
Abstract
The growing need for sustainable energy sources and stricter environmental regulations necessitate the development of alternative fuels with lower emissions and improved performance. This study addresses these challenges by optimizing the performance and emission characteristics of a single-cylinder diesel engine powered by neem oil biodiesel blends enhanced with alumina nanoparticlesusing the powerful desirability-based optimization. Neem oil, a non-edible feedstock, was selected to avoid competition with food resources, while alumina nanoparticles were utilized for their catalytic properties to enhance combustion efficiency. The process involved experimental evaluation of biodiesel blends (B10, B20, and B30) combined with alumina nanoparticles at concentrations of 100 ppm, 150 ppm, and 200 ppm using a design of experiments approach. With the engine running at maximum load of 100% and an aluminum oxide concentration of 100 parts per million, the optimal fuel mix comprises of 89.85% diesel and 30% biodiesel. The lowest brake-specific fuel consumption of 0.45 kg per kilowatt-hour that the optimization produced points to effective fuel use. With a little variance of 3.33%, the brake thermal efficiency was maximized at 38.18%, quite near to the validation result of 37.89%. The alumina nanoparticles enhanced combustion through improved fuel atomization and oxidation due to their high surface area and catalytic effects. To further validate the effectiveness of RSM, the results are compared with the performance of several advance machine learning algorithms, including linear regression, decision tree, and random forest. The random forest model demonstrated the highest predictive accuracy for performance (test R2 = 0.9620, Test MAPE = 3.6795%), making it the most reliable statistical approach for predicting BSFC compared to linear regression and decision Tree models. The random forest model also outperformed other approaches in predicting emissions, achieving the highest accuracy with a test R2 of 0.9826 and the lowest test MAPE of 9.3067%.This integrated experimental and predictive approach provided a robust framework for optimizing biodiesel formulations, identifying the ideal combination of biodiesel blend ratio and nanoparticle concentration. The findings highlight the potential of neem oil biodiesel blends enhanced with alumina nanoparticles to achieve a sustainable balance between improved engine performance and reduced emissions in CI engines.
Similar content being viewed by others


Introduction:
The growing concern over depleting fossil fuel reserves and escalating environmental pollution has accelerated the search for sustainable and eco-friendly alternatives1. Biodiesel, derived from renewable feedstocks, has emerged as a promising substitute for conventional diesel2,3. Among various biodiesel sources, neem oil, a non-edible and abundantly available feedstock, offers significant potential due to its high yield and minimal competition with food crops4,5. However, challenges such as lower thermal efficiency and higher nitrogen oxide (NOx) emissions limit its widespread application. To overcome these issues, researchers have explored various strategies, including the incorporation of nanoparticles as additives to enhance combustion and emission characteristics6,7. The nano particles release excess oxygen which helps in complete and clean combustion of fuels there by reducing combustible gases and hydrocarbons which could have released into atmosphere and resulted in air pollution8,9.
Advancements in biodiesel technology offer sustainable and environmentally friendly solutions, as these resources are both inexhaustible and eco-friendly10. ShaikMasthanShareef et al.11 in their investigation used 20% diary waste scum methyl ester blend and evaluated engine performance and combustible parameters. The results revealed that the biodiesel blend outperformed conventional diesel in key performance and environmental aspects. Manjunath et al.12 used copper nano fluid with dairy scum biodiesel and evaluated performance combustion and emission behaviour. They found that 75 ppm nanoadditive fuel blend exhibited the better performance features compared to other nanoadditive fuel blends. M.Venkatachalam et al.13 examined the performance and emission features of neem biodiesel with MLE additive. They found that B20 + 1% MLE blend outperformed conventional diesel by achieving a 3.2% improvement in BTE and a 3.5% reduction in BSFC. Notably, it also contributed to lower emission of HC and CO by 17.5% and 12%, respectively. G. Ramakrishnan et al.14 investigated the influence of CNT on emission features of neem biodiesel. The results showed that incorporating CNT nanoparticles into this biodiesel led to a reduction in smoke emissions, NOx, HC, CO. Rathinam et al.15 focused on the impact of size of CeO2 on emission features of 4-s Diesel engine having neem biodiesel. They found a reduction in CO and HC emissions due to the addition of CeO2 nanoparticles. J, N., and Balasubramanian, D.16 conducted experiments to find the impact of CAO nanofluid on performance of diesel engine having ternary blends (Calophyllum, Neem biodiesel and diesel) fuel. They found an increment in BTE and decrease in emission because of the addition of nanofluids. Nayak, S. K., & Mishra, P. C17 investigated the impact of neem biodiesel and dimethyl carbonate additive on diesel engines under various operating conditions. The results revealed a reductionHC and CO emission with increase in the percentage of additives. MdModassir Khan et al.18 used various blends of neem biodiesel under varying load and maintaining a constant speed of 2000 rpm. Compared to conventional diesel, the quaternary blends exhibited reduced CO, UHC, and smoke emissions, attributed to enhanced combustion efficiency.
Advancements in nanotechnology have profoundly impacted the automotive industry, introducing a transformative concept known as “nano fuels” into the existing body of scholarly research19. Notably, nanoparticles synthesized through the aqueous precipitation method have been widely used in numerous scientific investigations, highlighting their potential for enhancing fuel performance and combustion efficiency20. The different nano fillers that can be used in biodiesel for performance improvements are graphene, CNT, alumina, copper oxide and combination of nano fillers. The nano fillers are dispersed in bio diesel blends such that even distribution of fillers is achieved. The nano fillers in small quantities in terms of PPM are generally dispersed and this fuel is used to test performance measures and emission characteristics of CI diesel engines21. Based on the previous studies, in this investigation, three different blends and three proportions of nano fillers are used.The bio fuel blends used are 90% diesel and 10% neem oil, 80% diesel and 20% of neem oil and 70%diesel and 30% neem oil with alumina nanoparticles in the concentration of 100 PPM, 150 PPM and 200 PPM respectively.
Response Surface Methodology (RSM) and machine learning algorithms serve as powerful tools for predicting the performance, emission, and combustion characteristics of neem biodiesel blended with alumina nanoparticles22. While RSM provides a systematic approach for optimizing key engine parameters23, machine learning enhances predictive accuracy by capturing complex nonlinear relationships, enabling more efficient fuel formulation and emission reduction strategies24. Table 1 presents a comprehensive summary of studies that have employed advance ML and RSM techniques for predicting and optimizing engine performance, emission, and combustion characteristics. These studies highlight the synergistic advantages of combining ML’s predictive accuracy with RSM’s optimization capabilities to enhance engine efficiency and reduce emissions.
The novelty of this study lies in the pioneering use of nano-additives in neem oil-based biofuel at high dosage levels (100–200 ppm), a parameter that has not been explored by previous researchers. Furthermore, the identification of an optimal blend that minimizes CO and NOx emissions presents a significant advancement, offering a viable solution for improving engine performance and reducing emissions in compression ignition (CI) engines, particularly in heavy-duty vehicles within the global transportation sector.It begins by employing Response Surface Methodology (RSM), a statistical approach that systematically analyzes the complex interactions between multiple input variables—such as fuel blend composition, engine settings, and operational parameters—and output responses like fuel efficiency, emissions, and engine power. Through experimental design using RSMand Desirability based parametric optimization, the study effectively maps these interactions and identifies optimal conditions for biodiesel performance.
To further assess RSM’s effectiveness, its results are compared with advanced machine learning (ML) algorithms, including linear regression (LR), decision tree (DT), and random forest (RF). This comparison provides a thorough evaluation of the predictive accuracy and reliability of RSM versus modern data-driven models, highlighting their respective strengths and limitations in biodiesel optimization. By integrating these hybrid approaches, the study optimizes key performance factors such as combustion efficiency, emissions reduction, and fuel economy.This combined use of RSM and ML models not only fills existing research gaps but also presents a more comprehensive, efficient, and sustainable strategy for enhancing engine performance with biodiesel blends.
Methodology
Preparation of bio fuel blends
Initially the neem oil extracted from neem seeds is processed by transesterification process and three different blends with the following proportion are prepared as shown in Tables 2 and 3. The nano particles are suspended in these fuels with three different fuel systems viz., (1) diesel 90% with 10% bio fuel (2) diesel 80% with 20% bio fuel and (3) 70% diesel with 30% bio fuel and these fuels in-turn mixed with alumina particles in proportion of 100 PPM, 150 PPM and 200 PPM to prepare bio fuels for the proportion of bio fuels with nano particles by using ultrasonicator to ensure proper distribution of nano particulates. In blending the bio fuels with nano additives, the agitation time and frequency are important parameters and were set as per standards for a duration of 25–30 min at 49 kHz and were maintained to ensure proper dispersion of alumina particles. Table 2 shows the properties of alumina nanoparticles. The thermo physical properties of various bio diesel blends dispersed with nanoparticles are shown in Table 3.
Experimental setup
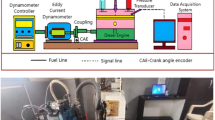
The experimental work has been carried out on single cylinder 4- stroke CI engine coupled with eddy current dynamometer and gas analyser as shown in Fig. 1.Three trails for each parameters /fuel blends are carried out and average values are considered for evaluation of performance measures and emission features. The engine started and run at rated speed and readings are taken after steady state is reached. The readings are recorded for lower and higher loading and medium loading conditions. Table 4 shows the specification of Engine Test rig and Table 5 shows specifications of the gas analyzer used for measurement of exhaust gases with its accuracy. The presence of exhaust gases like CO, Hydrocarbons and Nitrous oxide are measured using gas analyzer by vol% and PPM respectively.

Experimental setup.
Machine learning (ML)
ML algorithms play a crucial role in biodiesel research by enhancing predictive accuracy and optimizing fuel performance. The complexity of biodiesel combustion, influenced by multiple interacting parameters such as blend composition, engine settings, and operating conditions, necessitates advanced data-driven approaches. ML models can efficiently analyze vast datasets, identify hidden patterns, and generate reliable predictions for fuel efficiency, emissions reduction, and engine performance. By integrating ML with conventional techniques like Response Surface Methodology37, researchers can develop more robust and adaptive optimization strategies, accelerating the development of sustainable and high-performance biodiesel fuels38.
Linear regression
One of basic statistics methods is linear regression. It approximates the link between a dependent variable and one or more independent variables. Simple linear regression—one dependent and one independent variable—is the easiest version39. It treats variables as having a straight-forward connection. A straight line’s equation shows this link: y = mx + c, where m is the slope and c is the intercept. Linear regression seeks to identify the line of greatest fit. It reduces the total of the squared deviations from observed to expected values. One may grasp and use this approach easily. Still, it has some restrictions40. It takes linearity, which is not always the case. The outcomes can be much changed by outliers. Furthermore, challenging might be multicollinearity among independent variables. Linear regression is still somewhat often employed despite these disadvantages41. In disciplines including economics, finance, and the social sciences particularly it is quite popular. It forms a baseline model in machine learning. One can relate more complicated models against it. All things considered; linear regression is a quite effective yet basic instrument. It offers insightful analysis of the links among the variables42.
Decision tree
A decision tree is a flexible tool available in machine learning. Its applicability consists in both categorizing tasks and in regression. Branching and nodes define the tree building. Every node represents a choice motivated by a feature. Branches convey the outcome of these decisions. The tree divides data into categories based on most critical criteria43. This process continues until a stopping requirement is reached. The result is a tree in which every leaf node represents a last choice or result. Decision trees are obviously visible and understandable. They handle numerical and categorical data as well. Their key advantage is their ability to capture non-linear relationships. Still, decision trees may overfit easily44. This happens as the tree develops too complex and picks noise in the data. One can help to remedy this by using different pruning techniques. By simplifying the tree, one can reduce overfitting. Moreover, constrained by decision trees are imbalanced datasets. The performance may seem to be slanted in the direction of the minority class45. Still, decision trees are very common in spite of these challenges. Built on these are more intricate ensemble methods such random forests and gradient boosting. In conclusion, decision trees are very handy tool. Many vocations provide clear, reasonable results.
Random forest
One approach in ensemble learning is random forest. It uses many decision trees in order to enhance performance. Random forests are a potent ensemble technique. To provide strong and accurate forecasts, they integrate the powers of several decision trees. Every tree in the forest undergoes random subset of data training. Bootstrapping is the method used in creation of this subgroup46. Furthermore, taken into account at every tree split is a random collection of characteristics. This randomization promotes generalization and helps to lower overfit. The random forest produces, at last, the average prediction of every individual tree. For classifying chores, it’s the majority vote. Robust and good for many applications are random forests. They quickly manage high-dimensional areas and big datasets47. Their capacity to manage missing values is one main benefit. They also project feature prominence. Random forests, meanwhile, can be computationally costly. Training several trees calls additional resources. Random forests are quite popular in usage despite these shortcomings. From banking to healthcare, they are successful in many spheres. Many times, they provide the standard for other methods48.
Model evaluation
R-squared (R2)
The coefficient of determination, or R-squared, gauges the share of the dependent variable variation that is predicted from the independent variables49. It runs from 0 to 1; 0 denotes no predictive ability and 1 denotes flawless prediction.
Mean squared error (MSE)
MSE calculates the expected and actual values’ average squared difference. It shows the nearness of the forecasts to the actual numbers49. Reduced values show improved fit.
Mean Absolute percentage Error (MAPE)
MAPE reports the prediction accuracy as a percentage. It gauges the average absolute percentage difference between actual and projected values50.Reduced values point to improved accuracy.
Herein, \({y}_{i}\) is the measured value for ith observation, \(\widehat{{y}_{i}}\) is the forecasted value for ith observation, n is the total observations being considered, \(\overline{{y }_{i}}\) is the mean value of observations.
Violin cum box plots for model comparison
In machine learning, violin cum box plots combine the elements of violin plots and box graphs to offer a complete view for model comparison. With the width indicating the density of data points at various values, violin plots display the distribution of data among several models. A box plot showing the median, quartiles, and possible outliers sits inside the violin plot. Plotting the performance metrics—such as accuracy, R2, MSE—for every ML model helps one to evaluate them. The violin cum box plot will expose the distribution and dispersion of these measures. Whereas the form of the violin plot emphasizes the whole distribution, the box plot inside shows central tendency and variability. This display lets one find models with consistent performance, spot anomalies, and compare core trends and spreads. It makes it simpler to pick the most solid and dependable model as it offers a more thorough comparison than conventional box graphs51.
ML modelling
Data analysis and correlation values
The interactions among several elements influencing engine performance and emissions offer important new perspectives. The correlation heat map is depicted in Fig. 2. The correlation indices are listed in Table 6. Strong inverse correlation (− 1) indicates that when one climbs, the other falls; diesel and biodiesel percentages show this relation. Higher diesel percentage s show that diesel has a somewhat positive link with brake-specific fuel consumption (BSFC) (0.62). Al2O3 concentration is negatively linked with BSFC (− 0.7), meaning that increasing Al2O3 reduces fuel usage. Brake thermal efficiency (BTE) (0.85) has a substantial positive connection with the load; CO (0.76) and NOx (0.97) have quite high positive correlation as well. Higher loads, thus, both enhance efficiency and raise emissions. Higher fuel use lowers efficiency and raises emissions, according to BSFC’s negative association with BTE (− 0.16), CO (− 0.27), NOx (− 0.29), and HC (− 0.76). As efficiency rises, emissions also often tend to increase; BTE shows positive relationships with CO (0.44), NOx (0.74), and HC (0.48).

Correlation heat map.
Strongly positive correlation (0.85) between CO and NOx suggests they often rise simultaneously. With diesel (− 0.71) and BSFC (− 0.76), HC has negative correlations; with biodiesel (0.71), CO (0.62), and NOx (0.71), it exhibits positive relationships. Higher diesel use and fuel consumption hence lower HC emissions; higher biodiesel use and other contaminants raise HC emissions. These relationships underline the complicated connections among fuel types, engine load, and emissions, therefore directing the optimization of fuel mixes and running conditions for greater performance and reduced emissions.
Model development and evaluation
The model evaluation highlights that Random Forest consistently outperforms Linear Regression and Decision Tree models across all parameters, demonstrating superior accuracy and generalization with minimal Lack of Fit. While Linear Regression struggles with complex relationships, as seen in high MSE and MAPE for various parameters. Decision Trees tend to overfit the training data, leading to less reliable test performance. Random Forest’s ability to balance bias and variance makes it the most robust model for this dataset, ensuring high R2 and low errors in both training and testing phases.
BSFC models
The Statistical models were developed using experimental data collected in testing. The 70% data was used for model training while remaining was used for model test. The models were used for prediction. The comparison between measured and predicted values are shown in Fig. 3a–c for all three models. All three models performed well. The models were evaluated using statistical methods. The results of statistical evaluations are listed in Table 7. With Train R2 of 0.9587 and Test R2 of 0.8043, LR’s Train MSE is 0.0003 and Test MSE is 0.0010, therefore showing a decent fit but more inaccuracy on test data. Training MAPE is 3.6825%; test MAPE is 7.9165%. Test R2 of 0.8822 and Test MAPE of 6.1386% imply that DT model displays ideal training fit—Train R2 of 1. With Train MSE almost zero, Test MSE of 0.002, Train R2 of 0.9999, and Test R2 of 0.9620 RF works best. Test MAPE is 3.6795%; Train MAPE is minimal—0.2148%. The violin cum box plots also corroborates the finding the statistical findings as depicted in Fig. 4a, b to show that RF model performed best.

Model predicted versus actual BSFC values for (a) LR (b) DT (c) RF models.

Violin cum box plots for BSFC models during (a) training (b) testing.
BTE models
Experimental data gathered in testing was employed for the development of BTE models. Model training took use of the 70% data; model testing made use of the remaining data. Predicts made using the models as Fig. 5a–c shows for all three models the contrast between observed and expected values. All three models did well. Statistical techniques were used in evaluation of the models. Table 7 lists the findings of statistical assessments. Three models—linear regression (LR), decision tree (DT), and random forest (RF)—have their BTE model outcomes compared with one another. With a Train MSE of 6.74 and a Test MSE of 10.1520 LR exhibits a modest performance suggesting possible overfitting. Reflecting smaller predictive power on the test set, the Train R2 is 0.8177 and the Test R2 is 0.5290. The test MAPE is 8.1527%; the train MAPE is 7.0243%. With a Test MSE of 5.9991 and a Test R2 of 0.7217, DT shows improved generalization but perfect training fit—Train MSE = 0, Train R2 = 1. With almost flawless training (Train MSE = 0, Train R2 = 1) and outstanding test performance (Test MSE = 0.8498, Test R2 = 0.959 RF beats both. Its lowest MAPE values point to strong accuracy and prediction resilience41. The violin cum box plots further supports the statistical data displayed in Fig. 6a, b, demonstrating that the RF model performed superior to other approaches.

Model predicted versus actual BTE values for (a) LR (b) DT (c) RF models.

Violin cum box plots for BTE models during (a) training (b) testing.
CO emission models
Development of the CO emission models drew on experimental data gathered during testing. Model training made use of the 70% data; model testing made use the remaining data. One could forecast using the models. Figure 7a–c displays for all three models the comparison between observed and projected values. Every three models performed rather well. Statistical approaches were used for evaluation of the models. Table 7 provides the statistical evaluation results. The performance criteria of several models for CO emissions expose varied strengths. With a Train MSE of 0.45 and a Test MSE of 0.9108 Linear Regression (LR) shows very modest performance. With a Train R2 of 0.5920 and a Test R2 of 0.5489 it shows a modest fit. The strong prediction errors shown by the high Train MAPE of 107.71% and Test MAPE of 114.28% point By comparison, models showing better performance include Random Forest (RF) and Decision Tree (DT). With a Train MSE of 0, both DT and RF indicate ideal training fit. At 0.0358 for DT and 0.0351 for RF, their Test MSEs are rather low. With Test R2 values of 0.9823 and 0.9826, respectively, the Train R2 for both models equals 1, indicating perfect training fit. While RF has somewhat better Test MAPE of 9.3067%, DT has a Test MAPE of 9.8956%. This indicates RF’s much stronger predictive accuracy. The violin cum box graphs show that the RF model performed better than other methods, therefore supporting the statistical data shown in Fig. 8a, b.

Model predicted versus actual CO emission values for (a) LR (b) DT (c) RF models.

Violin cum box plots for CO emission models during (a) training (b) testing.
NOx emission model
The NOx emission models developed using experimental data acquired during testing. Using the 70% of the data, model training; using the remaining data, model testing. One might make forecasts with the models. Figures 9a–c show for each of the three models the observed against anticipated values comparison. Every three models showed fairly good performance. The models were evaluated using statistical methods. Table 7 offers the findings of statistical analysis. The models of NOx emission show somewhat different performance criteria. With a train MSE of 0.703 and a test MSE of 0.1040, the Linear Regression (LR) model exhibits excellent performance showing outstanding prediction accuracy. The model explains most of the variation in both sets according to the train R2 of 0.9717 and test R2 of 0.9972. Especially in testing (0.5109), the low MAPE values point to little prediction error. Showing overfitting, the Decision Tree (DT) model exhibits zero train MSE and R2 of 1. On fresh data, the test MSE of 6 and test R2 of 0.8389 point to inferior performance. Its low generalizability is especially confirmed by the high test MAPE (4.1744). With a test MSE of 2.2642 and test R2 of 0.9392, the Random Forest (RF) model balances generalizability and accuracy very well. With very low train and test MAPE values—0.0026 and 2.2773, respectively—it also indicates consistent predictions with low error. For NOx emissions prediction, the LR and RF models do generally better. The violin cum box graphs show that the RF model performed better than other methods, therefore supporting the statistical data shown in Fig. 10a, b.

Model predicted versus actual NOx emission values for (a) LR (b) DT (c) RF models.

Violin cum box plots for NOx emission models during (a) training (b) testing.
HC models
In the present study, the ML models were developed utilizing experimental data obtained during testing. Model training uses the 70% of the data; model testing uses the remaining data. One might use the models to create projections. Figures 11a–c depict for every one of the three models the observed against expected values comparison. Every three models displayed rather decent performance. Statistical techniques were used for evaluation of the models. Table 7 presents statistically analytical results.The performance measures of three models—Linear Regression (LR), Decision Tree (DT), and Random Forest (RF)—for HC emissions are shown in the table. Whereas the test MSE is lower at 342.0372, suggesting superior performance on unknown data, the train MSE for LR is 781.5, indicating a little mistake during training. Strong model fit is shown by the train R2 of 0.9425 and the test R2 of 0.9760. Showing acceptable prediction accuracy, the train MAPE is 14.37%; the test MAPE is 8.8571%. With zero train MSE, the DT model indicates ideal training performance; its test MSE, 349.3750, is somewhat greater. There is overfitting shown by the test R2 of 0.9754 when the train R2 is 1. With a 0% train MAPE and a 6.5480% test MAPE demonstrating great prediction accuracy, furthermore displaying zero train MSE and a test MSE of346.5180 is RF. Once more highlighting overfitting, the train R2 is 1 and the test R2 is 0.9756. The test MAPE is 7.2056%, showing accurate predictions with little error; the train MAPE is virtually nil. The violin cum box graphs show that the RF model performed better than other methods, therefore supporting the statistical data shown in Fig. 12a, b.

Model predicted versus actual HC emission values for (a) LR (b) DT (c) RF models.

Violin cum box plots for HC emission models during (a) training (b) testing.
Discussion on lack of fit (LoF) for different models
The detailed discussion of the lack of fit for different models is tabulated in Table 7. The table gives an overview of the training and testing mean squared errors (MSE), training and testing coefficient of determination (R2), training and testing Mean Absolute Percentage Error (MAPE) for different set of parameters.
BSFC: Linear Regression (LR) shows a significant lack of fit with a higher Test MSE (0.0010) compared to Train MSE (0.0003) and a lower Test R2 (0.8043). Decision Tree (DT) reduces LoF but suffers from overfitting with perfect Train R2. Random Forest (RF) performs the best, with minimal LoF indicated by consistent low Test MSE (0.0002) and high Test R2 (0.9620).
BTE: LR exhibits considerable LoF, with higher Test MSE (10.15) and low Test R2 (0.5290). DT improves Test performance but remains prone to overfitting. RF delivers the best results with near-perfect R2 and low Test MAPE (2.77%), indicating minimal LoF.
CO: LR has a high LoF, with a large gap in Train/Test MSE and extremely high Test MAPE (114.28%). DT and RF achieve low Test MSE and high Test R2 (0.9823 and 0.9826, respectively), showing minimal LoF and good generalization.
HC: LR performs well with low LoF, evidenced by a high Test R2 (0.9972) and low Test MAPE (0.51%). DT shows signs of overfitting and higher LoF with Test MSE (6). RF balances generalization and accuracy with minimal LoF.
NOx: LR shows reasonable generalization with lower Test MSE (342.0372) and high Test R2 (0.9760). DT and RF achieve similar performance, with RF showing slightly better metrics, including lower Test MAPE (7.21%).
In summary Random Forest consistently minimizes Lack of Fit across all parameters, delivering the best balance between accuracy and generalization. In contrast, Linear Regression often struggles, particularly with complex relationships. Decision Tree models frequently overfit but still perform well in certain scenarios.
Results and discussion on performance and emission features
Brake thermal efficiency
The significant factor that estimates the engine’s performance is defined as the amount of brake power developed by the engine relative to the calorific values and the amount of the mass of the fuel. It is technically expressed by the equation referred from52.
The highest BTE is achieved for the blends which have the highest calorific values. The release of chemical energy from these fuels tends to accelerate the piston rapidly to achieve brake power.
The variation of brake thermal efficiency versus Load for different blends dispersed with different proportions if the nano alumina particles is as shown from Figs. 13, 14 and 15 with different proportion of nano particles. In our experimental work we have considered three different blends as 90% diesel blends with 10% bio neem oil which in turn is dispersed with alumina nano particles in 100 PPM.150 PPM and 200 PPM.The variation of break thermal efficiency for 25% 50%, 75% and Full load are evaluated and plotted. The results show that the neem oil blend with 20% bio fuel fairly gives good results compared to other blends, similarly nano particles dispersion with 150 PPM shows better results as these nano particles acts as catalyst to speed up combustion reaction and release oxygen which results in the complete combustion thereby improving thermal efficiency of the engine53.

Variation of brake thermal efficiency versus load for 90% diesel and 10% bio fuel with nano particles.

Variation of brake thermal efficiency versus load for 80% diesel and 20% bio fuel with nano particles.

Variation of brake thermal efficiency versus load for 70% diesel and 30% bio fuel with nano particles.
The plots reveal that thermal efficiency increases with increase in load and will be maximum at ¾ load or 75% and it reduces further at full load capacity of engine, further the 80% diesel and 20% of bio fuel with 150 PPM nano particles shows better results when compared to 100 PPM and 200 PPM dispersion of nano particles for all the combinations of bio fuels54.
Exhaust gas temperature (EGT)
A straightforward method to diminish NOx emissions in a diesel engine is by delayed fuel injection into the combustion chamber. This technology is efficacious but elevates fuel consumption by 10–20%, hence requiring the use of more efficient NOx reduction methods such as recirculation of exhaust gases (EGR). Re-circulating a portion of the exhaust gas mitigates NOx emissions; nonetheless, significant particulate emissions occur at elevated loads, indicating a trade-off between NOx and smoke release55. To optimize this trade-off, a particle trap may be employed to diminish the quantity of unburned nanoparticles in EGR, hence also reducing particulate emissions.
The EGT for various loads for different blends of bio fuels with nano particles dispersed in it is shown in Figs. 16, 17, and 18. The results reveal that the exhaust gas temperature increases with the load (%). Exhaust gas temperature for 150 PPM dispersion of nano particles improves the combustion characteristics56.

Variation of exhaust gas temperature versus load for different blends of biodiesel blend with 90% diesel and 10% biofuel with nano particles.

Variation of exhaust gas temperature versus load for different blends of biodiesel blend with 80% diesel and 20% bio `fuel with nano particles.

Variation of exhaust gas temperature versus load for different blends of biodiesel blend with 70% diesel and 30% biofuel with nano particles.
Emission characterises of bio diesel blends dispersed with nano particles
The emission characteristics is analyzed using gas analyzer as shown in Fig. 19. The combustion gases such as CO unburnt hydrocarbons and NOx were analyzed.The variation of exhaust gases in vol% and PPM are plotted as shown below.

Variation of CO versus load for different blends of biodiesel blend with 90% diesel and 10% bio fuel with nano particles.
Figures 19, 20 and 21 depict the CO emissions in the CI engine for different loading conditions. The CO emission is almost the same for lower loading however at full load the CO emission is more as more fuel is consumed, and also due to the lag in ignition time57. However, the addition of nanoparticles ensures complete combustion of fuel due to the release of oxygen. Biofuel with 150 PPM shows better results compared to other fuel systems.

Variation of CO versus load for different blends of biodiesel blend with 80% diesel and 20% bio fuel with nano particles.

Variation of CO versus load for different blends of biodiesel blend with 70% diesel and 30% bio fuel with nano particles.
Figures 22, 23 and 24 depict the plots for the evaluation of NOx emissions against load. The graphs clearly show that the emission of nitrogen oxide for three different blends of biofuels dispersed with Nanoparticles in different proportions decreases with the increase in the nanoparticles due to better combustion of the blends in the CI engine58.

Variation of NOx versus load for different blends of biodiesel blend with 90% diesel and 10% bio fuel with nano particles.

Variation of NOx versus load for different blends of biodiesel blend with 80% diesel and 70% bio fuel with nano particles.

Variation of NOx versus load for different blends of biodiesel blend with 70% diesel and 30% bio fuel with nano particles.
The reactions involved in the NOX pattern is expressed by Zeldovich’s mechanism43, which reacts the amount of nitrogen molecules combined with the oxygen molecules at the tailpipe of the combustion chamber expressed by the Eqs. (2), (3) and (4)
Mathematical models developed with RSM
Here A denotes diesel, %, B denotes biodiesel, %, C denotes Al2O3, ppm and D denotes engine load in coded terms.
Desirability based parametric optimization
The best mix of fuel blend composition and engine running parameters was found by means of response surface methods combined with desirability-based optimizationfor enhanced performance and low emissions59. To strike a compromise between fuel economy, thermal efficiency, and emission characteristics, the study examined diesel–biodiesel mixes with different engine loads and concentrations of aluminum oxide nanoparticles. Maintaining a realistic desirability score, the optimization procedure sought to decrease brake-specific fuel consumption, enhance brake thermal efficiency, and lower carbon monoxide, nitrogen oxides, and hydrocarbon emissions. With the engine running at maximum load of 100% and an aluminum oxide concentration of 100 parts per million, the ideal fuel mix comprises of 89.85% diesel and 30% biodiesel (Table 8). The lowest brake-specific fuel consumption of 0.45 kg per kilowatt-hour that the optimization produced points to effective fuel use. With a little variance of 3.33%, the brake thermal efficiency was maximized at 38.18%, quite near to the validation result of 37.89%. Because of their combined effects, biodiesel and nanoparticles point to a better combustion process shown by lower fuel use and higher efficiency60
With carbon monoxide down to 2%, nitrogen oxides to 347.83 parts per million, and hydrocarbons to 49.98 parts per million, emission characteristics also were adjusted. Confirming the dependability of the ideal values, the validation findings revealed minimal percentage errors of 2% for carbon monoxide, 2.06% for nitrogen oxides, and 2.46% for hydrocarbons. The little discrepancies noted between the validated and optimal findings point to the response surface technique model’s resilience in underlining engine performance and emissions under the specified circumstances. With an overall desirability function value of 0.63, the consequence of well-balanced optimization guarantees a suitable trade-off between pollution control, performance improvement, and fuel economy. The findings show that by increasing combustion efficiency and lowering hazardous exhaust emissions, combining biodiesel with aluminum oxide nanoparticles can help to sustain engine running (Figs. 25, 26). Response surface methodology offers a methodical and efficient means of multi-objective optimization for engine parameter fine-tuning to reach best performance. These results show how well new fuel mixes and nano-additives could improve diesel engine efficiency while nevertheless addressing environmental issues. The method suggested in this work can be expanded to more investigation on alternate fuels and engine modifications to reach better performance criteria and compliance with pollution rules.

Ramp plots.

Desirability bar plots.
Conclusions
This study thoroughly investigated the performance and emission characteristics of a single-cylinder diesel engine using Neem Oil biodiesel blended with alumina nanoparticles. Various machine learning algorithms, including Linear Regression, Decision Tree, and Random Forest, were employed to predict engine behavior based on experimental data. The following results were obtained after the investigation:
-
With the engine running at maximum load of 100% and an aluminum oxide concentration of 100 parts per million, the optimal fuel mix comprises of 89.85% diesel and 30% biodiesel.
-
The lowest brake-specific fuel consumption of 0.45 kg per kilowatt-hour that the optimization produced points to effective fuel use.
-
With a little variance of 3.33%, the brake thermal efficiency was maximized at 38.18%, quite near to the validation result of 37.89%.
-
The addition of alumina nano particles improves the performance of the engines and emission characteristics of the engine, due to increase in surface pressure and surface area available for combustion with the addition of nano particles. Nano particles also acts as catalyst to speed up, combustion process and ensures complete combustion there by reducing emission characteristics of blends under consideration.
-
Exhaust gas temperature with 150 PPM dispersion of nano particles shows better results indicates better combustion efficiency and complete fuel oxidation, which can improve engine performance.
-
The Exhaust gas temperature and thermal efficiency is increased due to the higher calorific value of bio-fuel and increased thermal conductivity.
-
The chemical reaction with addition of nano particles releases more oxygen which further reduces emission rate by reducing CO emissions.
-
Addition of nano particles slightly increases the emission of NOx as a result of increase of radicals.
-
The Random Forest model demonstrated the highest predictive accuracy for performance (Test R2 = 0.9620, Test MAPE = 3.6795%), making it the most reliable statistical approach for predicting BSFC compared to Linear Regression and Decision Tree models.
-
The Random Forest model also outperformed other approaches in predicting emissions, achieving the highest accuracy with a Test R2 of 0.9826 and the lowest Test MAPE of 9.3067%.
-
The Linear Regression and Random Forest models demonstrated strong predictive accuracy for NOx emissions, with LR achieving the highest Test R2 (0.9972) and RF offering a balanced trade-off between accuracy and generalizability (Test R2 = 0.9392, Test MAPE = 2.2773%).
From an industrial perspective, these findings have significant implications for sustainable fuel development and diesel engine optimization. The use of biodiesel with nanoparticles can serve as a viable alternative to conventional diesel, promoting cleaner combustion and improved efficiency. The application of machine learning provides robust insights into the complex relationships between fuel blends, nanoparticle concentrations, and engine performance, offering a valuable tool for optimizing biofuel usage in CI engines. The use of ML models can further assist in real-time monitoring and predictive maintenance, reducing operational costs and enhancing sustainability in the transportation and energy sectors. Future studies could explore deep learning techniques for further refinement of predictive models and real-time implementation in engine control systems.
Data availability
The data that supports the findings of this study are available within the article.
Abbreviations
- θ:
-
Crank angle (°C)
- BTE:
-
Brake thermal efficiency (%)
- A/F:
-
Air fuel ratio (−)
- BSFC:
-
Brake specific fuel consumption (g/kWh)
- CI:
-
Compression ignition
- CO:
-
Carbon monoxide (Vol%)
- CN:
-
Cetane number
- CR:
-
Compression ratio
- DI:
-
Direct injection
- EGT:
-
Exhaust gas temperature (°C)
- HC:
-
Hydrocarbon (PPM)
- NOx:
-
Nitrogen oxides (PPM)
- ppm:
-
Parts per million (–)
- RSM:
-
Response surface methodology
- RPM:
-
Revolutions per minute (rev/min)
- DOE:
-
Design of experiments
References
Hassan, Q., Algburi, S., Sameen, A. Z., Salman, H. M. & Jaszczur, M. A review of hybrid renewable energy systems: Solar and wind-powered solutions: Challenges, opportunities, and policy implications. Results Eng. 20, 101621. https://doi.org/10.1016/j.rineng.2023.101621 (2023).
Magesh, N. et al. Experimental investigation and prediction of performance, combustion, and emission features of a diesel engine fuelled with pumpkin-maize biodiesel using different machine learning algorithms. Math. Probl. Eng. 2022(1), 9505424. https://doi.org/10.1155/2022/9505424 (2022).
Srikanth, H. V., Venkatesh, J., Godiganur, S. & Manne, B. Acetone and diethyl ether: Improve cold flow properties of Dairy Washed Milkscum biodiesel. Renew. Energy 130, 446–451. https://doi.org/10.1016/j.renene.2018.06.051 (2019).
Fadairo, A. A. et al. Impact of neem oil biodiesel blends on physical and chemical properties of particulate matter emitted from diesel engines. Environ. Pollut. 362, 124972. https://doi.org/10.1016/j.envpol.2024.124972 (2024).
Sakthivadivel, D. et al. A neem oil-based biodiesel with DEE enriched ethanol and Al2O3 nano additive: An experimental investigation on the diesel engine performance. Case Stud. Therm. Eng. 34, 102021. https://doi.org/10.1016/j.csite.2022.102021 (2022).
Hassan, T. et al. Effect of Ni and Al nanoadditives on the performance and emission characteristics of a diesel engine fueled with diesel-castor oil biodiesel-n-butanol blends. Case Stud. Chem. Environ. Eng. 8, 100531. https://doi.org/10.1016/j.cscee.2023.100531 (2023).
Jin, C. et al. Effect of nanoparticles on diesel engines driven by biodiesel and its blends: A review of 10 years of research. Energy Convers. Manag. 291, 117276. https://doi.org/10.1016/j.enconman.2023.117276 (2023).
Uyumaz, A. et al. Combustion, performance and emission evaluation of a diesel engine running on microwave-assisted corn oil biodiesel mixture with carbon quantum dot nanoparticle additive. Int. J. Hydrog. Energy 95, 849–859. https://doi.org/10.1016/j.ijhydene.2024.11.294 (2024).
Milano, J. et al. Strategies in the application of nanoadditives to achieve high-performance diesel, biodiesels, and their blends. Fuel Commun. 19, 100111. https://doi.org/10.1016/j.jfueco.2024.100111 (2024).
El-Araby, R. Biofuel production: Exploring renewable energy solutions for a greener future. Biotechnol. Biofuels Bioprod. 17(1), 129. https://doi.org/10.1186/s13068-024-02571-9 (2024).
Masthan Shareef, S. & Kumar Mohanty, D. Experimental investigation of emission characteristics of compression ignition engines using dairy scum biodiesel. Mater. Today Proc. 56, 1484–1489. https://doi.org/10.1016/j.matpr.2021.12.367 (2022).
Channappagoudra, M. Effect of copper oxide nanoadditive on diesel engine performance operated with dairy scum biodiesel. Int. J. Ambient Energy 42(5), 530–539. https://doi.org/10.1080/01430750.2018.1557553 (2021).
Venkatachalam, M., Balasubramani, P., Dhairiyasamy, R. & Rajendran, S. Performance and emission characteristics of neem biodiesel-diesel blend with mango leaf extract additive in diesel engines. Environ. Dev. Sustain. 26(8), 21725–21753. https://doi.org/10.1007/s10668-024-05213-0 (2024).
Ramakrishnan, G., Krishnan, P., Rathinam, S., Thiyagu, R. & Devarajan, Y. Role of nano-additive blended biodiesel on emission characteristics of the research diesel engine. Int. J. Green Energy 16(6), 435–441. https://doi.org/10.1080/15435075.2019.1577742 (2019).
Rathinam, S. et al. Assessment of the emission characteristics of the diesel engine with nano-particle in neem biodiesel. Energy Sources Part Recov. Util Environ. Eff. 42(21), 2623–2631. https://doi.org/10.1080/15567036.2019.1612487 (2024).
Nagarajan, J. & Balasubramanian, D. Effect of calcium oxide nano fluid additive on diesel engine characteristics fuelled with ternary blend. Presented at the International Conference on Advances in Design, Materials, Manufacturing and Surface Engineering for Mobility, 2021-28–0236. https://doi.org/10.4271/2021-28-0236 (2021).
Nayak, S. K. & Mishra, P. C. ‘Application of neem biodiesel and dimethyl carbonate as alternative fuels. Energy Sources Part Recov. Util. Environ. Eff. 39(3), 284–290. https://doi.org/10.1080/15567036.2015.1062828 (2017).
Khan, M. M., Kadian, A. K. & Sharma, R. P. An investigation of performance and emission of diesel engine by using quaternary blends of neem biodiesel–neem oil–decanol–diesel. Sādhanā 48(1), 28. https://doi.org/10.1007/s12046-023-02084-5 (2023).
Karagoz, M., Uysal, C., Agbulut, U. & Saridemir, S. Exergetic and exergoeconomic analyses of a CI engine fueled with diesel-biodiesel blends containing various metal-oxide nanoparticles. Energy 214, 118830. https://doi.org/10.1016/j.energy.2020.118830 (2021).
Chen, Y. et al. A comprehensive review of stability enhancement strategies for metal nanoparticle additions to diesel/biodiesel and their methods of reducing pollutant. Process Saf. Environ. Prot. 183, 1258–1282. https://doi.org/10.1016/j.psep.2024.01.052 (2024).
Abishek, M. S. et al. Exergy-energy, sustainability, and emissions assessment of Guizotia abyssinica (L.) fuel blends with metallic nano additives. Sci. Rep. 14(1), 3537. https://doi.org/10.1038/s41598-024-53963-8 (2024).
Rajak, U., Ağbulut, Ü., Dasore, A. & Verma, T. N. Artificial intelligence based-prediction of energy efficiency and tailpipe emissions of soybean methyl ester fuelled CI engine under variable compression ratios. Energy 294, 130861. https://doi.org/10.1016/j.energy.2024.130861 (2024).
Rajak, U., Apparao, K. C., Verma, T. N. & Ağbulut, Ü. Enhancing performance, and combustion efficiency, and reducing tailpipe emissions of an engine fuelled with hydrogen-enriched diesel and ethanol blends at varying CRs using RSM. Int. J. Hydrog. Energy 92, 1236–1247. https://doi.org/10.1016/j.ijhydene.2024.10.289 (2024).
Rajak, U. et al. Optimizing soybean biofuel blends for sustainable urban medium-duty commercial vehicles in India: An AI-driven approach. Environ. Sci. Pollut. Res. 31(22), 32449–32463. https://doi.org/10.1007/s11356-024-33210-3 (2024).
Gad, M. S. & Fawaz, H. E. Artificial neural network based forecasting of diesel engine performance and emissions utilizing waste cooking biodiesel. Sci. Rep. 14(1), 21980. https://doi.org/10.1038/s41598-024-71675-x (2024).
Muniyappan, S. & Krishnaiah, R. Investigation on CuO nanoparticle enhanced mahua biodiesel/diesel fuelled CI engine combustion for improved performance and emission abetted by response surface methodology. Sci. Rep. 14(1), 26882. https://doi.org/10.1038/s41598-024-77271-3 (2024).
Kumar, K. S. et al. Statistical and machine learning analysis of diesel engines fueled with Moringa oleifera biodiesel doped with 1-hexanol and Zr2O3 nanoparticles. Sci. Rep. 15(1), 7269. https://doi.org/10.1038/s41598-025-87818-7 (2025).
Zhu, C. et al. ANN-ANFIS model for optimising methylic composite biodiesel from neem and castor oil and predicting emissions of the biodiesel blend. Sci. Rep. 15(1), 5638. https://doi.org/10.1038/s41598-025-88901-9 (2025).
Elumalai, R. et al. Development of an ammonia-biodiesel dual fuel combustion engine’s injection strategy map using response surface optimization and artificial neural network prediction. Sci. Rep. 14(1), 543. https://doi.org/10.1038/s41598-023-51023-1 (2024).
Khan, O. et al. Modelling of compression ignition engine by soft computing techniques (ANFIS-NSGA-II and RSM) to enhance the performance characteristics for leachate blends with nano-additives. Sci. Rep. 13(1), 15429. https://doi.org/10.1038/s41598-023-42353-1 (2023).
Ghanbari, M. et al. Adaptive neuro-fuzzy inference system (ANFIS) to predict CI engine parameters fueled with nano-particles additive to diesel fuel. IOP Conf. Ser. Mater. Sci. Eng. 100, 012070. https://doi.org/10.1088/1757-899X/100/1/012070 (2015).
Ahmad, A., Yadav, A. K., Singh, A. & Singh, D. K. A machine learning-response surface optimization approach to enhance the performance of diesel engine using novel blends of Aloe vera biodiesel with MWCNT nanoparticles and hydrogen. Process Saf. Environ. Prot. 186, 738–755. https://doi.org/10.1016/j.psep.2024.04.013 (2024).
Paramasivam, P. et al. Machine learning based prognostics and statistical optimization of the performance of biogas-biodiesel blends powered engine. Case Stud. Therm. Eng. 61, 105116. https://doi.org/10.1016/j.csite.2024.105116 (2024).
Potnuru, B. D., Nvn, I. K. & Sagari, J. Predicting the operating characteristics of a diesel engine running on a ternary fuel blend of alcohol, hybrid biodiesel and diesel with nanoparticles: Experimental analysis and response surface methodology. Int. J. Thermofluids 26, 101063. https://doi.org/10.1016/j.ijft.2025.101063 (2025).
Al-jabiri, A. A. et al. Applied AMT machine learning and multi-objective optimization for enhanced performance and reduced environmental impact of sunflower oil biodiesel in compression ignition engine. Int. J. Thermofluids 24, 100838. https://doi.org/10.1016/j.ijft.2024.100838 (2024).
Godiganur, S., Telgane, V. & Srikanth, H. V. Effect of additive on engine performance with SVO and biodiesel blend as fuel. J. Mines Met. Fuels. https://doi.org/10.18311/jmmf/2023/40596 (2023).
Khan, M. K. A., Abdulhameed, A. S., Alshahrani, H. & Algburi, S. Development of chitosan biopolymer by chemically modified orange peel for safranin O dye removal: A sustainable adsorbent and adsorption modeling using RSM-BBD. Int. J. Biol. Macromol. 261, 129964. https://doi.org/10.1016/j.ijbiomac.2024.129964 (2024).
Aghbashlo, M. et al. Machine learning technology in biodiesel research: A review. Prog. Energy Combust. Sci. 85, 100904. https://doi.org/10.1016/j.pecs.2021.100904 (2021).
Shanmugasundar, G. et al. ‘A comparative study of linear, random forest and AdaBoost regressions for modeling non-traditional machining. Processes 9(11), 2015. https://doi.org/10.3390/pr9112015 (2021).
Quirk, T. J. Correlation and simple linear regression. In Excel 2016 in Applied Statistics for High School Students (Springer, Cham, 2018, pp. 107–152). https://doi.org/10.1007/978-3-319-89993-0_6.
Kanti, P. K., Sharma, P., Koneru, B., Banerjee, P. & Jayan, K. D. Thermophysical profile of graphene oxide and MXene hybrid nanofluids for sustainable energy applications: Model prediction with a Bayesian optimized neural network with K-cross fold validation. FlatChem 39, 100501. https://doi.org/10.1016/j.flatc.2023.100501 (2023).
Babbar, S. M., Lau, C. Y. & Thang, K. F. Long term solar power generation prediction using Adaboost as a hybrid of linear and non-linear machine learning model. Int. J. Adv. Comput. Sci. https://doi.org/10.14569/IJACSA.2021.0121161 (2021).
Kotsiantis, S. B. Decision trees: A recent overview. Artif. Intell. Rev. 39(4), 261–283. https://doi.org/10.1007/s10462-011-9272-4 (2013).
Abdi, J., Hadavimoghaddam, F., Hadipoor, M. & Hemmati-Sarapardeh, A. Modeling of CO2 adsorption capacity by porous metal organic frameworks using advanced decision tree-based models. Sci. Rep. 11(1), 24468. https://doi.org/10.1038/s41598-021-04168-w (2021).
Hafeez, M. A. et al. Performance improvement of decision tree: A robust classifier Using Tabu search algorithm. Appl. Sci. 11(15), 6728. https://doi.org/10.3390/app11156728 (2021).
Banik, R. & Biswas, A. Improving solar PV prediction performance with RF-CatBoost ensemble: A robust and complementary approach. Renew. Energy Focus 46, 207–221. https://doi.org/10.1016/j.ref.2023.06.009 (2023).
Schonlau, M. & Zou, R. Y. The random forest algorithm for statistical learning. Stata J. Promot. Commun. Stat. Stata 20(1), 3–29. https://doi.org/10.1177/1536867X20909688 (2020).
Zeini, H. A. et al. Random forest algorithm for the strength prediction of geopolymer stabilized clayey soil. Sustainability 15(2), 1408. https://doi.org/10.3390/su15021408 (2023).
Jain, A. et al. Application of hybrid Taguchi L16 and desirability for model prediction and optimization in assessment of the performance of a novel Water Hyacinth biodiesel run diesel engine. Fuel 339, 127377. https://doi.org/10.1016/j.fuel.2022.127377 (2023).
Said, Z., Sharma, P., Bora, B. J. & Pandey, A. K. Sonication impact on thermal conductivity of f-MWCNT nanofluids using XGBoost and Gaussian process regression. J. Taiwan Inst. Chem. Eng. 145, 104818. https://doi.org/10.1016/j.jtice.2023.104818 (2023).
Aberasturi, D. T. Violin plot. In Wiley StatsRef: Statistics Reference Online (eds Kenett, R. S. et al.) 1–7 (Wiley, New York, 2023). https://doi.org/10.1002/9781118445112.stat08426.
Kumar, K. S., Alqarni, S., Islam, S. & Shah, M. A. Royal poinciana biodiesel blends with 1-butanol as a potential alternative fuel for unmodified research engines. ACS Omega 9(12), 13960–13974. https://doi.org/10.1021/acsomega.3c09014 (2024).
Mofijur, M. et al. Impact of nanoparticle-based fuel additives on biodiesel combustion: An analysis of fuel properties, engine performance, emissions, and combustion characteristics. Energy Convers. Manag. X 21, 100515. https://doi.org/10.1016/j.ecmx.2023.100515 (2024).
Najafi, G. Diesel engine combustion characteristics using nano-particles in biodiesel-diesel blends. Fuel 212, 668–678. https://doi.org/10.1016/j.fuel.2017.10.001 (2018).
Annamalai, M. et al. An assessment on performance, combustion and emission behavior of a diesel engine powered by ceria nanoparticle blended emulsified biofuel. Energy Convers. Manag. 123, 372–380. https://doi.org/10.1016/j.enconman.2016.06.062 (2016).
Rangabashiam, D., Jayaprakash, V., Subbiah, G., Nagaraj, M. & Rameshbabu, A. Emission, performance, and combustion study on nanoparticle-biodiesel fueled diesel engine. Energy Sources Part Recov. Util. Environ. Eff. 45(3), 8396–8407 (2023).
Kumar, K. S. et al. Experimental analysis of cycle tire pyrolysis oil doped with 1-decanol + TiO2 additives in compression ignition engine using RSM optimization and machine learning approach. Case Stud. Therm. Eng. 61, 104863. https://doi.org/10.1016/j.csite.2024.104863 (2024).
Kumar, K. S. & Muniamuthu, S. Assessment of performance, combustion, and emission characteristics of single cylinder diesel engine fuelled by pyrolysis oil + CeO2 nanoparticles and 1-butanol blends. Int. J. Ambient Energy 45(1), 2344568. https://doi.org/10.1080/01430750.2024.2344568 (2024).
Wu, R. et al. Chitosan-Schiff base nano silica hybrid system for azo acid dye removal: Multivariable optimization, desirability function, and adsorption mechanism. Inorg. Chem. Commun. 162, 112237. https://doi.org/10.1016/j.inoche.2024.112237 (2024).
Kumar, S. & Pal, A. Multi-objective-parametric optimization of diesel engine powered with fuel additive 2-ethylhexyl nitrate-algal biodiesel. Sustain. Energy Technol. Assess. 53, 102518. https://doi.org/10.1016/j.seta.2022.102518 (2022).
Acknowledgements
"The authors extend their appreciation to the Deanship of Research and Graduate Studies at King Khalid University for funding this work through Large Research Project under grant number RGP2/301/45”.
Funding
Open access funding provided by University of Pannonia.
Author information
Authors and Affiliations
Contributions
Conceptualization, M.S.A, S.N; Writing—Review and Editing, S.H.V, S.K; Methodology, S.K, A.I.A; Supervision, S.A., O.J.A.S, A.B.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Aswathanrayan, M.S., Santhosh, N., Venkataramana, S.H. et al. Prediction of performance and emission features of diesel engine using alumina nanoparticles with neem oil biodiesel based on advanced ML algorithms. Sci Rep 15, 12683 (2025). https://doi.org/10.1038/s41598-025-97092-2
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-97092-2
Keywords
This article is cited by
-
Performance, combustion, emission and optimization characteristics of biodiesel–n-butanol blends enriched with Ni2O3 nanoparticles in a diesel engine
Scientific Reports (2026)
-
Artificial neural network model development of blended biodiesel
Environmental Science and Pollution Research (2026)
-
Optimizing the factors affecting the quality condition of 4WD tractors’ engine oil using the hybrid RSM-GRA method
Scientific Reports (2025)
-
Machine learning and response surface optimization to enhance diesel engine performance using milk scum biodiesel with alumina nanoparticles
Scientific Reports (2025)
-
Synergistic effect of biogas and waste Annona seed biodiesel on dual fuel engine performance and emissions
Discover Sustainability (2025)
