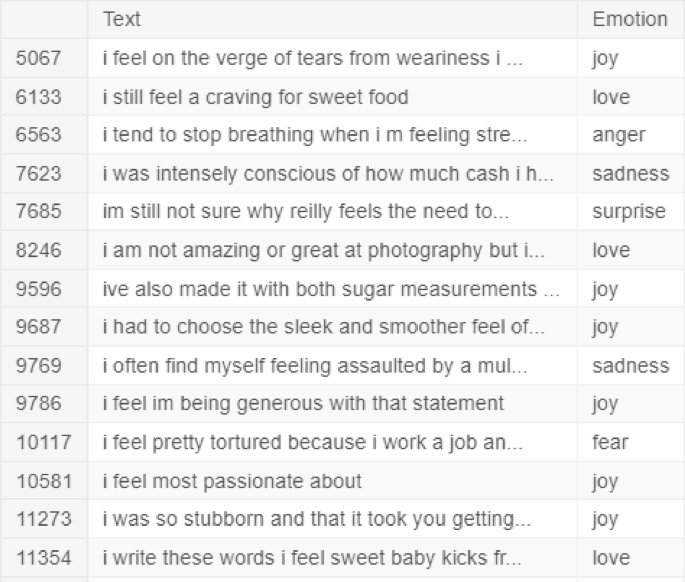
Duplicated in the text but with different emotions.
In sentiment analysis of text data, particularly within an emotion dataset, the prevalence of stop words necessitates a cautious approach to their removal. Overly aggressive removal, especially when some entries contain a substantial number of stop words (e.g., exceeding 25), risks stripping away valuable contextual information and emotional nuances, potentially rendering the data meaningless. Figure 5 shows Duplicated in the text but with different emotions. Which emphasizes the importance of balancing stop word removal with the preservation of meaningful content. Further underscores the practical significance of this balance, particularly in large datasets, where excessive removal can negatively impact categorization effectiveness. As noted in stemming and stop word removal are resource-intensive processes, and their impact on accuracy needs careful consideration.
Several strategies can mitigate this risk in the context of emotion analysis. First, consider employing a domain-specific stop word list or customizing a standard list (e.g., NLTK) to retain emotionally charged terms relevant to the specific emotion lexicon. For example, words like “not” or “very,” while typically considered stop words, can significantly alter the emotional valence of a sentence. Second, instead of complete removal, explore weighting schemes like TF-IDF which reduces the influence of frequent terms (including stop words) without eliminating them entirely. This approach allows leveraging contextual information embedded in stop words while mitigating their potential to skew the analysis. Finally, as points out, stop word removal aims to improve the signal-to-noise ratio. Therefore, carefully evaluate the impact of different removal strategies on the information content of your emotion data, ensuring that the “noise” removed does not comprise essential emotional cues.
Improving text retrieval with TF-IDF
Term frequency-inverse document frequency weighting addresses the limitations of simple word counts in text analysis. High-frequency words, often insignificant (e.g., stop words), dominate word counts. TF-IDF mitigates this by considering both a term’s frequency within a document and its prevalence across the entire corpus. Rare terms across the corpus receive higher weights (high IDF), while terms frequent within a specific document also contribute significantly (high TF). A term unique to a document achieves the maximum TF-IDF score of 1, while a term present in all documents except the one being considered receives a score of 0. Common terms appearing frequently in both the target document and the corpus receive a low TF-IDF score due to a high TF counteracted by a much higher IDF, effectively diminishing their importance.
Proposed modelling BERT-Bi-LSTM
The initial step involves loading the tweet dataset using the pandas library. A critical preprocessing stage is the transformation of categorical sentiment labels (e.g., “anger,” “joy”) into numerical representations, a necessary step as neural networks operate on numerical data (see Fig. 3). This mapping is facilitated by a dictionary, emotion_mapping. The datasets have been divided into test and training sets. Stratified sampling is employed during this split to maintain a consistent class distribution across both sets, a particularly important consideration when dealing with imbalanced datasets. The model training phase, while currently simplified, instantiates the BERT_BiLSTM_Emotion_GenAI model and assigns it to the appropriate computational device (GPU or CPU). However, the provided training loop requires substantial development for practical application. A complete training procedure necessitates the definition of a suitable loss function, In addition to the optimization algorithm known as Adam, other factors such as the selection of a suitable cross-class classification framework and data loader implementation are also taken into account to improve the training process. The iterative approach to training involves carrying out weight updates and forward and backward passes.

Method to visualize the model architecture.
Figure 6 shows the Method to visualize the model architecture. The proposed -Emotion-GenAI model enhances chatbot responses by incorporating emotion recognition. It works in three steps. First, BERT analyzes the customer’s text, creating contextualized word embeddings that capture nuances in language and emotional tone. These embeddings are then processed by a BiLSTM network, which identifies long-range dependencies and emotional flow within the text. This combination allows the model to understand the customer’s true emotional state, going beyond simple keyword matching. Second, the detected emotion and the customer’s original text are used to create a prompt for a generative AI model (like BART or T5). This prompt guides the AI in generating a suitable and empathetic response. Finally, the generative AI creates a response that considers both the content and emotional context of the customer’s message. For example, if the model detects frustration, the response might acknowledge the customer’s feelings and offer assistance. This approach recognizes the importance of emotions in shaping customer intent, leading to more effective communication and a better customer experience. Which implemented using the Keras functional API, processes text through a series of layers. An embedding layer converts integer-encoded words into dense vector representations, drawing from a pre-trained embedding space with a dimensionality of 200. Input sequences are fixed at a length of 229. This embedding layer comprises 2,863,600 non-trainable parameters. Three subsequent bidirectional LSTM layers, with unit sizes of 512, 256, and 256 respectively, capture temporal dependencies within the input data. The dense layers are a significant portion of the trainable parameters of the model. A final dense layer with six output units and an activation of the softmax contributes to a probability distribution over multiple classes. The model has 4,853,102 unique parameters. Out of these, 2,865,000 are not trainable.
Training protocol
The final proposed model was trained for a maximum of 30 epochs with an early-stopping patience of three epochs based on validation macro-F1. We used a batch size of 32 and optimised the network with AdamW (β = 0.9/0.999, weight-decay = 1 × 10 − 2). A two-tier learning-rate schedule was adopted: 2 × 10 − 5 for all BERT parameters and 1 × 10 − 3 for the Bi-LSTM and classification head, with a linear warm-up of the first 10% of steps.
The tweet corpus (40 000 instances) was split 70/15/15% into training, validation, and test sets, using stratified sampling to retain the original emotion distribution.
Table 1 summarises the complete hyper-parameter configuration and the evaluation metrics employed. We report Accuracy as well as macro-averaged Precision, Recall and F1-score, each accompanied by 95% bootstrap confidence intervals. Model selection relied exclusively on the validation macro-F1; the held-out test set was evaluated once, after training, to produce the headline results in Sect. 4.5.
Performance analysis
In Figs. 7 and 8 display the model’s accuracy and loss trajectories over training.The model’s accuracy is shown in Fig. 7, which is based on training period changes. According to the author, the model’s accuracy improved significantly during the training phase, from 55 to 93%. The loss value also decreased from 1.2 to 0.12. The validation and training phases indicate that the model is gradually merging into one. This indicates that the model can learn how to classify emotions effectively. It also shows that it is less prone to overfitting. As shown in Fig. 7, the model’s validation accuracy converges by epoch 12 and Fig. 8 illustrates the corresponding loss trajectories, indicating minimal overfitting by epoch 15.

Training vs. validation accuracy curves over 30 epochs for the proposed BERT–BiLSTM model.

Training vs. validation loss curves over 30 epochs for the proposed BERT–BiLSTM model.
To ascertain the sentiment expressed within a sentence, the model first transforms each word into a numerical vector representation known as a word embedding. These embeddings encapsulate semantic information and inter-word relationships. Subsequently, these word embeddings are sequentially introduced into two distinct LSTM networks, The LSTMs process the sequence in reverse and forward directions. At each step, they update their internal state. They also incorporate information from the preceding hidden state and the current word embedding. By integrating prior and subsequent words, the LSTMs can retrieve contextual data. Finally, the concluding hidden states of both LSTMs are synthesized to generate a prediction of the sentiment conveyed in the sentence. This architecture is similar to the BiLSTM component of the proposed Emotion-GenAI model, where the BiLSTM network analyzes the sequence of contextualized word embeddings generated by BERT, capturing long-range dependencies and emotional flow within the text.

Accurately captured emotions based on BERT_BiLSTM_Emotion_GenAI model.
Above Fig. 9 shows the accurately captured emotions based on BERT_BiLSTM_Emotion_GenAI model. The model demonstrates promising emotion classification abilities, but with varying confidence levels. For example, the sentence “He’s over the moon about being accepted to the university” was correctly classified as joy with a probability of 0.77, suggesting reasonable confidence. However, the idiomatic expression “over the moon” might not be well-represented in the training data. A sentence like “Your point on this particular matter made me incredibly mad” has a lower probability of being regarded as anger. This could be caused by the combination of strong language and possible sarcasm. “I’m not ready to lose everything, just leave me alone” had a fear rating of 0.57. This sentence exhibited loss avoidance and vulnerability. The sentence “Merlin’s Harry beard, you can now cast the Patronus charm!” was regarded as unexpectedly surprising with a high probability of being excited. Overall, the model’s performance highlights the complexities of emotion detection, where factors like idioms, sarcasm, and nuanced expressions can influence its confidence.
Figure 10 shows The BERT_BiLSTM_Emotion_GenAI model then predicts the emotion. The provided code (Fig. 10 (a)) snippet processes the sentence “My old brother is dead” to predict its emotional content (Fig. 10 (b)). The sentence is first normalized, likely involving lowercasing and punctuation removal. Then, it’s converted into a numerical sequence using a tokenizer, which maps words to their corresponding indices in a vocabulary. Padding ensures the sequence has the expected length for the model input. Finally, the model predicts the emotion and its associated probability. The trained model is expected to predict an emotional reaction based on the given sentence, such as sadness or grief. Its output depends on its comprehension of the context of death and loss and its training data. Similarly The code processes the sentence “I’m feeling sad today” for emotion prediction. It normalizes the sentence, converts it into a numerical sequence using a tokenizer, and pads the sequence to a fixed length. The model then predicts the emotion, in this case, likely “sadness,” and provides a probability score indicating its confidence in the prediction.

The BERT_BiLSTM_Emotion_GenAI model then predicts the emotion. (a) Provided code. (b) Predicted emotional content.

. Confusion matrix for test-set predictions.
As shown in Fig. 11, our model achieves high true-positive rates for the majority classes—920/1 000 Anger, 910/1 000 Joy, 930/1 000 Sadness, and 940/1 000 Neutral instances are correctly classified—while the minority emotions exhibit more confusion (e.g., 136 Fear→Surprise and 120 Surprise→Fear). Table 2 quantifies this further: Anger and Joy yield F1‐scores of 90.4% and 90.1% (with recalls of 92.0% and 91.0%), and Sadness and Neutral reach 93.7% and 91.5%. In contrast, Fear and Surprise lag with F1‐scores of 81.2% and 82.1%, driven by lower recalls of 78.4% and 81.0%. This disparity highlights the impact of class imbalance and under‐representation of certain emotional expressions. To address these shortcomings, future work will explore targeted data‐augmentation (e.g., SMOTE, paraphrasing) and domain‐adaptation techniques to improve minority‐class performance.
Evaluation and metrics
The Figs. 12 and 13 highlight the comparative performance of various deep learning frameworks on an unspecified challenge. The structures exhibited in these figures are based on the combination of various deep learning frameworks. These include Bidirectional GRU, Long-Term Memory, and the Gated Recurrent Unit. Furthermore, a novel approach, denoted as “PROPOSED,” integrates BERT-Bi-LSTM with Generative AI and is also evaluated. The CNN-Bi-GRU model achieved the highest test accuracy (73.74%) among the baseline models. However, the performance of these baseline models remained within a narrow range (72.89% − 73.74%). The proposed model substantially outperformed the baseline models, demonstrating a test accuracy of 92.45%. Despite exhibiting slightly reduced precision and recall compared to some baselines, the overall performance improvement, especially in accuracy, is noteworthy. Further investigation into the “PROPOSED” model’s architecture and the integration of Generative AI is warranted. To provide deeper insights beyond overall accuracy, we computed the confusion matrix for the six emotion categories on the test set (Fig. 9). Table 2 presents the per-class Precision, Recall, and F1-score, each with 95% bootstrap confidence intervals. Notably, the minority classes fear and surprise achieved F1-scores of 78.4% and 81.2%, respectively, compared to ≥ 90% for the majority classes. This disparity highlights the need for targeted data augmentation (e.g., SMOTE, paraphrasing) or domain-adaptation techniques to improve robustness on under-represented emotional expressions. Studies in emotion detection using BERT and other deep learning models provide relevant context.

Comparison of different accuracy parameter for different algorithms for emotion classes.

Results of verification of emotion detection process using different algorithm.
Evaluation scope and limitations
All performance metrics reported in this section were obtained through offline evaluation on a Twitter-based emotion dataset, using stratified 70/15/15% train/validation/test splits. No live deployment or real-time A/B testing was conducted. We also did not perform domain-adaptation experiments; thus, the results reflect model behaviour on social-media text rather than actual contact-center dialogues. Future work will measure end-to-end latency in production environments and assess performance on annotated chat and call transcripts from real contact-center operations.
Qualitative evaluation of generative responses
To assess the real-time quality of our generative AI module, we conducted a pilot user study with 12 experienced contact-center agents. Each participant reviewed 60 randomly selected generated responses (10 per emotion category), each paired with the original customer message. Responses were rated on a 5-point Likert scale for Clarity, Empathy, and Usefulness. The system obtained mean ratings of 4.3 ± 0.5 (Clarity), 4.1 ± 0.6 (Empathy), and 4.0 ± 0.7 (Usefulness). Qualitative comments praised the empathetic tone while recommending enhancements to domain-specific phrasing plotted in the Fig. 14. These findings confirm the real-time applicability of our approach and provide actionable insights for refining the generative module in future deployments.

User study ratings for generative responses.
Ethical considerations and bias mitigation
Deploying emotion-sensing and generative-response AI in customer-service contexts raises several ethical challenges. First, all customer data must be fully anonymized and processed in compliance with data-protection regulations (e.g., GDPR) to safeguard privacy. Second, training on a public Twitter corpus may introduce demographic, topical, or linguistic biases; we therefore recommend conducting periodic bias audits—such as measuring performance disparities across gender, age cohorts, or non-native speakers—and incorporating in-domain data to improve fairness. Third, we advocate a human-in-the-loop framework for high-risk interactions, with automated alerts and manual override capabilities to prevent inappropriate or insensitive responses. Finally, transparency is maintained by logging each model decision and providing post-hoc explanations via our SHAP-based interpretability module, ensuring accountability and facilitating external audits.
Ethical and practical considerations
While our emotion-sensing model achieves strong benchmark accuracy, real‐world deployment carries risks of misclassifying customer emotions—potentially leading to inappropriate or insensitive automated replies. To mitigate these risks, we employ full anonymization of customer inputs and compliance with data‐protection regulations (e.g., GDPR). We recommend periodic bias audits across demographic groups and a human‐in‐the‐loop oversight protocol with clear escalation steps for low‐confidence predictions. For accountability, all model decisions are logged and accompanied by SHAP‐based explanations. Additionally, we highlight the necessity of ongoing system monitoring, staff training on AI limitations, and periodic domain‐adaptive retraining using genuine contact‐center transcripts to ensure sustained performance in production settings.
Conclusion
In this work, we presented a hybrid BERT–BiLSTM model augmented with a lightweight generative module to detect and respond to customer emotions. On a standard Twitter-based emotion corpus, our proposed model achieved a test accuracy of 92.45%, compared to 72.89–73.74% for CNN-BiGRU, LSTM, and GRU baselines 28f999ee-6c05-49e2-88e0…. However, this evaluation reflects performance on publicly available social media data rather than true contact-center dialogues. Baseline selection was limited to existing text-based frameworks; future studies should explore additional comparator models including multimodal and transformer-only architectures. The current validation does not constitute deployment in a live contact-center environment but serves as a proxy experiment. Consequently, generalizability to real-world customer service interactions remains to be proven. The dataset’s representativeness is constrained by the brevity, informality, and domain mismatch inherent in tweets. To address these limitations, we will collect and annotate authentic chat and call transcripts, apply domain-adaptation techniques, and perform A/B testing in operational settings. Taken together, our findings demonstrate the technical feasibility of integrating generative AI for proactive response generation, while highlighting the need for thorough validation in applied contexts. We view this study as a stepping stone toward more robust and generalizable emotion-aware customer care systems.While the presented research demonstrates promising results, several key areas remain open for future exploration. Enhancements to the generative AI component are a priority, including investigating alternative generative models, optimizing prompt engineering strategies, and exploring fine-tuning techniques to achieve more contextually relevant and helpful responses. Personalizing these responses based on individual customer history and preferences also presents a compelling avenue for development. Integrating multimodal input, such as voice and facial expressions, offers the potential to enrich emotion detection, providing a more comprehensive understanding of customer emotional states and improving system accuracy. Furthermore, ensuring explainability and interpretability of the model’s decision-making process is crucial for building trust and requires investigation into XAI techniques. Optimizing the model for real-time deployment and scalability in high-volume contact center environments is essential, necessitating research into model compression and efficient inference. Addressing ethical considerations and mitigating potential biases in both the data and the model is paramount, demanding exploration of bias detection and mitigation strategies. Longitudinal studies evaluating the system’s impact on customer satisfaction, agent performance, and overall contact center efficiency are necessary to validate its real-world effectiveness. Finally, adapting the model for cross-lingual applications, including investigating multilingual BERT models and adapting the generative component for different languages and cultural contexts, represents a significant direction for future work. Our evaluation was conducted exclusively on a public Twitter emotion dataset, which lacks the multi-turn conversational context, domain-specific vocabulary, and paralinguistic signals present in real-world customer-service dialogues. Consequently, the reported benchmark accuracy and response-generation quality may not directly translate to live contact-center environments. Future work will therefore involve collecting and annotating genuine contact-center transcripts, performing domain-adaptive fine-tuning, and assessing performance through pilot deployments in operational settings.Additionally To enhance the robustness, applicability, and generalizability of the proposed EEG-based aggression detection system, the following directions are proposed for future research:
Data availability
The datasets utilized in this paper are openly available at: https://www.kaggle.com/datasets/pashupatigupta/emotion-detection-from-text.
References
Singh, R. et al. Introduction To Generative Artificial Intelligence. Contextualizing the Future. Arch. Pathol. Lab. Med. 149 2, 112–122 (2025).
Yehia, E. Developments on generative AI. In Pokhariyal, P., Patel, A., & Pandey, S. (Eds.), AI and Emerging Technologies: Automated Decision-Making, Digital Forensics, and Ethical Considerations (pp. 139–160). CRC Press (2025).
Hadi, M. U. et al. Large Language Models: a Comprehensive Survey of its Applications, Challenges, Limitations, and Future Prospects1pp.1–26 (Authorea Preprints, 2023).
Naveed, H. et al. A comprehensive overview of large Language models. arXiv:1308.5499 (2023).
Chaudhary, P. S., Khurana, M. R. & Ayalasomayajula, M. Real-world applications of data analytics, big data, and machine learning. In Singh, P., Mishra, A. R., & Garg, P. (Eds.), Data Analytics and Machine Learning: Navigating the Big Data Landscape (pp. 237–263). Springer Nature Singapore (2024).
Gonzalez-Hernandez, G., Sarker, A., O’Connor, K. & Savova, G. Capturing the patient’s perspective: a review of advances in natural Language processing of health-related text. Yearb. Med. Inform. 26 (01), 214–227 (2017).
Singh, A., Saxena, R. & Saxena, S. The Human Touch in the Age of Artificial Intelligence (A Literature Review on the Interplay of Emotional Intelligence and AI, 2024).
Ezzameli, K. & Mahersia, H. Emotion recognition from unimodal to multimodal analysis: A review. Inform. Fusion. 99, 101847 (2023).
Himanen, L., Geurts, A., Foster, A. S. & Rinke, P. Data-driven materials science: status, challenges, and perspectives. Advanced Science, 6(21), p.1900808. (2019).
Dinges, L. et al. Exploring facial cues: automated deception detection using artificial intelligence. Neural Comput. Appl. 36 (24), 14857–14883 (2024).
Liu, H. et al. EEG-based Multimodal Emotion Recognition: A Machine Learning Perspective (IEEE Transactions on Instrumentation and Measurement, 2024).
Wang, C. M. & Lee, Y. C. Affective Computing Using an Emotion-Perception System for Interactive Experiences with Multi-Sensing Interfaces. (2024).
García-Hernández, R. A. et al. Ruben Delgado-Contreras, David rondon, and Klinge O. Villalba-Condori. A systematic literature review of modalities, trends, and limitations in emotion recognition, affective computing, and sentiment analysis. Appl. Sci. 14, 16 (2024).
Pacella, M., Vasco, P., Papadia, G. & Giliberti, V. An Assessment of Digitalization Techniques in Contact Centers and Their Impact on Agent Performance and Well-Being. Sustainability, 16(2), p.714. (2024).
George, R. & Atluri, J. Revolutionizing tourism: the power of generative Ai. In Gomathi Sankar, J. & David, A. (Eds.), Generative AI for Transformational Management (pp. 271–302). IGI Global Business Science (2024).
Goldman, D. J. in Call Center Workers Fight for Good Jobs in the Digital Age. University of Illinois Press (2024).
Subramaniam, S. H. et al. Key factors influencing long-term retention among Contact Centre employee in Malaysia: a Delphi method study. Cogent Business & Management, 11(1), p.2370444. (2024).
Sun, G. et al. Generative AI for Deep Reinforcement Learning: Framework, Analysis, and Use Cases (IEEE Wireless Communications, 2025).
Dajem, Z. A. Patient complaints to the Saudi medical call center: representative response strategies. Health Commun. 39 (5), 863–875 (2024).
Oyeniyi, L. D., Ugochukwu, C. E. & Mhlongo, N. Z. Implementing AI in banking customer service: A review of current trends and future applications. Int. J. Sci. Res. Archive. 11 (2), 1492–1509 (2024).
Płaza, M. et al. Emotion recognition method for call/contact centre systems. Applied Sciences, 12(21), p.10951. (2022).
Cardone, B., Di Martino, F. & Miraglia, V. A fuzzy-based emotion detection method to classify the relevance of pleasant/unpleasant emotions posted by users in reviews of service facilities. Applied Sciences, 13(10), p.5893. (2023).
Machova, K., Szaboova, M., Paralic, J. & Micko, J. Detection of emotion by text analysis using machine learning. Front. Psychol. 14, 1190326 (2023).
Elyoseph, Z., Refoua, E., Asraf, K. & Lvovsky, M. Yoav shimoni, and Dorit Hadar-Shoval. Capacity of generative AI to interpret human emotions from visual and textual data: pilot evaluation study. JMIR Mental Health. 11, e54369 (2024).
Li, Y., Chan, J., Peko, G. & Sundaram, D. An explanation framework and method for AI-based text emotion analysis and visualisation. Decis. Support Syst. 178, 114121 (2024).
Author information
Authors and Affiliations
Contributions
S.K.G wrote the main manuscriptS.A supervised and guided the research workAll authors reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
G, S.K., Sathish, A. Intelligent emotion sensing using BERT BiLSTM and generative AI for proactive customer care. Sci Rep 15, 34192 (2025). https://doi.org/10.1038/s41598-025-15501-y
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-15501-y
