
Abstract
Post-hepatectomy liver failure (PHLF) is a severe complication following liver surgery. We aimed to develop a novel, interpretable machine learning (ML) model to predict PHLF. We enrolled 312 hepatocellular carcinoma (HCC) patients who underwent hepatectomy, and 30% of the samples were utilized for internal validation. Variable selection was performed using the least absolute shrinkage and selection operator regression in conjunction with random forest and recursive feature elimination (RF-RFE) algorithms. Subsequently, 12 distinct ML algorithms were employed to identify the optimal prediction model. The area under the receiver operating characteristic curve, calibration curves, and decision curve analysis (DCA) were utilized to assess the model’s predictive accuracy. Additionally, an independent prospective validation was conducted with 62 patients. The SHapley Additive exPlanations (SHAP) analysis further explained the extreme gradient boosting (XGBoost) model. The XGBoost model exhibited the highest accuracy with AUCs of 0.983 and 0.981 in the training and validation cohorts among 12 ML models. Calibration curves and DCA confirmed the model’s accuracy and clinical applicability. Compared with traditional models, the XGBoost model had a higher AUC. The prospective cohort (AUC = 0.942) further confirmed the generalization ability of the XGBoost model. SHAP identified the top three critical variables: total bilirubin (TBIL), MELD score, and ICG-R15. Moreover, the SHAP summary plot was used to illustrate the positive or negative effects of the features as influenced by XGBoost. The XGBoost model provides a good preoperative prediction of PHLF in patients with resectable HCC.
Similar content being viewed by others

Introduction
Primary liver cancer (PLC) is one of the most common malignancies worldwide, ranking sixth in morbidity and third in mortality1. PLC is also listed as the fourth most common malignant tumor and the second most cancer-related cause of death in China2. hepatocellular carcinoma (HCC) is the most common subtype of PLC, and its incidence is closely related to hepatitis virus infection3,4. Despite the tremendous progress of targeted therapy and immunotherapy in the treatment of HCC in recent years, surgical resection is still the first choice for patients with resectable HCC. However, Post-hepatectomy liver failure (PHLF), as a severe postoperative complication, greatly affects the prognosis of patients. PHLF has become the main cause of short-term death after surgery5.
Due to the high risk and incidence of PHLF, effective perioperative evaluation and postoperative management are critical. At present, there are a variety of liver function assessment methods, such as Child–Pugh grade, the model for end-stage liver disease (MELD) score, albumin-bilirubin (ALBI) score, and indocyanine green retention rate at 15 min (ICG-R15). While these models offer some predictive value for PHLF, they have limitations and do not comprehensively reflect the prognosis of liver cancer patients. The Child–Pugh grade is less effective for non-cirrhotic patients and does not comprehensively indicate liver cancer outcomes6,7,8. Although the ALBI score removes the subjective variables in the Child–Pugh grade, it still does not cover all aspects of liver function8,9. The MELD score was widely used in liver transplantation, cirrhosis, and other prognostic situations, and it assigned different weights to variables based on their impact on prognosis, leading to complex calculations and difficulty in categorizing the results of the assessment6,10,11. Although the indocyanine green (ICG) clearance test is a dynamic and quantitative liver function test, ICG-R15 has been proven to be an independent risk factor for predicting PHLF4,12. The reliability of ICG-R15 in assessing liver function may be affected by factors such as hepatic blood flow and biliary obstruction13.
Cirrhotic patients typically exhibit reduced liver function compared to non-cirrhotic individuals with similar volumes. Although imaging can show the presence of liver fibrosis in cases of cirrhosis, noninvasive biomarkers can be used to determine the degree of cirrhosis. The World Health Organization has recently validated various non-invasive scores based on biological parameters14,15, including aspartate aminotransferase to platelet ratio index (APRI)16, fibrosis-4(FIB-4) index17, γ glutamyl transpeptidase to platelet ratio (GPR)18, and aspartate aminotransferase to alanine aminotransferase ratio (AAR)19.
In oncology, systemic inflammation is commonly linked to alterations in blood markers. Specific immune and inflammatory biomarkers—including the lymphocyte to monocyte ratio (LMR), neutrophil to lymphocyte ratio (NLR), platelet to lymphocyte ratio (PLR), and γ glutamyl transpeptidase to lymphocyte ratio (GLR) have predictive value for post-resection outcomes in hepatocellular carcinoma patients20,21,22.
Traditional liver function assessment models are widely used to predict the risk of developing PHLF, but their predictive accuracy is relatively low. By analyzing the data of 13,783 patients, one researcher found that the AUC of ALBI score and MELD in predicting PHLF was respectively 0.67 and 0.6023. In recent years, with the development of artificial intelligence technology, more and more advanced algorithms incorporating more comprehensive risk factors have been applied in the field of PHLF prediction. Machine learning (ML) algorithms analyze a large amount of data to identify patterns, trends, and associations automatically, and they have been widely used in many different sciences. ML algorithms can find non-linear and seemingly unrelated factors that are difficult to find by traditional methods24,25. Previous studies have used ML methods to construct a model to predict PHLF. The AUC value of the model reached 0.944 in the training cohort. However, the AUCs of ALBI, FIB-4, APRI, MELD and Child-Turcotte-Pugh scores were 0.570, 0.595, 0.568, 0.512 and 0.512, respectively26. ML algorithms construct models that are praised for their excellent predictive performance. But at the same time, due to the opacity and complexity of their internal decision-making processes, these models are often referred to as “black box” models. To date, lack of interpretability has been a major barrier to implementing ML models in medicine27. To interpret the results of ML models, we combined ML algorithms with the SHapley Additive exPlanations (SHAP) to gain insight into the complex relationship between variables and PHLF28.
Given the limitations of existing assessment methods, this study focused on applying ML algorithms to construct a more comprehensive and accurate risk prediction model for PHLF, in order to facilitate postoperative recovery and reduce mortality rates.
Methods
Patients population
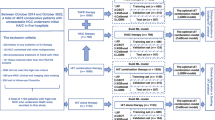
A retrospective cohort study enrolled 704 patients hospitalized in Liaoning Cancer Hospital from October 2016 to May 2020. Following rigorous screening, 392 patients were excluded for not meeting the predefined inclusion and exclusion criteria, resulting in a final cohort of 312 patients for subsequent analysis. A predictive model was developed based on the entire cohort, with 30% of the sample randomly selected for internal validation. From February 2023 to February 2024, a prospective cohort of 62 patients was recruited for our model accuracy assessment through prospective validation. Patients were categorized into PHLF and non-PHLF groups according to the International Study Group of Liver Surgery (ISGLS) criteria. In this investigation, HCC patients deemed suitable for surgical intervention were selected based on China liver cancer staging (CNLC) criteria. All participants provided written informed consent. Schematic of the study workflow was detailed in Fig. 1.

Schematic of the study workflow.
Inclusion and exclusion criteria
The inclusion criteria were as follows: (1) Patients underwent hepatectomy for liver cancer; (2) Preoperative ICG clearance test and ICG-R15 < 30; (3) Primary liver cancer surgery; (4) Preoperative Child–Pugh grade was A or B; (5) Eastern Cooperative Oncology Group (ECOG) performance score ≤ 2.
The exclusion criteria were as follows: (1) Patients with severe comorbidities involving critical organs such as the heart, brain, lungs, and kidneys; (2) Patients had received transcatheter arterial chemotherapy and/or embolization before the operation; (3) Hepatitis virus replication was active before surgery; (4) Previous history of liver surgery; (5) Patients whose pathological assessments did not confirm; (6) Patients with Child–Pugh grade C who were unlikely to improve to Child–Pugh grade A or B even with short-term liver-protective therapy; (7) Incomplete clinical data.
Data collection
65 clinical characteristics and predictors associated with PHLF were collected. These included patient demographics, complications, imaging data, preoperative laboratory tests, inflammatory and immune function indicators, traditional models, tumor markers, postoperative pathology, ICG clearance test data, and operative data. Detailed variables were presented in Table S1.
In this study, the majority of patients (n = 252) in the training cohort chose to undergo conventional open surgery through a right subcostal incision, while a minority (n = 60) underwent laparoscopic surgery. All procedures were performed by physicians with over 10 years of expertise in hepatobiliary surgery. The Pringle maneuver was employed to temporarily occlude blood flow to the liver to minimize hepatic bleeding and ensure a clear surgical field during the procedure. The duration of hepatic blood flow occlusion should not exceed 15 min per session, followed by prompt restoration of hepatic blood supply for 5 min after each occlusion period. The extent of resection was categorized as major hepatectomy (≥ 3 segments) or minor hepatectomy (< 3 segments)29. Liver resection was performed using the clamp-crushing technique. Drainage tubes were routinely placed on the liver wound before the end of the operation to promote postoperative recovery.
The Child–Pugh grade is calculated based on five items: serum albumin (ALB), serum total bilirubin (TBIL), prothrombin time, hepatic encephalopathy, and ascites. Child–Pugh grade is defined as follows: grade A (5–6 points), grade B (7–9 points) and grade C (10–15 points). There were no patients with Child–Pugh grade C in this study. MELD score = 11.2 × ln [international normalized ratio(INR)] + 9.6 × ln (Creatinine [mg/dL]) + 3.8 × ln (TBIL [mg/dL]) + 6.410. ALBI score = -0.085 × ALB [g/L] + 0.66 × log10 (TBIL [μmol/L])9. A lower ALBI score indicates better liver function. APRI score = (AST/ upper limit of normal)/platelet (PLT)[109/L]) × 10030, the upper limit of normal is 40. FIB-4 index = aspartate aminotransferase (AST)[U/L] × age [years]/PLT [109/L] × alanine aminotransferase (ALT) [U/L])1/231. A higher score on this scale reflects a higher level of liver fibrosis. PNI = lymphocyte × 5 + ALB. Diagnosis of portal hypertension: clinically significant portal hypertension (CSPH) is diagnosed by endoscopy with the presence of oesophageal varices or a low PLT count (< 100 × 109/L) with splenomegaly (greater than 12 cm in diameter on ultrasound, CT, or MRI images)17.
Definition of PHLF
In most hepatectomy patients, TBIL and INR levels return to normal within 5 days after surgery. According to the criteria proposed by the International Study Group of Liver Surgery (ISGLS), patients with an increased INR and increased serum bilirubin level on or after postoperative day 5 were diagnosed with PHLF32. Combined with the reference values of the clinical laboratory in our hospital, INR > 1.2 and TBIL > 20.5 μmol/L on the 5th or after the 5th day after surgery were used as diagnostic criteria in this study.
Indocyanine green clearance test
Before the ICG clearance test, we checked for iodine allergy and biliary obstruction and ensured the patient fasted for 4–6 h. We then drew blood to check hemoglobin and recorded the patient’s height and weight. The DDG-5301K+ analyzer used these data to calculate ICG dose. A nurse prepared a 5 mg/ml ICG solution in sterile water. The patient had a quick venipuncture through the median cubital vein for ICG injection and waited 6 min for the ICG test using the Pulse Dye Density (PDD) method. This process provided key indicators: ICG clearance rate, ICG-R15, effective hepatic blood flow, and circulating blood volume.
Statistical analysis
The data of patients with missing values were excluded. Patient data were categorized as continuous or categorical variables, and the Kolmogorov–Smirnov test assessed whether the data followed a normal distribution. Normally distributed continuous variables were expressed as means ± standard deviations and compared between groups using t test. Continuous variables that were not normally distributed were reported as medians (interquartile ranges) using the Mann–Whitney U test. Categorical variables were presented as numbers and frequencies and compared using χ2 or Fisher’s exact test. Delong test was used to determine whether there were statistical differences between the receiver operating characteristic (ROC) curves, all statistical tests were two-sided, and P < 0.05 was considered statistically significant. Statistical analyses were performed with R, version 4.0.3.
We developed and compared 12 ML models to predict the risk of PHLF, including Logistic Regression (LR), K-Nearest Neighbor (KNN), XGBoost, Random Forest (RF), Naive Bayes (NB), ADAboost classifier (ADA), Support Vector Machine (SVM), Neural Network (NN), Gaussian Processes (GP), Gradient Boosting Machine (GBM), C5.0, Multi-Layer Perception (MLP).
The model construction and evaluation steps were as follows: (1) 65 clinical variables and predictors associated with PHLF were collected. After excluding near-zero variance and highly correlated variables, the remaining variables were screened using random forest and recursive feature elimination (RF-RFE) algorithm combined with the least absolute shrinkage and selection operator (LASSO) regression; (2) 5-repeated tenfold cross-validation method combined with a random search method were used to control and adjust hyperparameters33, and the optimal combination of hyperparameters was selected to construct the model; (3) 12 different ML algorithms were selected to construct 12 models. The area under the curve (AUC), accuracy (ACC), sensitivity (SEN), specificity (SPE), F1 score and learning curve were used to compare the performance of each models, and the best prediction model was finally determined; (4) The ROC curve, Calibration curve, and decision curve analysis (DCA) curve were performed on the training, validation, and prospective cohorts to evaluate the discrimination, calibration, and clinical utility of the model; (5) The constructed model was compared with the conventional models; (6) The “black box” model was interpreted using SHAP. SHAP revealed how each variable affected the results of the XGBoost model; (7) The construction of an online web page allowed further visualization and practicality of the XGBoost model.
Results
Patient characteristics
In this study, we initially identified a total of 704 hospitalized patients, of which 392 patients who failed to meet the inclusion criteria were excluded. Eventually, 312 patients were incorporated for analysis. PHLF occurred in 25.64% of the patients (n = 80). Table 1 summarized the baseline clinical characteristics of the training cohort (n = 312), validation cohort (n = 93), and prospective cohort (n = 62). The training cohort consisted of 312 patients who were used to construct a predictive model for PHLF. The validation and prospective cohorts were employed to assess the accuracy and generalizability of the XGBoost model.
Variables selection
A total of 65 variables were included in this study. Direct bilirubin, carbohydrate antigen 199, white blood cells, prothrombin time before surgery, fibrinogen to albumin ratio, ALBI, and APRI/ALBI—seven variables with the variance of 0 or collinearity—were excluded using the “finCorrelation” and “nearZeroVar” function from the “caret” package and the “vif” function from the “car” package of R. The remaining 58 variables were further screened by RF-RFE algorithm and LASSO regression. LASSO regression compressed the regression coefficients by increasing the penalty term. We found the best model fit by adjusting the λ (lambda) value. When the model included 21 variables, it achieved the best-fitting effect (Fig. 2A,B). RFE enhanced the generalization ability and effectiveness by initially considering all variables, then sequentially removing irrelevant or redundant ones based on a specific ranking criterion, ultimately retaining the most important variables34. RFE can be combined with different ML models. RF-RFE was used in this study. In the RF-RFE process, when the number of variables was reduced to 20, the model’s accuracy reached 0.772 (Fig. 2C). Variable importance was then ranked using the RF-RFE algorithm (Fig. 2D). Further, we selected the intersection of variables selected by LASSO regression and the RF-RFE algorithm to determine the key variables of the model (Fig. 2E). Finally, we determined the 12 best variables for the model’s construction, which included TBIL, MELD, ICG-R15, PLT, tumor size, hepatic portal occlusion time, operation time, LMR, GLR, intraoperative blood transfusion, Child–Pugh grade, and Major hepatectomy.

The LASSO regression and RFE-RF algorithms were used to screen the variables. (A) Path plot of LASSO regression coefficients for 58 risk variables. The vertical axis showed the value of the coefficients, the lower horizontal axis showed the log(λ) of the regularization parameter, and the upper horizontal axis indicated the number of nonzero coefficients retained in the model at each point. (B) Cross-validation curve. The vertical axis represented the log value of the penalty coefficient, denoted as log(λ). The lower horizontal axis represented the likelihood bias, while the upper horizontal axis indicated the number of variables selected. Smaller values on the vertical axis indicated a better fit of the model. (C) Variable ranking change curve. The horizontal axis represented the number of variables, and the vertical axis represented the accuracy of the curve after fivefold cross-validation. Among them, the accuracy for 20 variables was 0.772. The closer this value was to 1, the higher the accuracy. (D) The 20 variables after RF-RFE screening were ranked by importance, and only the top 13 variables were shown in this figure. (E) Venn diagram. Visually presented the commonalities and differences in variable selection between LASSO and RF-RFE.
Model construction
In this study, the “trainControl” function of “caret” package in R software was used to set the training control parameters for model tuning. reduce the influence of randomness on model evaluation. During the training process, hyperparameter tuning was performed by adopting a random search method. The tolerance method was used to select the optimal combination of hyperparameters to build the machine learning model. Then the “train” function of the “caret” package in R software was used to build 12 different ML models through different machine learning algorithms. The evaluation results of the 12 ML models were summarized in the ROC curve (Fig. 3) and the performance evaluation Table (Table 2).

The Receiver operating characteristic (ROC) curves of the twelve models. (A) Training cohort. (B) Validation cohort. (C) Prospective cohort. Note SVM, support vector machine; KNN, K-nearest neighbor; XGB, eXtreme gradient boosting; MLP, multi-layer perception.
To observe whether the model was overfitting or underfitting, we drew learning curves (Figure S5) to observe the generalization ability of the model and the trend of model performance as the number of internal training sets changes. When the number of internal training was small, the accuracy of GBM, ADA, and RF models was 1, and there was no significant change in accuracy as the proportion of internal training sets increased. The accuracy of the internal validation set fluctuated greatly, and the overall level was lower than the accuracy of the internal training set. This may indicate an overfitting problem in the model. When analyzing the learning curves of XGBoost, SVM and KNN models, the accuracy of XGBoost model decreasesd with the increase of the proportion of internal training set, and the accuracy of internal validation set increased, indicating that XGBoost algorithm was more suitable for building our expected machine learning model than SVM and KNN algorithms. Therefore, we chose the XGBoost algorithm to build the model.
The XGBoost model not only performed well in avoiding overfitting but also showed excellent performance in multiple evaluation indicators such as AUC, ACC, SEN, SPE, and F1 score, which made it an ideal choice for our prediction task. Finally, we used a confusion matrix to show the prediction results of the prediction model and the actual results in detail (Figure S1).
Model evaluation and comparison
We analyzed the ROC curves to validate the XGBoost model: the AUC was 0.983 in the training cohort, 0.981 in the validation cohort, and 0.942 in the prospective cohort (Fig. 3A–C). Our model showed high accuracy in predicting PHLF. The calibration curves of the training, validation, and prospective cohorts for predicting PHLF demonstrated a strong correlation between the predictions of the model and the actual observations (Fig. 4A–C). To confirm the clinical utility of the XGBoost model, we used DCA to plot the curves on the training, validation, and prospective cohorts. The XGBoost model showed high net clinical benefit within a certain threshold probability range (Fig. 4D–F).

The calibration curve and decision curve analysis curve were used to evaluate the accuracy and clinical application value of the XGBoost model. (A) Calibration curve for the training cohort. (B) Calibration curve for the validation cohort. (C) Calibration curve of the test cohort. (D) DCA curve for the training cohort. (E) DCA curve for the validation cohort. (F) DCA curve for the prospective cohort. Note The all curve illustrated the benefit rates for all cases that received the intervention, while the none curve depicted the benefit rates for all cases that did not received any intervention. The pred curves represented the XGBoost model. DCA, decision curve analysis.
When comparing the constructed XGBoost model with the conventional model, we observed that the XGBoost model showed excellent performance. Specifically, the AUC of the XGBoost model reached 0.983, which was significantly better than the traditional models such as the MELD score (AUC = 0.664), APRI score (AUC = 0.646), FIB-4 index (AUC = 0.694), ALBI score (AUC = 0.577) and Child–Pugh grade (AUC = 0.663) (P < 0.05) (Fig. 5). These data powerfully demonstrated the significant advantage of the XGBoost model in prediction accuracy and its high AUC value, meaning that the model has high accuracy and reliability in its ability to distinguish PHLF.

The prediction accuracy of the XGBoost model and conventional models for post-hepatectomy liver failure was compared. Note MELD, the model for end-stage liver disease; ALBI, albumin-bilirubin score; ICG R15, indocyanine green retention rate at 15 min; APRI, aspartate aminotransferase to platelet ratio index; FIB-4, fibrosis-4 index; XGB, eXtreme Gradient Boosting.
Model interpretation
In this study, We ranked each variable in the XGBoost model in order of importance (Fig. 6A). Figure 6A showed that TBIL had the greatest impact on the model prediction results, followed by the MELD, ICG-R15, PLT, and other factors. Figure 6B illustrated the specific contributions of each variable to the prediction of PHLF using SHAP analysis. Points were colored based on individual patient eigenvalues and accumulated vertically to represent density. SHAP values indicated the degree to which each variable contributes to model predictions. Positive values indicated an increased likelihood of the predicted outcome, while negative values indicated a decreased likelihood. We found that the increase of TBIL, MELD, ICG-R15, tumor size, hepatic portal occlusion time, operation time, GLR, intraoperative blood transfusion, Child–Pugh grade, and major hepatectomy improved the predictive risk of PHLF. The increase of PLT and LMR reduced this risk. In addition, we provided two typical examples, one predicting the occurrence of PHLF (Fig. 6C) and the other predicting the absence of PHLF (Fig. 6D), to demonstrate the interpretability of the model. The Waterfall plots not only illustrated the influence of key variables on the model output but also helped us understand the specific role of each variable by means of visualization. SHAP force plot was used to visually display the SHAP values of a single sample and its impact on the model’s prediction results (Fig. 6E). In order to improve the clinical practicability, we constructed an online PHLF prediction network calculator based on the “shiny” package of the R software, which was easy to display the data analysis and visualization (http://124.221.189.227/webapp/) (Figure S4).

SHAP explained the XGBoost model. (A) Global bar graph. The average SHAP absolute value for each variable was on the X-axis. The Y-axis was sorted by variable importance, with the most critical variable appearing at the top of the graph. (B) SHAP summary plot. Yellow indicates high SHAP values, while red indicates low SHAP values. The farther a point was from the baseline SHAP value of 0, the greater its effect on the output. (C) and (D) Waterfall plot. (C) represented a sample with PHLF, and (D) represented a sample without PHLF. The X-axis showed the SHAP values. The Y-axis was sorted by variable importance, with the most essential variables appearing at the top of the graph. Variables with positive contributions were colored yellow, and those with negative contributions were red. The length of the bars represents the contribution magnitude of the variables. (E) SHAP predictions for sample without PHLF. Yellow arrows signified an increased risk of PHLF, while red arrows denoted a decreased risk of PHLF. The length of the arrows served to illustrate the predicted degree of influence, with longer arrows representing more substantial effects.
Discussion
In this study, we successfully developed a personalized prediction model utilizing the ML algorithm to assess the risk of PHLF in HCC patients. Firstly, we applied LASSO and RF-RFE to screen out 12 critical variables, including TBIL, MELD, ICG-R15, PLT, tumor size, hepatic portal occlusion time, operation time, LMR, GLR, intraoperative blood transfusion, Child–Pugh grade, Major hepatectomy. After a comprehensive evaluation, the XGBoost model was selected as the final model for its excellent predictive performance, significantly superior to traditional clinical models such as Child–Pugh grade, MELD, FIB-4, ALBI, APRI, and ICG-R15. The XGBoost model showed excellent AUC values on training, validation, and independent prospective cohort, which verified its good predictive performance and robustness. To enhance the transparency and interpretability of the model, we used SHAP analysis to reveal the specific contribution of each variable to the predicted outcome, which helped to enhance the trust of clinicians in the model.
Previous research has extensively employed traditional logistic regression to construct clinical models for predicting PHLF, showing that these models outperform conventional models in terms of predictive accuracy4,12,35. Although there were relatively few studies about ML methods to construct predictive PHLF, studies that have utilized artificial neural network algorithms36,37,38, LightGBM37 and XGBoost algorithms39 have indicated superior predictive performance than traditional logistic regression. Therefore, it was essential to develop an individualized prediction model for PHLF, tailored specifically for HCC patients, using ML algorithm. The XGBoost algorithm built a strong prediction algorithm by integrating multiple weak prediction models. The XGBoost algorithm excelled at managing complex nonlinear relationships between variables and was particularly favored in medical data analysis for its strong generalization capabilities, low risk of overfitting, and high interpretability40. After comparing 12 ML algorithms, we adopted XGBoost algorithm to build the model.
Among the variables we included, ICG-R15 mainly aimed at PHLF in patients with cirrhosis4,41. For non-cirrhotic ones, the predictive accuracy of it was relatively low and had certain limitations 42. Studies have shown that the preoperative ICG clearance test alone was not necessarily a reliable method for predicting liver failure after hepatectomy43. However, it played an important role in predicting PHLF in a multivariate model combining clinical and imaging data4.Although rarely adapted in Western countries, ICG-R15 was widely used to assess liver reserve before hepatectomy in Asia44. In our hospital, ICG test was an important basis for us to evaluate liver function reserve. The specific value of ICG-R15 as a prerequisite for surgical resection varied in different studies45. In China, ICG-R15 < 30 was considered to be a necessary condition for surgical resection. Tumor size and resection range had a significant impact on postoperative liver function. Studies have shown that patients with large tumors and a wide resection range had a significantly increased risk of PHLF12,46. Therefore, tumor size and resection range should be comprehensively evaluated in surgical planning. Hepatic ischemia–reperfusion injury was aggravated, and the risk of PHLF was increased by the repeated process of blocking and restoring hepatic blood flow during surgery47. Therefore, it was recommended to use individualized hepatic blood flow control techniques to reduce the duration and frequency of hepatic portal occlusion and balance the reduction of bleeding and liver injury. Intraoperative blood transfusion affected the immune function of patients, leading to a decrease in the immune ability of the body, increased the risk of postoperative systemic infection, and then affected the liver function48. There was a certain association between intraoperative blood transfusion and PHLF, and more studies were needed to further explore this relationship. In the context of hepatectomy, precise assessment of intraoperative blood loss was vital for evaluating patient prognosis and implementing appropriate therapeutic interventions. An inaccurate estimation of blood loss could have resulted in a misinterpretation of the patient’s condition, potentially impacting treatment decisions. In this study, blood loss and blood transfusion were included as categorical variables to reduce error due to numerical estimation. This method could help to reduce the inaccuracies caused by subjective estimation of blood loss and improve the reliability of the study results. Current studies mainly focused on the relationship between LMR, GLR, and the prognosis of HCC after resection rather than directly linking LMR, GLR, and PHLF49,50. This study found that LMR and GLR were risk variables that led to PHLF. To gain a deeper understanding of the relationship between LMR, GLR and PHLF, further clinical research might have been required to explore this connection and determine the effectiveness of LMR and GLR in predicting the risk of PHLF.
A significant strength of our study was constructing a risk assessment model that can efficiently and accurately predict PHLF. The XGBoost model showed an AUC of 0.983 in the training cohort and 0.981 in the validation cohort. Further analysis found that the XGBoost model performed best in overall prediction performance, surpassing several clinical models, including Child–Pugh grade, MELD, FIB-4, ALBI, APRI, and ICG-R15. Secondly, our model was also prospectively tested, and an AUC of 0.942 was found in the prospective cohort, indicating good generalization ability. We employed SHAP analysis to address ML models’ “black box” nature and enhance interpretability. This method visualized model outcomes, offering medical staff clearer insights into the model’s predictive mechanisms. By leveraging SHAP’s game-theoretic approach to fairness, we could attribute each variable’s contribution to the model’s output, thus demystifying the decision process and fostering greater trust in the model’s predictions.
To facilitate the clinical use of this model, a free web calculator was developed to predict the risk of PHLF (http://124.221.189.227/webapp/).
There are several limitations to this study that deserve attention in future studies. Firstly, the lack of 3D reconstruction techniques to assess the preoperative liver volume and anticipated resection volume limits our ability to thoroughly investigate the impact of liver volume on PHLF. Second, the predominance of hepatocellular carcinoma linked to hepatitis B virus infection in our cohort resulted in an incomplete evaluation of other potential causes of HCC, which may limit the applicability of our findings. Third, MELD score and Child–Pugh grade both include TBIL. During the data cleaning process, this study found that the correlation coefficients between TBIL, MELD score, and Child–Pugh grade were all less than 0.5. A correlation coefficient greater than 0.7 was usually considered to indicate potential collinearity51 (Figure S3A). In addition, the variance inflation factors for these three variables were all less than 2, far below the threshold of 10, which was commonly regarded as indicative of multicollinearity51 (Figure S3B). This suggested that the collinearity among these three variables was weak, and including them together in the model was unlikely to cause collinearity issues. This study used RF-RFE and LASSO for variable selection and found that all three variables made significant contributions to the model, which also supported their inclusion. The SHAP analysis of the XGBoost model also showed that these 3 variables were the ones with a higher degree of influence. Therefore, 3 variables were finally included in the model. Both the MELD score and Child–Pugh grade include TBIL, but they also integrate a variety of other factors. These factors may complement the information reflected by TBIL, thus helping to improve the predictive efficacy of the model for patient prognosis. Fourth, this investigation is being conducted at a single center, making further validation through external multi-center studies necessary to confirm the model’s effectiveness and practicality. Lastly, the relatively small sample size may introduce variability in results. Consequently, while this study provides valuable insights, additional research efforts are essential for validating and refining these conclusions.
Conclusion
We successfully developed the XGBoost model to predict the risk of PHLF in HCC patients after hepatectomy. This predictive model can help identify patients with PHLF and can provide patients with early and personalized treatment to further improve outcomes and quality of life.
Data availability
The data that support the findings of this study are available from the corresponding author upon reasonable request.
Abbreviations
- AAR:
-
Aspartate aminotransferase to alanine aminotransferase ratio
- ACC:
-
Accuracy
- ADA:
-
ADAboost classifier
- ALB:
-
Albumin
- ALBI:
-
Albumin-bilirubin
- ALT:
-
Alanine aminotransferase
- APRI:
-
Aspartate aminotransferase to platelet ratio index
- AST:
-
Aspartate aminotransferase
- AUC:
-
Area under the curve
- CNLC:
-
China liver cancer staging
- CSPH:
-
Clinically significant portal hypertension
- DCA:
-
Decision curve analysis
- ECOG:
-
Eastern Cooperative Oncology Group
- FIB-4:
-
Fibrosis-4
- GBM:
-
Gradient boosting machine
- GLR:
-
γ-Glutamyl transpeptidase to lymphocyte ratio
- GP:
-
Gaussian processes
- GPR:
-
γ Glutamyl transpeptidase to platelet ratio
- HCC:
-
Hepatocellular carcinoma
- ICG:
-
Indocyanine green
- ICG-R15:
-
Indocyanine green retention rate at 15 min
- INR:
-
International normalized ratio
- ISGLS:
-
International Study Group of Liver Surgery
- KNN:
-
K-nearest neighbor
- LASSO:
-
The least absolute shrinkage and selection operator
- LMR:
-
Lymphocyte to monocyte ratio
- LR:
-
Logistic regression
- MELD:
-
Model for end-stage liver disease
- ML:
-
Machine learning
- MLP:
-
Multi-layer perception
- NB:
-
Naive Bayes
- NLR:
-
Neutrophil to lymphocyte ratio
- NN:
-
Neural network
- PLC:
-
Primary liver cancer
- PLR:
-
Platelet to lymphocyte ratio
- PLT:
-
Platelet
- PHLF:
-
Post-hepatectomy liver failure
- RF:
-
Random forest
- RF-RFE:
-
Random forest and recursive feature elimination
- ROC:
-
Receiver operating characteristic
- SEN:
-
Sensitivity
- SHAP:
-
SHapley additive exPlanations
- SPE:
-
Specificity
- SVM:
-
Support vector machine
- TBIL:
-
Total bilirubin
- XGBoost:
-
EXtreme gradient boosting
References
Bray, F. et al. Global cancer statistics 2022: GLOBOCAN estimates of incidence and mortality worldwide for 36 cancers in 185 countries. CA: A Cancer J. Clin. 74(3), 229–263 (2024).
Han, B. et al. Cancer incidence and mortality in China, 2022. J. Natl. Cancer Center 4(1), 47–53 (2024).
Llovet, J. M. et al. Molecular pathogenesis and systemic therapies for hepatocellular carcinoma. Nat. Cancer 3(4), 386–401 (2022).
Zhang, D. et al. A nomogram based on preoperative lab tests, BMI, ICG-R15, and EHBF for the prediction of post-hepatectomy liver failure in patients with hepatocellular carcinoma. J. Clin. Med. 12(1), 324 (2022).
Gilg, S. et al. The impact of post-hepatectomy liver failure on mortality: A population-based study. Scand. J. Gastroenterol. 53(10–11), 1335–1339 (2018).
Durand, F. & Valla, D. Assessment of prognosis of cirrhosis. Semin. Liver Dis. 28(1), 110–122 (2008).
Durand, F. & Valla, D. Assessment of the prognosis of cirrhosis: Child-Pugh versus MELD. J. Hepatol. 42(1), S100–S107 (2005).
Morandi, A. et al. Predicting post-hepatectomy liver failure in HCC patients: A review of liver function assessment based on laboratory tests scores. Medicina 59(6), 1099 (2023).
Johnson, P. J. et al. Assessment of liver function in patients with hepatocellular carcinoma: A new evidence-based approach—The ALBI grade. J. Clin. Oncol. 33(6), 550–558 (2015).
Kamath, P. A model to predict survival in patients with end-stage liver disease. Hepatology 33(2), 464–470 (2001).
Wang, Y. et al. Comparison of the ability of Child-Pugh score, MELD score, and ICG-R15 to assess preoperative hepatic functional reserve in patients with hepatocellular carcinoma. J. Surg. Oncol. 118(3), 440–445 (2018).
Fang, T. et al. A nomogram based on preoperative inflammatory indices and ICG-R15 for prediction of liver failure after hepatectomy in HCC patients. Front. Oncol. 11, 667496 (2021).
Lu, Q. et al. Intraoperative blood transfusion and postoperative morbidity following liver resection. Med. Sci. Monit.: Int. Med. J. Exp. Clin. Res. 24, 8469–8480 (2018).
Ben Ayed, H. et al. A new combined predicting model using a non-invasive score for the assessment of liver fibrosis in patients presenting with chronic hepatitis B virus infection. Med. Mal. Infect. 49(8), 607–615 (2019).
Guidelines for the prevention, care and treatment of persons with chronic hepatitis B infection. Geneva: World Health Organization (2015).
Lin, Z. H. et al. Performance of the aspartate aminotransferase-to-platelet ratio index for the staging of hepatitis C-related fibrosis: an updated meta-analysis. Hepatology 53(3), 726–736 (2011).
Zhou, P. et al. Comparison of FIB-4 index and Child–Pugh score in predicting the outcome of hepatic resection for hepatocellular carcinoma. J. Gastrointest. Surg. 24(4), 823–831 (2020).
Lemoine, M. et al. The gamma-glutamyl transpeptidase to platelet ratio (GPR) predicts significant liver fibrosis and cirrhosis in patients with chronic HBV infection in West Africa. Gut 65(8), 1369–1376 (2016).
Imperiale, T. F. et al. Need for validation of clinical decision aids: use of the AST/ALT ratio in predicting cirrhosis in chronic hepatitis C. Am. J. Gastroenterol. 95(9), 2328–2332 (2000).
Itoh, S. et al. Prognostic significance of inflammatory biomarkers in hepatocellular carcinoma following hepatic resection. BJS Open 3(4), bjs5.0170 (2019).
Ma, W. et al. Prognostic value of platelet to lymphocyte ratio in hepatocellular carcinoma: A meta-analysis. Sci. Rep. 6(1), 35378 (2016).
Casadei Gardini, A. et al. Immune inflammation indicators and ALBI score to predict liver cancer in HCV-patients treated with direct-acting antivirals. Dig. Liver Dis. 51(5), 681–688 (2019).
Fagenson, A. M. et al. Albumin–bilirubin score vs model for end-stage liver disease in predicting post-hepatectomy outcomes. J. Am. Coll. Surg. 230(4), 637–645 (2020).
Deo, R. C. Machine learning in medicine. Circulation 132(20), 1920–1930 (2015).
Han, Y. & Wang, S. Disability risk prediction model based on machine learning among Chinese healthy older adults: Results from the China health and retirement longitudinal study. Front. Public Health 11, 1271595 (2023).
Wang, J. et al. Machine learning prediction model for post-hepatectomy liver failure in hepatocellular carcinoma: A multicenter study. Front. Oncol. 12, 986867 (2022).
Cabitza, F., Rasoini, R. & Gensini, G. F. Unintended consequences of machine learning in medicine. JAMA 318(6), 517–518 (2017).
Lundberg, S. & Lee, S. I. A unified approach to interpreting model predictions. arXiv (2017).
Chopinet, S. et al. Short-term outcomes after major hepatic resection in patients with cirrhosis: A 75-case unicentric western experience. HPB: Off. J. Int. Hepato Pancreato Biliary Assoc. 21(3), 352–360 (2019).
Shi, J. Y. et al. A novel online calculator based on noninvasive markers (ALBI and APRI) for predicting post-hepatectomy liver failure in patients with hepatocellular carcinoma. Clin. Res. Hepatol. Gastroenterol. 45(4), 101534 (2021).
Sterling, R. K. et al. Development of a simple noninvasive index to predict significant fibrosis in patients with HIV/HCV coinfection. Hepatology 43(6), 1317–1325 (2006).
Rahbari, N. N. et al. Posthepatectomy liver failure: A definition and grading by the international study group of liver surgery (ISGLS). Surgery 149(5), 713–724 (2011).
Wong, T. T. Performance evaluation of classification algorithms by k-fold and leave-one-out cross validation. Pattern Recogn. 48(9), 2839–2846 (2015).
Iranzad, R. & Liu, X. A review of random forest-based feature selection methods for data science education and applications. Int. J. Data Sci. Analyt. https://doi.org/10.1007/s41060-024-00509-w (2024).
Wang, J. et al. A novel nomogram for prediction of post-hepatectomy liver failure in patients with resectable hepatocellular carcinoma: A multicenter study. J. Hepatocell. Carcinoma 9, 901–912 (2022).
Mai, R. Y. et al. Artificial neural network model for preoperative prediction of severe liver failure after hemihepatectomy in patients with hepatocellular carcinoma. Surgery 168(4), 643–652 (2020).
Lu, H. Z. et al. Developmental artificial neural network model to evaluate the preoperative safe limit of future liver remnant volume for HCC combined with clinically significant portal hypertension. Future Oncol. (London, England) 18(21), 2683–2694 (2022).
Jin, Y. et al. Online interpretable dynamic prediction models for clinically significant posthepatectomy liver failure based on machine learning algorithms: A retrospective cohort study. Int. J. Surg. https://doi.org/10.1097/JS9.0000000000001764 (2024).
Tashiro, H. et al. Utility of machine learning in the prediction of post-hepatectomy liver failure in liver cancer. J. Hepatocell. Carcinoma 11, 1323–1330 (2024).
Bentéjac, C., Csörgő, A. & Martínez-Muñoz, G. A comparative analysis of gradient boosting algorithms. Artif. Intell. Rev. 54(3), 1937–1967 (2021).
Mizumoto, M. et al. Association between pretreatment retention rate of indocyanine green 15 min after administration and life prognosis in patients with HCC treated by proton beam therapy. Radiother. Oncol. 113(1), 54–59 (2014).
Ibis, C. et al. Value of preoperative indocyanine green clearance test for predicting post-hepatectomy liver failure in noncirrhotic patients. Med. Sci. Monit. 23, 4973–4980 (2017).
Granieri, S. et al. Preoperative indocyanine green (ICG) clearance test: Can we really trust it to predict post hepatectomy liver failure? A systematic review of the literature and meta-analysis of diagnostic test accuracy. Photodiagn. Photodyn. Ther. 40, 103170 (2022).
Le Roy, B. et al. Indocyanine green retention rates at 15 min predicted hepatic decompensation in a western population. World J. Surg. 42(8), 2570–2578 (2018).
Gao, J. et al. Safe threshold rate of indocyanine green retention and intervention of nutrition management after hepatectomy. Nutr. Cancer 77, 1–8. https://doi.org/10.1080/01635581.2024.2431348 (2024).
Kishi, Y. et al. Three hundred and one consecutive extended right hepatectomies: Evaluation of outcome based on systematic liver volumetry. Ann. Surg. 250(4), 540–548 (2009).
Peng, W. et al. Spleen stiffness and volume help to predict posthepatectomy liver failure in patients with hepatocellular carcinoma. Medicine 98(18), e15458 (2019).
Bekheit, M. et al. Post-hepatectomy liver failure: A timeline centered review. Hepatobiliary Pancreat. Dis. Int. 22(6), 554–569 (2023).
Yang, Y. T. et al. The lymphocyte-to-monocyte ratio is a superior predictor of overall survival compared to established biomarkers in HCC patients undergoing liver resection. Sci. Rep. 8(1), 2535 (2018).
Chen, W. et al. Gamma-glutamyl transpeptidase to platelet and gamma-glutamyl transpeptidase to lymphocyte ratio in a sample of Chinese han population. BMC Gastroenterol. 22(1), 442 (2022).
Dormann, C. F. et al. Collinearity: A review of methods to deal with it and a simulation study evaluating their performance. Ecography 36(1), 27–46 (2013).
Acknowledgements
We thank all participants for their endeavour and contribution to this study.
Funding
This work was supported by the Liaoning Provincial Key Laboratory of Precision Medicine for Malignant Tumors (Project number: 220569).
Author information
Authors and Affiliations
Contributions
Tianzhi Tang and Tianyu Guo; Data collection and analysis: Tianzhi Tang and Tianyu Guo; Drafting of the article: Tianzhi Tang and Qihui Tian; Important revision of the article: Bo Zhu and Yefu Liu; Guidance for the “shiny” package of R software: Yang Wu; All authors have given their approval for the article.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Ethical approval
Informed consent was obtained from each patient included in the study. The study protocol complied with the ethical guidelines of the 1975 Declaration of Helsinki and was approved a priori by the Medical Ethics Committee of Liaoning Cancer Hospital (KY20240413).
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Tang, T., Guo, T., Zhu, B. et al. Interpretable machine learning model for predicting post-hepatectomy liver failure in hepatocellular carcinoma. Sci Rep 15, 15469 (2025). https://doi.org/10.1038/s41598-025-97878-4
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-025-97878-4
