
Abstract
Microsatellite instability (MSI) is crucial for immunotherapy selection and Lynch syndrome diagnosis in colorectal cancer. Despite recent advances in deep learning algorithms using whole-slide images, achieving clinically acceptable specificity remains challenging. In this large-scale multicenter study, we developed Deepath-MSI, a feature-based multiple instances learning model specifically designed for sensitive and specific MSI prediction, using 5070 whole-slide images from seven diverse cohorts. Deepath-MSI achieved an AUROC of 0.98 in the test set. At a predetermined sensitivity threshold of 95%, the model demonstrated 92% specificity and 92% overall accuracy. In a real-world validation cohort, performance remained consistent with 95% sensitivity and 91% specificity. Deepath-MSI could transform clinical practice by serving as an effective pre-screening tool, substantially reducing the need for costly and labor-intensive molecular testing while maintaining high sensitivity for detecting MSI-positive cases. Implementation could streamline diagnostic workflows, reduce healthcare costs, and improve treatment decision timelines.
Similar content being viewed by others
Introduction
Colorectal cancer (CRC) is the third most commonly diagnosed cancer globally and the second most prevalent malignancy in China1,2. Microsatellite instability (MSI), resulting from defects in the DNA mismatch repair (MMR) system, occurs in approximately 15% of CRC cases in Western populations and 7.4% in Chinese populations3,4. MSI status is crucial in informing immunotherapy choices, assessing patient prognosis, and diagnosing Lynch syndrome5.
Immunohistochemistry (IHC) and polymerase chain reaction (PCR) are the most commonly used methods for detecting MSI, as recommended by clinical guidelines6,7. However, both approaches demand experienced pathologists and specialized technicians to conduct the tests and interpret the outcomes, making them resource- and time-intensive, especially in low-resource settings.
Deep learning-based artificial intelligence (AI) has emerged as a transformative tool for biomarker prediction using routine hematoxylin and eosin (H&E) stained slides8. Omar et al. describes a practical workflow for solid tumor associative modeling in pathology (STAMP), enabling prediction of biomarkers directly from whole-slide images (WSIs) by using deep learning9. Deep learning models developed from WSIs of tumor H&E slides have demonstrated significant potential in predicting MSI status in CRC, with area under the receiver operating characteristic curve (AUROC) values reported between 0.85 and 0.96 across several studies10,11,12,13. Notably, MSIntuit–the first CE-IVD-approved AI-based product achieved high sensitivity (96–98%) but modest specificity (46–47%), underscoring AI’s ability to rule out MSI-negative cases while highlighting the need for specificity improvements14.
To address this challenge, we developed Deepath-MSI, a feature-based multiple instance learning model trained on 5070 primary colorectal tumor WSIs from seven geographically diverse, independent cohorts. Model performance was rigorously assessed using both an independent multicenter test set and a real-world validation cohort to establish clinical utility. Deepath-MSI demonstrated excellent discrimination in the multicenter test set (AUROC = 0.98), achieving 92% specificity and 92% overall accuracy at a 95% sensitivity operating point. In the real-world cohort, Deepath-MSI maintained high sensitivity (94.6%) against standard methods (such as IHC and PCR) and correctly excluded 90.7% of non-MSI-H tumors. This robust performance led to Deepath-MSI receiving “Breakthrough Device” designation from China’s National Medical Products Administration (NMPA) on March 26, 2025, marking its approval as the AI-driven, deep-learning-based Class III Innovative Medical Device in digital pathology.
Results
Dataset description
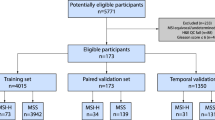
Among the total cases (N = 5070), 712 cases (14.0%) were identified as MSI-H/dMMR, while 4358 cases (86.0%) were classified as MSS/pMMR (Fig. 1A, Table S1). The distribution of cases across the seven cohorts is illustrated in Fig. 1B. WSIs from six cohorts (APH, FUSCC, NBPC, SHGH, ZCH, and TCGA) were randomly divided into a training set (n = 1600) and a test set (n = 1234). To further assess the model’s performance, we included an independent real-world validation set (FUSCC-RD), consisting of consecutively collected, surgically resected primary colorectal cancer specimens. In this cohort, MSI status was determined by IHC for MLH1, MSH2, MSH6, and PMS2, with cases classified as dMMR if any of the four proteins were deficient. Importantly, the FUSCC-RD cohort is completely non-overlapping with the FUSCC cohort, in which MSI status was assessed either PCR or NGS. Clinical characteristics of training and test sets are summarized in Table S2, and real-world validation set characteristics are provided in Table 2.

A Overview of the seven cohorts of colorectal cancer (FUSCC-RD, n = 2236; FUSCC, n = 1334; TCGA, n = 529; ZCH, n = 327; SHGH, n = 284; NBPC, n = 247; APH, n = 113). B Distribution of cases across the seven cohorts. C Workflow overview of model architecture.
Performance of the Deepath-MSI model across cohorts
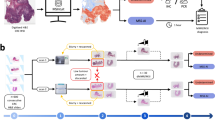
In this study, a Deepath-MSI model was employed to predict MSI status directly from digitized H&E slides of CRC tissue (Fig. 1C). Our findings indicate that MSI status can be accurately determined using histopathological images, with the model achieving an AUROC of 0.976 in test set (Table 1, Fig. 2A). The Deepath-MSI model displayed robust performance across various cohorts. Specifically, AUROC values ranged from 0.967 in the NBPC cohort to 0.988 in the SHGH cohort. Scanner variability was also assessed, with AUROC values ranging from 0.950 for the 3D Histech scanner to 0.991 for the KFBIO scanner. Population-based analyses further revealed that the model performed similarly in the Chinese population (AUROC 0.977) compared to the Western population (AUROC 0.968) (Figs. S1–2).

A AUROC for the test set. B Distribution of MSI scores in MSI-H and MSS specimens. C Relationship between AUROC, the percentage of included specimens and the number of tiles per specimen. D Representative examples of MSI-H and MSS predictions.
To enhance clinical utility, we established an optimal MSI score threshold for the Deepath-MSI model by fixing the sensitivity at 95% across the test set. This yielded an MSI score threshold of 0.4, at which the model achieved a sensitivity of 95.0%, specificity of 91.7%, PPV of 69.0%, NPV of 99.0% and an overall accuracy of 92.2% (Table 1).
The distribution of MSI score in test set was shown in Fig. 2B. To ensure sufficient representation of tumor tissue and model reliability, we determined the minimum number of tumor tiles required for quality control. From the analysis of the test set, we established a requirement of at least 100 tiles, achieving an AUROC of 0.971 and covering 100% of samples (Fig. 2C, Table S3). This threshold corresponds to approximately 6.6 mm² of tumor area, ensuring stable predictive performance. Figure 2D represents representative examples of MSI-H and MSS predictions.
Diagnostic performance on real-world validation set
Initially, 2267 colorectal cancer cases were included. Of these, 2236 cases meet the minimum tumor tiles (n = 100) and enrolled in this study, achieving a successful rate of 98.6% (2236/2267) (Fig. 3A). Among the enrolled cases, 111 (5.0%) were classified as dMMR, while the remaining 2125 (95.0%) were classified as pMMR. Detailed clinicopathological features are presented in Table 2. The dMMR ratio showed a significant association with factors such as age, primary tumor site, tumor size, histological type and tumor differentiation.

Performance evaluation of the model in the real-world validation set. A Overview of the real-world validation set with dMMR/pMMR status. B Distribution of the number of tiles per slide for real-world validation set. C Distribution of MSI scores in dMMR and pMMR specimens. D AUROC for the real-world validation set. E The overall accuracy, sensitivity, specificity, PPV and NPV of the model in the real-world validation set.
In the real-world validation set, the median number of tiles per sample was 681, with a range from 106 to 2924 (Fig. 3B). The distribution of MSI score in real-world validation set was shown in Fig. 3C. With a prespecified threshold of 0.4, the model achieved AUROC of 0.978 (Fig. 3D), along with a sensitivity of 94.6%, a specificity of 90.7%, a PPV of 34.7%, a NPV of 99.7% (Fig. 3E). Overall, 90.9% of specimens were accurately classified according to their true MSI status. Additionally, performance was evaluated across various clinicopathological subgroups. Notably, the model exhibited relatively diminished performance in specific subgroups, including those with tumors located in the ascending or transverse colon, right-sided colon cancer, tumors larger than 6 cm, tumors present with mucus, or poorly differentiated tumors (Table 2).
Discussion
Recent advancements in predicting MSI status from WSIs have been promising, with numerous studies reporting high AUROCs of 0.85 to 0.9610,11,12,13. A commonly utilized method involves fully supervised approaches that assume a uniform MSI status across each WSI, applying a consistent slide-level label to all constituent tiles during training15. However, this approach overlooks the heterogeneity in the distribution of MSI-H and MSS patterns within a WSI, which may impact the performance of models. To address this limitation, weakly supervised learning methods, particularly MIL, have shown significant advantage by enabling more accurate MSI status prediction based on only slide-level labels. In our study, Deepath-MSI model demonstrated superior performance over previous weakly supervised model in surgical samples, achieving an AUROC of 0.976 compared to 0.8416.
Interestingly, while some models have shown impressive performance, two studies on TCGA cohorts observed notably lower AUROCs. For instance, MSINet achieved an AUROC of 0.779, whereas WiseMSI’s performance was comparatively lower, with an AUROC of 0.63212,13. In our study, the Deepath-MSI model demonstrated superior performance relative to these prior models. Moreover, when comparing Deepath-MSI with MSIntuit, the sensitivities of the two models were comparable, with Deepath-MSI and MSIntuit both achieving sensitivities of approximately 95%. However, Deepath-MSI demonstrated markedly higher specificity at 90.7–91.7%, compared to MSIntuit’s 46–47%, potentially excluding up to 44% more MSS CRC patients from unnecessary further molecular testing14.
The pathological characteristics observed in dMMR cases within the FUSCC-RD cohort were largely consistent with previously reported clinicopathological patterns of dMMR colorectal cancers. Specifically, dMMR tumors in our cohort were more frequently located in the right-sided colon, exhibited larger size (>6 cm), poor differentiation, and mucinous histology, and were more common in younger patients. These features have been well-documented in multiple studies as hallmarks of MSI-H colorectal cancers, reflecting distinct tumor biology and clinical behavior3,17. The alignment between our real-world data and established literature underscores the clinical validity and generalizability of our findings, further supporting the utility of our dataset for evaluating the diagnostic performance of Deepath-MSI in routine clinical practice. To evaluate Deepath-MSI model’s performance across clinicopathological subgroups, we identified patterns of false MSI predictions. Similar to findings reported by Wu and Echle16,18, false predictions in our model were more frequent in cases involving tumors located in the right-sided colon, and tumors present with mucus. Additionally, our analysis indicated that false predictions were also associated with tumors larger than 6 cm or those with poor differentiation. These findings underscore the potential influence of clinicopathological characteristics on MSI prediction accuracy and highlight specific patient subgroups that may benefit from model refinements to improve predictive reliability.
Traditional AI model relied on supervised deep learning, necessitating expert pathologist annotations for each pathological image, a process that is both time-consuming and resource-intensive19. To overcome these challenges, this study introduces a novel preprocessing step for digitized pathological images, enabling efficient identification of ROI and significantly minimizing the need for extensive pathologist annotation. A key challenge in implementing AI systems in clinical practice is their limited generalizability, often attributed to variations in the color and brightness of H&E-stained slides across medical centers, scanner-related technical differences, and histological diversity between populations20. To address this, our training set incorporated a robust, multi-center dataset, comprising both Western and Chinese populations across five institutions. In addition, the feature extractor was trained on a large number of tiles with extensive data augmentation, without the use of any labels. The diverse data collection and feature extractor strengthened the model’s ability to generalize across different ethnic and clinical environments. Our validation studies demonstrated that Deepath-MSI model maintained high performance not only across different scanners but also among various demographic groups and clinical centers.
Traditionally, CRC patients undergo testing for MSI/MMR status, a process that will take several days or even weeks using IHC or PCR methods14. Pathology laboratories are under increasing pressure to meet the rising demand for biomarker testing, exacerbated by a global shortage of pathologists. In low- and middle-income countries, this testing may be further hindered by resource limitations. AI-based approaches offer the advantage of rapid, automated analysis, easing the burden on pathologists and streamlining clinical workflows, particularly in high-throughput or resource-constrained settings. In a future real-world context (Fig. 4), the diagnosed H&E slides of CRC patients would first be assessed with the Deepath-MSI model within one hour, potentially allowing those classified as MSS to bypass routine IHC or PCR testing. Only patients predicted to be MSI-H would require confirmatory testing. This approach could reduce the testing workload by 85.6% (1914/2236), significantly shortening the time from surgery to molecular determination of MSI status, and enabling earlier initiation of immunotherapy, when indicated. Its robust performance across various clinical contexts highlights its potential for widespread adoption, especially in regions with limited access to advanced molecular diagnostic tools.

The diagram compares the current workflow, where all colorectal cancer cases (N = 2236) undergo IHC/PCR testing, with the proposed Deepath-MSI workflow. The proposed approach utilizes Deepath-MSI analysis of H&E slides for initial screening, directing only predicted MSI-H cases (N = 322, 14.4%) to confirmatory IHC/PCR. This potentially excludes approximately 90.7% of MSS patients from further testing, significantly reducing the burden of ancillary tests.
Although the Deepath-MSI model shows promise for predicting MSI status from digitized pathology images, several limitations warrant consideration. First, biopsy samples were not included in this study. Echle et al. report a lower performance on biopsy tissue than on surgical resection tissue (biopsy AUROC: 0.78, resection AUROC of 0.96)10. Wu et al. also find a significant performance gap between biopsy and surgical tissues, with lower AUROC in biopsy cohort (0.77 and 0.84, respectively)16. Ongoing validation studies are aimed at evaluating the Deepath-MSI model on biopsy samples to determine its utility in these contexts. Second, while the model achieved high accuracy within Chinese populations, its generalizability to other populations remains to be validated. Variations in tumor biology and histopathological features across populations necessitate large-scale studies to confirm its robustness across diverse ethnic and clinical settings.
In conclusion, this study develops a novel deep learning-based approach for pre-screening MSI using WSIs, offering a promising solution for accurate and efficient MSI evaluation in clinical practice. Future work will focus on prospectively multi-center validation of the Deepath-MSI model to further evaluate the model’s generalizability of this model. As artificial intelligence tools continue to advance in pathology, this approach has the potential not only to streamline the diagnostic process but also to improve patient outcomes by facilitating timely and appropriate therapeutic interventions.
Methods
Cohort description
In this multicenter retrospective study, we collected H&E-stained slides from formalin-fixed paraffin-embedded tissue sample obtained from seven independent CRC patient cohorts. Six of seven cohorts were derived from five Chinese institutions, including Anhui Provincial Hospital (APH), Fudan University Shanghai Cancer Center (FUSCC), Fudan University Shanghai Cancer Center-Real World (FUSCC-RD), Ningbo Pathology Center (NBPC), Shanghai General Hospital (SHPH) and Zhejiang Cancer Hospital (ZCH), with samples collected between January 2017 and February 2024. These cohort predominantly represent Chinese population. Ethics approval was granted by the ethics committee of the lead institution, FUSCC (Approval No. 2306276-4) and this study adhered to the ethical principles outlined in the Declaration of Helsinki. All patients provided written informed consent. The seventh cohort was derived from the Cancer Genome Atlas (TCGA) dataset, representing a Western population. MSI status for these cases was determined by integrating clinical information retrieved from cBioPortal (https://www.cbioportal.org/) with corresponding pathology reports downloaded from the Genomic Data Commons (GDC) portal (https://portal.gdc.cancer.gov/). The inclusion of both Chinese and Western cohorts ensures multi-ethnic representation, enhancing the generalizability and clinical applicability of the Deepath-MSI model across diverse populations. In total, 5070 CRC cases were included in the study. A detailed description of datasets is provided in Table S1. The WSI formats varied across datasets, comprising SQDC (Shengqiang, Shenzhen, China), KFB (KFBIO, Ningbo, China), MRXS (3D Histech, Budapest, Hungary), and SVS (Leica, Wetzlar, Germany).
Identification of region of interest
A novel preprocessing method was utilized to identify regions of interest (ROIs) as follows: first, WSIs were divided into smaller tiles, each measuring 256 × 256 μm (resolution: 32 μm/pixel). Second, tiles with more than 50% background (white area) or containing artifacts, such as blurry regions and pen markings, were excluded. To efficiently identify artefacts, we developed a robust two-stage algorithm that first applies pixel clustering to group similar regions in low-resolution tiles, followed by a deep learning model to accurately detect artifacts. Third, the nuclear-cytoplasmic ratio was employed as a key indicator to filter tiles as ROIs. Finally, corresponding high-resolution tiles (resolution: 0.5 μm/pixel) were extracted, and MSI status was annotated at the patient level. MSI status for each sample was determined using IHC, PCR, or next-generation sequencing (NGS). Based on these results, cases were classified by a pathologist as either microsatellite instability-high/deficient mismatch repair (MSI-H/dMMR) or microsatellite stable/proficient mismatch repair (MSS/pMMR).
Feature extractor
To predict MSI status, we developed a Feature-based Multiple Instance Learning (FMIL) system, consisting of two primary components: a feature extractor and an aggregation module. The feature extractor is pretrained using an image self-supervised learning framework (DINOv2), a state-of-the-art self-supervised learning framework for image analysis21.
A known challenge in histopathological image analysis is the inconsistency in color and intensity among sections, even within the same institution. These inconsistencies arise from several factors, such as variations in tissue fixation affected by sample size, section thickness due to procedural differences, and the choice of staining reagents during H&E staining. Such variations can interfere with the efficacy of quantitative image analysis. To mitigate this issue, the feature extractor was trained on a large number of image tiles, utilizing extensive data augmentation techniques to simulate diverse conditions, and was trained in a completely label-free manner.
The feature extractor processes each image tile independently, transforming it into a compact embedding. Importantly, the feature extractor’s weights remain fixed during both the training and inference phases of the FMIL system, ensuring consistent feature extraction across all analyses.
Self-learning pretraining
The self-supervised pretraining phase employs a student-teacher architecture, utilizing momentum-updated teacher weights. In this framework, the teacher network receives global crops of each image, while the student network processes both global and local crops with varying augmentation strengths.
Specifically, global crops are augmented with weaker augmentations, such as random resized cropping and horizontal flipping, while local crops undergo stronger augmentations, including color jittering, Gaussian blurring, and solarization. The difference in augmentation strength promotes learning more nuanced and localized features by the student model.
The total loss function is a weighted combination of the cross-entropy and iBOT losses:
where \(\lambda\) balances the two losses.
Cross-Entropy Loss (LCE): This loss encourages local-to-global correspondence. It’s computed between the student’s output for local crops and the sharpened, centered output of the teacher for global crops of the same image:
\({P}_{t}^{globa{l}^{{\prime} }}\) is the sharpened and centered teacher output for a global crop, and \({P}_{s}^{local}\) is the student output for a local crop. Centering and sharpening are applied to the teacher output:
iBOT Loss (LiBOT): This loss promotes invariance to masking and encourages learning robust, context-aware representations. It’s calculated between the teacher’s output for a global crop and the student’s output for a masked global crop of the same image:
Where \({f}_{i}^{t,global}\) is the teacher output for the global crop of image i, and \({f}_{i}^{s,maskedglobal}\) is the student output for the masked global crop of image i. \(sim(\cdot ,\cdot )\) denotes cosine similarity, and \({\tau }^{{\prime} }\) is a temperature parameter. The pretrained encoder resulting from minimizing this combined loss is then used to initialize the encoder of our segmentation network.
MSI classifier
To construct the MSI classifier, a MIL approach was employed, following methods previously established for handling WSI data22,23. Unlike approaches that rely on sub-sampling a fixed number of tiles, MIL utilizes all tiles from a patient’s WSI as a “bag” without assuming every tile within the bag directly reflects the MSI status, which allows for greater resilience to intratumor heterogeneity. Furthermore, an attention mechanism was incorporated within the decoder, providing access to the full scope of encoded information. This mechanism assigns variable attention weights to different input regions, identifying the significance of each token and allocating priority for the generation of output tokens at every step.
Implementation
The Deepath-MSI model was implemented using PyTorch and trained on an NVIDIA RTX 4090 GPU with 24 GB of memory24. To address the class imbalance in the patient labels during training, tiles from the more abundant class were randomly under-sampled, thereby ensuring equal numbers of tiles from positive and negative classes. This approach facilitated the training of the Deepath-MSI model on tile-level-balanced datasets. For model deployment on the test partition during cross-validation or on the external validation set, no class balancing procedure was applied.
Statistical analysis
Statistical endpoints included the AUROC, sensitivity, specificity, positive predictive value (PPV), and negative predictive value (NPV). The optimal MSI score threshold for the Deepath-MSI model was determined by fixing the sensitivity at 95% in the test set. To assess the minimum tumor tiles required per slide for optimal Deepath-MSI model performance and to establish quality control criteria for the real-world validation set, we randomly selected a specific number of tiles per slide in the test set, analyzing predictions only for slides meeting the minimum tile threshold. The MSI score threshold and minimum tile number were then applied to the real-world validation set. The association between clinicopathological features and performance was analyzed using Fisher’s exact test.
Data availability
High-resolution diagnostic whole slide image data from TCGA, as well as the associated diagnoses, can be publicly accessed via the National Institutes of Health Genomic Data Commons. To protect patient privacy, pathology image datasets and other patient-related information of the collected in-house datasets are not publicly available. However, all these data can be accessed upon reasonable request by contacting the corresponding author via email.
Code availability
The underlying code for this study is not publicly available but may be made available to qualified researchers on reasonable request from the corresponding author.
References
Han, B. et al. Cancer incidence and mortality in China, 2022. J. Natl Cancer Cent. 4, 47–53 (2024).
Bray, F. et al. Global cancer statistics 2022: GLOBOCAN estimates of incidence and mortality worldwide for 36 cancers in 185 countries. CA Cancer J. Clin. 74, 229–263 (2024).
Xu, M. et al. The development and implementation of pathological parameters and molecular testing impact prognosis of colorectal adenocarcinoma. J. Natl Cancer Cent. 4, 74–85 (2024).
Boland, C. R. & Goel, A. Microsatellite instability in colorectal cancer. Gastroenterology 138, 2073–2087.e3 (2010).
Diao, Z., Han, Y., Chen, Y., Zhang, R. & Li, J. The clinical utility of microsatellite instability in colorectal cancer. Crit. Rev. Oncol. Hematol. 157, 103171 (2021).
Kawakami, H., Zaanan, A. & Sinicrope, F. A. Microsatellite instability testing and its role in the management of colorectal cancer. Curr. Treat. Options Oncol. 16, 30 (2015).
Luchini, C. et al. ESMO recommendations on microsatellite instability testing for immunotherapy in cancer, and its relationship with PD-1/PD-L1 expression and tumour mutational burden: a systematic review-based approach. Ann. Oncol. 30, 1232–1243 (2019).
Niazi, M. K. K., Parwani, A. V. & Gurcan, M. N. Digital pathology and artificial intelligence. Lancet Oncol. 20, e253–e261 (2019).
El Nahhas, O. S. M. et al. From whole-slide image to biomarker prediction: end-to-end weakly supervised deep learning in computational pathology. Nat. Protoc. 20, 293–316 (2025).
Echle, A. et al. Clinical-Grade Detection of Microsatellite Instability in Colorectal Tumors by Deep Learning. Gastroenterology 159, 1406–1416.e11 (2020).
Cao, R. et al. Development and interpretation of a pathomics-based model for the prediction of microsatellite instability in Colorectal Cancer. Theranostics 10, 11080–11091 (2020).
Yamashita, R. et al. Deep learning model for the prediction of microsatellite instability in colorectal cancer: a diagnostic study. Lancet Oncol. 22, 132–141 (2021).
Chang, X. et al. Predicting colorectal cancer microsatellite instability with a self-attention-enabled convolutional neural network. Cell Rep. Med 4, 100914 (2023).
Saillard, C. et al. Validation of MSIntuit as an AI-based pre-screening tool for MSI detection from colorectal cancer histology slides. Nat. Commun. 14, 6695 (2023).
Kather, J. N. et al. Deep learning can predict microsatellite instability directly from histology in gastrointestinal cancer. Nat. Med 25, 1054–1056 (2019).
Jiang, W. et al. Clinical actionability of triaging DNA mismatch repair deficient colorectal cancer from biopsy samples using deep learning. EBioMedicine 81, 104120 (2022).
Guo, T.-A. et al. Clinicopathologic features and prognostic value of KRAS, NRAS and BRAF mutations and DNA mismatch repair status: A single-center retrospective study of 1,834 Chinese patients with Stage I-IV colorectal cancer. Int J. Cancer 145, 1625–1634 (2019).
Echle, A. et al. Artificial intelligence for detection of microsatellite instability in colorectal cancer-a multicentric analysis of a pre-screening tool for clinical application. ESMO Open 7, 100400 (2022).
Montezuma, D. et al. Annotating for Artificial Intelligence Applications in Digital Pathology: A Practical Guide for Pathologists and Researchers. Mod. Pathol. 36, 100086 (2023).
Ruusuvuori, P., Valkonen, M. & Latonen, L. Deep learning transforms colorectal cancer biomarker prediction from histopathology images. Cancer Cell 41, 1543–1545 (2023).
Oquab M. et al. DINOv2: Learning Robust Visual Features without Supervision. https://doi.org/10.48550/ARXIV.2304.07193. (2023).
Campanella, G. et al. Clinical-grade computational pathology using weakly supervised deep learning on whole slide images. Nat. Med 25, 1301–1309 (2019).
Lu, M. Y. et al. Data-efficient and weakly supervised computational pathology on whole-slide images. Nat. Biomed. Eng. 5, 555–570 (2021).
Paszke A. et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. https://doi.org/10.48550/ARXIV.1912.01703. (2019).
Acknowledgements
This work was supported by the following funders: Science and Technology Key Project of Songjiang District (Grant No. 2023SJKJGG038); Shanghai Key Clinical Specialty Construction Project; Ningbo Top Medical and Health Research Program (Grant No. 2023010211); Project of Ningbo Leading Medical and Health Discipline (Grant No. 2022-F30); Zhejiang Provincial Medicine and Health Research Foundation (Grant No. 2023KY040). The funders of the study had no role in study design, data collection, analysis, interpretation, writing of the manuscript, or the decision to submit for publication.
Author information
Authors and Affiliations
Contributions
X.Y.Z., D.S., L.Y. and M.Z. conceived the study and designed the experiments. X.F., W.J.Y., Y.Y.C., Q.Y., J.Z., Q.F.W. and Q.W. provided the slides. H.E.W., Y.F.S. and Q.H.X. built the model. H.E.W., Y.F.S. and X.F. wrote the manuscript. Q.H.X., M.Z., L.Y. D.S. and X.Y.Z. discussed and reviewed the manuscript. All authors accessed the data, and verified the data.
Corresponding authors
Ethics declarations
Competing interests
H.E.W., Y.F.S. and Q.H.X. are employees of Canhelp Genomics, Co., Ltd. All other authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Feng, X., Yin, W., Ye, Q. et al. Deepath-MSI: a clinic-ready deep learning model for microsatellite instability detection in colorectal cancer using whole-slide imaging. npj Precis. Onc. 9, 302 (2025). https://doi.org/10.1038/s41698-025-01094-2
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41698-025-01094-2
