
Abstract
Predicting the evolution of a large system of units using its structure of interaction is a fundamental problem in complex system theory. And so is the problem of reconstructing the structure of interaction from temporal observations. Here, we find an intricate relationship between predictability and reconstructability using an information-theoretical point of view. We use the mutual information between a random graph and a stochastic process evolving on this random graph to quantify their codependence. Then, we show how the uncertainty coefficients, which are intimately related to that mutual information, quantify our ability to reconstruct a graph from an observed time series, and our ability to predict the evolution of a process from the structure of its interactions. We provide analytical calculations of the uncertainty coefficients for many different systems, including continuous deterministic systems, and describe a numerical procedure when exact calculations are intractable. Interestingly, we find that predictability and reconstructability, even though closely connected by the mutual information, can behave differently, even in a dual manner. We prove how such duality universally emerges when changing the number of steps in the process. Finally, we provide evidence that predictability-reconstruction dualities may exist in dynamical processes on real networks close to criticality.
Similar content being viewed by others
Introduction
The relationship between structure and function is fundamental in complex systems1,2,3, and important efforts have been invested in developing network models to better understand it. In particular, models of dynamics on networks4,5,6,7 have been proposed to assess the influence of network structure over the temporal evolution of the activity in the system. In turn, data-driven models8, 9, dimension-reduction techniques10,11,12,13,14, and mean-field frameworks15,16,17,18,19 have deepened our predictive capabilities. Among other things, these theoretical approaches have shed light on the relationship between dynamics criticality and many network properties such as the degree distribution15,17, the eigenvalue spectrum20,21,22, and their community structure23,24. Fundamentally, these contributions justify our inclination for measuring and using real-world networks as a proxy to predict the behavior of complex systems.
Models of dynamics on networks have also been used as reverse engineering tools for network reconstruction25, when the networks of interactions are unavailable, noisy26,27,28 or faulty29. The network reconstruction problem has stimulated many technical contributions30: Thresholding matrices built from correlation31 or other more sophisticated measures32,33 of time series, Bayesian inference of graphical models34,35,36,37,38,39, and models of dynamics on networks40, among others. These techniques are widely used (e.g., in neuroscience41,42,43, genetics44, epidemiology40,45, and finance46) to reconstruct interaction networks on which network science tools can then be applied.
Interestingly, dynamics prediction and network reconstruction are usually considered separately, even though they are related to one another. The emergent field of network neuroscience47,48 is perhaps the most actively using both notions: Network reconstruction for building brain connectomes from functional time series, then dynamics prediction for inferring various brain disorders from these connectomes49,50. Recent theoretical works have also taken advantage of these notions to suggest that dynamics may hardly depend on the structure. In ref. 51, it was shown that time series generated by a deterministic dynamics evolving on a specific graph can be accurately predicted by a broad range of other graphs. These findings highlight how poor our intuition can be with regard to the relationship between predictability and reconstructability. Furthermore, recent breakthroughs in deep learning on graphs have benefited from proxy network substrates to enhance the predictive power of their models52,53, with applications in epidemiology9, and pharmaceutics54,55. However, the use of graph neural networks and those proxy network substrates is only supported by numerical evidence and lacks a rigorous theoretical justification. As a result, their enhanced predictability remains to be fully corroborated. There is therefore a need for a solid, theoretical foundation of reconstructability, predictability, and their relationship in networked systems.
In this work, we establish a rigorous framework that lays such a foundation based on information theory. Information theory has been regularly applied to networks and dynamics in the past. In network science, it has been used to characterize random graph ensembles56,57,58—e.g. the configuration model59,60 and stochastic block models61,62—, to develop network null models63 and to perform community detection64,65. In stochastic dynamical systems, information-theoretical measures have been proposed to quantify their predictability66,67,68,69,70,71,72,73, complexity74,75 and causal emergence76. In statistical mechanics, information transmission has been shown to reach a maximum value near the critical point of spin systems in equilibrium77,78.
Our objective is to combine these ideas into a single framework, motivated by recent works involving spin dynamics on lattices79,80 and deterministic dynamics51. Our contributions are fourfold. First, we use mutual information between structure and dynamics as a foundation for our general framework to quantify the structure-function relationship in complex systems. Second, this codependence naturally leads to the definition of measures of predictability and reconstructability. Doing so allows us to conceptually unify prediction and reconstruction problems, i.e., two classes of problems that are usually treated separately. Third, we design efficient numerical techniques for evaluating these measures on large systems. Finally, we identify a new phenomenon—a duality—where our prediction and reconstruction capabilities can vary in opposite directions. These findings further our understanding of the complexity of modeling networked complex systems, such as the brain, where both prediction and reconstruction techniques play critical roles.
Results
Information theory of dynamics on random graphs
Let us consider a random graph G whose support, \({{{{{{{\mathcal{G}}}}}}}}\), consists in the set of all graphs of N vertices, each of which has its respective nonzero probability P(G = g) with \(g\in {{{\mathcal{G}}}}\). In our framework, P(G) can be any graph distribution and reflects, from a Bayesian perspective, our prior knowledge of the structure of the system. We also consider a general discrete-time stochastic process (also called dynamics hereafter) with T time steps evolving on a realization of G and representing the possible states of the system. More precisely, we denote P(X∣G) the probability of a random and discrete-state time series \({{{{{{{\bf{X}}}}}}}}={({X}_{i,t})}_{i,t}\) conditioned on G, where Xi,t is the random state, with discrete support Ω, of vertex i ∈ {1,...,N} at time t ∈ {1,...,T}. We stress that X is at this point any stochastic process be it Markovian or not. The initial condition of the process is \({{{{{{{{\boldsymbol{X}}}}}}}}}_{1}={({X}_{i,1})}_{i}\). While we only exposed our framework in terms of discrete-time and discrete-state processes, it can be used for continuous-state deterministic dynamics (see Supplementary Note III) and in principle, it can also be generalized to continuous-state stochastic processes by considering a probability density function ρ(X∣G).
The variables X and G form themselves a Bayesian network G → X, where the arrow indicates conditional dependence81. From this model, we are interested in the mutual information between X and G—denoted I(X; G)—which is a symmetric measure that quantifies the codependence between the dynamics X and the structure G82, where I(X; G) = 0 when they are independent. It is equivalently given by
where \(H(G)=-\left\langle \log P(G)\right\rangle\) and \(H({{{{{{{\bf{X}}}}}}}})=-\left\langle \log P({{{{{{{\bf{X}}}}}}}})\right\rangle\) are respectively the marginal entropies of G and X, and \(H(G| {{{{{{{\bf{X}}}}}}}})=-\left\langle \log P(G| {{{\bf{X}}}})\right\rangle\) and \(H({{{\bf{X}}}}| G)=-\left\langle \log P({{{\bf{X}}}}| G)\right\rangle\) are their corresponding conditional entropies. In the previous equations, the marginal distribution for X, the evidence, is defined as \(P({{{{{{{\bf{X}}}}}}}})={\sum }_{g\in {{{{{{{\mathcal{G}}}}}}}}}P(G=g)P({{{{{{{\bf{X}}}}}}}}| G=g)\), and the posterior is obtained from Bayes’ theorem as P(G∣X) = P(G)P(X∣G)/P(X), using the given graph prior P(G) and the dynamics likelihood P(X∣G). I(X; G) is a non-negative measure bounded by \(0\le I({{{{{{{\bf{X}}}}}}}};G)\le \min \left\{H(G),H({{{{{{{\bf{X}}}}}}}})\right\}\). Figure 1a provides an illustration of Eq. (1) in terms of information diagrams.

a Areas represent amounts of information: The entropies related to G are shown on the left in blue and those related to X are on the right in orange. Mutual information---the red intersection of X and G---corresponds to the information shared by both G and X. b The highly predictable / weakly reconstructable scenario, where H(G) ≫ H(X) meaning that I(X; G) contains most of the information related to the dynamics, but only a small fraction of the information related to the graph. c The reverse scenario, i.e., highly reconstructable / weakly predictable, where H(X) ≫ H(G) meaning that I(X; G) contains most of the information related to the graph, but only a small fraction of the information related to the dynamics.
The measures presented in Eq. (1) and above can all be interpreted in the context of information theory. Information is generally measured in bits which in turn is interpreted as a minimal number of binary—i.e., yes/no—questions needed to convey it. While entropy measures the uncertainty of random variables like X and G, i.e., the minimal number of bits of information needed to determine their value, mutual information represents the reduction in uncertainty about one variable when the other is known. The fact that it is symmetric means that this reduction goes both ways: The reduction in the dynamics uncertainty when the structure is known is equal to that of the structure when the dynamics is known. Hence, mutual information measures the amount of information shared by both X and G.
As an illustration, let us consider the physical example of a spin system that depends on G through a coupling parameter J ≥ 0, where the spins are more (large J) or less (small J) likely to align with their first neighbors in G. At J = 0, the spins are completely uncorrelated and flip with probability \(\frac{1}{2}\). In this case, H(X∣G) = NT bits, corresponding to the maximum entropy of X: We need precisely one binary question for each spin at each time for a given structure G—e.g., is the spin of vertex i at time t up? When J > 0, correlation is introduced between connected spins. As a result, a single question about the spin of vertex i at time t can provide additional information about the spins of other vertices at other times, and thus, H(X∣G) < NT. The interpretation of H(X) is analogous to that of H(X∣G), as it measures the number of binary questions needed to determine X when the graph is unknown. From this perspective, the mutual information I(X; G), as expressed by the difference between H(X) and H(X∣G), is the reduction in the number of questions needed to predict X ensuing from the knowledge of G. Hence, I(X; G) measures to which extent the knowledge of the graph G improves our ability to forecast X, i.e. its temporal predictability.
Similar observations can be made from the structural perspective. Suppose that X is the spin dynamics mentioned previously and G is a random graph, where each edge exists independently with probability p. This yields \(H(G)=-\left(\begin{array}{l}N\\ 2\end{array}\right)[p\log p+(1-p)\log (1-p)]\), where \(\left(\begin{array}{l}N\\ 2\end{array}\right)\) is the total number of possible undirected edges. When \(p=\frac{1}{2}\), we have \(H(G)=\left(\begin{array}{l}N\\ 2\end{array}\right)\) bits, which is again the maximum entropy of G. We therefore need precisely one binary question for each of the \(\left(\begin{array}{l}N\\ 2\end{array}\right)\) edges in the graph—e.g., is there an edge between i and j?—to completely determine its state. When the dynamics X is known, H(G∣X) is interpreted similarly to H(G), but also takes into account the observation of the spins X which introduces correlation between the edges of G. As a result, each bit can provide information about more than one edge, even in the case \(p=\frac{1}{2}\) where we a priori need one bit per possible edge to fully reconstruct G. Consequently, the knowledge of X reduces uncertainty about G (i.e., H(G∣X) ≤ H(G), see ref. 82, Theorem 2.6.5), and therefore allows for its reconstruction; I (X; G) thus measures the reconstructability of G, i.e. the extent to which information about G can be revealed from X.
In practice, I(X; G) can be used to explain the performance of both prediction and reconstruction algorithms (see “Performance of prediction and reconstruction algorithms” section for further detail). From the prediction perspective, it quantifies the sensitivity of the time series to the structure of interactions prescribed by G, i.e., the gain in predictability of including G for the extrapolation of X. This can be measured by comparing the true transition probabilities of the process X as given by the conditional model P(X∣G), with those predicted by models that do not include G in their predictions. This experiment was performed in ref. 51 for deterministic dynamics on graphs, to show that high prediction accuracy of time series can sometimes be achieved without the knowledge of the true graph. In Fig. 2a, we use the mean absolute error—the same measure as in ref. 51—to perform the comparison. In turn, we associate the high predictive capabilities of the true conditional model where the error with the graph-independent model is high. Likewise, I(X; G) provides strong insights into the reconstruction accuracy of algorithms such as the transfer entropy method33 (Fig. 2b). By interpreting the reconstruction problem as a binary classification, we are allowed to quantify the reconstruction accuracy with the area under the curve (AUC) of the receiver operating characteristic (ROC) curve. In all cases, I(X; G) peaks in the same coupling interval as the different reconstruction methods even if the two measures are a priori different.

a Prediction algorithms and b reconstruction algorithms. This comparison is performed with time series of length T = 100 generated with the Glauber dynamics evolving on Erdős-Rényi graphs with N = 100 nodes and M = 250 edges, for different coupling constants J. a The mean absolute error between the true transition probabilities used in P(X∣G) and the ones predicted by different graph-independent models models: a logistic regression (green diamonds) and a multilayer perceptron (MLP, purple triangles). b The average area under the curve (AUC) of the receiver operating characteristic (ROC) curve for different reconstruction algorithms: the correlation matrix method31 (light blue squares), the Granger causality method32 (green diamonds), and the transfer entropy method33 (purple triangles). In both panels, we use two axes to represent (left axis) I(X; G), denoted by the gray area bounded by the two biased estimators (red lines, see “Estimators of the mutual information” section), and (right axis) the performance measures; the maximum of I(X; G) is shown with the horizontal dashed line. See “Performance of prediction and reconstruction algorithms” section for further details.
The mutual information I(X; G) is, therefore, both a measure of predictability and reconstructability, thereby unifying these two concepts. We say that a system is perfectly predictable when the mutual information contains all the information about X, that is when I(X; G) = H(X) (see Fig. 1b). Likewise, we say that it is perfectly reconstructable when I(X; G) = H(G) (see Fig. 1c). Consequently, whenever I(X; G) > 0, we expect the system to be predictable and reconstructable to a certain degree. Otherwise, when I(X; G) = 0, the system is said both unpredictable and unreconstructable. Yet, I(X; G) by itself is hardly comparable from one system to another. Indeed, a specific value of I(X; G) may correspond to opposing scenarios when it comes to predictability and reconstructability, as shown in Fig. 1b, c. Thus, it is more convenient to use normalized quantities such as the uncertainty coefficients
which are bounded between 0 and 1. Contrary to I(X; G), U(X ∣ G) and U(G ∣ X) represent relative amount of information. For instance, U(G ∣ X) = 1 implies that I(X; G) = H(G), which in principle means that perfect reconstruction can be achieved as all the information of G is contained in X. Likewise, U(X ∣ G) = 1 means that I(X; G) = H(X), which indicates that all the information in X is determined by G: a perfectly accurate prediction of X can be made with G alone. This maximum value is guaranteed when X is deterministic and there is only one initial condition (see Supplementary Note III). Having I(X; G) = 0 implies that U(X ∣ G) = U(G ∣ X) = 0, which again means that G and X are independent. Any value in-between of U(X ∣ G) and U(G ∣ X) represents different degrees of predictability and reconstructability, respectively.
The “Simple example” section will present simple concrete examples to provide a better intuition about these concepts. Before we get to these examples, we investigate the influence of the knowledge of the past of X over the relationship between its future and its structure, as measured through reconstructability and predictability.
Past-dependent mutual information
It is often the case that predictability measures the sensitivity to the initial conditions of a process X. For instance, refs. 66,68,83,84 used different versions of the mutual information between X1 and X as a direct measure of predictability. Then, a system is more predictable if the past allows it to better predict the future. In this spirit, we generalize our framework in such a way that the mutual information between the process X and its structure G includes some information about the past of X.
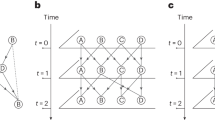
We define Xpast as the past of X and \({{{{{{{{\bf{X}}}}}}}}}_{{{{{{{{\rm{future}}}}}}}}}\) as its future, such that \({{{{{{{\bf{X}}}}}}}}=({{{{{{{{\bf{X}}}}}}}}}_{{{{{{{{\rm{past}}}}}}}}},{{{{{{{{\bf{X}}}}}}}}}_{{{{{{{{\rm{future}}}}}}}}})\), see Fig. 3a. We define τ as the length of Xpast and T − τ as the length of the future \({{{{{{{{\bf{X}}}}}}}}}_{{{{{{{{\rm{future}}}}}}}}}\). Our measure of interest in this case is \(I({{{{{{{{\bf{X}}}}}}}}}_{{{{{{{{\rm{future}}}}}}}}};G| {{{{{{{{\bf{X}}}}}}}}}_{{{{{{{{\rm{past}}}}}}}}})\), and it is equal to
which is a conditional mutual information—the green intersection in Fig. 3a. In turn, a small τ includes less contribution to the observed past, which leads to a scenario increasingly similar to that presented in “Information theory of dynamics on random graphs” section as shown by Fig. 3b. As τ gets larger, more contribution is left to Xpast resulting in a smaller \(I({{{{{{{{\bf{X}}}}}}}}}_{{{{{{{{\rm{future}}}}}}}}};G| {{{{{{{{\bf{X}}}}}}}}}_{{{{{{{{\rm{past}}}}}}}}})\), even though the total mutual information I(X; G)—the union of the red, green, and gray sets—is large (see Fig. 3c). Similarly to “Information theory of dynamics on random graphs” section, we then define the partial uncertainty coefficients, bounded between 0 and 1:
measuring the partial predictability of \({{{{{{{{\bf{X}}}}}}}}}_{{{{{{{{\rm{future}}}}}}}}}\) from G and partial reconstructability of G given \({{{{{{{{\bf{X}}}}}}}}}_{{{{{{{{\rm{future}}}}}}}}}\), respectively. The above quantities can be expressed in terms of previously visited ones. For instance, in Eq. (3), I(X; G) and I(Xpast; G) can be expressed using Eq. (1). Likewise, the normalizing factor \(H({{{{{{{{\bf{X}}}}}}}}}_{{{{{{{{\rm{future}}}}}}}}}| {{{{{{{{\bf{X}}}}}}}}}_{{{{{{{{\rm{past}}}}}}}}})\) is expressed in terms of state entropies using the joint entropy \(H({{{{{{{\bf{X}}}}}}}})=H({{{{{{{{\bf{X}}}}}}}}}_{{{{{{{{\rm{past}}}}}}}}},{{{{{{{{\bf{X}}}}}}}}}_{{{{{{{{\rm{future}}}}}}}}})\), i.e., \(H({{{{{{{{\bf{X}}}}}}}}}_{{{{{{{{\rm{future}}}}}}}}}| {{{{{{{{\bf{X}}}}}}}}}_{{{{{{{{\rm{past}}}}}}}}})=H({{{{{{{\bf{X}}}}}}}})-H({{{{{{{{\bf{X}}}}}}}}}_{{{{{{{{\rm{past}}}}}}}}})\). And finally, H(G∣Xpast) is evaluated similarly to H(G∣X).

In a, we show the information diagram of the random variable triplet \(({{{{{{{{\bf{X}}}}}}}}}_{{{{{{{{\rm{past}}}}}}}}},{{{{{{{{\bf{X}}}}}}}}}_{{{{{{{{\rm{future}}}}}}}}},G)\), where Xpast represents the past states, \({{{{{{{{\bf{X}}}}}}}}}_{{{{{{{{\rm{future}}}}}}}}}\), the future states, and G, the structure of the system. The quantities of interest are \(I({{{{{{{{\bf{X}}}}}}}}}_{{{{{{{{\rm{future}}}}}}}}};G| {{{{{{{{\bf{X}}}}}}}}}_{{{{{{{{\rm{past}}}}}}}}})\) indicated by the green set, \(H({{{{{{{{\bf{X}}}}}}}}}_{{{{{{{{\rm{future}}}}}}}}}| {{{{{{{{\bf{X}}}}}}}}}_{{{{{{{{\rm{past}}}}}}}}})\) shown by the union of the pink and green sets, and H(G∣Xpast), represented by the union of the blue and green sets. b, c Two extreme scenarios where the length of the past τ is small and large, which illustrates how the different information measures change with τ.
Whereas the interpretation of the partial uncertainty coefficients is analogous to those presented in the previous section, they nevertheless measure conceptually different quantities. Indeed, by using \(I({{{{{{{{\bf{X}}}}}}}}}_{{{{{{{{\rm{future}}}}}}}}};G| {{{{{{{{\bf{X}}}}}}}}}_{{{{{{{{\rm{past}}}}}}}}})\), it is implied that the information about the past has been removed from the total mutual information between X and G. As a result, the partial predictability \(U({{{{{{{{\bf{X}}}}}}}}}_{{{{{{{{\rm{future}}}}}}}}}| G;{{{{{{{{\bf{X}}}}}}}}}_{{{{{{{{\rm{past}}}}}}}}})\) measures the gain in predictability over \({{{{{{{{\bf{X}}}}}}}}}_{{{{{{{{\rm{future}}}}}}}}}\) when including G in the prediction, compared to a model which only uses Xpast. Additionally, the removed information likely includes some information about G, since I(Xpast; G) ≥ 0. Hence, the partial reconstructability, as defined by \(U(G| {{{{{{{{\bf{X}}}}}}}}}_{{{{{{{{\rm{future}}}}}}}}};{{{{{{{{\bf{X}}}}}}}}}_{{{{{{{{\rm{past}}}}}}}}})\), measures the reconstructability of the remaining information about G when observing \({{{{{{{{\bf{X}}}}}}}}}_{{{{{{{{\rm{future}}}}}}}}}\), i.e., information which has not been unveiled from the observation of Xpast.
In essence, for some ξ > 0, the case τ = 1 with T = ξ + 1 is similar to the case τ = T − ξ with T > ξ since \({{{{{{{{\bf{X}}}}}}}}}_{{{{{{{{\rm{future}}}}}}}}}\) have the same length ξ in both cases. From a reconstruction perspective, they quantify the reconstructability of G from a process with ξ time steps. However, the reconstructed information is quite different in both cases, since with τ = 1 and T = ξ + 1 no prior information is given—assuming that the initial conditions X1 are independent from G—, while a lot of information has already been processed when τ = T − ξ. Furthermore, increasing τ draws our attention away from the actual relationship between X and G of interest, since this relationship should exclude all information about Xpast. For this reason, we will mostly focus on the case τ = 1 in the remainder of the paper.
Simple example
The interpretation of reconstructability and predictability in terms of U(G∣X) and U(X∣G) can be grasped more firmly through an elementary example. We consider a system where only two graphs are possible, namely g1 and g2, such that P(g1) = p and P(g2) = 1 − p (see Fig. 4a). The entropy of this graph is therefore \(H(G)={{{{{{{\mathcal{H}}}}}}}}(p)\), where \({{{{{{{\mathcal{H}}}}}}}}(p)=-p\log p-(1-p)\log (1-p)\) is the binary entropy. These two graphs can generate together three outcomes for X, i.e., x1, x2, or x3. The graph g1 generates x1 and x2 with probabilities r and 1 − r respectively. Likewise, g2 generates x2 and x3 with respective probabilities s and 1 − s. As we can see, x1 can only be generated by g1 and x3 can only be the outcome of g2, while x2 can be generated by both graphs.

a The stochastic system consists of two possible graphs, \(g_{1}\) and \(g_{2}\), and three possible time series, \({{\bf{x}}}_{1},\, {{\bf{x}}}_{2}\), and \({{\bf{x}}}_{3}\). b, c The reconstructability \(U(G|{{{\bf{X}}}})\) (solid blue line) and the predictability \(U({{{\bf{X}}}}|G)\) (dashed orange line) are shown for \(s=1\) (b) and \(s=\frac{1}{2}\) (c). The shaded area in (c) indicates the region where \(U({{\bf{X}}}|G) \, {{{\rm{and}}}} \, U(G|{{{\bf{X}}}})\) vary in opposite directions.
We now focus on the scenario with s = 0—the general expressions for I(X; G) and the other entropies are obtained in Section II of the Supplementary Information. In this case, only g1 can generate x1 and x2, while g2 can only generate x3. Therefore, we have perfect reconstructability of either graphs, meaning U(G∣X) = 1 for any p and r, since the outcome of X tells us immediately which graph generated it. However, X is imperfectly predictable from G since \(U({{{{{{{\bf{X}}}}}}}}| G)=\frac{{{{{{{{\mathcal{H}}}}}}}}(p)}{{{{{{{{\mathcal{H}}}}}}}}(p)+p{{{{{{{\mathcal{H}}}}}}}}(r)} \, < \, 1\) when 0 < p, r < 1, even though x3 can be perfectly predicted from g2 as it is its only possible outcome. The remaining entropy, i.e. the second term of the denominator, \(p{{{{{{{\mathcal{H}}}}}}}}(r)\), corresponds to the uncertainty related to whether g1 generates x1 or x2.
When s = 1, the system is both partially predictable and reconstructible, with \(U({{{{{{{\bf{X}}}}}}}}\,| \,G)=1-\frac{p{{{{{{{\mathcal{H}}}}}}}}(r)}{{{{{{{{\mathcal{H}}}}}}}}(pr)} < 1\) and \(U(G\,| \,{{{{{{{\bf{X}}}}}}}})=\frac{{{{{{{{\mathcal{H}}}}}}}}(pr)-p{{{{{{{\mathcal{H}}}}}}}}(r)}{{{{{{{{\mathcal{H}}}}}}}}(p)} < 1\) for all 0 < p, r < 1. Both g1 and g2 can generate x2, but the probability that g1 generates x2 decreases with r. This results in a gradual increase of predictability and reconstructability as r approaches 1, where the systems tend to a one-to-one mapping between the outcomes of G and X.
The intermediate cases when 0 < s < 1 are also interesting because they give rise to an interval in r where the system becomes less predictable but more reconstructable as r increases, as highlighted by the gray area in Fig. 4c. This happens because, as r increases for a fixed s, the growth of entropy of X dominates I(X; G), resulting in the dual behavior of U(X∣G) and U(G∣X).
θ-duality between predictability and reconstructability
Predictability and reconstructability in dynamics on random graphs offer two perspectives of the same information shared by G and X—two sides of the same coin. However, as we have previously seen with simple examples, predictability, and reconstructability do not necessarily go hand in hand even though they are related: An increasing U(G ∣ X) according to some parameter θ of the system does not necessarily imply an increase of U(X ∣ G) and vice versa. Furthermore, a high value of U(G ∣ X) is not tied to a high value of U(X ∣ G), and conversely, as illustrated in Fig. 1b, c. Indeed, U(G ∣ X) and U(X ∣ G) can take opposing values, depending on H(G) and H(X), for the same value of I(X; G). This phenomenon can also be observed in the performance of prediction and reconstruction (see Supplementary Note I). In the literature, a hint of the existence of such dual behavior was recently corroborated in ref. 51 for continuous-state deterministic dynamics. The authors showed that high prediction accuracy can be achieved with graphs reconstructed from the very time series they want to predict, even if they are different from the original graph that generated the time series. This phenomenon can be understood through our framework (see Section III of the Supplementary Information) and we now devote the rest of the section to precisely define and characterize the somewhat counterintuitive phenomenon of duality.
We identify a duality when U(X ∣ G) and U(G ∣ X) vary in opposite directions when a parameter, say θ, is changed. More specifically, we say that they are dual with respect to θ, or θ-dual, in an interval Θ if and only if the signs of their derivative with respect to θ are different for every θ* ∈ Θ:
This criterion formally relies on the existence of regions Θ where the variations of U(G ∣ X) and U(X ∣ G) with respect to θ are opposite, regardless of their amplitude (see also “Formal definition of θ-duality” section). We use this criterion to relate the existence of extrema of U(G ∣ X) and U(X ∣ G) with that of regions of θ-duality (see Lemma 1 in “Formal definition of θ-duality” section).
With our intuition being established from simple examples and our precise definition, we are finally ready to state one of the main results of the paper. Recalling that T is the length of process X, we prove that reconstructability and predictability are T-dual for a vast class of Markov chains.
Theorem 1
Let X = (X1, X2,⋯,XT) be a Markov chain of length T whose transition probabilities are conditional to some discrete random variable G that is independent of T and such that H(Xt+1∣Xt) > 0 for all t ∈ {1,…,T − 1} (i.e., X is non-deterministic). Moreover, suppose that the state spaces of X and G are finite, and that X has a finite nonzero entropy rate and that G has a nonzero entropy. Then there exists a positive constant ϕ such that the uncertainty coefficients U(G∣X) and U(X∣G) are T-dual for all T ≥ ϕ.
The proof of this theorem is in “Proof of the universality of the T-duality” section. It is a consequence of the fact that the mutual information is strictly increasing with T—and so is U(G ∣ X) since H(G) is independent of T—whenever the entropy rate of X is positive. As a result, U(G ∣ X)—and numerator, I(X; G)—stagnates at some point in T, while U(X ∣ G) keeps decreasing because its denominator increases in an asymptotically linear manner with T. We refer to this opposing behavior as a duality between U(G ∣ X) and U(X ∣ G) with respect to T, or a T-duality for short (not to be confused with target space duality in string theory85.) When the entropy rate is not well-defined, like for non-stationary processes, the universality of the T-duality might not hold, while it remains possible to observe it in localized intervals of T.
Figure 5 illustrates the universality of the T-duality using the special case of binary Markov chains (i.e., \({{\Omega }}=\left\{0,1\right\}\), see “Binary Markov chains on graphs” section). These systems are parametrized by their activation (0 → 1) and deactivation (1 → 0) probability functions, denoted α(ni,t, mi,t) and β(ni,t, mi,t), respectively. In general, the activation and deactivation functions depends solely on ni,t and mi,t, i.e., the number of active and inactive neighbors of vertex i at time t. We present multiple examples of binary Markov processes with different origins in Table 1: The Glauber dynamics, the Suspcetible-Infectious-Susceptible (SIS) dynamics, and the Cowan dynamics.

a, d Glauber dynamics, b, e SIS dynamics, and c, f Cowan dynamics. Each panel shows the reconstructability U(G ∣ X) ∈ [0, 1] (blue) and the predictability coefficient U(X ∣ G) ∈ [0, 1] (orange) as a function of the number of time steps T. We used graphs of N = 5 vertices and E = 5 edges, meaning an average degree of 〈k〉 = 2; we fixed τ = 1 in the top row, and τ = T/2 in the bottom row. Each symbol corresponds to the average value measured over 1000 samples. We also show different values of the coupling parameters using different symbols: a, d \(J \in \left\{\frac{1}{2},1,\,2\right\}\) for Glauber, b, e \(\lambda \in \left\{\frac12,1,\, 2\right\}\) for SIS, and c, f \(\nu \in \left\{\frac12,1,\,2\right\}\) for Cowan.
The aforementioned Glauber dynamics86, which have been used to describe the time-reversible evolution of magnetic spins aligning in a crystal, have been tremendously studied because of its critical behavior and its phase transition. Its stationary distribution is given by the Ising model which has found many applications in condensed-matter physics87 and statistical machine learning81,88, to name a few. The SIS dynamics is a canonical model in network epidemiology5 often used for modeling influenza-like disease89, where periods of immunity after recovery are short. In this model, susceptible (or inactive) vertices get infected by each of their infected (active) first neighbors, with a constant transmission probability, and recover from the disease with a constant recovery probability. The simplicity of the SIS model has allowed for deep mathematical analysis of its absorbing-state phase transition15,17,20. Finally, the Cowan dynamics90 has been proposed to model the neuronal activity in the brain. In this model, quiescent neurons fire if their input current, coming from their firing neighbors, is above a given threshold. Its mean-field approximation91 reduces to the Wilson-Cowan dynamics92, one of the most influential models in neuroscience93. For each model, we can identify an inactive state—down, susceptible, or quiescent—and an active one—up, infectious, or firing. The corresponding activation and deactivation probabilities are given in Table 1.
Figure 5 numerically supports Theorem 1 and clearly illustrates the T-duality for each dynamics, with different values of their parameters and different past lengths τ. We used the Erdős-Rényi model as the random graph on which these dynamics evolve. The support \({{{{{{{\mathcal{G}}}}}}}}\) is the set of all simple graphs of N vertices with E edges, and
Note that, in this example, we consider the well-known Erdős-Rényi model for simplicity (Eq. (6)). Furthermore, we considered very small graphs of size N = 5, because the exact evaluation of I(X; G) is computationally intractable. For larger systems, biased estimators can be designed to bound I(X; G) as we show in “Estimators of the mutual information” section. We demonstrate the flexibility of our framework with regard to the random graph models by using more sophisticated and data-driven graph models in the following section.
The T-duality persists for the past-dependent measures presented in “Past-dependent mutual information” section, as illustrated by the bottom row of Fig. 5, for τ = T/2. However, note that for sufficiently large τ, the duality seems to disappear. We refer to Section VII of the Supplementary Information for further detail. One can only wonder how many different kinds of parameters can lead to θ-dualities. Maybe some may control the general behavior of the dynamics, and others some aspect of the system structure which, in turn, may also impact the dynamics. In the next section, we investigate those that are related to critical phenomena in complex systems.
Duality and criticality
Despite their different nature and range of applications, the three models presented in Table 1 share several properties of interest. For instance, each model has a coupling parameter that controls the influence of the state of the first neighbors on the transition probabilities. They also all feature a phase transition in the infinite size limit whose position is determined by the coupling parameter (see Section IX of the Supplementary Information). We now investigate the influence of criticality over the existence of θ-dualities, where θ is a coupling parameter.
For the Glauber dynamics, this parameter is the coupling constant J, which dictates the reduction (increase) in the total energy of a spin configuration when two neighboring spins are parallel (antiparallel). The Glauber dynamics features a continuous phase transition at a critical point Jc between a disordered and an ordered phase, where for J < Jc the spins are disordered resulting in a vanishing magnetization, and for which this magnetization is nonzero when J > Jc.
For the SIS dynamics, it is the transmission rate λ that acts as a coupling parameter. Like the Glauber dynamics, the SIS dynamics possesses a continuous phase transition where, when λ < λc, the system reaches an absorbing—or inactive—state from which it cannot escape, and an active state, when λ > λc, where a nonzero fraction of the vertices remain active over time. It should be emphasized that in our considered version of the SIS dynamics, referring to the system reaching a true absorbing state is not strictly accurate due to the allowance for self-infection ϵ, which enables escape from the completely inactive state. Instead, the system approaches a metastable state with most vertices becoming asymptotically inactive. However, it can be shown that the two-phase transitions are quite similar for small ϵ94.
The Cowan dynamics can both feature a continuous or a first-order phase transition between an inactive and an active phase depending on the value of slope a, for which the coupling parameter is ν, i.e., the potential gain for each firing neighbors. The continuous and first-order phase transitions of the Cowan dynamics are quite different in that the latter is characterized by two thresholds, namely the forward and backward thresholds \({\nu }_{{{{{{{{\rm{c}}}}}}}}}^{{{{{{{{\rm{b}}}}}}}}} \, < \, {\nu }_{{{{{{{{\rm{c}}}}}}}}}^{{{{{{{{\rm{f}}}}}}}}}\), respectively (see Section IX in the Supplementary Information). Hence, the Cowan dynamics has a first-order phase transition that exhibits a bistable region \(\nu \in ({\nu }_{{{{{{{{\rm{c}}}}}}}}}^{{{{{{{{\rm{b}}}}}}}}},\, {\nu }_{{{{{{{{\rm{c}}}}}}}}}^{{{{{{{{\rm{f}}}}}}}}})\), where both the inactive and active phases are reachable depending on the initial conditions.
To account for the heterogeneous network structure observed in a wide range of complex systems1, we simulate the dynamics on the configuration model, a random graph whose—potentially heterogeneous—degree sequence k is fixed and whose support \({{{{{{{\mathcal{G}}}}}}}}\) corresponds to the set of all loopy multigraphs of degree sequence k. The probability of a multigraph g in this ensemble is
where Mij counts the number of edges connecting vertices i and j in the multigraph g and 2E = ∑iki is the number of half-edges in g. Like the Erdős-Rényi model, the configuration model fixes the number of edges, but also fixes the degree sequence k = (k1,⋯, kN).
Figure 6 shows the predictability and reconstructability, as estimated by the MF estimator, of the three dynamics evolving on instances drawn from the configuration model. The top row shows the results when using a synthetic degree sequence obtained from a geometric degree distribution, while for the bottom row, degree sequences from different real networks are used for each dynamics. These distributions are shown in Fig. 7. We used the Little Rock Lake food web95 (as in ref. 40) jointly with the Glauber dynamics to simulate a simplification of the interaction between species. In the case of the SIS dynamics, we considered the European airline network96 to mimic the spread of an epidemic. Finally, to simulate the neural activity of the Cowan dynamics, we used the C. Elegans neural network97.

a, d Glauber dynamics, b, e SIS dynamics, and c, f Cowan dynamics. We used the configuration model (see Eq. (7)) to generate multigraphs of varying sizes and degree distributions. In the top row, we generated multigraphs with geometric degree distribution of size N = 1000 and with M = 2500 edges (see Fig. 7a). In the bottom row, we used the degree distribution of real networks: d Little Rock Lake food web95, e European airline route network96, f C. Elegans neural network97. The parameters used to generate the time series are the same in the top and bottom panels (see Table 1), except in f the time series length is T = 5000 while in the others T = 2000. Similar to Fig. 5, U(G ∣ X) is shown in blue (left axis) and U(X ∣ G) is shown in orange (right axis). We show, for each dynamics, the uncertainty coefficients as a function of the coupling parameter: J for Glauber, λ for SIS, and ν for Cowan. Each shaded area indicates a range of couplings over which duality was observed. The vertical dotted-dashed lines correspond to the phase transition thresholds of each dynamics, which are estimated from Monte Carlo simulations (see Section IX of the Supplementary Information). For the Cowan dynamics, the forward and backward branches are shown with their corresponding thresholds and dual regions (see main text).

First, the results of Fig. 6 show a meaningful comparison between the dynamics for different types of structures. For example, on the one hand, the Glauber dynamics is globally less predictable than the other two, since its predictability coefficient is overall smaller. In other words, the knowledge of a graph g provides less information about X in the Glauber dynamics in comparison with the others, relative to the total amount of information needed to predict X. This is related to the time reversibility of the Glauber dynamics, which allows any vertex to transition from the inactive to the active state (and vice versa) with nonzero probability, at any time, effectively making the Glauber dynamics more random than the others—i.e. H(X) is greater for Glauber than the other processes. On the other hand, the SIS and Cowan dynamics are shown as practically unpredictable and unreconstructable when their coupling parameter is below their respective critical point. This precisely occurs in the inactive phase, where the system rapidly reaches the inactive state and no mutual information can be generated. By contrast, the Glauber dynamics does not reach an inactive state below its critical point, which explains the gradual increase in predictability and reconstructability in that region.
Several additional observations are worth making. All dynamics exhibit maxima for U(X ∣ G) and U(G ∣ X), which delineate a region of duality illustrated by the shaded areas (two for Cowan, that is one for each branch). These regions are close to, but systematically above, their respective phase transition thresholds, regardless of type of degree sequence. A similar phenomenon in spin dynamics on non-random lattices has been reported by previous works79,80, in which the information transmission rate between spins—a measure akin to I(X; G)—is maximized above the critical point. Our numerical results are consistent with theirs, and suggest that their findings regarding near-critical systems even apply beyond spin dynamics on fixed lattices, to other types of processes on more heterogeneous and random structures.
Discussion
In this work, we used information theory to characterize the structure-function relationship with mutual information. We showed how mutual information is a natural starting point to define both predictability and reconstructability in dynamics on networks, and even how it explains the performance accuracy of prediction and reconstruction algorithms. In turn, we demonstrated how prediction and reconstruction in complex systems are intrinsically related. Our approach is quite general, allowing the exploration of different configurations of dynamics on networks of the form G → X, thus varying the nature of the process itself as well as the random graph on which it evolves. Our framework could be extended to adaptive systems98,99,100,101 where both X and G influence each other (i.e., X ↔ G). The relationship between X and G could also go the other way around: A system in which X generates a graph G (i.e., X → G). Hyperbolic graphs102,103 fall into this category, where X represents a set of coordinates, and our framework could be extended to quantifying the feasibility of network geometry inference104,105,106.
We exposed various examples where our measures can be computed analytically and found efficient ways to estimate them numerically when needed, thus allowing thorough investigation of large systems. More work on this front is required, however, since the evaluation of these estimators remains quite computationally costly. It would be worth investigating dimension-reduction methods11,13,14 and approximate master equations18,107, among others, for obtaining more efficient and reliable approximations of I(X; G), U(X ∣ G) and U(G ∣ X).
Central to our findings is the peculiar discovery that predictability and reconstructability are not only related, but sometimes dual to one another. We found many examples of this duality in systems of increasing complexity, while we also emphasized that its universality is limited to certain circumstances. One of those circumstances occurs when we change the length of the processes, for which we mathematically proved the existence of duality. We also presented numerical evidence of duality near-critical points in three different dynamics on real networks. These findings generalize and formalize—while being consistent with—previous works79,80 and suggest that the reconstructability-predictability duality with respect to order parameters is closely linked to the criticality in these systems.
From a practical perspective, the existence of such a θ-duality can be critical to network modeling applications, since it also suggests a predictability-reconstructability trade-off. On one hand, by choosing the parameter θ, we can minimize the uncertainty of the reconstructed structure, but this may result in a structure that is less informative regarding the dynamics. On the other hand, we can consider the reverse case, where the process is maximally influenced by the inferred structure, whose uncertainty is nevertheless not minimized. Analogous to the position-momentum duality in the Heisenberg uncertainty principle of quantum mechanics, the predictability-reconstructability duality must be accounted for in our network models if we are to disentangle complex systems.
Methods
Binary Markov chains on graphs
The models used throughout the paper are for the most part Markov chains X = (X1,X2,...,XT), that are governed by a conditional probability P(X∣G) that can be factored as follows:
The probability P(Xt+1∣Xt, G) is the global transition probability from state Xt to state Xt+1, and P(X1) represents the probability distribution of the initial conditions, which is independent of G in our case. More specifically, we assume that Xi is a random binary vector of size N, and that the global transition probability can be factored in terms of local transition probabilities as follows:
As mentioned in “θ-duality between predictability and reconstructability” section, the functions α and β correspond to the activation and deactivation probabilities. In the general case, they are dependent on the number of active neighbors mi, and inactive neighbors ni of a node i such that mi + ni = ki where ki is the degree of this node.
Performance of prediction and reconstruction algorithms
To substantiate our claim about the interpretation of I(X; G), we used different prediction and reconstruction algorithms and compared in Fig. 2 their performance with I(X; G). In this section, we elaborate on this analysis.
Prediction algorithms
The prediction algorithms used in Fig. 2 correspond to Markov models that predicts a transition—activation and deactivation—probability matrix P, where Pi,t corresponds to the probability that node i at time t transition to the active state in the next time step. To make the comparison with I(X; G), we compare the transition probability matrix P* of the true model—in the case of Fig. 2, the Glauber dynamics where the entries of P* are given by the activation α and deactivation β probabilities (see Table 1)—with those predicted by models learned from time series generated by the Glauber dynamics. These models are trained with 100 concatenated time series, each generated using a different graph sampled from the Erdős-Rényi model. The models are then trained to predict the time series without the knowledge of the structure. The input of these models is the complete state of the system at time t, i.e., Xt, and the output is a vector \({\hat{P}}_{t}=({\hat{P}}_{1,t},\cdots \,,{\hat{P}}_{N,t})\), where \({\hat{P}}_{i,t}\) is the predicted probability that node i transition to the active state at time t. We use the mean absolute error (MAE) between P* and \(\hat{P}\) to compare them, i.e.,
In doing so, the MAE quantifies the difference between a graph-dependent model and a graph-independent one, which highlights the importance of G over the prediction of X, which is a proxy of I(X; G).
We consider two graph-independent prediction models: a logistic regression model and a multilayer perceptron (MLP). In both models, the predicted transition probabilities at time t are given by
where f(Xt) is a learnable function, that is linear for the logistic regression model, i.e.
and non-linear for the MLP:
such that
The weight matrices A, W1, and W2, and bias vectors b, b1, and b2, are learned via stochastic gradient descent using a cross-entropy loss.
Reconstruction algorithms
In Fig. 2, we also illustrated the relationship between the performance of reconstruction algorithms and I(X; G). These algorithms are given the time series and they compute a score matrix S, such that Sij for each pair of nodes (i, j) correlates with a probability that an edge exists between them. For the correlation matrix method31, this score is simply the correlation coefficient:
where \({{\bar{X}}}_i=\frac{1}{T}{\sum}_{t=1}^T X_{i,t}\) and \(\sigma_i=\frac{1}{T}{\sum}_{t=1}^T (X_{i,t} - {{\bar{X}}}_i)^2\). In the Granger causality method32, we compare via a F-test the prediction of the time series of a single node i using a linear auto-regressive model, with another auto-regressive model that includes the time series of node j. Then, the test determines if the models error are similar or different by computing the following F-statistic:
where Σi is the error variance of the auto-regressive model of i, and Σij is the error variance of the other model that also includes j. Finally, in the transfer entropy method33, the score is given by the transfer entropy from the time series of j to the time series of i:
where
The entropies involved in the computation of \({T}_{{X}_{j}\to {X}_{i}}\) are evaluated using the maximum likelihood estimators of the probabilities P(Xi,t∣Xi,t−1) and P(Xi,t∣Xi,t−1, Xj,t−1), estimated from the time series itself.
We quantify the accuracy of the reconstruction using the area under the curve (AUC) of the receiver operating characteristic (ROC) curve. This curve is obtained by comparing the true positive rate with the false positive rate, for different thresholds \(\phi \in [\min \left\{S\right\},\max \left\{S\right\}]\). The AUC, being the integral of that curve, therefore represents the probability that the score matrix S classifies correctly a node pair connected by an edge.
Formal definition of θ-duality
In what follows, we define the duality between predictability and reconstructability by taking a more general stance: Instead of considering a stochastic process X evolving on a random graph G, we let G be any discrete random variable conditioning the probability of X. First, we define the local duality of the uncertainty coefficients. The latter are considered as continuously differentiable functions with respect to a parameter θ whose domain is some non-empty interval of the real line.
Definition 1
(Local duality). The uncertainty coefficients U(X ∣ G) and U(G ∣ X) are locally dual with respect to θ at θ = θ* if and only if
The definition of the θ-duality, a global property, follows that of the local duality.
Definition 2
(θ-Duality). The uncertainty coefficients U(X ∣ G) and U(G ∣ X) are dual with respect to θ, or θ-dual, in the interval Θ if and only if they are locally dual for all values of θ* in Θ.
From these definitions, we relate the presence of extrema of U(X ∣ G) and U(G ∣ X) with the existence of a θ-duality.
Lemma 1
(θ-duality between extrema). Let Θ be a non-empty subinterval of the variable θ whose one endpoint is a local extremum of U(X ∣ G) and the other, a local extremum of U(G ∣ X). Moreover, suppose that U(X ∣ G) and U(G ∣ X) do not have critical points in Θ. Then the extrema points delineate a region of θ-duality if and only if they are both maxima (or both minima).
The proof of this lemma is available in Supplementary Note IV.
Proof of the universality of the T-duality
In what follows, we prove Theorem 1, that shows the universality of the T-duality, where T is the number of steps in the process X. We make use of the two following lemmas, that are proved in Supplementary Information (Notes V and VI), regarding the monotonicity of I(X; G) with respect to T and the existence of continuous extensions of U(X ∣ G) and U(G ∣ X), that will allow us to apply the Definition 1 involving derivatives.
Lemma 2
(Monotonicity of mutual information information with T). Let X = (X1, X2, ⋯ , XT) be a Markov chain of length T whose transition probabilities are conditional to some discrete random variable G that is independent of T and such that H(Xt+1∣Xt) > 0 for all t ∈ {1, …, T − 1}. Suppose moreover that the state spaces of X and G are finite. Then the mutual information I(X; G) is nonzero and monotonically increasing with \(T\in {{\mathbb{Z}}}_{+}\).
Lemma 3
(Continuous extension of uncertainty coefficients with T). Let X = (X1, X2, ⋯ , XT) and G respectively be a Markov chain and a discrete random variable as in Lemma 2. Then the uncertainty coefficients U(G ∣ X) and U(X ∣ G), interpreted as functions of \(T\in {{\mathbb{Z}}}_{+}\), can be uniquely generalized to functions, respectively f(T) and g(T), that are holomorphic for all \(T\in {\mathbb{C}}\), and thus real analytic for all \(T\in {{\mathbb{R}}}_{+}\). Moreover, H(X) can be extended to a function h(T) that is analytic for all \(T\in {{\mathbb{R}}}_{+}\) except where f(T) = 0.
Next, we prove Theorem 1.
Proof
According to Lemma 3, the quantities U(X ∣ G), U(G ∣ X), and H(X), which were originally defined as real functions of \(T\in {{\mathbb{Z}}}_{+}\), have unique analytic extensions on the positive real axis, i.e., \(T\in {{\mathbb{R}}}_{+}\). This allows us to treat U(X ∣ G), U(G ∣ X), and H(X) as continuously differentiable functions with respect to T, where \(U(G\,| \,{{{{{{{\bf{X}}}}}}}})=\frac{I({{{{{{{\bf{X}}}}}}}};G)}{H(G)}\) and H(X) are also monotone.
Now, by hypothesis, the entropy rate of the Markov chain X, \(R:={\lim }_{T\to \infty }\frac{H({{{{{{{\bf{X}}}}}}}})}{T}\), is well defined and nonzero. Hence, H(X) ~ RT, i.e., H(X) is positive and asymptotically linearly increasing with T. Moreover, since G is independent of T and I(X; G) > 0, it follows that I(X; G) is monotonically increasing with respect to T by Lemma 2. As a result, \(U(G\,| \,{{{{{{{\bf{X}}}}}}}})=\frac{I({{{{{{{\bf{X}}}}}}}};G)}{H(G)}\) is also monotonically increasing, since its denominator is independent of T, by assumption. This translates to the strict inequality \(\frac{\partial U(G\,| \,{{{{{{{\bf{X}}}}}}}})}{\partial T} > \, 0\). If there exists a T-duality, i.e., there is a domain of T where Eq. (19) is true, then U(X ∣ G) must be monotonically decreasing with T—or \(\frac{\partial U({{{{{{{\bf{X}}}}}}}}\,| \,G)}{\partial T} < \, 0\)—in that domain. To prove this, note that we can relate the two uncertainty coefficients using
This leads to the following differential equation
where we used the fact that \(\frac{\partial H(G)}{\partial T}=0\). Hence, to show that U(X ∣ G) is monotonically decreasing with T, the following inequality must hold
Suppose for a moment that U(X ∣ G) is in fact increasing, such that Eq. (22) is false. This will eventually give rise to a contradiction. Let g(T): = U(G ∣ X) and h(T): = H(X) be continuous functions of T such that their derivative with respect to T are respectively given by \({g}^{{\prime} }(\tau ):={\left.\frac{\partial f(T)}{\partial T}\right\vert }_{T=\tau }\) and \({h}^{{\prime} }(\tau ):={\left.\frac{\partial h(T)}{\partial T}\right\vert }_{T=\tau }\). Note that 0 < f(τ) ≤ 1 and h(τ) > 0 for all \(\tau \in {{\mathbb{R}}}_{+}\). If Eq. (22) is false, then
Using Grönwall’s inequality108, Theorem 1.2.1, we get
So far, we have established that h(T) = H(X) ~ RT and that U(G ∣ X) is monotonically increasing. We have also proved that if U(X ∣ G) is not monotonically decreasing with T, then inequality (24) is satisfied. However, the latter inequality and h(T) ~ RT readily imply that g(T) belongs to the class Ω(T), which is the set of all \(\tilde{g}(T)\) such that there exist positive constants, S and T*, for which \(\tilde{g}(T)\ge ST\) for all T ≥ T* (i.e., Knuth’s Big Omega109).
Two cases must be considered. First, if ST* > 1, then \(\tilde{g}(T)\ge S{T}^{*} > 1\), which is in direct contradiction with g(T) ≤ 1 whenever T ≥ T*. Second, if ST* ≤ 1, then choose T** > S−1 ≥ T*, so that \(\tilde{g}(T)\ge S{T}^{*\ast } > 1\) for all T ≥ T**. This again contradicts the inequality g(T) ≤ 1 whenever T ≥ T**. As a result, inequality (24) cannot be satisfied when T ≥ ϕ, with \(\phi=\max \{{T}^{*},{T}^{*\ast }\}\). We thus conclude that U(X ∣ G) is monotonically decreasing for all T ≥ ϕ. Therefore, U(G ∣ X) and U(X ∣ G) are T-dual in the interval [ϕ, ∞). □
Estimators of the mutual information
The mutual information I(X; G) is generally intractable. Its intractability stems from the evaluation of the evidence probability, which is defined by the following equation:
Indeed, this sum potentially counts a number of terms which grows exponentially with the number of vertices N in the random graph. More specifically, the evidence probability appears in two entropy terms needed to compute the mutual information, namely the marginal entropy \(H({{{{{{{\bf{X}}}}}}}})=-\left\langle \log P({{{{{{{\bf{X}}}}}}}})\right\rangle\) and the reconstruction entropy \(H(G| {{{{{{{\bf{X}}}}}}}})=-\langle \log \frac{P(G)P({{{{{{{\bf{X}}}}}}}}| G)}{P({{{{{{{\bf{X}}}}}}}})}\rangle\), where \(\left\langle f(Y)\right\rangle\) denotes the expectation of f(Y). Fortunately, the evidence probability, and in turn the mutual information, can be estimated efficiently using Monte Carlo techniques, which we present in this section.
Graph enumeration approach
For sufficiently small random graphs (N ≤ 5), the evidence probability can be efficiently computed by enumerating all graphs of \({{{{{{{\mathcal{G}}}}}}}}\) and by adding explicitly each term of Eq. (25). Then, we can estimate the mutual information by sampling M graphs \({\left\{{g}^{(m)}\right\}}_{m=1..M}\), followed by M time series \({\left\{{{{{{{{{\bf{x}}}}}}}}}^{(m)}\right\}}_{m=1..M}\)—such that x(m) is generated with g(m)—, and by computing the following arithmetic average:
The variance of this estimator scales with the inverse of \(\sqrt{M}\). In Fig. 5, we used this estimator to compute the mutual information, where M = 1000.
Variational mean-field approximation
In this approach, we estimate the posterior probability instead of the evidence probability. According to Bayes’ theorem, the posterior probability is
Behind this estimator is a variational mean-field (MF) approximation that assumes the conditional independence of the edges. For simple graphs, the MF posterior is
where πij(X): = P(Aij = 1∣X) is the marginal conditional probability of the existence of the edge (i, j) given X. For multigraphs, a similar expression can be obtained, but instead involves a probability πij(m∣X): = P(Mij = m∣X) that there are m multiedges between i and j. In this case, the MF posterior becomes
where δx,y is the Kronecker delta. The MF approximation allows to compute a lower bound of the true posterior entropy, such that
as a consequence of the conditional independence between the edges82, Theorem 2.6.5. Using the MF approximation and a strategy similar to the exact estimator, we compute the MF estimator of the mutual information as follows:
To compute \({P}_{{{{{{{{\rm{MF}}}}}}}}}\left(G={g}^{(m)}| {{{{{{{\bf{X}}}}}}}}={{{{{{{{\bf{x}}}}}}}}}^{(m)}\right)\), we sample a set \({{{{{{{{\mathcal{Q}}}}}}}}}^{(m)}: = \left\{{g}_{1}^{(m)},\cdots \,,{g}_{Q}^{(m)}\right\}\) of Q graphs from the posterior distribution P(G∣X = x(m)). Then, we estimate the probabilities \({\pi }_{ij}({{{{{{{\bf{X}}}}}}}})\simeq \frac{{n}_{ij}^{(m)}}{Q}\) using their corresponding maximum likelihood estimate, where \({n}_{ij}^{(m)}\) is the number of times the edge (i, j) is seen in \({{{{{{{{\mathcal{Q}}}}}}}}}^{(m)}\). An analogous maximum likelihood estimate is made in the multigraph case, where \({\pi }_{ij}(\omega | {{{{{{{\bf{X}}}}}}}})\simeq \frac{{n}_{ij;\omega }^{(m)}}{K}\) and \({n}_{ij;\omega }^{(m)}\) counts the number of times there were ω multiedges between i and j in \({{{{{{{{\mathcal{Q}}}}}}}}}^{(m)}\). This estimator is a lower bound of the mutual information—a consequence of Eq. (30). Hence, it is biased, and the extent of this bias is dependent on the quality of the conditional independence assumption with respect to the true random graph. Note that the MF estimator can yield negative estimates of the mutual information (see Section VIII of the Supplementary Information).
In Fig. 6, we fix the number of graphs sampled from the posterior distribution to Q = 1000, and propose 5N moves between each sample (see also “Markov chain Monte Carlo algorithm” section for more detail).
Markov chain Monte Carlo algorithm
To sample from the posterior distribution, we use a Markov chain Monte Carlo (MCMC) algorithm where, starting from a graph g, we propose a move to graph \({g}^{{\prime} }\), according to a proposition probability \(P({G}^{{\prime} }={g}^{{\prime} }| G=g)\), and accept it with the Metropolis-Hastings probability:
where \({{\Delta }}=\frac{P(G={g}^{{\prime} })P({{{{{{{\bf{X}}}}}}}}={{{{{{{\bf{x}}}}}}}}| G={g}^{{\prime} })}{P(G=g)P({{{{{{{\bf{X}}}}}}}}={{{{{{{\bf{x}}}}}}}}| G=g)}\) is the ratio between the joint probability of the two graphs with the time series X. This ratio can be computed efficiently in \({{{{{{{\mathcal{O}}}}}}}}(T)\), by keeping in memory ni,t, the number of inactive neighbors, and mi,t, a number of active neighbors, for each vertex i at each time t (see ref. 40). Equation (32) allows to sample from the posterior distribution P(G∣X) without the requirement to compute the intractable normalization constant P(X). We collect graph samples at every Nδ move, where we fix δ = 5 in all experiments.
We consider two types of random graphs with different constraints: The Erdős-Rényi model and the configuration model. Hence, we need two different sampling propositions to apply our MCMC algorithm, that is one for each model. We assume that the support of the Erdős-Rényi model is the set of all simple graphs of N vertices with E edges. In this case, we consider a hinge flip move, where an edge (i, j) is sampled uniformly from the edge set of the graph G and a vertex k is sampled uniformly from its vertex set. Then, with probability \(\frac{1}{2}\), we rewire edge (i, j) by either selecting i or j to connect with k. Note that, because we consider the support \({{{{{{{\mathcal{G}}}}}}}}\) of G to be a space of simple graphs, all moves resulting in the addition of a self-loop or a multiedges are rejected with probability 1. As a result, the proposition probability is the same for any move from g to \({g}^{{\prime} }\):
For the configuration model, we assume that the support is the set of all loopy multigraphs of N vertices whose degree sequence is k. In this case, we propose double-edge swap moves according to the prescription of ref. 110. We refer to it for further details.
Real networks
In this section, we present the real networks used in the bottom panels of Fig. 6. The networks have been downloaded from the Netzschleuder network catalog111.
Little Rock Lake food web
The Little Rock Lake food web95 is composed of N = 183 nodes and M = 2 494 edges, where nodes represent taxa (like species) found in Little Rock Lake in Wisconsin, and edges represent feeding patterns between two taxa. As presented in ref. 95, this network is directed, but for the purpose of our paper we reciprocated all edges. Also, note that the Glauber dynamics, which we used jointly with the Little Rock Lake food web in Fig. 6, was also used in ref. 40 to simulate a simplified interaction between the taxa.
European airline route network
The European airline route network96 is a multiplex network composed of N = 450 and M = 3 588 edges, where nodes represent airports and edges are routes between them. These edges have different types, encoding the different airlines. In our paper, we do not make any distinction between the edge types for simplicity.
C. Elegans neural network
The C. Elegans neural network97 used in Fig. 6 is an undirected network of N = 514 and M = 2363 edges representing the neural network of male C. Elegans worms. The nodes are neurons and edges represent when there are gap junctions between neurons.
Reporting summary
Further information on research design is available in the Nature Portfolio Reporting Summary linked to this article.
Data availability
The real network data used in the paper were downloaded from the network repository Netzschleuder111. The details are given in “Real networks” section.
Code availability
The Python code used to generate the results of the paper is available on GitHub112.
References
Barabási, A.-L. Network science. Phil. Trans. R. Soc. A 371, 20120375 (2013).
Latora, V., Nicosia, V. and Russo, G. Complex Networks: Principles, Methods and Applications (Cambridge Univ. Press, 2017).
Newman, M. E. J. Networks 2nd edn (Oxford Univ. Press, 2018).
Barzel, B. & Barabási, A.-L. Universality in network dynamics. Nat. Phys. 9, 673–681 (2013).
Pastor-Satorras, R., Castellano, C., Van Mieghem, P. & Vespignani, A. Epidemic processes in complex networks. Rev. Mod. Phys. 87, 925 (2015).
Boccaletti, S. et al. Explosive transitions in complex networks’ structure and dynamics: percolation and synchronization. Phys. Rep. 660, 1–94 (2016).
Iacopini, I., Petri, G., Barrat, A. & Latora, V. Simplicial models of social contagion. Nat. Commun. 10, 2485 (2019).
Hébert-Dufresne, L., Scarpino, S. V. & Young, J.-G. Macroscopic patterns of interacting contagions are indistinguishable from social reinforcement. Nat. Phys. 16, 426–431 (2020).
Murphy, C., Laurence, E. & Allard, A. Deep learning of contagion dynamics on complex networks. Nat. Commun. 12, 4720 (2021).
Gao, J., Barzel, B. & Barabási, A.-L. Universal resilience patterns in complex networks. Nature 530, 307 (2016).
Laurence, E., Doyon, N., Dubé, L. J. & Desrosiers, P. Spectral dimension reduction of complex dynamical networks. Phys. Rev. X 9, 011042 (2019).
Pietras, B. & Daffertshofer, A. Network dynamics of coupled oscillators and phase reduction techniques. Phys. Rep. 819, 1–109 (2019).
Thibeault, V., St-Onge, G., Dubé, L. J. & Desrosiers, P. Threefold way to the dimension reduction of dynamics on networks: an application to synchronization. Phys. Rev. Res. 2, 043215 (2020).
Thibeault, V., Allard, A. and Desrosiers, P. The low-rank hypothesis of complex systems, Nat. Phys. https://doi.org/10.1038/s41567-023-02303-0 (2024).
Pastor-Satorras, R. & Vespignani, A. Epidemic spreading in scale-free networks. Phys. Rev. Lett. 86, 3200 (2001).
Hébert-Dufresne, L. & Althouse, B. M. Complex dynamics of synergistic coinfections on realistically clustered networks. Proc. Natl. Acad. Sci. USA 112, 10551–10556 (2015).
St-Onge, G., Young, J.-G., Laurence, E., Murphy, C. & Dubé, L. J. Phase transition of the susceptible-infected-susceptible dynamics on time-varying configuration model networks. Phys. Rev. E 97, 022305 (2018).
St-Onge, G., Thibeault, V., Allard, A., Dubé, L. J. & Hébert-Dufresne, L. Master equation analysis of mesoscopic localization in contagion dynamics on higher-order networks. Phys. Rev. E 103, 032301 (2021).
St-Onge, G., Sun, H., Allard, A., Hébert-Dufresne, L. & Bianconi, G. Universal nonlinear infection kernel from heterogeneous exposure on higher-order networks. Phys. Rev. Lett. 127, 158301 (2021).
Ferreira, S. C., Castellano, C. & Pastor-Satorras, R. Epidemic thresholds of the susceptible-infected-susceptible model on networks: a comparison of numerical and theoretical results. Phys. Rev. E 86, 041125 (2012).
Castellano, C. & Pastor-Satorras, R. Relating topological determinants of complex networks to their spectral properties: structural and dynamical effects. Phys. Rev. X 7, 041024 (2017).
Pastor-Satorras, R. & Castellano, C. Eigenvector localization in real networks and its implications for epidemic spreading. J. Stat. Phys. 173, 1110–1123 (2018).
Hébert-Dufresne, L., Noël, P.-A., Marceau, V., Allard, A. & Dubé, L. J. Propagation dynamics on networks featuring complex topologies. Phys. Rev. E 82, 036115 (2010).
St-Onge, G., Thibeault, V., Allard, A., Dubé, L. J. & Hébert-Dufresne, L. Social confinement and mesoscopic localization of epidemics on networks. Phys. Rev. Lett. 126, 098301 (2021).
Brugere, I., Gallagher, B. & Berger-Wolf, T. Y. Network structure inference, a survey: motivations, methods, and applications. ACM Comput. Surv. 51, 1–39 (2018).
Peixoto, T. P. Reconstructing networks with unknown and heterogeneous errors. Phys. Rev. X 8, 041011 (2018).
Young, J.-G., Cantwell, G. T. & Newman, M. E. J. Bayesian inference of network structure from unreliable data. J. Complex Netw. 8, cnaa046 (2020).
Young, J.-G., Valdovinos, F. S. & Newman, M. E. J. Reconstruction of plant–pollinator networks from observational data. Nat. Commun. 12, 3911 (2021).
Laurence, E., Murphy, C., St-Onge, G., Roy-Pomerleau, X. and Thibeault, V. Detecting structural perturbations from time series using deep learning, http://arxiv.org/abs/2006.05232 (2020).
McCabe, S. et al. netrd: A library for network reconstruction and graph distances. J. Open Source Softw. 6, 2990 (2021).
Kramer, M. A., Eden, U. T., Cash, S. S. & Kolaczyk, E. D. Network inference with confidence from multivariate time series. Phys. Rev. E 79, 061916 (2009).
Schreiber, T. Measuring information transfer. Phys. Rev. Lett. 85, 461–464 (2000).
Seth, A. K. Causal connectivity of evolved neural networks during behavior. Netw. Comput. Neural Syst. 16, 35–54 (2005).
Abbeel, P., Koller, D. & Ng, A. Y. Learning factor graphs in polynomial time and sample complexity. J. Mach. Learn. Res. 7, 1743–1788 (2006).
Salakhutdinov, R. & Murray, I. On the quantitative analysis of deep belief networks, In Proc. 25th International Conference on Machine Learning 872–879 (Association for Computing Machinery, 2008).
Bento, J. and Montanari, A. Which graphical models are difficult to learn? In Advances in Neural Information Processing Systems 1303–1311 (MIT Press, 2009).
Salakhutdinov, R. and Larochelle, H. Efficient learning of deep Boltzmann machines. In Proc. Thirteenth International Conference on Artificial Intelligence and Statistics 693–700 (Proceedings of Machine Learning Research, 2010).
Bresler, G., Mossel, E. & Sly, A. Reconstruction of Markov random fields from samples: some observations and algorithms. SIAM J. Comput. 42, 563–578 (2013).
Amin, M. H., Andriyash, E., Rolfe, J., Kulchytskyy, B. & Melko, R. Quantum Boltzmann machine. Phys. Rev. X 8, 021050 (2018).
Peixoto, T. P. Network reconstruction and community detection from dynamics. Phys. Rev. Lett. 123, 128301 (2019).
Hinne, M., Heskes, T., Beckmann, C. F. & Van Gerven, M. A. J. Bayesian inference of structural brain networks. NeuroImage 66, 543–552 (2013).
Breakspear, M. Dynamic models of large-scale brain activity. Nat. Neurosci. 20, 340–352 (2017).
Bassett, D. S., Zurn, P. & Gold, J. I. On the nature and use of models in network neuroscience. Nat. Rev. Neurosci. 19, 566 (2018).
Wang, Y., Joshi, T., Zhang, X.-S., Xu, D. & Chen, L. Inferring gene regulatory networks from multiple microarray datasets. Bioinformatics 22, 2413–2420 (2006).
Prasse, B., Achterberg, M. A., Ma, L. & Van Mieghem, P. Network-inference-based prediction of the COVID-19 epidemic outbreak in the Chinese province Hubei. Appl. Netw. Sci. 5, 35 (2020).
Musmeci, N., Battiston, S., Caldarelli, G., Puliga, M. & Gabrielli, A. Bootstrapping topological properties and systemic risk of complex networks using the fitness model. J. Stat. Phys. 151, 720–734 (2013).
Bassett, D. S. & Sporns, O. Network neuroscience. Nat. Neurosci. 20, 353 (2017).
Sporns, O. Structure and function of complex brain networks. Dialogues Clin. Neurosci. 15, 247–262 (2013).
Fornito, A., Zalesky, A. & Breakspear, M. The connectomics of brain disorders. Nat. Rev. Neurosci. 16, 159–172 (2015).
Van den Heuvel, M. P. & Sporns, O. A cross-disorder connectome landscape of brain dysconnectivity. Nat. Rev. Neurosci. 20, 435–446 (2019).
Prasse, B. & Van Mieghem, P. Predicting network dynamics without requiring the knowledge of the interaction graph. Proc. Natl. Acad. Sci. USA 119, e2205517119 (2022).
Zhang, Z., Cui, P. & Zhu, W. Deep learning on graphs: A survey. IEEE Trans. Knowl. Data Eng. 34, 249–270 (2020).
Zhou, J. et al. Graph neural networks: a review of methods and applications. AI Open 1, 57–81 (2020).
Fout, A., Byrd, J., Shariat, B. & Ben-Hur, A. Protein interface prediction using graph convolutional networks. In Advances in Neural Information Processing Systems, Vol. 32, 6530–6539 (MIT Press, 2017).
Zitnik, M., Agrawal, M. & Leskovec, J. Modeling polypharmacy side effects with graph convolutional networks. Bioinformatics 34, i457–i466 (2018).
Bianconi, G. Entropy of network ensembles. Phys. Rev. E 79, 036114 (2009).
Anand, K. & Bianconi, G. Entropy measures for networks: toward an information theory of complex topologies. Phys. Rev. E 80, 045102(R) (2009).
Anand, K. & Bianconi, G. Gibbs entropy of network ensembles by cavity methods. Phys. Rev. E 82, 011116 (2010).
Johnson, S., Torres, J. J., Marro, J. & Munoz, M. A. Entropic origin of disassortativity in complex networks. Phys. Rev. Lett. 104, 108702 (2010).
Anand, K., Bianconi, G. & Severini, S. Shannon and von Neumann entropy of random networks with heterogeneous expected degree. Phys. Rev. E 83, 036109 (2011).
Peixoto, T. P. Entropy of stochastic blockmodel ensembles. Phys. Rev. E 85, 056122 (2012).
Young, J.-G., Desrosiers, P., Hébert-Dufresne, L., Laurence, E. & Dubé, L. J. Finite-size analysis of the detectability limit of the stochastic block model. Phys. Rev. E 95, 062304 (2017).
Cimini, G. et al. The statistical physics of real-world networks. Nat. Rev. Phys. 1, 58 (2019).
Peixoto, T. P. Hierarchical block structures and high-resolution model selection in large networks. Phys. Rev. X 4, 011047 (2014).
Peixoto, T. P. Nonparametric bayesian inference of the microcanonical stochastic block model. Phys. Rev. E 95, 012317 (2017).
DelSole, T. & Tippett, M. K. Predictability: Recent insights from information theory. Rev. Geophys. 45, RG4002 (2007).
Song, C., Qu, Z., Blumm, N. & Barabási, A.-L. Limits of predictability in human mobility. Science 327, 1018 (2010).
Kleeman, R. Information theory and dynamical system predictability. Entropy 13, 612 (2011).
Garland, J., James, R. & Bradley, E. Model-free quantification of time-series predictability. Phys. Rev. E 90, 052910 (2014).
Pennekamp, F. et al. The intrinsic predictability of ecological time series and its potential to guide forecasting. Ecol. Monogr. 89, e01359 (2019).
Scarpino, S. V. & Petri, G. On the predictability of infectious disease outbreaks. Nat. Commun. 10, 1 (2019).
Radicchi, F. & Castellano, C. Uncertainty reduction for stochastic processes on complex networks. Phys. Rev. Lett. 120, 198301 (2018).
Krause, A., Singh, A. & Guestrin, C. Near-optimal sensor placements in Gaussian processes: theory, efficient algorithms and empirical studies. J. Mach. Learn. Res. 9, 235–284 (2008).
Crutchfield, J. P. & Young, K. Inferring statistical complexity. Phys. Rev. Lett. 63, 105 (1989).
Feldman, D. P. & Crutchfield, J. P. Measures of statistical complexity: why? Phys. Lett. A 238, 244 (1998).
Rosas, F. E. et al. Reconciling emergences: an information-theoretic approach to identify causal emergence in multivariate data. PLoS Comput. Biol. 16, 1–22 (2020).
Matsuda, H., Kudo, K., Nakamura, R., Yamakawa, O. & Murata, T. Mutual information of ising systems. Int. J. Theor. Phys. 35, 839–845 (1996).
Gu, S.-J., Sun, C.-P. & Lin, H.-Q. Universal role of correlation entropy in critical phenomena. J. Phys. A 41, 025002 (2007).
Barnett, L., Lizier, J. T., Harré, M., Seth, A. K. & Bossomaier, T. Information flow in a kinetic Ising model peaks in the disordered phase. Phys. Rev. Lett. 111, 177203 (2013).
Meijers, M., Ito, S. & ten Wolde, P. R. Behavior of information flow near criticality. Phys. Rev. E 103, L010102 (2021).
Edwards, D. Introduction to Graphical Modelling, 2nd edn (Springer, 2000).
Cover, T. M. & Thomas, J. A. Elements of Information Theory, 2nd edn (John Wiley & Sons, 2006).
Feder, M. & Merhav, N. Relations between entropy and error probability. IEEE Trans. Inf. Theory 40, 259 (1994).
Giannakis, D., Majda, A. J. & Horenko, I. Information theory, model error, and predictive skill of stochastic models for complex nonlinear systems. Phys. D 241, 1735–1752 (2012).
Giveon, A., Porrati, M. & Rabinovici, E. Target space duality in string theory. Phys. Rep. 244, 77–202 (1994).
Glauber, R. J. Time-dependent statistics of the ising model. J. Math. Phys. 4, 294–307 (1963).
Mézard, M. & Montanari, A. Information, Physics, and Computation (Oxford Univ. Press, 2009).
Binder, K. & Heermann, D. Monte Carlo Simulation in Statistical Physics (Springer, 2010).
Anderson, R. M. and May, R. M. Infectious Diseases of Humans: Dynamics and Control (Oxford Univ. Press, 1992).
Cowan, J. D. Stochastic neurodynamics. In Advances in Neural Information Processing Systems, Vol. 3 62 (Morgan Kaufmann, 1990).
Painchaud, V., Doyon, N. & Desrosiers, P. Beyond Wilson-Cowan dynamics: oscillations and chaos without inhibition. Biol. Cybern. 116, 527–543 (2022).
Wilson, H. R. & Cowan, J. D. Excitatory and inhibitory interactions in localized populations of model neurons. Biophys. J. 12, 1 (1972).
Destexhe, A. & Sejnowski, T. J. The Wilson–Cowan model, 36 years later. Biol. Cybern. 101, 1 (2009).
Van Mieghem, P. & Cator, E. Epidemics in networks with nodal self-infection and the epidemic threshold. Phys. Rev. E 86, 016116 (2012).
Martinez, N. Artifacts or attributes? effects of resolution on the Little Rock Lake food web. Ecol. Monogr. 61, 367–392 (1991).
Cardillo, A. et al. Emergence of network features from multiplexity. Sci. Rep. 3, 1344 (2013).
Cook, S. J. et al. Whole-animal connectomes of both caenorhabditis elegans sexes. Nature 571, 63–71 (2019).
Gross, T. & Blasius, B. Adaptive coevolutionary networks: a review. J. R. Soc. Interface 5, 259–271 (2008).
Marceau, V., Noël, P.-A., Hébert-Dufresne, L., Allard, A. & Dubé, L. J. Adaptive networks: coevolution of disease and topology. Phys. Rev. E 82, 036116 (2010).
Scarpino, S. V., Allard, A. & Hébert-Dufresne, L. The effect of a prudent adaptive behaviour on disease transmission. Nat. Phys. 12, 1042–1046 (2016).
Khaledi-Nasab, A., Kromer, J. A. & Tass, P. A. Long-lasting desynchronization of plastic neural networks by random reset stimulation. Front. Physiol. 11, 622620 (2021).
Krioukov, D., Papadopoulos, F., Kitsak, M., Vahdat, A. & Bogu ná, M. Hyperbolic geometry of complex networks. Phys. Rev. E 82, 036106 (2010).
Bogu ná, M. et al. Network geometry. Nat. Rev. Phys. 3, 114–135 (2021).
Bogu ná, M., Papadopoulos, F. & Krioukov, D. Sustaining the internet with hyperbolic mapping. Nat. Commun. 1, 1–8 (2010).
Papadopoulos, F., Aldecoa, R. & Krioukov, D. Network geometry inference using common neighbors. Phys. Rev. E 92, 022807 (2015).
García-Pérez, G., Allard, A., Serrano, M. A. & Bogu ná, M. Mercator: uncovering faithful hyperbolic embeddings of complex networks. New J. Phys. 21, 123033 (2019).
Gleeson, J. P. High-accuracy approximation of binary-state dynamics on networks. Phys. Rev. Lett. 107, 068701 (2011).
Lakshmikantham, V. & Leela, S. Differential and Integral Inequalities-Ordinary Differential Equations, Vol. I (Academic Press, 1969).
Knuth, D. E. Big Omicron and Big Omega and Big Theta. SIGACT News https://doi.org/10.1145/1008328.1008329 (1976).
Fosdick, B. K., Larremore, D. B., Nishimura, J. & Ugander, J. Configuring random graph models with fixed degree sequences. SIAM Rev. 60, 315–355 (2018).
Peixoto, T. P. The Netzschleuder network catalogue and repository. Zenodo https://doi.org/10.5281/zenodo.7839981 (2023).
Murphy, C., Thibeault, V., Allard, A. and Desrosiers, P. DynamicalLab/code-duality. Zenodo https://doi.org/10.5281/zenodo.10779392 (2024).
Acknowledgements
We are grateful to Guillaume St-Onge and Vincent Painchaud for useful comments, and to Simon Lizotte and François Thibault for their help in designing the software. This work was supported by the Fonds de recherche du Québec – Nature et technologies (V.T.), the Conseil de recherches en sciences naturelles et en génie du Canada (C.M., A.A., P.D.), the Sentinelle Nord program of Université Laval, funded by the Fonds d’excellence en recherche Apogée Canada (C.M., A.A., P.D.), and the Fonds d’accélération des collaboration en santé du Québec – Alliance Neuro-CERVO (A.A., P.D.). We acknowledge Calcul Québec and Digital Research Alliance of Canada for their technical support and computing infrastructures.
Author information
Authors and Affiliations
Contributions
C.M., V.T., A.A. and P.D. developed the framework and wrote the paper. C.M., V.T. and P.D. wrote the mathematical proofs. C.M. performed the numerical analysis.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Peer review
Peer review information
Nature Communications thanks Filippo Radicchi, and the other, anonymous, reviewers for their contribution to the peer review of this work. A peer review file is available.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Murphy, C., Thibeault, V., Allard, A. et al. Duality between predictability and reconstructability in complex systems. Nat Commun 15, 4478 (2024). https://doi.org/10.1038/s41467-024-48020-x
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41467-024-48020-x
This article is cited by
-
Higher-order Laplacian renormalization
Nature Physics (2025)
-
Tensor product algorithms for inference of contact network from epidemiological data
BMC Bioinformatics (2024)
