
Abstract
Ancient stone inscriptions are vital sources of traditional knowledge and historical heritage. However, because of the unrestricted stroke writings, age-related deterioration, and variability, their digital recognition is still difficult. Modern OCR technologies are inadequate for the accurate recognition of Tamil inscriptions. A Dynamic Profiling Bound (DPB) approach is proposed for character localization, achieving a high localization rate of 98.25% across varied inscription image conditions, including noise, deterioration, and compact writing. Using these localized characters, SignaryNet, a fine-tuned deep convolutional neural network (CNN), is developed to recognize 100 classes of ancient Tamil and Grantha characters based on Unicode mappings. SignaryNet outperforms the baseline Classic-CNN, achieving 98.61% validation and 96.81% prediction accuracy versus C-CNN’s 83.33% and 84.74%. The method proves effective on benchmark datasets and supports the digital preservation of heritage inscriptions, such as those on the Brihadisvara temple walls, facilitating their storage in accessible digital archives for historical research and conservation.

Similar content being viewed by others

Introduction
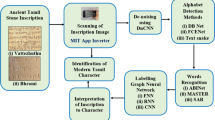
Stone inscriptions, which are old artefacts inscribed on ancient temple walls, pillars, caverns, rocks, and the like, are the most reliable source of historical data since they are everlasting. The proposed work is based on stone inscriptions from South Indian temples originating in the 11th century. These stone inscriptions have been severely damaged and devastated by time and the environment, making it difficult to recognize the text. Epigraphic preservation techniques are ineffective in preserving this valuable resource, and manual skill is also needed. The development of image processing and computing technologies may be applied in this situation, allowing for the digitization and processing of the content of the stone inscriptions. An effective signary localization technique needs to be created to obtain the historical information contained in stone inscriptions. The process of segmenting the individual characters in an inscription image is known as signary localization. The recognition approach may be used for the correctly localized character as a sub-image. The localization process includes several sequential steps, including line localization for segmenting line images, character localization for segmenting individual character images, over-segment reduction, touching, and broken character localization, etc. The inscription image is noisy due to the background’s unevenness in the stone, and eroded parts cause discontinuities in strokes. Localizing the characters is the greatest obstacle. An over-segmentation issue is caused by the inscriptions’ unrestricted writing style as well as intricate patterns like clustered, stacked (compound characters that integrate two or three characters into one character), overlapped writings, and compound characters. Writings that are skewed and have uneven legibility make localization more difficult. Additionally, the slanted writing in rural scripts makes line localization difficult. Existing methods are ineffective for these images of stone inscription scripts. To address the issues raised above, an improvised technique must be developed. The difficulty of recognizing signary in present systems derives from the need to comprehend characters.
Images of the characters from several inscriptions in the Great Chola Temple area mainly Brihadisvara temple (Big Temple) revealing the King’s culture, passion and history in stone inscriptions as written in an article by Subramanian1, were gathered for identification. Rajarajesvaram, also known as Brihadisvara Temple, is a heritage monument situated on the south bank of the Cauvery River, not far from Thanjavur, Tamil Nadu, and India, which uses the architectural style of Chola. As one of the “Great Living Chola Temples” on the UNESCO World Heritage Convention list, the temple was constructed between earlier 11th century periods by Rajaraja I, the Chola king2. The description about inscriptions of Rajaraja Chola I is detailed in ref. 3. The monument’s lighting is intended to draw attention to the sculptural forms that embellish every nook and cranny of the temple, in addition to the stone’s natural hue. Inscriptions can be found on the pillars, walls, and entrance of the central shrine. The temple walls have numerous inscriptions in Tamil that give a brief history of the king who gave his approval. Most of them talk about presents given to the temple or its staff, and occasionally they even mention city dwellers. Digital inscription acquisition saves epigraphers time since the technology digitally enhances raw stone inscriptions to provide character clarity. Since the writings on the stone image are different from those in contemporary Tamil, reading its contents is necessary. It is also difficult to digitally recognize because of the broken and damaged inscriptions.
The proposed Dynamic Profiling Bound (DPB) approach for signary localization is an exceptional segmentation or localization method for localized images from the inscriptions. This approach utilizes trace profiling to locate lines, employs a dynamic bounding box algorithm based on profile data, and applies dynamic vertical trace profiling to identify signary. Without omitting or misaligning the constituents of the character strokes in the sequence of script continuation, the suggested model localizes the character images successively. On the inscription images, state-of-the-art methods of segmentation are also used, and performance is evaluated in terms of Signary Localization Rate (SLR) or segmentation rate to contrast with the proposed. By including morphological erosion and dilation, concerns like over- and under-segmentation were also addressed, and the outcome was improved localization. The technique also addresses other bounded box issues like overlapping, space-constrained, and deteriorating characters. After that, the model is developed, and single-character images are trained using a deep neural network, such as a Classic Convolutional Neural Network (C-CNN). Then it is refined for the inscription signary recognition by adding, dropping, and hyper-parameter fine-tuning the model known as a novel SignaryNet, and then the training is done. The modern Tamil version of the characters is returned when the signary is identified by mapping to the appropriate Unicode.
Some of the similar works in the Tamil inscriptions were addressed with the issues and challenges faced in them. The Ashokan Brahmi Character dataset from Indoskript manuscripts from the Brahmi and Kharosthi database of 3500 images was used for OCR using CNN for Ashokan Brahmi inscriptions. As demonstrated in ref. 4, data augmentation was performed on up to 227,000 images. For inscription pre-processing, Otsu thresholding, median blur, nonlinear digital filtering, and adaptive thresholding are used. Although projection profiling techniques like the vertical and horizontal projection profiles are used, the results are not thoroughly examined. The problem of not distinguishing between words and characters is still present. An OCR method that used image recognition-based classification for old Tamil inscriptions5 made use of Tesseract text-to-speech for written Tamil literature, Otsu for binarization, and 2D CNN transfer learning and data augmentation. The work claims that there were difficulties with the segmentation process, where errors led to incorrect recognition. Additionally, during the augmentation phase, book scanning and pre-processing failed to segment effectively. The accuracy of segmentation differed among samples. 91% comes from printed Tamil literature, 68% from text-to-voice, and 70% from handwritten modern Tamil. CNN image slicer and an OCR scanner are used to scan old Tamil script. Thirty samples are examined. According to the work, there is no solution for the sparse dataset. The scripts on the inscription are irregular, lack equal spacing, and have an uneven surface, making it difficult and incorrect to identify ancient Tamil characters. For digital erosion minimization, high resolution is required, and its accuracy rate is 77.7%.
An image-based character recognition documentation system6 was developed that employs Tesseract and modern ICR and OCR methods to interpret temple inscriptions in ancient Tamil. The dataset from the previous century is limited, has little information, and has no spaces between words. 400 images are scanned using the powdered limestone on the temple walls. Bilateral filtering, erosion, histogram equalization, median blur, and Otsu thresholding are all employed. Each unique character inside the digital inscriptions has its bounding box adjusted for correctness, which includes physical intervention for misaligned and unclear characters. CNN is utilized when there is a paucity of data and incorrect output categorization. There are only ten tested photos, and they yield 80.8%. The approach highlights morphological characters, multi-character compounds, single characters, and curves over neighbouring characters in addition to segmentation problems. The proposed work resolves the problems raised by the existing works.
Character segmentation has been the subject of extensive research, and this work is still ongoing. They were segmented using contour-based convex hull bounding box segmentation7, which uses polygon lines to outline the region where the characters’ curves were detected before drawing the bounding box. The Tamil Palm Leaf Inscription dataset is used, and the characters are recognized using GLCM features with a recognition accuracy of 85.3%. Due to the prevalence of curves in the Tamil language, it overcomes the limitations of edge detection approaches; nonetheless, it is ineffective in precisely segmenting the connected components.
For Indian document images, a multilingual character segmentation and recognition scheme is suggested8. In this study, the overlapping and joined characters are segmented using projection profiles and graph distance theory, and a preliminary segmentation path is constructed using a Gaussian low pass filter profile with smoothening. Proprietary Devanagari, CPAR, CVLSD, Proprietary Latin, and Chars74k datasets are used. The K-nearest neighbour (KNN) classifier is used, which gives an accuracy of 87.42%, and the SVM classifier is used to assess these data overall for high accuracy. Although this method at least avoids over-segmentation in cases where ligatures and connections between, inside, and some connected characters are present, it is effective only for document images with strong foreground–background discriminating.
For the character recognition system for Tulu palm leaf manuscripts studied as in ref. 9, a region of interest (ROI) selection based on connected component analysis (CCA) is raised along with Deep CNN with an accuracy of 88.07%. This suggestion requires a manual implementation to choose the stacked characters. Using a convolutional neural network on Android is suggested to recognize handwritten characters as in ref. 10. This work identifies the connected components before the labelled elements are segmented for the cursively written words using the vertical projection approach. Additional small disjoint connection steps include vertical cursive word projection, over-segment elimination, and small disjoint connection steps. This work uses 1000 random words with 85.74% recognition accuracy. However, the approach would not be appropriate for the inscription images since it does not solve the overlapping character segmentation for strokes and slanted line segmentation.
The HP India 2013 laboratory dataset, which consists of 100 Tamil characters, is used to suggest a structure representation-based method for recognizing handwritten Tamil characters11. Normalization, skeletonization, noise reduction, and binarization are carried out. Features are extracted and predicted using the PM-Quad tree (82.4%) for locational analysis, the z-ordering approach (88.3%) for shape ordering, and stripping tree-based sequential reconstruction for forms. SVM provides an accuracy of 90.3%. Complex structures, curve variation, and shape similarity are discussed. There is no mention of other characters. There is no use of deep learning or character extraction techniques. It is only appropriate for handwritten characters and only addresses distinct vowels and consonants that are not vowel consonant characters.
High-speed vehicle number recognition and detection using the bound box approach12 is proposed for edge processing both vertically and horizontally based on the bound box and detecting the license plate detection region. The car images are captured and pre-processed, and the images of the big blobs are clipped. The license plate region is located using a Sobel edge detector operator, median filtering, dilation, erosion, and flood fill. Pixels corresponding to images are found by comparing the bound box with predetermined templates of the alphanumeric database, which contains a numeric index for all sub-images using correlation coefficients, mapping with box values, and characters compared with letter pixel values. This offers a 93% accuracy rate and eliminates unnecessary related objects.
Devanagari character segmentation is carried out using an approach that combines polynomial-based thresholding with adaptive thresholding13. The polynomial thresholding line fitting delivers the minimum distance using the least-square distance from the original line, and it gives the minimum value with its index when the input block size fluctuates. The smaller dataset is used with Devanagari shades of grey from the ISI collection. Nevertheless, there was no discussion of how to separate structures that overlap, slant, or are uncontrolled.
In the skewed line segmentation technique for cursive script OCR, widely studied as in ref. 14, for line segmentation, noiseless, skew-free character images are used. It makes use of a method for detecting headers, which are the first few characters of a line. A ligature segmentation technique is used to precisely divide the ligatures into smaller ones and arrange them in sequential order. The Urdu dataset, which is very small that has 687 handwritten character images and 495 printed images. Out of 687 lines, 674 lines are detected correctly, with a segmentation accuracy of 96%. The suggested strategy is successful for printed text but has not been investigated for inscription images. The inability to effectively split dots and diacritics is a drawback to this effort.
Using the HP-Lab-India datasets from 2017 and 2013, which comprise 125 characters and two distinct handwritten manuscripts, gathered from Tamil Nadu residents, a statistical algorithmic approach for Tamil handwritten character detection is provided15. The characters are separated into nine equal zones for feature extraction (upper, middle, and lower zones), and structural features are extracted using a directional algorithmic technique. 16 locational features, including 153 potential features, 170 forms, and four quads, make up the zone. Deep learning and character extraction techniques are not applied and are only appropriate for handwritten characters.
Text lines in Kannada manuscripts written by hand have been segmented using a segmentation method suggested in ref. 16. Additionally, it utilized horizontal projection profiling for the computation of local maxima, constrained seam carving, seam computation, coordinate values, and ROI extraction. With Vijayanagara dynasty manuscripts, this method has a line segmentation accuracy of 81.89%, and with Wadiyar dynasty manuscripts, it has an accuracy of 87% with KNN and 92% with support vector machine (SVM). The Horver method of touching character segmentation was proposed17. The Tamil Heritage Foundation (THF) provided the manuscripts on palm leaves for the authors to use. To determine a character’s weight, the Horver technique with DLA recognizes touching characters with horizontal touching, vertical touching, and multi-touching characters with a touching point. It has a 90.63% accuracy rate and a 92.43% recognition rate. However, this can be done after using proper segmentation methods for extracting characters.
Character segmentation, feature extraction, block-by-block transformation, Niblack, morph operations, and 2D Log-Gabor feature extraction were used to recognize Malayalam characters18. Finding and recognizing the local maxima and minima of the histogram’s peaks and dilation using disk and line structuring elements, area opening, bound box position, and horizontal and vertical projections with connected component analysis are all part of the segmentation technique. In any case, the division of lines and characters is not detailed. For feature extraction, rotation-invariant LBP is employed. Recall is 90.95%, precision is 92.86%, and segmentation F1 score is 93.05%. For a 95.45% recognition rate, Staked ResNet CNN and LSTM are utilized. These techniques do not work with inscription images.
Manuscript character recognition19 for electronic Beowulf old English manuscript photos with 404 characters and resampling 1–3 of the manuscript dataset using an Image Data generator. Additionally, the MNIST dataset has been employed. Numerous models, including CNN, SVM, KNN, decision trees, Random Forest, XG Boost, VGG16, Mobile Net, and ResNet50, have been examined in this work. With 22 classes and 352 characters for training and testing, the accuracy for resampling 1 (a tiny dataset) is 88.67% and resampling 2 is 90.91%.
Character recognition in Tamil using CNN has a test accuracy of 99.39% training accuracy, 89% validation accuracy, and 97.7% test accuracy after dropouts, despite the model exhibiting overfitting. CNN was proposed20 using handwritten Tamil character recognition (HTCR) for the dataset HP Labs India (hpl-tamil-iso-char) that isolated characters of 156 classes and 82,929 images. It is proposed to use CNN21 for Kannada handwriting character identification for handwritten vowels, consonants, and numerals. The dataset of character 74,000 contains 50 classes, including 16 vowels, 34 consonants, and numbers from 0 to 9. Since each class had 25 images, augmentation was used. Each class had 350 images. Following transfer learning, training correctness is 91.9% and validation correctness is 93.06%, with training correctness being 89% and validation correctness being 86.92%. The dataset is small, and no segmentation is done in this work.
Using a Chinese scene text dataset, a multi-segmentation network-based street view text spotting at the character level for smarter autonomous driving22 was presented. Chinese store sign pictures from the ICDAR 2013, ICDAR 2015, MSRA TD 500, SCUT, RCTW, ReCTS, and Shopsign databases were used. Point of Interest and multi-segmentation network for character-level scene text detection (MSTD) and ResNet attention mechanism are used for character-level and line-level instance localization and scene text detection for Chinese scene text datasets. The overall F score of the datasets is 92% and the correctness is 92.98%, SCUT is 92.4%, CTW is 95%, RCTW is 92.3%, and ReCTS is 94.9%. For the line-level F score, ICDAR13 is 90%, ICDAR15 is 84%, MSRA is 84%, and Shop sign is 70.1%. The overall accuracy of character recognition is 92.53%.
Using ROI detection and a comprehensive learning system, characters from variable-length license plates that surpass fixed-length license plates are recognized and segmented23. Using the COCO dataset from GitHub, which consists of 1913 images for training and 287 images for validation, a transfer learning technique based on Faster RCNN with Inception V2 is applied to Macau license plates. Utilized were region proposal network (RPN), ROI pooling, template matching and position predicting (TMPP), and cross class removal of character (CCRC). The accuracy and recognition rate for segmentation projection profiles, MSER, CCA, ROI, and ROI + CCRC + TMPP are 99.68% and 99.19%, respectively. The technique is not appropriate for unconstrained writing in inscription images in an unrestricted manner, but it yields good accuracy in similar characteristic license plates.
The typical pre-processing steps of noise reduction, normalization, thinning, and bounding box extraction are followed by feature extraction techniques like chain codes, gradient angles, curve estimation, profile histogram, and stroke estimation in this review work on handwritten Hindi character recognition24 using document analysis and recognition (DAR). Character, word, and curved text recognition; page segmentation; Devanagari script identification; graphical analysis of signatures, diagrams, flowcharts, and tables; and other elements are all part of DAR’s textual analysis. SVM and ensemble are used for classification. Although the segmentation approaches are not described in detail, this study provides an overview of feature extraction strategies. To segment the printed Chinese characters as in ref. 25 raises the character recognition rate to 96% and the segmentation accuracy of printed characters to 90.6%. The character is segmented and interpolated using a multi-threshold segmentation method with vertical projection. There’s also the maximum backtracking method. There were 6423 Chinese characters used. The technique works with printed characters; it is not appropriate for characters used in inscriptions.
The iterative split analysis technique26 is suggested for Telugu handwritten characters and words from application form documents to segment touching and overlapping characters at the block level in Telugu printed and handwritten documents. Both horizontal and vertical projection profiles are used to convert lines into words and sentences into characters. Then, employing correlation analysis between segmented blocks and invalid character blocks that contain touching and overlapping characters, we come to valid character blocks. In total, there were 55 symbols, 36 consonants, and 16 vowels. With an accuracy of 91.17%, the iterative split analysis technique is employed in conjunction with bounding boxes and linked component analysis. Morphological operations and projection profiles (MOPP) yield 58.09%, multiple projection profiles (MPP) yield 78.26%, and recursive cut approach analysis yields 80.08%. Convenience sampling is a non-probability sampling strategy that uses 25%, 20%, 15%, and 10% as sampling percentages and divides them into different samples across several rounds. The collection includes English and Telugu handwritten characters. For 215 lines, accuracy is 85.37% with a 25% sampling, 87.91% with a 20% sampling, 91.45% with a 15% sampling, and 95.37% with a 10% sampling. Only touching and overlapping at the word level are handled by this method, which works well for handwritten or printed materials but is slower for splitting wider blocks. The algorithm is incredibly slow and takes a long time to run.
A survey on the recognition of handwritten characters in English is conducted using datasets from the banking and healthcare industries27. Following line, word, and character segmentation, projection histogram, zoning, crossing DFT, DCT, and DWT are used to extract statistical and structural characteristics. SVM and HMM are then utilized for HCR classification. There is little vocabulary and inadequate segmentation because it is highly complex and not detailed. It is suggested to use an over-segmentation technique to recognize handwritten mathematical expressions by extracting their strokes from bitmap images28. Topological sort and recursive projection are used to standardize the stroke order. A competition on recognition of online handwritten mathematical expression (CROHME) 2019 is the dataset that was used. Noise reduction, stroke direction recognition, stroke order normalization, stroke tracing, and double-traced stroke restoration were all carried out. The results show an accuracy of 58.22%, 65.65%, and 65.22% for CROHME14, 16, and 19 datasets. This is inappropriate for the character strokes used in the inscription.
The braille character segmentation for heavily dotted braille image environments29 is suggested. Two-stage braille recognition is available. The first is a Gaussian diffusion-based braille dot identification system, and the second uses post-processing algorithms to create a braille grid to identify a braille character. Convex dots in braille images produce Gaussian heat maps, and 114 images from the public braille dataset are used to detect convex dots. A total of 88 images were there. Probabilistic diffusion process-based optical braille recognition (OBR) with UNet and BddNet, virtual braille grid creation, braille dot range detection with linked component analysis, and braille dot clustering based on horizontal and vertical distances. The F1 scores are 98.96% and 98.57% for braille dot detection and 99.56% and 99.78% for braille character recognition. The overall summary indicating the works, languages, techniques used, and their shortfalls is shown in Table 1.
Some of the benchmark datasets are also studied, and some are used in the experiments. A detailed examination of relevant benchmark works is presented. Using CNN and long short-term memory (LSTM) networks, the benchmark datasets were used to identify the script in scene text images, as suggested in ref. 30. The standard dataset CVSI-201531 is used to evaluate the document analysis community. There are written images as well as video images from the news and sports. It is based on CNN and provides data in several other languages, including Arabic, Bengali, English, Gujarati, Hindi, Kannada, Oriya, Punjabi, Tamil, and Telugu. It also boasts 97.25% accuracy. Each one contains 50 sample test images that were tested and taken for Tamil. The dataset SIW-13, with 16,291 multiscript texts, is used to gather the images. The model is based on CNN and has a correctness of 94.10%. It includes thirteen language scripts. The implementation is also visible in the GitHub repositories created32. The collection consists of multiscript handwritten documents, lines written in several scripts with 276 Tamil-language images each, printed lines with 301 Tamil-language images each, and multiscript printed sentences with 2118 Tamil-language images each.
The benchmark dataset for image-based text recognition is the ICDAR-2017 dataset33. For the Tamil language, there are 68,613-word images, 1255-line images were utilized for training, and 300-line images were used for testing, yielding an accuracy of 87.30%. Scene text images are processed using the multi-language end-to-end (MLe2e) dataset. 1178-line images were used for training and 643 for testing in Tamil, yielding an accuracy of 90.23%. More than 12,000 photos of Chinese scenery, street views, posters, menus, and screenshots may be found in RCTW-17, the work in ref. 34.
The MSRATD50 benchmark dataset, which contains 3000 images of text in both English and Chinese and scores 95.22%, is utilized for scene text recognition35. For segmentation, a contour-based approach is used; feeding CNN input images with the ordered features of contoured images done as in ref. 36. In addition to using CVSI2015, which has pre-segmented texts from various video sources and scene texts, SIW-13—which consists of 13 types of script languages and 16,291 images, was also used for scene text script identification. Of the SIW-13’s 16,291 images, 6500 were used for training and 500 for testing in each language. This results in an accuracy of 87.74%.
The benchmark datasets for English scene text identification and recognition of street view text recognition are included as in ref. 37, such as MSRA-TD500, which has Chinese scripts, RCTW, which has English and Chinese scene texts, and ICDAR 2003, 2015 image datasets, which provide 78.3% accuracy. ICDAR2019 provides 83.3% accuracy for multilingual scene text with 2000 images in each language and texts in 9 different languages.
Ancient Tamil Script Recognition designed as in ref. 38, has attempted to recognize stone inscriptions using a CNN deep neural network with a pre-trained VGG19 model utilizing 61 Tanjore Tamil inscription scripts and 882 segmented characters, which is a relatively tiny dataset. For character segmentation in this study, which features poorly segmented characters, the standard bound box technique was also applied. Tamil character categorization39 yields an accuracy of 95.15% and includes 2009 samples and 3k Tamil vowel characters, each with 300 images. Only vowels and handwritten characters are used in this.
Despite the extensive research in character segmentation and recognition, several gaps remain in the existing methodologies, especially for unconstrained palaeography languages and inscription scripts. For unclear and irregular background images, such as images of stone inscriptions, several existing techniques cannot be employed. Many of the reviewed techniques also rely on small, specific datasets or require manual interventions, limiting their scalability. However, many have trouble with characters that overlap, touch, or curve, common in languages like Tamil, Kannada, and Tulu. The problem of segmenting overlapping, slanted, and unconstrained structures has not yet been solved. The methods previously in use could not handle characters with discontinuity, multiple boundaries for a single character, and under-segmented and bounding noise strokes. Many segmentation methods have been used, including contour-based convex hull, projection profiles, connected component analysis (CCA), and deep learning models. Furthermore, the approaches are often unsuitable for inscriptions, which contain highly distorted, noisy, and poorly segmented characters, making accurate segmentation and recognition challenging. Only in document images with notable foreground/background contrasts do explicit and implicit segmentations perform better; they can only be used effectively for printed text. Additionally, the use of deep learning methods for complex, historical scripts like stone inscriptions remains underexplored, especially when compared to more standardized handwritten or printed document datasets. In some cases, the thinning method fails to accurately segment characters. Where ligatures and connections between, within, and some linked characters exist and are not addressed by existing approaches, over-segmentation (more than one character constrained in a single bound) occurs. There is a need for better handling of intricate script features and variations in stroke widths, which are common in inscriptions, as well as techniques that can work effectively on degraded, real-world script images. Addressing these challenges could significantly enhance the accuracy and applicability of character segmentation systems in preserving and recognizing historical scripts. These problems are resolved by the proposed DPB signary localization methodology. Despite significant progress in character recognition, existing OCR methods still face challenges in accurately recognizing characters from ancient inscriptions. The scarcity and imbalance of datasets for scripts like Ashokan Brahmi and old Tamil limit the effectiveness of deep learning models in achieving high generalization and robustness, especially for low-resource scripts and languages. These are addressed by the SignaryNet model.
Methods
Digital acquisition of inscription images is captured using a high-quality imaging camera. These camera-captured images are post-processed, adjusted, resized, and sequentially numbered to identify script continuity. Digital image enhancement is implemented where a variety of techniques for digitally processing images include smoothing the image first and then using the discrete wavelet transform (DWT) to remove Gaussian noise. Smoothing and binarization techniques included grayscale conversion, Sauvola thresholding, and non-local means (NLM) de-noising. A novel strategy has been proposed for signary localization to address the problems with the existing localization techniques. The claimed Dynamic Profiling Bound (DPB) technique entails tracing the bound box enclosing each line-localized image while also retrieving the bound box pixel positions. Morphological operations are required for the better enhancement of broken or eroded character strokes for better recognition. Morphological thinning, thresholding, blurring, erosion, and dilation are applied to the localized line images to solve the under- and over-segmentation issues. The character width is calculated from the maximum of the pixel position points at the bound box edge, referential coordinates of an outlined box enclosing a character. The vertical projection profiling is projected based on the character width. The dynamic vertical projection profile approach performs vertical signary localization by modifying the hyperparameters. As in the line image, the signary are localized continuously. The localized characters are fed to the Classic Convolutional Neural Network (C-CNN), a deep neural model for signary recognition, which is tested and trained to predict the character sequence. To improve the performance of recognition, the neural network is designed with specifications such as adding layers, normalization, and learning parameters that are tuned for recognizing the signary of the inscriptions known as SignaryNet, and then the characters are trained. A dataset containing the character sequence and its matching Unicode is defined, and the model is optimized to estimate the precise character sequence. These recognized characters are transliterated and validated using the book South Indian Inscriptions Volume II, written by Hultzsch E.40, which is the ground truth and the inscription heritage content is digitally preserved in a digital archive. The overall flow with outcomes is shown in Fig. 1a, and Enhancement, signary localization and signary recognition in a step-by-step manner for a sample line localized image is given in Fig. 1b.

a Overall flow with outcomes. b Enhancement, signary localization and recognition of line image.
Dataset description
Images of Tamil stone inscriptions discovered on temple walls and pillars serve as the dataset for this experiment. According to Indian epigraphic statistics, the 11th century saw an abundance of stone inscriptions, many of which were found in the Great Chola temples that are now protected by UNESCO. The archaeology field has amassed a collection of these inscriptions’ remnants on special A3-sized paper called “Estampages,” still being preserved conservatively. However, a visit to the Tanjore Brihadisvara Temple must be authorized by the Archaeological Survey of India (ASI) to take photographs digitally. With the permission and approval of the Archaeological Survey of India (ASI), a visit to the Tanjore Brihadisvara Temple was made to capture the images digitally. High-definition camera Canon EOS 80D with EF-S 18-135, with a lighting kit Elinchrom FXR 400 Kit Light, Kodak T210 150 cm Three Way Pan Movement, tripod for camera, and UV protection lens filter—67 mm was used to acquire the stone inscription photographs that are currently available from the area. PNG files are used to store the images since they are more accurate when training neural networks. The dataset used for this research and experimentation contains 1216 script images of 24 GB. Images from the camera would have a maximum resolution of 6000 × 3800 and a 25 MB file size. The images have been normalized to have a maximum size of 1 MB and a dimension of 1500 × 800. The images are then pre-processed using several image processing techniques to improve the quality and obtain a greater rate of localization and recognition. Each image has a maximum size of 1500 × 100 and is line-localized. 50 × 100 pixels make up each localized character image. Each script image has 90–160 characters, at most. For implementation, 18,924 distinct character images have been localized. Nine Tamil vowels, 71 Tamil consonants, five Sanskrit characters, and fifteen Grantha mixed Malayalam, Sinhalese and Brahmi characters are among the 100 classes of ancient Tamil characters that are categorized. There are 1000 images in each class. As a result, 100,000 character images are collected. Further, each character image is normalized to 64 × 64 dimensions. On average, 20% for validation, 80% for training and finally 10% of the entire character’s image data (i.e.), real-time data is used for testing in random. The dispersion of data for the process experiment is provided in Table 2.
The camera acquired raw inscription images, which were then annotated by the placements of the temple’s central shrine (such as north, west, south, and east), as well as the entrance and pillars. Based on the continuation of the script’s sequence, line images are indexed. The character image dataset is labelled separately with the letter that each character in the dataset corresponds to. The character images are grouped from classes 0 to 99. The evolution of characters that are in the inscription script at different centuries and different periods of the king’s reign from the Pallava, Chola, etc., and the palaeography are given in Fig. 2. It is taken from the CILS library of the Indian Scripts Gallery, Grantha Tamil from http://library.ciil.org/Sites/Photography/GranthaTamil.html.

Evolution of Inscription script characters in different centuries, including the Chola period.
Digitally acquisitioned enhancement
The inscriptions are digitally acquired using a high-resolution camera during data collection with prior permission from the ASI, and the post-processing of the captured inscription images is executed before digital enhancement. Discrete wavelet transforms are used in medical image compression applications, such as ref. 41, since maintaining medical information takes up a lot of space. It is also used for MRI pictures. After wavelets are discretely sampled, the image is put through a succession of filters of low-pass and high-pass kernels to preserve components. In the same way, the images of stone inscriptions taken by the camera are wavelet decomposed. This approach produces two signals, approximation and details, from the separation of the high-frequency and low-frequency components of the image using a high-pass filter and a low-pass filter. The image is then divided into four quarter-size images using a 2D discrete wavelet transform. Discrete wavelet transform coefficients are used in wavelet-based denoising to take Gaussian noise out of the images. Image pixels can be converted into wavelets using the Mallat Wavelet Transform technique. The functions f (x) and Ψj,k(x) relate to the discrete variable x = 0,1,2,…, M−1 as given in Eq. (1). Typically, we choose to let j = 0 and set M to be a power of two, or M = 2j
The additive Gaussian noise has an impact on the wavelet transform coefficients. Most noise in the sample is contained in the wavelet detailed components. But the image also features sharp contrasts and important details. Therefore, thresholding is used for these coefficients to filter the wavelet coefficients from the detail sub-bands, and the original image is rebuilt using these changed coefficients. To improve the spatial and spectral localization of image generation, a wavelet de-noising technique42 that incorporates wavelet transform of sparsity, multi-resolution analysis, structure, and adaptability to unsupervised learning models is used. Without losing any information, the parts can be put together to create the original. Results include 2D DWT generalization, highly accurate reconstruction, and efficient noise reduction. The wavelet thresholding technique de-noises the wavelet coefficients, and then the inverse DWT is used to modify the coefficients to provide a de-noised image with improved performance. When using soft thresholding, the coefficients whose magnitude is below the threshold are set to zero, and the nonzero coefficients are subsequently shrunk towards zero. Soft thresholding can smooth the image out. The next step is NLM de-noising. The weight of each pixel’s mean value according to how similar it is to the target pixel is filtered by Non-local means. Consider a pixel and its immediate surroundings as a window of pixels in this method, and search for comparable windows of pixels in the images. The mean of a category of pixels with comparable characteristics is then determined. Let p and q be two locations inside an image, and let Ω be the image’s area. If the weighting function is denoted by f (p, q), the integral is calculated, and the filtered value of the image at point p is represented by uf (p) and the unfiltered value by vuf(q). Normalizing factor C(p) as given in Eq. (2). In continuous analysis, the image is mapped on to a rectangular region, say \(\varOmega =\left[0,H\right]\times \left[0,W\right],\) (height × width), and in a digital image of size H × W means, \({q}_{x}=[0,W]\), and \({q}_{y}=[0,H]\).
The primary feature that makes NLM robust is that it takes into account both the geometric layout of an entire neighbourhood and the grey level in a single pixel. Before two-toning, the de-noised image must be transformed to monochrome. Grey levels typically vary between 0 and 255. Each pixel in this image merely conveys information about intensity. Sauvola thresholding43 employs the average and variability within a local area to set a unique threshold for each pixel. Even with large differences in the background, poorly illuminated papers, irregular illuminations, document degradations, and uneven lighting circumstances, it removes the problem of background noise. It works well with document images that have background non-text pixels with a grey value of 255 and foreground text pixels with a grey value close to 0. By utilizing Sauvola binarization, the Sauvola thresholding function essentially produces a two-tone image. It is an improved form of a Niblack technique that, when compared to Otsu, produces excellent results in a variety of lighting situations and against dark backgrounds. Sauvola thresholding is the method that works well in this situation since stone inscriptions are photographed in a variety of lighting situations. The mean m(x, y) and standard deviation s(x, y) of the pixel intensities in a w × w window surrounded by the pixel (x,y) are used to calculate the threshold t(x, y) in Sauvola’s binarization approach, where R is the pre-set image grey-level value and k is a control factor in the interval [0.2, 0.5] as given in Eq. (3). Figure 3 shows the raw inscription image and the enhanced image.

Camera captured inscription image and digitally enhanced image.
Line localization
For this analysis, assume that each enhanced image has a different number of engraved or carved lines (r), with every character in a line having a different height and width. Let us start with the enhanced image E. The character images in each line also vary in size because of the free-form nature of the inscriptions and the unstructured writing style. Localization is required for 145-character images, of which r is 8 (i.e., 8 carved line writings) in the sample image shown in Fig. 3. First, the horizontal projection profiling approach is applied to the enhanced image E to localize the lines from the script image. The horizontal lines are projected, and E is divided into segments of lines with length x and width y. Based on the varied lengths of the characters’ strokes, the y value may be modified and localized correspondingly. The projection lines needed for image E are (r−1) lines, which correspond to (8−1), or 7 lines when r equals 8. The horizontal line profiled image is given in Fig. 4a. Identifying the horizontal kernel of each line is used to segment or localize each line, as in Fig. 4b, where a line-localized image is obtained. Iteratively extracting the image’s row-wise lines using morphological techniques enables the detection of the horizontal kernels. The alpha and beta weighting factors are 0.5 and 1−alpha for iterations i equals 3, respectively.

a Horizontal projection profile. b Line localized image \({L}_{i}.\) c Bounded box image \({{BP}}_{i}\).
Dynamic Profiling Bound (DPB) technique
Applying the existing bounded box to script images with adequate line spacing, character spacing between characters, and continuous unbroken strokes will result in a clear bounding, but images with irregular spacing, broken strokes, clustered, overlapped, and staked writing styles do not properly bound the characters, which hurts the localization rate. The Dynamic Profiling Pound (DPB) technique is proposed as a solution to these problems. DPB is applied to the line-localized image \({L}_{i}\). For each obtained box, it entails extracting the bounded box coordinates. Gaussian blur, canny edge detection, dilation, and erosion are first used, and then the contours are found and sorted to determine the bound box tracing and the extraction of coordinates.
In Eq. (4), Gaussian blur \({G}_{i}\) is represented by function \(G\left(x,y\right)\), where x and y are the distances from the origin in the horizontal and vertical axes, respectively, and are the standard deviations of the Gaussian distribution. Then, the image is processed using a filter in both the horizontal axes and vertical axes to obtain the first derivative in both the horizontal axes (\({G}_{x}\)) and the vertical axes (\({G}_{y}\)), which may be used to determine the edge gradient \({{\rm{E}}{\rm{G}}}_{i}\) and direction for each pixel.
Finding the gradient’s magnitude is specified by Eq. (5). If it is true, it utilizes the more precise equation given above; otherwise, it uses Eq. (6).
Further, it is followed by numpy min and max computation of the traced points represented as min(diff) and max(diff). The coordinates are returned as ordered coordinates for detecting edges. The contours are arranged in order from left to right. As box point is computed as given in Eq. (7), if the contour area \({\rm{Ca}}\) is below the box point area \({B}_{\min }\) then it is ignored. \({B}_{\min }\) can be assumed at least to the value of 100. Only those having large sufficient contours are taken.
As a result, the bound box coordinates \({B}_{i}\), along with the bound box image \({{\rm{B}}{\rm{P}}}_{i}\) is obtained. The coordinate values of a box are displayed. The bound box image \({{\rm{B}}{\rm{P}}}_{i}\) is shown in Fig. 4c. The dynamic profiling bound technique is described in Algorithm 1 as in Fig. 5. In Algorithm 1, the axispts are the point values that are traced during contouring over the strokes. The difference is calculated between the axispts and pts assigned to zero and the values are stored in diff. The box coordinate values as an array of values represented as Bi will be the minimum and maximum values of s and diff. Profiling Bound box traced image \({{\rm{B}}{\rm{P}}}_{i}\) is obtained.

Algorithm 1 DPB.
Vertical projection and signary localization
After pulling the bound box edge coordinates \({B}_{{\rm{c}}}\) for each character, bound points of a character (x4, y4), (x3, y3), (x2, y2), and (x1, y1) are acquired as these points are in a clockwise direction, and likewise for all bound boxes the equivalent points are acquired. The character width is computed for each box, such as the distance between (x1, y1) and (x4, y4) or between (x2, y2) and (x3, y3). The distances are compared, and the maximum distance is taken as character width. The distance is found initially by applying Euclidean distance as follows in Eq. (8). Here, d denotes the Euclidean distance and x1, y1, x4, y4 are the Euclidean vectors.
It is followed by maximum coordinate value calculation, which is the greatest value of the x point values may be x3 or x4. For each box, the maximum point value \({{\rm{M}}{\rm{A}}{\rm{X}}}_{{\rm{p}}{\rm{t}}}\) is computed. With the increment offset value b, which is 1 by default, the \({{\rm{M}}{\rm{A}}{\rm{X}}}_{{\rm{p}}{\rm{t}}}\) value is incremented to avoid projection over edge strokes of a character, as in Eq. (9).
The number of max coordinate values identified will be equal to the total number of characters in the line image. Hence, the number of lines projected \({\rm{N}}{\rm{u}}{\rm{m}}{\rm{b}}{\rm{e}}{\rm{r}}\,{\rm{o}}{\rm{f}}\,{L}_{p}\) will be one less than the number of \({{\rm{M}}{\rm{A}}{\rm{X}}}_{{\rm{p}}{\rm{t}}}\) values computed as in Eq. (10).
The vertical projection lines denoted by \({L}_{{\rm{p}}}\) are projected at each \({{\rm{M}}{\rm{A}}{\rm{X}}}_{{\rm{p}}{\rm{t}}}\) value over the line image, where \({{\rm{M}}{\rm{A}}{\rm{X}}}_{{\rm{p}}{\rm{t}}}\) consists of points from \({{\rm{M}}{\rm{A}}{\rm{X}}}_{{\rm{p}}{\rm{t}}1}\)…………….. \({{\rm{M}}{\rm{A}}{\rm{X}}}_{{\rm{p}}{\rm{t}}{\rm{n}}}\), where n is the number of maximum point values, and \({{\rm{L}}}_{{\rm{p}}}\) consists of \({L}_{{\rm{p}}1}\)………. \({L}_{{\rm{p}}m}\), where m is the number of lines projected. The result is shown in Fig. 6a for the sample image.

a Vertical line projection \({L}_{{\rm{p}}}\). b Signary localization.
By identifying the vertical kernel of the profile line, signary localization, or vertical character segmentation over \({L}_{{\rm{p}}}\), is carried out. Iteratively extracting the image’s vertical lines using morphological techniques enables the detection of the vertical kernels. The weighting values alpha and beta are taken as 0.5 and 1−alpha, respectively, for iterations i. Signary are localized appropriately by altering the height h and width w hyper-parameters. A variation in image size can be used to modify the w and h parameters. The characters are localized, and the signary is represented as \({{\rm{S}}{\rm{C}}}_{i}\), where \({{\rm{S}}{\rm{C}}}_{i}\) is a group of character images \({{\rm{S}}{\rm{C}}}_{i1}\), \({{\rm{S}}{\rm{C}}}_{i2}\), and \({{\rm{S}}{\rm{C}}}_{i3}\)……\({{\rm{S}}{\rm{C}}}_{in}\) where n is the total number of character images in a line. Each localized character image has a unique index idx. The character images in \({{\rm{S}}{\rm{C}}}_{i}\) are organized and sorted in a way that is successively localized by the line image. The method maintains the order of characters in the inscription script, and the localized signary shown in Fig. 6b are obtained. The signary localization is described in Algorithm 2 as in Fig. 7. In Algorithm 2, bound points of a character \({B}_{{\rm{c}}}\) that has four coordinates, \({K}_{{\rm{v}}}\) is the kernel detection point of vertical lines, and height h and width w are hyper-parameters. Here, it is assumed as 80 and 10.

Algorithm 2 Signary localization.
Solving the bound box issues
To address the different issues while applying the bound box for the line image, such as resulting in a single box for two or more characters or a split bound box for a single character, or superimposed bound boxes. Due to unconstrained carvings of characters in the inscription images, there appear like touching characters, wide-spaced characters (i.e.) large spacing between characters, or less spaced characters (i.e.) condensed spacing between characters and deteriorated characters. These cases are discussed below as follows:
While inscribing the stones, there might be less space to complete a script within a particular stone, hence the writings may be crammed. Some of the characters in the image are with condensed space, with touching strokes, and overlapped, which may be bounded by a single bound box during localization, which in turn reduces the performance of character recognition. This is solved by applying sequential morphological operations like thinning, Gaussian blur, thresholding, and dilation, erosion to the enhanced line-localized image. Thinning is a procedure that relies on a specific element known as the morphological kernel element j to determine its course. Binary structuring elements are utilized in this process, which is linked to a transformation. This transformation represents a general binary morphological process designed to aim at detecting specific configurations of object and non-object pixels in an image, incorporating both 1 and 0 s. The thinning process is carried out by systematically positioning the anchor point of the morphological kernel element at each pixel location throughout the image. At every position, a comparison is made between the structuring element and the corresponding image pixels. The thinning of a line image \({L}_{i}\) by a morphological kernel element j can be described as follows in Eqs. (11) and (12). It defines the thinned layer \({L}_{{\rm{i}}{\rm{t}}}\) as the result of a thinning function applied to\(({L}_{i},j)\), while Eq. (12) expresses that thinning involves subtracting a transformation from the original layer to get \({L}_{{\rm{i}}{\rm{t}}}\).
The separation of light and dark regions is accomplished by thresholding after applying a Gaussian blur as in Eq. (4) over \({L}_{{it}}\). By setting all pixels below a certain threshold to zero and all pixels within that threshold to one, thresholding converts greyscale images into binary ones. If g(x, y) is a version of f(x, y) that has been thresholded to obtain \({L}_{{\rm{i}}{\rm{t}}{\rm{h}}{\rm{r}}{\rm{e}}{\rm{s}}{\rm{h}}}\) at some global threshold T as in Eq. (13),
Erosion that shrinks regions of interest and eliminates fine details or noise from a binary image is denoted by\({M}_{{\rm{e}}}\). Finally, the structural element erodes the thresholded line image. A new binary image, \(g={L}_{{\rm{i}}{\rm{t}}{\rm{h}}{\rm{r}}{\rm{e}}{\rm{s}}{\rm{h}}}\theta s\), is created when a line image \({L}_{{\rm{i}}{\rm{t}}{\rm{h}}{\rm{r}}{\rm{e}}{\rm{s}}{\rm{h}}}\) is eroded by a structuring element s (denoted \({L}_{{\rm{i}}{\rm{t}}{\rm{h}}{\rm{r}}{\rm{e}}{\rm{s}}{\rm{h}}}\theta s\)) as in Eq. (14).
Then DPB is applied to \({M}_{e}\) as in Algorithm 1 to get the bound boxes of all the characters individually. Sample results for touching and condensed spaced characters are shown in Fig. 8a–d.

a \({L}_{i}\), b grouped bound box, c morphological transformations, d DPB.
Concentrating on the deteriorated characters, and if the bound box is applied to the image, some of the unwanted strokes curvatures, and noises like dots and lines may also get bound. As some of the script writings have more gaps among characters, and if the bound box is applied to the image, a split bound box for a single character is obtained since there are some minute fissures (i.e.) broken strokes in the corresponding character. This also results in poor localization and degrades the performance of signary recognition. This is solved by applying Gaussian blurring as in Eq. (4) over the image \({L}_{i}\) followed by thresholding as in Eq. (14) and dilation. The morphological kernel probe dilates the thresholded line image. A new binary image, \({g=L}_{{ithresh}}{\rm{\theta }}s\), is created by the dilation of an image \({L}_{{ithresh}}\) by a morphological kernel element s (denoted \({L}_{{\rm{i}}{\rm{t}}{\rm{h}}{\rm{r}}{\rm{e}}{\rm{s}}{\rm{h}}}\theta s\)), and the dilation of the image is denoted by \({M}_{{\rm{d}}}\) as in Eq. (15).
Dilation fills the fissures and gaps exist in the strokes of the corresponding character. Then \({M}_{{\rm{d}}}\) undergoes the DPB algorithm as in Algorithm1 and this avoids a split bound box and results in the perfect bound of a character. Samples of line images with deteriorated and wide space characters are shown in Fig. 9a–d.

a \({L}_{i}\), b split bound box, c morphological transformations, d DPB.
Morphological transformation is depicted in Algorithm 3 for solving bound box issues as in Fig. 10. In Algorithm 3, boxcount is initialized as the total count of the \({{\rm{M}}{\rm{A}}{\rm{X}}}_{{\rm{p}}{\rm{t}}}\) values obtained for \({L}_{{\rm{i}}}\), countval is the parameter value of the estimated \({{\rm{M}}{\rm{A}}{\rm{X}}}_{{\rm{p}}{\rm{t}}}\) values to be obtained for \({L}_{{\rm{i}}}\). If boxcount value is larger than countval then morphological erosion \({M}_{{\rm{e}}}\) is applied otherwise morphological dilation \({M}_{{\rm{d}}}\) is applied. Morphologically transformed images \({M}_{{\rm{i}}}\) are collectively obtained and these images in turn represent \({L}_{{\rm{i}}}\) which undergoes Algorithm 1 again.

Algorithm 3 Morphological transformation.
Signary recognition with C-CNN and SignaryNet
The localized characters are grouped and binned separately according to the classes numbered from 0 to 99, verifying the characters with the 11th-century Tamil, Grantha, and Sanskrit letters mentioned. They are then size-normalized, and the less frequent character images are augmented, such as mostly Grantha and Sanskrit letters; needed this, and each class consists of 1000 character images. A sequential architecture called the Classic-CNN (C-CNN) model was created to categorize 64 × 64 grayscale images into 100 different classes. An output feature map of shape (62, 62, 16) is produced by starting with a Conv2D layer with 16 filters, a kernel size of (3, 3), ReLU activation, and an input shape of (64, 64, 1). The dimensions are then reduced to (31, 31, 16) via a MaxPooling2D layer with a pool size of (2, 2). The output of the second convolutional layer is (14, 14, 32) and is composed of 32 filters and the same (3, 3) kernel, followed by another (2, 2) max pooling. A third MaxPooling2D layer that uses 64 filters with a (3, 3) kernel and ReLU activation comes after the third Conv2D layer. A third MaxPooling2D layer reduces the output to (6, 6, 64) after the third Conv2D layer uses 64 filters with a (3, 3) kernel and ReLU activation. After that, the feature maps are flattened into a 2304-unit 1D vector. To avoid overfitting, this vector is sent to a dense layer with 512 units and ReLU activation, then a dropout layer with a dropout rate of 0.5. With 100 units and a softmax activation function, the final dense layer generates probability scores for every class. The Adam optimizer is used to construct the model, with accuracy as the evaluation metric, sparse_categorical_crossentropy as the loss function (for outputs with integer labels), and a learning rate automatically set by default.
The C-CNN is then fine-tuned specifically for the signary recognition of ancient Tamil inscription characters, which is known as SignaryNet. SignaryNet is an optimized convolutional neural network (CNN), a hyperparameter-tuned deep neural network and is the most advanced image categorization model that is more than adequate to digitally recognize individual characters from the inscriptions designed for recognizing inscription characters, such as Tamil vowels ( etc.), Tamil consonants (
etc.), Tamil consonants ( etc.), Sanskrit (
etc.), Sanskrit ( etc.), the adjacent prefix suffix supporters of consonants (
etc.), the adjacent prefix suffix supporters of consonants ( etc.), and the Grantha or Brahmi characters in modern Tamil characters. It is an approach that uses deep CNN architecture for recognizing ancient Tamil characters with sequence characters employed to complete the task. The proposed design uses deep neural network layers to extract features from input character images, and signary recognition is then fed to the feature map. Here, labelled set sequences are used to train the network. The three key equations that represent its core functionality of Convolutional operation feature extraction layer and each convolution layer applies filters (kernels) to the input image to produce a feature map as in Eq. (16).
etc.), and the Grantha or Brahmi characters in modern Tamil characters. It is an approach that uses deep CNN architecture for recognizing ancient Tamil characters with sequence characters employed to complete the task. The proposed design uses deep neural network layers to extract features from input character images, and signary recognition is then fed to the feature map. Here, labelled set sequences are used to train the network. The three key equations that represent its core functionality of Convolutional operation feature extraction layer and each convolution layer applies filters (kernels) to the input image to produce a feature map as in Eq. (16).
\({F}_{i,j}^{k}\) is the output feature map at position (i, j) for filter k, I is the input image or previous layer’s output, Kk is the kth convolutional kernel of size M × N, and bk is the Bias for the kth filter. After convolution, activation \({A}_{i,j}^{k}\) is applied to introduce non-linearity, such as in Eq. (17).
The final classification is done using softmax, which outputs a probability distribution over all classes as in Eq. (18).
\({z}_{c}\) is the Output (logit) of the dense layer for class, C is the total number of character classes, \(P\left(y=c|x\right)\) is the probability that input x belongs to class c. In this case, SignaryNet is represented as a 2D convolutional network made up of layers called Conv2D and MaxPooling2D. Conv2D will analyse character image snapshots, and pooling layers will consolidate the analysis. Then this initializes a model and prepares a training dataset for a classification task. The architecture accepts input of shape (64 × 64 × 1) and begins with stacked convolutional layers: the first block comprises two Conv2D layers with 32 filters each and ReLU activation, interleaved with BatchNormalization layers and followed by a ZeroPadding2D and MaxPooling2D operation to preserve spatial resolution and reduce dimensionality. The convolution class’s yield is blended with the ReLU activation function and the same padding, conserving the spatial confines of the input image, similar to the yield image, which is the same size as the input image. Applying the zero padding as (2, 2) adds zeros to the end of the input sequence. This pattern continues through progressively deeper layers with 64 and 128 filters, each block incorporating dropout layers (rates: 0.25, 0.25, and 0.4, respectively) for regularization. After flattening, the network includes a dense layer of 256 units with ReLU activation, and an additional Dropout of 0.5 is used to handle vanishing gradients, followed by a final dense softmax layer outputting 100 classes with float32 precision. The output softmax layer receives the probabilities of output character prediction for the corresponding number of classes from the dense layers of filters together. Using mixed_float16, hybrid precision training is enabled to maximize training performance, and tf.config.optimizer.set_jit(True) activates XLA XAccelerated Linear Algebra to increase execution efficiency. With a learning rate of 0.001 and a loss function of categorical cross-entropy, the model is constructed using the Adam optimizer. Greyscale images from designated data for training and validation are prepared for processing and pre-processed by the training pipeline. Data augmentation strategies include random horizontal flipping, rotation (±10%), and zooming (±10%), applied only to the training dataset. All images are normalized by rescaling pixel values to the [0, 1] range. For model training, we incorporate early stopping with a patience of 5 epochs to prevent overfitting and learning rate reduction on plateau (factor = 0.5, patience = 2) to enable finer convergence during stagnation. The model is trained using a batch size of 64 and a maximum of 50 epochs. Final evaluation includes plotting training and validation accuracy curves, confusion matrices, and precision-recall-F1 statistics derived via classification_report. The model is saved in the Keras format (.keras), and its performance can be fine-tuned using the built-in learning rate scheduler or further extended with transfer learning by freezing initial layers and re-training on new data. Using Unicode mapping, the signary are recognized in modern Tamil. The signary is predicted as shown in Algorithm 4, as in Fig. 11.

Algorithm 4 signary recognition with SignaryNet.
For signary recognition as in flow of SignaryNet in Fig. 12, shows how an inscription character image is recognized to a contemporary Tamil character, which has a mapping file that contains the Unicode of the relevant character images of 0–99 classes, as seen in Fig. 13a–c.

Flow of SignaryNet.

a–c Unicode mapping.
Results
Enhancement and line localization of script images
The sample enhanced images from the dataset of the high-resolution camera captured 11th-century inscription images archived as in ref. 44, are experimented as below for line localization, signary localization, SLR computations, and also for the state-of-the-art methods comparison. The inscription images with different inscribing styles (i.e.) clear as well as glutted writing with varying numbers of lines are taken as samples and are enhanced. The inscription images are enhanced as shown in Fig. 14a are then line localized using horizontal line projection and the results are represented as in Fig. 14b localization of line images from each image is done as in Algorithm 1.

a Sample pre-processed script images. b Sample line localized images.
Signary localization in script images
The proposed DPB method to process signary localization for sample images has been experimented and the number of localized characters is compared with existing bound box methods. Table 3 displays the results and the SLR in Eq. (19) as discussed. The existing methods demonstrate that the localized characters are not distributed in a sequential manner and with split strokes and over-segmented characters as a result. The proposed DPB technique eliminates the over-segmentation problem by displaying evenly sized characters sequentially ordered, without split strokes. For example, in Image (1), the Existing Bound Box correctly localized 68.96% of characters, whereas the Proposed DPB significantly improved accuracy to 98.62%. Similarly, the Proposed DPB outperformed the existing bound box in the other two images, offering higher localization success rates, particularly in Image (2) (96.59% vs. 64.77%).
According to Eq. (19), the signary localization rate (SLR) or Segmentation Rate is determined by subtracting one and the number of characters that were incorrectly localized from the total number of characters that need to be localized, which is expanded in Eq. (20). Characters that are wrongly localized show evidence of being under- or over-segmented. If there are more strokes from the adjacent characters, the segmented character image is under-segmented. When two or more characters are segmented as the same character due to touching strokes or when a single character is split into numerous segments, this is known as over-segmentation. As a result, as shown in Eq. (20), the localization rate may also be calculated by subtracting one and the sum of the under-segmentation rate USR as the ratio of under-segmented characters to the total number of characters to be localized in Eq. (21) and the over-segmentation rate OSR as the ratio of over-segmented characters to the total number of characters to be localized as in Eq. (22), and SLR as in Eq. (23).
The signary localization rate is calculated for segmenting images having 1730 lines and 19,137 original characters. With 206 under-segmented and 127 over-segmented characters, we obtain 18,924 actual localized characters and 18,804 correctly localized characters, which are then plotted as shown in Fig. 15a. According to Table 4, an overall signary localization rate of 98.25% was found, and Fig. 15b illustrates the same with USR and OSR.

a Plot of Signary Localization computation. b SLR, USR, OSR.
Some of the touching characters and overlapping strokes of the characters are detected and they are not localized individually. Some of those samples are shown as follows in Fig. 16.

Over and under-segmented overlapping strokes, condensed, spaced and touching characters.
Binning, augmentation and standardization
The characters are grouped through the process of binning into 100 classes based on their structural similarity, combining Tamil consonants, vowels, Sanskrit, Grantha, mixed Sinhalese, Brahmi, and Malayalam characters, which are classified as 0–99. Each image represents a different character class, ensuring that each class has a total of 1000 images to balance the dataset for character classification tasks. The process initially counts the number of images currently available for each class to determine how many more examples are needed. If there are not enough images in the dataset, it does transformations including rotation, shifts, shearing, zoom, and horizontal flipping using an ImageDataGenerator to increase data diversity and model resilience. For every underrepresented class, new images are made using existing ones until the target number is met. This process also safeguards the original images by copying them to the directory containing the improved samples. The augmentation process assists in providing a constant distribution of data across classes, which is necessary for training stable and objective models. This method is particularly useful for ancient character detection, where dataset imbalance is common. All things considered, it improves model generalization and reduces overfitting. The input dimensions of the images for the model should be standardized. At this step, every image is shrunk to a fixed resolution of 64 × 64 pixels using high-quality Lanczos resampling. This reduction step is crucial for preparing image datasets for training since a constant input size is required for batch processing and model compatibility. Additionally, scaling reduces and standardizes image resolution, which minimizes training computational costs. When dealing with extensive image datasets, this method is quite advantageous.
Signary recognition C-CNN and SignaryNet model outcomes
Each class of 1000 characters in the model, including augmented characters, contains 100 classes and hence contains 100,000 character images. There are approximately 80,000 character images in the training data, 20,000 character images in the validation data, and 10,000 character images in the testing data, which are used for prediction. The character images in the training/test set are labelled with the range 0–99 in the folders and also separately stored with the appropriate letters in classname.npy file for isolated character recognition. The class ID labels on the character images in the training/test set match the Unicode of contemporary Tamil characters in a CSV file.
The C-CNN model has a total of 1,253,756 parameters, all of which are trainable, indicating a fully parameterized architecture designed for complex classification tasks. After the convolutional layers, the output is reshaped into a 2304-dimensional linear array. The fully connected dense layer has 512 units with ReLU activation, followed by a softmax output layer with 100 units for classification. The model uses the Adam optimizer and sparse categorical cross-entropy as the loss function, but it does not include data augmentation or mixed precision. The model has undergone forty epochs of the learning phase. While the accuracy for training was 86.67%, the accuracy for validation was 83.33% and the prediction accuracy of 84.74%. The SignaryNet model is created and has been evaluated using different test data. Tamil and grantha/Sanskrit characters can be found in the test instances. The SignaryNet model architecture, as summarized as in Fig. 17a, is a deep convolutional neural network specifically tailored for high-accuracy recognition across 100 classes. It begins with two convolutional layers with 32 filters, followed by batch normalization and zero padding to preserve spatial dimensions. The model then applies max pooling and dropout (25%) for spatial reduction and regularization, which are applied after the MaxPooling layers corresponding to feature maps of sizes (32 × 32 × 32), (16 × 16 × 64), and (8 × 8 × 128). This pattern continues with 64 and 128 filters in deeper convolutional blocks, each followed by batch normalization, pooling, and increasingly aggressive dropout (up to 40%), effectively preventing overfitting and enabling robust feature extraction. Post-convolution, the model flattens the output into an 8192-dimensional vector, passing it through a fully connected dense layer with 256 units and 50% dropout, ensuring strong high-level abstraction with regularization. Finally, a softmax layer with a 100-unit map is added to the output classes. The total parameter count is ~2.26 million, with only 640 non-trainable parameters, indicating an almost fully trainable model. This balance between depth, regularization, and trainability makes SignaryNet both computationally efficient and highly effective for complex inscription signary image classification tasks. While the accuracy for training is 96.20%, the accuracy for validation is 98.61%, and the prediction of the signary is made for the single characters as shown in Fig. 17b from test data, and the prediction accuracy is 96.81%. The detailed metrics of C-CNN and SignaryNet are given in Table 5.

a SignaryNet model summary. b Sample Signary prediction.
SignaryNet performance optimization and hyper-parameter tuning
Together with adjustment, the hyperparameter settings can greatly increase the SignaryNet model’s accuracy and resilience. Enhancing the dataset and pre-processing images can significantly improve generalization. In this instance, adding random changes such as rotation, scaling, zoom, and horizontal flip to Tamil characters will help the model better manage input variations. These augmentations are applied before normalizing the images to the range [0, 1]. To prevent stochastic behaviour from leaking into the validation phase, training = True is removed from the augmentation pipeline during .map(). Dropout is a key regularization method used to drop units at random during training to avoid overfitting. Achieving equilibrium between regularization and model capacity can be facilitated by adjusting the dropout rate. For SignaryNet, a dropout of 0.25 for hidden layers and 0.5 for dense layers is used. In a SignaryNet, the quantity and size of filters are critical. Effectively capturing local and global elements is crucial for intricate scripts, such as Tamil inscriptions. The model begins with two Conv2D layers employing ‘same’ padding to preserve spatial resolution, ReLU activation, and 32 filters of size (3 × 3). The second block doubles the filters to 64, maintaining the same structure with MaxPooling2D to reduce dimensionality and Dropout (0.25) to prevent overfitting. Due to increased feature complexity, the third block extends filters to 128 and increases dropout to 0.4 for stronger regularization. The extracted feature maps are flattened and fed into a fully connected layer containing 256 neurons, with a dropout rate of 0.5 applied to enhance regularization.
Zero padding is used after batch normalization in architectures like SignaryNet to ensure that the spatial dimensions of the feature maps are preserved before further convolution or pooling operations. After a convolutional layer, the spatial size of the feature map can shrink depending on the kernel size and stride. Zero padding ensures the output has the same height and width as the input, which is important when it is needed to retain spatial information, especially with ancient script characters that may have intricate or fine details especially ancient scripts (like Grantha or Brahmi) often have small strokes near the edges and hence, zero-padding helps prevent these edge features from getting lost in repeated convolutions. Batch normalization levels off learning, speeds up convergence, reduces internal covariate shift, and is applied immediately after convolution and before non-linearity (ReLU). After batch normalization and activation, zero padding can be applied before the next convolution to ensure proper receptive field alignment and control over output dimensions. This preserves detail and dimension while ensuring stability and performance.
By adding non-linearity to the model, the activation function enables it to recognize increasingly intricate patterns. ReLU is effective, and since it determines how quickly the model learns, the learning rate is to be adjusted. The adaptive learning rate approach, which uses optimizers like Adam to modify the learning rate during training based on the gradient, is employed in the SignaryNet model. It is initially set to a default of 0.001 and uses categorical cross-entropy. During training, optimizers regulate how the weights are changed. Adam’s adjustable learning makes it a good option. Training speed and convergence can be improved with proper weight initialization. Although it could be slower and more computationally costly, a smaller batch size might provide a finer gradient estimate for the model. Training can be accelerated with a larger batch size, but the gradient estimations may be less accurate. The initial value for medium-sized datasets is 32. Since the GPU RAM in this SignaryNet model supports 64, it is utilized. The frequency count of the model depends on the epochs. Here, 50 epochs are used to train the SignaryNet model while early stopping is in place. Training may be stopped early if the validation accuracy begins to decrease while the training accuracy increases. To monitor validation accuracy or loss, 5–10 epochs of patience can be allowed before discontinuing. Meanwhile, EarlyStopping ensured training halted once improvements plateaued, thereby saving resources and preventing overfitting. Here, the SignaryNet model makes use of a learning rate schedule such as ReduceLROnPlateau. To facilitate finer learning in later stages, two important call backs are utilized during training: ReduceLROnPlateau (factor = 0.5, patience = 2) to halve the learning rate when performance plateaus and Early Stopping (patience = 5) to stop training if validation loss doesn’t improve. To maintain a good trade-off between learning new information and fine-tuning existing knowledge, the learning rate is systematically adjusted throughout training using scheduling techniques.
A ModelCheckpoint callback is added to automatically save the model weights corresponding to the highest validation accuracy, ensuring both the preservation of the best model and maximum reproducibility. It successfully saved the best-performing model whenever validation accuracy improved. EarlyStopping conserves resources by halting the progress once improvements plateau. Learning rate scheduling worked effectively, reducing the rate smoothly without triggering early stopping prematurely, indicating the model was still improving even up to epoch 38. Additionally, the use of mixed precision training for computational efficiency and XLA (accelerated linear algebra) compilation improved computational efficiency. Despite achieving over 96% training accuracy, the tight alignment with validation accuracy indicated strong generalization and low variance.
The SignaryNet model demonstrated that the training dynamics show efficient learning driven by smart use of callbacks and well-optimized adaptive learning rate adjustments. The model is trained for 48 epochs, but early stopping was triggered, restoring the best weights from epoch 43, where it achieved the highest validation accuracy of 98.61%. Initially, in epoch 1, training correctness was extremely low at 3%, while validation correctness started at 20.3%, with a high loss of 4.53. As training progressed, accuracy improved rapidly—by epoch 5, the model had reached 64.9% training correctness and a remarkable 90.2% validation correctness, with validation loss sharply dropping to 0.37. The learning rate began at 0.001, and when improvements plateaued (e.g., between epochs 10 and 11), the ReduceLROnPlateau callback reduced the learning rate to 0.0005 (epoch 11), then successively to 0.00025, 0.000125, 0.0000625 and so on, eventually reaching very fine-tuned values like 7.81e−6, 3.91e−6, and 1.95e−6 by epoch 47 helping the model fine-tune during later stages and avoid overshooting and to fine-tune learning as performance plateaued and the loss function was categorical cross-entropy. This adaptive reduction helped maintain performance and prevent overfitting. Between epochs 12 and 30, the validation accuracy oscillated in the 97–98.5%, and with the peak performance recorded at 98.61% by epoch 43, showing strong generalization. Loss values dropped for both training and validation, with training loss reaching approximately 0.12 and validation loss stabilizing around 0.05. The consistent narrowing gap between training and validation accuracy, with final training accuracy reaching 96.2%, indicates strong generalization performance. The EarlyStopping callback is activated at epoch 48 after detecting no further improvement, and the best weights are restored from epoch 43. Overall, the model learned efficiently, benefited from automated learning rate adjustments, and converged well before the 50th epoch.
The training performance of the proposed SignaryNet model highlights its robustness in handling complex multi-class image classification tasks, specifically for character recognition across 100 categories. The architecture is well-structured, with progressively increasing depth and regular dropout layers. The data pipeline was also well-optimized with proper augmentation and prefetching, maximizing GPU utilization. Overall, SignaryNet model proved to be a model capable of reliably learning and distinguishing intricate visual patterns. Fine-tuning the hyper-parameters of the SignaryNet model can significantly enhance its performance in character recognition, especially when dealing with complex scripts like ancient Tamil inscriptions.
Below, as in Table 6, are the key hyper-parameters that can be adjusted and suitable values based on best practices and the model’s specific task. Fine-tuning based on training results (e.g., accuracy, loss) and using validation performance to adjust these hyper-parameters can help further enhance performance. The classification report demonstrates that the model exhibits superior classification capabilities across all 100 classes. Most characters show precision, recall, and F1-scores very close to or equal to 1.00, indicating highly reliable predictions with minimal false positives or false negatives. A few characters, such as “ ” and “
” and “ ,” exhibit slightly lower scores, suggesting occasional misclassifications. However, the consistency in high scores across macro and weighted averages confirms that the model generalizes well across both balanced and imbalanced label distributions, even across visually similar Tamil and Brahmi characters.
,” exhibit slightly lower scores, suggesting occasional misclassifications. However, the consistency in high scores across macro and weighted averages confirms that the model generalizes well across both balanced and imbalanced label distributions, even across visually similar Tamil and Brahmi characters.
Confusion matrices for a multi-class character recognition model with 100 distinct classes are grouped into vowels, Sanskrit characters, Grantha characters, and consonants. It is constructed using specified values for true positives (TP), false positives (FP), true negatives (TN), and false negatives (FN), randomly distributing correct and incorrect predictions across the matrix. The overall confusion matrix provides a high-level view of prediction accuracy across all categories, while category-specific matrices illustrate how well the model distinguishes similar characters within each group and are useful for analysing the model’s performance on complex scripts and their historical variants. The classification task involves 100 distinct classes comprising 9 vowels, 5 Sanskrit classes, 15 Grantha characters, and 71 consonants, evaluated on a dataset containing a total of 100,000 images. For validation, a subset of ~20,000 images was used. The Classic-CNN model on a validation dataset of ~20,000 images yields 9752 true positive predictions, indicating correctly identified positive cases. There are 1,858 false negatives, where the model failed to identify positive instances. Additionally, the model produced 1219 false positives, where it incorrectly classified negative instances as positive. Lastly, it correctly identified 7180 true negatives. Based on the evaluation results, the SignaryNet model correctly identified 17,935 images as true positives, while 1543 were correctly classified as true negatives. However, it also produced 261 false positives and 270 false negatives, which were misclassified during validation. The separate confusion matrices of SignaryNet are shown in Fig. 18a–d, as for 0–8 classes of Tamil vowels, 9–13 classes of Sanskrit characters such as  etc., 14–28 classes of Grantha/brahmi/Sinhalese/Malayalam characters that include stacked letters such as
etc., 14–28 classes of Grantha/brahmi/Sinhalese/Malayalam characters that include stacked letters such as  and
and  etc., and 29–99 classes of Tamil consonants that include compound characters such as
etc., and 29–99 classes of Tamil consonants that include compound characters such as  etc., in the ancient Tamil style of palaeography.
etc., in the ancient Tamil style of palaeography.

a Tamil vowels, b Sanskrit, c Grantha, and d Tamil consonants.
Top-performing classes are characters like  (brahmi),
(brahmi),  (grantha),
(grantha),  , and
, and  — each of which achieved a perfect or near-perfect F1-score of 1.00. This indicates the model can classify these letters with extremely high precision and recall, meaning it rarely misclassifies or misses these characters. Mid-range classes include letters like
— each of which achieved a perfect or near-perfect F1-score of 1.00. This indicates the model can classify these letters with extremely high precision and recall, meaning it rarely misclassifies or misses these characters. Mid-range classes include letters like  , and
, and  , with F1-scores roughly between 0.94 and 0.98. These classes still perform well, but with slightly more classification errors compared to the top group. For example, the letter
, with F1-scores roughly between 0.94 and 0.98. These classes still perform well, but with slightly more classification errors compared to the top group. For example, the letter  shows a precision of 0.95 and a recall of 0.94, indicating some minor confusion or missed predictions. Lower-performing classes consist of characters such as
shows a precision of 0.95 and a recall of 0.94, indicating some minor confusion or missed predictions. Lower-performing classes consist of characters such as  , where F1-scores dip to between about 0.90 and 0.97. For instance, the vowel marker
, where F1-scores dip to between about 0.90 and 0.97. For instance, the vowel marker  has the lowest F1-score of 0.91, meaning the model sometimes confuses this mark or fails to detect it accurately, showing the model finds it challenging to classify reliably.
has the lowest F1-score of 0.91, meaning the model sometimes confuses this mark or fails to detect it accurately, showing the model finds it challenging to classify reliably.
Comprehensive performance metrics for Signary recognition
The following is a graph of the accuracy and loss during training and validation of Classic CNN and SignaryNet are shown in Fig. 19. The training, validation and testing accuracies of the C-CNN model and SignaryNet also have been compared.

C-CNN and SignaryNet Training/validation accuracy and loss.
In the SignaryNet model, an anomaly occurred at epoch 8, where validation accuracy briefly declined and validation loss spiked. This transient fluctuation was not sustained, as both metrics recovered by epoch 9 and continued on a steady improvement trajectory, indicating that the model retained its generalization capability without long-term adverse effects. Such a temporary dip differs from classic overfitting, which typically causes a prolonged degradation in validation performance with continuously increasing loss and decreasing accuracy. The most plausible explanation for this transient anomaly is that the model was still operating under a relatively high learning rate before any adjustments were made by the ReduceLROnPlateau scheduler. This reduces the learning rate only after the validation loss has plateaued for several epochs, so at epoch 8, the learning rate would still be high. High learning rates are known to cause momentary instability, as the optimizer may overshoot optimal regions in the loss landscape, resulting in the observed transient spike in validation loss and dip in accuracy. Despite disabling dropout during validation, the stochastic nature of dropout during training still influences the weights learned in each epoch. This stochasticity can cause fluctuations in generalization performance on the validation set, especially during early to mid-training when the model is still converging. An elevated learning rate at this stage may have led to parameter updates that momentarily moved the model away from some generalizable minima, explaining the spike in validation loss. However, the very next epoch (epoch 9) saw validation accuracy shoot back up to 96.00% with improved loss, showing that the model quickly recovered. The overall training and validation metrics trend remained smooth and steadily improving. This brief fluctuation highlights the importance of combining learning rate scheduling with stable validation procedures when training deep learning models.
The signary recognition rate (SRR) is a crucial metric used to evaluate the overall performance. SRR, as in Eq. (24), calculates the percentage of characters that the model correctly identifies out of the total characters it is tasked to recognize. It provides a direct measure of the model’s accuracy in recognizing the characters, where a higher SRR indicates better performance in terms of correct classifications. Additionally, precision as in Eq. (25), recall as in Eq. (26), and F1 score as in Eq. (27) are other important metrics. Precision measures how many of the predicted positive classes (recognized characters) are actually correct, while recall evaluates how many of the true positive classes (actual characters) were correctly identified by the model. The F1 score, being the harmonic mean of precision and recall, provides a balanced metric that takes into account both false positives and false negatives.
In a 100-class inscription character classification issue, having high values for sensitivity, specificity, and NPV, combined with low values for FNR, FDR, and FPR, will ensure that the model is effective, dependable, and accurate in categorizing images correctly. In the context of inscription character classification, negative predictive value (NPV) tells how reliable the model is when it predicts that an image belongs to one of the negative classes (i.e., a class that is not the correct label for a given image). A high NPV ensures that when the model predicts a character does not belong to a particular class, that would mean that this prediction is likely to be accurate, ensuring fewer false negatives among all the negative predictions. A high NPV (>0.85) indicates that the model makes accurate predictions for characters that do not belong to the actual class, which means that the model can reliably exclude incorrect classes. It is represented as in Eq. (28).
Specificity or true negative rate (TNR) is particularly important when there are many classes, such as in a 100-class problem. It measures the model’s ability to correctly reject the incorrect classes (i.e., avoiding false positives). In the case of inscription character recognition, specificity would indicate how often the model correctly identifies an image as not belonging to a specific class. A high specificity (>0.85) indicates that the model is effective at recognizing images that do not belong to a certain class, which is particularly useful when distinguishing between numerous similar-looking characters in the dataset. It is represented as in Eq. (29).
Sensitivity or true positive rate (TPR) is critical in cases where it is more important to correctly identify the positive class (i.e., correctly classify a character from one of the 100 classes). In the context of inscription characters, high sensitivity would mean that the model correctly identifies characters from the true class most of the time. For example, if the correct character is a “vowel” from a specific set of characters and the model correctly predicts this, the sensitivity is high. A high sensitivity (>0.90) correctly identifies characters from the true class, especially when the script is complex with many visually similar characters from each of the 100 classes, minimizing the false negatives. It is represented as in Eq. (30).
False negative rate (FNR) evaluates how frequently the model incorrectly assigns an image to the wrong class instead of its actual class, indicating a misclassification. In the case of inscription characters, a low FNR (<0.10) means the model does not miss true positives, ensuring that characters from the true class are correctly detected. It is represented as in Eq. (31).
False discovery rate (FDR) measures the proportion of positive predictions that are actually incorrect. In the case of inscription characters, it helps determine how often the model is misclassifying characters by predicting them as belonging to a certain class when they do not. A low FDR (<0.10) means fewer false positive predictions, making the model more reliable in assigning characters to the correct classes and less likely to falsely predict incorrect characters as belonging to a certain class. It is represented as in Eq. (32).
False positive rate (FPR) indicates how often the model incorrectly classifies an image as belonging to a certain class when it does not. In the case of inscription character recognition, a low FPR is critical for ensuring that the model does not incorrectly label a character as belonging to a class it does not belong to, ensuring that the FPR is low helps the model avoid confusing one class for another, thereby improving the precision of the model’s predictions. It is represented as in Eq. (33). The metrics are computed for Classic-CNN and SignaryNet as follows:
Table 6 compares two deep learning models—Classic-CNN and SignaryNet—across various evaluation parameters and performance metrics. It is evident that SignaryNet significantly outperforms Classic-CNN in nearly all areas. Training, validation, and testing accuracies for SignaryNet are notably higher, indicating better learning and generalization capabilities. The Testing accuracy and signary recognition rate (SRR) are computed from the 10000 test samples of real-time inscription data. SignaryNet model’s precision (98.57%) and recall (98.52%) indicate that it accurately predicts relevant classes with minimal false positives and negatives, resulting in a strong F1-score (98.54%), demonstrating exceptional accuracy in correctly identifying both positive and negative cases. Specificity and sensitivity are higher for SignaryNet, while its error metrics—FNR, FDR, and FPR—are remarkably low, confirming its reliability. The model also achieves high specificity, NPV, and AUC (0.9203), highlighting its robust performance in distinguishing characters and rejecting incorrect ones. Furthermore, the low FNR (1.48%), FDR (1.43%), and FPR confirm the model’s reliability in minimizing classification errors. The area under the curve (AUC) for SignaryNet also surpasses that of Classic-CNN (0.8474), highlighting superior overall model performance. These results demonstrate SignaryNet’s superior accuracy and more balanced classification performance, offering better precision, recall, and overall efficiency than Classic CNN. These metrics are plotted as in Fig. 20.

Comparison plot of model performance of C-CNN vs SignaryNet.
When dealing with multi-class situations, such as identifying 100 inscription characters, ROC-AUC is helpful. Receiver operating characteristic (ROC) curves show the trade-off between false positive rate and true positive rate (sensitivity) across various classification thresholds in inscription signatory classification. The model’s overall ability to differentiate between classes is measured by the area under the curve (AUC); a score around 1 denotes exceptional performance. The model performs better at prioritizing true classes over false ones when its AUC is larger. The Fig. 21a illustrates how performance metrics for several classes are processed, with a particular emphasis on recall values and true positive (TP) rates for the analysis of classification accuracy. By deducting true positives and true negatives (derived via recall) from the overall sample count, it determines the false positive (FP) rate for each class, which is used to calculate the false positive rate (FPR) for each class. To assess classifier performance across many classes, the data is presented on a scatter plot, which shows the link between FPR and true positive rate (TPR). A Receiver Operating Characteristic (ROC) curve is displayed in Fig. 21b to assess binary classification performance using recall scores. Each class is given a binary label: classes are classified as positive (1) if their true positive rate (TPR) is 0.97 or above, and as negative (0) if it is <0.97. The classifier’s confidence score is represented by the recall value. The ROC curve is generated by computing the TPR and FPR at various decision boundary levels based on the predicted scores and corresponding ground truth labels. The overall classification performance is also measured using AUC, which comes out to be 0.9203. With a diagonal reference line showing random performance, the ROC curve is shown, enabling a visual evaluation of how well the classification is performed.

a FPR vs. TPR and b ROC curve.
Comparison of DPB method over benchmark datasets
The DPB technique has been examined on the benchmark datasets for CVSI 2015, SIW-13, and the Ancient Tamil script, gathered from Wikipedia sources and available in a GitHub repository. The samples of Tamil script images used for the experimentation are available from the CVSI 2015 dataset, which contains 50-word images, the SIW-13 dataset, which contains 321 multiscript printed line images, and 2118 multiscript printed word images, and the GitHub dataset, which contains 253 inscription line images but is much smaller than our dataset. The images are pre-processed, resized to a minimum height and width of 100 × 500, and then the proposed DBP technique is used. For the SIW-13 (Printed) dataset, the SLR accuracy is 92.64% and 94.73%, respectively, indicating strong performance on both granular levels of script recognition. In the CVSI-2015 dataset, which features 50 line images derived from scene text, the SLR remains high at 94.73%, demonstrating the model’s robustness in complex visual contexts. Lastly, the GitHub Scripts dataset, with 253 line images, shows the highest accuracy at 96.15%, suggesting that the model performs exceptionally well on clean, script-based textual content. The approach is effective for the images, and sample outcomes of the proposed approach for the dataset images are shown below in Fig. 22 and included with the localization rate in Table 7.

DPB method applied over sample images of benchmark datasets.
Comparison of DBP method over state-of-the-art methods
The state-of-the-art methods of character localization approaches have been tested on inscription images, although they yielded less accurate results. The majority of survey work employs techniques like contouring, convex hulls, and normal bound boxes. Convex hull representations are made by identifying neighbouring pixels with the same intensity that defines the convex polygon’s shape. By joining the points that are continuous along the boundary and have the same intensity, contouring is a technique for identifying structural outlines or boundaries. The boundaries of the existing bound box technique are points on a patch of a region of interest.
The proposed DPB technique and the other state-of-the-art methods are applied over script images and the localized signary shown in Fig. 23 and the comparison of localization rate is described in Table 8.

DPB method over state-of-the-art methods sample script images.
Compared to state-of-the-art approaches, there is an improved rate of performance with the proposed technique. Figure 24 is a plot of the localization rate for sample instances.

Plot of SLR comparison over state-of-the-art methods.
Comparison of DPB method over different inscription test cases
The results of the existing methods show that the characters are improperly localized and out of order after localization. Characters are perfectly localized and in the right order as a result of the technique proposed. As test cases for the proposed DPB approach, followed by signary localization, a few sample line-localized images are provided. Table 9 displays the ideal scenario in which every character is precisely localized, as well as the typical scenario with unbounded and touching characters. Demonstrating the worst-case line image, some characters are improperly localized when they have degraded characters and less space or constricted writing between characters. Each image’s localization rate is provided.
Comparison of SignaryNet over benchmark datasets
The SignaryNet model, implemented over the SIW-13 dataset, has a total of 683,495 parameters, with an approximate total memory footprint of 2.61 MB. This makes the model compact and well-suited for deployment in environments with limited computational resources. SIW-13 dataset, which has been pre-processed and split into 71 classes, that includes 28,400 training images and 7100 validation images, indicating a well-balanced train-validation split (roughly 80–20), ensuring enough data for both model learning and performance evaluation. The dataset comprises 71 classes, categorized into 6 vowels, 2 Sanskrit characters, 15 pure consonants, and 48 consonants. In modern Tamil, consonants with a dot at the top are called pure consonants, and they are produced without the involvement of any vowel. The training process reached epoch 32, where the model achieved nearly perfect training accuracy, with a very low validation loss of approximately 2.75e−05. The learning rate was progressively reduced via ReduceLROnPlateau, helping fine-tune the model further, and at this point was automatically reduced to 3.91 × 10−6 by the call-back, indicating convergence and minimal further improvement, effectively marking this as a logical stopping point. The model outline is given in the Fig. 25a. The classification metrics for the SignaryNet model indicate strong performance, with 6635 true positives and 546 true negatives, meaning most characters were accurately recognized. There were relatively few errors, with 79 false positives and 56 false negatives, showing that misclassifications were minimal. Confusion matrices for the SIW-13 dataset are visualized in Fig. 26a–d.

a Model summary of SIW-13, b Model summary of CVSI-15, c model summary of Wikipedia ancient script, d accuracy plot of SIW-13, e accuracy plot of CVSI-15, and f accuracy of Wikipedia script.

a Vowels, b Sanskrit, c pure consonants, and d consonants.
The SignaryNet model was applied to the CVSI-15 to recognize 65 distinct classes. The model contains a total of 681,953 parameters, occupying ~2.60 MB of memory. The dataset is divided into 26,000 training images and 6500 validation images, ensuring a balanced split for effective learning and evaluation. The dataset includes a total of 65 character classes, consisting of 6 vowels, 3 Sanskrit-specific characters, 13 pure consonants, and 43 standard consonants. The SignaryNet model trained on the CVSI-15 dataset, by the 25th epoch, while validation loss consistently decreased to 0.0039, indicating effective learning and generalization. The learning rate was adaptively reduced using call-backs, it had decreased to 6.25e−05, enabling the model to make finer adjustments, helping the model fine-tune its performance and stabilize around minimal validation loss from epoch 15 onward. The model summary is given in the Fig. 25b. The model’s performance shows it correctly identified 6000 true positives and 442 true negatives, while misclassifying 78 instances as false positives and 60 as false negatives. Confusion matrices are visualized in Fig. 27a–d.

a Vowels, b Sanskrit, c pure consonants, and d consonants.
The model is implemented over Wikipedia Ancient Tamil script dataset for classifying 64 different character classes, with a total of 681,120 parameters and a memory footprint of approximately 2.60 MB. It was trained on 25,600 images and validated on 6400 images. The character dataset consists of 64 distinct classes, including 7 vowels, 2 Sanskrit characters, 3 Grantha characters, and 52 consonants. The learning rate was adaptively reduced through the call-backs, starting from 0.001 and decreasing incrementally to as low as 4.88e−07 to fine-tune the learning process. The model report is given in Fig. 25c. The classification results indicate strong performance with 6000 true positives, meaning the model correctly identified 6000 relevant samples, while 368 true negatives show accurate rejection of irrelevant ones. The lower numbers of 39 false positives and 32 false negatives suggest high precision and recall. Confusion matrices for the Wikipedia Ancient script dataset are visualized in Fig. 28a–d.

a Vowels, b Sanskrit, c grantha, and d consonants.
Table 10 presents a comparative analysis of SignaryNet’s performance across three benchmark datasets: SIW-13 (Printed), CVSI-2015 (Scene Text), and Wikipedia Ancient Tamil Script. The model demonstrates consistently high accuracy across all datasets, with training accuracies ranging from 0.9600 to 0.9916 and validation accuracies exceeding 0.9880. Testing accuracy is also strong, peaking at 0.9890 for the Wikipedia dataset. The Testing accuracy and signary recognition rate (SRR) are computed from the validation set for all the benchmark datasets. Precision and recall values are uniformly high, reflecting SignaryNet’s robust capability in correctly classifying characters while minimizing both false positives and false negatives. The model achieves the highest F1 score (0.9944) on the Ancient Tamil script dataset, indicating excellent balance between precision and recall. While specificity is slightly lower for CVSI-2015 (0.8500), the model maintains high sensitivity across all datasets (above 0.9900), confirming its reliability in detecting true positives. The Area Under Curve (AUC) values—ranging from 0.9201 to 0.9500—further affirm the model’s overall classification strength, with the Ancient Tamil script dataset showing the most balanced and precise performance. The training, validation accuracy and loss plots are shown in the Fig. 25d–f.
Although the proposed model demonstrates high test accuracies from the validation data—98.16% for SIW-13, 97.80% for CVSI-2015, and 98.90% for the Ancient Tamil script dataset—its real-time performance on new and real data from the same domain is slightly lower. Therefore, a conservative drop of 1–5% in real-time accuracy is observed. Factors such as domain variability, limited dataset size, potential overfitting to the training distribution, and inconsistencies in pre-processing can contribute to this drop. As a result, the accuracy is around 95–97% for SIW-13, 93–96% for CVSI-2015, and 94–97% for the Wikipedia Ancient script dataset.
Comparison of C-CNN and SignaryNet over inscription test cases
The DPB algorithm is used to process the improved line image samples for localization, while Classic CNN and SignaryNet are used for signary recognition. Table 11 compares two handwriting recognition models, C-CNN and SignaryNet, on inscription line images under various conditions. Each test case represents a different type of image input: noiseless, condensed, average, and noisy. For example, in Case 1, where the input image is clear and noiseless, SignaryNet accurately recognizes the text as “ ” with 100% accuracy. At the same time, C-CNN produces “
” with 100% accuracy. At the same time, C-CNN produces “ ”, achieving only 69.23% accuracy, indicating some recognition errors. In Case 2, with condensed writing where characters are closely packed, both models perform well—C-CNN reaches 87.5% accuracy and SignaryNet achieves 93.75%, demonstrating the DPB models’ capacity to handle tightly inscribed text. For average-quality input in Case 3, C-CNN identifies most of the characters but misses some, resulting in 75% accuracy, while SignaryNet maintains higher accuracy at 92.30%, recognizing the line almost perfectly. In the most challenging scenario, Case 4 with noisy or distorted input, both models show a decline in performance; C-CNN drops to 60%, while SignaryNet still performs better at 78.57%. These results show that SignaryNet is more robust and accurate across varying image qualities, making it better suited for real-world Tamil inscription recognition tasks.
”, achieving only 69.23% accuracy, indicating some recognition errors. In Case 2, with condensed writing where characters are closely packed, both models perform well—C-CNN reaches 87.5% accuracy and SignaryNet achieves 93.75%, demonstrating the DPB models’ capacity to handle tightly inscribed text. For average-quality input in Case 3, C-CNN identifies most of the characters but misses some, resulting in 75% accuracy, while SignaryNet maintains higher accuracy at 92.30%, recognizing the line almost perfectly. In the most challenging scenario, Case 4 with noisy or distorted input, both models show a decline in performance; C-CNN drops to 60%, while SignaryNet still performs better at 78.57%. These results show that SignaryNet is more robust and accurate across varying image qualities, making it better suited for real-world Tamil inscription recognition tasks.
Comparison of C-CNN and SignaryNet over benchmark dataset’s test cases
Table 12 compares the performance of two models—Classic CNN and SignaryNet—on benchmark datasets featuring Tamil printed text, including modern and ancient scripts. Three distinct test scenarios are evaluated. In the SIW-13 word image case, the ground truth word is “ ”, where C-CNN recognizes it as “
”, where C-CNN recognizes it as “ ”, with some character errors, resulting in an accuracy of 60%, while SignaryNet perfectly recognizes the word with minor errors contributing to 87.5%. The second case, from the CVSI-15line image dataset, involves the word “
”, with some character errors, resulting in an accuracy of 60%, while SignaryNet perfectly recognizes the word with minor errors contributing to 87.5%. The second case, from the CVSI-15line image dataset, involves the word “ ”; C-CNN outputs a slightly flawed “
”; C-CNN outputs a slightly flawed “ ”, achieving 66.66% of accuracy, whereas SignaryNet again delivers 90% accuracy. The most complex input comes from the Wikipedia Ancient Tamil script, with a long and intricate sequence. C-CNN introduces some recognition errors, reducing its accuracy to 88%, while SignaryNet accurately reproduces the entire sequence, maintaining complete accuracy. These results highlight that SignaryNet outperforms Classic CNN across diverse data types, showing particular strength in handling complex and ancient Tamil script with high precision. The DPB is used for signary localization respectively.
”, achieving 66.66% of accuracy, whereas SignaryNet again delivers 90% accuracy. The most complex input comes from the Wikipedia Ancient Tamil script, with a long and intricate sequence. C-CNN introduces some recognition errors, reducing its accuracy to 88%, while SignaryNet accurately reproduces the entire sequence, maintaining complete accuracy. These results highlight that SignaryNet outperforms Classic CNN across diverse data types, showing particular strength in handling complex and ancient Tamil script with high precision. The DPB is used for signary localization respectively.
Comparison of DPB and SignaryNet over sample inscriptions
As shown in Table 13, the raw inscription samples were obtained with varying backgrounds and under various restrictions on inscribing styles. There are 145 characters in the first sample, 88 in the second, 231 in the third, and 272 in the fourth. Using the model, they correctly identified 138, 80, 204, and 237 characters in each script. They are improved, signary localization is completed using the DPB technique, signary recognition is done using SignaryNet for each script sequence separately, and SLR and SRR rates are provided. The values represent accuracy percentages, where SLR ranges from 92.64% to 98.62% and SRR from 87.13% to 95.17%. This demonstrates that under different inscriptional conditions, the increased accuracy in signary localization translates into greater accuracy in signary identification.
Discussion
As evidenced by the results across diverse datasets, including CVSI 2015, SIW-13, and a Tamil inscription dataset from GitHub, the proposed DPB consistently achieves higher SLR, indicating its robustness in handling varied scripts and image qualities. Unlike existing methods that often struggle with misaligned or out-of-order character outputs, especially in the presence of degraded or closely packed scripts, DPB effectively preserves the structural and sequential integrity of the characters. Its ability to dynamically adapt to the image content allows for better localization even in challenging conditions, such as inscriptions with noise or minimal inter-character spacing. These results suggest that DPB can be a reliable foundation for downstream tasks such as script signary recognition and digital epigraphy, offering both accuracy and generalizability across multiple datasets.
SignaryNet implications over Classic-CNN features prove that SignaryNet is superior to C-CNN due to several critical innovations, novel tuning refinements, architectural adjustments, hyperparameter optimizations, and specific methodologies that enhance its ability to recognize ancient Tamil inscriptions effectively. Typical CNN models start by applying a series of convolution operations followed by down-ampling layers to reduce spatial dimensions. In contrast, SignaryNet uses deeper layers with increasingly larger numbers of filters. This increased depth allows the model to extract more complex hierarchical features from the image data, which is crucial for recognizing nuanced characters in ancient inscriptions. The model optimizes pooling with smaller strides to avoid excessive resolution loss. SignaryNet applies non-standard convolutional kernel sizes that are tailored to better capture the unique characteristics, stroke variations, and subtle features in small signary and broader patterns in larger ones of Tamil script. SignaryNet employs self-tuning learning step techniques that change the step size. The batch size for training SignaryNet is set to 64, effective balance between computational effectiveness and parameter confluence when applied to inscriptions. A frequent issue encountered when training deep neural networks is the occurrence of exploding gradients, which is particularly problematic in networks with many layers. SignaryNet uses gradient clipping to limit the gradients during backpropagation, ensuring that the model does not suffer from instability during training. This technique helps prevent large updates that could damage the model’s learning.
Furthermore, SignaryNet leverages hybrid precision training and XLA compilation, enabling quicker computation and reduced memory usage. This increased capacity in SignaryNet facilitates more effective learning, especially in large-scale datasets with high class diversity. However, these advantages come with certain limitations. The model is heavier and more complex, requiring additional GPU or CPU resources, and has a slightly longer training time per epoch due to its depth and the inclusion of batch normalization. In contrast, the classic CNN, with roughly 1.25 million parameters, making it about 46% smaller, is simpler and lighter, resulting in faster training and greater suitability for low-resource environments or rapid prototyping. Nevertheless, its lack of normalization, data augmentation, and fewer layers limits its ability to generalize well on complex or large-scale datasets, increasing the risk of overfitting, which leads to quicker training per epoch and lower computational requirements—ideal for prototyping, quick experimentation, or deployment in resource-constrained environments. Overall, SignaryNet is better suited for achieving high accuracy and production-scale applications and is suitable for more than 100-class inscription dataset, while the classic CNN remains an efficient choice for lightweight and edge applications. These advancements allow SignaryNet to recognize signary with robustness, making it a powerful tool for heritage preservation and inscription recognition. The features are compared in Table 14.
The proposed work on literary works is also discussed. The survey’s closely related existing works were examined, and the results of their overall analysis, as well as the proposed work and their datasets, accuracy of localization, and recognition techniques, are tabulated in Table 15 and the plot of comparison is displayed in Fig. 29.

Plot literary works vs. proposed.
The digital preservation of the heritage content from the scripts and the possibility to construct a digital archive of the heritage content of inscriptions with transcripts and metadata for the images of the stone inscription script is more than enough. The images of the inscriptions and their locations within the temple walls can be categorized and preserved according to the walls, such as north, east, west, south, entrance, portico, and pillars. The transcript of the inscription sequence is displayed in Fig. 30. The sequence of images organized according to temple wall locations, improved inscription visuals, character image progressions, and the transliterated forms of each script can all be compiled and digitally saved, conserved, and maintained together with the inscription IDs in libraries for future access.

Inscription sequence with its recognized signary transcript.
The proposed work holds significant value in advancing the digital preservation and recognition of ancient Tamil inscriptions, which are repositories of cultural and historical heritage. By introducing the dynamic profiling bound (DPB) method for character localization and the SignaryNet model for classification, this research effectively addresses long-standing challenges in the segmentation and recognition of ancient script images. The integration of advanced image pre-processing techniques, morphological operations, and vertical projection profiling significantly improves character localization accuracy. Moreover, the development of SignaryNet—a deep convolutional neural network fine-tuned for classifying 100 distinct characters—achieves superior performance in recognizing ancient Tamil, Grantha, and Sanskrit scripts, far outperforming baseline models such as Classic-CNN. The model architecture preserves fine spatial details crucial for ancient script recognition through zero-padding and careful filter design. Training strategies like early stopping and ReduceLROnPlateau enabled efficient convergence and strong generalization. The classification report further confirms exceptional performance across all classes, with most characters achieving near-perfect precision, recall, and F1 scores. The significance of this research is further underscored by its scalability and adaptability. Overall, the work contributes a reliable solution for the automated transcription of inscriptions, aiding in the digital archiving and study of inscription palaeography.
However, further refinements are required for broader applicability and real-time deployment in heritage conservation. The system’s performance depends on high-quality, accurately labelled datasets for training, and its accuracy may decrease when inscriptions are highly degraded. While the method handles noise and segmentation issues effectively, extreme deterioration, complex stroke variations, and minor input variations may still pose challenges. Environmental factors like lighting, camera angles, or resolution can also impact the model’s performance. Additionally, the model’s generalization to other scripts or ancient languages is uncertain. One key limitation is the scarcity of high-quality labelled data, which is often difficult to obtain for historical texts. The model may also struggle with generalization if trained on data that doesn’t reflect the full range of real-world scenarios. Finally, tasks like data annotation, classification of localized characters dataset creation, and error analysis may require significant language expertise.
The proposed dynamic profiling bound (DPB) approach for signary localization and SignaryNet for ancient stone inscriptions presents a significant advancement in digital preservation and recognition of historical heritage, particularly for the Brihadisvara temple by creating a digital archive. The work’s main importance is enhancing the Signary recognition and accurately extracting and preserving the heritage content of the historical inscriptions. The methodology effectively addresses the challenges posed by deteriorated, noisy, and unconstrained stroke writings commonly found in ancient inscriptions. The proposed signary localization methodology addresses the shortcomings of state-of-the-art segmentation methods, such as convex hull, contour creation, bounded boxes without coordinates, and profiling. The integration of techniques like morphological operations and the incorporation of the DWT for noise removal and various image processing strategies effectively handles issues, such as over- and under-segmentation, as well as overlapping and space-constrained characters. By employing DPB for signary localization, the model achieves an impressive localization rate of 98.25%, which outperforms existing segmentation techniques. This localization rate ensures the accurate identification of individual character images without misplacing or missing components of the character strokes. The suggested technique divides the characters precisely, avoiding any loss or missing modifiers, i.e., supporters of consonant base characters such as  or strokes belonging to the same character. To maintain continuity in recognition, the character images are localized in the same sequence as they appear in the script image. The proposed approach is used on test instances with different types of inscription images and benchmark dataset images, and the outcomes are compared and assessed against cutting-edge techniques with improved segmentation of space-constrained, degraded, and complex characters, including Tamil, Grantha, and Sanskrit scripts. Subsequently, the SignaryNet model, a fine-tuned deep CNN, uses the localized character images with the appropriate class and Unicode that are used to train the model, which outperforms traditional models like Classic-CNN by attaining a validation accuracy of 98.61% and a prediction accuracy of 96.81% across 100 character classes. Experiments were conducted on signary localization and signary recognition, and then the SLR and SRR were computed for test sample-enhanced images. The work showcases the model’s potential in the anticipated transliteration of the inscription image into the signary sequence of modern Tamil, making it suitable for real-world applications in the field of digital heritage conservation.
or strokes belonging to the same character. To maintain continuity in recognition, the character images are localized in the same sequence as they appear in the script image. The proposed approach is used on test instances with different types of inscription images and benchmark dataset images, and the outcomes are compared and assessed against cutting-edge techniques with improved segmentation of space-constrained, degraded, and complex characters, including Tamil, Grantha, and Sanskrit scripts. Subsequently, the SignaryNet model, a fine-tuned deep CNN, uses the localized character images with the appropriate class and Unicode that are used to train the model, which outperforms traditional models like Classic-CNN by attaining a validation accuracy of 98.61% and a prediction accuracy of 96.81% across 100 character classes. Experiments were conducted on signary localization and signary recognition, and then the SLR and SRR were computed for test sample-enhanced images. The work showcases the model’s potential in the anticipated transliteration of the inscription image into the signary sequence of modern Tamil, making it suitable for real-world applications in the field of digital heritage conservation.
For future fine-tuning, to smooth out transient dips in validation performance, the initial learning rate can be slightly reduced (e.g., from 0.001 to 0.0008) to minimize the chance of overshooting optimal regions in the loss landscape. Additionally, using validation_freq = 2 during training can help skip every other validation check, which not only speeds up training but also reduces validation noise, leading to more stable performance tracking. With or without minor changes to the hyper-parameters, the suggested approach can also be used to generalize the model to inscriptions in other languages. The Kancheepuram region’s inscription images from the 7th to 10th centuries of the Chola period, as well as other century-old inscription images, are intended to be utilized with the model. Future improvements will include the use of hybrid deep learning methods for signary recognition. Proper data collection, data labelling, and binning of the character image datasets from the localized signary with expertise can further enhance recognition accuracy. Another improvement in the future will be the application of language models, natural language processing techniques, and transformers for the word and context recognition of the inscription character sequence. The model’s applicability in epigraphy and linguistic studies can be increased by using it as a basis for cross-lingual inscription analysis. Additionally, by creating expert-annotated datasets and improving Unicode mapping, a basic model can be trained by adjusting it according to the available inscription dataset. Both the transliteration of the sequential scripts and interpretable scripts from the inscriptions are provided by this research. This will provide a platform for the extraction of valuable information from them through inscription mining. It not only supports historical research but also opens new possibilities for education, cultural engagement, and the democratization of ancient knowledge by making these inscriptions accessible to linguists, historians, archaeologists, and the public, with the dual purpose of cultivating a pool of heritage-based researchers. Digital preservation can ensure the future availability of cultural heritage resources before they undergo significant deterioration.
Data availability
The datasets generated and analysed during the current study are available in the Inscriptionimagedataset repository, which is the minimal dataset. figshare. 2024; https://figshare.com/articles/dataset/Inscriptionimagedataset_pdf/25523005, https://doi.org/10.6084/m9.figshare.25523005.
Code availability
The complete code developed in this article is available from the corresponding author upon requesting.
References
Subramanian, T. S. Written in stone—Big Temple’s inscriptions reveal a King’s passion. The Hindu e-paper https://www.thehindu.com/features/friday-review/history-and-culture/Written-in-stone-Big-Temples-inscriptions-reveal-a-Kings-passion/article16047268.ece (2021).
World Heritage Committee. Great Living Chola Temples. The List. UNESCO World Heritage Convention license CC-BY-SA IGO3.0 https://whc.unesco.org/en/list/250/ (2004).
Balasubramanyam, S. R. Middle Chola Temples 1–670 (Thomson Press (India) Limited Publication Division, Central Archaeological Library, Department of Archaeology, New Delhi, 1975).
Agrawal, Y. et al. Optical character recognition using convolutional neural networks for Ashokan Brahmi inscriptions. Computer Vision and Pattern Recognition. https://arxiv.org/abs/2501.01981. https://doi.org/10.48550/arXiv.2501.01981 2024.
Velmathi, G., Shangavelan, M., Harish, D., Krithikshun, M. S. Image-based character recognition, documentation system to decode inscription from temple. Computer Vision and Pattern Recognition. 2024. https://arxiv.org/abs/2405.17449.
Giridhar, L. et al. A novel approach to OCR using image recognition-based classification for ancient Tamil Inscriptions in temples. Computer Vision and Pattern Recognition. 2019: 1–7. https://arxiv.org/abs/1907.04917.
Devi, P. M. & Sornam, M. Classification of ancient handwritten Tamil characters on palm leaf inscription using modified adaptive backpropagation neural network with GLCM features. ACM Trans. Asian Low-Resour. Language Inf. Process. 19-6, 1–24 (2020).
Parul, S. & Sanjay, B. D. Multilingual character segmentation and recognition schemes for Indian document images. IEEE Access 6, 10603–10617 (2018).
Savitha, C. K. & Antony, P. J. PNN and deep learning based character recognition system for Tulu manuscripts. Int. J. Eng. Adv. Technol. Blue Eyes Intell. Eng Sci. Publ.(BEIESP) 8, 2249–8958 (2019).
Zin, T. T., Thant, S., Pwint, M. Z. & Ogino, T. Handwritten character recognition on android for basic education using convolutional neural network. Electronics 10-8, 904 (2021).
Raj, A. R. M. & Abirami, S. Structural representation-based off-line Tamil handwritten character recognition. Soft Comput. 24, 1447–1472 (2020).
Baranidharan, V., Kiruthiga, V., Sudhakar, K. & Lokesh, N. V. Bounding box method based accurate vehicle number detection and recognition for high speed applications. ICTACT J. Image Video Process. 09, 1867–1871 (2018).
Gaikwad, S. S., Nalbalwar, S. L. & Nandgaonkar, A. B. An approach towards Devanagari character segmentation using adaptive thresholding and polynomial. Int. J.Adv. Sci. Technol. 29, 7888–7896 (2020).
Malik, S. et al. An efficient skewed line segmentation technique for cursive script OCR. Sci. Program. 2020, 1–12 (2020).
Antony Robert Raj, M., Abirami, S. & Shyni, S. M. Tamil handwritten character recognition system using statistical algorithmic approaches. Comput. Speech Language 78, 101448 (2023).
Bannigidad, P. & Gudada, C. Historical Kannada handwritten scripts recognition system using line segmentation with LBP features. Alliance International Conference on artificial intelligence and Machine learning (AICAAM). Int. J. Comput. Sci. Eng. 7-3, 754–763 (2019).
Mohamed Sathik, M. & Spurgen Ratheash, R. Optimal character segmentation for touching characters in Tamil language palm leaf manuscripts using Horver method. International Journal of Innovative Technology and Exploring Engineering (IJITEE). Blue Eyes Intelligence Engineering &. Int. J. Eng. Adv. Technol. Blue Eyes Intell. Eng Sci. Publ. (BEIESP) 9-6, 2278–3075 (2020).
Sudarsan, D. & Sankar, D. Development of an effective character segmentation and efficient feature extraction technique for Malayalam character recognition from palm leaf manuscripts. Sådhanå Indian Acad.Sci. 48, 156 (2023).
Islam, M. A. & Iacob, I. E. Manuscripts character recognition using machine learning and deep learning. Modelling 4, 168–188 (2023).
Kavitha, B. R. & Srimathi, C. Benchmarking on offline handwritten Tamil character recognition using convolutional neural networks. J. King Saud University—Comput. Inf. Sci. 34, 1183–1190 (2022).
Parikshith, H., Naga Rajath, S. M., Shwetha, D., Sindhu, C. M. & Ravi, P. Handwritten Character Recognition of Kannada Language Using Convolutional Neural Networks and Transfer Learning, Materials Science and Engineering 1110, 012003 (IOP Publishing, 2021).
Zhang, C. et al. Character-level street view text spotting based on deep multi segmentation network for smarter autonomous driving. IEEE Trans. Artif. Intell. 3, 297–308 (2022).
Wang, B., Xia, H., Zheng, J., Yu, D. & Chen, C. L. P. Character segmentation and recognition of variable-length license plates using ROI detection and broad learning system. Remote Sens. 14, 1560 (2022).
Yadav, M., Purwar, R. K. & Mittal, M. Handwritten Hindi character recognition: a Review IET Image Processing. IET Image Process. 12, 1919–1933 (2018).
Wang, X., Du, H. & Wen, X. Research on segmentation and recognition of printed Chinese characters. J. Phys. Conf. Ser. 1237, 022011 (2019).
Shobha Rani, N. & Vasudev, T. A block level segmentation of touching and overlapping characters in Telugu printed and handwritten documents using iterative split analysis technique. Int. J. Mach. Intell. 6, 458–465 (2015).
Patel, M. & Thakkar, S. P. Handwritten character recognition in English: a survey. Int. J. Adv. Res. Comput. Commun. Eng. 4, 345–350 (2015).
Chan, C. Stroke extraction for offline handwritten mathematical expression recognition. IEEE Access 8, 61565–61575 (2020).
Meng, Z. et al. Braille character segmentation algorithm based on Gaussian diffusion. Comput. Mater. Continua 79, 1481–1496 (2024).
Bhunia, A. K. et al. Script identification in natural scene image and video frames using an attention-based Convolutional-LSTM network. Pattern Recognit. 85, 172–184 (2019).
Sharma, N., Mandal, R., Sharma, R., Pal, U. & Blumenstein, M. ICDAR2015 Competition on video script identification (CVSI). In 13th IAPR Proceedings of the International Conference on Document Analysis and Recognition (ICDAR), Nancy, France, 1196–1200, (IEEE Computer Society, 2015).
Bhunia, A. AttenScriptNetPR http://github.com/ankanbhunia/AttenScriptNetPR/tree/master/Samples (2018).
Nayef, N. et al. ICDAR2017 Robust reading challenge on multi-lingual scene text detection and script Identification–RRC-MLT. In Proc. 14th IAPR International Conference Document Analysis and Recognition (ICDAR), 224, 1454–1459 (IEEE Xplore, 2017).
Shi, B. et al ICDAR2017 Competition on reading Chinese text in the wild (RCTW-17). In International Conference on Document Analysis and Recognition Proc. ICDAR. pp. 1429–1434 (IEEE, 2017).
Kantipudi, M.V.V.P., Kumar, S. & Jha, A. K. Scene text recognition based on bidirectional LSTM and deep neural network. Comput. Intell. Neurosci. https://doi.org/10.1155/2021/2676780 (2021).
Mei, J., Dai, L., Shi, B. & Bai, X. Scene text script identification with convolutional recurrent neural networks. In 23rd International Conference on Pattern Recognition (ICPR), Cancún Center, Cancún, México, pp. 4042–4047 (IEEE, 2016).
Zhang, C., Ding, W., Peng, G., Fu, F. & Wang, W. Street view text recognition with deep learning for urban scene understanding in intelligent transportation systems. IEEE Trans. Intell.Transp. Syst. 22, 4727–4743 (2021).
Harsh120. Ancient-Tamil-Script-Recognition. http://github.com/Harsh120/Ancient-Tamil-Script-Recognition/ (2020).
Dhuruvapriyan. Tamil Character Classification. http://www.kaggle.com/code/dhuruvapriyan/tamil-character-classification (2019).
Hultzsch, E. Tamil Inscriptions in the Rajarajesvara Temple at Tanjavur and other Miscellaneous Records of the Chola, Pallava and Vijayanagara Dynasties. South Indian Inscriptions Vol. 2 (Government Press, ASI, Government of India, 1991).
Goyal, V., Saxena, R., Chaudhary, A., Bhatt, S. C. & Uniyal, M. The application of discrete wavelet transform in medical image compression. J. Mountain Res. 18, 257–265 (2023).
Bnou, K., Raghay, S. & Hakim, A. A wavelet denoising approach based on unsupervised learning model. EURASIP J. Adv. Signal Process. 36, https://doi.org/10.1186/s13634-020-00693-4 (2020).
Chandrakala, M. et al. Image analysis of Sauvola and Niblack thresholding techniques. Int. J. Res. Appl. Sci. Eng. Technol. 9, https://doi.org/10.22214/ijraset.2021.34569 (2021).
Ezhilarasi, S. & Maheswari, P. U. Inscription image dataset. Figshare. https://figshare.com/articles/dataset/Inscriptionimagedataset_pdf/25523005 (2024).
Acknowledgements
The authors declare that no funding was received for conducting this research. The authors express their gratitude to the Archaeological Survey of India (ASI) for approving data collection.
Author information
Authors and Affiliations
Contributions
E.S. contributed to the material preparation and data collection and analysis, the first draft of the manuscript writing, conceptualization, methodology, formal analysis, and investigation, writing—original draft preparation, writing—review, and editing. M.P.U. contributed to the material preparation and data collection, acquisition, resources, and supervision. All authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Ezhilarasi, S., Uma Maheswari, P. Leveraging digital acquisition and DPB based SignaryNet for localization and recognition of heritage inscription palaeography. npj Herit. Sci. 13, 362 (2025). https://doi.org/10.1038/s40494-025-01913-6
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s40494-025-01913-6
