
Abstract
In UAV-based downstream tasks, intelligent interpretation of UAV images demands higher real-time performance and accuracy. However, achieving high-precision, real-time object detection in UAV images poses significant challenges due to the prevalence of small objects (e.g., persons and bicycles), uneven target distribution, occlusion, and other factors. Current UAV object detection algorithms lack comprehensive solutions to the multifaceted challenges encountered in real-world deployment scenarios, resulting in suboptimal performance. Moreover, direct application of mainstream real-time detection algorithms like the YOLO series to UAV images lead to a significant performance drop. To address these issues, this paper presents an enhanced real-time object detection network named YOLO-UD, which is built upon the YOLO11 architecture. Our approach aims to achieve superior feature representation through the effective integration of contextual information and adaptive multi-scale fusion. Specifically, we incorporate a novel C3kHR module, which employs dilated convolutions with varying rates to capture contextual information across multiple granularity hierarchy, enabling superior and richer multi-scale feature representation. Additionally, an efficient adaptive feature fusion network (EAFN) is designed to filter and prioritize key information from multi-scale feature layers and flexibly provide the detection head with the information needed for the detection process. A small object detection layer (SMDL) is also introduced to enhance the detection of small objects and provide rich information about small targets. Finally, extensive experiments on the VisDrone2019 and UAVDET datasets demonstrate that YOLO-UD achieves excellent balance between accuracy and inference speed, validating its effectiveness.
Similar content being viewed by others
Introduction
Recent advances in unmanned aerial vehicle (UAV) image analysis have been propelled by two key developments: the widespread adoption of UAVs, which offer unique overhead perspectives and extensive field-of-view coverage, and significant progress in deep learning for intelligent image interpretation. Leveraging the end-to-end optimization capabilities of deep learning, UAV object detection is now extensively used in both military1,2,3 and civilian4,5 applications.
However, UAV imagery presents distinct challenges that set it apart from natural images, primarily due to its unique acquisition perspective and complex scenes. As illustrated in Fig.1, these challenges can be summarized as follows: (a) predominant small objects that become indistinguishable after repeated downsampling in deep networks, (b) the distribution of targets is uneven, with objects densely clustered in certain areas (the marked area in images), while background regions dominate the image, and (c) objects of various sizes are often accompanied by complex backgrounds and challenging environments. Critically, these challenges must be solved within the stringent real-time processing limits required for practical drone deployment. Therefor, developing accurate and real-time detectors that address these inherent characteristics is essential.

Analysis of the labels for the VisDrone2019 dataset. The top images (a) are samples of the dataset and show the uneven distribution of targets in UAV images (targets are concentrated in some regions with a high percentage of backgrounds). The bottom (b) shows the normalized size of the target bounding box for each category (a lot of small targets).
Currently, mainstream deep learning-based object detection algorithms can be categorized into two-stage and one-stage detection methods. Two-stage detection algorithms first generate region proposals to identify potential target areas and then refine the detection in a second stage. R-CNN6 marked a milestone in two-stage approaches. Subsequently, a series of optimized two-stage algorithms emerged, achieving improvements in both accuracy and speed7,8,9. For instance, Sun et al.10 developed a set of learnable sparse proposal boxes to mitigate the issue of dense candidate sampling, thereby substantially improving detection efficiency. Nevertheless, these methods still fall short of meeting the stringent real-time requirements of many practical applications. In contrast, one-stage algorithms directly regress object bounding boxes on multi-scale feature maps, achieving faster inference speeds. Prominent examples include the YOLO family11,12,13 and anchor-free algorithms14,15,16,17. However, both single-stage and two-stage general object detection algorithms exhibit fundamental limitations when directly applied to complex tasks such as UAV image object detection. Two-stage methods often deliver higher detection accuracy but suffer from inadequate inference speed, making them unsuitable for real-time scenarios. On the other hand, one-stage detectors struggle with accuracy degradation due to information loss in small or obscured objects and insufficient handling of complex backgrounds.
Later, UAV-specific approaches18,19 have attempted to address these challenges through various strategies. To enhance the representational capacity of multi-scale features and facilitate effective information fusion, recent work by Tan et al.20 presented UAV-YOLO, an enhanced architecture building upon YOLOv521, which incorporates deformable convolutions in deeper backbone layers to expand the receptive field while capturing long-range dependencies. To improve small-object representation, UAV-YOLO adaptively weights shallow features during fusion stages. However, this approach fails to adequately mitigate the issues of target information degradation in the backbone network’s deep feature and interference from complex backgrounds, while simultaneously exhibiting limitations in both computational efficiency and detection accuracy. To enhance the detection accuracy of small objects in UAV images, Chalavadi et al.22 incorporated a Hierarchical Dilated Network (HDN) into the backbone of EfficientDet23 to effectively capture contextual information across various object types, scales, and viewpoints. However, the complex architecture of HDN overlooks the loss of small object features during early feature extraction and introduces a computational burden that hinders real-time performance. Li et al.24 proposed the GSDet network to extract sample distance information as prior knowledge and integrated it into the detection process, thereby improving detection performance. Although the GSDet can be flexibly incorporated into two-stage detectors, it lacks faster inference speed and an effective multi-scale feature processing strategy. Liu et al.25 developed a denoising feature fusion network (DNTR) to address the noisy and interfering features generated during the feature fusion process in Trans RCNN26, achieving considerable performance improvements. However, to enhance the detection performance for small objects, DNTR incorporates a self-attention mechanism into the two-stage network, which significantly increases inference time and raises the difficulty of deployment in practical applications. Fan et al.27 developed LUD-YOLO based on YOLOv8, introducing a sparse attention mechanism within the C2f module to enhance feature extraction of small objects and expand receptive field through global context modeling. But this strategy does not adequately preserve information of objects at multiple scales.For the feature fusion process, LUD-YOLO employs skip connections with same-scale upsampling to address feature fusion deficiencies. Although LUD-YOLO is computationally efficient and meets real-time requirements, it fails to effectively mitigate interference from complex background clutter and does not adequately capture contextual information of the targets.
In summary, current methods suffer from three major limitations due to a lack of comprehensive consideration during the model design process: they fail to effectively mitigate the irreversible information loss of small objects during deep feature extraction, lack robust mechanisms to suppress complex background interference without losing critical target details during feature fusion, and, crucially, do not incorporate real-time computational constraints into their architectural design. As a result, these approaches fail to achieve a balance between accuracy and efficiency, which is essential for practical applications such as drone-based operations.
These challenges collectively hinder the performance of current UAV image object detection algorithms. Addressing them in an integrated manner is critical for substantial and comprehensive improvements. To this end, this paper proposes YOLO-UD, an algorithm tailored for UAV image object detection, based on the lightweight YOLO11 framework. Our method holistically tackles typical UAV-based challenges including dense small objects, complex environments, and significant scale variations, while maintaining a favorable accuracy-speed trade-off and strong robustness.
Specifically, to alleviate irreversible information loss during feature extraction, we propose C3kHR that incorporates dilated convolutions with strategically varied dilation rates throughout the backbone network. This design not only expands the receptive field early in the feature extraction process but also facilitates comprehensive contextual capture for multiple objects in UAV scenes. Furthermore, we design an Efficient Adaptive Feature Fusion Network (EAFN) to integrate multi-scale features effectively. By adaptively assigning joint attention weights during fusion, the EAFN suppresses background noise while preserving critical information across scales. The overall architecture employs efficient convolutional operators and sampling module to significantly reduce computational overhead while maintaining high accuracy, thereby ensuring superior real-time performance. The proposed model features a dual-optimized architecture that synergistically enhances both feature extraction and fusion capabilities, while systematically incorporating real-time design principles across the network. Through this comprehensive co-optimization, YOLO-UD demonstrates significant advancements over existing methods in addressing the key challenges of UAV image object detection. The main contributions are as follows:
-
To enhance the multi-scale feature extraction capability of our method, we design the C3kHR module in the backbone network. C3kHR uses dilated convolutions with various dilation rates to expand the receptive field, capturing features, positional information, and details of objects at different scales and granularity levels. This enhances and preserves more the feature representation of objects with different characteristics in UAV images.
-
To ensure that features at each scale can obtain valuable information from other feature layers, we design an efficient adaptive feature fusion network (EAFN). EAFN uses an efficient attention mechanism to aggregate important information distributed across multiple feature layers, blocking irrelevant information interference and providing higher quality features for the detection head. Additionally, to address the loss of small-object information during network down-sampling, higher-resolution feature layers are incorporated to supply more information about small objects.
-
To handle the large number of small objects in UAV images, we add a dedicated small-object detection layer (SMDL), which performs detection on higher-resolution feature maps. Furthermore, to improve the processing speed of the network, we replace the traditional down-sampling scheme with Adown, which reduces model parameters, enhances real-time performance. With the combined effect of the above methods, YOLO-UD achieves a better balance between speed and accuracy.
Related work
YOLO-based real-time object detection
In UAV-based object detection tasks, rapid processing of visual information is critically essential. Compared to two-stage object detection algorithms, single-stage algorithms offer significant advantages in real-time performance, making them more suitable for time-sensitive tasks such as UAV image object detection. Currently, the YOLO series dominate real-time object detection algorithms. The YOLOv1 algorithm28 employed a strategy of making individual predictions for each region, dividing an image into multiple grids where each grid predicts objects with centers located within it. This approach eliminates the need for the region proposal network used in two-stage algorithms, greatly reducing inference time. YOLOv229 introduced the anchor mechanism inspired by Faster R-CNN, leveraging K-means clustering to generate optimized anchor templates from the training data, which enhances recall rates and accelerating network convergence. YOLOv330 used the Darknet-53 network as its backbone for multi-scale feature extraction and incorporated a feature pyramid structure to better detect objects of varying sizes. YOLOv431 improved efficiency by incorporating CSPDarknet53 as its backbone and introducing an SPP module to enlarge the receptive field. YOLOv5 further reduced computational overhead by introducing the focus structure. Fundamental change in the regression strategy of the detection box in YOLOv832 compared to YOLOv5, adopting an anchor-free approach and replacing traditional IoU-based matching with the Task-Aligned Assigner, which offered a fast, accurate, and user-friendly method for various detection tasks. Recently, YOLO1133 further optimized YOLOv8, achieving a notable increase in speed while slightly improving accuracy, outperforming all prior YOLO models.
However, when YOLO series are applied to object detection tasks in UAV images, their performance drop significantly. These approaches fail to meet the unique characteristics of UAV images, which are critical for improving detection performance. Specifically, due to the limited information and weak representation of small objects in UAV images, YOLO often suffers from missed detections and false positives.
Object detection in UAV image
To address the challenges in UAV images, researchers developed customized designs based on general object detection algorithms. Lu et al.34 and gao et al.35 found that many small targets were undetected in the global detection of complete images. Their findings highlighted the importance of integrating both local and global region detection to enhance small object recognition accuracy. Yang at el.36 introduced a non-uniform cropping strategy that focuses only on regions densely populated with objects for fine detection. Leng at el.37 further improved this framework by employing the Reverse-Attention Exploration Module (REM) to identify challenging small-object regions and integrating global information to assist local detection, achieving significant performance gains. Liu at el.38 utilized the anchor-free detector CenterNet, leveraging its heatmap to describe focus areas, thereby improving detection speed and accuracy. However, although these focus-based detection frameworks achieved high precision, they often suffered from poor real-time performance. Therefore, considering that UAV-based applications often require better real-time performance, some works focused on customized designs based on single-stage detectors. Based on the multi-scale feature processing pipeline, existing approaches can be categorized into two aspects: multi-scale feature extraction and feature fusion.
Multi-scale feature extraction
UAV images exhibit significant scale variation among targets, with small objects representing a substantial portion of detection instances. In order to increase the receptive field, downsampling and convolution operations are stacked, which can cause information about small targets to be lost in deep features. Multi-scale feature extraction is key step, which can obtain rich feature information about targets of various sizes, effectively improving target detection accuracy. Gu et al.39 proposed a new parallel multi-branch attention mechanism GLE-AM, which simultaneously captures global and local features and the difference between them, making the global features more focused on the region where the object exists. While the proposed GLE-AM module significantly improves detection accuracy through multi-stage integration in the backbone network, this improvement comes at the cost of increased computational complexity, which was not systematically optimized. Ma et al.40 optimized the C3 module from the original YOLOv5 by adding multiple consecutive convolutions to enhance the backbone’s feature extraction capability. It enhances feature diversity and reduces information loss by performing dense connections between the outputs of multiple convolutional layers from bottom to top. Dilated convolution can increase the receptive field without losing resolution compared to standard convolution. By strategically adjusting dilation rates, it captures multi-scale context at the same feature level and retains more target information, making it an effective solution for dense prediction. Zhang et al.41 enhanced the residual module through a parallel multi-branch architecture employing 1\(\times\)1, 3\(\times\)3, and 5\(\times\)5 convolutions, constructing a multi-scale feature extraction module. This module is strategically positioned at the network’s deepest layer to strengthen multi-scale representation capabilities. While effective for dense target detection on VisDrone2019 dataset, the design necessitates channel compression to maintain computational efficiency, inadvertently discarding valuable feature information. Chalavadi et al.22 proposed a context extraction module composed of parallel dilated convolutions with varying dilation rates, deployed in the final two layers of backbone to model multi-target contextual relationships. This method achieves meaningful performance improvements in drone target detection tasks, but it does not take into account the loss of small target information in deep feature layers.
Current methods fail to simultaneously address the information loss problem for small objects, , effectively model contextual relationships and maintain high computational efficiency, thus falling short of achieving a satisfactory balance between accuracy and speed. Our method uses convolutions with multiple dilation rates, carefully structured to form Hierarchical Residual (HR) modules, combined with lightweight C3K module to ensure real-time processing capabilities while enhancing multi-target feature discrimination. Meanwhile, we embed the C3kHR model into the entire feature extraction process, increasing the receptive field in the early stages of feature extraction, modeling long-distance contextual relationships, and retaining sufficient target information.
Multi-scale feature fusion
In object detection networks, the effective interaction of shallow-level detail features (high resolution, rich edge/texture information) and high-level semantic features (strong category perception, large receptive field) is the core mechanism for achieving efficient detection. Cross-level feature fusion significantly improves the detection capability of multi-scale objects and enhances the robustness of the model. Wang et al.42introduced an attention-guided feature fusion framework, where adaptive gating coefficients are learned to optimally combine multi-scale feature representations. Their recursive feature pyramid architecture with information filtering capability achieves satisfactory results by preserving task-relevant features while eliminating interference from less informative feature components. Fan et al.43 tackled the insufficient multi-scale feature fusion problem by proposing Bi-PAN-FPN, which asross connecting multi-scale feature maps to provide more original object information for the detection process, reducing false positives and missed detections. Zhou et al.44 uses spatial channel attention (CBAM) to lock the feature information of the target in each feature input process of the PANet network structure based on FPN. To further enhance small-object detection capability, they integrate an SE attention45 within the top-down feature propagation path. This new feature fusion structure increases the utilization of multi-scale feature layer information by adding multiple attention modules, but it inevitably introduces additional computational overhead, resulting in both increased parameter count and reduced inference speed. Xiong et al.46 introduced a new feature fusion method on YOLOv5 that combines deep semantic features with shallow detailed features to prevent small object information loss. They also proposed an improved subspace attention mechanism to enhance the model’s spatial localization capability for small objects.

Feature fusion structure based on FPN.
The aforementioned feature fusion structures are designed based on the FPN architecture, utilizing a hierarchical, multi-path progressive aggregation strategy. As illustrated in Fig. 2, deep-layer features must undergo iterative upsampling and interact with intermediate-layer features before being transmitted to shallow layers (e.g., Level 1 requires relay through Level 2 and Level 3 to fuse with Level 4). This propagation process leads to semantic information being diluted or diminished.
We argue that minimizing intermediate processing paths in feature fusion can better preserve the integrity of the original information. Thus, unlike existing methods, we introduce a cross-layer direct connection fusion mechanism that enables any two multi-scale features to be fused directly through joint attention. Our approach allows flexible aggregation of critical information scattered across multi-scale feature layers. Moreover, many existing approaches focus solely on detection accuracy while inadequately addressing the limited processing capabilities of embedded edge devices. Therefore, in this work, we propose a synergistic approach that co-optimizes feature extraction and feature fusion, explicitly addressing the critical trade-off between accuracy and speed for UAV image object detection.
Proposed method
Overall architecture
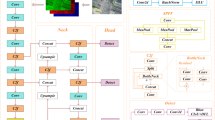
UAV images have a wide field of view and contain numerous small objects amidst complex backgrounds, posing challenges for the interpretation of visual information. In this article, we propose YOLO-UD, a robust, reliable, and real-time UAV image object detection algorithm designed to address the challenges. Based on the YOLO11 network, its overall structure consists of three main components, as shown in Fig. 3. Backbone: performs high-quality multi-scale feature extraction on UAV images. Neck: fuses multi-scale information to adapt to objects of varying sizes. Detection head: locates object positions and classifies them based on the fused feature maps.
For channel adaptation and downsampling of the input image in the backbone network, we jointly use CBS (Conv, BN, SiLU) modules with different convolution kernels and lightweight ADown modules from YOLOv9. Additionally, we design the C3kHR module to be embedded into the feature extraction process of the entire network to extract multi-granularity contextual information and capture features of objects at various granularities. Considering the efficiency of dilated convolutions compared to standard convolutions with large kernels, in C3kHR we employ convolutions with different dilation rates to design the Hierarchical Residual (HR) module. This enhances the model’s receptive field during the early stages of feature extraction and enables the capture of more challenging target information. Subsequently, the high-level features are passed through the SPPF and C2PSA modules to enhance the feature representation. Finally, the backbone network generates feature maps of different sizes. In the neck, we propose an Efficient Adaptive Feature Fusion Network (EAFN) used direct cross-layer fusion strategy, which takes four multi-scale feature layers from the backbone as input. EAFN performs direct fusion between any two feature maps, ensuring each scale layer can leverage key information from others. In the detection head, a dedicated small-object detection layer is added to enhance detection performance for small targets. A lightweight decoupled detection head is then employed for separate localization and classification tasks. These combined improvements enhance robustness and enable the model to effectively handle the complexities of UAV image object detection.

The architecture of our proposed YOLO-UD. Where the modules denoted by colours like SPPF, Detect, CBS and C2PSA are modules from the original YOLO11. The settings of C3k=True for deep features and C3k=False for shallow features also follow the best experimental settings of YOLO11.
C3kHR module
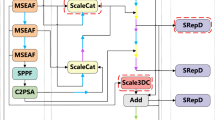
The ability of a network to extract multi-scale features significantly impacts detection results, particularly in the context of UAV images, which are characterized by targets exhibit significant scale variations, accompanied by prevalent small objects with limited pixel resolution and frequent occlusions. During feature extraction, the information pertaining to small objects tends to degrade progressively. Robust and adequate feature representation and comprehensive contextual information can have a positive impact on the detection results. The backbone network of YOLO11 mainly uses the C3K module for feature extraction, which fully considers computational efficiency and feature extraction capabilities. Nevertheless, since the C3K module is based on standard convolution operations, its limited receptive field inherently restricts its ability to preserve comprehensive target information. Therefor, we design a more efficient multi-scale feature extraction module called the Hierarchical Residual (HR) module, which is combined with the lightweight C3k module from YOLO11 to form the C3kHR module, as shown in Fig.2. The proposed C3kHR module is specifically engineered to effectively capture multi-scale contextual information and enriched feature representations throughout the entire feature extraction pipeline.
The proposed HR is show in Fig.4. In HR module, a 3x3 convolution with a BN layer and SiLU activation is first applied to perform basic feature extraction and activate regional features. Given the efficiency of dilated convolutions compared to standard convolutions with large kernels, we construct the core part of the HR module using parallel connections of dilated convolutions. Multi-rate dilated convolutions (DConv) are then used to generate \(H_1,H_2,H_3\) to expand the receptive field and capture changes in target perspectives and sizes, which effectively capturing contextual information of targets at multiple granularity levels and enhancing the robustness of feature representation for objects of different scales. For the convolution with a dilation rate of 1, we extend the feature map depth from n to 2n to represent more object detail information effectively. The remaining parallel branches maintain their original channel outputs while employing dilated convolutions with larger dilation rates to capture long-range dependencies and substantially expand the model’s receptive field. After refining target feature representation and capturing multi-granularity contextual information, the outputs are concatenated. A 1x1 convolution is then applied to fuse these features. Finally, the input feature maps are added to the fused features using a residual connection, producing more comprehensive and stable feature representations. This process can be represented by the following equation:
where DConv stands for dilated convolution, CBS stands for Convolution + Batch Normalization + Silu activation function.

The architecture of Hierarchical Residual (HR) module, n denotes the number of channel of features. The r is dilation rate of the convolution.
Efficient adaptive feature fusion network (EAFN)
Traditional FPN-based feature fusion methods suffer from indirect multi-path fusion structures, leading to insufficient information exchange and inefficient fusion, leaving significant room for improvement in detection performance47. Therefore, we propose an Efficient Adaptive Feature Fusion Network (EAFN) to achieve fuller information interaction of multi-scale feature maps. The EAFN uses a cross-layer direct fusion strategy in the feature fusion process, locking important information distributed across multi-scale feature layers by assigning learned joint attention weights, thereby preventing interference from irrelevant information. As illustrated in Fig. 2, we utilize four multi-scale feature maps extracted from the backbone as inputs to the EAFN module. EAFN-1, EAFN-2, EAFN-3, and EAFN-4 denote the feature fusion of the corresponding layers, respectively. In EAFN, the fusion of the corresponding layer and other layer features respectively is performed.
Specifically, we take EAFN-2 as an example to explain the working principle of our EAFN module. First, features from other levels (Level-1, Level-3, Level-4) are resized to match the dimensions of the Level-2 by \(1 \times 1\) convolution and upsampling or downsampling. Then, the other layers are fused to L2 in turn, respectively. Thus the input to EAFN is two features at a single time. Our model flexibly chooses between using the high-level branch or low-level branch processing based on the resolution of the original feature maps. Among any two input features, high-level feature (original feature with low resolution) is processed by the high-level branch, while low-level feature (original feature with high resolution) is processed by the low-level branch. In this way, the other layers interact with Level-2 separately.

The structure of efficient adaptive feature fusion network. The CCB denote Concat+Conv+BN. MUL is kronecker product. L-high represents feature processed by the high-level branch, and L-low similarly for the low-level branch.
The structure of the EAFN is illustrated in Fig. 5. First, we concatenate the two input features to generate a joint feature (\(E_{joint}\)). Then, attention weights are allocated based on the joint feature information. Specifically, in high-level branch, \(E_{joint}\) generates a \(1\times H \times W\) feature map through \(1 \times 1\) convolution, which is then reshaped into a \((H \times W)\) vector. Subsequently, an efficient 1D convolution is applied to produce spatial attention weights (\(W_s\)), a design choice motivated by real-time processing considerations. Next, these weights are reshaped to match the spatial resolution of the \(L\_high\) and normalized through Sigmoid. Finally, \(W_s\) are applied to \(L\_high\) to retain critical information while filtering irrelevant details introduced during dimension matching before feeding EAFN. Similarly, in the low-level branch, generates a \(C\times 1\times 1\) feature through adaptive average pooling, and then channel attention weights (\(W_c\)) are produced via an efficient 1D convolution followed by a sigmoid function. The \(W_c\) are used to capture more detailed information, such as color and texture. The weighted features from both branches are then concatenated and processed through a convolution layer to facilitate feature interaction, producing the fused features (called \(P_{21},P_{23},P_{24}\)). Subsequently, the fused features are combined via addition to generate the output of the corresponding layer’s feature fusion process (e.g., \(F_2 = P_{21}+P_{23}+P_{24}\)). Finally, these outputs (F1, F2, F3, F4) are further refined using the C3kHR module and then fed into the detection head. By jointly allocating attention, EAFN can flexibly and directly extract critical information for the final prediction from other feature layers. The processing of EAFN can be described by the following equation:
where EConv is efficient 1D convolution, and R denotes reshape. \(A\breve{\,}avgpool\) performs 2D adaptive average pooling.
Small object detection layer (SMDL)
In the original YOLO11, three feature maps are used to detect targets of large, medium, and small sizes. However, UAV images often contain numerous small targets. During multiple down-sampling processes, the information about small targets diminishes, and the original three-scale feature layers may not provide sufficient small-target information, making the detection network prone to missing small targets. Therefore, we introduce a small-object detection layer in the detection head and feed the high-resolution feature layer Level-1 into the feature fusion module, which provide more information about small objects48. Specifically, the original three feature layers at different scales (Level-2, Level-3, Level-4) are fused with Level-1 by EAFN to produce combined features, which are then passed to the detection head. During the feature fusion process, the high-resolution Level-1 layer provides detailed information and precise localization for small objects, while additional small-object features are supplemented from the other feature layers, enhancing the detection performance for small objects. A lightweight decoupled detection head is added to the small-object detection branch, reducing computational complexity while effectively handling localization and classification. This method reduces the miss rate and false detection rate for small objects, improves the detection accuracy of small objects in UAV images, and makes a meaningful contribution to the overall performance of our algorithm.
Experiments
Dataset
We mainly use two benchmark datasets to evaluate our algorithm in UAV image object detection: VisDrone201949 and UAVDT50. VisDrone2019 is a representative UAV dataset, consisting of 8599 images, containing 10 object categories: Pedestrain, Motor, Van, Person, Truck, Car, Bus, Awning, Bicycle and Tricycle. It includes a variety of complex environments and scenes, such as urban, rural, and highway areas, and covers different weather conditions, times, flight heights, and camera angles. Following previous work51, we use 6,471 images for training and 548 images for testing. The UAVDT dataset is collected by UAVs across a range of complex environments. It comprises images extracted from 100 video sequences recorded in different cities, under varying scenes and altitudes, with annotations for Cars, Truck, and Bus, totaling more than 80,000 labeled instances. Following previous works5227, we randomly selected 3000 images and split them into a training set and a validation set with an 8:2 ratio.

Statistical analysis of category-wise instance distribution: (a) VisDrone2019, (b) UAVDT.
As shown in the Fig. 6, Fig. 6a displays the number of instances per category in VisDrone2019, while Fig. 6b presents the instance count for each category in UAVDT. It can be seen some additional characteristics in these datasets. First, the number of instances per category is substantial in both datasets, yet there is a significant imbalance between different categories. In VisDrone2019, for example, the Car class has 144,867 instances, whereas Awning only has 3,246. Similarly, in UAVDT, the Car class significantly outnumbers the other two categories. The imbalanced distribution of samples across classes imposes higher demands on the robustness of the detection model. Second, there exist easily confusable categories, such as Ped and Person, which are difficult to distinguish in certain scenarios. Despite these challenges, both datasets effectively represent real-world aerial scenarios, particularly in terms of small object detection, dense object clustering, and real-time processing demands. Their diversity enables a rigorous assessment of aerial detection algorithms under practical conditions.
Experimental setting
Experimental details: under the open-source PyTorch framework, we evaluated the performance of our proposed YOLO-UD. Images were resized to 640\(\times\)640 without complex preprocessing. To ensure fairness, no pre-trained weights were used, and the model was trained for 300 epochs. During optimization, we used the SGD optimizer with a momentum of 0.9 and a initial learning rate of 0.01. The training and validation processes were conducted on two RTX 3090 GPUs with batch size 16. The other configurations are the same as Ultralytics53.
Evaluation metrics: on the VisDrone2019 and UAVDT datasets, following previous work, this article uses mAP with \(IOU=0.5\), FPS, Parameters (Para), and GFLOPs as metrics to compare and evaluate our model against other methods. AP, a key metric for assessing model performance, represents the area under the PR curve, offering a comprehensive evaluation of Precision and Recall. mAP is the average AP across all categories. AP and mAP are de defined as:
In the PR curve, P stands for Precision and R for Recall. Precision and Recall are de defined as:
FPS reflects the processing speed of the algorithm, with its value being influenced by both the network weight and the hardware configuration of the testing equipment.
GFLOPs denote the number of floating-point operations performed during the forward propagation of a model, serving as a measure of the model’s computational complexity. Parameters are used to measure the size of the model.
Experimental analyses
Quantitative analysis
First, we validate the effectiveness of our proposed model on the VisDrone2019 dataset by comparing it with several excellent YOLO series methods. As shown in Table 1, compared to the baseline YOLO1133, our smallest model, YOLO-UD-n, achieves a 5.9% performance improvement with only a slight increase in parameters, while the YOLO-UD-s model also demonstrates meaningful improvements (+5.9%). When compared with other classical YOLO series algorithms, our model shows a large advantage in both speed and accuracy. For instance, compared to the recently proposed YOLOv12n and YOLOv12s56, our model demonstrates significant improvements in both processing speed (FPS: +10, +6) and detection accuracy (mAP: +7.8%, +7.1%) for UAV image object detection tasks. Moreover, our model outperforms YOLO series methods in terms of class-wise Average Precision. As mentioned in the previous section, the performance of the classical YOLO series algorithms directly migrated to UAV image object detection is significantly dropped, and these conclusions can fully prove that our model can effectively solve this problem. Regarding the FPS metric, although there is a slight drop compared to the lightweight YOLO11 baseline, our model still achieves real-time processing for UAV images, maintaining a good balance between accuracy and speed. Since inference speed is hardware-dependent, particularly on resource-constrained embedded devices. To rigorously evaluate practical deployment potential, we conducted comprehensive inference speed analysis on resource-constrained Jetson Orin NX platform. As demonstrated in Table 2, YOLO-UD achieves an inference speed of 24.6 ms per frame (\(\approx\) 40.7 FPS), and it meets real-time requirements (\(>30\) FPS) for UAV applications. Compared with advanced competitors including FEYOLO62 and recent YOLO variants, our model maintains superior performance under computational constraints, demonstrating strong robustness across diverse deployment environments.
Meanwhile, Table 1 presents a comparison between our YOLO-UD and state-of-the-art methods in UAV image object detection field. Our YOLO-UD achieves the best mAP (39.5% and 45.5%) results among all the compared algorithms, with a 4.3% and 3.8% improvement over the recently proposed LUDY-n and LUDY-s, respectively. Similarly, our YOLO-UD-s outperforms AD-YOLO57 and EDGS-YOLOv858 by a clear margin (e.g., +7.4% and +14.2% in mAP), which further solidifies our superiority in detection accuracy. Furthermore, our lightweight variant (YOLO-UD-n) demonstrates significant advantages over recent efficient models. Compared to FEYOLO62, YOLO-UD-n not only achieves a higher mAP (+4.6%) but also reduces the number of parameters by 47%, highlighting superior architectural efficiency. When compared to PSO-YOLO63, our YOLO-UD-n delivers a more substantial performance gain with an +8.6% improvement in mAP, despite a moderate increase in parameters (2.59M to 3.3M), indicating that the added computational cost is justified by a significant boost in accuracy. These comparisons clearly demonstrate the performance superiority and excellent design trade-offs of our method. According to the FPS metric, our model achieves the fastest speeds compared to other methods, which proves that the structure of our model is much finer. Moreover, these results deliver optimal performance across most categories. While the AP for the ’Truck’ (39.3% vs. 45.3%) and ’Awn’ (18.8% vs. 20.7%) categories is slightly lower than that of UAV-YOLO20, our method demonstrates significant improvements for other challenging objects, notably for small objects such as Person, Pedestrian, and Motor. These results indicate that our optimized model, based on YOLO11, exhibits stronger overall adaptability for UAV image object detection tasks.

Visual comparison of metric values between our YOLO-UD algorithm and other models in UAVDT. X-axis represents model categories, while Y-axis indicates metric values.
To further validate the generalization capability of our method, this paper explores its performance on the UAVDT dataset using various one-stage methods. Unlike previous comparisons, we focus solely on YOLO series benchmark models and their improved variants. The experimental results are shown in Table 3, where our YOLO-UD-s achieves an overall threshold-wise mAP of 90.6, surpassing all compared methods and gaining a 5.5% improvement over the baseline model YOLO11s. In addition, our model achieves the best in both Precision, Recall and class-wise AP metrics. Similarly, we optimise on YOLO11 to make it suitable for UAV image target detection, thus introducing additional parameters and a slight decrease in FPS metrics compared to YOLO11. But our method outperforms other models on the FPS metric and still meets the real-time performance. Looking at multiple metrics together, our method achieves a good balance of speed and accuracy.
Finally, to more intuitively demonstrate our model’s performance within the YOLO series benchmark models and their improved variants, we employ histogram visualization for comparative evaluation. As show in Fig. 7, the results clearly indicate our model’s superior comprehensive performance. Our model achieves higher mAP than comparable models with similar parameter counts. In terms of category-wise AP, our model achieves the best performance among models of the same magnitude, while demonstrating corresponding improvements in both Recall and Precision. Extensive comparative experiments demonstrate the efficacy of the proposed enhancement strategies, with YOLO-UD exhibiting superior object detection performance and robust generalization capabilities across different dataset.
The above results across diverse datasets highlight the robustness and strong generalization capability of our proposed model, particularly in capturing features of small objects and other challenging samples. These outcomes confirm that our model, combined with the C3kHR module, efficient adaptive feature fusion network, and the small object detection layer, effectively handles the challenges of small objects and multi-scale targets in UAV images across diverse scenarios. Importantly, the design of our model prioritizes computational efficiency, a crucial factor in maintaining real-time inference capabilities without compromising its competitive accuracy.
Qualitative analysis
The Fig. 8 compares the detection results of our model with the baseline YOLO11. The experimental results were evaluated across several representative detection scenarios, including: complex backgrounds, densely clustered small objects, long-distance camera perspectives, and occluded targets. It can be observed in the black box that our model detects more small (Person) and distant objects (Car) while reducing misclassifications. And our model is still able to detect some occluded targes. Additionally, Fig. 9 demonstrates YOLO-UD’s detection results in some complex scenarios, showing its ability to precisely capture and localize objects of varying scales. The white box on the image demonstrates that our model is able to detect more targets that are not easily observed under dim light conditions.

Comparison of detection results between our YOLO-UD algorithm and the baseline YOLO11.
Finally, we compare the attention regions of our model against the baseline through representative samples to visually demonstrate its superior target localization capability. As depicted in Fig. 10, the first row displays detection performance for dense small objects under normal weather conditions, the second row presents target detection in challenging high-interference scenarios, and the third row shows nighttime detection cases. Through systematic attention analysis of the feature fusion layers, our model demonstrates precise localization of target regions. This indicates that the detector optimized with our strategy can more effectively extract multi-scale features from UAV images, distinguish targets from complex environments, and significantly enhance the perception of small objects.

Comparison of detection results in some complex scene between our YOLO-UD algorithm and the baseline YOLO11.
These results confirm that our model performs equally well on targets of different scales and in complex backgrounds, demonstrating superior adaptability and robustness in UAV images object detection. The backbone network is equipped with an efficient multi-scale feature extraction module (C3kHR) to enhance feature contextual representation. An effective fusion strategy (EAFN) is employed to integrate multi-scale features by capturing critical information while filtering out interfering noise. Furthermore, a lightweight small object detection layer (SMDL) in the head focuses on small targets. Together, these methods significantly enhance the detection performance of our model.

Visualization of attention heatmaps.
Ablation experiment
This section primarily validates the contributions of the C3kHR, efficient multi-scale feature fusion network (EAFN), small object detection layer (SMDL), and the down-sampling module (ADown). In this part, we use YOLO-UD-n on the VisDrone2019 dataset to experimentally verify the effect of each module. The ablation experiments evaluate Precision (P), Recall (R), mean Average Precision (mAP), Frames Per Second (FPS), and Parameters. The results of the ablation experiments are presented in the Table 4.

Module contribution visualization. The X-axis enumerates model variants integrating specific modules, while Y-axis indicates metric values.
From the Table 4, it can be observed that adding the small object detection layer results in a 2.4 % increase in mAP, along with improvements in Precision and Recall. The performance gain contributed by the SMDL demonstrates its ability to provide additional information about small targets during the detection process. Subsequently, introducing the C3kHR module into the backbone network shows an overall upward trend in the evaluation metrics, with mAP reaching 37.9%. The proposed C3kHR module addresses a critical limitation in conventional convolutional operations by strategically expanding the model’s receptive field through its unique architecture. This design enables the network to capture richer contextual information across different spatial scales, which is particularly advantageous for UAV object detection where targets exhibit significant size variations. Experimental results from our ablation studies confirm that C3kHR’s expanded receptive field preserves intricate details of small objects through localized feature retention while concurrently capturing broader contextual relationships for obscured targets via comprehensive feature integration. At the same time, it highlights that enhancing the feature extraction capabilities of the backbone network positively impacts detection results. When only EAFN and SMDL are used, the contextual information fusion and key feature capture capabilities of EAFN enable the mAP to reach 38%. Meanwhile, the large-scale feature layers provide additional small object information to the detection head during multi-scale feature interaction, ensuring that Precision and Recall consistently maintain excellent levels throughout the detection process. When EAFN, C3kHR, and SMDL are combined, the mAP improves by 6.5% compared to the baseline model. Although the combined use of these modules slightly increases the number of parameters and reduces FPS to 210, our method still ensures real-time detection performance. Finally, to better balance accuracy and speed, the ADown module is added to replace convolution-based down-sampling. Although the accuracy is slightly reduced, the number of parameters has been reduced by 20%. Such lightweight optimization ensures that our model achieves a good balance between accuracy and speed, making it more suitable for deployment on edge devices.
Furthermore, to visually demonstrate the contribution of each module, we employ histogram representations to illustrate the variations in performance metrics including Precision (P), Recall (R), mean Average Precision (mAP), and Parameters. As illustrated in Fig. 11, the results clearly indicate that the combined implementation of SMDL, C3kHR, and EAFN modules yields optimal mAP and Recall performance. Notably, the incorporation of C3kHR (YOLO11n-D) results in a marginal decrease in Precision while achieving a significant improvement in Recall. We hypothesize this phenomenon may stem from C3kHR’s enhanced capability to capture discriminative features from challenging targets, potentially introducing minor fluctuations in Precision. Overall, our comprehensive evaluation demonstrates that the proposed optimization strategies effectively enhance the baseline model’s performance.

Performance comparison on each category between our YOLO-UD algorithm and the baseline YOLO11. The blue line in the center represents the Precision of baseline YOLO11. Each category and corresponding accuracy is shown in the outermost circle (blue font). The gray line represents the magnification of the Precision compared to the baseline.
Finally, we use using a radar chart to show the performance contribution of our model on each category. As shown in the Fig. 12, the improvement on the Person, Ped and Bicycle categories is more obvious, proving that our model has more prominent detection ability on small targets and can be better suited for real-world UAV image object detection tasks.
To further demonstrate the generalization capability and effectiveness of our proposed modules, we conduct extensive ablation studies on representative one-stage (CenterNet) and two-stage (Faster R-CNN) frameworks. The contributions of each module are presented in Table 5. Our observations reveal that in the two-stage Faster R-CNN framework7, the simultaneous application of all three modules improves the mAP from 17.7% to 21.4%. Notably, when employing the lightweight ADown module, no performance degradation is observed, unlike in YOLOv11. Similarly, the synergistic integration of our modules with one-stage CenterNet framework demonstrates a notable 5.2% mAP gain, showcasing their complementary benefits. A particularly noteworthy finding is the significant enhancement in recall metrics across both model types, with recall rates increasing from 8.7% to 13.2% for Faster R-CNN and from 6.2% to 10.7% for CenterNet, indicating that our method effectively captures features of challenging targets. Comprehensive data analysis demonstrates that our modules make meaningful contributions to both two-stage and one-stage detection frameworks. These extended experimental results robustly validate the effectiveness of our proposed modules in UAV-based object detection tasks while highlighting their strong generalization capability across diverse architectural frameworks.
Conclusion and future work
In this paper, we analyze the challenges of object detection in UAV (unmanned aerial vehicle) aerial images and propose a feature-enhanced real-time object detection network for unmanned aerial vehicle images, called YOLO-UD. To address these issues, we introduce the C3kHR module, which captures rich contextual information by employing dilated convolutions at varying rates. This enables superior multi-scale feature extraction, providing high-quality feature layers and detailed target information. Additionally, we design an efficient adaptive multi-scale feature fusion network (EAFN) to enhance the selection and interaction of useful information in multi-scale features during the detection process. A small-object detection layer is also introduced to address the large number of small objects present in UAV images. Finally, we replaced our downsampling module with the Adown module from YOLOv9 to further enhance real-time performance. Through the combined effects of these modules, YOLO-UD improves resistance to interference from complex backgrounds, captures more target information, and effectively enhances object detection performance. Comparisons on the VisDrone2019 and UAVDT datasets demonstrate YOLO-UD’s excellent performance and robustness, achieving a meaningful balance between speed and accuracy, and significantly improving UAV image object detection capabilities.
Although our proposed method demonstrates strong performance in UAV object detection tasks, it still has certain limitations. First, while the C3kHR module effectively extracts rich target features during the feature extraction stage, it also retains substantial background information without an efficient mechanism to filter out irrelevant background noise. Additionally, we observed some false detections, particularly in regions with densely distributed small objects, leading to occasional misclassifications. From an overall performance perspective, the slight increase in model parameters leads to a reduction in real-time inference speed, which may hinder its deployment on high-efficiency edge devices with strict latency constraints. Consequently, the speed-accuracy trade-off presents considerable opportunities for further optimization. In future work, we will further leverage attention mechanisms to enhance the network’s utilization of contextual knowledge of various objects, thereby improving the algorithm’s accuracy in detecting dense and occluded small targets. At the same time, we aim to enhance the algorithm’s real-time performance and its capability for deployment on edge devices.
Data availability
The datasets used and analyzed during the current study are available from the corresponding author upon reasonable request.
References
Xue, Y. et al. Smalltrack: Wavelet pooling and graph enhanced classification for UAV small object tracking. IEEE Trans. Geosci. Remote Sens. 61, 1–15 (2023).
Wu, C., Ye, M., Li, H. & Zhang, J. Object detection model design for tiny road surface damage. Sci. Rep. 15, 11032 (2025).
Xue, Y. et al. Consistent representation mining for multi-drone single object tracking. IEEE Trans. Circuits Syst. Video Technol. 34, 10845–10859 (2024).
Rao, J. et al. Path planning for dual UAVs cooperative suspension transport based on artificial potential field-a* algorithm. Knowl.-Based Syst. 277, 110797 (2023).
Xue, Y. et al. Avltrack: Dynamic sparse learning for aerial vision-language tracking. In IEEE Transactions on Circuits and Systems for Video Technology (2025).
Girshick, R., Donahue, J., Darrell, T. & Malik, J. Region-based convolutional networks for accurate object detection and segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 38, 142–158 (2015).
Ren, S., He, K., Girshick, R. & Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 39, 1137–1149 (2016).
Cai, Z. & Vasconcelos, N. Cascade r-cnn: Delving into high quality object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 6154–6162 (2018).
Zhang, H., Chang, H., Ma, B., Wang, N. & Chen, X. Dynamic r-cnn: Towards high quality object detection via dynamic training. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XV 16. 260–275 (Springer, 2020).
Sun, P. et al. Sparse r-cnn: End-to-end object detection with learnable proposals. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 14454–14463 (2021).
Wang, C.-Y., Bochkovskiy, A. & Liao, H.-Y. M. Yolov7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 7464–7475 (2023).
Wang, C.-Y., Yeh, I.-H. & Mark Liao, H.-Y. Yolov9: Learning what you want to learn using programmable gradient information. In European Conference on Computer Vision. 1–21 (Springer, 2025).
Wang, A. et al. Yolov10: Real-time end-to-end object detection. arXiv preprint arXiv:2405.14458 (2024).
Zhou, X., Wang, D. & Krähenbühl, P. Objects as points. arXiv preprint arXiv:1904.07850 (2019).
Yang, Z., Liu, S., Hu, H., Wang, L. & Lin, S. Reppoints: Point set representation for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 9657–9666 (2019).
Zhou, X., Zhuo, J. & Krahenbuhl, P. Bottom-up object detection by grouping extreme and center points. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 850–859 (2019).
Yao, Z., Ai, J., Li, B. & Zhang, C. Efficient Detr: Improving end-to-end object detector with dense prior. arXiv preprint arXiv:2104.01318 (2021).
Xue, Y. et al. Handling occlusion in UAV visual tracking with query-guided redetection. In IEEE Transactions on Instrumentation and Measurement (2024).
Xue, Y. et al. Target-distractor aware UAV tracking via global agent. In IEEE Transactions on Intelligent Transportation Systems (2025).
Tan, S., Duan, Z. & Pu, L. Multi-scale object detection in UAV images based on adaptive feature fusion. Plos one 19, e0300120 (2024).
Khanam, R. & Hussain, M. What is yolov5: A deep look into the internal features of the popular object detector. arXiv preprint arXiv:2407.20892 (2024).
Chalavadi, V. et al. msodanet: A network for multi-scale object detection in aerial images using hierarchical dilated convolutions. Pattern Recognition 126, 108548 (2022).
Tan, M., Pang, R. & Le, Q. V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 10781–10790 (2020).
Li, W., Wei, W. & Zhang, L. Gsdet: Object detection in aerial images based on scale reasoning. IEEE Trans. Image Process. 30, 4599–4609 (2021).
Liu, H.-I. et al. A denoising FPN with transformer r-cnn for tiny object detection. IEEE Trans. Geosci. Remote Sens. 62, 1–15 (2024).
Dosovitskiy, A. et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929 (2020).
Fan, Q., Li, Y., Deveci, M., Zhong, K. & Kadry, S. Lud-yolo: A novel lightweight object detection network for unmanned aerial vehicle. Inf. Sci. 686, 121366 (2025).
Redmon, J. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (2016).
Redmon, J. & Farhadi, A. Yolo9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 7263–7271 (2017).
Farhadi, A., & Redmon, J. Yolov3: An incremental improvement. In Computer Vision and Pattern Recognition. Vol. 1–6 (Springer, 2018).
Bochkovskiy, A., Wang, C.-Y. & Liao, H.-Y. M. Yolov4: Optimal speed and accuracy of object detection. arXiv preprint arXiv:2004.10934 (2020).
Reis, D., Kupec, J., Hong, J. & Daoudi, A. Real-time flying object detection with yolov8. arXiv preprint arXiv:2305.09972 (2023).
Khanam, R. & Hussain, M. Yolov11: An overview of the key architectural enhancements. arXiv preprint arXiv:2410.17725 (2024).
Lu, Y., Javidi, T. & Lazebnik, S. Adaptive object detection using adjacency and zoom prediction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2351–2359 (2016).
Gao, M., Yu, R., Li, A., Morariu, V. I. & Davis, L. S. Dynamic zoom-in network for fast object detection in large images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 6926–6935 (2018).
Yang, F., Fan, H., Chu, P., Blasch, E. & Ling, H. Clustered object detection in aerial images. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 8311–8320 (2019).
Leng, J. et al. Pareto refocusing for drone-view object detection. IEEE Trans. Circuits Syst. Video Technol. 33, 1320–1334 (2022).
Liu, C. et al. Yolc: You only look clusters for tiny object detection in aerial images. In IEEE Transactions on Intelligent Transportation Systems (2024).
Gu, Q., Huang, H., Han, Z., Fan, Q. & Li, Y. Glfe-yolox: Global and local feature enhanced yolox for remote sensing images. In IEEE Transactions on Instrumentation and Measurement (2024).
Ma, C. et al. Yolo-UAV: Object Detection Method of Unmanned Aerial Vehicle Imagery Based on Efficient Multi-Scale Feature Fusion. (IEEE Access, 2023).
Zhang, M., Zhang, B., Liu, M. & Xin, M. Robust object detection in aerial imagery based on multi-scale detector and soft densely connected. IEEE Access 8, 92791–92801 (2020).
Wang, J., Yu, J. & He, Z. Arfp: A novel adaptive recursive feature pyramid for object detection in aerial images. Appl. Intell. 52, 12844–12859 (2022).
Li, Y., Fan, Q., Huang, H., Han, Z. & Gu, Q. A modified yolov8 detection network for UAV aerial image recognition. Drones 7, 304 (2023).
Zhou, Y. A yolo-nl object detector for real-time detection. Expert Syst. Appl. 238, 122256 (2024).
Hu, J., Shen, L. & Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 7132–7141 (2018).
Xiong, X. et al. Adaptive feature fusion and improved attention mechanism based small object detection for UAV target tracking. IEEE Internet Things J. (2024).
Wang, C. et al. Gold-yolo: Efficient object detector via gather-and-distribute mechanism. Adv. Neural Inf. Process. Syst. 36 (2024).
Yang, R., Li, W., Shang, X., Zhu, D. & Man, X. Kpe-yolov5: An improved small target detection algorithm based on yolov5. Electronics 12, 817 (2023).
Zhu, P., Wen, L., Bian, X., Ling, H. & Hu, Q. Vision meets drones: A challenge. arXiv preprint arXiv:1804.07437 (2018).
Du, D. et al. The unmanned aerial vehicle benchmark: Object detection and tracking. In Proceedings of the European Conference on Computer Vision (ECCV). 370–386 (2018).
Yang, C., Huang, Z. & Wang, N. Querydet: Cascaded sparse query for accelerating high-resolution small object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 13668–13677 (2022).
Jiang, L. et al. Mffsodnet: Multi-scale feature fusion small object detection network for UAV aerial images. In IEEE Transactions on Instrumentation and Measurement (2024).
Jocher, G. & Qiu, J. Ultralytics yolo11 (2024).
Ge, Z. Yolox: Exceeding yolo series in 2021. arXiv preprint arXiv:2107.08430 (2021).
Wang, C.-Y., Yeh, I.-H. & Mark Liao, H.-Y. Yolov9: Learning what you want to learn using programmable gradient information. In European Conference on Computer Vision. 1–21 (Springer, 2024).
Tian, Y., Ye, Q. & Doermann, D. Yolov12: Attention-centric real-time object detectors. arXiv preprint arXiv:2502.12524 (2025).
Zhou, W., Cai, C., Li, C., Xu, H. & Shi, H. Ad-yolo: A real-time yolo network with swin transformer and attention mechanism for airport scene detection. In IEEE Transactions on instrumentation and Measurement (2024).
Huang, M., Mi, W. & Wang, Y. Edgs-yolov8: An improved yolov8 lightweight UAV detection model. Drones 8, 337 (2024).
Mao, G., Deng, T. & Yu, N. Object detection in UAV images based on multi-scale split attention. Acta Aeronaut. Astronaut. Sin 43, 326738 (2022).
Yue, M., Zhang, L., Huang, J. & Zhang, H. Lightweight and efficient tiny-object detection based on improved yolov8n for UAV aerial images. Drones 8, 276 (2024).
Zhong, R. et al. Spd-yolov8: An small-size object detection model of UAV imagery in complex scene. J. Supercomput. 80, 17021–17041 (2024).
Cai, S., Meng, H. & Wu, J. Fe-yolo: Yolo ship detection algorithm based on feature fusion and feature enhancement. J. Real-Time Image Process. 21, 1–13 (2024).
Zhao, Z., Liu, X. & He, P. Pso-yolo: A contextual feature enhancement method for small object detection in UAV aerial images. Earth Sci. Inform. 18, 258 (2025).
Anggraini, N. et al. Development of face mask detection using ssdlite mobilenetv3 small on raspberry pi 4. In 2022 5th International Conference of Computer and Informatics Engineering (IC2IE). 209–214 (IEEE, 2022).
Dai, Y., Zhao, P. & Wang, Y. Maturity discrimination of tobacco leaves for tobacco harvesting robots based on a multi-scale branch attention neural network. Comput. Electron. Agric. 224, 109133 (2024).
Wu, Y., Tang, Y. & Yang, T. An improved nighttime people and vehicle detection algorithm based on yolo v7. In 2023 3rd International Conference on Neural Networks, Information and Communication Engineering (NNICE). 266–270 (IEEE, 2023).
Acknowledgements
The authors would like to thank the National Key R&D Program of China (No. 2019YFE0105400) for providing support for this paper.
Author information
Authors and Affiliations
Contributions
Junbao Wu. wrote the main manuscript text , methodology, conceptualization, review and editing manuscript text , Ming Yuan. validation, visualization; Chang Liu. formal analysis, Junbao Wu.; , Zhe Lu. data curation; Hao Meng. project administration and funding acquisition; All authors have read and agreed to the published version of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Wu, J., Meng, H., Yuan, M. et al. Enhanced feature representation for real time UAV image object detection using contextual information and adaptive fusion. Sci Rep 15, 33711 (2025). https://doi.org/10.1038/s41598-025-19145-w
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-19145-w
