
Abstract
Normalized mutual information is widely used as a similarity measure for evaluating the performance of clustering and classification algorithms. In this paper, we argue that results returned by the normalized mutual information are biased for two reasons: first, because they ignore the information content of the contingency table and, second, because their symmetric normalization introduces spurious dependence on algorithm output. We introduce a modified version of the mutual information that remedies both of these shortcomings. As a practical demonstration of the importance of using an unbiased measure, we perform extensive numerical tests on a basket of popular algorithms for network community detection and show that one’s conclusions about which algorithm is best are significantly affected by the biases in the traditional mutual information.
Similar content being viewed by others

Introduction
A common task in data analysis is the comparison of two different labelings of a set of objects. How well do demographics predict political affiliation? How accurately do blood tests predict clinical outcomes? These are questions about how similar one labeling of individuals/items/results is to another, and they are commonly tackled using the information-theoretic measure known as mutual information, in which an experimental or computational measure of some kind is compared against a ground truth.
Mutual information works by asking how efficiently we can describe one labeling if we already know the other1. Specifically, it measures how much less information it takes to communicate the first labeling if we know the second versus if we do not. As an example, mutual information is commonly used in network science to evaluate the performance of algorithms for network community detection2. One takes a network whose community structure is already known and applies a community detection algorithm to it to infer the communities. Then one uses mutual information to compare the output of the algorithm to the known correct communities. Algorithms that consistently achieve high mutual information scores are considered good. We will use this application as an illustrative example later in the paper.
Mutual information has a number of appealing properties as a tool for comparing labelings. It is invariant under permutations of the labels, so that, for example, two divisions of a network into communities that differ only in the numbering of the communities will be correctly identified as being the same. It also returns sensible results in cases where the number of distinct label values is not the same in the two labelings. However, the standard mutual information measure also has some significant shortcomings, and two in particular that we highlight in this paper. First, it has a bias towards labelings with too many distinct label values. For instance, a community detection algorithm that incorrectly divides networks into significantly more groups than are present in the ground truth can nonetheless achieve a high mutual information score. A number of approaches for correcting this flaw have been proposed. One can apply direct penalties for incorrect numbers of groups3 or subtract correction terms based on the average mutual information over some ensemble of candidate labelings4,5 or on the statistics of the contingency table6,7. For reasons we discuss shortly, we favor the latter approach, which leads to the measure known as the reduced mutual information.
The second drawback of the mutual information arises when the measure is normalized, as it commonly is to improve interpretability. The most popular normalization scheme creates a measure that runs between zero and one by dividing the mutual information by the arithmetic mean of the entropies of the two labelings being compared8, although one can also normalize by the minimum, maximum, or geometric mean of the entropies. As we demonstrate in this paper, however, these normalizations introduce biases into the results by comparison with the unnormalized measure, because the normalization factor depends on the candidate labeling as well as the ground truth. This effect can be large enough to change scientific outcomes, and we provide examples of this phenomenon.
In order to avoid this latter bias, while still retaining the interpretability of a normalized mutual information measure, we favor normalizing by the entropy of the ground-truth labeling alone. This removes the source of bias but introduces an asymmetry in the normalization. At first sight, this asymmetry may seem undesirable, and previous authors have gone to some lengths to avoid it. Here, however, we argue that it is not only justified but actually desirable, for several reasons. First, many of the classification problems we consider are unaffected by the asymmetry, since they involve the comparison of one or more candidate labelings against a single, unchanging ground truth. Moreover, by contrast with the multitude of possible symmetric normalizations, the asymmetric measure we propose is the unique way to normalize the mutual information without introducing biases due to the normalization itself.
More broadly, the asymmetric measure is more informative than the conventional symmetric one. Consider, for instance, the common situation where the groups or communities in one labeling are a subdivision of those in the other. We might, for example, label individuals by the country they live in on the one hand and by the town or city on the other. Then the more detailed labeling tells us everything there is to know about the coarser one, but the reverse is not true. Telling you the city fixes the country, but not vice versa. Thus, one could argue that the mutual information between the two should be asymmetric, and this type of asymmetry will be a key feature of the measures we study.
Both drawbacks of the standard mutual information—bias towards too many groups and dependence of the normalization on the candidate labeling—can be addressed simultaneously by using an asymmetric normalized reduced mutual information as defined in this paper. In support of this approach, we present an extensive comparison of the performance of this and other variants of the mutual information in network community detection tasks, generating a large number of random test networks with known community structure and a variety of structural parameters, and then attempting to recover the communities using popular community detection algorithms. Within this framework, we find that conclusions about which algorithms perform best are significantly impacted by the choice of mutual information measure, and specifically that traditional measures erroneously favor algorithms that find too many communities, but our proposed measure does not. Code implementing our measure can be found at https://github.com/maxjerdee/clustering-mi.
Results
Mutual information can be thought of in terms of the amount of information it takes to transmit a labeling from one person to another. We represent a labeling or division of n objects into q groups as a vector of n integer elements, each with value in the range 1…q. We assume there to be a ground-truth labeling, which we denote g, with qg groups, and a candidate labeling for comparison c with qc groups, generated for instance, by some sort of algorithm. The mutual information I(c; g) between the two is the amount of information saved when transmitting the truth g if the receiver already knows the candidate c. We can write this information as the total entropy of g minus the conditional entropy of g given c:
Loosely, we say that I(c; g) measures how much c tells us about g. Since the conditional information content H(g∣c) is nonnegative, the mutual information must satisfy inequalities
which are saturated by
Carefully accounting for all of the constituent information costs, we can compute the mutual information from7
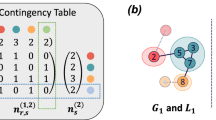
In this expression, the quantity \({n}_{r}^{(g)}\) denotes the number of objects in labeling g that belong to group r = 1…qg, and similarly for \({n}_{s}^{(c)}\). The quantities \({n}_{rs}^{(gc)}\) are the entries of the contingency table, and are equal to the number of objects that simultaneously belong to group s in the candidate labeling c and group r in the ground truth g. Evaluating the sums and products over these table entries numerically, the value of I(c; g) can be computed in time O(qcqg). The parameter values αg and αg∣c are chosen to optimize the transmission process using a fast line search, providing good compression for realistic labelings as discussed in ref. 7.
The first term in Eq. (4) represents the information cost of transmitting the labelings given knowledge of the contingency table \({n}_{rs}^{(gc)}\). The remaining terms account for the information costs associated with the transmission of the table itself. In some cases, the information required to transmit the qg × qc contingency table is significantly smaller than that needed for the n-vectors representing the labelings, and it is neglected in most treatments6,7, leading to the traditional mutual information measure, which we denote I0:
In other cases, however, the information cost of the contingency table can play a significant role and should be retained as in Eq. (4), which yields the quantity known as the reduced mutual information.
As an example, suppose a community detection algorithm simply places each node in its own group, resulting in a candidate labeling c = (1, 2, 3, …). No matter what the ground truth is, this choice of c clearly contains no information about it whatsoever, so we might expect the mutual information to be zero. If we use the traditional mutual information, however, we get I0(c; g) = I0(g; g), which is not merely nonzero but implies that the candidate labeling is maximally informative, telling us everything about the ground truth. This is as wrong as it could be—in fact the candidate tells us nothing at all. The reduced mutual information, on the other hand, correctly says that I(c; g) = 0 (see Section S2 in the Supplementary Information).
For the same reason, the traditional mutual information gives a maximum score to any candidate c which is a refinement of the true g, i.e., every community in c is a subset of a community in g. More generally, the traditional mutual information is biased towards labelings with too many groups3,4,6,7,9.
A related shortcoming of the traditional mutual information is that for finite n even a random labeling c will have positive mutual information with respect to any ground truth in expectation: because the traditional mutual information is non-negative, fluctuations due to randomness will produce non-negative values only and hence their average will in general be positive4,10. This seems counterintuitive; we would expect the average value for a random labeling to be zero.
We can solve this problem by using another variant of the mutual information, which subtracts off the expected value, thereby making the average zero by definition. To do this we must first specify how the expectation is defined—over what distribution of candidate labelings are we averaging? The conventional choice is to take the uniform distribution over labelings that share the same group sizes n(c) as the actual candidate c. This yields the adjusted mutual information of Vinh et al.4:
where the expectation 〈…〉 is over the relevant ensemble.
The adjusted mutual information can also be derived in a fully information-theoretic manner, as described in ref. 6. There it is shown that the subtracted term \({\langle {I}_{0}(c;g)\rangle }_{\{c| {n}^{(c)}\}}\) is precisely equal to the average cost of transmitting the contingency table when labelings are drawn from the uniform distribution. However, this distribution heavily favors contingency tables with relatively uniform entries, simply because there are many more labelings that correspond to uniform tables than to non-uniform ones. Real contingency tables, on the other hand, are often highly non-uniform, since applications of the mutual information focus on labelings that are somewhat similar to the ground truth (producing a non-uniform table). In such cases, the average used in the adjusted mutual information puts most of its weight on configurations that are very different from those that occur in reality, making it a poor representation of true information costs. The reduced mutual information considered in this paper, by contrast, deliberately allows for non-uniform tables by drawing them from a Dirichlet-multinomial distribution, and we argue that this is a strong reason to favor it over the adjusted mutual information. Nonetheless, in Section “LFR benchmark networks” we give results using both reduced and adjusted mutual information, and find fairly similar outcomes in the two cases.
Normalization of the mutual information
A fundamental difficulty with mutual information as a measure of similarity is that its range of values depends on the particular application, which makes it difficult to say when a value is large or small. Is a mutual information of 10 a large value? Sometimes it is and sometimes it isn’t, depending on the context. To get around this obstacle one commonly normalizes the mutual information so that it takes a maximum value of 1 when the candidate labeling agrees exactly with the ground truth. There are a number of ways this can be achieved and, as we show here, they are not all equal. In particular, some, including the most popularly used normalization, can result in biased results and should, in our opinion, be avoided. In its place, we propose an alternative, unbiased, normalized measure.
The most popular normalized measure, commonly referred to simply as the normalized mutual information, uses the plain mutual information I0(c; g) as a base measure and normalizes it thus:
This measure has a number of desirable features. Because of the inequalities in (2), its value falls strictly between zero and one. And since both the base measure and the normalization are symmetric under interchange of c and g, the normalized measure also retains this symmetry (hence the superscript (S), for symmetric).
Equation (7) is not the only normalization that achieves these goals. Equation (2) implies that
which gives us three more options for a symmetric denominator in the normalized measure. The arithmetic mean in Eq. (7), however, sees the most use by far11,12,13,14.
We can extend the notion of symmetric normalization to any other base measure of mutual information IX(c; g) satisfying the inequality Eq. (2), such as adjusted or reduced mutual information7, by writing
All such measures, however, including the standard measure of Eq. (7), share a crucial shortcoming, that the normalization depends on the candidate labeling c and hence that the normalized measure can prefer a different candidate labeling to the base measure purely because of the normalization.
Figure 1 shows an example of how this can occur. In this example, 64 objects are split into four equally sized groups in the ground-truth labeling g, against which we compare two candidate labelings, c1 and c2. Neither candidate is perfect. Labeling c1 identifies the correct number of groups but misplaces certain objects, while labeling c2 contains only two groups, each an aggregation of a pair of true groups. Under the unnormalized mutual information of Eq. (5), c1 receives a higher score than c2, but under the normalized measure of Eq. (7) the reverse is true. This behavior is due to the difference in entropy I0(c; c) between the two candidate divisions. Since the candidate entropy appears in the denominator of the symmetric normalization, Eq. (7), the symmetric measure favors simple labelings with smaller entropy. In this example, candidate c2 has only two groups, which results in a smaller entropy and a bias in its favor.

In this example 64 objects are split into four equally sized true groups g, denoted by their color. Against this ground truth, we compare two candidate labelings, c1 and c2. The standard unnormalized mutual information I0(c; g) of Eq. (5) reports that labeling c1 shares more bits of information with the ground truth than does c2. By definition, the asymmetrically normalized mutual information NMI(A) will always agree with the unnormalized measure, as in this example. The symmetrically normalized NMI(S), on the other hand, is biased in favor of simpler labelings, which makes it prefer labeling c2 in this case.
We argue that the unnormalized measure is more correct on this question, having a direct justification in terms of information theory. The purpose of the normalization is merely to map the values of the measure onto a convenient numerical interval, and should not change the outcome as it does here. Moreover, different symmetric normalizations can produce different results. For instance, if one normalizes by \(\max ({I}_{0}(c;c),{I}_{0}(g;g))\) in Fig. 1 then candidate c1 is favored in all cases.
The choice of normalization can also change conclusions even when the number of groups does not vary. Consider the example shown in Fig. 2, in which the ground truth g splits the objects into two equally sized groups. Candidate c1 also has two groups of equal size, although each is slightly polluted with the objects of the opposite group. Candidate c2 has two groups of different sizes, a small group with one color only, and a larger group with objects of both colors. Although both labelings have the same number of groups, candidate c2 has a smaller entropy I0(c; c), since it is easier to communicate group identity within c2—most objects belong to the larger group. As a result, the symmetrically normalized mutual information prefers c2, while the unnormalized measure prefers c1.

Although both candidates c1 and c2 correctly split the objects into two groups, candidate labeling c1 scores higher with respect to both the unnormalized and asymmetrically normalized mutual informations, while the symmetric normalization prefers c2.
These issues are unavoidable when using a symmetric normalization scheme. In any such scheme, the normalization must depend on both c and g and hence can vary with the candidate labeling. However, if we drop the requirement of symmetry, then we can normalize in a way that avoids these issues. We define the asymmetric normalization of any base measure IX as
This definition still gives \({\,{\mbox{NMI}}\,}_{X}^{(A)}(g;g)=1\), but now the normalization factor in the denominator has no effect on choices between candidate labelings, since it is independent of c. In fact, Eq. (10) is the only way to normalize such that \({I}_{X}^{(A)}(g;g)=1\) while simultaneously ensuring that the preferred candidate is always the same as for the base measure. Thus, this measure also removes any ambiguity about how one should perform the normalization. Loosely, this asymmetrically normalized mutual information measures how much c tells us about g as a fraction of all there is to know about g. Asymmetrically normalized measures have appeared in other contexts under the name “coefficient of constraint” or “coefficient of uncertainty”15,16,17, although symmetric normalizations are almost universally used in the model validation context, where they introduce the bias we discuss here.
The amount of bias inherent in the symmetrically normalized measure when compared with the asymmetric one can be quantified by the ratio between the two:
If the base measure IX is itself symmetric (which it is, either exactly or approximately, for all the measures we consider), then this simplifies further to
Values of this quantity below (above) 1 indicate that the symmetric measure is biased low (high). Thus, for instance, complex candidate labelings c that have higher entropy than the ground truth will result in a symmetric measure whose values are too low. As discussed in the introduction, traditional mutual information measures are particularly problematic when the candidate is a refinement of the ground truth, meaning the candidate groups are subsets of the ground-truth groups. In that case the traditional measure returns values that are too high. Equation (12) implies that, to some extent, the symmetric normalization will correct this issue: a candidate c that takes the form of a refinement of g will have H(c) > H(g), which will lower the value of the symmetrically normalized mutual information. This may in part explain why these biases have been overlooked in the past: two wrongs have conveniently canceled out to (approximately) make a right.
We argue, however, that this is not the best way to address the problem and that the correct approach is instead to use the reduced mutual information. The reduced mutual information also corrects for the case where one labeling is a refinement of the other, but does so in a more principled manner that directly addresses the root cause of the problem, rather than merely penalizing complex candidate labelings in an ad hoc manner as a side-effect of normalization.
We will see examples of these effects shortly, when we apply the various measures to community detection in networks and find that indeed the traditional symmetrically normalized mutual information is biased. In some cases, it is fortuitously biased in the right direction, although it is still problematic in some others.
An obvious downside of asymmetric normalization is the loss of symmetry in the final measure. In the most common applications of normalized mutual information, where labelings are evaluated against a ground truth, an inherently asymmetric situation, the asymmetric measure makes sense, but in other cases the lack of symmetry can be undesirable. Embedding and visualization methods that employ mutual information as a similarity measure, for example, normally demand symmetry18. And in cases where one is comparing two candidate labelings directly to one another, rather than to a separate ground truth, a symmetric measure may be preferable. Even in this latter case, however, the asymmetric measure may sometimes be the better choice, as discussed in the introduction. For instance, when one labeling c1 is a refinement of the other c2, the information content is inherently asymmetric: c1 says more about c2 than c2 does about c1. An explicit example of this type of asymmetry is shown in Fig. 3, where we consider two labelings of 27 objects. The left labeling c1 is a detailed partition of the objects into nine small groups while the right labeling c2 is a coarser partition into only three groups, each of which is an amalgamation of three of the smaller groups in c1. Because of this nested relationship, it is relatively easy to transmit c2 given knowledge of c1 but more difficult to do the reverse. This imbalance is reflected in the asymmetric normalized mutual information values in each direction (top and bottom arrows in the figure), but absent from the symmetric version (middle row).

The left partition c1 divides the objects into nine groups of three objects each and is a refinement of the right partition c2, which divides them into only three groups. The arrows indicate the direction of the comparison and the accompanying notations give the values of the mutual information measures. All three asymmetrically normalized measures capture the intuition that the partition c1 tells us more about c2 than c2 tells us about c1.
Combining the benefits of asymmetric normalization and the reduced mutual information, we advocate in favor of the asymmetrically-normalized reduced mutual information defined by
where the mutual information I(c; g) is quantified as in Eq. (4). This measure correctly accounts for the information contained in the contingency table, returns a negative value when c is unhelpful for recovering the ground truth, returns 1 if and only if c = g, and always favors the same labeling as the unnormalized measure. The traditional normalized mutual information possesses none of these desirable qualities.
Example: copurchasing network of books
As an example of the performance of the various measures discussed above, in this section, we use them to score the output of algorithms for network community detection. We consider a selection of networks with known true groups and attempt to recover those groups using various standard community detection algorithms, quantifying the accuracy of recovery with six different measures: the symmetrically and asymmetrically normalized versions of the traditional mutual information, the adjusted mutual information, and the reduced mutual information.
As a first example, Fig. 4 shows a network compiled by V. Krebs of 105 books about US politics published around the time of the 2004 US presidential election. The true groups g in this case represent the political lean of each book’s content: liberal, conservative, or neutral19, as determined by Krebs. Network edges connect pairs of books frequently purchased together on Amazon.com, and such books typically are of the same political bent, either both liberal or both conservative, so that the political positions form communities of connected network nodes. Community detection algorithms, which aim to find such communities, should therefore be able to recover political positions, at least approximately, from the network of connections alone. The figure shows the results of applying two of the most popular such algorithms, InfoMap and modularity maximization (with resolution parameter γ = 2), but we find that these algorithms identify quite different partitions of the network, with InfoMap finding six groups where modularity finds nine. We use the normalized mutual information in its various forms to assess how closely each division matches the ground truth.

True and recovered groups are indicated by node color, and similarity between the two is assessed using the mutual information in its traditional I0, adjusted IA, and reduced I variants, normalized asymmetrically NMI(A) and symmetrically NMI(S). The choices of both the base measure and the normalization impact which algorithm is preferred.
We find that both the base mutual information measure IX and its normalization considerably impact our assessments. For instance, the asymmetrically normalized traditional mutual information gives a score of \({\,{\mbox{NMI}}\,}_{0}^{(A)}({c}_{2};g)=0.728\), out of a maximum of 1, for the partition found by modularity maximization, which is over twice the score of NMI(S)(c2; g) = 0.294 given to the same partition by the symmetrically normalized reduced measure.
The choice of mutual information measure can also change which algorithm is preferred. For the traditional unreduced base measure I0, the asymmetrically normalized mutual information favors the groups found by modularity while the symmetric version favors the simpler partition found by InfoMap. The same pattern holds if the adjusted IA is used. The reduced measure I, however, prefers InfoMap regardless of normalization, although by a narrower margin in the asymmetric case. As discussed in the previous section, we favor the asymmetrically normalized reduced measure on formal grounds, and view the (often large) deviations from its assessment as unnecessary biases.
LFR benchmark networks
In one sense the previous example is unusual: there are relatively few cases like this of networks with known ground-truth communities to compare against. To get a more comprehensive picture of algorithm performance, therefore, researchers have turned to synthetic benchmark networks like those generated by the popular Lancichinetti-Fortunato-Radicchi (LFR) graph model20, which creates networks with known community structure and realistic distributions of node degrees and group sizes. A number of studies have been performed in the past to test the efficacy of community detection algorithms on LFR benchmark networks11,12,13,14, but using only the symmetrically normalized, non-reduced mutual information as a similarity measure. Our results indicate that this measure can produce biased outcomes and we recommend the asymmetric reduced mutual information instead.
The LFR model contains a number of free parameters that control the size of the networks generated, their degree distribution, the distribution of community sizes, and the relative probability of within- and between-group edges. (See Section S1 in the Supplementary Information for details of the LFR generative process). We find that the distributions of degrees and community sizes do not significantly impact the relative performance of the various algorithms tested and that performance differences are driven primarily by the size n of the networks and the mixing parameter μ that controls the ratio of connections within and between groups, so our tests focus on performance as a function of these parameters.
Comparison between variants of the mutual information
Fig. 5 summarizes the relative performance of the various mutual information measures in our tests. In this set of tests we limit ourselves, for the sake of clarity, to the top three community detection algorithms—InfoMap and the two variants of modularity maximization—and measure which of the three returns the best results according to each of our six mutual information measures, as a function of network size n and the mixing parameter μ. Each point in each of the six panels is color-coded with some mix of red, green, and blue to indicate in what fraction of cases each of the algorithms performs best according to each of the six measures and, as we can see, the results vary significantly among measures. An experimenter trying to choose the best algorithm would come to substantially different conclusions depending on which measure they use.

The colors in each panel of this figure indicate which of the three is best able to find the known communities in a large set of LFR benchmark networks, according to the six mutual information measures we consider. Mixtures of red, green, and blue denote the proportions of test cases in which each algorithm performs best. Regions in gray indicate parameter values for which no algorithm achieved a positive mutual information score.
One consistent feature of all six mutual information measures is the large red area in each panel of Fig. 5, which represents the region in which the InfoMap algorithm performs best. Regardless of the measure used, InfoMap is the best performer on networks with low mixing parameters (i.e., strong community structure) and relatively large network size. For higher mixing (weaker structure) or smaller network sizes, modularity maximization does better. Which version of modularity is best, however, depends strongly on the mutual information measure. The traditional symmetrically normalized mutual information (top left panel) mostly favors the version with a high resolution parameter of γ = 10 (blue), but the asymmetric reduced measure for which we advocate (bottom right) favors the version with γ = 1 (green). (The regions colored gray in the figure are those in which no algorithm receives a positive mutual information score and hence all algorithms can be interpreted as failing).
These results raise significant doubts about the traditional measure. Consider the lower right corner of each plot in Fig. 5, which is the regime of small network sizes n and high mixing μ, so that the community signal is weak and the noise is high. Here, the adjusted and reduced mutual informations indicate that all algorithms are failing. This is expected: for very weak community structure all detection algorithms are expected to show a “detectability threshold” beyond which they are unable to identify any communities21,22,23. The standard normalized mutual information, on the other hand, claims to find community structure in this regime using the γ = 10 version of modularity maximization. This occurs because the γ = 10 algorithm finds many small communities and, as discussed in “Results”, a labeling with many communities, even completely random ones, is accorded a high score by a non-reduced mutual information. The presence of this effect is demonstrated explicitly in the Supplementary Information, Section S1 A for the case of modularity maximization with γ = 10, and this offers a clear reason to avoid the standard measure.
The bottom left panel in Fig. 5 shows results for the asymmetrically normalized version of the traditional mutual information, which gives even worse results than the symmetric version, with hardly any region in which the γ = 1 version of modularity maximization outperforms the γ = 10 version. This behavior arises for the reasons discussed previously—the bias inherent in the symmetric normalization fortuitously acts to partially correct the errors introduced by neglecting the information content of the contingency table. The asymmetric normalization eliminates this correction and hence performs more poorly. The correct solution to this problem, however, is not to use a symmetric normalization, which can bias outcomes in other ways as we have seen, but rather to adopt a reduced mutual information measure.
Finally, comparing the middle and right-hand columns of Fig. 5, we see that the results for the adjusted and reduced mutual information measures are quite similar in these tests, although there are some differences. In particular, the adjusted measure appears to find more significant structure for higher mixing than the reduced measure. This occurs because, as discussed in “Results” and ref. 6, the adjusted measure encodes the contingency table in a way that is optimized for more uniform tables than the reduced measure, and thus penalizes uniform tables less severely, leading to overestimates of the mutual information in the regime where detection fails—in this regime the candidate and ground-truth labelings are uncorrelated which results in a uniform contingency table. This provides further evidence in favor of using a reduced mutual information measure.
Comparison between community detection algorithms
Settling on the asymmetrically normalized reduced mutual information as our preferred measure of similarity, we now ask which community detection algorithm or algorithms perform best according to this measure? We have already given away the answer—InfoMap and modularity maximization get the nod—but here we give evidence for that conclusion.
Figure 6 shows results for all six algorithms listed in the Supplementary Information, Section S1B. Examining the figure, we see that in general the best-performing methods are InfoMap, traditional modularity maximization with γ = 1, and the inference method using the degree-corrected stochastic block model. Among the algorithms considered, InfoMap achieves the highest mutual information scores for lower values of the mixing parameter μ in the LFR model, but fails abruptly as μ increases, so that beyond a fairly sharp cutoff around μ = 0.5, other algorithms do better. As noted by previous authors24, InfoMap’s specific failure mode is that it places all nodes in a single community, and this behavior can be used as a simple indicator of the failure regime. In this regime one must use another algorithm. Either the modularity or inference method are reasonable options, but modularity has a slight edge, except in a thin band of intermediate μ values which, in the interests of simplicity, we choose to ignore. (We discuss some caveats regarding the relationship between the degree-corrected stochastic block model and the LFR benchmark in Section S1 of the Supplementary Information).

Gray areas indicate parameter values for which NMI < 0, so that the conditional encoding is less efficient than the direct encoding.
Thus—always assuming the LFR benchmark is a good test of performance—our recommendations for the best community detection algorithm are relatively straightforward. If we are in a regime where InfoMap succeeds, meaning it finds more than one community, then one should use InfoMap. If not, one should use standard modularity maximization with γ = 1. That still leaves open the question of how the modularity should be maximized. In our studies, we find the best results with simulated annealing, but simulated annealing is computationally expensive. In regimes where it is not feasible, we recommend using the Leiden algorithm instead. (Tests using other computationally efficient maximization schemes, such as the Louvain and spectral algorithms, generally performed less well than the Leiden algorithm).
Discussion
In this paper, we have examined the performance of a range of mutual information measures for comparing labelings of objects in classification, clustering, or community detection applications. We argue that the commonly used normalized mutual information is biased in two ways: (1) because it ignores the information content of the contingency table, which can be large, and (2) because the symmetric normalization it employs introduces spurious dependence on the labeling. We argue in favor of a different measure, an asymmetrically normalized version of the reduced mutual information, which rectifies both of these shortcomings.
To demonstrate the effects of using different mutual information measures, we have presented results of an extensive set of numerical tests on popular network community detection algorithms, as evaluated by the various measures we consider. We find that conclusions about which algorithms are best depend substantially on which measure we use.
Reporting summary
Further information on research design is available in the Nature Portfolio Reporting Summary linked to this article.
Data availability
All datasets analyzed here have been deposited in the Zenodo database under accession code https://doi.org/10.5281/zenodo.17211478, except for the synthetic LFR benchmark networks, which were randomly generated using the open-source NetworkX package as described in the Supplementary Information, Section S1.
Code availability
Python code implementing the mutual information measures discussed in this paper is available at https://github.com/maxjerdee/clustering-mi or ref. 25.
References
Cover, T. M. & Thomas, J. A. Elements of Information Theory. John Wiley, New York, 2nd edition (2006).
Danon, L., Duch, J., Diaz-Guilera, A. & Arenas, A. Comparing community structure identification. J. Stat. Mech. 2005, P09008 (2005).
Amelio, A. & Pizzuti, C. Correction for closeness: Adjusting normalized mutual information measure for clustering comparison. Computational Intell. 33, 579–601 (2017).
Vinh, N. X., Epps, J. & Bailey, J. Information theoretic measures for clusterings comparison: Variants, properties, normalization and correction for chance. J. Mach. Learn. Res. 11, 2837–2854 (2010).
Gates, A. J. & Ahn, Y.-Y. The impact of random models on clustering similarity. J. Mach. Learn. Res. 18, 1–28 (2017).
Newman, M. E. J., Cantwell, G. T. & Young, J.-G. Improved mutual information measure for clustering, classification, and community detection. Phys. Rev. E 101, 042304 (2020).
Jerdee, M., Kirkley, A. & Newman, M. E. J. Mutual information and the encoding of contingency tables. Phys. Rev. E 110, 064306 (2024).
Ana, L. and Jain, A. Robust data clustering. In 2003 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 2003. Proceedings., volume 2, pp. II–II (2003).
Lai, D. & Nardini, C. A corrected normalized mutual information for performance evaluation of community detection. J. Stat. Mech.: Theory Exp. 2016, 093403 (2016).
Zhang, P. Evaluating accuracy of community detection using the relative normalized mutual information. J. Stat. Mech. 2015, P11006 (2015).
Lancichinetti, A. & Fortunato, S. Community detection algorithms: A comparative analysis. Phys. Rev. E 80, 056117 (2009).
Orman, G. K., Labatut, V. & Cherifi, H. Qualitative comparison of community detection algorithms. Commun. Computer Inf. Sci. 167, 265–279 (2011).
Yang, Z., Algesheimer, R. & Tessone, C. J. A comparative analysis of community detection algorithms on artificial networks. Sci. Rep. 6, 30750 (2016).
Fortunato, S. & Hric, D. Community detection in networks: A user guide. Phys. Rep. 659, 1–44 (2016).
Coombs, C. H., Dawes, R. M. & Tversky, A. Mathematical psychology: An elementary introduction. Prentice-Hall (1970).
Theil, H. Henri Theil’s contributions to economics and econometrics: econometric theory and methodology. volume 1. Springer Science & Business Media (1992).
Effenberger, F. A primer on information theory with applications to neuroscience. In Computational Medicine in Data Mining and Modeling, pp. 135–192, Springer (2013).
Peel, L., Larremore, D. B. & Clauset, A. The ground truth about metadata and community detection in networks. Sci. Adv. 3, e1602548 (2017).
Unpublished network compiled and labeled by V. Krebs.
Lancichinetti, A., Fortunato, S. & Radicchi, F. Benchmark graphs for testing community detection algorithms. Phys. Rev. E 78, 046110 (2008).
Decelle, A., Krzakala, F., Moore, C. & Zdeborová, L. Inference and phase transitions in the detection of modules in sparse networks. Phys. Rev. Lett. 107, 065701 (2011).
Massoulié, L. Community detection thresholds and the weak Ramanujan property. In Proceedings of the 46th Annual ACM Symposium on the Theory of Computing, pp. 694–703, Association of Computing Machinery, New York (2014).
Mossel, E., Neeman, J. & Sly, A. Reconstruction and estimation in the planted partition model. Probab. Theory Relat. Fields 162, 431–461 (2015).
Aref, S., Mostajabdaveh, M. & Chheda, H. Bayan algorithm: Detecting communities in networks through exact and approximate optimization of modularity. Phys. Rev. E 110, 044315 (2024).
Jerdee, M., Kirkley, A. & Newman, M. E. J. Normalized mutual information is a biased measure for classification and community detection. Zenodo, https://doi.org/10.5281/zenodo.17211478 (2025).
Acknowledgements
The authors thank Samin Aref for useful comments and feedback. This work was supported in part by the US National Science Foundation under grants DMS–2005899 and DMS–2404617 (MN), the National Science Foundation of China through Young Scientist Fund Project grant 12405044 (AK), and computational resources provided by the Advanced Research Computing initiative at the University of Michigan.
Author information
Authors and Affiliations
Contributions
All authors (M.J., A.K. and M.N.) conceptualized the research and wrote and edited the paper. Code development and data analysis were performed by M.J.; All authors have read the final manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Peer review
Peer review information
Nature Communications thanks the anonymous reviewers for their contribution to the peer review of this work. A peer review file is available.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Jerdee, M., Kirkley, A. & Newman, M. Normalized mutual information is a biased measure for classification and community detection. Nat Commun 16, 11268 (2025). https://doi.org/10.1038/s41467-025-66150-8
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41467-025-66150-8
