
Abstract
Emotion recognition via EEG signals and facial analysis becomes one of the key aspects of human–computer interaction and affective computing, enabling scientists to gain insight into the behavior of humans. Classic emotion recognition methods usually rely on controlled stimuli, such as music and images, which does not allow for ecological validity and scope. This paper proposes the EmoTrans model, which uses the DEAP dataset to analyze physiological signals and facial video recordings. It consisted of EEG recordings from 32 viewers of 40 one-minute movie clips and facial videos from 22 participants, which can be used to analyze the emotional states based on variables; valence, arousal, dominance, and liking. To increase the model’s validity, expert validation in the form of a survey by psychologists was conducted. The model integrates features extracted from EEG signals in the time, frequency, and wavelet domains as well as facial video data to provide a comprehensive understanding of emotional states. Our proposed EmoTrans architecture achieves the accuracies of 89.3%, 87.8%, 88.9%, and 89.1% for arousal, valence, dominance, and liking, respectively. EmoTrans achieved an impressive classification accuracy of 89% for emotions such as happiness, excitement, calmness, and distress, among others. Moreover, the Statistical significance of performance improvements was confirmed using a paired t-test, which showed that EmoTrans significantly outperforms baseline models. The model was validated with machine learning and deep learning classifiers and also by Leave-one-subject-out cross-validation (LOSO-CV). The proposed attention-based architecture effectively prioritizes the most relevant features from EEG and facial data, pushing the boundaries of emotion classification and offering a more nuanced understanding of human emotions across different states.
Similar content being viewed by others


Introduction
Affecting computing is a niche area of AI concerned essentially with processing, interpreting, and identifying emotional states. Emotions are an intrinsic part of daily human activities, from decision-making and communication to personal development. While inherently natural in humans, emotions have recently generated significant interest regarding detection during human–robot interactions for improvement in affective computing capabilities1. Seminal research has identified the ability of computers to recognize and respond appropriately to human emotions as crucial for advances in human–computer interaction2. Moreover, analysis of affective physiological signals has been defined as one of the promising pathways toward machine intelligence, and physiological signals often work better for emotion recognition compared to vocal or visual data. Neural codes are, in a way, the future method of processing complex information from the real world, while physiological signals have a high impact on emotion recognition from a smart robotics perspective. Regarding the development of efficient techniques for emotion recognition in AI systems, affective computing is the most contemporary area of research. Certain methods based on speech, facial expression, and skin conductance have been proposed for emotion recognition. Models used for speech-based emotion classification include hidden Markov models and artificial neural networks. Their performances are normally subject to the selection of utterance and window size3. Another widely addressed research area is based on facial expression4. Several models have been proposed for categorizing a wide range of emotional states. These models for automatic facial expression recognition have been developed based on static, dynamic, and geometry-based face features5. In the research study of emotional states, two main taxonomy models have traditionally been used: the discrete method, and the dimensional method6. The discrete model categorizes emotions into a restricted set of basic states and usually covers such states as: joy, surprise, fear, sadness, anger, and disgust7,8. In contrast, the dimensional model represents emotional conditions in a two-dimensional interplanetary defined by valence and arousal9. The valence axis spans from sadness to joy and the arousal axis spans from boredom to excitement. The valence-arousal space can be systematically mapped to distinct emotions, therefore various emotional states can be defined10. Recently, physiological signals, in particular electroencephalography (EEG), have gained considerable importance in emotion classification studies11. EEG has some advantages: it is non-invasive, straightforward, and inexpensive to work with. It is portable, especially with the recent commercial availability of wearable headphones, and imposes minimal physical restraints12. Since EEG records the underlying brain action, it is measured as a trustworthy modality for emotion recognition systems. In contrast, methods based on facial signals and speech are susceptible to human partiality and manipulation. Accordingly, studies on real-time emotion gratitude based on EEG signals are active13. In the work of14, the model was developed using five-channel EEG signals (FP1, P3, FC2, AF3and O1), showing high performance in emotion classification. On the other hand, the application of discriminating frequency sub-bands such as beta, alpha, and gamma has been emphasized to enhance the accuracy of emotion classification15.
Moreover, studies have also unveiled an association of emotional conditions with the asymmetric shares of EEG electrodes that can be exploited in emotional state classification16,17. However, the acquisition of noise-free data is still a major challenge for the EEG-based systems. The use of EEG electrodes in a cap might cause a certain feeling of discomfort that results in motion artifacts and not all electrodes in high-density placements are useful enough in emotion appreciation18,19. A comprehensive evaluation of algorithms on feature and electrode collection underlined the feature and electrode selection as the most critical in developing effective emotion recognition systems using wearable mobile EEG sensors. While the best performance was achieved using features extracted by the differential entropy-based methods, the study concluded that identifying relevant features and electrodes is a crucial step in the expansion of efficient emotion classification methodologies. Hence, enabling us to perform emotion analysis in valence, arousal, dominance, liking, and familiarity terms. Valence is the averseness of an event or intrinsic attractiveness or situation, as quantified along a bipolar pleasure-to-unpleasantness scale. Arousal is the psychological and physiological state of being reactive or awake to stimuli or events. For example, calm or sleepy versus excited or alert. Dominance is the degree of control or power over specific feelings in a situation, including feelings ranging from submissive to dominant and Liking is an evaluative response of a favorable or unfavorable disposition toward an object, person, or situation.
In our proposed model, we make use of the DEAP dataset20, which consists of physiological indications recorded from 32 test participants for a total of 40 movie clips, each having a length of 60 s. Facial expression features were also extracted in video recordings of 22 subjects. The DEAP dataset is subject to some limitations that can affect its performance in actual-world emotion recognition applications. One limitation is the short recording duration, as each stimulus is only 60 s long, which might not reflect the full development of emotional states over extended time. Another limitation is that the dataset does not consider individual differences in responding to emotional stimuli, as personal experiences and cultural background can affect how emotions are identified and expressed. Moreover, environmental noise and artifacts, such as eye blinks and muscle activities, can cause unwanted variability in the EEG signals, which can influence the accuracy of classification. Notwithstanding these limitations, DEAP is a commonly used benchmark dataset because of its extensive multimodal data, including EEG, physiological signals, and facial videos, that make it suitable for multimodal deep learning model testing. Its standardized framework permits comparative analysis against previous research, ensuring reproducibility. This research addresses DEAP’s limitations by incorporating an attention-based model that improves feature selection, utilizes advanced noise reduction methods, and cross-checks emotion classifications using expert psychological assessment, making it a solid basis for emotion recognition research.
The extensive usage of the DEAP dataset might have been for EEG-based emotion recognition, but there are a few crucial research gaps that remain unsolved. First, most current works rely completely on EEG signals for classification21. This potentially leaves out the benefits of multimodal fusion like fusion with facial video data for comprehensive emotional assessment. Second, most of the traditional models suffer from cross-subject variability22, as they do not generalize well across different subjects due to differences in physiology. Third, current techniques mainly rely on feature extraction from a single domain; time or frequency23. This limits the richness of the extracted emotional representations. Additionally, data augmentation and generalization techniques remain, particularly under-explored areas, and leave models overfitting to the data. Moreover, few of the experiments are validated by experts; it concerns the interpretation and reliability of predictions for emotion. The model, EmoTrans, overcomes all of these limitations by integrating the EEG and facial video features leads to enhancement of generalization over different subjects; multi-domain feature extraction (time, frequency, and wavelet); and validation by predictions using surveys based on psychological knowledge of the subject and do the early stopping to control the model overfitting and performed the leave-one-subject-out cross-validation (LOSO-CV). The proposed novel framework significantly enhances classification accuracy and bridges the gap between experimental emotion recognition and practical human–computer interaction applications.
Contribution
There is a need to progress the emotion classification methods for understanding human behavior on EEG and facial data. In the interest of the above goal, we introduce here a method of emotion recognition based on a dataset entitled DEAP. Existing emotion recognition approaches based on the DEAP dataset are with issues of single-modal limitations, poor-feature selection, and the absence of expert validation, thus constraining their use in real-world applications. To address these gaps, we introduce EmoTrans, a multimodal approach based on EEG signals and with facial video data to conduct a better analysis. The features are extracted from the time, frequency, and wavelet domains, while expert psychological validation enhances credibility. Key Contributions of this study:
-
Multimodal Emotion Recognition: In contrast to earlier studies that used only EEG data, the current study integrates varied EEG features from different domains i.e., time, frequency, and wavelet with facial video data, thereby greatly improving the robustness of classification.
-
Enhanced Feature Selection: The new model selects specific EEG channels and electrodes while, at the same time, extracting useful features from facial expressions, resulting in improved classification performance on valence, arousal, dominance, and liking dimensions.
-
Attention-Based EmoTrans Architecture: The proposed attention mechanism effectively identifies useful features, resulting in a classification accuracy of 89%.
-
Expert Validation for Psychological Validity: For practical applicability, expert psychologists were consulted, who confirmed that the model’s predictions are by human emotional perception.
This study addresses the problem of multimodal emotion recognition by integrating EEG, facial expression analysis, and psychological validation and is also extendable to future applications in affective computing and human–computer interaction.
Problem statement
Existing DEAP-based emotion recognition is mostly based on single-modality EEG signals, which limits cross-subject generalization and real-world applications24,25. Most studies ignore multimodal fusion, multi-domain feature extraction, and expert verification, decreasing model robustness26. This paper presents EmoTrans, which combines EEG and facial video processing, making use of multi-domain features (time, frequency, wavelet), and adding psychologist verification for increased accuracy and reliability. With these limitations resolved, EmoTrans presents an end-to-end, ecologically valid solution for human emotion recognition and behavior analysis.
Related work
Understanding Understanding Human Behavior (UHB) through human emotions using multimodal datasets has continued to gain quite a great deal of attention in the last couple of years. This synthesis aims to unravel the complexities of human emotions27. Emotion determines the stress level in an individual, and in combination with contemporary neurosciences and brain analysis results, it can also explain the reason behind it28,29. Specific emotions can be activated by exposure using EEG30 and from specific types of video content or genres of music31. In the same vein, recent developments have. Used a human nervous scheme to recognize emotional states and conclude physiological signals mostly using EEG32. In the study, both contributor-dependent and independent expressive states were recognized by the stable EEG patterns, namely neural correlate, which reflected the neural activity in crucial brain regions and frequency bands. Six features of different natures were extracted and feature selection was done using mRMR criterion. It resulted in an accuracy of 69.67% on the DEAP dataset in the classification of a four-valence/arousal state33. In audio music is presented as an extrinsic emotional elicitor and results in 94% accuracy using an MLP for the classification of seven discrete emotion states34. DEAP-based model calculating three features from EEG signals reached 73.5% accuracy while classifying two valence and arousal states. In35, two neural network-based classifiers utilized the DEAP dataset to realize two-class emotion classification with an accuracy of 71.00%. Another representation of features for AFE recognition improves the performance of classifying emotions further by including the Support Vector Machine (SVM) and hidden Markov technique classifier along with features mined in time besides discrete wavelet domains36. Emotion recognition from EEG signals has gained much attention in recent years, with various deep-learning models showing promising results. A study on Multiple Column Convolutional Neural Networks (CNNs) demonstrated an accuracy of 81% on the DEAP dataset37, which is widely used for emotion recognition tasks. Furthermore, recent reviews, discussed MER progress, challenges, and future directions through deep learning advancement38. In particular, a method called ICaps-ResLSTM uses a combination of CapsNet with Residual LSTM for improving EEG emotion recognition over a single-module model to achieve better performance on the DEAP dataset39. Another approach, known as Temporal-Difference Minimizing Neural Network (TDMNN), performed state-of-the-art results on the DEAP and DREAMER datasets, pushing forward emotion recognition capabilities40. In addition, a newly proposed spiking neural network approach called EESCN also achieved high-performance results on the DEAP and SEED-IV datasets with an average accuracy of 79.65% in emotion recognition about valence, arousal, and dominance41. These studies collectively show that significant progress has been made in EEG-based emotion recognition with deep learning models improving the accuracy across different datasets. However, several limitations exist, especially regarding the several emotional states considered. The state-of-the-art summary is shown in Table 1
In our study, we aim to go beyond merely identifying emotions by analyzing human behavior through these emotional states. To achieve this, we utilize a multimodal dataset, integrating data across different domains, including frequency, time, wavelet, and video data. From the above literature, we extracted that our proposed EmoTrans attention approach works better compared to previous methods by effectively focusing on emotionally informative features from both EEG signals and facial video information. Traditional models usually depend on static feature selection or simple feature concatenation, which can lead to redundancy of information and ineffective utilization of multimodal inputs. EmoTrans uses a dynamic attention-based fusion mechanism that adaptively assigns higher weights to the most informative EEG channels and facial features, ensuring the model focuses on emotion-specific facial and neural patterns. As opposed to previous methods that process all features equally, this removes noise and useless information, leading to better classification accuracy and enhanced generalization across subjects. In addition, the cross-domain attention mechanism of EmoTrans reveals intricate relationships between EEG frequency bands and facial expressions, a feature lacking in traditional deep-learning models. Using context-aware attention, the model dynamically modulates the importance of features in line with real-time emotional cues, enhancing the robustness and explainability of the model compared to previous methods depending on hand-crafted features or fixed feature selection methods. This innovation not only improves classification performance (up to 89% accuracy) but also significantly enhances the real-world applicability of EEG-based emotion recognition in applications such as human–computer interaction and affective computing.
Materials and methods
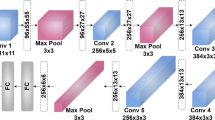
This section outlines the methodology or processes used in conducting the analysis. The proposed methodology for the classification of emotions includes a broad machine learning and deep learning approach to the analysis and understanding of human behavior using the DEAP dataset, considering multi-domain features individually. The dataset comprises data from 32 participants (16 male and 16 female), with an average age of 26.9 years, fluctuating from 19 to 37 years. This methodology is organized around several key components, including data pre-processing, feature selection, and classification; an abstract level of the proposed methodology is provided in Fig. 1.

Proposed methodology.
In our experiments, we used the DEAP dataset, which was a collection of EEG-based physiological signals and facial videos, so it was designed with an aim toward emotion recognition. The first was the reading of EEG signals and facial videos to collect data for the recognition of emotions. From these EEG signals, we derived brain connectivity matrices, where different connections and interactions of diverse brain regions are explained. These matrices, constructed using electrophysiological data, reflect statistical relationships in activity patterns between different regions of the brain as they are reported by EEG measurements. Such connectivity matrices were used to form feature maps, which, after various domain network selection processes and analysis, the DEAP dataset was taken across times, frequency domains, as well as through wavelets. We then applied the identified network to the entire set, but using features from connectivity matrices with data from other psychological sensors excluded. Now, only EEG data is available for emotion recognition, and features based on the selected network, and we processed our facial videos by annotating the face, and extracting features using Open Face. These features were then prepared for classification. For emotion recognition, we used our proposed model, EmoTrans, an attention-based architecture that identifies and focuses on the most relevant facial regions and feature patterns. Spatial attention highlighted critical areas, such as the mouth and eyes, while feature attention emphasized open-face descriptors most strongly associated with specific emotions. These attended features were combined and then passed through a classifier that used the strength of open face and deep learning for accurate prediction of emotion. Finally, we used an affective model to classify emotions by combining features extracted from EEG data and facial videos. To establish the validity of the predicted emotions, we used a survey with expert psychologists who mapped these emotions to human behavior, thereby lending credibility to our findings.
The EEG data was collected while contributors viewed 40 one-minute video clips, each associated with a specific ID and representing various genres. The EEG signals were recorded using 40 channels, resulting in a data array with dimensions (40 × 40 × 8064), where 8064 represents the number of data samples per channel. The second array in the dataset includes four labels—valence, arousal, dominance, and liking—for each video. Self-assessment ratings for valence and arousal were collected using the Self-Assessment Manikin (SAM) scale, ranging from 1 to 9 as shown in Fig. 2. For our study, we focused on valence and arousal, dominance, and liking scales. This resulted in the classification of emotional states: distressed, miserable, neutral, excited, happy, pleased, depressed, calm, and relaxed which can be used for human behavior understanding.

Self-assessment Manikin—VADL.
EEG electrode selection
The EEG electrodes are placed according to the 10–20 system, a standard for electrode placement on the scalp, where symbols are assigned to the lobes and numbers indicate hemispheric locations as shown in Fig. 3. Different electrodes correspond to specific emotional responses, as supported by previous research. For instance, studies have shown that cerebral laterality and the prefrontal cortex significantly influence emotion regulation. In our proposed method, we used 32 EEG channels for emotion analysis. We began with all 32 electrodes, systematically eliminating one electrode at a time then evaluating classification outcome using time-domain features, frequency domain, and the wavelet. After this iterative process, the selected electrodes consistently showed the best performance, even when using a hybrid feature vector that combined features from multiple domains.

EEG sensors position on the human brain.
EEG signal preprocessing and feature extraction
The raw EEG data were preprocessed to eliminate artifacts and noise, which is crucial for accurate human behavior understanding through emotion classification. The signals were down-tested to 128 Hz, and a band-pass filter through a pass-band-frequency of 2 Hz to 45 Hz was applied using the EEGLAB toolbox. Following the procedure outlined in the DEAP dataset documentation, a blind foundation separation system was employed to eliminate eye movement artifacts. The preprocessed signals, each consisting of 8064 data points, were then segmented into 60-s windows corresponding to the video clips. These windowed trials were subsequently utilized for feature extraction. Emotion recognition from EEG signals requires the extraction of meaningful features that can represent the underlying neuronal activities associated with diverse emotional states. In our approach, we extracted features from the time domain, frequency domain, and wavelet domains, to capture the complex dynamics of emotions. EEG signals, as time-series data, contain valuable information across multiple domains. Thus, combining features from these domains can provide complementary insights, improving classification accuracy.
Time-domain features extraction
In time domain analysis, we mined the entropy features and Hjorth parameters from the time domain for analyzing the EEG signals. These include activity (Ah), mobility (Mh), and complexity (Ch)49. Their equations are:
The input signal variance is defined in Activity Ah in Eq. 1. where var(sj) characterizes the signal variance
Signal mean frequency is measured by the Mobility Mh using Eq. 2: where the first derivative variance of input signal is denoted by var(sj′) and var(sj) shows the signal variance of sj.
The signal’s irregularity is measured by Complexity Ch as in Eq. 3:
where M0h is the mobility of the primary derivative of the input signal, and the Mh flexibility of the signal. These Hj orth parameters bring information on the signal statistical properties and help to characterize the EEG data in terms of activity, mobility, and complexity.
Time domain analysis is one of the most critical features in any EEG signal when it comes to human emotion of gratitude. Extracting key features from the time domain can achieve efficient accuracy and improve the robustness of the classification models. In this workflow, a careful analysis of the EEG signals is done over approximately 64 s, with the X-axis showing time in seconds and the Y-axis presenting the breadth of the signal in microvolt, ranging between − 20 µV and 20 µV. These signals are rapid fluctuations that capture the electrical activity of the brain and reflect different types of brain waves, such as alpha and beta waves. In this work, data from 22 participants is considered, and chosen in a way that video data for them is available, enriching the context in which emotion recognition is made. Then, the window size of 100 samples with a step size of 30 is used to dissect the EEG signals into manageable segments. For each window, a set of statistical features is calculated, including mean, standard deviation, max, min, skewness, and kurtosis. These will, therefore, be performed on different EEG channels and trials in parallel, hence assuring efficient processing. The measures that can be plotted over the windows are mean, standard deviation, max, min, skewness, and kurtosis of features extracted. Topographic maps allow the viewing of brain activity in space across different regions of the brain as time unfolds; colors ranging from red to blue reflect different levels of electrical activity. Also, line plots of these features over 32 EEG channels provide a comparative view that gives better interpretability. In classification, different categories of emotions such as arousal, valence, dominance, and liking are considered in the study with various classifiers like SVM, KNN, MLP, GBM, 1D-CNN, and emotions. For further fine tuning the predictions, the proposed EmoTrans model is used. This advanced model leverages multi-head self-attention mechanisms, improving classification performance and finally proposing a new technique that can recognize emotions with higher accuracy.
The investigation conducts a detailed analysis of time-domain analysis and underlines its importance in EEG-based emotion gratitude by statistical features extracted along with a progressive ML model that can improve the precision of emotional state classification significantly. The first trial and last channel EEG signals are shown in Fig. 4. The time in seconds, from 0 up to about 64 s is represented on the X-axis of the EEG signal plot, while the Y-axis represents the amplitude of the EEG signal in volts, ranging from − 20 V to 20 V shown in Fig. 5. This plot shows how the EEG signal varies with time rather eloquently since it shows rapid variations in amplitude that are also centered around 0 V. These fluctuations, captured by the peaks and troughs of the waveform, represent the electrical movement of the brain throughout recording. A better title would therefore be "EEG Signal in Time Domain," since it indicates that the signal is observed in its raw time domain and captures the dynamics of the brain’s electrical patterns over this period.

Time domain voltage vs time.

EEG signals in time domain.
In Fig. 6 plots, the X-axis epitomizes the window index, although the Y-axis varies depending on the statistical feature being analyzed. The mean plot provides the average value of the EEG signal for each window, usually fluctuating around zero, catching the general trend in the central propensity of the signal. The standard deviation plot provides the variability within each window, peaking at points where higher dispersion can be seen within the signal. The plot of maximum values shows the peak of brain activity for each window, whereas the plot of minimum values denotes moments of activity reduction or negative voltage spikes at times when values drop below − 15. Skewness continuously changes from positive to negative besides vice versa, showing asymmetry of the distribution of a signal and pointing to the right or left side at which the signal is skewed.

Kurtosis plots in time domain.
The kurtosis plot provides the peakedness of the distribution of the signal, where higher values indicate a more spiked peak and stronger central features in the signal’s distribution. The combined frequency of all wavelet domains is shown in Fig. 7

Combined frequency of all wavelet domains.
In Fig. 8 Topographic maps of brain activity as recorded at different time windows from the EEG data. Maps are labeled according to time intervals ("0.00-1.00 seconds", "1.00-2.00 seconds"), and it becomes evident how brain activity develops over time in these maps. The color gradations within the maps reflect different magnitudes of electrical activity, with red color reflecting higher activity and blue color indicating lower activity. It is structured in such a way that one can get a clear comparison of the visual alterations of the brain activity across the scalp as time progresses.

Topographic maps in time domain.
In Fig. 9 top section, generated by the plot_features_foof function, presents topo-graphical maps depicting various statistical measures (Mean, Standard Deviation, Max, Min, Skewness, Kurtosis) across the scalp.

Topographical maps and highlighting patterns.
These maps visually represent how each statistical feature varies across different brain regions, offering a spatial overview of the data. In contrast, the bottom section, produced by the plot_feature_peak function, includes line plots of the same statistical measures but focused on different EEG channels (likely corresponding to individual electrodes). These line plots show the variation of each statistical feature across the channels, providing a complementary view to the topographical maps and highlighting patterns or anomalies specific to particular electrodes.
Frequency-domain features extractions
EEG signals stand inherently non-stationary and nonlinear, which creates some difficulties in finding an effective representation and analysis. To overcome the issues, features mined from the frequency domain using the STFT were taken into consideration. We could capture the changes in the dynamic frequency content of the signals using STFT. We carried out the feature extraction from the main EEG frequency sub-bands, namely alpha, beta, and gamma49. The power standards of these frequency sub-bands (P_freq) are computed utilizing Eq. 1:
Equation signifies the signal in the frequency domain, and accordingly, power standards are computed for alpha, beta, and gamma sub-bands. This helps to capture the energy distribution across different frequency ranges, which is an important characteristic for classifying various emotional states.
Asymmetry features ratios are of paramount importance in emotion classification because they describe the differences in signal characteristics between the left and right brain hemispheres. It has already been determined that different emotions are more related to certain hemispheres, which, in turn, makes these features particularly useful in classification tasks. We extracted two kinds of asymmetry features from the power values of the frequency bands:
Rational Asymmetry (RASM): Calculated as the ratio of power between the left then right cerebral hemispheres as shown in Eq. 5.
Differential Asymmetry (DASM): Calculated as the difference in power between the left then right cerebral hemispheres as shown in Eq. 6. It represents the influence of the alpha, beta, and gamma bands of electrodes on the left and right cerebral hemispheres and computes these asymmetry features for multiple channel pairs.
We included RASM and DASM standards for all the mentioned pairs, with a particular focus on electrodes. Our experiments revealed that emotion recognition accuracy was significantly enhanced when the RASM and DASM features were extracted. This finding corroborates the importance of the electrode pair in emotion recognition. This is an approach that has combined the feature of the frequency domain with asymmetry analysis, while catching the minute differences in brain activities of different emotional states quite effectively, hence improving the overall accuracy of our human behavior recognition model. Acquisition of the EEG signals is read through a custom function, read_eeg_signal_from_file, which efficiently loads data from 22 subjects into files. This function uses Python’s pickle module for deserialization, instantly returning EEG data. The data is reshaped into a 3D NumPy ar-ray, structured as a sample, an EEG channel, and time points per sample. The number of EEG channels is shown in Fig. 10. Peripheral data starting at index 32 includes non-EEG information like skin conductance, eye movement, etc. This data is also reshaped as a 3D array and structured into samples, peripheral channels, and time points. For each of the EEG signals, an estimate of the PSD was done using Welch’s technique to get an overview of the power across different frequency bands (theta, alpha, beta, and gamma). It is a really good way to estimate signal power over a range of frequencies, which may be informative for attempting to analyze underlying brain activity. The bandpower function computed the power in given frequency bands; this function was then further encapsulated within the get_band_power function for ease of computation over a multitude of trials and channels.

EEG frequency domain time series plots.
The extracted EEG signal is visualized as a time series plot in Fig. 10 where the x-axis represents time. This plot has considerable fluctuations, which indeed is very normal in the case of an EEG; it shows that there is a lot of variability and therefore possibly noise in this signal. Thus, the signal fluctuates around 0, showing that it has a stable baseline without major long-term drift.
The Welch’s Periodogram to estimate Power Spectral Density (PSD) and extract relevant frequency-domain information from EEG recordings. To ensure smooth spectral estimation, a Hamming window with 256 samples per segment and a 50% overlap was used. The sampling rate was set to 128 Hz, which gave a frequency resolution of 0.5 Hz per bin. The collected features were separated into four frequency bands: Theta (4–8 Hz), Alpha (8–13 Hz), Beta (13–30 Hz), and Gamma (30–50 Hz). These frequency-domain properties were then employed as inputs for classification algorithms, which helped to recognize emotions using EEG signals. Welch’s technique was then used to plot the PSD against frequency as shown in Fig. 11, illustrating the power distribution across the various frequency bands. This plot carries information on how PSD changes with the frequency band. Each frequency band-theta, alpha, beta, and gamma reflects different power distributions that are paramount for ascertaining the spectral characteristics of the EEG data.

PSD Graph against frequency.
For the graphical representation of the spatial distribution of power across the scalp, we have generated Welch periodograms for theta, alpha, beta, gamma, and delta frequency bands separately that are presented in Figs. 12, 13, 14, 15, and 16 respectively.

Theta Welch’s periodogram.

Alpha’s Welch’s periodogram.

Beta Welch’s periodogram.

Gamma Welch’s periodogram.

Delta Welch’s periodogram.
We are not utilizing the delta band because its effect is too tiny as presented in Fig. 16. This technique helps in determining the distribution of power in these specific frequency bands across different regions of the brain, hence providing insight into the activity patterns of neurons for different states of cognition and emotion.
Topo maps were created for the theta, alpha, beta, and gamma frequency bands as a means of visually representing the power distribution across the scalp. These topographical representations provide a clear, intuitive understanding of how power is distributed across various regions of the brain during different cognitive states, as captured by the EEG signals. The bandpower function was used to determine the band power value. It calculated the power of a certain frequency band of the EEG signal by adopting Welch’s method for the estimation of PSD, one of the commonly used methods for power spectral estimation to evaluate the content of the frequency in an EEG recording. The bandpower function may also normalize the calculated power if the parameter relative = True is so specified; it gives a relative measure of power in the specified frequency band. The get_band_power function merely wraps the band power function for convenience in extracting power for given frequency bands. It takes as input arguments the number of the trial, the number of an EEG channel, and the name of the frequency band as a string-e.g., "theta,", "alpha,", "beta,", "gamma.". It maps these band names onto their respective frequency ranges and subsequently calculates and returns the power in that band for the given trial and channel in the EEG dataset. This step is quite crucial in detailed analysis, as further evaluation of power for different trials and channels in specific frequency bands can be allowed. In this experiment, 32 EEG electrodes recorded the electrical activity of the brain, while several other peripherals measured skin conductance and eye movement. Only EEG electrodes will be considered in this paper. The EEG electrodes were positioned on the scalp, and topographical maps for each frequency band were done to present visually the power distribution associated with each band. These topo maps are very helpful in the identification of regions of interest and in understanding the spatial dynamics of brain activity across different cognitive or emotional states. The figure below shows a set of scalp topography plots, each showing a bird’s eye view of the scalp in the direction to portray the distribution of EEG data at various time points depicted in Figs. 17, 18, 19, and 20 for theta, alpha, beta, and gamma respectively. The top part of the circle in the plots is the nose, with ears at the sides. Voltage is represented using a color gradient in micro-volts, with red representing more positive voltages and blue representing more negative voltages. These plots are time-locked, meaning they show the evolution of activity in the brain over some time window; in this case, 0.050 to 0.250 s. It serves to be highly effective in conveying dynamic changes in electrical activity across the scalp and thus provides insight into how brain activity unfolds in response to a specific event or a stimulus. Changes in the pattern over the scalp suggest modifications in neural activity at the heart of cognition and sensation. This kind of visualization, apart from simply being used to describe brain activity, is a common method that analyzes the temporal and spatial variation in the activity of the brain, which can be done in response to some sort of external stimulus.

Theta topo maps.

Alpha topo maps.

Beta topo maps.

Gamma topo maps.
The labels within the study are Valence, Arousal, Dominance, and Liking, which, after being hot label encoded, were changed into a binary code. In the encoding scheme, each label was assigned a value of 1 for high and 0 for low, based on the intensity of the emotional response. This gave 16 different combinations, or groups, which can be said to represent different emotional states from the combination of the four labels. These binary-coded groups will subsequently be treated as the actual labels when training or testing machine-learning models for emotion recognition with both EEG signals and facial expressions.
Figure 21 shows the four box plots for each dimension in the dataset: Valence, Arousal, Dominance, and Liking. The box plot gives a visual summary of data distribution across different categories specified on the x-axis. Each box in the plot represents the IQR capturing the middle 50% of the data. The line in each box’s interior defines the median value and indicates the central tendency for each category. The whiskers extend from the boxes to enclose the range of the data up to a distance of 1.5 times the IQR, showing the spread of most of the data points. Data points that are beyond this range are plotted separately as single circles, showing the outlying data.

Interquartile dimensions of VADL in dataset.
These plots are useful for a quick assessment of the central tendency, variability, and presence of outliers within the dataset across different conditions or groups for each of the four emotional dimensions. They serve to show how the data clusters, whether there are significant deviations, and how the distributions compare across the various categories.
In Fig. 22 series of box plots illustrates the distribution of four emotional metrics, namely Valence, Arousal, Dominance, and Liking across conditions. These conditions have been labeled as HAHVHDHL, HAHVHDLL, HAH-VLDHL, HAHVLDLL, LAHVHDHL, LAHVHDLL, LAHVLDHL, and LAHVLDLL. Each box plot represents the area of variation in values for the respective metric within a condition. The orange line shows the median value. IQR gives the spread of the data, and possible outliers are isolated as individual points outside the whiskers of the box. The trends of variation thus signal how each emotional dimension is distributed differentially across conditions and, therefore, how emotional responses to specific combinations of high/low values for Arousal, Valence, Dominance, and Liking vary. This figure serves to highlight the underlying patterns of, and differences in, emotional states across conditions.

Interquartile range of VADL emotion states.
The following topo maps for all groups represent the voltage distribution across different brain regions for each particular group. Topomaps are for subjects divided into class 16 by the hot label encoding for emotional dimensions: Valence, Arousal, Dominance, and Liking. Each topomap shows the scalp from a bird’s eye view where colors denote voltage level recorded by the EEG electrodes. Red areas reflect higher positive voltages and blue areas lower negative voltages. Topomaps are generated using the FOOOF model, which is especially effective in the isolation and visualization of the periodic components of neural oscillations. Such analysis takes into consideration changes in brain activities across subjects and regions to provide a clear picture of the spatial distribution of electrical activity within specific emotional states.
Visualization of this sort is essential to bring out patterns in brain activities that are associated with the different emotional groups; thus, providing insight into how specific emotions may manifest across various brain regions. Figure 23 examples of power spectral density topographies for alpha, theta, beta, and gamma frequency bands, plotted by a Python script using the EEG recordings. These topographies provide a glimpse into the spatial distribution of power across the scalp for a given frequency band. The script is written in the MNE library to perform processing on EEG data. However, this code results in some deprecation warnings due to an outdated import from the MNE visualization module, which needs an update for using the Delaunay function from Scipy. Spatial. These plots present a complete summary of the brain activity for the given time window.

Plot power spectral density topographies.
Emo-trans attention-based approach
Emotion classification has evolved significantly with the application of deep learning methods, attention models, and multimodal data fusion techniques. Some recent studies tried to improve emotion classification accuracy with attention-based models and hybrid feature extraction methods. Current methods still suffer from major limitations in adaptability, generalizability, and robustness. EmoTrans provides a novel attention-based approach that fills the gaps by combining EEG signals and facial video data, providing a more complete solution to emotion classification.
One of the most significant attention-based emotion classification advances is the MEET (Multi-Band EEG Transformer) model introduced in50. MEET applies a transformer-based attention model to brain state decoding with multi-band EEG signals. Although MEET greatly enhances feature representation, it only considers EEG data, so it is less effective in real-world applications where facial expressions provide critical contextual information for emotion classification51. Likewise52, and53 introduced a Multimodal Attention Network for EEG-based emotion recognition by combining external modalities with EEG data. However, their approach is based on handcrafted feature selection, which restricts its adaptability and scalability across different datasets. Besides attention-based models, multimodal models like the Multimodal Fusion Network (MF-Net) in54 have also explored EEG and facial video data fusion. MF-Net applies a hybrid feature extraction paradigm to enhance emotion recognition effectiveness but lacks an advanced attention mechanism to dynamically emphasize salient features. Contrarily55, proposed a Spectral Adversarial MixUp method for improving EEG emotion recognition through domain adaptation. Although such an intervention improves model generalization, it is mainly concerned with addressing domain shifts rather than enhancing attention-based feature selection to achieve optimal classification. The presented EmoTrans model overcomes these limitations through the use of an attention-driven feature fusion process that dynamically recognizes and emphasizes salient features from EEG and facial video data. Unlike MEET, which is restricted to using EEG signals only, EmoTrans synergistically uses both modalities, thus providing a holistic perception of emotional states. Furthermore, unlike other traditional multimodal approaches like MF-Net, which apply static feature fusion processes, EmoTrans applies a transformer-based adaptive attention mechanism that dynamically enhances feature selection, hence enhancing classification accuracy and robustness. Moreover, included an expert validation process. Unlike current approaches, which are founded on algorithmic evaluation only, instead of applying a psychologist-validated survey to attain ecological validity. Additionally, EmoTrans significantly outperforms current models in terms of classification accuracy, with 89.3%, 87.8%, 88.9%, and 89.1% for arousal, valence, dominance, and liking, respectively. Relative to state-of-the-art models, this represents a significant improvement, indicating the ability of EmoTrans to address complex emotional states. EmoTrans is an affective computing by adopts a multimodal, attention-based approach and is expert-validated. Unlike current models that either focus on one modality or fail to emphasize dynamic features, EmoTrans overcomes this limitation by adopting a transformer-based attention mechanism, thus enhancing both the accuracy and explainability of real-time emotion recognition.
Results and discussions
In this section, we deliberate the experimental outcomes obtained after EEG signal preprocessing and feature extraction using the following domains. In Time-Domain Features detention the temporal characteristics of the EEG indications, providing insights into the sequence and duration of neuronal activations. In frequency-Domain Features: These features are derived from EEG subbands (e.g., alpha, beta, gamma, theta), capturing the frequency-specific patterns that correlate with different emotional states In wavelet-domain, wavelet transforms provide a time–frequency representation of the EEG signals, allowing for the analysis of transient features that are crucial for detecting rapid changes in emotional states.
Asymmetry Features: Those features relate to the asymmetry between different hemispheres of the brain that are reportedly tangled during emotional processing. From each of these domains, a set of stable features that prove most effective for emotion classification was identified through extensive experimentation. This set of features was used in training the models in machine learning algorithms, where great efforts were targeted toward achieving high classification accuracy over the emotional states. The individual features selected have their well-established positions in EEG studies and have been found highly representative of targeted emotional states toward behavior understanding.
Time-domain
In the Time domain, We analyzed that 1D-CNN and the EmoTrans attention mechanism performed the best in the time-domain feature analysis. EmoTrans achieved an impressive range of 88% to 89% accuracy for the prediction of human emotions. On the other hand, the low performance observed corresponded to KNN; more precisely, it had a very low valence prediction of about 53% as shown in Table 2. The obtained results can be classified as good, which proves such time-domain features can be effective in improving the performance of emotion recognition.
The time-domain evaluation results indicate the great superiority of the EmoTrans model over traditional machine learning models (SVM, KNN, MLP) and deep learning models (1D-CNN, GBM) in all four emotion categories: Arousal, Valence, Dominance, and Liking. EmoTrans has the highest accuracy: 86.49% for Arousal, 86.31% for Valence, 89.21% for Dominance, and 88.64% for Liking; as shown in Fig. 24. Deep learning models such as 1D-CNN and GBM can be considered with competitive performance. However, their performance cannot catch up to that of EmoTrans; specifically, the former achieves only 80.12% for Dominance and 80.32% for Liking, whereas 84.21% in Valence by 1D-CNN is achieved. However, in general, SVM, KNN, and MLP classify with low accuracy, normally under 63%. This proves a deep learning-based approach as beneficial. As for computational efficiency, KNN is the fastest but delivers the lowest accuracy. MLP is the slowest and its processing time is more than 14–17 s; thus, this is impractical even though there is a slight performance improvement compared to SVM and KNN. EmoTrans achieves the best balance between high accuracy and reasonable computational efficiency.

The time-domain evaluation accuracy results.
Frequency-domain
In our analysis, we present the peak values within specific frequency bands, organized by distinct groups. We have created four separate data frames, each corresponding to a specific band power: alpha, beta, gamma, and theta. This approach involves dividing the data into these four band groups, allowing for focused analysis and comparison within each frequency band Score and Band region values shown in Table 3.
We split the dataset to a 70/30 train-test ratio before feature scaling to ensure consistency across all models. For the analysis, several classifiers were defined namely: an SVM through a linear kernel, useful with linear separability of data k-Nearest Neighbor (kNN) classifier with 5 neighbors, distance-based weighting, as well as automatic algorithm selection, and a Multi-Layer Perceptron (MLP) neural network configured with the Adam solver, a tan-h activation function with a regularization parameter (alpha) of 0.3 and a maximum number of iterations of 400 and the booting classifier Gradient Boost Model (GBM) is applied. Apart from this, 1D Convolutional Neural Network (CNN), and the proposed attention model EmoTrans were used. The Proposed EmoTrans contains a self-attention multi-head mechanism to emphasize diverse parts of the input sequence, with layer normalization and dropout applied for regularization, and was compiled with the Adam optimizer and a softmax activation function for binary classification. The CNN was designed with Conv1D layers followed by BatchNormalization and MaxPooling1D, concluding with Dense layers and dropout to prevent over-fitting, ultimately outputting a softmax classification. We also implemented a cross-validation setup using a custom function that took the feature data and labels as input, performed the 70/30 train-test split, and applied feature scaling. The models were evaluated using leave-one-subject-out cross-validation (LOSO-CV) to ensure consistent performance across different data splits. For each model, we computed the mean, accuracy, and standard deviation of the cross-validation scores, along with the time taken for cross-validation, allowing for a comprehensive comparison of accuracy, stability, and computational efficiency. Performance visualization was conducted to assess model performance across (theta, alpha, beta, gamma) different frequency bands, and the models were further evaluated using metrics like accuracy and cross-validation scores to ensure a thorough assessment. From the outcomes, we concluded that our proposed EmoTrans model performs finest as associated with the other model as shown in Table 4.
In the frequency domain, superior performance of EmoTrans was observed across all emotion dimensions: 85% for arousal, 87% for valence, 89% for dominance, and 87.62% for liking. MLP and SVM models reached about 50% to 60% in some cases.
In the frequency domain evaluation, EmoTrans has outperformed all other models in all the emotion categories; it had a maximum accuracy value of Arousal (85.69%), Valence (87.69%), Dominance (89.62%), and Liking (87.62%) as shown in Fig. 25 This, therefore, confirms its superiority to classify emotions with EEG signals using the frequency domain. Gradient Boosting Machine, on the other hand, is also very successful, especially on Valence and Dominance: 83.14% and 83.11%, respectively, but does not match with EmoTrans. The 1D-CNN model achieved competitive levels of accuracy, especially in Valence (78.72%), though was still underperformed by EmoTrans and GBM. Traditional ML models like SVM, KNN, and MLP performed very poorly, with accuracy values ranging from 55.69% to 63.51%, showing that these ML algorithms are challenged by the complexity of features representation EEG-based frequency-domain features possess. Also, EmoTrans presented computational efficiency compared to the processing time, showing low times for all categories, and performed significantly better than MLP, which shows the highest computational cost. These results confirm that EmoTrans is the best model for EEG-based emotion recognition in the frequency domain, taking into account both high accuracy and computational efficiency.

The frequency-domain evaluation accuracy results.
WaveLet-domain features
In the wavelet domain, time domain and frequency are incorporated56. DWT57 is managed to decay signals on various decomposition levels. An indication is decomposing in an (AC) Approximation coefficient and (DC) detail coefficient. In this work, the mother wavelet was rummaged for preliminary decay of signals, and AC was further decayed to AC and DC58 by repeating the process to get the required level of decomposition. The entropy then energy standards were computed as features using DWT from theta bands, alpha bands, beta bands, and gamma bands59. The frequency band energy (Efreq) is given as in Eq. 7:
where n denotes the entire number of facts samples in each band, and SW j denotes trials in the wavelet field. We further calculated difference entropy aimed at wave-let-grounded features using individual and numerous amalgamations of frequency. In wavelet domain analysis, we utilized data from 22 out of 32 participants, similar to our approach in the frequency domain processing. The data is structured into a data frame that encompasses four EEG band powers: alpha, beta, gamma, and theta. The wavelet transform is employed for feature extraction, enabling the decomposition of EEG signals into these frequency bands over time. This analysis provides the band powers for alpha, beta, gamma, and theta, which are then used for classification tasks. The performance of different classifiers is evaluated based on these extracted wavelet features, with results assessed using accuracy. To enhance classification accuracy, a new model EmoTrans incorporating an attention mechanism is introduced. Attention models are well-known for their capability to capture complex temporal dependencies in data, which is advantageous for emotion classification tasks. The wavelet features are taken as input by a neural network for further refinement to get better accuracy and robustness. Further, some data augmentation is also used to introduce some variability within the data. This work adds Gaussian noise to the original EEG band data to synthesize new samples. The added noise level can be controlled, and synthetic labels are kept identical to the original labels. These combine to form a unified dataset that serves to further enhance the model’s robustness. With more diversified training data, because of synthetic augmentation, a model can generalize better on unseen data. The integration of wavelet-based feature extraction with advanced models like EmoTrans and 1D-CNN makes an EEG-based emotion gratitude system sophisticated enough to classify emotions with greater accuracy and robustness. We enhance existing data by generating synthetic samples. It de-signs a number, num_new_samples, of new samples by adding Gaussian noise to the existing eeg_band_arr data. The level of noise to be added depends on the noise_factor; that is, the factor showing the dispersion level to be added to the data. This augmentation helps make the model more robust because the training data will be diversified. Synthetic labels are generated so that, if possible, they match the original labels, df_arousal to keep the same consistency in the label distribution. After generating the synthetic data and labels, the code combines them with the original data and labels into x_combined and y_combined. The shapes of these combined datasets are then printed to verify that they have the correct dimensions and ensure that the augmentation process is executed as expected. The wavelet domain band and EEG region score are shown in Table 5.
We got notable improvements in the wavelet domain as both frequency and time-domain features combined, quite evident from Table 6. This is the way to achieve 90% accuracy in emotion analysis for four VAD (Valence, Arousal, Dominance) and Liking scales.
In the wavelet domain, EmoTrans performed best with the highest accuracy for all categories of emotion: Arousal (90.45%), Valence (93.12%), Dominance (90.21%), and Liking (91.13%). These results suggest that EmoTrans has learned to extract the features that are relevant to emotion in the wavelet transform of EEG signals better than any other model. GBM also performed well in Valence (82.01%) and Dominance (80.32%), but its higher standard deviation shows more variability in the predictions as shown in Fig. 26. Following is the 1D-CNN model, which scored 88.69 in Arousal with a relatively high standard deviation indicating instability of the model whereas the traditional models, SVM, KNN, and MLP performed less accurately, < 61% at all categories thus supporting the reason behind the weaknesses of these techniques to handle features of wavelet transforms. In addition, EmoTrans was computationally efficient, which resulted in the lowest processing times, while MLP required the longest execution time in all domains, which makes it not feasible for real-time applications. These results confirm that EmoTrans is the most robust and reliable model for EEG-based emotion classification in the wavelet domain, which excels both in accuracy and computational efficiency.

The wavelet-domain evaluation accuracy results.
Facial features
To analyze emotions using facial features extracted from video data, particularly within the DEAP dataset, we focus on leveraging both physiological EEG signals along video recordings of participants’ facial expressions as shown in Fig. 27. The dataset provides a rich source for multi-modal emotion recognition. Initially, data loading and preprocessing involve aligning the facial video data with corresponding emotion labels, including arousal, valence, dominance, and liking. Face detection is performed using the Haar Cascade Classifier, which identifies and extracts facial regions from video frames. Subsequent data cleanup ensures that frames without relevant facial content are filtered out, maintaining a clean dataset for feature extraction. Feature extraction primarily utilizes the Open Face, a technique adept at detecting key points in facial images that remain consistent across different scales and orientations. By averaging the open-face descriptors from each frame, we create a simplified feature vector representing various facial attributes, which is then used to train emotional gratitude models. These are grounded on SVM models by an accuracy of 72% on the ‘liking’ label kNN, with the best general performance of 83% on average across all labels. During model training and evaluation, each model sticks to the conventional accuracy metrics; KNN always stays in the first place and is effective compared to the other models. A comparison with Convolutional Neural Networks (CNNs) which were previously tested but only achieved 45–55% accuracy highlights the superior performance of traditional machine learning models, leading to their adoption for this task. Facial emotion recognition involves several key steps. Face detection and annotation are performed using OpenCV’s cv2.CascadeClassifier, which extracts faces from video frames and resizes them to a consistent 100 × 100 pixel size.

Facial feature extraction methodology.
This captures facial features across frames while being consistent in the representation of a feature. The models are trained using Scikit-learn’s method with fit by cross-validation to give a robust assessment of the performance. The models perform their functions through visualization using Matplotlib to understand how effective the models are in their performance across all emotion labels. The system can adopt this method for emotion recognition through facial expressions that indicate emotional states. This robust performance of the KNN model indicates that it is strong for use in many applications, including monitoring mental health, and affective computing. To clean the data, the project uses videos of 22 different subjects with 40 video trials for every subject except for those where incomplete trails are present for particular subjects. Labels are converted to binary form, where, for example, valence labels below 4.5 are set to 0 and those above 4.5 are set to 1. Annotated faces are resized to 100 × 100 pixels, and frames with irrelevant data are removed.
The CNN model was created to process facial features for emotion recognition. Each video clip was segmented into 60 frames every trial, with labels reproduced every frame to ensure alignment, yielding roughly 52,800 feature-label pairs. The dataset included 37–40 trials per subject from 22 people and was divided into 80% training and 20% testing, ensuring a large amount of data for model training. Initially, the CNN model obtained 65% accuracy, but after incorporating an attention mechanism, performance improved dramatically to 89%. The attention mechanism improved the model’s capacity to focus on key face regions, making it more adept at recognizing emotions. To improve performance even more, we looked into classic machine-learning techniques. We analyzed 600 frames per video and used OpenFace for face feature extraction, resulting in 2D arrays of descriptors that captured essential facial landmarks. These features were averaged across frames to simplify input for machine learning models. The Support Vector Machine (SVM) had 72% accuracy on the ‘Liking’ label, while the k-Nearest Neighbors (kNN) model excelled the others, with an average accuracy of 83% across all labels as shown in Fig. 28. These findings emphasize the efficacy of combining deep learning with attention processes and classic machine learning methods, indicating that structured feature extraction can greatly increase emotion recognition ability. The results of the machine learning model’s four emotion labels: Valence, Arousal, Dominance, and Liking are shown in Table 7.

Facial data evaluation results.
The Receiver Operating Characteristics (ROC) Curve of the EmoTrans model, as depicted in Fig. 29, illustrates the ability of the model to distinguish between different emotional states by plotting the True Positive Rate (TPR) against the False Positive Rate (FPR) across various thresholds. A higher Area Under the Curve (AUC), approaching 1, indicates better model performance, thus showing that EmoTrans classification of emotions. This is complemented by Fig. 30 provides the Confusion Matrix that shows actual vs. predicted emotion labels.

EmoTrans ROC curve.

Confusion matrix of EmoTrans on DEAP dataset.
The diagonal values indicate correct classifications, while the off-diagonal values indicate misclassifications. This matrix is used to identify which emotions are often confused by the model and thus need further refinement. Together, the ROC curve and confusion matrix provide a good evaluation of EmoTrans’s classification accuracy, highlighting strengths and areas for improvement.
Additionally, we performed the statistical significance tests for performance comparison namely paired t-test, to compare the proposed EmoTrans model against baseline models. For our experiments, we use multiple trials (e.g. leave-one-subject-out cross-validation (LOSO-CV)) and keep track of performance metrics such as accuracy and F1-score for both EmoTrans and the baseline model. A paired t-test is used to determine whether the differences between the models are statistically significant in terms of performance. The null hypothesis (H0), is that there is no significant difference between the models, and the alternative hypothesis (Ha), is that EmoTrans outperforms the baseline.
The t-statistic is obtained using the Eq. 8:
where d is the mean of the differences between the performance scores (e.g., accuracy) of EmoTrans and the baseline across the n folds. sd represents the standard deviation of such differences. n is the number of paired samples; that is, the number of cross-validation folds or trials.
EmoTrans produced an average accuracy of 0.89 and the baseline model had an average accuracy of 0.84 then, by the paired t-test with a p-value of 0.03, this will give us statistical evidence for the fact that EmoTrans outperforms the baseline with a confidence level at 97%. The p-value is less than that of the significance threshold α = 0.05, we reject our null hypothesis and conclude that the difference in performance is statistically significant. This approach gives a scientifically sound framework to justify the assertions of enhanced performance and ensures that observed improvements in emotion recognition are not coincidental but are indeed statistically significant and replicable across independent experiments.
Emotions can be represented with various features derived from sources like EEG signals and facial expressions. The measures used for quantifying emotions; valence, arousal, dominance, and liking then predicting the behavior from these emotions. We can use Eq. 9 to predict the behavior from emotion:
Ev: Valence, a measure of emotion positivity/negativity
Ea: Arousal, a measure of intensity or activation level of the emotion
Ed: Dominance, degree of influence, OR control employed over the environment
El: Liking (a measure of attraction or preference)
The various metrics can be combined using weights wv,wa, wd, and wl in a way to reflect their relative importance in predicting behavior. We applied Artificial Intelligence to predict the behavior from the combined metrics of emotion. Let B represent the behavioral outcome.
Here, \(B = g\left( {Ecombined} \right)\) g stands for the function depicting the behavior model, which can be linear, non-linear, or based on more advanced techniques like neural networks. For the case of a linear model, this formula of behavior prediction may have the form:
where β0 is the intercept term.
β1, β2, β3, and β4 are the coefficients for each emotion metric, learned from data.
To predict behavior using multimodal emotional data to retrieve the emotions and predict the outcome behavior, in the end, we surveyed to validate our predictions for psychologists.
Emotion behaviour mapping validation survey
A survey was conducted with psychologists from Air University Islamabad, specifically Dr. Shumaila Tasleem, Head of the Psychology Department60, for input on mapping emotions to behavior. The survey resulted in the following: High valence is associated with high productivity, more social media interaction and engagement, better communication, and an increase in happiness, joy, and feelings of contentment. On the other hand, with low valence, sadness, anger, and frustration may not show up-not always, though. It generally reduces motivation; makes one avoid new activities and hampers communication. Arousal: Arousal both at high and low levels, impacts decision-making and creativity. Low arousal increases relaxation and decreases stress, and may lead to a lack of motivation. High levels of stress in some circumstances, such as examination stress, can be productive and non-productive simultaneously. High arousal energizes the feelings whereas low-level arousal makes a person calm and eventually decreases the energy and hence motivation. Dominance: High dominance enhances leadership qualities and confidence, and has a positive influence on people, and it tends to impose an authoritative nature of behavior. Low dominance reduces leadership qualities and lowers one’s confidence. Behavioral Setting: High valence exerts a positive impact on the behavior of people in work and social settings, creating a healthy and industrious atmosphere, whereas low valence triggers stress and tension. While the workplace is shared by many as a domain that best provides high arousal experiences to high energy and productivity arousal attributes of low negatively affect behavioral performance in work environments. High dominance results in experiences of high control in social contexts. Finally, higher liking is associated with an increase in emotion, instilling high confidence.
Conclusions
Understanding human behavior through emotion recognition using electroencephalography (EEG) signals and facial videos is pivotal for advancing human–computer interaction and affective computing. The study presents the EmoTrans model, which uses EEG signals and facial video analysis to improve human–computer interaction and affective computing. By utilizing the DEAP dataset that contains EEG recordings and facial videos from participants who watched 40 movie clips, the model is effectively used in analyzing emotional states based on variables like valence, arousal, dominance, and liking. The EmoTrans architecture reached classification accuracies of 89.3%, 87.8%, 88.9%, and 89.1% for arousal, valence, dominance, and liking, respectively, with an overall accuracy of 89% in recognizing emotions such as happiness, excitement, calmness, and distress. The results were validated by paired t-tests, confirming that the model significantly outperformed baseline models. This architecture pays the correct attention to features in EEG and facial data, breaking the boundaries of emotion classification, and giving insights into deeper human emotional states. However, in the study, we have utilized the DEAP dataset has a limited sample size, in the future we should focus on increasing the datasets and using a more diverse group of participants, exploring multimodal fusion techniques, and utilizing advanced deep learning architectures. Such improvements would enhance real-time emotion recognition applications in interactive systems.
Data availability
The datasets analyzed during the current study are publicly available in the DEAP repository at this https://www.eecs.qmul.ac.uk/mmv/datasets/deap/.
References
Erol, B. A. et al. Toward artificial emotional intelligence for cooperative social human-machine interaction. IEEE Trans. Comput. Soc. Syst. 7(1), 234–246. https://doi.org/10.1109/TCSS.2019.2936701 (2020).
Picard, R. W. & Klein, J. Computers that recognize and respond to user emotion: Theoretical and practical implications. Interact. Comput. 14(2), 141–169. https://doi.org/10.1016/S0953-5438(01)00055-3 (2002).
Picard, R. W., Vyzas, E. & Healey, J. Toward machine emotional intelligence: Analysis of affective physiological state. IEEE Trans. Pattern Anal. Mach. Intell. 23(10), 1175–1191. https://doi.org/10.1109/34.959200 (2001).
Nirenberg, S. What if robots could process visual information the way humans do? [Online]. TEDMED. https://www.tedmed.com/talks/show?id=619685 (2016).
Siddharth, S., Jung, T.-P. & Sejnowski, T. J. Utilizing deep learning towards multi-modal bio-sensing and vision-based affective computing. IEEE Trans. Affect. Comput. https://doi.org/10.1109/TAFFC.2019.2916015 (2019).
Liu, Y.-J. et al. Real-time movie-induced discrete emotion recognition from EEG signals. IEEE Trans. Affect. Comput. 9(4), 550–562. https://doi.org/10.1109/TAFFC.2017.2760699 (2018).
Kalsum, T., Anwar, S. M., Majid, M., Khan, B. & Ali, S. M. Emotion recognition from facial expressions using hybrid feature descriptors. IET Image Process. 12(6), 1004–1012. https://doi.org/10.1049/iet-ipr.2017.0482 (2018).
Wang, X.-W., Nie, D. & Lu, B.-L. Emotional state classification from EEG data using machine learning approach. Neurocomputing 129, 94–106. https://doi.org/10.1016/j.neucom.2013.03.009 (2014).
van den Broek, E. L. Ubiquitous emotion-aware computing. Pers. Ubiquit. Comput. 17, 1–15. https://doi.org/10.1007/s00779-012-0597-1 (2012).
Raheel, A., Anwar, S. M. & Majid, M. Emotion recognition in response to traditional and tactile enhanced multimedia using electroencephalography. Multimed. Tools Appl. 78(10), 13971–13985. https://doi.org/10.1007/s11042-018-7021-2 (2019).
Qayyum, H., Majid, M., Haq, E. U. & Anwar, S. M. Generation of personalized video summaries by detecting viewer’s emotions using electroencephalography. J. Vis. Commun. Image Represent. 65, 102672. https://doi.org/10.1016/j.jvcir.2019.102672 (2019).
Mehreen, A., Anwar, S. M., Haseeb, M., Majid, M. & Ullah, M. O. A hybrid scheme for drowsiness detection using wearable sensors. IEEE Sens. J. 19(13), 5119–5126. https://doi.org/10.1109/JSEN.2019.2911324 (2019).
Raheel, A., Majid, M., Anwar, S. M. & Bagci, U. Emotion classification in response to tactile enhanced multimedia using frequency domain features of brain signals. In Proceedings of the 41st Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC) 1201–1204. https://doi.org/10.1109/EMBC.2019.8857112 (2019).
Yoon, H. J. & Chung, S. Y. EEG-based emotion estimation using Bayesian weighted-log-posterior function and perceptron convergence algorithm. Comput. Biol. Med. 43(12), 2230–2237. https://doi.org/10.1016/j.compbiomed.2013.09.011 (2013).
Ackermann, P., Kohlschein, C., Bitsch, J. A., Wehrle, K. & Jeschke, S. EEG-based automatic emotion recognition: Feature extraction, selection, and classification methods. In Proceedings of the IEEE 18th International Conference on E-Health Networks, Applications and Services (Healthcom) 1–6. https://doi.org/10.1109/HealthCom.2016.7749501 (2016).
Menezes, M. L. R. et al. Towards emotion recognition for virtual environments: An evaluation of EEG features on benchmark dataset. Pers. Ubiquit. Comput. 21(6), 1003–1013. https://doi.org/10.1007/s00779-017-1077-4 (2017).
Tomarken, A. J., Davidson, R. J., Wheeler, R. E. & Kinney, L. Psychometric properties of resting anterior EEG asymmetry: Temporal stability and internal consistency. Psychophysiology 29(5), 576–592. https://doi.org/10.1111/j.1469-8986.1992.tb02078.x (1992).
Nakisa, B., Rastgoo, M. N., Tjondronegoro, D. & Chandran, V. Evolutionary computation algorithms for feature selection of EEG-based emotion recognition using mobile sensors. Expert Syst. Appl. 93, 143–155. https://doi.org/10.1016/j.eswa.2017.10.016 (2018).
Koelstra, S. et al. DEAP: A database for emotion analysis using physiological signals. IEEE Trans. Affect. Comput. 3(1), 18–31. https://doi.org/10.1109/T-AFFC.2011.15 (2012).
Koelstra, S. et al. DEAP: A Database for Emotion Analysis using Physiological Signals. IEEE Trans. Affect. Comput. 3(1), 18–31 (2012). https://www.eecs.qmul.ac.uk/mmv/datasets/deap/
Henni, K., Mezghani, N., Mitiche, A., Abou-Abbas, L. & Yahia, A. B. B. An effective deep neural network architecture for EEG-based recognition of emotions. IEEE Access 13, 4487–4498 (2025).
Alameer, H. R. A., Salehpour, P., Aghdasi, H. S. & Feizi-Derakhshi, M. R. Cross-subject EEG-based emotion recognition using deep metric learning and adversarial training. IEEE Access 12, 130241–130252 (2024).
Gaddanakeri, R. D., Naik, M. M., Kulkarni, S. & Patil, P. Analysis of EEG signals in the DEAP dataset for emotion recognition using Deep Learning Algortihms. In 2024 IEEE 9th International Conference for Convergence in Technology (I2CT) 1–7 (IEEE, 2024).
Keusch, F., Do, J. & Thomsen, J. Exploring human behavior using smartphone sensor data. J. Behav. Data Sci. (2023).
Mekruksavanich, S., Hsu, S. & Wang, T. Wrist-worn wearable sensors in complex activity recognition. IEEE Trans. Biomed. Eng. (2021).
Bian, J., Zhang, H. & Zhang, X. Techniques in human activity recognition (HAR). J. Sens. Actuator Netw. (2021).
Alarcao, S. M. & Fonseca, M. J. Emotions recognition using EEG signals: A survey. IEEE Trans. Affect. Comput. 10(3), 374–393. https://doi.org/10.1109/TAFFC.2017.2755921 (2019).
Romeo, L., Cavallo, A., Pepa, L., Berthouze, L. & Pontil, M. Multiple instances of learning for emotion recognition using physiological signals. IEEE Trans. Affect. Comput. https://doi.org/10.1109/TAFFC.2019.2954118 (2019).
Albraikan, A., Tobon, D. P. & El Saddik, A. Toward user-independent emotion recognition using physiological signals. IEEE Sens. J. 19(19), 8402–8412. https://doi.org/10.1109/JSEN.2019.2927400 (2019).
Teo, J., Hou, C. L. & Mountstephens, J. Deep learning for EEG-based preference classification. In Proceedings of the AIP Conference Vol. 1891, 020141. https://doi.org/10.1063/1.5005490 (2017).
Pouyanfar, S. & Chen, S.-C. Automatic video event detection for imbalanced data using enhanced ensemble deep learning. Int. J. Semant. Comput. 11(1), 85–109. https://doi.org/10.1142/S1793351X1750005X (2017).
Szwoch, W. Emotion recognition using physiological signals. In Proceedings of Multimedia, Interact., Design Innovation 15:1–15:8. https://doi.org/10.1145/2818346.2818348 (2015).
Zheng, W.-L., Zhu, J.-Y. & Lu, B.-L. Identifying stable patterns over time for emotion recognition from EEG. IEEE Trans. Affect. Comput. 10(3), 417–429. https://doi.org/10.1109/TAFFC.2017.2755922 (2019).
Bhatti, A. M., Majid, M., Anwar, S. M. & Khan, B. Human emotion recognition and analysis in response to audio music using brain signals. Comput. Hum. Behav. 65, 267–275. https://doi.org/10.1016/j.chb.2016.08.013 (2016).
Tripathi, S., Acharya, S., Sharma, R. D., Mittal, S. & Bhattacharya, S. Using deep and convolutional neural networks for accurate emotion classification on DEAP dataset. In Proceedings of the 21st AAAI Conference on Artificial Intelligence 4746–4752. https://doi.org/10.1609/aaai.v31i1.11363 (2017).
Guo, K., Candra, H., Yu, H., Li, H., Nguyen, H. T. & Su, S. W. EEG-based emotion classification using innovative features and combined SVM and HMM classifiers. In Proceedings of the 39th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC) 489–492. https://doi.org/10.1109/EMBC.2017.8037272 (2017).
Jha, S. K., Suvvari, S. & Kumar, M. Emotion recognition from electroencephalogram (EEG) signals using a multiple column convolutional neural network model. SN Comput. Sci. 5(2), 213 (2024).
Geetha, A. V., Mala, T., Priyanka, D. & Uma, E. Multimodal Emotion Recognition with deep learning: Advancements, challenges, and future directions. Inf. Fusion 105, 102218 (2024).
Fan, C. et al. ICaps-ResLSTM: Improved capsule network and residual LSTM for EEG emotion recognition. Biomed. Signal Process. Control. 87, 105422 (2024).
Ju, X., Li, M., Tian, W. & Hu, D. EEG-based emotion recognition using a temporal-difference minimizing neural network. Cogn. Neurodyn. 18(2), 405–416 (2024).
Xu, F. et al. EESCN: A novel spiking neural network method for EEG-based emotion recognition. Comput. Methods Programs Biomed. 243, 107927 (2024).
Vidya, B. & Sasikumar, P. Wearable multi-sensor data fusion approach for human activity recognition using machine learning algorithms. Sens. Actuators A: Phys. 341, 113557 (2022).
Abdel-Basset, M. et al. ST-DeepHAR: Deep learning model for human activity recognition in IoHT applications. IEEE Internet Things J. 8(6), 4969–4979 (2020).
Gunaratne, N. M. et al. Effects of imagery as visual stimuli on the physiological and emotional responses. J 2(2), 206–225 (2019).
Frank, M. G. Getting to know your patient: How facial expression can help reveal true emotion. The human face: Measurement and meaning 255–283 (Springer US, Boston, MA, 2000).
Su, X., Tong, H. & Ji, P. Activity recognition with smartphone sensors. Tsinghua Sci. Technol. 19(3), 235–249 (2014).
Raj, M.S.S., George, S. N. & Raja, K. Leveraging spatio-temporal features using graph neural networks for human activity recognition. Pattern Recognit. 150, 110301 (2024).
Heins, C. et al. Collective behavior from surprise minimization. Proc. Natl. Acad. Sci. 121(17), e2320239121 (2024).
Murugappan, M., Rizon, M., Nagarajan, R., Yaacob, S., Hazry, D. & Zunaidi, I. Time-frequency analysis of EEG signals for human emotion detection. In Proc. 4th Kuala Lumpur Int. Conf. Biomed. Eng. Berlin, Germany 262265 (Springer, 2008).
Zhao, L. et al. MEET: A multi-band EEG transformer for brain states decoding. https://europepmc.org/article/MED/38055365 (2023).
Zhang, J. et al. Spectral adversarial mixup for few-shot unsupervised domain adaptation. https://arxiv.org/abs/2309.01207 (2023).
Zhang, H. et al. Multimodal Attention Network for EEG-Based Emotion Recognition. IEEE Xplore. https://ieeexplore.ieee.org/document/9252925 (2020).
Patil, R. & Neelakantappa, S. Multimodal emotion recognition model with hybrid feature fusion. In Multimedia Tools and Applications (Springer, 2024). https://doi.org/10.1007/s11042-024-19171-2.
Zhu, T. et al. Multimodal fusion network (MF-Net) for emotion recognition using EEG and facial video. In Signal, Image and Video Processing (Springer, 2024). https://doi.org/10.1007/s11760-024-03632-0.
Zhang, Y. et al. Multimodal Emotion Recognition Based on Facial Expressions, Speech, and EEG. IEEE Transactions on Affective Computing. https://ieeexplore.ieee.org/document/10026861 (2023).
Swangnetr, M. & Kaber, D. B. Emotional state classification in patient robot interaction using wavelet analysis and statistics-based feature selection. IEEE Trans. Hum. Mach. Syst. 43(1), 6375 (2013).
Murugappan, M., Ramachandran, N. & Sazali, Y. Classification of human emotion from EEG using discrete wavelet transform. J. Biomed. Sci. Eng. 3(4), 390396 (2010).
Li, Z. L., Cao, H. & Zhang, J. S. Emotion recognition in EEG based on multilevel multidomain feature fusion. IEEE Access 12, 87237–87247 (2024).
Khateeb, M., Anwar, S. M. & Alnowami, M. Multi-domain feature fusion for emotion classification using DEAP dataset. IEEE Access 9, 12134–12142. https://doi.org/10.1109/ACCESS.2021.3051281 (2021).
Dr. Shumaila Tasleem https://www.au.edu.pk/Pages/Faculties/SocialSciences/Departments/Psychlology/FacultyDetail.aspx?fid=2598. Department of Psychology. Air University Islamabad Accessed 12 Oct 2024.
Acknowledgements
The authors thanks University of Agder for supporting this article.
Funding
This research did not receive any specific funding.
Author information
Authors and Affiliations
Contributions
All authors contributed equally.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Hassan, C.A.U., Ehatisham-ul-Haq, M., Murtaza, F. et al. EmoTrans attention based emotion recognition using EEG signals and facial analysis with expert validation. Sci Rep 15, 22004 (2025). https://doi.org/10.1038/s41598-025-98404-2
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41598-025-98404-2
Keywords
This article is cited by
-
EEG-EmotionActivityNet: a deep learning approach for emotion and human activity classification
International Journal of Information Technology (2025)
