
Abstract
Carbapenemase-producing Enterobacterales (CPE) are considered among the highest threats to global health by WHO. Their detection is difficult and time-consuming. We developed a random-forest machine learning (ML) model, CarbaDetector, to predict carbapenemase production from inhibition zone diameters of eight antibiotics, using 385 isolates for training with whole genome sequencing as reference. Validation on two external datasets (A = 282, B = 518 isolates) shows high performance: sensitivity/specificity are 96.6%/84.4% (training), 96.3%/86.1% (A), and 91.2%/87.0% (B, five antibiotics). In contrast, the algorithms of EUCAST and the Antibiogram Committee of the French Society of Microbiology (CA-SFM) exhibit lower specificity (8.2% and 40.1%, respectively on the training dataset). In this work, we show that CarbaDetector, available as a web-app, reduces unnecessary confirmatory testing and accelerates the time to result. This approach offers high sensitivity and improved specificity compared to standard algorithms and has the potential to improve CPE detection, especially in resource-limited settings.
Similar content being viewed by others

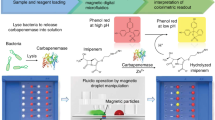
Introduction
Carbapenemase-producing Enterobacterales (CPE) are a global health threat and are listed in the “critical group” of the WHO’s 2024 Bacterial Priority Pathogens List1. CPE accounted for ~6.5% (34,934) of 541,000 deaths associated with bacterial antimicrobial resistance in the WHO European region in 2019, making them one of the most significant multidrug-resistant Gram-negative bacteria2. Infections caused by CPE are a challenge due to few therapeutic alternatives available3. Timely and accurate detection and confirmation of CPE is crucial not only to implement necessary infection control measures to help preventing the spread of carbapenemase genes and CPE outbreaks, but also to initiate adequate treatment.
The European Committee on Antimicrobial Susceptibility Testing (EUCAST) recommends the combination of a two-step procedure to detect CPE, with an initial screening step, followed by at least one confirmatory test4. The screening step involves determining the minimum inhibitory concentration (MIC) or the disk diffusion zone diameter using meropenem or ertapenem4. Confirmatory tests involve combination disk tests5, molecular diagnostics6, colorimetric tests such as CarbaNP7,8, the Carbapenem-Inactivation Method9, detection of carbapenem hydrolysis with MALDI-TOF mass spectrometry10,11 or lateral flow assays12. Since all these confirmatory tests require additional time, material and workforce, an efficient preselection of isolates for further testing is crucial.
Screening for CPEs as proposed by EUCAST using meropenem and/or ertapenem can be challenging, as there are certain carbapenemase types and species that are harder to detect than others. Especially OXA-48-like carbapenemase producers are often susceptible to meropenem and may thus be missed via a simple meropenem screening13. Carbapenemase-producing Proteus mirabilis are harder to detect due to increased carbapenem susceptibility14 and unique carbapenemase variants that are less frequent in other Enterobacterales, such as blaOXA-23. While species-specific algorithms have been established for P. mirabilis14, a universal algorithm would be more effective for use in the routine laboratories.
The Antibiogram Committee of the French Society of Microbiology (CA-SFM) proposed a CPE screening algorithm using three antibiotic disks (ceftazidime-avibactam, temocillin, and a carbapenem—either meropenem, imipenem, or ertapenem)15. This algorithm was tested by Duque et al. in 2024 on a collection of 518 isolates, yielding 97.8% sensitivity and 45.5% specificity1,16. For diagnostic algorithms, there is an inevitable tradeoff between sensitivity and specificity, and most current algorithms favor high sensitivity over specificity, increasing the amounts of unnecessarily tested false positive isolates in the laboratory.
In recent years, artificial Intelligence (AI) and especially machine learning has gained traction in aiding scientists and clinicians to interpret data and resolve patterns that may not be recognizable at first sight. There have been several attempts to use AI to improve carbapenemase detection, e.g., by using ChatGPT to analyse inhibition zones17, or by using it to identify peaks in MALDI-TOF MS spectra indicating the presence of a carbapenemase or a specific resistance18,19. However, detection of resistance using MALDI-TOF MS is usually an indirect method and requires large training datasets to reach acceptable sensitivities. Susceptibility testing using disk diffusion is an established, widely available method, which is performed in many clinical microbiology laboratories worldwide, and the data is thus readily available.
In this study, we therefore aim to develop an optimized screening approach by analyzing inhibition zone diameters of eight antibiotics on a collection of 385 clinical Enterobacterales isolates using a machine learning based model.
Results
Performance of existing screening algorithms on our dataset
We applied both the CA-SFM algorithm and the EUCAST screening cut-off to the 385 isolates in our dataset. The CA-SFM yielded a sensitivity of 95.0% (CI: 91.4–97.4%) and a specificity of 40.1% (CI: 32.2–48.5%), leading to a Youden index of 0.351 (Table 1). The number of negative isolates that would be sent for confirmatory testing after the screening was 88 out of 147 negative isolates, meaning that 59.9% of negative isolates would be further tested. This is 28.0% of all samples sent for confirmatory testing.
Application of EUCAST screening resulted in a slightly higher sensitivity of 97.9% (CI: 95.2–99.3%), but a lower specificity of 8.2% (CI: 4.3–13.8%). This would result in 135 negative isolates being unnecessarily tested with a confirmatory test, which is 91.8% of all negative isolates, and 36.7% of all samples sent for confirmatory testing.
Development of an algorithm
Based on the inhibition zone diameters of the eight antibiotics tested, we first built a simple decision tree based on only these diameters and the species. Using nested cross-validation, this yielded a model with 89.5% sensitivity (CI: 84.9–93.1%) and 86.4% specificity (CI: 79.8–91.5%) (Table 2).
To allow for a more accurate prediction, we trained a random forest model on the internal dataset. This model showed an increased sensitivity of 92.9% (CI: 88.8–95.8) and a specificity of 86.4% (CI: 79.8–91.5%). In addition, this model type can also calculate the probability of each classification, allowing users to adjust the cut-off and adjust the model towards a higher sensitivity.
To allow for a more robust model, the inhibition zone diameters were used to create new variables, i.e., the difference between each pair of inhibition zone diameters. The random forest model including the additional engineered features (random forest expanded) yielded 95.4% sensitivity (CI: 91.9–97.7%) and 87.8% specificity (CI: 81.3–92.6%). The additional modification of the custom threshold of 0.5 to 0.6 alters the translation of probability predictions into classification, adjusting the resulting model towards a higher sensitivity while decreasing specificity. The resulting model (random forest expanded sensitive = CarbaDetector) predicts carbapenemase production with a sensitivity of 96.6% (CI: 93.5–98.5%) and a specificity of 85.0% (CI: 78.2–90.4%), resulting in only 8.7% of isolates that need to be further tested being false positives, which is a significant decrease when compared to the EUCAST and CA-SFM algorithm (Supplementary Data 1).
For the CarbaDetector model that was trained on the whole internal dataset for use on external datasets, features with the highest importance as determined by mean decreased accuracy are imipenem-relebactam, imipenem, temocillin, the difference between temocillin and ceftazidime-avibactam, as well as the difference between ertapenem and imipenem-relebactam (see Fig. 1). While the species of an isolate has an impact on the outcome of the prediction, the difference between species does not warrant the construction of species-specific models (see Supplementary Information) (Fig. 2).

IMR imipenem-relebactam, TEM temocillin, IMI imipenem, CZA ceftazidime-avibactam, C/T Ceftolozan/Tazobactam, ETP ertapenem, MEM meropenem. “Difference” describes the difference of inhibition zone diameters for two antibiotic disks for the same isolate. See Table S1 for all variable importance parameters.

Interface of the CarbaDetector web-app.
The nested cross-validation estimate on the internal dataset resulted in eight false negative isolates. These included isolates producing VIM-1 (n = 3), OXA-244 (n = 2), IMP-13, OXA-181, and KPC-3 (n = 1 each), with 6/8 isolates being susceptible to at least one carbapenem by EUCAST breakpoints, Table S2. For imipenem-relebactam all isolates’ inhibition zones were larger than 22 mm (corresponding to susceptibility).
Validation of CarbaDetector using external datasets
The performance of CarbaDetector was assessed using two external datasets: (i) a dataset tested with all eight antibiotics (external dataset A), and (ii) a dataset provided by Duque et al. with only five of the eight measurements (external dataset B). To predict the presence of carbapenemases for external dataset B, the available five inhibition zone measurements were used to impute the missing three values (based on the internal training dataset). Finally, the predictions were performed using the available and the imputed values. CarbaDetector achieved a sensitivity of 96.3% (CI: 89.4–99.2%) and a specificity of 86.1% (CI: 80.6–90.6%) on dataset A, which was higher than the values obtained by the CA-SFM algorithm and the EUCAST screening cut-off on this dataset (Table 3).
When assessing the performance of CarbaDetector on the external dataset B, the CarbaDetector prediction algorithm yielded a sensitivity of 91.2% (CI: 87.8–93.9%) and a specificity of 87.0% (CI: 80.7–91.9%). CarbaDetector showed increased specificity when compared to the CA-SFM algorithm and EUCAST screening, with a better sensitivity than the EUCAST algorithm, but decreased sensitivity compared to the CA-SFM algorithm when imputing three out of eight measures (Table 3). The highest Youden index was achieved by CarbaDetector, both with eight and five inhibition zone diameters.
The CarbaDetector web-app
Using the validated CarbaDetector model, we created the web-app CarbaDetector, which can be found at https://uol.de/carba-detector. Here, the user can enter the inhibition zone diameters measured for their isolate (Fig. 2). Based on these measurements, the web-app predicts the probability that an isolate is a carbapenemase producer and informs the user in real-time.
Discussion
We investigated and tested current screening methods for CPE prediction and aimed to develop a machine learning tool to accurately predict the presence of carbapenemases in Enterobacterales using simple inhibition zone diameters.
EUCAST has established cut-offs that trigger further carbapenemase testing, based on meropenem and ertapenem inhibition zones or minimal inhibitory concentrations4. When applying these cut-offs to our dataset, a high sensitivity of 97.9% (CI: 95.2–99.3%) is achieved, but with a very low specificity of 8.2% (CI: 4.3–13.8%). CarbaDetector performs with a similar sensitivity of 96.6% (CI: 93.5–98.5%), but a significantly higher specificity of 85.0% (CI: 78.2–90.4%), resulting in an ~10-fold increase in specificity, leading to a 6-fold decrease of negative isolates that require confirmatory tests. This decrease of resources might be an important consideration especially in resource-limited settings. Moreover, even on an external dataset with missing values, CarbaDetector performed with 91.2% sensitivity and 87.0% specificity, showing its applicability even to incomplete data sets that miss some of the essential antibiotic test results. Even with missing values, the sensitivity was only slightly lower than that of the CA-SFM algorithm, but the specificity and the Youden index higher.
For dataset A, CarbaDetector predicted 28 isolates to be negative that both the EUCAST screening algorithm and the CA-SFM algorithm wrongfully marked as positive. These 28 isolates were mostly K. pneumoniae isolates (n = 15), followed by E. coli (n = 6), Enterobacter cloacae complex (n = 5), C. freundii (n = 1) and K. aerogenes (n = 1). All of these isolates showed an inhibition zone diameter smaller than 25 mm for ertapenem which leads to them being flagged by the EUCAST screening algorithm. There were two carbapenemase-producing isolates that were missed by all three screening algorithms. These were a K. pneumoniae and a P. mirabilis isolate, both harboring blaNDM-1. Since CarbaDetector presents a probability score with each prediction, the user can however, increase sensitivity by defining their own probability cutoff. Despite its promises, AI has not been extensively used for carbapenemase detection. Recently, a GPT agent has demonstrated potential for the prediction of ESBL, AmpC and carbapenemases based on inhibition zone measurements, adhering to the expert rules given by EUCAST. However, the GPT agent showed lower specificity in some resistance mechanisms compared to clinical microbiologists, leading to more additional tests17.
There are some limitations to our study. Even though the algorithm was tested on datasets from three different countries, the performance of CarbaDetector should be assessed using more and diverse isolates of different geographical origins and resistance mechanisms. Additionally, so far it includes inhibition zones of some antibiotics that are likely not included in all test panels (e.g., temocillin, imipenem-relebactam). Nevertheless, the model can be applied even if not all eight antibiotics have been tested, since missing diameters are imputed based on the underlying dataset. Importantly, the CarbaDetector is not IVDR (In Vitro Diagnostic Regulation) conform, and is for research use only. However, since we did not only use one dataset, but two completely independent external datasets for validation, we expect CarbaDetector to perform well when put to practice. It has to be considered that the control group was composed to include a very high proportion of challenging isolates, with increased carbapenem MICs but without carbapenemases. In the routine setting, all algorithms will likely achieve a higher performance than in this demanding strain set.
We chose disk diffusion as the susceptibility testing method for this pilot study, since it is commonly used worldwide and recommended by both EUCAST and CLSI. Additionally, it has the advantage of providing a wide range of quantitative inhibition zone data, which could be used for developing the model. Semi-automated susceptibility testing systems are also commonly used nowadays, but often have a limited calling range of minimal inhibitory concentrations. Nevertheless, further development of CarbaDetector will include MIC data from other susceptibility testing systems. One challenge when working with disk diffusion is that specific combinations of species and antibiotics can lead to difficult to interpret results, e.g., due to swarming or the formation of microcolonies in the inhibition zones. For this study, we adhered to EUCAST guidelines for disk diffusion methodology20. For optimal results, it is recommended to follow these standards when using CarbaDetector.
For training the algorithm, we used an isolate collection that consists of isolates from German centers and including isolates with high, medium and low carbapenem MICs. The species and carbapenemases are therefore not evenly distributed. It is important to note that this can affect the model outcome and bias the algorithm. The collection we chose is, however, representative of what would be encountered in a routine clinical setting in Germany, with predominance of OXA-48-like carbapenemases. Since the model was additionally evaluated with two external datasets, we are optimistic that this approach yielded the best balance between keeping as many isolates as possible in the training dataset, leading to more accuracy, and striving for little bias.
In conclusion, CarbaDetector is, to the best of our knowledge, the first AI-based open-access web-app to predict the production of carbapenemases in Enterobacterales isolates based on inhibition zones. The model combines the accuracy of sophisticated data analysis with the applicability of a simple algorithm and is thus a powerful tool in Enterobacterales analysis. It is easy-to-use and its application in the routine laboratory could help make informed decisions on whether or not isolates need to be further tested for carbapenemases.
For the further development, we will include more isolates with different species and resistance mechanisms, making the prediction even more accurate. With a larger collection including a greater variety of species and carbapenemase types including isolates from different locations globally, we are confident that future versions of CarbaDetector can also be applied to predict which category carbapenemase is present in an isolate, potentially further decreasing the need for confirmatory tests. Moreover, we are planning to include more antibiotics in future testing of the isolates, to further improve usability of the model.
Methods
Strain collection
This study comprised 385 non-duplicate clinical Enterobacterales isolates, collected from 2012 to 2021 at the University Hospital Cologne and Klinikum Oldenburg in routine diagnostics. Species identity was determined using MALDI-TOF mass spectrometry and confirmed by whole genome sequencing (WGS). Of all isolates, 238 (61.8%) were carbapenemase producers, 147 (38.2%) were carbapenemase-negative. Molecular characterization of all isolates was performed by WGS on the Illumina platform, as previously described21. Briefly, DNA was extracted from pure bacterial cultures using the DNeasy UltraClean Microbial Kit (Qiagen, Hilden, Germany). Whole genome sequencing was performed by Novogene (Beijing, China). Genomic DNA libraries were prepared with the Novogene NGS DNA Library Prep Set with an average insert size of 350 bp, followed by paired-end 150 bp sequencing on an Illumina NovaSeq platform (Illumina, San Diego, CA, USA). Presence or absence of carbapenemase genes was confirmed using ResFinder v4.7.222,23. The results of molecular characterization were used as reference standard to evaluate the algorithm performance. Six species constituted 88.8% of the isolates, namely K. pneumoniae, E. coli, C. freundii, E. cloacae, P. mirabilis and S. marcescens. The most frequent carbapenemase group present was blaOXA-48-like (46.6%). Detailed characteristics of isolates and datasets is provided in the Supplementary Information.
Susceptibility testing
Susceptibility testing was performed at the Institute of Medical Microbiology and Virology, University Oldenburg according to EUCAST standards20, employing disks containing meropenem, ertapenem, imipenem, meropenem-vaborbactam, ceftazidime-avibactam, ceftolozane-tazobactam, temocillin (Oxoid, Basingstoke, UK), and imipenem-relebactam (Mast Group, Merseyside, UK) on Mueller-Hinton agar (Oxoid, Basingstoke, UK). Inhibition zones were measured manually.
Assessing the performance of the novel CA-SFM algorithm and the EUCAST screening process
To set the baseline for our model, we assessed the CA-SFM algorithm and the EUCAST screening algorithm for carbapenemase detection by applying it to all three datasets, using WGS results as ground truth. To develop a universal algorithm using R (rpart (4.1.24) and RandomForest (4.7.1.2) packages24,25), we built a decision tree and a random forest model using (i) species and the standard-scaled inhibition zone diameters and (ii) additionally a random forest model using the scaled differences in inhibition zone diameters. The differences in inhibition zone diameters (instead of only the raw diameters) were included once per antibiotics pair in order to compensate for laboratory-specific differences between measurements. To increase sensitivity, several cutoffs (0.5, 0.6, 0.7, 0.75) in the random forest model classification were assessed, with the final cutoff being 0.6, meaning that samples were predicted as “negative”, if a probability of more than 60% was determined, as opposed to the default 50%.
To estimate model performance, we employed nested cross-validation with 10 outer and 10 inner folds using the nestedcv R package26. Where possible, sampling was stratified for species and presence of carbapenemase genes. Class weights were applied to address the imbalanced distribution between carbapenemase negative and positive samples.
After estimating the performance on our own dataset (Supplementary Data 1), the final model was trained on the whole dataset with hyperparameter tuning via 10-fold cross-validation and applied to the external datasets for additional validation.
Validation of our algorithm using external datasets
To further validate the trained model and its correct prediction of CPE, the resulting model (CarbaDetector) has been used firstly to predict carbapenemase production on a set of 282 Enterobacterales isolates from Switzerland (University of Zurich) with and without carbapenemase production (external dataset A, included in Supplementary Data 2). For this dataset, inhibition zone diameters for all eight antibiotics used in the algorithm were determined.
Secondly, prediction of carbapenemase production on incomplete datasets (where not all eight recommended antibiotic disks were used) was tested on a different, previously published dataset containing the disk diffusion diameters of 518 Enterobacterales isolates submitted for carbapenemase testing to the French reference laboratory for multidrug-resistant Gram-negatives (external dataset B, included in Supplementary Data 3, originally used for the assessment of the CA-SFM algorithm16). Here, the diameters were measured using SIRscan and verified manually. Using the inhibition zone diameters for ertapenem, meropenem, imipenem, temocillin, and ceftazidim-avibactam, we imputed the missing values for imipenem-relebactam, meropenem-vaborbactam, and ceftolozane-tazobactam based on our dataset applying the missRanger R package27. Then, using the built model, the presence or absence of carbapenemase production was predicted. Information on statistical analyses and the development of the app can be found in the Supplementary Information.
Ethics approval
The bacterial strains were isolated during routine diagnostics and anonymized. As no patient data were analyzed, ethical approval was not required for this type of study according to §15 of the professional code for physicians.
Reporting summary
Further information on research design is available in the Nature Portfolio Reporting Summary linked to this article.
Data availability
The inhibition zone measurement data as well as application of EUCAST, CA-SFM and CarbaDetector are available as source datasets and included in the Supplementary Information.
Code availability
Model code is available in the associated CodeOcean capsule: https://codeocean.com/capsule/8305077/tree.
References
World Health Organization. WHO Bacterial Priority Pathogens List 12–13 (World Health Organization, 2024).
Mestrovic, T. et al. The burden of bacterial antimicrobial resistance in the WHO European region in 2019: a cross-country systematic analysis. Lancet Public Health 7, e897–e913 (2022).
Hughes, S., Gilchrist, M., Heard, K., Hamilton, R. & Sneddon, J. Treating infections caused by carbapenemase-producing Enterobacterales (CPE): a pragmatic approach to antimicrobial stewardship on behalf of the UKCPA Pharmacy Infection Network (PIN). JAC-Antimicrob. Resist. 2, https://doi.org/10.1093/jacamr/dlaa075 (2020).
Giske, C. G. et al. EUCAST guidelines for detection of resistance mechanisms and specific resistances of clinical and/or epidemiological importance. European Committee on Antimicrobial Susceptibility Testing. 4–11 https://www.eucast.org/fileadmin/eucast/pdf/eucast_guidelines/EUCAST_detection_of_resistance_mechanisms_170711.pdf (2013).
Sattler, J., Brunke, A. & Hamprecht, A. Systematic comparison of three commercially available combination disc tests and the zinc-supplemented carbapenem inactivation method (zcim) for carbapenemase detection in Enterobacterales isolates. J. Clin. Microbiol. 59, e0314020 (2021).
Probst, K. et al. Molecular detection of carbapenemases in enterobacterales: a comparison of real-time multiplex PCR and whole-genome sequencing. Antibiotics 10, https://doi.org/10.3390/antibiotics10060726 (2021).
Dortet, L., Poirel, L. & Nordmann, P. Rapid identification of carbapenemase types in Enterobacteriaceae and Pseudomonas spp. by using a biochemical test. Antimicrob. Agents Chemother. 56, 6437–6440 (2012).
Nordmann, P., Poirel, L. & Dortet, L. Rapid detection of carbapenemase-producing Enterobacteriaceae. Emerg. Infect. Dis. 18, 1503–1507 (2012).
van der Zwaluw, K. et al. The carbapenem inactivation method (CIM), a Simple and low-cost alternative for the Carba NP test to assess phenotypic carbapenemase activity in gram-negative rods. PLoS ONE 10, e0123690 (2015).
Hrabák, J. et al. Detection of NDM-1, VIM-1, KPC, OXA-48, and OXA-162 carbapenemases by matrix-assisted laser desorption ionization–time of flight mass spectrometry. J. Clin. Microbiol. 50, 2441–2443 (2020).
Lasserre, C. et al. Efficient detection of carbapenemase activity in enterobacteriaceae by matrix-assisted laser desorption ionization-time of flight mass spectrometry in less than 30 minutes. J. Clin. Microbiol 53, 2163–2171 (2015).
Koroska, F. et al. Comparison of phenotypic tests and an immunochromatographic assay and development of a new algorithm for detection of OXA-48-like carbapenemases. J. Clin. Microbiol 55, 877–883 (2017).
Boyd Sara, E., Holmes, A., Peck, R., Livermore David, M. & Hope, W. OXA-48-Like β-lactamases: global epidemiology, treatment options, and development pipeline. Antimicrob. Agents Chemother. 66, e00216–00222 (2022).
Hamprecht, A. et al. Proteus mirabilis—analysis of a concealed source of carbapenemases and development of a diagnostic algorithm for detection. Clin. Microbiol. Infect. 29, 1198.e1191–1198.e1196 (2023).
Société Française de Microbiologie (SFM). Comité de l’antibiogramme de la société française de microbiologie recommandations 2023 v1.0 juin. (2022).
Duque, M., Bonnin, R. A. & Dortet, L. Evaluation of the French novel disc diffusion-based algorithm for the phenotypic screening of carbapenemase-producing Enterobacterales. Clin. Microbiol. Infect. 30, 397.e391–397.e394 (2024).
Giske Christian, G. et al. GPT-4-based AI agents—the new expert system for detection of antimicrobial resistance mechanisms?. J. Clin. Microbiol. 62, e00689–00624 (2024).
Gato, E. et al. Direct detection of carbapenemase-producing Klebsiella pneumoniae by MALDI-ToF analysis of full spectra applying machine learning. J. Clin. Microbiol. 61, e01751–01722 (2023).
Lin, T.-H. et al. Artificial intelligence-clinical decision support system for enhanced infectious disease management: accelerating ceftazidime-avibactam resistance detection in Klebsiella pneumoniae. J. Infect. Public Health 17, 102541 (2024).
EUCAST. Antimicrobial susceptibility testing EUCAST disk diffusion method. Version 13.0. (2025).
Hamprecht, A. et al. Pathogenicity of clinical OXA-48 isolates and impact of the OXA-48 IncL plasmid on virulence and bacterial fitness. Front. Microbiol. 10, 2509 (2019).
Bortolaia, V. et al. ResFinder 4.0 for predictions of phenotypes from genotypes. J. Antimicrob. Chemother. 75, 3491–3500 (2020).
Camacho, C. et al. BLAST+: architecture and applications. BMC Bioinforma. 10, 421 (2009).
Therneau, T., Atkinson, B., Ripley, B. & Ripley, M. B. Package ‘rpart’. Available online: cran. ma. ic. ac. uk/web/packages/rpart/rpart. pdf (accessed on 20 April 2016) (2015).
Breiman, L. Random forests. Mach. Learn. 45, 5–32 (2001).
Lewis, M. J. et al. nestedcv: an R package for fast implementation of nested cross-validation with embedded feature selection designed for transcriptomics and high-dimensional data. Bioinform. Adv. 3, vbad048 (2023).
Mayer, M. missRanger: fast imputation of missing values. https://github.com/mayer79/missRanger (2025).
Acknowledgements
We thank Dr. Chantal Quiblier, Natalia Kolesnik-Goldmann, Yukino Gütlin and Natalia Kolesnik-Goldmann from the Institute of Medical Microbiology at the University of Zurich for extraction of data.
Funding
Open Access funding enabled and organized by Projekt DEAL.
Author information
Authors and Affiliations
Contributions
Conceptualization: L.K.M., A.H. Methodology: L.K.M., J.S. Software: L.K.M. Formal Analysis: L.K.M. Investigation: C.C., L.T. Resources: A.H., O.N., L.D., R.A.B., A.E. Writing—Original Draft: L.K.M., C.C., A.H. Writing—Review and Editing: L.K.M., C.C., J.S., O.N., L.D., R.A.B., A.E., A.H. Visualization: L.K.M. Supervision: A.H. Funding Acquisition: A.H.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Peer review
Peer review information
Nature Communications thanks Edoardo Carretto and Gerald Mboowa, for their contribution to the peer review of this work. A peer review file is available.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Muhsal, L.K., Cimen, C., Sattler, J. et al. CarbaDetector: a machine learning model for detecting carbapenemase-producing Enterobacterales from disk diffusion tests. Nat Commun 16, 10023 (2025). https://doi.org/10.1038/s41467-025-66183-z
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41467-025-66183-z
