
Abstract
Traditional natural disaster response involves significant coordinated teamwork, where speed and efficiency are key. Nonetheless, human limitations can delay critical actions and inadvertently increase human and economic losses. Agentic Large Vision Language Models (LVLMs) offer an avenue to address this challenge, with the potential for substantial socio-economic impact, particularly by improving resilience and resource access in underdeveloped regions. We introduce DisasTeller, a multi-LVLM-powered framework designed to automate tasks in post-disaster management, including on-site assessment, emergency alerts, resource allocation, and recovery planning. By coordinating four specialised LVLM agents with GPT-4 as the core, DisasTeller can accelerate disaster response activities, reducing human execution time and structuring information flow. Our evaluation shows both benefits and challenges: while DisasTeller streamlines coordination and report generation, errors in early-stage assessments may propagate downstream, highlighting the need for human validation and improved LVLM accuracy. This framework acts as a complementary support system to expert teams, bridging the gap between traditional response methods and emerging LVLM-driven efficiency, while highlighting the importance of continued refinement and collaboration for safe, trustworthy deployment.
Similar content being viewed by others

Introduction
Natural disasters consist of various catastrophic events, including earthquakes, hurricanes, floods and wildfires. These events can cause extensive damage, loss of life and have long-term impacts on societies and economies. For instance, earthquakes can cause buildings to collapse, trapping people under rubble, while hurricanes and floods can result in drowning and physical damage. These natural disasters also lead to extended social challenges, such as the disruption of community cohesion and the psychological effects of trauma and loss. According to the report from the United Nations office, the overall global economic losses from natural disasters in 2023 were estimated to be US$250 billion, which roughly equals the entire gross domestic product of New Zealand1. Beyond immediate losses, disasters would have long-lasting economic effects, including reduced economic growth, increased poverty and disruption to markets and industries. The frequency and intensity of natural disasters have been rising due to factors such as climate change, urbanisation and environmental degradation, making the need for effective post-disaster management even more critical.
Post-disaster management involves activities, including disaster response and post-disaster recovery, aimed at mitigating the impacts of natural disasters. The Sendai Framework of the United Nations for Disaster Risk Reduction (2015–2030) highlights the crucial role of enhanced disaster risk governance in ensuring an effective response and promotes the concept of ‘Building Back Better’ in sustainable recovery, reconstruction and rehabilitation efforts2. Traditionally, the entire process of disaster response and post-disaster recovery requires broad collaboration and teamwork3,4. As shown in Fig. 1, the first step in the disaster response process involves the post-disaster on-site assessment through an expert team, which would focus on evaluating the structural integrity of buildings, transportation networks and other critical infrastructures. Based on the assessment of the expert team, the alerts team is activated. The role of the alerts team is to issue emergency alerts to the public, the emergency service team and government agencies. These alerts are crucial for ensuring that all parties are aware of the situation and can act accordingly. Simultaneously, the emergency services team is mobilised to provide immediate relief to affected populations and determines the number and locations of relevant facilities based on the information provided by the alerts team and the expert evaluations. The assignment team works closely with other teams and is tasked with distributing human resources for emergency service construction, determining where and how resources should be assigned depending on the other three teams’ reports. In addition, an essential component of the disaster response is keeping the affected communities informed. This includes advising them about the ongoing operations, where they can access shelter and medical care, and any other relevant updates. Effective communication helps to manage public expectations, reduce panic and foster cooperation among affected communities. After the response phase, the government and policymakers could rely on updates from the assignment team to make decisions about rebuilding strategies and long-term resilience measures.

Post-disaster evaluations conducted by the expert team are reported to both the alerts team and the assignment team. The alerts team issues danger alerts and media communications, while the assignment team manages resource allocation and releases public notices to affected communities. Based on assignment commands and alerts, emergency services are deployed. Updated reports from the assignment team further inform the government and policy makers for reconstruction planning.
Generally, the disaster response work would last several weeks due to the limitations of human execution and mobility5,6, and the response process can be even slower in underdeveloped areas due to insufficient support and infrastructure investment7, inevitably leading to vast losses. In all periods, enhancing the speed of disaster response efforts and ensuring marginalised groups are not left behind are widely recognised as crucial for reducing disaster-related losses and saving human lives8,9. Current disaster management research focuses on the analysis of disaster-related factors under specific scenarios10,11,12. Math equations or simple machine learning models cannot handle the complex scenarios in post-disaster management, let alone simulate human collaborations to reduce labour work, accelerate the response, or even mitigate the disaster response disparities between developed and underdeveloped areas.
As artificial intelligence (AI) technology develops, it will provide the possibility to better emulate human intelligence, thus rendering it possible to assist humans in improving operational efficiency under the oversight of humans. One of the most significant breakthroughs in AI has been the development of large vision language models (LVLMs), which extend the capabilities of large language models (LLMs) to handle multimodal tasks involving both textual and visual data. These models, which include OpenAI’s GPT-4 series13, are built on neural networks that mimic the structure of the human brain and trained on vast amounts of image and text data, enabling them to generate human-like text, process information from image and context and even perform complex tasks like summarisation and conversation. While these models do not truly ‘understand’ language in a human sense, their ability to model linguistic and visual patterns has made them useful tools in domains requiring large-scale information processing and analysis14. The recent progress in LLMs has laid a strong foundation for the development of LVLMs. Bharathi Mohan et al.15 offer a comprehensive review of LLM architectures and their expanding applications, illustrating the technological evolution toward more sophisticated multimodal models. Foundational works by Brown et al.16 and Radford et al.17 have demonstrated how few-shot learning and multitask generalisation in LLMs have shaped the design of current-generation LVLMs. Liu et al.18 further show how GPT-based evaluation systems enhance the alignment and reliability of generative models, while Yang et al.19 highlight the potential risks of misinformation, particularly in sensitive applications such as healthcare, underscoring the need for caution when deploying these models in critical domains like disaster response.
In the disaster management domain, integrating vision-language understanding is particularly valuable. Nguyen et al.20 show that social media imagery can be effectively leveraged for real-time damage assessment during disasters, pointing to the potential of LVLMs, which can jointly process visual and textual inputs to automate and enhance such tasks. Moreover, standardised frameworks such as the European Macroseismic Scale (EMS-98)21 provide structured criteria for assessing seismic intensity, which can be used as the rubric to evaluate the ability of LVLMs to interpret post-disaster images and reports. These developments support the increasing relevance of LVLMs in disaster response workflows, as the disaster response field advances toward more automated and accountable systems. Building on these insights, the use of multi-LVLM systems to support disaster response operations offers promising benefits, like accelerating the complete procedure, minimising disaster-related losses and narrowing the disaster response gap between developed and underdeveloped areas. Unlike humans, LVLMs can operate continuously without fatigue and facilitate tasks across regions with varying levels of development. They are capable of supporting team-based workflows through rapid interactions, efficiently referencing large volumes of historical data and offering standardised outputs. Although they may lack true understanding or judgement like humans, their standardised and algorithmic output could facilitate a faster, more uniform response during the initial disaster assessment phase, potentially reducing inconsistencies and biases inherent in human judgement15.
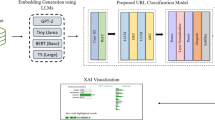
In this work, we propose a multi-LVLM-powered disaster response framework, DisasTeller, designed to streamline the collaboration of different teams in post-disaster management. As shown in Fig. 2, DisasTeller operates by prompting four independent LVLM agents (GPT-4o in our experiment) with specific task instructions and implementing three assistant tools to complete the process. The LVLM agents are provided with the descriptions of their roles, the utility of defined tools and the details of expected input and output. The expert team agent first analyses on-site local post-disaster and global region images, then shares their information with the other three teams. The alerts team and emergency team agents then generate alerting news and emergency service reports, respectively, while the assignment team agent consolidates all prior outputs to produce the human resource allocation command, public announcement and future reconstruction plan. Designed as a modular engine, DisasTeller can be readily extended with additional agents and tools for emerging applications. It will also support non-experts through user-facing interfaces such as mobile apps or dashboards, enabling real-time image submission, localised alerts, actionable guidance and transparent monitoring of resource distribution. Aggregated multi-source inputs from non-expert users further enhance system responsiveness. We assess the reasonability of all six output reports from the agents of the four teams in Supplementary Information. Overall, DisasTeller consistently produces coherent and actionable outputs across key disaster-management tasks, with GPT-4o exhibiting higher grading accuracy and lower annotation deviation than Gemma3, demonstrating the potential of multi-LVLM agent systems to provide standardised and rapid support for post-disaster response.

The alerts team agent analyses alert maps and social media information and generates alert news, which is sent to the assignment and emergency team agents. The assignment and emergency team agents receive both the disaster summary and alert news, and in turn produce public notices, human–resource allocation plans and emergency-service reports.
Results
Autonomous disaster response
To validate the autonomous process of DisasTeller, a case study of earthquake disaster (another two validations with flood and bushfire are introduced in Supplementary Information) was conducted in Fig. 3, utilising the data from previous literature20. We define LVLM agents by prompting task descriptions for several independent GPT-4o models with assigned tools, as shown in Fig. 3a, before the execution of DisasTeller. Like the initial action of the experts’ on-site inspections for the post-disaster response, the input of the framework starts with local on-site post-disaster and global map images. As shown in Fig. 3b, we manually defined the affected area by earthquake as the Wajima City in Japan, and the locations of the local-view images as Wajima Drama Memorial Hall, Hama Street, Concrete Bridge, Central Nishikigawa Street, North Asaichi Street and South Central Asaichi Street. DisasTeller first processes the local-view images for the location and visible damage descriptions. Utilising the file search tool, DisasTeller reads the local technical guideline file European Macroseismic Scale (EMS98)21 for the damage evaluation and grading (G1–G5, from slight damage to very heavy damage). The output of the post-disaster damage grading in Fig. 3b matches the local-view images well, confirming the successful collaborations of LVLM agents to analyse the severity of the disaster. After the damage evaluation of local areas, DisasTeller deploys the map annotation tool to search and annotate the damage grades in the relevant locations of the global map image, thus generating the alert map to visualise the overall situation in this disaster area. This alert map is then further reviewed by other LVLM agents in DisasTeller to generate different reports (partial output of reports shown in Fig. 3c). The first report is generated by the expert team agent in DisasTeller to briefly summarise the local-view disaster and its damage grades. After inspecting the expert team report and the alert map, the alerts team agent in DisasTeller starts reasoning and generating alert news, providing information and safety alerts about existing dangerous areas. For example, the alerts team agent reports: ‘Fire-Damaged Areas: Particularly around Asaichi Street and near the Wajima Morning Market, these zones have unstable structures and debris. Avoid these areas due to potential fire and structural hazards’. Analysing the reports of previous agent teams and taking reference to the historical disaster data with the real website link retrieved by the web search tool, the emergency team agent ensures the areas requiring immediate recovery and emergency services. One example of the retrieved historical disaster data via the tool is the article ‘An Overview of the Design of Disaster Relief Shelters’ from ScienceDirect22. Another example of the emergency team agent output is: ‘Concrete Bridge: Immediate assessment and restoration are crucial to reestablish vital transport links’. Afterwards, the assignment team agent integrates the information from the previous three reports and disaster archives obtained online via the web search tool, such as entries from the American Federal Emergency Management Agency Historic Disasters23, to generate the human resource allocation report. An example assignment of human resources is: ‘Wajima Drama Memorial Hall: This area will host a large emergency shelter. It requires a team of 20 medical personnel, including five doctors and 15 nurses, supported by 10 logistics personnel’. The assignment team agent also produces the public notice report, for instance: ‘We are coordinating with governmental agencies and non-governmental organisations to ensure a comprehensive response’. Finally, the assignment team agent prepares the future reconstruction plan. One example output is: ‘Based on previous case studies, an estimated budget of approximately $1 billion is needed to cover structural repairs’. DisasTeller saves the intermediate outputs of LVLM agent teams in memory and allows LVLM agents to reuse these intermediate outputs and the defined tools, provided they have access, thus automating the whole disaster response process by leveraging the reasoning capabilities of LVLMs.

a the descriptions for tasks of agents and tools assigned; b the running process of DisasTeller and intermediate tasks with disaster grades G1–G5; c the final output reports of agents in DisasTeller.
Reliable outputs of LVLM agents are critical for effectively executing DisasTeller. Yet, the quality of LVLMs’ outputs highly relies on the prompt inputs for the LVLM agents, and even the same instruction prompt can lead to different outputs16,17. Designing prompts to achieve optimal results is an iterative process. Since maintaining identical and best outputs of LVLM agents is complex, LVLM agents in DisasTeller are restricted to output contents with designated format templates when defining task prompts, thus providing relatively controlled results. This case study demonstrates DisasTeller’s ability to autonomously carry out post-disaster response tasks through LVLM agents’ successful simulation of the coordination of disaster management teams.
Agent output results evaluation
In recent years, integrating LVLMs into machine learning frameworks has accelerated the discoveries in different scientific areas14,19. Yet, LVLMs can generate incorrect or deceptive content, and there is a lack of standardised evaluation metrics, posing a great challenge to assessing the output quality of LVLM-based frameworks. In addition, since there is a rising concern about the time-dependent performance of closed-source LVLMs like OpenAI’s GPT models24, we additionally test our framework with Google’s lightweight open-source LVLM model Gemma3-27B25, which has 27 billion parameters (compared with the around 200 billion parameters of GPT-4o13), thus facilitating the reproducibility and better building upon for future research. Considering the previous studies14,19, we conducted five independent runs respectively for both GPT-4o and Gemma3-driven DisasTeller and implemented the comprehensive assessment with a combination of the LVLM (GPT-4o) and human inspection. The intermediate process tasks of GPT-4o and Gemma3-driven DisasTeller are evaluated manually due to their simplicity, and the six output reports of GPT-4o and Gemma3-driven DisasTeller are assessed by both LVLM (GPT-4o) and human inspection, considering their complexity. GPT-4o is prompted to act as a post-disaster management expert (which is called EvaluatorGPT18), provided with post-disaster on-site images, documents retrieved from the internet, and the evaluation rubric to enhance the accuracy of its assessments. The prompt for EvaluatorGPT is modified to grade the output reports of DisasTeller based on the rubric, which focuses on coherence and consistency of sentences and the accuracy of claims. Each evaluation of EvaluatorGPT requires a detailed explanation of the weakness of the report to support the corresponding grade. In addition, we select people who have civil engineering backgrounds with construction experience to manually inspect DisasTeller’s outputs and utilise the same rules to provide grades as a comparison of EvaluatorGPT for a more thorough evaluation. The full evaluation procedure for on-site disaster grading, global map annotations of disaster districts, six output reports and an additional error propagation study are included in Supplementary Information.
The initial response phase of real post-disaster scenarios typically occurs within the first 12–24 h, focusing on immediate response actions such as deploying survey and assessment expert teams to generate the initial alert reports and public announcement4,26. The subsequent actions by emergency service teams to provide necessary assistance generally start within the first 72 h, followed by the structured long-term recovery plan in 1–2 weeks3,4. Post-disaster response and recovery in real scenarios is a challenging and slow process due to the complexity of multi-stakeholder coordination and comprehensive damage assessment6. However, unlike human teams, taking several hours to communicate and intervene, from image inspection to disaster-relevant report generation, LVLM-driven DisasTeller would only utilise few minutes (GPT-4o with 3/35 input/output tokens per second, Gemma3-27B with 2/10 input/output tokens per second, on a workstation with the NVIDIA A100 80 G GPU and Intel Xeon Platinum 8352 V CPU) to coordinate all the agents and complete the given damage assessment tasks, thus simplifying the disaster response process and exhibit the potential to accelerate this process through the autonomous procedure.
The assessment of intermediate process tasks is crucial for each run of GPT-4o and Gemma3-driven DisasTeller since the incorrect output of an individual agent would spread wrong information within the whole workflow and result in misleading final reports for all the stakeholders in the disaster event. This section evaluates two main intermediate tasks, including local disaster grading and alert map generation. Figure 4 summarises the evaluation results across five independent rounds for both local disaster grading and alert map annotation tasks. The disaster grading error is defined through accumulating the deviation of DisasTeller’s damage grading output compared to our manual assessment, and the map annotation distance error is defined through comparing the spatial locations of DisasTeller’s autonomous annotations with our manual annotations. The average scores achieved by the GPT-4o-driven framework for local disaster grading (7.3/10) and map annotations (6.0/10) are higher than those (4.6/10 for disaster grading and 5.0/10 for map annotations) achieved by the Gemma3-driven framework, which only has 63% and 83% accuracy of the GPT-4o-driven framework in these two tasks. This drop in accuracy would be owing to the parameter discrepancy between Gemma3 (27 billion) and GPT-4o (around 200 billion), which would cause the drop in generalisation ability of Gemma3 compared to GPT-4o. Each bar in Fig. 4 represents the score for one of the five independent rounds, demonstrating fluctuations in the performances of both GPT-4o and Gemma3-driven DisasTeller during the intermediate process tasks. The discrepancies between local disaster grading and map annotation in both results of GPT-4o and Gemma3-driven DisasTeller exhibit the agent’s weakness in integrating disaster-image-based and map-based data. Improving the LVLM agent’s ability to process information from different sources could help address this gap. The details of the evaluation are introduced in the Supplementary Information.

Five coloured bars represent five independent runs of DisasTeller. The dashed line indicates the mean score across the five runs. The text box above each subplot reports the average accuracy score together with the corresponding deviation error: grading deviation (+G) for local disaster grading and distance deviation (in pixels) for map annotation. Source data are provided as a Source Data file.
The output report quality of DisasTeller is crucial for post-disaster management because it would be a foundation for rapid and accurate decision-making. As presented in Fig. 5, the human evaluator scores exhibit more variability than those provided by the automatic evaluation of EvaluatorGPT, reflecting the varying subject assessments for different persons. The overall scores of GPT-4o-driven results are higher than those of Gemma3-driven results, which would be attributed to the different model scales (Gemma3-27B has 27 billion parameters while GPT-4o has around 200 billion parameters). Reports like the future reconstruction plan, human allocation report and expert team report, which involve more technical, structured planning (budgeting, recovery and restoration tasks), were rated higher by EvaluatorGPT, likely because the GPT model favours well-defined, structured tasks. On the other hand, reports that require more subjective judgment or social considerations, such as the public notice and alert team report, may have been better appreciated by human evaluators. Although DisasTeller’s output reports achieve the matching score from the LVLM and human evaluators, further performance improvement is necessary for its integration into real-scenario disaster management workflow. The details for the human and GPT evaluation of six reports are introduced in the Supplementary Information.

For each task, five independent runs were evaluated by both EvaluatorGPT and human assessors. Grey points represent individual evaluation scores (0–10 scale). Light and dark yellow bars correspond to the mean automated (EvaluatorGPT) and human scores for GPT-4o-based DisasTeller, respectively; light and dark green bars represent the corresponding mean scores for Gemma3-based DisasTeller. Error bars indicate standard deviations across the five runs. Source data are provided as a Source Data file.
Limitations and deployment considerations
Although DisasTeller demonstrates the possibility of autonomous post-disaster response tasks completion, integrating multi-LVLM agent-based engines like DisasTeller for post-disaster response still presents several inherent limitations and risks that need to be carefully mitigated to ensure effective and safe deployment.
One prominent concern is the potential for spreading inaccurate or misleading information (LVLM hallucination) in high-stakes situations where flawed decisions may exacerbate disaster impacts19,27. Despite the use of domain-specific prompting, technical guidelines (e.g., EMS-98) and calibrated workflows, our experiments show that errors in early-stage agents (e.g., disaster grading) can propagate to downstream outputs like human allocations and reconstruction planning. However, the system also exhibits corrective behaviour in some cases, revalidating local summaries and overriding initial errors based on visual or contextual cues. To mitigate hallucination risks, our framework is designed to output step-by-step intermediate results (e.g., annotated maps, retrieved references and reasoning steps) at each stage, enabling human experts to audit and intervene during execution rather than waiting for final outcomes.
In post-disaster settings, establishing an optimal ground truth is inherently difficult due to the uniqueness of each event, and the absence of repeatable baseline data evaluating variables such as the ‘optimum’ number of doctors or shelters remains a challenge. In our case studies, we addressed this by comparing outputs with publicly available historical records retrieved via web tools. In future work, agents could interface with private databases to access more reliable baselines for self-validation.
Some errors identified during evaluation, such as shelter suggestions near collapsed structures, highlight deficiencies of LVLM-based spatial reasoning and the reliability of the map annotation tool used for geospatial understanding. While the agents can interpret image captions and geolocation inputs, their spatial logic and environmental safety awareness remain constrained. The present annotation module, built primarily for visual-semantic reasoning, lacks integration with established geographic information systems (GIS) infrastructures. In future work, coupling DisasTeller’s agents with GIS platforms such as QGIS28 could enable access to structured spatial layers (e.g., hazard zones, elevation and infrastructure networks) that can guide safer and more context-aware reasoning. Enhancing spatial awareness through GIS-linked heuristics and formal geospatial constraints29 will therefore be a key direction for improving both reliability and interpretability.
Effective deployment of DisasTeller requires timely access to local-view images or other situational data. In real-world conditions, acquiring such data may involve using drones, satellites, or crowdsourced images. However, logistical barriers in damaged or inaccessible areas, as well as limited access to private or proprietary datasets, remain major challenges. Moreover, any data, such as multi-angle, high-resolution images (e.g., aerial and satellite data for wildfire contexts) that can improve standard human assessment would also improve the contribution of DisasTeller. Future collaboration with relevant stakeholders and government agencies for shared image datasets could further strengthen the system’s credibility and better reflect real-world deployment conditions. Our framework assumes data collected by human teams for general assessment can be reused to trigger automated reasoning, thus providing an initial assessment that can become the basis for decision making, reducing delay and guiding more targeted on-site inspections.
As with all neural network-based AI, LVLMs suffer from limited interpretability30. This poses challenges for acceptance in mission-critical applications like disaster response. While the inherent complexity of neural networks cannot be eliminated, the integration of open-source LVLMs (like Gemma3 in our study) in DisasTeller offers certain advantages in mitigating interpretability concerns. Due to the transparency of model architecture and parameters, open-source LVLMs allow full access to the architecture, weights and training procedures, enabling researchers and practitioners to inspect how the model operates internally. Open-source LVLMs will also be under collective peer review and benchmarking within the research community, which often leads to faster identification of failure cases and better understanding of model behaviours. Benefiting from the attributes of open-source LVLMs, agents’ behaviours in DisasTeller will be more transparent and traceable. In addition, Our framework is designed to output not only final decisions but also the step-by-step reasoning results, and human can inspect the intermediate results (e.g., the visual evidence of annotated damage regions and the historical information retrieved from the internet as a reference for human allocation) without waiting the running finished, thus each intermediate reasoning progress and task output can be checked and allow human experts to verify how each conclusion was reached. Since fully resolving the interpretability challenge remains an open research problem at the current stage, to enhance the trustworthiness of DisasTeller for practical deployment, it is important to keep a human check in the running process. This human-in-the-loop format ensures that AI outputs serve as assistive recommendations rather than unquestioned directives, thereby reducing the risk of over-reliance on black-box results.
In real-world disasters, available resources are often insufficient, and planning must balance urgency, impact and logistical constraints. The scarcity of rescue forces and relief supplies makes mathematically optimal allocation nearly impossible within short response times. DisasTeller’s human allocation module does not perform strict mathematical optimisation in the sense of operations research. Instead, it emulates rule-based prioritisation and dynamic reallocation, reflecting how human decision-makers act under uncertainty. Specifically, it integrates spatial, temporal and historical cues to prioritise areas with higher estimated damage severity, thereby improving allocation relevance rather than guaranteeing optimality. DisasTeller is designed as a decision-support framework that assists human planners in rapidly generating and revising preliminary allocation plans. Future work could integrate real-time resource inventories or supply chain data and introduce more specific priority rules to improve scheduling under constrained scenarios.
The current retrieval-augmented generation component relies highly on web search to obtain reference information. While this ensures adaptability, the reliability of open-web data can fluctuate. Future iterations should integrate more human-curated or institutional knowledge bases to enhance factual grounding, especially for region-specific response standards and resource benchmarks.
As a decision-support tool, DisasTeller is not intended to replace human authority. All final decisions remain the responsibility of human operators and implementing organisations. To maintain ethical deployment, robust risk management, legal compliance and stakeholder oversight are necessary. In the case of incorrect AI-generated decisions, traceability and transparency of agent logic will be essential for accountability.
Given the rapid evolution of AI, maintaining system relevance over time is a challenge. To address this, DisasTeller is built with a modular architecture that allows seamless substitution of new LVLMs, tools and reasoning modules. Periodic retraining, version control and embedded performance monitoring can ensure future upgrades remain aligned with the system’s safety and usability requirements.
Discussion
This study develops a multi-LVLM-agent-based framework, DisasTeller, for autonomous disaster response, aiming to accelerate the information sharing and team response in the disaster event, reduce disaster-relevant losses and alleviate regional inequality in disaster response by its availability across developed and underdeveloped areas. Integrating the advanced reasoning ability of LVLMs with expert knowledge from external tools, DisasTeller can coordinate multiple LVLM agents and autonomously simulate various activities of human teams in the disaster event, including local on-site damage evaluation, alert map and disaster reports generation.
Assessment results showed that DisasTeller can reduce the time needed for coordination and task completion compared to the current human-based disaster response procedure. However, the efficiency gains must be interpreted alongside non-negligible limitations in accuracy. Our evaluation reveals that errors in early-stage agents, such as inaccurate disaster grading, can propagate to downstream decision outputs. While report-level evaluations show alignment with human judgment, intermediate results, particularly in image-grounded damage assessment and map annotation, expose weaknesses in the current LVLM spatial and contextual reasoning capacity. These findings reinforce that DisasTeller is intended as a complementary support tool, not a replacement for human disaster experts.
Further development is required to improve task-specific LVLM accuracy, integrate real-time multimodal sensor data and strengthen interactions with human decision-makers in the loop. Augmenting the system with fine-tuned LVLMs and specialised tools beyond the current framework could also enhance reliability under real-world constraints.
Additionally, challenges in evaluation stem from the lack of universal ground-truth benchmarks and the non-deterministic nature of LVLM outputs. Due to random sampling during inference16, repeated executions may yield slightly different results. Although the temperature parameter can regulate generation variability17, the deterministic output would cause bias and reduce LVLM’s problem-solving capability, particularly in disaster scenarios requiring diverse reasoning approaches16. Balancing output consistency with reasoning richness remains an open research direction.
In conclusion, despite current limitations, our work demonstrates the potential of multi-agent LVLM frameworks like DisasTeller to improve the speed, structure and accessibility of post-disaster response. Continued collaboration between AI developers, domain experts and field responders will be essential to realise safe, effective and trustworthy AI-assisted disaster management systems.
Methods
Large vision language models (LVLMs) with augmented generation
The rapid rise of LVLMs in recent years has created unprecedented opportunities across various domains. Based on pretrained knowledge from the large amount of data, one of the key factors behind the growing capabilities of LVLMs is their ability to perform zero-shot reasoning (solving tasks based on pretrained knowledge without specific re-training on those tasks)31. This ability is significantly amplified when LVLMs are used within advanced frameworks exhibiting the power of chain-of-thought reasoning32. LVLMs generate step-by-step logical explanations that can interact with external systems and databases through tool usage, rendering LVLMs’ ability to be intelligent agents33. However, the zero-shot reasoning of LVLMs has restrictions and low accuracy in domain-specific tasks. To mitigate this drawback, we supplement with domain-specific prompts and external technical guidelines (e.g., EMS98) to enhance the performance of our framework in this disaster domain. This is identified as in-text learning34 and retrieved augmented generation35, where external knowledge is injected into prompts to enhance model reliability without retraining. For practical deployment, further results could be achieved with specialised training. Additionally, to make LVLMs accessible to developers and businesses, Application Programming Interfaces (APIs) are commonly employed. In this study, we streamlined our framework by utilising the API of the most representative LVLM model GPT (version ‘gpt-4o-2024-08-06’), and we also conducted additional validation through the local deployment and integration of Google’s open-source LVLM model Gemma3-27B. The modularity of our framework allows for future integration of fine-tuned LVLMs for improved specialisation and robustness.
Custom multi-LVLM agent framework design
While foundational tools like LangChain36 and CrewAI37 provide essential infrastructure for chaining prompts and coordinating multi-agent systems, our work contributes a domain-specific, multi-role LVLM agent framework specifically tailored to automate tasks in disaster response. We designed a system where each LVLM-based agent is assigned a clearly defined functional role, such as damage grading, emergency alert generation and human resource planning, based on the operational needs of real-world disaster workflows. Building upon CrewAI, we customised the role-specific memory management to ensure each agent retains its context across interactions, developed the inter-agent communication protocols to enable agents to request and refine each other’s output, and designed the dynamic task allocation allowing the system to reassign subtasks based on runtime performance or conflict resolution.
Unlike prior generic implementations of CrewAI or LangChain, our framework demonstrates a vertical integration of multi-agent reasoning, domain grounding and multi-tool interaction designed explicitly for structured coordination in disaster scenarios.
Tools development
To maximise the capabilities of each LVLM agent, we designed a set of tools, mapped to agents’ responsibilities and modularly integrated into the pipeline of our framework. It is necessary to highlight that additional tools can be easily integrated into this toolset according to requirements due to the modularity of our framework. A key innovation in our design is the use of adaptive tool invocation, where each agent determines, based on task complexity and confidence thresholds, whether external tools are needed to enhance output quality. This conditional reasoning enables greater efficiency, avoids over-reliance on tools and mimics how human teams selectively consult external resources.
ImageInterpretationTool
To simplify the multi-agent framework of DisasTeller, we integrate two LVLMs into the local and global image interpretation tools instead of defining extra agents as the image interpreters. When these two image interpretation tools are invoked, they will start to read the content of local and global images and give responses for detailed descriptions of the image contents. This tool set helps different team agents check the local and global image information freely.
WebSearchTool
This tool is designed to empower the LVLM with the capability to access information from online sources, utilising LangChain36, DuckDuckGo Search38 and BeautifulSoup39 APIs. For a given invocation, this tool retrieves the top two search results using the DuckDuckGo search engine and returns them as a list. After accessing the webpage links in the list, the BeautifulSoup library is employed to parse the website content. The text from the webpage is extracted and truncated to avoid excessive token usage. This helps limit the amount of content processed, ensuring the relevant parts of the webpage are provided without overwhelming the system. Incorporating this tool allows DisasTeller to effectively broaden its knowledge repository through the up-to-date information online.
FileReadTool
The file read tool focuses on extracting relevant data from various file formats, such as PDFs, text files and DOCX documents, to assist LVLM agents in analysing and processing information. When this tool is invoked, agents will leverage the file read tool API in CrewAI37. The documents are first pre-processed into vector embeddings, which are mathematical representations of the text. Once relevant documents or information have been retrieved, the tool generates a summary relevant to the query. This summary is then integrated into the prompt to activate the LVLM’s potential for a more informed response. Instead of relying solely on the LVLM’s internal knowledge, this step augments the LVLM’s ability with specific information retrieved from the external documents, ensuring that DisasTeller’s response is grounded in actual data, thus mitigating the hallucination to a certain degree.
MapAnnotationTool
This tool aims to reflect the local on-site disaster grades in the global map, thus creating an alert map to illustrate the overall conditions in this disaster area. We customised this tool by integrating an LVLM to analyse the global map image and the input instruction from other agents. When this tool is invoked, it first retrieves the prompt from other agents with the local area names and their corresponding disaster grades and then identifies the location name in the global map image. Employing the reasoning ability of the LVLM, this tool outputs the coordinates of all relevant locations and calls Python image processing libraries40 to generate the news alert map.
Agents definition for post-disaster management
In our framework, each LVLM-based agent was defined through a combination of three core components: a role specification, a model assignment and a set of task-relevant tools. This modular structure enables each agent to behave intelligently and autonomously across different stages of post-disaster response33. To simulate the collaborative workflow of real-world disaster response teams, we defined four distinct agents, including the expert team, alerts team, emergency team and assignment team, each representing a key functional unit in disaster operations. These agents were instantiated with independent LVLM instances and customised prompts to reflect their unique responsibilities. Table 1 presents the LVLM agents we defined with a certain prompt input in our experiments. Agents interact through the CrewAI coordination layer, which facilitates inter-agent communication, memory exchange and dynamic task sequencing. Through this agent-oriented architecture, we modelled a multi-LVLM-powered disaster response framework that closely mirrors the structure and decision flow of actual post-disaster management teams.
Data availability
The crisis image dataset in the main text is released by Qatar Computing Research Institute for humanitarian computing research20, and can be accessed from the official project website: https://crisisnlp.qcri.org/data/ASONAM17_damage_images/ASONAM17_Damage_Image_Dataset.tar.gz. The bushfire and flood images in Supplementary Information are released by the Australian government report41,42: https://flooddata.ses.nsw.gov.au/flood-projects/post-2022-event-flood-behaviour-analysis-tweed-river-report-only, https://www.fire.qld.gov.au/sites/default/files/2021-04/Response-Magazine-Dec2019_0.pdf. The license terms for the crisis image dataset in the main text, as well as the flood and bushfire images in the Supplementary Information, can be accessed at the following links: https://crisisnlp.qcri.org/terms-of-use.html, https://flooddata.ses.nsw.gov.au/related-dataset/post-2022-event-flood-behaviour-analysis-tweed-river-report/resource/4faca39c-2163-4dde-a6b5-340229e9ae6b by a pop-up window during download, and https://www.fire.qld.gov.au/copyright. According to the licences, the raw data can be used for research purposes but cannot be publicly shared. Therefore, all image samples shown in this paper are synthetic illustrations and not taken from original datasets. The output data of DisasTeller are available at the Zenodo repository: https://doi.org/10.5281/zenodo.17785783. Source data are provided with this paper.
Code availability
All code and synthetic data supporting this study are available in the GitHub repository: https://github.com/zche3016/DisasTeller/tree/main.
References
Uncounted costs: data gaps hide the true human impacts of disasters in 2023, United Nations Office for Disaster Risk Reduction. https://www.undrr.org/explainer/uncounted-costs-of-disasters (2023).
Sendai Framework for Disaster Risk Reduction 2015-2030, United Nations Office for Disaster Risk Reduction. https://www.undrr.org/publication/sendai-framework-disaster-risk-reduction-2015-2030 (2015).
Natural Disaster and Emergency Learnings and Recommendations Report, New South Wales Rural Doctor Network, Australia. https://www.nswrdn.com.au/client_images/2244880.pdf (2021).
Edwin, M. L., Naomi, K. City and County of San Francisco Post Disaster Safety Assessment Guide. https://www.sf.gov/sites/default/files/2022-06/Post%20Disaster%20Safety%20Assessment%20Guide%202.0.June2016.pdf (2016).
Ao, Y., Bahmani, H. Current Research Status of Disasters and Human Response, Navigating Complexity: Understanding Human Responses to Multifaceted Disasters, pp 1–18 (2023).
Feng, Y. & Cui, S. A review of emergency response in disasters: present and future perspectives. Nat. Hazards 105, 1109–1138 (2021).
Park, S., Yao, T. & Ukkusuri, S. V. Spatiotemporal heterogeneity reveals urban-rural differences in post-disaster recovery. npj Urban Sustain. 4, 2 (2024).
Forrester, N. Meet the scientists planning for disasters. Nature 619, S1 (2023). https://www.nature.com/articles/d41586-023-02312-2.
Pollack, A. B., Helgeson, C., Kousky, C. & Keller, K. Developing more useful equity measurements for flood-risk management. Nat. Sustain. 7, 823–832 (2024).
Ceferino, L., Merino, Y., Pizarro, S., Moya, L. & Ozturk, B. Placing engineering in the earthquake response and the survival chain. Nat. Commun. 15, 4298 (2024).
Opabola, E. A. & Galasso, C. Informing disaster-risk management policies for education infrastructure using scenario-based recovery analyses. Nat. Commun. 15, 325 (2024).
Ding, M. et al. Reversal of the levee effect towards sustainable floodplain management. Nat. Sustain. 6, 1578–1586 (2023).
Achiam, J. et al. Gpt-4 technical report. Preprint at arXiv https://arxiv.org/abs/2303.08774 (2023).
Bran, A. M. et al. Augmenting large language models with chemistry tools. Nat. Mach. Intell. 6, 525–535 (2024).
Bharathi Mohan, G. et al. An analysis of large language models: their impact and potential applications. Knowl. Inf. Syst. 66, 5047–5070 (2024).
Brown, T. et al. Language models are few-shot learners. Adv. Neural Inf. Process. Syst. 33, 1877–1901 (2020).
Radford, A. et al. Language models are unsupervised multitask learners. OpenAI Blog 1, 9 (2019).
Liu, Y. et al. G-Eval: NLG Evaluation using gpt-4 with better human alignment. In Proc. 2023 Conference on Empirical Methods in Natural Language Processing, pp 2511–2522 (2023).
Yang, J. et al. Poisoning medical knowledge using large language models. Nat. Mach. Intell. 6, 1156–1168 (2024).
Nguyen, D. T., Ofli, F., Imran, M., Mitra, P. Damage assessment from social media imagery data during disasters. Proceedings of the 2017 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining, pp 569–576 (2017).
Grünthal, G. European Macroseismic Scale 1998 (EMS-98). https://www.gfz-potsdam.de/en/section/seismic-hazard-and-risk-dynamics/data-products-services/ems-98-european-macroseismic-scale (1998).
Bashawri, A., Garrity, S. & Moodley, K. An overview of the design of disaster relief shelters. Proc. Econ. Financ. 18, 924–931 (2014).
FEMA, Historic Disasters, Federal Emergency Management Agency. https://www.fema.gov/disaster/historic (2025).
Chen, L., Zaharia, M. Zou, J. How is ChatGPT’s behavior changing over time? Harvard Data Sci. Rev. https://arxiv.org/abs/2307.09009 (2024).
Team, G. et al. Gemma 3 Technical Report. https://arxiv.org/abs/2503.19786 (2025).
Ninivaggi, G. Ishikawa earthquake response sees growing opposition scrutiny. The Japan Times https://www.japantimes.co.jp/news/2024/01/11/japan/politics/kishida-disaster-response/ (2024).
Augenstein, I. et al. Factuality challenges in the era of large language models and opportunities for fact-checking. Nat. Mach. Intell. 6, 852–863 (2024).
Rosas-Chavoya, M., Gallardo-Salazar, J. L., López-Serrano, P. M., Alcántara-Concepción, P. C. & León-Miranda, A. K. QGIS a constantly growing free and open-source geospatial software contributing to scientific development. Cuad. Investig. Geogr. 48, 197–213 (2022).
Chrisman, N. Full circle: more than just social implications of GIS. Cartographica 40, 23–35 (2005).
Gao, L., Schulman, J. & Hilton, J. Scaling laws for reward model overoptimization. Int. Conf. Mach. Learn. pp 10835–10866 (2023).
Yao, S. et al. React: synergizing reasoning and acting in language models. Int. Conf. Learn. Represent. (2023).
Wei, J. et al. Chain-of-thought prompting elicits reasoning in large language models. Adv. Neural Inf. Process. Syst. 35, 24824–24837 (2022).
Schick, T. et al. Toolformer: language models can teach themselves to use tools. Adv. Neural Inf. Process. Syst. 36, 68539–68551 (2023).
Dong, Q. et al. A survey on in-context learning. In Proc. 2024 Conference on Empirical Methods in Natural Language Processing, pp 1107–1128 (2024).
Rocktäschel, P. et al. Retrieval-augmented generation for knowledge-intensive nlp tasks. Adv. Neural Inf. Process. Syst. 33, 9459–9474 (2020).
Chase, H. LangChain https://github.com/langchain-ai/langchain (2022).
Moura, J., Crew AI. https://github.com/crewAIInc/crewAI (2024).
Duckduckgo-search. https://github.com/deedy5/duckduckgo_search (2024),
Richardson, L. Beautiful Soup Documentation. https://readthedocs.org/projects/beautiful-soup-4/downloads/pdf/latest/ (2007).
Lundh, F., Ellis, M. Python Imaging Library (PIL). https://github.com/python-pillow/Pillow (2012).
Post 2022 Event Flood Behaviour Analysis—Tweed River, New South Wales Government, Department of Planning and Environment, Australia. https://flooddata.ses.nsw.gov.au/flood-projects/post-2022-event-flood-behaviour-analysis-tweed-river-report-only (2024).
Resilient and ready for the people of Queensland, Queensland Fire Department, Australia. https://www.fire.qld.gov.au/sites/default/files/2021-04/Response-Magazine-Dec2019_0.pdf (2019).
Acknowledgements
The authors acknowledge the Sydney Informatics Hub and the use of the University of Sydney’s high-performance computing cluster, Artemis. The authors also acknowledge support from the University of Sydney through the Digital Sciences Initiative programme and from the Australian Research Council (ARC) under the Discovery Project DP230100749. The work is supported in part by the National Natural Science Foundation of China (Grant No. 52479098).
Author information
Authors and Affiliations
Contributions
Z.C. contributed to the conceptualisation and data curation, developed the overall framework, conducted validation and visualisation and led the writing of the original draft and subsequent revisions. E.A.S. contributed to the conceptualisation and supported the formal analysis, investigation, methodological development and paper review and editing. S.J. contributed to the formal analysis, investigation and methodology, provided computational resources and funding acquisition and assisted with paper review and editing. L.S. supported the conceptualisation, formal analysis, investigation and methodology and provided funding, supervision and paper review and editing. D.D.C. contributed to the conceptualisation, formal analysis, investigation and methodology, oversaw project administration, provided funding and resources, offered supervision and assisted with paper review and editing.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Peer review
Peer review information
Nature Communications thanks Yu-Jun Zheng and the other anonymous reviewer(s) for their contribution to the peer review of this work. A peer review file is available.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Source data
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Chen, Z., Asadi Shamsabadi, E., Jiang, S. et al. Integration of large vision language models for efficient post-disaster damage assessment and reporting. Nat Commun 17, 1481 (2026). https://doi.org/10.1038/s41467-025-68216-z
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41467-025-68216-z
