
Abstract
Standard episodic patient monitoring of vital signs on the medical-surgical wards can potentially miss changes in health status and delay recognition of risk. To reduce these delays, we develop a clinical wearable-based deep learning model, using 9 inputs, comprised of continuous vital signs and demographics, to identify the onset of deterioration early and accurately. Using validated data from 888 adult non-intensive care unit inpatient visits with 135 outcomes, from two different clinical grade wearables, we train a recurrent neural network to predict clinical alerts and adverse clinical outcomes in the subsequent 24 hours. Our continuous clinical alert model is able to predict both clinical alerts (Area under both the Receiver Operator Characteristic curve 0.89 + /− 0.3, Precision Recall curve 0.58 + /− 0.14) and adverse clinical outcomes (accuracy: 81.8% on 11 events) up to 17 hours in advance. Our wearable based continuous clinical alert system outperforms episodic clinical support tools in detecting deterioration, retains its performance when tested on data from a different clinical wearable than the one it was trained on and can produce alerts ahead of a broad class of adverse clinical outcomes, enabling timely interventions that can avert preventable deteriorations and reduce hospital costs.
Similar content being viewed by others


Introduction
Up to 5% of patients admitted to non-critical care inpatient units develop deterioration requiring escalation of care and transfer to a critical care setting1. Delayed recognition of this critical illness is associated with increased morbidity and mortality2,3,4,5,6,7,8. Since the current standard of non-intensive care unit (ICU) care relies on intermittent vital signs measured every four to eight hours, the intervening period between measurements can result in missed warning signs of deterioration. Even in inpatient settings with continuous monitoring (CM) solutions in place, such as ICUs, step-down units, or telemetry units, many monitoring systems use simple thresholds or cutoffs that often result in a predictable cascade of events: over-alerting leading to hospital staff alert-fatigue9; dismissal of useful alerts; delayed recognition of critical illness10; and, ultimately, worse outcomes2,3,4,5,6,7. In conjunction with more discriminating alerting systems, continuous CM has the potential to facilitate timely and accurate early identification of deterioration on inpatient units.
While a large body of research and early warning scores (EWS) have focused on facilitating early identification of the deteriorating patient, newer wearable technologies that continuously monitor vital signs can help detect vital sign abnormalities sooner and thereby reduce provider workload through automated capture11,12. Enabling patient monitoring while minimizing staff exposure to infected patients, remote monitoring options through wearables received increased attention during the coronavirus disease 2019 (COVID-19) pandemic. These devices also expanded the ability of health systems to monitor the increased number of acute, high-risk, and/or rapidly deteriorating patients13, and some studies have explored the ability of these devices to improve outcomes11,12,14,15,16. In one of the few studies with many patients15 (over 7000), CM on wards was associated with significant decreases in total length of hospital stay, ICU days, and code blue rates. Other studies have reported lower rapid response team (RRT) rates17, decreases in ICU transfers16,18, reduced lengths of stay16,19,20, and lower readmission rates20. Overall, however, the clinical and operational impact of continuous monitoring is uncertain given a limited number of studies, mostly with small sample sizes11,16. Furthermore, these studies rely on standard alerting thresholds or existing deterioration models.
Solely based on episodically collected electronic health record (EHR) data, many models have been developed to predict risk of clinical outcomes for hospitalized patients21,22,23,24,25,26. Importantly, in most clinical predictive models, inference is anchored and performed at a certain point of the patient trajectory—for example, upon hospitalization27, transfer to the ICU28,29,30, or first or last clinical observations31. While similar approaches have been used in studies utilizing CM data28,29,30,31,32,33,34,35, CM-based deterioration algorithms can also be continuous with constantly updating inferences. Despite existing studies on continuously updating ICU-based mortality models using CM data32,34,35, no studies for medical-surgical ward patients have been published. Interpretation of multimodal continuous biometric data in this context opens the possibility for new methods to detect significant physiologic patterns to better predict the early onset of deterioration. The few studies that collected CM data focused on validation of the CM measurements, evaluation of the feasibility of deploying CM devices36, or correlations of existing clinical scores with various clinical outcomes (such as EWS)12,37,38,39,40. Predictive models developed from CM data that have been reported in select small (i.e., <100) outpatient populations demonstrate the feasibility of this approach41,42. Further, it has been shown that deep learning models achieve the best performance on continuous monitoring data compared to many existing modeling approaches, hence our selection of a deep learning model43. Thus, models that use larger numbers of CM monitored inpatients to evaluate whether they improve detection of inpatient deterioration need to be developed and evaluated.
In this study, we piloted the use of CM devices in four of our health system hospitals and collected CM data from 888 non-ICU inpatients (i.e., 2,897 patient days). We validated the correlation between CM and standard vital sign measurements, assessed the feasibility and benefits of using these data to generate clinical alerts, and developed a deep-learning model using CM data to identify patient deterioration up to 24 h before an EHR-based Modified Early Warning Score (MEWS) clinical alert. We collected CM data using two chest-worn wearable devices and validated the deep-learning model in three stages using three unique datasets: data held out for testing from the device used to train the model (Retrospective Device #1), prospective data from Device #1 at a separate hospital (Prospective Device #1), and data from a second wearable device (Alternate Device #2) used on a different patient population at a different hospital to function as an alternate device validation. To establish both the accuracy and specificity of a real-time implementation of this CM-based inpatient deterioration detection algorithm, we simulated deployment of this algorithm by generating a stream of continuous inferences at all timepoints where patients were wearing a wearable device. We then measured the performance of this algorithm in detecting deterioration, as well as the rate of false alerts, at all timepoints in which valid CM data was available.
Results
We piloted the use of two CM devices in four of our health system hospitals and collected CM data between March 2020 and November 2022 from 888 non-ICU inpatients over 2897 patient days. Table 1 summarizes the demographics of the study population and Fig. 1 outlines the steps taken in data validation and analysis.

(Diagram A) The three stages of clinical validation for a wearable-based alert system (Yellow Panel) Wearable data accuracy validation ensures the data is of sufficient accuracy to use for clinical decision making and this to end we align (1st step) and visualize differences (2nd step) using Bland-Altman plots, that visualize the difference between the two modalities (y-axis) vs their mean (x-axis). (Green Panel) Comparison of clinical alerts across measurement modalities demonstrates whether a wearable device provides an advantage over episodic monitoring, where we compare the numbers and timing of alerts for each modality and calculated the sources of these differences. (Blue Panel) Wearable clinical alert modeling and validation showing the feature and label construction and performance of this algorithm. (Diagram B) Feature and label selection, artifact rejection, signal processing and model training and testing steps followed to build a wearable device based clinical alert system. Source data are provided as a Source Data file.
Wearable data evaluation
Vital sign measurements from the wearable devices were evaluated by synchronizing and comparing with manually acquired vital signs logged in the EHR by constructing Bland-Altman plots (Fig. 2). We only used wearable vitals for modeling when 67% of measured values were within 10% error from the EHR values.

A–L Bland Altman plots of the comparison between vital measurement from the CM devices and EHR vitals, for the retrospective, prospective and alternate device datasets. M, O, P Features of elevated MEWS score alerts, detected by CM device and missed by EHR, and contribution of CM vitals in their generation. Dotted red lines indicate the 95% confidence intervals of the deltas between wearable measurements and EHR measurements. Dotted blue lines indicate the mean delta between wearable and EHR measurements. Green dotted lines indicate a 10% deviation of the wearable measurement from the EHR measurement at that mean value. Sub-panel titles detail the percentage of vital measurements that fall within the 10% deviation line (green dotted line). Bland Altman plots of (A–C) Device #1 retrospective HR, Device #1 Prospective HR and Alternate Device #2 HR; (D, E Device #1 Retrospective RR, Device #1 Prospective RR and Alternate Device #2 RR; (G–I) Device #1 Retrospective SpO2, Device #1 Prospective SpO2 (Device #1 Prospective dataset did not have SpO2) and Alternate Device #2 SpO2 J–L Device #1 Retrospective temperature, Device #1 Prospective temperature, and Alternate Device #2 temperature (M) Scatterplot and marginal distributions of the duration of wearable clinical alerts (MEWS > 6) that were detected by the wearable but missed by the EHR, along with the difference in magnitude of the MEWS score, between wearable vs EHR derived MEWS, at alert onset. O, P Heatmaps of MEWS contribution of RR. The wearable MEWS score was plotted on the y-axis and the EHR MEWS score on the x-axis. The diagonal green line represents equal scores given to both the wearable- and EHR-based vitals. Off diagonal values indicate that one modality was given a higher score than the others. We focused on respiratory rate and heart rate measurements, since both the temperature and SpO2 measurements were congruent between EHR and CM values. O and HR (P) from the wearable device (y-axis) against the EHR (x-axis, labeled “Manual”). Source data are provided as a Source Data file.
The Retrospective and Prospective Device #1 and Alternate Device #2 HR respectively had 75%, 75%, and 67% of measurements falling within the 10% deviation line, indicating sufficient HR concordance for use in modeling (Fig. 2A–C). Retrospective and Prospective Device #1 and Alternate Device #2 RR respectively had 29%, 29%, and 45% of measurements falling within the 10% deviation line (Fig. 2D–F). As EHR RR is often inaccurately measured, our inclusion criteria were not applied for this vital sign. Retrospective Device #1 and Alternate Device #2 SpO2 respectively had 87% and 77% of measurements falling within the 5% deviation line (Fig. 2G, I), while Prospective Device #1 did not include SpO2 measurements (Fig. 2H). Retrospective and Prospective Device #1 and Alternate Device #2 temperature had 99% of all datasets’ and devices’ measurements fall within the 5% deviation line (Fig. 2J–L). The threshold for acceptable agreement between the two measurements for both temperature and SpO2 readings was set at 5%, as ranges of normal values for these measurements are lower in clinical practice.
Clinical alert, vital contribution, and movement analyses
Two sets of clinical alerts were generated post hoc using vitals from Device #1 and the EHR, respectively, with differences in the resulting alert volumes and magnitudes compared. The alert algorithm detected 140 clinical alerts, defined as a MEWS greater than 6 for 30 minutes or longer. MEWS scores were calculated based on vital sign and demographic values (Supplementary Table 1). The marginal histogram plot (Fig. 2M) shows the number of elevated wearable-MEWS score events (not appearing in the EHR) plotted by delta in alert magnitude (wearable-MEWS – EHR-MEWS [x-axis]) against alert duration (y-axis). The CM devices detected 126 (or 9x) more alerts than manual monitoring (Fig. 2M). Of all alerts, 90% were detected by Device #1 alone, while fewer than 3% were only detected in the EHR. For 7% of alerts that were detected by both, the wearable-based alerts preceded the EHR alerts by an average of 105 min. The incongruity in alerts between wearable- and EHR-derived MEWS alerts was due to RR (Fig. 2O) and HR (Fig. 2P) measurements, contributing to higher MEWS scores and thus more alerts. In plotting the respective MEWS contributions of the vital signs from each modality against each other, RR and HR, respectively, contributed 30x and 10x as much to the MEWS scores as compared with other vital signs. For the 126 (i.e., 90%) of alerts that were missed by the EHR, accurate reporting of RR accounted for 89 (i.e., 71%) of these alerts, while elevated continuous HR measures accounted for 20 (i.e., 16%).
Since HR and RR can change significantly with patient movement, we sought to test whether movement-induced elevation of these two vitals might be contributing to elevated MEWS values (i.e., alerts) despite clinical and physiologic patient stability. We examined the values of the vitals (i.e., HR, RR) against the average SMA values over the duration of the detected alert and associated MEWS value. The lack of a correlation between increasing movement (i.e., SMA values) and increasing vital sign measurements (i.e., HR—R2 = 0.01, RR—R2 = 0.02) or MEWS values indicated that the alerts were generated independently of movement (Supplementary Figs. 1, 2, 3).
Clinical alert modeling performance and validation
We trained an LSTM deep learning model using various demographic and continuously monitored vital sign features to predict in-hospital deterioration with a 24-h time horizon using a 5-h sequence. A logistic regression (LR) based model was also trained for comparison, and all models were compared to a dataset using EHR data alone without continuous device data. The predictive performance of these models was evaluated retrospectively (i.e., Device #1 held out data), prospectively (i.e., Device #1 separate hospital), and externally (i.e., Device #2 alternate device). The prospective and alternative device validations were performed to verify the reproducibility of our findings. The validation steps on both of these datasets showed that our model successfully predicted clinical alerts. Setting an operating point to achieve a positive predictive value of 0.2, we also examined the confusion matrix for each of the three validation steps (Table 2).
Retrospective validation on device #1 data
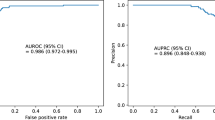
Using data held out for testing from Device #1, we validated the RNN-based model to predict the occurrence of CM-based clinical alerts. The RNN model performance on this retrospective dataset (blue trace) had mean ± SD ROC AUC 0.89 ± 0.03 and PR AUC 0.58 ± 0.14 as compared to the LR model (mean ROC AUC 0.80 ± 0.01 and PR AUC 0.26 ± 0.01, green trace—Fig. 3A, B and Table 2). The RNN-based model had worse performance when using EHR data alone (turquoise trace—Fig. 3A, B) versus device data with mean ROC AUC 0.84 ± 0.02 and PR AUC of 0.47 ± 0.06 compared to the LR model with EHR data (magenta trace—Fig. 3A, B) with mean ROC AUC 0.83 ± 0.01 and PR AUC of 0.33 ± 0.03).

A–J Wearable (Wrbl) based Recurrent Neural Network (RNN), Recalibrated Wearable (Wrbl) based Recurrent Neural Network (RNN Calib), Logistic Regression (LogReg) and EHR-based performances illustrated by receiver operator characteristic (ROC) and precision-recall (PR) curves for twenty-four types of validation. G–J Lead time analysis of wearable based RNN illustrates how far in advance model can predict both clinical alerts and hard outcomes. ROC and PR curves for predicting periods 30 min or greater of continuously elevated MEWS. A, B Retrospective RNN, Recalibrated RNN and LR model performances in predicting an elevated MEWS using randomly shuffled Device #1 data, and concurrently collected EHR data. Performance of each model, for each dataset, across folds is plotted (lighter shade). Mean performances are plotted (darker shade) with one standard deviation of performances across folds also plotted (gray). Chance performance of a binary classifier is plotted (dotted red line). C, D RNN, Recalibrated RNN and LR Model performances in predicting an elevated MEWS using prospective data from the same device (Device #1 Prospective) and concurrently collected EHR data.E, F RNN, Recalibrated RNN and LR Model performances in predicting an elevated MEWS using data from another device (Alternate Device #2), and concurrently collected EHR data. “ICU Trans” = Unplanned ICU Transfer, “Arrest” = Cardiac Arrest, “Vent” = Ventilator, “RRT” = Rapid response team call (G) Raster plot visualization of timing of all true positive predictions made by RNN model (not recalibrated) with wearable data preceding a clinical alert (Time 0). The colors represent the various datasets–Red raster: Device #1 Retrospective dataset, green raster: Device #1 Prospective dataset, blue raster: Alternate Device #2 dataset. H Probability density histogram of the lead times of the RNN model (not recalibrated) predictions for each alert. Colors correspond to those in the raster plot. I Raster plot visualization of timing of all true positive predictions (not recalibrated) relative to hard outcomes (Time 0). J Probability density histogram of the lead times of the RNN model (not recalibrated) predictions for each hard outcome. Source data are provided as a Source Data file.
Prospective validation on device #1 data
Using the prospective dataset held out entirely for testing from Device #1 (separate hospital), the model performance on this retrospective dataset (blue trace—Fig. 3C, D) had ROC AUC 0.9 and PR AUC 0.6, with LR model showing worse performance (ROC AUC 0.83 and PR AUC 0.3, green trace—Fig. 3C, D and Table 2). The RNN-based model using EHR data (turquoise trace—Fig. 3C, D) alone showed a degradation in performance with ROC AUC 0.82 and PR AUC 0.49 and LR model with EHR data (magenta trace—Fig. 3C, D) had ROC AUC 0.89 and PR AUC 0.43.
Alternate device testing on device #2
All data from Alternate Device #2 was held out for testing and used for external validation of the RNN-based model. The model performance showed (blue trace—Figs. 3E, F) ROC AUC 0.84 and PR AUC 0.37 (LR model ROC AUC 0.85 and PR AUC 0.09, green trace—Figs. 3E, F and Table 2). Using EHR data to predict alerts, the RNN-based model (turquoise trace, Fig. 3E, F) had ROC AUC 0.82 and PR AUC 0.4 (LR with EHR model; magenta trace—Figs. 3E, F, ROC AUC 0.89 and PR AUC 0.14).
Confusion matrix for each of the three validation steps (Device #1 retrospective, Device #1 prospective, Device #2 alternate). The operating point was chosen such that the PPV was equal to 0.2. The threshold that achieved this PPV is displayed in the upper left corner of each table section. Summary metrics (i.e., specificity, sensitivity, PPV, and negative predictive value) are listed at the periphery of each table.
Testing RNN and LR model accuracy on hard outcomes
Using the RNN model trained on detecting >30-min periods of elevated MEWS, we tested the model’s performance on predicting hard outcomes within 24 hours (Table 3). In summary, 50% of RRT calls, 83.6% of unplanned transfers to the ICU, 100% of intubation/mechanical ventilation, 100% of cardiac arrests, and 100% of death were detected using CM data. This performance was superior to that of using solely EHR data or an elevated MEWS as the predictor for a hard outcome.
Lead time and sampling rate analysis
To characterize the timing of predictions relative to alerts, we examined lead times of predictions of the RNN model for each alert and hard outcome. Lead times are the first true positive preceding actual alerts and hard outcomes. We visualized the true positives on a raster plot that showed all RNN-based alerts 24 hours preceding a clinical alert (Fig. 3G) along with the distribution of lead times (Fig. 3H). For the three stages of validation—Device #1 retrospective, Device #1 prospective, Device #2 alternate—the median and interquartile range (IRQ) of lead time was 17.12 [6.81–24.0], 24.0 [22.88–24.0] and 8.25 [5.25–21.75], respectively. For this analysis, we limited the scope of true positives to 24 h, though several alerts for each validation had lead times greater than 24 h. The percentage of alerts whose lead time was greater than 24 h for Device #1 retrospective, Device #1 prospective, Device #2 alternate was 14%, 75%, and 21%, respectively.
We repeated this analysis for hard outcome predictions with all true positives preceding an outcome being visualized (Fig. 3I). The timing of these first true positives is plotted in a probability density histogram plot with median (IQR) lead time of 16.5 [10.5–17.5] (Fig. 3J).
To determine the effect of sampling rate on prediction performance, we varied the inter-sample timing of vital measurements from one to three hundred minutes and measured the effect on ROC AUC and PR AUC at each inter-sample interval (Supplementary Fig. 4). Going from one to three hundred minutes, the ROC AUC dropped 16.2% and the PR AUC dropped 17.0%. The ROC and PR AUC maximum occurs at inter-sample intervals of one and thirty minutes, respectively.
Discussion
In this study, we sought to investigate three lines of inquiry with respect to a wearable biosensor-based clinical alert system: (1) are the wearable devices comparable to manual episodic vital sign measurements, (2) do they provide an advantage over episodic monitoring in producing more timely and earlier clinical alerts, and (3) can wearable biosensor data be used in a deterioration prediction algorithm. With CM data on 888 patients across four hospitals, we found that CM- and EHR-based data are congruent and that, primarily due to high frequency, accurate RR, and HR measurements, wearable devices generate more and earlier clinical alerts. Finally, we showed that a deep-learning model based upon CM data accurately predicts patient deterioration up to eight to twenty-four hours before a MEWS-based clinical alert and seventeen hours before an actual clinical event.
The current standard of care in patients admitted on medical and surgical floors, where the study took place, implements a vital sign check every 3-4 hours depending on the hospital and unit where a patient is situated. When a patient reaches a MEWS score above seven, vital sign frequency is then increased to every 2 h. A MEWS score of eight results in increased vital sign frequency and an independent provider evaluation. Supplementary Table 2 details the additional steps that are taken as the MEWS score increases beyond eight. In this study, we only looked at MEWS alerts (MEWS > 6 for 30 minutes or longer) that were not preceded by any other MEWS alerts for at least 24 h. Therefore, the additional, earlier clinical alerts that were found in this study, represent truly unexpected deteriorations enabled by more frequent monitoring of the patient.
To address the concern of a selection bias existing in our patient selection process, we’d like to point out our deterioration event rate of ~1% was lower than what is reported in the clinical literature (~6%)1. While clinicians were basing the patch decision on their best clinical judgement, this didn’t lead to an increased deterioration event rate, for a variety of reasons, either due to the acuity of the wards, the patching occurring outside of acute time periods, or nurses patching patients based on assessment of risk while also waiting until a convenient time to patch them. If a selection bias existed that benefited the model, i.e. more deterioration event labels and more balanced data for the model to train more effectively on, we would expect to see higher rates of deterioration, which we don’t see. The patching scheme thus reflected real world conditions and therefore a real-world scenario of the patching situation.
Several studies have validated CM devices in real-world settings and found that these devices are comparable to current gold standard of vital measurements44,45,46. Using common evaluation methods, we show accuracy results consistent with previously published results. While a formal measurement validation study is usually carried out in controlled settings with matched controls, this validation step was not the primary focus of our study. However, it provides evidence on these devices’ performance in real-world conditions, i.e. in a hospital environment with rotating clinical staff, and is an important part of our proposed framework. It should be noted that, while certain vital signals had an error magnitude that might preclude its use in clinical decision making (e.g. temperature), the goal in this paper was to capture trends via continuous monitoring wearable devices to predict adverse clinical events. It was not our intention in this paper to try to justify the use of raw vital signal readings from clinical wearables for use in clinical decision making. Since the vitals that went into the predictive algorithm were normalized, the absolute error of each vital signal was therefore not as important as the trends.
In our analysis, we attempted to rule out confounders, such as patient movement, in producing false alerts from CM data. We found no correlation between increased movement and occurrence of alerts or elevated vitals. Thus, the additional alerts we report are due to real vital signal aberrations caused by physiological decline or deterioration. We also investigated the driving components that led to these additional wearable-based alerts and found that respiratory rate and heart rate were the two major factors. This is not a surprising result for RR, since inaccurate documentation of RR in the EHR is well known due to digit preference and the increased burden of measuring and reporting an accurate RR47. On the other hand, while measured accurately in the EHR, HR can provide more insights when measured more frequently (likely because of its highly dynamic nature). It should be noted, however, that this study was not intended to comment on the clinical utility of the additional wearable-generated alerts, since all the additional alerts were generated post-hoc and offline.
Our results show that the proposed deep learning model performs better with CM data than with episodic monitoring data. In addition to the increased accuracy of RR and HR CM measurements (shown in several studies to be two of the most important factors in predicting risk of deterioration), this outcome is due to the temporally richer nature of the CM data that better represents subtle signs of deterioration26,48,49,50. However, even when CM devices are unavailable, the performance of the algorithm using only episodic EHR data remains comparable to that of other deterioration prediction algorithms23,25,27,32,41,51,52,53 thus demonstrating the versatility of the proposed approach.
We’d also like to note the higher, and comparable, AUROCs for Device #2, and Device #1, logistic regression EHR models, respectively. These anomalies are a good example of why the inclusion of the Precision-Recall curve is important—the ROC plot can be misleading on the performance of a classifier on a highly imbalanced dataset such as the one in this study (99.7%/0.3% negative/positive class balance). Given this, we’d like to point out that the RNN significantly outperformed the logistic regression model on the precision-recall curve for the Prospective Device # 1 validation and both EHR and wearable data being comparable for the Device # 2 validation. This discrepancy captures the fact that the logistic regression model simply performed better than the RNN on predicting true negatives (hence the higher AU-ROC), however the RNN was still significantly superior on predicting true positives (hence the higher AU-PR).
In our analysis, we designated false negatives as more detrimental than false positives because the main goal of our algorithm is to identify patients experiencing unanticipated deterioration, i.e. minimizing missed deteriorations was the priority. This approach could potentially lead to an increased number of alerts. To avoid contributing to alert fatigue, a balanced choice of a minimum positive predictive value needs to be made. In our study, a tentative choice of positive predictive value (PPV) = 0.2 (i.e., 1 true positive per 5 alerts) was made; this is a stricter value than the usual 0.1 PPV used in prior studies54. However, one of the benefits of our approach is that the alerting threshold can be adjusted based upon risk tolerance and resource considerations.
To assess model calibration, we looked at calibration curves of the LSTM RNN model for each stage of validation. The results are not surprising, given that modern neural network architectures are known to exhibit overconfidence, pushing predicted probabilities toward 0 or 1, mostly arising from the interplay between softmax/sigmoid activations and unregularized logit magnitudes. This confidence sharpening is evident in our Retrospective Device #1 calibration curve (Device #1 Retrospective Supplementary Fig. 5). Between approximately a 5% and 10% fraction of positives, the mean predicted probability jumps from 10% to >95%, since the model has set its decision boundary at a point in the input space corresponding to approximately a 7% true risk of deterioration (i.e. fraction of positives) and scales the risk exponentially as one crosses this boundary. The same behavior is seen in the prospective validation calibration curve, however since the dataset is smaller and there are less acute patients, the highest risk patients in this dataset are only at a ~10% risk of deterioration as opposed to the ~25% seen in the retrospective dataset. The Alternate Device #2 dataset takes this point even further in that the highest risk group of patients only have ~1-2% chance of deterioration. Additionally, given the multiple nested non-linear activation functions inherent in a deep neural network LSTM architecture, it is not surprising that this produces a non-continuous, non-linear numerical output that does not correspond to an estimate of the risk of deterioration. While it is evident from the calibration curve and Brier scores that the model is not well initially well calibrated, this does not undermine our findings in the ROC and PR of the model’s strong discriminatory ability. Finally, recalibration can correct model calibration across the observed ranges of patient risk.
We also showed preliminary capability of the model in predicting a broad class of hard outcomes against which the model was not trained. Despite having very few of these outcomes, the algorithm performed quite well in detecting a broad class of them and demonstrates the utility of our approach in using clinical alerts as a proxy label for model training. We also demonstrate the advantage of an RNN-based algorithm with CM data, as it outperformed a MEWS-based alert and alerts using EHR data alone. Further, by looking at the average lead time of the model predictions with respect to hard outcomes, we show that risk for these outcomes could be detected between 12 to 18 hours in advance and allow for anticipatory clinical intervention.
The lead time analysis of our predictive model revealed that we can expect to predict clinical alerts up to eight to twenty-four hours in advance and hard outcomes up to seventeen hours in advance, thus hospital staff will have many opportunities to intervene and change the trajectory a deteriorating patient’s physiological decline. This intervention could look much like the current protocol in place for existing early warning score systems (Supplementary Table 2) except with further integration into wearable dashboards in addition to smarter EHR alerting. Moreover, our approach offers other implementation possibilities, e.g. the predictions could be served to a central monitoring team, displayed to clinicians in the EHR, or sent to a clinician as a direct notification via a secure text message.
By downsampling the continuous vital signals and measuring the impact, we found that a lower sampling rate does not degrade the predictive performance of the algorithm and, in fact, may slightly improve it at an inter-sample interval of 30 minutes. Notably, we did not train the RNN model with downsampled data, and a higher sampling rate may be needed initially to train models with subsequent deployment using lower sampling rates. If true, this lower sampling rate could extend the battery life and overall longevity of single use devices, including those used in this study, thus lowering costs for hospitals to implement continuous monitoring via wearable devices as a standard of care for non-ICU inpatients. This contention, however, requires further study and evaluation.
This study had several limitations. It did not implement eligibility criteria during participant selection that would maximize focus on patients who experience adverse events more frequently. For this reason, the total number of hard outcomes was under 2% (i.e., 11 total outcomes). While this small number made training a model specifically for said outcomes infeasible, our limited validation of the deep learning algorithm on these events showcases that this approach could be applicable to prediction of hard outcomes. It should be noted that, while the limited validation on the hard outcomes is promising, the small number of events just points to the feasibility of developing a model capable of predicting hard outcomes. However, no strong conclusions can be made. Collecting more data with more patients and more hard clinical outcomes will enable a better validation of this algorithm on hard outcome prediction capabilities. Stricter eligibility criteria for outfitting patients with CM patches, including MEWS thresholds upon hospitalization or focus on higher-risk comorbidities/diagnoses, could maximize the number of hard outcomes captured while patients are monitored continuously, enabling better training and validation of future models on such hard clinical outcomes.
This study presents a framework that uses continuously monitored vital signs obtained via wearable devices to predict clinical alerts related to inpatient deterioration. Through validation and subsequent analysis of the continuously measured vitals against episodically measured vitals and the resulting clinical deterioration alerts, we show that use of CM data can result in more and earlier clinical alerts compared to EHR data alone. We also present a deep learning algorithm that uses CM and EHR data to predict these clinical alerts up to 24 hours ahead of time, which maintains performance across different patient cohorts, hospital settings, and CM devices. The algorithm shows promise in predicting hard outcomes, including ICU transfer and death. To our knowledge, this is the first study of its size to propose a comprehensive inpatient CM framework tested on hard clinical outcomes that is validated against real-time deployment scenarios.
Methods
Data sources, patient population and eligibility criteria
The study design and protocol was approved by Northwell’s Institutional Review Board (study #: 23-0534-350CD) that includes a waiver of informed consent for all the retrospective data analysis performed in this manuscript. This study was not pre-registered and no protocol was previously published. We obtained all EHR data collected for 888 hospitalized patients that received the CM devices between March 2020 and November 2022 across four hospitals within the Northwell Health system. We collected the CM data using two chest worn wearable devices, Vital Connect Vital Patch (Device #1) and Biobeat Chest Monitor (Alternate Device #2). The episodic data were collected from the enterprise EHR (Sunrise Clinical Manager, Altera [formerly Allscripts]) and included demographics (e.g., age and body mass index [BMI]) as well as manually monitored vital signs (i.e., heart rate [HR], systolic blood pressure [SBP], respiratory rate [RR], skin and body temperature, and oxygen saturation [SpO2]) and the continuously monitored vital signs (i.e., HR, RR, temperature, and SpO2). It should be noted that the wearable device provided both a skin temperature measurement and a body measurement, which reflects core body temperature. Upon placement of the patch, the body temperature is calibrated by the nurse. For the wearable data validation, we used the body temperature measurement from the device. Wearable device data was provided monthly by the device manufacturers. Table 4 provides a summary of the data source for each of the continuous monitoring and demographic variables.
While our retrospective analysis was approved by IRB as a research study, the patching of patients was performed as a quality initiative, that augmented the standard of care for these patients, as such no informed consent was acquired or participant compensation was offered. The patients that were patched were selected based often on the best clinical judgement of the staff in each of the wards where the wearable devices were deployed. In practice, this meant the nurse overseeing the patient would often decide whether to have a wearable device placed on the patient or not based on their assessment of how at risk the patient was for decompensating. Information about gender was not collected as part of this study. Patients were not involved in the design, conduct, reporting, interpretation or dissemination of this study. The study was conducted and reported according to the Transparent Reporting of a multivariable prediction model for Individual Prognosis Or Diagnosis (TRIPOD-AI) guidance (Supplementary Table 3).
Study design
We sought to develop and evaluate, in a real-world clinical environment, a wearable clinical alert system (Fig. 1). Our goals were to assess whether these devices were a viable clinical alternative for monitoring on the medical wards, whether increased frequency of vital signs provide an advantage over episodic monitoring, and whether the data acquired combined with a machine learning approach can yield an accurate predictive algorithm. We followed the steps outlined in Fig. 1, diagram A, by aligning (step one) and visualizing (step two) differences between continuously monitored vitals and episodically monitored vitals using Bland-Altman plots (see green panel in Fig. 1). To examine any advantages CM provides over episodic monitoring (see yellow panel in Fig. 1, diagram A), we compared the numbers and timing of clinical alerts across measurement modalities. Finally, we used clinical alerts as labels to train a model and predict periods of clinical deterioration further into the future than current early warning systems (see blue panel in Fig. 1, diagram A). Sample size for both wearable data validation and model convergence were estimated (Supplementary Table 4).
Wearable data evaluation
All data processing, analysis and modeling were performed in Python (v.3.12.2) using the Pandas (v2.2.3), Numpy (v1.26.4), Scikit-learn (v1.6.1), Tensorflow (v2.16.1), and Keras (v3.2.1) packages. Visualizations were created using the Matplotlib (v3.8.4) and Plotly (v5.13.1) packages.
We compared the vital sign measurements by synchronizing the CM vital signs with the manually acquired vital signs. To synchronize the two data sources, the wearable data was converted from UNIX time to human-readable time, shifted to account for both daylight savings and time zone differences, and then resampled to align with EHR data timestamps. The EHR data was organized chronologically by patient ID number and timestamps and resampled to align to the closest minute with the wearable data.
Using this time-aligned data, we constructed Bland-Altman plots, which visualize the agreement between two measurement modalities by plotting the difference (i.e., \(\Delta\)) between the time-aligned signal from the two modalities (1) (\(\Delta={{{\rm{Signal}}}}1\left({{{\rm{Wearable}}}}\right)-{{{\rm{Signal}}}}2\left({{{\rm{EHR}}}}\right)\)) on the y-axis against their mean (2) (\(\, \mu=\frac{({{{\rm{Signal}}}} \; 1+{{{\rm{Signal}}}} \; 2)}{2}\)) on the x-axis. The greater the agreement between the two modalities, the closer each of the points on the plot is to the horizontal line, where Δ = 0. For visualization purposes, we plotted the 95% confidence intervals (i.e., red dotted lines), mean delta (i.e., blue dotted line) and either the 5% or 10% error line (3) (Δ = µ * 0.1) for each of the Bland-Altman plots. We also calculated the percentage of measurements that fell within the 5% or 10% error line. In subsequent analyses, we only used records where at least 2/3 (i.e., 67%) of a value for a given patient were within a 10% error for HR (±3–20 bpm) and a 5% error for temperature (±1.4–2C) and SpO2 (±4.25–5%) from the EHR values. This criterion was not applied to respiratory rate because of the well-documented digit preference among healthcare workers when manually measuring the respiratory rate55.
Clinical alert analysis
To assess the benefits of using wearable data to produce more and earlier clinical alerts, we compared the volume, timing, and duration of alerts that arose from continuous versus episodic monitoring. We used the MEWS score56 as the basis for our clinical alerts for a number of reasons: it is derived from measurements acquired across all inpatients; includes a number of vitals that are measured by the wearable device; and is already implemented as part of the standard of care in many hospitals and health systems, including Northwell Health, where it is calculated automatically within the EHR and clinicians are alerted when defined thresholds are exceeded (Supplementary Table 2).
We generated two distinct sets of MEWS scores, one derived from continuous wearable vitals and the other from episodic vitals, which resulted in two sets of alerts. The MEWS calculation is based upon vital sign measurements given by the Eq. (4) below:
Depending on the range of each item, it is given a score ranging from 0 to 3 (Supplementary Table 1), and the final score is tallied (range 0-15), with higher values indicating greater risk of clinical decompensation. It should be noted that this is a commonly used score, not only in our system, but in health systems around the world, as an early warning system. Based upon Northwell Health system protocol (Supplementary Table 2) and expert consensus among our clinical collaborators, we defined a meaningful clinical alert as a MEWS > 6 for 30 minutes or more. We quantified the total number of alerts, onset timing, and duration for each alert. Two sets of wearable clinical alerts were generated post-hoc using vitals from Device #1 and EHR, respectively. Differences in the resulting alert onsets and magnitudes were compared between these two sets. To understand the underlying cause of the differences between CM- and EHR-based clinical alerts, we measured the contribution of each vital sign to the MEWS score from each modality at the time of alert onset.
Movement analysis
To rule out the possibility that motion-related events caused temporary changes in vital signs and thereby triggered alerts unrelated to early signs of deterioration, we analyzed biomarkers with respect to movement during each alert. Movement was captured by the device with a three-axis accelerometer and represented as the signal magnitude area (SMA), the sum of a one-second average of accelerations in all three axes57. The alerts and their corresponding average SMA values, ranging from two minutes preceding the alert onset to the end of the alert, were grouped into three classes: stationary, activities of daily living (ADL), and strenuous, based on manufacturer-determined SMA cutoff values57 (Supplementary Table 5).
Predictive deterioration modeling
Artifact rejection, signal processing, imputation and model selection
Figure 1, Panel B illustrates the artifact rejection and signal processing steps applied to the data. We implemented artifact rejection to remove segments of data where the measurements assumed physiologically implausible values either due to lost connectivity or low battery issues with the device (i.e., HR or RR were zero and the temperature was above 50⁰C). To determine the optimal window length for predicting clinical alerts 0.5 to 24 h in the future, we performed a grid search of window lengths from 1 to 12 hours at 1-h increments and determined 5 h to be the optimal length based on retrospective model performance. For the purposes of predicting 0.5 to 24 h into the future, sufficient data of 5.5 h (i.e., 5-hour sequence + 0.5-hour censor) preceding the clinical alert label were needed. We removed the segments and labels where <50% of data was present within the 5-hour sequence. This was the only data that was excluded from this analysis for model training, due to excessive missingness. All other data was included.
The two devices that were used to continuously monitor vital signs had different sampling rates and were therefore processed differently to make them compatible with the same deep learning model. Device #1 had a four-second sampling interval and was down sampled to a one-minute interval using a one-minute-wide rolling mean window with a one-minute stride. Alternate Device #2 was sampled variably with a one- to fifteen-minute sampling interval and was up-sampled to one minute using linear interpolation. The EHR data was sampled with a three- to five-hour sampling interval and was up-sampled to one minute using forward-filling imputation. We z-scored the input features to bring them to the same scale for faster model convergence. Whenever continuous data was missing (Supplementary Table 6), we used 30 minutes forward filling and imputed with zeros beyond 30’. For the prospective Device #1, SpO2 was not available so the variable was imputed with all zeroes for the final model.
Model training and testing
We trained a recurrent neural network (RNN) with long-short-term-memory (LSTM) units model that incorporated age, BMI, SBP, and continuously monitored vital signs (HR, RR, temperature, SpO2, MEWS value, and motion signals) to predict in-hospital deterioration with a 0.5-24 hour time horizon using a 5-hour sequence (Fig. 2). We constructed the clinical alert labels detailed previously, based on smoothed MEWS values using a 30-minute-wide rolling average window.
To select a model to test on clinical alerts and hard outcomes, we performed hyperparameter optimization across the following parameters: number of LSTM layers, sequence length, time horizon, and censor length. The selected model showed superior performance across the various validation steps performed in this study.
Class imbalance was addressed by first randomly removing samples from the negative majority class and oversampling the positive class until we achieved a balance of 95%/5% negative/positive classes of the training set, instead of the original 99.7%/0.3% class balance.
We evaluated the predictive performance of this model in three stages: retrospective, prospective, and alternate Device validations. In the first retrospective validation stage, we validated the model using 5-fold stratified shuffle split cross-validation at the patient level, i.e., no patients in the training set were included in the test set. This resulted in an approximately 80%/20% train/test split. We then compared predictive performance across all folds, using common model validation metrics (ROC AUC, PR AUC) and averaged the resulting ROC and PR curves. After the initial validation stage, we then tested the model in two additional validation stages using two unique datasets: 1) data collected prospectively from Device #1, i.e. entirely after Device #1’s retrospective data used to train the model, at a separate hospital and from a different patient cohort, and 2) data from a second wearable device used at a separate hospital and on an entirely different patient population to function as an alternate device test set. In each subsequent stage of validation, i.e. Prospective and Alternate Device validations, the model that was trained exclusively on Device #1’s retrospective dataset was then tested on each of these pure validation datasets. Neither data from prospective Device #1 data nor Alternate Device #2 was used to optimize, hyperparameter tune or train the retrospectively trained model. These datasets, and their accompanying validation results, therefore functioned as two true unique test sets for the retrospectively optimized and trained model.
These three validation stages contrasted performance of the LSTM RNN model against logistic regression (LR) using two concurrently collected datasets: 1) CM data from the wearable device and EHR data collected alongside that wearable data (EHR).
Model calibration
Calibration curves were constructed for the LSTM RNN model across the three stages of validation (Supplementary Fig. 5). Isotonic regression recalibration was performed on the calibration curves for each stage of validation. Brier scores (BS) were also calculated on all calibration curves. All RNN performance metrics were recalculated using the recalibrated model (Fig. 3, Panels A–F)
Testing wearable RNN model accuracy on hard outcomes
Using the RNN model trained to detect > 30-min periods of elevated MEWS, we tested the model’s performance on prespecified hard outcomes with sufficient wearable data prior (i.e., at least 5.5 h). In total 11 hard outcomes were found in the Retrospective Device #1 dataset with sufficient preceding wearable data to make predictions. We also ensured that the hard outcomes being predicted upon were at least 24 hours away from each other. To predict hard outcomes, we used the same features, processing steps, and testing procedure of the previous modeling steps with the exception that the label being predicted was one of five hard outcomes: RRT call, unplanned transfer to the ICU, intubation/mechanical ventilation, cardiac arrest, and death (expiration). Successful detections were counted if a true positive was generated within the 24 hours leading up to the outcome. The performance of the RNN algorithm in detecting hard outcomes was compared using CM data against EHR data alone. A comparison was also made using an elevated MEWS (>6) as the predictor for the hard outcome.
Lead time and sampling rate analysis
To characterize the timing of predictions relative to alerts, we looked at the lead times of predictions of the wearable-based RNN for each alert and hard outcome. Lead time was defined as the first true positive preceding alerts and hard outcomes.
To determine the effect of sampling rate on prediction performance, we varied the inter-sample timing of vital measurements and measured the effect on overall performance. Data was downsampled from the original inter-sample interval of 1 min down to three hundred minutes. Performance was measured by ROC AUC and PR AUC at each inter-sample interval.
Reporting summary
Further information on research design is available in the Nature Portfolio Reporting Summary linked to this article.
Data availability
The data that support the findings of this study are available in this manuscript in the Source Data Supplementary Information. Additional raw data contain protected health information (PHI) and cannot be completely deidentified, due to the importance of timestamps on both the continuous monitoring data, and the EHR variables in our analysis. They cannot be shared publicly due to privacy and confidentiality concerns and access to the data is restricted in accordance with patient privacy regulations and institutional policies. Researchers who meet the criteria for access to confidential data may submit a request to the Northwell Institutional Review Board (IRB) for consideration. For inquiries regarding data access, please contact the IRB at irb@northwell.edu. The timeframe for response to access requests is usually 10–15 business days with a duration of data availability determined by the IRB. Source data are provided with this paper.
Code availability
Code necessary to reproduce the Python-generated figures in this study are provided and maintained at: https://codeocean.com/capsule/9888403/tree.
References
Churpek, M. M., Yuen, T. C. & Edelson, D. P. Predicting clinical deterioration in the hospital: the impact of outcome selection. Resuscitation 84, 564–568 (2013).
Colon Hidalgo, D., Patel, J., Masic, D., Park, D. & Rech, M. A. Delayed vasopressor initiation is associated with increased mortality in patients with septic shock. J. Crit. Care 55, 145–148 (2020).
Nauclér, P. et al. Impact of time to antibiotic therapy on clinical outcome in patients with bacterial infections in the emergency department: implications for antimicrobial stewardship. Clin. Microbiol. Infect. 27, 175–181 (2021).
Chalfin, D. B. et al. Impact of delayed transfer of critically ill patients from the emergency department to the intensive care unit. Crit. Care Med. 35, 1477–1483 (2007).
Kline, J. A. et al. Prospective study of the clinical features and outcomes of emergency department patients with delayed diagnosis of pulmonary embolism. Acad. Emerg. Med. 14, 592–598 (2007).
Gerall, C. D. et al. Delayed presentation and sub-optimal outcomes of pediatric patients with acute appendicitis during the COVID-19 pandemic. J. Pediatr. Surg. 56, 905–910 (2021).
Richardson, J. D. et al. Effective triage can ameliorate the deleterious effects of delayed transfer of trauma patients from the emergency department to the ICU. J. Am. Coll. Surg. 208, 671–678 (2009).
Goel, N. N., Durst, M. S., Vargas-Torres, C., Richardson, L. D. & Mathews, K. S. Predictors of delayed recognition of critical illness in emergency department patients and its effect on morbidity and mortality. J. Intensive Care Med. 37, 52–59 (2022).
Ash, J. S., Sittig, D. F., Campbell, E. M., Guappone, K. P. & Dykstra, R. H. Some unintended consequences of clinical decision support systems. AMIA Annu. Symp. Proc. 2007, 26–30 (2007).
Graham, K. C. & Cvach, M. Monitor alarm fatigue: standardizing use of physiological monitors and decreasing nuisance alarms. Am. J. Crit. Care 19, 28–34 (2010).
Areia, C. et al. The impact of wearable continuous vital sign monitoring on deterioration detection and clinical outcomes in hospitalised patients: a systematic review and meta-analysis. Crit. Care 25, 351 (2021).
Weenk, M. et al. Continuous monitoring of vital signs in the General Ward using wearable devices: randomized controlled trial. J. Med. Internet Res. 22, e15471 (2020).
Eisenkraft, A. et al. Continuous remote patient monitoring shows early cardiovascular changes in COVID-19 patients. J. Clin. Med. 10, 4218 (2021).
Bonnici, T.A. Early Detection of Inpatient Deterioration Using Wearable Monitors, PhD Thesis, King's College London (2019).
Brown, H., Terrence, J., Vasquez, P., Bates, D. W. & Zimlichman, E. Continuous monitoring in an inpatient medical-surgical unit: a controlled clinical trial. Am. J. Med. 127, 226–232 (2014).
Downey, C. L., Chapman, S., Randell, R., Brown, J. M. & Jayne, D. G. The impact of continuous versus intermittent vital signs monitoring in hospitals: a systematic review and narrative synthesis. Int. J. Nurs. Stud. 84, 19–27 (2018).
Weller, R. S., Foard, K. L. & Harwood, T. N. Evaluation of a wireless, portable, wearable multi-parameter vital signs monitor in hospitalized neurological and neurosurgical patients. J. Clin. Monit. Comput. 32, 945–951 (2018).
Verrillo, S. C., Cvach, M., Hudson, K. W. & Winters, B. D. Using continuous vital sign monitoring to detect early deterioration in adult postoperative inpatients. J. Nurs. Care Qual. 34, 107–113 (2019).
Downey, C. L. et al. Trial of remote continuous versus intermittent NEWS! monitoring after major surgery (TRaCINg): a feasibility randomised controlled trial. Pilot Feasibility Stud. 6, 183 (2020).
Downey, C., Randell, R., Brown, J. & Jayne, D. G. Continuous versus intermittent vital signs monitoring using a wearable, wireless patch in patients admitted to surgical wards: pilot cluster randomized controlled trial. J. Med. Internet Res. 20, e10802 (2018).
Ruiz, V. M. et al. Early prediction of clinical deterioration using data-driven machine-learning modeling of electronic health records. J. Thorac. Cardiovasc. Surg. 164, 211–222.e3 (2022).
Shah, P. K. et al. A simulated prospective evaluation of a deep learning model for real-time prediction of clinical deterioration among ward patients. Crit. Care Med. 49, 1312–1321 (2021).
Escobar, G. J. et al. Automated identification of adults at risk for in-hospital clinical deterioration. N. Engl. J. Med. 383, 1951–1960 (2020).
Wijnberge, M. et al. Effect of a machine learning-derived early warning system for intraoperative hypotension vs standard care on depth and duration of intraoperative hypotension during elective noncardiac surgery: the HYPE randomized clinical trial. JAMA 323, 1052–1060 (2020).
Kwon, J. M., Lee, Y., Lee, Y., Lee, S. & Park, J. An algorithm based on deep learning for predicting in-hospital cardiac arrest. J. Am. Heart Assoc. 7, e008678 (2018).
Churpek, M. M. et al. Multicenter comparison of machine learning methods and conventional regression for predicting clinical deterioration on the wards. Crit. Care Med. 44, 368–374 (2016).
Sundrani, S. et al. Predicting patient decompensation from continuous physiologic monitoring in the emergency department. npj Digit. Med. 6, 60 (2023).
Caicedo-Torres, W. & Gutierrez, J. ISeeU: visually interpretable deep learning for mortality prediction inside the ICU. J. Biomed. Inform. 98, 103269 (2019).
Ge, W. et al. An interpretable ICU mortality prediction model based on logistic regression and recurrent neural networks with LSTM units. AMIA Annu. Symp. Proc. 2018, 460–469 (2018).
Thorsen-Meyer, H. C. et al. Discrete-time survival analysis in the critically ill: a deep learning approach using heterogeneous data. npj Digit. Med. 5, 142 (2022).
Desautels, T. et al. Using transfer learning for improved mortality prediction in a data-scarce hospital setting. Biomed. Inform. Insights 9, 1178222617712994 (2017).
Na Pattalung, T., Ingviya, T. & Chaichulee, S. Feature explanations in recurrent neural networks for predicting risk of mortality in intensive care patients. J. Pers. Med. 11, 934 (2021).
Jun, E., Mulyadi, A. W., Choi, J. & Suk, H. I. Uncertainty-gated stochastic sequential model for EHR mortality prediction. IEEE Trans. Neural Netw. Learn. Syst. 32, 4052–4062 (2021).
Aczon, M. et al. Dynamic mortality risk predictions in pediatric critical care using recurrent neural networks. Preprint at https://arxiv.org/abs/1701.06675 (2017).
Suresh, H. et al. Clinical intervention prediction and understanding with deep neural networks. PMLR 68, 322–377 (2017).
Leenen, J. P. L. et al. Current evidence for continuous vital signs monitoring by wearable wireless devices in hospitalized adults: systematic review. J. Med. Internet Res. 22, e18636 (2020).
Weenk, M. et al. Wireless and continuous monitoring of vital signs in patients at the general ward. Resuscitation 136, 47–53 (2019).
de Ree, R. et al. Continuous monitoring in COVID-19 care: a retrospective study in time of crisis. JAMIA Open 4, ooab030 (2021).
Zimlichman, E. et al. Early recognition of acutely deteriorating patients in non-intensive care units: assessment of an innovative monitoring technology. J. Hosp. Med. 7, 628–633 (2012).
Elvekjaer, M. et al. Physiological abnormalities in patients admitted with acute exacerbation of COPD: an observational study with continuous monitoring. J. Clin. Monit. Comput. 34, 1051–1060 (2020).
Stehlik, J. et al. Continuous wearable monitoring analytics predict heart failure hospitalization: the LINK-HF multicenter study. Circ. Heart Fail. 13, e006513 (2020).
Li, D. et al. Feasibility study of monitoring deterioration of outpatients using multimodal data collected by wearables. ACM Trans. Comput. Healthcare 1, 5 (2020).
Purushotham, S., Meng, C., Che, Z. & Liu, Y. Benchmarking deep learning models on large healthcare datasets. J. Biomed. Inform. 83, 112–134 (2018).
Breteler, M. J. M. et al. Vital signs monitoring with wearable sensors in high-risk surgical patients: a clinical validation study. Anesthesiology 132, 424–439 (2020).
Breteler, M. J. M. et al. Reliability of wireless monitoring using a wearable patch sensor in high-risk surgical patients at a step-down unit in the Netherlands: a clinical validation study. BMJ Open 8, e020162 (2018).
Hernandez-Silveira, M. et al. Assessment of the feasibility of an ultra-low power, wireless digital patch for the continuous ambulatory monitoring of vital signs. BMJ Open 5, e006606 (2015).
Badawy, J., Nguyen, O. K., Clark, C., Halm, E. A. & Makam, A. N. Is everyone really breathing 20 times a minute? Assessing epidemiology and variation in recorded respiratory rate in hospitalised adults. BMJ Qual. Saf. 26, 832–836 (2017).
Churpek, M. M. et al. Predicting cardiac arrest on the wards: a nested case-control study. Chest 141, 1170–1176 (2012).
Escobar, G. J. et al. Early detection of impending physiologic deterioration among patients who are not in intensive care: development of predictive models using data from an automated electronic medical record. J. Hosp. Med. 7, 388–395 (2012).
Churpek, M. M. et al. Multicenter development and validation of a risk stratification tool for ward patients. Am. J. Respir. Crit. Care Med. 190, 649–655 (2014).
Un, K. C. et al. Observational study on wearable biosensors and machine learning-based remote monitoring of COVID-19 patients. Sci. Rep. 11, 4388 (2021).
Yadaw, A. S. et al. Clinical features of COVID-19 mortality: development and validation of a clinical prediction model. Lancet Digit. Health 2, e516–e525 (2020).
Hatib, F. et al. Machine-learning algorithm to predict hypotension based on high-fidelity arterial pressure waveform analysis. Anesthesiology 129, 663–674 (2018).
Bedoya, A. D. et al. Minimal impact of implemented early warning score and best practice alert for patient deterioration. Crit. Care Med. 47, 49–55 (2019).
Palmer, J. H., James, S., Wadsworth, D., Gordon, C. J. & Craft, J. How registered nurses are measuring respiratory rates in adult acute care health settings: an integrative review. J. Clin. Nurs. 32, 4515–4527 (2023).
Subbe, C. P., Kruger, M., Rutherford, P. & Gemmel, L. Validation of a modified Early Warning Score in medical admissions. QJM 94, 521–526 (2001).
Nakanishi, M. et al. Physical activity group classification algorithm using triaxial acceleration and heart rate. Annu. Int. Conf. IEEE Eng. Med. Biol. Soc. 2015, 510–513 (2015).
Acknowledgements
The authors thank Andrew Dominello, Jennifer Connell and Ariana McGinn for their help in the copyediting and submission of this article. This work is supported by NIH R01NR020774 (T.P.Z.).
Author information
Authors and Affiliations
Contributions
T.P.Z. conceived this study and supervised the project; B.F. and M.O. collected the data; M.R.S. analyzed the data; M.R.S. prepared the manuscript; M.R.S., B.F., M.O., J.S.H., and T.P.Z. edited the manuscript;
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Peer review
Peer review information
Nature Communications thanks Peter Watkinson, Shishir Rao, and the other, anonymous, reviewer(s) for their contribution to the peer review of this work. A peer review file is available.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Source data
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Scheid, M.R., Friedmann, B., Oppenheim, M. et al. Development and validation of a clinical wearable deep learning based continuous inhospital deterioration prediction model. Nat Commun 16, 9513 (2025). https://doi.org/10.1038/s41467-025-65219-8
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41467-025-65219-8
