
Abstract
Exposure to fine particulate matter (PM2.5) poses a significant global health risk, yet extreme concentration patterns remain underexplored. This study estimates daily PM2.5 concentrations from 1980–2023, validated against the WHO ambient air quality database. An ensemble of deep learning models (CNN, LSTM, DNN) incorporating meteorological inputs achieved robust predictive accuracy (RMSE < 17.85 µg/m³, R² > 0.894). Global and regional variations in population-weighted PM2.5 extremes [average annual, annual maximum, 99th percentile, days exceeding the USEPA standard of 35.5 μg/m³ (AQI > 100) weighted by population density] were analysed. Results reveal persistently high PM2.5 extremes in China, India, and Pakistan, contrasted with declining levels in Europe and North America. Significant variability in African nations like Rwanda and Benin was also observed. 79.7% of the global population and 66.3% of land areas exceeded the USEPA annual standards (9 μg/m³). Seasonal disparities underscore region-specific pollution trends. These findings advocate for phased, locally adaptive air quality strategies, especially in low-income and emerging economies.
Similar content being viewed by others

Introduction
Exposure to fine particulate matter (PM2.5) is a major environmental and public health concern, linked to increased risks of disease and early mortality1. Outdoor air pollution, which includes ambient PM2.5, contributed to approximately 6.67 million (95% UI: 5.90–7.49) premature deaths worldwide in 20192. PM2.5 is a composite mixture of various aerosols and chemical compounds with varying toxicity and mass fractions3. Consequently, the actual health impact of ambient PM2.5 could be greater than what is estimated by looking at the total PM2.5 mass alone4. Exposure to ambient PM2.5, whether for a short duration or over an extended period, poses significant health risks, even at low concentrations5,6. Similarly, the World Health Organisation (WHO) has updated its air quality guidelines (AQG) to set new standards for outdoor PM2.5 exposure7. The revised air quality standards have lowered the permissible annual mean PM2.5 exposure threshold from 10 to 5 μg/m³, while the 24 h mean exposure criterion has been adjusted from 25 to 15 μg/m³, reflecting a more stringent regulatory framework for public health protection. However, still over 99% of the global population remained subjected to ambient PM2.5 concentrations surpassing the WHO’s annual AQG threshold, indicating widespread exceedance of recommended exposure limits2,8.
Estimating global PM2.5 concentrations is essential for assessing population exposure and evaluating the associated epidemiological and health risks of air pollution9. Although ground-based PM2.5 monitoring networks have expanded globally, including those integrated into the WHO ambient air pollution database, their spatial heterogeneity and insufficient coverage pose significant challenges in accurately quantifying global PM2.5 exposure8. While early studies relied on interpolation methods and chemical transport models (CTMs) to quantify PM2.5 concentrations10. However, the incorporation of satellite-derived aerosol optical depth (AOD) has enhanced estimation precision by providing higher spatial and temporal resolution11,12. Ji et al.13 utilised Moderate Resolution Imaging Spectroradiometer (MODIS) AOD datasets, validated by AERONET, integrating multi-source remote sensing and meteorological parameters to predict PM2.5 concentrations in the Beijing–Tianjin–Hebei region with high precision. However, Zhang et al.14 introduced an alternative approach using multi-angle polarised top of atmosphere reflectance observations acquired from the GaoFen-5B satellite, demonstrating improved retrieval accuracy over traditional AOD-based methods. Similarly, integrating machine learning and deep learning (ML/DL) models with satellite data, reanalysis datasets, ground-based monitoring stations and model simulations, offer promising opportunities to reduce the uncertainties in global PM2.5 assessments, which further improves the accuracy15,16,17. These technologies are increasingly employed for PM2.5 concentration forecasting due to their high predictive accuracy and capability to handle complex, nonlinear relationships. Wang et al.18 integrated meteorological variables from the ERA5 reanalysis dataset with machine learning algorithms to mitigate AOD discontinuities and enhance the spatiotemporal resolution of PM2.5 estimations in North China. Similarly, Li et al.19 employed a two-stage regression model with bias correction to compute PM2.5 concentrations using AOD, further assessing the mortality risk associated with pollution exposure in Iran. However, DL models, especially convolutional neural networks (CNNs) and long short-term memory (LSTM) networks, have shown higher accuracy in spatiotemporal PM2.5 estimation than conventional regression and ML models20,21. Similarly, Koo et al.22 developed a ConvLSTM-DNN hybrid model tailored for Seoul, demonstrating superior performance over traditional Community Multiscale Air Quality (CMAQ) models by better capturing spatiotemporal patterns. Liu et al.23 further advanced short-term PM2.5 forecasting by incorporating a complex decomposition-based CNN-LSTM hybrid framework, optimising feature extraction and temporal sequence prediction through the combined advantages of convolutional and recurrent architectures.
The ensemble ML/DL methods, have shown great promise in geospatial air pollution prediction1,24,25,26,27,28. The ensemble learning algorithms combine predictions from multiple models to achieve optimal results29. Previous studies have shown that ensemble ML consistently achieve higher accuracy than individual models in evaluating environmental exposures30,31. Di et al.32 developed an ensemble modelling framework by integrating multiple ML algorithms with diverse predictor variables to quantify daily PM2.5 concentrations at a 1 km × 1 km resolution across the U.S., achieving cross-validated R² values of 0.86 for daily estimates and 0.89 for annual averages. Similarly, Mohammadi et al.33 used meteorological data and four machine learning models (ANN, RF, SVM, KNN) and ensembles of classification trees RF to predict PM2.5 levels in Isfahan, finding ANN to be the most accurate (90.1%) for air pollution forecasting. Nowadays, a more advanced approach called deep ensemble machine learning model (DEMLM), which integrates various bases and other parameters to enhance prediction performance is used to predict atmospheric variables8,34.
Exposure and risk assessment of mean PM2.5 and its extremes is crucial, as its concentration is expected to rise significantly in many regions worldwide35. Extreme PM2.5 events can be categorised into short-term spikes, which occur due to sudden emissions or meteorological conditions lasting a few days, and long-term exposure, which results from persistently high levels over months or years35. Recent global studies on PM2.5 concentrations have emphasised long-term exposure, typically using annual or monthly data. However, research on short-term PM2.5 exposure, spanning hours to days, remains relatively limited globally36,37. More studies are now estimating daily PM2.5 concentrations at regional scales in countries like the United States, China, India, and Europe5,36,38,39,40. These studies focus on short-term exposure and its global spatio-temporal variations. Kelly et al.41 developed Nine PM2.5-Exposure models, including CTMs, interpolation, satellite-derived, Bayesian, and machine learning methods, estimated a 1 µg/m³ average PM2.5 decrease from 2011 to 2028, with greater reductions in high-emission areas and reduced exposure inequality among racial/ethnic groups. Similarly, Aunan et al.42 developed an Integrated Population-Weighted Exposure (IPWE) method combining ambient and household PM2.5 exposure, estimating 1.15 million annual premature deaths in China, with rural exposure nearly twice that of urban areas. However, variability in global training datasets and methodological inconsistencies in PM2.5 estimation hinder the comparability of regional assessments, complicating efforts to derive a consistent global exposure profile43. Therefore, it is essential for studies to estimate extreme ambient global daily PM2.5 concentrations and track their variations over time and space using consistent study designs, modelling methods, and data source15,41. Additionally, advancements in data collection and integration techniques will be essential in overcoming current limitations and providing more reliable and actionable insights into air quality management and policymaking44.
Several challenges remain in global PM2.5 estimation and exposure assessment. The lack of ground-based observations in developing regions limits model accuracy, necessitating improved data integration techniques. Existing models exhibit limitations in accurately predicting extreme pollution events due to their low frequency and high variability, underscoring the necessity for more resilient forecasting frameworks. Inconsistencies in methodological approaches across studies hinder the comparability of global PM2.5 estimates, underscoring the importance of standardised modelling frameworks. While deep learning models have shown promise, their interpretability remains a challenge, requiring the development of ensemble ML/DL approaches for air quality prediction. This research introduces key innovations in extreme air pollution monitoring and analysis to address these gaps. The primary methodological advancement lies in the deployment of a DEMLM (hybrid deep leaning CNN-LSTM-DNN model) model for global PM2.5 quantification and prediction at an unprecedented spatiotemporal resolution of 0.5° × 0.625° and 1 day, respectively, using the meteorological and geographic features, spanning 1980 to 2023 and biases in the predicted data has been removed using WHO ambient air quality database. This long-term and high-resolution approach significantly improves existing models, enabling more precise tracking of pollution patterns. Furthermore, national and regional population-weighted mean PM2.5 concentrations were examined, including the number of days populations were exposed to PM2.5 levels that exceeded the US EPA daily limit of 35.5 μg/m³ (Air Quality Index > 100 ie;unhealthy for sensitive groups), maximum one-day pollution and 99th percentile of PM2.5, respectively. In this context, population-weighted pollution extremes (PWPE) encompasses four distinct metrics that collectively characterise severe air pollution exposure: (1) exceedances of the USEPA standard of 35.5 μg/m³ for 24-hour PM2.5 concentrations, representing regulatory threshold violations; (2) annual maximum daily PM2.5 concentrations, capturing the most severe pollution episodes; (3) 99th percentile PM2.5 values, indicating recurrent extreme pollution events; and (4) population-weighted mean concentrations that exceed health-based guidelines, where all metrics are weighted by population density to prioritise human exposure assessment over simple spatial averaging. This analysis aimed to reveal the spatiotemporal distribution of exposure to PM2.5 over the four decades, providing insights into patterns and trends that could inform public health strategies and policy decisions. The DEMLM framework represents a significant leap forward in environmental health research, offering enhanced capabilities for capturing subtle spatiotemporal variations in PM2.5 distribution. This study advances existing knowledge by providing a more granular, comprehensive view of global air pollution patterns, enabling better-informed public health strategies and policy decisions. However, the practical significance extends to identifying regions experiencing extreme pollution events and temporal fluctuations, thereby facilitating targeted intervention strategies for air quality management.
Results
This study presented the spatial distribution of annual mean PM2.5 concentrations for the periods 1980–1990 (Fig. 1a), 1990–2000 (Fig. 1b), 2001–2010 (Fig. 1c), and 2011–2020 (Fig. 1d), along with their spatio-temporal changes (Fig. 1e) and long-term trends (Fig. 1f). The analysis identified substantial surge in PM2.5 concentrations across Eastern Asia particularly China where concentrations exceeded 80-100 μg/m³ in many regions such as Southern Asia including the Indo-Gangetic Plains where peak concentrations reached similar levels, Western Africa, and the western regions of North America and Russia. The highest PM2.5 concentrations (>60 μg/m³) were consistently observed in a continuous belt stretching from Northern India through Eastern China. Conversely, Europe, Northern Africa, the eastern regions of North America, and Australia experienced notable decreases in PM2.5 concentrations, with many areas showing reductions of 10–20 μg/m³ over the study period. The spatio-temporal change analysis (Fig. 1e) reveals that while some regions experienced increases of up to 20 μg/m³, others saw comparable decreases, and the long-term trend analysis (Fig. 1f) indicates that significantly increasing trends (shown in red) dominated much of Asia, while significantly decreasing trends (shown in blue) were more prevalent in Europe and parts of North America (Fig. 1f). According to US-EPA revised standards, 66.30% of the global land area (Fig. 2a) and 79.70% of the global population (Fig. 2b) were subjected to annual PM2.5 concentrations exceeding 9 μg/m³. The results indicated that 98% of Asia’s population, 86% of Africa’s, 84% of Europe’s, 83% of North America’s, 60% of Australia’s, and 52% of South America’s population are exposed to PM2.5 levels exceeding 9 μg/m³ (Fig. 2). However, based on the WHO revised guidelines in 2019, over 99% of the global land area and population are exposed to PM2.5 concentrations exceeding 5 μg/m³.

Mean annual PM2.5 for the periods a 1981–1990, b 1990–2000, and c 2001–2010, d 2011–2020 along with e the changes in mean annual PM2.5 per decade and f trends in mean annual PM2.5 during 1980–2023.

a Global land area where mean annual PM2.5 concentrations exceed 9 µg/m³, and b corresponding population exposure to PM2.5 levels above 9 µg/m³, based on revised USEPA air quality standards.
This study also computed long-term seasonal variability of mean annual PM2.5 concentrations over 44 years (1980–2023) across various regions and countries (Fig. S1). During the winter months (November to February), high PM2.5 levels were recorded in the Indo-Gangetic Plain (55.4–255.5 μg/m³), Niger ( > 255.5 μg/m³), and the northeastern regions of China (35.5–125.4 μg/m³) whereas, Southern America, significant air pollution was noted in July, August, and September (35.5–55.4 μg/m³). Relatively, the eastern region of North America experienced elevated PM2.5 concentrations during the summer months (35.5–55.4 μg/m³). Northern Africa showed consistently high PM2.5 levels throughout the year primarily driven by substantial dust aerosol emissions.
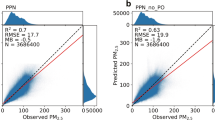
Figure 3 presents a spatial comparison between computed and predicted PM2.5 concentrations, demonstrating that the DEMLM framework effectively captures the global spatio-temporal variability of PM2.5 levels at a representative time steps. The performance metrics for training, validation, and testing datasets confirm the model’s robustness and generalisation capabilities. The RMSE values are relatively low across all phases, increasing slightly from 16.23 μg/m³ during training to 17.36 μg/m³ during testing, indicating good predictive accuracy even on unseen data (Table 1). Correspondingly, MSE values increase from 263.41 μg/m³ in training to 301.53 μg/m³ in testing. The R² values remain consistently high across all phases, with 0.922 for training and 0.902 for testing, suggesting strong agreement between observed and predicted values. Similarly, the NSE values drop marginally from 0.920 to 0.889, reaffirming the model’s ability to replicate the observed dynamics effectively. The PBIAS values are within acceptable limits, rising slightly from 11.28% in training to 12.15% in testing, indicating a minimal and consistent bias across datasets (Table 1). Despite the model’s strong performance, a slight decline in accuracy is observed in the testing phase, suggesting that the model might struggle with generalisation when faced with unseen data45. The observed decline may be due to the influence of extreme PM2.5 concentrations or unaccounted regional variability that was not adequately represented in the training data46. Additionally, the increased bias in testing suggests a potential systematic deviation, which might stem from the model’s sensitivity to specific meteorological or emission-related factors29,47.

Comparison of observed and predicted PM2.5 concentrations (µg/m³) over the globe using the DEMLM; Example sets a 31st December 2022(Observed) b 31st December 2022 (Predicted) c 31st December 2023 (Observed) and d 31st December 2023 (Predicted).
Population Weighted Pollution Extremes
Globally, across 195 countries, the PWPM2.5 concentration for 1990-2020 ranges from 28.63 μg/m³ [Coefficient of Variation (COV): 69.25%] to 40.56 μg/m³ (COV: 68.36%), indicating a substantial rise in average pollution levels, although with a marginal decrease in relative variability. However, the increase in population-weighted PM2.5D from 38 days (COV: 62%) to 44 days (COV: 64%) suggests more frequent exposure to high pollution, accompanied by a slight increase in variability. The 99th percentile of population-weighted PM2.5 saw a dramatic rise from 50.94 μg/m³ (COV: 56.97%) to 65.72 μg/m³ (COV: 60.37%), highlighting a concerning increase in extreme pollution events with more significant relative variability. Similarly, the maximum one-day PM2.5 levels rose from 56.2 μg/m³ (COV: 68.43%) to 65.11 μg/m³ (COV: 64.11%), indicating higher peaks in daily pollution, though with a reduction in relative variability.
The mean exposure of different extremes over the regions is shown in Fig. 4 and represents a comprehensive analysis of population-weighted PM2.5 and related metrics across six continents from 2000 to 2020 (Fig. S2). Africa’s PM2.5 levels increased significantly in 2015 (17.26 µg/m³) before a slight decline in 2020 (16.95 µg/m³) (Fig. S2). Similarly, the continent saw an increase in PM2.5D and PM2.5x1day, with PM2.5D remaining stable at 53 days in 2015 and 2020 and PM2.5x1day rising sharply to 66.18 in 2020 (Fig. S2). Asia consistently rose in PM2.5 from 20.86 µg/m³ in 2000 to 25.99 µg/m³ in 2015, followed by a slight decrease in 2020 (Fig. S2). The continent also had significant PM2.5D and high PM2.5x1day and 99th Percentile values, indicating severe pollution episodes. Europe, North America, and Oceania showed lower PM2.5 levels, with Europe and North America maintaining relatively stable yet low PM2.5D (Fig. S2). Notably, Europe’s PM2.5 levels and 99th Percentile values declined over the years, suggesting improved air quality. In contrast, Oceania maintained minimal pollution with consistent PM2.5D at zero (Fig. S2). South America’s PM2.5 levels were low, peaking slightly in 2020, with a unique increase in PM2.5x1day to 92.62 in 2015 before falling to 76.47 in 2020. The continents such as Africa and Asia continue to grapple with rising pollution levels, and Europe and North America show the effectiveness of stringent air quality regulations.

Country level distribution of population weighted a mean annual PM2.5 b PM2.5D, c PM2.5x1day and d PM2.5 99th Percentile values.
Figure 4 illustrates the global distribution of population-weighted PM2.5 metrics, highlighting regional pollution hotspots from 2000 to 2020. High PM2.5 concentrations are prominent in South Asia, particularly India, Pakistan, Bangladesh, and parts of Africa and East Asia, with China showing significant values. The number of days PM2.5 levels exceed USEPA guidelines reveals notable hotspots in India, Pakistan, Bangladesh, and regions in Africa such as Niger and Benin. The maximum daily PM2.5 values indicate severe pollution episodes in South Asia, the Middle East, and parts of Africa, with Lebanon, Rwanda, and Nigeria frequently exceeding safe levels. The depiction of the 99th percentile PM2.5 showcases extreme pollution events in India, Bangladesh, and Nigeria. However, countries in North and South America, Australia, and Europe exhibit improved air quality, with their extreme values shown to be at minimum levels.
This study further identifies and ranks countries based on the highest population-weighted extreme estimates (Fig. 5), covering the period from 2000 to 2020. The rankings reveal persistent and emerging air pollution hotspots, emphasising both chronic and acute exposure scenarios. China dominates the Mean PM2.5 rankings from 2000 to 2010, indicating a prolonged period of severe air pollution. However, by 2015 and 2020, Rwanda surpasses China, reflecting significant changes in pollution patterns and possible regional industrialisation or urbanisation impacts. Pakistan and Bangladesh consistently appear in the top three, highlighting their ongoing struggle with high PM2.5 levels. In the PM2.5D category, Niger consistently ranked first from 2000 to 2015, signifying continuous exceedances of USEPA PM2.5 guidelines, with Benin taking over in 2020. This trend underscores the persistent air quality challenges in these regions. Nepal, Bangladesh, and China also feature prominently, pointing to frequent safe air quality level breaches. The 99th Percentile rankings show China leading from 2000 to 2010, reflecting extremely high pollution episodes, while Benin rose to the top in 2015 and 2020, indicating an increase in severe pollution events. The PM2.5x1day rankings reveal Lebanon and Rwanda frequently topping the list, with Qatar emerging in 2020. These countries experience extraordinarily high daily PM2.5 values, suggesting acute pollution spikes possibly due to specific events such as wildfires or industrial activities. The presence of countries like Nigeria and Ghana in the top rank’s points to regional spikes in daily PM2.5 levels, highlighting the necessity for region-specific air quality control measures.

Countries with the highest Population-weighted PM2·5 extremes during 2000-2020 categorised by economical status.
India’s rankings across these metrics are noteworthy. Consistently appearing in the top ten for Mean PM2.5 and PM2.5D, India shows a persistently high level of air pollution exposure and frequent exceedance of USEPA guidelines. India’s ranking in the 99th Percentile and PM2.5x1day metrics underscores the occurrence of extreme pollution events, likely exacerbated by rapid urbanisation and industrial activities. These patterns suggest that while India has made some strides in addressing air pollution, significant challenges remain, necessitating comprehensive policy measures and enforcement to protect public health.
Discussion
This comprehensive study on daily PM2.5 concentrations across a grid system offers a pioneering global outlook on PM2.5 concentrations and their extremes, examining how population exposure has varied spatially and temporally from 2000 to 2020. The study developed, tested, and validated the DEMLM using computed datasets of PM2.5, meteorological conditions, and land use factors, demonstrating strong predictive accuracy. Notably, nations in South Asia, East Asia, and Northern Africa consistently showed high PM2.5 levels, aligning with previous research. Moreover, the forecasted PM2.5 values exhibited clear seasonal fluctuations.
In this study, the empirical model is less commonly applied for estimating global PM2.5 concentrations, whereas the DEMLM approach demonstrates superior predictive accuracy. The prediction of PM2.5 globally in the fine spatiotemporal resolution with meteorological and land-use datasets to train a CNN-LSTM model for each independent validation dataset. Other studies have also quantified worldwide monthly and yearly average exposure to PM2·5. Hammer et al.48 analysed global assessments of annual mean PM2·5 levels during 1998–2018 combining satellite data, ground-based measurements and CTM, achieving R² ranging from 0.90 to 0.92. Shaddick et al.49 employed a global Bayesian hierarchical model (BHM) integrating multiple datasets to determine the average annual PM2·5 exposures for 2014, achieving an R² ~ 0.91. Comparing these findings with previous global PM2.5 estimation studies is challenging due to the limited availability of research quantifying global mean 24-hour PM2.5 exposure levels. Additional comparative analyses are therefore necessary. Bont et al.5 conducted a comprehensive time-series analysis across ten Indian cities during 2008–2019, employing novel spatiotemporal and causal models to examine the relationship between PM2.5 concentrations and mortality, identifying significant correlations and estimating the proportion of deaths exceeding WHO and Indian AQG. The outcomes of this study is closely matched with Yu et al.8, who developed an advanced model for global PM2.5 estimation by integrating deep learning techniques, CTMs, and meteorological variables, achieving high prediction accuracy. However, Rautela and Goyal35 analysed trends and slopes of extreme pollution indices, showing an expected increase in event intensity across most global regions (Fig. 1), while Kelly et al.41 used nine PM2.5 exposure models to estimate 2011 concentrations and projected a ~ 1 µg/m³ average decrease by 2028 due to regulations. Similarly, Yu et al.8 observed a reduction in population-weighted PM2.5 exposure in Europe and North America, while it increased in South Asia, Australia, and Latin America, with over 70% of days in 2019 surpassing the WHO daily limit (Figs. 2 and 4). For region-specific studies Aunan et al.42 assessed PM2.5 exposure in China using the IPWE metric, reporting an average of 151 μg/m³, with rural populations exposed to nearly double the levels compared to urban areas, while Jaganathan et al.50 highlighted that there is 10 μg/m³ rise in annual population-weighted PM2.5 in India (Fig. 1).
However, high-income countries, including Israel, Taiwan, Qatar and Kuwait frequently exceeded daily mean PM2·5 levels of 35.5 μg/m³ for ~50% of the year51,52,53. However, the countries that lie in lower-middle-income countries contribute more to air pollution (Behrersam and Heft-Neal54; Rentschler and Leonova55). Moreover, some regions over and near the global deserts show high air pollution due to the substantial dust aerosol emissions56. The Indian dust storm (2018)57 and Godzilla dust storm (2020)58 are the most well-documented dust storms that increased the PM2.5 concentrations by more than 10–20 times over the Indian and eastern USA regions. Similarly, regions, such as IGP, southeast Asia and eastern China with high population density also contribute to severe air pollution59. PM2.5 concentration variations across space and time are driven by a combination of human-made emissions from fuel combustion and alterations in natural sources, with extreme aerosol events such as bushfires and windblown dust intensifying these fluctuations60. During winter, northeastern China experiences higher PM2.5 concentrations, likely due to favourable meteorological conditions and increased emissions from fossil fuel combustion for heating. Conversely, countries in South America, particularly Brazil, experience higher PM2.5 levels in August and September due to human-driven activities like slash-and-burn agriculture61. Similarly, during winters, countries like India, Pakistan, Nepal etc. also see and increased PM2.5 concentrations due to agricultural burning combined with temperature inversions and atmospheric circulation.
The historical trajectory of air quality policies, as illustrated through global PM2.5 concentration maps, demonstrates the progressive impact of regulatory interventions on pollution levels (Fig. S3). Major legislative milestones, such as the U.S. National Ambient Air Quality Standards (NAAQS) and the Clean Air Act of 1970, followed by the Acid Rain Programme in 1990, significantly reduced pollution levels in North America62,63. Similarly, the European Union implemented the Ambient Air Quality Directive in 1996 and the National Emission Ceilings Directive (NECD) in 2001, leading to marked improvements across Western Europe64. Subsequent initiatives, such as the Clean Vehicle Directive of 2009, reinforced urban air quality improvements65. Significant decreases in PM2.5 concentrations have been observed across the northern hemisphere, especially in North Africa and the Middle East, where levels dropped from severe pollution (>150.4 μg/m³) in the 1980s to moderate concentrations (35.5–55.4 μg/m³) by the 2020 s. More recent interventions, such as the Clean Power Plan (2015), the Air Pollution Action Plan (2013), and India’s National Clean Air Programme (NCAP) (2019), have further contributed to pollution mitigation, particularly in South and East Asia66,67,68. High PM2.5 levels in the Sahara Desert and parts of the Middle East highlight the continued impact of natural sources such as mineral dust, which are not addressed by standard regulatory measures.
A phased approach to implementing air quality standards in these regions could involve setting initial, achievable targets that progressively become more stringent, considering economic limitations for a feasible advancement69. Moreover, from the study findings and the previously discussed air pollution prevention policies (Fig. S3), we can craft a comprehensive approach for low-income, lower-middle-income, and emerging economies such as Niger, Pakistan, Bangladesh, Benin, Nigeria, India etc. (Fig. 5). These countries encounter significant obstacles in adopting effective air quality management strategies due to resource constraints, fast-paced urban growth, and conflicting developmental priorities70. For low-income countries, the focus should be on developing foundational air quality monitoring systems through cost-effective sensors and community-driven data collection, alongside promoting cleaner cooking technologies to mitigate indoor air pollution, a significant health risk70,71,72. Lower-middle-income countries should focus on gradually implementing air quality standards, enforcing emissions regulations for key pollution sources such as industries and vehicles, and investing in targeted interventions like urban greening and cleaner public transportation73. Emerging economies with more financial and technical capacity should adopt advanced pollution control measures, integrate smart air quality monitoring with policy frameworks, promote sustainable urban planning, and strengthen regional cooperation for transboundary pollution mitigation74,75,76.
This study underscores the pressing global challenge of PM2.5 pollution, particularly the rise in extremes across densely populated and rapidly urbanising regions. Through the integration of deep learning models, especially DEMLM (CNN-LSTM-DNN), it provides robust spatiotemporal predictions of PM2.5, revealing significant exposure disparities across countries and regions. The findings highlight persistent pollution hotspots in South Asia and parts of Africa, emphasising the urgent need for region-specific air quality management strategies. Population-weighted analyses show that a large share of the global population remains exposed to PM2.5 levels far exceeding health-based standards, amplifying health risks and socio-economic inequalities. However, limitations related to data sources, model generalizability, and spatial resolution suggest the need for improved data integration, hybrid modeling, and localised assessments. Future research should focus on refining prediction accuracy, incorporating health and socio-economic dimensions, and strengthening international cooperation to effectively address air pollution and support sustainable development goals.
Methods
Data sources
The present study uses Modern-Era Retrospective analysis for Research and Applications, Version 2 reanalysis datasets for surface mass concentrations of anthropogenic aerosols (sulphates, black and organic carbon) and natural aerosols (dust and sea salts) with a spatiotemporal resolution of 0.5° × 0.625° and 1 h respectively, during 1980–202377. Further, the concentration of PM2.5 was assessed using the Global Modelling and Assimilation Office (GMAO) (https://gmao.gsfc.nasa.gov/reanalysis/MERRA-2/FAQ/) model and correlated with the WHO datasets (version 5) (https://www.who.int/data/gho/data/themes/air-pollution/who-air-quality-database/2022) for the year 2011, 2014, 2016, 2018 and 2022 with a correlation coefficient and coefficient of determination of 0.87 and 0.75, respectively17,78. Furthermore, satellite-based meteorological data with a spatial resolution of 0.25° × 0.25° were obtained from the ERA5 dataset to enhance the modelling process79. This dataset provided comprehensive information on precipitation, temperature, and wind speed, crucial for accurate and detailed meteorological analysis and modelling. Daily data were determined by averaging 24 h of observations, beginning each day. Additionally, the population density data has been acquired from Gridded Population of the World (GPW) for the years 2000, 2005, 2010, 2015 and 2020 (https://cmr.earthdata.nasa.gov/search/concepts/C1597159135-SEDAC.html).
Methodology
We employed the DEMLM framework (Fig. S4) to predict daily PM2.5 concentrations at a global scale by integrating CNNs, LSTM, and DNN. We initially investigated the association between PM2.5 levels and meteorological variables. Utilising datasets for PM2.5 concentrations, precipitation, temperature, and wind speed for 1980-2023, we ensured proper alignment and integrity of the data. Each dataset was upscaled to a uniform spatial resolution of 0.5° × 0.625° using bilinear interpolation to ensure consistency with the PM2.5 grid for accurate cell-based analysis (Fig. S4)51. Missing values were handled using forward fill, backward fill, and median imputation techniques to avoid potential bias imputation could be introduced. We introduced multiple time-lagged features, including PM2.5 data shifted by one day (PM25 lag1), and enhanced feature engineering with seasonal indicators (day of year, month, season) to capture temporal dependencies. After imputing missing values, the dataset was partitioned into training (80%), testing (20%), and validation (integrated into training through validation split = 0.2) subsets using time-series splitting to preserve temporal order where applicable, ensuring reproducibility with a random state for 1980-202380,81.
We employed three advanced neural network architectures for the model development phase: CNNs, LSTMs, and DNN82. The CNN model, consisting of several convolutional layers followed by fully connected layers, was developed to extract and learn spatial patterns in the data. It included 32 filters with a stride of (1,1), kernel size of (3,3) and valid padding to handle border regions (Table 2). The ReLU activation function was used, along with max pooling to reduce spatial dimensions. A dropout rate of 30% was applied to minimise overfitting. The LSTM model, structured with multiple sequential LSTM layers followed by dense layers, efficiently processed the temporal dependencies in the time-series data, capturing underlying patterns. It featured 32 and 16 LSTM units, with 2 stacked LSTM layers (Table 2). The tanh activation function was used, along with a recurrent dropout rate of 0.3 and an overall dropout rate of 0.30. The Dense model, consisting of fully connected layers with L1/L2 regularisation, served as a baseline for comparison with 64, 32, and 16 hidden units respectively. Both models were optimised using the Adam algorithm with a learning rate of 0.001 with ReduceLROnPlateau callback, employing mean-squared error (MSE) as the objective function for loss minimisation. The model was trained for 100 epochs with adaptive batch size (minimum 64). Early stopping was implemented with patience = 15 to prevent overfitting and learning rate reduction with factor = 0.5 and patience = 7 (Table 2).
To enhance the robustness of our predictions, we ensembled the CNN, LSTM, and DNN models by weighted averaging based on the inverse RMSE performance of their predictions. This ensemble method aimed to leverage the unique strengths of each model, reducing overfitting and improving generalisation capabilities34. The ensemble weights were calculated dynamically based on individual model performance, with better-performing models receiving higher weights. The ensemble model’s performance was rigorously evaluated using the testing dataset, and key metrics such as training, validation, and testing losses were analysed to the model’s learning process and computational efficiency24. Additionally, bias correction was implemented using real-world city PM2.5 data from geocoded locations to adjust systematic prediction errors. The method matches each grid point in the model predictions to the nearest city monitoring station using Euclidean distance based on WHO ambient air quality database for years 2011, 2014, 2016, 2018 and 2022. For each matched pair, it calculates the bias as the difference between observed annual mean PM2.5 concentrations and model-predicted values at that location. A global mean bias is computed from all matched city-station pairs and uniformly applied to all grid predictions. This approach assumes spatially homogeneous bias patterns and provides a first-order correction by leveraging high-quality observational data to reduce systematic model errors across the prediction domain. The ensemble approach demonstrated improved performance, effectively capturing spatiotemporal dependencies, and underscored the efficacy of combining CNN, LSTM, and DNN architectures for predicting PM2.5 concentrations based on meteorological data. Further, the ensemble modelling framework is employed for global-scale prediction of PM2.5 concentrations.
Statistical analysis
The spatiotemporal generalisation and reliability of the DEMLM framework were assessed using multiple model efficiency parameters, including MSE, Root Mean Squared Error (RMSE), Coefficient of Determination (R²), Nash-Sutcliffe Efficiency (NSE), and Percentage Bias (PBIAS)83 to quantify predictive accuracy and systematic bias. RMSE, computed as the square root of MSE, quantifies the average magnitude of prediction errors, where lower values indicate higher model accuracy84. MSE, while similar, provides an unscaled measure of error, making it useful for comparing different models84. quantifies the proportion of variance in PM2.5 concentrations accounted for by the model, with values approaching 1 signifying higher predictive accuracy and model reliability85. NSE assesses the predictive power of the model relative to the mean observed values, where an NSE above 0.5 suggests acceptable model performance and values close to 1 indicate excellent agreement86. PBIAS evaluates the model’s tendency to overestimate or underestimate observed values, with an acceptable range typically within ±25% for hydrological and air pollution studies87. The metrics were calculated separately for the training, validation, and testing datasets to comprehensively assess model performance across different data partitions. Their selection provides a multi-faceted assessment of the model, addressing both absolute error and predictive reliability, ultimately strengthening confidence in DEMLM’s spatiotemporal applicability.
Computation of decadal and month-wise change in PM2.5 concentrations
We systematically assessed the global distribution of PM2.5 concentrations, examining their spatiotemporal variability across decadal and monthly timescales to quantify long-term trends and seasonal dynamics88. This assessment provided critical insights into how air quality changes over time across different regions, allowing for a nuanced understanding of pollution dynamics. The Mann-Kendall test was applied to detect monotonic trends in annual PM2.5 concentrations without assuming data normality, while Sen’s slope quantified trend magnitude through robust median-based calculations resistant to outliers. The selection of monthly averages over a 44-year period, along with decadal means, was intended to account for both intra-annual fluctuations and long-term trends in PM2.5 concentrations. Monthly averaging facilitates the identification of seasonal variations in PM2.5 concentrations, providing insights into the influence of meteorological dynamics, emission patterns, and atmospheric transport processes on air quality over annual cycles. A key component of our analysis included determining the proportion of global and regional land areas, as well as the population exposed to PM2.5 levels, in accordance with the revised USEPA guidelines, which now set the annual PM2.5 standard at 9 μg/m³ to enhance public health protection68. This updated threshold aligns more closely with the WHO’s recommended guideline of 5 μg/m³, emphasising the need for stringent air quality control measures89. By examining these exposure metrics, we aimed to systematically assess air quality trends and quantify associated health risks, enabling the identification of high-risk regions that require targeted pollution control interventions.
Computation of population-weighted pollution extremes
To assess air pollution levels and the population affected in each region, we identified several key metrics: Population-weighted PM2.5 (PWPM2.5), population-weighted exposed days (PWPM2.5D) where daily PM2.5 concentrations exceeded the USEPA standard of 35.5 μg/m³, population-weighted annual maximum PM2.5 (PWPM2.5x1Day), and the population-weighted PM2.5 99th percentile. These metrics collectively offer a multidimensional perspective on pollution intensity and exposure scale, where PWPM2.5 provides an estimate of the average exposure level, PWPM2.5D highlights the frequency of severe pollution days, PWPM2.5x1Day captures the highest PM2.5 concentration recorded in a year, and the 99th percentile reflects extreme pollution events, helping to identify regions with recurrent hazardous conditions35. The rationale for selecting these population-weighted pollution extreme indices stems from their ability to integrate both pollution severity and population density, ensuring that the analysis is not just focused on absolute pollution levels but also on human exposure risks. The population-weighted PM2.5 different extremes were identified as8:
In this analysis, PM2.5i represents the daily mean concentration of PM in a grid cell (i). PM2.5Dij is a Boolean indicator, signifying whether the daily mean PM2.5i on a specific day j within a year in a specific grid cell (i) exceeds 35.5 μg/m³ (Dij = 1) or not (Dij = 0). PM2.5x1Dayi denotes the annual maximum PM2.5 concentration observed in grid cell (i), while PM2.5 99th Percentilei refers to the 99th percentile of PM2.5 concentrations within that grid cell. The variable pi represents the annual average population within a given grid cell (i), and P denotes the total population within a specified region, computed as the aggregate sum of pi across all grid cells.
The study regions were delineated according to the regional and national groupings defined by the UN Statistics Division, covering 195 countries. We assessed global, regional and national PWPM2.5, PWPM2.5D, PWPM2.5x1Day and PM2.5 99th percentile exposure for the years 2000, 2005, 2010, 2015, and 2020 respectively. Countries were ranked by their exposure levels, with labels indicating their income group based on the World Bank classification. Monthly mean PM2.5 concentrations were computed for each grid cell globally over a 44-year period to analyse seasonal variability. This approach provided a comprehensive view of both global, regional and national trends in PM2.5 exposure, highlighting areas with the highest pollution levels and seasonal variations in air quality. Additionally, we reviewed existing policies implemented globally and regionally to combat pollution. Through an evaluation of policy effectiveness, we identified key strategies and best practices that have demonstrated success in mitigating air pollution. Based on this analysis, we formulated region-specific policy recommendations to enhance air quality management. Our objective was to provide data-driven insights that support the implementation of targeted measures for pollution reduction and environmental health improvement.
Data availability
The datasets utilised in this study are publicly available from reputable global sources. Aerosol surface mass concentrations were obtained from the MERRA-2 reanalysis dataset provided by NASA's Global Modelling and Assimilation Office (https://gmao.gsfc.nasa.gov/reanalysis/MERRA-2/FAQ/). The ground-based observations of PM2.5 for the global cities were obtained from WHO Air Quality Database version 5 (https://www.who.int/data/gho/data/themes/air-pollution/who-air-quality-database/2022). Meteorological variables such as precipitation, temperature, and wind speed were sourced from the ERA5 dataset with 0.25° spatial resolution. Population density data were obtained from the Gridded Population of the World (GPW) for selected years between 2000 and 2020 (https://cmr.earthdata.nasa.gov/search/concepts/C1597159135-SEDAC.html). The DEMLM estimated PM2.5 datasets can be downloaded from https://zenodo.org/records/16670675.
Code availability
The code will be made available online on a reasonable request to the corresponding author.
References
Shakya, D., Deshpande, V., Goyal, M. K. & Agarwal, M. PM2.5 air pollution prediction through deep learning using meteorological, vehicular, and emission data: a case study of New Delhi, India. J. Clean. Prod. 427, 139278 (2023).
Chaudhary, E. et al. Cumulative effect of PM2.5 components is larger than the effect of PM2.5 mass on child health in India. Nat. Commun. 14, 6955 (2023).
Skiba, A. et al. Source attribution of carbonaceous fraction of particulate matter in the urban atmosphere based on chemical and carbon isotope composition. Sci. Rep. 14, 7234 (2024).
Fann, N., Coffman, E., Timin, B. & Kelly, J. T. The estimated change in the level and distribution of PM2.5-attributable health impacts in the United States: 2005–2014. Environ. Res. 167, 506–514 (2018).
de Bont, J. et al. Ambient air pollution and daily mortality in ten cities of India: a causal modelling study. Lancet Planet. Heal. 8, e433–e440 (2024).
Feng, Y. et al. Long-term exposure to ambient PM2.5, particulate constituents and hospital admissions from non-respiratory infection. Nat. Commun. 15, 1518 (2024).
Pai, S. J., Carter, T. S., Heald, C. L. & Kroll, J. H. Updated World Health Organization air quality guidelines highlight the importance of non-anthropogenic PM 2.5. Environ. Sci. Technol. Lett. 9, 501–506 (2022).
Yu, W. et al. Global estimates of daily ambient fine particulate matter concentrations and unequal spatiotemporal distribution of population exposure: a machine learning modelling study. Lancet Planet. Heal. 7, e209–e218 (2023).
Apte, J. S., Brauer, M., Cohen, A. J., Ezzati, M. & Pope, C. A. Ambient PM 2.5 reduces global and regional life expectancy. Environ. Sci. Technol. Lett. 5, 546–551 (2018).
Friberg, M. D., Kahn, R. A., Limbacher, J. A., Appel, K. W. & Mulholland, J. A. Constraining chemical transport PM2.5 modeling outputs using surface monitor measurements and satellite retrievals: application over the San Joaquin Valley. Atmos. Chem. Phys. 18, 12891–12913 (2018).
Lin, C. et al. Observation of PM2.5 using a combination of satellite remote sensing and low-cost sensor network in Siberian urban areas with limited reference monitoring. Atmos. Environ. 227, 117410 (2020).
van Donkelaar, A. et al. Global estimates of ambient fine particulate matter concentrations from satellite-based aerosol optical depth: development and application. Environ. Health Perspect. 118, 847–855 (2010).
Ji, Y., Wang, Y., Wang, C., Tang, X. & Song, M. Remote sensing fine estimation model of PM2.5 concentration based on improved long short-term memory network: a case study on Beijing–Tianjin–Hebei urban agglomeration in China. Remote Sens 16, 4306 (2024).
Zhang, R. et al. Estimation of PM2.5 using multi-angle polarized TOA reflectance data from the GF-5B satellite. Remote Sens 16, 3944 (2024).
Yu, W., Song, J., Li, S. & Guo, Y. Is model-estimated PM2.5 exposure equivalent to station-observed in mortality risk assessment? A literature review and meta-analysis. Environ. Pollut. 348, 123852 (2024).
Masood, A. et al. Improving PM2.5 prediction in New Delhi using a hybrid extreme learning machine coupled with snake optimization algorithm. Sci. Rep. 13, 21057 (2023).
Buchard, V. et al. Evaluation of the surface PM2.5 in Version 1 of the NASA MERRA aerosol reanalysis over the United States. Atmos. Environ. 125, 100–111 (2016).
Wang, Z., Chai, H., Chen, P., Zheng, N. & Zhang, Q. Estimation of PM2.5 concentrations in North China with high spatiotemporal resolution using the ERA5 dataset and machine learning models. Adv. Sp. Res. 74, 711–726 (2024).
Li, G. et al. Estimation of PM 2.5 using high-resolution satellite data and its mortality risk in an area of Iran. Int. J. Environ. Health Res. 34, 3771–3783 (2024).
Zeng, T. et al. A deep learning PM2.5 hybrid prediction model based on clustering–secondary decomposition strategy. Electronics 13, 4242 (2024).
Zhou, S., Wang, W., Zhu, L., Qiao, Q. & Kang, Y. Deep-learning architecture for PM2.5 concentration prediction: a review. Environ. Sci. Ecotechnology 21, 100400 (2024).
Koo, J.-S., Wang, K.-H., Yun, H.-Y., Kwon, H.-Y. & Koo, Y.-S. Development of PM2.5 forecast model Combining ConvLSTM and DNN in Seoul. Atmosphere (Basel) 15, 1276 (2024).
Liu, R. et al. A novel short-term PM2.5 forecasting approach using secondary decomposition and a hybrid deep learning model. Electronics 13, 3658 (2024).
Rautela, K. S., Singh, S. & Goyal, M. K. Characterizing the spatio-temporal distribution, detection, and prediction of aerosol atmospheric rivers on a global scale. J. Environ. Manag. 351, 119675 (2024).
Rautela, K. S., Singh, S. & Goyal, M. K. Resilience to air pollution: a novel approach for detecting and predicting aerosol atmospheric rivers within earth system boundaries. Earth Syst. Environ. https://doi.org/10.1007/s41748-024-00421-0 (2024).
Qiu, Y. et al. Regional aerosol forecasts based on deep learning and numerical weather prediction. npj Clim. Atmos. Sci. 6, 71 (2023).
Masood, A. & Ahmad, K. A review on emerging artificial intelligence (AI) techniques for air pollution forecasting: Fundamentals, application and performance. J. Clean. Prod. 322, 129072 (2021).
Nargund, R. et al. Assessing soybean yield in Madhya Pradesh by using a multi-model approach. F. Crop. Res. 322, 109716 (2025).
Samad, A., Garuda, S., Vogt, U. & Yang, B. Air pollution prediction using machine learning techniques – An approach to replace existing monitoring stations with virtual monitoring stations. Atmos. Environ. 310, 119987 (2023).
Requia, W. J. et al. An ensemble learning approach for estimating high spatiotemporal resolution of ground-level ozone in the contiguous United States. Environ. Sci. Technol. 54, 11037–11047 (2020).
Warad, A. A. M., Wassif, K. & Darwish, N. R. An ensemble learning model for forecasting water-pipe leakage. Sci. Rep. 14, 10683 (2024).
Di, Q. et al. An ensemble-based model of PM2.5 concentration across the contiguous United States with high spatiotemporal resolution. Environ. Int. 130, 104909 (2019).
Mohammadi, F., Teiri, H., Hajizadeh, Y., Abdolahnejad, A. & Ebrahimi, A. Prediction of atmospheric PM2.5 level by machine learning techniques in Isfahan. Iran. Sci. Rep. 14, 2109 (2024).
Yu, W. et al. Deep ensemble machine learning framework for the estimation of PM2.5 concentrations. Environ. Health Perspect. 130, 37004 (2022).
Rautela, K. S. & Goyal, M. K. Spatio-temporal analysis of extreme air pollution and risk assessment. J. Environ. Manag. 373, 123807 (2025).
Wei, J. et al. First close insight into global daily gapless 1 km PM2.5 pollution, variability, and health impact. Nat. Commun. 14, 8349 (2023).
Thangavel, P., Park, D. & Lee, Y.-C. Recent Insights into particulate matter (PM2.5)-mediated toxicity in humans: an overview. Int. J. Environ. Res. Public Health 19, 7511 (2022).
Arfin, T. et al. An overview of atmospheric aerosol and their effects on human health. Environ. Sci. Pollut. Res 30, 125349–125369 (2023).
Shisong, C. et al. Comparison of remotely sensed PM2.5 concentrations between developed and developing countries: results from the US, Europe, China, and India. J. Clean. Prod. 182, 672–681 (2018).
Liu, S. et al. Tracking daily concentrations of PM 2.5 chemical composition in china since 2000. Environ. Sci. Technol. 56, 16517–16527 (2022).
Kelly, J. T. et al. Examining PM2.5 concentrations and exposure using multiple models. Environ. Res. 196, 110432 (2021).
Aunan, K., Ma, Q., Lund, M. T. & Wang, S. Population-weighted exposure to PM2.5 pollution in China: an integrated approach. Environ. Int. 120, 111–120 (2018).
Berrocal, V. J. et al. A comparison of statistical and machine learning methods for creating national daily maps of ambient PM2.5 concentration. Atmos. Environ. 222, 117130 (2020).
Neo, E. X. et al. Artificial intelligence-assisted air quality monitoring for smart city management. PeerJ Comput. Sci. 9, e1306 (2023).
Zhang, C., Bengio, S., Hardt, M., Recht, B. & Vinyals, O. Understanding deep learning (still) requires rethinking generalization. Commun. ACM 64, 107–115 (2021).
Xue, T. et al. Spatiotemporal continuous estimates of PM2.5 concentrations in China, 2000–2016: A machine learning method with inputs from satellites, chemical transport model, and ground observations. Environ. Int. 123, 345–357 (2019).
Thunis, P. et al. Sensitivity of air quality modelling to different emission inventories: A case study over Europe. Atmos. Environ. X 10, 100111 (2021).
Hammer, M. S. et al. Global estimates and long-term trends of fine particulate matter concentrations (1998–2018). Environ. Sci. Technol. 54, 7879–7890 (2020).
Shaddick, G. et al. Data integration for the assessment of population exposure to ambient air pollution for global burden of disease assessment. Environ. Sci. Technol. 52, 9069–9078 (2018).
Jaganathan, S. et al. Estimating the effect of annual PM2·5 exposure on mortality in India: a difference-in-differences approach. Lancet Planet. Heal. 8, e987–e996 (2024).
Weger, M. & Heinold, B. Air pollution trapping in the Dresden Basin from gray-zone scale urban modeling. Atmos. Chem. Phys. 23, 13769–13790 (2023).
Zakzak, L. et al. Arab Region SDG Index and Dashboards Report 2023. Dubai and Paris: Mohammed bin Rashid School of Government (MBRSG) and UN Sustainable Development Solutions Network (SDSN) (2023).
Hien, T. T. et al. Characterization of particulate matter (PM1 and PM2.5) from incense burning activities in temples in Vietnam and Taiwan. Aerosol Air Qual. Res. 22, 220193 (2022).
Behrer, P. & Heft-Neal, S. A Surprising truth: Wealthy areas in low- and middle-income countries face higher ambient air pollution levels [WWW Document]. (2024) https://blogs.worldbank.org/en/developmenttalk/surprising-truth-wealthy-areas-low-and-middle-income-countries-face-higher-ambient (accessed 7.10.24).
Rentschler, J. & Leonova, N. Global air pollution exposure and poverty. Nat. Commun. 14, 4432 (2023).
Querol, X. et al. Monitoring the impact of desert dust outbreaks for air quality for health studies. Environ. Int. 130, 104867 (2019).
Sarkar, S., Chauhan, A., Kumar, R. & Singh, R. P. Impact of deadly dust storms (May 2018) on air quality, meteorological, and atmospheric parameters over the Northern Parts of India. GeoHealth 3, 67–80 (2019).
Yu, H. et al. Observation and modeling of the historic “Godzilla” African dust intrusion into the Caribbean Basin and the southern US in June 2020. Atmos. Chem. Phys. 21, 12359–12383 (2021).
Acharja, P. et al. Thermodynamical framework for effective mitigation of high aerosol loading in the Indo-Gangetic plain during winter. Sci. Rep. 13, 13667 (2023).
Chakraborty, S., Guan, B., Waliser, D. E. & da Silva, A. M. Aerosol atmospheric rivers: climatology, event characteristics, and detection algorithm sensitivities. Atmos. Chem. Phys. 22, 8175–8195 (2022).
Pivello, V. R. et al. Understanding Brazil’s catastrophic fires: Causes, consequences and policy needed to prevent future tragedies. Perspect. Ecol. Conserv. 19, 233–255 (2021).
National ambient air quality monitoring. Air quality trends and action for plan. Naaqms 5 (2006).
McCarthy, J. E., Copeland, C., Parker, L. & Schierow, L. J. Clean Air Act: A summary of the act and its major requirements. N. Trends Environ. Sci. 147, 168 (2014).
Kuklinska, K., Wolska, L. & Namiesnik, J. Air quality policy in the U.S. and the EU – a review. Atmos. Pollut. Res. 6, 129–137 (2015).
ACEA. ACEA Position paper: review of the clean vehicles directive. (2018).
Feng, Y. et al. Defending blue sky in China: effectiveness of the “Air Pollution Prevention and Control Action Plan” on air quality improvements from 2013 to 2017. J. Environ. Manag. 252, 109603 (2019).
Ganguly, T., Selvaraj, K. L. & Guttikunda, S. K. National Clean Air Programme (NCAP) for Indian cities: Review and outlook of clean air action plans. Atmos. Environ. X 8, 100096 (2020).
EPA. National Ambient Air Quality Standards (NAAQS) for PM | US EPA. (EPA, 2020).
USAID, Columbia University Mailman School of Public Health. LMIC Urban Air Pollution Solutions. (2019).
Awewomom, J. et al. Addressing global environmental pollution using environmental control techniques: a focus on environmental policy and preventive environmental management. Discov. Environ. 2, 8 (2024).
Srivastava, R. P., Kumar, S. & Tiwari, A. Continuous emission monitoring systems (CEMS) in India: performance evaluation, policy gaps and financial implications for effective air pollution control. J. Environ. Manag. 359, 120584 (2024).
Jonidi Jafari, A., Charkhloo, E. & Pasalari, H. Urban air pollution control policies and strategies: a systematic review. J. Environ. Heal. Sci. Eng. 19, 1911–1940 (2021).
Gurjar, B. R., Ravindra, K. & Nagpure, A. S. Air pollution trends over Indian megacities and their local-to-global implications. Atmos. Environ. 142, 475–495 (2016).
Rautela, K. S. & Goyal, M. K. Transforming air pollution management in India with AI and machine learning technologies. Sci. Rep. 14, 20412 (2024).
Seesaard, T., Kamjornkittikoon, K. & Wongchoosuk, C. A comprehensive review on advancements in sensors for air pollution applications. Sci. Total Environ. 951, 175696 (2024).
R. Letsoalo, M. et al. Sustainable Approaches to Monitoring Urban Particulate Matter Monitoring: Challenges and Innovations. in Urban Pollution - Environmental Challenges in Healthy Modern Cities [Working Title] (IntechOpen, 2024).
Randles, C. A. et al. The MERRA-2 aerosol reanalysis, 1980 onward. Part I: system description and data assimilation evaluation. J. Clim. 30, 6823–6850 (2017).
Provençal, S., Buchard, V., da Silva, A. M., Leduc, R. & Barrette, N. Evaluation of PM surface concentrations simulated by Version 1 of NASA’s MERRA Aerosol Reanalysis over Europe. Atmos. Pollut. Res. 8, 374–382 (2017).
Muñoz-Sabater, J. et al. ERA5-Land: a state-of-the-art global reanalysis dataset for land applications. Earth Syst. Sci. Data 13, 4349–4383 (2021).
Rautela, K. S., Kumar, D., Gandhi, B. G. R., Kumar, A. & Dubey, A. K. Application of ANNs for the modeling of streamflow, sediment transport, and erosion rate of a high-altitude river system in Western Himalaya, Uttarakhand. RBRH 27, e22 (2022).
Sofi, M. S. et al. Modeling the hydrological response of a snow-fed river in the Kashmir Himalayas through SWAT and Artificial Neural Network. Int. J. Environ. Sci. Technol. 21, 3115–3128 (2023).
Gilik, A., Ogrenci, A. S. & Ozmen, A. Air quality prediction using CNN+LSTM-based hybrid deep learning architecture. Environ. Sci. Pollut. Res 29, 11920–11938 (2022).
Abirami, S. & Chitra, P. Regional air quality forecasting using spatiotemporal deep learning. J. Clean. Prod. 283, 125341 (2021).
Karunasingha, D. S. K. Root mean square error or mean absolute error? Use their ratio as well. Inf. Sci. 585, 609–629 (2022).
Karimi, B. & Shokrinezhad, B. Spatial variation of ambient PM2.5 and PM10 in the industrial city of Arak, Iran: A land-use regression. Atmos. Pollut. Res. 12, 101235 (2021).
Rautela, K. S., Kumar, D., Gandhi, B. G. R., Kumar, A. & Dubey, A. K. Long-term hydrological simulation for the estimation of snowmelt contribution of Alaknanda River Basin, Uttarakhand using SWAT. J. Water Supply Res. Technol. 72, 139–159 (2023).
Rautela, K. S., Kuniyal, J. C., Alam, M. A., Bhoj, A. S. & Kanwar, N. Assessment of daily streamflow, sediment fluxes, and erosion rate of a pro-glacial stream basin, Central Himalaya, Uttarakhand. Water, Air, Soil Pollut. 233, 136 (2022).
Sokhi, R. S. et al. A global observational analysis to understand changes in air quality during exceptionally low anthropogenic emission conditions. Environ. Int. 157, 106818 (2021).
WHO. WHO global air quality guidelines: particulate matter (PM2.5 and PM10), ozone, nitrogen dioxide, sulfur dioxide and carbon monoxide. (World Health Organization, 2021).
Acknowledgements
We would like to express our sincere gratitude to the Department of Civil Engineering, Indian Institute of Technology Indore and Department of Civil and Environmental Engineering, Princeton University for their support and resources, which have been instrumental in the successful completion of the present study. We also extend our heartfelt thanks to the DST-Centre for Policy Research (DST/PRC/CPR/IITIndore), IIT Indore, for their invaluable guidance and contributions, particularly in reviewing existing air pollution policies, which have significantly enriched the quality of this research.
Author information
Authors and Affiliations
Contributions
K.S.R. and M.K.G. design the research, compiled the data, conducted analyses, prepared the figures, and wrote the manuscript. A.S.N. reviewed the research and performed statistical analysis. All authors discussed the study results and reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Rautela, K.S., Goyal, M.K. & Nagpure, A.S. Unequal spatio-temporal distribution of population-weighted pollution extremes through deep learning. npj Clim Atmos Sci 8, 340 (2025). https://doi.org/10.1038/s41612-025-01183-w
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41612-025-01183-w
