
Abstract
Climate change and its severe health impacts raise serious concerns about climate justice. To measure a population’s vulnerability to climate change, researchers often apply indicator-based composite indices. In this work, we present a modeling framework for constructing a climate health vulnerability index (CHVI) and examine how methodological choices influence the identification of vulnerable communities. Using 44 indicators in New York State and two structural designs—inductive (principal component analysis) and deductive (indicator aggregation)—we conducted multiple sensitivity analyses to evaluate the robustness of CHVI outcomes. The deductive design was less sensitive to model inputs and specifications than the inductive design. Among the construction steps, principal component selection and indicator normalization were the most influential factors for the inductive and deductive designs, respectively. Quantification of climate-change-related vulnerability through transparent and reproducible index development can inform policy planning and resource allocation for the most disadvantaged populations.
Similar content being viewed by others

Introduction
In recent years, there has been growing interest among researchers, communities, and policymakers in quantifying health vulnerability to climate change hazards and environmental burdens1,2. Despite varying definitions in the literature, vulnerability is generally categorized into two types: biophysical vulnerability, measured by hazardous exposures that increase the likelihood of adverse impacts (e.g., health effects of climate hazards such as floods or heatwaves), and social vulnerability, measured by factors that affect the susceptibility of human populations to potential losses from those exposures (e.g., children or people with low income)3, both contributing to a population’s overall health risk.
Indicator-based composite vulnerability indices are commonly used to capture multiple dimensions of vulnerability that cannot be measured by a single indicator. These indices offer an interpretable and operational method to rank the vulnerability of geographically defined communities, assisting the public and policymakers in understanding these risks4,5,6,7. Despite critiques of its sensitivity, consistency, and validity8,9, the indicator-based approach serves as a quantitative decision-making tool to support targeted climate change mitigation and adaptation, urban planning, funding decisions, and climate justice advocacy. Furthermore, climate risk and adaptation planning is strengthened by co-development of indicators by scientists and stakeholders. This collaborative approach ensures that the indicators are not only scientifically robust but also practically relevant and actionable, facilitating more equitable and just climate change risk assessment. However, challenges remain, such as the resource-intensive nature of this approach and the difficulty of aligning divergent interests among parties10.
Numerous studies have developed health vulnerability indices at the local, regional, and national scales for unfavorable climatic conditions, particularly focusing on excess heat1,7,11,12,13,14. These studies typically employ frameworks that incorporate exposure, sensitivity, and/or adaptive capacity, capturing the abovementioned biophysical and social vulnerabilities15. Demographic and socioeconomic characteristics and temperature metrics are the most used indicators for index development, while health conditions and environmental exposures other than temperature have been less frequently included1,7,11,12,13,14.
Previous studies on social vulnerability to hazards have outlined some key steps in index development16,17, including indicator selection, structural design, transformation, normalization, weighting, and aggregation. Although a general framework can be adopted, no universally agreed methodology for constructing climate-change-related health vulnerability indices exists. Usually, indices are constructed by compiling individual indicators within a specific analytical framework that involves a series of intricate steps1,7,11,12. However, the various options available at each step make it challenging to generalize the development process. Moreover, subjective decisions at each stage could lead to variations in the model input, and the numerous combinations of alternatives across the modeling steps can, therefore, introduce considerable uncertainties in the final index.
Several attempts have been made to test the potential impacts of different methodological choices at each step, often through local (evaluating one step at a time)5,18,19,20,21,22,23,24 or global (assessing multiple steps simultaneously)16,17 sensitivity analyses. The goal of these sensitivity analyses is to guide index developers with quantitative metrics to compare how the output index responds to variations in the model input during different construction stages, offering a better understanding of how methodological choices affect model performance. To date, most assessments of model robustness have focused on several key steps, such as normalization, weighting, and aggregation, while other steps are rarely investigated16,17,19,20,21,22,23, with many local analyses primarily focusing on how different approaches affected the identification or ranking of disadvantaged communities19,20,21.
Despite existing frameworks for assessing climate health vulnerability, there remains an important gap in integrating multifaceted socio-economic and environmental data into methodological assessments. Furthermore, few studies have comprehensively summarized methodological steps and choices using sensitivity analyses16,17, which is crucial for understanding how different methodological decisions impact the robustness and reliability of vulnerability indices. Aiming to address these gaps by developing a robust framework that integrates a wide array of indicators to better inform policy and decision-making, the objectives of this study were twofold: (1) to present an updated modeling framework for index development, and (2) to use 44 individual indicators in the State of New York to construct a climate health vulnerability index (CHVI), systematically evaluating the impact of each methodological choice on the final index output. Additionally, this paper discusses the practical application of the modeling framework for constructing a composite CHVI, aiming to inform future research practice and decision-making in climate health.
Results
Modeling framework: indicator selection
When selecting indicators for a composite vulnerability index, developers should consider the availability, accuracy, and relevance of indicators, as well as the relationship between them6. Many composite index studies use a structured conceptual framework for indicator selection, such as the driver-pressure-state-impact-response framework adopted by the European Environment Agency, the exposure-sensitivity-adaptive capacity framework used by the Intergovernmental Panel on Climate Change25, the Methods for the Improvement of Vulnerability Assessment in Europe sponsored by the European Commission26, or the framework for the assessment of coupled human-environment systems27. Despite variations in terminology, these frameworks share common components, including exposure, susceptibility (or sensitivity), and community adaptive capacity.
The purpose of indicator selection is to choose the variables that best represent the underlying dimensions of vulnerability. The choice of an exposure indicator(s), each of which represents a specific type of vulnerability, often fundamentally distinguishes one index from another. For example, high-temperature days may be used in a heat vulnerability index28, flood-prone land area in a flood vulnerability index21, disaster frequency in a typhoon vulnerability index29, and climate and pollution variables in our CHVI (see details below). Both quantitative and qualitative indicators can be used to assess vulnerability30, although quantitative indicators are more frequently employed in aggregation for the final index. In this paper, we focus exclusively on quantitative indicators in the CHVI.
Common strategies for selecting indicators for composite vulnerability indices include literature review31, subjective judgment, and expert panel consultation28. Among these, the literature review is the most frequently used method, offering an evidence-based approach to identifying relevant variables that impact vulnerability. However, literature reviews are time-intensive and resource-demanding. Subjective selection introduces a high risk of bias but is suitable for resource-limited settings. Similarly, expert panels may also introduce bias, but provide a unique opportunity to include interdisciplinary perspectives in the process and provide a well-informed synthesis of complex information.
Modeling framework: structural design
Structural design refers to how indicators are organized to create the composite index. The two main approaches are inductive and deductive19. The inductive design uses methods such as principal components analysis (PCA) to decrease the dimensionality of the data32 by reducing a large number of indicators into a smaller set of uncorrelated principal components (PCs) that are aggregated in the index. This design enables a nuanced understanding of underlying drivers of vulnerability by combining the richness of a large set of indicators with the succinctness of a small set of components33. However, subjective decisions during the PC selection process can introduce bias, and the interpretation and communication of PCA results to stakeholders and policymakers may be challenging20.
In contrast, the deductive design directly aggregates a smaller set of indicators into the index without using intermediate methods like PCA34. This design is straightforward and easily understandable, making it particularly useful for policy applications. However, it may obscure the complex underlying relationships between indicators driving vulnerability in the final index33.
Finally, both the inductive and deductive designs can be hierarchical (i.e., hierarchical inductive or hierarchical deductive design), which separates indicators into sub-indices based on similarities in the dimensions of vulnerability35,36. For example, to separately capture socioeconomic and environmental susceptibility, individual indicators are first grouped into a socioeconomic sub-index or an environmental sub-index37. These sub-indices are then further combined into a final composite index. This approach facilitates understanding of the fundamental components of vulnerability, but can be highly sensitive to the weighting scheme17.
In summary, the inductive design is beneficial for exploring underlying vulnerability drivers but may complicate communication with non-technical audiences, whereas the deductive design is easier to interpret but may mask important interrelationships between indicators. The hierarchical scheme, whether inductive or deductive, strikes a balance by structuring indicators into sub-indices, though it requires careful consideration of weighting the sub-indices.
Modeling framework: other key steps
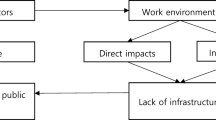
We show all other key steps in the development of a composite vulnerability index in Fig. 1, and in Supplementary Information (Text S1) we briefly discuss the methodological options and advantages and disadvantages of each step. The following steps are discussed: sampling adequacy test, transformation, normalization, principal component (PC) selection, direction correction, component score ranking, weighting, and aggregation.

Blue-colored text highlights the key steps discussed in the framework. A dashed arrow means that retained components can be used to weight indicators in the deductive design.
Sensitivity analysis results
We categorized our 44 census-tract-level indicators from New York State into two groups: biophysical vulnerability and social vulnerability (see “Data” in Methods). We then constructed two CHVIs using two benchmark models: a hierarchical inductive model and a hierarchical deductive model (see “Benchmark models” in Methods). For a given model, we defined census tracts with the top 30% CHVI scores across the state as disadvantaged communities (DACs). We then compared CHVI scores and classification of census tracts as DACs between the benchmark inductive and deductive models and between each benchmark model and sensitivity analyses that used alternative approaches in various key modeling steps (see “Alternative approach” sections in Methods).
Generally, there were stronger correlations between the indicators in the social vulnerability group than in the biophysical vulnerability group (Fig. S1). The Kaiser-Meyer-Olkin (KMO) statistics were 0.70 for the biophysical vulnerability group and 0.84 for the social vulnerability group, suggesting that the data were well-suited for factor analysis based on their correlation and partial correlation matrices. For the inductive model, five PCs were retained for the biophysical vulnerability group and five were retained for the social vulnerability group. The contributing indicators for each PC within each group are presented in Table S2. No direction correction was performed based on the loadings of the indicators.
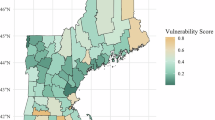
The spatial distributions of CHVI final scores at the census tract level across New York State, based on both benchmark models, are shown in Fig. 2. The distribution of scores for the biophysical and social vulnerability groups across census tracts varied considerably between the inductive and deductive designs (Fig. 3). Pearson’s correlation between the two indices was 0.65 (p < 0.01), with a coefficient of determination (R2) of 0.42 and a root-mean-square error (RMSE) of 21.96 (Fig. 4).

Left: Quintiles of census-tract-level climate health vulnerability index scores using the benchmark inductive model. Right: Quintiles of census-tract-level climate health vulnerability index scores using the benchmark deductive model.

Left: Scores for biophysical versus social vulnerability using the benchmark inductive model. Right: Scores for biophysical versus social vulnerability using the benchmark deductive model.

X-axis represents the climate health vulnerability index scores using the benchmark deductive model and Y-axis represents the climate health vulnerability index scores using the benchmark inductive model. RMSE root mean square error.
In the sensitivity analyses, the methodological changes in the benchmark models generally had a greater influence on the final scores in the inductive model compared to the deductive model (Figs. 5 and 6). For the inductive design, the alternative method for PC selection had the most substantial impact on the final score, resulting in the lowest R2, the highest RMSE (Fig. 5), and the highest average absolute shift in score rankings of 18.0 (out of 100) across all census tracts (Fig. S2). PC score multiplicative aggregation and PC scores ranked by mean-standard deviation (SD) categorization also considerably influenced the results, with an average absolute shift in score rankings of 10.5 and 10.3, respectively (Fig. S2). In contrast, PC scores ranked as deciles and removal of race indicators had substantially less influence on the final scores, with an average absolute shift in score rankings of 3.9 and 4.6, respectively.

X-axis represents the climate health vulnerability index scores for a sensitivity analysis and y-axis represents the climate health vulnerability index scores for the benchmark inductive model. RMSE: root mean square error; PC: principal component.

X-axis represents the climate health vulnerability index scores for a sensitivity analysis and Y-axis represents the climate health vulnerability index scores for the benchmark deductive model. RMSE root mean square error, PCA principal component analysis.
For the deductive design, maximum normalization emerged as the most influential alternative approach, with an R2 of 0.85, an RMSE of 11.28 (Fig. 6), and an average absolute ranking shift of 8.6 (Fig. S2). Transforming renter-occupied homes as count or density and group score additive aggregation had negligible effects on the final index scores, and removal of race indicators and regrouping driving time to hospital, had relatively little influence.
We observed some discrepancies in the DACs identified by the two benchmark models (Figs. S3 and S4). The inductive design identified 747 DACs in New York City and 729 DACs outside New York City, whereas the deductive design identified 1192 DACs in New York City and 284 DACs outside New York City. The overall agreement between the two benchmark models was 75.3%, with 868 (17.6%) of the 4918 census tracts identified by both models as DACs and 2834 (57.6%) identified by both models as non-DACs.
We then compared DAC identification between each of the two benchmark models and each of the sensitivity analyses that were performed for the respective design (Table S3, and Figs. S5–S23). We found that across the sensitivity analyses, percent agreement between the benchmark model and a given sensitivity analysis model ranged from 77.9% to 96.5% for the inductive design and 90.3% to 98.0% for the deductive design. Furthermore, the number of census tracts classified as DACs in the benchmark model but as non-DACs in a given sensitivity analysis ranged from 1.8% to 11.0% for the inductive design and 1.0% to 4.8% for the deductive design (Table S3).

Left: Disadvantaged and non-disadvantaged communities identified using the inductive design. Right: Disadvantaged and non-disadvantaged communities identified using the deductive design. DAC disadvantaged community.
We found that the deductive design continued to be less sensitive to modeling choices than the inductive design when we restricted the sensitivity analyses to the seven that were performed for both designs, to obtain a fairer comparison (Fig. 7, Table S3). In total, 825 (16.8%) out of all 4918 census tracts were identified as DACs and 2649 (53.9%) as non-DACs by all analyses (benchmark and seven sensitivity analyses that were performed for both designs) using the inductive design, whereas 1095 (22.3%) and 3038 (61.8%) census tracts were identified as DACs and non-DACs, respectively, by all analyses using the deductive design. Agreement across the benchmark model and all seven sensitivity analysis models was 84.0% for the deductive design and 70.6% for the inductive design. Differences between the two designs appear to be driven by the relatively low percent agreement between the benchmark model and four of the sensitivity analysis models (indicator grouping, the two transformations, and weighting) for the inductive design compared to the deductive design (Table S3).
Discussion
This paper details the essential steps involved in the construction phase of a CHVI, along with several relevant alternative approaches, thereby advancing the understanding of the comprehensive modeling framework for quantifying climate health vulnerability. Restricting to the seven sensitivity analyses performed for both the inductive and deductive designs, we found that 84.0% of all census tracts were consistently identified as DACs or non-DACs by the benchmark deductive model and its corresponding sensitivity analysis models, versus only 70.6% by the benchmark deductive model and its corresponding sensitivity analysis models.
Some key steps in both structural designs are identical: indicator selection and grouping, transformation, normalization, weighting, and aggregation. However, the inductive design includes an additional step, PC selection, and differs from the deductive design in that it weights and aggregates PC scores, while the deductive design weights and aggregates normalized indicators. Few studies have assessed the systematic difference in the final indices produced by these two designs. Similar to a previous study that assessed social vulnerability to natural disasters19, we found a moderate correlation (0.65) between our CHVI indices generated from each method. A global sensitivity and uncertainty analysis of a social vulnerability index found that the hierarchical deductive design was more accurate (lower median value of the deviation of simulated index rankings from the baseline ranking), while the inductive design was more precise (simulated index rankings closer to each other)17. This global analysis also found that the hierarchical deductive design was highly sensitive to weighting and transformation. In contrast, the inductive design’s uncertainty was substantially driven by indicator selection, spatial unit of analysis, PC selection, and weighting, although aggregation was not evaluated17.
Our findings indicate that PC selection had the most substantial impact on the final index in the inductive design. Other studies have also identified this step to be among the most important drivers of uncertainty17. Some statistical studies have indicated that the Kaiser criterion, which selects components with eigenvalues greater than one for inclusion in the composite index, tends to over-extract PCs, potentially causing component misinterpretation38. Therefore, it should be used with caution or performed in combination with other criteria. In addition, we found the PC score ranking to be one of the most influential steps in the inductive design. Specifically, ranking by mean-SD in the sensitivity analysis classified PC scores into only six possible values, which limited the number of aggregated values for both the biophysical and social vulnerability groups.
Despite the considerable differences between the inductive and deductive designs, several consistent findings emerge across the designs, including higher biophysical vulnerability along the Hudson River and in midtown and lower Manhattan, higher social vulnerability in the Bronx, Brooklyn, and Queens, and higher biophysical and social vulnerability in the Bronx (Fig. 3). To inform development of targeted interventions, research is needed to identify factors driving these elevated vulnerabilities – potentially factors such as high population density, socioeconomic disadvantage, and environmental stressors (e.g., projected flooding risk). Furthermore, these high-vulnerability areas should be prioritized for the development of equitable and effective adaptation strategies.
To date, 12 U.S. states have reported the proportion of the population residing in DACs, with values ranging from 10% to 50%, depending on the DAC definition adopted by the state39. We chose to define DACs as census tracts with CHVI scores in the top 30%, echoing the nationwide definition used by the Climate and Economic Justice Screening Tool40.
It is important to note that while there was moderate agreement in DAC identification across the inductive and deductive designs and across methods within each design, some communities identified as DACs in the benchmark inductive model were classified as non-DACs in the benchmark deductive model, and for each design, some communities classified as DACs in the benchmark model were classified as non-DACs in sensitivity analysis models. Thus, it is critical to recognize that although it is difficult to identify a gold-standard model, different modeling choices could introduce bias in the CHVI, potentially impacting the prioritization of some vulnerable communities in policymaking. Misclassification of vulnerable populations would further entrench inequities rather than alleviate them. Therefore, careful consideration of methodological robustness, transparency, and stakeholder engagement is essential to ensure that the index development process is equitable and minimizes unintended consequences for community prioritization.
Studies have shown that heat vulnerability indices have not been extensively used in policymaking and intervention41 and that this approach has largely remained within the realm of academic exercise and theoretical exploration. However, heat vulnerability indices can play an increasingly important role in advancing climate justice and raising awareness of the disproportionate impacts of climate change on vulnerable populations among stakeholders and the public42. Integration of heat vulnerability indices into actionable policies and interventions could spur such integration of broader CHVIs in the future. The current gap between vulnerability mapping and policymaking arises mainly from limited knowledge about how to effectively integrate scientific outputs into decision-making processes. Some key barriers include representation of complex vulnerability by a single index, inherent methodological subjectivity and uncertainty, unclear reliability in terms of effectiveness and accuracy, and limited research-policy interface and stakeholder engagement41. We used a policy-oriented list of indicators and a wide range of sensitivity analyses to maximize the transparency and minimize the subjectivity of our analysis. However, future implementation science studies are needed to strengthen the practical application of CHVIs in community engagement and policymaking processes.
It is important to recognize that distinct perceptions of climate health vulnerability persist between stakeholders and researchers43, likely stemming from variations in knowledge bases, professional versus community priorities, and goals. Although it is feasible to conduct vulnerability assessments based on stakeholders’ perspectives44, which can provide contextual expertise and shape effective interventions, methodological challenges remain one of the major barriers in the process aimed at bridging the gaps between researchers and stakeholders45. In addition, not all indicators are equally intuitive or easy for stakeholders to use and interpret45. Therefore, it is the responsibility of researchers to construct CHVIs using sound and understandable methods, ensuring that these indices serve effectively as communication tools to support climate justice interventions, and for other purposes, which can vary by audience (e.g., community groups, government entities).
Our study focused specifically on the critical steps involved in the CHVI construction phase. Within the broader lifecycle of vulnerability assessment, monitoring and evaluation46 constitutes an essential subsequent phase that enables the tracking of index behavior, as well as the assessment of policy and health outcomes over time. However, the application of the index for ongoing monitoring and policy development lies beyond the scope of the present study.
While our quantitative analysis is based on data from New York State in the US, the framework’s adaptability allows for its application in varying contexts, although comparisons across states, countries, or regions may be challenging due to data discrepancies. Nevertheless, this adaptability enables scalable applications across larger regions in the US, potentially revealing regional variability in climate health vulnerabilities. However, the generalization of findings might smooth out local nuances, necessitating cautious interpretation.
Finally, we reiterate that our aim was not to identify the “best” model but to illustrate the various influences of methodological choices. Each model and its options have distinct advantages and disadvantages, so understanding their relative impacts is essential to enhance the local applicability and relevance of CHVIs. The most ideal model can vary considerably by application scenario, CHVI goal, input data availability, user feedback, etc.
We acknowledge several limitations of this study. First, due to the unavailability of statewide data for health outcomes, we were unable to conduct a regression analysis to validate the developed CHVIs. However, studies have shown that the performance of such validation highly depended on the method employed1,11, limiting its practical use. Second, our sensitivity analyses included some of the most common methodological options but not all possible alternatives for each step. This may have hindered our ability to identify the most influential choices in the process. Additionally, subjective decisions (e.g., six categories in PC score ranking by mean-SD, a mandatory 60% threshold for cumulative variance explained in PC selection) were inevitably introduced at multiple critical steps. However, this subjectivity does not necessarily void the final output since we have ensured transparency throughout the process6. Third, we used a pre-defined set of indicators to generate the CHVI, whereas the choice of input variables can have a substantial impact on the final output, especially for the inductive design17. Specifically, we did not include indicators of gender, sexual identity, and some other types of vulnerability. Fourth, our model is reliant on the quality of the underlying data, which may vary in uncertainty, spatial resolution, etc. For example, studies have demonstrated the influence of spatial scale on vulnerability mapping23,47. Our study was unable to examine sub-census-tract vulnerabilities because the smallest geographic unit for which all data were available was the census tract.
In summary, this paper provided a detailed examination of the essential elements and methodological options in constructing a CHVI, advancing our understanding of the comprehensive modeling framework for quantifying climate health vulnerability and how methodological choices could affect results. Additionally, we identified several influential steps in the process by conducting multiple sensitivity analyses and found that both the inductive and deductive designs were reasonably robust to modeling choices, with the deductive design considerably more robust than the inductive design. The development of these indices requires rational and practical decision-making, informed by data usability, an evaluation of local contexts, and close collaboration with stakeholders, to effectively bridge the gap between vulnerability research and policymaking practices.
Methods
After the State of New Yorks Climate Leadership and Community Protection Act—one of the most ambitious pieces of climate legislation in the United States—was signed into law, the State sought to identify DACs disproportionately affected by climate-change-related public health burdens and ensure they receive at least 35% of the overall benefits from the spending mandated by the new law42. Accordingly, the State’s Department of Environmental Conservation established the Climate Justice Working Group (CJWG) to provide strategic advice on incorporating the needs of DACs and promote climate justice. One of the CJWG’s activities was the creation of an index to rank the vulnerability of each census tract in the state42.
To explore our second research aim, this study used the same variables and data used in the State’s index to develop our own census-tract-level CHVI for the State of New York (N = 4918 census tracts; 2168 in New York City and 2750 outside of New York City) as a case study to quantitively evaluate the potential influence of alternative methodological choices in several index development steps, through multiple sensitivity analyses (see “Alternative approach” sections below). For each sensitivity analysis, we computed the R2 and the RMSE, comparing the sensitivity analysis with a benchmark inductive or deductive model. In addition, the Climate and Economic Justice Screening Tool, published by the White House in the United States, developed criteria for DACs and identified 33.0% of all census tracts nationwide as DACs40. Therefore, for a given model, we defined census tracts with the top 30% CHVI scores across the state as DACs. The aim of the sensitivity analyses was to compare the impacts of different methodological choices rather than to identify the “best” model. It is important to note that most, but not all, commonly used methodological alternatives from previous studies were included in the sensitivity analyses.
Data
We used a list of 44 census-tract-level indicators (Table S1) developed by the CJWG42. These indicators represent various aspects of exposure, susceptibility, and adaptive capacity. We categorized all indicators into two groups—biophysical vulnerability and social vulnerability. We further divided biophysical vulnerability into dimensions capturing potential pollution exposures; land use associated with historical discrimination or disinvestment; and potential climate change risks and built environment; we further divided social vulnerability into dimensions capturing income, education, and employment; race, ethnicity, and language; health impacts and burdens; and housing, energy, and communications. The data source and detailed calculation for each indicator are presented in Supplementary Information (Data sources and detailed calculations).
Benchmark models
We first developed the CHVI using two different benchmark models with two sets of specifications: a hierarchical inductive model and a hierarchical deductive model17. Then, we conducted multiple sensitivity analyses (see “Alternative approach” sections below) and compared their results to those of the benchmark models. Specifically, we compared CHVI scores and classification of census tracts as DACs between the benchmark inductive and deductive models and between the benchmark model and each sensitivity analysis for each design. The head-to-head comparisons between the benchmark model and various sensitivity analyses show the influence of different modeling strategies on the final DAC identification. In the benchmark models, all indicators with raw data in areas and counts, including low vegetative cover, agricultural land, renter-occupied homes, manufactured homes, and homes built before 1960, were transformed into percentages.
For the hierarchical inductive model, we first took the natural logarithm of indicators that were highly skewed. After all indicators were normalized using the z-score method, we conducted separate PCAs for the biophysical and social vulnerability groups. Following a varimax rotation23, we derived principal components within each group that met at least two of the following criteria: (1) had an eigenvalue greater than one; (2) showed a large break in scree test plot; or (3) cumulatively explained more than 60% of the overall variance. Next, each principal component score for each census tract was recalculated as its percentile in the distribution of all scores from this component. For example, if a census tract ranked in the 95th percentile among all tracts, it was assigned a new score of 95. Then, we summed all component scores within each group for each census tract using equal weighting and recalculated these summed scores as their percentiles across all census tracts in each group. The final score for each census tract was calculated as the product of the scores from the biophysical and social vulnerability groups and was further assigned a percentile in the distribution of all final scores.
For the hierarchical deductive model, we first used percentiles to assign individual scores to all census tracts for each raw indicator. To avoid undesirable skewed distributions, especially for indicators with a large number of raw zero values, we initially assigned a zero percentile to census tracts with zero values, and then calculated percentile scores from 0−100 for the remaining tracts. For each census tract, we then averaged all indicator scores (equal weighting) within each dimension in the biophysical and social vulnerability group, respectively. Next, we calculated a weighted average score across dimensions for each of the two groups, following the CJWG’s method, which assigned double weight to the biophysical vulnerability group dimension of potential climate change risks and built environment to address the unequal weighting effect caused by the imbalance in the total number of dimensions (i.e., three in the biophysical vulnerability group versus four in the social vulnerability group)42 and indicators (i.e., 19 in the biophysical vulnerability group versus 25 in the social vulnerability group) between groups6. This adjustment also prioritized the importance of climate risks in our CHVI. Similar to the inductive model, the final score for each census tract was generated by multiplying the scores of each group and assigning a percentile across all census tracts.
Alternative approach: indicator selection
Race is an important variable closely linked to environmental vulnerability48. Many studies include race or ethnicity as an indicator in composite vulnerability indices based on expert opinion32 and literature review49, reflecting the social context and specific vulnerabilities of different communities. In the first sensitivity analysis, we removed race/ethnicity indicators (i.e., “Latino/a or Hispanic,” “Black or African American,” “Asian,” and “Native American or indigenous”). We also tested the impact of excluding indicators related to future climate change (i.e., “extreme heat projections” and “projected flooding risk”), which have been rarely considered in previous vulnerability assessments.
Alternative approach: indicator grouping
In a hierarchical structure, the categorization of individual indicators depends heavily on the subjective judgment of the index developer. For instance, under CJWG’s methodology, the indicator “driving time to hospital” was classified as a characteristic of the built environment rather than as an indicator of individual vulnerability. Thus, it was categorized within the dimension of potential climate change risks and built environment in the biophysical vulnerability group42. In this sensitivity analysis, we reclassified this indicator under the dimension of health impacts and burdens in the social vulnerability group to examine the influence of indicator categorization on the index.
Alternative approach: transformation
In our benchmark models, the indicator “renter-occupied homes” was calculated as the percentage of housing units within each census tract that were occupied by renters. To test the influence of transformation on the CHVI, we replaced this percentage with the absolute number of renter-occupied homes in each census tract. In an additional sensitivity analysis, we calculated the areal density of renter-occupied homes by dividing the count by the total area of each census tract.
Alternative approach: normalization
Since z-score standardization is the standard method for the inductive design23, for this design we did not perform any sensitivity analyses related to normalization. However, for the deductive design, we performed a sensitivity analysis using maximum normalization as an alternative to the percentile ranking normalization used in the benchmark model to mitigate distorted scores caused by potential outliers in some indicators16.
Alternative approach: principal component selection
In the benchmark model for the inductive design, the percentage of total variance explained by the derived PCs can be low if the first two criteria are met. For this sensitivity analysis, to examine the impact of PC selection, we used a mandatory 60% threshold for cumulative variance explained as the sole criterion for component selection.
Alternative approach: principal component score ranking
In two sensitivity analyses for the inductive design, instead of using percentile assignment, we used mean-SD categorization or decile categorization to rank all PC scores within both the biophysical and social vulnerability groups, and subsequently summed them to generate the group-specific scores.
Alternative approach: weighting
Weighting is widely regarded as the most influential step in index construction using hierarchical models17. In a sensitivity analysis for the inductive design, instead of the equal weighting used in the benchmark model, we weighted each retained principal component by multiplying its calculated percentile score by the percentage of variance it explained across all retained components (i.e., the sum of squared loadings for a component divided by the sum of squared loadings for all retained components).
In a sensitivity analysis for the deductive design, instead of the equal weighting used in the benchmark model, we used a method previously described in the literature, where weights were calculated from PCA50. We calculated a crude weight for each indicator by multiplying the percentage of variance explained by a principal component by the squared loading of the indicator most heavily loaded on that component. Then, each crude weight was recalculated as the percentage across all individual weights to produce a final weight for each indicator. Subsequently, the final weight for each indicator was applied to calculate a weighted summed score for each dimension. Finally, we used the same weighting scheme in the benchmark deductive model to calculate weighted summed scores for the biophysical and social vulnerability groups, respectively. Participatory approaches to weight assignment, such as the analytical hierarchical process, were not assessed in this study due to their strong subjectivity and extensive knowledge requirements.
Alternative approach: aggregation
In sensitivity analyses for both the inductive and deductive designs, instead of using equally weighted multiplicative aggregation, we applied equally weighted additive aggregation to combine the two scores from the biophysical and social vulnerability groups. In an additional sensitivity analysis for the inductive design, we tested multiplicative aggregation within each group. Specifically, for each census tract, we multiplied all equally weighted percentile scores from the retained PCs within each group, followed by the multiplicative combination of the two equally weighted group scores. However, this additional multiplicative combination cannot be applied to the deductive design, as many census tracts had a zero percentile score for certain indicators, which would result in a product of zero.
All data analyses were conducted in R statistical software (version 4.1.0), using the “psych” package for PCA. All maps were generated using the New York State shapefiles provided by the United States Census Bureau51.
Reporting summary
Further information on research design is available in the Nature Portfolio Reporting Summary linked to this article.
Data availability
Data sources and manipulation of all indicators used to construct the climate health vulnerability index in the case study are fully described in the Supplementary Information. Most data sources are publicly available, with the exception of five health indicators, which must be requested from the New York State Department of Health. All other aggregated data at the census tract level in New York State is available at https://github.com/pw-umd/CHVI.
Code availability
The programming code for the benchmark models of the inductive and deductive designs is available at https://github.com/pw-umd/CHVI.
References
Niu, Y. et al. A systematic review of the development and validation of the heat vulnerability index: major factors, methods, and spatial units. Curr. Clim. Change Rep. 7, 87–97 (2021).
Pradyumna, A. & Sankam, J. Tools and methods for assessing health vulnerability and adaptation to climate change: A scoping review. J. Clim. Change Health 8, 100153 (2022).
Cutter, S. L. Vulnerability to environmental hazards. Prog. Hum. Geog. 20, 529–539 (1996).
Cutter, S. L., Boruff, B. J. & Shirley, W. L. Social vulnerability to environmental hazards. Soc. Sci. Quart. 84, 242–261 (2003).
Hudrlikova, L. Composite indicators as a useful tool for international comparison: the Europe 2020 example. Prague Econ. Pap. 22, 459–473 (2013).
Organisation for Economic Co-operation and Development. Handbook on constructing composite indicators: methodology and user guide. https://www.oecd.org/content/dam/oecd/en/publications/reports/2008/08/handbook-on-constructingcomposite-indicators-methodology-and-user-guide_g1gh9301/9789264043466-en.pdf (2008).
Schmeltz, M. T. & Marcotullio, P. J. Examination of human health impacts due to adverse climate events through the use of vulnerability mapping: a scoping review. Int. J. Environ. Res. Public Health 16, 3091 (2019).
Fekete, A. Social vulnerability (re-)assessment in context to natural hazards: review of the usefulness of the spatial indicator approach and investigations of validation demands. Int J. Disaster Risk Sc. 10, 220–232 (2019).
Spielman, S. E. et al. Evaluating social vulnerability indicators: criteria and their application to the Social Vulnerability Index. Nat. Hazards 100, 417–436 (2020).
André, K. et al. Improving stakeholder engagement in climate change risk assessments: insights from six co-production initiatives in Europe. Front Clim. 5, 1120421 (2023).
Bao, J., Li, X. & Yu, C. The construction and validation of the heat vulnerability index, a review. Int J. Environ. Res. Public Health 12, 7220–7234 (2015).
Cheng, W., Li, D., Liu, Z. & Brown, R. D. Approaches for identifying heat-vulnerable populations and locations: a systematic review. Sci. Total Environ. 799, 149417 (2021).
Manware, M., Dubrow, R., Carrion, D., Ma, Y. & Chen, K. Residential and Race/Ethnicity Disparities in Heat Vulnerability in the United States. Geohealth 6, e2022GH000695 (2022).
Fajardo-Gonzalez, J., Lovell, C. A. K., Lovell, J. & Edmonds, H. Measuring climate risks: A new multidimensional index for global vulnerability and resilience. Environ. Dev. 56, 101227 (2025).
Tee Lewis, P. G. et al. Characterizing vulnerabilities to climate change across the United States. Environ. Int. 172, 107772 (2023).
Tate, E. Uncertainty analysis for a social vulnerability index. Ann. Assoc. Am. Geogr. 103, 526–543 (2013).
Tate, E. Social vulnerability indices: a comparative assessment using uncertainty and sensitivity analysis. Nat. Hazards 63, 325–347 (2012).
Jones, B. & Andrey, J. Vulnerability index construction: methodological choices and their influence on identifying vulnerable neighbourhoods. Int. J. Emerg. Manag. 4, 269–295 (2007).
Yoon, D. K. Assessment of social vulnerability to natural disasters: a comparative study. Nat. Hazards 63, 823–843 (2012).
Reckien, D. What is in an index? Construction method, data metric, and weighting scheme determine the outcome of composite social vulnerability indices in New York City. Reg. Environ. Change 18, 1439–1451 (2018).
Nazeer, M. & Bork, H. R. Flood vulnerability assessment through different methodological approaches in the context of north-west Khyber Pakhtunkhwa, Pakistan. Sustainability 11, 6695 (2019).
Moreira, L. L., de Brito, M. M. & Kobiyama, M. Effects of different normalization, aggregation, and classification methods on the construction of flood vulnerability indexes. Water 13, 98 (2021).
Schmidtlein, M. C., Deutsch, R. C., Piegorsch, W. W. & Cutter, S. L. A sensitivity analysis of the Social Vulnerability Index. Risk Anal. 28, 1099–1114 (2008).
Wilson, M., Lane, S., Mohan, R. & Sugg, M. Internal and external validation of vulnerability indices: a case study of the Multivariate Nursing Home Vulnerability Index. Nat. Hazards 100, 1013–1036 (2020).
Anandhi, A. et al. DPSIR-ESA vulnerability assessment (DEVA) framework: synthesis, foundational overview, and expert case studies. T ASABE 63, 741–752 (2020).
Birkmann, J. et al. Framing vulnerability, risk and societal responses: the MOVE framework. Nat. Hazards 67, 193–211 (2013).
Turner, B. L. et al. A framework for vulnerability analysis in sustainability science. Proc. Natl. Acad. Sci. USA 100, 8074–8079 (2003).
Zhu, Q. et al. The spatial distribution of health vulnerability to heat waves in Guangdong Province, China. Glob. Health Action 7, 25051 (2014).
Ye, J., Zhang, M., Lin, G., Chen, F. & Yu, S. in Proceedings 2011 IEEE International Conference on Spatial Data Mining and Geographical Knowledge Services. 577–581.
Tonmoy, F. N., El-Zein, A. & Hinkel, J. Assessment of vulnerability to climate change using indicators: a meta-analysis of the literature. Wires Clim. Change 5, 775–792 (2014).
Reid, C. E. et al. Mapping community determinants of heat vulnerability. Environ. Health Perspect. 117, 1730–1736 (2009).
Yu, J. et al. Geospatial indicators of exposure, sensitivity, and adaptive capacity to assess neighbourhood variation in vulnerability to climate change-related health hazards. Environ. Health 20, 31 (2021).
Abson, D. J., Dougill, A. J. & Stringer, L. C. Using principal component analysis for information-rich socio-ecological vulnerability mapping in Southern Africa. Appl. Geogr. 35, 515–524 (2012).
Ho, H. C., Knudby, A., Chi, G., Aminipouri, M. & Yuk-FoLai, D. Spatiotemporal analysis of regional socio-economic vulnerability change associated with heat risks in Canada. Appl. Geogr. 95, 61–70 (2018).
Tran, D. N. et al. Spatial patterns of health vulnerability to heatwaves in Vietnam. Int J. Biometeorol. 64, 863–872 (2020).
Vommaro, F., Menezes, J. A. & Barata, M. M. L. Contributions of municipal vulnerability map of the population of the state of Maranhao (Brazil) to the sustainable development goals. Sci. Total Environ. 706, 134629 (2020).
Grigorescu, I. et al. Socio-economic and environmental vulnerability to heat-related phenomena in Bucharest metropolitan area. Environ. Res. 192, 110268 (2021).
Patil, V. H., Singh, S. N., Mishra, S. & Donavan, D. T. Efficient theory development and factor retention criteria: Abandon the ‘eigenvalue greater than one’ criterion. J. Bus. Res. 61, 162–170 (2008).
Sotolongo, M. Justice40 and community definition: how much of the U.S. population is living in a “disadvantaged community”?, https://iejusa.org/justice-40-and-community-definition-blog/ (2023).
Council on Environmental Quality. Climate and economic justice screening tool, https://climateprogramportal.org/resource/climate-and-economic-justice-screening-tool-cejst/ (2022).
Wolf, T., Chuang, W. C. & McGregor, G. On the science-policy bridge: do spatial heat vulnerability assessment studies influence policy? Int J. Environ. Res. Public Health 12, 13321–13349 (2015).
Climate Justice Working Group. Disadvantaged communities criteria, https://climate.ny.gov/Resources/Disadvantaged-Communities-Criteria (2022).
McCormick, S. Assessing climate change vulnerability in urban America: stakeholder-driven approaches. Clim. Change 138, 397–410 (2016).
Hazarika, N., Barman, D., Das, A. K., Sarma, A. K. & Borah, S. B. Assessing and mapping flood hazard, vulnerability and risk in the Upper Brahmaputra River valley using stakeholders’ knowledge and multicriteria evaluation (MCE). J. Flood Risk Manag 11, S700–S716 (2018).
Navi, M., Hansen, A., Nitschke, M., Hanson-Easey, S. & Pisaniello, D. Developing Health-Related Indicators of Climate Change: Australian Stakeholder Perspectives. Int J. Environ. Res. Public Health 14, 552 (2017).
Ebi, K. L., Boyer, C., Bowen, K. J., Frumkin, H. & Hess, J. Monitoring and evaluation indicators for climate change-related health impacts, risks, adaptation, and resilience. Int J. Environ. Res. Public Health 15, 1943 (2018).
Conlon, K. C. et al. Mapping human vulnerability to extreme heat: a critical assessment of heat vulnerability indices created using principal components analysis. Environ. Health Perspect. 128, 97001 (2020).
Lievanos, R. S. Retooling CalEnviroScreen: cumulative pollution burden and race-based environmental health vulnerabilities in California. Int. J. Environ. Res. Public Health 15, 762 (2018).
Nayak, S. G. et al. Development of a heat vulnerability index for New York State. Public Health 161, 127–137 (2018).
Bizimana, J. P., Twarabamenye, E. & Kienberger, S. Assessing the social vulnerability to malaria in Rwanda. Malar. J. 14, 2 (2015).
U.S. Census Bureau. TIGER/Line Shapefiles, https://www2.census.gov/geo/tiger/TIGER2019/TRACT/ (2019).
Acknowledgements
We acknowledge funding from the Environmental Defense Fund through a subcontract from Resources for the Future. We thank Dr. Yang Zhang’s team at Northeastern University for providing PM2.5 data. We thank the following people for their constructive comments in developing the climate health vulnerability index in the State of New York: Wesley Look, Alan Krupnick, and Molly Robertson from Resources for the Future; and Victoria Sanders, Eddie Bautista, Kevin Garcia, Daniel Chu, Shravanthi Kanekal, and Celeste Perez from the New York City Environmental Justice Alliance. We also acknowledge the help of Aline Maybank with language editing.
Author information
Authors and Affiliations
Contributions
K.C., R.D., and P.W. conceived and designed the study and developed the statistical analyses strategy. P.W. and K.C. have directly accessed and verified the underlying data. P.W. prepared and cleaned the data and conducted the statistical analyses. P.W. and J.S. performed the exposure assessment. P.W. and F.O. wrote the original draft of the manuscript. J.S., S.H., M.L.B., R.D., and K.C. contributed to the interpretation of the results, reviewed the manuscript, and edited the original version. All authors have approved the final draft of the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Peer review
Peer review information
Nature Communications thanks Joanna Mcmillan and the other anonymous reviewers for their contribution to the peer review of this work. A peer review file is available.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Wang, P., O’Brien, F., Son, JY. et al. An updated modeling framework and sensitivity analysis of methodology for the climate health vulnerability index. Nat Commun 17, 1417 (2026). https://doi.org/10.1038/s41467-025-68162-w
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41467-025-68162-w
