
Abstract
Microorganisms have evolved diverse strategies to propel themselves in viscous fluids, navigate complex environments, and exhibit taxis in response to stimuli. This has inspired the development of miniature robots, where artificial intelligence (AI) is playing an increasingly important role. Can AI endow these synthetic systems with intelligence akin to that honed through natural evolution? Here, we demonstrate, in silico, chemotactic navigation in a multi-link robotic model using two-level hierarchical reinforcement learning (RL). The lower-level RL allows the model—configured as a chain or ring topology—to acquire topology-adapted swimming gaits: wave propagation characteristic of flagella or body oscillation akin to an amoebae. Such chain and ring swimmers, further enabled by the higher-level RL, accomplish chemotactic navigation in prototypical biologically relevant scenarios that feature conflicting chemoattractants, pursuing a swimming bacterial mimic, steering in vortical flows, and squeezing through tight constrictions. Additionally, we achieve reset-free RL under partial observability, where simulated robots rely solely on local scalar observations rather than global or vectorial data. This advancement illuminates potential solutions for overcoming persistent challenges of manual resets and partial observability in real-world microrobotic RL.
Similar content being viewed by others
Introduction
Throughout biological evolution, organisms ranging from single cells to multicellular species have evolved diverse strategies in response to environmental stimuli, collectively termed taxis1. These responses include directed movement toward or away from cues such as light (phototaxis)2, temperature (thermotaxis)3, chemical gradients (chemotaxis)4,5, and many others. Of these, chemotaxis emerges as one of the most phylogenetically widespread and functionally critical strategies, underpinning essential biological processes, for instance: (1) immune response—neutrophils migrate toward infection sites by sensing chemoattractants like interleukin-8 (IL-8) released by damaged tissues or pathogens6; (2) microbial survival—Escherichia coli execute a run-and-tumble movement to climb nutrient gradients for optimal foraging; and 3) reproductive success—mammalian sperms navigate the female reproductive tract to the egg by tracing the gradients of its secreta7.
Chemotaxis is a feedback-regulated tactic employed by organisms. They sense chemical gradients through receptors and dynamically adjust their actions via feedback mechanisms, thereby enabling fitness-enhancing directed movement. This strategy of feedback regulation is not unique to chemotaxis or other tactic behaviors, but reflects a universal principle of natural intelligence shaped by evolution and natural selection8. In parallel, this feedback-regulated principle is equally widespread in engineered systems, its logic foreshadowing the rise of artificial intelligence (AI) born of human ingenuity.
Despite longstanding recognition of chemotaxis, synthetic systems that exhibit chemotactic intelligence remain rare9,10. Beyond the technical hurdles of engineering such systems, especially at scales comparable to those of chemotactic organisms, a lingering question persists: Can the evolutionary wisdom underlying biological taxis be meaningfully translated into engineering platforms? Modern AI, with its capacity to decipher and emulate biological feedback architectures, may hold the key to bridging this gap11. However, it remains elusive how AI might endow synthetic agents with such evolution-informed natural intelligence.
To explore these questions, we leverage reinforcement learning (RL)—an AI framework—to achieve chemotaxis in bio-inspired model swimmers within viscous fluids. Mimicking the goal-oriented, trial-and-error process fundamental to biological learning, RL enables an artificial agent to iteratively refine its behavior through environmental interactions12: sensing its surroundings, executing feedback-regulated actions, and continually optimizing strategies to maximize a cumulative goal-encoding reward. RL-based design and manipulation of robotic swimmers is an emerging field13,14,15,16,17, involving strokes of swimmers18,19,20,21,22, navigation in laminar23,24,25,26,27,28,29,30,31,32 and turbulent flows33,34, pursuit35,36,37, evasion35, and cloaking38.
Results
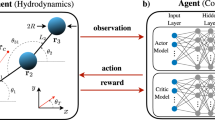
In our study, we apply RL to articulated model swimmers mimicking two prototypical chemotactic organisms—spermatozoa and neutrophils—both of which perform vital physiological functions by chemotactically migrating to hard-to-reach targets. Remarkably, a fertilizing mammalian spermatozoon, undertakes a long and obstructed journey from vagina to the Fallopian tube hosting the egg. This process is facilitated by sperm chemotaxis—navigating up a gradient of chemoattractants, e.g., progesterone, released from the egg39. Neutrophils, a type of immune cell that occasionally swims like an ameba40, similarly leverage strong chemotactic responsiveness to molecular cues from inflamed or infected tissues6. To better mimic these two inspiring organisms, our articulated swimmers incorporate their distinctive topologies: (1) the chain topology of spermatozoa and (2) the ring topology (projected view) of neutrophils. Respectively, the swimmers consist of multiple links: (1) connected in a linear chain, and (2) looped end-to-end in a ring, via N≥3 hinges (see Fig. 1a, b). The former represents a generalized Purcell’s swimmer19,41; its microscopic prototype has been successfully fabricated and magnetically actuated for locomotion42. This topological biomimicry gives hope that the twin swimmers will exhibit swimming patterns analogous to their biological counterparts.

The model adopts either a chain (a) or ring (b) topology. c Workflow of the lower-level RL: training simulated robots to acquire primitive swimming skills—propulsion and reorientation. d Workflow of the higher-level RL: training robots to steer up chemoattractant gradients.
We develop a two-level hierarchical RL framework tailored for the chain and ring model swimmers, enabling their self-propulsion followed by chemotaxis in a numerical environment. Firstly, we demonstrate that the lower level of our hierarchical RL framework enables swimmers with chain (linear) or ring topologies to discover swimming strokes adapted for their respective structural configurations. These topology-adapted strokes not only reflect the inherent constraints imposed by each topology but also partially emulate those of their biological counterparts. Specifically, the chain swimmer propels like a whipping flagellum, while the ring model deforms in a manner resembling ameboid movement. Therefore, RL facilitates the discovery of novel locomotion robophysics43 by leveraging biological insights. Secondly, utilizing the learnt strokes, the higher level of the hierarchical RL allows both microswimmers to achieve map-free chemotactic navigation in one shot across diverse scenarios: steering upwards a static chemical source with and without disturbance cues, pursuing a moving source, and chemotaxing within a background flow or through tight constrictions. Notably, at both levels of RL training, neither a swimmer’s configuration nor its environment is reset, corresponding to a non-episodic RL setting in contrast to the typical episodic approach in similar studies. This reset-free RL setting is adopted for two reasons. First, it aligns with the scenario of biological learning, where organisms cannot “restart” their environments. Second, manually resetting robots, especially those at chemotaxis-relevant scales, presents a tremendous challenge for robotic RL in real-world experiments44,45. Hence, we employ reset-free training in simulated environments to emulate this experimental challenge.
More specifically, both the chain and ring swimmers of a contour length of L, move in viscous fluids with dynamic viscosity μ, by sequentially rotating their N hinges to adjust the respective joint angles, \({{\boldsymbol{\Theta }}}={({\theta }_{1},...,{\theta }_{i},...,{\theta }_{N})}^{{\mathsf{T}}}\). Here, θi corresponds to the i-th hinge between two neighboring links (see Fig. 1a). The angular velocities \({{\boldsymbol{\Omega }}}=\dot{{{\boldsymbol{\Theta }}}}={({\Omega }_{1},...,{\Omega }_{i},...,{\Omega }_{N})}^{{\mathsf{T}}}\) of the hinges represent the swimmer’s stroke. Here, \({\Omega }_{i}\in [-\hat{\Omega },\,\hat{\Omega }]\), with \(\hat{\Omega }\) denoting the maximum rotational rate. To mimic chemotaxis, the swimmers sense the local concentration C of a chemoattractant and learn to move up its gradients. They are constrained to planar locomotion in the xy-plane of three-dimensional (3D) space. Under these micro-hydrodynamic conditions, viscous forces dominate over inertial effects, making the system well approximated by the Stokes equation, as is conventionally done46. Accordingly, we use a regularized Stokeslet method to emulate the flow environment47 (see “Methods” and SI). Further, we assume that the diffusion of chemoattractant dominates over its advection, allowing us to solve the Laplace equation ∇2C = 0 that governs the spatial distribution of C (see “Methods”).
In our non-episodic RL setup, the RL agent interacts with a partially observable environment. Reflecting both biological and synthetic constraints, the agent lacks access to the swimmer’s global position and orientation—a sensory limitation shared by chemotactic organisms and typical of the operational challenges synthetic miniature robots face in the human body48. To navigate this partial observability, the agent here relies on two complementary sensory streams: (1) proprioceptive signals (internal state sensing), captured by joint angles Θ, and (2) exteroceptive inputs (external stimuli), specifically local hydrodynamic pressure p and chemical concentration C, measured at the swimmer’s hinges or tips. These inputs, Θ, p, and C, collectively form the agent’s observational space.
Hierarchical RL framework for chemotactic navigation
We develop a two-level hierarchical RL framework to equip the swimmer with autonomous chemotactic navigation capabilities (see Fig. 1). Firstly, the swimmer acquires two primitive skills, propulsion—moving forward or backward, and reorientation—adjusting swimming directions, in viscous fluids. Secondly, it learns to sequence these skills for swimming up chemical gradients. For both levels, we utilize the proximal policy optimization (PPO) algorithm49 implemented in the RLlib library50.
Learning primitive swimming skills
At this level, the swimmer learns sequences of a vectorial action a of length N to master propulsion and reorientation in an unbounded space. Here, a is linearly associated with the angular velocity Ω of hinges, namely the stroke (see “Methods”). The chain swimmer masters these two skills through separate RL processes. Conversely, the ring counterpart requires only the propulsion ability, from which it can derive reorientation. This difference stems from the geometric features of the two models. The ring model exhibits a high (N) order of rotational symmetry without intrinsic polarity (tail-to-head direction), allowing it to flexibly maneuver in N directions. This flexibility is achieved by \({{{\mathcal{N}}}}_{{{\rm{prm}}}}=N\) primitive actions \({a}_{{{\rm{prm}}}}\in \{1,2,...,{{{\mathcal{N}}}}_{{{\rm{prm}}}}\}\), with each representing a polarity acquired by the swimmer to propel along (see “Methods”). Notably, the ring swimmer with a large N would resemble a flying saucer. In contrast, the chain swimmer featuring a fore-aft polarity cannot execute sideways movement conveniently, thereby requiring reorientation skills to enhance its maneuverability. Specifically, these skills enable it to redirect itself in the left-forward, right-forward, left-backward, and right-backward directions with respect to its orientation, in addition to its forward and backward propelling abilities. Overall, the chain swimmer possesses \({{{\mathcal{N}}}}_{{{\rm{prm}}}}=6\) primitive actions.
We design a reward r1 using locally sensed pressure p, rather than commonly used global vectorial quantities such as velocity or displacement. Specifically, \({r}_{1}=\lambda ({p}_{{{\rm{f}}}}-{p}_{{{\rm{r}}}})/(\mu \hat{\Omega })\) quantifies the pressure difference between the front (pf) and rear (pr) of the swimmer, measured at the chain tips or averaged over the ring model’s halves (Fig. 1c), see “Methods”. This reward determines the swimming direction: from the rear to the front tip for chain swimmers, and from the center of the rear half to that of the front half for ring models. We design a reward r1 using locally sensed pressure p, rather than commonly used global vectorial quantities such as velocity or displacement. Specifically, \({r}_{1}=\lambda ({p}_{{{\rm{f}}}}-{p}_{{{\rm{r}}}})/(\mu \hat{\Omega })\) quantifies the pressure difference between the front (pf) and rear (pr) of the swimmer, measured at the chain tips or averaged over the ring model’s halves (Fig. 1c), see “Methods”. This reward determines the swimming direction: from the rear to the front tip for chain swimmers, and from the center of the rear half to that of the front half for ring models.
Chemotactic navigation utilizing primitive actions
The higher-level policy aims to identify an optimal sequence of primitive actions that enables efficient chemoattractive motion of the swimmer. Figure 1d demonstrates an example where swimmers successfully navigate toward a chemical source of strength Q.
We implement a two-step approach at this level: a coarse selection followed by an adjustment. In the coarse step, a set of primitive actions is determined based on the chemical concentration detected at hinges. From this set, a single action aprm is randomly selected—not necessarily the optimal one. Subsequently, we refine aprm by applying a stepwise adjustment aadj through RL, resulting in a refined action \({a}_{\,{\mbox{prm}}}^{{\prime} }={a}_{{{\rm{prm}}}}+{a}_{{{\rm{adj}}}}\). Next, this primitive action \({a}_{\,{\mbox{prm}}\,}^{{\prime} }\) is executed over a fixed interval T. Notably, the adjustment action space \({a}_{{{\rm{adj}}}}\in \left\{-1,0,1\right\}\) encompasses rightward (−1), no shift (0), and leftward (+1) deviations from the initial coarse action aprm. This adjustment process is repeated across multiple intervals of T, with rewards scaling linearly with the cumulative change in hinge-averaged concentration during each interval.
Propulsion and chemotactic navigation
We focus on a chain model with N = 9 hinges and a ring model with N = 20, with results for other N presented in SI. We first show the acquisition of primitive swimming skills by these models. Subsequently, we demonstrate their chemotactic navigation in diverse biologically relevant settings.
Topology-adapted motility mechanisms
As illustrated in Fig. 2a (Movie S1), the chain swimmer learns to propel by actuating the hinges cyclically, thus causing its body to bend like a traveling transverse wave, a strategy harnessed by biological flagella51. Likewise, the ring swimmer acquires propulsion through periodic contraction and expansion, reminiscent of a longitudinal wave, see Fig. 2c (Movie S3). This suggests that RL endows topologically distinct robotic swimmers with topology-adapted locomotion mechanisms, effectively aligning them with their biological counterparts developed through Darwinian natural selection.

a A chain swimmer achieves propulsion through symmetric beating, with vectors indicating the flow field. The inset shows the horizontal (x) and vertical (y) displacements of the swimmer’s tip, resembling a traveling transverse wave. b The chain swimmer reorients through asymmetric actuation. c A ring swimmer propels by periodically contracting and expanding its body. The inset displays the x and y displacements of the swimmer’s front, typical of a longitudinal wave propagating horizontally. d Evolution of front-rear pressure differences during the policy iteration process: training the chain swimmer for propulsion (purple solid line) and reorientation (purple dashed), and the ring model for propulsion (green solid in the inset). This quantity is time-averaged over one policy. e, f Similar to d, but for the rotational rate and centroid translational velocity of the swimmers, respectively. The latter reaches a plateau value (dashed line), \({{\mathcal{U}}}/(\hat{\Omega }L)\), representing the swimming speed of simulated agents once training has converged. Source data are provided as a Source Data file.
For the propulsion demonstrated above, the joint angles of both swimmers are bounded within a symmetric range, i.e., \({\boldsymbol{\Theta}} \,\in \,{[-\hat{\theta },\hat{\theta }]}^{N}\). Nonetheless, enabling the chain swimmer to reorient, as indicated in Fig. 2b (Movie S2), necessitates choosing an asymmetric bound, \({[-\alpha \hat{\theta },\hat{\theta }]}^{N}\) with α ∈ [0, 1]. The choice mimics the structural asymmetries in the flagellar scaffold of spermatozoa, which facilitates their reorientation52,53. In this study, we set α = 0.5 to balance the translational and rotational capacities of the chain swimmer, as explained in SI.
We further demonstrate the learning curves of the two swimmers acquiring these primitive skills. As the policy evolves, the swimmer learns to increase the front-rear pressure difference (proportional to the reward), which reaches a saturated value after ≈ 400 policy iterations (see Fig. 2d). The saturation value is significantly lower for the ring swimmer than the chain counterpart. Realizing the linear pressure-velocity relationship in the Stokesian limit—where viscous effects dominate inertia—both simulated robots effectively learn to propel, even though their velocities are not explicitly targeted or measured. This linear relationship is reflected in the translational velocities of the swimmers, which follow a similar trend to the pressure difference, as depicted in Fig. 2f. The chain and ring swimmers’ translational velocities eventually plateau at \({{\mathcal{U}}}\approx 0.017\hat{\Omega }L\) and \({{\mathcal{U}}}\approx 0.0013\hat{\Omega }L\), respectively, which implies the swimming capacity of the learnt robotic models. Using the same pressure-encoded reward but with the asymmetric angular bound, the chain model develops the rotational capacity (Fig. 2e), therefore enabling its reorientation.
Besides Newtonian fluids, we have also successfully trained the chain swimmer to propel in a gel-like medium that holds important biological relevance, as detailed in SI.
Navigation towards a static chemical source
Based on the learnt primitive skills, the agents are first trained to learn chemotaxis toward a stationary chemical source with strength Q, positioned in the swimming plane. As illustrated in Fig. 3a, d (Movie S4 and 5), both the chain and ring swimmers successfully navigate to the source located to the east of their initial positions, with the former executing a more meandering trajectory.

a A chain swimmer initially at (0, 0) swims toward the target source at (4, 0). b Similar to a, but with a disturbing chemical source (star symbol) at (0, 4) featuring strengths of Qd = 0.2Q (left panel) and 0.6Q (right panel), respectively. Here, ΔC signifies the difference in the chemoattractant concentration produced by the target and disturbance sources. c Akin to a, but for a ring model. d Analogous to b, but for a ring swimmer, with the disturbing source strengths of Qd = 0.6Q (left panel) and 0.8Q (right panel), respectively. Source data is provided as a Source Data file.
To examine the resilience of the robotic chemotaxis in environments with multiple chemoattractants, as typically encountered in chemotaxis6,54, we introduce a disturbing chemical source with strength Qd. This disturbance is positioned to the north of the swimmer’s initial position and at an equal distance from it as the target source. Accordingly, these settings feature two orthogonal chemoattractant gradients. In the presence of a weak disturbance Qd = 0.2Q, the chain swimmer consistently reaches the target source (see Fig. 3b). However, at a stronger disturbance of Qd = 0.6Q, the swimmer occasionally fails and approaches the disturbance source. At the same disturbance level, the ring swimmer shows great resilience, successfully navigating to the target in all trials, see Fig. 3c. Nonetheless, its success rate drops to ≈ 60% when Qd = 0.8Q.
Chasing a moving chemical source
Having demonstrated chemotaxis towards a static chemical source, the robotic swimmers are now tasked with pursuing a moving source that follows a predefined trajectory. This scenario emulates the behavior of white blood cells, such as neutrophils, which chase invading bacteria by tracking their chemoattractants55.
The chain and ring swimmers are trained to purchase a chemoattractant-releasing bacterial mimic executing a circular and figure-eight path at a constant speed Us, respectively. Here, \({U}_{{{\rm{s}}}}=1{0}^{-3}\hat{\Omega }L\) and \(3\times 1{0}^{-4}\hat{\Omega }L\) for the two swimmers. Time-lapse sequences depicted in Fig. 4 (Movies S6 and 7) illustrate the swimmers’ chemotactic navigation, highlighting their approach to the source (a, d), interception (b, e), and subsequent tracking (c, f). As shown in Fig. 4g, both models struggle to precisely track the source moving at an increasing speed Us.

a–c A chain swimmer chasing (a), encountering (b), and following (c) a chemical source (symbolized by a star) moving along a circular orbit. d–f Similar to a–c, but for a ring swimmer and a source executing a figure-eight-shaped path. g Trajectories of chain (left column) and ring (right column) swimmers pursuing a source at varying speeds. Source data are provided as a Source Data file.
Chemotaxing within an ambient flow
Organisms and robots typically do not swim in a quiescent environment but are commonly subject to an underlying flow. Here, we investigate how such flows affect RL-based synthetic chemotaxis. As displayed in Fig. 5, we navigate the swimmers towards a static chemical source in spatially periodic cellular vortices \(\tilde{{{\bf{u}}}}={U}_{{{\rm{v}}}}\sin (\pi x/L)\cos (\pi y/L){{{\bf{e}}}}_{x}-{U}_{{{\rm{v}}}}\cos (\pi x/L)\sin (\pi y/L){{{\bf{e}}}}_{y}\)56, where Uv denotes the vortical strength. Here, we have set the size of cells to match the swimmer length, L, serving as a representative demonstration.

Swimmers start from (0, 0) with the goal of reaching a chemical source positioned at (4, 4). a, b A chain model swims in vortices with \({U}_{{{\rm{v}}}}=0.005\hat{\Omega }L\) and \({U}_{{{\rm{v}}}}=0.03\hat{\Omega }L\), respectively. The background color denotes the dimensionless flow vorticity. The inset of A depicts the typical streamlines. c Statistics of successful chemotaxis versus the vortical strength Uv, where crosses and circles signify failures and successes, respectively. d, e similar to a and b, but for a ring swimmer, with \({U}_{{{\rm{v}}}}=0.0005\hat{\Omega }L\) and \({U}_{{{\rm{v}}}}=0.005\hat{\Omega }L\), respectively. f Similar to c, while for a ring swimmer. Source data is provided as a Source Data file.
In a weak cellular flow, both chain and ring models achieve chemotaxis with ease, as indicated in Fig. 5a, d (Movies S8 and 10). However, when the vortices are substantially strengthened, the swimmers tend to be occasionally trapped with these vortices before reaching the chemoattractant source, see Fig. 5b, e (Movies S9 and 11). With further increased Uv, the chain swimmer fails to reach the target, while the ring counterpart cannot escape from the trapping vortices (see SI). Figure 5c, f characterizes the success rate of robotic chemotaxis versus the vortical strength Uv, with 30 data samples collected for each strength. For the chain model, the success rate exhibits a sharp transition from 0 (indicating complete failure) to nearly 1 as the ratio \({U}_{{{\rm{v}}}}/{{\mathcal{U}}}\) decreases to approximately 3. Conversely, for the ring swimmer, this rate gradually increases from 0 at \({U}_{{{\rm{v}}}}/{{\mathcal{U}}}\approx 4\) to 1 at \({U}_{{{\rm{v}}}}/{{\mathcal{U}}}\approx 2\), displaying an approximately linear trend.
Squeezing through a narrow constriction
Microorganisms exhibit chemotaxis within complex, confined spaces. Human spermatozoa, measuring ≈ 60 μm in length, must navigate constricted regions like cervical crypts and folds of the ampullary Fallopian tube, with constrictions as tight as about 100 μm57. More impressively, neutrophils with a typical diameter of 7–8 μm undergo extreme cellular deformation to rapidly squeeze through ~ 1 μm tissue barriers of blood vessels during transendothelial migration—a process critical for mounting an immediate immune response58,59.
To emulate this biomimetic, we task our simulated robots with navigating a 3D spanwise (z)-uniform channel formed by two plates (see Fig. 6a). The bottom plate features a sinusoidal protrusion that narrows the passage to a width d. The swimmers, initially on one side of the resulting constriction, are trained to traverse the narrowed path to reach a chemical source with concentration C0 located on the opposite side.

a The swimmer navigates a constriction of height d to reach the chemical source located on the opposite side. The source and locomotion are within the same xy-plane. A chain swimmer successfully traverses a constriction of d = 0.3L (b), but fails to pass through a narrower one of d = 0.2L (c). d Similar to b, but for a ring swimmer, which squeezes through the narrow gap of d = 0.5L/π, where L/π denotes the effective diameter of ring models. e analogous to d, but with a tighter constriction of d = 0.4L/π, which obstructs the swimmer. Source data is provided as a Source Data file.
As depicted in Fig. 6b (Movie S12), the chain swimmer successfully navigates the constriction of d/L = 0.3 toward the chemical source, yet it is obstructed by the narrower constriction of d/L = 0.2 (see Fig. 6c). On the other hand, the ring swimmer struggles more in the confined space. Fig. 6e indicates that it cannot traverse a passage that is narrowed to 0.4 times its effective diameter, L/π. However, by enlarging the constriction to d = 0.5L/π, the ring model manages to pass through, as illustrated in Fig. 6d (Movie S13).
We notice a pitfall in our ring model; it cannot replicate the biological template—the neutrophils’ capacity to squeeze through extremely tight gaps. The failure of the synthetic ameba stems from its constant contour length L that renders zero surface extensibility, in contrast to neutrophils possessing highly extensible surfaces59. This difference implies a potential solution leveraging elastic and flexible inter-link joints to develop soft multi-link robots.
Discussion
In this study, we employ a two-level hierarchical RL to achieve, in silico, chemotactic navigation of an articulated robotic swimmer comprising sequentially connected links. The swimmer, via the lower-level RL, first learns the primitive skills of propulsion and reorientation. Subsequently, using these learned actions, the higher-level RL endows the swimmer with the ability of chemotaxis across representative biologically-inspired settings, including scenarios with conflicting chemoattractants, chemotactic pursuit of a moving bacterial mimic, chemotaxis in an ambient flow or through throat-like constrictions. Notably, at both training stages, the RL agent achieves the goal in one shot, without resetting the swimmer, global positioning, or vectorial observations.
Depending on the topology of inter-link connectivity—chain or ring, RL imparts a topology-adapted locomotory gait to the multi-link robotic model. Specifically, the linearly linked model, resembling a chain, swims by propagating a transverse bending wave characteristic of flagellar organisms such as spermatozoa and the nematode Caenorhabditis elegans. Conversely, the ring-shaped counterpart undergoes longitudinal body oscillations to enable ameboid movement60,61,62, as observed in amoebae and certain types of leukocytes like neutrophils40 and leukocytes63.
These findings demonstrate that RL enables simulated robots with biologically relevant topologies to discover locomotion patterns adapted to their respective structural configurations. Such topology-adapted patterns not only reflect the inherent constraints of each topology but also partially resemble their biological counterparts. More importantly, this adaptation highlights that RL can reproduce, in a robophysics context, the morpho-functional relationship ubiquitous in biology. This relationship emerges from evolutionary processes, where morphology constrains and defines functional patterns64. In the robophysical analogy, a robot’s topology directly informs its topology-adapted locomotor principles through RL. Taken together, our work demonstrates that RL, guided by biological insights, can advance novel locomotion robophysics. More broadly, this demonstration suggests opportunities to merge bio-inspirations with AI to foster new discoveries in robophysics and bionics.
Naturally, we may wonder whether such robophysical intelligence achieved through RL can be extended to organisms with other topologies. An immediate prospect is the star topology featured by octopuses and octopus-inspired robots, as depicted in ref. 65. We hypothesize that RL could allow multi-link robots with this topology to acquire the lesser-known arm-sculling swimming gait66,67 of certain octopuses. Besides imitating these natural mobility mechanisms, applying RL to the multi-link architecture with topologies not found in nature could uncover novel, counterintuitive mechanisms beyond those evolved by living systems. An inspiring analogy is the RL-facilitated computer Go program, AlphaGo68, which can generate inventive winning moves unprecedented in human-to-human Go matches. Further stretching our imagination, the integration of RL with other AI techniques could empower multi-link robots to intelligently reconfigure their topology, adapting to environmental variations and fulfilling multitasking demands69. For instance, a ring robot could learn to transform into a chain robot or to disassemble into multiple chain robots, and vice versa.
Beyond acquiring the motility mechanism, our robotic swimmers have been trained to exhibit chemotaxis in diverse settings, in resonance with recent studies of intelligent chemotactic active particles29,37,70,71,72. The demonstrated chemotactic swimming capacity, though in simulated environments, may shed light on AI-guided, autonomous navigation of miniature robots inside the human body73,74,75,76,77. This task requires accurately directing robots to their intended sites of action, typically located within confined, hard-to-reach, and sensitive regions78. Our work has demonstrated employing hierarchical RL to achieve reset-free training of robots, offering valuable insights into RL-based manipulation of swimming microrobots in wet-lab settings—an emerging field in its infancy79,80,81. Besides potentially advancing the navigation of medical robots, our research focus on programming chemotactic robotic intelligence may inspire the development of cleaning robots for remediation tasks82,83, specifically targeting the removal of micro/nanoplastics, heavy metals, and radioactive contaminants from polluted waters. In addition to chemotaxis, our learning framework can be generalized to engineer diverse robotic taxis84, including phototaxis, rheotaxis, magnetotaxis, and combinations thereof. This generalization will promote the development of more intelligent and versatile robotic systems.
Methods
Numerical methods
We build the numerical hydrodynamic environment of microswimmers using a 3D boundary integral method85 to solve the Stokes equation. Specifically, we adopt a regularized Stokeslet method47, with more details provided in SI.
Lower-level RL
Observations
At the lower level of our hierarchical RL framework, the agent observes the joint angles Θ of a simulated robot as proprioceptive sensory inputs. For ring swimmers, the angles are within a symmetric range, namely \({{\boldsymbol{\Theta }}}\in {[-\hat{\theta },\hat{\theta }]}^{N}\). However, this situation changes for a flagellar swimmer: its propulsion admits a symmetric range, whereas its reorientation necessitates an asymmetric one, \({[-\alpha \hat{\theta },\hat{\theta }]}^{N}\) with α = 0.5. We illustrate the influence of α on the swimmer’s translational and rotational velocities in the SI. Moreover, the maximum angle \(\hat{\theta }\) of flagellar swimmers is limited to 2π/(N + 1) to prevent links from crossing. For ring swimmers, \(\hat{\theta }=\pi /3\) is adopted to allow reasonable body deformation while avoiding intersections of links.
When training the robots, we judge whether an obtained action might result in limit-exceeding joint angles or crossing links. If either condition is met, a null action is implemented.
Actions
The action of an agent is encoded by a vector a ∈ [−1, 1]N, which correlates with the angular velocities Ω via a linear mapping, Ω = Ba. Here, the linear operator B depends on the topology of the multi-link swimmer. For chain swimmers, \({{\bf{B}}}=\hat{\Omega }{{\bf{I}}}\). In contrast, for a ring swimmer, the formulation of B warrants special consideration due to the geometric constraints imposed by its links, which form an N-sided equilateral polygon.
For this polygon, the links form a closed loop, imposing the following constraints on the joint angles Θ and uniform side length L/N:
Taking the time derivative of Eq. (1), we obtain the constraint on Θ,
which simplifies to CΩ = 0 where
This constraint is fulfilled by setting \({{\bf{B}}}=\hat{\Omega }({{\bf{I}}}-{{{\bf{C}}}}^{+}{{\bf{C}}})\), with C+ denoting the Moore-Penrose inverse of C.
Reward
In the lower-level RL framework, the pressure difference between the front and rear of a swimmer is used to design the reward \({r}_{1}=\lambda ({p}_{{{\rm{f}}}}-{p}_{{{\rm{r}}}})/(\mu \hat{\Omega })\). For a chain swimmer, as shown in Fig. 1c, pf and pr are simply measured at the front and rear tips, respectively. The situation is slightly more complicated for a ring swimmer. As depicted in Fig. 1c, the swimmer is divided into a front half (orange links) and a rear half (gray links), with pf and pr the average pressures over these halves. For an even number of links, N, each half contains N/2 links; Otherwise, the front and rear halves comprise (N − 1)/2 and (N + 1)/2 links, respectively.
Symmetry-encoded policies
The chain and ring swimmers possess \({{{\mathcal{N}}}}_{{{\rm{prm}}}}=6\) and N primary actions, respectively. However, exploiting the geometric symmetry of both swimmers can reduce the number of RL tasks for learning all these actions to two for the former and one for the latter.
Specifically, the chain swimmer requires learning policies only for forward (aprm = 1) and left-forward (aprm = 2) swimming. Policies for other primitive actions are derivable through symmetry. As illustrated in Fig. 1c, for example, using left-right symmetry, the policy for right-forward movement (aprm = 6) can be obtained by inputting—Θ into the policy network for left-forward swimming (aprm = 2). Likewise, fore-aft symmetry allows deriving the policy for left-backward swimming by flipping Θ for the left-forward swimming policy (aprm = 2). A similar strategy applies for deriving the backward and right-backward swimming policies.
The ring swimmer features an N-order rotational symmetry, allowing the agent to master the policy for only one primitive action, e.g., aprm = 1. The policy for any other action aprm > 1 can be derived by permuting Θ to \({({\theta }_{{a}_{{{\rm{prm}}}}},...,{\theta }_{N},{\theta }_{1},...,{\theta }_{{a}_{{{\rm{prm}}}}-1})}^{{\mathsf{T}}}\).
Higher-level RL
At the higher level, we adopt a coarse-to-fine, two-step approach. In the coarse step, we first need to identify a set of primitive actions. For the chain swimmer, if the concentration at the front tip exceeds that at the rear tip, the set comprises primitive actions {1, 2, 6}, which facilitate forward motion; conversely, if lower, the set is {3, 4, 5}, supporting backward motion. For the ring swimmer, the process begins by pinpointing the hinge with the highest concentration. Subsequently, any primitive action whose corresponding front half includes this hinge is included as a constituent element of the set.
Solution of the concentration equation
In our chemotactic navigation, the chemical sources are positioned on the xy-plane (z = 0), where the swimmers are restricted to.
As depicted in Fig. 3, a static chemical source of strength Q is located at rt serving as the target, while another static source with strength Qd positioned at rd acts as a disturbance. The 3D chemical concentration field C(r) is governed by the equation ∇2C = Qδ3(rt) + Qdδ3(rd), with δ3( ⋅ ) denoting the 3D Dirac delta function. The resultant chemical distribution can be analytically expressed as \(C({{\bf{r}}})=Q/\left(4\pi | {{\bf{r}}}-{{{\bf{r}}}}_{{{\rm{t}}}}| \right)+{Q}_{{{\rm{d}}}}/\left(4\pi | {{\bf{r}}}-{{{\bf{r}}}}_{{{\rm{d}}}}| \right)\). For a moving chemical source with a prescribed trajectory rm(t) shown in Fig. 4, the chemical concentration is \(C({{\bf{r}}},t)=Q/\left(4\pi | {{\bf{r}}}-{{{\bf{r}}}}_{{{\rm{m}}}}(t)| \right)\). The chain swimmer follows a source along the circular trajectory \({{{\bf{r}}}}_{{{\rm{m}}}}(t)=2L\cos (\hat{\Omega }t/1000){{{\bf{e}}}}_{x}+2L\sin (\hat{\Omega }t/1000){{{\bf{e}}}}_{y}\); the ring swimmer pursues a source moving along the figure-eight path \({{{\bf{r}}}}_{{{\rm{m}}}}(t)=L\sin (\hat{\Omega }t/4000){{{\bf{e}}}}_{x}+L\sin (\hat{\Omega }t/4000)\cos (\hat{\Omega }t/4000){{{\bf{e}}}}_{y}\).
For navigation within a confined domain shown in Fig. 6, the chemical field is solved numerically using COMSOL Multiphysics (I-Math, Singapore), as detailed in SI.
Code availability
The numerical solver87 used to emulate the flow environment is available at https://github.com/xiongtongzhao/microrobot_dynamics. The RL implementation88 is available at https://github.com/xiongtongzhao/RL_microrobots.
References
Fraenkel, G. S. & Gunn, D. L. The Orientation of Animals, Kineses, Taxes and Compass Reactions. (Dover, 1961).
Jékely, G. Evolution of phototaxis. Philos. Trans. R. Soc. B 364, 2795–2808 (2009).
Poff, K. L. & Skokut, M. Thermotaxis by pseudoplasmodia of Dictyostelium discoideum. Proc. Natl Acad. Sci. USA 74, 2007–2010 (1977).
Adler, J. Chemotaxis in bacteria: motile Escherichia coli migrate in bands that are influenced by oxygen and organic nutrients. Science 153, 708–716 (1966).
Berg, H. C. Chemotaxis in bacteria. Annu. Rev. Biophys. Bioeng. 4, 119–136 (1975).
Petri, B. & Sanz, M.-J. Neutrophil chemotaxis. Cell Tissue Res. 371, 425–436 (2018).
Eisenbach, M. Sperm chemotaxis. Rev. Reprod. 4, 56–66 (1999).
Friston, K. The free-energy principle: a unified brain theory? Nat. Rev. Neurosci. 11, 127–138 (2010).
Liebchen, B. & Lowen, H. Synthetic chemotaxis and collective behavior in active matter. Acc. Chem. Res. 51, 2982–2990 (2018).
Joseph, A. et al. Chemotactic synthetic vesicles: design and applications in blood-brain barrier crossing. Sci. Adv. 3, e1700362 (2017).
Richards, B. A. et al. A deep learning framework for neuroscience. Nat. Neurosci. 22, 1761–1770 (2019).
Sutton, R.S. & Barto, A.G. Reinforcement Learning: An Introduction. (MIT Press, 2018).
Tsang, A. C., Demir, E., Ding, Y. & Pak, O. S. Roads to smart artificial microswimmers. Adv. Intell. Syst. 2, 1900137 (2020).
Cichos, F., Gustavsson, K., Mehlig, B. & Volpe, G. Machine learning for active matter. Nat. Mach. Intell. 2, 94–103 (2020).
Nasiri, M., Löwen, H. & Liebchen, B. Optimal active particle navigation meets machine learning. Europhys. Lett. 142, 17001 (2023).
Yang, L. et al. Machine learning for micro-and nanorobots. Nat. Mach. Intell. 6, 605–618 (2024).
Jiao, Y., Ling, F., Heydari, S., Heess, N., Merel, J. & Kanso, E. Deep dive into model-free reinforcement learning for biological and robotic systems: theory and practice. Preprint at arXiv https://doi.org/10.48550/arXiv.2405.11457 (2024).
Tsang, A. C. H., Tong, P. W., Nallan, S. & Pak, O. S. Self-learning how to swim at low Reynolds number. Phys. Rev. Fluids 5, 074101 (2020).
Qin, K., Zou, Z., Zhu, L. & Pak, O.S. Reinforcement learning of a multi-link swimmer at low Reynolds numbers Phys. Fluids 35, 032003 (2023).
Abdi, H. & Pishkenari, H. N. Self-learning swimming of a three-disk microrobot in a viscous and stochastic environment using reinforcement learning. Eng. Appl. Artif. Intell. 123, 106188 (2023).
Lin, L.-S., Yasuda, K., Ishimoto, K. & Komura, S. Emergence of odd elasticity in a microswimmer using deep reinforcement learning. Phys. Rev. Res. 6, 033016 (2024).
Xu, Z. & Zhu, L. Training microrobots to swim by a large language model. Phys. Rev. Appl. 23, 044058 (2025).
Schneider, E. & Stark, H. Optimal steering of a smart active particle. EPL 127, 64003 (2019).
Gunnarson, P., Mandralis, I., Novati, G., Koumoutsakos, P. & Dabiri, J. O. Learning efficient navigation in vortical flow fields. Nat. Commun. 12, 7143 (2021).
Zou, Z., Liu, Y., Young, Y.-N., Pak, O. S. & Tsang, A. C. Gait switching and targeted navigation of microswimmers via deep reinforcement learning. Commun. Phys 5, 158 (2022).
Nasiri, M. & Liebchen, B. Reinforcement learning of optimal active particle navigation. New J. Phys. 24, 073042 (2022).
Monderkamp, P. A., Schwarzendahl, F. J., Klatt, M. A. & Löwen, H. Active particles using reinforcement learning to navigate in complex motility landscapes. Mach. Learn. 3, 045024 (2022).
Qiu, J., Mousavi, N., Gustavsson, K., Xu, C., Mehlig, B. & Zhao, L. Navigation of micro-swimmers in steady flow: The importance of symmetries. J. Fluid Mech. 932, A10 (2022).
Mo, C., Fu, Q. & Bian, X. Chemotaxis of an elastic flagellated microrobot. Phys. Rev. E 108, 044408 (2023).
El Khiyati, Z., Chesneaux, R., Giraldi, L. & Bec, J. Steering undulatory micro-swimmers in a fluid flow through reinforcement learning. Eur. Phys. J. E 46, 43 (2023).
Sankaewtong, K., Molina, J. J., Turner, M. S. & Yamamoto, R. Learning to swim efficiently in a nonuniform flow field. Phys. Rev. E 107, 065102 (2023).
Putzke, M. & Stark, H. Optimal navigation of a smart active particle: directional and distance sensing. Eur. Phys. J. E 46, 48 (2023).
Biferale, L., Bonaccorso, F., Buzzicotti, M., Di Leoni, P. C. & Gustavsson, K. Zermelo’s problem: optimal point-to-point navigation in 2D turbulent flows using reinforcement learning. Chaos 29, 103138 (2019).
Alageshan, J. K., Verma, A. K., Bec, J. & Pandit, R. Machine learning strategies for path-planning microswimmers in turbulent flows. Phys. Rev. E 101, 043110 (2020).
Borra, F., Biferale, L., Cencini, M. & Celani, A. Reinforcement learning for pursuit and evasion of microswimmers at low Reynolds number. Phys. Rev. Fluids 7, 023103 (2022).
Zhu, G., Fang, W.-Z. & Zhu, L. Optimizing low-Reynolds-number predation via optimal control and reinforcement learning. J. Fluid Mech. 944, A3 (2022).
Nasiri, M., Loran, E. & Liebchen, B. Smart active particles learn and transcend bacterial foraging strategies. Proc. Natl. Acad. Sci. USA 121, e2317618121 (2024).
Mirzakhanloo, M., Esmaeilzadeh, S. & Alam, M.-R. Active cloaking in Stokes flows via reinforcement learning. J. Fluid Mech. 903, A34 (2020).
Eisenbach, M. & Giojalas, L. C. Sperm guidance in mammals—an unpaved road to the egg. Nat. Rev. Mol. Cell Biol. 7, 276–285 (2006).
Barry, N. P. & Bretscher, M. S. Dictyostelium amoebae and neutrophils can swim. Proc. Natl. Acad. Sci. USA 107, 11376–11380 (2010).
Purcell, E. M. Life at low Reynolds number. Am. J. Phys. 45, 3–11 (1977).
Xing, L., Liao, P., Mo, H., Li, D. & Sun, D. Preformation characterization of a torque-driven magnetic microswimmer with multi-segment structure. IEEE Access 9, 29279–29292 (2021).
Aguilar, J. et al. A review on locomotion robophysics: the study of movement at the intersection of robotics, soft matter and dynamical systems. Rep. Prog. Phys. 79, 110001 (2016).
Zhu, H. et al. The ingredients of real-world robotic reinforcement learning. In conference paper published in International Conference on Learning Representations (2020).
Ibarz, J. et al. How to train your robot with deep reinforcement learning: lessons we have learned. Int. J. Robot. Res. 40, 698–721 (2021).
Lauga, E. & Powers, T. R. The hydrodynamics of swimming microorganisms. Rep. Prog. Phys. 72, 096601 (2009).
Smith, D. J. A nearest-neighbour discretisation of the regularized Stokeslet boundary integral equation. J. Comput. Phys. 358, 88–102 (2018).
Nelson, B. J. & Pané, S. Delivering drugs with microrobots. Science 382, 1120–1122 (2023).
Schulman, J., Wolski, F., Dhariwal, P., Radford, A. & Klimov, O. Proximal policy optimization algorithms. Preprint at arXiv https://doi.org/10.48550/arXiv.1707.06347 (2017).
Liang, E. et al. RLlib: abstractions for distributed reinforcement learning. in: ICML (2018).
Taylor, G. I. Analysis of the swimming of microscopic organisms. Proc. R. Soc. A 209, 447–461 (1951).
Brokaw, C. Calcium-induced asymmetrical beating of triton-demembranated sea urchin sperm flagella. J. Cell Biol. 82, 401–411 (1979).
Lindemann, C. B. & Goltz, J. S. Calcium regulation of flagellar curvature and swimming pattern in triton X-100–extracted rat sperm. Cell Motil. Cytoskeleton 10, 420–431 (1988).
Jin, T. Gradient sensing during chemotaxis. Curr. Opin. Cell Biol. 25, 532–537 (2013).
Liu, X. et al. Moesin and myosin phosphatase confine neutrophil orientation in a chemotactic gradient. J. Exp. Med. 212, 267–280 (2015).
Stommel, H. Trajectories of small bodies sinking slowly through convection cells J. Mar. Res. 8, 24–29 (1949).
Denissenko, P., Kantsler, V., Smith, D. J. & Kirkman-Brown, J. Human spermatozoa migration in microchannels reveals boundary-following navigation. Proc. Natl Acad. Sci. USA 109, 8007–8010 (2012).
Rowat, A. C. et al. Nuclear envelope composition determines the ability of neutrophil-type cells to passage through micron-scale constrictions. J. Biol. Chem. 288, 8610–8618 (2013).
Manley, H. R., Keightley, M. C. & Lieschke, G. J. The neutrophil nucleus: an important influence on neutrophil migration and function. Front. Immunol. 9, 2867 (2018).
Allen, R. D. Chapter 3—Ameboid Movement in The Cell (eds J. Brachet & A. E. Mirsky) pp. 135–216 (Academic Press, 1961).
Farutin, A. et al. Amoeboid swimming: a generic self-propulsion of cells in fluids by means of membrane deformations. Phys. Rev. Lett. 111, 228102 (2013).
Wu, H. et al. Amoeboid motion in confined geometry. Phys. Rev. E 92, 050701 (2015).
Aoun, L. et al. Amoeboid swimming is propelled by molecular paddling in lymphocytes. Biophys. J. 119, 1157–1177 (2020).
Williams, G. C. Adaptation and Natural Selection: A Critique of Some Current Evolutionary Thought. (Princeton University Press, 2018).
Fras, J., Noh, Y., Macias, M., Wurdemann, H. & Althoefer, K. Bio-inspired octopus robot based on novel soft fluidic actuator. in: 2018 ICRA, pp. 1583–1588, (IEEE, 2018).
Kazakidi, A. et al. Swimming patterns of the Octopus vulgaris. in: 22nd Annual Meeting NCM Society, pp. 23–29 (2012).
Sfakiotakis, M., Kazakidi, A. & Tsakiris, D. Octopus-inspired multi-arm robotic swimming. Bioinspir. Biomim. 10, 035005 (2015).
Silver, D. et al. Mastering the game of Go with deep neural networks and tree search. Nature 529, 484–489 (2016).
Xie, H. et al. Reconfigurable magnetic microrobot swarm: multimode transformation, locomotion, and manipulation. Sci. Robot. 4, eaav8006 (2019).
Hartl, B., Hübl, M., Kahl, G. & Zöttl, A. Microswimmers learning chemotaxis with genetic algorithms. Proc. Natl Acad. Sci. USA 118, e2019683118 (2021).
ovey, S., Lohrmann, C. & Holm, C. Emergence of chemotactic strategies with multi-agent reinforcement learning. Mach. Learn.: Sci. Technol 5, 035054 (2024).
Mohamed, O. & Tsang, A. C. H. Reinforcement learning of biomimetic navigation: a model problem for sperm chemotaxis. Eur. Phys. J. E 47, 59 (2024).
Nelson, B. J., Kaliakatsos, I. K. & Abbott, J. J. Microrobots for minimally invasive medicine. Annu. Rev. Biomed. Eng. 12, 55–85 (2010).
Li, J., Esteban-Fernández de Ávila, B., Gao, W., Zhang, L. & Wang, J. Micro/nanorobots for biomedicine: Delivery, surgery, sensing, and detoxification. Sci. Rob. 2, eaam6431 (2017).
Palagi, S. & Fischer, P. Bioinspired microrobots. Nat. Rev. Mater. 3, 113–124 (2018).
Ceylan, H., Yasa, I. C., Kilic, U., Hu, W. & Sitti, M. Translational prospects of untethered medical microrobots. Prog. Biomed. Eng. 1, 012002 (2019).
Iacovacci, V., Diller, E., Ahmed, D. & Menciassi, A. Medical microrobots. Annu. Rev. Biomed. Eng. 26, 561–91 (2024).
Yang, L. & Zhang, L. Motion control in magnetic microrobotics: from individual and multiple robots to swarms. Annu. Rev. Control Rob. Auton. Syst. 4, 509–534 (2021).
Mui nos-Landin, S., Fischer, A., Holubec, V. & Cichos, F. Reinforcement learning with artificial microswimmers. Sci. Robot. 6, eabd9285 (2021).
Behrens, M. R. & Ruder, W. C. Smart magnetic microrobots learn to swim with deep reinforcement learning. Adv. Intell. Syst. 4, 2200023 (2022).
Abbasi, S. A. et al. Autonomous 3D positional control of a magnetic microrobot using reinforcement learning. Nat. Mach. Intell. 6, 92–105 (2024).
Soler, L., Magdanz, V., Fomin, V. M., Sanchez, S. & Schmidt, O. G. Self-propelled micromotors for cleaning polluted water. ACS Nano 7, 9611–9620 (2013).
Parmar, J., Vilela, D., Villa, K., Wang, J. & Sánchez, S. Micro-and nanomotors as active environmental microcleaners and sensors. J. Am. Chem. Soc. 140, 9317–9331 (2018).
You, M., Chen, C., Xu, L., Mou, F. & Guan, J. Intelligent micro/nanomotors with taxis. Acc. Chem. Res. 51, 3006–3014 (2018).
Pozrikidis, C. Boundary Integral and Singularity Methods for Linearized Viscous Flow. (Cambridge University Press, 1992).
Xiong, T., Liu, Z., Wang, Y., Ong, C. J. & Zhu, L. Datasets for figures 2-6 of “chemotactic navigation in robotic swimmers via reset-free hierarchical reinforcement learnin.” Zenodo https://doi.org/10.5281/zenodo.15340601 (2025).
Xiong, T., Liu, Z., Wang, Y., Ong, C. J. & Zhu, L. Hydrodynamic solver for “chemotactic navigation in robotic swimmers via reset-free hierarchical reinforcement learnin.” Zenodo https://doi.org/10.5281/zenodo.15490905 (2025).
Xiong, T., Liu, Z., Wang, Y., Ong, C. J. & Zhu, L. Reinforcement learning implementation for “chemotactic navigation in robotic swimmers via reset-free hierarchical reinforcement learnin.” Zenodo https://doi.org/10.5281/zenodo.15490877 (2025).
Acknowledgements
T.X. thanks the research scholarship provided by the National University of Singapore. We thank Ran Cheng for helping test and organize the GitHub repositories. L.Z. and C.J.O. thank the Singapore Ministry of Education Academic Research Fund Tier 2 grant (MOE-T2EP50221-0012). Part of the work, such as the development of the hydrodynamic solver for multi-link slender swimmers, is supported by the Singapore Ministry of Education Academic Research Fund Tier 2 grant (MOE-T2EP50122-0015). The computation was performed on the resources of the National Supercomputing Center, Singapore.
Author information
Authors and Affiliations
Contributions
L.Z. designed the research. L.Z. and C.J.O. supervised the research. T.X. implemented the research with the support from Z.L. and Y.W. All authors contributed to data analysis. T.X. and L.Z. wrote the paper.
Corresponding author
Ethics declarations
Inclusion an ethics statement
All collaborators of this work have fulfilled the criteria for authorship required by Nature Portfolio journals and have been included as authors, as their participation was important for the design and implementation of the study. Roles and responsibilities were agreed upon among collaborators ahead of the research. This work includes findings that are locally and globally relevant. The research was not restricted or prohibited in the setting of the researchers and does not result in stigmatization, incrimination, discrimination or personal risk to participants. Local and regional research relevant to our study was taken into account in citations.
Competing interests
The authors declare no competing interests.
Peer review
Peer review information
Nature Communications thanks Clément Moreau and the other, anonymous, reviewers for their contribution to the peer review of this work. A peer review file is available.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Xiong, T., Liu, Z., Wang, Y. et al. Chemotactic navigation in robotic swimmers via reset-free hierarchical reinforcement learning. Nat Commun 16, 5441 (2025). https://doi.org/10.1038/s41467-025-60646-z
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41467-025-60646-z
