
Abstract
Large Language Models (LLMs) have shown success in predicting neural signals associated with narrative processing, but their approach to integrating context over large timescales differs fundamentally from that of the human brain. In this study, we show how the brain, unlike LLMs that process large text windows in parallel, integrates short-term and long-term contextual information through an incremental mechanism. Using fMRI data from 219 participants listening to spoken narratives, we first demonstrate that LLMs predict brain activity effectively only when using short contextual windows of up to a few dozen words. Next, we introduce an alternative LLM-based incremental-context model that combines incoming short-term context with an aggregated, dynamically updated summary of prior context. This model significantly enhances the prediction of neural activity in higher-order regions involved in long-timescale processing. Our findings reveal how the brain’s hierarchical temporal processing mechanisms enable the flexible integration of information over time, providing valuable insights for both cognitive neuroscience and AI development.
Similar content being viewed by others

Introduction
Recent works in cognitive neuroscience have demonstrated the power of computational large language models (LLMs) in predicting language-evoked neural signals among humans1,2,3,4,5,6,7,8,9,10. LLMs have revolutionized the natural language processing (NLP) field, demonstrating human- and super-human-level performance in many language tasks11,12,13. These models are capable of producing a rich language representation, manifested via multidimensional numerical vectors, also known as word embedding representations. The representations are also contextualized as the embedding representation of a word may be changed according to the context in which it appears, namely the preceding words in the input text. A growing number of studies show that these contextual representations can be linearly mapped to neural signals (e.g., fMRI, EEG, ECoG) recorded from human participants listening to spoken narratives—an analysis commonly referred to as neural encoding4,7,8,10. In this method, a contextualized word embedding vector is extracted for each word in the narrative by providing the LLM with that word, along with a context window of the N preceding words (Fig. 1c). The extracted vectors then serve as the input to a linear regression model that predicts the neural signal evoked by the corresponding words. The success of the neural encoding method, together with the human-like cognitive mechanism that leverages contextual information in the LLM, suggests that the internal language representations and processes of LLMs could shed light on the internal neural representations and processes of language in the human brain10,14,15.

a The neuroanatomical hierarchical organization according to multiple timescales of processing. Partially adapted from ref. 18 with the authors’ permission. b Our proposed neural mechanism of integrating long-term contextual information at the top level of the timescale hierarchy. c The baseline implementation of contextual integration via Large Language Models (LLMs). The model is exposed to the entire incoming context window and processes it in a parallel manner. d Our proposed alternative model of contextual integration via LLM. Instead of processing the entire context window at once, the incremental-context LLM is applied sequentially along the story. The LLM accumulates long-term contextual information by generating a concise summary of the past, and, at each step, integrating this summary with the incoming context window and updating the summary to be used in the next step (see more details in Fig. 3 and S3).
One of the drawbacks in considering LLMs as cognitive models, however, is manifested in the way these models process natural texts, such as stories or narratives, which unfold over long timescales. In contrast to the human brain, LLM digests large bodies of text, comprising thousands of words in parallel, using a fixed-size contextual window. Thanks to the underlined attention mechanism16, the LLM can learn the contextual dependencies across all words in parallel. In contrast, the human brain processes the incoming linguistic input serially, word by word, as speech and text unfold over time. Furthermore, while listening to a long narrative, humans do not have the ability to hold all the hundreds and thousands of words in their working memory that have been processed since the beginning of the narrative. Rather, humans operate an online mechanism for accumulating information and integrating it into a broader contextual memory, which is changed and updated as the story unfolds17,18. In this study, we aim to provide an alternative model for how the brain, as opposed to current LLMs, integrates linguistic information over short-term and long-term contexts.
A series of studies showed that the brain gradually integrates temporal information across cortical areas in a topographic hierarchical manner. In such a topography, the temporal receptive windows (TRW) gradually increase along the cortical processing hierarchy, with early sensory areas integrating speech-related information (e.g., phonemes) into words over short periods of time (tens to hundreds of milliseconds). Adjacent cortical regions then integrate word-level information into sentences over several seconds and transfer the information into adjacent areas, which integrate the sentences into paragraphs. Finally, areas along the default mode network (DMN), located at the top of the temporal integration hierarchy, can integrate the paragraphs into a coherent narrative by integrating information accumulated over hundreds of seconds as the story unfolds, with relevant past information stored in long-term memories (Fig. 1a)18,19,20. Such temporal processing hierarchical topography provides an alternative processing scheme for integrating short-term and long-term linguistic information over time within the DMN (Fig. 1b).
We hypothesize that unlike LLMs which process large contextual windows of thousands of words, DMN networks can receive information about the incoming context (IC) through a small window of just tens of words (Fig. 1b). To test this hypothesis, a group of participants listened to several spoken stories while undergoing fMRI scans (a total of 297 scans recorded from 219 individuals). We then designed and implemented several encoding models to predict their BOLD responses using contextual embeddings extracted from an LLM after parametrically adjusting the contextual window size of the LLM from just a few words to a thousand words. We demonstrate empirically that the fit between the LLM and the brain decreases as the size of the LLM’s context window increases beyond tens of words, and that the maximal fit is obtained when the context window size is ~32 tokens in length. This result supports our prediction that the incoming contextual information to the brain integrates information over a few sentences.
Next, we hypothesize that incoming contextual information at time n (ICn) is integrated with the aggregated context information (ACn−1) already accumulated in the DMN (Fig. 1b). At the beginning of a story, where no contextual information has been accumulated yet, the accumulated context matches the IC (AC1 = IC1). As the story unfolds, the accumulated contextual information is the sum of the incoming and aggregated context information. To test this prediction, we suggested an alternative LLM-based incremental-context model that fuses the incoming short-term context (ICn) with the aggregated context (ACn-1). The aggregated prior context is operationalized by asking the LLM to generate a concise summary of the incoming contextual information—a summary that is incrementally changed and updated as the model progresses through the narrative (see Figs. 1d and 3b, S3, and Method). Adding a summary of the aggregated context information to the incoming information greatly improved our ability to predict the BOLD responses in the brain while processing all narratives, and this improvement was mainly evident in the higher-order areas among the DMN. Combined, our results suggest that the DMN constantly engages in online summarization and integration of paragraph-level incoming contextual information with information accumulated across minutes, hours, and even days. Such online summarization and integration provide the brain with the necessary capacity to flexibly integrate information accumulated over multiple timescales, a capacity that is currently lacking in the fixed contextual window architecture of many LLMs.
Results
Overview
The results and analyses are divided into three consecutive phases. First, we carried out a systematic analysis to investigate the effect of increasing the size of the IC window of the LLM’s input on the ability to predict the fMRI signals from the LLM’s embedding representations. For that, we applied the well-established neural-encoding analysis7,8,10 and tested its performances while varying the size of the context window from 8 tokens to the maximal possible size of 2048 tokens. In the second stage, we introduced our incremental context model, which combines both a short-term IC window and a long-term aggregated context. Then, we tested our model’s performance in predicting brain activity compared to a baseline LLM with either a long or short IC window. Lastly, in the third complementary stage, we performed a spectral analysis on the BOLD signal for each brain area to estimate how fast/slow the information changes—a measurement that is equivalent to estimating the amount of prior context the brain area processes in the present. Based on the results of this analysis, we identified brain areas that utilize long/short context windows and tested whether our incremental long-term context model predicts their activity better/worse than a short-term context model. All these stages are detailed in the following sections.
IC is processed in the brain through small context windows
From the Narratives fMRI dataset21, we extracted data from 219 individuals who passively listened to narrative stimuli. The data contained a total of 297 scans from 8 different relatively long stories/narratives (~7 min or longer), which together encompass 15,978 tokens (See Table S1 and Method). Word-embedding representations were created for each story using a state-of-the-art, open-source GPT-3-like model (GPT-neoX22) and were subsequently used to predict the neural signals recorded from individuals who listened to that story, via the well-established neural-encoding analysis7,10,23 (see Method). The neural encoding analysis was applied on a voxel-by-voxel basis across the 9258 stimulus-locked voxels (i.e., voxels that yielded a significant inter-subjects correlation score, see Method). We systematically tested the model’s predictions while varying the amount of prior context (i.e., the number of tokens) the model was exposed to during the word embedding extraction. We tested the following context window sizes: 8, 16, 32, 64, 128, 256, and 512 tokens, as well as the maximal window size containing the entire narrative (up to 2048 tokens; this size is different from narrative to narrative, see Table S1). The neural encoder model was trained and tested using fivefold cross-validation for each window size, scan, and voxel, as detailed in the Method section.
The pattern of the results was clear. As Fig. 2 presents, the performances of the neural encoder (as measured via the averaged Pearson’s r correlation between the original and the predicted signal) are getting better as the window size increases, but only up to a window size of 32 tokens. From that point onwards, however, the performance tends to decrease as the window size increases, eventually reaching a plateau above 128 tokens. This pattern is reflected both in terms of the extent of cortical areas where the averaged r-score was statistically significant (from big clusters of voxels across temporal, parietal, and frontal areas at window size = 32 tokens to only a few small clusters in the parietal lobule for larger window sizes; see Fig. 2a), as well as in the magnitude of the averaged r-scores (ranging from −0.02 to 0.02, 0.00 to 0.13, −0.01 to 0.15, −0.01 to 0.07, −0.02 to 0.08, −0.01 to 0.063, −0.03 to 0.069, and 0.00 to 0.07 for window sizes of 8, 16, 32, 64, 128, 256, 512, and Max tokens, respectively). The same pattern is demonstrated in Fig. 2b for five selected voxels, each taken from a different language-related region of interest (ROI). These results are replicated almost identically when using the (relatively) older GPT-2 model, as presented in Fig. S1. Moreover, in Fig. S2 we show that the failure of large context-window LLMs in predicting the brain is also observed with other LLMs that were designed specifically for long contexts: Long T524, Transformer XL25, and Longformer26.

a Cortical maps for different window sizes showing voxels where the neural encoder score (Pearson’s r calculated between the predicted and the original signals, averaged across 297 fMRI scans) was statistically significant using a non-parametric Wilcoxon signed-rank test and FDR correction. b Averaged r-scores by window size for five different voxels, each located in a different language-related region of interest (ROI) in the left hemisphere. Error bars represent the 95% confidence interval of the mean as calculated via 10,000-iterations bootstrap analysis. Anatomical locations are provided as MNI coordinates. c A cortical map showing ROIs that were predicted significantly better using a window size of 32 tokens than with a window size of up to 2048 tokens (red areas), or vice versa (green areas). A1 primary auditory cortex, STG superior temporal gyrus, IFG inferior frontal gyrus, TPJ temporoparietal junction. Source data are provided as a Source Data file.
To further validate the results, we also conducted a direct comparison between the short window size of 32 tokens and the maximal long window size of up to 2048 tokens. For each voxel, we calculated \({\Delta r}_{32{tokens}-{MAX\; tokens}}\) which equals to the averaged r-score obtained from the LLM with a window size of 32 tokens, minus the averaged r-score obtained from the LLM with a large window size of up to 2048 tokens. The resulted map yielded 2594 significant voxels, all of which were in favor of the short window size (i.e., positive \({\Delta r}_{32{tokens}-{MAX\; tokens}}\) value; qFDR < 0.05; Max = 0.028, Mean = 0.01, SD = 0.004; Fig. 2c red areas). None of the voxels have shown a significant negative \({\Delta r}_{32{tokens}-{MAX\; tokens}}\) value (qFDR>0.05).
The above results suggest that the success of fixed-size context LLMs in predicting language-related BOLD responses is effective only when the encoded information is related to a relatively short context window, equivalent to a timescale of several sentences. Moreover, as illustrated in Fig. 2, this limitation was not only observed in temporal areas, which were previously linked to short timescales19,20, but also identified in higher-order areas at the DMN associated with longer timescales. This confirms our first hypothesis that the IC to the brain is limited to small context windows containing up to tens of words, as the brain, unlike LLMs, cannot compute hundreds and thousands of tokens in parallel. In the next section, we present an alternative model that is capable of incorporating and maintaining very long contextual information in a sequential and incremental manner—similar to how we believe the human brain functions.
An alternative cognitively plausible model for short and long-context integration—the incremental context model
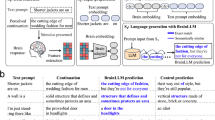
The main limitation in using LLMs with large context windows to model long-term contextual computing in the human brain is the necessity to process hundreds of words in parallel. To cope with this limitation, we designed an alternative model where the window size of the input is kept (relatively) small and yet contains both short-term and long-term contextual information. In this model, the context window comprises two components: incoming short-term context and aggregated long-term context. The IC consists of the last N words, where N is no more than several dozen tokens. The long-term component contains earlier information that appeared outside the narrower short-term window. Importantly, this information is no longer the original (hundreds or thousands) words from the stimulus, but instead a concise summary that is generated by the model itself.
Specifically, using a dedicated prompt design (see Method), we interact with the model and request it to generate a short summary based on previous information. This interaction was applied every several words, such that the summary is continuously updated and changed as the model advances through the story. Importantly, in order to capture long-term context, the summary of each step was generated based on the content of both the last several tokens, as well as the summary from the previous step (See Figs. 3b and S3b, and Method). In this way, the model always maintains an incremental long-term context through natural language text, which can then be used as input to the model again. As depicted in Fig. 3b, a word embedding representation of a token is obtained from this model by concatenating two elements into its input: a short-term context window (consisting of the last 32 tokens; see the Method section for details on this choice) and the most recent state of the incremental summary, which provides the long-term context. A more detailed schematic illustration, including a textual example from the actual data, is presented in Fig. S3.

a The short-term, N-tokens (N = 32) model. The word embedding representation of the token i is extracted by providing the LLM with that token, as well as the preceding N tokens. b The long-term, incremental context model. To extract the word embedding representation for the same token i, the input to the model included both the short N-token window (as in the N-tokens model) and a concise natural language summary generated by the model, which was based on information from the long-term context. This long-term contextual summary is updated as the model progresses through the story. It is generated based on the text that appeared before the short N-token window, as well as on the summary generated at the previous update step by the model. See Fig. S3 for more details.
The incremental context model better predicts neural activity in many higher-order brain areas
To assess the predictive power of the incremental model in modelling the integration between short- and long-term contexts in the human brain, we directly compared its performance in neural encoding against the following two baseline models: An LLM with a short-term IC window of 32 tokens (we chose 32 tokens as it was the optimal model in our first analysis. See Fig. 2) and a “full-size” LLM with the maximum length of window size, i.e., up to 2048 tokens. Note that all three models (i.e., Incremental context, 32 tokens window size, and MAX-tokens window size) are based on the same pre-trained LLM and they differ only in the type/size of the context used in the input during the encoding phase (i.e., the extraction of the word-embedding representations).
Figure 4 presents the cortical maps of the comparisons between the models. For each pair of models, we calculated \(\Delta r\) per voxel, which equals the difference between the averaged neural encoder r-score of one model and of the other model. First, compared to the MAX tokens model, our incremental context model significantly improves the r-score in many parietal, temporal, and frontal areas, as reflected by positive \({\Delta r}_{{Incremental\; Context}-{MAX\; tokens}}\) values (a total of 5023 significant voxels; Max = 0.02, Mean = 0.008, SD = 0.001; Fig. 4a). Furthermore, none of the voxels showed a significant negative \({\Delta r}_{{Incremental\; Context}-{MAX\; tokens}}\) score, namely, there are no brain areas where their signal is predicted better by the MAX-tokens model comparing to the incremental context model. The results of this comparison demonstrate the substantial advantage of modeling long-term context in the brain using an incremental mechanism instead of parallel computing over hundreds of tokens.

a, b Cortical maps show the differences between the models in the neural encoder scores. The following comparisons were made: Incremental Context vs. MAX tokens (a), and Incremental Context vs. 32 tokens (b). The maps display only the voxels that demonstrate a significant difference using a non-parametric Wilcoxon signed-rank test and FDR correction. c Bar plots display the averaged neural encoder results (y axis) for selected voxels located at different language-related ROIs, depending on the model used for embedding representations (32 tokens/MAX-tokens/Incremental Context). Error bars represent the 95% confidence interval of the mean as calculated via 10,000-iterations bootstrap analysis. A1 primary auditory cortex, STG superior temporal gyrus, IFG inferior frontal gyrus, TPJ temporoparietal junction. Source data are provided as a Source Data file.
Second, we compared the results of our incremental context model to the results of the 32 tokens model, which according to our previous analysis (Fig. 2) is the best model for the incoming short-term context. Fig. 4b presents the cortical map of the \({\Delta r}_{{Incremental\; Context}-32{tokens}}\) values and discovers both brain areas that are better predicted by the incremental model (positive \({\Delta r}_{{Incremental\; Context}-32{tokens}}\) values), as well as brain areas that are better predicted by the short-term context model (negative \({\Delta r}_{{Incremental\; Context}-32{tokens}}\) values). Our long-term context model (incremental context) significantly outperforms the short-term context model (32 tokens) in many areas among the DMN, including parietal (Precuneus and TPJ) and frontal (mainly among the medial prefrontal cortex) areas, as depicted in Fig. 4b (679 significant voxels, Max = 0.02, Mean = 0.006, SD = 0.003; blue areas). On the other hand, we also found brain areas that were predicted significantly better by the short-term context model (32 tokens), compared to the long-term incremental context model. This effect was mainly observed in the superior temporal gyrus, including the primary auditory cortex, as well as the “Broca” area in the inferior frontal gyrus (435 significant voxels; Min = −0.01, Mean = −0.003, SD = 0.0007; Fig. 4b red areas).
Importantly, the full cortical map of the \({\Delta r}_{{Incremental\; Context}-32{tokens}}\) values (Fig. 4a, b) is aligned with the hierarchical structure of the timescale changes discovered elsewhere19,20, where the primary auditory cortex (located on the superior temporal gyrus) is involved in the most short-scale processing, and the more high-order DMN areas in the parietal lobule, as the TPJ and the precuneus, are associated with more long-term processing (Fig. 1a). Moreover, the finding that DMN areas were better predicted by our incremental model, while the lower-level areas were better predicted by the short- IC LLM, is well aligned with our second hypothesis. That is, higher-order DMN areas receive the incoming paragraph-level (i.e., short window of ~32 tokens) contextual information from the downstream, lower-level areas, and engage in online summarization and integration of this information with information accumulated across the narrative (Fig. 1b).
A model-free spectral analysis of the frequency domain supports the model-based analyses
In this analysis we focused on the above-presented cortical map of the contrast between the r-scores of our incremental model and the short-term context model (i.e., the \({\Delta r}_{{Incremental\; Context}-32{tokens}}\) values; Fig. 4b). As mentioned earlier, this map revealed a hierarchical organization of the cortex in terms of the timescale of the context processing and confirmed our hypothesis regarding the long-term contextual integration at the top level of the hierarchy. In Fig. 5a we re-visualize this map, this time over the entire set of 9258 stimulus-locked voxels (i.e., voxels that yielded significant inter-subjects correlation scores, see Method), with no statistical threshold (as in Fig. 4b). This map demonstrates the gradient between the red areas—areas that are more associated with the short-term context (negative \({\Delta r}_{{Incremental\; Context}-32{tokens}}\) values)—and the blue areas, which are more associated with the long-term context (positive \({\Delta r}_{{Incremental\; Context}-32{tokens}}\) values). In the subsequent analysis, we conducted a complementary, model-free analysis on the fMRI (BOLD) signals, which provides additional validation for the timescale hierarchy revealed through the models.

a The cortical map of the \({\Delta r}_{{Incremental\; Context}-32{tokens}}\) (abbreviated as \({\Delta r}_{{IncCon}-32T}\)) scores replicated from Fig. 3b but with no statistical thresholding. This map shows the overall pattern of the cortical hierarchy between voxels that are better predicted by the long-term Incremental context model (more blue areas) and voxels that are better predicted by the short-term (32 tokens) model (more red areas). b The power spectral density (PSD) calculated for the BOLD signal within four important ROIs: inferior parietal lobule (IPL), dorsolateral prefrontal cortex (DLPFC), the Precuneus, and the primary auditory area. Source data are provided as a Source Data file. c, d Cortical maps showing the power of high (c) and low (d) frequencies across the cortex. These measurements were extracted from the PSD curve as described in the Method. e, f Scatter plots representing the correlation between the \({\Delta r}_{{Incremental\; Context}-32{tokens}}\) scores (Fig. 4a) and the high (e) or low (f) frequency power of the signal. The statistical significance of the correlations was tested using Fisher’s Z test for correlation coefficients.
Timescale differences were investigated by looking at the frequency domain of the signal. Intuitively, when a signal mostly consists of low frequencies, it indicates that the encoded information changes slowly and gradually. As a result, the information at a certain time point does not deviate significantly from the information encoded far away in the past. Conversely, high frequencies in the signal suggest rapid changes in the information, and as such, the value of a certain time point is merely influenced by nearby time points, with less impact from distant past information. Therefore, performing a spectral analysis of the fMRI signal provides a reliable approximation of the extent of past contextual information processed by a certain brain area20.
For each voxel, we estimated the power spectral density (PSD) of the averaged signal (See Method for detailed information), which illustrates how the power of the signal is distributed across different frequencies (see Fig. 5b for selective ROIs). Next, we quantified the power of the high frequencies of the signal (which are equivalent to short context window sizes) by calculating the area under the PSD curve within the high frequencies range. Since the optimal size of the IC to the LLM is 32 tokens (Fig. 2), we chose frequencies that demonstrate cycles (wavelengths) equivalent to the time taken to produce 32 tokens or less. According to our data, this time interval is approximately 12 s, and the corresponding frequency is ~0.08 Hz (\({0}{.}{08}{{Hz}}\, {\approx }\ {1}{/}12\)). Therefore, we calculated the integral of the PSD function between 0.08 Hz and the Nyquist frequency, 0.33 Hz, and denoted this value as the high-frequency power (HFP) of the signal (\({HFP}={\int }_{0.08}^{0.33}{PSD}\left({Hz}\right){dx}\); Fig. 5c). Most importantly, we found a strong significant negative correlation between the HFP and the \({\Delta r}_{{Incremental\; Context}-32{tokens}}\) values (r = −0.63, p < 0.0001; Fig. 5e). Namely, the higher the power of high frequencies within the voxel, the better it is predicted by the short-term context model compared to the long-term context model (i.e., a more negative \({\Delta r}_{{Incremental\; Context}-32{tokens}}\) value).
The above analysis was replicated for the low frequencies as well. We calculated the low-frequency power (LFP) of the ROI’s signal by taking the integral of the PSD between 0 Hz to 0.02 Hz (\({LFP}={\int }_{0}^{0.02}{PSD}\left({Hz}\right){dx}\); Fig. 5d). This range of frequencies is equivalent to window sizes of 256 tokens or longer (the cutoff of 256 tokens best demonstrates our results, but the overall pattern is preserved for different thresholds above 32 tokens as well). In contrast to the HFP, the LFP scores showed a strong positive correlation with the \({\Delta r}_{{Incremental\; Context}-32{tokens}}\) values (r = 0.66, p < 0.0001; Fig. 5f). This means that the greater the presence of LFP in the voxel, the better it is predicted by the long-term incremental-context model compared to the short-term context model.
Discussion
We hypothesized that, unlike the ability of current LLMs to process large contextual windows of hundreds and thousands of words in parallel, the human brain applies a different, more sequential, and flexible mechanism. In line with previous studies that demonstrated the topographical timescale hierarchy of temporal processing in the brain (Fig. 1a)18,19,20, we proposed that (1) downstream, primary areas in the brain process the entire IC window up to tens of words (i.e., paragraph level), and that (2) higher-order areas in the DMN constantly engage in online summarization and integration of this short incoming contextual information with information accumulated across minutes, hours, and even days. First, we demonstrated that the default implementation of the IC window in LLMs, i.e., simply feeding the last N tokens into the model, can be considered a good model for the brain only when N is relatively small (N = 32). However, when it comes to longer window sizes, the LLMs are no longer efficient in predicting the fMRI signal (Fig. 2). This supports our first hypothesis that the brain can process the entire IC window only when the window contains no more than tens of words (equivalent to a paragraph-level).
Second, according to our second hypothesis, we proposed an alternative LLM-based incremental model for integrating long-term context information, beyond the recent tens of words. In contrast to feeding the entire text all at once to the model, our incremental context model preserves a modest number of tokens for parallel processing while retaining essential contextual information from tokens that were processed much earlier. By employing prompt-engineering techniques27, we have the model intermittently interact with the text and generate a natural language aggregated summarization that is integrated with the incoming short context window (Fig. 3). Next, we empirically show that our incremental context model outperforms the alternative long context-window LLM in predicting neural signals of long narratives (Fig. 4). Moreover, in line with our second hypothesis, we found that among the DMN areas (located at the top level of the timescale hierarchy), the incremental model (which integrates both incoming and aggregated contexts) outperforms the short- (32 tokens) IC window LLM. In contrast, the short-context LLM outperforms the incremental model in predicting lower-level brain areas located downstream of the timescale hierarchy (e.g., STG). Finally, we used a complementary spectral analysis to map cortical areas on a scale ranging from short- to long-term contextual processing by quantifying the power of low and high frequencies (the lower the frequency of the signal, the slower its fluctuations, and consequently, its timescale). Next, we demonstrated that the more dominant the brain area is in low frequencies, the better its signal was predicted by our long-term incremental context model. Similarly, when a brain area exhibited more high frequencies, it was predicted more accurately by the short-term context (32 tokens) implementation of the LLM (Fig. 5).
It is important to emphasize that our research does not aim to argue that LLMs are a feasible cognitive model for language processing in the brain. Rather, we focus on a key difference between LLMs and the human brain: how they integrate information over multiple timescales. While LLMs can simultaneously process information across all words within its contextual window, the brain accumulates information gradually and sequentially as the narrative unfolds. Indeed, we observed that by restricting LLMs’ contextual window to match the DLM’s temporal integration windows, there was an improvement in the alignment between their internal representations. Additionally, we found that enhancing LLM’s paragraph-level contextual window with an incremental summarization term enhanced its internal representations to better fit with the human brain. This provides evidence that the human brain, unlike LLMs, has an internal mechanism to summarize and accumulate contextual information over a broader range of timescales rather than processing all words within a fixed large contextual window in parallel.
Although the results of this study suggest that our incremental context model is a better fit for long-term context processing in the brain, it is not guaranteed that this model is completely cognitively plausible, but rather that it is more plausible than the default transformer model. First, it is not clear whether the long-term context is aggregated in the brain in the form of discrete words, as implemented in our model (i.e., through the generated summary), or rather in a more continuous way. Second, it is not clear whether aggregating information via summarization is, in fact, cognitively plausible. It could be that there are other, more cognitively plausible methods of aggregating contextual information rather than via summarization. As one way of justifying our proposed model as a cognitive mechanism, we have considered several alternative aggregation methods, such as extraction of key sentences from the earlier information or asking the model to generate leading keywords out of the text. All of these alternative aggregation methods were substantially inferior compared to our proposed summary generation model. Nevertheless, we do not rule out the possibility that future studies may uncover more effective alternatives.
In addition to the above, there is another limitation concerning the finding that the incremental context model predicts long-term context in the brain better than a transformer model with a maximum window. Previous studies have shown that LLMs with large context windows tend to lose information that appears in the middle of the window and are biased towards tokens appearing at the beginning or end of the sequence28. Therefore, the incremental context model might be preferable not because it is more cognitively plausible, but because it overcomes this issue and optimally utilizes the full context. Either way, this alternative explanation does not necessarily contradict the hypothesis we presented regarding the cognitive mechanism of long context processing in the brain, as it is possible that the brain evolved to process long context incrementally because it is the most efficient way to avoid losing content.
This study is the first to use LLMs for modeling (very) long-term context processing of language comprehension in the brain. Previous studies in the neural encoding literature all used LLMs that were only aware of the short-term context, i.e., where the context window size was as large as several tens of words1,2,3,4,5,6,7,8,9,10. This was the case even though the participants in these studies were exposed to language stimuli that encompassed hundreds and even thousands of words. To the best of our knowledge, no study has yet systematically investigated the effect of the LLM input contextual window size on neural encoding performance with language comprehension data. It should be noted here that one recent study by Aw & Toneva29 reported a similar systematic input context-size analysis, but their fMRI data involved participants who were reading the story (i.e., language production) rather than passively listening (language comprehension), as in our study. Their main findings suggest that models trained (fine-tuned) to summarize long narratives were significantly better in neural encoding compared to baseline models, specifically for large context windows (20–1000 words). This method resembles our incremental-model method, as in both studies, summarization plays a crucial role in guiding the model on how to process long contexts. However, unlike their method, which involves two different models (base and fine-tuned), our prompt-based mechanism allows us to use the same model for both short-term and long-term contextual processing (i.e., with or without the incremental-summary module). This single model approach allows us to make a direct comparison between short- and long-term contexts. Moreover, a single model that operates differently in short vs. long contexts is more cognitively plausible than two distinct (fine-tuned) models for short and long contexts. Nevertheless, future studies are needed to compare both methods, as well as to compare language comprehension and production.
In the same context, it is also important to refer here to Caucheteux’s et al.’s4 work, where they empirically investigated the timescale hierarchy in the brain using LLMs. The current work is different for two reasons. First, unlike the current study, they did not manipulate the timescale by varying the number of tokens in the input; instead, they achieved this by scrambling the text at multiple levels (words, sentence etc.), similar to Lerner’s et al.’s work19. Second, in all experimental conditions, they used a fixed window size of 256 tokens in the context. Consequently, the maximum timescale of processing they could investigate was limited to the size of one or two paragraphs. In our study, on the other hand, we primarily focused on very large timescales, spanning hundreds and thousands of tokens.
From the NLP-field perspective, our proposed incremental context model provides a new approach to dealing with the processing of very large texts30. Apart from the cognitive plausibility gap addressed in this paper, the parallel computing nature of the transformer-based LLMs yields a quadratic computational complexity (\({O}{(}{{n}}^{{2}}{)}\)) which makes the processing of long texts significantly more expensive. Several solutions have been proposed in recent years to cope with this computational complexity problem. These included novel architectures of the attention matrix (e.g., sparse-attention31, dilated sliding window26,30,32, transient global attention24, LLM with external memory33, and others), hierarchical combination of multiple transformers9,34, and implementations of RNN-like (recurrent neural network) modules within the transformer block25. To the best of our knowledge, our incremental context model is the only model that instead of processing the entire text all at once, repeatedly applies itself along the text, interacting with the information in a manner akin to human-like comprehension [note that the Transformer XL model25 incorporates some form of recurrent processing within the transformer block, but it still takes the entire text as its input in parallel. In Fig. S2, we empirically demonstrate that this model is indeed less effective at predicting human neural signals.]. While this study does not delve into assessing the incremental context model’s performance in various NLP tasks related to long texts, we hold the belief that its potential extends far beyond the field of cognitive neuroscience.
Methods
FMRI data
The data for the present research was retrieved from the narratives dataset published elsewhere21. The narratives dataset contains a variety of functional MRI datasets collected while human subjects listened to naturalistic spoken stories. Since the current work focuses on long-term context, we only gathered data on stimuli that contain a single coherent long story (there are stories like “Schema” and “The 21st Year” that contain multiple narratives within the story), and that do not contain any ambiguities or special experimental manipulations (such as “Shape” and “Green eyes”). Our final sample included data from 8 stories (“Lucy”, “Merlin”, “Pie man”, “Tunnel”, “Bronx”, “Sherlock”, “Not the fall”, and “Milky way”). It consists of 297 scans recorded from 219 individuals (78 individuals participated in more than a single stimulus; ages 18–53 years, mean age 22.1 ± 3.1 years, 171 reported female), after excluding ‘bad’ scans based on the publisher’s recommendation. Table S1 describes, for each story, the number of individuals, number of tokens in the story (according to the GPT’s tokenizer), and the number of TRs. The publishers’ dataset paper reports the technical details regarding the MRI acquisition, as well as the entire preprocessing pipeline of the data21. For our analyses, we downloaded the version of the data that was normalized to a surface template (the fsaverage6 template of the FreeSurfer software35).
To filter out stimulus-irrelevant voxels, we executed a voxel-wise inter-subject correlation analysis36 across all of the gray matter: for each voxel, we isolated each subject’s time-course and correlated it with the averaged time-course of the remaining subjects. The voxel’s ISC-score is calculated by averaging the correlation scores (after Fisher’s Z transformation) obtained from repeating this process for all subjects. To assess how significantly each ISC-score is different from zero, we conducted a non-parametric permutation test by randomizing the phase of the signal37 1000 times prior to ISC calculation and used the obtained null distribution to estimate the p value. We ran this procedure separately for each narrative and selected for subsequent analyses only voxels that achieved a significant ISC-score (p < 0.01, corrected for multiple tests using FDR) in all narratives. The process yielded a total of 9258 ‘stimulus-locked’ voxels.
Language model
All of the main analyses and models in this paper were based on the open-source, 20 billion parameters, GPT-NeoXT model (retrieved from https://huggingface.co/togethercomputer/GPT-NeoXT-Chat-Base-20B), developed by Together.ai and Eleuther.ai. This model is similar to Eleuther.ai’s GPT-NeoX model22, but it has undergone further fine-tuning using a small amount of feedback data. According to the developers, GPT-NeoX and GPT-NeoXT are considered comparable to OpenAI’s GPT-3 and ChatGPT models, respectively. For replication and validation we also used the OpenAI’s GPT-2 model11, as well as other LLMs designed for long contexts, Long T524, Transformer XL25, and Longformer26.
Analyzing the effect of the context window size on neural encoding
Story representations
For each story in our dataset (out of 8 stories), we extracted word embedding representation for every single token. The word embedding representation is a 6144-dimensional vector provided in the last layer of the GPT-NeoXT model. To extract a representation for a token, the token is fed into the model together with tokens that appeared in the text prior to this token (i.e., the context window). We varied the number of tokens in the context window between 8, 16, 32, 64, 128, 256, 512, and MAX tokens (up to 2048 tokens; this size is different from narrative to narrative, see Table S1; on average, a single token contains 0.75 words). This process yielded eight sets of word embedding representation vectors, corresponding to the eight window sizes. Each set takes the form of a d by k matrix, where d is the dimensionality of the word embedding vector and k is the number of tokens in the story, or the “time” dimension. To match the time resolution of the fMRI data (which was sampled every TR = 1.5 s), we down-sampled the token-based time signal of the word embedding vectors to n, where n equals the number of TRs in the scan. This was done by averaging the vectors of all the tokens that appeared within each TR interval.
Neural encoder model
For each narrative and participant (a total of 297 scans) we constructed a voxel wised neural encoder model, which is simply a linear regression model that predicts the neural signal, for each voxel (9258 ‘stimulus-locked’ voxels), from the word embedding representation vectors. Formally, the neural encoder maps the embedding vectors matrix, \({M}_{d,n}\), to the neural data matrix, \({Y}_{9258,{n}}\), where n is the length of the story (i.e., number of TRs) and d is the dimensionality of the word embedding representation. Following previous studies9,10 we reduced the dimensionality of the word embedding representations, d, into 32 dimensions via principal component analysis (PCA). To train and test the neural encoder model, we applied 5-fold cross-validation. The story was split into five sections, and for each iteration, we left one section out for testing and trained the model on the remaining sections. The model was evaluated by calculating Pearson’s correlation coefficient (r) between the predicted signal and the actual brain signal of the test section. The r-scores obtained from the five folds were transformed to Fisher’s Z, averaged together, and then converted back to r score.
Statistical testing
The significance scores (p value) of the results were assessed using a non-parametric Wilcoxon signed-rack test. Correction for multiple hypothesis testing was applied using the false discovery rate (FDR) method38. 95% confidence intervals were calculated using a 10,000-iteration bootstrap analysis.
The incremental context model
In the first analysis, we varied the context window size of the model and found that a window size of 32 tokens is optimal (Fig. 2), and that increasing the context window is not beneficial in modeling long-term context. In our incremental context model, the long-term context is not embodied with more tokens from the past, but rather with a compressed version of the past, which is a self-generated textual summary. Formally, when extracting the word embedding representation of a token i, the input to the model takes the following form:
Specifically, the token i is concatenated with the preceding 32 tokens, denoted as \({{window}}_{i-32:i}\), and before them, the kth (i.e., last updated, as described below) summary is presented. The strings \(\hbox{''}{\tt{Background}}:\hbox{''}\) and \(\hbox{''}{\tt{Continuation of the story}}:\hbox{''}\) are attached in the right places to help the model distinguish between the summary and the context window (see example in Fig. S3). Note that k is different from i as the summary is not updated from toke to token, but for every 50 tokens. We adopted this slow updating method to (1) preserve a stable long-term summary and (2) because of the extreme computational and time resources that the model consumes during textual generation.
To obtain \({{summary}}_{k}\) (once in 50 tokens as described above), we used the pre-trained language model head of the model to generate new text. The input to the model then was as follows:
Where ‘Prompt’ refers to our specifically designed textual instruction for the model, which was chosen after manual testing of several possibilities. The request prompt was “Here are paragraphs taken from a story. Can you summarize the main theme in a few short sentences?”. “\({{{summary}}}_{{k}{-}{1}}{\hbox{''}}\) represents the last summary generated at the previous step (we set \({{{summary}}}_{{0}}\) to an empty string). The expression “\({{{window}}}_{{i}{-}{32}{-}{l}{:}{i}{-}{32}}\)” refers to the text from the story that will be summarized along with the previous summary (Fig. 3b). We tested multiple values of l (50, 100, 150, 200, and 250) by manually inspecting the generated text in some portions of the data (~20%) and eventually set l = 100. Note from the subscript of “\({{{window}}}_{{i}{-}{32}{-}{l}{:}{i}{-}{32}}\)” that the text for summarization does not include the last 32 tokens, as this window is preserved intact in the input to the model when extracting the word embedding of token i, as described above.
In the summary generation, we limited the length of the generated text to a maximum of 50 tokens. As a result, the total length of the input to the model during word embedding extraction was never >90 tokens (the last token + 32 tokens of \({{{window}}}_{{i}{-}{32}{:}{i}}\) + 50 tokens of \({{{summary}}}_{{k}}\) + 7 tokens of the strings in between). Importantly, this method allows us to provide the model with long-term context while preserving a reasonable number of tokens to be computed in parallel. We used the recommended method for text generation in this model22, which was multinomial sampling with temperature of 0.9.
Direct comparisons between the models
To test the performance of the Incremental context model in neural encoding, we directly compare its r scores to two baseline models. One baseline was a short-term context model that takes only the last 32 tokens as its input (i.e., {\({{{window}}}_{{i}{-}{32}{:}{i}}\,{+}\,{{{token}}}_{{i}}\)}) with no additional long-term information. The other baseline model was a long-term context model that does not compress the long-term information but takes in its input all the tokens preceding the current tokens (up to the maximal possibility of 2048 tokens; i.e.,{\({{{window}}}_{{i}{-}{2048}{:}{i}}\,{+}\,{{{token}}}_{{i}}\)}).
For each pair of models {Incremental context vs. 32 tokens, Incremental context vs. MAX tokens, 32 tokens vs. MAX tokens}, we subtracted the r scores of one model (9258 r-scores in total, corresponding to the 9258 ‘stimulus-locked’ voxels) from the r-scores of the other model and denoted the results as \({\triangle r}_{{model\; a}-{model\; b}}\). In total, we calculated the following scores: \({\triangle r}_{{Incremental\; Context}-{32} \; tokens}\), \({\triangle r}_{{Incremental\; Context}-{MAX\; tokens}}\), and \({\triangle r}_{{32} \; {tokens}-{MAX\; tokens}}\). To test the statistical significance of the results, we applied a non-parametric Wilcoxon signed-rack test. Correction for multiple hypothesis testing was applied using the FDR method38.
Correlating low-frequency and HFD with \({\triangle \, r}_{{Incremental\; Context}-{32} \; {tokens}}\)
The fMRI BOLD signal of each voxel was first analyzed through a spectral analysis. After Z-normalizing the signal to mean = 0 and variance = 1, we calculated the PSD of the signal using the Welch method39 with a Hann window of 100 s and 50% overlap. The PSD curve describes how the power in a signal is distributed across different frequencies in the spectrum. Specifically, it is well-suited to our data as it enables the processing of signals with varying durations. Given that we have eight different stories, each with its unique duration, this method allows us to normalize the power to units of Hz in a consistent manner.
From the PSD curve, we derived the LFP and HFP scores as follows:
-
(1)
\({HFP}={\int }_{0.08}^{0.33}{PSD}\; \left({Hz}\right){dx}\)
-
(2)
\({LFP}={\int }_{0}^{0.02}{PSD}\; \left({Hz}\right){dx}\,\)
The lower bound for the integral of HFP is 0.08 Hz because it is equivalent to a wavelength (cycle) of 32 tokens (32 tokens takes ~12 s, and therefore, 0.08 Hz ≈ 1/12), and the higher bound, 0.33 Hz, is the Nyquist frequency (the maximum decomposed frequency). The range of the integral on LFP starts from Zero (the minimum decomposed frequency) to 0.02 Hz, which is equivalent to a window of 256 tokens. 0.02 Hz was chosen because it maximizes the correlation between LFP and \({{\triangle }{r}}_{{{Incremental\; Context}}{-}{32}{{tokens}}}\), however, the pattern of the results is preserved for different thresholds as well.
HFP and LFP scores were subsequently averaged across the 297 scans. Last, we calculated the correlations between \({{\triangle }{r}}_{{{Incremental\; Context}}{-}{32}{{tokens}}}\) and both the HFP and the LFP scores, over the 9258 voxels, using Pearson’s r.
Reporting summary
Further information on research design is available in the Nature Portfolio Reporting Summary linked to this article.
Data availability
The data for the present research were retrieved from the narratives dataset published elsewhere21 and can be accessed at https://datasets.datalad.org/?dir=/labs/hasson/narratives. Source data are provided with this paper.
Code availability
Code for the analysis of this paper can be found at https://github.com/RefaelTikochinski/Incremental-Accumulation-of-Linguistic-Context-in-Artificial-and-Biological-Neural-Networks.
References
Pereira, F. et al. Toward a universal decoder of linguistic meaning from brain activation. Nat. Commun. 9, 963 (2018).
Schwartz, D., Toneva, M. & Wehbe, L. Inducing brain-relevant bias in natural language processing models. Adv. Neural Inf. Process. Syst. 32 (2019).
Schrimpf, M. et al. Artificial neural networks accurately predict language processing in the brain. BioRxiv https://www.biorxiv.org/content/10.1101/2020.06.26.174482v1 (2020).
Caucheteux, C., Gramfort, A. & King, J.-R. Model-based analysis of brain activity reveals the hierarchy of language in 305 subjects. In: EMNLP 2021-Conference on Empirical Methods in Natural Language Processing (2021).
Caucheteux, C., Gramfort, A. & King, J.-R. Evidence of a predictive coding hierarchy in the human brain listening to speech. Nat. Hum. Behav. 7, 430–441 (2023).
Caucheteux, C., Gramfort, A. & King, J.-R. Deep language algorithms predict semantic comprehension from brain activity. Sci. Rep. 12, 16327 (2022).
Huth, A. G., de Heer, W. A., Griffiths, T. L., Theunissen, F. E. & Gallant, J. L. Natural speech reveals the semantic maps that tile human cerebral cortex. Nature 532, 453–458 (2016).
Jain, S. & Huth, A. Incorporating context into language encoding models for fMRI. Adv. Neural Inf. Process. Syst. 31, (2018).
Tikochinski, R., Goldstein, A., Yeshurun, Y., Hasson, U. & Reichart, R. Perspective changes in human listeners are aligned with the contextual transformation of the word embedding space. Cereb. Cortex 33, 7830–7842 (2023).
Goldstein, A. et al. Shared computational principles for language processing in humans and deep language models. Nat. Neurosci. 25, 369–380 (2022).
Radford, A. et al. Language models are unsupervised multitask learners. OpenAI Blog 1, 9 (2019).
Peters, M. E. et al. Deep Contextualized Word Representations. In: Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2018, New Orleans, Louisiana, USA, June 1–6, 2018, Vol. 1 (Long Papers) 2227–2237 https://doi.org/10.18653/v1/n18-1202 (2018).
Devlin, J., Chang, M.-W., Lee, K. & Toutanova, K. BERT: pre-training of deep bidirectional transformers for language understanding. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers) 4171–4186 https://doi.org/10.18653/v1/N19-1423 (Association for Computational Linguistics, Minneapolis, Minnesota, 2019).
Antonello, R. & Huth, A. Predictive coding or just feature discovery? an alternative account of why language models fit brain data. Neurobiol. Lang. 1, 16 (2022).
Hasson, U., Nastase, S. A. & Goldstein, A. Direct fit to nature: an evolutionary perspective on biological and artificial neural networks. Neuron 105, 416–434 (2020).
Vaswani, A. et al. Attention is all you need. Adv. Neural Inf. Process. Syst. 30 (2017).
Yeshurun, Y., Nguyen, M. & Hasson, U. The default mode network: where the idiosyncratic self meets the shared social world. Nat. Rev. Neurosci. 22, 181–192 (2021).
Hasson, U., Chen, J. & Honey, C. J. Hierarchical process memory: memory as an integral component of information processing. Trends Cogn. Sci. 19, 304–313 (2015).
Lerner, Y., Honey, C. J., Silbert, L. J. & Hasson, U. Topographic mapping of a hierarchy of temporal receptive windows using a narrated story. J. Neurosci. 31, 2906–2915 (2011).
Stephens, G. J., Honey, C. J. & Hasson, U. A place for time: the spatiotemporal structure of neural dynamics during natural audition. J. Neurophysiol. 110, 2019–2026 (2013).
Nastase, S. A. et al. The “Narratives” fMRI dataset for evaluating models of naturalistic language comprehension. Sci. Data 8, 250 (2021).
Black, S. et al. Gpt-neox-20b: an open-source autoregressive language model. ArXiv https://arxiv.org/abs/2204.06745 (2022).
Jain, S. & Huth, A. Incorporating context into language encoding models for fMRI. In: Advances in Neural Information Processing Systems (eds. Bengio, S. et al.) vol. 31 (Curran Associates, Inc., 2018).
Guo, M. et al. LongT5: Efficient Text-To-Text Transformer for Long Sequences. In: Findings of the Association for Computational Linguistics: NAACL 2022 724–736 https://doi.org/10.18653/v1/2022.findings-naacl.55 (Association for Computational Linguistics, Seattle, United States, 2022).
Dai, Z. et al. Transformer-XL: attentive language models beyond a fixed-length context. In: Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics 2978–2988 (Association for Computational Linguistics, Florence, Italy, 2019).
Beltagy, I., Peters, M. E. & Cohan, A. Longformer: the long-document transformer. ArXiv https://arxiv.org/abs/2004.05150 (2020).
Ben-David, E., Oved, N. & Reichart, R. PADA: example-based prompt learning for on-the-fly adaptation to unseen domains. Trans. Assoc. Comput. Linguist 10, 414–433 (2022).
Liu, N. F., et al. Lost in the middle: How language models use long contexts. Transactions of the Association for Computational Linguistics, 12, 157–173 (2024)
Aw, K. L. & Toneva, M. Training language models to summarize narratives improves brain alignment. Preprint at https://doi.org/10.48550/arXiv.2212.10898 (2023).
Tsirmpas, D., Gkionis, I. & Mademlis, I. Neural natural language processing for long texts: a survey of the state-of-the-art. ArXiv https://arxiv.org/abs/2305.16259 (2023).
Child, R., Gray, S., Radford, A. & Sutskever, I. Generating long sequences with sparse transformers. arXiv https://arxiv.org/abs/1904.10509 (2019).
Zaheer, M. et al. Big bird: transformers for longer sequences. Adv. Neural Inf. Process. Syst. 33, 17283–17297 (2020).
Wang, W. et al. Augmenting language models with long-term memory. In Advances in Neural Information Processing Systems 36 (NIPS, 2024).
Yang, Z. et al. Hierarchical attention networks for document classification. In: Proceedings of the 2016 conference of the North American chapter of the Association for Computational Linguistics: Human Language Technologies, 1480–1489 (2016).
Fischl, B. FreeSurfer. Neuroimage 62, 774–781 (2012).
Hasson, U., Nir, Y., Levy, I., Fuhrmann, G. & Malach, R. Intersubject synchronization of cortical activity during natural vision. Science 303, 1634–1640 (2004).
Simony, E. et al. Dynamic reconfiguration of the default mode network during narrative comprehension. Nat. Commun. 7, 12141 (2016).
Benjamini, Y. & Hochberg, Y. Controlling the false discovery rate: a practical and powerful approach to multiple testing. J. R. Stat. Soc. Ser. B Methodol. 57, 289–300 (1995).
Welch, P. The use of fast Fourier transform for the estimation of power spectra: a method based on time averaging over short, modified periodograms. IEEE Trans. Audio Electroacoustics 15, 70–73 (1967).
Acknowledgements
R.T. is funded by the Israel Council for Higher Education fellowship. U.H. and A.G. are supported by the National Institutes of Health under award number R01DC022534.
Author information
Authors and Affiliations
Contributions
R.T., A.G., R.R., and U.H. contributed to the conceptualization and design of the study. R.T., A.G., and Y.M. contributed to data analysis and computational models. R.T. was responsible for writing the manuscript, while A.G., R.R., and U.H. provided feedback, revisions, and final approval. R.R. and U.H. supervised the project.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Peer review
Peer review information
Nature Communications thanks Richard Antonello, and the other, anonymous, reviewer(s) for their contribution to the peer review of this work. A peer review file is available.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Source data
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Tikochinski, R., Goldstein, A., Meiri, Y. et al. Incremental accumulation of linguistic context in artificial and biological neural networks. Nat Commun 16, 803 (2025). https://doi.org/10.1038/s41467-025-56162-9
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41467-025-56162-9
This article is cited by
-
Event segmentation applications in large language model enabled automated recall assessments
Communications Psychology (2025)
-
Generative language reconstruction from brain recordings
Communications Biology (2025)
-
Treatments of Heavy Metals in Bio Electrochemical Systems (BES) and Microbial Transfer Mechanisms: Analyses of Influencing Factors, Future Research Directions, Prospect and Outlook
Water, Air, & Soil Pollution (2025)
