
Abstract
Acute-on-chronic liver failure is a complex condition with varied definitions, complicating risk stratification and targeted management. We apply unsupervised clustering to data from 1,256 patients with acute-on-chronic liver failure as defined by the North American Association for the Study of End-Stage Liver Disease. We systematically evaluate multiple algorithmic models to enable unbiased cohort stratification and to determine key clustering factors and clinical impacts across clusters. The optimal number of clusters is determined using the Partitioning Around Medoids with Ambiguous Clustering algorithm. The clusters from the best-performing nonnegative matrix factorization algorithm are selected, with the Lee’s algorithm demonstrating the best performance. Two distinct clusters are identified, showing markedly different 30-day mortality rates (70.35% vs 26.06%). Importantly, acid-base balance-related variables, including bicarbonate, pH, base excess, lactate, and anion gap, are among the primary clustering drivers. An external validation cohort, a decompensated cirrhosis cohort, and a European Association for the Study of the Liver-Chronic Liver Failure Consortium defined Acute-on-chronic liver failure patients cohort confirm consistent distributions of key clustering variables and divergence in 30-day mortality rates, supporting the role of acid-base balance variables. In summary, we show that the unbiased clustering approach successfully identifies distinct acute-on-chronic liver failure clusters with different mortality risks and emphasizes the critical role of metabolic regulation in acute-on-chronic liver failure outcomes, as well as consistent validation.
Similar content being viewed by others


Introduction
Acute-on-chronic liver failure (ACLF) is a syndrome with high short-term mortality and complex mechanisms, often triggered by systemic inflammation and organ failures (OFs)1,2,3.
Different regions have varying definitions, with the European Association for the Study of the Liver-Chronic Liver Failure Consortium (EASL-CLIF)1, the North American Association for the Study of End-Stage Liver Disease (NACSELD), and the Asia Pacific Association for the Study of the Liver (APASL)4 being the most common. The NACSELD definition of ACLF is based on a North American cohort of patients hospitalized with acute decompensated cirrhosis and infections. and evaluates four organ systems: circulatory (shock), respiratory (mechanical ventilation), renal (renal replacement therapy), and cerebral (grade III or IV hepatic encephalopathy)5.
Risk stratification of ACLF has predominantly been derived from clinical experience and diverse definition standards. The EASL-CLIF and NACSELD definitions emphasize the presence and number of OFs1,6, whereas the APASL classification focuses primarily on liver function impairment4. Predictive models, such as the CLIF-C ACLF score, have been developed to improve short-term mortality prediction in ACLF patients1,7. However, these models have been developed on selected patients in observational studies, not a real-world cohort, and rely on variables selected based on prior clinical and research knowledge, potentially missing complex interactions between factors that contribute to disease outcomes.
Unsupervised machine learning models offer an alternative for identifying unbiased patterns within data, independent of prior clinical assumptions in large heterogenous, real-world populations8. Clustering analysis can systematically uncover distinct patient subgroups characterized by previously unrecognized combinations of clinical features, enhancing understanding of ACLF heterogeneity9.
In this study, we aimed to apply unsupervised clustering techniques to stratify mortality risk in real-world ICU settings NACSELD-defined ACLF patients without predefined clinical assumptions. We sought to compare the predictive performance of this model to traditional stratification based on the number of OFs, explored the contribution of various clinical and biochemical variables to mortality risk. We also validated the model using a cohort with decompensated cirrhosis, an EASL-CLIF-defined ACLF patients cohort, and an independent ICU NACSELD-defined ACLF patients cohort.
Results
Training cohort: patients with ACLF
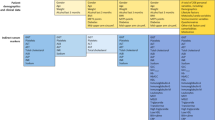
Fig. 1a shows the selection process of ACLF patients. The final cohort of 1256 ACLF patients was included in the main analysis. The baseline characteristics of this cohort are depicted in Table 1. The median age of the cohort was 59 years (Q1–Q3: 51–67 years), and 62.8% of the cohort was male. The prevalence of OFs was as follows: respiratory failure (83.4%), circulatory failure (74.2%), brain failure (51.1%), and kidney failure (22.9%). The prevalence of triggering factors was as follows: infection (36.1%), alcohol (28.4%), and bleeding (40.5%).

a The MIMIC-IV Database: The Cohort of Patients with Acute-on-Chronic Liver Failure (ACLF) Using the NACSELD Criteria and the Cohort of Patients with Decompensated Cirrhosis. b The eICU Database: External Validation Cohort. Source data are provided as a Source Data file.
Determination of the best clustering model
The optimal number of clusters was determined by testing values between 2 and 10 across five NMF clustering algorithms, utilizing the PAC algorithm to evaluate boundary regions in the clustering results. All five algorithms consistently identified two as the optimal number of clusters (Table 2). Among the five methods, the Lee algorithm performed best, as determined by six evaluation metrics of the PAC algorithm (Table 3).
Figure 2 presents the best model (Lee-2) clustering results. In the mixed coefficient matrix, each column represents a patient, and each row represents the probability of cluster membership, where darker colors indicate a higher probability (Fig. 2a). The basis matrix shows each feature’s weight within the clusters, with darker colors indicating greater weight (Fig. 2b). Fig. 2c presents the consistency matrix, a key diagnostic tool for evaluating the stability of NMF clustering results. In the symmetric matrix, both rows and columns represent individual patients. Each cell (i,j) indicates the proportion of times patients i and j were assigned to the same cluster across multiple NMF runs. The consistency matrix reveals clear and non-overlapping boundaries, demonstrating the stability of the clustering results.

a Mixed Coefficient Matrix. Each column represents a patient, and each row represents the probability of cluster membership, with darker colors indicating higher probabilities. b Basis Matrix. Each row represents a feature. The darker the color, the greater the weight of the feature in the cluster. c Consistency Matrix. The clearer the boundaries, the better the clustering stability. Source data are provided as a Source Data file.
Subgroup Analysis
t-SNE visualization of the Lee-2 clustering outcome indicated that, while there was some overlap between the two clusters, the majority of the data points were distinctly grouped, suggesting an effective clustering performance (Fig. 3a). Survival analysis revealed significant differences in mortality probability between the two clusters, with Cluster 1 having a higher 30-day mortality rate (70.35%) compared to Cluster 2 (26.06%) (Fig. 3b). Traditional classification by OFs grade also showed increasing mortality with higher OFs (Grade 1: 45.05%, Grade 2: 62.86%, Grade 3: 69.05%) (Fig. 3c). Multivariable Cox regression analysis demonstrated that the Lee-2 clustering model outperformed the traditional classification method based on the number of organ failures in mortality risk prediction, with Cluster 1 showing an adjusted mortality risk at 3.60 (95% CI 3.06–4.22) compared to Cluster 2 (Supplementary Fig. 1 and Supplementary Table 1).

a t-SNE Visualization of the Clustering Outcome. The green dots represent Cluster 1, and the yellow dots represent Cluster 2. b Mortality Probability of Patients with Acute-on-Chronic Liver Failure at Day 30, by the Lee-2 Model. The red line denotes patients with ACLF in Cluster 1, while the cyan-blue represents patients with ACLF in Cluster 2. P value was computed using log-rank test to determine the difference in mortality probability across the severity clusters. c Mortality Probability of Patients with Acute-on-Chronic Liver Failure at Day 30, by the Number of Organ Failures. The red line denotes patients with ACLF with two organ failures, while the green and blue represent three and four organ failures, respectively. P value was computed using log-rank test to determine the difference in mortality probability across the severity subgroups. d The Top Ten Contributing Variables of Two Clusters Categorized by the Lee-2 Model. The contribution of the variables to the classification was determined by the Kim method. Source data are provided as a Source Data file.
Figure 3d shows the top 10 contributing characteristics of the two clusters. Statistical analysis revealed significant differences in the distribution of these features between the two clusters (Table 4 and Fig. 4). Cluster 1 demonstrated significantly higher vasopressor requirements, and creatinine levels. Notably, parameters related to acid-base balance, including bicarbonate, pH, base excess, and anion gap, also played a significant role in the clustering of ACLF patients. Cluster 1 had markedly lower bicarbonate levels, lower pH, a more pronounced base deficit, and a higher anion gap. Based on the t-SNE visualization results, we removed the overlapping patients and obtained the distribution of important features of clusters with more obvious differences (Supplementary Table 2).

a The Number and Proportion of ACLF Patients in the Two Clusters. b Radar Chart Comparing the Top Ten Baseline Characteristics of the Two Clusters. Baseline data were normalized to avoid the influence of different feature magnitudes, and the average values of clusters were taken for plotting. c Radar Chart Comparing the Proportion of Organ Failure and Precipitating Factors in the Two Clusters. The red denotes patients with ACLF in Cluster 1, while the blue represents patients with ACLF in Cluster 2. Source data are provided as a Source Data file.
Additionally, an analysis of OFs types demonstrated notable differences in organ involvement between the two clusters. Cluster 1 had a higher prevalence of kidney (Cluster 1 vs Cluster 2: 32.85% vs 10.92%) and circulatory (Cluster 1 vs Cluster 2: 84.01% vs 62.50%) failure, whereas respiratory failure (Cluster 1 vs Cluster 2: 77.33% vs 90.85%) was more common in Cluster 2, with brain failure (Cluster 1 vs Cluster 2: 48.55% vs 54.23%) observed in both clusters (Table 4). Supplementary Table 3 shows the distribution of OFs and triggering factors between clusters after removing the overlapping of t-SNE visualization, revealing a consistent distribution of OFs.
To investigate the high prevalence of respiratory failure in Cluster 2, we analyzed variables related to respiratory function, vital signs, and brain failure (Supplementary Table 4). Notably, the proportion of patients with brain failure was higher in Cluster 2 (50.78%) compared to Cluster 1 (40.41%). However, markers of respiratory dysfunction were more prevalent in Cluster 1. Cluster 1 exhibited a lower median PO2/FiO2 ratio and a higher proportion of patients with PO2/FiO2 ratios between 100–200 mmHg (32.33% vs. 22.09%) and below 100 mmHg (19.55% vs. 10.66%).
To further explore the key characteristics contributing to mortality in each cluster, a Random Forest algorithm was applied (Supplementary Fig. 2 and Supplementary Table 5). Both overall and subgroup analyses identified INR, PT, PTT, total bilirubin, and temperature as significant predictors of mortality risk, highlighting the universal importance of coagulation dysfunction, liver function impairment, and temperature abnormalities across all patients. In subgroup analyses, lactate, PO₂, SpO₂, norepinephrine, and SBP were significant mortality risk factors in Cluster 1. Conversely, ALT, sodium, RBC, BUN, and RDW were identified as significant predictors in Cluster 2.
Validation EASL-CLIF definition ACLF cohort
We studied the performance of Lee-2 model on ACLF patients defined in EASL-CLIF, and screened 1411 ACLF patients who met the EASL-CLIF definition from MIMIC-IV database. Supplemental Table 6 shows that the median age of the cohort was 59 years (Q1-Q3: 52-67 years), and 63.36% of the cohort was male. The prevalence of OFs was as follows: liver failure (24.4%), kidney failure (51.5%), coagulation failure (35.9%), brain failure (44.6%), circulation failure (58.7%), lung failure (56.6%). The prevalence of triggering factors is as follows: infection (37.0%), alcohol (28.3%), and bleeding (38.6%). When applying the Lee-2 model, the 30-day mortality rates of Cluster 1 and Cluster 2 were 69.0% and 27.0%, respectively (Supplementary Fig. 3). The distribution of the top 10 clustering factors in ACLF patients defined by EASL-CLIF was similar to the distribution observed in ACLF cohorts defined by NACSELD (Supplementary Fig. 4 and Supplemental Table 7). It was worth noting that the incidence of liver failure, kidney failure, coagulation failure, circulation failure, lung failure, and infection in Group 2 was significantly lower, while there was no significant difference in the incidence of brain failure, alcohol, and bleeding between the two clusters.
Validation analysis: decompensated cirrhosis cohort
We expanded the study cohort to include all patients with decompensated cirrhosis admitted to the ICU. A total of 1334 decompensated cirrhosis patients were obtained (Fig. 1a, right panel). Supplemental Table 8 shows that the median age of the cohort was 59 years (Q1-Q3: 52–67 years), and 65.3% of the cohort was male. The prevalence of OFs was as follows: respiratory failure (50.8%), circulatory failure (44.5%), brain failure (39.3%), and kidney failure (13.9%). The prevalence of triggering factors was as follows: infection (35.7%), alcohol (27.5%), and bleeding (43.9%). When applying the Lee-2 model, the 30-day mortality rates for Clusters 1 and 2 were 73.4% and 31.7%, respectively (Supplementary Fig. 5). The distribution of the top 10 clustering-contributing factors in patients with decompensated cirrhosis closely mirrored those observed in the ACLF cohort (Supplementary Fig. 6 and Supplemental Table 9). Notably, Cluster 2 exhibited a significantly lower prevalence of kidney and circulatory failure, as well as infection, while there was no significant difference in the prevalence of brain failure, respiratory failure, alcohol, and bleeding between the two clusters.
Validation analysis: independent ACLF cohort
The screening process for the external validation cohort is presented in Fig. 1b. Supplemental Table 10 shows that the median age of the cohort was 57 years (Q1–Q3: 51–64 years), and 62.03% of the cohort was male. The prevalence of OFs was as follows: respiratory failure (94.9%), brain failure (82.9%), circulatory failure (68.4%), and kidney failure (28.5%). The analytical results for the external validation cohort are presented in Supplementary Fig. 7. The first validation method confirmed that the optimal number of clusters for NMF clustering in the external validation cohort is also two. Additionally, 7 of the top 15 important variables in this cohort aligned with the top 10 important variables identified in the original cohort. The second validation method demonstrated that the characteristics of the two clusters, obtained by directly applying the Lee-2 model to the external validation cohort, were consistent with those identified in the original cohort. These findings suggest that the Lee-2 model developed from the original cohort is stable and reliable.
Website Generation
In order to help healthcare providers better judge the subtype of patients so as to further treatment, we have established a website that can judge the subtype of patients after entering the relevant parameters of patients (https://aclf-clustering.streamlit.app/).
Discussion
In this study, we unveiled insights into the heterogeneity of ACLF by applying an unsupervised machine learning approach to objectively stratify patients. We identified two distinct clusters within a real-world cohort of ACLF patients defined by NACSELD criteria, each characterized by significantly different mortality rates. The identification of clinically relevant factors, such as acid-base balance-related variables, further revealed the significant role of acid-base homeostasis in ACLF. In the validation analysis, the generalizability of the model to a larger cohort of patients with decompensated cirrhosis admitted to the ICU with and without ACLF defines the robustness of this model built on the machine learning approach and its potential usability in a real-world setting. At the same time, the good performance of the model on the ACLF cohort defined by EASL-CLIF definition proved its wide applicability. The model was also externally validated using an independent cohort. Of the 7 variables in the external validation cohort that aligned with the top 10 important variables identified in the original cohort, 6 were acid-base related. This study demonstrates the unsupervised clustering in understanding a complex syndrome like ACLF, revealing clusters that differ not only in mortality risk but also in underlying pathophysiological characteristics.
The current classification methods for ACLF are primarily based on definitions and scoring systems. The EASL-CLIF system, proposed by the EASL Chronic Liver Failure Consortium1,10, integrates multiple OF indicators to assess both the severity and prognosis of patients. In contrast, the APASL classification focuses on liver decompensation, considering ACLF as the decompensation of chronic liver disease triggered by superimposed acute liver injury4. The SOFA score, commonly used in ICU, predicts mortality based on the evaluation of multi-organ dysfunction11,12, while the MELD and MELD-Na scores incorporate liver and renal function indicators to estimate the short-term survival of cirrhotic patients13.
In contrast, the Lee-2 unsupervised classification method developed in this study uses many routinely collected clinical data and reveals significant differences in mortality among different categories of patients. Unlike traditional scoring systems, which rely on the presence and the absence of OFs to define prognosis, the Lee-2 model does not rely on specific clinical hypotheses, making it more adaptable and applicable to a wider range of clinical scenarios. Traditional classification often focuses on specific clinical scenarios, which may limit their generalizability to all patient profiles. The Lee-2 model provides a more holistic approach, unencumbered by these specific constraints. The study showed robust performance of the model not only in patients with decompensated cirrhosis presenting with ACLF but also in those who did not have ACLF. This underscores the potential of this clustering model in a broader context among patients with decompensated cirrhosis. Moreover, studies have demonstrated the utility of unsupervised clustering, such as K-means, in categorizing liver transplant candidates into clusters with distinct survival outcomes14 and in identifying sepsis phenotypes relevant for guiding clinical interventions15. These findings underscore the potential of data-driven clustering in refining patient management across different contexts.
A detailed examination of the variables that contributed to clustering provides important insights into the pathophysiology of ACLF. Notably, several of these variables, such as vasopressor use, lactate, and creatinine, are established predictors of severity and prognosis in ACLF. Vasopressor use is indicative of circulatory failure, a critical determinant of poor outcomes in ACLF, as persistent hypotension often exacerbates organ dysfunction16. Similarly, elevated lactate levels indicate impaired tissue oxygenation, reflecting both metabolic stress and systemic hypoperfusion, which are sequelae of circulatory failure and a known predictor for mortality in patients with ACLF17,18,19. Elevated creatinine reflects impaired kidney function, a common complication in ACLF linked with increased mortality20.
The differences in OF profiles between the two clusters are noteworthy. Cluster 1, with significantly higher mortality, had predominant circulatory and kidney failure along with increased infection rates, indicating a severe phenotype characterized by hemodynamic instability and renal dysfunction. In contrast, the higher prevalence of respiratory failure in Cluster 2 appears to be driven by its definition, which only requires ventilator use and does not necessarily reflect primary respiratory dysfunction. Many patients in this cluster were likely intubated for airway protection due to high-grade hepatic encephalopathy rather than intrinsic respiratory failure. This interpretation is supported by our findings: Cluster 2 exhibited a higher prevalence of brain failure, which often necessitates airway protection, while Cluster 1 had a significantly higher prevalence of respiratory dysfunction, evidenced by lower PO2/FiO2 ratios, a greater proportion of patients with PO2/FiO2 values between 100–200 mmHg, and more cases with values below 100 mmHg.
Interestingly, our study also identified several factors that have been less frequently discussed in the ACLF literature but were highlighted by this unbiased clustering approach. Factors such as bicarbonate, pH, base excess, and anion gap emerged as significant contributors to the clustering. The physiological roles of these markers, particularly in the context of critical illness, provide additional insight into the underlying processes of ACLF. Bicarbonate levels and base excess are key indicators of the body’s metabolic acid-base balance. Deviations in these markers can indicate acidosis or alkalosis, both of which impact multiple organ systems. For instance, base excess measured upon ICU admission has been linked to mortality in patients with acute kidney injury, with extremes in base excess values associated with higher 30-day mortality21. Similarly, a high anion gap, often indicative of metabolic acidosis, has been associated with increased mortality in critically ill patients, including those with chronic obstructive pulmonary disease and other comorbid conditions22,23. Given the role of systemic inflammation and metabolic dysregulation in ACLF24, these findings suggest that acid-base imbalances may significantly affect prognosis by contributing to multi-organ stress and failure and underscore the need for further exploration of acid-base parameters as potential prognostic markers and therapeutic targets in ACLF management.
This study primarily focuses on ACLF. However, we validated the model in all patients with decompensated cirrhosis admitted to the ICU to address the diagnostic complexities and real-world challenges of managing these patients. By demonstrating good performance of the model in this cohort, we highlighted that the clustering model retained its consistency in this broader ICU population. Importantly, this finding further underscores the role of acid-base balance in hepatic decompensation and its potential prognostic significance in acute decompensation. Given the critical interplay between metabolic derangements and organ dysfunction, these results suggest that acid-base balance may serve as a unifying pathophysiological factor influencing outcomes in both ACLF and other critically ill decompensated cirrhosis patients who do not fulfill criteria for the diagnosis of ACLF. Further studies are needed to explore whether targeted interventions aimed at proactively correcting acid-base disturbances could modify disease progression and improve clinical outcomes.
Unsupervised clustering algorithms have been widely applied in disease classification and subgroup analysis recently. A recent study applied K-means clustering method to effectively classify liver transplant patients based on MELD score variables14. Another study that analyzed 1568 ACLF patients using various clustering algorithms identified subgroups with distinct phenotypes, trajectories, and outcomes25. Compared to the distance-, density-, and model-based clustering methods, the NMF clustering algorithm used in our study offers significant advantages over traditional methods in handling complex, high-dimensional data26. Moreover, NMF’s additive structure provides strong clinical interpretability, as it allows the identification of key factors affecting clustering27.
The strengths of our study are manifold. First, the unsupervised machine learning approach allowed for stratification without prior assumptions, offering a fresh perspective on the heterogeneous nature of ACLF, which has varying definitions and management strategies across regions. This unbiased approach has the potential to uncover clinically relevant factors that traditional models might overlook. Second, the distinct mortality differences between the two clusters surpassed traditional stratification based solely on the number of OFs. Finally, external validation with a U.S.-based ICU cohort in patients with and without ACLF demonstrated consistent results, enhancing the robustness of our findings.
This study has several limitations. First, our cohort included patients from the ICU setting, most of whom were critically ill with OF, which might not represent all individuals with NACSELD-defined ACLF. However, given that the NACSELD definition requires at least two OFs, our cohort likely encompassed most patients fitting this definition. We suggest implementing clustering models in other non ICU cohorts in the future to improve the applicability of the model. Second, we used the Glasgow Coma Scale (GCS) score rather than the West Haven criteria to define hepatic encephalopathy due to missing data on the West Haven classification. This might have introduced some variation in the assessment of hepatic encephalopathy. Third, residual confounding may exist due to the observational nature of the study and the use of retrospective data, but the external validation cohort supported the robustness of our findings. Fourth, the MIMIC-IV data used in this study is up to 2019, and early identification of ICU nursing and ACLF may have improved in recent years, which may limit the generalizability of the research results. Fifth, in the training cohort, we excluded patients with more than 20 missing variables. This threshold was chosen to balance sample size retention with data completeness, thereby supporting robust clustering. In the eICU external validation cohort, we applied a stricter criterion (≤5 missing variables). To ensure comparability and robustness of the validation results, we prioritized data completeness over sample size in the external cohort, considering only patients with ≤5 missing variables as reducing the number of missing data can improve data accuracy and authenticity. ~75% of patients in the external validation cohort were excluded due to excessive missing data, which may introduce selection bias. However, the stringent data filtering improved data completeness and enhanced the credibility and reliability of the validation results. Sixth, the study explored the important factors that affect patient classification through unsupervised clustering. In future research, a machine learning model similar to liver cirrhosis prediction28,29,30 can be established based on this important factor to predict the risk of death for each ACLF patient. Lastly, ACLF is a dynamic condition, and the disease trajectory can evolve rapidly, previous ACLF medical history and transplantation treatment also have a potential impact on mortality risk. In the cohort of 5,994 patients with cirrhosis, only 254 patients (4.2%) underwent transplantation. Given the limited number of patients undergoing transplantation in the database, those who received transplants were excluded from the study. Therefore, the liver transplantation constitutes an important competing risk was not considered in the analysis of the study. Future clustering studies should incorporate serial data to capture these changes over time, which may require advanced computational techniques to fully analyze temporal dynamics.
In conclusion, our study highlights the value of unsupervised machine learning in identifying and externally validating distinct patient clusters with significant differences in mortality, pathophysiology, and metabolic regulation. The potential role of metabolic regulation in ACLF was particularly notable, suggesting avenues for prognosis and treatment. Further research is needed to validate these findings and explore the clinical utility of the identified phenotypes in improving patient outcomes.
Methods
Data source
Data was obtained from the MIMIC-IV database (version 2.2)31,32,33. Due to the public availability and de-identification of the data, approval from the local institutional review board was not obtained. In this study, patients with cirrhosis (Supplemental Table 11) admitted to the intensive care units (ICUs) at the Beth Israel Deaconess Medical Center (BIDMC) between 2008 and 2019 who met the NACSELD-defined criteria (Supplemental Table 12) for ACLF were included5. For patients with multiple episodes of ACLF, only the most recent episode was included to avoid potential biases related to repeated measures. The study followed the TRIPOD guidelines.
Definition of clinical variables
A total of 50 variables were extracted, covering demographic characteristics, vital signs, laboratory results, microbial infections, and medication use. Specifically, demographic characteristics included age and sex. Vital signs included heart rate, systolic blood pressure (SBP), diastolic blood pressure (DBP), mean arterial pressure (MAP), respiratory rate, body temperature, SpO2, and blood glucose. Laboratory measurements comprised partial pressure of oxygen (PO2), partial pressure of carbon dioxide (PCO2), pH, base excess, total CO2, lactate, anion gap, bicarbonate, blood urea nitrogen (BUN), calcium, chloride, creatinine, sodium, potassium, magnesium, phosphate. international normalized ratio (INR), prothrombin time (PT), partial thromboplastin time (PTT), hematocrit, hemoglobin, mean corpuscular hemoglobin (MCH), mean corpuscular hemoglobin concentration (MCHC), mean corpuscular volume (MCV), platelet count, red blood cell count (RBC), red cell distribution width (RDW), white blood cell count (WBC), alanine transferase (ALT), alkaline phosphatase (ALP), aspartate transferase (AST), total bilirubin. Respiratory parameters collected included total respiratory rate, minute ventilation volume, observed tidal volume, positive end-expiratory pressure (PEEP), fraction of inspired oxygen (FiO2), Microbial infection data observed in culture (blood, urine, sputum) from the microbiologyevents table. Finally, medication use included antibiotics (antibiotic prescriptions data from prescriptions table)34,35 and vasopressors (calculates norepinephrine equivalent dose for vasopressors based on formula36). The clinical and laboratory variables used in the study were collected within 24 h prior to the diagnosis of ACLF in patients.
To handle missing data, K-Nearest Neighbors (KNN) algorithm37 was used for imputation(k = 5). Patients with missing data in more than 20 variables were excluded. The number and proportion of missing values for each parameter were shown in Supplemental Table 13.
The study categorized the variables based on clinical experience and transformed all continuous variables into categorical variables (Supplemental Table 14).
Unsupervised clustering method
Nonnegative Matrix Factorization (NMF) is a matrix factorization technique38 that ensures a purely additive description of data by constraining all components to be nonnegative. We first determined the optimal number of cluster(s), followed by evaluating the top-performing clustering method.
Determination of the optimal number of clusters
The Partitioning Around Medoids with Ambiguous Clustering (PAC) algorithm was used to determine the optimal number of clusters, k39. The fundamental principle of the PAC method is to identify the number of clusters by calculating the proportion of samples that belong to the ambiguous region in the clustering outcome.
Evaluating the best clustering algorithm
Five commonly used NMF clustering methods were conducted and compared (Brunet40, Lee40, nsNMF41, snmf/r, and snmf/l42)
Brunet
This is a standard NMF algorithm based on the Kullback-Leibler divergence, using a simple multiplicative update rule proposed by Lee and Seung and enhanced to avoid numerical underflow.
Lee
This is a standard NMF algorithm based on Euclidean distances, using a simple multiplicative update rule proposed by Lee and Seung.
nsNMF
This is a non-smoothed NMF algorithm that uses a modified version of Lee and Seung’s multiplication update rules for extensions of NMF models based on Kullback-Leibler divergence, aiming to obtain more sparse results.
snmf/r, snmf/l
Both of these algorithms belong to the Alternate Least Squares (ALS) method, and they are very fast compared to other methods, where snmf/r with L2 regularization and snmf/l with L1 regularization.
The results of the PAC algorithm and the six evaluation indexes are used to determine the best clustering algorithm.
Residual sum of squares (RSS)
This method measures the difference between the original data and the data reconstructed by the NMF model. A smaller RSS value indicates a better fit of the NMF model.
Explained variance (EVAR)
This method represents the degree to which the NMF model explains the variance in the original data. A larger EVAR value indicates that the model can explain more variability in the data.
Silhouette coefficient (Sil)
This method assesses the tightness and separation of clusters. A larger silhouette coefficient indicates better clustering results.
Cophenetic correlation coefficient (CCC)
This method evaluates the consistency and stability of hierarchical clustering results by comparing the distances in the original data with the branch lengths in the clustering dendrogram.
Dispersion (Disp)
This method refers to the degree of spread among observations within a cluster. A smaller dispersion value indicates that the observations are more tightly clustered, leading to better clustering results.
Silhouette consensus (SC)
It is an ensemble method that assesses the consistency of clustering results by calculating the silhouette coefficient across multiple clustering outcomes. A higher value indicates greater consistency in the clustering results.
Statistical Analysis
All statistical analyses were performed using MySQL(8.0), Python (3.8.18) and R (4.3.2). Patients with ACLF, according to the NACSELD definition, were identified and characterized using descriptive analysis. Categorical variables were analyzed using the chi-square test. Normally distributed variables were compared using the Student’s t-test, whereas non-normally distributed variables were compared using the Mann-Whitney U test.
Visualization of clustering results
t-SNE (t-distributed Stochastic Neighbor Embedding) is a nonlinear dimensionality reduction and visualization technique used to map high-dimensional data to a lower-dimensional space (usually two or three dimensions) to facilitate human understanding and interpretation43.
Analysis of clusters
Following clustering with the optimal NMF algorithm, mortality analyses were performed for the identified clusters. Survival probabilities were compared over time to assess differences in mortality risk between clusters. The predictive performance of the optimal NMF clustering model and the traditional classification based on the number of OFs was evaluated using the area under the receiver operating characteristic curve (AUROC). The two classification methods were further compared using the Akaike Information Criterion (AIC) from the corresponding Cox regression models and the DeLong test.
We subsequently used the Kim method42 to identify the contribution of each of the 50 variables to different patterns or topics in the model. After identifying the top ten important variables using the Kim method, we conducted statistical analyses to compare the distribution of these variables across subgroups. Additionally, we compared the proportion of patients with different numbers of OFs in each subgroup as well as the proportion of different precipitating factors (for definition, see Supplemental Table 15) and used the chi-square test to assess the differences between the subgroups, thereby observing the characteristics of each subgroup. We also used the Random Forest algorithm to analyze the variables most strongly related to mortality in each subgroup.
Classification of ACLF patients according to the EASL-CLIF definition
Due to the widespread application of the EASL-CLIF definition of ACLF, we conducted a validation analysis of the clustering model on the ACLF patient cohort defined by EASL-CLIF definition. We screened 1760 ACLF patients who met the EASL-CLIF definition from the MIMIC-IV database, excluded patients with 20 or more missing variables, and filled in the missing data using the KNN algorithm. Finally, we obtained a cohort of 1441 ACLF patients defined by EASL-CLIF definition. Subsequently, we applied the established clustering model to the cohort and conducted mortality analysis and feature importance analysis on the classified clusters to verify the clustering effect of the model on the EASL-CLIF definition cohort.
Classification of patients with decompensated cirrhosis
Given the challenges of diagnosing ACLF in clinical practice, we conducted a validation analysis by expanding the study population to include all patients with decompensated cirrhosis. Of 5994 patients with cirrhosis from the MIMIC-IV database, we identified patients with decompensated cirrhosis using ICD-9 and ICD-10 codes (Supplemental Table 16). We excluded patients with missing data in more than 20 variables and imputed the missing data using the KNN algorithm. Finally, we obtained a cohort of 1334 patients with decompensated cirrhosis. We subsequently applied the established clustering model to this broader cohort and conducted mortality analysis on the classified clusters. The model’s efficacy was validated by analyzing the distribution of key clustering variables, as well as the prevalence of OFs and precipitating factors.
External validation
Our external validation analysis was an external validation cohort obtained from the eICU Collaborative Research Database44. It contains data from many intensive care units in the continental United States and covers patients admitted to intensive care units in 2014 and 2015. A total of 588 ACLF patients using the NACSELD definition were identified. After excluding patients with missing data in more than 5 variables and imputing remaining missing values using the KNN algorithm, 158 patients were included in this validation cohort.
Since the eICU database lacks follow-up data on patient mortality, we were only able to compare clinical and laboratory characteristics between clusters during validation, without performing survival outcome analysis. We validated our unsupervised clustering results through two distinct approaches. First, we applied the same NMF clustering approaches used in the training cohort to the external validation cohort. This allowed for a comparison of the optimal clustering model and the key factors influencing clustering between the two cohorts. Second, we applied the optimal clustering model derived from the training cohort to the external cohorts to assess whether the resulting subtypes and their characteristics were consistent with those from the original analysis.
Website generation
To assist physicians in identifying and treating subtypes of ACLF patients, we developed an online classification tool after determining the best NMF clustering algorithm. By entering the relevant patient parameters, healthcare providers can instantly obtain the patient’s subgroup type online, allowing for a better understanding of the patient’s disease severity and mortality risk.
Reporting summary
Further information on research design is available in the Nature Portfolio Reporting Summary linked to this article.
Data availability
The datasets (MIMIC-IV and eICU-CRD) analyzed during this study are publicly available on the PhysioNet website, (https://physionet.org/content/mimiciv/2.2/; https://physionet.org/content/eicu-crd/2.0/). The study used only de-identified, publicly available data from the MIMIC-IV and eICU databases via PhysioNet. Yee Hui Yeo and Mengyi Zhang completed the required credentialing and CITI training, and all analyses comply with the respective data use agreements. Source data are provided with this paper.
Code availability
The analysis codes are available on GitHub at (https://github.com/Mengyizhang0427/Unbiased-Clustering-Code.git) archived with Zenodo45 under https://doi.org/10.5281/zenodo.17900836.
References
Moreau, R. et al. Acute-on-chronic liver failure is a distinct syndrome that develops in patients with acute decompensation of cirrhosis. Gastroenterology 144, 1426–1437 (2013). 1437.e1421-1429.
Arroyo, V., Moreau, R. & Jalan, R. Acute-on-chronic liver failure. N. Engl. J. Med 382, 2137–2145 (2020).
Zaccherini, G., Weiss, E. & Moreau, R. Acute-on-chronic liver failure: definitions, pathophysiology and principles of treatment. JHEP Rep. 3, 100176 (2021).
Sarin, S. K. et al. Acute-on-chronic liver failure: consensus recommendations of the Asian Pacific association for the study of the liver (APASL): an update. Hepatol. Int 13, 353–390 (2019).
Bajaj, J. S. et al. Survival in infection-related acute-on-chronic liver failure is defined by extrahepatic organ failures. Hepatology 60, 250–256 (2014).
Perricone, G. & Jalan, R. Acute-on-chronic liver failure: a distinct clinical syndrome that has reclassified cirrhosis. Clin. Liver Dis. (Hoboken) 14, 171–175 (2019).
Mahmud, N., Hubbard, R. A., Kaplan, D. E., Taddei, T. H. & Goldberg, D. S. Risk prediction scores for acute on chronic liver failure development and mortality. Liver Int 40, 1159–1167 (2020).
Eckhardt, C. M. et al. Unsupervised machine learning methods and emerging applications in healthcare. Knee Surg. Sports Traumatol. Arthrosc. 31, 376–381 (2023).
Zhang, W., Wu, L. & Zhang, S. Clinical phenotype of ARDS based on K-means cluster analysis: a study from the eICU database. Heliyon 10, e39198 (2024).
Jalan, R. et al. Development and validation of a prognostic score to predict mortality in patients with acute-on-chronic liver failure. J. Hepatol. 61, 1038–1047 (2014).
Sy, E., Ronco, J. J., Searle, R. & Karvellas, C. J. Prognostication of critically ill patients with acute-on-chronic liver failure using the chronic liver failure-sequential organ failure assessment: a Canadian retrospective study. J. Crit. Care 36, 234–239 (2016).
Pan, H. C. et al. Scoring systems for 6-month mortality in critically ill cirrhotic patients: a prospective analysis of chronic liver failure - sequential organ failure assessment score (CLIF-SOFA). Aliment Pharm. Ther. 40, 1056–1065 (2014).
Biggins, S. W. et al. Evidence-based incorporation of serum sodium concentration into MELD. Gastroenterology 130, 1652–1660 (2006).
Rosenstengle, C. et al. Variation in intention-to-treat survival by MELD subtypes: all models created for end-stage liver disease are not equal. J. Hepatol. 82, 268–276 (2025).
Ding, M. & Luo, Y. Unsupervised phenotyping of sepsis using nonnegative matrix factorization of temporal trends from a multivariate panel of physiological measurements. BMC Med Inf. Decis. Mak. 21, 95 (2021).
Fichet, J. et al. Prognosis and 1-year mortality of intensive care unit patients with severe hepatic encephalopathy. J. Crit. Care 24, 364–370 (2009).
Gao, F. et al. Prognostic value of serum lactate kinetics in critically ill patients with cirrhosis and acute-on-chronic liver failure: a multicenter study. Aging (Albany NY) 11, 4446–4462 (2019).
Lin, S. H., et al. Comparing three profoundly influential prognostic scores in cirrhotic patients with acute-on-chronic-liver failure admitted to the ICU: prediction of one-month mortality-a retrospective cohort study. Diagnostics (Basel) 13, 3160 (2023).
Drolz, A. et al. Lactate improves prediction of short-term mortality in critically ill patients with cirrhosis: a multinational study. Hepatology 69, 258–269 (2019).
Khatua, C. R. et al. Acute kidney injury at admission is a better predictor of mortality than its persistence at 48 h in patients with acute-on-chronic liver failure. J. Clin. Transl. Hepatol. 6, 396–401 (2018).
Cheng, Y. et al. Association between base excess and mortality among patients in ICU with acute kidney injury. Front Med (Lausanne) 8, 779627 (2021).
Li, R. et al. Relationship of admission serum anion gap and prognosis of critically Ill patients: a large multicenter cohort study. Dis. Markers 2022, 5926049 (2022).
Chen, X. et al. Association between serum anion gap and mortality in critically Ill patients with COPD in ICU: data from the MIMIC IV Database. Int J. Chron. Obstruct Pulmon Dis. 19, 579–587 (2024).
Wu, X., Zheng, X. & Ye, G. WGCNA combined with machine learning to explore potential biomarkers and treatment strategies for acute liver failure, with experimental validation. ILIVER 3, 100133 (2024).
Verma, N. et al. Identification of four novel acute-on-chronic liver failure clusters with distinct clinical trajectories and mortality using machine learning methods. Aliment Pharm. Ther. 60, 1534–1548 (2024).
Wang, Y. X. & Zhang, Y. J. Nonnegative matrix factorization: a comprehensive review. IEEE Trans. Knowl. Data Eng. 25, 1336–1353 (2013).
Li, T. D.C. et al. Nonnegative matrix factorizations for clustering: A survey. Data Clustering (2018).
Kanwal, F. et al. Development, validation, and evaluation of a simple machine learning model to predict cirrhosis mortality. JAMA Netw. Open 3, e2023780 (2020).
Silvey, S., et al. Enhancement of inpatient mortality prognostication with machine learning in a prospective global cohort of patients with cirrhosis with external validation. Gastroenterology 2025, S0016-5085(25)05770-05771 (2025).
Yeo, Y. H. et al. Predictive machine learning model in intensive care unit patients with acute-on-chronic liver failure and two or more organ failures. Clin. Mol. Hepatol. 31, 1355–1371 (2025).
Johnson, A. E. W. et al. MIMIC-IV, a freely accessible electronic health record dataset. Sci. Data 10, 1 (2023).
Johnson, A. et al. MIMIC-IV (version 2.2): PhysioNet. https://doi.org/10.13026/6mm1-ek67 (2023).
Goldberger, A. L. et al. PhysioBank, PhysioToolkit, and PhysioNet: components of a new research resource for complex physiologic signals. Circulation 101, E215–E220 (2000).
Yang, J. et al. Brief introduction of medical database and data mining technology in big data era. J. Evid. Based Med 13, 57–69 (2020).
Johnson, A. E., Stone, D. J., Celi, L. A. & Pollard, T. J. The MIMIC Code Repository: enabling reproducibility in critical care research. J. Am. Med Inf. Assoc. 25, 32–39 (2018).
Goradia, S., Sardaneh, A. A., Narayan, S. W., Penm, J. & Patanwala, A. E. Vasopressor dose equivalence: A scoping review and suggested formula. J. Crit. Care 61, 233–240 (2021).
Troyanskaya, O. et al. Missing value estimation methods for DNA microarrays. Bioinformatics 17, 520–525 (2001).
Lee, D. D. & Seung, H. S. Learning the parts of objects by non-negative matrix factorization. Nature 401, 788–791 (1999).
Șenbabaoğlu, Y., Michailidis, G. & Li, J. Z. Critical limitations of consensus clustering in class discovery. Sci. Rep. 4, 6207 (2014).
Brunet, J. P., Tamayo, P., Golub, T. R. & Mesirov, J. P. Metagenes and molecular pattern discovery using matrix factorization. Proc. Natl. Acad. Sci. USA 101, 4164–4169 (2004).
Pascual-Montano, A., Carazo, J. M., Kochi, K., Lehmann, D. & Pascual-Marqui, R. D. Nonsmooth nonnegative matrix factorization (nsNMF). IEEE Trans. Pattern Anal. Mach. Intell. 28, 403–415 (2006).
Kim, H. & Park, H. Sparse non-negative matrix factorizations via alternating non-negativity-constrained least squares for microarray data analysis. Bioinformatics 23, 1495–1502 (2007).
van der Maaten, L. & Hinton, G. Visualizing Data using t-SNE. J. Mach. Learn. Res. 9, 2579–2605 (2008).
Pollard, T. J. et al. The eICU collaborative research database, a freely available multi-center database for critical care research. Sci. Data 5, 180178 (2018).
Mengyizhang0427. Mengyizhang0427/Unbiased-Clustering-Code: Code for “Unbiased Clustering of Acute-on-Chronic Liver Failure Patients Using Machine Learning in a Real-World ICU Cohort” v1.0.0. Zenodo; (2025).
Acknowledgements
We would like to acknowledge Dr. Vinay Sundaram, whose wisdom and invaluable insights were instrumental in initiating this study just weeks before his passing. His passion and thoughtful contributions continue to resonate within our team, and we honor his memory as we carry forward the work inspired by his guidance. This study was funded by National Natural Science Foundation of China (82170626[FJ], 12471470[JZ], 12071366[XS], 82473291[FJ]), Shaanxi Province “Three Qin Scholars” Innovation Team Project (2023001[FJ]), the Fundamental Research Funds for the Central Universities (xtr062023003[FJ]) and the Health and Wellness Scientific Research and Innovation Project of Shaanxi Province (2025TD-09[FJ]). The funder played no role in study design, data collection, analysis and interpretation of data, or the writing of this manuscript.
Author information
Authors and Affiliations
Contributions
Study conception and study supervision: R.J., Y.H.Y., J.Z., V.S. Study design: R.J., Y.H.Y., J.Z., F.J. Data analysis: M.Z., F.J., J.Z., Y.H., T.C., Y.L., H.T., J.D.Y., V.S., Y.W., X.S., Z.C., C.Y.W., Y.H.Y., R.J. Data interpretation: all authors. Drafting of the manuscript: M.Z., F.J., J.Z., Y.H.Y. Critical revision of the manuscript: Y.H., T.C., J.D.Y., X.S., Z.C., Y.H.Y., R.J. All authors reviewed the manuscript. R.J., Y.H.Y., J.Z., M.Z., and F.J. take responsibility for the integrity of the data and the accuracy of the data analysis.
Corresponding authors
Ethics declarations
Competing interests
R.J. is the founder of Yaqrit Discovery, Hepyx (spin-out companies from University College London), and Cyberliver. He has research collaborations with Yaqrit Discovery. He reviews grants for Grifols and consults with Boehringer Ingelheim and Cellbricks. F.J.: Speaker: Gilead Sciences, MSD and Ascletis. Consulting/advisory board: Gilead, MSD. J.D.Y. provides a consulting service for AstraZeneca, Eisai, Exact Sciences, and FujiFilm Medical Sciences. All other authors do not have any conflicts of interest.
Peer review
Peer review information
Nature Communications thanks Terry Cheuk-Fung Yip, and the other, anonymous, reviewer(s) for their contribution to the peer review of this work. A peer review file is available.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Source data
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License, which permits any non-commercial use, sharing, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if you modified the licensed material. You do not have permission under this licence to share adapted material derived from this article or parts of it. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc-nd/4.0/.
About this article

Cite this article
Zhang, M., Ji, F., Zu, J. et al. Unbiased clustering of acute-on-chronic liver failure patients using machine learning in a real-world ICU cohort. Nat Commun 17, 1670 (2026). https://doi.org/10.1038/s41467-026-68368-6
Received:
Accepted:
Published:
Version of record:
DOI: https://doi.org/10.1038/s41467-026-68368-6
