
Abstract
How physical neuronal networks, bound by spatio-temporal locality constraints, can perform efficient credit assignment, remains an intriguing question. Both backward- and forward-propagation algorithms rely on assumptions that violate this locality in various ways. We introduce Generalized Latent Equilibrium (GLE), a framework for fully local spatio-temporal credit assignment in physical, dynamical neuronal networks. From an energy based on neuron-local mismatches, we derive neuronal dynamics via stationarity and parameter dynamics as gradient descent. The result is an online approximation of backpropagation through space and time in deep networks of cortical microcircuits with continuously active, local synaptic plasticity. GLE exploits dendritic morphology to enable complex information storage and processing in single neurons, as well as their ability to react in anticipation of their future input. This “prospective coding” enables the computation of spatio-temporal convolutions in the forward direction and the approximation of adjoint variables in the backward stream.
Similar content being viewed by others
Introduction
The world in which we have evolved appears to lie in a Goldilocks zone of complexity: it is rich enough to produce organisms that can learn, yet also regular enough to be learnable by these organisms in the first place. Still, regular does not mean simple; the need to continuously interact with and learn from a dynamic environment in real-time faces these agents—and their nervous systems—with a challenging task.
One can view the general problem of dynamical learning as one of constrained minimization, i.e., with the goal of minimizing a behavioral cost with respect to some learnable parameters (such as synaptic weights) within these nervous systems, under constraints given by their physical characteristics. For example, in the case of biological neuronal networks, such dynamical constraints may include leaky integrator membranes and nonlinear output filters. The standard approach to this problem in deep learning (DL) uses stochastic gradient descent, coupled with some type of automatic differentiation (AD) algorithm that calculates gradients via reverse accumulation1,2. These methods are well-known to be highly effective and flexible in their range of applications.
If the task is time-independent, or can be represented as a time-independent problem, the standard error backpropagation (BP) algorithm provides this efficient backward differentiation3,4,5. We refer to this class of problems as spatial, as opposed to more complex spatio-temporal problems, such as sequence learning. For the latter, the solution to constrained minimization can be sought through a variety of methods. When the dynamics are discrete, the most commonly used method is backpropagation through time (BPTT)6,7. For continuous-time problems, optimization theory provides a family of related methods, the most prominent being the adjoint method (AM)8, Pontryagin’s maximum principle9,10, and the Bellman equation11.
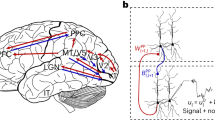
AM and BPTT have proven to be very powerful methods, but it is not clear how they could be implemented in physical neuronal systems that need to function and learn continuously, in real time, and using only information that is locally available at the constituent components12. Learning through AM/BPTT cannot be performed in real time, as it is only at the end of a task that errors and parameter updates can be calculated retrospectively (Fig. 1). This requires either storing the entire trajectory of the system (i.e., for all of its dynamical variables) until a certain update time, and/or recomputing the necessary variables during backward error propagation. While straightforward to do in computer simulations (computational and storage inefficiency notwithstanding), a realization in physical neuronal systems would require a lot of additional, complex circuitry for storage, recall and (reverse) replay. Additionally, it is unclear how useful errors can be represented and transmitted in the first place, i.e., which physical network components calculate errors that correctly account for the ongoing dynamics of the system, and how these then communicate with the components that need to change during learning (e.g., the synapses in the network). It is for these reasons that AM/BPTT sits firmly within the domain of machine learning (ML), and is largely considered not applicable for physical neuronal systems, both biological and artificial. (We use the term neuronal to differentiate between physical, time-continuous dynamical networks of neurons and their abstract, time-discrete artificial neural network (ANN) counterparts).

a To illustrate the different learning algorithms, we consider three neurons within a larger recurrent network. The neuron indices are indicative of the distance from the output, with neuron i + 1 being itself an output neuron, and therefore having direct access to an output error ei+1. b Information needed by a deep synapse at time t to calculate an update \({\dot{w}}_{i-1,k}^{(t)}\). Orange: future-facing algorithms such as BPTT require the states \({r}_{n}^{({t}^{+})}\) of all future times t+ and all neurons n in the network and can therefore only be implemented in an offline fashion. These states are required to calculate future errors \({e}_{n}^{({t}^{+})}\), which are then propagated back in time into present errors \({e}_{n}^{(t)}\) and used for synaptic updates \({\dot{w}}_{i-1,k}^{(t)}\propto {e}_{i-1}^{(t)}{r}_{k}^{(t)}\). Purple: past-facing algorithms, such as RTRL, store past effects of all synapses \({w}_{jk}^{({t}^{-})}\) on all past states \({r}_{n}^{({t}^{-})}\) in an influence tensor \({M}_{n,j,k}^{({t}^{-})}\). This tensor can be updated online and used to perform weight updates \({\dot{w}}_{i-1,k}^{(t)}\propto {\sum}_{n}{e}_{n}^{(t)}{M}_{n,i-1,k}^{(t)}\). Note that all synapse updates need to have access to distant output errors. Furthermore, the update of each element in the influence tensor requires the knowledge of distant elements and is thus itself nonlocal in space. Green: GLE operates exclusively on present states \({r}_{n}^{(t)}\). It uses them to infer errors \({e}_{n}^{(t)}\) that approximate the future backpropagated errors of BPTT.
Instead, theories of biological (or bio-inspired) spatio-temporal learning focus on other methods, either by using reservoirs and foregoing the learning of deep weights altogether, or by using direct and instantaneous output error feedback, transmitted globally to all neurons in the network, as in the case of FORCE13 and FOLLOW14. Alternatively, the influence of synaptic weights on neuronal activities can be carried forward in time and associated with instantaneous errors, as proposed in real-time recurrent learning (RTRL)15. While thereby having the advantage of being temporally causal, RTRL still violates locality, as this influence tensor relates all neurons to all synapses in the network, including those that lie far away from each other (Fig. 1). The presence of this tensor also incurs a much higher memory footprint (cubic scaling for RTRL vs. linear scaling for BPTT), which quickly becomes prohibitive for larger-scale applications in ML. Various approximations of RTRL alleviate some of these issues16, but only at the cost of propagation depth. We return to these methods in the Discussion, as our main focus here is AM/BPTT.
Indeed, and contrary to prior belief, we suggest that physical neuronal systems can approximate BPTT very efficiently and with excellent functional performance. More specifically, we propose the overarching principle of generalized latent equilibrium (GLE) to derive a comprehensive set of equations for inference and learning that are local in both time and space (Fig. 1). These equations fully describe a dynamical system running in continuous time, without the need for separate phases, and undergoing only local interactions. Moreover, they describe the dynamics and morphology of structured neurons performing both retrospective integration of past inputs and prospective estimation of future states, as well as the weight dynamics of error-correcting synapses, thus linking to experimental observations of cortical dynamics and anatomy. Due to its manifest locality and reliance on rather conventional analog components, our framework also suggests a blueprint for powerful and efficient neuromorphic implementation.
We thus propose a new solution for the spatio-temporal credit assignment problem in physical neuronal systems, with substantial advantages over previously proposed alternatives. Importantly, our framework does not differentiate between spatial and temporal tasks and can thus be readily used in both domains. As it represents a generalization of latent equilibrium (LE)17, a precursor framework for bio-plausible, but purely spatial computation and learning, it implicitly contains (spatial) BP as a subcase. For a more detailed comparison to LE, see section “Discussion”.
This manuscript is structured as follows: In section “The GLE framework”, we first propose a set of four postulates from which we derive network structure and dynamics. This is strongly inspired by approaches in theoretical physics, where a specific energy function provides a unique reference from which everything else about the system can be derived. We then discuss the link to AM/BPTT in section “GLE dynamics implement a real-time approximation of AM/BPTT”. Additionally, we show how our framework describes physical networks of neurons, with implications for both cortex and hardware (section “Cortical/neuromorphic circuits”). Subsequently, we discuss various applications, from small-scale setups that allow an intuitive understanding of our network dynamics (section “A minimal GLE example” and section “Small GLE networks”), to larger-scale networks capable of solving difficult spatio-temporal classification problems (section “Challenging spatio-temporal classification”) and chaotic time series prediction (section “Chaotic time series prediction”). Finally, we elaborate on the connections and advantages of our framework when compared to other approaches in section “Discussion”.
Results
The GLE framework
At the core of our framework is the realization that biological neurons are capable of performing two fundamental temporal operations. First, as is well-known, neurons perform temporal integration in the form of low-pass filtering. We describe this as a “retrospective” operation and denote it with the operator
where τm represents the membrane time constant and x the synaptic input.
The second temporal operation is much less known but well-established physiologically18,19,20,21,22,23: neurons are capable of performing temporal differentiation, an inverse low-pass filtering that phase-shifts inputs into the future, which we thus name “prospective” and denote with the operator
The time constant τr is associated with the neuronal output rate, which, rather than being simply φ(u) (with u the membrane potential and φ the neuronal activation function), takes on the prospective form \(r=\varphi ({{{\mathcal{D}}}}_{{\tau }^{{{\rm{r}}}}}^{+}\{u\})\).
In brief, this prospectivity can arise from two distinct mechanisms. On one hand, it follows as a direct consequence of the output nonlinearity in spiking neurons21. In more complex neurons that are capable of bursting, the input slope also directly affects the spiking output24. On the other hand, prospectivity appears when the neuronal membrane (alternatively but equivalently, its leak potential or firing threshold) is negatively coupled to an additional retrospective variable. Such variables include, for example, the inactivation of sodium channels, or slow adaptation (both spike frequency and subthreshold) currents22,23, thus giving neurons access to a wide range of prospective horizons. For more detailed, intuitive explanations of these mechanisms, we refer to the Supplement, section “Biological mechanisms of prospectivity”. For a more technical discussion of prospectivity in neurons with adaptation currents, we refer to section “Prospectivity through adaptation” in the Methods. We also note that in analog neuromorphic hardware, adaptive neurons are readily available25,26,27,28, but a direct implementation of an inverse low-pass filter would evidently constitute an even simpler and more efficient solution.
Importantly, the retrospective and prospective operators \({{{\mathcal{I}}}}_{{\tau }^{{{\rm{m}}}}}^{-}\) and \({{{\mathcal{D}}}}_{{\tau }^{{{\rm{r}}}}}^{+}\) have opposite effects; in particular, for τm = τr, they are exactly inverse, which forms the basis of LE17. In that case, the exact inversion of the low-pass filtering allows the network to react instantaneously to a given input, which can solve the relaxation problem for spatial tasks. However, this exact inversion also precludes the use of neurons for explicit temporal processing in spatio-temporal tasks, which represents the main focus of this work.
We can now define the GLE framework as a set of four postulates, from which the entire network structure and dynamics follow. The postulates use these operators to describe how forward and backward prospectivity work in biological neuronal networks. As we show later, the dynamical equations derived from these postulates approximate the equations derived from AM/BPTT, but without violating causality, with only local dependencies and without the need for learning phases.
Postulate 1
The canonical variables describing neuronal network dynamics are \({{{\mathcal{D}}}}_{{\tau }_{i}^{{{\rm{m}}}}}^{+}\{{u}_{i}(t)\}\) and \({{{\mathcal{D}}}}_{{\tau }_{i}^{{{\rm{r}}}}}^{+}\{{u}_{i}(t)\}\), where each neuron is denoted with the subscript i ∈ {1,…,n}.
This determines the relevant dynamical variables for the postulates below. They represent, respectively, the prospective voltages with respect to the membrane and rate time constants. Importantly, each neuron i can in principle have its own time constants \({\tau }_{i}^{x}\), and the two are independent, so in general \({\tau }_{i}^{{{\rm{m}}}}\,\ne \,{\tau }_{i}^{{{\rm{r}}}}\). This is in line with the biological mechanisms for retro- and prospectivity, which are also unrelated, as discussed above.
Postulate 2
A neuronal network is fully described by the energy function
where \({e}_{i}(t)={{{\mathcal{D}}}}_{{\tau }_{i}^{{{\rm{m}}}}}^{+}\{{u}_{i}(t)\}-{\sum}_{j}{W}_{ij}\varphi ({{{\mathcal{D}}}}_{{\tau }_{j}^{{{\rm{r}}}}}^{+}\{{u}_{j}(t)\})-{b}_{i}\) is the mismatch error of neuron i. Wij and bi respectively denote the components of the weight matrix and bias vector, φ the output nonlinearity and β a scaling factor for the cost. The cost function C(t) is usually defined as a function of the rate and hence of \({{{\mathcal{D}}}}_{{\tau }_{i}^{{{\rm{r}}}}}^{+}\{{u}_{i}\}\) of some subset of output neurons.
This approach is inspired by physics and follows a time-honored tradition in ML, dating back to Boltzmann machines29 and Hopfield networks30 as well as computational neuroscience models, such as, e.g., Equilibrium Propagation31 and predictive coding frameworks32. The core idea of these approaches is to define a specific energy function that provides a unique reference from which everything else follows. In physics, this is the Hamiltonian, from which the dynamics of the system can be derived; in our case, it is a measure of the “internal tension” of the network, from which we derive the dynamics of the network and its parameters. Under the weak assumption that the cost function can be factorized, this energy is simply a sum over neuron-local energies \({E}_{i}(t)=\frac{1}{2}{e}_{i}^{2}(t)+\beta {C}_{i}(t)\). Each of these energies represent a difference between a neuron’s own prospective voltage, i.e., what membrane voltage the neuron predicts for its near future (\({{{\mathcal{D}}}}_{{\tau }_{i}^{{{\rm{m}}}}}^{+}\{{u}_{i}(t)\}\)), and what its functional afferents (and bias) expect it to be (\({\sum}_{j}{W}_{ij}\varphi ({{{\mathcal{D}}}}_{{\tau }_{j}^{{{\rm{r}}}}}^{+}\{{u}_{j}(t)\})+{b}_{i}\)), with the potential addition of a teacher nudging term for output neurons that is related to the cost that the network seeks to minimize (βCi(t)).
Postulate 3
Neuron dynamics follow the stationarity principle
As the two rates of change (the partial derivatives) are with respect to prospective variables, with temporal advances determined by τm and τr, they can be intuitively thought of as representing quantities that refer to different points in the future—loosely speaking, at t + τm and t + τr. To compare the two rates of change on equal footing, they need to be pulled back into the present by their respective inverse operators \({{{\mathcal{I}}}}_{{\tau }^{{{\rm{m}}}}}^{-}\) and \({{{\mathcal{I}}}}_{{\tau }^{{{\rm{r}}}}}^{-}\). It is the equilibrium of this mathematical object, otherwise not immediately apparent (hence: “latent”) from observing the network dynamics themselves (see below), that gives our framework its name. It is also easy to check that for the special case of \({\tau }_{i}^{{{\rm{m}}}}={\tau }_{i}^{{{\rm{r}}}}\quad \forall i\), GLE reduces to LE17—hence the ‘generalized’ nomenclature.
Postulate 4
Parameter dynamics follow gradient descent (GD) on the energy
with individual learning rates ηθ.
Parameters include θ = {W, b, τm, τr}, with boldface denoting matrices, vectors, and vector-valued functions. These parameter dynamics are the equivalent of plasticity, both for synapses (Wij) and for neurons (\({b}_{i},{\tau }_{i}^{{{\rm{m}}}},{\tau }_{i}^{{{\rm{r}}}}\)). The intuition behind this set of postulates is illustrated in Fig. 2. Without an external teacher, the network is unconstrained and simply follows the dynamics dictated by the input; as there are no errors, both cost C and energy E are zero. As an external teacher appears, errors manifest and the energy landscape becomes positive; its absolute height is scaled by the coupling parameter β. While neuron dynamics \(\dot{u}\) trace trajectories across this landscape, plasticity \(\dot{\theta }\) gradually reduces the energy along these trajectories (cf. Fig. 2). Thus, during learning, the energy landscape (more specifically, those parts deemed relevant by the task of the network, lying on the state subspace traced out by the trajectories during training) is gradually lowered, as illustrated by the faded surface. Ultimately, after learning, the energy will ideally be pulled down to zero, thus implicitly also reducing the cost, because it is a positive, additive component of the energy. Beyond this implicit effect, we later show how the network dynamics derived from these postulates also explicitly approximate gradient descent on the cost.

Network dynamics define trajectories (black) in the cost/energy landscape, spanned by external inputs I and neuron outputs r. Parameter updates (red, here: synaptic weights) reduce the cost/energy along these trajectories. a AM records the trajectory between two points in time and calculates the total update ΔW that reduces the integrated cost along this trajectory. b GLE calculates an approximate cost gradient at every point in time, by taking into account past network states (via retrospective coding, \({{{\mathcal{I}}}}_{\tau }^{-}\)) and estimating future errors from the current state (via prospective coding, \({{{\mathcal{D}}}}_{\tau }^{+}\)). Learning is thus fully online and can gradually reduce the energy in real-time, with the (real) trajectory slowly dropping away from the (virtual) trajectory of a network that is not learning (dashed line).
The four postulates above fully encapsulate the GLE framework. From here, we can now take a closer look at the network dynamics and see how they enable the sought transport of signals to the right place and at the right time.
Network dynamics
With our postulates at hand, we can now infer dynamical and structural properties of neuronal networks that implement GLE. We first derive the neuronal dynamics by applying the stationarity principle (Postulate 3, Eqn. (4)) to the energy function (Postulate 2, Eqn. (3)):
where \(\varphi^{{\prime}}_{i}\) is a shorthand for the derivative of the activation function evaluated at \({{{\mathcal{D}}}}_{{\tau }_{i}^{{{\rm{r}}}}}^{+}\{{u}_{i}\}\). For a detailed derivation, we refer to section “Derivation of the network dynamics” in the Methods. This is very similar to conventional leaky integrator dynamics, except for two important components: first, the use of the prospective operator for the neuronal output, which we already connected to the dynamics of biological neurons above, and second, the additional error term. With this, we have two complementary representations for the error term ei. First, as mismatch between the prospective voltage and the basal inputs (cf. Eqn. (3)), describing how errors couple two membranes, and second, as a function of other errors ej, as given by the error propagation equation (cf. Eqn. (6)). Thus, in the GLE framework, a single neuron performs four operations in the following order: (weighted) sum of presynaptic inputs, integration (retrospective), differentiation (prospective), and the output nonlinearity. The timescale associated with retrospectivity is the membrane time constant τm, whereas prospectivity is governed by τr. This means that even if the membrane time constant is fixed, as may be the case for certain neuron classes or models thereof, single neurons can still tune the time window to which they attend by adapting their prospectivity. This temporal attention window can lie in the past (retrospective neurons, τr < τm), in the present (instantaneous neurons, τr = τm, as described by LE), but also in the future (prospective neurons, τr > τm). These neuron classes can, for example, be found in cortex33,34 and hippocampus35,36; for a corresponding modeling study, we refer to ref. 23. The prospective capability becomes essential for error propagation, as we discuss below, while the use of different attention windows allows the learning of complex spatio-temporal patterns, as we show in action in later sections. Note that for τr = 0, we recover classical leaky integrator neurons as a special case of our framework.
Eqn. (6) also suggests a straightforward interpretation of neuronal morphology and its associated functionality. In particular, it suggests that separate neuronal compartments store different variables: a somatic compartment for the voltage ui, and two dendritic compartments for integrating \({\sum}_{j}\,{W}_{ij}\,{r}_{j}\) and ei, respectively. This separation also gives synapses access to these quantities, as we discuss later on. Further below, we also show how this basic picture extends to a microcircuit for learning and adaptation in GLE networks.
The error terms in GLE also naturally include prospective and retrospective operators. As stated in Postulate 2 (Eqn. (3)), the total energy of the system is a sum over neuron-local energies. If we now consider a hierarchical network, these terms can be easily rearranged into the form (see Methods and SI for a detailed derivation)
where ℓ denotes the network layer and \({\varphi }^{{\prime}}\) denotes the derivative of φ evaluated at \({{{{\boldsymbol{{\mathcal{D}}}}}}}_{{{\boldsymbol{\tau}}}^{{{\rm{r}}}}}^{+}\{{{{\boldsymbol{u}}}}_{\ell }\}\). In this form, the connection to BP algorithms becomes apparent. For τr = τm, the operators cancel and Eqn. (7) reduces to the classical (spatial) error BP algorithm, as already studied in ref. 17. When τr ≠ τm, however, the error exhibits a switch between the two time constants when compared to the forward neuron dynamics (Eqn. (6)): whereas forward rates are retrospective with τm and prospective with τr, backward errors invert this relationship. In other words, backward errors invert the temporal shifts induced by forward neurons. As we discuss in the following section, it is precisely this inversion that enables the approximation of AM/BPTT.
As for the neuron dynamics, parameter dynamics also follow from the postulates above. For example, synaptic plasticity is obtained by applying the gradient descent principle (Postulate 4, Eqn. (5) with respect to synaptic weights W) to the energy function (Postulate 2, Eqn. (3)):
where \({v}_{i}={\sum}_{j}\,{W}_{ij}\,{r}_{j}\) is the membrane potential of the dendritic compartment that integrates bottom-up synaptic inputs. Such three-factor error-correcting rules have often been discussed in the context of biological DL (see ref. 37 for a review). For a more detailed biological description of our specific type of learning rule, we refer to ref. 38. Notice that parameter learning is neuron-local, and that we are performing GD explicitly on the energy E, and only implicitly on the cost C. This is a quintessential advantage of the energy-based formalism, as the locality of GLE dynamics is a direct consequence of the locality of the postulated energy function. This helps provide the physical and biological plausibility that other methods lack. In the section “Cortical/neuromorphic circuits”, we discuss how GLE dynamics relate to physical neuronal networks and cortical circuits, but first, we show how these dynamics effectively approximate AM/BPTT.
GLE dynamics implement a real-time approximation of AM/BPTT
The learning capabilities of GLE arise from the specific form of the errors encapsulated in the neuron dynamics, which make the similarity to AM/BPTT apparent, as discussed below. For a detailed derivation of the following relationships, we refer to Methods and the SI.
Just like in GLE, learning in AM/BPTT is error-correcting:
where the continuous-time adjoint variables λ in AM are equivalent to the time-discrete errors in BPTT. While typically calculated in reverse time, as for the backpropagated errors in BPTT, for the specific dynamics of cost-decoupled GLE networks (β = 0 ⇒ e = 0 ⇒ E = 0), it is possible to write the adjoint dynamics in forward time as follows:
Here, we use adjoint operators \({{{\mathcal{D}}}}_{\tau }^{-}\{x(t)\}=\left(1-\tau \frac{\,{{\mbox{d}}}}{{{\mbox{d}}}t}\right)x(t)\) and \({{{\mathcal{I}}}}_{\tau }^{+}\{x(t)\}=\frac{1}{\tau }\int_{t}^{\infty }x(s)\,{e}^{\frac{t-s}{\tau }}\,\,{{\mbox{d}}}s\) to describe the hierarchical coupling of the adjoint variables. We note that the adjoint dynamics (Eqn. (10)) can also be derived in our GLE framework by simply replacing \({{{\mathcal{I}}}}_{{\tau }_{i}^{{\mathrm{m}}}}^{-}\) with \({{{\mathcal{D}}}}_{{\tau }_{i}^{{\mathrm{m}}}}^{-}\) in Postulate 3.
Note the obvious similarity between Eqns. (10) and (7). The inner term \({{\bf{\varphi}}}^{{\prime}}_{\ell }\circ {{{\boldsymbol{W}}}}_{\ell+1}^{{{\rm{T}}}}{{{\boldsymbol{\lambda }}}}_{\ell+1}\) is identical and describes backpropagation through space. The outer operators perform the temporal backpropagation, enacting the exact opposite temporal operations compared to the representation neurons (first retrospective with τr then prospective with τm, cf. Eqn. (6)).
The intuition is as follows. Training ANN on sequential data usually requires unrolling the network in time and then backpropagating errors via AM/BPTT, as given by the adjoint equations (Eqn. (7)). However, these adjoint equations effectively operate in reverse time, i.e., are nonlocal in time and thus not applicable for real-time learning in physical neuronal systems. This nonlocality (noncausality) is due to the operator \({{{\mathcal{I}}}}_{\tau }^{+}\), which effectively calculates an integral over the future. (The operator \({{{\mathcal{D}}}}_{\tau }^{-}\) is unproblematic in this regard.) By replacing \({{{\mathcal{I}}}}_{\tau }^{+}\) by \({{{\mathcal{D}}}}_{\tau }^{+}\), GLE solves the noncausality problem. This of course happens at the expense of precision, because the extrapolation carried out by \({{{\mathcal{D}}}}_{\tau }^{+}\) cannot look arbitrarily far into the future. Still, \({{{\mathcal{D}}}}_{\tau }^{+}\) maintains much of the computation performed by \({{{\mathcal{I}}}}_{\tau }^{+}\) in Fourier space, as discussed below. The GLE framework further replaces \({{{\mathcal{D}}}}_{\tau }^{-}\) by \({{{\mathcal{I}}}}_{\tau }^{-}\). This is not an algorithmic necessity, as \({{{\mathcal{D}}}}_{\tau }^{-}\) is fully local in time, but the resulting dynamics map nicely to the retrospective component of biologically observed neuronal membrane dynamics, which are better described as leaky integrators rather than negative differentiators.
How GLE can perform an online approximation of AM/BPTT is best seen in frequency space, where we can analyze how the combined temporal operators affect individual Fourier components (see also Fig. 3). For a single such component—a sine wave input of fixed angular frequency ω—each operator causes a temporal (phase) shift: the retrospective operator \({{{\mathcal{I}}}}_{\tau }^{-}\) causes a shift of the input signal towards later times, while the prospective operator causes an inverse shift towards earlier times. These phase shifts are exactly equal to those generated by the adjoint operators \({{{\mathcal{D}}}}_{\tau }^{-}\) and \({{{\mathcal{I}}}}_{\tau }^{+}\). Therefore, in terms of temporal shift, the GLE errors are perfect replicas of the adjoint variables derived from exact GD; this is the most important part of the temporal backpropagation in AM.

a Effect of the individual and combined GLE operators \({{{\mathcal{I}}}}_{\tau }^{-}\) and \({{{\mathcal{D}}}}_{\tau }^{+}\) with shared time constant τ on a single frequency component of an input current I. \({{{\mathcal{I}}}}_{\tau }^{-}\) generates a negative phase shift (towards later times) and sub-unit gain. \({{{\mathcal{D}}}}_{\tau }^{+}\) is its exact inverse and generates a positive phase shift (towards earlier times) and supra-unit gain. b Phase shift and c gain of all four temporal operators in GLE and AM/BPTT across a wide range of the frequency spectrum. Note how the prospective operators \({{{\mathcal{D}}}}_{\tau }^{+}\) and \({{{\mathcal{I}}}}_{\tau }^{+}\) (orange) have the same shift but inverse gain; the same holds for the retrospective operators \({{{\mathcal{I}}}}_{\tau }^{-}\) and \({{{\mathcal{D}}}}_{\tau }^{-}\) (purple). d Phase shift and e gain of the combined operators as they appear in the neuron dynamics. Here, we choose an example forward neuron (blue) with a retrospective attention window (τm = 10τr). Both the associated GLE errors e (blue) and the adjoint variables λ (dotted) are prospective and precisely invert this phase shift, albeit with a different gain.
In terms of gain, GLE and AM/BPTT are inverted. For smaller angular frequencies ωτ ≲1, this approximation is very good and the gradients are only weakly distorted. We will later see that in practice, for hierarchical networks with sufficiently diverse time constants, successful learning does not strictly depend on this formal requirement. What appears more important is that, even for larger ωτ, GLE errors always conserve the sign of the correct adjoints, so the error signal always remains useful; moreover, higher-frequency oscillations in the errors tend to average out over time, as we demonstrate in simulations below.
Cortical/neuromorphic circuits
As shown above, GLE backward (error) dynamics engage the same sequence of operations as those performed by forward (representation) dynamics: first integration \({{{\mathcal{I}}}}_{\tau }^{-}\), then differentiation \({{{\mathcal{D}}}}_{\tau }^{+}\). This suggests that backward errors can be transmitted by the same type of neurons as forward signals39,40, which is in line with substantial experimental evidence that demonstrates the encoding of errors in L2/3 PYR neurons41,42,43,44,45,46. Note that correct local error signals are only possible with neurons that are capable of both retrospective (\({{{\mathcal{I}}}}_{\tau }^{-}\)) and prospective (\({{{\mathcal{D}}}}_{\tau }^{+}\)) coding—the core element of the GLE framework.
This symmetry between representation and error suggests a simple microcircuit motif that repeats in a ladder-like fashion, with L2/3 PYR error neurons counterposing L5/6 PYR representation neurons (Fig. 4). Information transmitted between the two streams provides these neurons with all the necessary local information to carry out GLE dynamics. In particular, error neurons can elicit the representation of corresponding errors in dendritic compartments of representation neurons, allowing forward synapses to access and correct these errors through local plasticity. Recent evidence for error representation in apical dendrites provides experimental support for this component of the model47.

Representation neurons form the forward pathway (red), error neurons form the backward pathway (blue). Both classes of neurons are pyramidal (PYR), likely located in different layers of the cortex. Lateral connections enable information exchange and gating between the two streams. The combination of retrospective membrane and prospective output dynamics allow these neurons to tune the temporal shift of the transmitted information. Errors are also represented in dendrites, likely located in the apical tuft of signal neurons, enabling local three-factor plasticity to correct the backpropagated errors.
The correct propagation of errors requires two elements that can be implemented by static lateral synapses. First, error neuron input needs to be multiplicatively gated by the derivative of the corresponding representation neuron’s activation function φ. This can either happen through direct lateral interaction, or through divisive (dis)inhibition, potentially carried out by somatostatin (SST) and parvalbumin (PV) interneuron populations48,49,50,51, via synapses that are appropriately positioned at the junction between dendrites and soma. The required signal \(\varphi^{\prime}\) can be generated and transported in different ways depending on the specific form of the activation function. For example, if φ = ReLU, lateral weights can simply be set to Lb = 1. For sigmoidal activation functions, \(\varphi^{\prime}\) can be very well approximated by synapses with short-term plasticity (e.g., ref. 52, Eqn. 2.80). The second requirement regards the communication of the error back to the error dendrites of the representation neurons; this is easily achieved by setting Lf = 1.
Ideally, synapses responsible for error transport in the feedback pathway need to mirror forward synapses: \({{{\boldsymbol{B}}}}_{\ell }={{{\boldsymbol{W}}}}_{\ell+1}^{{{\rm{T}}}}\) (cf. Eqn. (7)). This issue is known as the weight transport problem and has been already addressed extensively in literature. While it can, to some extent, be mitigated by feedback alignment (FA)53, improved solutions to the weight transport problem that are both online and local have also been recently proposed54,55,56,57,58. We return to the issue of weight symmetrization in section “Scaling, noise and symmetry”.
We now proceed to demonstrate several applications of the GLE framework. First, we illustrate its operation in small-scale examples, to provide an intuition of how GLE networks can learn to solve non-trivial temporal tasks. Later on, we discuss more difficult problems that usually require the use of sophisticated DL methods and compare the performance of GLE with the most common approaches used for these problems in ML.
A minimal GLE example
As a first application, we study learning in a minimal teacher-student setup. The network consists of a forward chain of two neurons (depicted in red in Fig. 5a) provided with a periodic step function input. The task of the student network is to learn to mimic the output of a teacher network with identical architecture but different parameters, namely, different weights and membrane time constants. Prospective time constants τr are not learned and set to zero for both student and teacher, such that the neurons are simple leaky integrators. The target membrane time constants τm are chosen to be on the scale of the dominant inverse frequency of the input signal, such that they cause a significant temporal shift without completely suppressing the signal. Due to these slow transient membrane dynamics, the task is not solvable using instantaneous backpropagation, but requires true temporal credit assignment instead.

a Network setup. A chain of two retrospective representation neurons (red) learns to mimic the output of a teacher network (identical architecture, different parameters). In GLE, this chain is mirrored by a chain of corresponding error neurons (blue), following the microcircuit template in Fig. 4. We compare the effects of three learning algorithms: GLE (green), BP with instantaneous errors (purple) and BPTT (point markers denote the discrete nature of the algorithm; pink, brown and orange denote different truncation windows (TW)). b Output of representation neurons (ri, red) and error neurons (ei, blue) for GLE and instantaneous BP (BP). Left: before learning (i.e., both weights and membrane time constants are far from optimal). Right: after learning. c Evolution of weights, time constants and overall loss. Fluctuations at the scale of 10−10 are due to limits in the numerical precision of the simulation.
We compare three different solutions to this problem: (1) a GLE network with time-continuous dynamics, including synaptic and neuronal plasticity; (2) standard error BP using instantaneous error signals \({e}_{i}=\varphi^{{\prime}}_{i}{w}_{i}{e}_{i+1}\); (3) truncated BPTT through the discretized neuron dynamics using PyTorch’s autograd functionality for different truncation windows.
We first note that the GLE network learns the task successfully and quickly, in contrast to instantaneous BP (Fig. 5c). To understand why, it is instructive to compare its errors to the instantaneous ones (ei panels in Fig. 5b). The instantaneous errors (BP, dashed lines) are always in sync with the output error, but their shape and timing become increasingly desynchronized from the neuronal inputs as they propagate toward the beginning of the chain, because they do not take into account the lag induced by the representation neurons. Thus, the correct temporal coupling between errors and presynaptic rates required by plasticity (cf. Eqn. (8), see also Eqns. (21), (22), (23), (24) in Methods) is corrupted, and learning is impaired. Note that instantaneous errors are already a strong assumption and themselves require a form of prospectivity17; without any prospectivity, learning performance would be even more drastically compromised. In contrast, the GLE errors gradually shift forward in time, matching the phase and shape of the respective neuronal inputs, and thus allowing the stable learning of all network parameters, weights and time constants alike.
Here, we can also see an advantage of GLE over the classical BPTT solution (Fig. 5c). Despite only offering an approximation of the exact gradient calculated by BPTT, it allows learning to operate continuously, fully online. As discussed above, BPTT needs to record a certain period of activity before being able to calculate parameter updates. If this truncation window is too short, it fails to capture longer transients in the input and learning stalls or diverges (brown and pink, respectively). Only with a sufficiently long truncation window does BPTT converge to the correct solution (orange), but at the cost of potentially exploding gradients and/or slower convergence due to the resulting requirement of reduced learning rates. For a demonstration of the noise robustness of this setup, we refer to section “Small GLE networks” in the Supplement.
Small GLE networks
To better visualize how errors are computed and transmitted in more complex GLE networks, we now consider a teacher-student setup with two hidden layers, each with one instantaneous and one retrospective neuron (Fig. 6a). Through this combination of fast and slow pathways between network input and output, such a small setup can already perform quite complex transformations on the input signal (Fig. 6b). From the perspective of learning an input-output mapping, this can be stated as the output neuron having access to multiple time scales of the input signal, despite the input being provided to the network as a constant stream in real time. This is essential for solving the complex classification problems that we describe later.

a Network setup. A network with one output neuron and two hidden layers (red) learns to mimic the output of a teacher network (identical architecture, different input weights to the first hidden layer). Each hidden layer contains one instantaneous (τm = τr = 1) and one retrospective (τm = 1, τr = 0.1) neuron. In GLE, the corresponding error pathway (blue) follows the microcircuit template in Fig. 4. The input is defined by a superposition of three angular frequency components ω ∈ {0.49, 1.07, 1.98}. Here, we compare error propagation, synaptic plasticity and ultimately the convergence of learning under GLE and AM. b Input and output rates (r, red), along with bottom layer errors (e, light blue) and adjoints (λ, dark blue) before and during the late stages of learning. A running average over e is shown in orange. c Phase shifts (compared to the output error e3) and d amplitudes of bottom layer errors and adjoints across a wide range of their angular frequency spectrum before and during learning. The moments “before” and “during” learning are marked by vertical dashed lines in (e). Top: \({e}_{1}^{\,{\mbox{i}}\,}\) and \({\lambda }_{1}^{\,{\mbox{i}}\,}\) for the instantaneous neuron. Bottom: \({e}_{1}^{\,{\mbox{r}}\,}\) and \({\lambda }_{1}^{\,{\mbox{r}}\,}\) for the retrospective neuron. Note that due to the nonlinearity of neuronal outputs, the network output has a much broader distribution of frequency components compared to the input (with its three components highlighted by the red crosses  ). Error amplitudes are shown at two different moments during learning. e Evolution of the bottom weights (\({w}_{0}^{\,{\mbox{i}}},{w}_{0}^{{\mbox{r}}\,}\)) and f of the loss during learning. The vertical dashed lines mark the snapshots at which adjoint and error spectra are plotted above.
). Error amplitudes are shown at two different moments during learning. e Evolution of the bottom weights (\({w}_{0}^{\,{\mbox{i}}},{w}_{0}^{{\mbox{r}}\,}\)) and f of the loss during learning. The vertical dashed lines mark the snapshots at which adjoint and error spectra are plotted above.
To isolate the effect of error backpropagation into deeper layers, we keep all but the bottom weights fixed and identical between teacher and student. The goal of the student network is to mimic the output of the teacher network by adapting its own bottommost forward weights. We then compare error dynamics and learning in the GLE network with exact gradient descent on the cost as computed by AM/BPTT.
While both methods converge to the correct target (Fig. 6b, e), they don’t necessarily do so at the same pace, since AM/BPTT cannot perform online updates, as also discussed above. Also, GLE error propagation is only identical to the coupling of adjoint variables (AM/BPTT) for instantaneous neurons with τm = τr (\({e}_{1}^{\,{\mbox{i}}}={\lambda }_{1}^{{\mbox{i}}\,}\)). In general, this is not the case (\({e}_{1}^{\,{\mbox{r}}}\ne {\lambda }_{1}^{{\mbox{r}}\,}\)), as GLE errors tend to overemphasize higher-frequency components in the signal (cf. also section “GLE dynamics implement a real-time approximation of AM/BPTT” and Fig. 6d). However, this only occurs for slow, retrospective neurons, which only need to learn the slow components of the output signal. For sufficiently small learning rates, plasticity in their afferent synapses effectively integrates over these oscillations and lets them adapt to the relevant low-frequency components. Indeed, the close correspondence to AM/BPTT is reflected in the average GLE errors, which closely track the corresponding adjoints. While it was not necessary to make use of such additional components in our simulations, high-amplitude high-frequency oscillations in the error signals could be mitigated by several simple mechanisms, including saturating activation functions for the error neurons, input averaging in the error dendrites or synaptic filtering of the plasticity signal.
Following the analysis in the previous section, our simulations now demonstrate how GLE errors encode the necessary information for effective learning. Most importantly, GLE errors and adjoint variables (AM/BPTT) have near-identical timing, as shown by the alignment of their phase shifts across the signal frequency spectrum (Fig. 6c). Moreover, for the errors of the retrospective neurons, these phase shifts are positive with respect to the output error, thus demonstrating the prospectivity required for the correct temporal alignment of inputs and errors. The amplitudes of e and λ also show distinct peaks at the same angular frequencies, corresponding to the three components of the input signal that need to be mapped to the output (Fig. 6d). These signals can thus guide plasticity in the correct direction, gradually learning first the slow and then the fast components of the input-output mapping. This is also evinced by Fig. 6e, where the input weights of the retrospective neurons \({w}_{0}^{\,{\mbox{r}}\,}\) are the first to converge. The ensuing reduction of the slow error components provides the input weights of the instantaneous neurons \({w}_{0}^{\,{\mbox{i}}\,}\) with cleaner access to the fast error components—the only ones that they can actually learn—which allows them to converge as well.
Challenging spatio-temporal classification
We now demonstrate the performance of GLE in larger hierarchical networks, applied to difficult spatio-temporal learning tasks, and compare it to other solutions from contemporary ML. An essential ingredient for enabling complex temporal processing capabilities in GLE networks is the presence of neurons with diverse time constants τm and τr (Fig. 7). Each of these neurons can be intuitively viewed as implementing a specific temporal attention window, usually lying in the past, proportionally to τm − τr. More specifically, for a given angular frequency component of the input ω, this window is centered around a phase shift of \(\arctan (\omega {\tau }^{{{\rm{r}}}})-\arctan (\omega {\tau }^{{{\rm{m}}}})\approx \omega ({\tau }^{{{\rm{r}}}}-{\tau }^{{{\rm{m}}}})\) for ωτ ≲ 1 (cf. Methods). By connecting to multiple presynaptic partners in the previous layer, a neuron thus carries out a form of temporal convolution, similarly to temporal convolutional networks (TCNs)59. Importantly, however, TCNs rely on some additional mechanism that allows for the mapping of temporal signals to spatial representations, for example, by using buffers or delays. In other words, TCNs do not process their input online, but require it to be rolled out in space and then act like a conventional convolutional network, without any temporal dynamics. Furthermore, network depth is an essential prerequisite for solving the tasks discussed below. Deeper networks also allow longer chains of such neurons to be formed, thus providing the output with a diverse set of complex transforms on different time intervals distributed across the past values of the input signal. GLE effectively enables deep networks to learn a useful set of such transforms.

In the simplest case, a single input signal I(t) is fed into a GLE network and all neurons in the bottom layer have access to the same information stream. However, the output of each neuron generates a temporal shift, depending on its time constants τm and τr (as highlighted by the neuron colors). Different chains of such neurons thus provide neurons in higher levels of the hierarchy with a set of attention windows across the past input activity. Synaptic and neuronal adaptation shape the nature of these temporal receptive fields (TRFs). For multidimensional input, neuron populations (gray) encode the additional spatial dimension and neuronal receptive fields become spatio-temporal (STRFs).
MNIST-1D
We first consider the MNIST-1D60 benchmark for temporal sequence classification. Other than the name itself and the number of classes, MNIST-1D bears little resemblance to its classical namesake. Here, each sample is a one-dimensional array of floating-point values, which can be streamed as a temporal sequence into the network (see Fig. 8a for examples from each class). This deceptively simple setup entails two difficult challenges. First, only a quarter of each sample contains meaningful information; this chunk is positioned randomly within the sample, every time at a different position. Second, independent noise is added on top of every sample at multiple frequencies, which makes it difficult to remove by simple filtering. To allow a direct comparison between the different algorithms, we use no preprocessing in our simulations.

Averages and standard deviations measured over ten seeds. Top row: samples from the a MNIST-1D, b GSC—including raw and preprocessed input—and c CIFAR-10 datasets. d Performance of various architectures on MNIST-1D. Here, we used a higher temporal resolution for the input than in the original reference60. e Performance of various architectures on GSC. f Performance of a (G)LE LagNet architecture on MNIST-1D. For reference, we also show the original results from ref. 60 denoted with the index 0. g Performance of a (G)LE convolutional network on CIFAR-10 (taken from ref. 17) and comparison with BP.
We first note that a multi-layer perceptron (MLP) fails to appropriately learn to classify this dataset, reaching a validation accuracy of only around 60%. This is despite the perceptron having access to the entire sequence from the sample at once, unrolled from time into space. This highlights the difficulty of the MNIST-1D task. More sophisticated ML architectures yield much better results, with TCNs59 and gated recurrent units (GRUs)61 achieving averages of over 90%. Notably, both of these models need to be trained offline, that is, they need to process the entire sequence before updating their parameters, with TCNs in particular requiring a mapping of temporal signals to spatial representations beforehand, and GRUs requiring offline BPTT training with direct access to the full history of the network.
In contrast, GLE networks are trained online, with a single neuron streaming the input sequence to the network and, and the network updating its parameters in real time. The network consists of six hidden layers with a mixture of instantaneous and retrospective neurons in each layer, and a final output layer of ten instantaneous neurons. We use either 53 or 90 neurons per layer, leading to a total of 15 thousand (as the MLP) or 42 thousand parameters, respectively (see Fig. 9b).

a The GLE network used to produce the results in Fig. 8e, where multiple input channels project to successive hidden layers with different time constants. All other networks can be viewed as using a subset of this architecture. b The GLE network trained on the MNIST-1D dataset uses a single (scalar) input channel. This architecture was used to produce the results in Figs. 8d, 10a−c. c “LagNet” architecture used to produce the results in Fig. 10f. It also receives a single input channel, but the weights of the four bottom layers are fixed to identity matrices. This induces ten parallel channels that process the input with different time constants. The MLP on top of this LagNet uses instantaneous neurons and is trained with GLE (which, in the case of equal time constants τm = τr reduces to LE as described in ref. 17). d The GLE network used to tackle spatial problems as per Fig. 10g. All neurons are instantaneous, and the network is equivalent to a LE network.
When faced with short informative signals embedded in a sea of noise, for which the target is always on, even in the absence of meaningful information, the online learning advantage of GLE networks represents an additional challenge to learning. Since only a fraction of each input actually contains a meaningful signal, GLE networks must be capable of remembering these informative combinations of inputs and targets throughout the uninformative portions of their training. However, because they learn continuously, they also do so during uninformative times, which ultimately slows down learning. In contrast, conventional ML models only receive target errors at the end of the sequence or train a readout layer on the unrolled activations of the penultimate layer. Moreover, GLE networks solve a more complex task than conventional models in that they learn both the temporal convolutions and the ultimate classification task simultaneously. This manifests as an increase in convergence time, but not in ultimate performance, as GLE maintains an overall good online approximation of the true gradients for updating the network parameters.
Thus, despite facing a significantly more difficult task compared to the methods that have access to the full network activity unrolled in time, GLE achieves highly competitive classification results, with an average validation accuracy of 93.5 ± 0.9% for the larger network and 91.7 ± 0.8% for the smaller network. The ANN baselines achieve an average validation accuracy of 65.5 ± 1.0% for the MLP, 96.7 ± 0.9% for the TCN and 94.0 ± 1.1% for the GRU, respectively. A more detailed comparison of the performance of GLE with the reference methods can be found in Table D.1 of the Supplement.
Google speech commands
To simultaneously validate the spatial and temporal learning capabilities of GLE, we now apply it to the Google Speech Commands (GSC) dataset62. This dataset consists of 105,829 one-second long audio recordings of 35 different speech commands, each spoken by thousands of people. In the v2.12 version of this dataset, the usual task is to classify ten different speech commands in addition to a silence and an unknown class, which comprises all remaining commands. The raw audio signal is transformed into a sequence of 41 Mel-frequency spectrograms (MFSs); this sequence constitutes the temporal dimension of the dataset and is streamed to the network in real-time. Each of these spectrograms has 32 frequency bins, which are presented as 32 separate inputs to the network, thus constituting the spatial dimension of the dataset. Figure 8e compares the performance of GLE to several widely used references: MLP, TCN, GRU (as used for MNIST-1D) and, additionally, short-term memory (LSTM) networks63—all trained with a variant of BP. Similarly to the MNIST-1D dataset, the GLE network is trained online and updates its parameters in real time, while the reference networks can only be trained offline; furthermore, the MLP and TCN networks do not receive the input as a real-time stream, but rather as a full spectro-temporal “image”, by mapping the temporal dimension onto an additional spatial one. Here, the GLE network receives its input through 32 neurons streaming 32 MFS bins to the network. The network consists of three hidden layers with a mixture of instantaneous and retrospective neurons in each layer, and a final output layer of 12 instantaneous neurons (see Fig. 9a). As with MNIST-1D, we see how our GLE networks surpass the MLP baseline and achieve a performance that comes close to the references, with an average test accuracy of 91.44 ± 0.23%. The ANN baselines achieve an average test accuracy of 88.00 ± 0.25% for the MLP, 92.32 ± 0.28% for the TCN, 94.93 ± 0.25% for the GRU, and 94.00 ± 0.19% for the LSTM, respectively. We thus conclude that, while offering clear advantages in terms of biological plausibility and online learning capability, GLE remains competitive in terms of raw task performance. We also note that, in contrast to the reference baselines, GLE achieves these results without additional tricks such as batch or layer normalization, or the inclusion of dropout layers. A more detailed comparison of the performance of GLE with the reference methods can be found in Table D.1 of the Supplement.
GLE for purely spatial problems
The above results explicitly exploit the temporal aspects of GLE and its capabilities as an online approximation of AM/BPTT. However, GLE also contains purely spatial BP as a subcase, and the presented network architecture can lend itself seamlessly to spatial tasks such as image classification. In cases like this, where temporal information is irrelevant, one can simply take the LE limit of GLE by setting τm = τr for all neurons in the network17 (see Fig. 9d). In the following, we demonstrate these capabilities in two different scenarios. Note that GLE learns in a time-continuous manner in all of these cases as well, with the input being presented in real-time.
First, we return to the MNIST-1D dataset, but adapt the network architecture as follows. The 1D input first enters a non-plastic preprocessing network module consisting of several parallel chains of retrospective neurons. The neurons in each chain are identical, but different across chains: the fastest chain is near-instantaneous with τm → 0, while the slowest chain induces a lag of about 1/4 of the total sample length. The endpoints of these chains constitute the input for a hierarchical network of instantaneous neurons (τm = τr). By differentially lagging the input stream along the input chains, this configuration approximately maps time to space (the output neurons of the chains). This offers the hierarchical network access to a sliding window across the input—hence the acronym “LagNet” for this architecture—and changes the nature of the credit assignment problem from temporal to spatial. While the synaptic weights in the chains are fixed, those in the hierarchical network are trained with GLE, which in this scenario effectively reduces to LE. As shown in Fig. 8f, GLE is capable of training this network to achieve competitive performance with the reference methods discussed above.
As a second application to purely spatial problems, we focus on image classification. Since GLE does not assume any specific connectivity pattern, we can adapt the network topology to specific use cases. In Fig. 8g we demonstrate this by introducing convolutional architectures (LeNet-564) and applying them to the CIFAR1065 dataset. With test errors of (38.0 ± 1.3)%, GLE is again on par with ANNs with identical structure at (39.4 ± 5.6)%. We therefore conclude that, as an extension of LE, GLE naturally maintains its predecessor’s competitive capabilities for online learning of spatial tasks.
Scaling, noise, and symmetry
To evaluate the effect of network size on classification performance, we trained GLE networks of different widths and depths on the MNIST-1D dataset (Fig. 10a−c). Because this dataset requires significant depth for neurons to be able to tune their temporal attention windows, good performance can only be reached for depths of four layers and above. The network width plays only a secondary role, with relatively small performance gains for wider layers. The small decline in performance for larger networks is likely caused by overfitting due to overparametrization.

Averages and standard deviations were measured over ten seeds. All figures depict validation accuracy on the MNIST-1D dataset. a Heatmap of scaling in network width and depth. b Learning with 128 neurons per layer across different depths. c Learning in six-layer networks for different layer widths. d Robustness to spatial noise on τm and τr in a six-layer network for two different layer widths n. Zoomed inlay of epoch 60 to 150. e Robustness to correlated noise on all feedforward rates ri for different noise levels corresponding to the fraction of the input signal amplitude. f Robustness to feedback misalignment \({{{\boldsymbol{B}}}}_{\ell }={{{\boldsymbol{W}}}}_{\ell+1}^{{{\rm{T}}}}+{{\mathcal{N}}}(0,{\sigma }^{2})\) for different noise levels σ. g Final validation accuracy for different noise levels σ plotted against the corresponding alignment angle \(\angle ({{{\boldsymbol{B}}}}_{\ell },{{{\boldsymbol{W}}}}_{\ell+1}^{{{\rm{T}}}})\) for the individual layers ℓ ∈ [1, …, L − 1]. Note that FA performs better than the largest noise levels, because the constant randomization of feedback weights prevents FA to take effect.
The robustness of GLE to input level noise has already been implicitly demonstrated, as both MNIST-1D and GSC datasets include either explicitly applied noise or implicit measurement noise and speaker variance. However, whether biological or biologically inspired, analog systems are always subject to additional forms of noise. Spatial noise refers to neuronal variability, caused by either natural biological growth processes or fixed-pattern noise in semiconductor photolitography. Temporal noise refers to variability in all transmitted signals, usually due to quantum or thermal effects, and is typically modeled as a wide-spectrum random process. In the following, we discuss the robustness of GLE with respect to both of these effects during learning of the MNIST-1D task.
First, we established baseline performances for two different network sizes without added noise. To model spatial variability, we then introduced Gaussian noise with increasing levels of variance to the time constants, as all other parameters were optimized through learning Fig. 10d. The effect on training accuracy was insignificant, despite the highest simulated noise level of 0.1 being relatively large compared to the time constants ranging from 0.2 to 1.2 (cf. Table 1 in the Methods). The effects of temporal variability were investigated by adding correlated noise to all feedforward rates ri (Fig. 10e). This type of noise can be much more detrimental than spatial variability, as it gradually and irrevocably destroys information while it passes through the network. We noticed a gradual performance decline for noise levels above 2%, with classification performance dropping by about 10% at a noise level of 10%. Note that, across layers, this sums up to a total noise-to-signal ratio of about 60%, which would represent a major impediment for any network model.
While FA53 is known to have issues with scaling in depth (as we shall also see below), several learning algorithms for active weight alignment have been proposed to explain how biological and bio-inspired systems could solve this problem locally. However, these cannot always guarantee a perfect alignment of forward and backward weights \({{{\boldsymbol{B}}}}_{\ell }={{{\boldsymbol{W}}}}_{\ell+1}^{{{\rm{T}}}}\). We thus study the performance of GLE networks under varying levels of weight asymmetry. To allow a general assessment independent of particular alignment algorithms, we train GLE networks with backward weights that are noisy versions of the forward weights (Fig. 10f). We resample this noise after each epoch, thus making the problem harder by ensuring that the forward weights cannot mitigate this asymmetry by aligning with the feedback weights during forward learning (as in FA). Fig. 10g shows how the performance of GLE degrades gracefully with increasing weight misalignment. In particular, for alignment angles \(\angle ({{{\boldsymbol{B}}}}_{\ell },{{{\boldsymbol{W}}}}_{\ell+1}^{{{\rm{T}}}}) < \!3{0}^{\circ }\), network performance is barely affected. This lies well within the alignment capabilities of multiple alignment algorithms, as we show in section “Bio-plausibility and the weight transport problem” of the Supplement.
Altogether, these results illustrate the robustness of the GLE framework to realistic types of noise, thereby substantiating its plausibility as a model of biological networks, as well as its applicability to suitable analog neuromorphic devices.
Chaotic time series prediction
As a final application, we now turn to a sequence prediction task, where an autoregressively recurrent GLE network (with its output feeding back into its input) is trained to predict the continuation of a time series based on its previous values. To this end, we use the Mackey-Glass dataset67, a well-known chaotic time series described by a delayed differential equation that exhibits complex dynamics. Figure 11a shows the network setup, which consists of four input neurons, two hidden layers with a mixture of instantaneous and retrospective neurons, and one output neuron. Each Mackey-Glass sequence has a length of 20 Lyapunov times λ, with λ = 197 for our chosen parametrization of the Mackey-Glass equation. The first half of the sequence is used for training, while the second half is used for autoregressive prediction. The resulting requirement of predicting the continuation of the time series across ten Lyapunov times (for which initial inaccuracies are expected to diverge by at least a factor of e10) is what makes this problem so difficult. During training, the network’s target y*(t) is given by the next value in the time series x(t + 1) based on the ground truth x(t). After training, the external input x(t) is removed after the first 10 λ and the network needs to predict the second half of the sequence (which it has never seen during training) using its own output as an input. To provide an intuition for how the network learns, we consider its prediction at an earlier and at a later stage of training. Figure 11b shows the target sequence and the network’s output after 40 epochs of training. The network has already learned a periodic pattern that is superficially similar to parts of the sequence, but the output diverges from the target sequence after only half a Lyapunov time. From here, it takes another 100 epochs (Fig. 11c) for the network’s output to closely match the target sequence over the full period of 10 λ. Figure 11d shows the symmetric mean absolute percentage error (sMAPE), a commonly used metric for evaluating the performance of time series prediction models, over the course of training and averaged over 30 different sequences and initializations. The final average sMAPE of 14.25% for our GLE network is on par with the 14.79% for ESNs and 13.37% for LSTMs reported in ref. 66. If we average the lowest sMAPE over the course of training, we find that our GLE networks can achieve an even lower sMAPE of 9.25%.

a GLE network architecture with 93 hidden neurons per layer. Input neurons are delayed w.r.t. each other by Δ = 6 (same units as λ = 197). b, c Target sequence (dashed black) vs. network output (solid blue) after 40 (b) and 138 (c) epochs of training. d sMAPE loss over the course of training for 30 different sequences compared to ESN and LSTM results as described in ref. 66. The best performance for each sequence is marked as a blue dot.
Discussion
We have presented GLE, a novel framework for spatio-temporal computation and learning in physical neuronal networks. Inspired by well-established approaches in theoretical physics, GLE derives all laws of motion from first principles: a global network energy, a conservation law, and a dissipation law. Unlike more traditional approaches, which aim to minimize a cost defined only on a subset of output neurons, our approach is built around an energy function which connects all relevant variables and parameters of all neurons in the network. This permits a unified view on the studied problem and creates a tight link between the dynamics of computation and learning in the neuronal system. The extensive nature of the energy function (i.e., its additivity over subsystems) also provides an important underpinning for the locality of the derived dynamics.
In combination, these dynamics ultimately yield a local, online, real-time approximation of AM/BPTT—to our knowledge, the first of its kind. Moreover, they suggest a specific implementation in physical neuronal circuits, thus providing a possible template for spatio-temporal credit assignment in the brain, as well as blueprints for dedicated hardware implementations. This shows that, in contrast to conventional wisdom, physical neuronal networks can implement future-facing algorithms for temporal credit assignment. More recently, tentative calls in this direction have indeed been formulated12, to which GLE provides an answer.
In the following, we highlight some interesting links to other models in ML, discuss several biological implications of our model, and suggest avenues for improvement and extension of our framework.
Connection to related approaches
Latent Equilibrium (LE)
As the spiritual successor of LE17, GLE inherits its energy-based approach, as well as the derivation of dynamics from energy conservation and minimization. GLE also builds on the insight from LE that prospective coding can undo the low-pass filtering of neuronal membranes. The core addition of GLE lies in the separation of prospective and retrospective coding, leading to an energy function that depends on two types of canonical variables instead of just one, and to a conservation law that accounts for their respective time scales. The resulting neuron dynamics can thus have complex dependencies on past and (estimated) future states, whereas information processing in LE is always instantaneous. Functionally, this allows neurons to access their own past and future states (through appropriate prospective and retrospective operators), thereby allowing the network to minimize an integrated cost over time, whereas LE only minimizes an instantaneous cost.
Because LE can be seen as a limit case of GLE, the new framework offers a more comprehensive insight into the effectiveness of its predecessor, and also answers some of the questions left open by the older formalism. Indeed, the GLE analysis demonstrates that LE errors are an exact implementation of the adjoint dynamics of the forward system for equal time constants, further confirming the solid grounding of the method, and helping explain its proven effectiveness. Conversely, GLE networks can learn to evolve towards LE via the adaptation of time constants if required by the task to which the framework is applied. While LE also suggests a possible mechanism for learning the coincidence of time scales, GLE provides a more versatile and rigorous learning rule that follows directly from the first principles on which the framework is based. More generally speaking, by having access to local plasticity for all parameters in the network, GLE networks can either select (through synaptic plasticity) or adapt (through neuronal plasticity) neurons and their time constants in order to achieve their target objective.
Thus, GLE not only extends LE to a much more comprehensive class of problems (spatio-temporal instead of purely spatial), but also provides it with a better theoretical grounding, and with increased biological plausibility. Recently68, also proposed an extension of LE by incorporating hard delays in the communication channel between neurons. In order to learn in this setting, they propose to either learn a linear estimate of the future errors (similar to our prospective errors) or to learn an estimate of future errors by a separate network. In contrast to this, GLE implements a biologically plausible mechanism for retrospection, and a self-contained error prediction which we show gives a good approximation to the exact AM solution.
Neuronal least-action (NLA)
Similarly, inspired by physics, but following a different line of thought, the NLA principle69 also uses prospective dynamics as a core component. It uses future discounted membrane potentials \(\tilde{u}={{{\mathcal{I}}}}_{{\tau }^{{{\rm{m}}}}}^{+}\{u\}\) as canonical variables for a Lagrangian L and derives neuronal dynamics as associated Euler-Lagrange equations. A simpler but equivalent formulation places NLA firmly within the family of energy-based models such as LE and GLE, where L is replaced by an equivalent energy function E that sums over neuron-local errors and from which neuronal dynamics can be derived by applying the conservation law \({{{\mathcal{D}}}}_{{\tau }^{{{\rm{m}}}}}^{+}\{\partial E/\partial u\}=0\).
The most important difference to GLE is that NLA cannot perform temporal credit assignment. Indeed, other than imposing a low-pass filter on its inputs, an NLA network effectively reacts instantaneously to external stimuli and can neither carry out nor learn temporal sequence processing. This is an inherent feature of the NLA framework, as the retrospective low-pass filter induced by each neuronal membrane exactly undoes the prospective firing of its afferents.
This property also directly implies that, except for the initial low-pass filter on the input, all neurons in the network need to share a single time constant for both prospective and retrospective dynamics. In contrast, both LE and GLE successively lift this strong entanglement by modifying the energy function and conservation law. LE correlates retro- and prospectivity within single neurons and allows their matching to be learned, thus obviating the need for globally shared time constants, while GLE decouples these two mechanisms, thus enabling temporal processing and learning, as discussed above.
RTRL and its approximations
RTRL70 is a past-facing algorithm that implements online learning by recursively updating a tensor Mijk that takes into account the influence of every synapse wjk on every neuronal output ri in the network. As evident from the dimensionality of this object, this requires storing \({{\mathcal{O}}}({N}^{3})\) floating-point numbers in memory (where N is the number of neurons in the network). Because this is much less efficient than future-facing algorithms, RTRL is rarely used in practice, and the manifest nonlocality of the influence tensor also calls into question its biological plausibility. Nonetheless, several approximations of RTRL have been recently proposed, with the aim of addressing these issues16.
A particularly relevant algorithm of this kind is random feedback online learning (RFLO)71, in which a synaptic eligibility trace is used as a local approximation of the influence tensor, at the cost of ignoring dependencies between distant neurons and synapses. With a reduced memory scaling of \({{\mathcal{O}}}({N}^{2})\), this puts RFLO at a significant advantage over RTRL, while closing the distance to BPTT (with \({{\mathcal{O}}}(NT)\), where T is the length of the learning window). In its goal of reducing the exact, but nonlocal computation of gradients to an approximate, but local solution, RFLO shares the same spirit as GLE. In the following, we highlight several important differences which we consider to give GLE both a conceptual and a practical advantage.
First, the neuron membranes and synaptic eligibilities in RFLO are required to share time constants, in order for the filtering of the past activity to be consistent between the two. In the cortex, this would imply the very particular neurophysiological coincidence of synaptic eligibility trace biochemistry closely matching the leak dynamics of efferent neuronal membranes. In contrast, the symmetry requirements of GLE are between neurons of the same kind (PYR cells), which share their fundamental physiology, and whose time constants can be learned locally within the framework of GLE.
Second, the dimensionality reduction of the influence tensor proposed by RFLO also puts it at a functional disadvantage, because the remaining eligibility matrix only takes into account first-order synaptic interactions between directly connected neurons. This is in contrast to GLE, which can propagate approximate errors throughout the entire network. This flexibility also allows GLE to cover applications over multiple time scales, from purely spatial classification to slow temporal signal processing. Moreover, GLE accomplishes this within a biologically plausible, mechanistic model of error transmission, while admitting a clear interpretation in terms of cortical microcircuits. Finally, GLE’s additional storage requirements only scale linearly with N (one error per neuron at any point in time), which is even more efficient than BPTT.
While both RFLO and GLE are inspired by and dedicated to physical neuronal systems, both biological and artificial, it might still be interesting to also consider their computational complexity for digital simulation, especially given the multitude of digital neuromorphic systems72 and ANN accelerators73 capable of harnessing their algorithmic capabilities. For a single update of their auxiliary learning variables (eligibility traces / errors), both RFLO and GLE incur a computational cost of \({{\mathcal{O}}}({N}^{2})\). Thus, for an input of duration T, all three algorithms—RFLO, GLE, and BPTT (without truncation)—are on par, with a full run having a computational complexity of \({{\mathcal{O}}}({N}^{2}T)\).
State space models (SSMs)
GLE networks are linked to locally recurrent neural networks (LRNNs) (see, e.g., refs. 74). In recent years there has been renewed interest in similar models in the form of linear recurrent units (LRUs)75,76, which combine the fast inference characteristics of LRNNs with the ease of training and stability stemming from the linearity of their recurrence. These architectures are capable of surpassing the performance of Transformers in language tasks involving long sequences of tokens77,78.
More specifically, GLE networks are closely linked to LRUs with diagonal linear layers79 and SSMs80,81, where a linear recurrence only acts locally at the level of each neuron, as realized by the leaky integration underlying the retrospective mechanism. Additionally, the inclusion of prospectivity enables the direct pass-through of input information across layers as in SSMs (see discussion in Methods). GLE could thus enable online training of these models, similarly to how82 demonstrate local learning with RTRL, but with the added benefits discussed above. Since such neuron dynamics are a de-facto standard for neuromorphic architectures72, GLE could thus open an interesting new application area for these systems, especially in light of their competitive energy footprint83,84.
As GLE is strongly motivated by biology, it currently only considers real-valued parameters for all connections, including the self-recurrent ones, in contrast to the complex-valued parameters in LRUs. However, an extension of GLE to complex activities appears straightforward, by directly incorporating complex time constants into prospective and retrospective operators, or, equivalently, by extending them to second order in time. With this modification, GLE would also naturally extend to the domain of complex-valued neural networks (CVNNs)85.
Neurophysiology
Neuronal prospectivity is a core component of the GLE framework. Prospective coding in biological neurons is supported by considerable experimental and theoretical evidence21,22,23,33,34,35,86 on both short and long time scales. We note that our Fourier analysis (Section “GLE dynamics implement a real-time approximation of AM/BPTT” above and Methods section “Prospectivity through adaptation”) also offers a rigorous account of prospectivity in neuron models with multiple, negatively coupled variables such as the Hodgkin-Huxley mechanism or adaptation currents.
In the specific GLE implementations used to solve the more challenging spatio-temporal classification tasks, we explicitly employ neurons with both short and long (effective) integration time constants. This is necessary since the tasks require access to (almost) instantaneous stimulus information, as well as to a temporal context in which to interpret it. While we do not explicitly model spikes, these two “classes” of neurons can be interpreted through the concepts of integration and coincidence detection87,88,89. Our results thus suggest how the cortex can benefit from neurons in both operating modes, as they can provide orthogonal pieces of information to guide behavior.
GLE further predicts functional aspects of PYR neuron morphology, as well as cortical microcircuits (CMCs) for signal and error propagation. In these CMCs, PYR cells are responsible for the transmission of both representation and error signals, as supported by ample experimental data41,42,43,44,45,46. Moreover, the morphological separation of the cell body into multiple distinct units, including soma, basal and apical trees, corresponds to a functional separation that allows the simultaneous representation of different pieces of information—bottom-up input, top-down errors and the resulting integrated signal—within the same cell47. This is also what gives synapses local access to this information, allowing the implementation of the proposed three-factor, error-correcting plasticity rule38. Furthermore, by representing forward activities and backward errors in separate pathways, these CMCs are capable of robust learning.
While building on many insights from previous proposals for CMCs, most notably17,90, we argue that our proposed model features significant improvements. Our model does not require nerve cells belonging to two different classes (somatostatin-expressing (SST) interneurons and PYR cells) to closely track each others’ activity, which is more easy to reconcile with the known electrophysiology of cortical neurons. This also makes training more robust and obviates the need to copy neuronal activities when training the network for more complex tasks. Additionally, the original CMC model for error backpropagation90 suffers from a relaxation problem, as already addressed in ref. 17. As it subsumes the capabilities of LE, GLE is inherently able to alleviate this problem.
Most importantly, these other CMC models are, by construction, only capable of solving purely spatial classification problems. We have shown that GLE CMCs can perform spatial and temporal tasks across a range of scales, by adapting the network parameters to the characteristic temporal and spatial time scales of the problem at hand. All of the above observations notwithstanding, it is worth noting that GLE can also apply to these alternative CMC models by implementing prospective coding in the apical dendrites of the PYR representation neurons rather than in PYR error neurons.
Open questions and future work
While the efficacy of GLE relies on correctly phase-shifting the backpropagated errors for all frequency components of the signal, their frequency-dependent gain diverges from the one required for exact gradient descent. This is not surprising, as a perfect match of gains would require the kind of perfect knowledge of the future that is available to AM/BPTT. A reasonable approximation of AM can be said to hold for ωτ ≲ 1, but outside of this regime there is no guarantee for convergence to a good solution. Our simulations clearly demonstrate that such solutions exist and can be achieved, but it would be preferable to have a more robust mechanism for controlling gain discrepancies at high frequencies. Some straightforward and sufficient mitigation strategies might include a simple saturation of error neuron activations or the inclusion of a small synaptic time constants as proposed in ref. 17. However, primarily for neuromorphic realizations of GLE, we expect linear time-invariant (LTI) system theory to provide more elegant solutions, such as Bessel or all-pass (active) filters, with favorable phase-response properties and circuit-level implementations.
On a more technical note, gain amplification in prospective neurons requires particular attention in discrete-time forward-Euler simulations, where fast transients can cause a breakdown of the stability assumption for finite, fixed-size time steps on which this integration method relies. In physical, time-continuous neuronal systems, this effect is naturally mitigated by the finite time constants of all physical components, including, for example, the synapses themselves, as mentioned above.
Ideally, to ensure a close correspondence of synaptic updates between GLE and AM, errors should not disrupt representations. This can be easily achieved in the limit of weak teacher coupling β ≪ 1 and/or weak somato-dendritic coupling γ. Indeed, for larger networks and more complex tasks requiring fine-tuning of neuronal activities and weights, we observed an increasing sensitivity of our networks to these parameters. To avoid these effects, we simply operated our large-scale simulations in the β → 1, γ → 0 regime. As this sensitivity also manifests as a consequence of the high-frequency gain amplification, we expect it to be correspondingly mitigated by the above-mentioned solutions.
To guarantee a perfect match between error and representation signals, pairs of PYR neurons in the two pathways ideally require an exact inversion of time constants τm ↔ τr. This relationship also needs to be maintained when time constants are learned. Similarly to the weight transport problem, we expect a certain degree of robustness to some amount of symmetry breaking53. However, it would be preferable to have an additional local adaptation mechanism to ensure scalability, while maintaining full compatibility with the locality constraints of physical neuronal systems. To this end, we expect that local solutions based on decay during adaptation54, mirroring55, and especially correlations57 are likely to apply here as well, even more so as the matching needs to develop between active, reciprocally connected and physically proximal neurons as opposed to passive, uncoupled synapses.
GLE can be naturally extended to (more) complex neuron dynamics, as already discussed in the context of LRUs and CVNNs. Even more importantly, a GLE mechanism for (sparse) spiking dynamics as opposed to (population) rates is of eminent interest. The recently described family of solutions for BP through spike times, including surrogate methods91, exact solutions84 and, notably, adjoint dynamics92 suggest several starting points for deriving corresponding GLE operators.
In the presented simulations, we only applied GLE to hierarchical networks, in order to highlight its versatility in switching between spatial, temporal and spatio-temporal classification tasks without changing the underlying architecture. We expect these capabilities to extend naturally to problems of sequence generation and motor control. Moreover, the theoretical framework of GLE is architecture-agnostic, and the inclusion of lateral recurrence represents an obvious next step. We expect the approximation of AM/BPTT to be adaptable to this scenario as well, but a dedicated proof and demonstration is left for future work.
Conclusion
With Generalized Latent Equilibrium, we have proposed a new and flexible framework for inference and learning of complex spatio-temporal tasks in physical neuronal systems. In contrast to classical AM/BPTT, but still rivaling its performance, GLE enables efficient learning through fully local, phase-free, online learning in real time. Thus, GLE networks can achieve results competitive with well-known, powerful ML architectures such as GRUs, TCNs, and convolutional neural networks (CNNs).
Our framework carries implications both for neuroscience and for the design of neuromorphic hardware. For the brain, GLE provides a rigorous theory and experimental correlates for spatio-temporal inference and learning, by leveraging an interplay between retrospective and prospective coding at the neuronal level. For artificial implementations, its underlying mechanics and demonstrated capabilities may constitute powerful assets in the context of autonomous learning on low-power neuromorphic devices.
Methods
Derivation of the network dynamics
The neuron dynamics in Eqn. (6) are derived from the stationarity condition stated in Eqn. (4). The partial derivatives of the energy function E with respect to the prospective voltages \({{{{\mathcal{D}}}}}_{{\tau }_{i}^{{{\rm{m}}}}}^{+}\{{u}_{i}\}\) and \({{{{\mathcal{D}}}}}_{{\tau }_{i}^{{{\rm{r}}}}}^{+}\{{u}_{i}\}\) are given by
and
Substituting these into the stationarity condition from Eqn. (4)
yields the neuronwise error dynamics
with the instantaneous error
where we used the identity \({{{\mathcal{D}}}}_{\tau }^{+}\left\{{{{\mathcal{I}}}}_{\tau }^{-}\left\{x\right\}\right\}(t)=x(t)\). Substituting the definition of the mismatch error ei (Eqn. (3)) produces the neuronal dynamics from Eqn. (6).
Instead of writing these equations for individual neurons i, we can also write them in vector form for layers ℓ as this is more convenient for the following derivations and, in addition, makes the similarity to BP more apparent. Then, ∀ ℓ < L the vector of instantaneous errors \({e}_{\ell }^{{{\rm{inst}}}}\) is the backpropagated error signal
with \({{\bf{\varphi }}}^{{\prime}}_{\ell }={{\bf{\varphi }}}^{\prime} ({{\boldsymbol{{{\mathcal{D}}}}}}_{{{\boldsymbol{\tau}} }_{\ell }^{{{\rm{r}}}}}^{+}\{{{{\boldsymbol{u}}}}_{\ell }\})\) and under the assumption that only neurons in the topmost layer L contribute directly to the cost function C.
The instantaneous target error for a mean-squared error (MSE) or cross-entropy (CE) loss in the last layer is given by
Detailed parameter dynamics
Using the layerwise instantaneous errors from Eqn. (17) and the layerwise target errors from Eqn. (18) we can express the neuronwise error dynamics in Eqn. (15) in vector form as
Parameter dynamics are derived from gradient descent on the energy function E (Eqn. (5)):
Depending on the specific parameter θℓ, we can work out its direct influence on the error via the partial derivative \(\frac{\partial {{{\boldsymbol{e}}}}_{\ell }}{\partial {{{\boldsymbol{\theta }}}}_{\ell }}\) and obtain
GLE approximates AM/BPTT in real time
In section “GLE dynamics implement a real-time approximation of AM/BPTT” we discuss the link between GLE errors e (Eqn. (7)) and adjoint variables λ (Eqn. (10)):
For a detailed derivation of the adjoint equations, we refer to the Supplement. In the following, we provide a detailed analysis of this relation in Fourier (angular frequency) space.
For a linear system with input x and output y, their relation in Fourier space is defined by the transfer function H(ω) = y(ω)/x(ω). In our case, these transfer functions correspond to the Fourier transforms of the prospective and retrospective operators, which we denote as \(\widehat{{{\mathcal{I}}}}\) and \(\widehat{{{\mathcal{D}}}}\). We first note the following identities:
Since any signal can be written as a linear composition of such frequency components eiωt + ψ, the above relation directly translate to the Fourier transforms our operators. For a single error neuron with prospective and retrospective time constants τm and τr, we can thus calculate
From here, the phase shifts Δψ and gains G of our operators become apparent.
The phase shifts of \({\widehat{{{\mathcal{I}}}}}_{{\tau }^{{{\rm{r}}}}}^{-}\) and \({\widehat{{{\mathcal{D}}}}}_{{\tau }^{{{\rm{r}}}}}^{-}\) are exactly equal; the same is true for the pair \({\widehat{{{\mathcal{D}}}}}_{{\tau }^{{{\rm{m}}}}}^{+}\) and \({\widehat{{{\mathcal{I}}}}}_{{\tau }^{{{\rm{m}}}}}^{+}\) (see also Fig. 3 and 12):
Thus, in the combinations in which they appear in the GLE errors and adjoint equations, they induce identical phase shifts:

Expressed as a function of τr/τm and calculated for ωτm = 1. Colored regions indicate different regimes of interest: negative τr (orange), effectively retrospective (τr < τm, blue), effectively prospective (τr > τm, red).
The gains of the operators are given by
This means that the GLE errors have an inverse frequency-dependent gain compared to the adjoint variables:
However, the ratio of GLE and AM gains is bounded by the ratio of prospective and retrospective time constants, so that the discrepancy induced by a GLE error neuron can never exceed \({\left({\tau }^{{{\rm{m}}}}/{\tau }^{{{\rm{r}}}}\right)}^{2}\).
These results extend to vectors λℓ and eℓ, where neuronal time constants {τm, τr} are replaced by the corresponding entries in \(\{{{{\boldsymbol{\tau }}}}_{\ell }^{{{\rm{m}}}},{{{\boldsymbol{\tau }}}}_{\ell }^{{{\rm{r}}}}\}\). As the operators are linear, the above considerations apply straightforwardly to inputs with arbitrary frequency spectra, for which the operators can simply be written as convolutions over frequency space with the expressions in Eqn. (28).
Overall this shows how, by inducing phase shifts that are identical to AM for every individual frequency component of the signal, GLE errors produce parameter updates that are always in phase with the correct gradients. Even though their respective frequency-specific gains are inverted with respect to AM, their mismatch is bounded and their sign is conserved. Therefore, despite distortions at higher frequencies, GLE parameter updates remain well-aligned with their true gradients. As in GLE, the propagation of (feedback) errors and (feedforward) signals is governed by the same operators; both can be easily implemented by leaky integrator neurons with prospective output dynamics.
Prospectivity through adaptation
In general, when neurons have additional variables that couple negatively into the membrane potential, such as certain voltage-gated ionic currents in the Hodgkin−Huxley model, or adaptation currents, such as in Izhikevich93 or AdEx94 models, prospectivity on various time scales can naturally emerge. The intuition behind the phenomenon is as follows: an additional variable that performs a low-pass filter over either the neuronal input or the membrane potential produces a negative phase shift and attenuates high-frequency components; if subtracted from the membrane, it has the opposite effect, namely inducing a positive phase shift and increasing the gain of higher-frequency components, thus acting similarly to the prospective operator \({{{\mathcal{D}}}}_{\tau }^{+}\). Here, we demonstrate prospectivity in leaky integrator neurons with two different kinds of adaptive currents: voltage- and current-dependent adaptation.
Voltage-dependent adaptive current
Consider the two-variable neuron model
where u is the membrane potential, \(w\) the adaptive current with time constant τw, and γu a coupling factor. Without loss of generality, we assume R = 1 for the membrane resistivity.
As in section “GLE approximates AM/BPTT in real time”, we now seek the transfer function H(ω) = u(ω)/I(ω). To this end, we can simply rewrite the above equations using our differential operators:
We can now apply the Fourier transform to both equations (using Eqn. (28) for the operators) and solve for u(ω), which yields the transfer function
The neuronal phase shift is given by \(\Delta \psi=\arctan \left(\frac{\,{\mbox{Im}}(H)}{{\mbox{Re}}(H)}\right)\). Figure 13 shows a positive shift (phase advance) over a broad frequency spectrum (blue lines).

The first-order analytical approximations are shown with dashed lines. Simulation parameters: τm = 1, τw = 0.9, γu = 10τm/τw, and γI = (τm + 0.9τw)/(τm + τw).
We follow up with an analytical argument for low frequencies. For this model, H can be approximated by a first-order expansion in {ωτm, ωτw}:
which yields a phase shift of
This makes it apparent that for \({\gamma }_{u} > \frac{{\tau }^{{{\rm{m}}}}}{{\tau }^{w}}\) the phase shift is positive, so the neuron is prospective.
Input-dependent adaptive current
With a small change, the above two-variable model can be made directly adaptive to the input current:
The transfer function is now given by
which also yields a phase advance for lower input frequencies Fig. 13 (orange lines).
As above, we can do a first-order approximation of H in {ωτm, ωτw}:
which yields a phase shift of
Thus, for \(\frac{{\tau }^{{{\rm{m}}}}}{{\tau }^{{{\rm{m}}}}+{\tau }^{w}} < {\gamma }_{I} < 1\) the membrane is prospective with respect to its input.
Relation to SSMs
To illustrate the connection between SSMs and GLE, we consider a single layer of the GLE model (and drop the index ℓ and explicit time dependence (t) for brevity). First, we define a shorthand y for prospective states \({{{{\boldsymbol{{\mathcal{D}}}}}}}_{{{\boldsymbol{\tau}}}^{{{\rm{r}}}}}^{+}\{{{{{\boldsymbol{{\mathcal{I}}}}}}}_{{{\boldsymbol{\tau}}}^{{{\rm{m}}}}}^{-}\{{{\boldsymbol{W}}}{{\boldsymbol{r}}}\}\}\) (i.e., the neuronal output before being passed through the nonlinearity) and, as before, we use \({{\boldsymbol{u}}}={{{{\boldsymbol{{\mathcal{I}}}}}}}_{{{\boldsymbol{\tau}}}^{{{\rm{m}}}}}^{-}\{{{\boldsymbol{W}}}{{\boldsymbol{r}}}\}\) to denote membrane potentials. For simplicity, we have ignored the biases. We can now rewrite y as
where we plugged in the integral form of the membrane potential u (cf. Eqn. (1)) in the last step, 1 denotes the identity vector and α ≔ τr/τm. We use “∘” and “/” to denote element-wise multiplication and division, respectively. Then, the dynamics of membranes u and prospective states y are given by a system of two coupled equations
Similarly, in SSMs, inputs r, latent states u and observations y are related by80
where A, B, C, and D are matrices of appropriate dimensions. Comparing equations Eqn. (41), (42), it is apparent that membrane potentials in GLE correspond to latent states in SSMs by setting A = −diag(1/τm) and B = diag(1/τm)W. Furthermore, prospective outputs in GLE correspond to observations in SSMs by setting C = diag(1 − α) and D = diag(α)W. Thus, GLE forward dynamics can implement a specific (diagonal) form of SSMs.
Simulation details
Numerical integration
We use forward Euler integration to solve the system of implicit coupled differential equations that determine the network dynamics, which simultaneously includes neuron (membrane potentials for the different compartments) and parameter (synaptic weights, neuronal biases, and time constants) dynamics.
Recall the neuronal dynamics of our networks, characterized by feedforward signals at time t (we drop the (t) here for brevity)
with feedback errors
We first approximate the temporal derivatives of the membrane potentials uℓ(t) by a finite difference
where the fraction is understood to be component-wise. This equation can then be solved for the membrane potentials at the next time step:
Similarly, we can approximate the derivative of the error neuron potentials vℓ(t) and solve for the potentials at the next time step:
The learning dynamics (Eqn. (21), (22), (23), (24)) are discretized accordingly. For example, the update of the synaptic weights Wℓ is given by
This system of equations is summarized in Algorithm 1.
Algorithm 1
Forward Euler simulation of GLE network
initialize network parameters θ = {W, b, τm, τr}
initialize network states at t = 0: u(0), v(0), r(0), e(0)
for time step t in [0, T] with step size dt Recall the neuronal dynamics of do
for layer ℓ from 1 to L do
if ℓ = L then
calculate instantaneous target error:
\({{{\boldsymbol{e}}}}_{L}^{{{\rm{inst}}}}(t)\leftarrow \beta {{\bf{\varphi }}}^{{\prime}}_{L}(t)\circ ({{{\boldsymbol{r}}}}^{{{\rm{trg}}}}(t)-{{{\boldsymbol{r}}}}_{L}(t))\)
else
propagate feedback error signals:
\(\quad \quad \quad {{{{\boldsymbol{e}}}}_{\ell }^{{{\rm{inst}}}}(t)\leftarrow {{\bf{\varphi }}}^{\prime}_{\ell }(t)\circ {{{\boldsymbol{W}}}}_{\ell+1}^{{{\rm{T}}}}(t){{{\boldsymbol{e}}}}_{\ell+1}(t)}\)
end if
sum input currents:
Iℓ(t) = Wℓ(t)rℓ−1(t) + bℓ(t) + γeℓ(t)
approximate membrane potential derivatives:
\(\Delta {{{\boldsymbol{u}}}}_{\ell }(t)\leftarrow {({{{\boldsymbol{\tau }}}}_{\ell }^{{{\rm{m}}}}(t))}^{-1}\circ \left(-{{{\boldsymbol{u}}}}_{\ell }(t)+{{{\boldsymbol{I}}}}_{\ell }(t)\right)\)
update membrane potentials:
uℓ(t + dt) ← uℓ(t) + dtΔuℓ(t)
approximate error potential derivatives:
\(\Delta {{{\boldsymbol{v}}}}_{\ell }(t)\leftarrow {({{{\boldsymbol{\tau }}}}_{\ell }^{{{\rm{r}}}}(t))}^{-1}\circ \left(-{{{\boldsymbol{v}}}}_{\ell }(t)+{{{\boldsymbol{e}}}}_{\ell }^{{{\rm{inst}}}}(t)\right)\)
update error potentials:
vℓ(t + dt) ← vℓ(t) + dtΔvℓ(t)
update prospective error potentials:
\({{{\boldsymbol{e}}}}_{\ell }(t+{{\mbox{d}}}t)\leftarrow {{{\boldsymbol{v}}}}_{\ell }(t)+{{{\boldsymbol{\tau }}}}_{\ell }^{{{\rm{m}}}}(t)\circ \Delta {{{\boldsymbol{v}}}}_{\ell }(t)\)
calculate prospective outputs:
\({{{\boldsymbol{r}}}}_{\ell }(t+{{\mbox{d}}}t)\leftarrow {{\boldsymbol{\varphi }}}\left({{{\boldsymbol{u}}}}_{\ell }(t)+{{{\boldsymbol{\tau }}}}_{\ell }^{{{\rm{r}}}}(t)\circ \Delta {{{\boldsymbol{u}}}}_{\ell }(t)\right)\)
update synaptic weights:
\({{{\boldsymbol{W}}}}_{\ell }(t+{{\mbox{d}}}t)\leftarrow {{{\boldsymbol{W}}}}_{\ell }(t)+{\eta }_{W}{{{\boldsymbol{e}}}}_{\ell }(t){{{\boldsymbol{r}}}}_{\ell -1}^{{{\rm{T}}}}(t)\)
update biases:
bℓ(t + dt) ← bℓ(t) + ηbeℓ(t)
update membrane time constants:
\({{{\boldsymbol{\tau }}}}_{\ell }^{{{\rm{m}}}}(t+{{\mbox{d}}}t)\leftarrow {{{\boldsymbol{\tau }}}}_{\ell }^{{{\rm{m}}}}(t)-{\eta }_{\tau }{{{\boldsymbol{e}}}}_{\ell }(t)\circ \Delta {{{\boldsymbol{u}}}}_{\ell }(t)\)
update prospective time constants:
\({{{\boldsymbol{\tau }}}}_{\ell }^{{{\rm{r}}}}(t+{{\mbox{d}}}t)\leftarrow {{{\boldsymbol{\tau }}}}_{\ell }^{{{\rm{r}}}}(t)+{\eta }_{\tau }{{{\boldsymbol{e}}}}_{\ell }^{{{\rm{inst}}}}(t)\circ \Delta {{{\boldsymbol{u}}}}_{\ell }(t)\)
end for
end for
Note that in addition to the nudging strength β that scales the target error, we introduce another parameter γ to scale the coupling between the apical dendritic and somatic compartments, thus controlling the feedback of the error signals e into the somatic potentials u.
General simulation details for the GLE networks
Our networks are implemented in Python using the PyTorch library. All vector quantities with a layer index ℓ are implemented as PyTorch tensors. Neuronal activation functions are hyperbolic tangents.
For the cost function C, we either use an MSE
with outputs
or a CE loss
with softmax outputs
depending on the task. In both cases, the rtrg is either a target rate or a one-hot vector encoding the target class.
In the two teacher-student setups, the target output rate is produced by a teacher network with the same architecture as the student, but with fixed weights and time constants. Student networks trained with different algorithms are initialized with identical but randomized parameters. The outputs of the teacher and student are compared via the MSE loss.
Time units are fixed but arbitrary, so we can treat time as unit-free in the following.
GLE chain (Fig. 5)
The input signal is a smoothed square wave of amplitude 1 and period T = 4, with a simulation time step of dt = 0.01. Batches of 100 samples are generated by shifting the input randomly in time by values between 0 and T/2. Teacher weights and time constants are w0 = 1, w1 = 2, \({\tau }_{0}^{{{\rm{m}}}}=1\), \({\tau }_{2}^{{{\rm{m}}}}=2\), \({\tau }_{0}^{{{\rm{r}}}}={\tau }_{1}^{{{\rm{r}}}}=0.1\). The two student networks trained with GLE and instantaneous BP use a learning rate of 0.0001 and a nudging strength of β = 0.01. The three student networks trained with truncated BPTT and truncation windows of 1, 2, and 4 use learning rates of 0.01, 0.02, and 0.04, respectively. All networks use the Adam optimizer95 with default parameters for momentum and decay rates for faster convergence.
Small networks (Fig. 6)
The input signal is a composition of three sine signals with frequencies ω1 = 0.49, ω2 = 1.07, and ω3 = 1.98. To isolate the effect of backpropagated errors over multiple layers, only the bottom weights are initialized randomly and then learned. The loss depicted in Fig. 6f is filtered with a rectangular window of width 1. The AM (see also Algorithm 2 in the Supplement) uses a truncation window of duration 3. Learning rates are ηGLE = 2 × 10−2 and ηAM = 7 × 10−2. We use a teacher nudging strength of β = 1, and a somato-dendritic coupling of γ = 10−3. The frequency resolution in Fig. 6c, d is given by \(\frac{2\pi }{n\,{{\mbox{d}}}t}\), where n is the window length over which the frequency spectrum is calculated. To calculate the frequency spectrum of the signals before and during the early learning phase, the network is simulated for n = 8000 steps with fixed weights (yielding a frequency resolution of ≈ 0.078).
MNIST-1D (Figs. 8d, f, 10a−c, e, f)
The GLE networks in Fig. 8d use a layered architecture with a single input neuron in the first layer, six fully connected hidden layers and an output layer with ten neurons (see Fig. 9b). Each hidden layer has three different, equally-sized populations of neurons, each with different time constants τm and τr, corresponding to a fast, medium, and slow population. The time constants of the slow population τslow were chosen such that \(2.5{\sum}_{\ell \in [1,L]}{\tau }_{{{\rm{slow}}}}=L{\tau }_{{{\rm{slow}}}}\approx \,\,{\mbox{pattern}} \,\,{\mbox{duration}}\,=90\,\,{{\mbox{d}}}t\). This is inspired by ref. 96 where the factor 2.5 was determined empirically. The (G)LE networks in Fig. 8f use a custom, non-plastic LagNet of purely retrospective neurons (τr = 0) with different membrane time constants τm that allow for an approximate, partial mapping of the temporal sequence to the neuronal space (see Fig. 9c for an architecture diagram).
In the network scaling experiments for Fig. 10a−c, the number of layers was chosen from {2, 4, 6, 8, 10}, and the total number of neurons per hidden layer from {32, 64, 128, 256, 512}.
In the experiments assessing robustness to parameter noise in Fig. 10d, a six-layer network was used and each neuron’s time constants, τm and τr, were sampled from a normal distribution centered around the original time constants of the respective neuron population, with standard deviations chosen from {0, 0.01, 0.05, 0.1}.
In Fig. 10e, we added additional correlated noise to the rates of the feedforward neurons, including the input and output layers. The noise was generated from a normal distribution with mean 0 and standard deviation 2π{0.01, 0.02, 0.05, 0.1, 0.2} for each neuron and time step in the original sequence. It was correlated over the sequence length of 72 time steps using a Gaussian kernel with a standard deviation of two time steps. Then, it was interpolated to the new sequence length of 360 time steps and finally added to the individual neuron rates at each time step. The rescaling factor of 2π ensures that the standard deviation of the correlated noise corresponds to the reported standard deviations.
For Fig. 10f, g, we added Gaussian noise to the feedback weight matrices \({{{\boldsymbol{B}}}}_{\ell }={{{\boldsymbol{W}}}}_{\ell+1}^{{{\rm{T}}}}+{{\mathcal{N}}}(0,{\sigma }^{2})\), sampled from a normal distribution with mean 0 and standard deviation σ = {0.01, 0.05, 0.1, 0.2}. This noise is regenerated before every training epoch, except for the FA experiment, where it is fixed for the entire training. The alignments reported in Fig. 10g are calculated as the angle between the original and the noisy feedback weight matrix, \(\angle ({{\boldsymbol{A}}},{{\boldsymbol{B}}})=\arccos \left(\frac{\langle {{\boldsymbol{A}}},{{\boldsymbol{B}}}\rangle }{\parallel {{\boldsymbol{A}}}{\parallel }_{2}\parallel {{\boldsymbol{B}}}{\parallel }_{2}}\right)\), where 〈 ⋅ , ⋅ 〉 denotes the inner product.
Detailed parameters for the different GLE networks are given in Table 1.
The original publication of the dataset60 uses a downsampled version of the sequences to 40 time steps (baseline results with index 0 in Fig. 8f). For a more continuous input, we interpolate the original sequences of length 72 to 360 time steps. To ensure a fair comparison, we also retrain the baseline architectures on these higher-resolution sequences (Fig. 8d). An overview of the different reference models, their size and final performance on the MNIST-1D dataset is shown in Table D.1 in the Supplement.
Google speech commands
The GLE networks use a layered architecture with 32 input neurons in the first layer, three fully connected hidden layers and an output layer with twelve neurons (see Fig. 9a). Each hidden layer has five different populations of neurons, each with different time constants τm and τr. Detailed parameters for the different GLE networks are given in the last column of Table 1.
To provide a fair comparison, the dataset (v2.12) and data augmentation process from ref. 97 is used to train and test all models. For a more continuous input, the original sequences are interpolated, increasing the number of time steps by a factor of 20. The train/validation/test set split ratio is 80:10:10. The training data is augmented with background noise and random time shifts of up to 100 ms. The length and stride of the Fourier window, the number of frequency bins and the type of Mel-frequency representation is optimized for each method independently; all parameters are given in Table D.2 in the Supplement.
GLE for purely spatial patterns
In Fig. 8g we compare the validation accuracy of (G)LE (in the instantaneous case where \({\tau }_{i}^{{{\rm{m}}}}={\tau }_{i}^{{{\rm{r}}}}\) for all neurons i) with standard BP on a purely spatial task, namely the CIFAR-10 dataset65. In both cases, the architecture follows LeNet-598 (see Fig. 9d). These results are taken from the original publication17, to which we refer for further details.
Chaotic time series prediction
For the Mackey−Glass time series prediction task, we follow the benchmark setup of ref. 66 to allow a fair comparison with their results. The Mackey−Glass time series is generated by the following delay differential equation:
with delay constant τ and parameters β, γ, and n. Depending on the parameters, the Mackey−Glass system can exhibit periodic and chaotic behavior. As in ref. 66, we use β = 0.2, γ = 0.1, n = 10, and τ = 17 leading to chaotic behavior. The Lyapunov time λ for this system, a measure of the timescale over which two different initial conditions are expected to diverge by at least a factor of e, is λ = 197. The NeuroBench framework66 provides a pregenerated Mackey-Glass time series of a length of 50 λ, which is used as the training set with a discretization 75 steps/λ corresponding to a time step of ~2.63. For the simulation of our GLE networks, we require a much finer discretization of the time series, so we use a time step of 0.2 corresponding to 985 steps/λ using the jitCDDE library99. Furthermore, instead of the Euler integration scheme for the simulation of our GLE networks, we use the fourth-order Runge-Kutta method, which, together with the finer discretization, allows for improved numerical stability of our simulation.
The original time series of length 50 λ is then split into 30 sequences of length 20 λ, shifted by 0.5λ time each. The first 10 λ of each sequence are used for training, where the network is trained to predict the next step x(t + 1) from input x(t) (and possibly delayed inputs x(t − Δ)). After the first 10 λ, the network switches to the autoregressive mode, where the network’s prediction of x(t + 1), i.e., the output y(t), is fed back as input for the next time step and without providing the true value x(t + 1) as a target. For each of the 30 sequences, a separate network with different random initialization is trained over 150 epochs and then evaluated on the last 10 λ of the sequence using the sMAPE metric and finally averaged over all 30 sequences. Our GLE networks use four input neurons, each delayed by Δ = 6 and two hidden layers with 93 neurons each, that is, in total 186 hidden neurons, identical in size to the ESN baseline network. For details on the ESN and LSTM baselines as well as the benchmark setup, we refer to the original publication66.
Data availability
All datasets used in this manuscript are publicly available and do not require restricted access. The MNIST-1D data used in this study are available in the public GitHub repository https://github.com/greydanus/mnist1d, see also ref. 60. The GSC dataset is publicly accessible from the TensorFlow Speech Commands repository, https://www.tensorflow.org/datasets/catalog/speech_commands, see also ref. 62. The CIFAR-10 dataset is available from the Kaggle CIFAR-10 database and CIFAR-10 repository, https://www.kaggle.com/c/cifar-10 and https://www.cs.toronto.edu/~kriz/cifar.html. See also ref. 65. The Neurobench Mackey−Glass task data generated and used in this study are available in the Neurobench repository https://github.com/neurobench/neurobench, see also ref. 66. No data were protected or unavailable due to data privacy laws. Full details and references to the source data and any processed data files are provided in the Methods and the Supplementary Information.
Code availability
Code to reproduce the results presented in this manuscript is available at https://github.com/unibe-cns/gle-code.
References
Baydin, A. G., Pearlmutter, B. A., Radul, A. A. & Siskind, J. M. Automatic differentiation in machine learning: a survey. J. Mach. Learn. Res. 18, 1–43 (2018).
Pearlmutter, B. Gradient calculations for dynamic recurrent neural networks: a survey. IEEE Trans. Neural Netw. 6, 1212–1228 (1995).
Linnainmaa, S. Taylor expansion of the accumulated rounding error. BIT Numer. Math. 16, 146–160 (1976).
Werbos, P. J. Applications of advances in nonlinear sensitivity analysis. System Modeling and Optimization: Proceedings of the 10th IFIP Conference 762–770 (1981).
Rumelhart, D. E., Hinton, G. E. & Williams, R. J. Learning representations by back-propagating errors. Nature 323, 533–536 (1986).
Pineda, F. J. Generalization of back-propagation to recurrent neural networks. Phys. Rev. Lett. 59, 2229–2232 (1987).
Werbos, P. Backpropagation through time: what it does and how to do it. Proc. IEEE 78, 1550–1560 (1990).
Kelley, H. J. Method of gradients. Math. Sci. Eng. 5, 205–254 (1962).
Todorov, E. in Bayesian Brain (ed. Doya, K.) Ch. 6 (MIT Press, 2006).
Chachuat, B. Nonlinear and dynamic optimization: from theory to practice. Lecture Notes, EPFL 1–187 (2007).
Sutton, R. Reinforcement Learning 2nd edn (MIT Press, 2018).
Lillicrap, T. P. & Santoro, A. Backpropagation through time and the brain. Curr. Opin. Neurobiol. 55, 82–89 (2019).
Sussillo, D. & Abbott, L. F. Generating coherent patterns of activity from chaotic neural networks. Neuron 63, 544–557 (2009).
Gilra, A. & Gerstner, W. Predicting non-linear dynamics by stable local learning in a recurrent spiking neural network. eLife 6, e28295 (2017).
Williams, R. J. & Zipser, D. A learning algorithm for continually running fully recurrent neural networks. Neural Comput. 1, 270–280 (1989).
Marschall, O., Cho, K. & Savin, C. A unified framework of online learning algorithms for training recurrent neural networks. J. Mach. Learn. Res. 21, 1–34 (2020).
Haider, P. et al. Latent Equilibrium: A unified learning theory for arbitrarily fast computation with arbitrarily slow neurons. Adv. Neural Inf. Process. Syst. 34, 17839–17851 (2021).
Hodgkin, A. L. & Huxley, A. F. A quantitative description of membrane current and its application to conduction and excitation in nerve. J. Physiol. 117, 500–544 (1952).
Puccini, G. D., Sanchez-Vives, M. V. & Compte, A. Integrated mechanisms of anticipation and rate-of-change computations in cortical circuits. PLoS Comput. Biol. 3, e82 (2007).
Köndgen, H. et al. The dynamical response properties of neocortical neurons to temporally modulated noisy inputs in vitro. Cereb. Cortex 18, 2086–2097 (2008).
Plesser, H. E. & Gerstner, W. Escape rate models for noisy integrate-and-fire neurons. Neurocomputing 32–33, 219–224 (2000).
Pozzorini, C., Naud, R., Mensi, S. & Gerstner, W. Temporal whitening by power-law adaptation in neocortical neurons. Nat. Neurosci. 16, 942–948 (2013).
Brandt, S., Petrovici, M. A., Senn, W., Wilmes, K. A. & Benitez, F. Prospective and retrospective coding in cortical neurons. Preprint at arXiv:2405.14810 (2024).
Kepecs, A., Wang, X.-J. & Lisman, J. Bursting neurons signal input slope. J. Neurosci. 22, 9053–9062 (2002).
Aamir, S. A. et al. A mixed-signal structured adex neuron for accelerated neuromorphic cores. IEEE Trans. Biomed. Circuits Syst. 12, 1027–1037 (2018).
Rubino, A., Payvand, M. & Indiveri, G. Ultra-low power silicon neuron circuit for extreme-edge neuromorphic intelligence. In 26th IEEE International Conference on Electronics, Circuits and Systems (ICECS) 458–461 (IEEE, 2019).
Shaban, A., Bezugam, S. S. & Suri, M. An adaptive threshold neuron for recurrent spiking neural networks with nanodevice hardware implementation. Nat. Commun. 12, 4234 (2021).
Billaudelle, S., Weis, J., Dauer, P. & Schemmel, J. An accurate and flexible analog emulation of adex neuron dynamics in silicon. In 2022 29th IEEE International Conference on Electronics, Circuits and Systems (ICECS) 1–4 (IEEE, 2022).
Ackley, D. H., Hinton, G. E. & Sejnowski, T. J. A learning algorithm for Boltzmann machines. Cogn. Sci. 9, 147–169 (1985).
Hopfield, J. J. Neural networks and physical systems with emergent collective computational abilities. Proc. Natl. Acad. Sci. USA 79, 2554–2558 (1982).
Scellier, B. & Bengio, Y. Equilibrium Propagation: Bridging the Gap between Energy-Based Models and Backpropagation. Front. Comput. Neurosci. 11, 246298 (2017).
Whittington, J. C. R. & Bogacz, R. An approximation of the error backpropagation algorithm in a predictive coding network with local Hebbian synaptic plasticity. Neural Comput. 29, 1229–1262 (2017).
Mainen, Z. F., Joerges, J., Huguenard, J. R. & Sejnowski, T. J. A model of spike initiation in neocortical pyramidal neurons. Neuron 15, 1427–1439 (1995).
Gerstner, W., Kistler, W. M., Naud, R. & Paninski, L. Neuronal Dynamics: From Single Neurons to Networks and Models of Cognition 1st edn (Cambridge Univ. Press, 2014).
Traub, R. D. & Miles, R. Neuronal Networks of the Hippocampus 1st edn (Cambridge Univ. Press, 1991).
Linaro, D., Biró, I. & Giugliano, M. Dynamical response properties of neocortical neurons to conductance-driven time-varying inputs. Eur. J. Neurosci. 47, 17–32 (2018).
Richards, B. A. et al. A deep learning framework for neuroscience. Nat. Neurosci. 22, 1761–1770 (2019).
Urbanczik, R. & Senn, W. Learning by the dendritic prediction of somatic spiking. Neuron 81, 521–528 (2014).
Markov, N. T. et al. Anatomy of hierarchy: feedforward and feedback pathways in macaque visual cortex. J. Comp. Neurol. 522, 225–259 (2014).
Shai, A. S., Anastassiou, C. A., Larkum, M. E. & Koch, C. Physiology of layer 5 pyramidal neurons in mouse primary visual cortex: coincidence detection through bursting. PLoS Comput. Biol. 11, e1004090 (2015).
Zmarz, P. & Keller, G. B. Mismatch receptive fields in mouse visual cortex. Neuron 92, 766–772 (2016).
Fiser, A. et al. Experience-dependent spatial expectations in mouse visual cortex. Nat. Neurosci. 19, 1658–1664 (2016).
Attinger, A., Wang, B. & Keller, G. B. Visuomotor coupling shapes the functional development of mouse visual cortex. Cell 169, 1291–1302 (2017).
Keller, G. B. & Mrsic-Flogel, T. D. Predictive processing: a canonical cortical computation. Neuron 100, 424–435 (2018).
Ayaz, A. et al. Layer-specific integration of locomotion and sensory information in mouse barrel cortex. Nat. Commun. 10, 2585 (2019).
Gillon, C. J. et al. Responses to pattern-violating visual stimuli evolve differently over days in somata and distal apical dendrites. J. Neurosci. 44, e1009232023 (2024).
Francioni, V., Tang, V. D., Brown, N. J., Toloza, E. H. & Harnett, M. Vectorized instructive signals in cortical dendrites during a brain-computer interface task. Preprint at arXiv:2023.11.03.565534 (2023).
Wilson, N. R., Runyan, C. A., Wang, F. L. & Sur, M. Division and subtraction by distinct cortical inhibitory networks in vivo. Nature 488, 343–348 (2012).
Seybold, B. A., Phillips, E. A., Schreiner, C. E. & Hasenstaub, A. R. Inhibitory actions unified by network integration. Neuron 87, 1181–1192 (2015).
Lee, S., Kruglikov, I., Huang, Z. J., Fishell, G. & Rudy, B. A disinhibitory circuit mediates motor integration in the somatosensory cortex. Nat. Neurosci. 16, 1662–1670 (2013).
Dorsett, C., Philpot, B. D., Smith, S. L. & Smith, I. T. The impact of sst and pv interneurons on nonlinear synaptic integration in the neocortex. eNeuro 8, ENEURO.0235-21.2021 (2021).
Petrovici, M. A. Form Versus Function: Theory and Models for Neuronal Substrates Vol. 1 (Springer, 2016).
Lillicrap, T. P., Cownden, D., Tweed, D. B. & Akerman, C. J. Random synaptic feedback weights support error backpropagation for deep learning. Nat. Commun. 7, 13276 (2016).
Kolen, J. F. & Pollack, J. B. Backpropagation without weight transport. Proc. 1994 IEEE Int. Conf. Neural Netw. (ICNN’94) 3, 1375–1380 (1994).
Akrout, M., Wilson, C., Humphreys, P., Lillicrap, T. & Tweed, D. B. Deep learning without weight transport. Adv. Neural Inform. Process. Syst. 32, 974−982 (2019).
Meulemans, A., Farinha, M. T., Cervera, M. R., Sacramento, J. & Grewe, B. F. Minimizing control for credit assignment with strong feedback. In International Conference on Machine Learning 15458–15483 (2022).
Max, K. et al. Learning efficient backprojections across cortical hierarchies in real time. Nat. Mach. Intell. 6, 619–630 (2024).
Gierlich, T., Baumbach, A., Kungl, A. F., Max, K. & Petrovici, M. A. Weight transport through spike timing for robust local gradients. Preprint at arXiv:2503.02642 (2025).
Bai, S., Kolter, J. Z. & Koltun, V. An empirical evaluation of generic convolutional and recurrent networks for sequence modeling. Preprint at arXiv:1803.01271 (2018).
Greydanus, S. Scaling down deep learning. Preprint at arXiv:2011.14439 (2020).
Cho, K. et al. Learning phrase representations using rnn encoder-decoder for statistical machine translation. Preprint at arXiv:1406.1078 (2014).
Warden, P. Speech Commands: A Dataset for Limited-Vocabulary Speech Recognition. CoRR (2018).
Hochreiter, S. & Schmidhuber, J. Long short-term memory. Neural Comput. 9, 1735–1780 (1997).
LeCun, Y. et al. Backpropagation applied to handwritten zip code recognition. Neural Comput. 1, 541–551 (1989).
Krizhevsky, A. & Hinton, G. Learning multiple layers of features from tiny images, Master's thesis, University of Toronto, (2009).
Yik, J. et al. The neurobench framework for benchmarking neuromorphic computing algorithms and systems. Nat. Commun. 16, 1545 (2025).
Mackey, M. C. & Glass, L. Oscillation and chaos in physiological control systems. Science 197, 287–289 (1977).
Fayyazi, R., Weilbach, C. & Wood, F. Prospective messaging: learning in networks with communication delays. Preprint at arXiv:2407.05494 (2024).
Senn, W. et al. A neuronal least-action principle for real-time learning in cortical circuits. eLife 12, RP89674 (2023).
Williams, R. J. & Zipser, D. in Backpropagation: Theory, Architectures, and Applications (eds Chauvin, Y. & Rumelhart, D. E.) (L. Erlbaum Associates Inc., 1995).
Murray, J. M. Local online learning in recurrent networks with random feedback. eLife 8, e43299 (2019).
Schuman, C. D. et al. A survey of neuromorphic computing and neural networks in hardware. Preprint at arXiv:1705.06963 (2017).
Deng, L., Li, G., Han, S., Shi, L. & Xie, Y. Model compression and hardware acceleration for neural networks: a comprehensive survey. Proc. IEEE 108, 485–532 (2020).
Campolucci, P., Uncini, A. & Piazza, F. Causal back propagation through time for locally recurrent neural networks. 1996 IEEE Int. Symp. Circuits Syst. Circuits Syst. Connect. World ISCAS 96 3, 531–534 (1996).
Orvieto, A. et al. Resurrecting recurrent neural networks for long sequences. In Proc. 40th International Conference on Machine Learning 26670–26698 (2023).
Orvieto, A., De, S., Gulcehre, C., Pascanu, R. & Smith, S. L. Universality of linear recurrences followed by non-linear projections: finite-width guarantees and benefits of complex eigenvalues. Proceedings of the 41st International Conference on Machine Learning 38837–38863 (2024).
Gu, A. & Dao, T. Mamba: Linear-time sequence modeling with selective state spaces. First conference on language modeling (2024).
De, S. et al. Griffin: Mixing Gated Linear Recurrences with Local Attention for Efficient Language Models. CoRR (2024).
Gupta, A., Gu, A. & Berant, J. Diagonal state spaces are as effective as structured state spaces. Adv. Neural Inf. Process. Syst. 35, 22982–22994 (2022).
Gu, A. et al. Combining recurrent, convolutional, and continuous-time models with linear state space layers. Adv. Neural Inf. Process. Syst. 34, 572–585 (2021).
Gu, A., Goel, K., & Ré, C. Efficiently Modeling Long Sequences with Structured State Spaces. International Conference on Learning Representations (2022).
Zucchet, N., Meier, R., Schug, S., Mujika, A., & Sacramento, J. Online learning of long-range dependencies. Adv. Neural. Inf. Process. Syst. 36, 10477–10493 (2023).
Wunderlich, T. et al. Demonstrating advantages of neuromorphic computation: a pilot study. Front. Neurosci. 13, 260 (2019).
Göltz, J. et al. Fast and energy-efficient neuromorphic deep learning with first-spike times. Nat. Mach. Intell. 3, 823–835 (2021).
Lee, C., Hasegawa, H. & Gao, S. Complex-valued neural networks: a comprehensive survey. IEEE/CAA J. Autom. Sin. 9, 1406–1426 (2022).
Brette, R. et al. Simulation of networks of spiking neurons: a review of tools and strategies. J. Comput. Neurosci. 23, 349–398 (2007).
Abeles, M. Role of the cortical neuron: integrator or coincidence detector? Isr. J. Med. Sci. 18, 83–92 (1982).
König, P., Engel, A. K. & Singer, W. Integrator or coincidence detector? the role of the cortical neuron revisited. Trends Neurosci. 19, 130–137 (1996).
Ratté, S., Hong, S., De Schutter, E. & Prescott, S. A. Impact of neuronal properties on network coding: roles of spike initiation dynamics and robust synchrony transfer. Neuron 78, 758–772 (2013).
Sacramento, J., Ponte Costa, R., Bengio, Y. & Senn, W. Dendritic cortical microcircuits approximate the backpropagation algorithm. In Proc. 32nd International Conference on Neural Information Processing Systems 8735−8746 (Curran Associates Inc., 2018).
Cramer, B. et al. Surrogate gradients for analog neuromorphic computing. Proc. Natl. Acad. Sci. USA 119, e2109194119 (2022).
Wunderlich, T. C. & Pehle, C. Event-based backpropagation can compute exact gradients for spiking neural networks. Sci. Rep. 11, 12829 (2021).
Izhikevich, E. M. Simple model of spiking neurons. IEEE Trans. Neural Netw. 14, 1569–1572 (2003).
Brette, R. & Gerstner, W. Adaptive exponential integrate-and-fire model as an effective description of neuronal activity. J. Neurophysiol. 94, 3637–3642 (2005).
Kingma, D. P. & Ba, J. Adam: A method for stochastic optimization. Preprint at arXiv:1412.6980 (2014).
Weidel, P. & Sheik, S. WaveSense: efficient temporal convolutions with spiking neural networks for keyword spotting. Preprint at arXiv:2111.01456 (2021).
Zhang, Y., Suda, N., Lai, L. & Chandra, V. Hello edge: keyword spotting on microcontrollers. Preprint at arXiv:1711.07128 (2018).
LeCun, Y., Bottou, L., Bengio, Y. & Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 86, 2278–2324 (1998).
Ansmann, G. Efficiently and easily integrating differential equations with JiTCODE, JiTCDDE, and JiTCSDE. Chaos 28, 043116 (2018).
Acknowledgements
We thank Simon Brandt for sharing his expertise on prospectivity in mechanistic neuron models, Timo Gierlich for the simulations of spike-based alignment learning, Maxim Kondratenko for proofreading and Walter Senn for many stimulating discussions about various aspects of dendritic computation, energy-based models, error-correcting plasticity and bio-plausible credit assignment. We gratefully acknowledge funding from the European Union under grant agreements #945539 (Human Brain Project, SGA3; PH, LK, MAP) and #101147319 (EBRAINS 2.0; PH, JJ, FB, MAP), the Volkswagen Foundation under the call “NEXT—Neuromorphic Computing” (KM) and ESKAS for a Swiss Government Excellence Scholarship (IJ). We would like to express particular gratitude for the ongoing support from the Mandred Stärk Foundation (MAP). Our work has greatly benefited from access to the Fenix Infrastructure resources, which are partially funded by the European Union’s Horizon 2020 research and innovation program through the ICEI project under the grant agreement No. 800858 (MAP). Furthermore, we thank Marcel Affolter, Reinhard Dietrich and the Insel Data Science Center for the usage and outstanding support of their Research HPC Cluster (BE).
Author information
Authors and Affiliations
Contributions
B.E. and P.H. share first authorship of the manuscript. M.A.P., P.H., and B.E. conceived the core ideas and designed the project. B.E. and M.A.P. initiated the project and generated the first results. P.H. developed and maintained most of the code. P.H., B.E., I.J., J.J., and L.K. performed the simulations. P.H. developed the additional autoregressive experiment. P.H., K.M., F.B., I.J., and M.A.P. developed the proof of correspondence between GLE and AM. All authors contributed to the development of the theory and to the writing and editing of the manuscript. P.H., F.B., and M.A.P. were responsible for the manuscript resubmissions.
Corresponding authors
Ethics declarations
Competing interests
The authors declare no competing interests.
Peer review
Peer review information
Nature Communications thanks Luca Manneschi and the other anonymous reviewer(s) for their contribution to the peer review of this work. A peer review file is available.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Ellenberger, B., Haider, P., Benitez, F. et al. Backpropagation through space, time and the brain. Nat Commun 17, 66 (2026). https://doi.org/10.1038/s41467-025-66666-z
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41467-025-66666-z
