
Abstract
Thangka murals, as a vital carrier of Tibetan Buddhist culture, pose unique challenges for automatic image colorization due to their intricate structures and rich symbolic content. To address the critical issues of color overflow and semantic inconsistency in Thangka image colorization, we propose MACColor, a novel end-to-end framework that integrates two key components: (1) a Multi-Scale Adaptive Color-Constrained Attention (MACCA) module to enforce color locality and suppress overflow; (2) a Cross-Dimensional Synergistic Attention (CDSA) module to enhance semantic coherence by jointly modeling spatial, channel, and scale interactions. In addition, we build a dedicated Thangka grayscale colorization dataset, consisting of 8500 high-resolution images (512 × 512), to support future research in this domain. Extensive experiments demonstrate that our method achieves superior performance compared to existing approaches on both objective metrics and subjective evaluations, producing visually vivid and semantically consistent colorization results, while effectively constraining color diffusion and introducing a lightweight MACColor-Tiny variant for practical applications.
Similar content being viewed by others

Introduction
Thangka art, characterized by its unique style and intricate thematic content, serves as a significant historical record of Tibetan social life and cultural traditions spanning over a thousand years. As an invaluable cultural heritage, Thangka murals face several critical preservation challenges: (1) early artworks frequently suffer from severe color degradation due to pigment oxidation, resulting in faded fragments or partial loss of original colors; (2) historical archives are often limited to black-and-white photographs or grayscale scans owing to technological constraints, severely compromising the original semantic richness and artistic details; and (3) traditional manual restoration methods heavily rely on artisans’ subjective experience, making it impractical for large-scale restoration of numerous faded or monochrome Thangka paintings1,2.
Color holds profound cultural and symbolic significance in traditional Thangka art, where each hue is intentionally selected to represent specific religious meanings, deities, and ritual functions. Improper or inaccurate colorization may distort these cultural semantics, potentially leading to misinterpretations of the underlying symbolism. Therefore, restoring Thangka paintings requires not only visually pleasing colors but also strict preservation of culturally constrained chromatic relationships. This motivates the need for a colorization framework that explicitly controls color propagation and enforces structure-aware semantic consistency. To mitigate ethical risks associated with automated Thangka colorization, our attention-based design explicitly restricts color propagation based on semantic and structural cues. This helps ensure culturally appropriate color assignment and reduces the likelihood of generating misleading or culturally inaccurate interpretations.
Recent works have also explored graph convolutional networks (GCNs) for visual feature propagation and contextual reasoning in image analysis tasks3,4,5. However, despite their ability to model relational dependencies, GCN-based architectures often struggle to capture fine-grained spatial correlations and long-range semantic dependencies required for high-quality image colorization. In contrast, our approach leverages Transformer-based attention mechanisms, which provide a more flexible and global representation, enabling more accurate and context-aware color generation.
Recent progress in lightweight convolutional neural networks (CNNs) has shown promising results in improving computational efficiency while maintaining strong feature representation ability. For instance, several studies have explored lightweight architectures for visual tasks such as vehicle detection, fine-grained recognition, cultural heritage preservation, and biometric identification6,7,8,9. These approaches emphasize efficient model design through depthwise separable convolution, hybrid attention, and semantic feature compression. Inspired by these developments, our work also emphasizes lightweight design, as reflected in the MACColor-Tiny variant, which achieves a better trade-off between performance and model complexity for practical colorization applications.
Recent advancements in computer vision and deep learning technologies, particularly visual Transformers10,11, offer promising opportunities for addressing these preservation challenges. Visual Transformers leverage a multi-head self-attention mechanism, which excels at capturing complex global relationships and extracting high-level semantic features from images, thus significantly benefiting image colorization tasks. However, despite these advances, existing Transformer-based approaches still encounter two major challenges specific to the colorization of Thangka images12. Moreover, the automation of Thangka colorization raises potential ethical and cultural concerns, as improper colorization may misrepresent symbolic meanings, alter traditional aesthetics, or inadvertently distort the original artistic intent. Therefore, while automated methods provide technical support for preservation and digital analysis, expert oversight remains essential to ensure cultural authenticity.
Challenge 1: Color overflow is another prevalent challenge, particularly in Thangka image colorization. This is due to the unique chromatic constraints and cultural symbolism embedded in Thangka art. Most Transformer models rely on single-scale feature extraction, which is insufficient to manage the multi-scale complexity of Thangka images. Effective colorization in this domain demands a more advanced multi-scale attention strategy.
Challenge 2: Semantic consistency remains a critical issue in grayscale image colorization. Semantic consistency refers to the coherence and uniformity of color across the same semantic objects (e.g., halos, ritual implements, and the faces of deities). However, the generated colors often fail to align with the true semantics or contextual meaning of the original scene. Although conventional Transformer-based models are capable of modeling global dependencies, they struggle to capture the intricate visual and stylistic nuances of Thangka murals, which are deeply embedded with cultural and symbolic significance.
To tackle the aforementioned challenges and fully exploit the capabilities of Transformers in grayscale image colorization, this paper proposes a novel framework tailored for Thangka murals. Our method incorporates two core modules: the Multi-Scale Adaptive Color-Constrained Attention (MACCA) module and the Cross-Dimensional Synergistic Attention (CDSA) module.
First, to address Challenge 1 (color overflow), the MACCA module is designed to incorporate multi-scale and cross-spatial attention mechanisms, along with information reshaping strategies and adaptive color constraints. This module effectively reduces color overflow by dynamically adjusting attention weights at multiple levels, thereby preserving the stylistic integrity and cultural symbolism of Thangka art.
Second, to address Challenge 2 (semantic inconsistency), the CDSA module is proposed to enhance feature representation through joint modeling of channel-wise, spatial, and scale-aware information. By merging multidimensional features, the module ensures semantic consistency in the generated colors, allowing the faithful restoration of the visual semantics of Thangka murals.
Finally, although image colorization techniques have achieved remarkable progress in the domain of natural images, existing mainstream colorization datasets—such as ImageNet13 grayscale variants, COCO-Stuff14 Gray—primarily focus on natural scenes and everyday objects. These datasets exhibit significant differences from religious artworks in terms of image composition, texture style, and semantic representation. Consequently, they fall short in meeting the training demands for structurally faithful and semantically consistent colorization of complex cultural images such as Thangka murals. The lack of suitable datasets not only limits the applicability of current models but also impedes further research and evaluation in this domain. To address this gap, we construct a dedicated grayscale colorization dataset specifically for Thangka images, comprising 8,500 high-resolution samples enriched with diverse structural types and cultural style annotations. This dataset is designed to support colorization tasks that demand high levels of semantic fidelity and chromatic coherence, particularly in artistic and religious imagery.
Extensive qualitative and quantitative experiments on grayscale Thangka datasets demonstrate that: (1) our method can accurately and efficiently colorize grayscale Thangka images without requiring additional post-processing; and (2) our approach not only achieves visually compelling results, but also outperforms existing methods across multiple evaluation metrics.
In summary, the main contributions of this work are as follows:
We propose the Multi-Scale Adaptive Color-Constrained Attention (MACCA) module, which guides the model’s color selection to align with the stylistic conventions and semantic expectations of Thangka art. This module effectively prevents color mismatches and overflow, ensuring that the generated colors remain faithful to the original artistic intent;
We design the Cross-Dimensional Synergistic Attention (CDSA) module, which enhances color representation through multi-dimensional feature integration across channels, spatial layouts, and scales. This contributes to improved semantic consistency in the colorization results;
We construct the first publicly available Thangka grayscale colorization dataset, containing 8500 images at a resolution of 512 × 512. This dataset provides a valuable benchmark and resource for future research in Thangka image restoration and stylization.
Methods
Automatic image colorization based on deep learning
In recent years, deep learning has significantly advanced automatic image colorization. Early CNN-based methods achieved impressive results on natural images, but they often fail to preserve semantic consistency and cultural color constraints in images such as Thangka paintings. For example, Cheng et al.15 pioneered deep CNN colorization but may produce color overflow in complex regions. Zhang et al.16 proposed a classification-based framework that structures color prediction but does not account for culturally meaningful symbols. Su et al.17 combined object segmentation with local colorization, improving detail accuracy but lacking global cultural consistency. Kim et al.18 incorporated structural color priors to guide colorization in images with complex layouts and scene compositions. More recently, a number of Transformer-based networks19,20,21 have been proposed, further demonstrating the strong potential of attention mechanisms in image-to-image translation and visual understanding tasks. Although these methods perform well on natural images, they still face challenges on images with strict cultural or symbolic color constraints, such as Thangka paintings. The complexity of decorative patterns and the need for semantic consistency of cultural symbols are difficulties not effectively addressed by existing approaches, motivating the design of our MACCA and CDSA modules.
Vision transformer
In recent years, Transformer models have gained widespread attention in computer vision due to their superior capability in modeling long-range dependencies and global context. Numerous studies have explored their applications in low-level vision tasks, including image colorization22,23. Kumar et al.21 introduced a probabilistic Transformer model that learns color distributions to generate coarse low-resolution outputs, which are later upsampled to produce high-resolution colorized images. However, it lacks fine-grained control for complex decorative regions. Weng et al.24 formulated colorization as a classification task by feeding image patches and color tokens into a ViT-based network, where luminance selection was guided by precomputed probability maps. But its reliance on precomputed probability maps limits adaptability to cultural color constraints. Ji et al.25 designed a hybrid Transformer framework using memory-enhanced self-attention to incorporate semantic color priors, yet single-scale modeling still struggles with intricate Thangka patterns. Kang et al.26 proposed a dual-decoder architecture that learns multi-scale color queries in an end-to-end manner, eliminating handcrafted priors. Although it improves multi-scale learning, it does not explicitly consider cultural semantics or color constraints specific to Thangka paintings. Du et al.27 focused on multi-channel color synthesis to improve restoration quality. However, it is primarily designed for natural images and cannot guarantee semantic consistency in culturally sensitive regions Fig. 1.

The proposed method produces visually consistent and vibrant outputs faithful to Thangka aesthetics.
Despite these advancements, most existing Vision Transformer-based colorization models rely on single-scale feature extraction, which limits their effectiveness in handling visually complex domains. In the context of Thangka murals, which contain intricate structures and strict stylistic constraints, such approaches often fail to provide fine-grained color control. Therefore, a more robust model capable of multi-level feature fusion is essential for achieving semantically consistent and stylistically faithful Thangka colorization Fig. 2.

Challenge 1 shows the difficulty in preserving accurate semantic color intensity, while Challenge 2 highlights the issue of color overflow in structurally dense regions. The existing method, CT2, still struggles to address these challenges effectively.
Network architecture
The proposed method adopts an encoder-decoder architecture, as shown in Fig. 3, and performs image colorization in the CIE-Lab color space. Given a grayscale input image \({P}_{L}\in {{\mathbb{R}}}^{H\times W\times 1}\), where H and W denote the height and width, respectively, the model is trained to predict the missing chrominance channels \({P}_{ab}\in {{\mathbb{R}}}^{H\times W\times 2}\). The final output image \(P\in {{\mathbb{R}}}^{H\times W\times 3}\) is obtained by concatenating the predicted a,b channels with the input luminance channel L. In this work, the term “grayscale image” specifically refers to the L channel extracted from the original color image by conversion to the CIE-Lab color space. Unlike grayscale images derived from a weighted average of RGB values, the L channel in Lab space represents luminance as perceived by the human visual system, offering superior preservation of structural details and edge contrast. We adopt the L channel as the single-channel input to our network to better guide the learning of semantic and structural features.

a Overview of the proposed MACColor network. The input is a grayscale Thangka image PL, which is processed by a shared encoder incorporating multiple MACCA modules to extract multi-scale semantic features. During decoding, color queries are derived from a Transformer decoder, which generate color embeddings aligned with the target distribution. These embeddings are passed to the Cross-Dimensional Synergistic Attention (CDSA) module, which fuses spatial, scale, and channel-level information between encoder features and color queries. The fused features are then projected to generate the final colorized image P. b Internal structure of the proposed Multi-Scale Adaptive Color-Constrained Attention (MACCA) module. MACCA computes grouped attention maps using three distinct pathways (horizontal, vertical, and feature-level), each followed by normalization and adaptive aggregation. The module dynamically generates attention weights to constrain the model’s color distribution, thereby enforcing stylistic fidelity to traditional Thangka art.
In the encoder stage, a feature extractor generates multi-scale intermediate feature maps through a cascade of convolutional layers. The MACCA module is embedded within each stage to apply adaptive color constraints based on learned multi-scale attention distributions, thereby regularizing the color predictions according to the semantic structure of the input. After the feature extraction, the maps are progressively upsampled to recover spatial resolution and align with decoder inputs.
In the decoder stage, a set of learned color queries are employed to interact with the encoder features via attention mechanisms. The Cross-Dimensional Synergistic Attention (CDSA) module further enhances semantic color fidelity by fusing the encoder outputs with query-informed color representations across spatial, channel, and scale dimensions. The final colorized image is generated by combining these fused features.
A detailed description of each module is presented in the following subsections.
MACCA module
In contrast to conventional attention mechanisms, the proposed MACCA module integrates group-wise attention modeling, directional semantic pooling, and context-aware convolutions. This design enables fine-grained spatial dependency learning across multiple scales, which is particularly beneficial for handling the ambiguity and intricate visual patterns commonly found in grayscale Thangka image colorization.
The Multi-Scale Adaptive Color-Constrained Attention (MACCA) module is designed to generate spatially adaptive attention maps that guide color distribution during training. Given an input feature map \(I\in {{\mathbb{R}}}^{C\times H\times W}\), the MACCA module first divides the channel dimension into F groups:
This grouping ensures that semantic features are evenly distributed and independently processed across each subset of channels. To extract spatial attention information, three parallel branches are utilized for each group: (1) Two 1 × 1 convolutional branches, each followed by a 1D global average pooling28,29 operation along horizontal and vertical directions, respectively, encode directional semantics; (2) One 3 × 3 convolutional branch captures contextual information from multi-scale receptive fields. The outputs of the two 1 × 1 branches are processed using 2D global average pooling to obtain aggregated spatial responses. For each channel c, the output YC is computed as:
After generating spatial attention maps from the three parallel branches, each map is fused and preserved to retain precise location-aware context. For each channel group, the output feature is modulated by two spatial attention weights—horizontal and vertical—both of which are computed via global pooling followed by a sigmoid activation function. These weights emphasize pixel-level semantic dependencies while integrating the global structure of the image. The final output of the MACCA module maintains the same spatial dimensions as the input feature map I, allowing seamless integration into the encoder pipeline.
In our network, the encoder employs a ConvNeXt-V2 backbone30 to extract rich semantic features from the grayscale input image \({P}_{L}\in {{\mathbb{R}}}^{H\times W\times 1}\). The encoder generates four hierarchical feature maps O = {O1, O2, O3, O4} with progressively reduced resolutions: \(\frac{H}{4}\times \frac{W}{4}\), \(\frac{H}{8}\times \frac{W}{8}\), \(\frac{H}{16}\times \frac{W}{16}\), and \(\frac{H}{32}\times \frac{W}{32}\). These multi-scale features are then gradually upsampled through a dedicated upsampling block to recover the original spatial resolution. Each upsampled output is refined using MACCA modules, which apply adaptive attention constraints to enhance the feature representations.
The resulting refined feature maps are denoted as \(Y\in {{\mathbb{R}}}^{C\times H\times W}\), serving as input to the decoder for color query fusion. Notably, the encoder design ensures both global context and local details are preserved across all resolutions, which is essential for accurate and stylistically faithful colorization.
Transformer decoder
The Transformer Decoder in our framework employs a standard encoder-decoder attention mechanism to progressively refine the color query embeddings. This process involves three major steps: cross-attention, multi-head self-attention, and feed-forward transformation.
First, the initial embedding at the l-th layer is updated via cross-attention with encoder feature maps:
where CA( ⋅ ) denotes the cross-attention operation, where linear projections fQ,fK,fV are applied to generate the query, key and value representations from the color embedding and encoder features.
Second, the intermediate result is passed through a multi-head self-attention mechanism to enhance intra-query dependencies:
where MHSA( ⋅ ) refers to the standard multi-head self-attention module and LN( ⋅ ) represents layer normalization.
Finally, the refined embedding undergoes a feed-forward transformation with residual connection:
where FFN( ⋅ ) refers to the feed-forward networks, the output \({Y}_{c}^{l}\) is the updated color query representation at the l-th Transformer layer.
In our implementation, we apply this pipeline across multiple Transformer Decoder layers, where the first three layers incorporate encoder features O1, O2, O3 extracted from different encoder scales.
Attention fusion structure
Different from conventional attention mechanisms that focus on single or sequential dimensions, the proposed Cross-Dimensional Synergistic Attention (CDSA) module decomposes feature maps into three orthogonal branches—channel, height, and width—and introduces a novel cross-dimensional fusion strategy. This architecture effectively captures synergistic dependencies across multiple dimensions, which is particularly advantageous for colorizing semantically complex and structurally intricate artworks such as Thangka.
The Cross-Dimensional Synergistic Attention (CDSA) module is designed to fuse the upsampled encoder features with the refined color query embeddings from the Transformer decoder. As shown in Fig. 4, the CDSA module consists of three parallel branches, each capturing inter-dimensional dependencies across the channel (C), height (H), and width (W) dimensions.

The CDSA module first processes input features through three separate branches, each undergoing feature transformation. Subsequently, interactions among different feature dimensions are conducted to capture inter-dimensional dependencies. Finally, outputs from the three branches are aggregated via an averaging operation to produce the final representation.
Each branch processes the input tensor along a distinct dimension: The first branch models the interaction between the H and C dimensions. The input tensor of shape C × H × W is rotated 90∘ counterclockwise along the H-axis to obtain W × H × C, and Z-pooling is performed as:
The result is passed through a convolution layer and batch normalization, followed by a sigmoid function to produce the attention weights. The feature map is then rotated back to its original orientation. The second and third branches follow the same design along different axes to capture width-related and channel-related dependencies. The outputs of all three branches are aggregated via averaging, as formulated above:
where ψi( ⋅ ) denotes the attention function and σ( ⋅ ) is the sigmoid activation and \({\hat{x}}_{l}\) are intermediate representations from each branch.
Final color prediction
The final output of CDSA is fused with the color query embedding \({Y}_{c}^{l}\) using a convolution operation to predict the chrominance channels:
Where O4 is the restored feature map from the encoder, and \({Y}_{c}^{l}\) is the result of the color query embedding in the Transformer Decoder. The convolution operation uses a 1 × 1 kernel, and the final result is \({P}_{ab}\in {{\mathbb{R}}}^{H\times W\times 2}\), where a and b are the chroma channels in the CIE-LAB color space.
The full colorized image is obtained by concatenating PL with Pab, forming the final output \(P\in {{\mathbb{R}}}^{H\times W\times 3}\).
Comparison with recent attention mechanisms
We compare our proposed attention modules, MACCA and CDSA, with several recent and representative designs, including CBAM31, CoTNet32, MogaAttention33, and GCViT34.
CBAM adopts a sequential strategy that applies channel and spatial attention using global pooling operations. However, it lacks directional awareness and is limited in capturing multi-scale contextual dependencies. In contrast, our MACCA module employs three parallel branches to extract horizontal, vertical, and contextual semantic cues, thereby enabling fine-grained spatial attention specifically guided by chromatic constraints.
The CDSA module further extends cross-dimensional modeling by explicitly capturing synergistic dependencies across channel, height, and width dimensions. It leverages Z-pooling and two-dimensional convolution operations to maintain both simplicity and computational efficiency. In contrast, CoTNet and GCViT rely on complex transformer blocks or gating-based mechanisms, which significantly increase the computational burden without being specifically optimized for color-guided dense prediction tasks.
While MogaAttention employs multiple attention heads to model coarse-to-fine granularity, it is primarily designed for high-level classification tasks. In comparison, MACCA and CDSA are lightweight, plug-and-play modules that introduce minimal parameter overhead, making them better suited for pixel-level generation tasks such as image colorization.
Training objective
To optimize the proposed image colorization network, we design a composite loss function that includes: pixel loss, perceptual loss, adversarial loss, and colorfulness loss.
Pixel loss
The pixel loss is based on the L2 norm, which computes the pixel-wise difference between the predicted and the ground truth images:
Where yi is the pixel value of the real image, \({\bar{y}}_{i}\) is the pixel value of the generated image, and N is the total number of pixels in the image.
Perceptual loss
Perceptual loss leverages a pre-trained VGG1635 network to extract high-level feature maps, and measures the distance between predicted and real images in the feature space:
Where ϕi(x) is the feature map of the generated image x at the i-th layer, ϕi(y) is the feature map of the real image y at the i-th layer, and λi is the weight for the i-th layer.
Adversarial loss
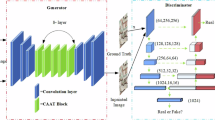
The adversarial loss uses a PatchGAN discriminator29 to encourage photorealism in generated images. It is formulated as:
Where Ic is the real image, \({\hat{I}}_{c}\) is the generated image, and D( ⋅ ) is the output of the discriminator.
Colorfulness loss
To encourage more vibrant and saturated colors, we introduce the colorfulness loss 36, defined based on color distribution statistics:
Where σrgyb( ⋅ ) and μrgyb( ⋅ ) represent the standard deviation and mean of the pixel cloud in the color planes, respectively.
Full objective
The complete loss L used by the image colorization network in this paper is:
where λ are weighting parameters that balance the contribution of each loss component, and are specified in the implementation details.
Results
Experimental setting
Dataset
Due to the lack of publicly available datasets specifically tailored for Thangka image colorization, we constructed a dedicated dataset to support this task. We collected 64 ultra-high-resolution Thangka images (12869 × 16710 pixels) from multiple open Tibetan Buddhist Thangka art repositories, covering various historical periods and artistic styles. From these, 8500 image patches (512 × 512 pixels) were extracted through systematic cropping and preprocessing.
All images were carefully selected to ensure complete color information and a resolution higher than 512 × 512, with samples containing severe damage, stains, or blurriness excluded. The collection process followed standardized protocols: all images were acquired using professional scanning equipment to guarantee accurate color reproduction and uniformly converted into a standard color space for subsequent processing.
Statistical analysis of the dataset revealed an overall warm color tone consistent with traditional Tibetan Buddhist Thangka styles. Although the color distribution shows some concentration, it covers a broad color gamut. The dataset mainly depicts religious symbols such as Buddhas, mandalas, and ritual implements, with relatively balanced category distribution and no severe class imbalance observed. However, due to the inherent thematic focus of Thangka art, the dataset exhibits limited diversity in content. These biases may affect the model’s generalization ability, especially when handling atypical colors or less common subjects. Future work aims to expand the dataset with more diverse artistic styles and themes to enhance model robustness and generalizability.
In addition, we employ the COCO-Stuff dataset14, an extension of the COCO dataset enriched with a wide range of “stuff” categories (e.g., sky, road, grass), comprising approximately 160,000 annotated images covering diverse natural scenes. COCO-Stuff is widely used in image understanding and colorization tasks due to its high-quality multi-semantic labels, making it suitable for evaluating semantic understanding capabilities of colorization models. We adopt COCO-Stuff as one of the benchmark datasets to compare our model against existing methods, aiming to verify the model’s performance and generalization in complex natural scenes. Experiments on COCO-Stuff provide a comprehensive evaluation of the model’s robustness and practical value.
Evaluation metrics
To evaluate model performance, we adopted three commonly used metrics: Fréchet Inception Distance (FID)37, Colorfulness Score (CF)36, and Peak Signal-to-Noise Ratio (PSNR) 38. In this work, the Fréchet Inception Distance (FID) metric37 is computed following the official standard procedure. Specifically, features are extracted from the pool3 layer (2048-dimensional feature vector) of a pretrained Inception-v3 network. The mean and covariance of these features are estimated separately for the real and generated images, and the Fréchet distance between the two Gaussian distributions is calculated to quantitatively assess the quality of the generated images. FID measures the distance between distributions of real and generated images in the feature space. CF evaluates color saturation and vibrancy, while PSNR assesses pixel-wise similarity. Additionally, since a high CF score may indicate color oversaturation, we also report the absolute colorfulness score difference (ΔCF) between generated and ground truth images.
Implementation details. We trained our network using the AdamW optimizer39 with β1=0.9, β2=0.99 and weight decay = 0.01. The learning rate was initialized to 1e-4. For the loss terms, we set λpix = 0.1, λper = 5.0, λadv = 1.0 and λcol = 0.5. We used ConvNeXt-V230 as the backbone network. For the upsampling layers, the feature dimensions after the four upsampling stages were 512, 512, 256, and 256, respectively. The entire network was trained in an end-to-end self-supervised manner for 200,000 iterations, with a batch size of 8. Training was conducted on a single NVIDIA RTX 3090 GPU, and the average training time was approximately 35 hours. We design a lightweight MACColor-Tiny model by reducing network complexity, achieving significantly fewer parameters and faster inference while maintaining competitive colorization performance, making it suitable for resource-constrained applications.
Quantitative comparison
We compare the proposed method with several state-of-the-art colorization approaches16,17,18,21,24,25,26,27,40 on both our custom Thangka dataset and the COCO-stuff dataset14. Quantitative results are summarized in Tables 1 and 2.
Table 1 presents a quantitative comparison between the proposed method and several state-of-the-art baselines, including CIC16, InstColor17, DeOldify40, CT224, BigColor18, ColorFormer25, and DDColor26, at resolutions of 256 × 256 and 512 × 512. At 256 × 256, our method achieves the highest SSIM (0.8925) and highest PSNR (24.0659), as well as the highest colorfulness (CF) (50.7837), indicating strong structural fidelity and vivid color reproduction. The color-deviation measure (ΔCF) is 1.101, which is not the lowest (ColorFormer: 1.0100; MACColor-tiny: 1.3285), but still markedly better than most baselines. At 512 × 512, our approach attains the best FID (17.9443), highest SSIM (0.8709), highest CF (51.4480), and highest PSNR (23.8310). The ΔCF is 0.5523, representing a substantial improvement over DDColor. Compared with DDColor, the proposed method delivers a + 2.27 dB PSNR gain at 256 × 256 (24.0659 vs. 21.7974) and a + 1.29 dB gain at 512 × 512 (23.8310 vs. 22.5366), while reducing ΔCF at both scales (1.101 vs. 1.4575; 0.5523 vs. 1.8197) and achieving a superior FID at 512 × 512 (17.9443 vs. 18.6270). We further analyzed the performance of our MACColor-Tiny model in comparison to the full MACColor model. Although the parameter count of MACColor-Tiny is significantly reduced (from 235.7M to 59.7M), the performance in terms of PSNR and FID only slightly decreases (PSNR drops by 3.6567 dB and the FID increases by 1.6941). This indicates a substantial improvement in efficiency with minimal loss of quality. These results substantiate the effectiveness of the proposed CDSA and MACCA modules.
As shown in Table 2, our method achieves state-of-the-art performance across all metrics on the COCO-Stuff dateset. Specifically: Our model obtains the lowest FID score of 2.25, outperforming the previous best MultiColor (FID = 2.59) and DDColor (FID = 5.18), indicating superior realism in feature distribution. Compared to advanced baselines like DDColor and MultiColor, which are specifically optimized for color saturation and style preservation, our model provides consistent and superior performance across realism, colorfulness, and accuracy. Our method also generalizes well to natural images in COCO-Stuff. This is because MACCA captures multi-scale color constraints that are not domain-specific, and CDSA models structural correlations shared across image categories. Importantly, we made no domain-specific adjustments, further demonstrating the robustness and transferability of our design.
Qualitative comparison
Figure 5 presents the visual comparison results on representative grayscale inputs from the Thangka dataset. The compared methods include CIC16, InstColor17, DeOldify40, BigColor18, ColorFormer25, and DDColor26. As shown, our method consistently produces more visually compelling results, demonstrating: Sharper structural boundaries and significantly reduced color bleeding artifacts; More vivid and semantically consistent color tones, particularly in complex decorative regions such as halos, ornaments, and garments.

From left to right: input grayscale images, results produced by CIC, DeOldify, InstColor, BigColor, ColorFormer, DDColor, the proposed MACColor method, and the ground truth.
For example, in the first row, the proposed method achieves the highest color consistency across the same semantic regions (e.g., halos in the bottom-left corner), clearly outperforming BigColor and DDColor in both uniformity and precision. In rows 2 to 4, our method avoids obvious color shifts and delivers more vibrant and perceptually pleasing results on facial and symbolic regions of the Buddha figures. In rows 5 and 6, it maintains color richness and local detail without introducing semantic inconsistencies or color spillovers, which are evident in the outputs of competing methods.
These qualitative improvements align well with the superior PSNR, CF, and ΔCF metrics reported in Table 1, further validating the effectiveness of our CDSA and MACCA modules for structure-aware and color-faithful image colorization.
User study
To assess the subjective perception of colorization quality, we conducted a user study involving 15 participants with backgrounds in computer vision or digital art. We randomly selected 30 grayscale images from the Thangka dataset and generated colorized versions using five methods: our proposed method, CT224, BigColor18, ColorFormer25, and DDColor26.
For each image, participants were presented with the five colorized results in a random order and asked to select the version that exhibited the best overall visual quality, considering criteria such as color vividness, semantic consistency, and structural fidelity.
As illustrated in Fig. 6, our method received the highest number of favorable votes, clearly demonstrating strong subjective preference. Among the 15 participants: 14 participants ranked our method as the most visually appealing; 12 participants also gave positive feedback for DDColor and ColorFormer; 11 participants considered BigColor acceptable; and only 8 participants expressed a preference for CT2.

The figure shows the distribution of user preferences among different colorization methods, indicating that our method received the highest number of favorable votes.
These results confirm that our method not only achieves competitive objective performance but also excels in subjective perceptual quality, particularly for complex and symbolically rich Thangka images.
Ablation study
To further verify the effectiveness and novelty of the proposed MACCA and CDSA modules, we designed two types of experiments:(1) Module Replacement Experiments and (2) Module Ablation Experiments. In the module replacement experiments, we replaced the proposed MACCA with the widely used multi-scale attention module CBAM, and substituted CDSA with the classic Non-local Attention mechanism, which models long-range cross-dimensional dependencies. All experiments were conducted on the 512 × 512 Thangka dataset. The results demonstrate that these replacements led to noticeable performance drops in key metrics, including PSNR, SSIM, ΔCF, and FID. This suggests that conventional attention designs struggle to effectively capture multi-scale spatial details and maintain semantic consistency in grayscale image colorization tasks—particularly for culturally complex artworks like Thangka. To further isolate the contribution of each module, we conducted ablation experiments on our model. As summarized in Table 3, both MACCA and CDSA contribute significantly to performance improvements. Integrating MACCA enhances spatial attention modeling across semantic scales, while CDSA facilitates synergistic feature fusion along channel, height, and width dimensions. In addition to the quantitative results, Fig. 7 presents qualitative comparisons. Visualizations confirm that the inclusion of MACCA and CDSA leads to improved color fidelity, edge sharpness, and semantic consistency, especially in highly detailed regions such as halos, ornaments, and facial contours. These findings validate the individual and combined effectiveness of our proposed modules in enhancing the overall colorization quality.

Compared with the baseline, MACCA enhances local color consistency, while CDSA improves global semantic alignment. The combined model produces visually superior results with richer textures and more accurate colorization.
The result of real murals
To further evaluate the generalization ability of our method, we applied it to a set of historical mural photographs that were not included in the training dataset. As shown in Figs. 8 and 9, the grayscale images were colorized using our proposed method and compared with the original color images. Visually, our results demonstrate comparable semantic consistency and color plausibility to the ground truth. The method effectively preserves fine-grained structural details while significantly reducing color overflow and distortion. These findings indicate that our approach generalizes well across diverse mural styles and is capable of generating context-aware color assignments without relying on explicit style templates.

The first row shows the grayscale input images, and the second row presents the corresponding colorized outputs generated by our method.

The first row shows the grayscale input images, and the second row presents the corresponding colorized outputs generated by our method.
To evaluate the generalization capability of MACColor across different cultural styles, we conducted cross-style tests on two unseen mural datasets: Dunhuang murals and European medieval religious frescoes. As shown in Table 4, despite the absence of any fine-tuning on these datasets, our model consistently preserves high structural fidelity—as reflected by strong PSNR and SSIM scores—and maintains low perceptual errors.
In addition, subjective user evaluations indicate that MACColor successfully retains the stylistic color patterns and clearly delineates structural boundaries in both domains. These results demonstrate the model’s robust cross-style adaptability and its ability to generalize to diverse artistic domains beyond the training distribution.
Visual interpretability analysis
To further verify the semantic consistency and cultural alignment of our proposed model, we conduct a qualitative interpretability analysis by visualizing the attention maps generated from the MACCA and CDSA modules. Specifically, we extract and visualize spatial attention weights from different branches (horizontal, vertical, and contextual in MACCA; channel, height, and width in CDSA), and generate corresponding heatmaps using a fusion of normalized attention scores. These heatmaps are overlaid on the grayscale input to highlight the regions the model focuses on during colorization.
As illustrated in Fig. 10, the attention maps of our model consistently concentrate on semantically meaningful regions, such as facial contours, halos, ornaments, and garment textures, which are critical for achieving culturally consistent Thangka colorization. For instance, the MACCA module demonstrates a strong capability to preserve structural boundaries and suppress color bleeding around fine decorative patterns, while the CDSA module captures cross-dimensional dependencies that enhance the coherence of color across spatial extents.

The first column shows the input grayscale images (L channel), the second column presents the corresponding ground-truth color images, the third column displays the fused attention heatmaps from MACCA and CDSA, and the fourth column shows the attention map derived from CBAM.
Compared with conventional attention-based baselines, our attention maps exhibit finer localization and more semantically aligned focus. These observations substantiate that the proposed modules not only improve objective metrics but also provide interpretable guidance aligned with human visual and cultural understanding.
This interpretability analysis supports the claim that MACCA and CDSA contribute to colorization that respects the structural and symbolic intricacies inherent in traditional Thangka artworks.
Limitation
Although our method achieves promising performance in both objective metrics and visual quality, it still presents several limitations. As shown in Fig. 11, the model may generate semantically inconsistent or contextually implausible colors, particularly in fine-grained regions such as facial features of Buddhas, small ornaments, or complex background patterns. These issues mainly arise from three factors: (1) the lack of explicit user guidance or semantic constraints during the colorization process; (2) limited diversity in the Thangka dataset, which may affect generalization to rare or atypical patterns; and (3) the inherent difficulty of modeling highly intricate structures even with multi-scale attention. In future work, we plan to incorporate interactive or user-controllable color priors, refine the attention mechanisms for fine-grained regions, and leverage cultural color priors to improve controllability and correctness in challenging scenarios.

Examples show semantic inconsistency or incorrect color predictions due to the absence of explicit color guidance.
While the Thangka dataset provides high-quality images suitable for research on Thangka image colorization, it is currently limited in thematic diversity. Most images primarily depict religious symbols and motifs, which may restrict the generalizability of models trained on this dataset. Expanding the dataset to cover a broader range of themes will be part of our future work.
The user study involved 15 participants, providing an initial assessment of subjective preferences. A larger and more diverse group, including professional artists, would yield more statistically robust and culturally informed results, which will be considered in future work.
Discussion
In this paper, we proposed a novel Thangka mural image colorization framework that integrates a Multi-Scale Adaptive Color-Constrained Attention (MACCA) module and a Cross-Dimensional Synergistic Attention (CDSA) module. Specifically, the MACCA module mitigates color overflow by enforcing adaptive multi-scale attention with chromatic constraints, while the CDSA module enhances semantic consistency by fusing features across spatial, channel, and scale dimensions. To support future research, we also constructed a dedicated Thangka grayscale colorization dataset comprising 8,500 high-resolution images. Extensive experiments on the Thangka dataset demonstrate that our approach outperforms existing methods across multiple evaluation metrics and produces visually compelling results on images of varying complexity and resolution.
To the best of our knowledge, this is the first Transformer-based colorization framework dedicated to Thangka murals worldwide. Despite being trained on a relatively small dataset, our method has already demonstrated satisfactory performance, indicating strong potential for further optimization. This characteristic highlights the robustness of our framework in low-data regimes, which is especially valuable in cultural heritage domains where large-scale annotated datasets are often unavailable. Furthermore, our colorization approach provides meaningful insights for the restoration and digital preservation of other mural traditions, offering a practical reference for research and applications based on small-scale datasets.
In future work, we plan to explore interactive user-guided colorization to further improve semantic control and personalization. We also envision extending our framework to cross-domain adaptation for other types of digital heritage artworks, thereby broadening its impact in both academic research and real-world cultural preservation.
Materials availability
All materials used in this study are available from the corresponding author upon request.
Data availability
The datasets used in this study, including Thangka images and cocostuff artworks, are publicly available. The Thangka dataset is available at https://github.com/cvlabdatasets/ThangkaDatasets, and the COCO-Stuff dataset can be accessed from https://github.com/nightrome/cocostuff.
Code availability
The code is available from the corresponding author on request.
References
Ji, L. et al. Thangka mural super-resolution based on nimble convolution and overlapping window transformer. In Chinese Conference on Pattern Recognition and Computer Vision (PRCV), 211–224 (Springer, 2024).
Jia, Y. et al. Image inpainting of thangka murals using edge-assisted feature fusion and self attention based local refine network. IEEE Access 11, 84360–84370 (2023).
Ding, Y. et al. Multi-scale receptive fields: graph attention neural network for hyperspectral image classification. Expert Syst. Appl. 223, 119858 (2023).
Ding, Y., Zhao, X., Zhang, Z., Cai, W. & Yang, N. Multiscale graph sample and aggregate network with context-aware learning for hyperspectral image classification. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 14, 4561–4572 (2021).
Yao, D. et al. Deep hybrid: multi-graph neural network collaboration for hyperspectral image classification. Def. Technol. 23, 164–176 (2023).
Shen, J. et al. Finger vein recognition algorithm based on lightweight deep convolutional neural network. IEEE Trans. Instrum. Meas. 71, 1–13 (2021).
Shen, J. et al. An anchor-free lightweight deep convolutional network for vehicle detection in aerial images. IEEE Trans. Intell. Transport. Syst. 23, 24330–24342 (2022).
Shen, J., Liu, N., Sun, H., Li, D. & Zhang, Y. An instrument indication acquisition algorithm based on lightweight deep convolutional neural network and hybrid attention fine-grained features. IEEE Trans. Instrum. Meas. 73, 1–16 (2024).
Shen, J. et al. An algorithm based on lightweight semantic features for ancient mural element object detection. npj Herit. Sci. 13, 70 (2025).
Vaswani, A. et al. Attention is all you need. Adv. Neural Inform. Process. Syst. 30, 5998–6008 (2017).
Khan, S. et al. Transformers in vision: a survey. ACM Comput. Surv. (CSUR) 54, 1–41 (2022).
Li, H. et al. Thangka sketch colorization based on multi-level adaptive-instance-normalized color fusion and skip connection attention. Electronics 12, 1745 (2023).
Deng, J. et al. Imagenet: a large-scale hierarchical image database. In 2009 IEEE Conference on Computer Vision and Pattern Recognition 248–255 (IEEE, 2009).
Caesar, H., Uijlings, J. & Ferrari, V. Coco-stuff: thing and stuff classes in context. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 1209–1218 (2018).
Cheng, Z., Yang, Q. & Sheng, B. Deep colorization. In Proceedings of the IEEE International Conference on Computer Vision, 415–423 (2015).
Zhang, R., Isola, P. & Efros, A. A. Colorful image colorization. In Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11-14, 2016, Proceedings, Part III 14, 649–666 (Springer, 2016).
Su, J.-W., Chu, H.-K. & Huang, J.-B. Instance-aware image colorization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 7968–7977 (2020).
Kim, G. et al. Bigcolor: Colorization using a generative color prior for natural images. In European Conference on Computer Vision, 350–366 (Springer, 2022).
Dosovitskiy, A. et al. An image is worth 16×16 words: Transformers for image recognition at scale. In Proc. Int. Conf. Learn. Represent (ICLR) (2021).
Liu, Z. et al. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 10012–10022 (2021).
Kumar, M., Weissenborn, D. & Kalchbrenner, N. Colorization Transformer. In Proc. Int. Conf. Learn. Represent (ICLR) (2021).
Touvron, H. et al. Training data-efficient image transformers & distillation through attention. In International Conference on Machine Learning, 10347–10357 (PMLR, 2021).
Fan, H. et al. Multiscale vision transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 6824–6835 (2021).
Weng, S., Sun, J., Li, Y., Li, S. & Shi, B. Ct 2: Colorization transformer via color tokens. In European Conference On Computer Vision 1–16 (Springer, 2022).
Ji, X. et al. Colorformer: image colorization via color memory assisted hybrid-attention transformer. In European Conference on Computer Vision, 20–36 (Springer, 2022).
Kang, X. et al. Ddcolor: towards photo-realistic image colorization via dual decoders. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 328–338 (2023).
Du, X. et al. Multicolor: Image colorization by learning from multiple color spaces. In Proceedings of the 32nd ACM International Conference on Multimedia, 6784–6792 (2024).
Lin, M., Chen, Q. & Yan, S. Network in network. In Proc. Int. Conf. Learn. Represent (ICLR) (2014).
Isola, P., Zhu, J.-Y., Zhou, T. & Efros, A. A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 1125–1134 (2017).
Woo, S. et al. Convnext v2: Co-designing and scaling convnets with masked autoencoders. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 16133–16142 (2023).
Woo, S., Park, J., Lee, J.-Y. & Kweon, I. S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), 3–19 (2018).
Li, Y., Yao, T., Pan, Y. & Mei, T. Contextual transformer networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 45, 1489–1500 (2022).
Li, S. et al. MogaNet: Multi-order gated aggregation network. In Proc. Int. Conf. Learn. Represent (ICLR) (2024).
Hatamizadeh, A., Yin, H., Heinrich, G., Kautz, J. & Molchanov, P. Global context vision transformers. In International Conference on Machine Learning, 12633–12646 (PMLR, 2023).
Simonyan, K. & Zisserman, A. Very deep convolutional networks for large-scale image recognition. Int. Conf. Learn. Represent. (ICLR) (2015).
Hasler, D. & Suesstrunk, S. E. Measuring colorfulness in natural images. In Human Vision and Electronic Imaging VIII, vol. 5007, 87–95 (SPIE, 2003).
Heusel, M., Ramsauer, H., Unterthiner, T., Nessler, B. & Hochreiter, S. GANs trained by a two time-scale update rule converge to a local Nash equilibrium. Adv. Neural Inform. Process. Syst. 30, 6626–6637 (2017).
Huynh-Thu, Q. & Ghanbari, M. Scope of validity of PSNR in image/video quality assessment. Electron. Lett. 44, 800–801 (2008).
Loshchilov, I. & Hutter, F. Decoupled weight decay regularization. Int. Conf. Learn. Represent. (ICLR) (2019).
Antic, J. jantic/deoldify: A deep learning based project for colorizing and restoring old images (and video!). https://github.com/jantic/DeOldify (2019).
Acknowledgements
The authors would like to thank the anonymous reviewers for their constructive feedback. The authors also appreciate the support of the Laboratory of Visual Computing at Northwest Minzu University for providing computing resources. This work is jointly supported by NSFC (Grant No. 62366047) and the Fundamental Research Funds for the Central Universities (Grant No.31920240060)
Author information
Authors and Affiliations
Contributions
Conceptualization, Z.W. and N.Y.W.; methodology, Z.W.; validation, Z.W., Y.B.Y., and X.Y.Z.; formal analysis, Z.W.; investigation, Z.W. and Y.T.W.; data curation, Z.W. and M.Y.Z.; writing---original draft preparation, Z.W.; writing---review and editing, Z.W. and N.Y.W.; supervision, N.Y.W.; project administration, N.Y.W.; funding acquisition, N.Y.W. All authors have read and agreed to the published version of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Wang, Z., Wang, N., Yang, Y. et al. MACColor: multi-scale and cross-dimensional attention for thangka image colorization. npj Herit. Sci. 13, 668 (2025). https://doi.org/10.1038/s40494-025-02255-z
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s40494-025-02255-z
