
Abstract
Ensuring road safety and advancing autonomous driving technology necessitate the accurate and timely detection of traffic signs. Traffic sign detection faces challenges from complex backgrounds and varying sizes, and substantial computational demands. To tackle these challenges, this study presents YOLO-SAL, a lightweight model for traffic sign detection. Initially, the model adopts and innovates on the SCConv concept by introducing the SCC2f design. This innovation optimizes the conventional convolutional residual block using spatial and channel mechanisms, drastically cut-ting the model’s parameters and computational load. Furthermore, the model enhances the Adaptive Feature Pyramid Network (AFPN) by fostering improved interactions across different layers through a progressive feature pyramid network. This enhancement boosts the accuracy of detecting traffic signs across a range of sizes. Additionally, the model incorporates the Long-Sequence Knowledge Attention (LSKA) at the detection layer, leveraging attention principles to refine the model’s focus on crucial information. Experimental results demonstrate that, compared with the baseline YOLOv8n model, the proposed YOLO-SAL improves mean Average Precision (mAP) by 4.9%, while reducing model parameters by 13.3% and computational load (FLOPs) by 8.6%, respectively. These advancements highlight the model’s ability to meet the needs for fast and accurate traffic sign detection.
Similar content being viewed by others

Introduction
Traffic signs, serving as crucial tools for conveying road information and preventing traffic accidents, are crucial for safety and essential for intelligent transportation systems1. With rapid advancements in autonomous driving, the self-driving car market is projected to reach $65 million by 20302. In 2020, China experienced 247,646 traffic accidents, resulting in 62,763 fatalities and an economic loss of 1.46 billion yuan3. It is noteworthy that most traffic accidents are, to some extent, related to drivers’ misinterpretation of traffic signs4. Adverse weather conditions, obstructions, and variations in light intensity further impact traffic sign detection accuracy and robustness5. Hence, developing efficient methods for traffic sign detection is essential not only for reducing traffic hazards but also for further advancing intelligent transportation systems6. Its applications span intelligent transportation systems (ITS), autonomous driving scenarios, advanced driver-assistance systems (ADAS), and real-time roadside monitoring. These revisions help clarify how artificial intelligence enables automatic, scalable, and reliable traffic sign detection in practical deployment environments.
Initially, research on traffic sign detection primarily focused on traditional image processing techniques and basic machine learning techniques. Traditional detection methods rely on color and shape detection techniques to identify and locate traffic signs. Color-based detection methods, for instance, segment and preliminarily detect signs by recognizing their standardized colors. De La Escalera et al.6 introduced a method using the RGB color space model to locate and extract traffic signs in images through standardized colors. Paclik et al.7 employed a color segmentation approach for detection. Although these methods are straightforward and quick, their accuracy and reliability in practical applications are compromised by changes in lighting, environmental disturbances, color degradation, and weather conditions. Shape-based detection methods identify and locate traffic signs by analyzing and matching specific geometric shapes. Piccioli et al.8 introduced such a method that analyzes the edges extracted from images and incorporates approximate prior knowledge of the scene, thus overcoming the effects of complex scenarios to some extent. Despite being more stable than color-based methods, this approach is less effective at detecting small or blurred-edge traffic signs due to resolution limitations and edge blurriness. Against this backdrop, the emergence of computer vision technology has provided a more intuitive and concrete solution for traffic sign detection.
Early adoption of techniques for traffic sign image detection mainly utilized ma-chine learning algorithms to automatically recognize and analyze road traffic signs, aiming to enhance detection precision and efficiency. Chen et al.9, for instance, developed an AdaBoostbased model capable of identifying traffic sign candidates in images. This model utilized a novel iterative codebook selection algorithm to create unique codebooks, improving candidate recognition accuracy. Furthermore, Dalal et al.10 introduced the Histogram of Oriented Gradients (HOG) algorithm for image feature analysis using gradient orientation histograms, effectively isolating target features. Ellahyani et al.11 and Yuan et al.12 applied Random Forest and Support Vector Machine (SVM) techniques for detecting and classifying traffic signs. Despite their reliance on manually designed features, these methods struggle to balance time efficiency with accuracy and typically require extensive training samples for optimal performance.
Deep learning technologies, noted for their superior accuracy and automated feature extraction, have addressed the drawbacks of traditional detection methods related to manual feature design and adaptability13,14,15. Fredj et al.16 created a Convolutional Neural Network (CNN) framework for object classification, showcasing high efficiency and precision in detection. Yang et al.17 significantly improved traffic sign detection by combining an Attention Network (AN) with a Fine-Grained Region Proposal Network (FRPN) to enhance Faster-RCNN. Arcos-García et al.18 proposed an efficient two-stage detection system that first identifies then classifies target areas for precise detection. Qian et al.19 employed Fast R-CNN for road sign detection, and Shao et al.20 used Faster R-CNN to expedite detection, minimizing workload relative to conventional methods. Tabernik et al.21 refined Mask R-CNN for end-to-end detection of traffic sign. While these approaches create more generalized detectors through extensive training, their slower speeds and higher computational demands make them less suitable for real-time detection22. Thus, single-stage algorithms, balancing speed and accuracy, present a more effective strategy for traffic sign detection.
Single-stage object detection algorithms, leveraging big data for training, have substantially improved detection performance across varied environments and complex backgrounds23,24,25. These algorithms surpass traditional image processing methods in real-time processing and adaptability. For example, the ESSD feature fusion method, introduced by Sun et al.26, uses upsampling to enhance traffic sign features and minimize background noise, though it increases computational demand. Flores-Calero et al.27 developed the Color GLOEMP technique to uniquely identify traffic signs, showcasing innovation in feature distinction. Yu et al.28 combined YOLOv3 and VGG19 to achieve over 90% accuracy in detecting traffic signs across diverse settings, outperforming standard methods despite accuracy declines in complex scenes. Song et al.’s algorithm29, tailored to China’s needs, relies on YOLOv4-tiny to accurately detect traffic signs in challenging scenes, catering to the real-time requirements of smart vehicles without addressing extreme weather conditions. Qu et al.30 enhanced small sign detection in adverse weather using an upgraded YOLOv5 model with a balanced pyramid structure and global context blocks, albeit struggling with occlusions. Oreski et al.31 further boosted detection capabilities for small objects by integrating the MCTX module into YOLOv7, crucial for navigating complex traffic scenarios. Lastly, Kumar et al.32 employed YOLOv8, incorporating adverse weather data for transfer learning, showcasing cutting-edge techniques for real-time object detection and classification despite the challenge of managing large model parameters.
Despite significant progress in traffic sign detection technology, challenges remain in computational efficiency and accuracy. Existing models often struggle under complex conditions, not fully meeting application requirements. For example, YOLOv5 is known for its balance between speed and robustness, YOLOv7 introduces architectural optimization for better real-time performance, and YOLOv8n provides a lightweight alternative suited for edge deployment. However, limitations in feature fusion and attention modeling still leave room for improvement. This study introduces the innovative YOLO-SAL model for efficient, real-time traffic sign detection. Incorporat-ing the SCConv concept, it designs the SCC2f architecture to optimize convolutional blocks by merging spatial and channel mechanisms, significantly lowering parameter count and computational needs. The model also applies an Adaptive Feature Pyramid Network (AFPN) for effective multi-scale feature integration, substantially improving detection accuracy across various sign sizes. Incorporating the LSKA attention mechanism enhances focus on information-rich image areas, ensuring high sensitivity to traffic signs amid distractions, thus boosting accuracy in challenging scenes.
The subsequent sections are as follows. Section “Materials and methods” describes the structure and func-tion of the YOLO-SAL model’s components. Section “Experimental findings and outcomes” introduces the experimental equipment and presents the methods and findings. Section “Discussion” looks into the future through discussion. Section “Conclusion” summarizes the paper.
Materials and methods
YOLOv8n model
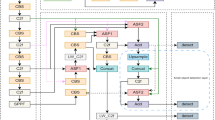
The YOLOv8 model33, the most advanced and efficient in the YOLO series, enhances object detection with its unparalleled generalization and robustness across multiple domains. This model comprises four variants–YOLOv8n, YOLOv8s, YOLOv8m, and YOLOv8x–each tailored to meet specific application needs and com-putational constraints. Due to hardware deployment considerations, our study focuses on optimizing YOLOv8n. This variant is built on four fundamental components: the input layer, backbone network, neck structure, and output layer. The structure is shown in Fig. 1.

YOLOv8n architecture diagram. The YOLOv8n architecture consists of three main components: the Backbone, Neck, and Head. The Backbone extracts features from the input image using a series of convolutional and C2f modules, followed by a Spatial Pyramid Pooling Fast (SPPF) block for multi-scale feature aggregation. The Neck adopts a feature fusion strategy with upsampling, concatenation, and additional C2f layers to enhance multi-level representation. The Head performs prediction at multiple scales and outputs object classification and bounding box regression. Supplementary diagrams for SPPF and C2f modules are shown at the bottom for structural clarity.
The input layer processes raw image data through essential pre-processing tasks, including resizing, normalization, and, optionally, data augmentation, setting the stage for effective feature extraction and object detection.
At its core, the backbone layer employs a deep convolutional neural network34, crucial for drawing out rich visual features from the images. It incorporates techniques like residual connections and batch normalization, enabling the net-work to refine features across various levels, thereby significantly boosting the model’s effectiveness and efficiency.
The neck layer advances this process by further refining the backbone’s feature maps. It integrates technologies such as the Feature Pyramid Network (FPN)35 and the Path Aggregation Network (PAN), merging feature maps from different scales to enhance detection precision and efficiency.
Finally, the output layer consists of multiple sub-networks, each designed for specific tasks. These networks leverage the refined features from the neck structure for accurate predictions, equipping the model to adeptly navigate a range of complex detection scenarios.YOLO-SAL is based on YOLOv8n, which mainly integrates modules (SCC2f, AFPN, LSKA) to its backbone, neck and head stages respectively. Specific details are given in the following sections.
Innovative design of YOLO-SAL model
SCC2f structure
Accurate and efficient detection of traffic signs is essential for preventing traffic accidents and ensuring road safety. While the YOLOv8n model exhibits strong potential, it still faces significant challenges due to its high computational overhead. These challenges are largely attributed to its backbone architecture, which relies on numerous convolutional operations, thereby constraining its detection efficiency and real-time performance.To address this issue, our study designs the SCC2f structure, leveraging the SCConv36 technique. This approach reconstructs spatial and channel information within feature maps, significantly enhancing feature representation. Such enhancement not only boosts the accuracy but also the robustness of object detection. The process involves initial refinement of spatial features by a Spatial Reconstruction Unit (SRU), followed by Channel Feature optimization via a Channel Reconstruction Unit (CRU), culminating in an optimized feature representation, illustrated in Fig. 2.

SCC2f’s structure. This figure illustrates the architecture of the proposed SCC2f module. The input feature first passes through a 3\(\times\)3 convolution (SCConv), followed by a split operation and a series of lightweight bottleneck blocks. After feature concatenation and refinement, a second SCConv is applied. The output is further enhanced through two sequential branches: a Spatial Refinement Unit (SRU) and a Channel Refinement Unit (CRU), producing the final spatial-channel refined feature representation.
SCConv’s innovative approach centers on integrating spatial and channel reconstruction mechanisms within the convolution process, employing SRU and CRU for comprehensive reconstruction. Unlike traditional convolutions that process all spatial and channel dimensions uniformly, SRU and CRU leverage learnable gating strategies to selectively enhance useful information. The SRU focuses on spatial attention by identifying and emphasizing high-importance regions in the feature map, thereby suppressing background interference and spatial redundancy. In parallel, the CRU applies a soft-attention mechanism across channels, dynamically recalibrating channel responses to highlight informative features while discarding less relevant ones. This dual-level gating mechanism leads to better feature representation, reduces overfitting, and enables the network to learn more efficiently with fewer parameters.
The Separable-Reconstruction Unit (SRU) integrates residual connections and spatial attention mechanisms within convolutions, aiming to amplify spatial details and minimize redundancy, as shown in Fig. 3.

The SRU’s structure.
The architecture of the SRU commences by distinguishing between feature maps rich in information and those less so, as demonstrated in Eq. (1):
Where, \(X\) denotes the input features. \(W \gamma\) signifies the weights employed by the SRU, \(GN\) is for group normalization, Sigmoid functions as the activation mechanism, and Gate identifies the gating process.
Following this, a cross-reconstruction approach is applied to amalgamate and assign weights to two distinct feature maps based on their informational content. This leads to the creation and linkage of enhanced, spatially precise feature maps, labeled as \(X^{W}.\)

The CRU’s structure. The spatial-refined feature \(X''\) is split into two channel groups and processed by separate \(1\times 1\) convolutions. One branch undergoes global and point-wise convolutions (GWC and PWC) to generate intermediate features \(Y_1\) and \(Y_2\). In the fusion stage, global context descriptors \(S_1\) and \(S_2\) are obtained via global pooling and fused through a softmax-weighted mechanism to generate channel attention weights \(\beta _1\) and \(\beta _2\), which are applied to \(Y_1\) and \(Y_2\), respectively. The final output is the channel-refined feature Y.
The CRU uses segmentation, transformation, and fusion to extract channel features with high specificity using channel attention mechanisms and feature rearrangement. This approach is designed to bolster channel information and minimize redundancy, as depicted in Fig. 4.
In the CRU framework, the process starts by dividing the spatially refined input features, \(X^{W}\), into two segments with channel counts of \(\alpha C\) and \((1-\alpha )C\). These segments are then compressed through a 1\(\times\)1 convolution kernel to produce \(X_{up}\) and \(X_{low}\). Subsequent convolution operations on \(X_{up}\) and \(X_{low}\) yield the feature maps \(Y_{1}\) and \(Y_{2}\), respectively. The final feature map is obtained by merging \(Y_{1}\) and \(Y_{2}\) using a streamlined SKNet methodology. The specifics of this computational procedure are detailed in Eq. (2):
Where, pooling operations on \(Y_{1}\) and \(Y_{2}\) generate \(S_{1}\) and \(S_{2}\). The feature weight vectors, \(\beta _{1}\) and \(\beta _{2}\), are derived by applying the Softmax function to \(S_{1}\) and \(S_{2}\), improving the model’s precision in feature extraction and integration.
While YOLOv8n employs the C2f mechanism for feature extraction, incorporating numerous residual blocks that escalate the model’s computational load, this study is committed to the principle of lightweight design37. To this end, we have innovatively revised its backbone structure. By introducing the novel SCC2f architecture, we have optimized the original C2f framework, markedly diminishing computational requirements and improving the model’s detection efficiency. Further details on this modified backbone are in Fig. 5.

Innovative backbone structure.
Adaptive feature pyramid network
In traffic sign detection scenarios, the diversity in sign sizes significantly challenges computer vision-based algorithms. The YOLOv8n algorithm, which employs an FPN + PAN structure, effectively merges multi-level feature information, facilitating information flow from lower to higher levels. However, adding extra fusion layers and connection weights increases the model’s complexity and risks overfitting. To address this, our study introduces the Adaptive Feature Pyramid Network (AFPN)38 to re-fine feature fusion strategies. AFPN improves detection across various sign sizes with a progressive feature fusion mechanism and adaptive spatial fusion techniques, en-hancing key information extraction. This approach is shown in Fig. 6.

The AFPN’s structure.
Initially, AFPN merges features from two foundational layers; it then incorporates more advanced features in the intermediate stage. In the final stage, it integrates the highest-level features. This progressive integration of features from the bottom, middle, and top levels effectively reduce the semantic gap between feature levels, particularly in non-adjacent layers.
AFPN also extracts crucial features from different layers of the backbone network, forming a varied scale feature set {C2, C3, C4, C5}. It starts with lower-level features C2 and C3, gradually incorporating C4 and C5 layers. This results in a multi-scale feature set {P2, P3, P4, P5}, where each layer offers unique spatial resolutions, laying a comprehensive information groundwork for prediction tasks. AFPN’s distinctive fusion path design ensures effective information capture across levels, significantly enhancing object detection performance.
Long-sequence knowledge attention
In practical traffic sign detection scenarios, complex and dynamic backgrounds–such as occlusions, varying illumination, and dense visual clutter–pose significant challenges to accurate sign recognition. To address this, attention mechanisms have been widely adopted to improve the model’s focus on critical regions. Nevertheless, many existing attention modules fall short in modeling long-range dependencies and often incur substantial computational overhead. In contrast, the proposed Long-Sequence Knowledge Attention (LSKA) module introduces a lightweight yet effective mechanism that captures spatial dependencies across extended receptive fields while maintaining high computational efficiency. This design significantly enhances the model’s ability to detect traffic signs in challenging environments without sacrificing real-time performance.
This study introduces a novel attention mecha-nism–Long-Sequence Knowledge Attention (LSKA)39 mechanism, aimed at achieving stable and precise identification of traffic signs in complex backgrounds. The core design of the LSKA mechanism is its unique structure, as shown in Fig. 7.

The LSKA’s structure.
The LSKA structure first employs a \(1\times (2d-1)\) depthwise separable convolution (Dw-Conv) to process the features in the horizontal direction of the input feature map \({F}^{c}\), followed by a \((2d-1)\times 1\) depthwise separable convolution for processing features in the vertical direction, to obtain the preliminarily processed feature map \(\overline{Z}^{c}.\)
Subsequently, \(\overline{Z}^{c}\) undergoes a depthwise separable convolution operation using \(1\times [\frac{k}{d}]\) and \([\frac{k}{d}]{\times 1}\) convolution kernels to obtain the feature map \(\overline{Z}^{c}\). Then, by applying a 1\(\times\)1 convolution to the feature map \({Z}^{c}\) produces the feature map \({A}^{c}\). Finally, by element-wise multiplication of \({Z}^{c}\) and \({A}^{c}\), the final output feature map \(\overline{F}^{c}\) is obtained, with the related computational process detailed in Eqs. (3)–(6):
where, \(*\) and \(\otimes\) denote convolution and the Hadamard product, with \(C\) for input channels, while \(H\) and \(W\) for feature map height and width.
Experimental findings and outcomes
Dataset choice and rationale
This research utilized the TT100K dataset, a comprehensive benchmark dataset widely applied in traffic sign recognition across China, developed through a collaboration between Tsinghua University and Tencent40. Originating from Tencent Street View panoramic images, the dataset organizes traffic signs into three categories based on resolution: below 32\(\times\)32, 32\(\times\)32 to 96\(\times\)96, and above 96\(\times\)96 pixels. From this dataset, we carefully chose 1890 images spanning 42 categories. To align with the experimental design’s objectives, we allocated these images into training, validation, and testing sets following an 8:1:1 distribution ratio. with the training set including detailed detection box data for each category, as depicted in Fig. 8.

Training set data categories and label distribution. (a) Coordinate parameters of the labeled box center; (b) number of 42 traffic signs; and (c) dimensions of the labeled boxes in vertical and horizontal directions.
Experimental environment and evaluation criteria
This study conducted all experiments on a Linux system, leveraging PyTorch 1.7.0 and Python 3.8 for the experimental setup. We utilized an NVIDIA RTX 4090 Ti with 24 GB of video memory for computing resources. The hyperparameter configuration was as follows: an initial learning rate of 0.01, a training duration of 300 epochs, a momentum of 0.937, and a weight decay rate of 0.0005 to optimize the model and mitigate overfitting. We selected a batch size of 16 to enhance training efficiency.
This study assessed the model’s performance through precision, recall, and mean Average Precision (mAP)41,42. Precision quantifies the accuracy of the model’s pre-dictions, while recall gauges its capability to identify all pertinent instances. AP represents the mean precision at varying levels of recall, with mAP averaging the AP across different categories or queries. Furthermore, the F1 score, which is the harmonic mean of precision and recall, provides a unified measure that balances both metrics. See Eqs. (7)–(10) for details:
where, \(TP\) (True Positive) is the count of correctly predicted positives by the model, \(FP\) (False Positive) is the count of incorrectly predicted positives, and \(FN\) (False Nega-tive) refers to the number of positive samples incorrectly predicted as negative. \(P\) and \(R\) are the values on the precision-recall curve43.
Additionally, the study incorporates the concept of lightweight by introducing parameters and floating-point operations (FLOPs). Parameters, consisting of learnable weights and biases, are critical for evaluating the model’s capability to interpret data. FLOPs quantify the model’s computational demands, indicating its complexity. These indicators play a significant role in assessing the model’s efficiency and applicability.
Discussion of experimental results
Performance comparison pre- and post-optimization
This study evaluated the YOLO-SAL model’s performance against YOLOv8n, as shown in Table 1.
Table 1 reveals that the precision, recall, F1, and mAP have increased by 4.3%, 6.0%, 5.3%, and 4.9%, respectively. This significant improvement is attributed to the modifications made to the model. Initially, the integration of the SCC2f model reconstructed feature spatial and channel information and reduced the YOLOv8n model’s parameters, making the network more efficient. Furthermore, the improvements in precision, recall, F1 score, and mAP were due to the addition of AFPN. This addition merges various mechanisms, including a feature pyramid structure, adaptive feature fusion, and the integration of both deep and shallow features alongside efficient con-textual information utilization. This blend significantly boosts object detection performance, notably in identifying traffic signs of varying sizes. Additionally, incorporating the LSKA attention mechanism, which focuses on crucial information by capturing long-term dependencies, has effectively minimized complex background disturbances in traffic sign detection. In summary, the YOLO-SAL model, with its net-work efficiency and enhanced detection accuracy, demonstrates considerable potential for real-world application, outperforming the original model.
To corroborate the model’s enhanced effectiveness, the study illustrated Precision-Recall (PR) curves in Figs. 9 and 10. The PR curves indicate that a larger gap between the curve and the axis signifies superior model detection performance. It is evident from the figures that, compared to the YOLOv8n model, the improved model proposed here demonstrates enhanced detection performance.

Precision-Recall curve for YOLOv8n.

Precision-Recall curve for YOLO-SAL.
Ablation experiment analysis
To assess the impact of diverse enhancement strategies, this study executed ablation analyses by sequentially integrating improvement modules into a consolidated test set, as illustrated by the results in Table 2, Figs. 11 and 12.

Comparison of mAP using various model parameters.
Analysis of Table 2’s data indicates a notable 8.6% reduction in FLOPs following the integration of the SCC2f lightweight model. This decreases chiefly results from SCC2f ’s adoption of spatial and channel reconfiguration mechanisms within convolution operations, aiming for a more efficient model by minimizing parameter redundancy and computational complexity.

Comparison of mAP using various model FLOPs.
Subsequent enhancements to the AFPN module led to a 3.5% increase in the model’s mean Average Precision (mAP). This rise stems from AFPN’s ability to capture image features across multiple scales using a feature pyramid structure. This structure’s feature maps, corresponding to various resolutions across different levels, enable the effective processing of targets of diverse sizes. Incorporating the LSKA attention mechanism yielded an additional 2% increase in mAP. This progress is linked to LSKA’s integration of a balanced feature pyramid structure with global context blocks, which bolsters feature fusion and extraction capabilities. By more intricately analyzing the dynamics between targets and their environments, the LSKA approach significantly improves traffic sign detection precision in complex scenarios.
To further validate the effectiveness of the proposed model, a visual analysis was conducted using representative samples from the test set. As illustrated in Fig. 13, the YOLO-SAL model demonstrates noticeably higher confidence scores compared to existing baseline models. This result highlights the model’s superior ability to accurately detect traffic signs, particularly under challenging visual conditions.

Visual representation of test results: (a) YOLOv8n; (b) YOLO-SAL.
Comparative study with state-of-the-art models
To validate the enhanced YOLO-SAL algorithm’s traffic sign detection performance, this study conducted comparative experiments with Faster R-CNN, YOLOv3-tiny15, YOLOv5, and YOLOv7-tiny on the same dataset. Detailed experimental results are presented in Table 3 and Fig. 14.

Findings from the comparative analysis with Leading Models.
The data analysis from Table 3 reveals that The results show that traditional models such as Faster-RCNN, while leveraging complex region proposal mechanisms, yield relatively lower performance in both Precision (82.5%) and Recall (70.3%), limiting their effectiveness in real-time applications. SSD achieves the highest Precision (93.1%) but suffers from low Recall (70.9%) and mAP (79.9%), indicating insufficient overall detection robustness. Among the YOLO series, performance improves progressively from YOLOv3-tiny to YOLOv7-tiny, with YOLOv7-tiny achieving the best results among the baseline models (Precision: 87.9%, mAP: 82.6%). In contrast, our proposed YOLO-SAL model significantly outperforms all baseline methods, achieving a Precision of 92.8%, Recall of 80.7%, F1-score of 86.3%, and mAP of 87.9%. These improvements are attributed to the integration of the SCC2f structure for efficient feature representation, the Adaptive Feature Pyramid Network (AFPN) for enhanced multi-scale fusion, and the Long-Sequence Knowledge Attention (LSKA) module for robust focus on informative regions. Compared to YOLOv7-tiny, YOLO-SAL improves mAP by 5.3 percentage points and Recall by 6.4 percentage points.
To ensure that the performance improvements of the YOLO-SAL model are not coincidental, we further performed statistical significance testing. By applying paired t-tests on evaluation metrics across the test set, including precision, recall, F1-score, and mAP, we observed that all corresponding p-values were less than 0.05 when comparing YOLO-SAL to each baseline model. These results confirm that the performance improvements achieved by our model are statistically significant. This reinforces the effectiveness of the proposed SCC2f, AFPN, and LSKA modules, and supports the model’s robustness and practical application value in traffic sign detection.
Discussion
To enhance traffic safety and foster the evolution of intelligent traffic systems, this study introduces the YOLO-SAL model. This innovative model addresses traffic sign detection challenges, including computational redundancy, size diversity, and com-plex background extraction. It outperforms existing YOLO series models in detection efficiency.
The paper presents a novel SCC2f structure, inspired by the SCConv architecture, to mitigate the computational demands associated with the advanced YOLOv8n model. This structure reduces the model’s parameters and computational load by eliminating traditional residual convolutions. Through AFPN optimization, our model effectively merges feature maps across different levels, improving detection of multi-scale and multi-ratio targets. The integration of the Luong-style attention mechanism (LSKA) within the detection layer notably enhances traffic sign detection accuracy and robustness, significantly advancing autonomous driving technology.
Compared to previous studies, the YOLO-SAL model proposed in this research achieves notable results in enhancing the precision and efficiency of target detection, better addressing real-world traffic scenarios. As shown in Table 3, complex structures like the Faster R-CNN model22, which includes RPN, subsequent classification, and regression parts, require higher computational resources; the YOLOv3-tiny, as a light-weight model, improves detection efficiency but sacrifices detection precision, leading to a lower overall recall rate; YOLOv5, combining FPN and PAN networks, enhances generalization and robustness but tends to miss detections for different scale targets; YOLOv7-tiny reduces model weight through reparameterization but lowers the ability to extract targets; whereas the YOLO-SAL model significantly improves detection precision for high-precision and real-time traffic sign detection. Moreover, this model detects traffic signs accurately and swiftly in complex backgrounds, paving a new path for traffic sign detection.
While the YOLO-SAL model has shown promising results in traffic sign detection, opportunities for enhancing its performance remain. The current datasets exhibit a lack of diversity, inadequately representing traffic signs across varying lighting, weather conditions, and traffic scenarios. This limitation affects the model’s generalization capabilities. The algorithm also struggles to balance parameters with accuracy in changing environments and to operate efficiently on edge devices with restricted computational resources. Furthermore, the model’s capability to perform reliably under severe weather conditions or in the presence of strong light interference necessitates more thorough evaluation.
Future research will aim to refine and enlarge the training dataset to encompass a wider range of environmental conditions and traffic scenarios, thereby mitigating the present dataset’s limitations. Efforts will be made to enhance computational efficiency without compromising accuracy, through the adoption of techniques like neural architecture search (NAS), model distillation, quantization, and weight pruning. Additionally, the development of innovative architectures and algorithms, including local and multi-scale attention mechanisms, will aim to enhance the model’s traffic sign detection performance, thereby contributing to the advancement of autonomous driving technologies.
Conclusions
This study introduces the YOLO-SAL model, a novel approach to traffic sign detection that embodies lightweight design principles. By merging SCConv and YOLOv8n sub-networks and replacing the traditional C2f layer with the SCC2f layer, the model streamlines the network architecture and markedly boosts detection efficacy. This enhancement makes the model ideal for resource-constrained environments. The AFPN structure enhances multi-level feature fusion, improving the model’s ability to recognize traffic signs of different sizes and its overall generalizability. A key feature is incorporating the LSKA attention mechanism within the detection layer, which greatly enhances the model’s efficiency in identifying traffic signs in complex settings. Empirical results indicate that the YOLO-SAL model reduces computational demands by 8.6% and elevates the mean Average Precision (mAP) by 4.9%. However, the model’s streamlined design does marginally impact precision. Furthermore, the AFPN’s multi-level feature fusion and the use of expansive convolution kernels increase the computational burden and parameter count. Future studies will focus on refining detection accuracy and efficiency, aiming for lightweight configurations conducive to hardware implementation.
Data availability
The data used in this study can be obtained from the corresponding authors.
References
Liu, T. & Dongye, C. The research on lightweight traffic sign recognition algorithm based on improved yolov5 model. In 2023 IEEE 3rd International Conference on Computer Communication and Artificial Intelligence (CCAI) 284–288 (IEEE, 2023).
Suwattanapunkul, T. & Wang, L.-J. The efficient traffic sign detection and recognition for taiwan road using yolo model with hybrid dataset. In 2023 9th International Conference on Applied System Innovation (ICASI) 160–162 (IEEE, 2023).
Ye, F.-F., Yang, L.-H., Wang, Y.-M. & Lu, H. A data-driven rule-based system for china’s traffic accident prediction by considering the improvement of safety efficiency. Comput. Ind. Eng. 176, 108924 (2023).
Pei, Y. et al. Towards a novel magnetic asphalt mixture containing ceramic ferrites for intelligently encoding road traffic sign information. Constr. Build. Mater. 394, 132227 (2023).
Aghdam, H. H., Heravi, E. J. & Puig, D. A practical approach for detection and classification of traffic signs using convolutional neural networks. Robot. Auton. Syst. 84, 97–112 (2016).
De La Escalera, A., Moreno, L. E., Salichs, M. A. & Armingol, J. M. Road traffic sign detection and classification. IEEE Trans. Industr. Electron. 44, 848–859 (1997).
Paclık, P., Novovičová, J., Pudil, P. & Somol, P. Road sign classification using laplace kernel classifier. Pattern Recogn. Lett. 21, 1165–1173 (2000).
Piccioli, G., De Micheli, E., Parodi, P. & Campani, M. Robust method for road sign detection and recognition. Image Vis. Comput. 14, 209–223 (1996).
Chen, T. & Lu, S. Accurate and efficient traffic sign detection using discriminative adaboost and support vector regression. IEEE Trans. Veh. Technol. 65, 4006–4015 (2015).
Dalal, N. & Triggs, B. Histograms of oriented gradients for human detection. In 2005 IEEE computer society conference on computer vision and pattern recognition (CVPR’05), vol. 1 886–893 (Ieee, 2005).
Ellahyani, A., El Ansari, M. & El Jaafari, I. Traffic sign detection and recognition based on random forests. Appl. Soft Comput. 46, 805–815 (2016).
Yuan, X., Hao, X., Chen, H. & Wei, X. Robust traffic sign recognition based on color global and local oriented edge magnitude patterns. IEEE Trans. Intell. Transp. Syst. 15, 1466–1477 (2014).
Ahmed, S., Kamal, U. & Hasan, M. K. Dfr-tsd: a deep learning based framework for robust traffic sign detection under challenging weather conditions. IEEE Trans. Intell. Transp. Syst. 23, 5150–5162 (2021).
Luo, H., Yang, Y., Tong, B., Wu, F. & Fan, B. Traffic sign recognition using a multi-task convolutional neural network. IEEE Trans. Intell. Transp. Syst. 19, 1100–1111 (2017).
Yao, Z., Song, X., Zhao, L. & Yin, Y. Real-time method for traffic sign detection and recognition based on yolov3-tiny with multiscale feature extraction. Proc. Inst. Mech. Eng. Part D: J. Automobile Eng. 235, 1978–1991 (2021).
Fredj, H. B., Chabbah, A., Baili, J., Faiedh, H. & Souani, C. An efficient implementation of traffic signs recognition system using cnn. Microprocess. Microsyst. 98, 104791 (2023).
Yang, T., Long, X., Sangaiah, A. K., Zheng, Z. & Tong, C. Deep detection network for real-life traffic sign in vehicular networks. Comput. Netw. 136, 95–104 (2018).
Arcos-Garcia, A., Soilán, M., Alvarez-Garcia, J. A. & Riveiro, B. Exploiting synergies of mobile mapping sensors and deep learning for traffic sign recognition systems. Expert Syst. Appl. 89, 286–295 (2017).
Qian, R., Liu, Q., Yue, Y., Coenen, F. & Zhang, B. Road surface traffic sign detection with hybrid region proposal and fast r-cnn. In 2016 12th International Conference on Natural Computation, Fuzzy Systems and Knowledge Discovery (ICNC-FSKD) 555–559 (IEEE, 2016).
Shao, F. et al. Improved faster r-cnn traffic sign detection based on a second region of interest and highly possible regions proposal network. Sensors 19, 2288 (2019).
Tabernik, D. & Skočaj, D. Deep learning for large-scale traffic-sign detection and recognition. IEEE Trans. Intell. Transp. Syst. 21, 1427–1440 (2019).
Han, C., Gao, G. & Zhang, Y. Real-time small traffic sign detection with revised faster-rcnn. Multimedia Tools Appl. 78, 13263–13278 (2019).
She, F., Hong, Z., Zeng, Z. & Yu, W. Improved traffic sign detection model based on yolov7-tiny. IEEE Access 11, 126555–126567 (2023).
Du, Y., Liu, X., Yi, Y. & Wei, K. Incorporating bidirectional feature pyramid network and lightweight network: a yolov5-gbc distracted driving behavior detection model. Neural Comput. Appl. 2023, 1–15 (2023).
Du, Y., Liu, X., Yi, Y. & Wei, K. Optimizing road safety: advancements in lightweight yolov8 models and ghostc2f design for real-time distracted driving detection. Sensors 23, 8844 (2023).
Sun, C., Wen, M., Zhang, K., Meng, P. & Cui, R. Traffic sign detection algorithm based on feature expression enhancement. Multimedia Tools Appl. 80, 33593–33614 (2021).
Flores-Calero, M. et al. Traffic sign detection and recognition using yolo object detection algorithm: a systematic review. Mathematics 12, 297 (2024).
Yu, J., Ye, X. & Tu, Q. Traffic sign detection and recognition in multiimages using a fusion model with yolo and vgg network. IEEE Trans. Intell. Transp. Syst. 23, 16632–16642 (2022).
Song, W. & Tsr-Yolo, S. S. A chinese traffic sign recognition algorithm for intelligent vehicles in complex scenes. Science 23, 749. https://doi.org/10.3390/s23020749 (2023).
Qu, S., Yang, X., Zhou, H. & Xie, Y. Improved yolov5-based for small traffic sign detection under complex weather. Sci. Rep. 13, 16219 (2023).
Oreski, G. Yolo* c-adding context improves yolo performance. Neurocomputing 555, 126655 (2023).
Kumar, D. & Muhammad, N. Object detection in adverse weather for autonomous driving through data merging and yolov8. Sensors 23, 8471 (2023).
Yu, Z. & Ye, T. Autonomous traffic sign detection for self-driving car system using convolutional neural network algorithm. J. Opt. 2023, 1–11 (2023).
Li, J. & Wang, Z. Real-time traffic sign recognition based on efficient cnns in the wild. IEEE Trans. Intell. Transp. Syst. 20, 975–984 (2018).
Wang, J., Chen, Y., Dong, Z. & Gao, M. Improved yolov5 network for real-time multi-scale traffic sign detection. Neural Comput. Appl. 35, 7853–7865 (2023).
Li, J., Wen, Y. & He, L. Scconv: spatial and channel reconstruction convolution for feature redundancy. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 6153–6162 (2023).
Talaat, F. M. & ZainEldin, H. An improved fire detection approach based on yolo-v8 for smart cities. Neural Comput. Appl. 35, 20939–20954 (2023).
Yang, G. et al. Afpn: asymptotic feature pyramid network for object detection. In 2023 IEEE International Conference on Systems, Man, and Cybernetics (SMC) 2184–2189 (IEEE, 2023).
Lau, K. W., Po, L.-M. & Rehman, Y. A. U. Large separable kernel attention: rethinking the large kernel attention design in cnn. Expert Syst. Appl. 236, 121352 (2024).
Chen, J., Jia, K., Chen, W., Lv, Z. & Zhang, R. A real-time and high-precision method for small traffic-signs recognition. Neural Comput. Appl. 34, 2233–2245 (2022).
Arcos-García, Á., Alvarez-Garcia, J. A. & Soria-Morillo, L. M. Evaluation of deep neural networks for traffic sign detection systems. Neurocomputing 316, 332–344 (2018).
Du, Y., Xu, X. & He, X. Optimizing geo-hazard response: Lbe-yolo’s innovative lightweight framework for enhanced real-time landslide detection and risk mitigation. Remote Sens. 16, 534 (2024).
Meng, W. & Yuan, Y. Sgn-yolo: detecting wood defects with improved yolov5 based on semi-global network. Sensors 23, 8705 (2023).
Author information
Authors and Affiliations
Contributions
Conceptualization: J.X. and Y.D.; Formal analysis: Y.Y. and H.D.; Methodology: J.X. and Y.D.; Software: Y.Y. and H.D.; Validation:Y.Y. and H.D.; Writing – original draft: J.X. and Y.D.; Writing – review & editing, Y.D.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Xu, J., Du, Y., Yi, Y. et al. An improved lightweight algorithm for traffic sign detection. Sci Rep 15, 33554 (2025). https://doi.org/10.1038/s41598-025-18469-x
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-025-18469-x
