
Abstract
Hyperthermia (HT) in combination with radio- and/or chemotherapy has become an accepted cancer treatment for distinct solid tumour entities. In HT, tumour tissue is exogenously heated to temperatures between 39 and 43 °C for 60 min. Temperature monitoring can be performed non-invasively using dynamic magnetic resonance imaging (MRI). However, the slow nature of MRI leads to motion artefacts in the images due to the movements of patients during image acquisition. By discarding parts of the data, the speed of the acquisition can be increased - known as undersampling. However, due to the invalidation of the Nyquist criterion, the acquired images might be blurry and can also produce aliasing artefacts. The aim of this work was, therefore, to reconstruct highly undersampled MR thermometry acquisitions with better resolution and with fewer artefacts compared to conventional methods. The use of deep learning in the medical field has emerged in recent times, and various studies have shown that deep learning has the potential to solve inverse problems such as MR image reconstruction. However, most of the published work only focuses on the magnitude images, while the phase images are ignored, which are fundamental requirements for MR thermometry. This work, for the first time, presents deep learning-based solutions for reconstructing undersampled MR thermometry data. Two different deep learning models have been employed here, the Fourier Primal-Dual network and the Fourier Primal-Dual UNet, to reconstruct highly undersampled complex images of MR thermometry. MR images of 44 patients with different sarcoma types who received HT treatment in combination with radiotherapy and/or chemotherapy were used in this study. The method reduced the temperature difference between the undersampled MRIs and the fully sampled MRIs from 1.3 to 0.6 °C in full volume and 0.49 °C to 0.06 °C in the tumour region for a theoretical acceleration factor of 10.
Similar content being viewed by others

Introduction
Hyperthermia (HT) has become one of the well-accepted cancer treatments in combination with radio- and/or chemotherapy. In HT, tumour tissue is exogenously heated to temperatures between 39 and 44 °C for 60 min to sensitise tumour cells for chemo- and/or radiotherapy1,2,3,4. Temperature monitoring is an important part of quality-controlled HT and can be performed non-invasively by Magnetic Resonance Imaging (MRI). However, a major challenge is that MRI is inherently slow during several traditional sequences5. Consequently, the scan time for high-resolution imaging is long, which reduces temporal resolution. Longer scan times can also lead to an increase in motion artefacts due to patient movements during image acquisition. The speed of image acquisition can be increased by discarding parts of the data, known as undersampling5. However, this leads to blurriness and can also produce aliasing artefacts due to invalidation of the Nyquist criterion6,7. Hence, MR image reconstruction and reduction of motion artefacts are in high demand.
Several studies have attempted to accelerate MRI acquisition while addressing the challenges of undersampling without employing any learning-based techniques5,8,9, including efforts to expedite MR thermometry10,11,12. However, deep learning has recently emerged as the dominant approach in MRI reconstruction, offering superior image quality and faster processing times compared to traditional methods such as compressed sensing13,14,15. Although several deep learning approaches for MRI reconstruction have been proposed in recent years16,17,18, to the best of the authors’ knowledge, such methods have not yet been explored for MR thermometry.
This work aims to reconstruct highly undersampled MR thermometry acquisitions of patients with sarcoma with better resolution and with fewer artefacts compared to conventional techniques such as compressed sensing. The use of deep learning in the medical field is spreading, including for undersampled MRI reconstruction. Using the ReconResNet model as the network backbone, the NCC1701 pipeline has been shown to be able to remove artefacts from highly undersampled images17 with acceleration factors as high as 20. However, this work not only focuses on the magnitude images; it also ignores the phase images, which are fundamental requirements for MR thermometry17.
Thermal therapy and thermometry
Magnetic Resonance Imaging (MRI) has the ability to map temperatures19,20, and it has been more than 30 years since several extensive studies have been conducted to understand the quality of temperature monitoring in thermal treatment21. MR imaging provides a powerful, non-invasive tool for real-time temperature monitoring during minimally invasive thermal therapies. By utilising temperature-sensitive MRI parameters, clinicians can accurately measure and control temperature distributions within tissues, ensuring effective treatment while minimising damage to surrounding healthy tissue22. The hotspot must be located correctly during ablation therapy with the use of MR guidance. It is necessary to locate the ablation site extremely precisely in order to burn only the unhealthy cells and spare the normal ones. Temperatures are achieved using microwave (MW), radio frequency (RF), ultrasound (US), or infrared (IR) techniques. Thermal therapy can be divided into two techniques. Low temperature or hyperthermia (HT), where tumour tissue is heated to a temperature between 40 and 44 °C for 60 min with the aim of directly killing cancer cells, increasing oxygenation, and thus also increasing the radiosensitisation of the cancer cell23. Local, regional, and whole body hyperthermia can be classified on the basis of the size of the heated area. External heat sources, as well as intraluminal or interstitial insertion of microwave-guided wires, can be used to apply heat to the tumour. High-temperature thermal ablation, in which tumour tissues are heated to temperatures of 50–80 °C or higher for a shorter period of time, aims to kill cancer cells directly24.
Deep learning in medical imaging
The use of deep learning in the medical field, especially in the field of medical imaging, is increasing rapidly. Deep learning has achieved outstanding performance in the task of undersampled MR image reconstruction and the elimination of artefacts present in these MRIs25,26,27 applied deep learning to compressed sensing MRI. Deep Residual Network (ResNet) was proposed by28 to optimise and improve the accuracy of deep learning models. ResNet was able to solve the vanishing gradient problem and open up the door to a deeper network. ResNet was proposed mainly for image classification, but it has later been used for many other applications, such as image classification29,30, image segmentation31, and image denoising32,33. The residual learning model also proved to be very efficient in MRI reconstruction17.
One of the most commonly used network architectures for MRI reconstruction is UNet34, which was first employed for the task of MR reconstruction in 2018. UNet is capable of reconstructing highly undersampled images.17 came up with the NCC1701 pipeline with the ReconResNet model as the backbone. This has shown an improvement in the reconstruction of undersampled Cartesian and radial MRIs over UNet, and it has demonstrated that it is capable of reconstructing up to acceleration factors of 20 and 17, for Cartesian and radial MRIs, respectively.
UNet and ReconResNet work only in the image space (magnitude images), completely discarding the phase images. Although these methods work with both the image and the k-space, they apply real-valued convolution operations to complex-valued image space and k-space data, disrupting the rich geometric relationships within the complex data. In 2021, the first time complex-valued convolutions were applied for the task of undersampled MRI reconstruction directly in the k-space 35.
On the other hand,36 proposed the primal-dual network or PDNet, for the reconstruction of sparse computed tomography (CT) data. Given that CT and radial MRI reconstructions have mathematical similarities due to the Fourier slice theorem,37 applied PDNet successfully for the task of undersampled radial MRI reconstruction, and also extended PDNet to PDUNet, which outperformed PDNet with statistical significance. Both networks employ two types of network blocks, filtering in the image space and sinogram space. In 2022, these models were further extended using complex-valued convolutions into Fourier-PDNet and Fourier-PDUNet by 38. These two models work in the k-space (i.e. the raw data space of MRI) instead of the sinogram space (i.e. the raw data space in the context of computed tomography), in addition to working in the image space.
Although several models have been proposed for reconstructing undersampled MRIs, including models that work in both image and k-space, and models that work directly with complex data, the main focus of the evaluations carried out was on magnitude images. Current research aims to bridge this gap by focusing on both magnitude and phase images and then further evaluating the quality of MR thermometry from the reconstructed MRIs.
MR-guided thermometry

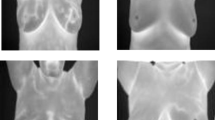
An example of non-invasive PRF shift MR thermometry to monitor and control temperature during clinical hyperthermia (HT). The initial temperature map at time step t0 requires two MR images, which are calculated by voxel-wise subtracting the second phase image from the first reference phase image. This reference image is subtracted from the phase images of further acquired MR images, which are taken every 10 minutes during HT therapy. In the initial high-precision magnitude MR image, the temperature map is shown as a color overlay (blue: relative temperature decrease; green: constant temperature; red: relative temperature rise).
With the benefit of obtaining 3D temperature maps, MR-guided hyperthermia provides a non-invasive approach for temperature monitoring39.On the basis of proton density, T1 or T2 relaxation time, the water molecule’s molecular diffusion coefficient, magnetisation transfer, temperature-sensitive contrast agents, proton resonance frequency (PRF) shift imaging, or spectroscopy, various methods of measuring temperature with an MR system have been reported40,41,42,43,44. Techniques such as measuring longitudinal and transverse relaxation times20, the diffusion coefficient, or the proton density rely heavily on the characteristics of the tissue. PRF shift imaging is independent of the tissue type and provides good linearity, and a desent temperature sensitivity. Because of this, the PRF shift technique is now the preferred technique for MRI-based temperature measurements due to its potential for online imaging and tumour control during treatments45,46,47. The PRF shift method’s pre-clinical calibrations and uses are outlined in48. The current standard for non-invasive temperature assessments in daily clinical practice is the PRF shift measurement. The PRF-based phase mapping method stands out due to its linearity and reliability across different tissue types. Advances in MR imaging techniques continue to improve the precision and efficacy of thermal therapies22. The goal of the guided system is to understand the real-time temperature distribution and deliver quality controlled treatment and also be able to co-relate treatment temperature with treatment outcome in terms of actual thermal tissue damage. Figure 1 shows an example of MR-based temperature monitoring at different time points.
Contributions
This research introduces Fourier-PDNet and Fourier-PDUNet - complex-valued neural networks that reconstruct undersampled MRIs, preserving the rich geometric structure of complex MRI data. As the MRI data are obtained in Fourier space - a complex data space - and the reconstructed images are also complex-valued, complex-valued convolutions would be essential to preserve the structure of the data properly. These methods are employed and evaluated here for the task of reconstructing highly undersampled (up to a theoretical acceleration factor of 10) MR thermometry data in terms of both reconstruction quality and the quality of the temperature maps obtained afterwards. To the authors’ best knowledge, this is the first research addressing the problem of undersampled MR thermometry data (including hyperthermia). Moreover, the methods proposed here can also be used for the reconstruction of other types of undersampled MRI (including undersampled dynamic MRI).
Methodology
Most of the previous work took either of these two directions: working only with the magnitude images (ignoring the phase images completely) or working with the complex image by splitting the data into real and imaginary parts before supplying it to the network as two separate channels. The first approach is not suitable for the current task at hand, while the second approach destroys the rich geometric structure present in the complex data. Both of these approaches apply real-valued convolution operations. As the data are complex-valued, applying complex-valued convolution should be better suited, which is capable of working directly with the complex-valued data without splitting them into channels, effectively preserving the geometric structure.
Experiment design
MR images of 44 patients with different sarcoma cancers who have received the HT treatment in a combination of radiation/chemotherapy were used in this study (refer to Fig. 2). All methods were carried out in this study are in accordance with the ethical standards and approval (Application no. 24-168-Br) of the institutional research ethics committee of the Medical Faculty of the Friedrich-Alexnder-Universität Erlangen-Nürnberg, Erlangen, Germany, and with the 1964 Declaration of Helsinki and its later amendments. For this retrospective study, the requirement for formal consent was waived based on local legislation (BayKrG Art. 27 (4)).
One key goal of this work is the reconstruction of the temperature, so both magnitude and phase images are necessary. As the next step, the magnitude and phase images were combined together, and complex images were created. These complex images are artificially undersampled. Afterwards, the undersampled complex images were randomly divided into three different sets - Training, Validation and Test sets and the number of subjects was 26, 7 and 11, respectively. In the following steps, training and validation sets were used to learn the model weights of the modified PD Net36 / PDUNet37 models, and the test set was used to evaluate the final performance. After testing, to quantitatively evaluate the results produced by the models, the Structural Similarity Index (SSIM)49) has been used.

Experiment design.
Network architectures
Primal-Dual network or PD Net: The Primal-Dual network is a deep learning-based technique for computed tomography data with sparse sampling36. The algorithm unrolls a proximal-dual method with convolutional neural networks in place of the proximal operators to accommodate for (potentially non-linear) forward operators in deep neural networks. The algorithm is trained end-to-end, using only the raw measured data, and is not dependent on any initial reconstruction, such as filtered backprojection. This not only raises the standard of the final reconstruction, but also ensures data consistency. The quality of PD Net depends on the number of iterations, just like many iterative algorithms, for coverage of all the parameters of the network, an optimal number of iterations is needed. The fewer the parameters of the convolutional block, the more iterations are needed for convergence.
Primal-Dual UNet or PD UNet: Primal-Dual UNet37 is the improved version of the Primal-Dual network in terms of accuracy and reconstruction speed. A UNet has been used in place of a convolutional block of PD net for image space to obtain a higher number of parameters with low processing time.
In this study, these two network models were modified by employing complex-valued convolutions (see Sec. 2.6) to be able to work with complex-valued data, resulting in Fourier-PDNet and Fourier-PDUNet models (shown in Figs. 3 and 4, respectively).
Data consistency step
In the data consistency step, the actual acquired undersampled data replaces the network’s output. The network only helps to fill the data which were ignored before during the undersampled data, this is how the final output is not totally dependent on the network.
Following34, a data consistency step was performed for the after reconstructing the undersampled Cartesian data. To obtain the corresponding k-space, FFT was performed on the output image first. Then, to identify the k-space values that were not acquired, an inverted mask was applied to this. The missing estimated k-space data from the network were combined with the measured data. To obtain the final output, iFFT was applied to this combined k-space.

Fourier Primal-Dual Network (Fourier-PDNet) - modified version of the Primal-Dual network employing complex-valued convolution operations. Primal iterates are displayed in blue boxes, whereas dual iterates are displayed in green boxes. The architecture of all the blue boxes is the same and is shown in the matching large boxes. When several arrows lead to the same block, concatenation occurs before supplying the input to the first layer of the block. As the data are transmitted to the dual iterates, the initial estimates enter from the left. The primal blocks are responsible for removing artefacts from the image, while dual blocks attempt to predict the missing k-space frequencies.

Fourier Primal-Dual UNet (Fourier-PDUNet): The primal and dual iterates are represented by orange and green boxes, respectively. A complex-valued UNet architecture, as opposed to a complex-valued fully convolutional network (as used in Fourier-PDNet), is used in the primal block. The original primal-dual network is still present in the dual block, which is a complex-valued fully convolutional network.
Dataset
In this work, MRIs of 44 patients treated in the Department of Radiation Oncology of the Universitätsklinikum Erlangen, acquired from 2015 to 2020, who underwent HT treatment with MR thermometry, were used. The image sets of 44 different patients with different types of sarcoma cancer, originating mainly in the leg of the patients (details are in Table 3), have been acquired at Siemens Magnetom Symphony 1.5T scanner (Siemens Healthineers AG, Erlangen, Germany), the scanning sequence is GR or Gradient Recalled, Sequence Name fl2D or Fast low angle shot (FLASH 2D). A total of 24,486 MRI 2D slices, across 138 of treatment sessions, have been utilised in this work. Each subject’s static and dynamic scans were acquired in different sessions using the same sequence and parameters. The age range of the patients is 23 to 80 years. 26 subjects out of 44 were used for the training set selected randomly; seven subjects were used for the validation set, and 11 subjects were used for testing the model. MR thermometry images have two types of acquisition, static acquisition and dynamic acquisition, and the parameters of these two types of acquisition have been shown in Table 1 and in Table 2, respectively.
that several extensive studies have been performed.
Undersampling
For the Cartesian sampled experiment, all images from different subjects were treated as fully sampled images. As the datasets do not contain any raw MR data, using the MR-Under50 pipeline, the single-channel fully sampled raw data and various undersampled datasets were generated artificially.
Cartesian raw data have been artificially undersampled using the k-space sampling pattern5, also known as the sampling mask, which was created by randomly choosing completely sampled readout lines in the phase encoding direction, with the centre of the distribution following a one-dimensional normal distribution (Fig. 5a) that matches the k-centre space (referred to as 1D Varden). This sampling mask consisted of a densely sampled centre consisting of eight lines, while gradually decreasing the sampling density toward the edges of the k-space5. Furthermore, another mask is designed (Fig. 5b), referred here as 2D Varden, that contains a densely sampled centre covering 2.5% of the k space, while the rest of the k-space is sampled randomly and distributed according to a two-dimensional normal distribution pattern5. Three distinct Cartesian undersampling patterns were used in the first round of trials. 1D and 2D Varden masks were generated by randomly sampling 25% or 10% of the k-space, achieving theoretical acceleration factors of 4 and 10, respectively.
Implementation
As input, the complex undersampled images are used to train the network to obtain the reconstructed complex images. However, most deep learning networks are implemented only on real-valued data, not complex-valued data. Therefore, the use of complex-valued convolution or CV-CNN38 was a necessity. The convolution operation is the main component of CNNs, and it is computed by the sum of the product of two functions - the input (x) and the kernel (w) and the outcome is referred to as the feature map or activation map (s), and it is given by:
In this case, w and x are both real-valued. Complex-valued convolutional networks, commonly referred to as CV-CNNs, improve on this by using the complex-valued convolution operation, which is defined as:
where \(x_r\) and \(x_i\) are the real and imaginary components of the complex-valued input x, respectively. Similarly, \(w_r\) and \(w_i\) are components of the complex-valued kernel w, and \(C_r\) and \(C_i\) are components of the generated complex-valued feature map s. This can also be expressed in matrix notation:
CV-CNNs can learn more sophisticated representations while preserving the algebraic structure of complex-valued data. Figure 6 shows the working mechanism of the proposed framework.

(a) 1D Varden mask and (b) 2D Varden mask. All of them are for image size 256x256, taking 25% of the k-space.
Training and inference
Figure 6 demonstrates the operational principles of the complete framework, which include a network backbone and a data consistency step. During the training process, only the network backbone was used. However, the entire framework is used during inference. This framework is identical to the NCC1701 framework17, except for the backbone model. The original ReconResNet backbone was replaced with the complex-valued models Fourier-PDNet and Fourier-PDUNet to be able to reconstruct both magnitude and phase images. The loss function to train the backbone model of the original NCC1701 was also replaced with a complex-valued version of L1 loss or mean absolute error (MAE). The L1 loss between a prediction and the actual value is calculated using:
Where y is the actual value or ground truth, \(\hat{y}\) is the predicted value, and N is the number of samples in the whole dataset. Here, both y and \(\hat{y}\) are complex-valued with real r and imaginary i parts.
The model was trained for 100 epochs, with a batch size of one, and the loss value was then minimised using Adam Optimiser (Initial learning rate 0.0001, decayed by 10 after every 50 epochs; \(\beta _1 = 0.9, \beta _2 = 0.999, \epsilon = 1e-09\)). This network was implemented using PyTorch 51, Python version 3.10.9 was used and was trained using NVIDIA GeForce RTX 2080 Ti.

Workflow of neural network-based MRI reconstruction from undersampled k-space data: This figure outlines the workflow for reconstructing high-quality MRIs from undersampled k-space data using a neural network. Starting with undersampled Cartesian k-space data, an Inverse Fourier Transform (iFFT) generates an artefact-laden complex image. This image is fed into a neural network to produce a reconstructed complex image. The network’s output undergoes a Fast Fourier Transform (FFT) to form output k-space, which is combined with the original sampled k-space data using a missing mask. A final Inverse Fourier Transform (iFFT) converts the combined k-space back to the spatial domain, resulting in the final output image. The image is then compared to the ground truth for loss calculation and evaluation, guiding the network to improve its reconstruction accuracy.
Evaluation criteria
Structural Similarity Index 5(SSIM)49, Normalised root-mean-squared error (NRMSE, 7) and Universal Image Quality Index (UIQI)52 have been used to evaluate the results.
The range of SSIM values is between zero and one, where the higher the SSIM value, the higher the similarity between two images.
where x and y are the two images between which the structural similarity is to be calculated, \(\mu _x, \mu _y, \sigma _x, \sigma _y\) and \(\sigma _{xy}\), are the pixel means of x, pixel means of y, standard deviations, and cross-covariance for images x and y, respectively. \(c_{1}=(k_{1}L)^{2}\) and \(c_{2}=(k_{2}L)^{2}\) where L is the dynamic range of the pixel-values, \(k_{1}=0.01\) and \(k_{2}=0.03\).
To statistically compare the two images (output and ground truth), NRMSE was used, calculated as:
where the pixels of the fully sampled ground truth image have been denoted as \(Y_{i}\), the pixels of the undersampled image or the reconstruction (depending on the comparison performed) have been denoted as \(\hat{Y_{i}}\) and n denotes the number of pixels in the image.
Universal Image Quality Index (UIQI)52 Loss of correlation, luminance distortion, and contrast distortion are the three components that make up any image distortion when it is modelled. The proposed index is simple to calculate and adaptable to numerous image processing applications, as opposed to using conventional error summation techniques.
where x and y are two images, considered as matrices having M and N number of columns and rows with x[i,j], y[i,j] pixels where (0\(\ge\)i > M, 0 \(\ge\)j > N ) and Q is the Universal image quality index.
Q can be obtained by multiplying three components together. The correlation coefficient is the initial component, which quantifies the level of linear correlation between the images x and y; the range varies [−1,1]. The second component assesses the similarity of mean luminance between images and has a value range of [0, 1]. With a range of [0, 1], the third component quantifies how closely the contrasts of the images match.
Temperature map
Temperature maps were generated to evaluate the retrieved temperatures by the Fourier-PDUNet and Fourier-PDNet models, as well as from the undersampled inputs and ground-truth images for comparison. To create these temperature maps, the Proton Resonance Frequency Shift (PRFS)48 method has been used. For MRI-based temperature measurements, the PRF shift approach is currently the clinically recommended practice.
In Gradient Recalled Echo (GRE) images, the change of resonance frequency is expressed as phase change. The temperature difference can be derived by calculating the phase difference between a GRE image at a certain temperature and a reference temperature53. The linear relationship between the temperature difference and the phase change can be expressed as the following equation.
where \(\Delta T\) = Temperature difference, \(\alpha\) = Temperature sensitivity of PRFS, \(\Upsilon\) = Gyro-magnetic constant, \(\delta\) = Main Magnetic field strength and TE = Echo time. According to Eq. (10), a complex calculation has been performed to construct the phase difference, which could avoid the phase wrapping problem during the heating cycle54.
where Re and \(I_m\) are the real and imaginary components of the heated (\(I_H\)) and reference (\(I_{ref}\)) images.
Comparison of the temperature maps
As the focus of this research is hyperthermia (or even MR thermometry in general), it is not sufficient to evaluate only the reconstruction quality of the magnitude and phase images. Rather, it is important to evaluate the reconstructed temperature maps. Given that this paper used real clinical data that are not free of noise, and it is difficult to find noise-free non-heated regions in the temperature maps, conventional techniques, such as the temperature-to-noise ratio (TNR)55 cannot be applied reliably. Hence, the accuracy of the resultant temperature maps - the error in reconstructing the temperature maps from the undersampled volumes and the models’ outputs, compared to the temperature maps obtained from the fully-sampled ground-truth volumes were calculated following the equation:
where x is the fully-sampled data, y is the undersampled or reconstructed data, V is the total number of 3D voxels, \(\tau\) is the total number of time points, and finally, \(\Delta T_{\text {x}(v, t)}\) and \(\Delta T_{\text {y}(v, t)}\) represent the temperature values at voxel v and time point t for x and y. Two sets of \(E_T(x,y)\) were computed in this research: considering the whole volume, and only considering the region of interest by segmenting the tumour region. These demonstrate the overall error in terms of the temperature with respect to the whole volume and the region of interest.
Results
Baseline comparison
Initially, the performance of these complex-valued models was benchmarked against one of the MR reconstruction models - ReconResNet17. There were three main reasons behind choosing this model - ReconResNet is a stand-alone model that works directly with coil-combined images and not an end-to-end MRI reconstruction framework, the original paper demonstrated that this model works well with both 1D and 2D Varden masks, and finally, because it is the originally proposed backbone model for the NCC1701 framework that was also used here. However, this model was originally proposed to reconstruct only the magnitude images, and phase image reconstruction is essential for MR thermometry. Complex data can be supplied to a real-valued model in two different ways: a 2-channel input containing real and imaginary parts, or magnitude and phase. The ReconResNet model was modified to take input and produce output with two channels. For the baseline purposes, both possibilities were evaluated - real+imaginary and magnitude+phase for reconstructing MRIs undersampled with 1D Varden 25%.

Comparison of the reconstruction quality achieved by the complex-valued models-Fourier-PDNet and Fourier-PDUNet-and the real-valued model ReconResNet with two types of inputs-real and imaginary, and magnitude and phase-as well as the zero-padded k-space (denoted as undersampled) for k-space undersampled using 1D variable density sampling taking 25% of the k-space. SSIM values for (A) magnitude and (B) phase.
Figure 7 demonstrates the results in terms of SSIM for (A) magnitude and (B) phase, obtained from the real-valued baseline models - ReconResNet (real + imaginary) and ReconResNet (magnitude + phase), and from the complex-valued models - Fourier-PDNet and Fourier-PDUNet. These results are then compared against the zero-filled k-space reconstruction (denoted as undersampled).
The real-valued baseline models ReconResNet (Real + Imag) and ReconResNet (Magnitude + Phase) resulted in 76% and 74% median SSIM scores for the magnitude images, while achieving 33% and 32% for the phase images, respectively. These scores improved upon the undersampled (zero-filled) reconstruction, which achieved 63% and 31%, respectively. The complex-valued models resulted in even higher scores than the real-valued baselines; Fourier-PDNet and Fourier-PDUNet achieved 91% and 90% SSIM for the magnitude images and 44% and 40% SSIM for the phase images, respectively. All improvements observed were statistically significant, as determined using the Wilcoxon signed-rank test. Hence, it can be concluded that the complex-valued models significantly outperformed the real-valued baseline models in reconstructing both magnitude and phase images, and all further in-depth analyses were performed using the complex-valued models only.
Evaluation of the complex-valued models
Images from 44 patients with sarcoma cancer were undersampled with a theoretical acceleration factor of 4, resulting in average SSIM values of 1D varden 25% is 63% and 31%, for magnitude and phase images respectively, where the Fourier-PDNet and Fourier-PDUNet models managed to reconstruct those data with average SSIM values of 91% and 90% for magnitude images, while achieving 44% and 40% for phase images, respectively. The results are displayed using the violin plots in Fig. 11. Example outputs from two different subjects for 1D varden 25% sampling patterns are shown in Fig. 8 for qualitative evaluation.
The average SSIM values of the 2D varden undersampled MRIs with 25% undersampling were 43% and 29% for the magnitude and phase images. The Fourier-PDNet and Fourier-PDUNet models managed to reconstruct those with average SSIM values of 94% and 93% for the magnitude images while achieving 47% and 46% for the phase images, respectively. The SSIM values using violin plots and example results are shown in Figs. 9 and 11, respectively.
Finally, with a theoretical acceleration factor of 10, the SSIM values of the undersampled images of the 2D varden 10% were 39% and 28% for the magnitude and phase images, respectively. Fourier-PDNet and Fourier-PDUNet models improved the SSIM values to 87% and 86% for the magnitude images while achieving 43% and 41% for the phase images, respectively. The violin plots of the SSIM values and the qualitative comparison for two subjects are shown in Figs. 10 and 11, respectively.
Table 4 provides a complete qualitative overview of the results using NRMSE and UIQI, along with the SSIMs.
The temperature difference between the ground truth and the highest undersampled images (2D varden 10%) was 1.299 ± 0.032, which is 1.3 °C more than the ground truth. But the models managed to reduce the difference to 0.618 ± 0.016 and 0.643 ± 0.022, using Fourier-PDNet and Fourier-PDUNet models, respectively, which are only around half a °C more than the ground truth (see Table 5). So, the models give 60% better accuracy in reconstructing the temperature maps compared to undersampled MRIs. This means that the model can speed up MR acquisition by a factor of 10 with only half °C of temperature difference. Examples of the reconstructed temperature map are shown in Fig. 12.
Moreover, the temperature difference between the ground truth and the most undersampled images (2D Varden 10%) was 0.488 ± 0.161, which is 0.49 °C higher than the ground truth. However, the Fourier-PDNet and Fourier-PDUNet models managed to reduce this difference to 0.063 ± 0.009 and 0.11 ± 0.026 , respectively, which is only around 0.10 °C above the ground truth. These scores are presented in Table 6.
Discussion
The assessment of the proposed framework for reconstructing MR images from undersampled data has shown that it can be applied effectively not only to MRI but also to MR thermometry images, as the model was also capable of reconstructing the temperatures. To the authors’ best knowledge, this manuscript is the first one to deal with undersampled MR thermometry, and in extension, MR-guided hyperhermia, using deep learning-based methods; while this is also the first research discussing the need and possibility of accelerating MR-guided hypetrhermia.
From the results, it can be observed that the framework seems to be robust against various undersampling patterns. For example, the SSIM values of 1D varden 25% are 63% and 31%, for the magnitude and phase images where the Fourier-PDNet and Fourier-PDUNet models managed to reconstruct those data with average SSIM values of 91% and 90% for the magnitude images, while achieving 44% and 40% for the phase images, respectively. SSIM values of the 2D varden 25% are 43% and 29% for the magnitude and phase images. The Fourier-PDNet and Fourier-PDUNet models managed to reconstruct those data with average SSIM values of 94% and 93% for the magnitude images while achieving 47% and 46% for the phase images. 2D varden 10% is 39% and 28% for the magnitude and the phase images. The Fourier-PDNet and Fourier-PDUNet models managed to reconstruct those data with average SSIM values of 87% and 86% for the magnitude images while achieving 43% and 41% for the phase images, respectively, and the result has been displayed in violin plot11 as well as in Table 4
The results show that both the Fourier Primal-Dual network (PD Net) and Fourier Primal-Dual UNet (PDUNet) were able to alleviate the undersampling problem and show that the deep learning model has the potential to improve the novel hyperthermia treatment. From the quantitative result Table 4, it has been clear that Fourier PD net outperformed Fourier PDUNet in SSIM. The same phenomenon has been observed in UIQI, but a slightly different phenomenon has been reported for NRMSE. For the 1D varden 25% and the 2D varden 25%, the value of NRMSE for PDUNet outperformed the output PDNet.
Also, from the result, it has been clear that both of the models performed way better for magnitude images than the phase images, which could be the reason for the present 0.5 °C temperature difference in the reconstructed temperature from the ground truth. Improvement of the models for phase images can also decrease the difference in temperature. It is worth mentioning that temperature differences were computed considering the fully-sampled data as the ground truth, and the accuracy of the temperature maps generated from fully-sampled data was not explored, which might have been affected by different factors, such as the \(B_0\) drift, as that was outside the scope of this research.
Furthermore, it is important to consider that the proposed method currently functions with already coil-combined data, and the artificial undersampling technique employed here simulates only a single channel. Thus, to employ this in a clinical setting, zero-filled coil-combined data obtained directly from the scanner can be provided as input into this method for reconstruction. This may also facilitate further acceleration through the use of parallel imaging techniques.
This research demonstrates the possibility of accelerating MR thermometry during MR-guided hyperthermia. By using undersampling patterns such as 2D varden 10%, the acquisition can be ten times faster, and the methods presented here reduce the compromise in terms of temperature accuracy considerably. The static MRIs used in this research took between 33 and 93 s (see Table 1) to acquire the whole volume, while the dynamic acquisitions took 118 to 225 s (see Table 2). Reducing the scan duration with theoretical acceleration factors of 4 or 10 (using 3D sequences while using 2D undersampling), as presented here, can considerably reduce the probability of patient movements (voluntary or involuntary). Theoretically, the static scan time might be reduced to between 3 and 9 s, and the dynamic scan time to between 12 and 23 s with an acceleration factor of 10. Faster acquisition would not only reduce the chances of motion artefacts due to patient movements during the scan, but it would also significantly improve the temporal resolution of the imaging and enhance temperature tracking across time points by capturing subtle changes in temperature over time.
The usability of these temperature maps for clinical applications is called into question by the discrepancy between the ground truth in Fig. 12 and the network outputs. The observed deviations, particularly in low-magnitude regions, suggest that additional correction techniques may be required, despite the noticeable improvement over the undersampled input. Accuracy could be further enhanced by enforcing temporal consistency in dynamic MRI sequences or by incorporating domain-specific constraints. Moreover, future research should consider integrating advanced temporal regularisation techniques and exploiting latent space representations to further enhance reconstruction quality, particularly for phase images. While the current framework demonstrates robust performance in magnitude reconstruction, the lower fidelity of phase information remains a bottleneck for achieving precise temperature mapping. Tailoring network architectures and loss functions to emphasise phase accuracy-potentially through unsupervised or self-supervised learning approaches-could bridge this gap. In addition, adapting the framework to process raw multi-coil k-space data and incorporating parallel imaging techniques would better mirror clinical acquisition protocols, thereby enhancing its applicability in real-world settings without sacrificing diagnostic accuracy. In addition, a critical avenue for future exploration lies in evaluating the adaptability of the proposed framework across diverse clinical settings and imaging protocols. The current study was based on retrospectively acquired, coil-combined data with simulated undersampling, which may not fully encapsulate the variability encountered in routine clinical practice. Therefore, extending the evaluation to multi-centre datasets, acquired from different MR systems and using varied imaging parameters, would provide valuable insights into the method’s generalisability and robustness. Moreover, incorporating adaptive training strategies that dynamically adjust to specific noise characteristics and artefacts inherent in different scanners could further enhance performance. Such efforts would not only reinforce the translational potential of the framework but also pave the way for its seamless integration into clinical workflows, ultimately improving patient care in hyperthermia treatments.
Conclusion and future works
This paper introduced deep learning-based reconstruction of undersampled MR thermometry acquired during hyperthermia using Fourier-PDNet and Fourier-PDUNet models. After all the different experiments with different types of undersampling methods of different percentages, the results show that the methods were able to alleviate the undersampling problem and managed to get SSIM Score of 0.886 ± 0.004 for magnitude images and 0.429 ± 0.01 for phase images for highest underampling pattern 2D varden 10% - which means that the MR acquisition is now ten times faster and it also manages to bring the temperature difference close to the ground-truth which is 0.618 ± 0.016 in the full volume and 0.063 ± 0.009 in the tumour region. Still, half a °C temperature difference (in the full volume) can be seen in the deep learning results. This can be attributed to the performance difference of the models between the magnitude and phase images.
Future work will focus on improving the networks’ performance on the phase images, which should also reduce the temperature difference. Furthermore, combining the Fourier-PDNet and Fourier-PDUNet models with dynamic MRI-centric pipelines56,57 could allow these models to better exploit the spatio-temporal nature of MR thermometry data, improving the overall reconstruction quality. This work utilised already coil-combined single-channel input and functions as a post-hoc technique. In future research, this method might be extended to an end-to-end framework by working directly with coil images.
Another future direction for research is to focus on the latent space. Exploring the latent space can be useful for improving the image reconstruction quality in undersampled image reconstruction tasks where the input images contain artefacts; the latent space represents, in theory, a low-dimensional representation of the input images without the artefacts. The input images with artefacts can be considered as augmented versions of the input images. Different types of variational auto-encoder58 methods can be used, such as Factorised Variational Auto-encoder (FactorVAE)59, Vector Quantised Variational Auto-encoder (VQ-VAE)60, Masked autoencoders (MAE)61 etc. Use of post hoc explainability methods like Saliency62, Occlusion63, Guided Backpropagation64 etc. can give a better understanding of what went wrong with phase images, which can help the authors to improve the network accordingly.

Qualitative result: 1D Varden 25% - comparison of MR image reconstruction methods from undersampled data. This figure illustrates the qualitative results of MR image reconstruction from 1D Varden 25% undersampled k-space data, comparing two methods: PDUNet and PD. The input column displays the undersampled images with visible artefacts. The PDUNet and PD columns show the reconstructed outputs, while the ground truth column provides the fully sampled reference images.

Qualitative result: 2D Varden 25% - comparison of MR image reconstruction methods from undersampled data. This figure presents the qualitative results of MR image reconstruction from 2D Varden 25% undersampled k-space data, comparing two methods: PDUNet and PD. The input column shows the undersampled images with noticeable artefacts. The PDUNet and PD columns display the reconstructed outputs, with PDUNet demonstrating superior artefact reduction and clearer images compared to PD. The ground truth column provides the fully sampled reference images. Both magnitude and phase images are included.

Qualitative result: 2D Varden 10% - comparison of MR image reconstruction methods. This figure presents MR image reconstruction results from 2D Varden 10% undersampled k-space data, comparing PDUNet and PD methods. The input column shows undersampled images with artefacts. The PDUNet and PD columns display reconstructed outputs, with PDUNet providing superior artefact reduction and clearer images. The ground truth column shows fully sampled reference images. Both magnitude and phase images are included.

The reconstruction quality achieved by the complex-valued models - Fourier-PDNet and Fourier-PDUNet, compared against the zero-padded k-space (denoted as undersampled), for k-space being undersampled using (x.1.) 1D variable density sampling taking 25% of the k-space, (x.2.) 2D variable density sampling taking 25% of the k-space, and (x.3.) 2D variable density sampling taking 10% of the k-space. SSIM values for (A.n.) magnitude and (B.n.) phase are presented.

Reconstructed temperature maps: This figure illustrates the qualitative results of MR image reconstruction from different undersampled k-space data sets, comparing two methods: PDUNet and PD, against the ground truth. The datasets include 1D Varden 25%, 2D Varden 25%, and 2D Varden 10% undersampled k-space data. The maps demonstrate the difference in temperature from the previous reference (i.e. \(\Delta T\)).
Data availibility
The datasets used and/or analysed during the current study are available from the senior authors (U.O.G.: udo.gaipl@uk-erlangen.de and B.F.: benjamin.frey@uk-erlangen.de) on reasonable request, following the data privacy policy of Universitätsklinikum Erlangen.
References
Cihoric, N. et al. Hyperthermia-related clinical trials on cancer treatment within the clinicaltrials. gov registry. Int. J. Hyperth. 31, 609–614 (2015).
Datta, N. R., Stutz, E., Gomez, S. & Bodis, S. Efficacy and safety evaluation of the various therapeutic options in locally advanced cervix cancer: A systematic review and network meta-analysis of randomized clinical trials. Int. J. Radiat. Oncol. Biol. Phys. 103, 411–437 (2019).
Van der Zee, J. Heating the patient: A promising approach?. Ann. Oncol. 13, 1173–1184 (2002).
Kok, H. P. et al. Locoregional peritoneal hyperthermia to enhance the effectiveness of chemotherapy in patients with peritoneal carcinomatosis: A simulation study comparing different locoregional heating systems. Int. J. Hyperth. 37, 76–88 (2020).
Lustig, M., Donoho, D. & Pauly, J. M. Sparse MRI: The application of compressed sensing for rapid MR imaging. Magn. Reson. Med. 58, 1182–1195 (2007).
Nyquist, H. Certain topics in telegraph transmission theory. Trans. Am. Inst. Electr. Eng. 47, 617–644 (1928).
Shannon, C. E. Communication in the presence of noise. Proc. IRE 37, 10–21 (1949).
Knoll, F., Bredies, K., Pock, T. & Stollberger, R. Second order total generalized variation (TGV) for MRI. Magn. Reson. Med. 65, 480–491 (2011).
He, N., Wang, R. & Wang, Y. Dynamic MRI reconstruction exploiting blind compressed sensing combined transform learning regularization. Neurocomputing 392, 160–167 (2020).
Gaur, P. & Grissom, W. A. Accelerated MRI thermometry by direct estimation of temperature from undersampled k-space data. Magn. Reson. Med. 73, 1914–1925 (2015).
Madankan, R. et al. Accelerated magnetic resonance thermometry in the presence of uncertainties. Phys. Med. Biol. 62, 214 (2016).
Wang, F. et al. Fast temperature estimation from undersampled k-space with fully-sampled center for MR guided microwave ablation. Magn. Reson. Imaging 34, 1171–1180 (2016).
Knoll, F. et al. Deep-learning methods for parallel magnetic resonance imaging reconstruction: A survey of the current approaches, trends, and issues. IEEE Signal Process. Mag. 37, 128–140 (2020).
Liang, D., Cheng, J., Ke, Z. & Ying, L. Deep magnetic resonance image reconstruction: Inverse problems meet neural networks. IEEE Signal Process. Mag. 37, 141–151 (2020).
Wang, S. et al. Knowledge-driven deep learning for fast MR imaging: Undersampled MR image reconstruction from supervised to un-supervised learning. Magn. Reson. Med. 92, 496–518 (2024).
Hammernik, K. et al. Learning a variational network for reconstruction of accelerated MRI data. Magn. Reson. Med. 79, 3055–3071 (2018).
Chatterjee, S. et al. Reconresnet: Regularised residual learning for MR image reconstruction of undersampled cartesian and radial data. Comput. Biol. Med. 143, 105321 (2022).
Ekanayake, M., Chen, Z., Harandi, M., Egan, G. & Chen, Z. CL-MRI: Self-supervised contrastive learning to improve the accuracy of undersampled MRI reconstruction. Biomed. Signal Process. Control 100, 107185 (2025).
Cline, H. E. et al. MR temperature mapping of focused ultrasound surgery. Magn. Reson. Med. 31, 628–636 (1994).
Parker, D. L., Smith, V., Sheldon, P., Crooks, L. E. & Fussell, L. Temperature distribution measurements in two-dimensional NMR imaging. Med. Phys. 10, 321–325 (1983).
Rossmann, C. & Haemmerich, D. Review of temperature dependence of thermal properties, dielectric properties, and perfusion of biological tissues at hyperthermic and ablation temperatures Crit. Rev. Biomed. Eng. 42 (2014).
Rieke, V. & Butts Pauly, K. Mr thermometry. J. Magn. Reson. Imaging 27, 376–390 (2008).
Kim, J. & Hahn, E. Clinical and biological studies of localized hyperthermia. Can. Res. 39, 2258–2261 (1979).
Thomsen, S. Pathologic analysis of photothermal and photomechanical effects of laser-tissue interactions. Photochem. Photobiol. 53, 825–835 (1991).
Qin, C. et al. Convolutional recurrent neural networks for dynamic MR image reconstruction. IEEE Trans. Med. Imaging 38, 280–290 (2018).
Lyu, Q. et al. Cine cardiac MRI motion artifact reduction using a recurrent neural network. IEEE Trans. Med. Imaging 40, 2170–2181 (2021).
Wang, S. et al. 2016 IEEE 13th International Symposium on Biomedical Imaging (ISBI). 514–517 (IEEE, 2016).
He, K., Zhang, X., Ren, S. & Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 770–778 (2016).
Mou, L., Ghamisi, P. & Zhu, X. X. Unsupervised spectral-spatial feature learning via deep residual conv-deconv network for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 56, 391–406 (2017).
Zhang, J., Xie, Y., Xia, Y. & Shen, C. Attention residual learning for skin lesion classification. IEEE Trans. Med. Imaging 38, 2092–2103 (2019).
Pakhomov, D., Premachandran, V., Allan, M., Azizian, M. & Navab, N. Deep residual learning for instrument segmentation in robotic surgery. In International Workshop on Machine Learning in Medical Imaging, 566–573 (Springer, 2019).
Jifara, W., Jiang, F., Rho, S., Cheng, M. & Liu, S. Medical image denoising using convolutional neural network: A residual learning approach. J. Supercomput. 75, 704–718 (2019).
Zhu, J.-Y., Park, T., Isola, P. & Efros, A. A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, 2223–2232 (2017).
Hyun, C. M., Kim, H. P., Lee, S. M., Lee, S. & Seo, J. K. Deep learning for undersampled MRI reconstruction. Phys. Med. Biol. 63, 135007 (2018).
Chatterjee, S. et al. Going beyond the image space: undersampled mri reconstruction directly in the k-space using a complex valued residual neural network. In 2021 ISMRM & SMRT Annual Meeting & Exhibition, 1757 (2021).
Adler, J. & Öktem, O. Learned primal-dual reconstruction. IEEE Trans. Med. Imaging 37, 1322–1332 (2018).
Ernst, P., Chatterjee, S., Rose, G., Speck, O. & Nürnberger, A. Sinogram upsampling using Primal–Dual UNet for undersampled CT and radial MRI reconstruction. Neural Netw. 166, 704–721 (2023).
Chatterjee, S., Tummala, P., Speck, O. & Nürnberger, A. Complex network for complex problems: A comparative study of CNN and complex-valued CNN. In 2022 IEEE 5th International Conference on Image Processing Applications and Systems (IPAS), 1–5 (IEEE, 2022).
Wust, P., Cho, C. H., Hildebrandt, B. & Gellermann, J. Thermal monitoring: invasive, minimal-invasive and non-invasive approaches. Int. J. Hyperth. 22, 255–262 (2006).
Kuroda, K. Non-invasive MR thermography using the water proton chemical shift. Int. J. Hyperth. 21, 547–560 (2005).
Lüdemann, L. et al. Non-invasive magnetic resonance thermography during regional hyperthermia. Int. J. Hyperth. 26, 273–282 (2010).
Quesson, B., de Zwart, J. A. & Moonen, C. T. Magnetic resonance temperature imaging for guidance of thermotherapy. Magn. Reson. Med. 12, 525–533 (2000).
Rieke, V. & Pauly, K. B. MR thermometry. J. Magn. Reson. Imag. 27, 376–390 (2008).
Wlodarczyk, W. et al. Comparison of four magnetic resonance methods for mapping small temperature changes. Phys. Med. Biol. 44, 607 (1999).
Odéen, H. & Parker, D. L. Magnetic resonance thermometry and its biological applications-physical principles and practical considerations. Prog. Nucl. Magn. Reson. Spectrosc. 110, 34–61 (2019).
Cernicanu, A., Lepetit-Coiffe, M., Roland, J., Becker, C. D. & Terraz, S. Validation of fast MR thermometry at 1.5 t with gradient-echo echo planar imaging sequences: Phantom and clinical feasibility studies. NMR Biomed. 21, 849–858 (2008).
Gellermann, J. et al. Methods and potentials of magnetic resonance imaging for monitoring radiofrequency hyperthermia in a hybrid system. Int. J. Hyperth. 21, 497–513 (2005).
McDannold, N. Quantitative MRI-based temperature mapping based on the proton resonant frequency shift: Review of validation studies. Int. J. Hyperth. 21, 533–546 (2005).
Renieblas, G. P., Nogués, A. T., González, A. M., León, N. G. & Del Castillo, E. G. Structural similarity index family for image quality assessment in radiological images. J. Med. Imaging 4, 035501 (2017).
Chatterjee, S. soumickmj/mrunder: Initial release (version v0. 1), https://doi.org/10.5281/zenodo 3901455 (2020).
Paszke, A. et al. Pytorch: An imperative style, high-performance deep learning library. Adv. Neural Inf. Process. Syst. 32 (2019).
Wang, Z. & Bovik, A. C. A universal image quality index. IEEE Signal Process. Lett. 9, 81–84 (2002).
Ishihara, Y. et al. A precise and fast temperature mapping using water proton chemical shift. Magn. Reson. Med. 34, 814–823 (1995).
Peters, R. D. Magnetic Resonance Thermometry for Image-Guided Thermal Therapy (University of Toronto, 2000).
Madore, B., Panych, L. P., Mei, C.-S., Yuan, J. & Chu, R. Multipathway sequences for MR thermometry. Magn. Reson. Med. 66, 658–668 (2011).
Sarasaen, C. et al. Fine-tuning deep learning model parameters for improved super-resolution of dynamic MRI with prior-knowledge. Artif. Intell. Med. 121, 102196 (2021).
Chatterjee, S., Sarasaen, C., Rose, G., Nürnberger, A. & Speck, O. Ddos-unet: Incorporating temporal information using dynamic dual-channel unet for enhancing super-resolution of dynamic MRI. IEEE Access (2024).
Makhzani, A., Shlens, J., Jaitly, N., Goodfellow, I. & Frey, B. Adversarial autoencoders, arXiv preprint arXiv:1511.05644 (2015).
Kim, H. & Mnih, A. Disentangling by factorising. In International Conference on Machine Learning, 2649–2658 (PMLR, 2018).
Van Den Oord, A. et al. Neural discrete representation learning. Adv. Neural Inf. Process. Syst. 30 (2017).
He, K. et al. Masked autoencoders are scalable vision learners. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 16000–16009 (2022).
Simonyan, K., Vedaldi, A. & Zisserman, A. Deep inside convolutional networks: Visualising image classification models and saliency maps, arXiv preprint arXiv:1312.6034 (2013).
Zeiler, M. D. & Fergus, R. Visualizing and understanding convolutional networks. In European Conference on Computer Vision, 818–833 (Springer, 2014).
Mahendran, A. & Vedaldi, A. Salient deconvolutional networks. In European Conference on Computer Vision, 120–135 (Springer, 2016).
Acknowledgements
This research has received support from the European Union’s Horizon 2020 research and innovation programme under the Marie Skłodowska-Curie (MSCA-ITN) grant “Hyperboost” project, no. 955625. The present work was performed by Rupali Khatun in (partial) fulfilment of the requirements for obtaining the degree “Dr. rer. biol. hum.” at the Friedrich-Alexander-Universität Erlangen-Nürnberg (FAU).
Funding
Open Access funding enabled and organized by Projekt DEAL.
Author information
Authors and Affiliations
Contributions
U.S.G. and B.F. created the design and the concept of the work. R.K., S.C., C.B., M.W., A.N. and U.S.G. developed the idea. S.C. and A.N. created the model. R.K. performed the experiments, evaluated the results, created the tables and figures for the manuscript. R.K. and S.C. wrote the manuscript. C.B., M.W., O.J.O. and B.F. gave technical input. O.J.O. and S.S. gave clinical input. All authors reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Khatun, R., Chatterjee, S., Bert, C. et al. Complex-valued neural networks to speed-up MR thermometry during hyperthermia using Fourier PD and PDUNet. Sci Rep 15, 11765 (2025). https://doi.org/10.1038/s41598-025-96071-x
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-96071-x
